VTC-Net: A Semantic Segmentation Network for Ore Particles Integrating Transformer and Convolutional Block Attention Module (CBAM)
Yijing Wu, Weinong Liang, Jiandong Fang, Chunxia Zhou, Xiaolu Sun

TL;DR
This paper introduces VTC-Net, a new image segmentation model that improves accuracy in analyzing ore particle sizes for mineral processing.
Contribution
VTC-Net combines Transformer modules and CBAM with VGG16 to enhance segmentation of ore particles with complex features.
Findings
VTC-Net achieved 89.90% MIoU and 96.80% pixel accuracy on ore image datasets.
The model outperformed UNet and DeepLabV3 in handling multi-scale and occluded ore particles.
Ablation studies confirmed the effectiveness of the Transformer and CBAM modules.
Abstract
In mineral processing, visual-based online particle size analysis systems depend on high-precision image segmentation to accurately quantify ore particle size distribution, thereby optimizing crushing and sorting operations. However, due to multi-scale variations, severe adhesion, and occlusion within ore particle clusters, existing segmentation models often exhibit undersegmentation and misclassification, leading to blurred boundaries and limited generalization. To address these challenges, this paper proposes a novel semantic segmentation model named VTC-Net. The model employs VGG16 as the backbone encoder, integrates Transformer modules in deeper layers to capture global contextual dependencies, and incorporates a Convolutional Block Attention Module (CBAM) at the fourth stage to enhance focus on critical regions such as adhesion edges. BatchNorm layers are used to stabilize…
