Non-equilibrium active noise enhances generative memory in diffusion models
Agnish Kumar Behera, Alexandra Lamtyugina, Aditya Nandy, Daiki Goto, Carlos Floyd, Suriyanarayanan Vaikuntanathan

TL;DR
This paper shows that using active noise in diffusion models improves memory retention and helps generate complex structures more effectively.
Contribution
Introducing non-equilibrium active noise to enhance generative memory in diffusion models.
Findings
Active noise creates a memory effect by storing semantic information in temporal correlations.
Active mechanisms slow down information decay compared to passive Brownian motion.
Non-equilibrium protocols enable earlier and more robust symmetry breaking during generation.
Abstract
Generative diffusion models have emerged as powerful tools for sampling high-dimensional distributions, yet they typically rely on white gaussian noise and noise schedules to destroy and reconstruct information. Here, we demonstrate that driving the generative process out of equilibrium using active, temporally correlated noise sources fundamentally alters the information thermodynamics of the system. We show that coupling the data to an active non-Markovian bath creates a ‘memory effect’ where high-level semantic information (such as class identity or molecular metastability) is stored in the temporal correlations of auxiliary degrees of freedom. Using Fisher information analysis, we prove that this active mechanism significantly retards the rate of information decay compared to passive Brownian motion. Crucially, this memory effect facilitates an earlier and more robust symmetry…
Click any figure to enlarge with its caption.
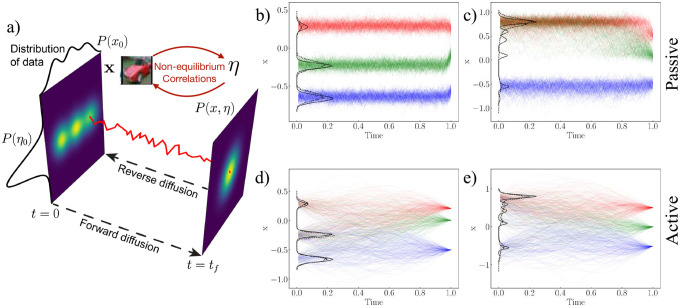 Figure 1
Figure 1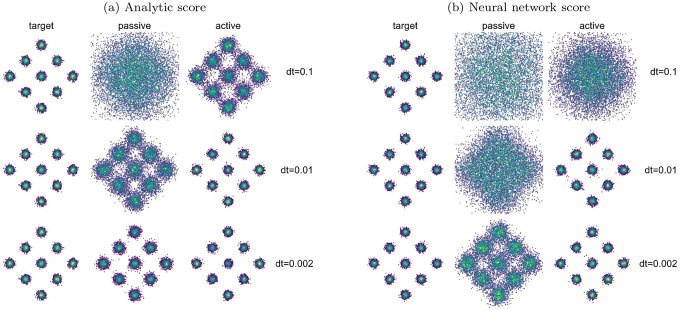 Figure 2
Figure 2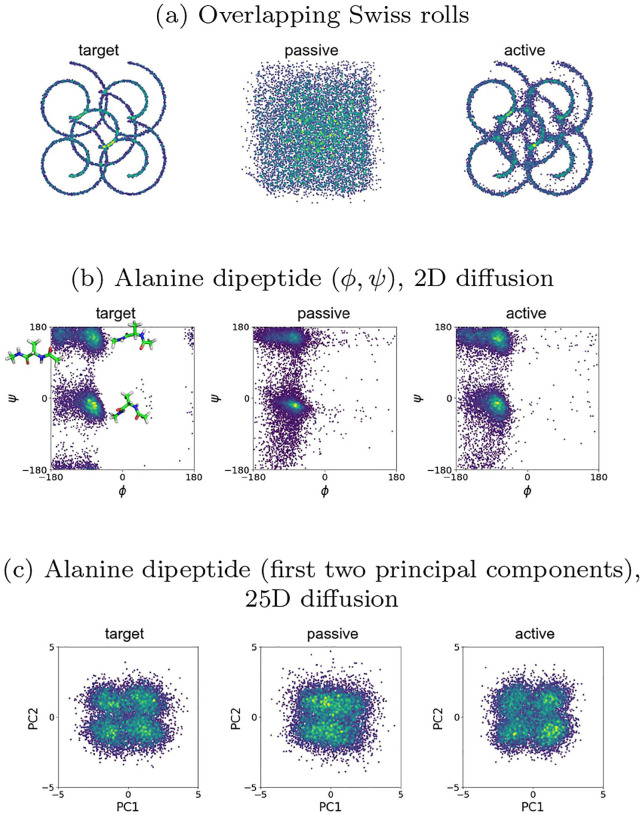 Figure 3
Figure 3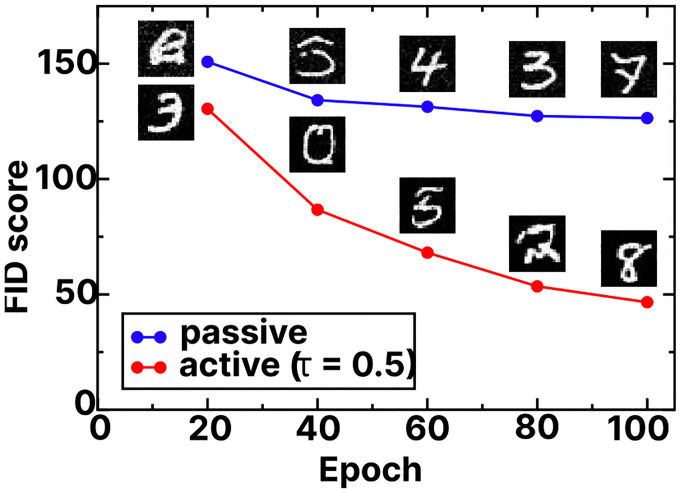 Figure 4
Figure 4 Figure 5
Figure 5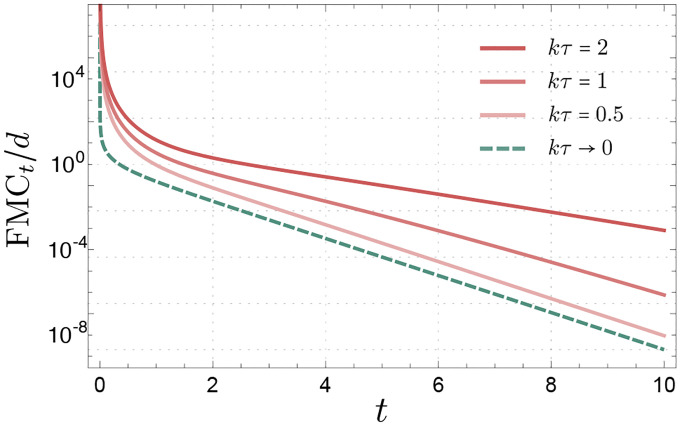 Figure 6
Figure 6 Figure 7
Figure 7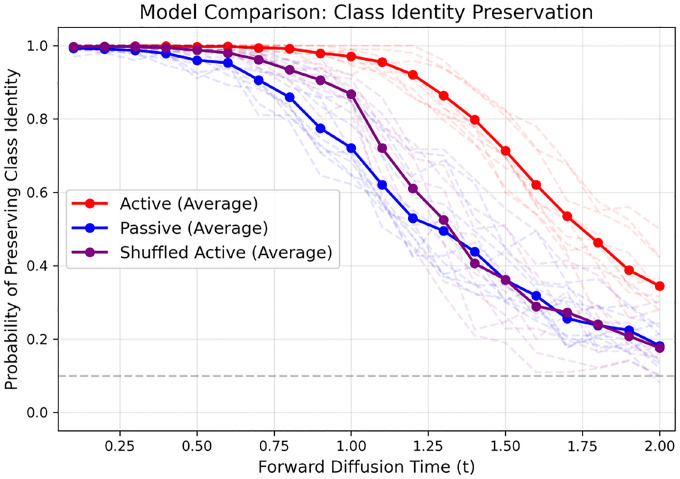 Figure 8
Figure 8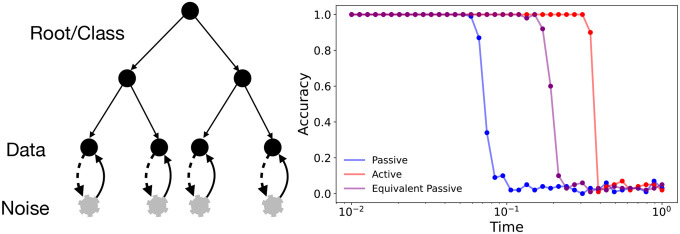 Figure 9
Figure 9Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsQuantum many-body systems · Advanced Thermodynamics and Statistical Mechanics · stochastic dynamics and bifurcation
INTRODUCTION
I.
