YOLO-WL: A Lightweight and Efficient Framework for UAV-Based Wildlife Detection
Chang Liu, Peng Wang, Yunping Gong, Anyu Cheng

TL;DR
This paper introduces YOLO-WL, a new algorithm for detecting wildlife in drone images, which improves accuracy and efficiency for biodiversity monitoring.
Contribution
YOLO-WL introduces novel modules for multi-scale feature processing and attention mechanisms tailored for UAV-based wildlife detection.
Findings
YOLO-WL achieves 94.2% [email protected] and 58.0% [email protected]:0.95 on the WAID dataset, outperforming existing methods.
The algorithm demonstrates robustness and generalization across diverse ecological environments.
YOLO-WL improves detection accuracy for small and low-resolution targets in UAV imagery.
Abstract
Accurate wildlife detection in Unmanned Aerial Vehicle (UAV)-captured imagery is crucial for biodiversity conservation, yet it remains challenging due to the visual similarity of species, environmental disturbances, and the small size of target animals. To address these challenges, this paper introduces YOLO-WL, a wildlife detection algorithm specifically designed for UAV-based monitoring. First, a Multi-Scale Dilated Depthwise Separable Convolution (MSDDSC) module, integrated with the C2f-MSDDSC structure, expands the receptive field and enriches semantic representation, enabling reliable discrimination of species with similar appearances. Next, a Multi-Scale Large Kernel Spatial Attention (MLKSA) mechanism adaptively highlights salient animal regions across different spatial scales while suppressing interference from vegetation, terrain, and lighting variations. Finally, a…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
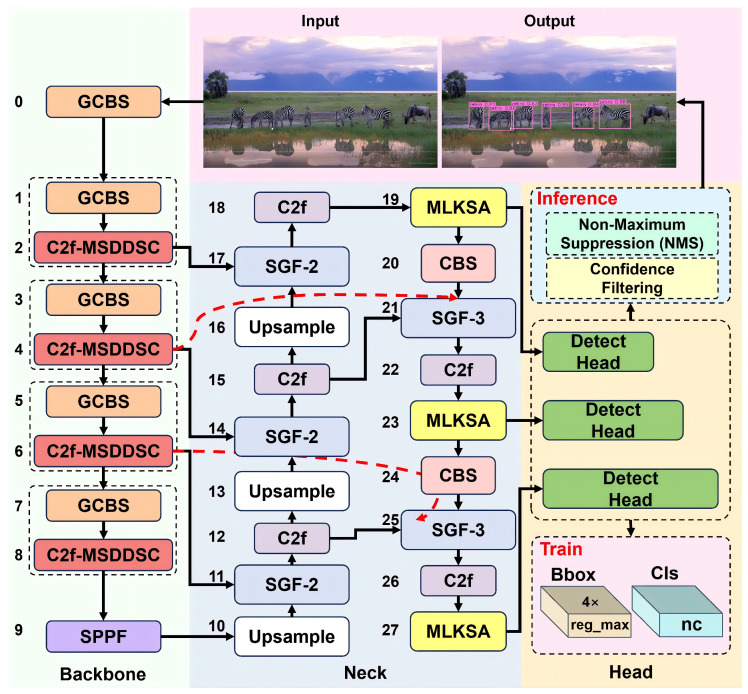 Figure 1
Figure 1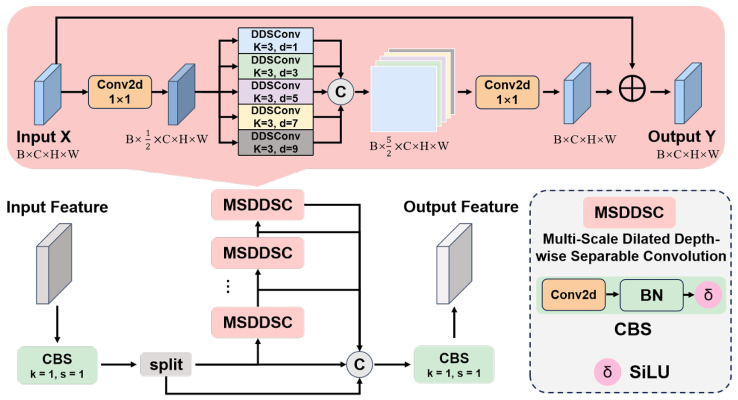 Figure 2
Figure 2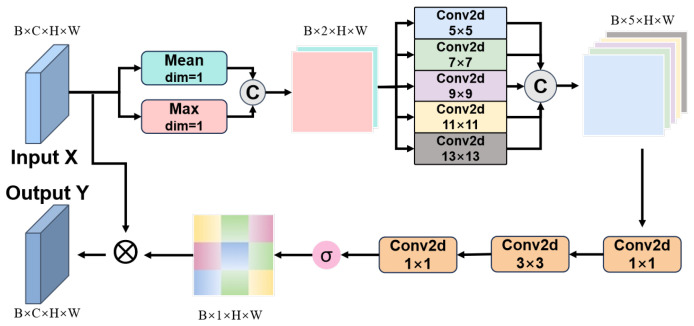 Figure 3
Figure 3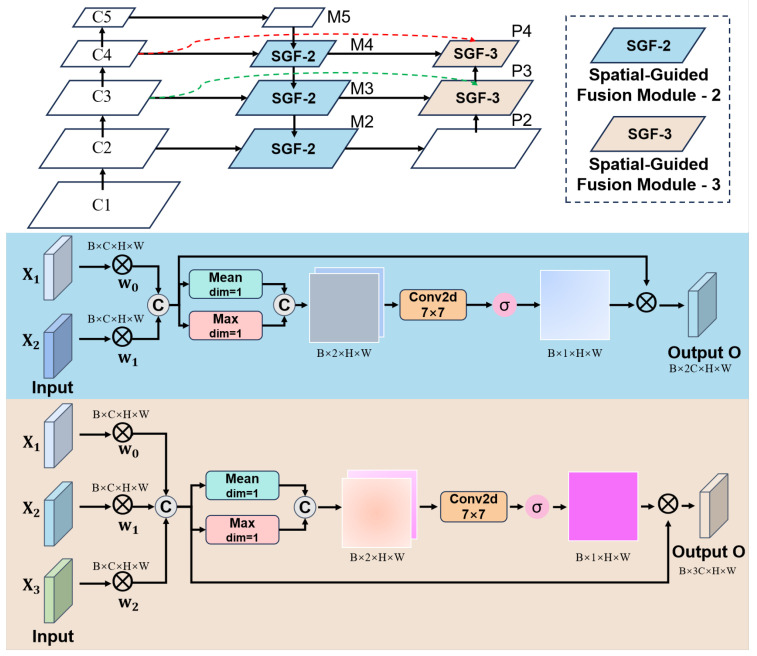 Figure 4
Figure 4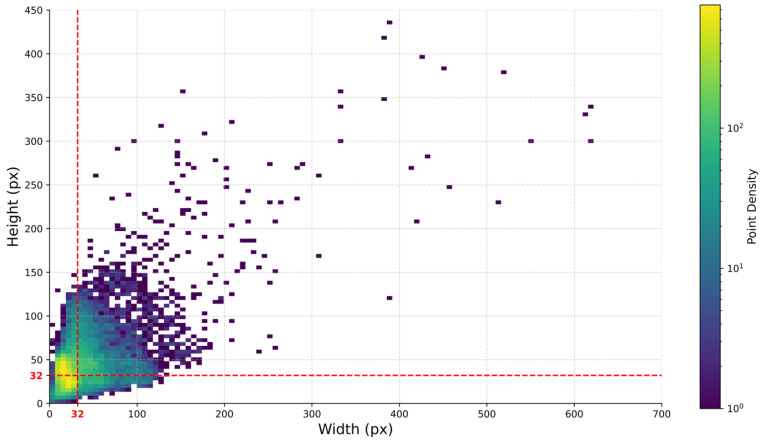 Figure 5
Figure 5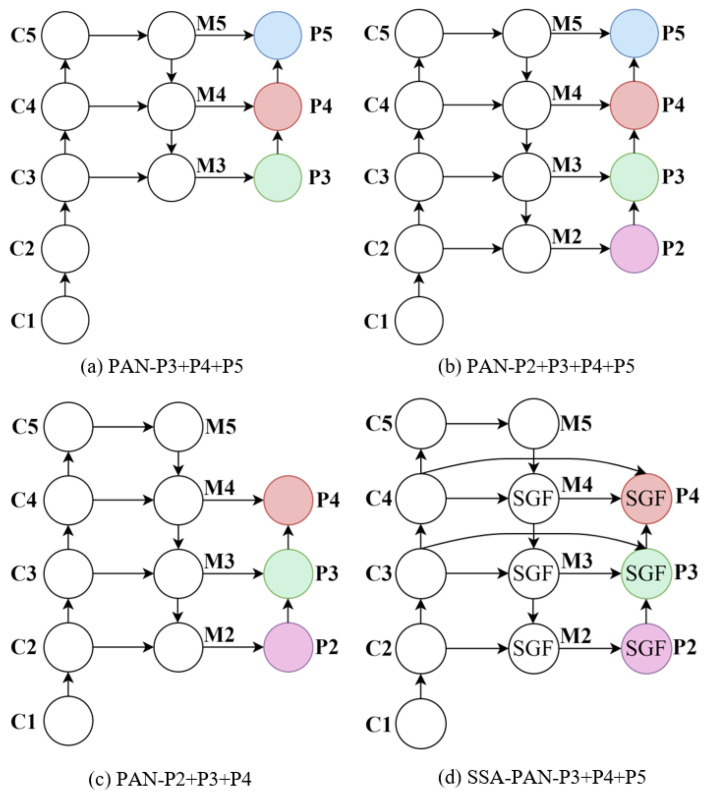 Figure 6
