Evaluation of Large Language Models in the Diagnosis, Urgency Triage, and Initial Management of Ophthalmic Emergencies
Surina Mittal, Yakshi Aggarwal

TL;DR
This study compares three large language models in diagnosing and managing eye emergencies, finding they perform similarly and accurately, but still need human oversight.
Contribution
The study evaluates the performance of three leading LLMs in ophthalmic emergencies using standardized clinical vignettes.
Findings
All three LLMs achieved diagnostic accuracies above 80% in ophthalmic emergencies.
No significant differences were found between the models in diagnostic accuracy, urgency triage, or management advice.
LLMs provided management advice aligned with recognized ophthalmology guidelines.
Abstract
Introduction Artificial intelligence (AI) technologies are progressing rapidly and becoming an integral part of how healthcare professionals obtain medical knowledge. Large language models (LLMs) now enable clinicians to have direct access to medical guidance and support in clinical reasoning. In ophthalmology, where prompt identification of sight-threatening symptoms is essential, these tools can offer diagnostic support, urgency triaging, and initial management guidance, thus potentially reducing delays in care and improving referrals. Limited evidence exists regarding their accuracy, reliability, and safety in eye emergencies. This study aims to compare the diagnostic accuracy, urgency triage, and initial management advice generated by the three leading LLMs, to evaluate their prospective role in the early assessment and management of acute eye presentations. Methods This…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
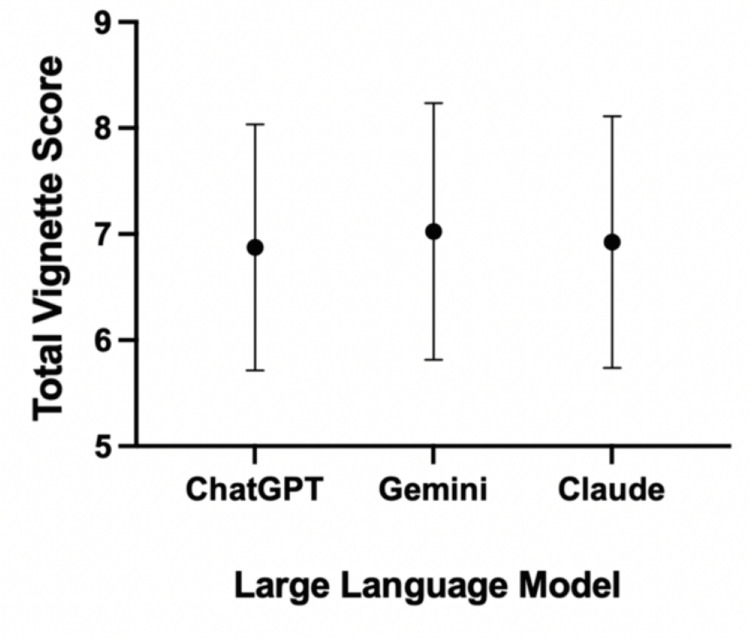 Figure 1
Figure 1| Ophthalmology subspeciality | Cases for vignettes |
| Cornea | Corneal abrasion, Bacterial keratitis, Herpes simplex epithelial keratitis, Bullous keratopathy, Photokeratitis, Corneal foreign body, Keratoconjunctivitis sicca |
| Retina | Rhegmatogenous retinal detachment, Branch retinal artery occlusion, Central retinal artery occlusion, Vitreous haemorrhage, Wet age-related macular degeneration, Macular hole, Central retinal vein occlusion, Hypertensive retinopathy |
| Glaucoma | Acute angle-closure glaucoma, Acute anterior uveitis, Acute endophthalmitis, Traumatic hyphaema, Phacomorphic glaucoma, Steroid-induced glaucoma, Congenital glaucoma, Scleritis |
| Orbit | Orbital cellulitis, Periorbital cellulitis, Globe rupture, Orbital floor fracture, Acute dacryocystitis, Orbital tumour, Cavernous sinus thrombosis, Thyroid eye disease |
| Neuro-Ophthalmology | Optic neuritis, Anterior retrobulbar optic neuritis, Arteritic anterior ischaemic optic neuropathy, Papilloedema due to raised intracranial pressure, Aneurysmal third-nerve palsy, Weber syndrome, Pituitary apoplexy, Non-arteritic anterior ischaemic optic neuropathy |
| Vignette scoring | Criteria |
| Diagnosis | |
| 2 | Correct or exact likely diagnosis |
| 1 | Partially correct or plausible diagnosis |
| 0 | Incorrect or dangerously misleading diagnosis |
| Urgency | |
| 2 | Correct classification (emergency, urgent, routine) |
| 1 | Partially correct classification |
| 0 | Incorrect classification |
| Management | |
| 3 | Entirely correct management advice |
| 2 | Mostly correct advice but misses an important step/detail |
| 1 | Some correct advice but significantly important advice is omitted |
| 0 | Incorrect/harmful advice |
| Red Flags | |
| 1 | Able to identify red flags when present |
| 0 | Fails to identify red flags when present |
| LLM | Number of correct diagnoses (n, %) | Diagnostic score (mean ± SD) | Urgency classification score (mean ± SD) | Management score (mean ± SD) | Red flag recognition score (mean ± SD) | Overall score (mean ± SD) |
