HBEVOcc: Height-Aware Bird’s-Eye-View Representation for 3D Occupancy Prediction from Multi-Camera Images
Chuandong Lyu, Wenkai Li, Iman Yi Liao, Fengqian Ding, Han Liu, Hongchao Zhou

TL;DR
HBEVOcc is a new method for 3D occupancy prediction that uses a height-aware approach to improve efficiency and performance in autonomous driving and robotics.
Contribution
The novel height-aware deformable attention module enhances BEV-based 3D occupancy prediction by incorporating latent height information.
Findings
HBEVOcc achieves state-of-the-art results on Occ3D-nuScenes and OpenOcc datasets.
The method reduces computing resource consumption while improving performance metrics like mIoU and RayIoU.
A height-aware voxel loss with adaptive vertical weighting improves supervision along the height axis.
Abstract
Due to the ability to perceive fine-grained 3D scenes and recognize objects of arbitrary shapes, 3D occupancy prediction plays a crucial role in vision-centric autonomous driving and robotics. However, most existing methods rely on voxel-based methods, which inevitably demand a large amount of memory and computing resources. To address this challenge and facilitate more efficient 3D occupancy prediction, we propose HBEVOcc, a Bird’s-Eye-View based method for 3D scene representation with a novel height-aware deformable attention module, which can effectively leverage latent height information within BEV framework to compensate for lack of height dimension, significantly reducing computing resource consumption while enhancing the performance. Specifically, our method first extracts multi-camera image features and lifts these 2D features into 3D BEV occupancy features via explicit and…
Click any figure to enlarge with its caption.
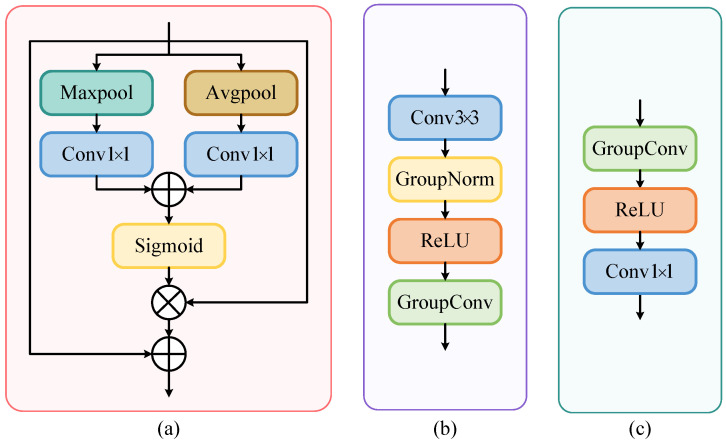 Figure 3
Figure 3- —National Key Research and Development Program of China
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsRobotics and Sensor-Based Localization · Advanced Neural Network Applications · Advanced Vision and Imaging
1. Introduction
Accurate 3D perception is a crucial foundation for scene understanding and obstacle avoidance in autonomous driving and robotics. In recent years, vision-based 3D perception methods have garnered significant attention over LiDAR-based methods due to their lower cost, superior generalization, stability, as well as their ability to obtain richer color information. Some vision methods have demonstrated notable success in 3D perception tasks, such as 3D object detection [1,2,3,4,5,6], semantic map reconstruction [7,8], depth estimation [9,10,11], and motion prediction [12], etc.
Unlike the above visual 3D perception tasks, 3D occupancy prediction [13,14,15] takes multi-camera images as input and represents the real 3D world into voxels, estimating and predicting the semantic occupancy state of each voxel in the surrounding environment. 3D occupancy prediction provides more fine-grained 3D scene perception ability, capable of describing arbitrary complex shapes [16]. Moreover, 3D occupancy prediction models can identify both general objects and unusual obstacles, which is extremely important for scene understanding and reconstruction in autonomous driving and robotics. As an effective alternative to LiDAR-based perception, 3D occupancy prediction offers better assistance for downstream tasks and possesses a very broad development prospect.