Generative diffusion models are a class of machine learning models which have been used to parameterize and sample complex, high-dimensional distributions [1–3]. Their applications range from image synthesis [4] to scientific problems including sampling the distributions of molecular conformations [5, 6], turbulent flows [7], and geological modeling [8]. In these models, samples from the training dataset are first transformed into multidimensional Gaussian distributions (with variance specified by the hyperparameters of the model) through a process analogous to overdamped Brownian diffusion in a harmonic potential [2, 9]. In score-based diffusion models, during the “forward” phase, a neural network (NN) is trained to learn the score function of the distribution, which encodes information about how the data samples are progressively transformed into Gaussian white noise. This process, based on standard stochastic calculus techniques with inspiration from non-equilibrium thermodynamics [2], is very effective at parameterizing the unknown target distribution from which the training samples are drawn. Combined with machine learning architectures such as U-nets, this approach can produce new samples from a high-dimensional target distributions (e.g., images) that are strikingly similar to the original data [10, 11]. While much effort has focused on improving neural network architectures and training procedures [12–18], a fundamental question remains largely unexplored: what physical diffusion process is optimal for learning and sampling? Specifically, although the widely successful current score-based diffusion models [19] rely on a forward process governed by effectively, passive diffusion with uncorrelated Gaussian white noise [2, 9], there is little reason a priori to expect that the simplistic setting of overdamped Brownian dynamics provides in all cases the optimal physical model on which to base the diffusion process. Here, inspired by active matter physics, where particles exhibit persistent, correlated motion [20, 21], we ask: can generative diffusion with non-equilibrium dynamics akin to active matter, referred to as active diffusion below, help improve performance of these generative models?
We systematically validate the generative capabilities of this non-equilibrium framework across a hierarchy of complexity, ranging from low-dimensional toy models and molecular conformations to the model high-dimensional datasets. In scenarios governed by complex, multi-scale geometries we find that active diffusion significantly outperforms standard passive dynamics, faithfully reconstructing features that are otherwise washed out by uncorrelated noise (Fig. 1,Fig. 3a). To identify the physical mechanism driving this enhancement, we employ information-theoretic tools to quantify the system’s memory retention, revealing that active non-equilibrium dynamics possess a fundamentally slower rate of information decay [22] (Fig.6). We demonstrate the practical consequence of this extended memory by examining the stability of categorical information [23] within the MNIST landscape (Fig. 4), observing that active noise preserves the distinct structural features that define a specific digit significantly longer than passive methods. Crucially, we show that this robustness arises because the correlated auxiliary variables (Fig. 1) inherent to the active process do not merely act as noise; rather, they actively store the categorical identity of the data (Fig. 7). These results are supplemented by analytical characterization of a hierarchical data model [23] where we show how the active noise is able to guide recovery of categorical identity even when the noised data has completely lost this information. This again demonstrates how the non-equilibrium correlations due to the active dynamics can have beneficial generative consequences. We postulate that this feature effectively partitions the generative task: by offloading the maintenance of global class identity to the auxiliary active variables, the generative dynamics are liberated to focus their capacity on resolving fine-scale, local fluctuations. Consequently, rather than expending the reverse trajectory on rediscovering which image class to generate, the model can dedicate the diffusion process to refining the intricate microscopic realizations of that digit—a strictly advantageous regime that manifests as sharper resolution in multi-scale distributions and clearer separation of metastable molecular state. Finally, and consistent with the aforementioned findings, we show how the speciation times corresponding to active generative processes is sooner, allowing the generative process to focus on the finer structure. We finally note that correlations between data and active noise degrees of freedom when viewed through the lens of active matter leads to terms like active pressure or dissipation [20]. Our work shows how these same correlations can help with data generation in generative diffusion.