| ChatGPT-5 | 34 (85%) | 1.85 ± 0.36 | 1.83 ± 0.38 | 2.25 ± 0.81 | 0.95 ± 0.22 | 6.88 ± 1.16 |
| Gemini Pro 2.5 | 32 (80%) | 1.83 ± 0.38 | 1.78 ± 0.48 | 2.50 ± 0.72 | 0.93 ± 0.27 | 7.03 ± 1.21 |
| Claude Opus 4.1 | 35 (87.5%) | 1.88 ± 0.33 | 1.75 ± 0.44 | 2.35 ± 0.70 | 0.95 ± 0.22 | 6.93 ± 1.19 |
| ChatGPT vs Gemini | ChatGPT vs Claude | Gemini vs Claude | |
| Diagnostic score | >0.9999 | >0.9999 | 0.5000 |
| Urgency classification | 0.7744 | 0.3750 | >0.9999 |
| Management score | 0.1039 | 0.5743 | 0.2130 |
| Red flag recognition | >0.9999 | >0.9999 | >0.9999 |
| Overall score | 0.4065 | 0.6625 | 0.5555 |
| Error domain | ChatGPT (n) | Gemini (n) | Claude (n) |
| Diagnosis | |||
| Complete error (score 0) | 0 | 0 | 0 |
| Partial error (score 1) | 6 | 7 | 5 |
| Urgency | |||
| Complete error (score 0) | 0 | 1 | 0 |
| Partial error (score 1) | 7 | 7 | 10 |
| Management | |||
| Complete error (score 0) | 2 | 1 | 0 |
| Key missed management (score 1) | 3 | 2 | 5 |
| Partial missed management (score 2) | 18 | 13 | 16 |
| Red flags | |||
| Complete omission (score 0) | 2 | 3 | 2 |
| Subspeciality | Best performing LLM (mean total) | X2 (df = 2) | p-value |
| Cornea and external disease | Gemini/Claude (tie) | 1.6875 | 0.43009 |
| Retina and vitreous | ChatGPT | 1.9375 | 0.37956 |
| Glaucoma and anterior segment | Gemini | 1.9375 | 0.37956 |
| Orbit and oculoplastic disorders | ChatGPT | 0.8125 | 0.66614 |
| Neuro-ophthalmology | Gemini | 1.5625 | 0.45783 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsArtificial Intelligence in Healthcare and Education · Clinical Reasoning and Diagnostic Skills · Ophthalmology and Visual Health Research
Introduction
Artificial intelligence (AI) is a rapidly developing field, involving computer-based systems emulating human cognitive processes such as learning, reasoning, and problem-solving [1]. The ability of AI to recognise patterns from comprehensive datasets and generate informed, evidence-based responses is a key rationale for its rapid introduction into the medical field. Modern medical practices are embracing AI, with common uses including the detection of disease from radiographic imaging, clinical decision making, and prediction of epidemiological disease patterns [2]. AI systems are commended for their adaptability and continuous learning as more data is entered, allowing them to be used in a field such as medicine, in which continuous advances and improvements are made [3].
Over the last decade, progress in AI technology has allowed for the development of more sophisticated systems, including the launch of large language models (LLMs) [4]. LLMs can interpret and generate human-like text to provide accessible responses in any style and context requested by the user. The release of the ChatGPT LLM in 2022 sparked global attention to the potential of AI, with public interest in AI systems surging, and many subsequent competitor systems, such as Google Gemini, Claude, and Microsoft Copilot, being released in quick succession [4,5]. AI models are being continuously developed to increase their ability to receive multimodal inputs and to improve the overall quality of their outputs. ChatGPT-5 (2025, OpenAI, San Francisco, CA, USA), Google Gemini 2.5 Pro (2025, Google DeepMind, London, UK), and Claude Opus 4.1 (2025, Anthropic, San Francisco, CA, USA) are some of the most current and advanced models accessible to the wider public. ChatGPT-5 has reportedly improved reasoning and reliability compared with its earlier models, reducing the rate of errors [6,7]. Gemini 2.5 Pro now utilises multimodal data inputs, including text, audio, and visual data, making it particularly applicable in medical diagnostics [8]. Claude Opus 4.1 has a reported focus on safety, precision, and excelling in coding and reasoning [9].
