A Cattle Behavior Recognition Method Based on Graph Neural Network Compression on the Edge
Hongbo Liu, Ping Song, Xiaoping Xin, Yuping Rong, Junyao Gao, Zhuoming Wang, Yinglong Zhang

TL;DR
This paper introduces a low-power wearable device using compressed graph neural networks to recognize cattle behavior in real-time on edge devices, improving livestock management efficiency.
Contribution
A novel edge-based cattle behavior recognition method using GNN compression and a lightweight model for wearable devices is proposed.
Findings
The compressed model achieves 93.20% accuracy with 46.8% lower power consumption compared to cloud inference.
The proposed method enables real-time cattle behavior classification on edge devices with limited resources.
The wearable device supports long-term automated monitoring in large-scale grazing environments.
Abstract
Behavior recognition is essential techniques in modern livestock and poultry farming, supporting precision agriculture and improving production efficiency. This study proposes an edge-based cattle behavior recognition method based on Graph Neural Network (GNN) compression. A Sequence Residual Network (S-ResNet) tailored for single-frame inputs is developed, and a lightweight model is obtained via GNN compression. The resulting model is successfully deployed on a wearable device with edge inference capability. Experimental results show that the compressed model achieves an accuracy of 93.20%, while its power consumption is only 46.8% of that required by cloud inference. The proposed method enables edge-side cattle behavior recognition and effectively extends device endurance, making it suitable for automated monitoring in large-scale free-grazing scenarios. Cattle behavior is closely…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
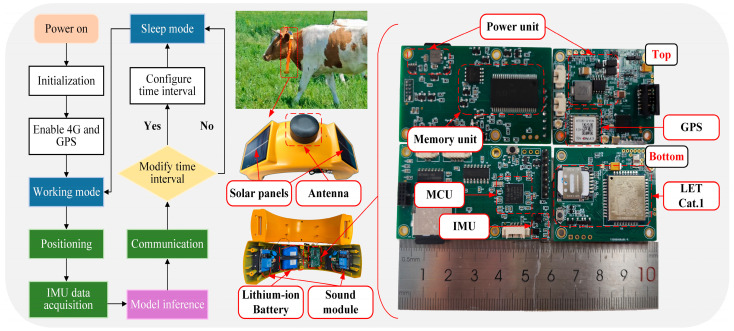 Figure 1
Figure 1 Figure 2
Figure 2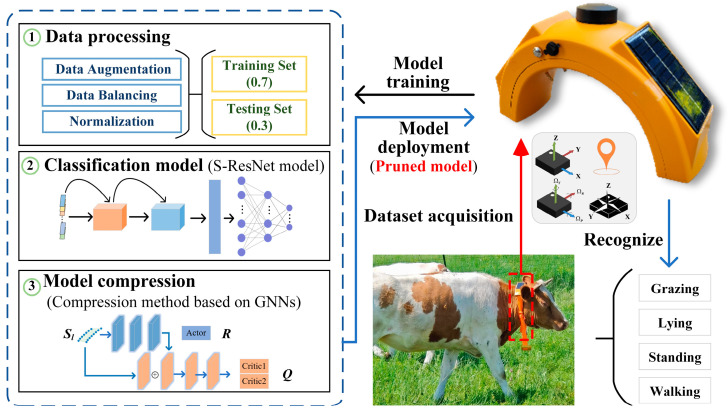 Figure 3
Figure 3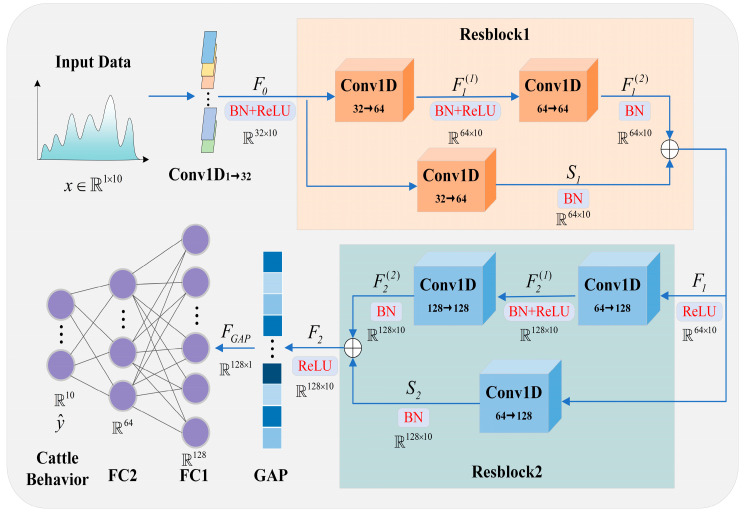 Figure 4
Figure 4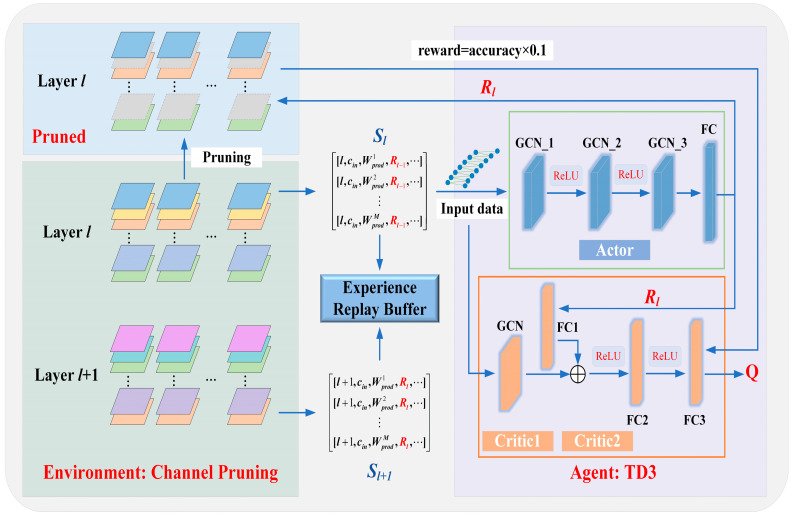 Figure 5
Figure 5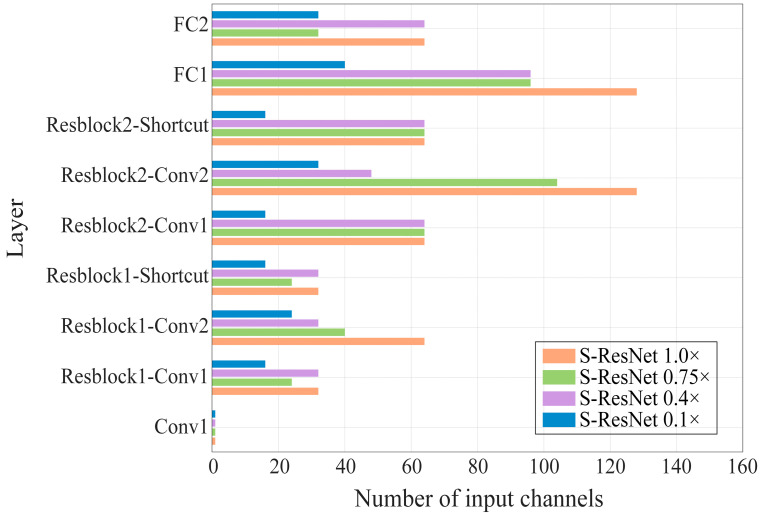 Figure 6
Figure 6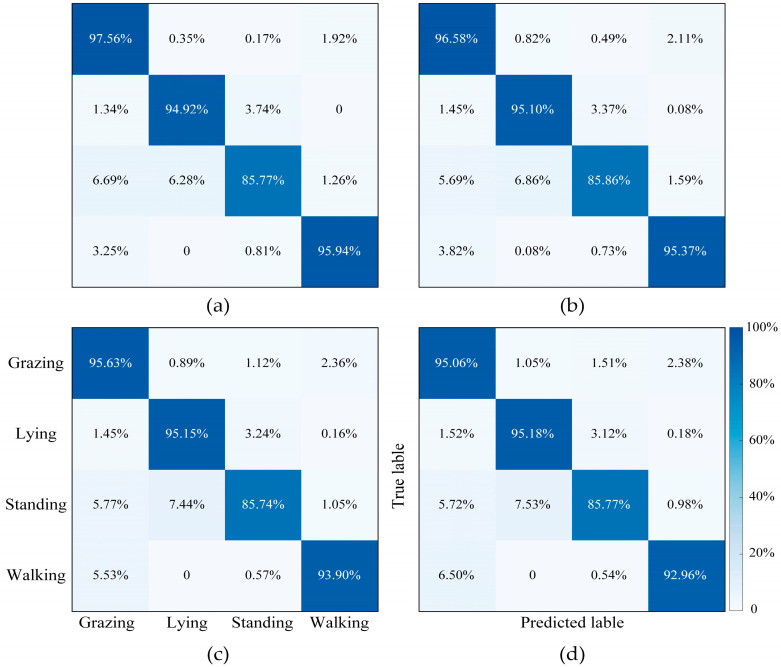 Figure 7
Figure 7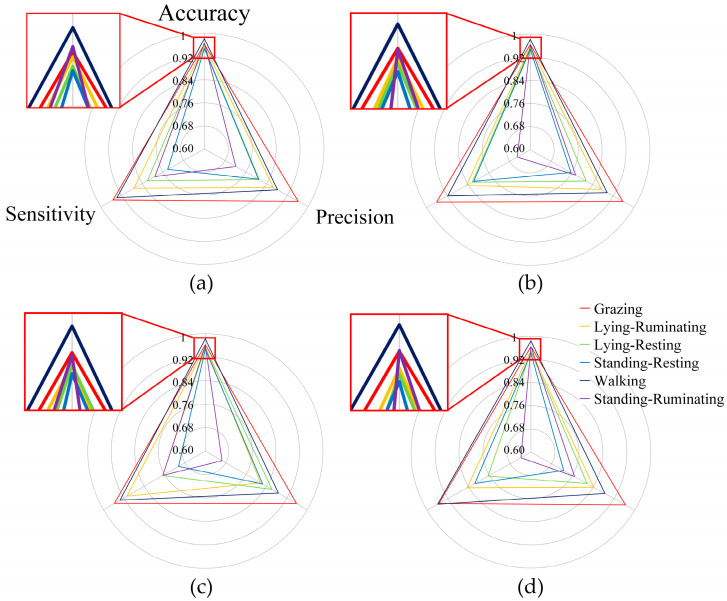 Figure 8
Figure 8- —National Key Research and Development Program of China