Click any figure to enlarge with its caption.
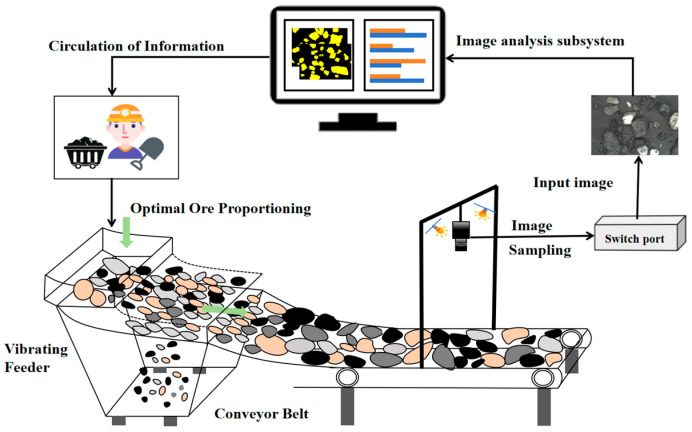 Figure 1
Figure 1 Figure 2
Figure 2 Figure 3
Figure 3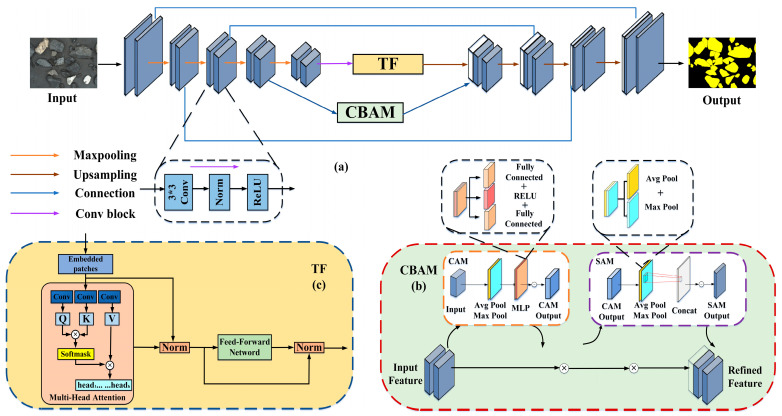 Figure 4
Figure 4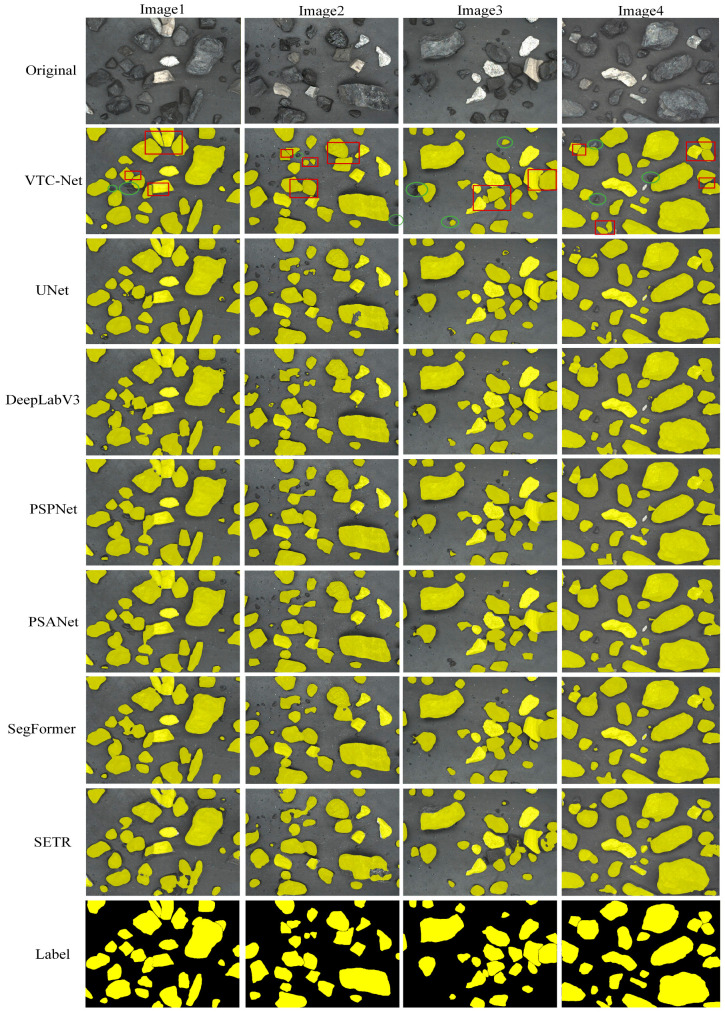 Figure 5
Figure 5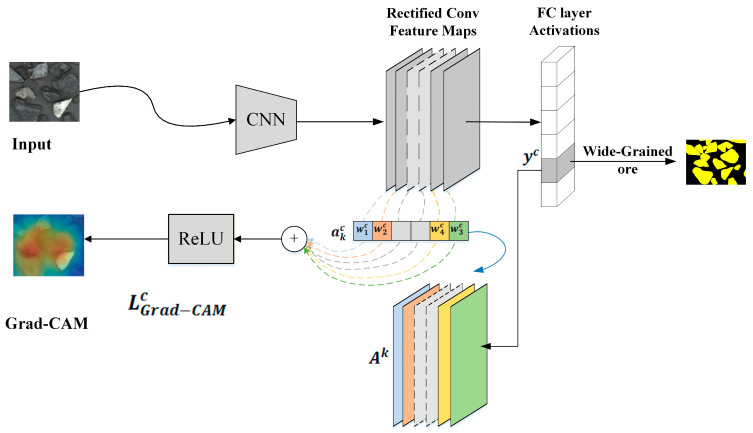 Figure 6
Figure 6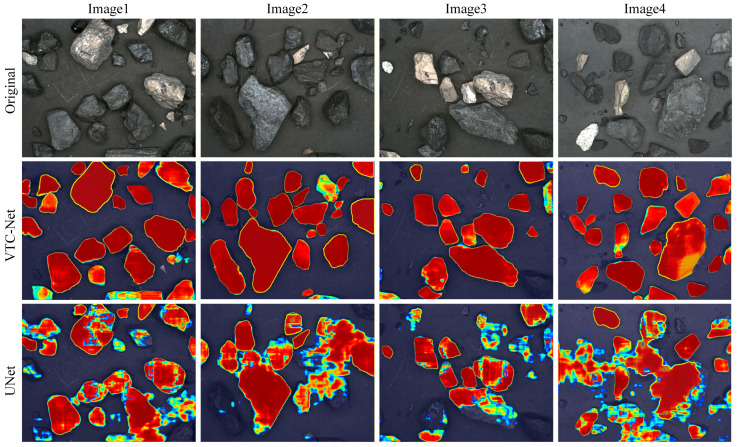 Figure 7
Figure 7- —Natural Science Foundation of Inner Mongolia Autonomous Region
- —Basic and Applied Basic Research Science and Technology Program Projects of Hohhot
- —Industrial Technology Innovation Program of IMAST
- —Inner Mongolia Scientific and Technological Project
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsMineral Processing and Grinding · Minerals Flotation and Separation Techniques · Geochemistry and Geologic Mapping
1. Introduction
In mineral processing, the particle size distribution of feed materials and products is a key indicator for assessing ore processability. It also provides critical guidance for adjusting operational parameters in crushing, screening, and sorting circuits [1,2,3]. Visual-based online particle size analysis systems must first segment individual particles from conveyor belt images to derive size distributions, where the accuracy of segmentation directly determines the reliability of subsequent statistical analysis. However, inherent particle adhesion and occlusion within ore particle clusters often lead to blurred or indistinct boundaries, which remains a primary constraint on the precision of visual inspection systems [4,5,6].
