6DoF Pose Estimation of Transparent Objects: Dataset and Method
Yunhe Wang, Ting Wu, Qin Zou

TL;DR
This paper introduces a new method and dataset for estimating the 3D position and orientation of transparent objects, which is crucial for robotic grasping.
Contribution
The paper proposes HFF6DoF, a novel hierarchical feature fusion network, and introduces TDoF20, a new dataset for transparent object 6DoF pose estimation.
Findings
HFF6DoF outperforms existing methods on transparent object pose estimation.
The TDoF20 dataset contains 61,886 RGB-D image pairs for 20 types of transparent objects.
The method achieves an average ADD of 50.5% on the TDoF20 dataset.
Abstract
6DoF pose estimation is one of the key technologies for robotic grasping. Due to the lack of texture, most existing 6DoF pose estimation methods perform poorly on transparent objects. In this work, a hierarchical feature fusion network, HFF6DoF, is proposed for 6DoF pose estimation of transparent objects. In HFF6DoF, appearance and geometry features are extracted from RGB-D images with a dual-branch network, and are hierarchically fused for information aggregation. A decoding module is introduced for semantic segmentation and keypoint vector-field prediction. Based on the results of semantic segmentation and keypoint prediction, 6DoF poses of transparent objects are calculated by using Random Sample Consensus (RANSAC) and Least-Squares Fitting. In addition, a new transparent-object 6DoF pose estimation dataset, TDoF20, is constructed, which consists of 61,886 pairs of RGB and depth…
Click any figure to enlarge with its caption.
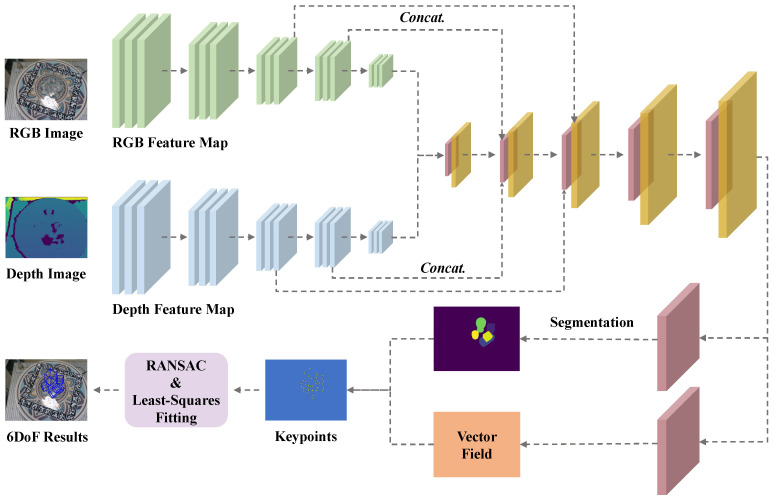 Figure 1
Figure 1 Figure 2
Figure 2 Figure 3
Figure 3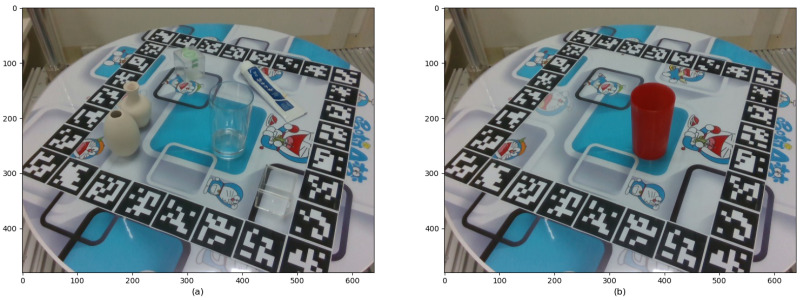 Figure 4
Figure 4 Figure 5
Figure 5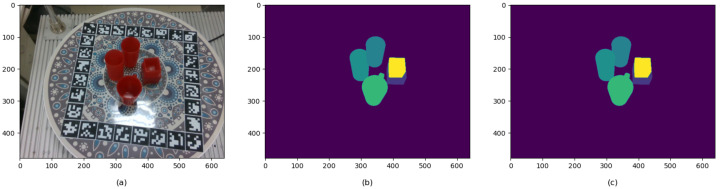 Figure 6
Figure 6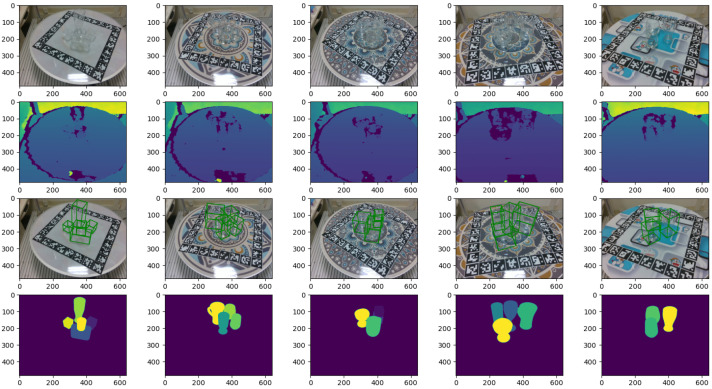 Figure 7
Figure 7 Figure 8
Figure 8- —Fundamental Research Funds for the Central Universities
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsRobot Manipulation and Learning · Robotic Path Planning Algorithms · Soft Robotics and Applications
1. Introduction
6DoF pose estimation aims to estimate the poses of objects, including 3D translation and 3D rotation. With the development of artificial intelligence technology, 6DoF pose estimation plays an important part in a wide range of applications, e.g., robotic grasping [1], industrial bin-picking [2], augmented reality [3], face alignment [4], and autonomous driving [5]. Although existing methods for 6DoF estimation have achieved remarkable success, 6DoF pose estimation of transparent objects remains a great challenge due to their transparency and lack of texture [6].