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsIoT and Edge/Fog Computing · Energy Efficient Wireless Sensor Networks · Gait Recognition and Analysis
1. Introduction
Understanding cattle behavior is crucial for health monitoring, welfare assessment, and productivity improvement [1]. In small-scale farming, cattle behavior abnormalities can be manually observed based on the farmer’s experience. However, in large-scale scenarios, where cattle are often widely dispersed over vast areas, manual observation and recording of animal behavior are labor-intensive and impractical. Therefore, adopting advanced data analysis technologies in high-tech farming is key to improving livestock production’s efficiency and economic benefits [2].
Researchers typically employ two primary methods for monitoring cattle behavior: fixed and wearable. Fixed devices utilize depth cameras, visual cameras, or audio devices installed in stationary scenes [3,4,5,6,7]. Fixed devices offer limited coverage and are only suitable for indoor cattle farming. Wearable devices integrate various sensors (such as pressure sensors, accelerometers, gyroscopes, magnetometers, and temperature sensors) into embedded systems to acquire behavioral data [8,9,10,11]. Wearable devices are suitable for large-scale free grazing due to their small size and light weight, and are widely used in the field of cattle behavior recognition [12,13,14].
In the research of wearable device behavior recognition algorithms, machine learning has gradually become the mainstream method in behavior classification tasks due to its ability to efficiently extract and describe features [15,16]. Many studies have employed models such as Multilayer Perceptron (MLP) [17], Convolutional Neural Networks (CNNs) [18], Recurrent Neural Networks (RNNs) [19], and Long Short-Term Memory (LSTM) [20,21] networks for behavior monitoring. However, in most of these studies, the wearable devices are primarily used for data acquisition, while model inference is largely performed on the servers or in the cloud. This latency inference requires storing sensor data on the device or transmitting raw data through wireless communication. Beyond low recognition efficiency, wireless transmission of raw data poses significant challenges to the battery life of wearable devices, where frequent battery replacements compromise monitoring continuity [22].