This paper is organized as follows. In Sec. II, we introduce the analytical theory of reverse-time diffusion in the presence of active noise-assisted forward process. In Sec. III we present the various datasets to which we apply our novel diffusion scheme and analyze its performance. Finally, in Sec. IV and Sec. V we propose possible mechanisms through which the correlated noise sources might be helping improve the generative properties of the diffusion process.
REVERSE-TIME DIFFUSION IN THE PRESENCE OF ACTIVE NOISE
II.
We first review one of the standard generative diffusion frameworks. We will refer to this as “passive” diffusion [10], and it is equivalent to the diffusion process described in Ref. [19]. In the passive forward process a given data distribution is evolved according to the following equation of motion:
where is the -dimensional data point and the Gaussian noise has the properties and for all , with denoting an ensemble average over independent noise realizations. This evolution systematically destroys the correlations in the data. The temperature and stiffness are hyperparameters that set the timescale of relaxation and the width of the multidimensional isotropic Gaussian distribution, with mean 0 and variance , that the system eventually settles into. The reverse diffusion process then reconstructs the data distribution back from the Gaussian distribution, with dynamics given by
where is the score function that helps guide the reverse trajectories to the original distribution [9]. The exact form of the score function depends on the initial distribution from which the data is drawn. For most distributions, the score function cannot be calculated analytically and is instead approximated from data using neural network models. The loss function guiding the construction of the neural network model is given as a mean-squared error between the true score function and that calculated from training data. Following [10], an expression for can be derived using
where is the data configuration at , and denotes an average with respect to the conditional (posterior) distribution . Using this, the mean-squared-error loss function is computed as
Here, is the neural network model for the score function, and denotes the weights of the neural network that are optimized using stochastic gradient descent algorithms.
Building on this existing framework, we now describe our “active” generative diffusion process. Under the influence of active noise, the forward process is
As shown in the schematic of Fig. 1, every “data” degree of freedom, , has an “active” degree of freedom, associated with its evolution. In essence the dimension of the system is increased from to , where is the dimension of the data. In Sec. A1 we show that the reverse diffusion for this process is given by
where and are the score functions for this process.
As in the passive case, one can construct the loss function for training the neural network as
Here and are two different neural networks used for approximating the score in and the score in , respectively. We derive the forms of and in Sec. A1. This choice leads to training of only the neural network for since becomes irrelevant for the reverse process.
In Fig. 1 (b–d), we qualitatively show how active and passive generative dynamics can start to differ for a simple one dimensional landscape. In Fig. 1 (b, d) we compare the trajectories seen in the two processes as they seek to recreate a distribution with three modes. In the passive case (b), trajectories commit to one of the modes early and then finer features are sampled. In the corresponding active case (d), the reverse process is more ergodic allowing the landscape to be better sampled. The benefits of such sampling are more dramatic in (c, e) where rare modes in the distribution are sampled much more efficiently in the active case. We note that such improvements in the sampling effectiveness are in line with theoretical work on the diffusion of active particles in rugged landscapes [24]. This result, on a minimal one dimensional setup, shows the potential promise of using active processes to enable generative diffusion. We also note that this qualitative result cannot be used to immediately comment on the so called speciation times in generative diffusion processes. We focus on that explicitly in the later part of the manuscript. We also note that a similar approach of expanding the dimensionality through additional degrees of freedom is taken in [25], which presents an underdamped passive Brownian diffusion process (referred to as critically-damped Langevin diffusion, CLD). In that case, destructive noise is not added to the data directly but instead to the degrees of freedom. Note however, that our method can access non-equilibrium regimes that are not allowed in the CLD method and hence these two are not equivalent. Indeed, in many cases (as reported in the SI), we find that the numerical performance of our method is better than the CLD method. Implementation details are discussed in Sec. A2. In the next section, we discuss various numerical experiments where we compare the performance of passive and active generative diffusion models.
REVERSE GENERATIVE DYNAMICS WITH ACTIVE SCORE FUNCTIONS
III.
The performance of score-based generative diffusion is governed by the ability to accurately learn the score function and efficiently evolve the equations of motion of the reverse diffusion process. In this section, we examine the effects of approximating the score function on the performance of passive and active diffusion. First, we examine diffusion performance on a target distribution for which the analytic form of the score is known. Then, we numerically approximate the score function with a multi-layer perceptron (MLP) from data and examine the effects of discretization of the learned score function in the sampling process of reverse diffusion. Details on the neural network architectures and numerical implementation are in Sec. A2.