Despite the aforementioned advantages, 3D occupancy prediction remains a highly challenging task that needs to achieve a balance of accuracy, robustness, and efficiency. Current 3D occupancy prediction methods mostly rely on voxel-based heavy 3D representation and processing, such as 3D convolutions and transformer operators [14,16,17]. These approaches lead to high computational cost and memory consumption, making them impractical for the actual perception requirements of autonomous driving and robotics. Recent works have aimed to address these issues through various optimizations. For instance, TPVFormer [15] uses tri-perspective view representations to reduce the amount of computation, and OctreeOcc [18] employs an octree structure to represent 3D scenes. However, these models still take up a large amount of memory during training.
Bird’s-Eye-View (BEV)-based methods have achieved remarkable success in 3D object detection with both accuracy and efficiency. Unlike voxel-based methods that explicitly model 3D spatial structure via voxels (leading to high memory and computational costs), BEV-based methods [1,2] project multi-view image features onto a 2D top-down plane, collapsing the height dimension into channel-wise features to enable efficient computation. However, in the task of 3D occupancy prediction, it is generally believed that BEV-based methods collapse the height information and are unable to effectively describe the fine-grained 3D scene details. Although some recent efforts have attempted to employ BEV representation for 3D occupancy prediction [19,20], they often fail to achieve satisfactory performance and do not achieve results comparable to voxel-based methods.
During the transformation from 2D image features to 3D occupancy features, there are two primary view transformations. One is the explicit view transformation (EVT) that performs forward projection based on the predicted depth map, and the other is the implicit view transformation (IVT) that conducts backward projection through cross-attention. The EVT can efficiently lift 2D image features to 3D space using the predicted depth map, but its drawback is that sparse LiDAR points limit the supervision of pixel-level depth prediction. On the other hand, IVT enables end-to-end transformation but suffers from inherent depth ambiguities.
To solve the above problems, we propose a BEV-based 3D occupancy prediction framework to achieve excellent results while reducing resource consumption. We adopt both explicit and implicit view transformations to take advantage of their strengths and compensate for their weaknesses simultaneously. To address the problem of the height information deficiency in BEV, we introduce a height-aware deformable attention module that can mine the potential latent height information, enabling interactions between features of the same and different heights. To complement this at the supervision level, we further introduce a height-aware voxel loss with adaptive height weighting to better guide the learning of sparsely distributed occupancy voxels.
Our contributions are summarized as follows:
- We design HBEVOcc, a framework leveraging BEV representation and a novel height-aware deformable attention module for 3D occupancy prediction. By effectively exploiting the latent height information embedded in BEV features, it addresses the absence of vertical dimensionality in BEV representations, resulting in a significant improvement in 3D occupancy prediction performance.
- Our proposed method learns 3D occupancy prediction from multi-camera images through both explicit and implicit view transformations. It enables the efficient fusion of explicit, implicit, and multi-scale BEV features, significantly reducing the memory usage of 3D occupancy prediction whilst maintaining high performance. To further improve height voxel supervision, we introduce a height-aware voxel loss with adaptive weighting along the height axis.
- Through extensive experiments on the Occ3D-nuScenes and OpenOcc dataset, we demonstrate that HBEVOcc outperforms existing methods in 3D occupancy prediction, achieving superior performance in this challenging task. Our results outperform not only BEV-based but also voxel-based methods, achieving a better trade-off between memory consumption and accuracy.