To overcome the latency and power consumption bottlenecks caused by cloud inference, an increasing number of studies have adopted lightweight models and efficient inference frameworks to move the inference process from servers to edge devices [23,24]. Recently, tiny machine learning techniques have gained traction in edge computing and embedded devices, aiming to enhance inference speed and energy efficiency by leveraging lightweight models and model compression techniques [25,26]. Among these techniques, pruning is a key strategy that reduces redundant parameters and computational complexity. Various studies have proposed different pruning strategies and optimization approaches to achieve optimal model performance, including methods based on norms [27], magnitudes [28], sparse regularization [29], loss change [30], reinforcement learning [31], and meta-learning [32]. Recently, there has been a growing trend of extending Automated Machine Learning (AutoML) methods and Neural Architecture Search (NAS) to pruning [33].
In recent years, graph neural networks (GNNs) have also been increasingly introduced into model compression and acceleration. Unlike approaches that treat net-work layers as independent features, GNNs can model the layers or channels of a neural network as a graph, thereby facilitating the extraction of structural dependencies across layers and their respective contributions to overall performance and computational overhead. Prior studies have noted both data redundancy and computational redundancy in two fundamental GNN operations, namely propagation and transformation. Accordingly, hierarchical compression frameworks have been proposed to re-duce redundancy and accelerate training and inference by compressing graph structures and exploiting similarities among node features [34]. Beyond model acceleration, GNNs have also been applied to coding and transmission scenarios. For multi-view data such as light-field video, GNN-based compression and multiple-description transmission strategies have been developed to jointly optimize compression efficiency and reconstruction quality under unstable network conditions [35]. In large-scale spatiotemporal data analytics for smart cities, GNNs have been employed for predictive compression, improving compression efficiency and controllability while maintaining decompression accuracy [36]. However, most compressed models rely on sparse matrix operations and hardware acceleration, which are unsuitable for extremely resource-constrained wearable devices. Furthermore, wearable devices have their own recognition tasks and are unsuitable for collaborative distributed inference methods [37].
In summary, fixed monitoring systems are constrained by deployment conditions, resulting in limited coverage and scalability, which makes them difficult to apply in large-scale free-range grazing environments. Although wearable devices are better suited for monitoring in open pastures, their limited on-device computing resources constrain edge inference. As a result, existing approaches often rely on wireless transmission or offline data transfer to servers for inference, thereby limiting real-time monitoring capability. A substantial knowledge gap remains in current technologies. On the one hand, for continuous multi-source time-series data in grazing scenarios, such as IMU and GPS data, there is still a lack of lightweight model designs that can perform on-device inference directly on the edge. On the other hand, a general-purpose compression framework that does not rely on specialized hardware is still missing, such that the compressed models can preserve recognition accuracy while simultaneously reducing computational overhead. To address these challenges, this paper proposes a cattle behavior recognition method based on Graph Neural Networks (GNNs) on the edge. The main contributions are as follows:
- Develop a wearable device with model inference capability: The device utilizes an embedded microcontroller to provide hardware support for model inference, transferring the model inference workload from the cloud to the edge.
- Construct a Sequence Residual Network (S-ResNet) model: The model is suitable for single-frame data containing time-series information and can effectively reduce the storage and computation of edge data.
- Propose a compression method based on GNNs: The method employs GNNs as the foundational network for the Actor–Critic model. Graph-structured data was constructed, and the TD3 algorithm was introduced to update the reinforcement learning strategy. The resulting lightweight model does not rely on hardware acceleration and is well-suited for deployment on edge devices.
- Deploy the S-ResNet model on wearable devices: Different variants of the S-ResNet model are deployed on wearable devices and compared with cloud inference for power consumption.
2. Materials and Methods
2.1. Wearable Devices
The wearable device developed in this study is illustrated in Figure 1. It comprises a lithium-ion battery, solar panels, an antenna, a processing module, and a sound module (the sound module is not discussed in this paper and is intended for executing behavior-triggered actions after cattle behavior recognition). The processing module includes a Microcontroller Unit (MCU), an Inertial Measurement Unit (IMU), a power unit, a storage unit, a Global Positioning System (GPS), and a communication module. After the device is powered on, it first performs initialization and enables the communication and positioning chips. It then enters the working mode and starts localization as well as IMU data acquisition. Model inference is conducted based on the collected data (inference is not required if the device is used only for data acquisition). The data are transmitted to the cloud, and the device receives commands from the cloud indicating whether the working time interval should be reconfigured. If reconfiguration is required, the device updates the settings and then enters sleep mode; otherwise, it enters sleep mode directly. The sleep mode helps extend the device’s endurance.
The device employs the STM32U585 microcontroller from STMicroelectronics (Geneva, Switzerland), featuring an ultra-low-power 32-bit Arm Cortex-M33 CPU with 2 MB of Flash memory and 786 KB of Static Random-Access Memory (SRAM). It uses the LYNQ N10 module from Shanghai Mobiletek Communication (Shanghai, China) for positioning and the ML307A-GCLN Long Term Evolution Category 1 (LTE Cat.1) module from China Mobile Internet of Things (Chongqing, China) for 4G data transmission. The IMU sensors are the STMicroelectronics (Geneva, Switzerland) ISM330DHCX and IIS2MDC. The ISM330DHCX integrates a 3-axis digital accelerometer and a 3-axis digital gyroscope, while the IIS2MDC is a digital magnetic sensor.
The wearable device is powered by a 3.7 V, 9000 mAh lithium-ion battery, which can be recharged via two solar panels mounted externally on the casing. Under optimal sunlight conditions, the solar panels provide a charging current of approximately 130 mA when the device is placed vertically and about 200 mA when oriented directly toward the sun. On cloudy days, the charging current is reduced to around 13 mA.
