Assessing performance, calibration, and explainability of machine learning versus traditional models for early outcome prediction after spontaneous intracerebral hemorrhage: a systematic review and meta-analysis protocol
Fan Bu, Rongzhen Xu, Xinyan Zhao, Qiaoxia He, Yandi Wen, Lile Xiong, Lan Qin, Hua Guan

TL;DR
This study will compare machine learning and traditional models for predicting outcomes after brain hemorrhage, focusing on accuracy, reliability, and explainability.
Contribution
A systematic review and meta-analysis protocol to evaluate machine learning versus traditional models for outcome prediction after ICH.
Findings
The study will assess discrimination, calibration, and explainability of ML models compared to traditional models.
It will use PRISMA-P guidelines and the PROBAST+AI tool for bias assessment.
Findings will guide future model design and clinical application for ICH prognosis.
Abstract
Early outcome prediction after spontaneous intracerebral hemorrhage (ICH) is critical for patient management and counseling. Although machine learning (ML) models are increasingly applied, their comparative performance and explainability relative to traditional statistical models remain unclear. To systematically compare the predictive performance, calibration, and explainability of ML versus traditional models for early outcomes after ICH. Following PRISMA-P guidelines and registered in PROSPERO (CRD420251166996), this systematic review and meta-analysis will include studies developing, validating, or comparing ML and traditional models for predicting early mortality or poor functional outcome (mRS ≥ 3 or GOS ≤ 3) after ICH. Data sources will include PubMed, Embase, Scopus, Web of Science, Cochrane CENTRAL, IEEE Xplore, and major Chinese databases (CNKI, Wanfang, VIP, CBM). Two…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
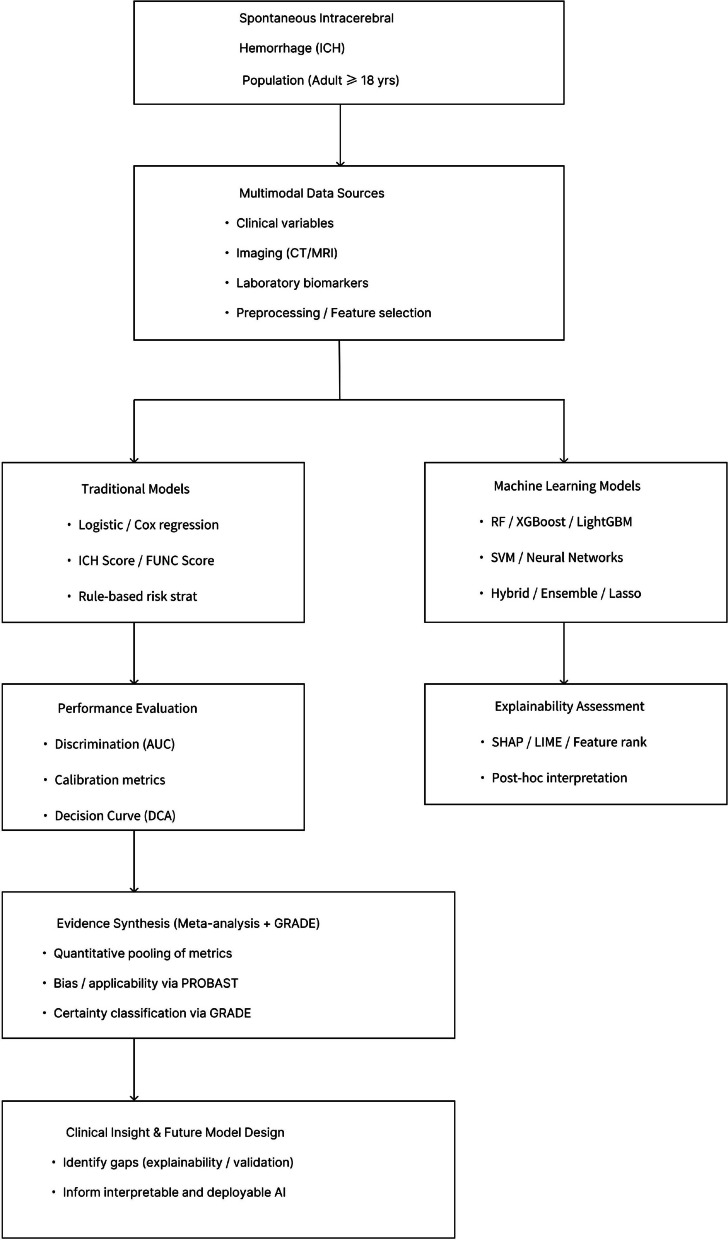 Figure 1