2. Related Work
2.1. Vision-Based 3D Occupancy Prediction
Recently, vision-based 3D occupancy prediction has attracted considerable attention in both academia and industry. PanoOcc [21] proposes a unified occupancy representation for camera-based 3D panoptic segmentation and occupancy prediction, aiming to integrate object detection and semantic segmentation into a single framework. It uses voxel queries to aggregate spatio-temporal information from multi-frame multi-view images via a coarse-to-fine scheme and introduces an occupancy sparsify module. RenderOcc [22] achieves 3D occupancy prediction using only 2D labels for supervision. SelfOcc [23] and OccNeRF [24] adopt a self-supervised approach for occupancy prediction, eliminating the dependence on occupancy labels. FB-OCC [25] enhances 3D occupancy prediction through forward–backward view transformation, integrating BEV and voxel representations, while employing depth and semantic pre-training. COTR [26] reconstructs a compact occupancy representation using a geometric encoder and a semantic decoder via the compact occupancy transformer. Nevertheless, it still relies on voxel-based modeling, which inherently incurs high GPU memory usage and computational costs, limiting scalability compared with BEV-based solutions. OctreeOcc [18] introduces a novel multi-granularity octree framework, which sparsifies the space and reduces the number of voxels. SAMOccNet [27] introduces the Segment Anything Model into occupancy prediction, enhancing fine-grained scene understanding through detailed visual feature extraction and fusion. OFMPNet [28] is an end-to-end model that jointly predicts future occupancy and motion flow using BEV inputs and a novel time-weighted loss. STCOcc [29] introduces a spatial–temporal cascade framework that explicitly utilizes the occupancy state to guide 3D feature refinement for improved scene understanding. Compared with these voxel-based methods, our approach avoids explicit voxelization and instead directly models height cues within BEV features. This design achieves effective height-aware occupancy prediction with significantly lower memory consumption and better scalability, making it more suitable for efficient deployment.
2.2. 3D Semantic Scene Completion
3D semantic scene completion (SSC) is most closely related to 3D occupancy prediction. It was first introduced in [30]. Monoscene [31] achieved 3D SSC using monocular image for the first time through 2D and 3D Unets, bridged by Feature Line of Sight Projection (FLoSP). VoxFormer [32] adopts a novel two-stage design, employing depth-based query proposals and a sparse voxel transformer with deformable cross-attention and self-attention to achieve 3D SSC. OccFormer [17] designs a dual-path transformer network and Mask2Former [33] to achieve semantic scene completion (SSC) and 3D occupancy prediction. OccDepth [34] exploits the implicit depth information in stereo images, using Stereo Soft Feature Assignment (STEREO-SFA) and Occupancy Aware Depth (OAD) modules to improve the effectiveness of 3D SSC. Symphonize [35] presents a novel paradigm that dynamically encodes instance-centric semantics, effectively mitigating geometric ambiguity through contextual scene reasoning.
2.3. BEV-Based 3D Scene Representation
BEV representations have been demonstrated to be a highly successful and effective approach in 3D object detection. BEV utilizes vectors to represent the features of BEV grids. Compared to voxel-based methods, BEV-based methods collapse the height dimension, thus improving the computational efficiency. BEVDet [1] projects image features into BEV features using predicted depth, achieving a good balance between accuracy and inference speed. BEVFormer [2] implements 3D object detection through a transformer and uses cross-attention and self-attention to complete the aggregation of spatial and temporal features. Recently, some works have also applied BEV methods to 3D occupancy prediction. FlashOcc [20] introduces a plug-and-play paradigm that replaces 3D convolutions with 2D convolutions, while using a channel-to-height prediction head to convert BEV features into 3D occupancy outputs. FastOcc [19] accelerates inference by collapsing voxel features into 2D BEV features, supplementing them with voxel features obtained through the interpolation of image features, while utilizing BEV semantic segmentation for supervision. Although the aforementioned methods utilize BEV for 3D occupancy prediction, there still remains a gap compared to voxel-based 3D occupancy prediction methods. DHD [36] introduces an explicit height prior into occupancy prediction by predicting height maps with LiDAR supervision and decoupling them into multiple height masks via the proposed Mask Guided Height Sampling (MGHS) module. These masks enable 2D features to be projected into separate 3D subspaces. This explicit height decoupling strategy improves the accuracy on Occ3D-nuScenes. However, DHD requires dense height labels and a relatively heavy architecture consisting of multiple dedicated modules (HeightNet, MGHS), which increases the model complexity and training overhead. In particular, projecting features into multiple height subspaces and aggregating them layer by layer incurs substantial GPU memory consumption, making DHD [36] less efficient compared to lightweight BEV-based approaches. In contrast, our method leverages height-aware deformable attention to implicitly mine latent vertical information already embedded in BEV features, without relying on external height labels or complex multi-stage subspace modeling. As a result, our framework achieves stronger efficiency–performance trade-offs: it improves height-aware representation while maintaining lightweight memory usage and architectural simplicity.
