Nonlinear optical extreme learner via data reverberation with incoherent light
Bofeng Liu, Xu Mei, Sadman Shafi, Tunan Xia, Iam-Choon Khoo, Zhiwen Liu, Xingjie Ni

TL;DR
This paper introduces an energy-efficient optical machine learning system using incoherent light to achieve nonlinear transformations without complex materials.
Contribution
A novel optical extreme learner using data reverberation in incoherent light to enable nonlinear learning with low power.
Findings
The optical learner outperforms linear digital networks in image classification and XOR benchmarks.
The system matches the accuracy of fully nonlinear digital models while using significantly less power.
The approach reduces complexity, cost, and energy consumption for scalable optical machine learning.
Abstract
Artificial neural networks have revolutionized fields from computer vision to natural language processing, yet their growing energy and computational demands threaten future progress. Optical neural networks promise greater speed, bandwidth, and energy efficiency but suffer from weak optical nonlinearities. Here, we demonstrate a low-power, incoherent-light-compatible optical extreme learner that leverages “data nonlinearity” from optical pattern reverberations, eliminating reliance on intrinsic nonlinear materials. By encoding input data in the spatial polarization distribution of a tailored optical cavity and allowing light to pass through it multiple times, we achieve nonlinear transformations at extremely low optical power. Coupled with a simple trainable readout, our optical learner consistently outperforms linear digital networks in standard image classification tasks and XOR…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
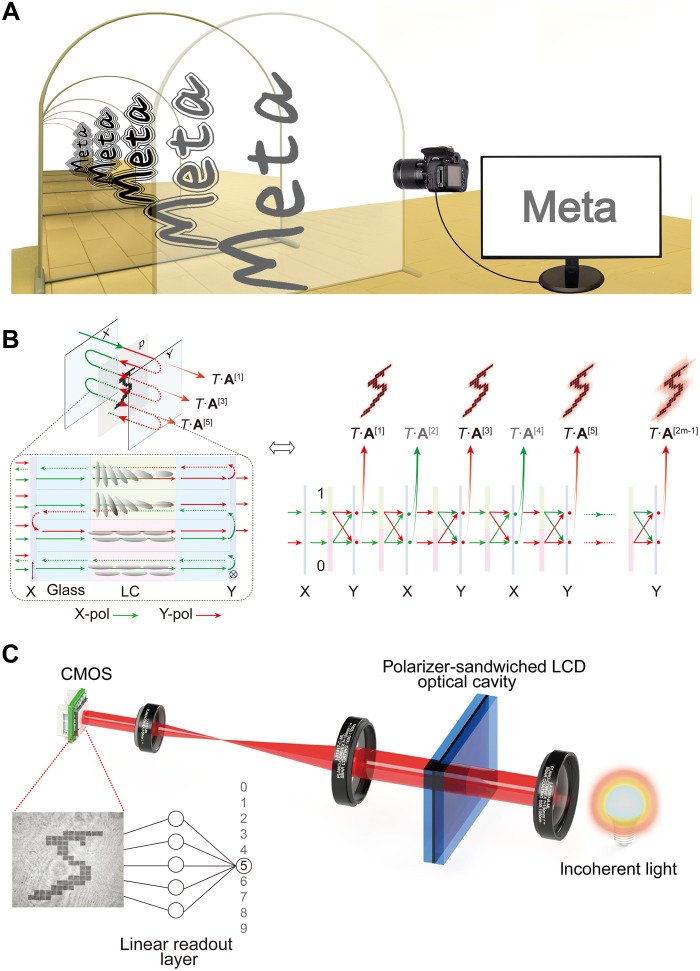 Fig. 1
Fig. 1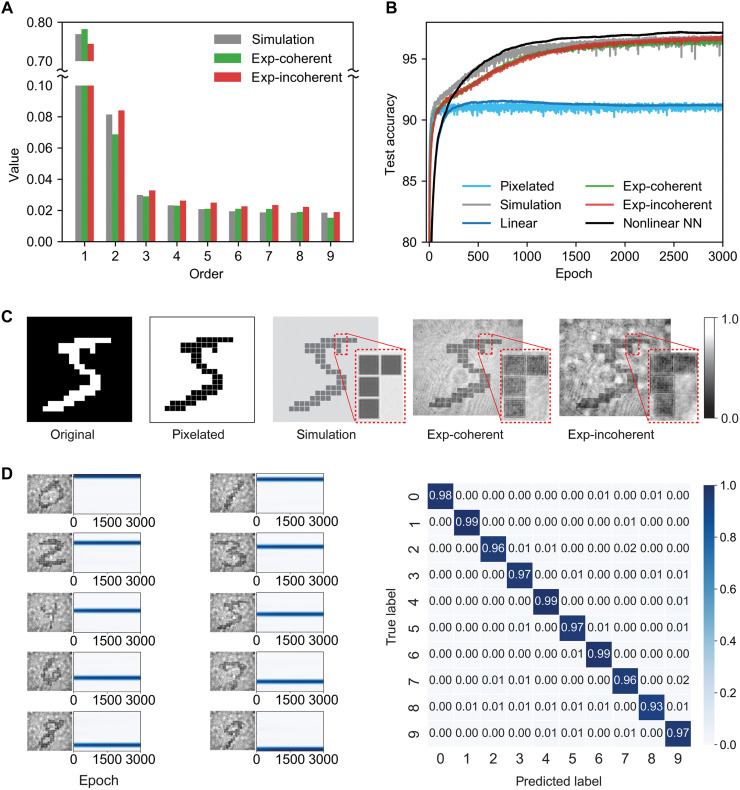 Fig. 2
Fig. 2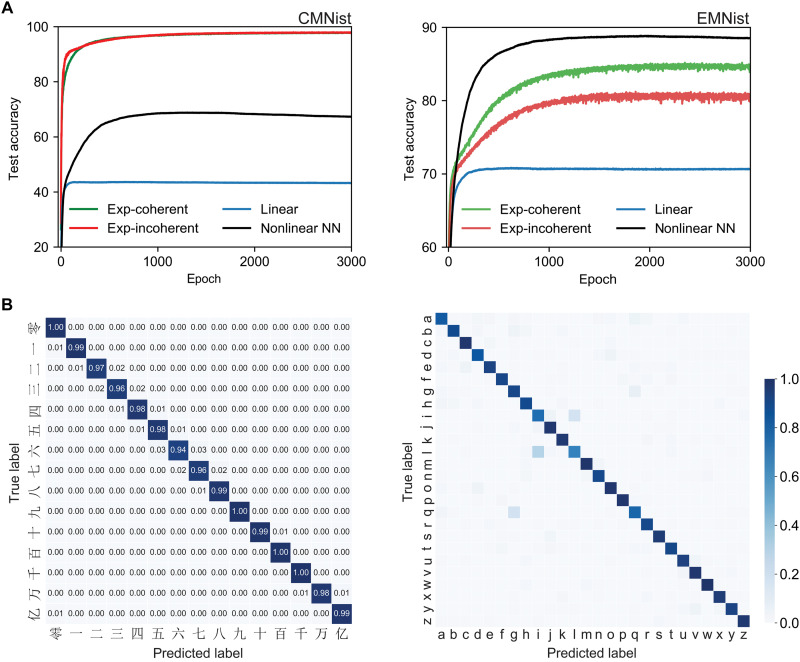 Fig. 3
Fig. 3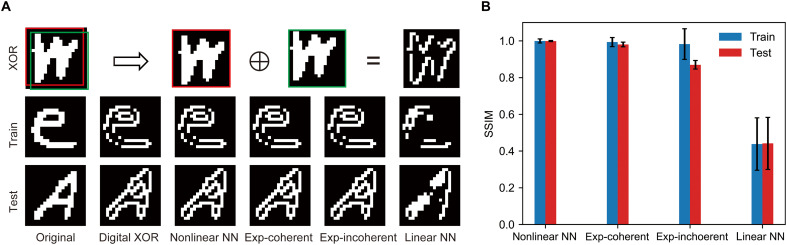 Fig. 4
Fig. 4| Method | Classification accuracy MNIST (%) | Classification accuracy CMNIST (%) | Classification accuracy EMNIST (%) | XOR training SSIM | XOR testing SSIM |
|---|---|---|---|---|---|
| Linear digital neural networks | 91.50 | 43.64 | 70.84 | 0.438 | 0.446 |
| Fully nonlinear digital neural networks | 97.21 | 68.82 | 88.86 | 0.999 | 0.998 |
| Our optical learner with coherent light | 96.54 | 98.19 | 85.18 | 0.993 | 0.980 |
| Our optical learner with incoherent light | 96.82 | 98.20 | 81.21 | 0.982 | 0.870 |
- —http://dx.doi.org/10.13039/100000001National Science Foundation
- —http://dx.doi.org/10.13039/100000181Air Force Office of Scientific Research