Figure 1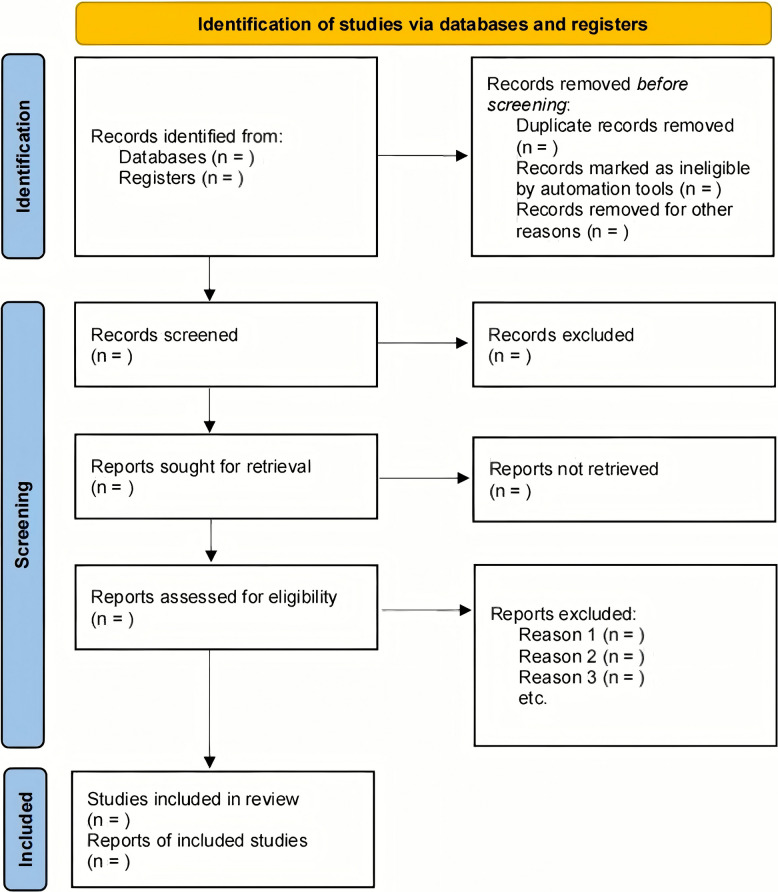 Figure 2
Figure 2- —Shenzhen Basic Research Project
- —Research Fund of Shenzhen Health Economics Association
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsIntracerebral and Subarachnoid Hemorrhage Research · Artificial Intelligence in Healthcare and Education · Acute Ischemic Stroke Management
Introduction
Spontaneous intracerebral hemorrhage (ICH) is a severe subtype of stroke characterized by spontaneous rupture of cerebral vessels and bleeding within the brain parenchyma [1]. Despite accounting for only 10–15% of all strokes, ICH contributes disproportionately to stroke-related mortality and long-term disability [2]. Early prediction of poor outcomes, such as death or severe functional dependence, is crucial for informing clinical management, prognostic counseling, and the design of interventional studies.
Over the past decade, machine learning (ML) techniques have gained increasing attention in prognostic modeling for ICH [3, 4]. These methods can handle complex, nonlinear interactions between high-dimensional variables, offering potential advantages over traditional regression-based models [5]. However, evidence regarding their comparative performance, calibration, and explainability remains limited and inconsistent. Existing studies vary substantially in design, sample size, data sources, feature selection, and validation methods, making it difficult to generalize their findings or draw consistent conclusions.
Moreover, recent advances in multimodal data integration—combining clinical, imaging, and laboratory information—have expanded the potential of ML-based prognostic tools. However, the lack of standardized feature definitions, heterogeneous preprocessing pipelines, and inconsistent validation practices across studies has hindered evidence synthesis and clinical translation.