Figure 6 Figure 7
Figure 7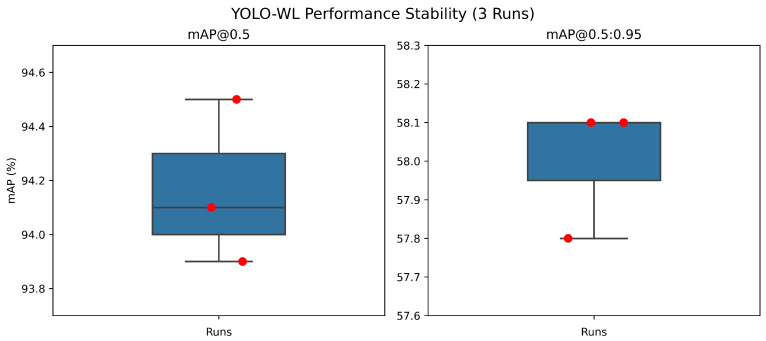 Figure 8
Figure 8 Figure 9
Figure 9 Figure 10
Figure 10 Figure 11
Figure 11 Figure 12
Figure 12 Figure 13
Figure 13- —the Chongqing Municipal Education Commission Scientific and Technological Research Projects
- —the Shapingba District Technological Innovation Project
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsUAV Applications and Optimization · Advanced Neural Network Applications · Video Surveillance and Tracking Methods
1. Introduction
Wildlife detection involves identifying animal species in natural habitats through direct observation or modern technologies such as computer vision, AI, and DNA analysis. As global biodiversity faces growing threats from habitat loss, climate change, and illegal poaching, accurate detection has become crucial for protecting endangered species and maintaining ecosystem stability [1,2]. It provides essential data, such as population size, distribution, and behavior, needed to assess ecological health and develop science-based conservation strategies.
In recent years, unmanned aerial vehicles (UAVs) have become valuable tools for wildlife monitoring and conservation, offering high efficiency, safety, and wide-area coverage. Unlike traditional manual surveys, UAVs can rapidly monitor complex terrains—such as forests, wetlands, and mountains—equipped with sensors like high-definition cameras, thermal imaging, and multispectral detectors. These enable remote, non-invasive, real-time data collection with minimal disturbance to animals. Integrated with AI-based image recognition, UAVs can automatically detect species in aerial imagery, significantly improving monitoring accuracy and efficiency. Their all-weather and low-light operation capabilities further support long-term data acquisition, enabling comprehensive ecological monitoring. This continuous data flow is essential for studying population dynamics, migration, and ecosystem responses, providing strong scientific support for conservation policies [3,4,5].
