CLM App: Interlamellar Distance of Pearlite via CLM Revisited and Automated
Martin Zouhar, Šárka Mikmeková, Jan Hovjacký, Petra Váňová

TL;DR
This paper introduces an automated tool using Python to measure pearlite microstructure in steel images, aiming to reduce manual work in quality control.
Contribution
A Python-based automation of the circular line method for measuring pearlite interlamellar distance is proposed.
Findings
The CLM automation performs well on certain types of pearlite microstructures.
Manual data from 465 images was used to assess the performance of the automated method.
The paper identifies microstructure types where automation is less effective.
Abstract
Pearlitic (stainless) steel is used in automotive, aerospace, and other industries where high strength, hardness, and wear resistance are required. Its quality control can be performed using mechanical tests or by examining the lamellar microstructure, namely, determining interlamellar distance. One of the related approaches is the circular line method (CLM). This paper reviews the challenges to automate employment of the CLM using custom Python code in order to reduce human time costs during image-based quality assessment of pearlite. The goal is to perform intersection counting automatically once the human operator has configured the application and selected the locations of measuring circles. Performance assessment using manually processed data from some 465 images is performed. We divide the imaged pearlite microstructures into different “types” when the code performs well or,…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
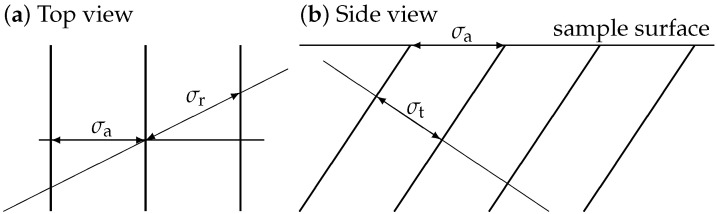 Figure 1
Figure 1 Figure 2
Figure 2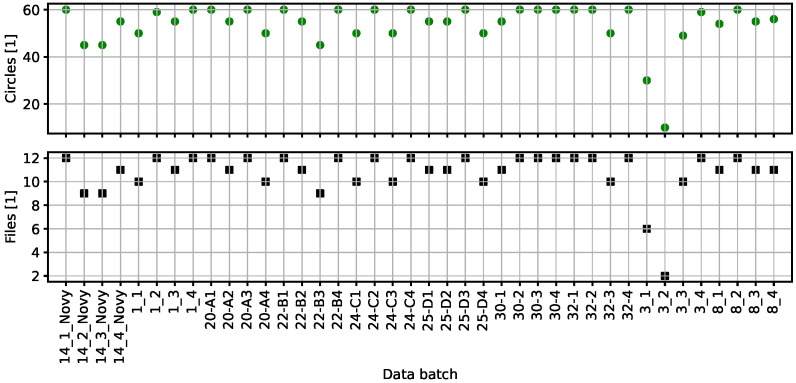 Figure 3
Figure 3 Figure 4
Figure 4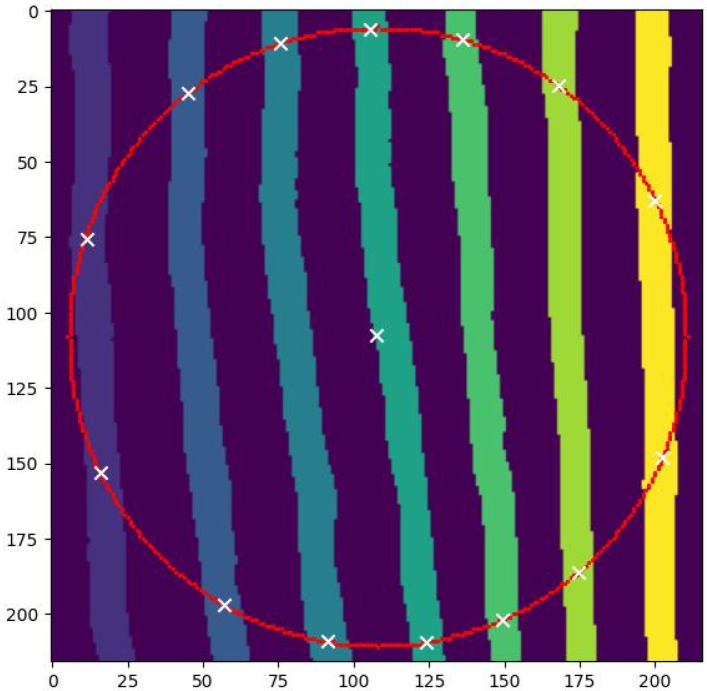 Figure 5
Figure 5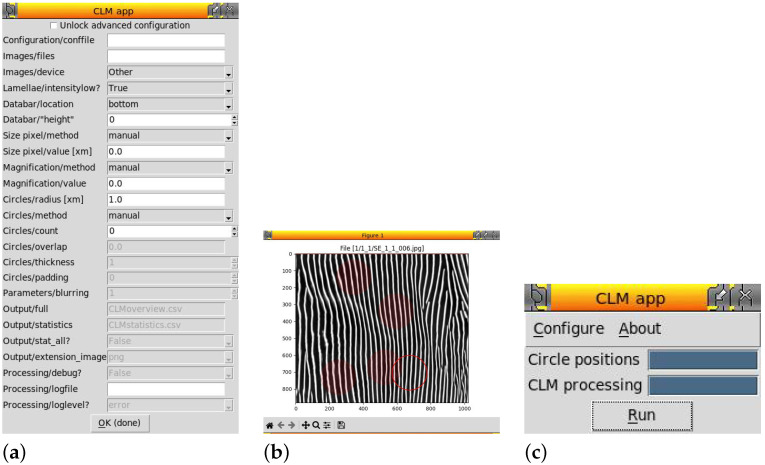 Figure 6
Figure 6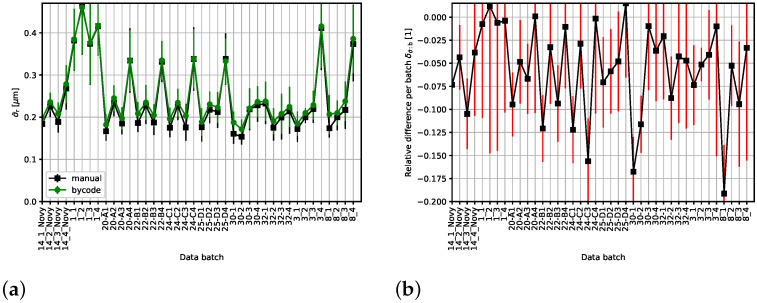 Figure 7
Figure 7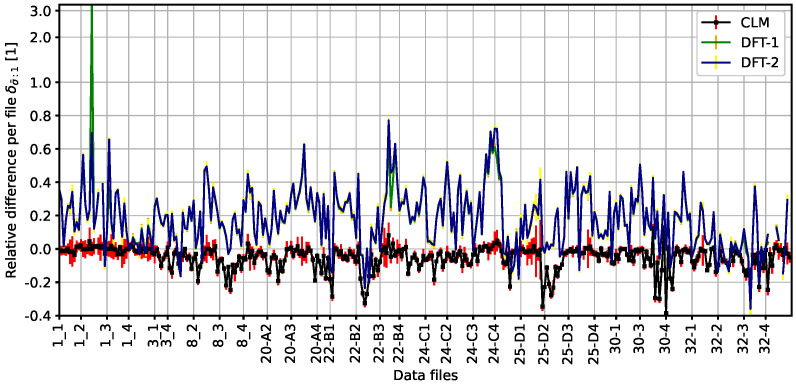 Figure 8
Figure 8- —Czech Academy of Sciences
- —Technology Agency of the Czech Republic (TA CR)
- —Ministry of Education, Youth and Sports of the Czech Republic
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsMachine Learning in Materials Science · Mineral Processing and Grinding · Image and Object Detection Techniques
1. Introduction
