Deep Learning-Based Liver Tumor Segmentation from Computed Tomography Scans with a Gradient-Enhanced Network
Hangyeul Shin, Kyujin Han, Seungyoo Lee, Harin Park, Seunghyon Kim, Jeonghun Kim, Xiaopeng Yang, Jae Do Yang, Jisoo Song, Hee Chul Yu, Heecheon You

TL;DR
This paper presents a deep learning method for automatically segmenting liver tumors in CT scans, achieving high accuracy and outperforming existing models.
Contribution
A novel gradient-enhanced network, G-UNETR++, is proposed for liver tumor segmentation with improved performance on public datasets.
Findings
The method achieved an average dice score of 0.844 on the LiTS dataset.
It also achieved a dice score of 0.832 on the 3DIRCADb dataset.
The model outperformed state-of-the-art methods on both datasets.
Abstract
Background/Objectives: This study aimed to develop a fully automatic method for liver tumor segmentation based on our previously developed gradient-enhanced network G-UNETR++. Methods: The proposed method consists of segmentation of the full liver region from computed tomography (CT) images using G-UNETR++, masking the CT images with the extracted liver region to exclude non-liver regions, and liver tumor segmentation from the masked CT images, also using G-UNETR++. To train and evaluate the model, a total of 131 CT scans (97 for training, 20 for validation, and 20 for testing) from the publicly available LiTS dataset were used. Furthermore, another public dataset, the 