Gaussian mixture 2D distribution: analytic score vs. score modeled by a neural network
A.
The score function for a simple distribution such as a mixture of Gaussian peaks can be expressed analytically. The analytical score functions for such distributions can be used to compare the performance of passive and active diffusion without needing to account for the learning performance of neural networks, since in this case the score functions are known exactly and do not need to be inferred from training data. In these numerical experiments, we investigate the performance with respect to the time step size for the reverse diffusion process. The time step step size is given by , where is the total time of a trajectory and is the number of sampling steps. For all diffusion trajectories presented here, .
The Gaussian mixture distribution is a typical simple distribution to test the performance of the neural networks in generating the reverse diffusion process. The score functions of Gaussian distributions have an exact analytic form. The data distribution we generate is given by
where denotes the dimension of the data, and describe the location of the mean and the corresponding variance, respectively, of the Gaussian in dimension, and represents the weight given to each of the Gaussian peaks in the mixture. The details of the derivation of the score functions for the passive and active processes are provided in Sec. A3.
We use a distribution where 9 Gaussians are spaced in a diamond formation (see Sec. A3 for parameters used to generate the distributions). We perform reverse diffusion using the analytical score function and the score function learned by a neural network (Fig. 2).
Using the analytical score function for the reverse process, we show in Fig. 2a that for large time step sizes ( and ), the active process outperforms its passive counterpart. If the time step is small enough ( ), both passive and active diffusion achieve comparable performance, and both are capable of faithfully reproducing the target distribution. When we use neural networks to learn the score function numerically for the same data distribution (Fig. 2b), passive and active processes show similar trends as in the analytical case in Fig. 2a, although the overall performance is lower than when the analytical score is used. We note that here, for exact comparison between the analytical case and the case with neural networks, we turn off denoising in the final step of the reverse diffusion process. Generally, for passive diffusion processes, the last step of reverse diffusion is carried out with only the drift term and the noise term is set to zero. This last denoising step has been observed to improve FID scores in image datasets [26]. In our case of active reverse diffusion, the denoising step has no effect as the denoising is applied to the dimension. However, in passive reverse diffusion, the denoising step affects the quality of the generated data since the denoising is applied to the data directly. Additional details are provided in Sec. A26.
Distributions with unknown score functions
B.
We next test the performance of passive and active diffusion on 2D distributions with reduced symmetry and increased multi-scale structure than the diamond of Gaussians. To compare passive and active processes, we consider a data distribution consisting of overlapping Swiss rolls (Fig. 3a) to test the method on a distribution for which the analytical form of the score function is not known. An important feature of this example is that the true distribution has structure at multiple length scales: both the position of the rolls and their interior structures need to be captured by the generative diffusion model. We use neural networks to learn the score functions, and, as in the Gaussian mixture model example, we observe that active diffusion outperforms passive diffusion (Fig. 2b). Additional results for this and other toy models are included in Sec. A3. We observe that the passive process is unable to generate the target distribution for all values of time step size and for the entire range of iterations that we have considered in Fig. A4, while the active process succeeds in accurately resolving both scales of the target distribution.
We also consider the alanine dipeptide molecule, a small model benchmark system whose fluctuations can be numerically simulated for long timescales to generate training data (Fig. 3b). We started with the geometry of the alanine dipeptide from a previous benchmarking study [27]. The details of the training data generation procedure are given in Sec. A4. For this sampling, we computed the Ramachandran dihedral angles for all conformations. Based on the energy landscape of the alanine dipeptide, three major conformations [28] emerge from the molecular dynamics simulation, with other conformations sampled less frequently. We use generative diffusion to resample the two-dimensional ( ) landscape. Relative to passive diffusion, active diffusion is able to better reproduce the conformational landscape sampled during molecular dynamics. In particular, the distribution of the Ramachandran dihedral angles of the conformation are better reproduced by active diffusion relative to passive diffusion. While the positions of the and angle distributions are also reproduced by both models, the separation between them is more evident in the samples generated by the active model in the same number of iterations.
