Order parameters and phase transitions of continual learning in deep neural networks
Haozhe Shan, Qianyi Li, Haim Sompolinsky

TL;DR
This paper introduces a theory for continual learning in deep neural networks, showing how task similarity and network depth affect learning and forgetting.
Contribution
A statistical-mechanics theory that identifies order parameters and phase transitions in continual learning.
Findings
Order parameters predict CL behaviors based on task similarity and network architecture.
Increasing network depth reduces interference between tasks and lowers forgetting.
Multihead CL shows phase transitions where performance drops sharply with low task similarity.
Abstract
Continual learning (CL), the ability to learn new tasks without forgetting existing ones, is one of the greatest challenges in AI. Our work provides an analytically tractable theory that captures some key phenomena of CL in deep, wide neural networks. We highlight several “order parameters” that measure the similarity between tasks and show that they can be highly predictive of CL behaviors on classic benchmark tasks. Strikingly, we identify a set of phase transitions where the network’s CL ability changes abruptly with the order parameter. Our results provide quantitative understanding of how CL ability depends on task relations, network architectures, and learning procedures. Continual learning (CL) enables animals to learn new tasks without erasing prior knowledge. CL in artificial neural networks (NNs) is challenging due to catastrophic forgetting, where new learning degrades…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
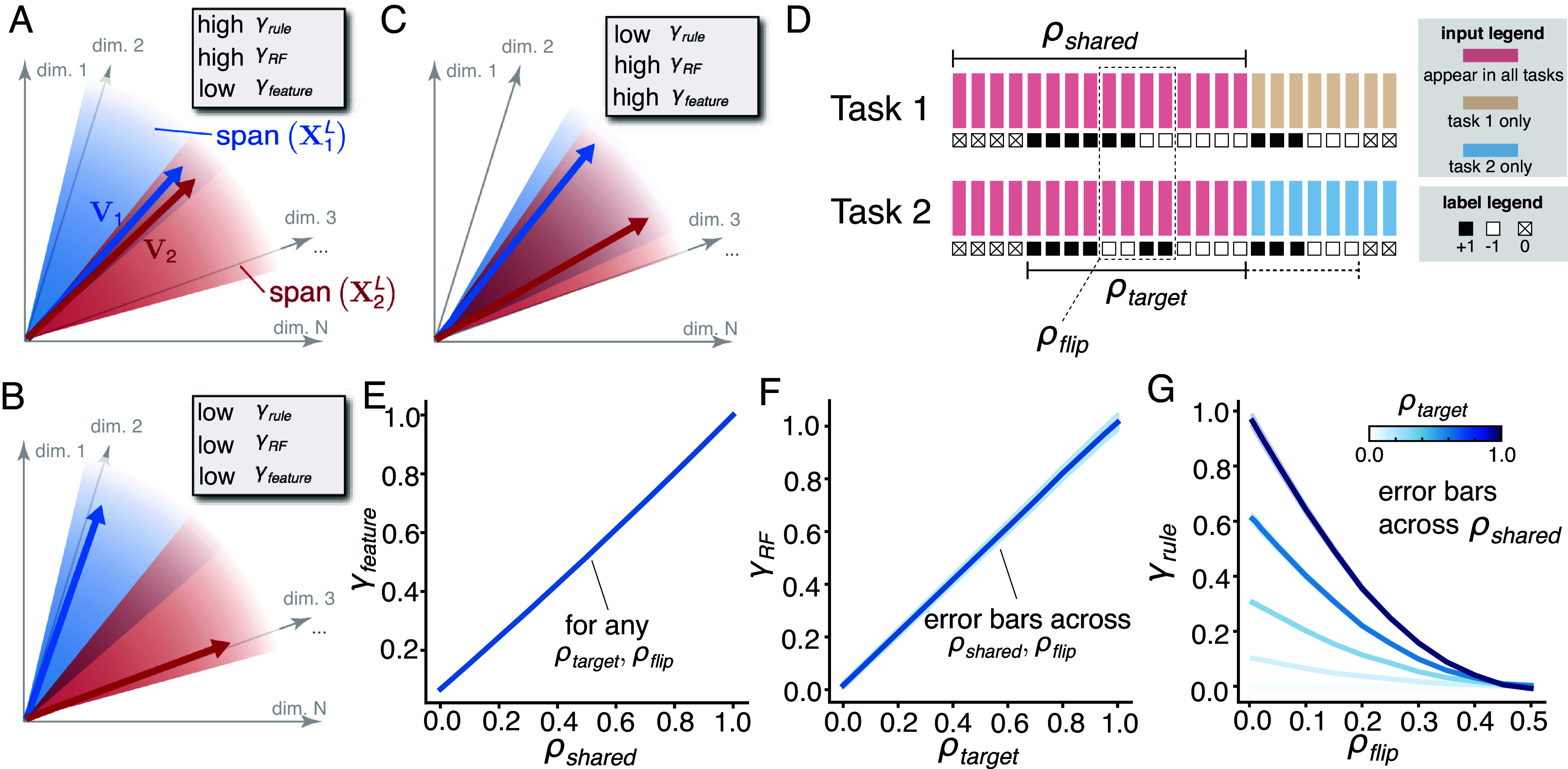 Fig. 2
Fig. 2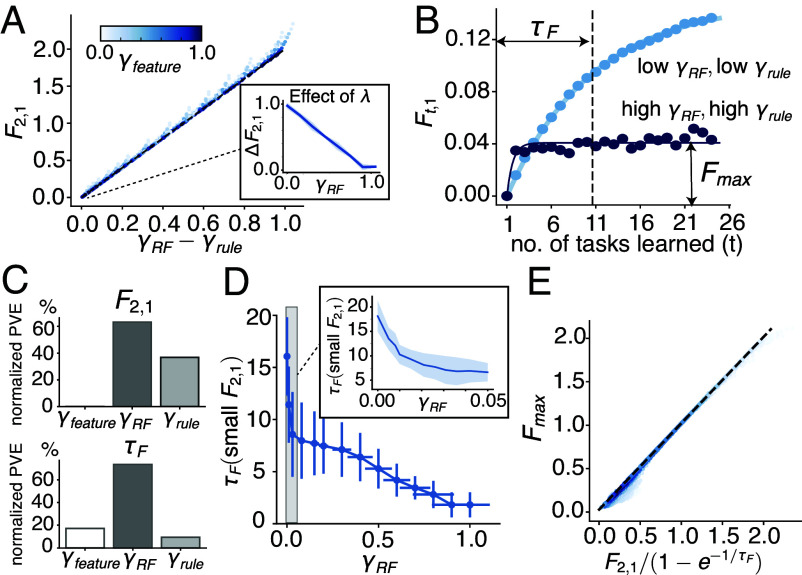 Fig. 3
Fig. 3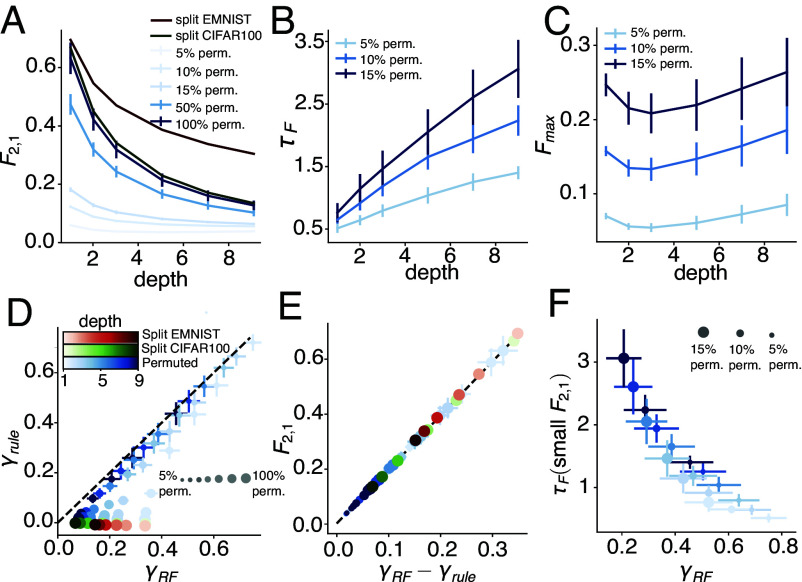 Fig. 4
Fig. 4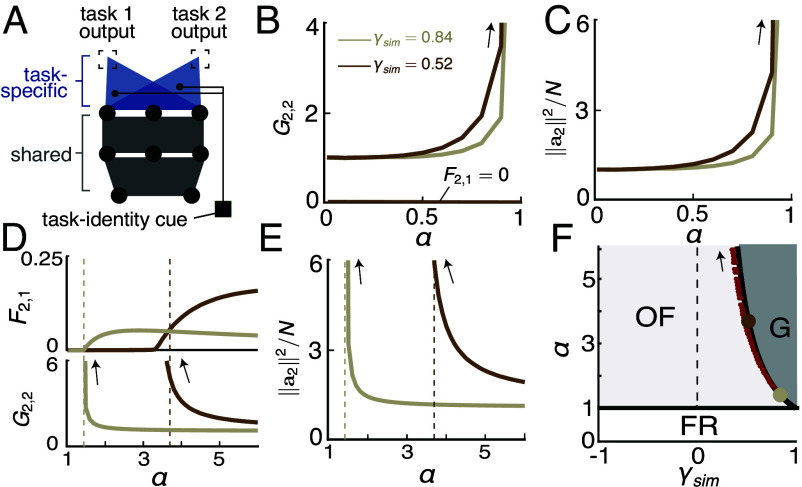 Fig. 5
Fig. 5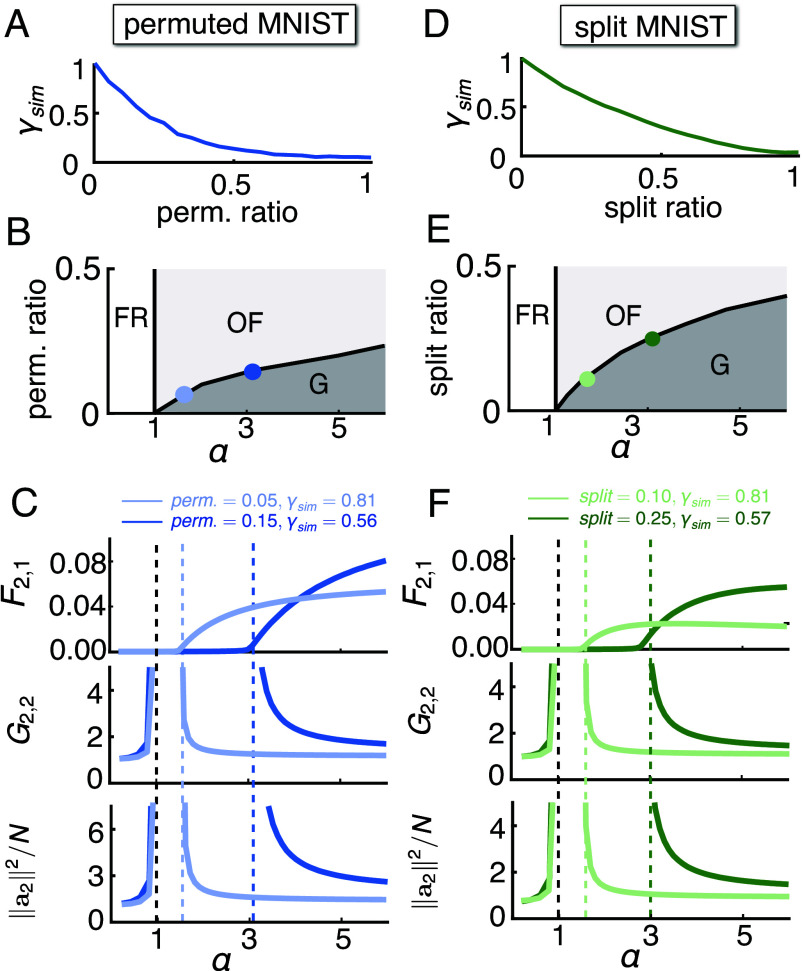 Fig. 6
Fig. 6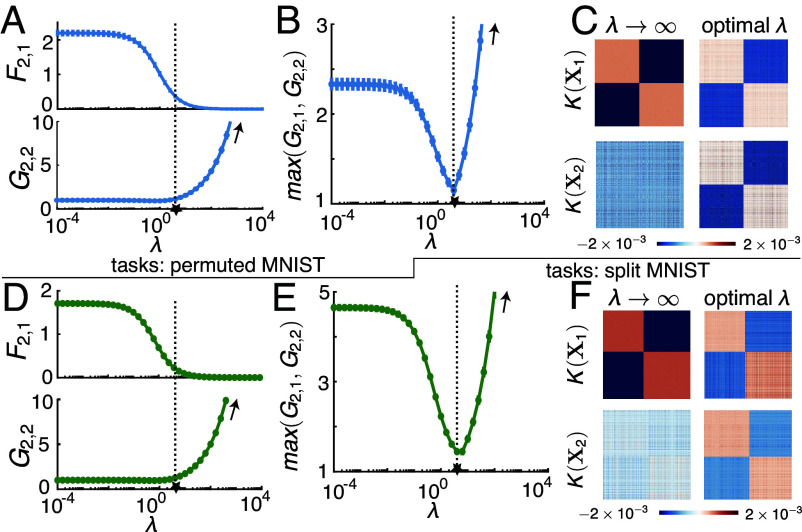 Fig. 7
Fig. 7- —DOD | USN | Office of Naval Research (ONR)100000006
- —National Science Foundation (NSF)100000001
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsDomain Adaptation and Few-Shot Learning · Neural Networks and Applications · Neural dynamics and brain function