For non-transparent-object 6DoF pose estimation, several deep learning-based methods have been proposed in the past decade. PoseNet [7] pioneered the work in this field by introducing deep learning to 6DoF pose estimation. Subsequent studies have employed models such as PVNet [8], DenseFusion [9], and FFB6DoF [10], and have progressively improved accuracy through more reliable keypoint extraction or tighter RGB-D feature fusion. Holistic regression frameworks are generally more robust to truncation and occlusion [11], while DenseFusion demonstrated that integrating dense geometric and appearance cues can further boost robustness. PVN3D [12] and FFB6DoF unify pixel-wise keypoint voting with dense RGB-D fusion, bridging the gap between these research lines.
It is worth noting that FFB6DoF introduced a cascade feature fusion strategy, where RGB and depth features are fused at each convolution stage and passed to the next. The RGB sensor captures appearance information, while the depth sensor describes geometry. This cascade feature fusion strategy demonstrated better performance than the extract-then-fuse strategy of DenseFusion. However, RGB and depth belong to distinct domains. Fusing them at every stage can cause mutual interference, which weakens modality-specific feature extraction. This drawback becomes critical for transparent objects because their depth cues are already sparse [13].
In our work, we also investigate 6DoF pose estimation using keypoint prediction and hierarchical feature fusion. Specifically, we propose a hierarchical feature fusion strategy. Unlike the extract-then-fuse and cascade fusion mentioned above, our proposed strategy hierarchically fuses convolutional features. During the encoding process, features at different scales are fused hierarchically and concatenated to decoding layers. By fusing multiple feature maps at different scales, the geometric features of shallow layers and the semantic features of deep layers are fully utilized, improving the accuracy of 6DoF pose estimation for transparent objects. The main contributions of this work are two-fold:
- First, we propose a hierarchical feature fusion network, HFF6DoF, for 6DoF pose estimation of transparent objects. By hierarchically fusing the appearance information from RGB images and the geometry information from depth images, HFF6DoF achieves enhanced features and improved performance for 6DoF pose estimation on transparent objects.
- Second, we construct an RGB-D transparent-object 6DoF pose estimation dataset, TDoF20. This dataset consists of 31,108 single-object samples and 30,778 multi-object samples of 20 transparent objects captured in RGB-D images. Each image is annotated with 6DoF pose values, pixel-wise semantic masks, and restored depth images. This dataset will help promote further research in this field.
2. Related Work
In this section, we briefly review the 6DoF pose estimation methods for non-transparent and transparent objects.