Evidence surrounding the applications of using AI in healthcare has been promising amongst multiple medical specialities, including cardiology, radiology, and chronic diseases, with studies showing improvements in patient care, diagnostic accuracy, treatment optimisation, and cost reduction [10-12]. Ophthalmology as a field particularly demonstrates strong potential for the use of AI due to its heavy reliance on image interpretation to reach diagnoses. There is a rising demand for the use of AI in non-ophthalmology settings, including general practice, general medical wards, and emergency departments, where access to urgent ophthalmology advice is variable across locations [13]. Ophthalmology services are predicted to rise in demand, and thus, AI is a tool which could alleviate pressure on healthcare systems if deemed a reliable clinical resource [14,15]. It has already been demonstrated to be useful in the interpretation of fundus photographs, optical coherence tomography (OCT), and fundus fluorescein angiography (FFA) imaging [16-18]. Therefore, there is some evidence in the literature which supports the use of AI in the diagnosis of ophthalmic conditions from images, aiding triage and referral processes.
However, AI diagnostics based on text-only prompts alone can be more challenging in ophthalmology due to the overlap of signs and symptoms, such as red eye, pain, photophobia, and decreased vision, across several conditions [19]. Correct recognition of ophthalmic emergencies for prompt investigations and management is essential to reduce the risk of permanent complications, including progression to permanent sight loss, and even patient fatality [20-22]. Though some studies show the promising potential of AI in the accurate diagnosis and safe management of medical emergencies, the evidence base is mixed, and its applications within ophthalmology remain a point of uncertainty. Previous research evaluating ChatGPT-4’s performance in the Taiwan Advanced Medical Licensing Examination found that although the model generally performed well, the highest number of mistakes were within ophthalmology [23]. AI models, though continually improving, can often generate inaccurate, misleading information when given medical prompts for interpretation [24]. This highlights the need for further studies assessing whether LLMs can deliver reliable and safe ophthalmic advice to healthcare professionals, particularly in emergency situations, where errors could provide detrimental outcomes for patients. Careful evaluation of the reliability and accuracy of modern AI systems is warranted to identify their safety profile prior to widespread usage of AI within the field of ophthalmology.
This study aims to evaluate and compare the performance of three LLMs: ChatGPT-5, Google Gemini 2.5 Pro, and Claude Opus 4.1 in the accurate and safe diagnosis, urgency triage, and initial management of ophthalmic emergencies, using standardised text-only clinical vignettes.
Materials and methods
Clinical case creation
A total of 40 vignettes were created to model common presentations of ophthalmic emergencies (see Appendix 1), evenly distributed across five major subspecialities: cornea and external disease, retina and vitreous, glaucoma and anterior segment, orbit and oculoplastic disorders, and neuro-ophthalmology (Table 1). The choice of 40 vignettes was to ensure representation of a broad range of conditions across each of the subspecialities, whilst also balancing the practical workload of meticulous response scoring. All vignettes were text-only to allow for consistency across the 40 cases. Cases were created using evidence-based clinical sources detailing the common symptoms, signs, aetiology, and examination findings for the ophthalmic emergencies [25-27]. Vignettes were standardised by including details of the patient’s age and sex, a summary of the presenting symptoms, clinically relevant examination findings, and key contextual information for each clinical case. Clinical guidelines for the best-practice, evidence-based management for each vignette were sourced and collated for each of the vignettes to be used as the gold-standard answers, against which the LLM responses will be compared [25-27]. Each clinical case - including the vignettes, most likely diagnosis, urgency status, and management principles - was reviewed and approved by two independent ophthalmologists to ensure accuracy of the cases prior to their usage in the study. Red flags, in this context, have been defined as symptoms, signs, or findings indicating sight-threatening or life-threatening pathology.
LLM selection
LLMs were selected based on their global popularity, accessibility, and appropriateness for use in this study context. Only models compatible with the English language were considered. ChatGPT, Claude, and Gemini were identified as the most widely used LLMs and were thus the three models selected. The most advanced available models of each LLM were selected in order to obtain clinically relevant results, which more accurately reflect the modern capabilities of AI; ChatGPT-5, Claude Opus 4.1, and Google Gemini 2.5 Pro were the LLM models selected for the study.
LLM evaluation and response collection
Each vignette was entered into a new conversation within each LLM, using a standardised prompt: ‘You are an ophthalmologist in the United Kingdom. The following patient is presented to you: (VIGNETTE). Answer the following questions only, producing a text-only response: (1) What is the single best diagnosis for this patient? (2) Grade the clinical urgency as either an emergency, urgent, or routine. (3) Outline the key management principles for this patient. (4) Specify whether red flags are present in this case, and provide details if appropriate.’
All LLMs were accessed using Google Chrome (Google, Inc., Mountain View, CA, USA) in one session during September 2025. New conversations within each LLM were used for each vignette, and browser sessions were refreshed between vignette entries to prevent any in-session conditioning, accumulated chat memory, or potential carryover effects from previous cases. Given that LLMs can adapt to multi-turn conversations, a new conversation for each vignette was used to allow for a more objective comparison of the unconditioned decision-making for each of the three models, reflecting baseline model behaviour. All inputs were restricted to plain text; no images, charts, links, or tables were used. Each raw response generated from the LLM was then translated into a spreadsheet for subsequent scoring.