Traditional image processing methods for ore segmentation mainly include thresholding, region-based analysis, edge detection, and watershed algorithms [7,8,9]. While effective for images with clear particle contours and simple backgrounds, these methods demonstrate limited accuracy when dealing with complex, adhering, and overlapping ore particle clusters. With advances in deep learning, convolutional neural network-based segmentation has become the mainstream approach. Representative architectures such as FCN, UNet, and DeepLabV3, leveraging their powerful multi-scale feature extraction capabilities, have significantly improved segmentation performance [10,11,12]. To further address the challenges of adhesion and stacking, researchers have proposed various enhanced algorithms. For example, Li et al. [13] introduced a two-stage detection-guided segmentation framework (Det-SAM-Ore), which locates ore particles, generates bounding boxes, and feeds them into the Segment Anything Model (SAM) to achieve precise segmentation, improving efficiency across multiple ore types. Yang et al. [14] increased model sensitivity to ore boundaries by incorporating contour-aware loss functions and using a pre-trained VGG16 as the encoder. Deo et al. [15] proposed an improved UNet with normalization layers and 1 × 1 convolutional modules to reduce computational complexity, effectively enhancing real-time performance and accuracy in segmenting iron ore pellets for size analysis. Wang et al. [16] developed a lightweight ReUNet model that showed strong performance across several public datasets. Collectively, these studies have focused on edge precision, multi-scale feature fusion, and model lightweighting. Nevertheless, many models still tend to prioritize larger ore particles, often overlooking finer particles that exhibit severe adhesion, particularly in datasets rich in small particle sizes.
To address the complexities of real-world industrial scenarios, Fu et al. [17] proposed integrating Simple Linear Iterative Clustering (SLIC) with UNet, treating ore particle contours as an independent category for three-class segmentation. This method demonstrated superior performance over traditional watershed algorithms on industrial conveyor belts. Wang et al. [18] developed MSBA-UNet, which combines multi-scale connectivity and boundary awareness, utilizing convex hull defect detection to separate deeply concave adhered particles and achieving precise classification of boundary pixels. Liu et al. [19] designed a two-stage network that first obtains preliminary segmentation results using UNet and then refines them with a self-training network to enhance accuracy. Zhang et al. [20] introduced OIS-Net for conveyor belt ore image segmentation, effectively improving feature fusion and showing good performance on single-type ore datasets. Although these studies partially account for practical transportation conditions, most enhanced methods still struggle with multi-scale, heavily adhered ore clusters exhibiting high textural similarity.
In mineral processing, particle clusters consist of ores with diverse sizes and compositions. Significant size variations often cause fine particle features to be overlooked, while inter-particle adhesion, shared boundaries, and similar gray scale values further complicate segmentation [21,22,23,24,25]. As a result, existing models show limited generalization under complex conditions, frequently leading to undersegmentation (merging of adjacent particles) and misjudgment (incorrect identification of non-ore regions). To overcome these challenges, this study proposes a semantic segmentation model for ore particles that integrates Transformer, BatchNorm, and CBAM attention mechanisms, aiming to improve segmentation accuracy across multi-scale ore particle clusters.
2. Methodology for Image Data
2.1. Datasets Collection
In mineral processing, a typical setup for visual-based particle size detection is illustrated in Figure 1. Ore material is first uniformly distributed onto a conveyor belt via a feeder or vibrating screen. An industrial camera, mounted above the belt, captures real-time images of the material flow. After preprocessing, these images are input into a trained segmentation model to perform online particle size recognition. The detection results are instantly fed back to the control system, providing operational guidance for subsequent sorting or for adjusting preceding crushing and screening stages [26]. To replicate actual working conditions, a laboratory image acquisition platform was established, as shown in Figure 2. The platform consists of a belt conveyor, an industrial camera (HIKVISION MV-CA004, Hangzhou, China), a lens (HIKVISION ZX-SF1214B, Hangzhou, China), and a linear light source (KOMAVISION KM-2BRD6020, Shenzhen, China) [27]. The experiments focused on raw coal fed into coal preparation processes, with particle sizes ranging from 13 mm to 100 mm. It should be noted that while the proposed VTC-Net model framework is designed for broad application in mineral processing (including coal, metallic, and non-metallic ores), the experimental validation and performance analysis presented in this paper are based specifically on raw coal (13–100 mm particle size) as the experimental validation material. Therefore, in the subsequent sections detailing the experiments, we will consistently use ‘raw coal’ to refer to the target material.