3DIRCADb dataset consisting of 20 CT scans was used for cross-validation of the effectiveness and generalizability of our method. Results: Experimental results showed that our method outperformed state-of-the-art models…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
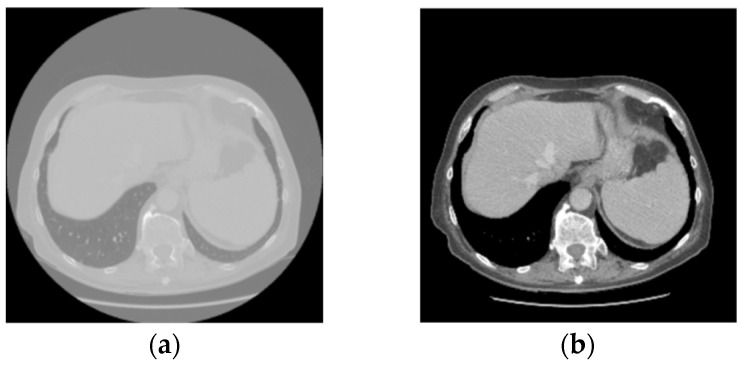 Figure 1
Figure 1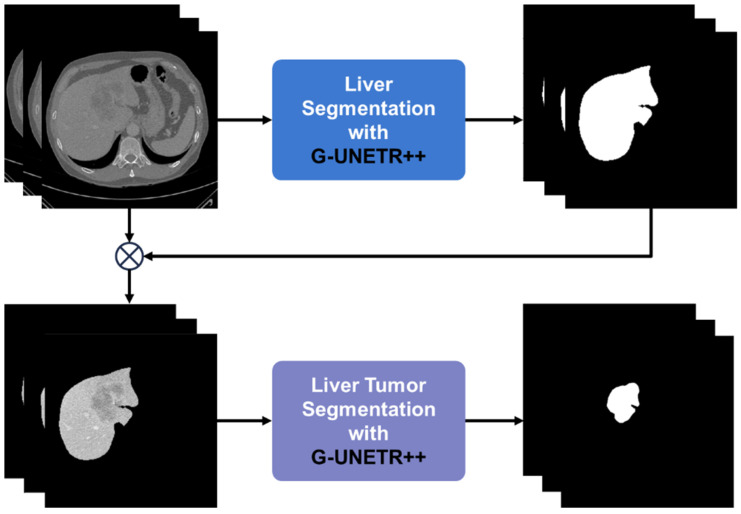 Figure 2
Figure 2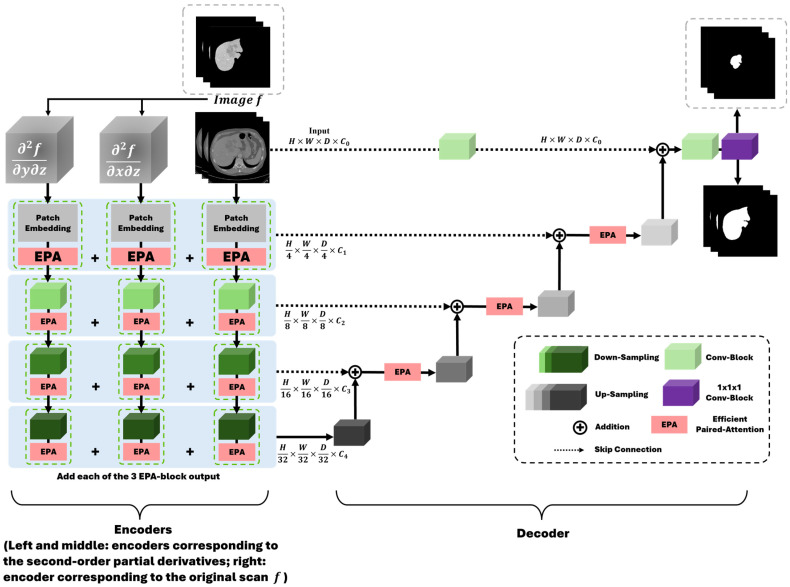 Figure 3
Figure 3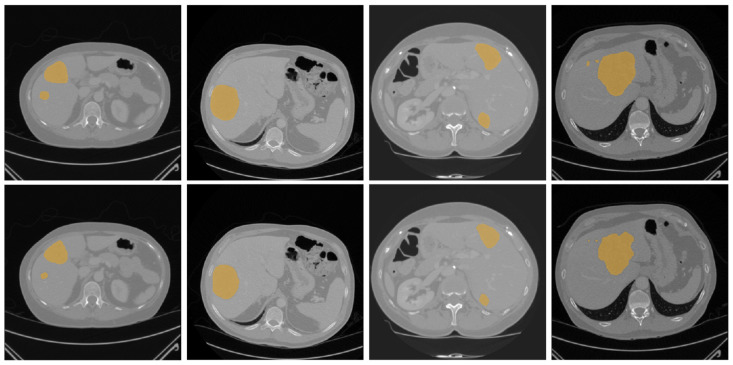 Figure 4
Figure 4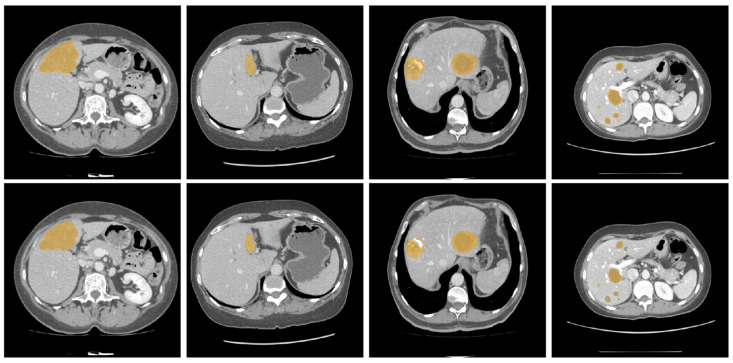 Figure 5
Figure 5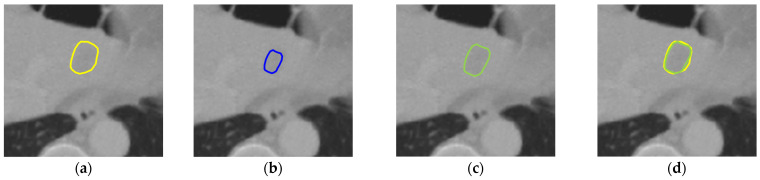 Figure 6
Figure 6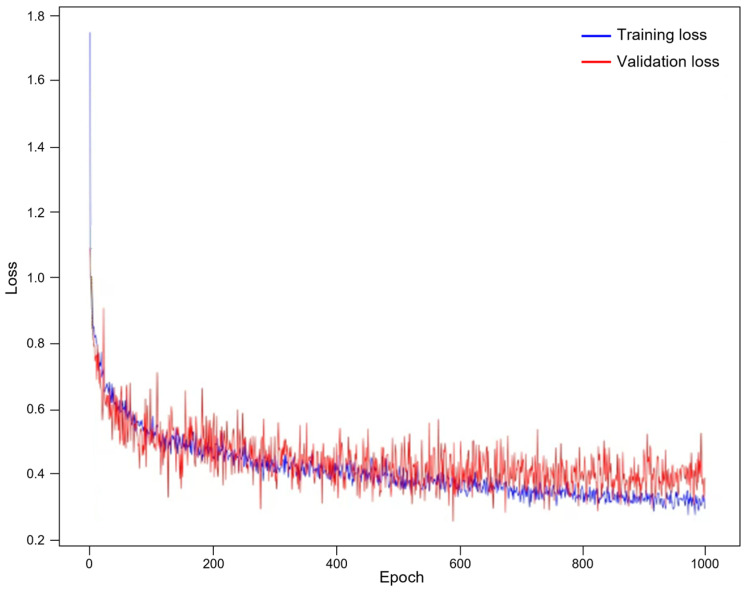 Figure 7
Figure 7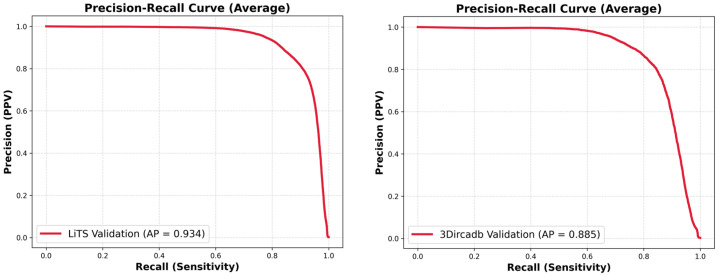 Figure 8
Figure 8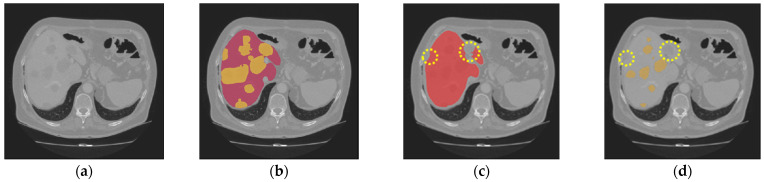 Figure 9
Figure 9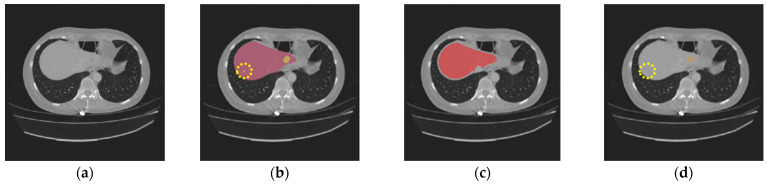 Figure 10
Figure 10- —Handong Global University
- —Jeonbuk National University
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAdvanced Neural Network Applications · Medical Image Segmentation Techniques · Brain Tumor Detection and Classification
1. Introduction
Liver cancer ranks as the fourth highest cause of death among all malignancies [1], making its diagnosis and surgical intervention critical tasks in the modern medical field. To enhance the success rates of these procedures, accurate segmentation of both the liver and tumors is essential. Computed tomography (CT) has emerged as a representative imaging modality, widely utilized by physicians for analyzing organs and detecting lesions. In clinical practice, physicians typically detect tumors from a patient’s CT scan through visual observation, relying on their knowledge and experience. This approach is subjective and time-demanding, potentially leading to an increased possibility of misdiagnosis or missed diagnosis [2]. Therefore, automatic and accurate liver tumor segmentation from CT scans is needed to assist physicians in detecting liver tumors efficiently and accurately.
With the advancement of deep learning technologies, numerous methods have been proposed for medical image segmentation tasks. Since the introduction of convolutional neural networks (CNNs) [3], significant progress has been made in the field of computer vision, leading to the development of various CNN-based architectures [4,5,6,7,8,9,10,11,12,13,14,15,16,17]. U-Net [4] has especially become one of the most popular network architectures for medical image analyses tasks. For example, Özcan et al. [17] proposed a hybrid model incorporating U-Net and inception models for automatic segmentation of the liver and liver tumors from CT scans. They reported that their model achieved 75.6% and 65.6% of dice similarity coefficient (DSC) over two public datasets, respectively. CNN-based models are able to capture local features but struggle to capture global contexts from medical images due to their localized receptive fields [18].