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsNeural Networks and Reservoir Computing · Mechanical and Optical Resonators · Metamaterials and Metasurfaces Applications
INTRODUCTION
Optical computing has its roots in the 19th century, with Ernst Abbe’s pioneering work on Fourier optics (1) and has captivated scientific imagination since Duffieux systematically introduced Fourier integrals into optics in the 1940s (2–6). Despite early enthusiasm, the rapid advancement of digital electronics and the subsequent explosion of general-purpose computing overshadowed optical computing (7, 8). However, in recent years, optical computing has seen a notable resurgence, driven by its inherent advantages in parallel processing capability, low latency, and substantially reduced power consumption (9–17). This renewed interest is particularly evident in applications targeting artificial neural network (ANN) acceleration (10, 12, 18–31). Optical neural network (ONN) architectures uniquely offer potential solutions to fundamental challenges faced by electronic neural networks, such as speed bottlenecks and escalating power consumption. These advantages are becoming increasingly critical as global artificial intelligence (AI) workloads continue their exponential growth trajectory (32–34). Optical methods, therefore, represent a promising frontier for overcoming the limitations inherent in traditional electronic computing paradigms.
A fundamental requirement for ANNs to serve effectively as universal approximators is the integration of nonlinear activation functions (35–38). In ONNs, optical nonlinearities can be introduced through various means, including leveraging intrinsic optical material nonlinearities such as Kerr effect (39–42), exploiting nonlinear responses in detector (43, 44), or using other specialized nonlinear optical media such as saturable absorbers (18), and laser-cooled atoms with electromagnetically induced transparency (19, 45). Nevertheless, each of these approaches has notable limitations, including the necessity of high-power laser sources, slow response times, or complex and costly fabrication processes (46).
Recently, an alternative approach has been proposed wherein input data undergo repeated scattering interactions within data-bearing structures, inducing nonlinear relationships between the scattered optical fields and the input data (17). This concept has been demonstrated through multiple scatterings involving a digital mirror device (DMD) coupled with an integrating sphere (47), as well as through interactions between a spatial light modulator (SLM) and a mirror (48). These systems