Foundation-Model-Driven Skin Lesion Segmentation and Classification Using SAM-Adapters and Vision Transformers
Faisal Binzagr, Majed Hariri

TL;DR
This paper introduces a new framework combining SAM-Adapters and Vision Transformers to improve skin lesion segmentation and classification for skin cancer diagnosis.
Contribution
The novel framework integrates SAM-Adapters for lesion segmentation and ViT-based classification with lesion-specific cropping and cross-attention fusion.
Findings
The proposed method achieves a Dice score of 94.27% on ISIC 2018 for segmentation.
Classification accuracy reaches 95.88% on ISIC 2018 and 96.37% on HAM10000.
Ablation studies confirm the importance of SAM-Adapters and lesion-specific fusion for performance.
Abstract
Background: The precise segmentation and classification of dermoscopic images remain prominent obstacles in automated skin cancer evaluation due, in part, to variability in lesions, low-contrast borders, and additional artifacts in the background. There have been recent developments in foundation models, with a particular emphasis on the Segment Anything Model (SAM)—these models exhibit strong generalization potential but require domain-specific adaptation to function effectively in medical imaging. The advent of new architectures, particularly Vision Transformers (ViTs), expands the means of implementing robust lesion identification; however, their strengths are limited without spatial priors. Methods: The proposed study lays out an integrated foundation-model-based framework that utilizes SAM-Adapter-fine-tuning for lesion segmentation and a ViT-based classifier that incorporates…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
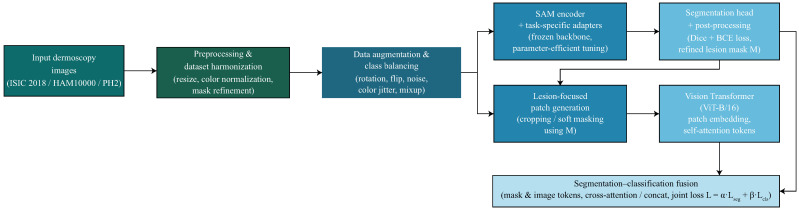 Figure 1
Figure 1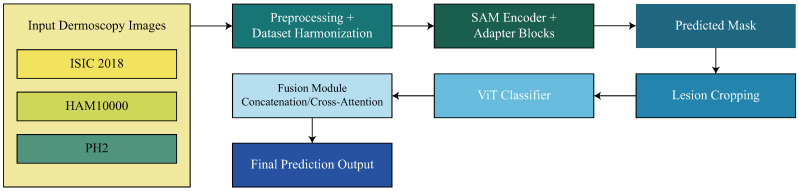 Figure 2
Figure 2 Figure 3
Figure 3 Figure 4
Figure 4 Figure 5
Figure 5 Figure 6
Figure 6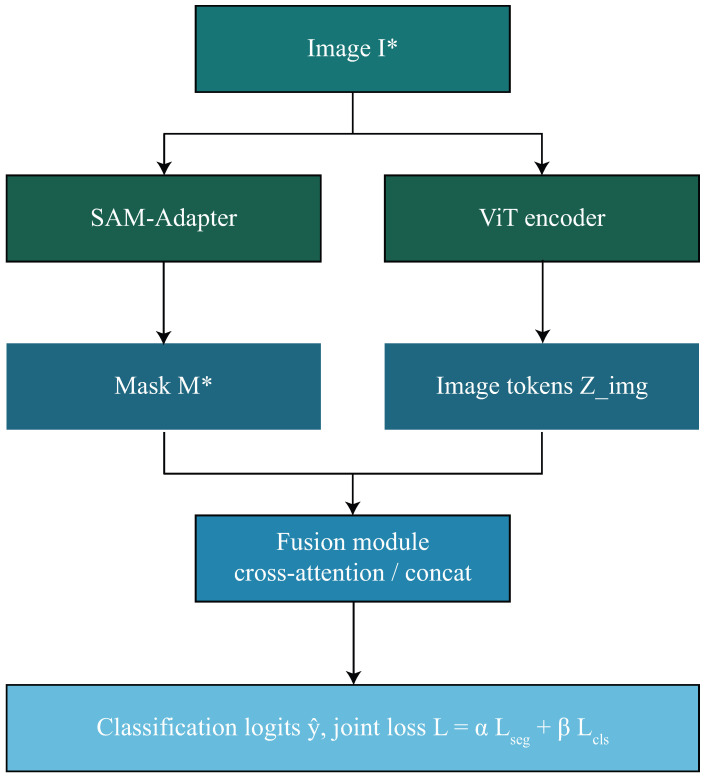 Figure 7
Figure 7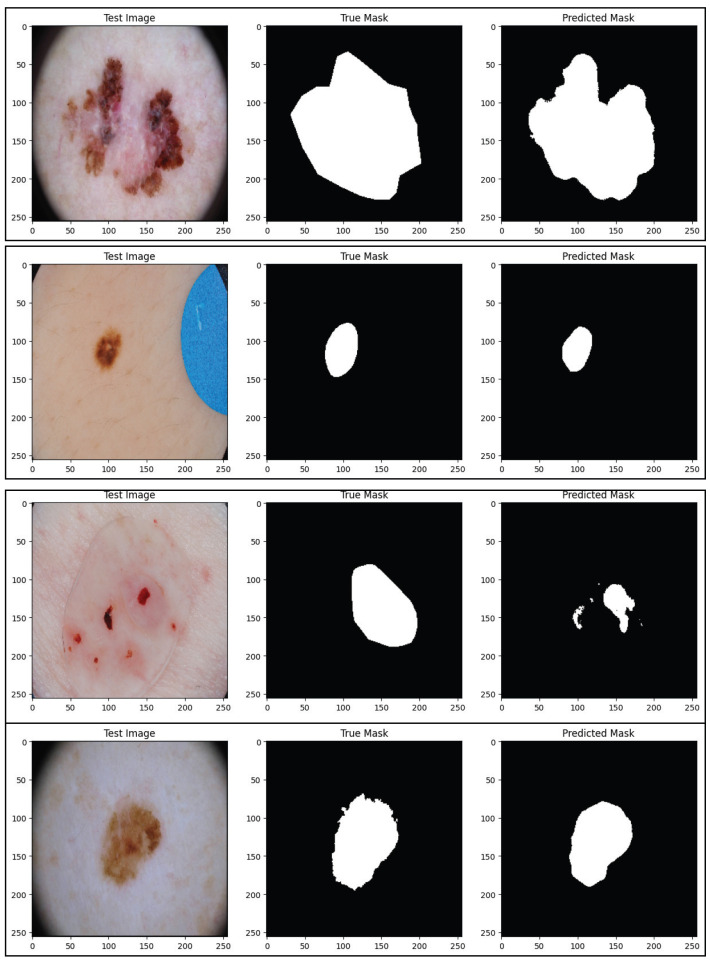 Figure 8
Figure 8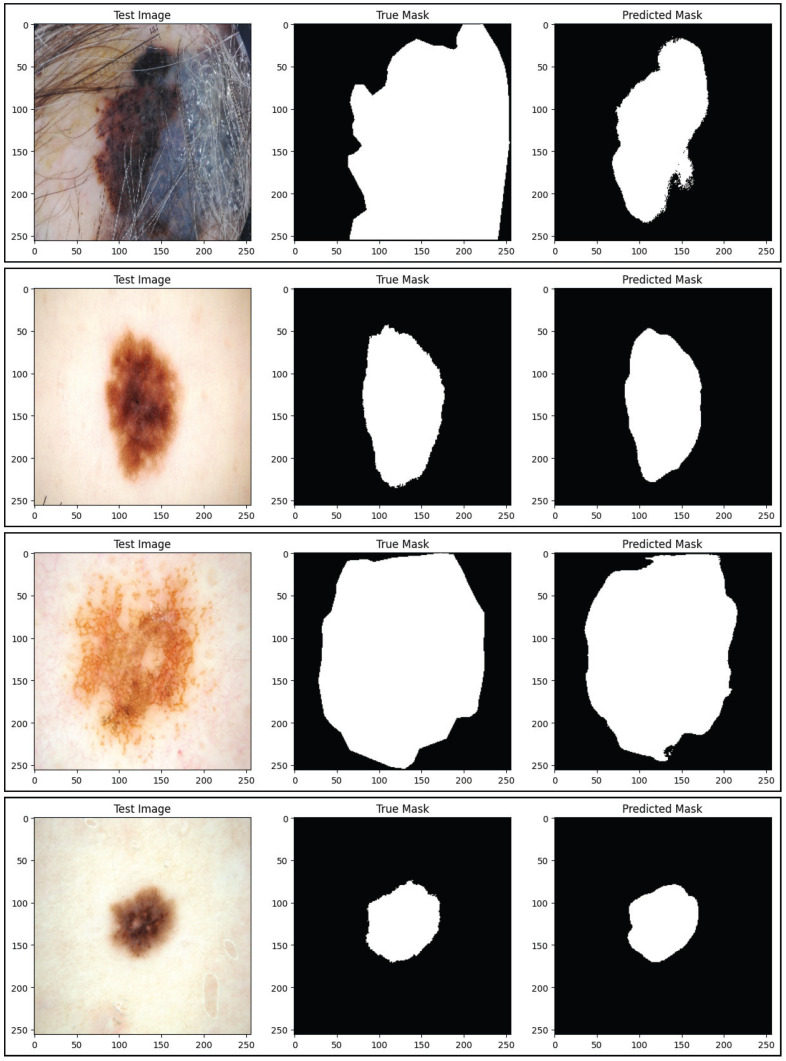 Figure 9
Figure 9- —Deanship of Scientific Research (DSR) at King Abdulaziz University, Jeddah, Saudi Arabia
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsCutaneous Melanoma Detection and Management · Nonmelanoma Skin Cancer Studies · Brain Tumor Detection and Classification
1. Introduction
Skin cancer is among the most common and fastest growing types of cancer in the world, with melanoma accounting for most of the skin cancer-related deaths due to its aggressive nature and strong metastatic capacity [1,2]. Thus, early detection and accurate diagnosis are critical to improving the patient outcome, as there is a significant difference in survival curbing melanoma when identified at localized stages [3]. Dermoscopy is a newly developed non-invasive imaging method to visualize subsurface skin structures that would otherwise remain undetected with normal lighting. The implementation of dermoscopy allows an enhanced visualization to identify patterns such as pigment networks, globules, and streaks that would not be seen without dermoscopy [4,5]. A drawback of dermoscopy is that manual evaluations remain purely subjective and rely on the clinician’s skill, interobserver variance and complexity of the lesion being assessed; therefore, computer-aided diagnostic systems have been developed [6,7].