The topic of establishing interlamellar distance in pearlitic steel from microstructure metallographic images is a long-standing one. Ref. [1] states that the topic has been explored at least since the 1920s and is still alive, as demonstrated by the appearance of fairly recent papers, e.g., Ref. [2]. One of the reasons for this longevity is the industrial importance of this two-phase lamellar structure consisting of ferrite ( -Fe) and cementite/carbide (Fe_3_C). Another contributing factor is that the development of scanning electron microscopes (SEMs) has allowed for an increase in magnification and in the resolution of steel microstructure images. This, in turn, has made related image analysis feasible in the case of finer pearlitic structures which are hard to resolve in light optical microscopes.
Despite the imaging technology advances, the work remains mostly tedious, comprising the straightforward analysis of visual data. There have been attempts to automate it [3,4] using custom code. One of the problems with full automation is selecting regions of interest (ROIs) that contain a reasonably regular distribution of the lamellae or subtracting “noise” corresponding to irregularities from regions among individual pearlite colonies. With the rise in applications of machine learning (ML) and so-called artificial intelligence (AI) applications, one may consider the use of such tools to assist in the selection of ROIs and in image segmentation. Image segmentation can be performed by classifying the two most relevant phases (see, e.g., Ref. [5]) using ML, or, more specifically, a support vector machine, to achieve a similar goal. Nevertheless, image processing has already been recognized as a well-established data science practice before the ML/AI boom. We strongly believe that it provides the sufficient tools to deal with the task at hand.
The approach of Ref. [4] (the authors of which kindly provided custom MATLAB software (The MathWorks, Inc., Natick, MA, USA) code (working with MATLAB version R2018b), shown in their Supplementary Materials) attempts to tackle both; it uses the good periodicity of the lamellar structure (especially true in case of an ROI singling out a regular pearlite colony) and employs discrete Fourier transformation (DFT). Analyzing the results of the DFT provides the (apparent) interlamellar distance.