Response scoring
Each vignette response from each LLM was graded against scoring criteria, devised by the study authors, assessing four domains: diagnosis (0-2 points), urgency classification (0-2 points), management advice (0-3 points), and ability to recognise red flags (0-1 points) (Table 2). A minimum of 0 points and a maximum score of 8 points were available for each LLM response per clinical vignette. Each LLM response was independently scored using the predefined scoring rubric. Where discrepancies in scoring arose, these were resolved through discussion and consensus. The final agreed score, after consensus, was reported and used for all data analysis.
Data analysis
Data was recorded using Microsoft Excel 365 (Microsoft® Corp., Redmond, WA, USA), and statistical analysis was conducted using GraphPad Prism (version 10.6.1; GraphPad Software, San Diego, CA, USA). Descriptive statistics for the quantitative scoring data across LLMs were presented as mean ± standard deviation (SD). The Wilcoxon signed-rank test was used to compare scores for each category and total scores between the three LLMs, with p < 0.05 considered to be statistically significant. Friedman’s test was used to compare overall scores between each LLM for each subspeciality.
Ethics statement
All 40 vignettes used in this study were author-generated, hypothetical scenarios of common ophthalmic emergencies. Any resemblance of vignette content to any patient or any subject is coincidental. No patients or human participants were involved in the creation or assessment of the clinical vignettes or in any other aspect of the study. Two senior ophthalmologists reviewed each of the vignettes solely for content validation and did not contribute any data to the study as participants. In accordance with the Health Research Authority (HRA) UK Policy Framework for Health and Social Care Research, and the UK Research and Innovation (UKRI) guidance, this work therefore did not require formal approval from an ethics committee.
Results
A total of 40 clinical case vignettes were inputted and evaluated by ChatGPT-5, Google Gemini 2.5 Pro, and Claude Opus 4.1, totalling 120 responses across all LLMs. Claude achieved the highest absolute diagnostic accuracy of all LLMs, with 35 correct diagnoses out of a possible 40 (87.5%), followed by ChatGPT with 34 (85%), and Gemini with 32 (80%) correct diagnoses (Table 3). Similarly, Claude achieved the greatest mean diagnostic score of 1.88 ± 0.33, compared with 1.85 ± 0.36 for ChatGPT and 1.83 ± 0.38 for Gemini. None of the vignettes across any of the three models received a diagnostic score of 0. Urgency classification scores were consistent across models, with ChatGPT-5 achieving 1.83 ± 0.38, Gemini 1.78 ± 0.48, and Claude 1.75 ± 0.44, with none scoring 0 for any of the vignettes. Gemini was the superior LLM for mean management scores, with a mean of 2.50 ± 0.72, succeeding Claude’s score of 2.35 ± 0.70, and ChatGPT with 2.25 ± 0.81. Red flag recognition was identically high for ChatGPT-5 and Claude (0.95 ± 0.22), but marginally lower for Gemini (0.93 ± 0.27). When combining the total scores across all domains, Gemini achieved a superior mean total score of 7.03 ± 1.21, compared to 6.93 ± 1.19 for Claude and 6.88 ± 1.16 for ChatGPT (Figure 1).
Dot-and-whisker plot demonstrating the mean total scores for the vignettes from ChatGPT-5, Google Gemini 2.5 Pro, and Claude Opus 4.1Mean values for each LLM are represented by dots, and minimum and maximum standard deviation values are represented by whiskers.LLM: Large language model
Using the Wilcoxon signed-rank test, pairwise comparisons were performed to help identify any differences between models for each of the scoring domains. The results show that no statistically significant differences were observed between ChatGPT-5, Gemini Pro 2.5, or Claude Opus 4.1 across any of the scoring domains, including diagnostic score, urgency classification, management advice, red flag identification, or overall score (Table 4).
Table 4: Paired performance comparisons between scoring domains of ChatGPT and Gemini, ChatGPT and Claude, and Gemini and ClaudeThe Wilcoxon signed-rank test was used to make pairwise comparisons, with p-values reported in the table. A p-value < 0.05 was deemed statistically significant.
To further investigate the strengths and weaknesses of each of the LLMs, the errors distributed across each of the scoring domains were summarised (Table 5). Though complete diagnostic errors were not observed, partial errors in the diagnosis were common across all models. Similarly, errors in the urgency classification were predominantly partial rather than complete, with one complete urgency error observed in the Gemini responses. The management domain displayed the highest overall error burden; complete management errors were infrequent, however, all models frequently missed key or partial management steps. Finally, a small number of complete red flag presentations were not recognised across all LLMs.
Subspeciality comparison
Comparison of mean total scores across the ophthalmic subspecialities showed small differences between the models. Gemini and Claude achieved identical mean scores in corneal and external disease, ChatGPT-5 scored the highest mean scores in retina/vitreous and orbit/oculoplastic disorders, whilst Gemini performed best in the glaucoma/anterior-segment and neuro-ophthalmology cases. The Friedman test was then used to assess the difference in performance between the three LLMs. No statistically significant differences were identified within any of the subspecialities, as p-values were > 0.05, indicating similar performance from each LLM between subspecialities (Table 6).