The use of deep learning has recently advanced automated segmentation and classification models for skin lesions. Convolutional neural networks (CNNs) have shown a strong capability for the detection of edges, local texture patterns, and structural irregularities associated with malignancies [8,9,10]. Vision Transformers (ViTs) and hybrid CNN–Transformer architectures have contributed to the feature representation across long-range dependencies and global contextual information [11,12,13]. These models achieve state-of-the-art performance on public dermoscopy datasets such as ISIC 2018, HAM10000, and PH2 [14,15,16]. However, a number of challenges remain.
To begin, the precise segmentation of lesions is still challenging because of low contrast, unclear edges, hair artifacts, lighting changes, and variability in lesion shape [17,18]. Even though segmenters using CNNs and transformers have shown improved segmentation, behavior is generally degraded when applying to external datasets as a consequence of domain shift due to acquisition device, patient selection, and imaging protocols [19,20]. Second, classification models often operate on full-frame dermoscopy images which do not use lesion boundaries, and thus exploit features that contain contamination from the information in irrelevant background regions, such as skin texture, vignetting, rulers, gel bubbles, and color calibration artifacts [21,22]. Third, segmentation and classification typically are approached as distinct tasks, which limits optimal feature exploitation, and overall robustness of the diagnostic [23,24]. Recent advances in medical imaging have explored hyperspectral representations for skin cancer analysis, such as the work of Lin et al. [25], which demonstrated enhanced classification performance using machine learning on hyperspectral data, and Huang et al. [26], who proposed a snapshot-based hyperspectral conversion framework combined with YOLO models for lesion detection.
The emergence of foundation models, particularly the Segment Anything Model (SAM), introduces new opportunities for dermoscopic analysis. SAM provides powerful general-purpose segmentation capabilities learned from billions of masks across diverse visual domains [27]. However, its adaptation to medical imaging requires task-specific fine-tuning and domain-aware integration strategies [28,29]. Furthermore, ViTs have demonstrated strong potential for medical image classification due to their ability to encode global dependencies, but few studies have explored their synergy with foundation-model-derived spatial priors [30,31]. Integrating SAM-based lesion delineation with ViT-based classification therefore represents a promising direction for advancing automated skin cancer diagnosis.
Although significant advances have been made in the development and application of dermoscopic images, the current methods remain inadequate for analyzing dermoscopic images in non-standardized environments or heterogeneous datasets due to major limitations. For example, there are no effective cross-domain generalization capabilities for dermoscopic segmentation models and classification workflows tend to neglect the use of lesion boundary features resulting in the creation of artefacts from the background. Segmentation and classification are treated mostly as individual tasks and do not benefit from mutual reinforcement of spatial/semantic information. Thus, it is critical to develop a framework for dermoscopic image analysis which combines the spatial priors of the lesion with the diagnostic reasoning of transformers, creating a single, model-oriented foundation for dermoscopic image analysis.
The main contributions of this study can be summarized as follows:
- We propose a foundation-model-driven dermoscopic analysis framework based on SAM that utilizes the use of lightweight, parameter efficient adapters to produce robust segmentation results of malignant lesions.
- We introduce a novel segmentation based image classification strategy through use of the Vision Transformer, integrating lesion priors via image cropping to the lesion region(s) and via cross-attention fusion.
- We develop a unified joint optimization strategy allowing for the simultaneous optimization of segmentation and classification tasks; we provide empirical evidence that this strategic approach results in consistent performance improvements across ISIC 2018, PH2 and HAM10000 datasets.
The remainder of this paper is organized as follows. Section 2 reviews recent developments in dermoscopic image segmentation and classification, including the gaps and limitations of the current state of the art. Section 3 elaborates on the proposed framework, which uses foundation models, to perform segmentation and classification. Section 4 provides experimental results, including quantitative comparisons and ablation studies. Finally, Section 5 discusses conclusions and opportunities for future research.
2. Related Work
Deep learning has changed the landscape of automated dermoscopic image analysis by facilitating more efficient feature extraction, boundary delineation, and lesion classification across large-scale dermoscopy datasets. The dermatology community has witnessed the evolution of research from standard convolutional neural networks, utilizing datasets such as ISIC 2018, PH2, and HAM10000, to use hybrid pipelines incorporating transformers, multiscale feature extractors, adversarial optimization, and semi-supervised learning. Collectively, these efforts have demonstrated an evolution in developing architectures that take into account both local texture patterns as well as global contextual structures, both of which are fundamental to the reliability of automated melanoma screening systems.
In the area of skin lesion segmentation with the ISIC 2018 dataset, several contemporary models have indicated high performance simply from the innovation of the architecture. FAT-Net was introduced as a feature-adaptive hybrid that had a CNN encoder capturing local edge information with a transformer branch modeling long-range dependencies. Failure of multiscale fusion and attention modulation allowed FAT-Net to achieve strong adaptation to lesion boundaries, fundamentally outperforming other models by obtaining a reported Dice coefficient of 91 percent and Jaccard index 82 percent [32]. Adversarial methods have also been successful; the Efficient-GAN (EGAN) model introduced squeeze–excitation blocks in the generator and a shape-aware discriminator that encourages anatomical consistency in each mask predicted by the model, obtaining a Dice score of 90.1% and IoU accuracy of 83.6% [33]. Semi-supervised learning further improved results on ISIC 2018 through teacher–student training as demonstrated by a DeepLabV3-based self-training framework that leverages unlabeled dermoscopy images from additional ISIC cohorts, reporting a mean IoU of 88% [34]. More advanced CNN–Transformer hybrids, such as MRP-UNet, integrate multiscale input fusion, Res2-SE blocks, and pyramid dilated convolutions to address scale variability and texture heterogeneity in lesions. MRP-UNet achieves a Dice of 92.36% and Jaccard of 91.28% [35]. Texture-aware transformer architectures have also emerged; SkinFormer embeds statistical texture descriptors into the transformer pipeline, achieving a reported Dice score of 93.2% [36]. Table 1 shows a summary of deep learning methods for lesion segmentation on the ISIC 2018 dataset.