This paper focuses on the CLM method. The CLM method, together with the data-processing algorithm and its code-implementation approach, is concisely formulated. The performance of the code is evaluated on a manually processed dataset. Furthermore, a comparison with the MATLAB DFT-based code is included.
2. Materials and Methods
2.1. Circular Line Method (CLM) in a Nutshell
Consider a periodic 3-dimensional lamellar structure.A microscopic image represents a cross-section of the 3-dimensional structure with the plane defined by surface of the sample. Determining the interlamellar distance from such a cross-section correctly requires keeping the relation of the cross-section to the 3-dimensional structure in mind. This leads to a practical necessity to distinguish among several kinds of interlamellar distance, as illustrated in Figure 1.
The different kinds of the interlamellar distance are random (“r”), apparent (“a”), and true (“t”). The first two are determined from the (imaged) sample surface plane, which, in general, is not perpendicular to the planes of the lamellae, which means that these two values overestimate the true one. This immediately follows from the fact that each of these two values corresponds to a hypotenuse in a suitably chosen right-angled triangle. Figure 1a shows a top-view, i.e., to the sample plane. It is clear that for any angle, the random intercept line leads to an interlamellar distance larger than or equal to the apparent value, . A similar conclusion can be drawn from Figure 1b for the apparent and true interlamellar distances, i.e., .
For the sake of completeness, let us note that corresponding variants of (nearest) edge-to-edge distance can be defined accordingly.
The statistical mean values of these center-to-center distances satisfy the following relation (see Equations (1) and (2) in Ref. [3]):
where the mean is indicated by an over-bar.
The CLM method is fairly simple and it consists of several steps described in the following.
1.Draw a measuring circle of a known real-space diameter d (m) in the field of view part of the microscopic image. As each pixel has a given real-space size, its value depending on magnification, this effectively means converting the value of diameter from real-space to its counterpart in pixel-coordinates.2.Count all intersections of the lamellae with the measuring circle n; counting the number of intersecting lamellae objects can also provide useful information.3.Calculate one of the (center-to-center) interlamellar distances ; its value is directly proportional to the ratio or .
4.Statistical processing of the data to arrive at the (batch or single file) mean value .
The processing is, therefore, relatively straightforward once the object is segmented into individual lamellae and the background components. The implicit assumption is that the circle diameter d is sufficiently large for it to enclose a rather large number of lamellae but sufficiently small to minimize occurrences of irregularities, e.g., among different pearlite colonies.
First, the CLM is applied to the sample surface plane. Second, the circle segments defined by a pair of nearest neighbor intersection are rather randomly oriented with respect to the lamellae colony. This means that the derived in Equation (2) is the “random” interlamellar distance (compare also with Equation (9) from Ref. [3]).
Thus, there are two opposite demands on the diameter d of the measuring circle that have to be balanced for each given microstructure image. In order to cover a reasonable number of random directions of the intercepting segments of the measuring circle, its diameter d has to be large, i.e., it is desirable to enclose as many lamellae as possible. This, on the other hand, increases the chance of including defects or adjacent pearlite colonies (which may have a different orientation). Furthermore, it leaves less space for other measuring circles with minimal overlap to provide enough statistically independent data coming from more circles located in the same image. For example, the number (respectively, the diameter d) of measuring circles in a given microstructure image may be restricted from below (respectively, from above) by standards providing a guide for applying CLM to a pearlitic steel for a given industry segment.
2.2. Manually Processed Dataset
The performance of the yet to be discussed automation is tested on manually processed data (analysis by J.H. and P.V.) of a pearlitic steel microstructure. The steel was imaged using a Quanta FEG microscope (Waltham, MA, USA) equipped with an Everhart-Thornley Detector (ETD) operating in the secondary electron mode. The advantage of secondary electrons is that they “enhance” the topography of the sample.
The image dataset corresponding to manually processed data consists of 465 pairs of microscopic images total and an accompanying MS Excel spreadsheet. Relevant data in the spreadsheet consists of values of intersection counts for a given image file (without assignment to a specific measuring circle) and derived interlamellar distances. The magnification ranges from 25,779× through 30,000× (the most frequent with 460 occurrences in the original microscopic images) up to 32,715×. The value 30,000× represents a reasonable compromise ensuring good image quality. The images are stored in JPG format.
Each image pair contains the original microscopic image and the image with measuring circles being marked; see Figure 2. These pairs correspond to 10 different samples prepared using various technological methods/processes, including, but not limited to, different duration of cooling.
As a result, the samples exhibit different microstructures, namely, interlamellar distance and thickness and average length of the lamellae. Furthermore, each sample is split into four batches, each batch corresponding to images from a different regions of the sample. A single batch contains approximately a dozen images.