Continual learning (CL), the capability to acquire and refine knowledge and skills over time, is fundamental to how animals survive in a nonstationary world. As an animal learns and performs many tasks, CL allows it to leverage previous learning to help learn a new task while retaining the ability to perform old ones. In artificial neural networks (NN), developing such abilities has been challenging. Artificial NNs especially struggle with catastrophic forgetting, where learning a new task overwrites existing information and dramatically degrades performance on previously learned tasks (1??–4). This problem is so prevalent and severe in machine learning (ML) that it has become one of the biggest challenges for developing human-level artificial general intelligence (5?–7). Despite also relying on NNs for computation, the brain clearly does not suffer from catastrophic forgetting to nearly the same extent (7). Not only does this offer an “existence proof” of successful CL in NNs (3, 7, 8), it also raises intriguing questions about mechanisms underlying CL in the brain. A wide range of possible underpinnings, ranging from memory reactivation (9), synaptic stabilization (10, 11), to representational drift (12), have been proposed. However, their specific contributions to CL in the brain are not well understood.
Engineering CL in ML and understanding its mechanisms in the brain both suffer from a lack of theoretical understanding of the problem in NNs. The challenges stem from two interconnected issues: 1) developing an analytical understanding of the learning process of CL in NNs and 2) characterizing and quantifying the diverse types of task relations and their impacts on forgetting. Recently, progress on the first challenge has been made by analyzing simplified cases where the network is a shallow linear network (13???–17), or equivalently so via the neural tangent kernel (NTK) approximation (18, 19). However, these approaches fail to account for the realistic and common scenario of NNs having multiple readouts dedicated to different tasks. Other studies have addressed task-dedicated readouts but focused on networks with only a single hidden layer and a limited number of neurons (20?–22), limiting their relevance to real-world NNs with typically hundreds of hidden units in each layer. Moreover, many of these studies (13, 14, 16, 17, 20??–23) rely on fully synthetic datasets, limiting the generalizability of their conclusions across diverse datasets and task relations.