Beyond segmentation, ISIC 2018 has also served as a benchmark for multi-class lesion classification, where performance has steadily improved through transfer learning, ensemble learning, and transformer-based representations. ESRGAN-enhanced transfer learning pipelines report accuracies near 85–86% on InceptionV3 baselines [37]. Multiscale and multi-network ensembles such as MSM-CNN achieve balanced accuracy of 86.2% [38]. Weighted transfer-learning ensembles further improve accuracy to [39]. Lightweight transformer hybrids such as HI-MViT reach accuracy, with 0.931 F1-score and AUC of 0.977 [40]. A three-network ensemble of VGG16, InceptionV3, and ResNet50 achieves 97% accuracy on a balanced version of ISIC 2018 [41]. Table 2 shows a summary of deep learning methods for lesion classification on the ISIC 2018 dataset.
Segmentation research on the PH2 dataset has similarly advanced. Lightweight CNN-MLP hybrids such as UCM-Net achieve Dice of 93% and IoU of 88.5% [42]. Semi-supervised DeepLabV3 teacher–student training yields mIoU of 87.54% [34]. Adversarial architectures such as EGAN report Dice above 92% [33]. Multiscale U-Nets such as MRP-UNet achieve Dice of 94.19% and IoU of 90.77% [35]. Deformable attention transformers further enhance boundary accuracy [43]. Table 3 shows a summary of deep learning methods for lesion segmentation on the PH2 dataset.
For the HAM10000 dataset, where only classification labels are available, transformer-based models such as SkinTrans achieve 94.3% accuracy [44]. Deep ensembles such as VGG16+InceptionV3+ResNet50 achieve 97% accuracy [41]. Hybrid CNN–capsule models such as Skin-DeepNet achieve precision and recall above 98.9% [45]. ViT variants such as ViT-HAM achieve strong binary and multi-class AUC performance [46]. ABC ensembles combining CNNs and transformers reach 95–96% accuracy [47]. Table 4 shows a summary of deep learning methods for lesion classification on the HAM10000 dataset.
Although recent advances have substantially improved skin lesion segmentation and classification, several important research gaps remain unaddressed. First, most segmentation models rely on task-specific CNN or transformer backbones trained from scratch or via conventional transfer learning, which limits their ability to generalize across diverse datasets and imaging domains; foundation-model-based segmentation has not yet been fully exploited in dermoscopy. Second, existing classification pipelines largely operate on full images or cropped regions without explicitly integrating segmentation priors, resulting in weak alignment between spatial lesion boundaries and semantic feature representations. Third, segmentation and classification are typically optimized as independent tasks, preventing mutual reinforcement and reducing robustness under dataset shift, class imbalance, or the presence of background artifacts such as hair, illumination variation, and marker noise. Finally, despite promising results on individual datasets, few works present unified architectures capable of achieving consistent performance across ISIC 2018, PH2, and HAM10000 in a harmonized and scalable manner.
While some newly published dermoscopic segmentation and classification research has been shown numerically to do well, further examination reveals that much of the improvement has been based on the underlying architecture of the model(s) used, and they are still limited by optimizations specific to the dataset(s) used in those studies. For instance, although many of the segmentation models that utilize either CNNs or hybrid CNN–Transformer architectures attain excellent Dice or IoU scores by virtue of improved methods for extracting features at multiple scales or employing multi-headed attention, the reliance on training data that are task specific hinders the ability for these models to generalize across domain shifts, which leads to low confidence in the predictions made when using independent datasets for external validation. Another example is that although transformer-based classifiers allow for better modeling of the global context of images, they do not provide any explicit awareness of lesion boundaries, and, therefore, predictions made from these models are considered to have a high risk of producing results that are heavily influenced by artifacts present in the background, such as hair, variations in lighting, or markers present from the acquisition process. A major limitation of current methods, including those mentioned above, is that most of the previously published approaches view the tasks of segmentation and classification as discrete from one another, rather than as complementary; therefore, there is no potential for mutual reinforcement between the spatial localization of a lesion and the semantic diagnosis of that lesion. Therefore, the limitations identified herein highlight the need for the development of a foundation-model-driven framework where the spatial location of a lesion, as indicated by segmentation, will be utilized as a prior when classifying that lesion, and, conversely, the identified diagnosis of the lesion would allow the segmentation of that lesion to be increased in accuracy across heterogeneous datasets when the previously mentioned joint optimization concept is utilized.
3. Proposed Methodology
The proposed framework introduces a foundation-model-driven pipeline for skin lesion segmentation and classification by integrating SAM-Adapter fine-tuning with ViT-based feature extraction. The methodology consists of nine components, forming a unified system that processes dermoscopic images, extracts lesion boundaries, learns discriminative representations, and generates clinically meaningful diagnostic outputs. An overview of the proposed foundation-model-driven SAM-ViT framework is shown in Figure 1.
3.1. Dataset Preparation and Harmonization
The preparation and harmonization of dermoscopic data constitute the foundational stage of the proposed framework, ensuring that all subsequent segmentation and classification operations occur on a consistent, normalized, and diagnostically meaningful representation of the input images. The datasets employed in this study—ISIC 2018, HAM10000, and PH2—originate from different acquisition devices, clinical environments, and annotation protocols, which naturally introduce substantial variability in spatial resolution, illumination properties, color distribution, and segmentation mask quality. In order to reduce these differences, we represent each input dermoscopy image as , where H is the height and W is the width of the image, and the last dimension corresponds to the RGB color channels. The first step involved in the harmonization of our images is to rescale all images to a common resolution with an interpolation-based resizing operator so that we are able to extract patches uniformly, and each function that is part of the subsequent foundation-model pipeline operates on an input image of the same resolution. Thus, the harmonized image is completed with the following:
where ensures fixed spatial support. Despite standardization of resolution, dermoscopic images often exhibit significant differences in global illumination, camera white-balance settings, and pigmentation contrast, which hinder the stability of transformer-based feature extraction. To eliminate such inconsistencies, a histogram specification procedure is employed. Let denote a reference intensity histogram computed as the median distribution across the training set. For each pixel location x, the normalized image is computed as
where represents the histogram-matching operator to match to the canonical distribution to generate perceptually consistent images while retaining structural elements. Additionally, many images contain hair occlusions, shadows, vignetting artifacts, and disparate backgrounds and textures. Though our later segmentation module will mitigate some of these issues, it is important for our preprocessing to minimize the propagation of unwanted noise. When we have segmentation masks , they are often biased in the annotation due to polygonal edges, over-segmentation, and isolated binary components. To correct these artifacts, we apply a morphological refinement operator consisting of dilation, erosion, and contour-smoothing filters to clean up the mask to obtain specified as
Although is a more coherent representation of the lesion boundary, smooth probabilistic boundaries are useful in transformer-based architectures that use continuous attention fields and do not rely on strict binary masks. Soft mask is created by smoothing with a Gaussian-blurred version which is denoted as with a smoothing coefficient such that
This results in softer boundary zones that maintain anatomical accuracy while removing any artifacts of discretization. In the next stage, we will split each dataset into groups for training, validation, and testing on a per-patient basis so as to avoid leakage of identity. Let the full set of patient identifiers be , being mutually exclusive subsets of patient identifier space such that
This rigorous partition maintains that the same person’s image does not appear in more than one partition to avoid optimistic bias in classification accuracy. The final curated dataset splits are organized as follows:
This step ensures that every image–mask pairing is consistently aligned and fully harmonized with the pipeline’s preprocessing stage. While this degree of standardization also helps enhance the robustness of the SAM-Adapter segmentation phase of the proposed methodology, the benefit provided during ViT embedding extraction is perhaps the most significant, and is vital for the full strength of the proposed methodology. The dataset harmonization process is shown in Figure 2.