The dataset has been meticulously rechecked (manual-part by P.V. and code-part by M.Z.) to avoid any inconsistencies. These may include corrupted or missing original microstructure images or circles slightly overflowing the field-of-view. The human evaluator/operator can extrapolate and “fill in” the missing parts of both the circle and lamellae as needed. This, however, is not possible for a code that operates strictly with data in the field of view which justifies the removal. On top of that, automatic circle detection misperformed on few files with measuring circles. These have been omitted in order to keep the data comparison as reproducible as possible on the code side.
As a result, only 431 microscopic images, corresponding to 10 samples and 40 batches, were used in the Python code (version 0.0.6) benchmarking. A typical batch contains from 9 to 12 images; the total number of measuring circles is not less than 39 and it does not exceed 62. We believe that some forty circles represent a large enough statistical sample for this kind of processing. There are two batches related to sample no. 3 with the image count rather significantly reduced due to the data reduction described above. The information on batches is visualized in Figure 3.
We note that the MS Excel sheet contains data-blocks corresponding to circles in a given file without any assignment of the actual circles, present in the corresponding image, to the individual records. This, of course, was irrelevant for the manual processing.
Furthermore, the naming convention of the as–were original microstructure images and those with measuring circles marked is not always consistent.
The “quality” of the as-imaged microstructures differ. Some regions, or even whole fields of view, are formed by high-contrast, bright, regular, well-separated lamellae on the backdrop of a dark background.This, however, does not apply to the whole dataset utilized; examples of more complex features in the pearlite colonies are displayed in Figure 4. The richest representative is shown in Figure 4a. First, a background grayish halo is present everywhere, leading to lower contrast between the lamellae and the background. This is not a serious issue if the background is fairly uniform and its intensity is sufficiently well separated from the intensity of the lamellae. If not the case, the local segmentation into lamellae might perform worse. Second, there is a scratch-like defect stretching from near the left-bottom corner both upwards and towards the right-hand-side direction. Third, some lamellae are bent. Fourth, the image exhibits merging of several lamellae or branching of some lamellae, especially in its right-hand-side half.
Figure 4b contains lamellae with strong kinks, sometimes even with strong-intensity spots centered rather well within the lamellae, or lamellae that are wavy. Furthermore, the leftmost incomplete lamella from the top has two notable features—its end is single-sidedly tilted (towards the right) and the upper part of the lamella is seemingly joined to another lamella by a fairly large bullet-like defect.
2.3. Interlude: Tackling Object Distance in Image Data of a Layered Structure
Let us disregard CLM for a moment and consider a daring approach—segment the image into individual lamellae and determine their distance directly.
This processing assumes a certain way of segmentation, i.e., specification of lamella boundary. Is it a threshold value for intensity gradient or simply for intensity? How exactly would the latter be related to the intensity values in the image is not unique as there are several competing well-established thresholding methods. The choice of the boundary definition affects the position of the boundary. One can argue that the effect would be only a few pixels and it could perhaps be neglected. Or, one could use some preliminary segmentation with an additional step selecting maximal intensity leading to a “skeleton” representation, a single lamella being represented by a 1-dimensional curve .
The distance would have to be determined locally, i.e., for each pixel from a given reference lamella, find the closest pixel from all the other lamellae and keep only the smallest value that should correspond to the nearest-neighbor lamella. The resulting computational overhead of the aforementioned robust finding of a single value could be justified by the reduced cost of human effort, but, still, this approach seems to be an overkill. One could use a locally perpendicular line and find the nearest intersection and do this along the whole lamella; this would determine the local value of apparent interlamellar distance . This could be repeated for all other remaining lamellae and then simply handle the overcounting due to the inclusion of the local distance of two lamellae and twice—the first one, i, from the other, j, and the other one, j, from the first one, i. On the one hand, the local-perpendicular direction is computationally less demanding than trying all directions. On the other hand, it requires construction of the local perpendicular direction. This may not be easy if there are local irregularities such as any of the following—kinks, asymmetric thinning or widening, bending (e.g., due to scratches of the sample surface) or lamellae being wavy, or sharp tilted ends of the lamellae (see Figure 4 and related discussion in the text). Such defects could cause misalignment of the local perpendicular direction and affect the values of .
One could represent the real lamellae by some fictitious idealized “straightened” out smoothened versions. Now, consider a pearlite colony whose lamellae locally highly deviate from a straight line (wavy “oscillations” or an overall bending) though they are straight lines “overall”. Should such a colony be replaced by a fictitious new one with its members being idealized straightened versions of the original ones? This will not work well if the ROI contains mostly uniform bending instead of wavy oscillations.
Furthermore, interlamellar spacing along the perpendicular direction is influenced by the sectioning plane effect [6].