To address these issues, we aim to develop a two-step method for liver tumor segmentation based on a gradient-enhanced network, referred to as G-UNETR++ [19]. G-UNETR++ is a hybrid network incorporating U-Net, vision transformer (ViT) [20], and gradient-based encoders, originally designed for liver segmentation. ViT is able to capture global contexts by its self-attention mechanisms. Gradient-based encoders further enable G-UNETR++ to learn 3D boundary features of the organs and tissues from medical images. First, the liver is segmented from CT images with G-UNETR++ and the CT images are masked by the extracted liver regions to remove non-liver regions. Then, the regions of liver tumors are delineated with G-UNETR++.
2. Related Work
2.1. CNN-Based Segmentation Networks
CNN-based architectures have been widely adopted for medical image segmentation, with many approaches derived from U-Net [5,6,10,11,12,13]. Milletari et al. [10] proposed a fully convolutional network, optimized using a dice-based loss for volumetric segmentation. Çiçek et al. [5] extended U-Net to 3D by replacing 2D operations with 3D convolutions, enabling effective volumetric analysis. Dou et al. [11] introduced a deeply supervised 3D network that improved liver segmentation performance on CT volumes. To enhance boundary delineation, Roth et al. [13] proposed a two-stage FCN, achieving higher dice scores in multi-organ CT segmentation. Despite these advances, CNN-based models are limited in capturing long-range dependencies and global contextual information.
2.2. Transformer-Based and Hybrid Segmentation Networks
Dosovitskiy et al. [20] introduced attention mechanisms to computer vision, motivating transformer-based medical image segmentation models. Pure transformer architectures without convolution have been proposed for both 2D and 3D segmentation tasks [21,22]. Cao et al. [22] designed a U-Net-like transformer with shifted window attention for encoder–decoder learning, achieving strong results on 2D medical datasets. Karimi et al. [21] introduced a convolution-free 3D model that applies self-attention across neighboring volumetric patches.
To combine local feature extraction with global context modeling, several studies proposed hybrid CNN–transformer architectures [23,24,25,26,27,28,29,30,31]. Oktay et al. [23] enhanced U-Net with attention gates in skip connections, improving abdominal multi-organ segmentation. Valanarasu et al. [24] proposed axial attention for more efficient positional encoding. TransUNet [30] employed a CNN-based encoder followed by transformer blocks and a CNN decoder for precise localization. Similarly, Xie et al. [31] combined CNN feature extraction with transformer-based contextual modeling for 3D segmentation. Hatamizadeh et al. [25] eliminated convolutional encoders and directly tokenized image patches using a transformer, while retaining a skip-connected decoder for multi-scale prediction. Zhou et al. [26] interleaved convolution and self-attention to learn volumetric representations and achieved superior liver segmentation performance on the Synapse dataset compared to UNETR. Shaker et al. [27] further introduced an efficient paired attention block that jointly models spatial and channel dependencies, improving segmentation accuracy and computational efficiency; however, its liver segmentation performance remained slightly lower than nnFormer, and tumor segmentation results were not reported.
2.3. Liver and Tumor Segmentation Networks
Several segmentation networks have been specifically designed for liver and tumor segmentation [2,32,33,34,35,36,37,38]. Jin et al. [32] replaced standard U-Net convolutional blocks with residual blocks to enhance feature learning and mitigate gradient vanishing, while integrating multi-scale attention to fuse hierarchical features. Chen et al. [2] proposed MS-FANet, incorporating residual attention blocks and multi-scale atrous downsampling to better capture tumor size and shape variations, achieving dice scores of 0.742 and 0.780 on two public datasets. Jiang et al. [34] introduced RMAU-Net, which integrates squeeze-and-excitation mechanisms and multi-scale feature fusion to model both inter-channel and spatial relationships, achieving dice scores of 0.762 and 0.831 on the same datasets. Muhammad and Zhang [35] leveraged the hybrid ResUNet model, a combination of both the ResNet and UNet models developed by the Monai 0.6 and PyTorch 1.10 frameworks and achieved a dice score of 0.87 for liver tumor segmentation over the public MSD Task03 Liver dataset. Yashaswini et al. [36] applied U-Net and a modified ResUNet to liver and tumor segmentation from CT scans using the 3DIRCADb dataset, demonstrating the effectiveness of fully convolutional networks for semantic segmentation. The ResUNet achieved superior performance, with dice scores of 91.44% for liver segmentation and 75.84% for tumor segmentation. Balaguer-Montero et al. [37] developed a fully automated liver tumor detection and segmentation system based on nnU-Net and achieved a dice score of 81.72% at lesion level. Zhang et al. [38] introduced a novel liver tumor segmentation framework that combines deformable attention, global context modeling, and dual cross-scale feature fusion to handle complex and irregular tumor structures. Their model achieved a dice score of 81.33% on their internal test set. Despite these efforts, accurate tumor segmentation remains challenging due to the heterogeneous appearance and complex morphology of liver tumors.