The rapid advancement of deep learning has revolutionized wildlife identification from UAV-captured imagery through Convolutional Neural Networks (CNNs) [6,7,8]. Thanks to their powerful feature extraction and pattern recognition capabilities, these methods can achieve high-accuracy classification of various species, even under complex and dynamic natural backgrounds. Numerous researchers have conducted extensive studies on wildlife identification in aerial imagery. For example, Roy et al. [9] introduced WilDect-YOLO, a high-performance object detection framework designed to enable real-time monitoring of endangered wildlife species. A YOLO-SAG-based method was later proposed by Chen et al. [10], which offers improved trade-offs between detection accuracy and computational efficiency. He et al. [11] proposed ALSS-YOLO, a compact and efficient detector specifically designed for wildlife detection in thermal infrared (TIR) aerial images. Ma et al. [12] proposed an improved version of YOLOv5s for lightweight wildlife detection in complex environments. Zhang et al. [13] developed a Channel-Enhanced RetinaNet (CE-RetinaNet), achieving high-precision detection in infrared imagery. Ye et al. [14] presented an improved ADD-YOLO algorithm tailored to enhance animal detection performance in aerial images. Furthermore, Jia et al. [15] proposed WL-YOLO, a lightweight detection algorithm that demonstrates superior performance in handling occlusion and complex environmental conditions.
Nevertheless, most existing approaches address only one or two aspects of the problem in isolation. For instance, some methods enhance small-object detection but neglect fine-grained discrimination among visually similar species, while others improve robustness to occlusion or background clutter yet remain vulnerable to the severe information loss caused by low-resolution imaging. Crucially, the lack of a unified design that simultaneously tackles weak inter-class discriminability, extreme scale variation, and complex environmental interference limits the practical applicability of current solutions in real-world ecological monitoring scenarios.
However, wildlife identification from UAV imagery still faces significant technical and environmental challenges. Many species exhibit similar morphological features—especially closely related or juvenile individuals—making visual differentiation difficult. High-altitude perspectives further limit the visibility of behavioral cues like posture and movement, reducing the effectiveness of behavior-assisted identification. Dense vegetation and complex terrain often cause partial or full occlusion of animals, particularly in forested or mountainous areas. Lighting variations due to shadows and solar angles lead to inconsistent image quality, hindering stable feature extraction. Similarities in color and texture between animals and background elements (e.g., rocks, dry leaves) increase false positive rates. Moreover, animals typically appear as small, low-resolution targets due to high-altitude UAV flight, limiting pixel-level detail and posing major challenges for vision-based algorithms reliant on high-quality input.
This paper proposes a UAV-based wildlife identification algorithm built on YOLO-WL, specifically optimized to address challenges of visually similar species, environmental disturbances, and small target sizes. The main contributions are:
- To address the challenge of visually similar wildlife species that are difficult to distinguish due to high inter-class similarity, we propose the MSDDSC module, which integrates multi-scale structures with dilated depthwise separable convolution to effectively fuse local details and global context, thereby expanding the receptive field and enhancing discriminative capability for morphologically similar animals.
- To tackle complex environmental disturbances such as occlusion from dense vegetation, terrain variations, and illumination changes that introduce strong background noise, we design the MLKSA mechanism, which combines multi-scale feature extraction, large-kernel convolution, and spatial attention to dynamically focus on critical regions across scales and effectively suppress environmental interference.
- To overcome the limited spatial perception caused by extremely small and low-resolution animal targets in high-altitude UAV imagery, we develop the SSA-PAN network, which incorporates a spatial-guided fusion module into the shallow feature pyramid to enable precise alignment and complementary fusion of shallow multi-scale features, significantly improving detection accuracy for small wildlife targets.
2. Related Work
2.1. Contextual Information Modeling
Wildlife species often inhabit complex, dynamic environments where challenges such as occlusion, scale variation, uneven lighting, and background clutter degrade visual features and object contours. This undermines local-feature-based detection methods, leading to high false positive and missed detection rates. To overcome these limitations, context-aware modeling has become a key strategy—leveraging semantic information from the surrounding environment (e.g., vegetation, terrain, co-occurring objects) to enhance recognition by jointly understanding the target and its contextual cues.
In context-aware modeling, model design and optimization are typically approached from multiple key perspectives to enhance perception and understanding of complex natural scenes. First, to expand the receptive field, large convolutional kernels [16,17,18] or dilated convolutions [19,20] are employed to alleviate the restricted spatial scope of standard convolutions, thereby capturing richer long-range contextual and semantic dependencies. Second, multi-scale modeling addresses significant scale variations in UAV imagery—caused by differences in distance or posture—through strategies such as multi-branch convolutions [21,22,23], feature pyramid structures, or Atrous Spatial Pyramid Pooling (ASPP) [24,25], allowing the model to capture features across multiple scales and improve discriminative robustness. Third, cross-level semantic integration emphasizes the complementary fusion of low-level and high-level features, where shallow layers provide rich spatial details and deep layers offer high-level semantics. By constructing fusion architectures such as those based on Feature Pyramid Networks (FPN) [26,27,28,29,30], features at different levels are effectively combined to generate more expressive and robust contextual representations. Together, these three aspects—receptive field expansion, scale adaptability, and feature-level fusion—collectively advance contextual information modeling and provide critical support for improving visual recognition performance in challenging environments.
Context-aware modeling is essential for UAV-based wildlife recognition. By integrating receptive field expansion, multi-scale feature learning, and cross-level fusion, the model gains stronger capabilities in handling objects across diverse scales, achieves higher feature representation quality and detection accuracy, and demonstrates improved adaptability and robustness in complex natural environments—thereby offering more reliable support for detection and recognition.
2.2. Visual Attention Mechanism
In UAV-based wildlife recognition, animals are often obscured by terrain, illumination changes, or background similarity, making them visually indistinguishable and hard to identify. Visual attention mechanisms address this by dynamically focusing on salient regions of the image.
Visual attention mechanisms enable models to automatically focus on key image regions, selectively enhancing discriminative features while suppressing background noise and irrelevant interference, thereby improving robustness and noise resistance in complex scenarios, especially under occlusion [31,32]. The generated attention weight maps can also be visualized to offer an interpretable explanation of how the model makes its predictions [33,34]. Depending on their design focus, attention mechanisms are typically classified into four types: channel attention, spatial attention, hybrid attention, and self-attention, all of which have demonstrated strong performance across a variety of visual recognition tasks.