Table 6: Comparison of overall LLM performance across subspecialitiesThe Friedman test was used to make comparisons across overall scores of the five subspecialties across the three LLM models. A p-value < 0.05 was considered statistically significant.LLM: Large language model
Discussion
The findings of this study provide a comprehensive comparison of three of the leading LLMs - ChatGPT-5, Google Gemini 2.5 Pro, and Claude 4.1 - in the diagnostic, urgency triage, and management capabilities of AI in ophthalmic emergencies, using text-based clinical case vignettes as inputs. Unlike previous studies assessing the diagnostic capabilities of AI LLMs using multimodal inputs such as fundus photographs, OCT scans, or slit-lamp images, this study purely uses text-only inputs to assess how LLMs interpret written clinical information alone [28,29]. To our knowledge, this is one of the first studies that compares these three advanced models in the context of acute ophthalmic presentations using text-based data sources only. Previous work has primarily focused on the assessment of examination-style questions or more narrow ophthalmic contexts, such as the work of Tailor et al., which compared the responses from five older LLMs in the neuro-ophthalmology context for response quality and empathy [30,31]. A recent study in 2025 compared LLMs with the virtual NHS 111 ophthalmology triage pathway, assessing their capability against pre-defined triage algorithms; however, it did not evaluate diagnostic accuracy or management advice in realistic clinical scenarios [32]. Therefore, our findings provide a valuable and updated insight into the current strengths, limitations, and potential clinical applications of LLMs to potentially support a full clinical decision-making pathway in the broader emergency ophthalmology setting.
Diagnostic accuracy
All three LLMs demonstrated high diagnostic performance, achieving overall accuracies of 80% or more. Claude achieved the highest diagnostic accuracy of 87.5%, followed by ChatGPT-5, scoring 85%, and Gemini, 80%; however, no statistically significant differences were identified between the models on pairwise testing. None of the vignettes across all 120 responses achieved a diagnostic score of 0 points, indicating that all models provided at least a partially correct, reasonable diagnosis for each clinical case. These results suggest that the current generation of LLMs may be able to assist in the identification of many common ophthalmic emergencies from text-based vignettes. However, despite their strong overall diagnostic accuracy, all models occasionally missed key diagnoses, particularly when disease symptoms were subtle or when presentations occurred early in the clinical course of the disease. For example, all three models failed to detect the early signs of bacterial keratitis, in which peripheral corneal infiltrates were not as recognisable as a central corneal opacity as a sign of bacterial keratitis in symptomatic contact-lens wearers. It was noted that the LLMs generally had poorer diagnostic capabilities when common ‘buzzwords’ were omitted from the text prompts, demonstrating the way in which AI uses pattern recognition, as opposed to true cognitive clinical reasoning [33]. This was further reflected by the LLMs demonstrating difficulty in correctly diagnosing less common and more complex clinical conditions, including macular hole and steroid-induced glaucoma, likely due to the reduced information available for the AI models to utilise for pattern recognition.
Furthermore, all models incorrectly assumed idiopathic intracranial hypertension (IIH), as opposed to papilloedema, when an IIH diagnosis cannot be made until other causes of raised intracranial pressure have been appropriately ruled out with imaging and investigations. LLMs are known to occasionally generate fabricated data or use assumed, false knowledge in their clinical reasoning [34]. Aljamaan et al. developed a reference hallucination score (RHS) system, in which ChatGPT scored the highest for hallucination levels across the six chatbots assessed [34]. Until these fictitious outputs are reduced or eliminated from LLM responses, AI cannot be a safe tool in clinical practice without senior-clinician oversight to identify the errors generated.
An example of poorer diagnostic accuracy noted in our study was that both Gemini and Claude confused branch retinal artery occlusion with branch retinal vein occlusion, highlighting a limitation in differentiating two similar clinical presentations based on text alone. The absence of images may also contribute to poorer LLM performance, though this may also reflect typical clinical practice within ophthalmology due to the heavy reliance on imaging and visual assessment in reaching an accurate clinical diagnosis.
These results highlight that, although LLMs show promising diagnostic capabilities, they remain limited in their recognition of subtle contextual details and early disease features that clinicians use when forming a diagnosis.
Urgency recognition and red flag detection
All three models performed well in the urgency recognition domain, with no vignettes receiving a score of 0. The narrow range of high mean urgency scores, with no statistical significance between any of the LLMs in this category, suggests that all three models were able to prioritise vision-threatening conditions effectively. In practice, this implies that LLMs may have the potential to help support non-specialists in differentiating urgent from non-urgent presentations, helping referral pathways and reducing the time taken for patients to receive ophthalmic care. Current literature similarly supports the use of AI in the urgency triaging of ophthalmology presentations, with Lyons et al., Chen et al., and Ahn demonstrating the high triage accuracy and robust severity classification of AI systems [35-37].