3. Materials and Methods
3.1. Data Preparation
Two public CT datasets, including the MICCAI 2017 LiTS dataset (LiTS) [39] and the 3DIRCADb dataset [40], were used in this study. The LiTS dataset is a public dataset from the liver tumor segmentation challenge held at ISBI 2017 and MICCAI 2017. It is the most widely used dataset for liver and tumor segmentation research. The LiTS dataset contains patients with diverse types of liver tumor diseases, consisting of primary tumor disease, such as hepatocellular carcinoma and cholangiocarcinoma, and secondary liver tumors, such as metastases from colorectal, breast, and lung primary cancers. The LiTS dataset, primarily focusing on portal venous phase CT scans, comprises a training set of 131 CT scans and a separate test set of 70 CT scans. The number of CT slices in each scan varies from 42 to 1026, with an axial resolution of 512 × 512 pixels, in-plane voxel dimensions of 0.55 to 1.0 mm and a slice thickness ranging from 0.45 to 6.0 mm. The training dataset was manually labeled by four radiologists from six clinical sites worldwide, whereas labels of the test set are not publicly available. It is challenging to segment tumors using this dataset because of the significant variations in slice thickness, scan image storage direction, image quality, and spatial resolution.
The 3DIRCADb dataset is another publicly available dataset that provides more complex data on the liver and tumors. The 3DIRCADb-01 dataset consists of enhanced CT scans of 10 females and 10 males, with 75% of cases having hepatic tumors, while the 3DIRCADb-02 dataset comprises two 3D CT scans. The voxel dimensions of the dataset are [0.56–0.87, 0.56–0.87, 1.6–4.0] mm, with an axial resolution of 512 × 512 pixels and the number of slices in each scan varying between 74 and 260. In some cases, the liver and tumors have low contrast and overlapping regions, which makes the tumor segmentation a challenging task. Labels of the dataset are publicly available.
In this study, the 131 CT scans from the LiTS dataset were randomly split into 97 cases for training, 20 for validation, and 20 for testing. Next, the 3DIRCADb-01 dataset was used for cross-validation of the effectiveness and generalizability of our method.
3.2. Data Preprocessing and Augmentation
Preprocessing was performed to normalize the Hounsfield Unit values of all CT scans to a range of −250 to 250 to enhance the visibility of the liver and tumor regions, as shown in Figure 1. All CT scans were resized from 512 × 512 to 256 × 256 to reduce computational cost. The same data augmentation strategies as G-UNERT++ [19], such as random rotation of 90, 180, and 270 degrees, random scaling, random mirroring, and random intensity shifting were applied.
3.3. Deep Learning Model Preparation and Training
Figure 2 shows the overall pipeline of liver tumor segmentation based on our G-UNETR++ model. First, the liver is segmented from CT images using G-UNETR++. Then the extracted liver region is multiplied with the original CT images to exclude non-liver regions. Lastly, liver tumors are delineated from the liver-only CT images using G-UNETR++. Figure 3 shows the architecture of our G-UNETR++ model. The model consists of a hierarchical encoder–decoder structure with skip connections between the encoder and the decoder, efficient paired attention (EPA) blocks, and convolutional blocks to obtain segmentation results. The encoder scheme consists of three 4-stage encoders in parallel one with CT scan as input, and the other two with second-order partial derivatives and as their inputs to learn 3D geometric features such as the boundaries between different organs and tissues especially along the z-axis. In the first stage, patch embedding is performed, where the input volume is divided into non-overlapping 3D patches of size (P1, P2, P3), producing a sequence with length . These patches are projected into channels to form a feature map, using a patch resolution of (4, 4, 2), followed by an EPA block. The remaining stages downsample the feature maps by a factor of two using non-overlapping convolutions, each followed by an EPA block. At every stage, features from the three encoders are fused via element-wise summation. The EPA block employs spatial and channel attention with shared keys and queries and separate value projections to jointly model spatial–channel features [27]. The decoder consists of four stages with deconvolution-based upsampling to progressively increase resolution. EPA blocks are used at all but the final stage. Skip connections fuse encoder and decoder features at each scale to recover spatial information, while channel dimensions are halved between stages. In the final stage, fused features are passed through 3 × 3 × 3 and 1 × 1 × 1 convolutions to generate voxel-wise segmentation outputs.