Last, but not least, consider a branching lamella (Figure 4a)—a single trunk/parent lamella apparently forks into several branches/children lamellae. How is this corner case to be treated? Should the distance among child lamellae be calculated as well? Let us note that our algorithm attempts to do so. If so, how can such a branching be automatically detected, and how can the split of the trunk and its branches be performed?
With these issues to tackle, we conclude that the daring approach is hard to implement correctly, starting from the definition of the boundary of a lamella and dealing with the corner cases described above and illustrated in Figure 4. This might not be a critical issue as the amount of data to be acquired is large. As a result, these corner cases may be relegated to marginal contributions only, not significantly affecting the average value. Still, the computational power and coding effort required to collect all these data (nearest neighbor distances along lamellae) is significantly larger than that of the well-established CLM approach. Therefore, we conclude that the above suggested daring approach is to be abandoned in favor of a much simpler CLM implementation that keeps in mind the lessons learned in the above discussion.
2.4. A Tale of Two Approaches
We propose two approaches and discuss their challenges:
- (A1)Geometric—single lamella treated as an idealized rectangle-like object, at most two crossings with the measuring circle.The number of crossings is determined from the positions of endpoints of this idealized lamella with respect to the measuring circle.This geometric approach leads to undercounting in general, as the desired result is that each child of a branching lamella can contribute to the (manual) crossing count. However, this is no longer guaranteed as the imposed restriction to the maximal number of intersections of a single object. To be more precise, the single object here means a single connected component characterized by a high value of intensity in the thresholded and segmented image. If branching lamellae are not correctly split into several objects, the undercounting occurs.A partial remedy is that the segmentation into individual lamellae occurs locally in the square-shaped vicinity of the measuring circle processed (padding of the measuring circle can be a free parameter). The local segmentation will detect each child lamella as an individual lamella, provided that the branching occurs outside of this immediate neighborhood. A full workaround is to instruct the end user not to select regions where branching lamellae occur in such a way that the branching point is excluded from the square enclosing the measuring circle.
- (A2)Image-data—count-connected components of the crossings of the measuring circle with the individual lamellae.The restriction of at most two crossings for a single lamellae from the approach (A1) is not applied here. As a result, this “image-data” approach tends to overestimate the actual counts. The reason for that being that noise and finite pixel-size effects (e.g., circle is represented by a collection of pixels that form a ragged curve) cause small spurious artifacts that are incorrectly counted as valid crossings. A partial remedy is to smear the image before the segmentation; this may reduce these artifacts. Furthermore, one could reduce the number of spurious artifacts by requiring a valid crossing to have a minimal size of at least s pixels, where s is an unsigned integer. It can be set as a fixed pixel size (or alternately as a fixed real-space size) or as a relative number (fraction of estimated thickness of a given lamella). This, however, leads to optimizing for a given test image dataset and its variations across different types of sample images (thick, well-separated, line-like lamellae vs. thin, curly lamellae). The most flexible solution would be a configurable parameter with a default value and suggestions on how to modify it for a given pearlite colony type which, at the end of the day, would be the responsibility of a human operator. This, however, does not handle overcounting due to locally (highly) non-linear lamellae; see Figure 4c.
With the above considerations in mind, we can present a high-level overview of image processing with the measuring circles already selected. The steps performed to arrive at the results are the following:
- (S1)Load the image data as grayscale (possible to invert intensity).
- (S2)Separate data bar, if present, from the field of view.
- (S3)Perform global thresholding of the image (method configurable).Thresholding improves separation of the lighter lamellae from a dark background. If there is a non-dark halo surrounding the lamellae, careful selection of the thresholding method may be needed.
- (S4)Smear the image (blurring window size configurable).This helps to reduce effects of noise, e.g., grainy images with lower intensity of the lamellae, and tiny artifacts.
- (S5)For each measuring circle:
- (a)Perform local segmentation into individual lamellae in the vicinity of the measuring circle.The local segmentation may help to avoid occurrences of a branching point. Its presence in the ROI enclosing the measuring circle would lead to a branching lamellae and all its children being considered as a single object by the code. This would decrease the number of lamellae intersecting the circle, thus affecting the “geometric” approach (item no. (A1) in Section 2.4).
- (b)Count intersections and store the final intersection count n.A count correction can be implemented as discussed in the presentation of the two approaches. For example, drop contributions of objects too small (likely defects or visible ends of lamellae which are predominantly located out of the field of view) allow for, at most, two intersections for a single object (the geometric approach vs. branching lamellae), etc. The intermediate image processing is visualized in Figure 5.
- (S6)Post-processing the intersection counts, values of n, is performed to arrive at the interlamellar distance .