We also perform diffusion on the full 25-dimensional dataset consisting of all of the parameters required to describe the conformation of an alanine dipeptide molecule (Fig. 3c). The score model for the diffusion of the 25D dataset was approximated with a U-net. To compare the effectiveness of the different types of diffusion to the training data, we visualize the first two principal components of the datasets.
As in the case of the lower-dimensional toy datasets, active diffusion better reproduces the target distribution at a lower number of training iterations than passive diffusion. Fig. A6 demonstrates the improvement in sample quality as the number of training iterations is increased.
Finally, we consider the MNIST dataset as an example of a well-studied, high-dimensional dataset. The MNIST dataset[29] is a widely used benchmark in machine learning, consisting of 70,000 grayscale 28×28 pixel images of handwritten digits (0–9) appearing as white pixels on a black background. The full dataset is partitioned into a standardized 60,000/10,000 train/test split. Although MNIST is simple compared to modern high-resolution image datasets such as ImageNet[30], it remains valuable for benchmarking due to its manageable size and well-defined evaluation metrics. These characteristics make it particularly suitable for investigating fundamental properties of diffusion models.
We trained both passive and active diffusion models using on the MNIST training set with the same underlying U-Net architecture and hyperparameters. To quantify the quality of samples, the Fréchet Inception Distance (FID) score[31] has emerged as the de facto standard for evaluating the quality of images produced by generative models. The FID score measures the statistical similarity between the distribution of real and generated images by comparing their activations in the feature space of a pre-trained neural network. FID scores are particularly valuable because they capture both the fidelity of individual generated samples and the diversity of the overall distribution. Lower FID scores indicate generated distributions that more closely match the real data distribution. Following standard practice, we employed the Inception-V3 network[32] pre-trained on ImageNet as the feature extractor for FID score calculations. While originally designed for RGB images at higher resolutions, we adapted the MNIST grayscale images by replicating the single channel across three channels and resizing from 28×28 to 299×299 pixels using bilinear interpolation before feeding them into the network. Features were extracted from the final pooling layer (2048-dimensional feature vectors), providing a rich representation space for comparing the statistical properties of image distributions. All FID scores were computed using the PyTorch implementation of FID.[33]
Computing the FID scores over training epoch number revealed notable differences between passive and active diffusion models. Across all training durations, active diffusion models consistently achieved lower (i.e. better) FID scores compared to the passive counterpart (Fig. 4). This difference was particularly pronounced in the early stages of training, suggesting that active diffusion accelerates the convergence to generating high-quality samples. Visual inspection of the generated samples revealed that a significant portion of the FID score improvement can be attributed to background quality of the MNIST digits. Samples from passive diffusion models frequently exhibited spurious white and gray specks in the background areas, particularly during early training stages. These artifacts gradually diminished with extended training but persisted even after 100 epochs. In contrast, active diffusion models consistently produced solid black backgrounds from relatively early in the training process, leading to cleaner sample generation and consequently better FID scores.
Finally, we trained both active and passive versions of the diffusion model on a CIFAR-10 dataset with parameters with 1000 diffusion steps. A total of ~ 2 × 10^5^ steps were used for training (see Appendix. 8 for details). The active version (the generated samples reported have an FID of 7.61) performs better than its passive counterpart in line with previous findings. We note that this FID score was obtained without any directed finetuning of the active generative diffusion algorithm. The typical tools used to improve FID scores in generative diffusion models, such as using noise scheduling etc, can also be readily applied and ported to the active context. Further, beyond the improvement in performance, as we detail in the next section, our work contributes new understanding for how non-equilibrium correlations have the potential to systematically improve generative diffusion.
ACTIVE GENERATIVE DIFFUSION PRESERVES MEMORY TRACES AND CLASS HISTORY LONGER
IV.