2.2. Data Preprocessing
To ensure the quality of the dataset, invalid images were removed and 500 images (resolution 720 × 540 pixels) were ultimately retained. Image annotation was performed using the Labelme (version 4.5.12) tool. For ambiguous particle boundaries, the point of maximum gradient change was marked by the annotators. Adhering particles with no visible separation were labeled as a single object, which aligns with the practical requirements of particle size analysis. A binary segmentation framework was adopted, as the core objective is to segment raw coal particles from the industrial background. Consequently, each pixel was assigned one of two mutually exclusive labels: ‘raw coal’ or ‘background’. For the evaluation metrics (e.g., MIoU, MPA), the total number of classes C is therefore 2. This labeling strategy directly supports the goal of accurately identifying and delineating individual particles on the conveyor belt for subsequent size analysis.
To enhance the model’s generalization capability, data augmentation techniques [28,29] were employed to expand the dataset, including color enhancement (0.5–1.5), random rotation (0–45°), flipping and cropping (0.8–1.2). To simulate lighting variations and changes in camera angles that may occur in real-world industrial environments, four enhancement techniques were randomly applied to each image during the process, with multiple methods allowed to be combined on the same image. As illustrated in Figure 3, this process increased the total number of images to four times the original size. The dataset was then split into training, validation, and test sets in an 8:1:1 ratio. Furthermore, all original images were resized to 512 × 512 pixels via bilinear interpolation [30] to accelerate model training.
3. Methods
3.1. VTC-Net Architecture
The architecture of the proposed VTC-Net is illustrated in Figure 4. The encoder employs VGG16 as its backbone for feature extraction. Each stage of the encoder consists of a convolutional block followed by a downsampling layer. The convolutional block uses 3 × 3 convolutions (stride = 1, padding = 1), each paired with a ReLU activation function and a BatchNorm layer. The BatchNorm layers standardize the inputs across the network during training, stabilizing gradient flow in deep feature learning and improving training efficiency. Downsampling is performed via 2 × 2 max-pooling layers (stride = 2), which reduce spatial resolution while expanding the receptive field to capture more abstract, global features.
To strengthen the model’s representational capacity, a Transformer module is integrated into the deepest layer of the backbone to model long-range contextual dependencies. Additionally, a Convolutional Block Attention Module (CBAM) is incorporated at the fourth feature stage to enhance focus on target raw coal regions within complex, mixed particle clusters.
The decoder reconstructs the segmented raw coal image through progressive upsampling and skip connections. At each decoder level, the input feature map is first upsampled via transposed convolution. It is then concatenated with the corresponding feature map from the encoder via skip connections, thereby preserving both high-level semantic information and low-level edge details. The fused features are subsequently refined through convolutional layers with progressively reduced channel dimensions (512, 256, 128, 64), ultimately producing a high-resolution segmentation map of the coal particles [31,32,33].
3.1.1. CBAM Attention Mechanism
To enhance the model’s capacity to recognize critical raw coal particle regions and weak boundaries, a Convolutional Block Attention Module (CBAM) is incorporated into the fourth encoder stage. This module adaptively generates channel-wise and spatial attention weights, enabling the network to concentrate on key features such as particle edges and adhesion zones while effectively suppressing interference from conveyor belt background noise. Consequently, segmentation accuracy under complex adhesive conditions is improved. As illustrated in Figure 4b, the CBAM comprises an input layer, a channel attention module, a spatial attention module, and an output layer [34]. Its computational procedure is as follows:
In the channel attention stage, the input feature map undergoes max pooling and average pooling operations in spatial dimensions, respectively, generating two channel description vectors to reflect each channel’s response intensity in the global space.
The two vectors are then fed into the shared two-layer MLP for mapping, with the Sigmoid function generating attention weights for each channel.
where denotes the Sigmoid function, which generates channel attention weights .
Finally, the generated channel attention weights are channel-wise multiplied , with the original feature map to enhance key channel information.
In the spatial attention stage, the feature maps enhanced by channel attention undergo max pooling and mean pooling along the channel dimensions, generating two-dimensional spatial representations that, respectively, capture maximum and average responses.
Subsequently, the two spatial maps are spliced along the channel dimension, and feature fusion is performed using a 7 × 7 convolution kernel to generate attention weight maps for each spatial position.