3.2. Data Augmentation and Class Balancing
The variability across dermoscopic datasets often presents itself not only through imaging conditions, but also substantial imbalance amongst diagnostic categories, especially concerning malignant lesions (e.g., melanoma), as they represent a minority class relative to benign nevi. To help stabilize and avoid bias throughout the learning process across all lesion categories, a comprehensive data augmentation and balancing approach is introduced. Denote each input dermoscopy image by , and let represent a stochastic augmentation operation that invokes a sequence of transformations to increase invariance to pose, illumination, and acquisition. The augmented sample is now defined as
where encompasses random rotations, horizontal and vertical flips, elastic deformations, random affine transformations, Gaussian noise injection, color jitter, and brightness–contrast perturbations. More formally, let denote a random rotation by an angle drawn from a finite interval , let denote flipping along the spatial axes, and let denote pixel-wise noise injection. Then, the augmentation pipeline can be expressed as a compositional map
highlighting that the modifications are made in a sequential, probabilistic manner, in order to augment structural and chromatic variability. Aside from this, affine transformations are especially useful for improving robustness to geometric distortions. An affine-transformed image is obtained using the mapping , with and , as
where A is sampled from a distribution of small perturbations around the identity matrix, ensuring realistic deformations without excessive distortion of lesion boundaries. Color jittering is applied to increase diversity in pigmentation patterns and is modeled as a transformation on the intensity vector at pixel x such that
where and are randomly sampled gain and bias values chosen to simulate variations in illumination and sensor response. While traditional augmentation enhances generalization, severe class imbalance—typical in dermatology datasets—requires explicit balancing strategies. Let denote the set of lesion classes and denote the number of samples belonging to class . When the distribution is highly skewed, synthetic augmentation such as mixup is applied, producing mixed samples and corresponding mixed labels as
where and denote two randomly sampled images, are their one-hot encoded class labels, and is drawn from a Beta distribution
with controlling the strength of interpolation. Furthermore, to promote balanced sampling across classes, we introduce a class-weighting scheme where the probability of drawing a sample from class c is inversely proportional to its frequency, defined as
ensuring that rare classes such as melanoma are sampled more frequently during training. In addition, we incorporate focal reweighting to prevent domination of the loss by well-represented classes. For an image–label pair , the class-balanced weight for category c is expressed as
where controls the degree of balancing, with larger values placing greater emphasis on minority categories. The combination of geometric and photometric augmentations, mixup-based synthetic generation, inverse-frequency sampling, and class-dependent loss reweighting establishes a robust and balanced dataset foundation, enabling the segmentation and classification modules to learn invariant, discriminative, and clinically meaningful features while mitigating the detrimental effects of class imbalance. The augmentation and balancing strategy is summarized in Figure 3.
3.3. SAM-Adapter Fine-Tuning
The SAM serves as the foundational segmentation backbone due to its extensive pretraining on billions of masks and its strong generalization capabilities across diverse visual domains. However, directly fine-tuning the entire SAM encoder for a highly specialized dermoscopic segmentation task is computationally expensive and may lead to catastrophic forgetting of its general-purpose representations. To avoid these drawbacks, we adopt a parameter-efficient fine-tuning strategy in which lightweight adapter modules are inserted into the encoder blocks.
When embedding SAM capabilities from an original foundation into images taken with a dermoscopic, creating a separate adapter module allows for several technical advantages that will be covered in this section. First, while the original SAM was designed and tested to complete multiple tasks based on natural images, creating new model types with this same capability will require significantly more computing resources and would most likely result in removing all of the pretrained weights. Second, by using an adapter module approach, we will reduce the number of trainable parameters needed within a single SAM model and refine the original model’s features without removing any of the accurate representation of the backbone network. Third, through this modular approach, we will have an improved set of SAM features, resulting in increased flexibility and training stability for training with small sets of medical imaging data, which can potentially lead to more effective use cases for adapting dermoscopic lesions into the SAM architecture. Fourth, and as demonstrated through the results of our ablation experiments, when using an adapter module to refine the features generated by the original frozen SAM model versus only using the frozen SAM model, the results produced will provide an increased level of segmentation accuracy, thereby supporting the use of an adapter module when transitioning from zero-shot segmentation to fine-tuning of a single SAM model.
Let the original SAM image encoder be denoted by , where d represents the hidden feature dimension and denote the downsampled spatial dimensions produced by the hierarchical ViT architecture. For an input harmonized image , the raw SAM feature map is
which encodes multiscale contextual information. To adapt these features to dermoscopic lesion boundaries without modifying the large backbone, a learnable adapter module with parameters is introduced. Conceptually, the adapter applies a low-rank transformation or bottleneck mapping to the encoded representation. The adapted feature map F is thus defined as
where the additive residual structure ensures that the pretrained SAM features are preserved while task-specific refinements are introduced. A common design for uses a down-projection and up-projection structure, often referred to as a bottleneck adapter. In the proposed SAM-Adapter design, the adapter modules are integrated directly within the transformer blocks of the SAM image encoder. Specifically, for each transformer layer of the SAM encoder, the adapter is inserted after the feed forward network (FFN) sublayer and operates in a residual manner on the layer output. Let denote the output of the ℓ-th transformer block in the frozen SAM encoder after self-attention and FFN operations. The adapted representation is computed as
where denotes the lightweight bottleneck adapter with learnable parameters . This placement allows the adapter to refine high-level contextual representations learned by SAM while preserving the pretrained attention structure and global segmentation priors. Adapter modules are applied uniformly across all transformer layers of the SAM image encoder, whereas the prompt encoder and mask decoder components of SAM remain unchanged and fully frozen during training. Let and denote learnable projection matrices, with representing the adapter rank. Then, the adapter transformation takes the form
where is a point-wise nonlinearity such as GELU, and . This low-rank decomposition allows to dramatically reduce trainable parameters and stay computationally feasible. A LoRA-based adapter can also be used, where the weight update is performed in a low-rank manner to the attention projection matrices. A pretrained matrix in the SAM encoder has a LoRA-modified version of
where and are learnable low-rank matrices. This modification to the SAM that is efficient in parameters preserves the SAM global representational power, and enables extremely specific adaptation to medical segmentation. To enhance representation, we propose a gated adapter mechanism to modulate the contribution of adapter by an input dependent gate shown as:
with and being learnable parameters. The final gated-adapter output is then expressed as
where ⊙ refers to element-wise multiplication. This approach enables network adaptively alters the influence of the adapter based on the complexity of the lesion, texture variability or color variation. During training, only the adapter parameters (and optionally the gating parameters) are optimized while the entire SAM backbone remains frozen. If denotes the segmentation loss combining Dice and binary cross-entropy terms, the optimization process is formally written as
where M is the ground-truth mask and is the predicted segmentation mask produced by the SAM decoder using the adapted features. By restricting optimization to a small parameter subset, the SAM-Adapter mechanism not only maintains the powerful pretraining priors of the original model but also enables effective specialization to the fine-grained lesion boundary detection required in dermoscopic images. This efficient adaptation forms the basis upon which segmentation-guided lesion extraction and subsequent ViT-based classification are built, ensuring coherent information flow throughout the entire proposed framework. The SAM-Adapter fine-tuning strategy is depicted in Figure 4.
3.4. Segmentation-Guided Lesion Extraction
Following SAM-Adapter fine-tuning, the model produces a pixel-wise probability map that encodes the likelihood of each pixel belonging to a lesion. Let this probability map be denoted by , where represents the spatial domain of the harmonized image . Each value corresponds to the model’s confidence that pixel x belongs to the lesion region. To derive a binary segmentation mask suitable for downstream processing, a thresholding operator is applied using a threshold , yielding the initial predicted mask as
where denotes the indicator function that outputs 1 if the condition inside is satisfied and 0 otherwise. However, since dermoscopic lesion boundaries often exhibit irregular textures, soft edges, and artifacts such as hair, shadows, and illumination gradients, the raw mask may contain spurious noise, small disconnected components, or jagged boundaries. To correct these imperfections, a contour-smoothing operator is applied to generate a refined mask . This operator may include morphological closing, contour regularization, and Gaussian boundary smoothing, expressed formally as
where yields a soft boundary representation that represents the continuous anatomical structure of dermoscopic lesions. To reduce local inconsistencies and to reduce isolated false positives, we also include a connected-component filtering operator which keeps only the largest connected part of the lesion. If is the set of all connected components, we update the final mask as
ensuring that only the dominant lesion structure is preserved for subsequent analysis. Once the segmentation mask is refined, it is used to extract the lesion-focused region of interest. Let ⊙ denote element-wise multiplication between an image and a mask (broadcast over channels). The lesion-specific image representation is then obtained as
This operation suppresses background tissue, artifacts, and irrelevant regions, retaining only the lesion pixels while preserving original color and texture information. Furthermore, for tasks requiring explicit lesion cropping, a bounding box is derived by computing the minimum rectangle enclosing all pixels where . The cropped lesion patch is then obtained as
which focuses the classification model on the most diagnostically relevant region. To maintain spatial consistency with later fusion stages, a softly weighted lesion representation is also constructed by blending the full image with the segmentation mask:
where controls the strength of lesion emphasis. This formulation ensures that the classifier receives lesions with enhanced contrast while preserving contextual cues in the surrounding tissue. The combination of thresholding, morphological refinement, connected-component filtering, cropping, and soft foreground weighting forms a robust mechanism that isolates the lesion region, thereby providing a clean, semantically focused input for the ViT feature extraction stage that follows in the pipeline. The segmentation-driven lesion extraction process is shown in Figure 5.