2.2. Dataset
2.2.1. Dataset Acquisition
The experiment was conducted at the National Hulunbuir Grassland Ecosystem Observation and Research Station (49.32–49.34° N, 119.94–119.96° E, 670–677 m a.s.l.) in Inner Mongolia, China. The region is characterized by a temperate semi-arid inland climate with a mean temperature of 22 to 27 °C. The experiment was divided into two phases: the first phase was conducted during August-September 2024, and the second phase was conducted during July–August 2025. The livestock are Simmental (red and white) cattle and Angus cattle. A total of 20 adult cattle (about 500 kg) were selected to wear the device for monitoring and observation. The devices were placed on the cattle’s neck and secured them with a strap and a counterweight, as illustrated in Figure 2. During the experiment, the cattle were allowed to feed freely, while ensuring the devices remained securely attached and no signal interruptions occurred. In addition, the device adopts a waterproof, sealed design to ensure stable operation under field conditions such as rainfall and high humidity. During data collection, daily environmental information and communication link status are recorded synchronously to support data archiving under different environmental conditions. When short-term network fluctuations occur, the data are temporarily buffered on the device and retransmitted after the signal is restored, thereby ensuring data integrity.
All sensor data were transmitted to cloud storage during the data acquisition phase. Following model deployment on edge devices, data processing occurred locally on the edge. The wearable device synchronously collected IMU and GPS data under a common clock source and transmitted them to the cloud via 4G communication for storage. Each data packet was assigned a unique identifier and linked to the corresponding cattle, ensuring accurate mapping between behavioral data and individual animals. The cattle behaviors were annotated through visual observation, with the categories defined as shown in Figure 2 and Table 1. To reduce potential bias arising from subjective differences, the annotations were independently completed by two observers following consistent criteria. Inter-observer agreement was quantitatively evaluated using Cohen’s Kappa coefficient to characterize the reliability of the annotations [38].
2.2.2. Dataset Construction and Processing
The single-frame data containing time-series information was constructed using GPS displacement and IMU pose features. Each data frame contained ten features: triaxial acceleration, triaxial gyroscope, triaxial magnetometer data, and displacement [39]. The displacement feature represented the movement distance calculated from two GPS positions recorded at a 10 s interval. The IMU sensors sampled at 1 Hz, and the average values over the sampling period were used as feature representations.
where and represent the latitudes of the two positions, and represent the longitudes of the two positions, and is the Earth’s radius, approximately 6371.393 km.
Due to the limited number of collected samples, potential sampling bias may exist and the class distribution is imbalanced. To mitigate the impact of class imbalance on prediction performance and improve the model’s generalization ability, Synthetic Minority Over-sampling Technique (SMOTE) was applied to oversample the minority classes for data augmentation [40,41]. In dataset , class was identified as a minority class, with the corresponding samples denoted as . The synthetic samples were generated as follows:
where represents a randomly selected sample from the k-nearest neighbors, , and follows a uniform distribution.
The augmented dataset was randomly partitioned into training and testing sets with a 7:3 ratio. Ten types of feature data were standardized using the mean and standard deviation calculated from the training set. Here, denotes the number of samples for the i-th type of feature, and represents the i-th type of feature data, .
where is the mean of the i-th type of feature data, is the standard deviation of the i-th type of feature data, and is the normalized data of the i-th type of feature data.
2.3. Proposed Method for Cattle Behavior Recognition
2.3.1. Method Overview
This study recognizes cattle behavior using pose and positional data collected from wearable devices equipped with built-in IMU and GPS. The trained classification model is deployed on edge wearable devices, leveraging their embedded systems for real-time inference. As illustrated in Figure 3, cattle behavior recognition on the edge is divided into two stages: model training and model inference. Data processing, classification model training, and model compression are performed on a personal computer during the training phase to obtain a lightweight model. In the inference phase, the lightweight model is deployed on the wearable device, which collects real-time data as input to generate behavioral predictions.
Neural network compression techniques are utilized to reduce the memory footprint and computational complexity of classification model inference while maintaining model accuracy as much as possible. Suppose the neural network model contains L prunable layers and the retention rate R is defined as . The optimization goal is to maximize the accuracy of the neural network model M under the constraint of R, expressed as:
where denotes the dataset utilized by the neural network model, denotes the retention rate of the l-th layer, and Floating-Point Operations (FLOPs) represent the required number of floating-point operations.
2.3.2. S-ResNet Model
The model input consists of statistical features extracted from the raw IMU signals within a fixed time window, together with the corresponding displacement. Although each sample is fed into the network in a single-frame form, the features implicitly encode motion sequence information over the time interval. To handle this one-dimensional feature representation with an inherent sequential structure, the S-ResNet is developed. Using one-dimensional convolutions and residual connections, the sequential features are modeled hierarchically, which significantly reduces computational complexity while maintaining classification accuracy, thereby meeting the requirements for edge deployment on wearable devices.
The architecture of the S-ResNet model is illustrated in Figure 4. The model input data corresponds to the mean values of tri-axis accelerometer, tri-axis gyroscope, tri-axis magnetometer, and displacement, directly matching the raw data format of the sensors. The initial convolutional layer that maps the single-channel input into 32 feature channels. This convolutional operation captures the interrelationships among data from multiple sensors, such as the coupling between acceleration and angular velocity.
where denotes the feature map obtained from the first convolutional layer, where the convolution kernel size is 3. BN represents a batch normalization operation, Rectified Linear Unit (ReLU) is the activation function.
The model progressively extracts deeper-level features through two Residual Blocks (Resblocks). Each Resblock consists of two convolutional layers and a shortcut connection, which helps maintain gradient stability and preserve feature integrity. All convolutional layers use a kernel size of 3, except those in the shortcut connections, which use a kernel size of 1. Batch normalization is incorporated to ensure training stability, while the ReLU provides nonlinear enhancement.
where and represent the output feature maps of the two convolutional layers in Resblock1, respectively. The convolution operations further integrate high-order relationships across channels, such as the orientation correlation between the magnetometer and gyroscope. The two convolutional layers expand the number of channels to 64, gradually extracting abstract features from the signal.
where is obtained by dimension expansion to match the main branch in size, ensuring element-wise addition can be performed. The shortcut connection helps mitigate the degradation problem in deep networks, enhances gradient flow, and prevents information loss in deeper layers. represents the output feature map of ResBlock1.
The Resblock2 expands the channels to 128, enabling the model to capture complex behavioral patterns and distinguish subtle differences between similar behaviors (such as Standing and Grazing).
where and represent the output feature maps of the two convolutional layers in Resblock1, respectively. is obtained by increasing the dimension of to 128. represents the output feature map of ResBlock2.
The model employs a Global Average Pooling (GAP) layer to compress sequential dimensions, followed by two Fully Connected (FC) layers for the final classification output.
where represents the predicted probability of each category. FC1 reduces the dimension to 64 to obtain a more compact intermediate representation, and FC2 reduces the dimension to the number of categories.