In contrast, traditional statistical models—such as logistic or Cox regression—have been long established in clinical prediction research and remain the reference standard for outcome modeling [6, 7]. Yet, their predictive power may be constrained by linear assumptions and limited capacity to incorporate complex multimodal data. It is therefore essential to systematically evaluate whether ML-based approaches genuinely offer superior predictive value or simply reflect overfitting or data-specific performance gains.
This systematic review and meta-analysis aims to comprehensively evaluate and compare the predictive performance, calibration, and explainability of ML versus traditional models in forecasting early outcomes after spontaneous ICH. By identifying methodological strengths, weaknesses, and reporting gaps, this study will help clarify the clinical utility of ML-based models and guide future research toward robust, interpretable, and clinically meaningful prognostic tools in neurocritical care.
Ultimately, by providing a transparent comparison of ML and traditional models, this review will not only summarize current evidence but also establish a methodological framework to inform future model development, validation, and implementation in clinical neurocritical care. The conceptual framework of this review is shown in Fig. 1, outlining the comparative evaluation between ML and traditional prognostic models.Fig. 1. Comparative framework of ML vs. traditional models for ICH outcome prediction
Methods
Protocol and registration
This protocol has been developed in accordance with the PRISMA-P 2015 statement and the Cochrane Handbook for Systematic Reviews of Interventions [8, 9]. The protocol is prospectively registered in PROSPERO (CRD420251166996). All stages of the review—including literature search, study selection, data extraction, risk of bias assessment, and evidence synthesis—will follow predefined procedures to minimize bias and enhance consistency. Any substantive amendments will be justified in the final report and updated in the PROSPERO record.
Because this review synthesizes data from previously published studies, ethical approval is not required. The protocol was internally peer-reviewed by two independent senior researchers in neurocritical care and clinical prediction modeling as part of an institutional, non-commercial funding scheme. This work is supported by existing academic funding and represents a secondary extension of prior research conducted under these grants.
A completed PRISMA-P checklist is provided in Supplementary material S2. Methods for prognosis and prediction model reviews will also be considered where applicable.
Eligibility criteria
The eligibility criteria were established a priori according to the PICOS framework. Additional detail beyond the PROSPERO record is provided to enhance clarity and reproducibility.
Population
Adult patients (≥ 18 years) with spontaneous ICH confirmed by CT or MRI, typically admitted within 24–72 h of symptom onset. No restrictions on sex, ethnicity, country, or healthcare setting.
Exclusions
Non-spontaneous ICH (traumatic, aneurysmal, vascular malformation–related, or anticoagulant-induced), pediatric populations, animal/preclinical studies, or mixed cohorts without separable ICH data. For studies including mixed adult and pediatric populations, inclusion will require that at least 80% of participants meet the adult eligibility criteria, or that extractable subgroup data for adults are available.
Intervention (exposure)
Application of ML/AI-based predictive models for early clinical outcomes after ICH, including supervised techniques such as tree-based ensembles (random forest, gradient boosting, XGBoost, LightGBM), SVM, regularized regression (LASSO, ridge, elastic net), neural networks, and hybrid/stacked approaches. Inputs may include clinical, imaging, and laboratory variables [10–12].
Eligible when ML is used for feature selection, multimodal fusion, or model calibration.
Exclusions
ML used solely for image segmentation or diagnosis without outcome prediction; unsupervised clustering/descriptive analytics only; or purely traditional regression without algorithmic learning/penalization.
Comparator (control)
Traditional statistical models or clinical risk scores used for early outcome prediction after ICH (e.g., multivariable logistic regression, Cox models; ICH score, FUNC score, ICH-GS; and other rule-based prognostic tools). Studies must report at least one comparable performance metric (AUC, accuracy, sensitivity, specificity, or calibration indices).
In this review, “traditional models” refer to regression-based or rule-based prognostic models with explicit statistical formulations (e.g., logistic regression, Cox regression, and established clinical risk scores).
Exclusions
No comparator model; univariable associations only; or non-outcome tasks (e.g., hematoma expansion prediction alone).
Outcomes
Primary evaluation dimensions:
- Predictive performance (discrimination).
- AUC, accuracy, sensitivity, specificity, C-statistic.
- Calibration
- Brier score, calibration slope, intercept.