Channel Attention adaptively reweights feature channels to emphasize discriminative and informative ones, significantly enhancing feature representational capacity. Representative methods include SENet [35], SENetv2 [36], ECA [37], and EncNet [38]. In contrast, Spatial Attention focuses on the spatial dimension by highlighting salient regions and suppressing background noise, improving perception of target details and context. Notable examples are STN [39] and DCN [40]. Hybrid Attention combines both channel and spatial modeling, enabling comprehensive feature capture from multiple dimensions and improving recognition in complex scenes, with representative approaches such as CBAM [41], BAM [42], and CA [43]. Furthermore, Self-Attention captures long-range pixel dependencies to better model global semantic structures, proving particularly effective for targets with complex spatial distributions. When integrated with Multi-Head Attention, it enables the model to learn diverse representations from multiple subspaces, enhancing expressive power and robustness. Key architectures leveraging this include ViT [44], Swin Transformer [45], DETR [46], Deformable DETR [47], DINO [48], and RT-DETR [49].
Although existing visual attention mechanisms improve feature representation and accuracy, they often neglect multi-scale feature fusion and large receptive field modeling. This leads to imprecise attention localization in complex scenes, increasing susceptibility to background interference and reducing recognition robustness. Additionally, some methods introduce high parameter overhead or over-attend to non-critical regions, harming computational efficiency and discriminative power. To address these issues, there is a need for attention mechanisms that effectively integrate multi-scale features while capturing long-range contextual dependencies.
2.3. Comparison with Existing Methods
Despite these advances in contextual modeling and attention mechanisms, most existing detectors still face a critical trade-off: methods with strong contextual or global reasoning capabilities (e.g., Transformer-based models) often suffer from high computational overhead and poor edge deployability, while efficient CNN-based detectors (e.g., YOLO variants) typically lack explicit multi-scale context awareness and robust spatial attention for small, camouflaged targets in UAV imagery. To bridge this gap, YOLO-WL integrates MSDDSC for hierarchical context enrichment and MLKSA, a lightweight yet powerful multi-scale spatial attention module that jointly expands receptive fields, validates cross-scale consistency, and suppresses scale-varying background clutter—without sacrificing inference speed.
To better illustrate the distinctions between our approach and representative prior works, we summarize their key characteristics in Table 1.
3. Methodology
3.1. YOLO-WL Model
YOLOv8 consists of four key modules: an input interface, a backbone for feature extraction, a neck for multi-scale feature fusion, and a detection head for generating final predictions. Owing to a series of well-designed optimizations, it achieves notable gains in both performance and adaptability. To meet diverse application requirements and computational limitations, YOLOv8 offers five scaled variants—n, s, m, l, and x—enabling flexible deployment. This work addresses UAV-based wildlife recognition by building upon the lightweight YOLOv8n model, which serves as the baseline for our proposed enhancements.
This paper introduces an MSDDSC module, seamlessly integrated with the C2f structure to replace the original C2f blocks in the YOLOv8n backbone. A novel SSA-PAN network is designed and incorporated into the feature fusion stage. Furthermore, an MLKSA mechanism is added between the neck and the detection head. We also propose a Layer-wise Feature Compression (LFC) strategy to reduce the channel dimension at stride = 32 from 512 to 256, specifically applied to layers 7–9. Based on these enhancements, we develop an efficient UAV-based wildlife recognition model named YOLO-WL. The overall architecture and module designs are illustrated in Figure 1, with detailed network configurations provided in Table 2.
3.2. MSDDSC Module
Wildlife recognition from drone imagery is challenged by low discriminability of species-specific features. Closely related species or individuals at different life stages often appear highly similar, making visual differentiation difficult. Meanwhile, aerial perspectives limit the observation of subtle behavioral cues due to distance and viewing angles, further compromising identification accuracy and reliability.
To address this issue, we propose the MSDDSC module. The module integrates rich contextual information, effectively combining local details with global structural features. This enhances the model’s ability to distinguish between visually similar species. Specifically, the multi-scale design enables the extraction of key features across different spatial ranges, improving the differentiation of morphologically similar individuals. At the same time, the dilated depthwise separable convolution expands the receptive field without increasing computational cost, enabling the extraction of richer semantic information. The integration of local and global information not only improves the model’s sensitivity to subtle morphological differences but also enhances its ability to interpret and utilize animal behavioral patterns from aerial viewpoints.
We then integrate MSDDSC into the lightweight C2f block of YOLOv8, forming the C2f-MSDDSC module (Figure 2). This design preserves the original efficiency of C2f while significantly improving discrimination of visually similar wildlife species, reducing both parameters and FLOPs, and maintaining detection performance.
Let the input feature map be denoted as , where B is the batch size, C represents the number of input channels, and denotes the spatial dimensions. The MSDDSC module performs multi-scale feature fusion through the following steps:
First, a convolutional layer is applied to compress the input feature map X along the channel dimension:
Here, denotes the number of channels after compression, where and e is the compression ratio.
Secondly, a set of pre-defined dilation rates is employed. For each dilation rate , a depthwise separable convolution is performed in parallel:
In the equation, denotes the convolutional kernel weight corresponding to channel c, and k represents the kernel size (in this case, ).
Then, all output feature maps from the parallel branches are concatenated along the channel dimension:
An additional convolutional layer is used to integrate the multi-scale features:
Finally, the output feature map is obtained by performing an element-wise addition between the integrated feature and the original input feature map X:
3.3. MLKSA Mechanism
In UAV-based wildlife recognition, multi-source environmental interferences significantly challenge system robustness and accuracy. Complex terrain and occlusion cause incomplete targets or feature loss, while dynamic lighting degrades image contrast and feature consistency. High similarity between animals and background elements (e.g., rocks, leaves, trunks) further increases false positives. These factors interact synergistically, complicating algorithm design and optimization.
To address these challenges, we propose the MLKSA mechanism (Figure 3), which integrates multi-scale feature extraction with large-kernel convolutions. This enables dynamic focus on key regions across spatial scales, effectively suppressing environmental interference. Specifically, the kernel sizes of 5/7/9/11/13 are carefully chosen to match the typical scale distribution of wildlife targets in UAV imagery, ensuring continuous and complementary coverage from fine details to global context. This multi-scale design not only captures targets of varying sizes but also suppresses background clutter at their native resolutions through cross-scale consistency validation. MLKSA enhances detailed texture capture in close-ups and holistic perception of distant small targets, expanding the receptive field for better foreground-background distinction. A spatial attention mechanism further improves semantic region representation while suppressing irrelevant background information, significantly boosting recognition accuracy and robustness in UAV-based wildlife scenarios.