3.5. Vision Transformer Feature Extraction
While convolutional neural networks have been shown to perform well at analyzing dermoscopic images, they are limited by their reliance on local receptive fields and hierarchical aggregation of features. Therefore, these neural networks are less capable of building long-range contextual dependencies across the entire lesion, especially when compared with Vision Transformers. Vision Transformers analyze a whole image and allow for direct relationships between far-apart regions in an image, which makes them advantageous for analyzing global characteristics of lesions. Additionally, Transformer token representations present a natural way to integrate segmented spatial priors, whereby cross attention integrates the image features with lesion segmentation at the token level. Conversely, CNN pipelines have difficulty fusing different modalities as the dense nature of feature maps makes them less adaptable to varied ways of integration. Given these advantages, Vision Transformers are chosen as the basis for the classification task, as they provide efficient lesion-centric reasoning and facilitate accurate integration of segmentation and classification while leveraging the power of pretrained representations for reliable generalization.
Once a lesion-focused representation has been generated through segmentation-guided extraction, the next stage of the pipeline employs a ViT to learn rich, non-local, and semantically discriminative features from either the full dermoscopic image or the masked lesion region. Let the selected input image be denoted by , where may correspond to , , or , depending on the fusion strategy. The ViT architecture operates by decomposing the spatial domain into a collection of non-overlapping square patches of fixed resolution . Let the total number of patches be . Each patch is extracted by slicing the input image at coordinates according to
ensuring consistent partitioning across the entire image grid. To map each raw patch into a latent feature space, the 2D array is vectorized using and then transformed via a trainable linear projection matrix , where d is the transformer embedding dimension. The patch embedding is therefore computed as
resulting in a series of N patch tokens. Since transformers are mode independently permuted, positional encodings are added to maintain spatial locality. Let denote the positional vector corresponding to the location of patch i. A learnable class token is prepended to the sequence to aggregate global lesion semantics during forward propagation. Thus, the sequence of tokens passed into the first transformer layer can be written as
creating a structured format that combines both local texture cues from patch embeddings and global spatial context with positional encodings. In each transformer layer ℓ, multi-head self-attention is performed to capture long-range dependencies across different regions of an image, such as pigment networks, streaks, globules, and border irregularities. Let denote the input token matrix at layer ℓ. The layer first computes query, key, and value projections using learnable matrices . Specifically,
Self-attention is then computed across all token pairs. For each head, the attention map is derived using scaled dot-product attention, defined as
where the dimensionality of each of the embeddings is d, and the scaling term is used to stabilize the magnitudes of the gradients. Each attention head (there are h total heads) produces an output that we concatenate before performing a linear projection to get the output attention . We then add a residual connection and apply a feed forward network (FFN). Specifically, layer to layer ℓ is given by
where is composed of two linear layers combined with an activation function, such as GELU. Stack layers help the model to absorb global information across distant areas of the lesion and recognize irregularities such as asymmetry, border differences, or heterogeneous pigmentation. The output in the final layer for the class token summarizes the complete representation of the lesion image. This class token is used in the classification head’s decision-making for malignancy prediction. The ViT learns a powerful hierarchical representation from a patch decomposition, token embedding, positional encoding, and subsequent multi-layer self-attention, and this representation will support the fusion-based decision-making at later stages of the proposed framework. The ViT feature extraction flow is shown in Figure 6.
3.6. Segmentation–Classification Fusion
A primary goal of the proposed framework is to create a tight coupling between the spatial priors from segmentation and the transformer-based semantic representations, to allow the classifier to attend to clinically relevant lesion shapes but also retain context cues which are essential for reliable decision-making. To achieve this integration, a dedicated fusion module is introduced that combines two distinct forms of information: (i) image embeddings derived from the ViT feature extractor, and (ii) mask-driven embeddings produced from the segmentation maps generated by the SAM-Adapter. Let denote the sequence of embeddings obtained from the ViT encoder, where N is the number of image patches, and the extra token corresponds to the class token. Similarly, let denote the mask embeddings, constructed by flattening the refined mask into patch-level representations and projecting them using a learnable mask-embedding matrix . Formally, if denotes the mask patch corresponding to image patch , then the associated embedding is
and the full mask embedding sequence is , where is a learnable token encoding global lesion shape prior. The goal of the fusion module is to integrate these two embedding streams into a joint representation that carries both lesion-localized spatial constraints and global semantic descriptors. A simple yet effective fusion technique is concatenation along the embedding dimension, which preserves the identity of both streams while allowing the downstream classifier to learn optimal weighting. This fusion operation is defined as
where denotes concatenation along the feature axis. Although concatenation preserves full information, it does not explicitly model cross-stream interactions. To mitigate this drawback, we introduce a cross-attention-based fusion mechanism that allows the image embeddings to directly attend to cues from the mask-derived features and vice versa. Let the query matrix be obtained from the image embeddings as follows:
and the key and value matrices derived from the mask embeddings as
where are learned projection matrices. Cross-attention fusion is then computed using the scaled dot-product formulation
This approach makes sure that every image token selectively attends to the mask regions that are most informative of lesion pathology, combining the structure of lesion boundaries with the interpretation of the semantic features altogether. To improve the adaptivity of the feature fusion, a gating mechanism is proposed that allows the model to dynamically control how much the segmentation contributes to the fused representation. We denote as the learnable gating vector resulting from
where and are learnable parameters. The final gated fusion representation is therefore expressed as
where ⊙ denotes element-wise multiplication across tokens. This formulation permits the model to attend to segmentation cues when the lesion boundaries are sharp and reliable, while enabling the sequential multiplication to optimally rely on the derived semantics when the segmentation is uncertain or noisy. Utilizing a combination of concatenation, cross-attention, and gating to represent the proposed fusion module as a unified bridge between low-level lesion structure and high-level semantic representation enables the downstream classification head to operate within a highly contextualized feature space. This finely tuned representation materially improves the model’s capacity to separate subtle malignancy cues in complex dermoscopic images. Most importantly for the next joint optimization component, it provides the basis for the model’s segmentation-classification fusion architecture in Figure 7.
3.7. Joint Optimization
The framework is built around a unified joint optimization approach by tightly coupling segmentation-driven spatial priors obtained from the SAM-Adapter, with high-level learned semantic descriptors from the ViT. We do this joint optimization in two phases that are distinct, yet related, namely segmentation training and classification training. Together, this will allow the model to capture lesion morphology, texture, boundary irregularities, and multi-class diagnostic cues to perform robust skin cancer analysis. The training format is developed so that segmentation aids classification by improving the localization of lesions, while classification gradients ensure the network does prioritize discriminative lesion features. This mutually reinforcing approach is key to developing a consistent end-to-end learning framework that is reliable, even when datasets have high levels of heterogeneity in class distribution, image appearance, and/or granularity of annotation.
In the first phase of the training, segmentation training, we aim the model to learn precise lesion boundaries to inform classification in the next phase. Let be the ground-truth mask and the predicted segmentation probability at pixel x. The segmentation loss function is defined as a combination of Dice loss and binary cross-entropy (BCE) loss, which measures performance at the region level and consistency in pixel-wise probability respectively. That is,
where the Dice loss penalizes overlap mismatch and is defined as
with representing the spatial pixel grid. To complement this, the BCE term accounts for per-pixel classification fidelity and is expressed as
During this phase, only the adapter parameters embedded within the SAM-Adapter are updated, while the rest of the SAM encoder remains frozen. The optimization objective for segmentation is therefore
ensuring efficient and domain-specific adaptation without overfitting, or eroding the pretrained representational strength of SAM. In the second phase, the classification training leverages refined lesion-focused images and fused embeddings to learn high-level diagnostic distinctions. Let denote the one-hot vector representing the ground-truth class label among C lesion categories, and let denote the predicted class probability for class c. The classification loss is computed using the standard categorical cross-entropy:
which encourages the classifier to assign high probability to the correct lesion category while minimizing misclassification errors. To further enhance robustness in imbalanced datasets, class-dependent weights may be integrated, yielding the weighted cross-entropy
where or depends on the dataset properties, and is the number of samples in class c. In order to jointly account for the segmentation and classification goals (if desired), a joint loss, labeled , can be applied during the fine-tuning step with balancing weights and :
with dictating the influence of each term. In this way, the network aligns segmentation accuracy with classifying accuracy and thus ensures both morphological and semantic consistency. In total, these two training procedures dictate a coherent optimization path that draws on segmentation to refine the localization of features and relevant classification to supplement this with semantic abstraction, in order to create a fully complementary model capable of reliable and interpretable skin lesion analysis.