3. Proposed Method
3.1. Problem Formulation
Given a sequence of multi-camera image inputs, the aim of 3D occupancy prediction is to estimate the occupancy state and semantic category of each voxel in 3D space surrounding the ego-vehicle. Specifically, the input images are defined as , where represents the i-th of N surround-view cameras, and denotes the current timestamp at T with historical frames. Here, H and W indicate the height and width of the input images, respectively. Furthermore, the extrinsic parameters and intrinsic parameters of the camera used for different coordinate systems conversion and ego-motion in each frame are also known. The range of 3D space around the ego vehicle is , and the resolution of the voxel label for 3D occupancy prediction is (e.g., in Occ3D [14]), with each voxel representing a real-world size of .
3.2. Overview
Figure 1 shows the pipeline of our method. Given multi-camera images as input, we first extract features of images using a backbone network (e.g., ResNet-50 [37]); then, we lift the image features to 3D BEV space. After obtaining the initial features of BEV, a BEV encoder and height-aware deformable attention module are used to further refine the features, and then a BEV decoder progressively restores the spatial resolution. Finally, the explicit and implicit features are fused and fed into the prediction head to obtain the 3D occupancy results.
EVT and IVT are designed to address the inherent ambiguity and information loss when lifting multi-view image features into the BEV space by jointly modeling the explicit geometric projection and implicit learned occupancy queries.
3.3. Explicit View Transformation
We follow previous works such as FlashOcc [20] and BEVDet [4] to implement EVT, which lifts image features into 3D space using depth-based projections. After extracting features from a 2D backbone, we can obtain the multi-camera image features . For EVT, the depth distribution can be predicted via a depth net, where denotes the number of depth bins. The outer product is applied to lift image features to pseudo-LiDAR points in the camera coordinates. Then, is transformed to ego-coordinate and wrapped into a voxel grid with fixed resolution based on their 3D positions, where is the height resolution along the z axis. Next, voxel pooling is performed to obtain the voxel feature , which is subsequently permuted and reshaped into . Finally, a 2D convolutional preprocessing network is applied to produce the initial explicit BEV occupancy feature .
3.4. Implicit View Transformation
For IVT, we adopt the query-based cross-attention strategy proposed in BEVFormer [2], where learnable BEV queries interact with multi-view image features via spatial cross-attention. In IVT, we only use the cross-attention component of BEVFormer [2], which projects 3D points into 2D image features to obtain the BEV features. As illustrated in Figure 1 (Implicit View Transformation), we predefine learnable parameters as implicit BEV occupancy queries. Then, we obtain the corresponding implicit BEV occupancy feature using spatial cross-attention. The above process can be expressed as follows:
where is the hit views of 3D reference points in IVT, and denotes the cross-attention. For each 3D point in , we use a project function to get the reference point on the i-th camera image.
3.5. Height-Aware Deformable Attention
BEV-based methods collapse the height dimension into channel-wise features, leading to the loss of vertical spatial information and the inability to capture fine-grained 3D scene details. This deficiency limits their performance in 3D occupancy prediction, as height is critical for distinguishing objects and describing the spatial structure. To address the shortcoming of the lack of height information in BEV methods, we design a height-aware deformable attention (HADA) module, as shown in Figure 2. Inspired by [38], we also use deformable sampling points in the sampling process. After the initial BEV occupancy feature is passed through the BEV encoder, the BEV feature is (e.g., ), where is the resolution of the current BEV feature. A grid of reference points is predefined, where is the number of attentional height heads.