Single-frame data containing time-series information has both temporal dynamic characteristics and avoids high computational cost sliding windows. Small-size convolution kernels and residual structures achieve multimodal fusion while balancing accuracy and efficiency. The S-ResNet model, with its lightweight design, performs cattle behavior recognition efficiently on embedded systems.
2.3.3. Compression Method Based on GNNs
To further reduce the resource consumption of the model on edge devices, this paper proposes a model compression method based on GNNs, as shown in Figure 5. This compression method is framed within a reinforcement learning approach, using Twin Delayed Deep Deterministic Policy Gradient (TD3) for policy updates. GNNs are the backbone for both the Actor and Critic networks in this method. The Actor network consists of three Graph Convolutional Network (GCN) layers with intermediate output dimensions of 400 and 300, respectively. A sigmoid activation function is applied to constrain the retention rate within the range of . The two Critic networks have identical architectures. Each Critic begins with a graph convolutional layer that processes the node feature graph, followed by a fully connected layer that processes the action features. These features are then mapped to the same dimensionality of 400. The combined graph and action features are passed through two fully connected layers to compute the reward, with an intermediate dimension of 300.
First, the trained neural network model features are selected as the state space for reinforcement learning. Given the high sensitivity of model compression to retention rates, the action space is defined as a continuous range R, where . This approach enables more precise compression compared to using discrete actions. The TD3 algorithm is employed as the reinforcement learning agent. The agent receives the state from the environment and determines the retention rate for the l-th layer. It then transitions to the next state provided by the environment. This iterative process continues until the final layer is processed. The reward value reward is subsequently calculated and stored in the experience replay buffer. This study determines the pruning strategy using a two-stage procedure consisting of exploration and exploitation. During the exploration stage, to sufficiently cover the strategy space and enhance the diversity of collected experience, the agent samples actions by taking the deterministic output of the Actor as the mean and adding truncated Gaussian noise. The noise scale decays exponentially with training episodes, enabling a smooth transition from exploration to exploitation. In the environment (channel pruning), a structured channel-pruning policy is adopted to execute the actions. Specifically, for layer l, the weight tensor associated with each input channel is treated as a pruning unit, and its L2-norm is computed as the channel-importance metric. The channels are then ranked in descending order of importance, and the top channels are retained. The remaining channels are removed along with their associated convolution kernels and connection weights in the subsequent layers, resulting in a pruned model.
The construction of graph-structured data is critical for the proposed compression method. Graph-structured data consists of nodes and edges representing the complex relationships among nodes. GNNs learn the features of each node by propagating and aggregating information from neighboring nodes, enabling information exchange between nodes [42]. In the context of compression tasks, a graph structure based on model channels is constructed as the state space, where each channel is treated as a node, and edges represent dependency relationships between closely related channels. Each layer of the network model corresponds to a graph structure, with the state space for the l-th layer defined as follows:
where l represents the layer index, and t represents the layer type. The weight dimensions are , and . The stride refers to the step size, is the product of parameters for the m-th input channel in the l-th layer, and represents the L2-norm of the parameters for the m-th input channel in the l-th layer. The denotes the total FLOPs reduced by the preceding layers, while represents the number of remaining FLOPs in subsequent layers. indicates the retention rate of the previous layer [31].
This study models layer-wise channel pruning as a Markov decision process. For layer l, the state is represented as graph-structured data, where nodes denote channels and edges capture channel dependencies. The Actor takes as input and outputs a continuous action , which is mapped to [0, 1] via a sigmoid function. The reward is calculated only after pruning the final layer, defined as , while the reward is set to 0 for all other layers.
The TD3 algorithm obtains a continuous action space in the policy update process, as shown in Algorithm 1. Compared to the Deep Deterministic Policy Gradient (DDPG), TD3 introduces two Critic networks to compute two Q-values, ultimately selecting the smaller Q-value as the target [43]. This clipped double Q-learning structure mitigates the risk of overestimating Q-values, enhancing the algorithm’s stability in noisy environments. When updating the target Critic network, a small Gaussian noise term is added to the action output by the Actor to perform smoothing, which stabilizes the computation of the target Q-value. This perturbation prevents overly deterministic policies from leading to suboptimal local solutions. The discount factor γ balances the trade-off between immediate and future rewards. Meanwhile, the Actor network is updated in a delayed manner and is maintained via an exponential moving average controlled by the soft-update coefficient . This design avoids policy instability caused by overly frequent updates.
Algorithm 1: TD3 algorithm strategy updateInput: Original model , Dataset , Output: Pruning strategy R
Initialize S according to the graph structure data format do for l in L do Prune the input channel of the l-th layer of model based on L2-norm if l==L else 0 in replay buffer if l==L and then from then Update ϕ by the deterministic policy gradient: Update target networks: end end end
end
Pruning operations on the original model are performed based on the optimal policy. Compared to fine-grained pruning, which operates at the weight level, coarse-grained pruning directly targets the channel level. For example, the weight dimensions of the l-th layer are , the weight tensor is compressed to . In this case, the sparsity of the l-th layer is given by , and the retention rate is defined as .
Graph convolution aggregates neighborhood information and can automatically extract channel topological relationships, overcoming the limitation of conventional pruning methods that ignore complex inter-channel dependencies. Compared to DDPG, TD3 has stronger convergence in noisy environments and is suitable for optimizing high-dimensional continuous action spaces for model compression. Compared to rule-based methods, this approach utilizes reinforcement learning to reduce dependence on manual rule design. Compared to sparse regularization, this method directly optimizes for model accuracy and computational efficiency, balancing pruning rate and performance loss to achieve the optimal pruning strategy. Compared to loss-based compression and meta-learning, the TD3 algorithm updates using experience replay to eliminate the need for multiple forward passes to compute loss changes, thus reducing computational complexity. Compared to fine-grained pruning, coarse-grained pruning reduces hardware adaptation difficulty and does not rely on specific hardware architectures. Therefore, the model pruned with coarse-grained methods can be deployed on any Internet of Thing (IoT) edge device, including wearable devices [44].