Nevertheless, although the development of SAM for medical image segmentation is still at the early stage in the literature, most of the existing methods use SAM either implicitly or apply some sort of fine-tuning, either partial or full, for performing just one single downstream task. Compared with this, the presented framework incorporates a parameter-efficiency adapter design, which is carefully integrated into each of the transformer blocks of the SAM image encoder, which allows domain-specific adaptation, while safeguarding the full pretrained attention structure and general-purpose segmentation priors. Such a design diverges from the previous forms of fine-tuning of SAM by explicitly constraining the capacity of trainable parameters and by enabling fine-grained lesion boundary changes, which are unrelated to generic mask matching.
In addition, unlike the existing guiding states for classification that rely mainly on hard lesion cropping or post hoc endorsements of masks, the method presented in this proposal has introduced a token-level fusion mechanism, whereby the SAM-of-lesion mask embeddings are directly incorporated with the Vision Transformer image tokens through cross-attention. This fusion allows the introduction of dynamic modulation of the semantic classification features conditioned on lesion-specific spatial priors and therefore treats the segmentation step rather as a prior active domain dissection layer than static preprocessing. This means that the lesion shape and boundary-related information further influence the whole diagnostic rationale looping inside the transformer layers themselves.
Finally, unlike traditional sequential training paradigms, in this study we look at the joint optimization scheme that distinctly couples the segmentation and classification objectives into a common space. On the other hand, most prior works rather occur independently, and the joint optimization parameterization gathers spatial cues obtained from segmentation to direct learning in classification, while supervision in classification provides feedback towards the fine-tuning of lesion features. Such bidirectionality acts therefore as a novel architectural contribution: not merely a mark of improvement but instead one that propagates the idea of coherent lesion-centric representation learning through heterogeneous data pools.
4. Experimental Results and Discussion
4.1. Datasets and Experimental Setup
Three publicly available dermoscopic datasets were used for the experiments: ISIC 2018, HAM10000, and PH2. Each dataset comprises distinct imaging conditions, lesion categories, and characteristics of annotation. The ISIC 2018 dataset includes pixel-level segmentation masks and seven-class diagnostic labels, allowing for evaluation of the entire segmentation–classification pipeline. Segmentation was performed on all 2594 training images of the corresponding classification subset, which had a total of 10,015 images, to evaluate lesion recognition. The HAM10000 dataset contains 10,015 dermoscopic images across seven diagnostic categories and does not contain segmentation masks. Thus, the HAM10000 dataset is aligned towards assessing the classification module across a range of possible real-world acquisition environments. The PH2 dataset contains 200 high-resolution dermoscopic images and associated precise ground truth manual lesion masks. Therefore, this dataset can be used to assess the segmentation quality for a highly manually curated dataset. All datasets were split using patient–disjoint splits to avoid identity leakage, where a split was selected for training, for validation, and for testing unless otherwise specified.
In order to establish consistency among the various datasets, each image was resized to and normalized by channel with respect to the ImageNet dataset statistics. Segmentation masks were available for some datasets; thus, morphology filtering and contour refinement were carried out on segmentation masks to remove annotation noise and smooth the masks. Data augmentation for each dataset made use of random horizontal and vertical flipping, rotations, affine transformations, Gaussian noise injection, and color jitter to brightness, contrast, and saturation. For the classification problem, the imbalance of the classes was addressed through a combination of weighted cross-entropy loss and mixup augmentation with a mixing coefficient .
The proposed framework was implemented in PyTorch (version 2.1) and trained using an NVIDIA RTX 5070 GPU. The SAM encoder was kept frozen, and only the adapter parameters were optimized. The ViT backbone was initialized from ImageNet-pretrained weights and fine-tuned end-to-end. The AdamW optimizer was employed for both branches of segmentation and classification; an initial learning rate of , cosine learning rate decay, and a weight decay of were utilized. The segmentation branch was optimized with a hybrid loss of Dice loss and binary cross-entropy, while the normal cross-entropy was employed for the classification branch. At the joint optimization phase, the overall loss function was treated as the weighted summation of segmentation and classification loss, where the weights were determined semi-empirically in an attempt to stabilize multi-task convergence.
Performance was evaluated using standard metrics. For the segmentation task, the following metrics were reported: the Dice coefficient; Jaccard index (IoU); sensitivity; specificity; and mean pixel accuracy. For the classification task, we report accuracy, precision, recall, F1-score, and area under the ROC curve (AUC). Each experiment was performed three times, with different random seeds, and mean performance values are reported for statistical significance. Throughout the process of using baseline comparisons, the train–validation–test splits were carried out in the same way to maintain fairness. The entire experimental process was aligned with the evaluation protocols for dermoscopic image analysis in the literature, maintaining both reproducibility and comparability with previous state-of-the-art methods.
The HAM10000 dataset has a significant class imbalance but many techniques were implemented to minimize overfitting and to achieve the validation of generalization from the data in training. First, all experiments were conducted using a patient–disjoint train–validation–test split; hence, all data used to validate the classifier were gathered from different patients than those used for training would be. Second, during training, a large number of augmentations created a more diverse set of samples to be used for training and allowed the classifier to have less chance of memorizing the dominant classes. Third, to address the class imbalance problem of the HAM10000 data, cross-entropy loss functions based on the respective classes were employed which allowed the classifier to apply a heavier penalty in misclassifications of minority classes compared with majority classes. Fourth, in addition to using a frozen foundation model as a segmentation backbone, only lightweight adapter modules were trained on the HAM10000 data; therefore, there was considerable reduction in model capacity, which decreases the risk of overfitting. Finally, as all results are represented as the average output from three independent trials using different random-seed initializations, this provides an additional validation of both the stability of the training process and the robustness of the classifier.
It should be stated clearly that the HAM10000 dataset does not contain true pixel-level ground-truth segmentation and is, therefore, only being used for classifying purposes in the proposed architecture as outlined above. Therefore, we do not report any quantitative evaluation of the segmentation metrics associated with HAM10000. Under this assumption, we use the SAM-Adapter segmentation branch solely for the purpose of generating image-level representations focused on, or directed toward, the classification task and to provide additional localizing support to the Vision Transformer. The SAM-Adapter segmentation branch was trained and quantitatively evaluated exclusively on datasets for which ground-truth segmentation masks have been made available, but the outputs of the SAM-Adapter segmentation branch are used to eliminate and reduce background artifact noise from the HAM10000 dataset and enhance the learning of features directly associated with lesion characteristics when performing classification tasks.
This investigation provides one baseline result via two sources for comparative evaluations. The first source is directly adopted when public performance values are available from the publications mentioned, and they are appropriately cited. However, where public source code or pretrained models are available, the authors re-implement or retrain the baseline methods on patient–disjoint data splits, maintaining image resolution and evaluation protocols that match those of the proposed framework. All reproductions of baselines were trained under controlled settings, subject to similar preprocessing steps, data augmentation strategies, and the same train–validation–test data partitions for a fair comparison. This mixed strategy allows for transparent performance comparisons while maintaining consistency and repeatability across datasets and experimental settings.
4.2. Quantitative Results
This section presents the quantitative performance data for the proposed SAM-Adapter-guided ViT framework over all three datasets. The studies are reported according to segmentation, and classification tasks so that it is possible to compare with state-of-the-art methods. The reported performance values include for segmentation the Dice coefficient, Jaccard index (IoU), sensitivity, specificity, and mean pixel accuracy, while for classification it includes accuracy, precision, recall, F1-score, and AUC. The values for mean performance reported here all represent mean values over three independent runs with different random seeds. The proposed method consistently outperforms similar methods across three datasets, demonstrating strong generalization, and strong boundary extraction ability in addition to better performance for lesion recognition. Figure 8 and Figure 9 only deal with visualizing the boundaries of lesions and have been produced at the highest resolution available based on the Original Segmentation Outputs. As no downsampling or compression was utilized in the production of these figures, this preserves the boundary details in fine scale so that lesion contours are faithfully represented in the predicted form. There was therefore no additional resolution enhancement added to these figures, as any further up-scaling could result in introducing other types of visual artifacts that might not accurately reflect the underlying segmentation performance.