We define the deformable sampling process as follows:
where is obtained from the 2D offset prediction network shown in Figure 3b, and is the number of sampling points in the horizontal direction at each height. is a 2D convolutional network. is the bilinear interpolation function, and is the sampled feature, where is the feature dimension per height head. is the corresponding sampling position. For this addition, the reference points p are broadcasted to match the dimensions of by replicating each reference point times along the sampling point dimension; so, when we perform , p will broadcast to . The query, key, and value features are then computed as
After using the 2D convolutional network on , is obtained. We use GroupConv in and ; then, we obtain , .
The architecture of each module in height-aware deformable attention. (a) Channel attention network. (b) Offset network. (c) Feedforward network.
In the height direction, we process using channel attention shown in Figure 3a,
where , , , and is the number of points in the height direction. Then, we compute attention by the following equation:
where the shapes of K and V are both . When we calculate the attention , Q only calculates with nearby points; so, Q will be reshaped to , , , and . After the is processed by feedforward network (FFN), the shape of the final output of HADA is . As can be seen from Figure 2 and Figure 3c, we use GroupConv and GroupNorm in FFN, which can achieve different processing of features at different heights.
3.6. 3D Occupancy Prediction Head
After the BEV processing network, the explicit and implicit BEV occupancy features are denoted as and , respectively. We upsample the low-resolution features and shown in Figure 1 and then fuse them with and to obtain their fused feature . Specifically, the explicit and implicit features are concatenated along the channel dimension, and the upsampled low-resolution fused features are added to the high-resolution fused features, followed by a convolution layer for feature fusion. The above process can be expressed as follows:
Like FlashOcc [20], we also employ Channel2Height prediction head, and we obtain after applying a convolution on . Finally, we permute and reshape to to get the final 3D occupancy prediction output.
3.7. Height-Aware Voxel Loss
In 3D occupancy prediction, voxels are unevenly distributed along the height axis (Z-axis): voxels near the ground (e.g., 0–2 m) are densely occupied by objects like vehicles and pedestrians, while voxels at higher altitudes (e.g., 2–5.4 m) are sparsely occupied. Conventional loss functions treat all voxels equally, leading to biased supervision—models prioritize learning from dense low-height voxels and underperform on sparse high-height voxels, reducing the overall prediction accuracy.
To address this issue, we propose a height-aware voxel loss (HAVL), which enhances voxel supervision along the height axis by introducing adaptive height-dependent weighting. Specifically, we randomly sample a set of positions in the XY plane and compute the loss over all height levels at those positions as shown in Figure 4. This sampling strategy reduces the computational cost while ensuring that vertical occupancy patterns are jointly optimized.
For each height, a weight is assigned based on the number of occupied voxels at that height. Heights with fewer occupied voxels are assigned larger weights. To penalize low-confidence errors more strongly, we apply the loss to function. This design increases the gradient magnitude when the predicted probability approaches zero, which is particularly important for sparse occupancy voxels. We adopt Smooth L1 to prevent excessively large gradients caused by extreme log-probability values. The final loss is formulated as
where is the height-aware weight at height z, is the number of occupied voxels at height i, and is the maximum among all . This exponential scheme emphasizes sparse heights and ensures smooth weighting without hard thresholds. denotes randomly sampled positions in the XY plane, and is the predicted probability of ground-truth class c at voxel .
3.8. Model Optimization
In the model training stage, we use the cross-entropy loss , depth loss supervised by sparse LiDAR points, lovasz-softmax loss from [39], affinity loss and from MonoScene [31], and our proposed height-aware voxel loss to optimize our model. So, the total loss function used for our model optimization can be defined as follows:
where is the weight of each loss, and we set , following [4,20,36,40] in our experiments. The weight for is chosen to ensure numerical consistency with the existing loss terms for stable training.