3. Results
3.1. Experimental Environment Configuration and Hyperparameters Settings
The S-ResNet model training and compression strategy search were conducted using PyTorch 1.7.1 and Python 3.7.3 on an NVIDIA Tesla T4 GPU. The specific parameters for model training are shown in Table 2. The fine-tuning parameters for the model after pruning were kept identical. The parameters of the model compression are shown in Table 3.
The Adam optimizer was selected for model training. To balance convergence speed and training stability, the learning rate was set to 0.001. To avoid overfitting during training, the training epochs were set to 100. Considering the memory capacity of the Tesla T4 GPU, the batch size was set to 128. This paper adopted the cross-entropy loss function commonly used in classification tasks [45]. During the model compression strategy search, a smaller batch size of 64 was used to reduce per-step memory consumption. Exploring with 100 episodes can establish an effective initial experience buffer. The compression strategy gradually converged to an optimal solution after 500 episodes. To prevent the loss of essential features caused by excessive pruning, the minimum channel retention rate for each layer was set to 0.2. The soft update coefficient was set to 0.01 to ensure the target network’s stability and learning efficiency.
3.2. Evaluation Indicators
In order to verify the performance of the model, accuracy, sensitivity and precision were used to evaluate the performance of the model. Its calculation formula is as follows:
where TP, TN, FP and FN are the number of true positive cases, true negative cases, false positive cases and false negative cases.
This study reported accuracy, sensitivity, and precision as the average values from five repeated randomized experiments.
3.3. Result of Cattle Behavior Recognition
Based on the experimental settings described in Section 3.1, the S-ResNet 1.0× model was trained on the dataset introduced in Section 2.2. The model was then pruned using the compression method based on GNNs, followed by fine-tuning to obtain different S-ResNet model variants. The number of input channels for each layer of the S-ResNet model variants is shown in Figure 6. Conv1, as the first layer, determined its input channel count based on the dimensions of the input data and was excluded from pruning. The shortcut layers were required to maintain the same number of channels as the main convolutional layers. As the channel retention rate decreased, the pruning strategy prioritized reducing the number of channels in less critical layers. Consequently, the overall channel count of the model exhibited a non-uniform yet significant reduction.
The classification accuracies of S-ResNet 1.0×, ResNet 0.75×, ResNet 0.4×, and S-ResNet 0.1× are 94.50% (±0.09%), 94.09% (±0.11%), 93.53% (±0.10%), and 93.20% (±0.18%), respectively. The confusion matrices of each model are shown in Figure 7. A confusion matrix is a 2-D square matrix, where one dimension contains actual classes (True label), and the other represents the classes predicted by the model (Predicted label). In the figure, the sensitivity for each behavior is explicitly displayed. The sensitivities for Grazing, Lying, and Walking behaviors exceed 90%, whereas the sensitivity for Standing is slightly above 85%. The Standing behavior is more likely to be misclassified as Grazing or Lying. These results demonstrate that the proposed model can effectively recognize cattle behaviors and maintain good performance even after pruning.
3.4. Deployment and Inference on the Edge
The S-ResNet model was deployed on a wearable device using STM32Cube.AI to enable real-time recognition of cattle behavior. STM32Cube.AI is a tool and framework provided by STMicroelectronics for running AI models on STM32 microcontrollers [46]. It converts deep learning models into efficient code optimized for STM32 microcontrollers, enabling embedded devices to perform artificial intelligence tasks efficiently. Meanwhile, STM32Cube.AI itself supports model compression.
Table 4 presents computational complexity, memory usage, and inference time when executing model inference on the wearable device. Multiply–accumulate (MACC) represents the total number of multiplication-accumulation operations the network requires. Flash memory includes the model weights, inference engine, and necessary functions. Random Access Memory (RAM) usage encompasses activation values during model inference, input and output data, and other temporary data. Time is required to infer a single data frame, excluding data acquisition time. The MCU in the wearable device provides access to 2 MB Flash and 768 KB RAM, which are sufficient to meet the memory requirements for model inference. Compared with the S-ResNet 1.0× model, the S-ResNet 0.1× model reduces of 80–90% in MACC, Flash, and Time metrics. Due to unchanged input and output data, the reduction in RAM usage is relatively minor, approximately 47%. When the compression level in STM32Cube.AI was set to High during deployment, only the Flash footprint was reduced, whereas the MACC, RAM usage, and inference time remained unchanged. This is because the adopted compression scheme is based on a k-means clustering method, which is mainly applicable to fully connected layers. For models dominated by convolutional layers, this approach provides limited compression benefits and may adversely affect performance.
The power consumption statistics of the edge inference and conventional cloud inference proposed in this paper were conducted on wearable devices, as shown in Table 5. The device was configured with a sleep mode to reduce power consumption. After each cycle, the device woke up to perform a single behavior recognition task and then returned to sleep mode. For cloud inference, each recognition task required data transmission to and from the cloud, whereas edge inference eliminated the need for data transmission.
Upon waking from sleep mode, the GPS required approximately 30 s to reacquire satellite information and complete positioning, while the 4G module took about 20 s to re-register with the base station and establish communication with the cloud. For a 5 min operational cycle, the power consumption for a single edge inference was 0.388 mAh, approximately 46.8% of the power consumption required for cloud inference (0.829 mAh). Calculations show that the daily power consumption for the edge inference approach is approximately 112 mAh. The device can maintain a balanced power supply by ensuring 30 min of adequate sunlight exposure for daily charging. After deploying the S-ResNet model on the edge device, the classification model consistently provided stable real-time predictions of cattle behavior.
4. Discussion
4.1. Generalization Experiment of S-ResNet Model
To further demonstrate the classification capability of the S-ResNet model, comparative experiments were conducted on a public dataset against other methods. The dataset also includes ten features, comprising triaxial acceleration, triaxial gyroscope, triaxial magnetometer data, and displacement. It enables the recognition of six distinct cattle behaviors: Grazing, Lying-Ruminating, Lying-Resting, Standing-Resting, Walking, and Standing-Ruminating [47]. These behaviors are defined in Table 6.
On the dataset, the original models are divided into two categories, one processing one-dimensional data, such as CNN-1D. Another type requires adding a dimension to the data, such as LeNet-5 AlexNet, MiniVGG-16, ResNet-50, MobileNetV1 [47]. The experimental results of these and S-ResNet models are shown in Table 7. Although LeNet-5, AlexNet, MiniVGG-16, ResNet-50, and MobileNetV1 extracted features in higher dimensions and exhibited FLOPs significantly higher than those of the CNN-1D model, their classification accuracy was lower than that of CNN-1D. This finding suggests that one-dimensional network models are better suited to this dataset. Since this dataset involves six distinct cattle behaviors, its accuracy is slightly lower compared to other studies.