3.4. Loss Function
We proposed different hybrid loss functions for liver segmentation and tumor segmentation. For liver segmentation, a hybrid loss function was proposed, consisting of dice loss , cross-entropy (CE) loss , and Hausdorff distance (HD) loss [41] . For tumor segmentation, a hybrid loss function was proposed, consisting of dice loss, focal loss [42] , and HD loss to address the class imbalance issue in tumor segmentation. The hybrid loss function for liver segmentation is defined as follows:
where . The hybrid loss function for tumor segmentation is defined as follows:
where . Dice loss is defined as follows:
where denotes the number of predicted voxels; indicates the prediction probability at voxel ; and represents the ground truth at voxel . CE loss is defined as follows:
where indicates the ground truth and denotes the prediction probability. HD loss is defined as follows:
where denotes the predicted binary segmentation with a threshold of 0.5 and indicates the ground truth. Focal loss is defined as follows:
where denotes the predicted probability for the correct class; indicates a weighting factor for class imbalance; and denotes the focusing parameter, controlling the rate at which easy examples are downweighted. A deep supervision technique [43] was applied into our decoder for better training efficiency.
3.5. Model Training
Identical settings were applied to train both the liver segmentation model and the tumor segmentation model. All experiments were performed with an NVIDIA RTX 3090 GPU. The initial learning rate was set to 5 × 10^−4^ with a poly decay strategy [26]. The Adam optimizer [44] was used with a weight decay of 3 × 10^−5^. The number of epochs was set as 1000. The batch size was set as 8.
3.6. Post-Processing
By visual inspection, we observed that our model tended to segment tumors with fewer voxels compared to the ground truth, even though the model accurately predicted the locations of the tumors. This undersizing of small tumors became more severe as the size of the tumor decreased in the ground truth. To address this issue, we empirically applied the morphological dilation method twice, with a pixel size of one in each operation to the predicted tumor regions smaller than 100 pixels from a CT slice after exhaustive experimentation.
3.7. Evaluation Metrics
To assess the performance of the proposed tumor segmentation method, we utilized a range of evaluation metrics, including the dice similarity coefficient (DSC) to measure overlap accuracy, volumetric overlap error (VOE) to measure volume consistency, relative absolute volume difference (RAVD) to assess volume disparity, and average symmetric surface distance (ASSD) to quantify surface deviation.
DSC quantifies the overlap between the predicted volumetric output (Pred) and the ground truth (GT). Ranging from 0 to 1, DSC = 1 indicates perfect overlap and segmentation, while DSC = 0 signifies no overlap between the predicted and the ground truth. The formula for DSC is as follows:
VOE quantifies the alignment between the predicted and the ground truth, assessing the error rate in segmentation. Ranging from 0 to 1, VOE = 0 indicates perfect overlap, while VOE = 1 signifies no overlap. The formula for VOE is as follows:
RAVD is used to measure the volume discrepancy between the predicted and the ground truth, ranging from 0 to 1, with a value of zero indicating no volume disparity, reflecting a perfect segmentation. RAVD is calculated as follows:
ASSD is the key metric for measuring the average deviation between the surfaces of the predicted and the ground truth, with a value of zero indicating a perfect segmentation. The shortest distance of a voxel to the set of surface voxels of is defined as follows:
where denotes the Euclidean distance between and . Then ASSD is defined as follows:
4. Results
We compared our model with state-of-the-art models for liver tumor segmentation, including HDU-Net [45], ResUNet [46], MS-FANet [2], HFRU-Net [47], and RMAU-Net [34]. Table 1 shows the comparison results for liver tumor segmentation over the LiTS and 3DIRCADb datasets. For both datasets, our model outperformed state-of-the-art models. For the LiTS dataset, our model showed a significant improvement in liver tumor segmentation compared with the other models. Our model achieved the best performance in terms of DSC (0.844), VOE (0.263), and ASSD (1.317 mm), with RAVD being the only exception, which indicates the high effectiveness of our model in accurately capturing tumor regions. Next, for the 3DIRCADb dataset, our model also achieved the best performance in terms of DSC (0.832) and ASSD (1.682), except for VOE and RAVD. The consistently high performance of our model across different datasets highlights its robustness and generalizability.