The second challenge involves systematically characterizing task relations, as illustrated by the hypothetical odor-mixture classification tasks in Fig. 1A. Task relations can vary depending on the overlap of the odors, whether overlapping odors are relevant to classification, and whether task rules are similar—different aspects of relations may well have diverging impacts on CL performance. This underscores the need for systematic, theory-motivated quantification of CL-relevant aspects of task relations. While recent work has proposed metrics of task relations (18, 24), whether and how they may be used to predict CL performance remains unclear.
In this work, we utilize a Gibbs formulation of CL and use tools from statistical physics to develop a theory of CL in deep, wide NNs (25, 26). Critically, our results require minimal data assumptions, enabling analysis across a broad range of tasks. The theory connects the degree of forgetting and anterograde interference during CL to task relations, the NN’s architecture, and hyperparameters of the learning process. A key contribution is the identification of scalar order parameters (OPs) quantifying different aspects of task relations that are predictive of CL performance on classic benchmark task sequences, as summarized in Table 1. For NNs without task-specific readouts, our theory identifies two critical OPs: one measuring relevant-feature similarity and another quantifying rule similarity. For networks with task-dedicated readouts, we introduce a third OP that captures overall task similarity. We also uncover three distinct CL regimes determined by this task-similarity OP and the ratio of training data to network width. While task-dedicated readouts generally reduce forgetting, sequentially learning dissimilar tasks can lead to “catastrophic anterograde interference,” where previous learning causes overfitting to the latest task. Our results offer a rigorous and predictive framework for understanding CL in deep NNs, highlighting measurable task and architecture factors that influence performance. Finally, we discuss the broader implications of our findings for understanding the neuroscience of CL.
Gibbs Framework of CL in Deep Neural Networks
We studied a task-based CL setting (27) where the network learns a sequence of tasks, respectively represented by training datasets of identical size. , where is the number of examples per task and is the input dimensionality. Each row of , , is an input example with its corresponding label given by the -th element of , . While learning task , the network accesses but not the other datasets. We use “at time ” to refer to the state of the network after sequentially learning through .
We first considered the simplest architecture: a multilayer perceptron where all weights are shared across tasks [“single-head” CL (28, 29)]. The network has fully connected hidden layers, each containing nonlinear neurons, assumed to be ReLU for concreteness. The network load is denoted . The input–output mapping of the network at time is given by
where and are the readout and hidden-layer weights at time , respectively. is the activation vector in the last hidden layer for input . The more complex “multihead” CL scenario, where the network utilizes task-specific readouts, is introduced and studied later.
We assume that learning involves selecting the weights according to a cost function
The first term measures the error of on . The second term acts as regularization that favors weights with small norm, which is known to encourage good generalization (30). The third term is a perturbation penalty that favors small weight changes relative to , a natural strategy for mitigating forgetting (6, 10, 11, 31). denotes the inverse temperature, controlling how well interpolates . and respectively scale the regularization and the perturbation penalty. The cost function for learning , , has the same form but without the penalty.
Learning at each stage is modeled as a posterior distribution of conditioned on , . This distribution defines a Markovian transition from to , controlled by . Multiplying all such transition matrices for and the posterior of learning the first task, , yields a joint posterior over (16, 17, 32). This posterior fully describes how the network evolves during CL, from which various statistics can be calculated. We focus on overparameterized NNs (33) in the limit. In this case, there is a large space of that perfectly interpolates the dataset (Fig. 1B). At , there is no coupling between weights from different times, and the network has no memory of previous tasks. On the other hand, at , the network makes the minimum perturbation to weights that is required to interpolate (34). Performance of the network on some dataset at time is measured by averaging the normalized mean-squared-error (MSE) loss,
over the posterior of , denoted .
Networks Using a Readout Shared Across Tasks
Our theory of single-head CL, exact in the infinite-width limit of , allows analytical evaluations of for arbitrarily long task sequences (SI Appendix, Eqs. S16 and S17). For intuition, we here discuss a naively simplified version of the full theory that 1) nevertheless reproduces the key qualitative behaviors of the full theory (SI Appendix, Fig. S1) and 2) provides simple geometric intuitions of task relations. We also focus our discussion here on the case where forgetting is minimized by taking and (SI Appendix, section 3.A.1).
Task-Relation Order Parameters (OPs).
2.1.
The naive simplification, which is not required for the full theory, is motivated by the well-known observation that learning in networks in the infinite-width limit tends to induce only small modifications of the hidden weight matrices (35). In the simplified theory, we neglect learning-induced changes to the hidden-layer weights and assume them to be fixed at throughout learning. Thus, CL in the network can be viewed as solely learning the readout from a fixed feature layer. We denote the training data of the two tasks as , and the features at the -th hidden layer as , where the -th row is given by . Additionally, we assume the two tasks to have a “symmetric” relation (SI Appendix, section A.2). In this case, short-term forgetting, defined as the error on the training data of task 1 after learning two tasks ( ), adopts a simple form:
where
and are matrices,
and are -dimensional vectors,
These expressions allow us to describe task relations in terms of the geometry in the network’s -dimensional feature space. projects vectors in this space onto the -dimensional subspace spanned by the training examples of task , . represents the projection of the input features of one task onto those of the other task. is the normalized readout from the top hidden layer of the network, generated when learning alone. We refer to it as the rule vector since it fully characterizes the learned input–output rule of each task. The two terms in Eq. 4 have interesting geometrical interpretations in the feature space, as illustrated in Fig. 2A–C. The first term, denoted as , measures how much the rule vectors of individual tasks project onto the shared input feature subspace of both tasks. Intuitively, it corresponds to the similarity of the input features which are relevant to the task rules, and thus is referred to as the relevant-feature (RF) similarity. The second term, , measures the similarity between the two task rule vectors projected onto the shared input feature subspace, and thus is referred to as the rule similarity. We note that both and depend on the target outputs and the input features. It is also instructive to define a third OP, , which measures the degree of overlap between the input feature subspaces. It is thus a similarity metric between the input feature vectors, independent of the target outputs. By definition, they are algebraically bounded: , and . Under reasonable assumptions (SI Appendix, section 3.A.2) we further have and , which empirically hold for our results throughout this paper.
Schematics of the OPs and the target-distractor task. (A–C) Schematics of the OPs. The input features of each task span a P-dimensional subspace in the N dimensional feature space. span(X1L) (shown in blue) denotes the space spanned by task 1 input features at the L-th layer, while span(X2L) (shown in red) denotes the space spanned by task 2 input features at the L-th layer. V1 and V2 are the rule vectors of task 1 and task 2, and by definition lie in span(X1L) and span(X2L) respectively. γRF measures how much the rule vectors project onto the shared feature dimensions. In (A and C), both rule vectors fully lie in the shared subspace and γRF is high. In contrast, in (B) the rule vectors are away from the shared subspace, thus γRF is small. γrule measures the similarity between the projection of the rule vectors on to the shared feature dimensions. In a γrule is high and in (B and C) γrule is low. γfeature measures the degree of overlap between the shared feature dimensions and is low in (A and B) but high in (C). (D) Schematics of the target-distractor task. Each task consists of a set of P images (rectangles) from CIFAR-100, assigned labels ±1 or 0 (squares). ρshared controls the ratio of shared images between two tasks. ρtarget controls the ratio of images with ±1 labels that are shared between the tasks. For the shared images, some of the labels are flipped between the tasks, and ρflip controls the ratio of the images with flipped labels. Varying these parameters allows us to explore the full range of the OPs. (E–G) Controlling the 3 OPs with the target-distractor task. γfeature depends only on ρshared (E), as ρshared increases, the overlap between the shared feature subspaces increases, resulting in higher γfeature. γRF depends mainly on ρtarget (F). As ρtarget increases, the rule vectors project more onto the shared feature dimensions, thus γRF increases. γrule is tuned by both ρtarget and ρflip (G). ρtarget sets an upper bound of γrule, for a fixed ρtarget, γrule decreases with ρflip. At ρflip=0.5 about half of the labels are flipped, and γrule goes to 0. In both (F and G), error bars represent a uniform grid of 5 ρshared values in [0.1,0.9] crossed with 11 values of ρflip or ρtarget (respectively) in [0,1].