Finally, the spatial attention and channel-enhanced feature map are multiplied with the input feature to enhance key spatial positions, thereby suppressing background interference and highlighting the raw coal target region in the feature map.
Through this two-stage attention mechanism, the CBAM output feature map is significantly enhanced in both the channel and spatial dimensions. This enhancement enables the network to more accurately highlight target ore regions when processing mixed ore particles of varying sizes, thereby mitigating the adverse effects of particle adhesion and multi-scale variations.
3.1.2. Transformer Blocks
As shown in Figure 4, a Transformer module is integrated into the deepest layer of the backbone network to address the inherent characteristics of multi-granular ore images. Utilizing a multi-head self-attention mechanism, the module establishes long-range dependencies across different regions of the image and enhances multi-scale information interaction through feature fusion. This design compensates for a key limitation of purely convolutional architectures—their local receptive fields, which often fail to capture relationships between distant ore particles within the same image. By enabling the simultaneous integration of local texture details and global contextual cues, the model’s ability to represent complex spatial structures is substantially improved [35,36]. Figure 4c illustrates the architecture of the Transformer module, which processes the input feature map through the following computational steps:
First, the input feature map is divided into a sequence of non-overlapping patches. Each patch is linearly projected into a -dimensional vector . A learnable position embedding is then added to the sequence, resulting in the input representation .
For the input feature , trainable weight matrices , are used to map it into query (Q), key (K), and value (V) matrices, respectively.
where represent the single-head attention dimension for the calculation of attention weights as follows.
The outputs of multiple attention heads are computed in parallel, concatenated, and then projected through the linear transformation to obtain the multi-head self-attention output . This output is then added to the original input via a residual connection, followed by layer normalization, yielding the intermediate representation after the MHSA stage.
The resulting representation is then passed through a two-layer feedforward neural network (FFN) for nonlinear transformation. Subsequently, a residual connection is applied, followed by another layer normalization operation, producing the final output . This output effectively integrates both global contextual information and non-local structural features.
where and are the weight matrices for the first and second fully connected layers.
3.2. Parameter Settings
On the hardware side, the experimental platform was equipped with an Intel^®^ Core™ i9-10900X CPU and an NVIDIA GeForce RTX A5000 GPU, along with 32 GB of RAM. For the software environment, the model was developed using TensorFlow 2.5 and Python 3.8, with CUDA 11.4 and cuDNN 8.2.2 configured to enable GPU-accelerated computing. The detailed hyperparameter settings of the model are provided in Table 1.
3.3. Loss Function
The improved Focal Loss and Dice Loss were combined to form a joint loss function system, as expressed in Equations (15) and (16). During model training, Dice Loss primarily ensures precise segmentation between raw coal and background regions, preserving the contour integrity of coal particles. Meanwhile, Focal Loss focuses on hard-to-distinguish samples by down-weighting the contribution of easy examples, thereby enhancing the model’s robustness against class imbalance and ambiguous boundaries. Specifically, this is achieved by adjusting weights for different samples by and implementing a dynamic weight mechanism through . The coordinated use of these two losses significantly improves the model’s ability to delineate indistinct raw coal boundaries and adhesion regions under complex imaging conditions [37].
where N refers to the total number of samples, C denotes the total number of classes, the true label of sample i in class c is represented by , while the predicted probability of sample i in class c by the model is indicated by . is the class balancing factor in the Focal Loss to address the imbalance between positive and negative samples. The probability of sample i being predicted as positive is denoted by and the Focal Loss focus parameter is specified by .
3.4. Evaluation Indicators
To quantitatively evaluate the performance of the segmentation model, a set of standard metrics is employed, with Mean Intersection over Union (MIoU), Mean Pixel Accuracy (MPA), and overall Accuracy serving as the primary evaluation criteria [38,39], as detailed in Equations (17)–(19).
Here, represents the total number of classes; denotes the number of correctly classified pixels for a certain class; indicates the number of pixels falsely predicted as this class; and refers to the number of pixels that actually belong to this class but are incorrectly predicted as other classes. A higher MIoU value reflects better segmentation consistency across all classes.
Here, represents the total number of classes. A higher MPA value indicates more stable pixel classification accuracy within each category.
is the number of negative classes correctly predicted as negative. The higher the Accuracy value, the stronger the model’s ability to distinguish between positive and negative classes.