2.1. 6DoF Pose Estimation of Non-Transparent Objects
Holistic methods directly estimate 3D object translation and rotation from images. Classic approaches relied on template matching to select the closest pre-rendered shape [14]. Deep learning methods attempt to regress 6DoF poses directly, either refining them iteratively [15] or discretizing the rotation space [16]. Others use flexible template sets, as well as training models with both rendered and real data [17,18]. The Model-Free Transformer Framework further explores texture-free pose estimation by leveraging geometry-based features from depth data, using transformer architectures to predict rotation and translation jointly without relying on CAD models [19].
Keypoint-based methods compute pose by detecting 2D or 3D keypoints. Typical deep learning-based methods estimate keypoints through heat maps [7,8] or regression [20,21]. PVN3D [12] introduces a 3D keypoint voting network to fully leverage point cloud features, achieving high performance on the LINEMOD [22] and YCB [23] datasets. Recently, CheckerPose [24] sampled a dense set of surface keypoints and refined 2D correspondences with a graph network, maintaining robust pose accuracy even under heavy occlusion. SD-Net [25] addresses symmetry-induced ambiguity in keypoint prediction through a robust 3D keypoint selection strategy and an effective filtering algorithm to eliminate multiple ambiguity and outlier candidates, achieving state-of-the-art performance on bin-picking scenarios. PoseFusion [26] employs a two-level nested U-shaped architecture with multi-scale keypoint correspondence to enhance keypoint refinement and establish accurate 3D-2D point correspondences for camera-to-robot pose calibration.
Dense methods predict 3D coordinates for each pixel and vote for the final result. Early work relied on random forests [27], while deep learning methods adopted CNNs for feature extraction and 3D coordinate prediction [28]. To enhance accuracy and robustness, some methods introduce joint classification and segmentation [29], disentangle rotation and translation [30], use discretized descriptors for dense surface representation [31], or output pose distributions [32].
Handling occlusion and symmetry remains a critical challenge in 6DoF pose estimation. Occlusion-Aware methods [33] leverage depth-guided graph neural networks to model non-adjacent relationships between surface points in occluded scenarios, adaptively fusing mask and binary code semantics to extract effective 2D-3D correspondences. For symmetric objects, PS6D [2] proposes symmetry-aware rotation loss and center-distance sensitive translation loss, using attention-guided multi-scale feature extraction and two-stage clustering to handle slender and multi-symmetric industrial workpieces in bin-picking applications.
Furthermore, PVNet [8], PVN3D [12], and FFB6DoF [10] combine keypoint-based and dense methods. They generate results for each pixel and obtain a set of keypoints through voting. These methods show high performance in the experiments, providing a valuable reference for 6DoF pose estimation of transparent objects.
2.2. 6DoF Pose Estimation of Transparent Objects
The reflective and refractive characteristics of transparent objects present significant challenges for detection, recognition, and 6DoF pose estimation. Early work combined edge distortion and specular cues to classify boundaries of transparent objects [34], but such features do not support reliable segmentation or 3D reconstruction [35]. With advances in hardware, some studies have adopted laser rangefinders [36], depth sensors [37], or structurally polarized light [38] to detect transparent objects. More recently, TA-Stereo [39] segmented transparent regions and homogenized their appearance so that stereo matchers could recover dense disparities over glass surfaces. FuseGrasp [40] extends the sensor repertoire by pairing a synthetic aperture mm-wave radar with the RGB-D input. Its two-stage network first completes the depth, and then refines grasp planning, which improves material recognition accuracy and grasp success.
The increasing adoption of RGB-D sensors has contributed to progress in 6DoF pose estimation for non-transparent objects, yet the depth signal is unreliable for transparent-object pose estimation. Traditional methods detected and recognized objects by extracting the local edges of transparent objects caused by specular reflection or refraction [37]. However, these methods generally lack accuracy under changeable lighting conditions. Some deep learning-based methods directly predict the bounding box of transparent objects [41], or utilize the characteristic of missing depth in transparent objects to locate objects and estimate poses [42]. Recent research has explored various modalities to overcome these limitations. StereoPose [43] replaces active depth with stereopsis, fusing dual-view NOCS maps through parallax attention to produce category-level 6DoF. Sodano et al. [44] designed a double-encoder network that merges RGB and depth features, which strengthens panoptic segmentation and yields more robust transparent-object poses. Keypoints that are invisible due to occlusion or truncation can be effectively inferred [45,46]. To address data scarcity, synthetic datasets have been proposed to enlarge the training corpus [47,48]. Furthermore, ClearPose [49] and TransCG [50] contributed large-scale real-world datasets, focusing on benchmarking pose estimation and depth completion for transparent objects, respectively. Zhang et al. [51] addressed the sim-to-real gap by adapting RGB-D instance segmentation to unseen objects, providing cleaner masks that benefit downstream pose estimation. Zhang et al. [52] and Lin et al. [53] enabled category-level pose estimation that handles previously unseen instances within a known category. ReFlow6D [54] learns a refractive intermediate representation for RGB-only input. Implicit-NeRF Pose [55] optimizes view-dependent radiance fields without CAD models. MVTrans [56] unifies multi-view depth, segmentation, and pose prediction in a single transformer that is trained on the photorealistic Syn-TODD dataset, while Quere et al. [57] leveraged its improved perception to achieve higher grasp success through probabilistic shared control in assistive robots.