4. Experiments
4.1. Dataset
We conduct experiments on two large scale 3D occupancy prediction benchmarks: Occ3D-nuScenes [14] and OpenOcc [41]. Each dataset comprises 700, 150, and 150 scenes in the training, validation, and testing sets, respectively, and each scene is 20 s in duration and 2 HZ in frequency. Each frame consists of 6 surround-view camera images. 3D occupancy labels have a spatial range of [−40 m, −40 m, −1 m, 40 m, 40 m, 40 m, 5.4 m] across the X, Y, and Z axes, a voxel resolution of [200, 200, 16], and a size of each voxel of [0.4 m, 0.4 m, 0.4 m]. Each voxel of Occ3D-nuScenes has 18 categories (1 “other” class and 1 “free” class), and the labels provide a visible mask for the camera. OpenOcc annotates each voxel with 17 categories (1 “free” class) and provides per-voxel motion flow prediction.
4.2. Experimental Settings
Implementation Details
For explicit BEV features, our initial resolution is set to , and the encoder follows the design of FlashOcc [20]. HADA is applied at resolutions of and , where the BEV feature dimensions are set to 128/512 for single-frame input and 160/640 when temporal history frames are used. Accordingly, the explicit BEV feature has a shape of or , depending on the presence of a temporal input. For EVT, the voxel grid resolution along the z axis, denoted as , is set to 8 for single frame or 1 history frame input and reduced to 1 for multiple historical frames inputs to save computation. For implicit BEV features, the initial resolution is , with feature dimensions of 128 and 160 for single frame and temporal inputs, respectively. The resulting BEV feature has a shape of or , followed by an upsampling operation and a two-layer convolution. HADA is applied at a resolution of . In HBEVOcc, both explicit and implicit BEV outputs, and , are unified to a channel dimension of 256, and the fused BEV feature has a final dimension of 512. Under the setting without history frames, our approach does not rely on LiDAR-based depth supervision. We also construct a fast version, HBEVOcc-Fast, where an explicit and implicit BEV feature is added at the resolution, and HADA is applied solely at . In this case, the final fused feature is reduced to 256. For temporal fusion in HBEVOcc and HBEVOcc-Fast, we adopt Stereo4D and Depth4D used in [4,20,36,40]. Specifically, when computing the BEV features of historical frames, gradients are disabled to reduce the memory usage. After obtaining 3D features from both the current and historical frames, we concatenate them after a lightweight preprocessing network and then feed the concatenated features into the BEV encoder.
4.3. Evaluation Metrics
For 3D semantic occupancy prediction, we use mIoU as the evaluation metric on Occ3D-nuScenes [14]. In addition, we also use the RayIoU proposed in SparseOcc [42] as the evaluation metric both on Occ3D and OpenOcc [41], which is defined as only if the class are consistent and the L1 distance between the predicted depth and the true depth is less than a certain threshold. We use the mean absolute velocity error (mAVE) to evaluate the scene flow prediction across defined categories (e.g., pedestrian, bus) on OpenOcc.
Training
During training, we adopt the AdamW [43] optimizer with a learning rate of 2 × 10^−4^ and weight decay of 0.01, using a linear warming up in the first 200 iterations. Models with a ResNet-50 backbone are trained on 8 RTX2080Ti GPUs (11 G memory) and those with a SwinB backbone are trained on 4 RTX4090 GPUs (24 G memory), both with a batch size of 2.
4.4. Main Results
4.4.1. 3D Occupancy Prediction Results on Occ3D-nuScenes
We report the quantitative results and qualitative visualizations of the 3D semantic occupancy prediction results on the Occ3D-nuScenes dataset. In Table 1, we report in detail the comparison results of our HBEVOcc and other existing state-of-the-art methods on mIoU and each semantic class. Our method consistently achieves the best performance, regardless of whether camera masks or history frames are used. In Figure 5, we visualize the training memory and performance comparison between HBEVOcc and other methods. Our method uses less memory but achieves better performance. In Figure 6, we visualize the results of our model and the state-of-the-art methods. Our method can predict the occupancy semantic classes more accurately compared to SOTA.
In Table 2, we also report in detail the comparison results of our HBEVOcc, HBEVOcc-Fast, and other existing methods on RayIoU and mIoU. Testing GPU is RTX 4090 refers to that we test the model according to its official code. Regardless of whether a camera mask is used or not, our method achieves state-of-the-art RayIoU while ensuring fast speed.