Let us note that none of the above methods is fully immune to the isolated point-like defects that cross the measuring circle. A significantly more complicated logic could be devised. First, check the pearlite colony or colonies in the whole image and determine the average “length” of lamellae not ending on the edges of the field of view (may be negatively affected by the branching lamellae). Second, eliminate isolated point-like defects (objects too short) not at the edge of the field of view (i.e., transforming the underlying data-image). This would still leave the point-like defects at the edge of the field of view, which could be handled by requesting the user not to place the measuring circles near these edges. Of course, one could consider implementing ML/AI through a neural network trained to classify the objects into a standalone lamella, a branching lamella, a point-like defect, etc. However, any inclusion of ML/AI would complicate code employment for the end user (additional dependencies and most likely an HW-specific installation/compilation), and a software as a service (SaaS) solution would be more meaningful in this case. Anyway, this is beyond the scope of the presented algorithm and its implementation.
We conclude this general section by commenting on pearlite colonies’ structural characteristics, other than interlamellar distance, that are available as a byproduct of the above-described algorithm. As we have the microstructure segmented into individual lamellae and the background, we can calculate the ratio of the surface corresponding to the background and lamellae. One could, in principle, attempt to determine the thickness of the individual lamellae. This is not a simple task due to two reasons. First, Figure 4c shows lamellae with varying thickness, i.e., lamella thickness is a local quantity. Thus, a single number would provide incomplete information in the form of extremal value or some form of average. Second, if the single segmented object is a branching lamella (discussed already in Section 2.3), then its local thickness determination as the most distant pixels along the locally perpendicular line would fail. It would provide the outer distance between the outermost child branches of the segmented object in its branched region, i.e., severely overestimating the thickness of the individual (though unresolved as such) child branches.
2.5. Implementation
The aforementioned algorithm has been implemented in a Python code by one of the authors (M.Z.) and it is tentatively titled “CLM App”. It can be called from the command line with several “expert” options and it provides an accompanying GUI. The code utilizes several non-standard Python libraries (see Appendix A) to achieve its goal, and its availability has recently been presented to the materials science community [7].
The various windows of the TkInter GUI are displayed in Figure 6. TkInter, a standard library of Python, was selected because the licensing was the least limiting when compared to other Python GUI frameworks.
The input files are microscopic 8-bit images. Benchmarking data discussed in the next sections are produced by SEM-ETD imaging. In the case of using SEM-CBS, the image intensity is essentially “inverted”. In order to account for different detector types, the data processing includes an intensity inversion switch to ensure that the lamellae of interest are represented by bright regions.
Pixel sizes of each image can be automatically detected from metadata (in the case of TIF(F) images), from optical character recognition of the data bar (provided that an optional dependence Google tesseract OCR [9] is installed), or it can be manually set to a constant value for all batch-processed images. The aforementioned automatic detection is available only in the case of several electron microscope devices—test images that were available to us—which are supported as of this moment, but adding more is not a difficult task.
This code produces several CSV output files and it has built-in logging. The CSV files are human readable, easy to process by other code, and easy to import into spreadsheet applications such as MS Excel and LibreOffice Calc.
The code can be distributed in the form of a binary (and accompanying additional files) using code-freezing. This approach makes it fairly portable and it minimizes the installation of dependencies on the on-premise PC to a bare minimum. Of course, the code-freezing is performed on the target OS, or its reasonable equivalent, which has to be available to us. An accompanying manual explaining the configurable parameters and outputs has already been written.
3. Results and Discussion
The MS Excel spreadsheets with manually processed data provide intersection counts without explicit association with corresponding measuring circles. Because of this ordering uncertainty, the deviation from the manual data is calculated as follows—we minimize the sum of absolute values of individual differences of the two intersection datasets across all possible permutations p of records from one of the datasets for a given microscopic image. This provides intersection count deviation for a single image, . We also define a relative deviation as follows.
where N labels the number of measuring circles within the considered microstructure image.
These quantities are the measure of performance for a single image. An initial test run used the Otsu threshold and the minimal non-trivial blurring window size (see Appendix B for more details). A comparison of the two lamellae treatment methods introduced in Section 2.4 reveals that there are data for which the first performs better than the second, and vice versa. The best performance is achieved on images with thick, well-separated, fairly linear lamellae, and the relative deviation does not increase over a few units of percent. The deviation increases up to tens of percent as the lamellae become thinner and locally highly curved.
However, the most significant quantity is the interlamellar distance . Therefore, we also compare mean values of the random interlamellar distance in each of the batches. Specifically, we shall focus on relative difference with respect to the manual data:
The statistical mean values of interlamellar distance appear in division. Hence, the scale factor, relating the three alternate distances in Equation (1), cancels out. Consequently, any mean interlamellar distance can be used in Equation (4).
We tested both the geometry-based and image-based approaches discussed in Section 2.4 using various thresholding methods. The relevant processing parameters, specific to the Python code, are presented in Appendix B. The best overall results—with minimal cumulative relative differences of —are obtained in the case of the image-based method and Otsu thresholding. They are displayed in Figure 7. The error bars are equal to Figure 7a, or derived from Figure 7b, with standard deviation as implemented in the NumPy library [10]. We note that the “isodata” and “mean” thresholds (all of the three available in SciKit-Image [11] used in our code; see Appendix A) perform similarly well on average.