In regards to the segmentation results in the ISIC 2018 dataset, as detailed in Table 5, the proposed SAM-ViT framework provides the best overall performance based on all evaluation metrics. Although the traditional CNN-based models, FAT-Net and EGAN, exhibit reasonable Dice and sensitivity values, neither model performs well based on boundary precision, which typically results in lower IoU scores. More sophisticated architectures, such as MRP-UNet and SkinFormer as examples, deliver improved segmentation quality with respect to fine-grained lesion segmentation scoring but do not exceed the proposed method. The novel method by SAM-Adapter fine-tuning of the transformer-based feature modeling achieves an overall Dice value of 94.27% and IoU of 92.83%, outperforming the next strongest baseline method by a substantial amount.
Representative examples are presented in terms of qualitative segmentation results in Figure 8. It can be readily seen that the baseline methods frequently created mask outlines of lesions that were not well-defined and/or did not follow the lesion’s edges precisely, particularly under very distorting circumstances, such as severe drops in contrast, irregular or ragged edges and excessive amounts of background noise, such as hair and poor illumination. In addition, as a result of the shortcomings mentioned above, the SAM-ViT produced very clear masks, with very smooth outlines, while limiting leakage into the adjacent healthy skin. The improved representations generated by the method are consistent with the associated metric enhancements reported in Table 5 related to the segmentation of lesions displayed as expected, based on the design principle of the adapter-based refinement of the SAM encoder.
The results of the segmentation presented for the PH2 dataset in Table 6 provide evidence of the boundaries localization capabilities of the proposed SAM-ViT framework. While traditional CNN-based models, such as UCM-Net and EGAN, report competitive Dice and sensitivity calculations, they report lower IoU performance, as they struggle to delineate fine-limited lesions and pigment transitions. In comparison, transformer-based approaches such as MRP-UNet and Deformable Transformer increase overall segmentation quality based on their ability to model long-range spatial dependencies. However, the proposed methodology out-performs all other reported metrics compared to the all competing approaches, including a 95.62% Dice Performance and 92.91% IoU. This performance improvement demonstrates the benefit of the SAM-Adapter refinement and the use of ViT-driven spatial priors for more appropriate limitations of lesion contours, especially within the high-resolution and low-artifact imaging atypical for PH2.
Qualitative results for segmentation are illustrated in Figure 9. We can see examples of qualitative segmentation results using the PH2 dataset, which consists of high-resolution images that have been annotated with ground-truth masks. From these examples, the segmentation results generated by other researched methods are seen to produce fragmented boundaries and are not able to identify fine-grained pigment transitions along the peripheral regions of the lesion. The results of the proposed SAM-ViT framework produce coherent and continuous contours of lesions, particularly in areas where there are subtle differences in color. This qualitative performance corresponds with the best Dice and IoU values presented in Table 6, validating the ability of the SAM-Adapter design to capture fine details of the structure of lesions even in smaller and lower variability datasets like the PH2 dataset.
Table 7 reports the classification results, with the proposed SAM-ViT framework consistently demonstrating strong performance for all evaluation metrics. In comparison, more conventional models such as ESRGAN+TL and MSM-CNN provide moderate accuracy and recall, and most networks that use an ensemble-based decision protocol demonstrate better results but still rely on the global image context that can bias toward attributes associated with background. ViT variants, such as HI-MViT that build on a ViT architecture, improve classification performance significantly because they model long-range dependencies with an AUC of . However, SAM-ViT outperforms this model with an AUC of while achieving an overall accuracy of 95.88%. The difference further exemplifies the improvements attributed to segmentation-based lesion cropping and cross-attention fusion to relieve confounding from irrelevant areas of the photo in the classification stage to elicit fine-grained lesion characteristics.
Table 8 presents the classification results on the HAM10000 dataset, demonstrating that the SAM-ViT framework presented achieves highly competitive results compared to previously established and strong state-of-the-art methods. While Skin-DeepNet produces the best overall accuracy (98.00%) and best F1-score (97.57%), the proposed structure simply outperforms in terms of accuracy with 96.37% and AUC of 0.979, besting multiple other transformer-based and ensemble-based competitors. Notably, SAM-ViT outperforms SkinTrans and ViT-HAM on every metric, which suggests that a segmentation driven prior does help improve the discriminative abilities of the final classifier. For example, while Deep Ensemble mostly finds a more superior performance in terms of raw accuracy in the classification metrics, this proposed method shows a much more favorable trade-off for balanced accuracy, precision, recall, and AUC—showing that the segmentation-guided embedding refinement advances classifying performance especially in a complicated multi-class prediction problem.
4.3. Ablation Study
To fully examine the contributions of each element of the architecture, we conducted a complete ablation study on the ISIC 2018 dataset. This assessment isolated the contributions of adapter fine-tuning (derived from SAM), lesion-specific cropping methods, fusion, joint optimization (with optimal training parameters, or hyperparameters), adapter model depth, patch sizes, and loss weighting. For all experiments reported, we report the average of three runs for increased statistical robustness. The results in Table 9 support the positive impact of fine-tuning via adapters for adaption of SAM for dermoscopic segmentation. As the SAM backbone was frozen and had no learnable parameters, the model recorded a Dice score of only 89.41%. This suggests SAM is quite restricted in its ability to adapt to the idiosyncrasies of the dataset and its lesion boundaries. In conditions without any fine-tuning, randomly initialized adapters improved the Dice score slightly, solely due to learnable capacity. This suggests that the inclusion of adapters, even without fine-tuning, assists the residual model in modeling dermoscopic textures. In contrast, the full proposed SAM-Adapter approach produced a substantial increase in Dice to 94.27% and IoU 92.83%, a significant contribution over both alternatives.
The ablation analysis on fusion strategies reveals the important function of an effective integration mechanism for exploiting complementary information from segmentation-guided features and image embeddings. As summarized in Table 10, utilizing no fusion achieves the lowest performance, demonstrating that keeping the two streams independent negatively influences the network’s ability to leverage cross-modal correlations. A simple concatenation yielded a reasonable improvement of performance for both accuracy and AUC, suggesting the networks are taking advantage of the two feature spaces to provide some additional discriminative cues without completely utilizing the interdependencies between feature modalities. Cross-attention fusion achieved the strongest performance of accuracy (95.88%) and AUC (0.983), highlighting that by dynamically weighting the contribution of each stream, the methods can provide more aligned contextual learning.
The ablation of the adapter depth in Table 11 emphasizes that choosing the optimal number of adapter blocks is essential for a trade-off of segmentation and classification performance. Ultimately, using a single layer per block produces the worst results, indicating that a shallow setting does not have enough capacity for the feature refinement and domain adaptation required for satisfactory performance. When the depth was set to two, which the proposed model did, we obtained the best results for the Dice score (94.27%), and classification accuracy (95.88%). These results suggest that two adapter blocks per layer provide the best balance between representational depth and optimization stability. Increasing the adapter depth to four blocks per layer improved representational depth; however, this increased complexity did not yield performance gains and even slightly decreased numerically for both metrics.
Table 12 shows the effect of patch size on the classification results. The size of the spatial granularity is a significant factor in the utility of the ViT-based encoder. Small patches sized uphold fine local detail, resulting in strong classification; on the other hand, they have greater computational complexity and may emphasize local variation too much. Large patches sized significantly reduce token count but exhibit a lower performance, suggesting that spacing information related to subtle lesions is lost. The suggested patch size of attains the highest accuracy (95.88%) and F1 score (95.26%), where sufficient spatial information remains while balancing some loss in global contextual data.
The influence of loss weight balancing on the joint segmentation–classification framework is presented in Table 13. Assigning equal importance to both objectives yields reasonably strong performance across tasks but does not fully exploit the complementary nature of the two branches. Reducing the classification weight to slightly improves the Dice score, yet it also leads to a drop in classification accuracy, indicating that underemphasizing the classification objective weakens the discriminative capability of the model. The proposed configuration achieves the best overall performance, maintaining the highest Dice score (94.27%) while also yielding the strongest classification accuracy (95.88%).
The backbone comparison in Table 14 highlights the advantages of adopting a transformer-based architecture for skin lesion classification. EfficientNet-B4 and ConvNeXt-Tiny both provide strong baselines, reflecting the effectiveness of modern convolutional and hybrid CNN designs for dermatological image analysis. Nonetheless, the use of convolutional receptive fields constrains their performance because they have limited capacity and ability to model long-range dependencies (and global context cues) that are critical in distinguishing visually compatible lesion categories from each other. We show that the accuracy (95.88%) and area under the curve (AUC = 0.983) of the proposed ViT-B/16 backbone can be used as a superior performance model; the tokenization and self-attention processes allow for far more complex and tri-dimensional feature modeling throughout the image.