generate speckle patterns whose nonlinear characteristics correlate with the input data and are processed in conjunction with a simple digital neural network to achieve tasks such as image classification. However, those systems experimentally only achieve relatively low classification accuracy, underperforming even basic linear digital networks. In addition, these methods rely on coherent input illumination, inevitably involving laser sources that tend to incur higher energy consumption and overall system costs. The need to use components like DMDs and SLMs are inherently complex and expensive, limiting the practicality and scalability of these systems for widespread applications.
Here, we introduce an optical extreme learner specifically designed to operate using only low-power incoherent light, consistently surpassing linear digital neural networks, reaching performance levels comparable to established nonlinear neural networks in diverse tasks such as image classification and nonlinear image processing. An extreme learner, also known as an extreme learning machine, is a neural network featuring nonlinear hidden nodes with randomly assigned, fixed parameters and a single trainable output layer. Our optical extreme learner uses a small pixelated transparent liquid crystal display (LCD) (49) panel that modulates transmitted light amplitude, sandwiched between two polarization-selective partial mirrors, with a compact total device thickness of 2 mm. Input data are encoded onto the LCD panel and illuminated by a uniform-intensity incoherent light beam. The repeated transmission of light through the LCD panel generates a nonlinear mapping from input data to output signals. These outputs are digitally captured and processed through a single-layer, trainable linear readout network. Using our optical extreme learner, we attained image classification accuracies 96.82, 98.20, and 81.21%—results that are unattainable by purely linear neural networks—on standard datasets [Modified National Institute of Standards and Technology (MNIST) database, Chinese MNIST (CMNIST), and Extended MNIST Letters (EMNIST)] with white light. In addition, we successfully demonstrated exclusive OR (XOR) operations on input images—a task inherently challenging for linear networks. Our approach provides a promising foundation for developing low-power, compact, and cost-effective optical processors without the need of optical nonlinearity or laser sources. We believe that this technology holds substantial potential to accelerate current AI applications, offering superior computational speed and improved energy efficiency.