Let be the input feature map with batch size B, channels , and spatial dimensions . The model computes the output .
First, two types of global statistical features are extracted along the channel dimension of the input X:
These two types of features are then concatenated along the channel dimension to form the initial fused feature:
Secondly, a set of pre-configured large-sized convolutional kernels is defined as , where is typically set to a relatively large value (in this work, we set ). The concatenated feature Z is processed by parallel convolutional branches, each with a distinct kernel size, to capture spatial features across multiple scales.
Here, denotes the feature map extracted using the kernel .
Subsequently, the multi-scale feature maps from the parallel branches are fused channel-wise to yield a consolidated feature representation:
To effectively fuse and refine the multi-scale information, two consecutive convolutional layers are employed:
Here, , and .
Finally, a standard convolutional layer is applied to map the fused feature into a spatial attention weight map A, which is then element-wise multiplied with the original input feature map X to produce the final output feature map Y:
3.4. SSA-PAN Network
In drone-captured aerial scenes, wildlife targets typically occupy only a few pixels due to the high altitude of image acquisition. This results in extremely small object sizes and blurred visual details, making it difficult to effectively extract and recognize critical visual features. At the same time, existing detection methods often rely heavily on high-level semantic features (e.g., P3–P5) for multi-scale feature fusion, while neglecting the rich spatial detail information present in shallow layers. Such fusion mechanisms lack explicit spatial guidance, leading to insufficient alignment and complementarity between features from different levels, which in turn results in suboptimal cross-scale feature integration. Particularly under complex background conditions and low-resolution inputs, the spatial perception capability of the model becomes limited, significantly degrading its performance in locating and recognizing tiny objects.
To address the challenges of tiny object size, insufficient feature representation, and inadequate multi-scale feature fusion in wildlife detection from drone-captured imagery, this paper proposes the SSA-PAN network, as illustrated in Figure 4. The proposed method introduces a SGF module based on the shallow feature pyramid (P2–P4). By performing more precise spatial alignment and information fusion of multi-scale features at an early stage, the model enhances its spatial perception capability for tiny targets. Compared to traditional FPN approaches that primarily rely on high-level semantic features (e.g., P3–P5) for feature fusion, the proposed SSA-PAN places greater emphasis on leveraging the rich spatial details present in shallow layers. Furthermore, the spatial-guided information flow improves the complementarity between features across different levels, thereby effectively alleviating the difficulties in recognition caused by small object size and limited image resolution.
4. Experimental Setup
4.1. Dataset
To comprehensively evaluate the effectiveness and generalization capability of the proposed method in complex scenarios, we conducted systematic experiments and comparative analyses on multiple publicly available datasets. The main experiments were carried out using the WAID (Wildlife Aerial Images from Drone) dataset [50], released by Beijing Forestry University’s College of Information Science. This dataset was extensively utilized in our study to validate the practical performance of the proposed algorithm in real-world applications.
The WAID dataset is currently among the largest, multi-category, and high-quality aerial image datasets specifically designed for wildlife monitoring using UAV platforms. It comprises six representative wildlife categories, namely sheep, cattle, seals, camels, kiangs, and zebras, and covers a variety of typical habitat environments, including deserts, grasslands, and beaches. The dataset contains a total of 14,366 UAV-captured images collected from diverse geographical regions and environmental conditions, which exhibit strong scene complexity and realistic detection challenges. These images are partitioned into three subsets: 10,056 for training, 2873 for validation, and 1437 for testing, with detailed class statistics presented in Table 3. The size distribution of object instances in the training set is shown in Figure 5. Statistical results indicate that the majority of target objects have pixel dimensions smaller than 32 × 32, suggesting a high proportion of small-scale targets. This characteristic aligns well with the focus and objectives of this study.
Additional experiments on the Aerial Sheep and AI-TOD datasets [51] validate the generalization capability of the proposed approach.
The Aerial Sheep dataset was constructed by Riis in June 2022 and publicly released on the Roboflow Universe platform. It is intended to advance research and applications of object detection algorithms for sheep in UAV-captured imagery. The dataset comprises a total of 4133 preprocessed and data-augmented aerial images, consisting of 3609 training images, 350 validation images, and 174 test images. Detailed statistical information is provided in Table 4. Due to variations in weather and lighting conditions, image quality exhibits significant fluctuations, which substantially increases the difficulty of object detection. Additionally, the sheep instances vary widely in scale and pose, further complicating target recognition and localization.
The AI-TOD dataset is a large-scale benchmark specifically designed for tiny object detection in aerial imagery. It contains 28,036 images, divided into 11,214 training, 2804 validation, and 14,018 test images. These images cover over 700,000 annotated object instances across eight common aerial object categories, such as airplanes, vehicles, and pedestrians, as detailed in Table 5. The average object size in AI-TOD is only 12.8 pixels, which is significantly smaller than that in most other aerial datasets, making it particularly challenging. This dataset provides a rigorous evaluation of the proposed method’s robustness and its ability to detect small objects.
4.2. Implementation Details and Evaluation Metrics
To comprehensively evaluate the performance of the proposed algorithm, a standardized experimental environment was established. All experiments were conducted on the CentOS 8.5.2 operating system, with the neural network models implemented using the PyTorch deep learning framework. The YOLOv8n model was selected as the baseline for comparative analysis. Detailed hardware and software configurations are presented in Table 6.
To ensure fair comparison of experimental results, all improved models were trained using an identical set of hyperparameters, and no pre-trained weights were utilized throughout the training process. The detailed hyperparameter configurations are summarized in Table 7.
To comprehensively evaluate the proposed model, we adopt standard metrics: Precision (P), Recall (R), mean Average Precision (mAP), parameter count, and GFLOPs. Precision reflects the reliability of positive detections, whereas Recall indicates the fraction of ground-truth instances successfully retrieved. mAP—computed as the average of per-class AP values, each derived from the area under its precision-recall curve—serves as the primary indicator of overall detection accuracy. Meanwhile, parameter count and GFLOPs characterize model compactness and computational load, respectively, bo th of which are pivotal for deployment on edge devices with limited resources.
In this context, TP, FP, and FN denote true positives (correctly detected ground-truth objects), false positives (background regions wrongly detected as objects), and false negatives (ground-truth objects that are missed), respectively.