By integrating MIoU, MPA, and Accuracy, a multidimensional evaluation framework is established, enabling a holistic assessment of semantic segmentation models in terms of segmentation consistency, within-class accuracy, and overall predictive performance. This comprehensive approach offers precise, actionable insights for subsequent model optimization.
3.5. Cross-Validation Experiments
To evaluate the model’s stability and generalization capability, a five-fold cross-validation strategy was employed. Specifically, the training and validation sets were combined into a single dataset (a total of 1800 images), which was then evenly partitioned into five subsets. In each round of experimentation, four subsets were used as the training set, while the remaining subset served as the validation set. The model was trained following the same procedure in each round, and performance was evaluated on the corresponding validation set using metrics including MIoU, MPA, and Accuracy. The mean, standard deviation, and variance of these metrics were then computed. This approach effectively mitigates the randomness inherent in single-round data partitioning, providing a more reliable assessment of the model’s performance. Experimental results are presented in Table 2.
As shown in Table 2, the average MIoU under five-fold cross-validation was 84.67% with a standard deviation of 0.64%. The small fluctuation range and low standard deviation of MIoU indicate that the model exhibits good stability under different data partitioning conditions. Additionally, the standard deviations for MPA and Acc were 0.70% and 0.15%, respectively, further validating the model’s stable performance. Based on the cross-validation results, the model demonstrating optimal performance on the validation set was selected for final evaluation on the test set. The performance comparison of the optimal model on the validation and test sets is presented in Table 3.
4. Discussion of the Results
4.1. Discussion on the Position of Adding CBAM
This section investigates the impact of integrating the CBAM attention module at different network stages by inserting it individually into the Feat1, Feat2, Feat3, and Feat4 layers. The corresponding prediction accuracies are summarized in Table 4.
Experimental results indicate that the placement of the CBAM module significantly affects model performance, with the deepest feature extraction stage yielding the best outcomes. Introducing CBAM solely at the Feat4 layer achieved the highest MIoU (88.30%), substantially outperforming placements at shallower layers such as Feat1 (85.80%) and Feat2 (85.95%). This discrepancy arises from the scale and semantic characteristics of the feature maps at each stage. In the Feat1 and Feat2 stages (with resolutions reduced to 256 × 256 and 128 × 128, respectively), features primarily contain low-level information such as texture and noise, while stable semantic structures are still underdeveloped. Applying CBAM at these stages tends to direct attention to irrelevant local details, which may interfere with the learning of deeper, more discriminative representations. In contrast, features at the Feat3 and Feat4 stages exhibit stronger semantic expression and retain more meaningful spatial structures. Here, CBAM can effectively highlight critical regions—such as adhesion boundaries between particles—thereby significantly improving segmentation accuracy. Notably, combining CBAM across multiple layers did not improve performance and even slightly underperformed compared to using it only at Feat4. This suggests that a single, strategically placed attention module in the deepest feature layer is sufficient, while adding more may introduce redundancy without gains. Therefore, deploying CBAM exclusively in the deepest layer (Feat4) represents an optimal strategy for balancing accuracy and computational efficiency.
4.2. Attention Mechanism Comparison Experiment
Different attention mechanism modules were integrated into the fourth layer of the backbone network, and their performance on the multi-granular coal validation set is shown in Table 5. It can be observed that the CBAM attention mechanism achieves the best result, with an MIoU of 88.30%, outperforming single dimensional attention mechanisms such as SE and ECA. This confirms the effectiveness of combining both channel and spatial attention. Compared with the CA mechanism, which also employs dual dimensional attention, the serial structure of CBAM yields slightly superior performance. These results indicate that in deeper feature layers, CBAM’s sequential filtering strategy can more accurately capture key details such as adhesion boundaries between coal particles, achieving an optimal balance between performance and efficiency.
4.3. Ablation Experiments
In the ablation experiments, we compared the effects of Transformer module, BatchNorm module, and CBAM module on model performance. The results are presented in Table 6.
Based on the ablation experiments results presented in Table 6, the Transformer module, the CBAM module, and the BatchNorm module all contribute to improving the performance of the base UNet model, with the first two exhibiting complementary effects. Introducing the Transformer module alone increases the MIoU by 2.29%, which surpasses the gain of 0.34% achieved by adding only the CBAM module. This indicates that global context modeling contributes more substantially to segmentation accuracy. When both modules are combined, the MIoU further rises to 88.73%, demonstrating the synergistic effect of the dual attention mechanism. Ultimately, VTC-Net achieves the best performance with an MIoU of 89.90%, confirming the effectiveness and necessity of the proposed architecture.