In summary, the quantity provides a direct measure of short-term forgetting (Eq. 4), which we hereafter refer to as the “conflict” between two tasks. Conflict can be small under two scenarios. The first occurs when both and are large but close in value, indicating that the tasks have similar relevant features and similar rules. The second is when both OPs are small, corresponding to the case where the tasks have dissimilar relevant features and rules. In contrast, two tasks would have high conflict if they share a lot of the relevant features (high ) but use different rules (low ).
Exploring the OPs with Target-Distractor Task Sequences.
2.2.
We next sought to understand how the 3 OPs are tied to the severity of forgetting. We began by studying them in the setting of task sequences with parametrically controllable input distributions and task rules. We constructed “target-distractor task sequences” (full details in SI Appendix, section 5), where each task consists of a set of randomly selected stimuli from a large pool of stimuli, e.g., images from CIFAR-100 (36), with random labels 1 or for each task (Fig. 2D). A subset of the inputs is shared across all tasks in the sequence, whereas other inputs are unique to each task. The parameter represents the proportion of shared inputs among all inputs across all tasks in the sequence and controls (Fig. 2E). Another parameter represents the proportion of shared inputs among the inputs with labels across all tasks; varying controls (Fig. 2F). For the shared images, part of the labels are flipped between tasks, and controls the ratio of images with flipped labels between tasks on average. It thereby affects how consistent the rules for different tasks are, as reflected in (Fig. 2G). Therefore, through varying , we can explore the full range of the 3 OPs and elucidate their respective roles in forgetting.
As expected from Eq. 4, is captured by the conflict (Fig. 3A) and is independent of (Fig. 3C, Top panel). We also measured the effect of by defining , where denotes forgetting on the first task without regularization (Fig. 3A, Inset). For tasks with low conflict, the effect of regularization on mitigating forgetting decreases as the tasks become more similar, as measured by (since the conflict is small, is close to for these tasks).
OPs predict short-term and long-term forgetting behaviors in target-distractor sequences. (A) Forgetting on the training data of the first task after learning two tasks (F2,1) is accurately predicted by 2(γRF−γrule), and does not depend on γfeature (represented by the color of the points). Each point represents a target-distractor task sequence with a different set of (ρtarget,ρshared,ρflip). Inset: ΔF2,1 measures the effect of the regularizer. When F2,1 is small (<0.05), γRF and γrule are close, the effect of the regularizer decreases as γRF (and γrule) increases, i.e., as the tasks become more similar. (B) Long-term forgetting in a task sequence can be approximated by an exponential relaxation process, where Fmax denotes its asymptote as t→∞, and τF denotes its time constant (SI Appendix, section 7). We show two examples, one for dissimilar tasks (low γRF, low γrule) with relatively large τF and Fmax, and the other for similar tasks (high γRF, high γrule), with relatively small τF and Fmax. (C) Normalized PVE (proportion of variance explained, 37) of F2,1 and τF by the 3 OPs (SI Appendix, section 5). F2,1 depends on γrule and γRF and is independent of γfeature, consistent with (A). τF mainly depends on γRF and weakly depends on γrule and γfeature. (D) For tasks where F2,1 is small (<0.05), τF decreases as γRF increases. Inset: zoomed-in region of γRF<0.05 highlights the fast decrease of τF for small γRF. Data are binned by γRF, error bars are SDs across data points within the same bin. (E) Fmax can be accurately predicted given F2,1 and τF. Each point represents a target-distractor task sequence with a different set of (ρtarget,ρshared,ρflip). The color represents the density of points. All Ft,1 and the corresponding OPs are averaged across 40 random seeds used for generating data. See SI Appendix, section 5 for detailed parameters.
Long-Term Forgetting.
2.3.
We next studied forgetting after learning sequences of multiple tasks, which we refer to as long-term forgetting. For simplicity, hereafter, we assume that all tasks in each sequence have identical pairwise relations; otherwise, task relations in a sequence of tasks would require at least characterizing all pairs. For such sequences, we empirically observed that forgetting of the first task ( ) increases over time approximately as an exponential relaxation process, . We thus characterized long-term forgetting by its time constant and long-time asymptote (Fig. 3B). Interestingly, task sequences can have similar short-term forgetting but very different long-term forgetting behaviors (Fig. 3B). This suggests that and depend on the OPs in ways that differ from short-term forgetting ( ). We analyzed the variance of explained by the 3 OPs (Fig. 3C, Bottom panel). mainly depends on , and weakly depends on the other two OPs.
Since can only be relatively mild when is small, we are particularly interested in long-term forgetting at small . For task sequences with small ( ), decreases with (Fig. 3D). The decrease is very fast around close to 0 (Fig. 3D, Inset), and slows down afterward. Finally, since the exponential fit of is remarkably accurate across all parameters of the target-distractor task, characterzing the relation between the OPs and and also characterizes (Fig. 3E).
In summary, our results suggest that while short-term forgetting is small as long as the tasks have low conflict (small ), long-term forgetting can still vary depending on the similarity (magnitude of and ) between tasks. Forgetting tends to accumulate slowly for dissimilar tasks over time but quickly rises and plateaus for similar tasks (smaller ). On the other hand, neither short-term nor long-term forgetting depends on , suggesting that a task-relation metric that includes only the input features is likely not informative of CL performance. Instead, it is crucial to consider the interaction between the task rules and the input features.
The Effect of Depth on Forgetting in Benchmark Sequences.
2.4.
Having varied the task relations to explore the entire OP space using the target-distractor task sequences, we next studied the effects of the network depth, . affects CL performance by modifying . To study the effect of on general data, we analyzed the forgetting on several benchmark task sequences in NNs with different depths ( ). Following standard practices, we created each sequence by applying a generation protocol (specified below) to a multiway classification dataset (“source datasets”): MNIST (38), EMNIST (39), Fashion-MNIST (40), or CIFAR-100. To generate long task sequences ( ) for the long-term forgetting analysis, we used the split protocol on EMNIST and CIFAR-100 and the permutation protocol on all source datasets, where a higher “permutation ratio” corresponds to less similar inputs between tasks (31) (see SI Appendix, section 6 for further details).
For permutation sequences, we aggregated over different source datasets as forgetting does not differ much between them. For split sequences, forgetting varies more between split EMNIST and split CIFAR-100, so we present their results separately. For all benchmark task sequences we explored, monotonically decreases with depth (Fig. 4A). is larger for split sequences and smaller for permutation sequences, and increases with a larger permutation ratio. As before, we are primarily interested in long-term forgetting for tasks with small , we thus show and for permutation sequences with 5 to 15% permutation ratio. As shown in Fig. 4B, increases with depth. Therefore, depth has opposing effects on and , while deeper networks forget less in the short term, forgetting accumulates over longer periods of time. As a result, the dependence of on depth is more complex. does not change as significantly as , and there may be an optimal depth where is at its lowest (Fig. 4C).