Similarly, red-flag recognition was high overall, though a small number of complete omissions were identified. Two vignettes received a red-flag score of 0 for both ChatGPT and Claude, and three for Gemini, highlighting areas of missed recognition of critical features. Although mean red-flag scores remained high, the absent detection of red flags in some clinical presentations potentially devalues the use of AI in automated triage; failure to recognise red flags can lead to devastating, and sometimes fatal, consequences for the patient, particularly in ophthalmology. Missed red-flag signs of raised intracranial pressure can lead to cerebral ischaemia or herniation, and missed red flags for conditions such as optic neuritis can result in irreversible sight loss [27].
Management advice
All three LLMs performed well in producing management advice for the clinical vignettes, with mean scores above 2 across all three models. Whilst some variations were observed, with Gemini producing the highest mean management score (2.50 ± 0.72), marginally outperforming Claude (2.35 ± 0.70) and ChatGPT (2.25 ± 0.81), these differences were not statistically significant, suggesting that all three models were capable of providing initial management recommendations for the majority of emergency vignettes. The overall management scores highlight the ability of LLMs to deliver clinically relevant recommendations. With further research and adaptations, LLMs may eventually serve as supportive adjuncts for non-specialist healthcare workers or in settings where specialist advice is limited. This may be particularly applicable in emergency settings, where delays could risk visual outcomes, or in remote environments, where specialist input is not immediately available.
Whilst most responses were thorough, there were some instances in which key omissions in the advice provided could potentially compromise patient safety. In clinical settings, these missed management steps by LLMs would likely be identified by an ophthalmologist or senior clinician. This oversight highlights scope for further research and development in order to make LLM-generated responses at least as safe as initial management plans provided by senior clinicians in the field. Furthermore, to ensure safe application in a clinical setting, LLMs need to be continuously validated against established and updated management guidelines relevant to UK clinical practice to provide reliable and supportive clinical guidance.
Clinical relevance
The consistency across LLMs in our study indicates that all three models can perform with a high level of accuracy and reliability, showcasing the advancements in the development of the most current AI models. Rather than exposing a particular LLM’s weakness, the results have shown that many modern LLMs are capable of producing reliable clinical information and are consistent in their ability to interpret complex clinical text. Their overall performance supports further exploration of LLMs as a supportive adjunct in clinical ophthalmology. Recent studies support this potential, demonstrating that AI systems can improve workflow efficiency, assist in diagnostic decisions, and achieve high accuracy when screening for various ophthalmology diseases [38]. Furthermore, embedding these LLMs into electronic patient record (EPR) systems could, in the future, potentially automatically generate differential diagnoses and management considerations based on clinicians’ notes, subject to clinician review and validation, thus possibly improving the speed and consistency of patient assessment. Such integration could be particularly helpful in emergency departments, where patient turnover is high.
Moreover, given that each model demonstrated slightly different strengths - with Claude achieving the highest diagnostic accuracy, Gemini performing best in management advice, and ChatGPT excelling in some subspecialities - future integration could benefit from combining the best features of different LLMs. Such an approach could help improve reliability and balance individual model weaknesses, enhancing its performance in clinical applications. In support of this, a systematic review published in April 2025 reported that ensemble modelling approaches, combining outputs from multiple AI systems, have shown improved accuracy and reliability when compared to a single-model framework [39].
Beyond direct clinical use, LLMs have an increasingly important role in medical education. The findings of our study support the educational value of LLMs, as they mirror the key elements of clinical reasoning that ophthalmic trainees are expected to develop. In line with this, Antaki et al. reported that ChatGPT has demonstrated performance comparable to that of a first-year ophthalmology doctor on standardised ophthalmology examinations [40]. This shows the potential capability of LLMs in supporting ophthalmic trainees in their diagnostic reasoning and structured decision-making, whilst also recognising that supervised clinical experiences remain paramount to specialist training.
Limitations of LLMs
Although LLMs show substantial potential in supporting clinical decision-making, their current diagnostic capabilities are limited due to difficulty identifying borderline presentations, which require deeper contextual reasoning beyond simple pattern recognition. Furthermore, although this study did not specifically evaluate reproducibility, it remains a recognised limitation of LLMs. Previous research has shown that identical prompts run under controlled variable conditions can still produce varied outputs [41]. This poses challenges for standardisation and validation, which are crucial in the context of ophthalmology, thus highlighting a barrier to clinical implementation.
A crucial concern associated with using LLMs in medicine is the issue of liability and accountability, particularly for medicolegal purposes. Using LLMs in healthcare decision-making often raises questions regarding the placement of liability in the event of patient harm, misdiagnosis, or poor clinical management. As outlined by Naik et al., responsibility becomes unclear when AI systems contribute to medical decision-making, as to whether errors should be attributed to the clinician or the AI developer [42]. This uncertainty highlights the need for clear governance frameworks and human oversight to guarantee the safe use of LLMs in clinical settings.