Working principle
The working principle of our optical extreme learner can be conceptualized as an input data-bearing structure placed within an infinity mirror configuration (Fig. 1A). The input data are encoded on a small, transparent LCD panel sandwiched between two polarization-selective partial mirrors (Fig. 1B; further elaborated in note S1). A light beam passing through it acquires an intensity pattern modulated by the encoded information. As the modulated beam propagates, diffraction slightly alters its intensity distribution. Upon reflection by the polarization-selective partial mirrors, the beam retraverses the LCD, and each pass further modulates the spatial intensity distribution of the encoded data. This data reverberation process—repeated cycles of diffraction, reflection, and transmission—causes the incident field to interact with its own diffracted field, ultimately generating a nonlinear mapping between the input data and the output intensity pattern.
Optical extreme learner with multipass data reverberation.(A) Conceptual illustration of an “infinity-mirror” configuration that repeatedly reinjects the field, effectively multiplying the input by itself across passes. (B) Practical implementation of the optical cavity formed by two orthogonally oriented polarization-selective partial mirrors (X and Y; hereafter the X-polarizer and Y-polarizer) and a transparent, pixelated LCD panel (90° twist, planar aligned). At each interaction, the X-polarizer transmits X and largely reflects Y, while the Y-polarizer transmits Y and reflects X. The incident beam first passes the X- polarizer and is modulated by the liquid crystal (LC) with input pattern p, and—after diffraction at the LC cell’s exit glass—the Y component is transmitted by the Y-polarizer, yielding the first transmitted intensity pattern, denoted as T . A[1]. Successive internal reflections and LC-induced polarization conversions generate higher-order transmissions T . A[3], T . A[5], etc. (C) Experimental setup of our optical extreme learner: A collimated beam illuminates the LCD-based cavity, and a grayscale CMOS camera images the output transmitted through the Y-polarizer (the “Y plane”) to record the resulting nonlinear patterns. A final linear readout layer performs the classification.
To explicitly illustrate this iterative process, we “unfold” the infinity-mirror cavity into a linear sequence of identical layers, each modulated by the same input data distribution, p (Fig. 1B). Here, a pair of orthogonally oriented polarizers act as polarization-selective partial mirrors: When the incident polarization is aligned with a polarizer’s transmission axis, the field is transmitted with transmittance T; when it is orthogonal, the field is attenuated and partially reflected with reflectance R. Initially, the incident light has uniform intensity. After passing through the X-polarizer, the beam’s polarization is spatially modulated by the LCD pixels where the input data are encoded. A bright pixel (value “1”) rotates the polarization, whereas a dark pixel (value “0”) leaves the polarization unrotated. The modulated beam then diffracts toward the Y-polarizer, whose transmission axis is orthogonal to that of the X-polarizer, and only the rotated component can pass through, producing an intensity pattern *T·*A^[1]^. The unrotated component is partially reflected back into the cavity, entering the second effective layer, where it undergoes an identical polarization modulation and transmitted through the X-polarizer, resulting in intensity pattern *T·*A^[2]^. Repeating this process generates higher-order outputs *T·*A^[3]^, *T·*A^[4]^, …, and after traversing the nth layer, the output is *T·*A^[n]^. This iterative process can be mathematically described as
where denotes the Green’s function characterizing free-space propagation between two consecutive layers, ⊗ indicates the Kronecker product, and ⊛ represents convolution. The matrix P is obtained by diagonalizing the pattern vector . N denotes the dimension of the pattern vector, are identity matrices, and is the Pauli matrix. Details can be found in note S2. The final output pattern of the system is the sum of the intensity distributions emerging from all odd-numbered interfaces (equivalent to Y-polarization–selective partial mirror in Fig. 1B), which can be expressed as
where m is a positive integer. From Eq. 2, it is evident that the output pattern comprises a series multiplicative terms involving interactions with the input data, thereby establishing a nonlinear relationship between the input and output. Each passage of light through the LCD pixels multiplies the input data pattern, effectively increasing the nonlinear order of the data by one. The maximal achievable nonlinear order, determined by the effective number of reflections within the optical cavity, can be controlled by adjusting the reflectance coefficients of the mirrors. The resulting nonlinearly mapped output intensity pattern is captured by a standard complementary metal-oxide semiconductor (CMOS) camera positioned after the second mirror. The captured data are then processed by a simple, trainable linear network consisting of only a single readout layer, ensuring minimal computational load.