Forgetting in benchmark task sequences and the effect of depth. (A–C) The effect of depth on short-term (F2,1) and long-term (τF, Fmax) forgetting on benchmark sequences. For permutation sequences, we averaged over source datasets including MNIST, EMNIST, Fashion-MNIST, and CIFAR as their behaviors are similar, and error bars are SEs across the source datasets. For split sequences, we show separately split EMNIST and split CIFAR-100 sequences as their behaviors are more different. In all cases, F2,1 decreases with depth (A). We look at long-term forgetting only in sequences with small F2,1 (5, 10, 15% permutation sequences), τF increases with depth (B). Due to the opposing behaviors of F2,1 and τF, Fmax does not vary strongly with depth, and there may be an optimal depth where Fmax is lowest (C). (D) Task-relation OPs (γrule and γRF) on the benchmark sequences). Colors blue, red, and green correspond to permutation sequences, split EMNIST, and split CIFAR100, respectively. Colors from light to dark correspond to increasing depth of the network. In permutation sequences, larger sizes of the points correspond to larger permutation ratio. The benchmark sequences explore a more constrained region in the OP space compared to the target-distractor sequences. (E) F2,1 is accurately predicted by 2(γRF−γrule), as in Fig. 3A. Increasing depth or decreasing the permutation ratio results in smaller γRF−γrule (as also shown in D), and thus leads to smaller F2,1. (F) For tasks with small F2,1 (5,10,15% permutation sequences), τF decreases with γRF, consistent with Fig. 3D. For a fixed permutation ratio, increasing depth results in smaller γRF (as also shown in D), and thus leads to larger τF. All Ft,1 and the corresponding OPs are averaged across 50 random seeds used for generating data. See SI Appendix, section 6 for detailed parameters.
Forgetting in Benchmark Sequences are Explained by the OPs.
2.5.
In this section, we examine whether the dependence of forgetting on depth and across different benchmark sequences can be explained by the OPs as in the target-distractor sequences. To this end, we first computed the OPs for the task sequences, aggregated over the source datasets for the permutation sequences, and separately for split EMNIST and split CIFAR-100 sequences. As we showed in Section 2.2, forgetting does not exhibit significant dependence on , so we focus on and in this section.
As shown in Fig. 4D, the OPs on the benchmark sequences depend on both the sequence type and the network depth, and altogether partially fill the entire feasible OP space (below the dashed line in Fig. 4D). Split sequences including split EMNIST (red points) and split CIFAR-100 (green points) have close to zero , and decreases with depth (darker colors represent increasing depths). Permutation sequences with large permutation ratios (large blue points) behave similarly to the split sequences. Permutation sequences with small permutation ratios (small blue points) have close to across all depths, and for networks with larger depths, and decrease simultaneously, such that the tasks become more dissimilar.
To summarize, between-task conflict becomes lower in deeper networks, and in permutation sequences with lower permutation ratio. As verified in Fig. 4E, is still accurately predicted by the conflict. For task sequences with small conflict (permutation sequences with 5 to 15% permutation ratio), both OPs decrease with depth, predicting a larger , as verified in Fig. 4F. The relations between the OPs and forgetting in the target-distractor sequences in Section 2.2 also hold for general benchmark task sequences, and can be used to explain the effect of network depth. We also verified that our theory in this regime provides a good qualitative account of gradient descent-trained networks (SI Appendix, Fig. S4).
Networks with Task-Dedicated Readouts
Setup of Multihead CL.
3.1.
In many CL settings, both in ML applications and naturalistic environments for animals, the learner is aware (through external cues or inference) of the identity of the current task being learned or performed. A simple method of incorporating such information into the network (28, 29, 41) is to use task-specific readouts (“multihead” CL). Learning a new task involves modifying the shared hidden-layer weights while adding a new task-specific readout, leaving previous readouts untouched (Fig. 5A). The network has different input–output mappings after learning tasks, given by
Multihead CL exhibits phase transitions in the target-distractor sequence. (A) Schematics of multihead CL. Different tasks utilize the same shared hidden-layer weights but different task-specific readouts. The weight-perturbation penalty is only applied to the hidden-layer weights. (B) Forgetting of task 1 (F2,1) and the normalized generalization error on task 2 (G2,2) as a function of the network load (α) for 2 different sets of (ρtarget,ρshared,ρflip) in the target-distractor task in the fixed-representation regime (FR, α<1). Black arrows indicate divergence toward infinity as α approaches 1. Curves of different colors correspond to tasks with different parameters (ρtarget,ρshared,ρflip). light: (1,0.88,0),γsim=0.84; dark: (1,0.58,0.005),γsim=0.52. The generalization errors are calculated on the training data with small perturbations to the input (SI Appendix, section 5). (C) The norm of a2, ||a2||2/N, as a function of α in the fixed-representation regime (FR). Since the hidden layer representations are fixed, learning the second task is equivalent to learning the linear weights a2 in linear regression, thus the divergence of G2,2 results from the divergence of a2 when approaching the interpolation threshold in linear regression. (D) Same as (B), but for α>1. For each combination of (ρtarget,ρshared,ρflip), F2,1 and G2,2 exhibit abrupt changes as α crosses a critical load (αc, vertical dashed line). In the overfitting regime (OF, 1<α<αc), F2,1 is zero but G2,2 diverges. In the generalization regime (G, α>αc), both F2,1 and G2,2 are moderate and nonzero. (E) Same as (C), but for α>1. The divergence of G2,2 results from the divergence of a2 to compensate for minimal ||W2−W1|| when learning task 2. (F) The transition boundary between the fixed-representation regime (FR) and the overfitting regime (OF) is always at α=1 and does not depend on the task. The transition boundary between the overfitting regime (OF) and the generalization regime (G), αc, can be theoretically predicted by the task similarity metric γsim∈[−1,1] under reasonable assumptions (SI Appendix, section 4.A), as shown by the black line. Each red point shows the estimated transition boundary αc from the shape of F2,1 (SI Appendix, section 5) for a different combination of (ρtarget,ρshared,ρflip), and thus a different value of γsim. The red points lie on top of the black curve, demonstrating the accuracy of the theoretical prediction. The light and dark brown points correspond to the lines shown in (B and C).
At time , the network selects the mapping to perform the -th task. Since the readout weights are task-dedicated and the hidden-layer weights are shared, only the changes in need to be constrained in order to mitigate forgetting. Due to these differences from single-head CL, the objective function of learning is given by Eq. 2 but with replaced with and the regularization term replaced with .
The presence of task-specific parameters generally makes forgetting less severe than that in single-head CL (42). Importantly, this architecture allows the network to perform tasks with high conflict, which single-head networks struggle with, as shown in the previous section. In fact, in the infinite-width limit ( ) studied above, forgetting and anterograde effects can be entirely avoided regardless of task relations, since the network can simply freeze its random hidden-layer weights and learn a separate readout for each task. However, this simple scheme breaks down in the more realistic cases where resources are limited and the network may have to modify the hidden-layer weights to solve each task.
To study interesting properties of CL in the task-dedicated multihead architecture, we focus on the thermodynamic limit, defined by and . We focused on the case of and (due to the complexity of the theory in this limit, but see SI Appendix, Figs. S7 and S8 for results beyond these restrictions). Our theory analytically evaluates forgetting of task 1 and the anterograde effect on task 2 in multihead CL, respectively given by and , where is the generalization error on task 2 when learning it alone.
Phase Transitions in CL Performance in the Target-Distractor Sequence.
3.2.