5. Comparative Experiments
5.1. Comparison Experiments of Different Attention Mechanisms
To evaluate the MLKSA attention mechanism, state-of-the-art attention modules were integrated into YOLOv8n and compared on the WAID test set. Results are summarized in Table 8.
As shown in Table 8, several existing attention modules (e.g., SEv1, ECA, CBAM) fail to improve YOLOv8n’s performance and even reduce mAP slightly, while others offer only marginal gains. In contrast, the proposed MLKSA module achieves significant improvements with minimal increases in parameters and computational cost. It reaches an [email protected] of 93.2% (+0.6%) and [email protected]:0.95 of 57.4% (+0.5%), demonstrating strong effectiveness and robustness in drone-based small-object detection, with high potential for real-world applications.
5.2. Comparison Experiment of Shallow Feature Fusion Methods
To evaluate the effectiveness of SSA-PAN in multi-scale feature fusion, comparative experiments were conducted with different fusion strategies on the WAID test set (results in Table 9). Two factors were analyzed: (1) replacing the high-level P5 layer with the shallow P2 layer for improved small-object detection (Figure 6a–c), and (2) comparing the proposed SSA-PAN architecture against the conventional PAN structure (Figure 6d).
As shown in Table 9, the original YOLOv8n model employs a PAN structure comprising feature levels P3, P4, and P5 for multi-scale feature fusion, achieving an [email protected] of 92.6% and an [email protected]:0.95 of 56.9% on the test set. When the high-level semantic feature layer P5 was replaced with the higher-resolution shallow feature layer P2, forming a new PAN structure based on P2+P3+P4, the model demonstrated significant improvements in small-object detection performance. Specifically, the [email protected] and [email protected]:0.95 increased to 95.0% and 59.7%, respectively, while Precision and Recall also improved to 93.2% and 90.2%. These results indicate that incorporating high-resolution shallow features enhances the model’s ability to capture fine-grained details of small objects, thereby significantly improving overall detection performance.
However, incorporating features from levels P2, P3, P4, and P5 using the P2+P3+P4+P5 PAN structure resulted in a slight decline in detection performance compared to the P2+P3+P4 configuration. This observation suggests that the inclusion of high-level semantic feature layers—originally designed for large-object detection—along with excessive feature fusion stages, may introduce redundant information that interferes with the model’s ability to learn discriminative features for small objects, thereby degrading overall detection accuracy. In contrast, the proposed SSA-PAN feature fusion network, based on the P2+P3+P4 architecture, demonstrates a more rational structural design and enhanced practical effectiveness in multi-scale feature integration. With only a marginal increase in computational cost, the [email protected] and [email protected]:0.95 are improved to 95.2% and 59.8%, respectively, further validating its effectiveness and superiority in small-object detection tasks within the context of wildlife recognition from drone-based perspectives.
5.3. Ablation Experiments
To evaluate the contribution of each proposed module in drone-based wildlife detection, an ablation study was conducted by incrementally integrating components into the YOLOv8n baseline. The modules include C2f-MSDDSC, MLKSA attention, SSA-PAN, and lightweight elements LFC and GConv. Results are summarized in Table 10.
As shown in Table 10, in the single-module ablation experiments, the original baseline model achieves an [email protected] of 92.6% and an [email protected]:0.95 of 56.9% on the test set. When only the C2f-MSDDSC module is introduced to construct Model1, the model parameters increase by 0.4M, while the computational cost slightly decreases by 0.7 GFLOPs. The [email protected] and [email protected]:0.95 improve to 93.2% and 56.9%, respectively. This indicates that the module enhances the model’s ability to distinguish morphologically similar categories by effectively modeling contextual information and enabling the synergistic fusion of local fine-grained features with global structural information. In Model2, which incorporates only the MLKSA module, the detection performance improves significantly with almost no increase in model parameters or computational cost. Specifically, the [email protected] reaches 93.2%, and the [email protected]:0.95 increases to 57.4%. This demonstrates that the proposed multi-scale large-kernel spatial attention mechanism effectively enhances the model’s spatial perception capability and exhibits strong robustness in suppressing complex background noise. In contrast, Model3, which includes only the SSA-PAN module, achieves superior performance despite a 1.0 M reduction in parameters and an increase of 3.6 GFLOPs in computational cost. It attains an [email protected] of 95.2% and an [email protected]:0.95 of 59.8%, significantly outperforming the other two individual improvements. This result further confirms that SSA-PAN emphasizes the rich spatial details in shallow features and improves cross-level feature complementarity through effective spatial guidance, thereby substantially enhancing the overall detection performance.
In the multi-module ablation experiments, Model4, which integrates both the C2f-MSDDSC and MLKSA modules, achieves an [email protected] of 93.9% and an [email protected]:0.95 of 58.4%, indicating that the combination enhances both contextual semantic modeling and spatial perception while effectively suppressing background noise. Model6, which combines C2f-MSDDSC with SSA-PAN, achieves the best performance among all module combinations, with an [email protected] of 96.1% and an [email protected]:0.95 of 60.9%. This result further illustrates the significant synergistic and complementary advantages of semantic detail fusion and shallow feature enhancement strategies in small-object detection tasks.
Finally, based on the integration of multiple modules, lightweight design is introduced through the LFC operation and GConv to compress and optimize the model. Compared to the baseline, the proposed YOLO-WL reduces the total number of parameters by 53.3% and shrinks the model size to 45.9% of the original. Although the computational cost increases by 18.3%, the detection performance remains strong, with [email protected] and [email protected]:0.95 reaching 94.2% and 58.0%, respectively—representing improvements of 1.6% and 1.1% over the baseline model. These results clearly demonstrate that YOLO-WL not only enhances detection accuracy but also significantly improves model compactness and deployment feasibility, making it highly suitable for real-world applications.
To intuitively compare feature perception before and after improvement, Grad-CAM visualizations of YOLOv8n and YOLO-WL are presented in Figure 7 for six representative scenarios. Redder colors indicate higher attention, reflecting the model’s focus on target localization.
As shown in the visualization results in Figure 7, the proposed YOLO-WL demonstrates a stronger capability than the baseline model YOLOv8n in accurately capturing the morphological structures of wildlife. It achieves enhanced perception and modeling of target contours, and maintains robust performance even under complex background interference.