Figure 4 and Figure 5 illustrate some examples of the liver tumor segmentation results with our model from the LiTS dataset and the 3DIRCADb dataset, respectively. Visual inspection of the segmentation results reveals that the predicted tumor regions are properly aligned with the ground truth in terms of both the number of tumors and their morphology.
We conducted an ablation study to demonstrate the effectiveness of the proposed post-processing method. First, we evaluated the post-processing method on the LiTS and 3DIRCADb datasets. As shown in Table 2, for the LiTS dataset, there is a slight performance difference between the results with post-processing and those without post-processing, whereas for the 3DIRCADb dataset, the dice score has been improved by 2.9% and all other metrics have also been improved. Therefore, the proposed post-processing method is effective in improving tumor segmentation results.
To determine the right number of times of the morphological dilation operation in our post-processing method, we applied the morphological dilation operation from one to three times to compare their performance. As shown in Table 3, for the LiTS dataset, the best performance was achieved with the one-time application of the dilation operation, but the differences with the two-time application and the three-time application were small, whereas for the 3DIRCADb dataset, the results showed that applying dilation twice resulted in the best performance in terms of all evaluation metrics. Therefore, the post-processing method that applies the morphological dilation twice was adopted for our liver tumor segmentation method. As shown in Figure 6, after post-processing, the dilated tumor boundary is closer to the ground truth tumor boundary.
We conducted various analyses to further evaluate our model. Figure 7 shows the plotting of the training loss and validation loss, indicating that no overfitting occurred during our model development process. Table 4 summarizes the complexity of our model. Figure 8 presents the precision-recall plotting of our model over the LiTS dataset and the 3DIRACDb dataset, respectively.
5. Discussion
This study proposed a solid deep learning method for liver tumor segmentation based on G-UNETR++, a gradient-enhanced network originally developed in our previous study for liver segmentation from CT images. The proposed method consists of two steps: (1) segmentation of the liver from a CT scan by G-UNETR++ and masking the CT scan with the extracted liver region to exclude non-liver regions, and (2) segmentation of tumors from the masked CT scan by G-UNETR++.
Performance comparisons on the LiTS dataset show that our method outperforms existing state-of-the-art methods, achieving an average DSC of 0.844. To assess generalizability, the model was evaluated on one unseen dataset, 3DIRACDb, where it achieved an average DSC of 0.832. These results demonstrate strong robustness across datasets acquired under diverse conditions. The inclusion of two gradient-enhanced encoders ensures that our model effectively captures 3D geometric features. Furthermore, the proposed hybrid loss function can handle the class imbalance issue with focal loss and deal with difficult cases in tumor segmentation to ensure boundary precision with HD loss. Lastly, the post-processing method reduces tumor segmentation error by morphological dilation operation, especially when the tumor size is small.
Nevertheless, our study has limitations in certain aspects. The introduction of the two gradient-enhanced encoders increases the complexity level of our model and therefore the computational cost. Furthermore, the tumor segmentation performance can be affected by the liver segmentation performance. The proposed method achieved high performance on both the LiTS dataset and the 3DIRCADb dataset, with an average DSC of 97.38% and 97.50% for liver segmentation, respectively. However, in some cases, tumors may be missing in the segmented liver region, as shown in Figure 9c. Then, in the masking step, those tumors will be excluded from the CT images masked by the extracted liver region, which will be used as the input for tumor segmentation. In that case, those tumors will be missing in tumor segmentation, as shown in Figure 9d. In addition, our model may occasionally miss segmenting some extremely small tumors, as shown in Figure 10. This could be caused by tumor size imbalance and biased annotation for small lesions in the public datasets used for our model development. For our future work, the proposed two-step liver tumor segmentation pipeline can be reduced to a single-step pipeline by applying an end-to-end framework. This would enable a direct extraction of tumors from the original CT scans, thereby reducing computational costs and potentially enhancing the robustness of the segmentation process. Furthermore, the sizes of the datasets used for model training and evaluation are relatively small. To strengthen the experimental validity, the performance of the proposed model needs to be further evaluated using k-fold cross-validation or a larger dataset. Lastly, the ablation study is limited in scope and primarily focuses on the effect of post-processing. Though the ablation study in our previous work [19] concluded that the inclusion of the proposed gradient-enhanced encoders and a hybrid loss function that incorporates the HD loss are effective in improving the performance of liver segmentation, their effects on liver tumor segmentation were not studied in the current study. For future work, a comprehensive ablation study that analyzes the impacts of the gradient-enhanced encoders, the proposed hybrid loss function, and the EPA blocks on improving liver tumor segmentation performance will be conducted.