4.4.2. 3D Occupancy Prediction Results on OpenOcc
In Table 3, we report the results of our HBEVOcc and other existing methods on RayIoU and mAVE. Our model achieves better occupancy and flow prediction results while consuming less memory (only 7.5 GB).
4.5. Ablation Study
To verify the effectiveness of our proposed method and module, we perform ablation experiments on the Occ3D and OpenOcc dataset. For a fair comparison, we retrain FlashOcc [20] with the additional loss function, including the lovasz-softmax loss from [39] and the affinity loss and from MonoScene [31] and treat this enhanced model as our baseline. As shown in Table 4, incorporating both EVT and IVT results in a 0.98% improvement in mIoU compared to using EVT alone, demonstrating the benefits of their combination. Meanwhile, using HADA has a 1.08% higher mIoU than not using it, underscoring the effectiveness of HADA. In Figure 7, we visualize the 3D occupancy prediction results under three settings. It can be seen that our proposed HADA and HAVL enhance the geometric structure and semantic coherence of the 3D occupancy results, thereby improving scene understanding ability. Table 5 further shows that without using a camera mask, HADA can still improve RayIoU and mIoU to some extent, and HAVL can improve the mIoU by 1.7% without increasing the memory usage. Table 6 demonstrates the improvement effects of HADA and HAVL on OpenOcc. Due to the long training time, we use the image resolution of 256 × 704 and the image backbone ResNet-50 in the ablation experiments, and no history frame is used to reduce the training time.
As shown in Table 7, concatenation achieves the best mIoU performance among all evaluated fusion methods, outperforming additive fusion and gated fusion. In Table 8, we present the impact of different horizontal and height points in HADA on mIoU. The best performance is achieved when the horizontal point is 4 and the height point is 2. To investigate the impact of the voxel grid resolution along the z axis (height ) setting under different numbers of historical frames, we conduct experiments on Occ3D dataset in Table 9. When no historical frame or only a single historical frame is used, adopting leads to better performance compared with . However, when the number of historical frames increases to 4 or 8, consistently outperforms . The temporal fusion of multiple historical frames provides additional geometric cues, which compensates for the potential loss of vertical information caused by a smaller z-dimension.
We first investigate the influence of the number of height levels involved in HAVL. As shown in Table 10, increasing the number of height levels generally improves the performance, with the best result achieved when 16 height levels are used. This indicates that sufficiently fine-grained height supervision is beneficial for learning sparse occupancy patterns along the vertical axis, while too coarse height partitioning limits its effectiveness. We further analyze the effect of the number of sampled spatial positions in the XY plane. Table 11 shows that sampling 4000 positions achieves the best performance, while overly dense sampling (e.g., 20,000 or 40,000) does not bring further improvement. This suggests that HAVL does not rely on exhaustive voxel supervision, and a moderate number of sampled positions is sufficient to provide stable and effective height-aware gradients. Table 12 shows that, in HAVL, the best performance is achieved when using our proposed height-aware weights.
Table 13 shows the effect of different history frames in temporal fusion on RayIoU, and it can be seen that long-term sequences lead to a significant improvement in the results. To evaluate the capability of HADA in mining and exploiting height information, we visualize in Figure 8 the heatmaps of attention features at eight different height levels. As shown in Figure 8, the regions emphasized by HADA vary across different heights, indicating that the model attends to distinct spatial features, depending on the vertical dimension. This clearly demonstrates the effectiveness of HADA in capturing and leveraging height-aware representations. To quantify how HADA’s height setting impacts performance across different vertical ranges, we conduct additional ablation experiments by varying the number of height levels in HADA (2, 4, 8, 16). Table 14 presents the results: the model achieves the best mIoU of 36.76% when using 8 height levels. This result confirms that 8 height levels strike an optimal balance between capturing vertical details and computational efficiency. To further verify the effectiveness of our proposed HADA, we applied it to other methods. For BEV-based methods, HADA is directly applied to the BEV features. For voxel-based methods, we first transform the voxel features into BEV features by collapsing the z axis into the channel dimension and applying a 2D convolutional network. HADA is then applied to the transformed BEV features, which are subsequently mapped back into the voxel representation and fused with the original voxel features through addition. As can be seen in Table 15, both BEV-based and voxel-based models achieve a significant improvement in mIoU with only a limited increase in memory usage. Here, mIoU* denotes the performance of the original methods; to ensure the fairness of the experiment, we retrain these methods to obtain the mIoU.