In contrast to conventional material-based nonlinearities, which rely on intrinsic optical properties, the nonlinear relationship between the input and output fields in our system arises from passive multiple interactions among spatially distributed pixels on the LCD. This mechanism is inherently independent of input light power and coherence, enabling nonlinear transformations even with low-power continuous-wave and incoherent light sources. Consequently, our approach offers substantially improved energy efficiency compared to traditional nonlinear optical systems.
RESULTS
Each pixel of the LCD panel used in our optical extreme learner measures 370 μm by 420 μm, with a gap of 20 μm between adjacent pixels. A microcontroller is used to drive the LCD panel. Our experiments used both coherent and incoherent light sources: a coherent 633-nm helium-neon laser and a temporally incoherent white supercontinuum source filtered by a 40-nm bandpass centered at 650 nm. The collimated input beam passed through the optical cavity, and the resulting output pattern was captured by a monochrome camera positioned downstream. Details of the experimental setup are described in Materials and Methods.
To systematically evaluate our optical extreme learner, we used the widely used MNIST dataset, consisting of 60,000 training images and 10,000 testing images. Because of field-of-view limitations of our optical setup, we down-sampled the original MNIST images from 28 by 28 pixels to 20 by 20 pixels. The experimentally obtained nonlinearly transformed outputs were then processed through a single-layer linear readout network to get the classification results.
We also simulated the optical processes within our compact cavity using the beam propagation method. During simulations, MNIST images were pixelated to closely resemble their appearance on the LCD panel. The resulting simulated output patterns exhibited additional fine structures beyond the original images—an effect also observed in experimentally captured images (Fig. 2C). These features are attributed to the combined effects of diffraction and data reverberation, creating nonlinear transformations of the input data.
Performance analysis of the optical extreme learner on MNIST dataset.(A) Distribution of nonlinear orders derived via Boolean analysis. The exp-coherent and exp-incoherent indicate experiments using laser and white-light sources, respectively, showing minimal differences in higher-order nonlinear coefficients. (B) Blind test accuracy curves over training epochs. The optical extreme learner driven by a white-light source (red line) achieves 96.82% accuracy, while driven by a laser source (green line) achieves 96.54%. For comparison, a linear neural network (blue line) reaches 91.50%, the simulated optical learner (gray line) attains 96.88%, and a ReLU-based nonlinear neural network (black line) achieves 97.21%. (C) Example images used in the tests (from left to right): original MNIST image, pixelated MNIST image, simulated MNIST output image, experimentally obtained image using coherent illumination, and experimentally obtained image using incoherent illumination. The optical process encodes complex interactions between the diffracted input pattern and the original encoded data through multipasses of the beam through the LCD, thereby capturing subtle interpixel interactions within the resulting intensity patterns. (D) Left: convergence curves for 10 classes. Each subpanel shows a representative incoherent optical image of a given class captured by the camera. Adjacent to each image on the right is the corresponding test dataset convergence curve as a function of training epoch. It can be observed that all classes undergo a rapid convergence at the beginning of training, followed by stabilization until the end of the training process. Right: the confusion matrix of blind test, the horizontal row is predicted labels, and the vertical is the true labels. The diagonal elements represent the prediction accuracy corresponding to each classification.
For comparison, two baseline scenarios using linear digital neural networks were established. The first baseline involved directly inputting original MNIST images into a linear neural network to establish the linear performance limit. The second baseline used pixelated MNIST images to confirm that performance improvements were not merely due to image pixelation.
Experimental results from our optical extreme learner demonstrated classification accuracies of 96.54% (coherent illumination) and 96.82% (incoherent illumination), closely matching the simulation accuracy (within ~0.06%). These results notably exceed the performance limit of purely linear networks [~91.50% in our tests, similar to that reported in (50)] by more than 5%, approaching the performance of fully nonlinear digital neural networks (97.21%). In addition, training the linear readout layer consistently demonstrated rapid and robust convergence across different image classes (Fig. 2D). These findings clearly indicate that nonlinear interactions arising from input data reverberation in our optical system enable classification performance beyond the capabilities of linear neural networks.