4.4. Comparative Experiments
The VTC-Net model was compared with classical networks including UNet, DeepLabV3, PSPNet, PSANet, SegFormer, and SETR. UNet employs special skip connections to enhance the model’s ability to recover object edges and details [40]. DeepLabV3 introduces multi-scale hollow convolution modules to improve multi-scale object recognition and segmentation accuracy [41]. PSPNet utilizes pyramid pooling structures to fully leverage global contextual information [42]. PSANet achieves effective fusion of shallow and deep features through parallel self-attention mechanisms [43]. SegFormer employs a lightweight Transformer architecture to capture both global and local features, thereby enhancing multi-scale segmentation capability [44]. SETR enhances segmentation performance across various scenarios by partitioning images into sequences and modeling global information through self-attention mechanisms [45]. All comparison algorithms were trained under identical conditions as VTC-Net. Table 7 presents the accuracy, intersection–union ratio, and pixel precision of each network.
Experimental results demonstrate that VTC-Net outperforms mainstream segmentation networks on multi-granularity raw coal datasets, achieving the highest Mean Intersection Union (MIoU) score while delivering optimal performance in both Mean Pixel Accuracy (MPA) and Classification Accuracy (Acc). Although VTC-Net is not optimal in terms of model parameters (Params), computational complexity (GFLOPs), and single-frame inference speed (Inference Speed). However, for the specific task of online calculation of ore particle size distribution during transportation, real-time performance does not require millisecond-level response times. Instead, it prioritizes minute-level statistical accuracy, with segmentation precision being of greater importance. The improvements in VTC-Net’s MIoU, MPA, and Acc metrics make it more suitable for this application scenario. These findings validate the effectiveness and superiority of the proposed architecture for complex coal particle segmentation tasks.
Figure 5 presents the segmentation results of four sample images processed by different models. Compared to UNet, DeepLabV3, PSPNet, PSANet, SegFormer and SETR, the proposed VTC-Net demonstrates notably superior performance in segmenting multi-granular coal particles. The image simultaneously displays multi-scale raw coal samples, with distinct variations in scale. Red rectangular boxes highlight regions where undersegmentation commonly occurs, while blue circular boxes indicate areas prone to misclassification. Within the circular regions, VTC-Net achieves nearly error free identification and significantly reduces undersegmentation in the rectangular areas. For the segmentation of multi-grain-size ore (Images 1–4), VTC-Net maintains robust and consistent performance across varying grain scales, substantially mitigating errors in fine coal classification and excessive fusion of coarse coal. For coal particles with similar sizes and adhering edges (Images 1–4), the four benchmark models still exhibit noticeable errors, including residual adhesion between particles, misclassified regions, and merged segments of different sizes. In contrast, VTC-Net maintains high segmentation accuracy in most cases and effectively separates adhered particle boundaries.
Beyond the annotated regions, VTC-Net also shows stronger capability in recognizing multi-granular particles, with lower misclassification rates and more precise boundary delineation. While other models display partial errors or undersegmentation, VTC-Net accurately outlines particle contours and distinguishes adhesive interfaces clearly. The VTC-Net model demonstrates superior performance in segmentation scenarios characterized by coexisting multi-scale variations and adhesions. These results confirm VTC-Net’s ability to overcome challenges posed by complex backgrounds and substantially improve edge segmentation precision.
4.5. Feature Visualization and Analysis
Feature visualization is essential for analyzing the key regions on which a model focuses and for guiding model optimization. Currently, mainstream visualization methods include Feature Map, CAM, and Grad-CAM [46]. Compared to the first two, Grad CAM does not require architectural modifications and offers stronger generalization, making it the primary choice for complex scenarios. The structure of the Grad-CAM network is shown in Figure 6. In challenging conditions such as particle adhesion or stacking, the Grad-CAM algorithm utilizes gradient information to capture the model’s priority of attention toward adhering ore particles. This further enables the analysis of differences in the network’s response intensity at ore boundary regions, helping to understand why the model makes certain predictions in ore segmentation tasks.
Figure 7 displays the Grad-CAM results of VTC-Net and the baseline UNet network. Red indicates high activation in the region, while blue represents weak activation in the predicted category. The analysis reveals that the classical UNet model struggles with accurate positioning of raw coal targets, particularly in effectively identifying and segmenting adhered coal particles. In contrast, VTC-Net demonstrates significantly larger active regions for coal particles, achieving more precise alignment with their actual contours and showing heightened focus on adhered coal particles. Therefore, the proposed VTC-Net outperforms the baseline in segmenting adhered coal particles.