To provide a more comprehensive evaluation of the performance improvements achieved through the proposed model enhancements, this study also summarizes the detection results across different object categories before and after the modifications, as shown in Table 11.
As shown in Table 11, compared to the baseline model YOLOv8n, the proposed YOLO-WL achieves the most notable performance improvements on the Camelus, Kiang, and Zebra categories. Specifically, the [email protected] increases by 2.7%, 3.2%, and 2.2%, respectively, while the [email protected]:0.95 improves by 2.3%, 1.6%, and 2.1%. In contrast, a slight performance degradation is observed on the Seal category, with [email protected] and [email protected]:0.95 decreasing by 0.3% and 0.5%, respectively. Nevertheless, the overall performance across all four evaluation metrics shows consistent gains, which further confirms the effectiveness of the proposed model enhancements.
Moreover, when deployed on the RK3588 NPU, the model achieves a real-time inference speed of 72.1 FPS, demonstrating computational efficiency sufficient to support high-frame-rate real-time detection systems (which typically require an end-to-end frame rate of at least 30 FPS). This shows that YOLO-WL significantly improves detection accuracy without sacrificing real-time performance, effectively balancing precision and efficiency, and thus exhibits strong potential for edge deployment and practical applications.
5.4. The Impact of Training Dataset Scale on YOLO-WL Performance
To systematically investigate the performance of the proposed YOLO-WL algorithm under varying training set sizes, this paper randomly samples subsets of 20%, 40%, 60%, and 80% from the full training set and conducts separate training and evaluation on each. The experimental results are shown in Table 12.
As shown in Table 12, as the training set ratio increases from 20% to 100%, all performance metrics of YOLO-WL steadily improve, indicating that the model exhibits strong scalability with respect to data volume. Notably, when the training ratio increases from 20% to 40%, [email protected] improves significantly by 12.9 percentage points, demonstrating that adding data in the early stages yields the most pronounced performance gains. Even with only 20% of the training data, YOLO-WL achieves an [email protected] of 75.6%, showcasing its robust few-shot learning capability.
Moreover, all experimental results are reported as the average of three independent runs. Specifically, when trained on the full dataset, the variances of the model’s accuracy are 0.0622 for [email protected] and 0.0200 for [email protected]:0.95. This demonstrates that YOLO-WL exhibits high stability across multiple training and evaluation runs, with minimal performance fluctuation. Corresponding boxplots are provided in Figure 8.
5.5. Model Prediction Performance Across Multiple Scenarios
5.5.1. Robust Detection Under Favorable Conditions
To comprehensively evaluate the model’s generalization capability and robustness in complex real-world scenarios, we conduct a comparative evaluation between YOLO-WL and the baseline model YOLOv8n under six representative challenging conditions: (a) dense small-object scenes, (b) complex background clutter, (c) complex terrain environments, (d) blurry or low-detail scenes, (e) dynamic lighting conditions, and (f) multi-source coupled noise interference. The qualitative results are shown in Figure 9.
As shown in Figure 9, the proposed YOLO-WL network accurately and consistently detects wildlife targets across a variety of complex scenarios. Even under highly challenging imaging conditions, the method effectively suppresses false positives and missed detections, maintaining high localization accuracy and classification confidence, which clearly demonstrates its excellent robustness and adaptability to diverse environmental conditions.
5.5.2. Failure Modes and Challenging Scenarios
Although YOLO-WL demonstrates strong performance across most complex scenarios, several challenging failure cases remain. As shown in Figure 10 (highlighted with red boxes), the model may exhibit noticeable false positives or missed detections under the following conditions: (1) drastic viewpoint changes causing severe object deformation; (2) high visual similarity between the ground background and target animals in terms of color and texture, leading to significant ambiguity; and (3) extremely weak target features—such as ultra-low resolution, occlusion due to posture, or motion blur—that provide insufficient discriminative cues. Despite these limitations, YOLO-WL still significantly outperforms existing methods overall, with its failures primarily occurring in extreme edge cases that reflect common technical challenges in UAV-based wildlife detection.
5.6. Comparative Experiment of Advanced Algorithm on the WAID Dataset
To comprehensively evaluate YOLO-WL’s performance in drone-based wildlife detection, we compare it with mainstream lightweight models including YOLOv3-tiny [48], YOLOv5n [49], YOLOv6n [50], YOLOv7-tiny [51], and YOLOv8n [52] to YOLOv12n [53]. All models are trained and evaluated on the WAID dataset under identical settings—consistent training strategy, data pipeline, and evaluation metrics—to ensure fair and objective comparison. Results are summarized in Table 13.
As shown in Table 13, YOLO-WL achieves the highest [email protected] and [email protected]:0.95 scores of 94.2% and 58.0%, respectively, outperforming all compared models and demonstrating superior detection accuracy. Compared to the baseline YOLOv8n, YOLO-WL reduces model parameters and model size by 53.3% and 45.9%, respectively, with only an 18.3% increase in computational cost, while still achieving improvements of 1.7% and 1.2% in [email protected] and [email protected]:0.95. These results indicate that YOLO-WL not only significantly reduces model complexity and deployment cost but also enhances detection performance, effectively balancing accuracy and efficiency for practical deployment. To offer a more intuitive visualization of the detection performance of various algorithms on the WAID dataset, six representative scenarios are selected for a visual comparison of detection results across different models. The detailed prediction outcomes are shown in Figure 11, where dashed bounding boxes highlight regions with major false positives and false negatives observed during detection.
As illustrated in Figure 11, objects in the WAID dataset not only exhibit considerable scale variations but also show significant appearance differences under drone-captured viewpoints. Moreover, complex backgrounds containing distractors further complicate the task of target recognition. Under such challenging conditions, the YOLO-WL algorithm exhibits more comprehensive and accurate detection performance across all object categories. It effectively captures target features under multi-scale and multi-viewpoint settings, thereby demonstrating enhanced environmental adaptability and robustness in object detection.
6. Generalization Experiments
6.1. Performance Comparison on the Aerial Sheep Dataset
To validate the applicability and generalization capability of the YOLO-WL algorithm in drone-based wildlife detection tasks, comparative experiments are conducted against several mainstream object detection algorithms using the Aerial Sheep dataset. The results on the test set are summarized in Table 14.