Furthermore, to quantitatively assess the nonlinearity introduced by our optical system, we applied Boolean analysis (17, 51) to extract the expansion coefficients corresponding to different nonlinear orders of the input data present in the output patterns. Using binary inputs of 3 by 3 pixels (note S3), we evaluated the distribution of these coefficients, Ck, in both simulated and experimentally measured outputs. Results from both consistently exhibit the presence of higher-order nonlinear terms (Fig. 2A). These findings confirm that our optical structure generates nonlinearity for the input data effectively, which plays a vital role in enhancing system performance.
To further validate the generalizability of our optical extreme learner and its superiority over linear networks, we tested its performance on additional datasets: CMNIST dataset, comprising 15,000 images of handwritten Chinese characters across 15 classes, and the EMNIST dataset, which includes 145,600 images of uppercase and lowercase letters across 26 classes. It is important to note that, unlike the MNIST and EMNIST datasets, the CMNIST dataset does not provide a predefined division into training and testing subsets, complicating standard evaluation procedures. To address this issue, we use a 10-fold cross-validation approach—a widely used method to minimize data selection bias (52, 53). In this method, the entire dataset is randomly partitioned into 10 equally sized folds. During each iteration, one fold is held out for validation, while the remaining nine folds are used for training (note S5). This procedure guarantees that every sample serves exactly once as a validation data point and participates in training across all other iterations. By averaging the performance metrics across all folds, we achieve a robust and unbiased estimation of the model’s accuracy, effectively mitigating potential biases introduced by arbitrary data splits.
Experimental results (Fig. 3) show a notable improvement in classification accuracy due to the integration of optical nonlinear mapping. This improvement is evident in both the 15-class CMNIST task and the 26-class EMNIST task. Specifically, for CMNIST, classification accuracy increased from 43.64% (linear network) to 98.20% with incoherent light and 98.19% with coherent light—both even exceeding the performance of a fully connected nonlinear digital neural network (68.82%). For EMNIST, accuracy improved from 70.84% (linear network) to 81.21% (incoherent) and 85.18% (coherent). These advantages are further supported by confusion matrices, which show most predictions concentrated along the diagonal, indicating high classification accuracy (Fig. 3B). One exception is a notable confusion between the letters “i” and “l” in EMNIST. This misclassification can be attributed to their inherent visual similarity, compounded by down-sampling effects that sometimes eliminate the distinguishing dot above the letter i. Despite this minor challenge, our results demonstrate that the optical extreme learner delivers robust and superior classification performance in blind prediction tests across different datasets, substantially outperforming purely linear network architectures.
Performance analysis of the optical extreme learner on CMNIST and EMNIST datasets.(A) Blind test accuracy curves over training epochs. Left (CMNIST): Comparison of optical extreme learner performance under white-light illumination (red line, accuracy: 98.20%) and laser illumination (green line, accuracy: 98.19%), against a purely linear neural network (blue line, accuracy: 43.64%) and a nonlinear neural network with ReLU activation (black line, accuracy: 68.82%). Right (EMNIST): Comparison of optical extreme learner performance under white-light illumination (red line, accuracy: 81.21%) and laser illumination (green line, accuracy: 85.18%), against a purely linear neural network (blue line, accuracy: 70.84%) and a nonlinear neural network with ReLU activation (black line, accuracy: 88.86%). (B) Confusion matrices of blind tests for CMNIST (left) and EMNIST (right) datasets, highlighting the excellent classification performance of the optical extreme learner.
Our optical extreme learner is not limited to image classification tasks, it is also applicable to other computational problems. A historically important challenge in neural networks is the XOR problem, which early single-layer perceptrons were unable to solve. This limitation contributed to the AI winter of the 1960s (54, 55). The introduction of multilayer neural networks with nonlinear activation functions later overcame this barrier (56), sparking renewed interest and progress in the field—often referred to as the second spring of neural networks. To demonstrate the computational capability of our optical extreme learner in this context, we applied it to perform XOR operations on the EMNIST dataset. Specifically, we selected two regions within each image with a slight spatial offset, as highlighted by the red and green boxes in the top row of Fig. 4A and applied an XOR operation between these two regions. We conducted this task using four different configurations: a digital nonlinear neural network with Rectified Linear Unit (ReLU) activation, a purely linear network, and our optical extreme learner under both coherent and incoherent illumination.