- Explainability
- variable importance and post hoc methods (e.g., SHAP, LIME) [13].
- Early clinical outcomes
- Mortality
- all-cause death within 30–90 days after ICH;
- Functional outcome
- mRS or GOS, with poor outcome defined as mRS ≥ 3 or GOS ≤ 3.
Secondary outcomes
Sample size and outcome prevalence; data source (single- vs multicenter); study design (retrospective vs prospective); feature selection and preprocessing; validation type (internal vs external); handling of missing data and class imbalance.
Where available, we will extract decision-analytic measures—including net benefit and decision-curve analysis (DCA)—to contextualize model performance at clinically relevant threshold probabilities. If DCA is not reported, we will compute it when sufficient aggregate data are provided.
Study design and setting
Eligible designs
Original, non-randomized studies developing, validating, or comparing predictive models (retrospective/prospective cohorts; registry-based/multicenter observational studies; secondary analyses of RCT datasets or large databases).
Exclusions
Reviews, meta-analyses, editorials, commentaries, conference abstracts without sufficient methodological detail, case reports, animal studies. Clinical/hospital settings only; no geographic or income-level restrictions.
To ensure methodological robustness, studies will be required to include at least 10 outcome events for model development or validation.
Information sources and search strategy
A comprehensive search will follow the Cochrane Handbook and PRISMA-P 2015 standards.
Electronic databases
From inception to final search date, we will search.
PubMed/MEDLINE; Embase (Embase.com); Cochrane CENTRAL; Scopus; Web of Science – SCI; IEEE Xplore; CNKI; Wanfang; VIP (CQVIP); CBM.
No restrictions on language, year, or country. Inclusion of Chinese databases mitigates language/publication bias and improves global representativeness [14].
Search strategy
Controlled vocabulary (MeSH/Emtree) and free-text terms related to ICH, ML/AI, and outcome prediction will be used with database-specific syntax.
The complete search strings for all databases are provided in Supplementary material S1.
The search will undergo independent PRESS peer review and will be re-run within two weeks prior to data extraction to capture newly indexed studies; any incremental inclusions will be tracked and reported in an updated PRISMA flow.
Grey literature and additional sources
Searches will include ProQuest Dissertations and Theses Global, preprint servers (medRxiv, arXiv), conference proceedings (neurology/stroke/AI), and backward citation tracking. Citation alerts will be set in PubMed and Scopus.
For non-English/Chinese reports, titles/abstracts will be screened using machine translation; potentially eligible full texts will be translated by bilingual researchers or professional services. Translation decisions and uncertainties will be logged and presented in Supplementary material.
Study selection process
Records will be de-duplicated in EndNote and screened in Rayyan by two independent reviewers (titles/abstracts, then full texts). Disagreements will be resolved by consensus or a third reviewer.
The study selection process will be illustrated in a PRISMA 2020 flow diagram (Fig. 2) documenting the number of records identified, screened, excluded, and included at each stage.Fig. 2PRISMA 2020 flow diagram illustrating the literature screening and study selection process
Quality assurance of the search
The strategy will undergo PRESS 2015 peer review. All modifications will be documented, and the search will be rerun immediately before data extraction.
Study selection and data management
Study selection
Two reviewers will independently screen records against eligibility criteria; full texts will be assessed for inclusion. Inter-reviewer agreement will be quantified using Cohen’s κ (κ ≥ 0.80 as excellent).
Data extraction
A piloted Excel form will capture.
Study details; participant characteristics; model characteristics; performance metrics; explainability methods; and study-level covariates. Multiple models per study will be extracted separately. Authors will be contacted for clarifications where needed. Cross-checks will resolve discrepancies.
To avoid double counting, we will identify overlapping cohorts (by institution, timeframe, registry) and preferentially include the most comprehensive or externally validated report. When multiple models per study are reported, we will pre-specify a hierarchy—externally validated > internally validated > apparent performance—and extract all models for qualitative synthesis while nominating one “index model” per study for primary pooling.
We will extract and document how missing data were handled in each included study. No imputation will be performed at the review level; all analyses will rely on reported study-level results.