5. Discussion
As shown in Table 1, Table 2 and Table 3, our method consistently outperforms previous BEV-based and voxel-based approaches in terms of the occupancy prediction accuracy, while maintaining competitive inference efficiency. Compared with voxel-based methods, our approach avoids explicit 3D voxel computation and benefits from the compact BEV representation, leading to reduced inference memory consumption and favorable runtime performance. Although the proposed HADA module introduces additional computation, its cost is moderate due to the localized and sparse sampling strategy, making the overall complexity suitable for real-time or near-real-time deployment. Despite its effectiveness, our method has several limitations. First, extremely complex scenes with a large number of small or highly detailed objects may still pose challenges due to the inherent resolution limits of the BEV grid. Second, the current framework assumes relatively accurate camera calibration, and calibration errors may negatively impact the lifting process. Finally, like most vision-based methods, our approach may be affected by challenging environmental conditions such as low illumination, adverse weather, or sensor noise. In future work, incorporating temporal information or robustness-oriented data augmentation could further enhance performance under such conditions.
6. Conclusions
In this paper, we present HBEVOcc, a 3D occupancy prediction method based on BEV representation. To enhance the perception and understanding of 3D scenes, we employ both explicit and implicit view transformations to obtain BEV features. Our proposed HADA module and HAVL can effectively utilize the latent height information, addressing the challenge of missing height in BEV and significantly improving model performance. Our method achieves superior 3D occupancy prediction results while also reducing the training memory. Extensive experiments on the Occ3D-nuScenes and OpenOcc dataset demonstrate that HBEVOcc outperforms existing methods in both mIoU and RayIoU metrics, which proves the effectiveness of our proposed method.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Huang J. Huang G. Zhu Z. Ye Y. Du D. Bevdet: High-performance multi-camera 3d object detection in bird-eye-viewar Xiv 20212112.11790
- 2Li Z. Wang W. Li H. Xie E. Sima C. Lu T. Qiao Y. Dai J. Bevformer: Learning bird’s-eye-view representation from multi-camera images via spatiotemporal transformers Proceedings of the European Conference on Computer Vision Springer Cham, Switzerland 2022118
- 3Li Y. Bao H. Ge Z. Yang J. Sun J. Li Z. Bevstereo: Enhancing depth estimation in multi-view 3d object detection with temporal stereo Proceedings of the AAAI Conference on Artificial Intelligence AAAI Press Washington, DC, USA 2023 Volume 3714861494
- 4Huang J. Huang G. Bevdet 4d: Exploit temporal cues in multi-camera 3d object detectionar Xiv 20222203.17054
- 5Wu X. Ma D. Qu X. Jiang X. Zeng D. Depth dynamic center difference convolutions for monocular 3D object detection Neurocomputing 20235207381
- 6Tang Y. He H. Wang Y. Mao Z. Wang H. Multi-modality 3D object detection in autonomous driving: A review Neurocomputing 202355312658710.1016/j.neucom.2023.126587 · doi ↗
- 7Zhao T. Chen Y. Wu Y. Liu T. Du B. Xiao P. Qiu S. Yang H. Li G. Yang Y. Improving Bird’s Eye View Semantic Segmentation by Task Decomposition Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition IEEE Piscataway, NJ, USA 20241551215521
- 8Xu Z. Li S. Peng L. Jiang B. Huang R. Chen Y. Ultra-fast semantic map perception model for autonomous driving Neurocomputing 202459912816210.1016/j.neucom.2024.128162 · doi ↗