Performance analysis of the optical extreme learner on the image XOR operation.(A) The first row illustrates the XOR computational process. It shows two selected regions (highlighted by red and green boxes) from the original images, and their corresponding XOR result, forming a hollow character. The second and third rows display training and testing character sets evaluated by different neural networks. The first two columns present the original images and corresponding XOR ground truth. Columns labeled nonlinear NN, exp-coherent, exp-incoherent, and linear NN represent XOR results obtained from a nonlinear neural network, our optical extreme learner under coherent (laser) and incoherent (white-light) illumination, and a linear neural network, respectively. (B) Average SSIM comparing digitally computed XOR results to those obtained via a nonlinear neural network, our optical extreme learner experiments under coherent and incoherent illumination, and a linear neural network.
Figure 4A presents sample XOR outputs from the training and testing datasets across all four configurations. The results clearly show that both the digital nonlinear network and the optical extreme learner (under both illumination conditions) produce outputs that closely match the ideal XOR operation. In contrast, the linear network fails to generate meaningful XOR patterns. For quantitative comparison, we calculated the Structural Similarity Index Measure (SSIM) between each output and the digitally computed ground truth (Fig. 4B). The digital nonlinear network and both optical extreme learner configurations achieved SSIM values close to 1.0, indicating high structural similarity. In contrast, the linear network achieved an SSIM of only 0.45, reflecting poor XOR performance.
These results provide compelling evidence that the optical extreme learner effectively addresses the classical XOR problem—long considered a benchmark for demonstrating nonlinearity in neural systems. This success further validates the system’s capability to perform nonlinear operations and highlights the strength of optically induced data nonlinearity in enhancing computational power.
DISCUSSION
We successfully demonstrated an optical extreme learner—consisting of a compact optical cavity with two partial reflective mirrors and a liquid crystal screen only having a thickness of 2 mm. Our device exploits the nonlinear mapping between the input data and the output optical field, created by multiple passes of light reflection and diffraction—each pass multiplying the spatial transmittance distribution encoded by the input. Coupled with a simple, single-layer linear readout, our system delivers strong performance on a variety of tasks, including image classification with multiple commonly used benchmark datasets (MNIST, CMNIST, and EMNIST), as well as image XOR operations—a known challenge for purely linear networks. Both numerical simulations and experimental results confirm that the optical extreme learner surpasses linear networks across all tested tasks, matching the performance of fully nonlinear digital architectures (see Table 1)
A key advantage of our approach lies in its reliance on intensity-based modulation rather than phase modulation, making it inherently compatible with incoherent light sources. Our experiments show that using a low-power incoherent source yields results nearly identical to those achieved with a coherent laser, removing the need for more costly or high-power laser illumination. In addition, the system’s degree of nonlinearity can be adjusted by tweaking mirror reflectivity. Furthermore, the input pattern is provided by a low-cost LCD, which makes our system much more cost-effective compared to other optical computing implementations where expensive DMD or SLM has usually been used (26, 40, 57, 58). Looking ahead, our optical extreme learner can be readily integrated with optical diffractive neural networks (57), such as those based on metasurfaces, to create deeper, more sophisticated all-optical computing architectures.
In addition, in contrast to traditional approaches that typically depend on lower-order material nonlinearities or detector nonlinearities, our method harnesses higher-order nonlinearities through data reverberation. Boolean analysis of the optical output reveals the presence of many nonlinear terms beyond third order, substantially expanding the dimensionality of the input data space. The utilization of these higher-order nonlinearities improves data separability by enhancing computational expressiveness (59) and facilitating more comprehensive feature space expansion (60), thereby enabling superior generalization and adaptability in complex computational tasks.
In summary, our optical extreme learner operates seamlessly under incoherent white-light illumination. It exceeds the performance limit of purely linear neural networks and attains accuracy comparable to fully nonlinear digital systems marking a vital step forward for fast, low-latency, energy-efficient optical computing solutions that preserve the full capabilities of nonlinear neural networks.