Traditional transparent-object pose estimation methods primarily focus on estimating poses in 2D environments or simulated settings. Beyond vision, ACTOR [58] demonstrates that self-supervised tactile exploration can reconstruct category-level shapes and poses from sparse contacts, offering an alternative when transparent objects defeat optical sensors. The growing importance of 6DoF pose estimation in machine vision and industrial robotic applications has driven increased attention to this area [45].
3. Proposed Method
Given an RGB image and a depth image, the task of 6DoF pose estimation is to estimate a rigid transformation . The transformation is composed of a 3D rotation and a 3D translation , .
3.1. Overview
A hierarchical feature fusion network is proposed, as shown in Figure 1. In this network, features are extracted from the RGB and depth images by two separate ResNet34 [59] backbones, and the feature maps from the last three layers are densely fused. The fused features from the final residual layer are passed to the decoding network for up-sampling. The up-sampled features are concatenated with the densely fused features, which are then used for semantic segmentation and vector-field prediction. Finally, 6DoF poses are estimated by applying Least-Squares Fitting on the predicted and predefined keypoints.
3.2. Hierarchical Feature Fusion Network
The process begins with an aligned pair of images: an RGB image and a depth image. Instead of feeding unordered point clouds directly into the network, we construct a 6-channel structured geometry map. Specifically, the depth image is back-projected to align with the RGB image, forming a dense coordinate map ( ). Unlike PVN3D [12] and FFB6DoF [10], which employ PointNet++ [60] to consume unordered points, our structured input allows us to utilize a convolutional neural network to efficiently extract spatially correlated geometric features.
We employ ResNet34 [59] as the backbone encoder for RGB images and structured geometry maps separately. This choice represents a strategic trade-off between efficiency and accuracy. Using deeper backbones would significantly increase computational cost and hinder real-time performance. The hierarchical feature fusion network combines the feature maps from the last three layers. Shallow layers, with a small receptive field and high resolutions, excel in capturing geometric details for smaller objects, while deep layers with a larger receptive field and lower resolutions are better suited for capturing semantic information related to larger objects.
Integrating feature maps from different scales harnesses the geometric strengths of shallow layers and the semantic capabilities of deep layers, resulting in improved 6DoF pose estimation accuracy for transparent objects.
3.3. Semantic Instance Segmentation
After hierarchical feature fusion, the fused features are passed through a convolutional layer to predict a semantic segmentation map, where each value represents the probability that a pixel belongs to a particular object category.
The module enables the network to extract both global and local features, with the aim of segmenting the object of interest, which is crucial for accurate keypoint localization. Moreover, the appearance and geometry information extracted for keypoint vector-field prediction further support semantic segmentation.
3.4. Keypoint Vector-Field Map Calculation
In this paper, we use keypoints to estimate 6DoF poses. Since the keypoint prediction network outputs a keypoint vector-field map, it is essential to calculate the accuracy of this map during training. First, we use the Farthest Point Sampling (FPS) algorithm on the object surface to define a set of keypoints. Then, we calculate the vector-field from the point cloud of the object to the set of keypoints, which serves as the ground truth.
Keypoint selection. Similarly to PVN3D [12] and FFB6DoF [10], we predict 3D keypoints and calculate 6DoF poses using the Least-Squares Fitting algorithm. Keypoint selection follows the FPS algorithm, as employed in PVNet [8]. Initially, the object’s center point is added to the keypoint set, and subsequent keypoints are selected iteratively based on their distance from the existing set until they reach a size of K.