The observations in the previous sections raise a question: to what extent and over what time scale is the memory trace of the input data signal preserved in the active forward diffusion process? To address this question, we compute the Fisher memory curve (FMC), a measure initially introduced for reccurent neural networks in Ref. [22]. Defining the state vector , we consider two different input data: and its perturbed version . For the forward process with , the Kullback–Leibler (KL) divergence between two proximate distributions, conditioned on the two different initial inputs, is given by the following quadratic form:
where defines the spacetime Fisher memory matrix, and are the Jacobian and the covariance matrix of the forward SDE. The FMC is defined as the trace of over the spatial indices:
Notably, the FMC is a quantity independent of the provided input data and depends solely on the Jacobian and the noise statistics of the forward SDE under consideration (see e.g. Ref. [34]). As discussed in Refs. [22, 35], the FMC thus quantifies how much the system “remembers” its input over time as an inherent nature of the given dynamical system, independent of the input data statistics. Fig. 6 compares the FMC for various persistence times , where corresponds to the passive (white-noise) limit. As (and thus the activity) increases, the FMC exhibits a slower decay rate, indicative of a prolonged memory trace of the input signal.
One way to test this hypothesis it to look at how the “class structure” of a dataset decays with time. A large number of publicly available datasets – MNIST, CIFAR-10, ImageNet –to name a few, have labeled data with the labels corresponding to different classes. These classes can be understood as various distinct clusters of points in a high dimensional landscape. We can test our hypothesis by checking the rate at which the clusters collapse into a single clump of pure noise in high dimensions.
We test for preservation of class structure in the MNIST dataset under the passive and active forward processes. We hypothesize that information about the class is lost at a slower rate in active case than in the passive case. On top of this, the active degrees of freedom (dofs), , carry a significant part of the information about the class in the active case. To test this, we conduct the following numerical experiment which is inspired from Ref. [23] (see Fig. 7). We first learn the score functions for the passive and active processes by training the neural networks as described in Sec. II. Then we initialize the forward process with a random image from a specific class. We run the forward diffusion for a certain length of time, . This destroys the correlations between the pixels of the image and takes it closer to pure noise. We call this the partially noised image. Then we reverse the process starting from this partially noised image using the score function that was learned earlier. This reverse diffusion process generates a new image which could be from the same or different class that the forward process was initialized with. The classification of the images are performed using a LENet described in the github repository of Ref. [36]. We plot the statistics of how the fraction of the original recovered class as a function of in Fig. 8. We observe for the passive case, the class structure is lost rapidly as a function of forward time. For the active case it is much slower, but once we shuffle the active degrees of freedom at the beginning of the resampling process, the class recovery goes down to almost the same level as the passive case. This supports our hypothesis that active dofs carry significant information about the class structure.
To put this idea on a firmer footing, we followed Ref [23] and analyzed the effect of active noise using a hierarchical data model. Details of the calculation are in Appendix. A7. Specifically, we assume that the observed data at one level of the hierarchy is generated probabilistically from data at the previous level. The data at the lowest level is a proxy for the observed data while data at the highest, or root level, is a proxy for the class the data belongs to. In the context of MNIST images for example, class identity corresponds to the digit identity and finer details of how the digits are drawn are encoded in subsequent levels. We can explore the implication of memory traces due to active noise with these models. We begin by adding noise to the data at the finest level in a mimic forward noising process. We then compute as a function of noising time the class identity obtained at the root level in a denoising process (similar to the setup in Fig. 7. As in Fig. 7, we observe that class information is lost sharply in both the passive and active processes (Fig. 9). Importantly, information is retained longer in the active diffusion process as evidenced by the delayed transition. We note that at points prior to the delayed transition with the active dynamics, reverse dynamics applied on a marginal probability distribution with just the data degrees of freedom fail to recover the class information. In other words, even though the marginal data distribution has lost all information about its priors, this information can be recovered due to the active degrees of freedom. This again reinforces how the active noise degrees of freedom store crucial information about the data degrees of freedom. We note that correlations between and drive so called active pressure or dissipation in active matter systems [20]. Our work shows how these same correlations can help with data generation in generative diffusion. These findings are consistent with the empirical observations such as those in Fig. 2b where active diffusion is able to generate structure in a smaller number of steps. Indeed, since the active dynamics are able to generate root classes faster its not unreasonable to speculate that they can start to generate a reasonable description of the required data even with a small number of function calls.
FASTER SPECIATION WITH ACTIVE DYNAMICS
V.