Let us recall Equation (2) stating that is proportional to the inverse value of the intersection count n. Whenever the relative difference displayed in Figure 7b is positive, the code, on average, overestimates the intersection count n. Conversely, a negative relative difference indicates code underestimating the intersection count n.
The latter is typically the case, as demonstrated by the data displayed in Figure 7. This is a rather surprising conclusion, contradicting the simple expectation based on discussion of the image-based approach (A2) in Section 2.4.
The highest deviation, exceeding 10%, with respect to the manual processing occurs in the case of the following batches: , , , , , and , as is clearly seen from Figure 7b.
Exploring the corresponding image dataset, the following is revealed:
- : The images are somewhat “grainy” with lower contrast. The lamellae have somewhat less intensity and they are sometimes surrounded by a background halo of varying intensity. There are few regions with the lamellae being very close. This, and the presence of the halo, complicates proper segmentation, leading to several lamellae being treated as a single, connected, large object. This apparent “blobbing” leads to underestimation of the number of intersections.
- : Approximately half of the images are similar to those in containing an inhomogeneous halo. Several line-scratch-like defects are present, most likely “scratches” from sample preparation. This obviously complicates the local segmentation, as the scratch-like defects smear out the high-intensity lamellae along the defect’s direction.
- : This batch contains brighter spots both within and outside of the lamellae regions; see Figure 4b.
- : A combination of with several branching lamellae. The images with typically high-intensity lamellae are plagued by the accompanying background and sometimes also branching.
- : The batch data quality is pretty much similar to the .
- : Approximately 60% of the images have non-bright, somewhat grainy lamellae with a rather strong surrounding halo; see Figure 4a. The remaining 40% are somewhat grainy without the halo.
- : Approximately 50% of the images are rather grainy with lower intensities. Those with higher intensities exhibit branching/merging lamellae.
We note that the Otsu threshold provides the best result in this approach in the case of batches , , and . A decrease in absolute value of the relative difference is achieved within the approach (A2) by switching to the Yen threshold in the case of the other batches. The improvement ranges from fairly large 37% (in the case of the batch ) through to small 14% ( and ) to none ( , and ). This clearly shows that there is no “sweet” spot combination of settings that works for all the microstructure images very well.
The detailed analysis presented above implies that the higher deviation of the code-produced values with respect to the manually processed results clearly corresponds to images not containing bright regular lamellae well separated from the dark background not containing any halos.
It is possible that the performance on these data could be improved by altering the processing steps described in Section 2.4, namely, removing the global thresholding, step (S3), and adding local thresholding into the single measuring circle processing (currently step (S5)) as its first sub-step. However, suppression of the deviations due to this improvement might only be partial in the case of batches and . Both batches contain variations of (average local) intensity in the ROI; the former is characterized by an intensity gradient “across” lamellae, and the latter contains bright spots.
We have adapted the MATLAB DFT code from Ref. [4] for comparison with the CLM approach. In order to avoid coding in the flexibility in change of magnification (and pixel size), we have used it on 338 of the images with magnification 30,000× and a simple naming convention. This restriction minimizes the scope of necessary adjustments to the MATLAB code to a reasonable minimum, namely, cutting out the data bar and looping over different directories, each containing a single batch.
The DFT code provides apparent interlamellar distance by employing two processing methods. The best quantity to compare the two codes, Python CLM and MATLAB DFT, is the mean interlamellar distance with the mean across all measuring circles within a single image or batch average of these individual per-image values. We select the former approach.
Let us start the comparison by making some general comments. The DFT-based approach fails to a varying degree in the case of two images containing mostly a single, very regular pearlite colony. It fails completely, requiring more points to process in the Fourier-transformed domain in the case of an image with a corner-located irregularity (some 4% of the image) at the edge of the dominant pearlite colony. In the case of the other problematic image (from batch ), the result of a pearlite colony with some lamellae having endpoints within the field of view, the first method yields a negative result. We believe that both these failures can be circumvented by lowering the magnification, thus increasing the number of pearlite colonies in the field of view. Apart from these two exceptions, the code performed without issues.
In order to compare the MATLAB DFT-based code results with those here presented, the interlamellar distance is scaled from apparent to random using Equation (1). Then, we calculate the relative difference introduced in Equation (4) and plot the results in Figure 8. As the relative difference is per file, we use more precise notation of in accordance with Equation (3).