For keypoint prediction, we calculate a vector-field map representing the vectors from each point in the point cloud to the 3D keypoints. This approach emphasizes local features, reduces background interference, and effectively handles occlusion and truncation. Even when a keypoint is not directly visible, the visible keypoints provide sufficient information to infer its position correctly.
The vector-field from the point cloud to each corresponding keypoint is calculated for each object based on semantic labels. These individual vector-fields are then combined to create a vector-field map. Notably, when two objects are occluded, the label corresponds to the foreground object. The unit vector from a point x in the point cloud to a 3D keypoint is computed as follows:
3.5. 6DoF Pose Estimation of Target Objects
Voting-based keypoint localization. Keypoint coordinates are obtained from the predicted keypoint vector-field through a voting process. We generate keypoint hypotheses via RANSAC. Each point in the vector-field map has a unit vector, and we randomly select two points to calculate their intersection if their unit vectors are not parallel. The connection direction from the intersection point to other points is checked against their respective unit vectors, and votes are cast for the intersection point. The point with the highest voting score is selected as the predicted keypoint.
6DoF pose estimation. After determining the K keypoints from the predicted keypoint vector-field map, we calculate the transformation matrix between the predicted keypoints and the keypoints on the object model . The Least-Squares Fitting algorithm minimizes the square loss to solve for the 3D rotation R and 3D translation t,
3.6. Loss Functions
The loss functions include both semantic segmentation and keypoint detection loss. The semantic segmentation loss ensures the network’s predicted segmentation map closely matches the ground truth semantic labels. The keypoint detection loss ensures that the predicted keypoint vector-field map is consistent with the ground truth.
First, a softmax function is used to map the predicted semantic labels to the range . The semantic segmentation loss is formulated as
where N represents the total number of samples, and C is the number of categories. If the true category of sample n is c, equals 1; otherwise, it equals 0. is the predicted probability that the sample n is classified as c.
Then, we use Mean Absolute Error (MAE) to compute the similarity between the predicted keypoint vector-field map and the ground truth as follows:
where is the predicted unit vector, is the ground truth, and M is the total number of points.
The final loss function is the sum of the two loss functions,
where is a balancing weight, empirically set to 2.
4. TDoF20 Dataset
Multiple datasets for 6DoF pose estimation have been constructed for non-transparent objects such as YCB-M [61] and HOPE [62]. However, datasets for transparent objects remain scarce. Liu et al. [63] presented a large-scale stereo image object pose estimation dataset, StereOBJ-1M, where the RGB images were the only data source. KeyPose [45], ClearPose [49], and TransCG [50] provided RGB-D datasets. These datasets were collected using stereo cameras without occlusion or truncation, with each object appearing separately in the image, which fails to reflect the complexity of real-world environments. To address this, we constructed a new dataset, TDoF20, for transparent-object 6DoF pose estimation, which is closer to practical applications. Unlike existing datasets (e.g., ClearGrasp [64] and TransCG [50]), which largely focus on depth completion tasks or simplified single-object scenarios, TDoF20 is specifically designed to address heavy inter-object occlusion and multi-object interaction in robotic grasping scenarios. By providing high-quality 6DoF pose annotations under these complex conditions, TDoF20 serves as a more challenging and realistic benchmark for robust transparent-object perception (https://github.com/MightyCrane/HFF6DoF (accessed on 26 January 2026)), see Figure 2.
4.1. Data Collection
The data collection setup is illustrated in Figure 3. The collection contains 20 single-object scenes and 20 multi-object scenes. In each multi-object scene, 3–5 objects are placed simultaneously. The data collection follows the following steps.
(i) Start the camera and UR5 robot. Next, randomly select a background sticker, and place it on the turntable, then position one or more transparent objects.
(ii) Collect RGB-D data of the transparent objects from four robot arm positions (shooting angles). For each position, the turntable rotates 400 times, at increments of 0.9°. At each increment, a pair of images (an RGB image and a depth image) is captured.
(iii) Replace the transparent object with a non-transparent object of the same shape and size. To minimize alignment errors during this manual replacement, we utilized fixed positioning slots to ensure the pose remained consistent. Then, repeat step ii to collect the images.