Limitations of this study
Our study is limited by its non-randomised, non-blinded design, thus introducing a potential for bias in the scoring of the LLM responses against the standardised criteria created by the authors. Blinding of the LLM identity during response scoring, and randomising the order in which the LLM outputs were presented, could have prevented expectation bias or scoring fatigue.
Secondly, the scoring system used in this study was designed by the authors, as no validated assessment tool exists for evaluating LLM performance in clinical practice. Whilst the designed framework allowed structured and consistent scoring across the different domains, it remains a subjective approach and limits the comparability of results with other studies. Although each of the outputs was evaluated by two reviewers against predefined scoring criteria, there was inevitably an element of subjectivity, where reasoning can vary between the reviewers. Although all discrepancies were subsequently resolved through consensus, as mirrored in routine clinical practice, future studies would benefit from the inclusion of quantitative agreement metrics, such as Cohen’s kappa statistic, to further characterise scoring more objectively.
This study also included only 40 clinical vignettes. Whilst these attempted to cover a range of ophthalmic subspecialities and conditions, they may not fully capture the breadth and variability of clinical ophthalmic presentations in the emergency setting. Furthermore, all 40 vignettes used in this study were created by the study authors. Though efforts were made to minimise bias by involving verification by two independent ophthalmologists, it is important to note the potential for the introduction of significant design bias in this study. Additionally, cases were designed to be moderately stereotypical presentations of the relevant ophthalmic emergency, and, though useful as an introductory assessment of the LLMs in this context, these cases may not reflect the real-world variability seen in emergency eye departments. The inclusion of guideline cues in the phrasing of vignettes, such as examination signs unique to a particular ophthalmic condition, may have influenced the model accuracy demonstrated in the results of this study.
This study was also limited to text-based clinical vignettes and, therefore, did not assess the multimodal abilities of these LLMs. Ophthalmology is a field that relies heavily on visual assessment, such as slit-lamp findings, fundus images, and OCT scans; excluding these elements from the vignettes limits their real-world applications and restricts the LLMs from assessing imaging-dependent conditions. Hence, our findings reflect performance in text-only diagnostic reasoning rather than the full spectrum of ophthalmic assessment encountered in clinical practice.
When inputting prompts into each of the LLMs, the same standardised prompt was used across all vignettes, and each vignette was used only once within each LLM in a new conversation without any prior conversational warm-up. Though this approach reflects real-world utility in first-use scenarios, it does not assess the reproducibility of the results, nor does it evaluate the effects of prompt conditioning with prior conversational warm-up. There is potential for LLMs to produce variable output responses across repeated runs with identical prompts - a factor which was not assessed in this study. Future studies should consider using repeated runs of the vignettes to better assess reproducibility, consider the use of conversational warm-up to assess if different responses are produced, and investigate the effect of using alternative prompt structures for the same vignettes to assess output stability.
Finally, given that LLMs are continuously improving and developing, the findings of this study are time-sensitive. The performance observed in this study may not be reproducible in future versions. As newer and more advanced models continue to be developed, re-evaluation may be required to determine whether diagnostic accuracy, reasoning ability, and clinical application continue to improve.
Strengths of this study
At the time of writing, to our knowledge, this is one of the first studies comparing these three leading LLMs - ChatGPT, Google Gemini, and Claude - in the diagnosis and management of emergencies in ophthalmology using text-only case vignettes. Though studies evaluating the usage of novel prototype AI models in the ophthalmic emergency context were identified, we were unable to find research papers comparing the existing leading LLMs for the evaluation of text-based vignettes within ophthalmic emergencies [43]. Our research adds valuable evidence to the field, highlighting the equity of ChatGPT, Google Gemini, and Claude in their applications to ophthalmology decision-making, particularly in the emergency context. We provide evidence that all three AI models are capable of providing suggestions for diagnosing, triaging urgency, and providing management advice, which may assist clinicians as an adjunct in their clinical practice. Overall scores are high across all LLMs, and, with no statistical differences identified across scoring categories or between subspecialities, we are able to add supportive evidence to the field for using any of the three leading LLMs in the ophthalmology context.
Furthermore, our study utilises the most advanced models of each of the three LLMs at the time of writing, showcasing the maximum capabilities of modern AI in this context and producing the most meaningful results possible to date. Though AI models continue to develop, we produce results representing the greatest capabilities of AI currently due to the selection of these advanced models. This aspect of our study design ensures our results will remain clinically valid for longer than studies using outdated, free models.
Utilising 40 of the most common ophthalmic emergencies of varying difficulties, and across five widely categorised subspecialities, demonstrates the useful application of our findings across the general field of ophthalmology. Clinical cases were created using the most updated, evidence-based guidelines relevant to UK clinical practice, thus assessing the capabilities of AI LLMs to produce the most relevant management suggestions for each of the suspected diagnoses. The inclusion of independent ophthalmologists in the review process strengthens the internal validity of our findings and ensures that the clinical cases, and results produced from using the cases, reflect accurate clinical presentations of ophthalmic emergencies and evidence-based management plans.