The experimental results in Table 14. demonstrate that YOLO-WL achieves excellent detection performance on the Aerial Sheep dataset, achieving [email protected] and [email protected]:0.95 scores of 98.1% and 61.7%, respectively. These results significantly outperform those of other lightweight object detection models, indicating strong generalization capability. Compared to the baseline model YOLOv8n, YOLO-WL improves by 0.6 and 0.2 percentage points on these two metrics, highlighting its superior detection performance in scenarios involving densely distributed small targets.
To offer a more intuitive comparison of the detection performance of various algorithms on the Aerial Sheep dataset, six typical scenarios are selected to visualize the detection results of each model. The detailed detection results are shown in Figure 12.
As shown in Figure 12, in the Aerial Sheep dataset, sheep are densely distributed and exhibit small sizes, while the grassland background contains many distractors similar in appearance to the targets, posing significant challenges for accurate detection. In contrast, the YOLO-WL algorithm achieves superior performance by accurately localizing all targets, demonstrating enhanced robustness. In comparison, other algorithms suffer from various levels of false negatives and false positives in this scenario, indicating relatively limited detection capabilities.
6.2. Performance Comparison on the AI-TOD Dataset
Similarly, on the AI-TOD dataset, comparative experiments are conducted with several mainstream object detection algorithms. The experimental results, as shown in Table 15, further validate the proposed method’s generalization capability and detection performance in complex aerial scenarios.
The experimental results in Table 15 show that YOLO-WL continues to outperform existing lightweight object detection models on the AI-TOD dataset. It achieves [email protected] and [email protected]:0.95 scores of 32.3% and 14.0%, respectively, which represent the best performance among the compared lightweight models. Compared to the baseline YOLOv8n, YOLO-WL improves these metrics by 1.9 and 1.0 percentage points, further demonstrating its superior detection performance in complex aerial scenarios. These results indicate that YOLO-WL achieves higher accuracy and better generalization when handling drone-captured images with dense small objects and significant scale variations.
To provide a more comprehensive evaluation of the proposed method’s adaptability in complex aerial scenarios, we select six representative scenes from the AI-TOD dataset to visually compare the detection performance of different models. The detailed results are presented in Figure 13.
As can be observed from Figure 13, objects of different categories in the AI-TOD dataset are situated in environments with significant variations, resulting in a variety of complex background interferences. Additionally, due to the small size of the targets, their features are difficult to extract and learn effectively. Under such challenging conditions for small-object detection, other mainstream object detection algorithms exhibit varying degrees of missed detections or false positives across different environments. In contrast, the YOLO-WL algorithm demonstrates more comprehensive and accurate detection capabilities across all object categories, reflecting its superior robustness and adaptability.
7. Conclusions
This paper presents YOLO-WL, a wildlife detection algorithm designed for UAV-captured aerial imagery, to address the challenges posed by visually similar species, complex environmental interference, and the small size of target animals. To enhance feature representation, we design the MSDDSC module and construct the C2f-MSDDSC structure, enabling the integration of fine-grained local details with broader contextual information. To improve robustness against multi-source background disturbances, we introduce the MLKSA mechanism, which adaptively emphasizes salient animal regions across multiple scales. Furthermore, we propose the SSA-PAN framework, which achieves precise spatial alignment and complementary fusion of shallow features, thereby improving detection accuracy for tiny wildlife targets. Experimental evaluations on the WAID, Aerial Sheep, and AI-TOD datasets demonstrate that YOLO-WL surpasses state-of-the-art lightweight object detection models in both accuracy and robustness, while also exhibiting strong generalization ability across diverse scenarios.
However, despite its strong cross-scenario generalization on known categories, YOLO-WL’s training relies on large-scale, finely annotated wildlife datasets; consequently, its performance may degrade significantly when encountering unseen species or rare animal categories. To address this limitation, future work will explore few-shot learning (e.g., prototype-based meta-learning using only 1–5 support samples per class) and open-set recognition (e.g., energy-based uncertainty calibration or background-aware margin loss) to enable rapid and robust adaptation to novel classes with minimal labeled data. Additionally, to facilitate deployment on resource-constrained UAV platforms such as NVIDIA Jetson, we will investigate a model compression strategy that combines MLKSA attention-guided channel pruning with quantization-aware training (QAT) to further improve computational efficiency and scalability in large-scale ecological monitoring applications.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Hughes L.J. Morton O. Scheffers B.R. Edwards D.P. The ecological drivers and consequences of wildlife trade Biol. Rev.2023987757913657253610.1111/brv.12929 · doi ↗ · pubmed ↗
- 2ChavesÓ.M. Souza J.C.Jr. Buss G. Hirano Z.M.B. Jardim M.M.A. Amaral E.L.S. Godoy J.C. Peruchi A.R. Michel T. Bicca-Marques J.C. Wildlife is imperiled in peri-urban landscapes: Threats to arboreal mammals Sci. Total Environ.20228211528833503852510.1016/j.scitotenv.2021.152883 · doi ↗ · pubmed ↗
- 3Navarro A. Young M. Allan B. Carnell P. Macreadie P. Ierodiaconou D. The application of Unmanned Aerial Vehicles (UA Vs) to estimate above-ground biomass of mangrove ecosystems Remote Sens. Environ.2020242111747
- 4ButilăE.V. Boboc R.G. Urban traffic monitoring and analysis using unmanned aerial vehicles (UA Vs): A systematic literature review Remote Sens.202214620
- 5Lyu X. Li X. Dang D. Dou H. Wang K. Lou A. Unmanned Aerial Vehicle (UAV) Remote Sensing in Grassland Ecosystem Monitoring: A Systematic Review Remote Sens.2022141096
- 6Patel A. Cheung L. Khatod N. Matijosaitiene I. Arteaga A. Gilkey J.W.Jr. Revealing the Unknown: Real-Time Recognition of Galápagos Snake Species Using Deep Learning Animals 20201080610.3390/ani 1005080632384793 PMC 7278857 · doi ↗ · pubmed ↗
- 7Guo X. Shao Q. Li Y. Wang Y. Wang D. Liu J. Fan J. Yang F. Application of UAV remote sensing for a population census of large wild herbivores—Taking the headwater region of the Yellow River as an example Remote Sens.2018101041
- 8Zhang X. Xuan C. Xue J. Chen B. Ma Y. LSR-YOLO: A High-Precision, Lightweight Model for Sheep Face Recognition on the Mobile End Animals 20231318243788971610.3390/ani 13111824 PMC 10252084 · doi ↗ · pubmed ↗