MATERIALS AND METHODS
Data preparation and neural network training
To evaluate the optical extreme learner’s performance, we used the MNIST (61), EMNIST (62), and CMNIST (63) datasets. The MNIST dataset comprises 70,000 images of handwritten digits (0 to 9), each with dimensions of 28 pixels by 28 pixels. MNIST contains 70,000 handwritten-digit images (0 to 9) at 28 pixels by 28 pixels. EMNIST provides 145,600 handwritten-letter images spanning 26 classes (“A/a” to “Z/z”), also at 28 pixels by 28 pixels. CMNIST offers 15,000 handwritten-numeral images (values 0 to 108) originally at 64 pixels by 64 pixels. All images were down-sampled to 20 pixels by 20 pixels with bilinear interpolation to match our optical system’s field of view. Every classification and XOR results reported here use these down-sampled datasets.
In our experiments, the MNIST dataset was partitioned into a training set of 60,000 images and a test set of 10,000 images; the EMNIST dataset was divided into 124,800 training images and 20,800 test images; and the CMNIST dataset was split into 13,500 training images and 1500 test images in each fold of cross-validation. All neural networks, comprising a single linear readout layer, were implemented using the PyTorch framework. Cross-entropy loss function was used for classification, whereas mean-squared error loss function was applied in XOR experiments.
We used the Adam optimizer for network training, setting the learning rate to 1 × 10^−5^ to ensure stability. The batch sizes were 1200, 2400, and 500 for MNIST, EMNIST, and CMNIST datasets, respectively. We reshuffled the training data at every epoch to reduce bias and improve generalization. All runs were executed on a Linux workstation equipped with an NVIDIA GeForce RTX 4090 (24 GB).
Experiment setup
A collimated beam illuminates a compact binary LCD panel that served as the programmable input in our experiment (Fig. 1C). Light is coupled into a single-mode fiber (P1-630A-FC-5, Thorlabs) using a 10× objective (PlanC N 10×, Olympus). The fiber output is collimated by a fiber collimator followed by a 150-mm lens. The 2.2″ transparent LCD panel (Crystalfontz), with a pixel pitch of 420 μm by 370 μm, was positioned orthogonally to the incident beam and driven by an Arduino Nano microcontroller via serial communication. The measured overall transmittance of the LCD is 63.0% in the all-transparent state and 3.3% in the all-dark state.
Nonlinear modulation arises multipass data reverberation within the LCD cavity, which comprises two glass plates enclosing the liquid-crystal layer, which crossed polarization-selective partial mirrors on the glass plates’ outer surfaces. Multiple reflections, diffraction, and self-interaction of the intensity pattern within the LCD cavity collectively generate the desired high-order nonlinear response. The resulting optical intensity profile at the LCD plane was imaged onto a monochrome CMOS camera (DMK 33GX265, Imaging Source) through a 150-mm and a 50-mm lens configured as a 3× telescope setup.
To compare coherent and incoherent operation, we alternated between a 633-nm He-Ne laser and a supercontinuum source (SuperK COMPACT, NKT Photonics) passed through a 40-nm band-pass filter centered at 650 nm (FBH650-40, Thorlabs). These wavelengths were chosen on the basis of our laboratory availability, and the proposed method is not tied to a specific wavelength or source type.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1E. Abbe, Beiträge zur Theorie des Mikroskops und der mikroskopischen Wahrnehmung. Archiv für mikroskopische Anatomie 9, 413–468 (1873). [Contributions to the Theory of the Microscope and the Nature of Microscopic Vision].
- 2P. Ambs, Optical computing: A 60-year adventure. Adv. Opt. Technol. 2010, 372652 (2010).
- 3P. M. Duffieux, The Fourier Transform and Its Applications to Optics (John Wiley & Sons,1983).
- 4J. W. Goodman, A. R. Dias, L. M. Woody, Fully parallel, high-speed incoherent optical method for performing discrete Fourier transforms. Opt. Lett. 2, 1–3 (1978).19680386 10.1364/ol.2.000001 · doi ↗ · pubmed ↗
- 5D. Psaltis, D. Brady, X.-G. Gu, S. Lin, Holography in artificial neural networks. Nature 343, 325–330 (1990).2300184 10.1038/343325 a 0 · doi ↗ · pubmed ↗
- 6S. L. Yeh, R. C. Lo, C. Y. Shi, Optical implementation of the Hopfield neural network with matrix gratings. Appl. Optics 43, 858–865 (2004).10.1364/ao.43.00085814960081 · doi ↗ · pubmed ↗
- 7P. E. Ceruzzi, A History of Modern Computing (MIT press, 2003).
- 8D. R. Solli, B. Jalali, Analog optical computing. Nat. Photon. 9, 704–706 (2015).