Data management and storage
EndNote will manage references; Rayyan for screening; Excel for extraction/QA. A master decisions log will ensure auditability. Data will be stored on secure institutional servers with restricted access and version control. Upon review completion, the finalized dataset will be archived and may be made available to qualified researchers upon reasonable request following publication.
Risk of bias and quality assessment
The methodological quality and risk of bias of the included studies will be assessed using PROBAST + AI [15], which is specifically designed for evaluating the development and validation of prediction models. PROBAST + AI formally extends and replaces PROBAST-2019 by addressing additional sources of bias specific to machine learning and artificial intelligence–based prediction models. The use of PROBAST + AI ensures a structured and transparent evaluation of risk of bias and applicability across both ML and traditional statistical prediction models.
In parallel with PROBAST, we will pilot a brief TRIPOD-AI/PROBAST-AI–informed checklist focusing on AI-specific reporting domains, including predictor handling, feature leakage safeguards, preprocessing transparency, hyperparameter tuning, and external validation. This checklist will be used to qualitatively summarize the sufficiency of AI-related reporting; it will not alter PROBAST domain ratings but will be presented descriptively to highlight reporting consistency and completeness.
Assessment domains
PROBAST + AI evaluates key domains that contribute to potential bias and applicability concerns.
Participants, Predictors, Outcome, and Analysis [16]. Each signaling question within these domains will be answered as “Yes,” “Probably Yes,” “Probably No,” “No,” or “No information,” leading to a final judgment of low, high, or unclear risk of bias for each domain and overall.
Assessment process
Two reviewers will independently assess each included study using a standardized PROBAST + AI checklist, following a calibration exercise on a subset of studies. Disagreements will be resolved by discussion or consultation with a third reviewer with expertise in clinical prediction modeling. Development and validation phases will be evaluated separately when both are reported. Inter-rater reliability will be quantified using Cohen’s κ (κ ≥ 0.80 = excellent).
Presentation of quality assessment
Results will be presented in summary tables and as visualization plots generated in R 4.3 using the robvis package. Where feasible, sensitivity analyses will be conducted excluding studies at high risk of bias to examine the robustness of pooled estimates.
Data synthesis and statistical analysis
Overview
We will perform structured synthesis, quantitative meta-analysis where appropriate, and otherwise narrative synthesis (Cochrane guidance).
Analyses: R 4.3, packages metafor and meta.
Quantitative synthesis
With ≥ 3 comparable studies (e.g., AUC, C-statistic, calibration slope/Brier), random-effects (DerSimonian–Laird) pooling will be used; REML as a robustness check [7]. AUC may be logit-transformed; proportions via Freeman–Tukey transformation. Report 95% CIs.
When studies report multiple test sets from the same cohort, we will avoid dependency by selecting a single non-overlapping test set per cohort. For AUC pooling, if necessary, we will harmonize time horizons (e.g., 30–90 days) using author-reported aligned estimates; unmatched horizons will be summarized narratively.
Heterogeneity
Cochran’s *Q *and I^2^ (25/50/75% = low/moderate/high).
If I^2^ > 75%, explore via subgroup/meta-regression [17]. Prespecified subgroups: model type; data source; validation type; region; outcome type.
Planned moderators for meta-regression include:
Sample size (log-transformed), outcome prevalence, external vs internal validation, imaging inclusion (yes/no), multimodal inputs (clinical + imaging + labs), and region (Asia vs non-Asia). Meta-regression will be performed only when ≥ 10 studies contribute to a moderator.
Sensitivity analyses
Exclude high risk-of-bias studies; exclude small samples/lacking external validation [18]; apply alternative estimators (e.g., Hartung–Knapp–Sidik–Jonkman). Compare with main analyses.
We will construct a bias-resistant analysis set excluding studies at high risk of bias (overall PROBAST + AI“high”), studies without any form of validation, and studies with extreme class imbalance (outcome prevalence < 10% or > 90%) unless appropriate rebalancing was applied and reported.
Narrative synthesis
If pooling is infeasible, provide a structured narrative across performance, calibration, and explainability, with tables/figures.
Reporting bias and small-study effects
Formal funnel plots and statistical tests for funnel plot asymmetry were developed primarily for intervention-effect meta-analyses and are not appropriate for prediction model performance syntheses. Therefore, they will not be applied in this review. Instead, potential reporting bias will be assessed qualitatively by examining study characteristics, completeness of reporting, and availability of protocols or registrations.