5. Conclusions
To address the semantic segmentation challenges in mineral processing caused by multi-scale particle coexistence and particle adhesion, this study proposes a VTC-Net segmentation model that integrates Transformer, CBAM attention mechanism, and BatchNorm. Through systematic experimental analysis, the key findings are as follows:
- (1)The VTC-Net model effectively mitigates the common issues of “undersegmentation” and “misjudgment” in traditional methods for complex raw coal images. It achieves optimal segmentation performance (MIoU of 89.90%) on the validation set, significantly outperforming multiple classical segmentation networks. This demonstrates the architecture’s distinct advantage in enhancing segmentation accuracy for multi-scale, highly cohesive coal particles.
- (2)Ablation experiments demonstrate that the introduced Transformer module, CBAM module, and BatchNorm layer all significantly enhance model performance. The Transformer’s global context modeling capability and CBAM’s channel-space dual attention mechanism complement each other synergistically, enabling a more comprehensive capture of both long-range dependencies between raw coal samples and local feature details.
- (3)The placement of the CBAM module significantly impacts performance. Its optimal placement is at the deep encoder layer (Feat4), where the feature carries richer semantic information, enabling the attention mechanism to more precisely enhance the raw coal target region and weak boundaries.
- (4)The feature visualization (Grad-CAM) results demonstrate that, compared to the baseline model, the active regions of VTC-Net align more closely with the actual raw coal contours, with heightened focus on adhered areas, which intuitively explains the performance improvement.
In conclusion, the proposed VTC-Net model provides a high-precision inspection solution for online ore particle size analysis, offering practical value for advancing intelligent detection and control in mineral processing. Although the data augmentation strategies employed in this paper simulate common imaging conditions such as lighting variations and viewpoint changes to a certain extent, they still struggle to fully account for the complex factors that may exist in real industrial scenarios. Therefore, future work will focus on: (1) Collecting industrial data across diverse scenarios and ore types—including dust occlusion, severe motion blur, and intense camera shake—while expanding datasets with industry-specific augmentation techniques (e.g., simulating dust or mist) to enhance model generalization in complex environments; (2) Further reducing model complexity and accelerating inference speed to integrate the proposed segmentation model into actual ore processing and online inspection systems. This will enable field deployment and real-time performance validation, advancing the method toward engineering implementation.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Wang W. Li Q. Zhang D. Li H. Wang H. A survey of ore image processing based on deep learning Chin. J. Eng.20234562163110.13374/j.issn 2095-9389.2022.01.23.001 · doi ↗
- 2Zhao S. Zhan Y. Niu W. EU-Net and ACFS: An effective method for segmenting ore images collected on-site J. King Saud Univ. Comput. Inf. Sci.2025373510.1007/s 44443-025-00042-1 · doi ↗
- 3Wang W. Li Q. Xiao C. Zhang D. Miao L. Wang L. An Improved Boundary-Aware U-Net for Ore Image Semantic Segmentation Sensors 202121261510.3390/s 2108261533917873 PMC 8068300 · doi ↗ · pubmed ↗
- 4Chai X. Wu Z. Li W. Fan H. Sun X. Xu J. Image Segmentation Based on the Optimized K-Means Algorithm with the Improved Hybrid Grey Wolf Optimization: Application in Ore Particle Size Detection Sensors 202525278510.3390/s 2509278540363223 PMC 12074254 · doi ↗ · pubmed ↗
- 5Long Y. Cai B. Hu J. Hu W. Yang W. Zhang W. Qin Q. YOL Ov 8-ORE: An Efficient Ore Segmentation Network based on Adaptive Feature Extraction and Attention-Enhanced Spatial Fusion Signal Image Video Process.202519128010.1007/s 11760-025-04861-7 · doi ↗
- 6Zhang H. Chen G. Li H. Research on segmentation and reconstruction of overlapping ore contours based on EAM-SOL Ov 2 and convex hulls Signal Image Video Process.2024185987599510.1007/s 11760-024-03286-y · doi ↗
- 7Budzan S. Buchczik D. Pawełczyk M. Tůma J. Combining Segmentation and Edge Detection for Efficient Ore Grain Detection in an Electromagnetic Mill Classification System Sensors 201919180510.3390/s 1908180530991763 PMC 6515149 · doi ↗ · pubmed ↗
- 8Zhang G. Liu G. Zhu H. Segmentation algorithm of complex ore images based on templates transformation and reconstruction Int. J. Miner. Metall. Mater.20111838538910.1007/s 12613-011-0451-8 · doi ↗