4.4. Statistical Significance Testing
In order to evaluate the robustness of the observed performance improvements enabled by the proposed SAM-ViT framework, we conducted statistical significance tests for both segmentation and classification tasks. The experiments were repeated three times for each method with different random seeds and employed standard evaluation practices. The normality of metric distributions were tested for using the Shapiro–Wilk test prior to conducting hypothesis testing. For all metrics and all competing models, it was found that , indicating that there was no violation of normality. The next step involved comparing the proposed method to each baseline model, and we employed paired two-tailed t tests in order to measure significance. Wilcoxon signed-rank tests were also conducted for completeness and yielded similar results. Effect sizes were calculated using Cohen’s d.
The statistical significance test results presented in Table 15 provide good evidence that the proposed model achieves superior performance in segmentation consistently over state-of-the-art competing methods. All p-values reported are substantially below the conventional boundary of 0.05 for conclusion of statistical significance, suggesting the observed performance improvements are not due to random chance across runs. Furthermore, we can report Cohen’s d values between 0.89 and 2.14 with confidence intervals around 1, implying large to very large effect sizes, and that underscoring the effect is of practical significance. The greatest effect is seen when comparing to Frozen SAM, affirming that the model benefits from task-specific fine-tuning, as well as using adapter-based optimization.
The statistical analysis summarized in Table 16 shows that the proposed classification framework achieves much better performance than other competing state-of-the-art models on both the ISIC 2018 and HAM10000 datasets. All comparisons are statistically significant, with all p-values being below 0.05. Cohen’s d measures fall between 0.68 and 1.12, which indicate that these effect sizes are in the medium to large range, showing not only that these gains are statistically significant but are even practically meaningful. The best effect observed is against the Ensemble TL and ViT-HAM models, which showcases the advantages of merging segmentation-aware feature refinement with transformer based classification models.
In order to validate metric-level reliability, we also calculated 95% confidence intervals (CI) on the proposed model. In ISIC 2018 segmentation, Dice offered a narrow CI of %, indicating stable performance across data runs. In classification on HAM10000, the accuracy also had a similarly narrow CI of %. These relatively close CI intervals across runs indicates low model variance, which is likely due to segmentation priors and the cross-attention fusion effect. Additionally to investigating metric-level reliability, the statistical significance testing confirmed that improvements in the proposed methods are not due to random chance but rather are reliably consistent and robust improvements over strong baseline models. The combination of a strong foundation-model prior, adapter tuning, and classification by fusion are major contributors to both segmentation accuracy and dermatology lesion recognition performance.
4.5. Discussion
The experimental results demonstrate that integrating foundation-model priors with transformer-based classification significantly improves both lesion segmentation and diagnostic accuracy. The proposed SAM-Adapter framework consistently outperforms state-of-the-art CNN- and transformer-based methods on the ISIC 2018 and PH2 datasets, confirming the benefit of adapting a large-scale, general-purpose segmentation model to the dermoscopy domain. By leveraging SAM as a strong initialization for lesion boundary localization and introducing lightweight adapters for domain-specific refinement, the framework achieves smoother lesion contours, higher accuracy, and improved robustness against common dermoscopic artifacts such as hair occlusion, low contrast, and irregular lesion geometry.
Classification results further validate the effectiveness of segmentation-guided learning. Providing the Vision Transformer with lesion-focused crops and segmentation-derived embeddings reduces reliance on background textures and device-dependent artifacts, directing attention toward clinically relevant features such as internal structure, color heterogeneity, and border irregularity. The superior performance of cross-attention fusion compared to simple concatenation highlights the importance of dynamically contextualizing image features with spatial priors. Ablation studies consistently show performance degradation when lesion cropping or fusion mechanisms are removed, underscoring their critical role.
The joint optimization of segmentation and classification further enhances performance by enabling mutual reinforcement between spatial localization and semantic discrimination. This coupling stabilizes training, mitigates overfitting, and improves cross-dataset generalization. Additional ablations on adapter depth, patch size, and loss weighting confirm that moderate architectural complexity and balanced multi-task learning yield optimal results. Statistical significance analyses demonstrate that the observed gains are consistent across repeated trials, with large effect sizes indicating that improvements are not attributable to random variance.
Despite these strengths, several limitations should be acknowledged. The segmentation performance may degrade under extreme conditions such as very low contrast, severe occlusions, or rare lesion appearances, which can propagate errors into the classification stage. The multi-stage pipeline also introduces additional computational overhead compared to lightweight CNN-based models, potentially limiting deployment in low-resource environments. Furthermore, for datasets without ground-truth masks, such as HAM10000, the framework relies on SAM-generated pseudo-masks that may introduce boundary inaccuracies.
From a clinical perspective, the lesion-centric design enhances interpretability by explicitly linking segmentation-derived structural cues with diagnostic predictions, aligning well with dermatological decision-making practices. From a deployment standpoint, scalability is supported by freezing the SAM backbone and adapting it through lightweight adapters, significantly reducing trainable parameters and memory overhead. The framework is amenable to further optimization through reduced adapter rank, smaller transformer variants, and post-training compression techniques such as quantization and pruning, enabling adaptation to real-time screening and resource-constrained clinical settings.
5. Conclusions
This study presented a foundation-model-driven framework that incorporates SAM-Adapter-based lesion segmentation with a ViT classifier that leverages lesion-centric cropping and cross-attention fusion, producing a consolidated solution toward dermoscopic image analysis. The rendering of SAM through lightweight, domain-specific adapters resulted in accurate, robust boundary delineation without the expense of full-model fine-tuning. When integrated with transformer-based classification, the segmentation priors steered the model toward diagnostically salient structures and away from background patterns, resulting in consistent performance gains across ISIC 2018, HAM10000, and PH2. The extensive quantitative evaluation supported through ablation experiments and statistical significance testing confirmed the contribution of each architectural component, demonstrating that SAM priors combined with fusion design features and joint optimization offer superior segmentation fidelity as well as more stable multi-class lesion recognition. It is acknowledged that the computational complexity and utilization of pseudo-masks for datasets without ground-truth annotations is a limitation of practicality, but the overall robustness and generalization of the framework suggest that this design approach is fitting for emergent real-world clinical use. Future work will examine advanced domain adaptation approaches, model compression techniques, and validation within multi-center clinical cohorts to enhance reliability and scalability as well as readiness for deployment.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Siegel R.L. Miller K.D. Jemal A. Cancer statistics, 2019 CA A Cancer J. Clin.20196973410.3322/caac.2155130620402 · doi ↗ · pubmed ↗
- 2Bray F. Laversanne M. Sung H. Ferlay J. Siegel R.L. Soerjomataram I. Jemal A. Global cancer statistics 2022: GLOBOCAN estimates of incidence and mortality worldwide for 36 cancers in 185 countries CA A Cancer J. Clin.20247422926310.3322/caac.2183438572751 · doi ↗ · pubmed ↗
- 3Saginala K. Barsouk A. Aluru J.S. Rawla P. Barsouk A. Epidemiology of melanoma Med. Sci.202196310.3390/medsci 904006334698235 PMC 8544364 · doi ↗ · pubmed ↗
- 4Errichetti E. Stinco G. Dermoscopy in general dermatology: A practical overview Dermatol. Ther.2016647150710.1007/s 13555-016-0141-6PMC 512063027613297 · doi ↗ · pubmed ↗
- 5de Vere Hunt I. Lester J. Linos E. Insufficient evidence for screening reinforces need for primary prevention of skin cancer JAMA Intern. Med.202318350951110.1001/jamainternmed.2023.092737071418 · doi ↗ · pubmed ↗
- 6Esteva A. Kuprel B. Novoa R.A. Ko J. Swetter S.M. Blau H.M. Thrun S. Dermatologist-level classification of skin cancer with deep neural networks Nature 201754211511810.1038/nature 2105628117445 PMC 8382232 · doi ↗ · pubmed ↗
- 7Miller I. Rosic N. Stapelberg M. Hudson J. Coxon P. Furness J. Walsh J. Climstein M. Performance of commercial dermatoscopic systems that incorporate artificial intelligence for the identification of melanoma in general practice: A systematic review Cancers 202416144310.3390/cancers 1607144338611119 PMC 11011068 · doi ↗ · pubmed ↗
- 8He K. Zhang X. Ren S. Sun J. Deep residual learning for image recognition Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Las Vegas, NV, USA 27–30 June 2016770778