The error bars assigned to the two methods of the MATLAB code are derived solely from the standard deviation of the interlamellar distance from the manually processed dataset for all measuring circles within each given file. The MATLAB DFT-based code tends to underestimate the interlamellar distance when compared to the manually processed data; on average, the underestimation is by some 15%. The value is estimated from fitting a multiplicative scale and minimizing the deviation with respect to the manually processed data using the SciPy [12] non-standard Python library. The largest observed deviation occurs in the case of method 1 and batch ; the corresponding file contains a single pearlite colony with fairly uniform distribution apart from several interrupted or merging lamellae. This is where the DFT-based code, by design, does not perform well, as its above-discussed failures indicate. The fact that the results from the Python code match the manual processing better than the MATLAB DFT-based code is not surprising. Indeed, the dataset was used for fine-tuning configurable parameters of our code and the MATLAB DFT-based code implements a different method.
Compare the different types of results corresponding to the Python CLM code. The data for deviation both per batch (see Figure 7b) and per file (displayed in Figure 8) reveal that the statistical processing per batch averages out some outliers in the deviation per file. Consider the sample no. 1; although the individual per-file deviations may be larger, is less than %, and the per-batch deviation satisfies the stricter limit not exceeding %. We expect that a similar effect would also apply to the DFT-based code, thus making the differences less pronounced in a not-displayed equivalent of Figure 7b.
4. Conclusions and Outlook
We have presented a tool that partially automates the CLM method by counting the intersections for known positions of the measuring circles. This is achieved using simple image processing methods. It turns out that, naturally, the performance in the intersection count domain depends on the thickness and regularity/linearity of the lamellae and their intensity separation from the background. Despite this dependence, a suitable choice of parameters can ensure a reasonable deviation for all the samples in the benchmarking dataset available to us, as demonstrated in Figure 7.
Analysis of image batches with relative deviation of the mean values, , exceeding 10% showed that these batches contain images of “lesser” quality—grainy, lower intensity lamellae, branching, and presumably surface scratches (see left-hand side of Figure 4a for an example) from sample preparation, etc. We have proposed a method to improve performance on these batches by switching from global thresholding to local thresholding in the ROI defined by the square tightly enclosing the measuring circle. This could be explored in future work and versions of the application. One of the desirable extensions would be to be able to assess the “quality” of a region and decide whether placing a circle there was, or is, favorable or it is not; this could help to provide suggestions for circle positions to be (partially) accepted or rejected by the end user.
Despite the more feature-rich image data with irregularities leading to lower performance, the current code already exhibits excellent performance on images with highly regular, well-separated lamellae. They correspond to sample no. 1 (batches from to ), and the deviation does not increase above %.
As “There ain’t no such thing as a free lunch” (TANSTAAFL) applies here as well, reaching optimal performance may require more than a single run. The suggested method is that the end user visually inspects the images to be processed, they split them into several classes, and then they test the performance on a suitable representative of each class for different configuration parameters. Processing of each image class may benefit from using (slightly) different parameters.
The above-demonstrated good-to-excellent performance for interlamellar distance is proof that this tool can be used to automate the CLM data processing. As a result, it takes the burden of tedious manual counting of intersections for all the imaged microstructures from its operator, leaving only the selection of the positions of the measuring circles. Of course, there is a much smaller price to pay to achieve the best performance, namely, the testing of the configurable parameters on a small subset of images.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Vander Voort G. Roósz A. Measurement of the Interlamellar Spacing of Pearlite Metallography 19841711710.1016/0026-0800(84)90002-8 · doi ↗
- 2Jabłońska M. Lewandowski F. Chmiela B. Gronostajski Z. Advanced Heat Treatment of Pearlitic Rail Steel Materials 202316643010.3390/ma 1619643037834570 PMC 10573705 · doi ↗ · pubmed ↗
- 3Petitgand H. Benoit D. Moukassi M. Debyser B. Automatic Measurement of Pearlitic Interlamellar Spacing with Computer Image Processing ISIJ Int.19903054655110.2355/isijinternational.30.546 · doi ↗
- 4Matteis P. Automatic Measurement of Pearlite Spacing by Spectral Analysis Metallogr. Microstruct. Anal.2020915215810.1007/s 13632-020-00630-9 · doi ↗
- 5De Cost B.L. Holm E.A. A computer vision approach for automated analysis and classification of microstructural image data Comput. Mater. Sci.201511012613310.1016/j.commatsci.2015.08.011 · doi ↗
- 6Vander Voort G.F. The Interlamellar Spacing of Pearlite Prakt. Metallogr.-Pract. Metallogr.20155241943610.3139/147.110357 · doi ↗
- 7Zouhar M. MikmekováŠ. Circular Line Method Software for Interlamellar Distance in Pearlite Presented at the METAL 2025: 34th Anniversary International Conference on Metallurgy and Materials Brno, Czech Republic 21–23 May 2025
- 8Hunter J.D. Matplotlib: A 2D graphics environment Comput. Sci. Eng.20079909510.1109/MCSE.2007.55 · doi ↗