Finally, the quantitative scoring assessment utilised in this study allows for objective assessment and comparison across each of the AI models and subspeciality domains. This objective scoring allows for fair comparison between the LLMs and reduces the likelihood of bias being introduced, compared to the use of more subjective, qualitative evaluation tools.
Future research scope
The promising results of our study justify further research into the use of different LLMs in supporting clinicians with the diagnosis and management of clinical presentations within ophthalmology. Future clinical work should focus on the comparison of text-based vignettes in combination with multiple forms of multimodal media, such as Humphrey’s visual fields, OCT images, fundus photographs, and FFA imaging. This would more accurately emulate the real-world clinical environment in which an ophthalmologist would be making similar clinical decisions, and would thus test the AI as a truer comparison to decision-making at the level of an ophthalmologist.
Clinical scenarios should be expanded to incorporate an even broader range of clinical cases of varying complexity and clinical urgency, to further assess the ability of AI in the recognition of less common conditions and atypical presentations of common conditions. A wider range of cases will better simulate real-world diagnostic uncertainty and variation in clinical practice. Moving beyond author-generated vignettes to the assessment of anonymised patient encounters may yield more applicable results, with greater clinical relevance, and provide a greater measure of utility and safety of LLMs in real clinical practice.
Additional work in the field should, importantly, progress beyond simulated scenarios and investigate AI in real ophthalmology settings, using authentic clinical data, referral letters, and information from the wider EPRs. Examining the use of AI in live clinical workflows would provide important insights into their ability to be integrated into real-world clinical encounters. Their use in different settings, such as primary care and community optometry, will help obtain a more practical understanding of the potential of LLM systems and establish true clinical utility and safety in decision-making within ophthalmology.
Conclusions
This study provides direct comparisons between three advanced LLMs - ChatGPT-5, Google Gemini 2.5 Pro, and Claude Opus 4.1 - in the diagnosis, urgency triage, and initial management of ophthalmic emergencies using text-based clinical vignettes. All three LLMs demonstrated consistent accuracy across all evaluated domains, with no statistically significant differences in overall performance. These findings highlight the rapid progress of current LLMs in interpreting complex ophthalmic presentations and delivering preliminary diagnostic and management suggestions, which may support clinical decision-making in the emergency context. By supporting early recognition of urgent conditions and guiding initial management, these models have the potential to aid ophthalmic triage and clinical decision-making, particularly for non-specialist settings with limited ophthalmology expertise available at short notice.
However, as there were diagnostic inaccuracies and missed management details, continued refinement, validation, and evaluation within clinical practice remain essential, and highlight that LLMs should only be used as a clinical adjunct, not in isolation. Overall, our findings add further evidence supporting the incorporation of LLMs in modern clinical practice as supportive tools in the delivery of ophthalmic emergency care.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Artificial intelligence in healthcare: transforming the practice of medicine Future Healthc J Bajwa J Munir U Nori A Williams B 0948202110.7861/fhj.2021-0095 PMC 828515634286183 · doi ↗ · pubmed ↗
- 2The promise of artificial intelligence: a review of the opportunities and challenges of artificial intelligence in healthcare Br Med Bull Aung YY Wong DC Ting DS 41513920213440585410.1093/bmb/ldab 016 · doi ↗ · pubmed ↗
- 3The Future of Continual Learning in the Era of Foundation Models: Three Key Directions Bell J Quarantiello L Coleman EN Cornell University 2025
- 4Use of large language models as artificial intelligence tools in academic research and publishing among global clinical researchers Sci Rep Mishra T Sutanto E Rossanti R 316721420243973821010.1038/s 41598-024-81370-6PMC 11685435 · doi ↗ · pubmed ↗
- 5The breakthrough of large language models release for medical applications: 1-year timeline and perspectives J Med Syst Cascella M Semeraro F Montomoli J Bellini V Piazza O Bignami E 224820243836604310.1007/s 10916-024-02045-3PMC 10873461 · doi ↗ · pubmed ↗
- 6Chat GPT-5 in Education: New Capabilities and Opportunities for Teaching and Learning [Preprints] Choi WC Chang CI 2025
- 7The AI wars of 2025: how GPT-5, Claude Opus 4.1, Grok 4, and Gemini 2.5 Pro stack up 10 2025 4152025 https://medium.com/@cognidownunder/the-ai-wars-of-2025-how-gpt-5-claude-opus-4-1-grok-4-and-gemini-2-5-pro-stack-up-2c 754e 2ac 2e 7
- 8Comparative analysis of Chat GPT and Gemini (Bard) in medical inquiry: a scoping review Front Digit Health Fattah FH Salih AM Salih AM 1482712720253996311910.3389/fdgth.2025.1482712 PMC 11830737 · doi ↗ · pubmed ↗