We first used the target-distractor task sequences to probe how task relations affect CL performance in the limit of . In addition to varying as in the single-head analysis, we also varied the load . In Fig. 5B–E, we show two examples of task sequences generated under two combinations of , and plot and as increases. We found that, regardless of task relations, is zero as long as , while diverges to infinity as approaches (Fig. 5B). Such behaviors can be explained by the fact that when , learning the task-2 readout ( ) alone is sufficient to interpolate , requiring no change to the hidden-layer weights ( ). Due to the strong perturbation penalty ( ), do not change, maintaining the network representations after learning task 1 (as derived in SI Appendix, section 4.B.6). This can also explain the divergence of as : learning by modifying on top of the -dimensional fixed representations is effectively a linear regression, the generalization error of which is well known to diverge as approaches (43). This divergence is due to the divergence of the norm of (Fig. 5C). For smaller , the zero and remaining close to 1 demonstrate the advantage of using task-specific readouts. We term this regime of , where and is mostly finite, the “fixed representations” regime (FR).
As increases past 1, interpolating requires changing . Consequently, we expected that such changes would induce forgetting of task 1. Surprisingly, we found that there exists a critical load, , under which forgetting remains zero (Fig. 5D, Top). Further analysis showed that while changes in the network representations after learning task 1 no longer have zero norm, it is confined within the null space of and thus does not alter the output on task 1 (SI Appendix, section 4.B.6). Although the absence of forgetting is desirable, this regime is accompanied by the network’s inability to generalize on the second task, despite reaching zero training error. In fact, diverges (Fig. 5D, Bottom), indicating the surprising phenomenon we term “catastrophic anterograde interference,” where previous learning completely impedes generalization of new learning. We term this regime, where , and , the “overfitting” regime. The divergence of in this regime is also due to the divergence of (Fig. 5E). In this regime, the minimal changes in the hidden layer weights result in a hidden representation that does not learn the task rule of the second task (as we show later in Section 3.4), causing to diverge in order to compensate. As further increases past , the network abruptly enters the “generalization” regime where and becomes finite. In this regime, the changes in the representation after learning task 1 are no longer confined to the null space of , inducing forgetting. The network partially forgets task 1, but learns to generalize on task 2.
Importantly, the boundary separating the two regimes ( ) depends on task relations. Different combinations of are associated with a different , separating the overfitting and generalization regimes. We found that under reasonable approximations, is fully determined by a new OP measuring overall similarity of the two tasks, defined as
where and ( ) are defined as in Eqs. 8 and 9. Although the precise definitions of the three terms in are different from the 3 OPs for single-head CL (introduced in Section 2.1) since we now focus on a different limit in a different CL architecture, they are actually closely related. The first term in , , is exactly the same as defined in Section 2.1. The second term, , measures the cosine similarity between the rule vectors of the two tasks; it has a similar interpretation as . The third term, , measures the projection of the rule vector onto the shared input feature subspace of the two tasks; it has a similar interpretation as . is within the range of . For conflicting tasks with the same input feature subspaces but opposite rule vectors, , for identical tasks . For dissimilar tasks with small overlap between input feature subspaces (small ), and rule vectors lying in the nonoverlapping input feature subspaces of each task (small second and third terms in Eq. 11), is close to 0. As shown in Fig. 5F, for , the network is in the “fixed representation” regime, independent of task relations. For , the phase transition is accurately predicted by (black line) across different parameters of the target-distractor tasks (red points). is larger for more dissimilar tasks with smaller , resulting in a smaller generalization regime. For , , and the network is always in the overfitting regime as long as .
Phase Transitions in Benchmark Sequences.
3.3.
Our results suggest that the three phases are in fact general phenomena, and the OP can be used to predict the phase transition boundary across different task sequences. To verify, we computed the OP for two types of benchmark task sequences, permuted and split MNIST, where the task similarity is controlled by varying the permutation or split ratio (SI Appendix, section 6). Smaller permutation or split ratios correspond to intuitively more similar tasks and vice versa. As shown in Fig. 6 A and D, decreases with the permutation ratio or the split ratio, capturing the changes in the task similarity. When the permutation (split) ratio is 0, the tasks are identical and , whereas when the permutation (split) ratio is 1, the tasks are dissimilar and .
Similarity OP predicts phase transition in benchmark sequences. (A) For permuted MNIST with different permutation ratios, we can calculate the task similarity metric γsim, γsim decreases with increasing permutation ratio. (B) Using γsim shown in (A), the theory predicts a phase diagram in the permutation ratio-α space, showing the three regimes as in the target-distractor sequences: fixed representations (“FR”), overfitting (“OF”), and generalization (“G”). (C) F2,1, G2,2 and ||a2||2/N corresponding to the permutation ratios of the two points in (B) (light blue: perm. =0.05, γsim=0.81; dark blue: perm. =0.15, γsim=0.56), the transition from zero to positive F2,1 and from diverging to finite G2,2 or ||a2||2/N is accurately predicted by the theoretical αc (light blue dashed line: αc=1.51, dark blue dashed line: αc=3.19). (C) F2,1, G2,2 and ||a2||2/N corresponding to the permutation ratios of the two points in (B) (light blue: perm. = 0.05, γsim=0.81; dark blue: perm. =0.15, γsim=0.56), the transition from zero to positive F2,1 and from diverging to finite G2,2 or ||a2||2/N is accurately predicted by the theoretical αc (light blue dashed line: αc=1.51, dark blue dashed line: αc=3.19). (D–F) Same as (A–C), but for split MNIST, where we control the task similarity by changing the split ratio (SI Appendix, section 6). γsim decreases with increasing split ratio. The two examples shown in (E and F) correspond to split ratio 0.1 (light green, γsim=0.81) and 0.25 (dark green, γsim=0.57), and the theoretical prediction of their αc’s are 1.54 and 3.03 respectively.
Using , our theory predicts an for each permutation (split) ratio, producing a phase diagram in the permutation (split) ratio- space (Fig. 6 B and E), with the same three regimes as we showed in the target-distractor sequences: the fixed representations regime (FR), the overfitting regime (OF), and the generalization regime (G). To verify the prediction of the phase diagram, we selected two examples for each type of task sequences with different permutation (split) ratios, and thus different , and computed , and as a function of . As shown in Fig. 6 C and F, the theoretical prediction of (dashed lines) accurately captures the abrupt changes in the performance of the network: For , , and are finite and start to diverge as ; for , remains 0, and are diverging; for , , and are all finite and nonzero. Finally, these qualitative behaviors of phase transitions were reproduced in gradient-descent trained networks (SI Appendix, Fig. S7) as well as in CL of longer task sequences (SI Appendix, Fig. S8).
Balancing Memorization and New Learning with Finite λ.
3.4.
The analysis so far has shown that, when tasks are sufficiently dissimilar, can cause the network to memorize perfectly (zero ) at the expense of catastrophic anterograde interference (diverging ). We next characterized the trade-off for such dissimilar tasks between improving and maintaining low by lowering . As expected, as lowers, the network forgets the first task more (higher , Fig. 7 A and D, Top), resulting in weaker interference of the second task (lower , Fig. 7 A and D, Bottom). To evaluate and compare the performance on both tasks and quantify the trade-off, we also computed the normalized test loss on task 1 after learning task 2, denoted by , and studied as a function of (Fig. 7 B and E). We found that there exists a finite optimal that minimizes by keeping both and close to 1.