The results of the previous section also suggest an intriguing connection between active dynamics and so called speciation times, i.e. the time at which the first data structures begin to emerge in the reverse diffusion process. Indeed, from Fig. 7 we might expect faster speciation times with active processes. Here, following Ref. [11], we show that with active noise, it takes a shorter amount of time for trajectories in the reverse process to choose their primary class of data. For instance, in the case of Gaussian mixture model, active diffusion will choose one of the Gaussian basins to fall into sooner than in passive diffusion. The details of the calculation are provided in Sec. A6. Comparing the expression for speciation time with active noise , where is the largest eigenvalue of the data covariance matrix to the expression for the passive case, , we observe that for a fixed target distribution and for the same passive and active temperature , (here the time, , is being measured in the forward diffusion process i.e. corresponds to the data distribution at the start of the forward process). Thus for the reverse diffusion process, the speciation happens faster in the active case when compared to passive case. Faster speciation would imply that more time can be spent sampling the various peaks in the data distribution, which could lead to better fine-scale resolution in the generated configurations.
CONCLUSION
VI.
In this work, we have explored how driving generative diffusion out of equilibrium with active, correlated noise fundamentally change generative properties. Standard diffusion models rely on passive, memoryless Brownian motion and we argue that this approach can inherently struggle to resolve multi-scale structures in rugged energy landscapes. By coupling the data to auxiliary active degrees of freedom (with some implicit memory) active generative diffusion provides a route to alleviate some of these issues.
Crucially, we identified physical mechanism driving this enhancement. Our theoretical analysis reveals that active dynamics facilitate an earlier symmetry breaking in the reverse generative process. This allows the system to lock into the correct “basin of attraction” (class identity) much earlier than in passive methods, allowing the remainder of the diffusion trajectory to focus on refining fine-grained local fluctuations. This separation of timescales is particularly advantageous for sampling metastable molecular conformations and multi-scale geometries, where passive methods frequently fail to cross high energy barriers. Further, we speculate that the active timescale , smooths the temporal variation of the score function, reducing the functional complexity that the neural network must approximate. This suggests that “physics-informed” choices in the diffusion process simplify the learning task itself.
Ultimately, our results suggest that the principles of active matter physics can be repurposed to engineer more robust generative models. This opens a new avenue for “active generative AI”, where the dynamics of learning are tuned not just for algorithmic convergence, but for thermodynamic efficiency in navigating high-dimensional landscapes
Supplementary Material
1
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Yang Ling, Zhang Zhilong, Song Yang, Hong Shenda, Xu Runsheng, Zhao Yue, Zhang Wentao, Cui Bin, and Yang Ming-Hsuan. Diffusion models: A comprehensive survey of methods and applications. ACM Computing Surveys, 56(4):1–39, 2023.
- 2Sohl-Dickstein Jascha, Weiss Eric, Maheswaranathan Niru, and Ganguli Surya. Deep unsupervised learning using nonequilibrium thermodynamics. In International conference on machine learning, pages 2256–2265. PMLR, 2015.
- 3Ho Jonathan, Jain Ajay, and Abbeel Pieter. Denoising diffusion probabilistic models. Advances in neural information processing systems, 33:6840–6851, 2020.
- 4Ramesh Aditya, Pavlov Mikhail, Goh Gabriel, Gray Scott, Voss Chelsea, Radford Alec, Chen Mark, and Sutskever Ilya. Zero-shot text-to-image generation. (ar Xiv:2102.12092), February 2021. ar Xiv:2102.12092 [cs].
- 5Bilodeau Camille, Jin Wengong, Jaakkola Tommi, Barzilay Regina, and Jensen Klavs F. Generative models for molecular discovery: Recent advances and challenges. Wiley Interdisciplinary Reviews: Computational Molecular Science, 12(5):e 1608, 2022.
- 6Wang Yihang, Herron Lukas, and Tiwary Pratyush. From data to noise to data for mixing physics across temperatures with generative artificial intelligence. Proceedings of the National Academy of Sciences, 119(32):e 2203656119, August 2022.
- 7Whittaker Tim, Janik Romuald A, and Oz Yaron. Turbulence scaling from deep learning diffusion generative models. Journal of Computational Physics, 514:113239, 2024.
- 8Lochner J., Gain J., Perche S., Peytavie A., Galin E., and Guérin E.. Interactive authoring of terrain using diffusion models. Computer Graphics Forum, 42(7):e 14941, October 2023.