(iv) Repeat steps i–iii until all 20 single-object and 20 multi-object scenes are collected.
4.2. Data Processing
After data collection, the following steps are performed to calculate the 6DoF pose and semantic labels, and create a 3D model for each object:
(i) Calculate the transformation matrix between each image and the first image using the Iterative Closest Point (ICP) algorithm applied to point clouds converted from depth images. Since depth images of transparent objects are often incomplete or corrupted, we use the depth images of the corresponding non-transparent objects.
(ii) Reconstruct the scene point cloud using the obtained transformation matrix. Since the depth images of transparent objects may be inaccurate, we rely on depth images from non-transparent objects to reconstruct the point clouds. Based on these poses, we create models of the transparent objects, see Figure 4.
(iii) Generate the transparent-object model using the point cloud obtained in step ii. Initially, we convert the point cloud into a format compatible with CAD software, SolidWorks 2019, and then apply reverse engineering for structural modeling to construct a real-sized object model. Figure 5 provides an example. To obtain the final point cloud of a transparent object, we perform uniform sampling on the model using Monte Carlo sampling in MeshLab.
(iv) Calculate the 6DoF pose and image mask for each image. As the point cloud obtained in step iii is in the camera coordinate system, it needs to be transformed into the object coordinate system to obtain the ground truth 6DoF pose. To calculate the image mask, we project the point cloud in the camera coordinate system onto a 2D plane using the camera’s internal parameters. For images containing multiple objects, a far-to-near projection order is adopted. As shown in Figure 6a, the higher water cup in the front occludes the lower one. Therefore, the lower cup is projected first, followed by the higher one.
In total, the TDoF20 dataset contains 61,886 pairs of RGB and depth images, including 31,108 single-object samples and 30,778 multi-object samples.
5. Experiments
5.1. Datasets
We create a TDoF20-simple subdataset from all the single-object images in the TDoF20 dataset. Both our proposed method and the competitors are trained on two datasets: TDoF20-simple and TDoF20-hard. TDoF20-hard refers to the complete TDoF20 dataset. TDoF20-simple comprises a training set of 26,434 samples and a test set of 4674 samples. TDoF20-hard includes all 20 single-object scenes and 14 multi-object scenes for training, while the remaining 6 multi-object scenes are reserved for testing. The training set contains 52,747 samples, and the test set contains 9139 samples. Figure 7 shows some examples. To prevent data leakage, the TDoF20-hard test set consists of completely unseen scene sequences (Sequences 02, 08, 09, 10, 11, 15) that are physically distinct from the training configurations. Furthermore, during the inference phase, the network takes real, noisy transparent depth maps as input. The opaque depth maps described in Section 4.2 are used solely for offline ground truth generation and do not participate in network forward propagation.
5.2. Evaluation Metrics
We evaluate our method using two common metrics: the 2D projection metric [65] and the Average 3D Distance of model points (ADD) metric [66].
The 2D projection metric calculates the distance between the projected point sets of two 3D models given the estimated pose and the ground truth pose. The ADD metric calculates the distance between two 3D model point sets transformed by the estimated and ground truth poses. The distance is computed for symmetric objects based on the closest point distance.
5.3. Implementation Details
The experiments were conducted on an NVIDIA GTX 1080Ti and Ubuntu 18.04. The core algorithms were implemented using Python 3.7.12 and PyTorch 1.10.0. The proposed network includes two encoders based on ResNet34, both initialized with weights pre-trained on ImageNet. While recent works employing models such as RD3D+ [67] demonstrate the benefits of 3D CNN-based RGB-D pre-training, we opt for 2D ImageNet pre-training to prioritize inference speed. ImageNet weights are highly effective for the geometry branch, as depth maps share similar low-level visual patterns (e.g., edges and textures) with RGB images. During training, the batch size is 8, and the initial learning rate is . Following the design of PVNet, we set the number of keypoints to 9 and the weight of the final loss function to 2.
To evaluate the effectiveness of our method, we selected PVNet [8], DenseFusion [9], and FFB6DoF [10] as baselines. These methods represent state-of-the-art approaches in general RGB-D pose estimation. We excluded stereo-based methods (e.g., KeyPose [45], StereoPose [43]) from direct comparison due to the fundamental modality mismatch (Stereo Vision vs. Monocular RGB-D). Similarly, methods focusing primarily on depth completion (e.g., TransCG [50]) were not included to ensure a controlled evaluation of end-to-end pose estimation performance under standard RGB-D settings.