Optimal regularization strength balances memorization and learning new tasks. (A) Forgetting of task 1 (F2,1) monotonically decreases with the regularization strength (λ) while the normalized generalization error on task 2 (G2,2) monotonically increases. The two tasks considered here are sufficiently dissimilar (permuted MNIST with 100% permutation ratio) that they are in the overfitting regime and G2,2 diverges at large λ. (B) Maximum of the normalized generalization error on task 1 and task 2 (max(G2,1,G2,2)) as a function of the regularization strength λ. There exists an intermediate optimal λ which minimizes max(G2,1,G2,2) by keeping both of them close to 1 such that there is minimal interference coming from the other task, indicated by the star. (C) The learned component of the similarity matrix of the hidden layer activations on task 1 and task 2 training data (X1 and X2), after learning the two tasks, denoted K(X1) (Top row) and K(X2) (Bottom row) respectively. At λ→∞, only K(X1) but not K(X2) exhibits a task-relevant block structure. This indicates that the network fails to learn good representations for task 2, and overmemorizes task 1. In contrast, at the optimal λ (corresponding to the star in B), both K(X1) and K(X2) show a block structure aligned with their corresponding tasks, exhibiting a shared representation beneficial for both tasks. (D–F) Same as (A–C), but for split MNIST with 100% split. In (A, B, D, and E), error bars are SDs across 10 different random seeds of task sequence generation. α=3 in both examples, which is below the corresponding αc for these sequences.
We next sought to understand how the representations of task 1 and task 2 inputs depend on by studying the representation similarity matrix after learning both tasks. Specifically, we analyzed the learned component in the representation similarity matrix on the training data and (SI Appendix, sections 4.B and 6), denoted by and respectively. Prior work has indicated that, for binary classification tasks that we considered, a block structure in the similarity matrix suggests that the representations are clustered according to the task labels and is associated with good generalization performance (44??–47). Indeed, we found that at large , the similarity matrix has such block structure for but not (Fig. 7 C and F), explaining our previous finding that the network fails to generalize on task 2 in the overfitting regime. However, when using the optimal that minimizes , representations of inputs from both tasks have such block structure, consistent with the finding that both and are close to 1, highlighting the importance of representation learning on the generalization capabilities in CL.
Discussion
Related Works.
4.1.
Many mechanisms have been proposed for mitigating catastrophic forgetting (for a recent review, see ref. 48). We used the simplest approach by adding an penalty on weight changes to facilitate theoretical analysis. While this work’s aim is not to achieve state-of-the-art performance but to develop a theoretical understanding of CL, it is important that our theoretical results achieve reasonable performance compared to commonly used CL approaches. We confirmed this by comparing against networks trained using gradient descent with online EWC (49) or L2 regularizers (SI Appendix, section 8). Theoretical advances on CL have been made recently. For single-head CL, our theoretical results (SI Appendix, Eqs. S16 and S17) are consistent with refs. 18 and 24 in the limit. However, we stress that our theoretical framework and assumptions are different. While (18, 24) assume linearization of the dynamics around initialization in the NTK regime (19), our formulation does not rely on any assumptions on the learning dynamics. Interestingly, we recover an NTK-like theory of CL in the single-head scenario when . Furthermore, while these previous results proposed an analytical expression for the mean predictor, they did not provide explicit predictions of the theory on CL performance. In this work, combining our theoretical solutions and numerical evaluations, we characterized the connections between forgetting in CL and task relations using the theoretically inspired OPs. We qualitatively verified qualitative predictions in gradient descent-trained networks (SI Appendix, Fig. S4). Importantly, our Gibbs formulation also allows us to investigate the effect of (SI Appendix, Fig. S3), which is not amenable in the NTK formulation in refs. 18 and 24. For multihead CL, most theoretical works make specific assumptions about the tasks (20?–22), limiting their applicability. We became aware of a very recent work during the preparation of our manuscript (50), which adopts a Gibbs formulation for transfer learning similar to our multihead setup and does not make specific assumptions about the statistics of the tasks. However, this work focused on learning in the regime with finite , and therefore did not uncover the intriguing phenomenon of phase transitions that are determined by task similarities as in our work. It also does not identify the order parameters governing these transitions and predicting other aspects of CL performance.
Forgetting and Task Relation OPs.
4.2.
We systematically investigated how task relations influence forgetting in -regularized CL in wide DNNs in single-head and multihead scenarios, studying short-term forgetting (sequential learning of two tasks) and, in the case of single-head CL, long-term forgetting (a long sequence of tasks). In contrast to prior work, which mostly treated “task similarity” as a single variable (2, 16, 18, 21, 22, 51, but see refs. 13 and 20), our analysis emphasizes the importance of distinguishing different aspects of task relations on CL. Importantly, we identified several scalar OPs quantifying these task relations. These OPs can be evaluated given the training data of each task and are highly predictive of CL performance in the settings that we studied. We summarize the definitions of these OPs in Table 1.
For single-head CL, we studied , and . Interestingly, is only weakly related to forgetting, while the other two OPs play important roles. This suggests that the similarity between the input features, which are relevant for the task, rather than the input features themselves, are the determining factors of forgetting. , which we termed the conflict between tasks, is directly related to short-term forgetting. For tasks with low conflict and thus small short-term forgetting, long-term forgetting accumulates slowly for dissimilar tasks (small ) and quickly for similar tasks (high ). That lowering reduces forgetting is consistent with CL methods that explicitly learn representations of inputs from different tasks in mutually orthogonal subspaces (52, 53). A potential promising direction is to design methods that encourage networks to learn “reusable” features and increase . For multihead CL, our theory identifies another task similarity OP composed of 3 terms, each bearing resemblance to the 3 OPs in single-head CL including , which does not significantly affect single-head CL performance. The effect of this OP depends also on the load . For , task relations have no effect on forgetting as it vanishes at . However, for there exists a phase diagram (Fig. 5D). For a fixed load ( ), when are high, CL is in the generalization regime where forgetting is nonzero but moderate. When the tasks become sufficiently dissimilar, CL abruptly enters the overfitting regime where forgetting is zero but generalization on the new task fails despite reaching zero training error, a surprising phenomenon we termed “catastrophic anterograde interference.” For tasks in this regime, fine-tuning of the learner can reach a reasonable compromise and allow the network to perform both tasks (Fig. 7).
Architecture.
4.3.
Our analysis suggests that task relations are modulated by the architecture of the learner. Increasing depth effectively mitigates single-head forgetting for short task sequences (decreased , Fig. 4A) by reducing the conflict between tasks but has a more complicated effect on long-term forgetting (reflected in nonmonotonic , Fig. 4C) due to the opposing effects it has on and . In addition, increasing the width ( ), which we studied for multihead CL, can also mitigate forgetting. As increases for a fixed dataset size ( ), decreases below . As a result, CL transitions from the generalization regime, where forgetting is finite, to the overfitting regime, where it is zero. Although the specific value of depends on task relations, our theory indicates that the transition to zero forgetting is a general phenomenon. Widening the network further eventually causes to drop below 1 where network features are fixed and forgetting is zero for any tasks. The observed beneficial effects of depth and width on mitigating forgetting are consistent with empirical reports of less forgetting in larger networks (54).
Anterograde Effects.
4.4.
In addition to forgetting (retrograde interference), we investigated anterograde aspects of CL by studying how learning one task affects the generalization performance on a subsequently learned one. For single-head CL, we omitted discussion of anterograde effects from the main text as they are generally weak in the infinite width limit that we consider (SI Appendix, Fig. S2), consistent with previous reports. However, results from multihead (Figs. 5–7) CL indicate that anterograde interference can be severe and worsens as the tasks become less similar. This suggests a parameter regime at where, counterintuitively, single-head CL performs better than multihead (SI Appendix, Fig. S9). It would be interesting to rigorously verify this in a future theory of single-head CL with finite . The existence of diverging test loss for suggests that increasing the width of the network (reducing to a value below ) will have a very beneficial effect on sequential learning. While anterograde interference appears prevalent and severe in our analysis, this is partially due to the specific settings we focused on. Assuming the second task to have substantially fewer training examples than the first or a compositional structure between tasks (55) could lead to stronger positive transfer effects. In addition, making transitions between dissimilar tasks “smoother” by inserting intermediate datasets can mitigate anterograde interference in multihead CL (based on a generalization of the theory to ; SI Appendix, Fig. S8).