6. Conclusions
This study presents a deep learning framework for liver tumor segmentation from CT images using a two-step pipeline consisting of liver extraction followed by tumor segmentation. The proposed method achieves competitive performance, outperforming existing approaches on the LiTS dataset with a DSC of 0.844, and demonstrating strong generalizability on the unseen 3DIRACDb dataset with a DSC of 0.832.
The incorporation of gradient-enhanced encoders enables the effective learning of 3D geometric features, while the hybrid loss function addresses class imbalance and improves boundary delineation. In addition, post-processing with morphological dilation reduces segmentation errors, particularly for small tumors. Despite these advantages, the model’s complexity and reliance on accurate liver segmentation remain limitations, and very small tumors may still be missed.
Future work will focus on developing an end-to-end, single-stage framework to reduce computational cost and improve robustness, as well as validating the method using k-fold cross-validation or larger datasets with comprehensive ablation studies.
The proposed method shows strong clinical potential by accurately segmenting liver tumors from CT scans. The generated segmentation results allow radiologists to efficiently review tumor regions and assess imaging characteristics for diagnosis, supporting informed treatment planning by physicians.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Ahn S.H. Yeo A.U. Kim K.H. Kim C. Goh Y. Cho S. Lee S.B. Lim Y.K. Kim H. Shin D. Comparative clinical evaluation of atlas and deep-learning-based auto-segmentation of organ structures in liver cancer Radiat. Oncol.2019142133177582510.1186/s 13014-019-1392-z PMC 6880380 · doi ↗ · pubmed ↗
- 2Chen Y. Zheng C. Zhang W. Lin H. Chen W. Zhang G. Xu G. Wu F. MS-FA Net: Multi-scale feature attention network for liver tumor segmentation Comput. Biol. Med.202316310720810.1016/j.compbiomed.2023.10720837421737 · doi ↗ · pubmed ↗
- 3Krizhevsky A. Sutskever I. Hinton G.E. Imagenet classification with deep convolutional neural networks Commun. ACM 201760849010.1145/3065386 · doi ↗
- 4Ronneberger O. Fischer P. Brox T. U-Net: Convolutional Networks for Biomedical Image Segmentation Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI)Munich, Germany 5–9 October 2015234241
- 5ÇiçekÖ. Abdulkadir A. Lienkamp S.S. Brox T. Ronneberger O. 3D U-Net: Learning Dense Volumetric Segmentation from Sparse Annotation Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2016 Athens, Greece 17–21 October 2016
- 6Zhou Z. Rahman Siddiquee M.M. Tajbakhsh N. Liang J. U Net++: A Nested U-Net Architecture for Medical Image Segmentation Proceedings of the Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support: 4th International Workshop, DLMIA 2018, and 8th International Workshop, ML-CDS 2018 Granada, Spain 20 September 201831110.1007/978-3-030-00889-5_1PMC 732923932613207 · doi ↗ · pubmed ↗
- 7Zhou Z. Siddiquee M.M.R. Tajbakhsh N. Liang J. U Net++: Redesigning skip connections to exploit multiscale features in image segmentation IEEE Trans. Med. Imaging 2019391856186710.1109/TMI.2019.295960931841402 PMC 7357299 · doi ↗ · pubmed ↗
- 8Cai S. Tian Y. Lui H. Zeng H. Wu Y. Chen G. Dense-U Net: A novel multiphoton in vivo cellular image segmentation model based on a convolutional neural network Quant. Imaging Med. Surg.202010127510.21037/qims-19-109032550136 PMC 7276369 · doi ↗ · pubmed ↗