Long Short-Term Memory (LSTM) is a specialized recurrent neural network well-suited for processing sequential data [20]. Bidirectional Long Short-Term Memory (BiLSTM) extends LSTM by introducing a bidirectional processing mechanism [48]. On the dataset, both LSTM and BiLSTM demonstrated superior performance compared to the CNN-1D model, achieving an improvement of approximately 0.7%, while the FLOPs of LSTM were only half that of the CNN-1D model. However, as single-frame data with a time step of 1 was used for classification in this dataset, the advantages of the LSTM network could not be fully utilized.
The S-ResNet 1.0× model achieved the highest classification accuracy of 88.62% (±0.14%), but its FLOPs significantly exceeded those of the CNN-1D and LSTM models. The GNNs-based compression method optimized the S-ResNet model to explore lightweight strategies. By constraining the FLOPs and retaining the framework of the original model, channel pruning was performed to generate three different variants of the S-ResNet model. Among these, S-ResNet 0.1× exhibited extremely low FLOPs of only 0.087M while achieving an accuracy of 87.68% (±0.18%).
The accuracy, precision, and sensitivity of six behaviors under different S-ResNet model variants are shown in Figure 8. Among the six behaviors, Walking had the highest accuracy, while Standing-Resting exhibited the lowest accuracy. The accuracy of Lying-Ruminating and Lying-Resting ranked fourth and fifth, respectively, and this rank remained consistent across all S-ResNet model variants. Grazing and Standing-Ruminating ranked second and third in terms of accuracy. In the S-ResNet 1.0× model, the accuracy of Standing-Ruminating was higher than that of Grazing, whereas the opposite was observed in other models. Model pruning had a significant impact on the accuracy of Standing-Ruminating. In terms of precision, Grazing consistently outperformed all other behaviors across all models, while Walking consistently ranked second. The precision of Lying-related behaviors was higher than that of Standing-related behaviors, except the S-ResNet 0.4× model, where Standing-Resting slightly surpassed Lying-Ruminating. In the S-ResNet 1.0×, S-ResNet 0.75×, and S-ResNet 0.4× models, the sensitivity rank was Grazing, Walking, Lying-related behaviors, and Standing-related behaviors. However, in the S-ResNet 0.1× model, the sensitivity of Walking was higher than that of Grazing, and Standing-Resting had a higher sensitivity than Lying-Resting.
The model performed best on Grazing and Walking overall. The model channel pruning was performed under the constraint of overall accuracy to search for the optimal strategy, with slight variations in other evaluation metrics for each behavior category. The pruning process removed channels dependent on specific category features, leading to noticeable changes in the evaluation metrics for those categories. In multi-class classification tasks, predictions across different categories often influence each other, particularly when the categories are more similar, making them more susceptible to the impact of pruning.
4.2. Generalization Experiment of Compression Method
To validate the effectiveness of the compression method, the compression method based on GNNs was applied to both MobileNetV1 and MobileNetV2 models. The experiments were conducted using the ImageNet dataset containing 1000 categories [49]. The model compression strategy was conducted with the same settings described in Section 3.1. After completing the strategy search, the optimal strategy was fine-tuned to enhance model accuracy. The model fine-tuning was completed on NVIDIA GeForce RTX 4090. The batch size was set to 128 during fine-tuning, and the training process spanned 200 epochs. The initial learning rate was set to 0.05 and gradually decreased following a cosine annealing schedule as the training progressed.
Table 8 summarizes the accuracy of various models under different FLOPs configurations for other compression methods. For MobileNetV1, the proposed compression method achieved accuracy of 70.82% and 67.04% at FLOPs levels of 328M and 151M, respectively, surpassing the accuracy of models compressed using the baseline and MatePruning methods. Furthermore, when accuracy was similar, the FLOPs of the model obtained by this compression method was 225M, while that of the Uniform 0.75× model was 325M. For MobileNetV2, the proposed method achieved an accuracy 0.37% higher with a 136M FLOPs model compared to the Uniform model with 140M FLOPs. In ResNet-18, under the same FLOPs, the accuracy of the model obtained in this paper is slightly higher than that of the DMCP method.
4.3. Comparison with Other Studies
A comparison between this study and related research is shown in Table 9. Studies [8,9,10] share a similar approach to this study, wherein sensors are installed on the neck or legs of cattle to collect data for classification tasks. However, these three studies exclusively utilized wearable devices for data collection without considering the deployment of models to edge devices for real-time inference. The method relies on the combination of a leg-mounted and a neck-mounted accelerometer, requiring two wearable devices to work together [8]. In contrast, our approach achieves comparable classification performance using only a single neck-mounted wearable device with the S-ResNet 1.0× model.
Riaboff et al. utilized a decision tree algorithm with 18 selected features computed in both the time and frequency domains. They combined filters and windows of varying lengths and overlap rates to classify four behaviors: Grazing, Walking, Lying, and Standing [9]. These four behaviors are entirely consistent with the behaviors studied in this article, and the S-ResNet model provides better classification performance than their proposed model. Specifically, under their optimal configuration, the sensitivity for classifying the Walking (94%) surpassed that of the S-ResNet 0.1× model (92.95%) but was lower than S-ResNet 1.0× model (97.56%). For the other three behaviors, their sensitivities (Grazing: 95%; Standing: 82%; Lying: 90%) were all lower than those achieved by the model proposed in this study. Moreover, their overall classification accuracy was 90.25%, which is also lower than S-ResNet model.
In the reference [10], behavior data of dairy cows were recorded using sensor tags placed on the neck. The study classified three behaviors: Grazing, Walking, and Standing, achieving an overall accuracy of 94.35% using a 1D-CNN model. The classification accuracy with the LSTM model was 90.97%, which was lower than the accuracy achieved by the S-ResNet 1.0× model. Their tags can collect radio frequency energy to address power supply issues, whereas the wearable device designed in this study utilizes solar energy to recharge the battery.