Implications for CL in the Brain.
4.5.
Recent neuroscience experiments indicate that neural representations of a learned task can “drift” after learning has concluded (12, 56), raising the question of how the brain maintains stable task performance despite such drifts (57). While a multitude of mechanisms likely underlie this phenomenon, subsequent learning of other tasks by the same neural circuits likely contributes (12). As shown by our analysis, this can indeed occur during multihead CL at , where representations of task 1 inputs are altered by learning the second task. Our analysis hints at how the brain may deal with this issue. Task 1 performance can be unperturbed as long as representational changes occur only in the null space of its readout, consistent with the notion that the brain orthogonalizes representations for different tasks to reduce interference (12, 58, 59). The overfitting regime demonstrates that such orthogonality can occur without storing task 1 inputs and explicitly confining new learning in their null space, as long as the penalty on weight perturbations is sufficiently strong. To avoid the failure to generalize on task 2 in this regime, the brain may weaken the penalty or enforce a hard constraint on the strength of the readout weights, such that representational changes are still mostly orthogonal to the task 1 readout but sufficient for good generalization of task 2. These results suggest the possibility of enforcing near-orthogonality between task subspaces by having a regularization-like mechanism [e.g., synaptic stabilization (10, 11)] along with appropriately tuned penalty or constrained readout weight strength.
Our results also highlight how architectural elements of the brain can confer CL benefits. Sensory expansion, a motif often seen in sensory cortices, projects a low-dimensional input signal into a much higher-dimensional code within a large population of neurons (60). From the perspective of multihead CL, this may effectively increase the NN width and reduce forgetting, as discussed above. Additionally, our finding that increasing depth can mitigate forgetting may indicate an advantage of having a deep, multistage sensory processing system. This suggestion predicts that representations of different tasks are less similar in later stages of sensory processing (61, 62). To assess such similarity in high-dimensional neural codes without resorting to nonlinear dimensionality-reduction techniques (e.g., 59), it may be promising to adapt our OPs to experimental data.
Finally, it would be interesting to test whether the same connections between task relations and severity of forgetting hold in the brain. For instance, animals can be sequentially trained on a series of two-alternative forced choice tasks. In each task, the animal would need to distinguish two classes of simple stimuli with a few attributes, much like the example shown in Fig. 1A. Different tasks would contain different dichotomies on different attributes. The dichotomies should be consistent across tasks to ensure a small conflict . Assuming animals are using a single-head-like shared behavioral readout for these tasks (63) and a regularization-like mechanism for CL, our results predict forgetting will accumulate longer if attributes from different tasks are made more distinct (lower and ).
Extensions and Limitations.
4.6.
The presented theory can be extended in several important directions. First, our Gibbs formulation assumes a uniform perturbation penalty across all weights, while popular regularization-based CL methods typically use some metric to evaluate the importance of each individual weight for past performance and apply a stronger penalty to more important ones (6, 31). Our theory may be extended to the case with weight-specific penalties and elaborate on how different importance metrics affect CL outcomes.
Second, we assumed that the tasks are symmetric and have similar pairwise task relations in long task sequences, which prevents us from capturing how different orderings of the same set of tasks elicit different CL performance. While we have neglected ordering effects here because they are often small in common task sequences (16, 64), it remains an interesting future direction to systematically probe into the effect of task ordering in more structured progressive task sequences. Another important direction for future research is the study of heterogeneous task sequences, such as curriculum learning ones where the task difficulty progressively increases (65) While our analytical theory is also applicable to such cases, it remains to be seen what OPs can predict CL phenomena there.
Finally, while we have focused on leveraging task-identity information during CL using the multihead scheme, having multiple readouts is considered less realistic for CL in the brain. Conceptually, the task identity information can be incorporated through gating units that gate parts of the readout weights on or off depending on the task, as in ref. 66, making the multihead scheme more biologically relevant. Task-identity information can be incorporated into single-head CL by appending a task-identity embedding vector to relevant inputs (67) or gating individual neurons in a task-dependent manner (68?–70). In SI Appendix, Fig. S6, preliminary results show that while appending task-identity embedding vectors to the inputs helps mitigate forgetting, its beneficial effect is still weaker compared to adding task-dependent readouts (multihead CL). Extending our theory to other mechanisms of incorporating task-identity information such as gating and studying how they affect the OPs and CL performance is a promising future research direction.
matseccnt1
Methods
Additional results and further details are provided in SI Appendix. SI Appendix, section 1 precisely defines the feedforward network architecture under consideration. SI Appendix, section 2 derives and presents the generalized kernel functions, which extend the results of ref. 71 and are important building blocks for the theories. SI Appendix, section 3 presents full details of the single-head theory, where the network uses the same readout for all tasks. It includes results and discussions of the theory away from the limit discussed here. Analytical forms of generalized kernel functions for linear and ReLU networks are provided and the connection to NTK is specified. SI Appendix, section 4 presents the multihead theory, where the network uses a different readout for each task. Generalization of the kernel renormalization technique (41) to continual learning is discussed in detail. A detailed study of how hidden-layer representations change is provided. SI Appendix, sections 5 through 8 provide details on the numerical analyses: implementation details of the target-distractor tasks (SI Appendix, section 5) and benchmark tasks (SI Appendix, section 6), details on using exponential fitting to describe long-term forgetting (SI Appendix, section 7) and gradient descent simulations (SI Appendix, section 8). SI Appendix, sections 9 through 11 provide additional numerical results that support or supplement conclusions in the main text.
Supplementary Material
Appendix 01 (PDF)
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1M. Mc Closkey, N. J. Cohen, “Catastrophic interference in connectionist networks: The sequential learning problem” in Psychology of Learning and Motivation, G. H. Bower, Ed. (Elsevier, 1989), vol. 24, pp. 109–165.
- 2I. J. Goodfellow, M. Mirza, D. Xiao, A. Courville, Y. Bengio, An empirical investigation of catastrophic forgetting in gradient-based neural networks. ar Xiv [Preprint] (2013). http://arxiv.org/abs/1312.6211 (Accessed 1 November 2025).
- 3G. I. Parisi, R. Kemker, J. L. Part, C. Kanan, S. Wermter, Continual lifelong learning with neural networks: A review. Neural Netw. 113, 54–71 (2019).30780045 10.1016/j.neunet.2019.01.012 · doi ↗ · pubmed ↗
- 4G. M. Van de Ven, A. S. Tolias, Three scenarios for continual learning. ar Xiv [Preprint] (2019). http://arxiv.org/abs/1904.07734 (Accessed 1 November 2025).
- 5D. L. Silver, “Machine lifelong learning: Challenges and benefits for artificial general intelligence” in Artificial General Intelligence: 4th International Conference, AGI 2011, Mountain View, CA, USA, August 3-6, 2011. Proceedings 4, J. Schmidhuber, K. R. Thorisson, M. Looks, Eds. (Springer, 2011), pp. 370–375.
- 6J. Kirkpatrick , Overcoming catastrophic forgetting in neural networks. Proc. Natl. Acad. Sci. U.S.A. 114, 3521–3526 (2017).28292907 10.1073/pnas.1611835114 PMC 5380101 · doi ↗ · pubmed ↗
- 7R. Hadsell, D. Rao, A. A. Rusu, R. Pascanu, Embracing change: Continual learning in deep neural networks. Trends Cogn. Sci. 24, 1028–1040 (2020).33158755 10.1016/j.tics.2020.09.004 · doi ↗ · pubmed ↗
- 8D. Hassabis, D. Kumaran, C. Summerfield, M. Botvinick, Neuroscience-inspired artificial intelligence. Neuron 95, 245–258 (2017).28728020 10.1016/j.neuron.2017.06.011 · doi ↗ · pubmed ↗