5.4. Experimental Results and Analysis
Table 1 and Table 2 show the results of the ADD and 2D projection metrics for our proposed method, HFF6DoF, compared to other methods on the TDoF20-simple and TDoF20-hard datasets. Objects with bold names are asymmetric, and the best result for each object across different methods is also highlighted in bold.
As shown in Table 1 and Table 2, the results obtained when the method was trained on TDoF20-simple are significantly higher than those obtained when it was trained on TDoF20-hard. This is primarily due to the simplicity of TDoF20-simple, which contains only single objects without occlusions or truncations. The model benefits from training on transparent objects and backgrounds already seen in the dataset. However, when faced with unseen multi-object combinations, the model’s generalization decreases, leading to a notable drop in accuracy.
Table 1 and Table 2 reveal that HFF6DoF outperforms other methods on the TDoF20 dataset. HFF6DoF achieves a 7.13% higher ADD accuracy on TDoF20-hard compared to DenseFusion, which has the highest accuracy among the other methods. Additionally, HFF6DoF achieves a 2D projection metric accuracy that is 11.91% higher than that of FFB6DoF, which also achieves the best result. This improvement is due to the hierarchical feature fusion in HFF6DoF, which leverages both RGB and depth information more effectively. Unlike cascade fusion, which mixes features layer-by-layer and tends to blur shallow geometric details in deeper layers, our approach preserves independent geometric cues through parallel branches. This is critical for transparent objects, where preserving the subtle, noisy geometric edges from the depth map is key to accurate pose estimation. In contrast, other methods like DenseFusion produce fewer fused features, and FFB6DoF overlooks certain key characteristics. PVNet, which only uses RGB images and lacks depth information, also shows lower pose estimation performance compared to HFF6DoF. The visual comparison of 6DoF pose estimation results for different methods on the TDoF20-hard dataset is shown in Figure 8.
It can also be observed that the accuracy of asymmetric objects is lower than that of symmetric objects, and small objects tend to have lower accuracy than large objects. This is because the calculation for asymmetric objects is stricter compared to that for symmetric ones, which can have more than one valid pose due to symmetry invariance. For example, a centrosymmetric object rotated by 180 degrees should have the same pose, but using a homogeneous matrix to describe the 6D pose results in different representations before and after rotation. Additionally, the ADD metric is calculated by comparing the deviations to 10% of the object’s diameter, making smaller objects more prone to being judged as having an incorrect pose. As shown in Table 1, the results obtained when the method was trained on TDoF20-hard are lower than those obtained when it was trained on TDoF20-simple. This is because in TDoF20-hard, most test samples contain multiple objects, which can occlude each other. Smaller objects may experience more occlusion, leading to reduced accuracy. This drop validates TDoF20 as a challenging benchmark designed to simulate realistic, cluttered robotic scenarios, pushing the boundaries of robust perception.
We further evaluated the efficiency of our model, as shown in Table 3. HFF6DoF achieves an inference speed of 29.38 FPS. It is noteworthy that, while our dual-stream architecture naturally increases the parameter count (56.82 M) compared to single-stream methods like DenseFusion, our method achieves the lowest computational cost in terms of FLOPs (85.12 G), which is significantly lower than that of DenseFusion (142.25 G) and FFB6DoF (215.54 G). This demonstrates that our hierarchical fusion design efficiently aggregates features without incurring excessive computational overhead, making it highly suitable for deployment on resource-constrained robotic platforms.
5.5. Ablation Studies
Effect of feature fusion layers. We evaluate HFF6DoF on TDoF20-hard using different numbers of feature fusion layers, ranging from 1 to 5. Our experiments show that the highest ADD of 50.50% is achieved with three fusion layers, after which the performance stabilizes. Fusing texture and geometric features from different scales helps the network capture both semantic and detailed information, improving performance.
Effect of semantic segmentation modules. We also evaluated our method with and without the semantic segmentation module. According to the experimental results, the accuracy on the ADD and 2D projection metrics is improved by 8.52% and 2.63% by using the segmentation module. The semantic segmentation module promotes 6DoF pose estimation of transparent objects based on 3D keypoint detection. It assigns a semantic label to each pixel of images and separates transparent objects from scenes, helping the keypoint detection module better locate keypoints.