The studies in reference [3,4] fundamentally differ from our research. They capture the behavior of dairy cows through fixed devices and train complex deep-learning models to classify these behaviors. Video-based methods outperform sensor-based methods in terms of performance. However, the trade-off is that the computer system must be sufficiently robust to train the models, and the execution time is relatively long. Moreover, the models are too complex to be used for inference on the edge.
To further validate the effectiveness of the proposed method, we selected conventional machine-learning approaches (Random Forest and Decision Tree) and deep models (1D-CNN and LSTM) as baseline methods on the same dataset. These baselines were compared with different variants of the proposed S-ResNet (1.0×, 0.75×, 0.4×, and 0.1×). All methods used identical data preprocessing procedures and the same training/testing split. The comparison results are reported in Table 10. Among the conventional machine-learning methods, Random Forest (91.56% ± 0.10%) outperformed Decision Tree (90.04% ± 0.08%). For the deep-learning baselines, LSTM (92.67% ± 0.11%) achieved slightly higher accuracy than 1D-CNN (92.35% ± 0.07%), indicating that incorporating temporal modeling can improve recognition performance. In contrast, all S-ResNet variants consistently achieved higher accuracy. Under the edge lightweight configuration, S-ResNet-0.1× required only 0.087M FLOPs while still achieving an accuracy of 93.20%, exceeding both 1D-CNN and LSTM. Moreover, its computational cost was reduced by approximately 56.5% compared with LSTM and by approximately 82.0% compared with 1D-CNN, demonstrating the advantage of substantially lowering computation overhead while maintaining high recognition performance.
In summary, compared to other studies, the method proposed in this article can achieve behavior monitoring of freely grazed cattle while ensuring recognition accuracy. By reducing transmission-related power consumption and leveraging solar energy harvesting via solar panels, the proposed system extends device endurance and enables efficient cattle behavior monitoring and management.
5. Conclusions
This paper presented an edge-based cattle behavior recognition method that used GNNs for model compression. A wearable device integrating both data acquisition and on-device model inference was developed based on a high-performance embedded microcontroller. A series residual network suitable for single-frame data was designed to reduce the storage of original data, which can be well adapted to data containing time-series information. This paper proposed a compression method based on GNNs, in which the GNNs were used as the fundamental feature extractor within the Actor–Critic architecture. The TD3 algorithm was incorporated to update the reinforcement learning policy. This method enabled the search for an optimal pruning strategy under FLOPs constraints. Additionally, it did not require acceleration by specific hardware architectures, allowing the compressed model to be well-suited for edge devices. Furthermore, the classification model was deployed on an embedded system in this study, which demonstrated the wearable device’s effective inference capability and reduced the power consumption of edge devices.
The S-ResNet 1.0× model achieved a classification accuracy of 94.50% on the collected data for four-class cattle behaviors. It reached an accuracy of 88.62% on the six-class behavior dataset, outperforming the original models on the same dataset. After compression, the S-ResNet 0.1× model attained an accuracy of 93.20% for the four-class classification task and 87.68% for the six-class dataset. Meanwhile, the proposed compression method also demonstrated strong performance when applied to the MobileNetV1, MobileNetV2 and ResNet-18 models. Experimental results showed that, on the wearable device, a single behavior recognition task on the edge consumed only 46.8% of the energy required for cloud-based inference.
This study provides a promising direction for edge-based cattle behavior recognition, yet several challenges remain for deployment in real environments. First, sensor signals may contain outliers due to data-acquisition conditions and individual variability. This calls for incorporating on-device anomaly detection mechanisms, such as adaptive thresholds and sliding-window statistics. Second, long-term wearing on animals is constrained by comfort requirements, and further optimization is still needed in structural design and material selection. Third, real-world conditions such as rain and snow, magnetic interference, and wireless communication blockage may all compromise data stability. Future work will expand the cattle behavior dataset across multiple scenarios, long durations, and different individuals, and will conduct long-term continuous field tests under diverse conditions to facilitate practical deployment in grazing management.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Mahmud M.S. Zahid A. Das A.K. Muzammil M. Khan M.U. A systematic literature review on deep learning applications for precision cattle farming Comput. Electron. Agric.202118710631310.1016/j.compag.2021.106313 · doi ↗
- 2Taneja M. Jalodia N. Byabazaire J. Davy A. Olariu C. Smart Herd management: A microservices-based fog computing-assisted Io T platform towards data-driven smart dairy farming Softw. Pract. Exper.2019491055107810.1002/spe.270431423028 PMC 6686710 · doi ↗ · pubmed ↗
- 3Yin X.Q. Wu D.H. Shang Y.Y. Jiang B. Song H.B. Using an Efficient Net-LSTM for the recognition of single Cow’s motion behaviours in a complicated environment Comput. Electron. Agric.202017710570710.1016/j.compag.2020.105707 · doi ↗
- 4Wu D.H. Wang Y.F. Han M.X. Song L. Shang Y.Y. Zhang X.Y. Song H.B. Using a CNN-LSTM for basic behaviors detection of a single dairy cow in a complex environment Comput. Electron. Agric.202118210601610.1016/j.compag.2021.106016 · doi ↗
- 5Jung D.H. Kim N.Y. Moon S.H. Jhin C. Kim H.J. Yang J.S. Kim H.S. Lee T.S. Lee J.Y. Park S.H. Deep Learning-Based Cattle Vocal Classification Model and Real-Time Livestock Monitoring System with Noise Filtering Animals 20211135710.3390/ani 1102035733535390 PMC 7911430 · doi ↗ · pubmed ↗
- 6Pu Y. Zhao Y. Ma H. Wang J. A Lightweight Pig Aggressive Behavior Recognition Model by Effective Integration of Spatio-Temporal Features Animals 202515115910.3390/ani 1508115940281992 PMC 12024040 · doi ↗ · pubmed ↗
- 7Kong N. Liu T. Li G. Xi L. Wang S. Shi Y. Attention-Guided Edge-Optimized Network for Real-Time Detection and Counting of Pre-Weaning Piglets in Farrowing Crates Animals 202515255310.3390/ani 1517255340941348 PMC 12427216 · doi ↗ · pubmed ↗
- 8Tran D.N. Nguyen T.N. Khanh P.C.P. Tran D.T. An Io T-Based Design Using Accelerometers in Animal Behavior Recognition Systems IEEE Sens. J.202222175151752810.1109/JSEN.2021.3051194 · doi ↗