5.6. Generalization on Non-Transparent Objects
To further validate the generalization ability of our proposed HFF6DoF and address the concern regarding evaluation on public benchmarks, we conducted additional experiments on the YCB-Video dataset [23]. YCB-Video is a widely used benchmark for 6DoF pose estimation of non-transparent objects, containing 21 objects with diverse textures and shapes. Table 4 presents the quantitative comparison results using the ADD(S) metric. Bold object names indicate symmetric objects. The “ADDS” column treats all objects as symmetric, while the “ADD(S)” column applies the standard metric (ADD for non-symmetric, ADD-S for symmetric).
As shown in Table 4, our method achieves an average ADD(S) accuracy of 91.5%, which is highly competitive compared to methods designed specifically for non-transparent objects, such as DenseFusion and PVN3D, and is comparable to FFB6DoF. Notably, HFF6DoF achieves the best performance on several specific objects, including 005_tomato_soup_can and 036_wood_block. These results demonstrate that although HFF6DoF is tailored for the challenging task of transparent-object pose estimation, its hierarchical fusion architecture is inherently robust and effective for opaque objects as well. This confirms that our method does not rely on transparency-specific priors (which would fail on opaque objects) but rather learns a generalized representation of geometry and appearance.
6. Conclusions
A hierarchical feature fusion network, HFF6DoF, was proposed for 6DoF pose estimation of transparent objects. The network densely fuses feature maps to make comprehensive use of RGB and depth information. A new dataset, TDoF20, was constructed, containing 61,886 pairs of RGB and depth images covering 20 types of objects in real-world scenarios. The experimental results showed that HFF6DoF outperforms state-of-the-art approaches on the TDoF20 dataset, achieving an average ADD of 50.5%. Ablation studies further demonstrated that the semantic segmentation module enhances feature extraction and overall performance. Furthermore, experiments on the YCB-Video dataset validated that HFF6DoF effectively generalizes to non-transparent objects without modification, suggesting its potential as a unified framework for mixed-material scenarios. Limitations remain regarding sensitivity to strong specular highlights that corrupt depth data. Future work will focus on addressing this limitation and exploring domain-specific pre-training to further enhance robustness in complex environments.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Zhu X. Wang X. Freer J. Chang H.J. Gao Y. Clothes grasping and unfolding based on RGB-D semantic segmentation Proceedings of the 2023 IEEE International Conference on Robotics and Automation (ICRA)London, UK 29 May–2 June 202394719477
- 2Yang Y. Cui Z. Zhang Q. Liu J. PS 6D: Point cloud based symmetry-aware 6D object pose estimation in robot bin-picking Proceedings of the 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)Abu Dhabi, United Arab Emirates 14–18 October 202471677174
- 3Michel F. Kirillov A. Brachmann E. Krull A. Gumhold S. Savchynskyy B. Rother C. Global hypothesis generation for 6D object pose estimation Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)Honolulu, HI, USA 21–26 July 2017462471
- 4Albiero V. Chen X. Yin X. Pang G. Hassner T. img 2pose: Face alignment and detection via 6Do F face pose estimation Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)Colorado Springs, CO, USA 20–25 June 201176177627
- 5Zakharov S. Shugurov I. Ilic S. DPOD: 6D pose object detector and refiner Proceedings of the IEEE International Conference on Computer Vision (ICCV)Seoul, Republic of Korea 27 October–2 November 201919411950
- 6Kuang Y. Han Q. Li D. Dai Q. Ding L. Sun D. Zhao H. Wang H. STOP Net: Multiview-based 6-Do F suction detection for transparent objects on production lines Proceedings of the 2024 IEEE International Conference on Robotics and Automation (ICRA)Yokohama, Japan 13–17 May 202453895396
- 7Kendall A. Grimes M. Cipolla R. Pose Net: A convolutional network for real-time 6-Do F camera relocalization Proceedings of the IEEE International Conference on Computer Vision (ICCV)Santiago, Chile 13–16 December 201529382946
- 8Peng S. Liu Y. Huang Q. Zhou X. Bao H. PV Net: Pixel-wise voting network for 6Do F pose estimation Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)Long Beach, CA, USA 15–20 June 201945614570