Statistical significance
Two-sided tests; α = 0.05. Report per PRISMA 2020, with full code/parameters for reproducibility.
Confidence in the body of evidence
There is no single official GRADE approach specifically for prediction model performance syntheses. Accordingly, the following framework is intended to provide a descriptive and supportive summary, rather than a formal GRADE rating. We will therefore summarize confidence in the body of evidence using an adapted framework informed by GRADE principles for prognosis evidence, considering risk of bias (PROBAST + AI), inconsistency, indirectness, imprecision, and potential reporting bias [19]. Evidence summaries will be descriptively categorized (e.g., higher vs lower confidence) to aid interpretation, without implying formal GRADE ratings. Two reviewers will independently assess and summarize confidence in the body of evidence with calibration and consensus resolution. Summary tables will be prepared using structured evidence profiles; software such as GRADEpro GDT may be used solely as a reporting aid, without assigning formal GRADE certainty ratings [20].
We will adapt GRADE wording to the prediction context.
Inconsistency will follow I^2^ and overlap of confidence intervals; indirectness will consider deviation from spontaneous ICH populations or early time windows; imprecision will incorporate optimal information size for AUC differences ≥ 0.05; we will note situations where findings appear consistent across externally validated studies and clinically meaningful, while avoiding formal upgrading/downgrading decisions.
Patient and public involvement
No patients or members of the public were directly involved in the design, conduct, or reporting of this protocol. To enhance clinical relevance, outcome selection and interpretation frameworks were informed by consultation with clinical neurologists and data scientists experienced in ICH management and prognostic modeling.
Upon publication, we aim to deposit the cleaned extraction sheet, analytic code, and figure scripts in an open repository (e.g., OSF/GitHub) with a permanent DOI; any licensed database search strings will be shared in full in Supplementary material to maximize reproducibility.
Expected results
This systematic review and meta-analysis is expected to provide a comprehensive synthesis of the current evidence comparing ML and traditional statistical models for early outcome prediction following spontaneous ICH.
This review will summarize and compare reported discrimination and calibration of ML-based and traditional models, and explore whether performance profiles differ across model types and validation settings (e.g., internal vs. external validation and multimodal vs. unimodal inputs) [21].
Furthermore, the review is expected to highlight important heterogeneity in model design and validation practices across studies.
Specifically, differences are likely to emerge in sample size, feature selection techniques, data preprocessing strategies, and external validation efforts [22].
These methodological variations are anticipated to influence both predictive performance and generalizability of ML models.
The review will also summarize the degree to which model explainability has been incorporated into current ML approaches.
We will describe the extent to which interpretability techniques (e.g., SHAP, LIME, feature importance) are reported and evaluated. We will also identify gaps in explainability reporting and assessment across studies [23].
By quantitatively pooling available performance metrics, the meta-analysis will generate pooled estimates of discrimination and calibration, offering an evidence-based benchmark for future prognostic modeling efforts in ICH.
Subgroup and sensitivity analyses are expected to identify factors—such as validation type, model complexity, and study quality—that account for observed heterogeneity and may guide the design of more robust prediction frameworks.
Ultimately, this review aims to produce an evidence-informed summary of the strengths, limitations, and clinical applicability of ML-based versus traditional models.
The results are expected to inform clinical researchers, neurologists, and data scientists about the practical potential and current methodological gaps in applying ML for early prognostication after ICH, providing direction for future studies and the development of clinically implementable predictive tools.
Discussion and significance
Rationale and expected contribution
Spontaneous ICH remains one of the most devastating subtypes of stroke, characterized by high mortality and long-term disability despite advances in acute care. Accurate early prognostication is therefore crucial for guiding treatment decisions, resource allocation, and family counseling [24].
In recent years, the rapid growth of ML and artificial intelligence (AI) methods has offered new opportunities for enhancing prognostic modeling in neurological disorders. However, their comparative performance against traditional statistical models—and their interpretability in clinical contexts—remains incompletely understood.
This review will systematically evaluate and synthesize the available evidence on ML and traditional models for early outcome prediction after ICH. By quantitatively comparing predictive performance, calibration, and explainability, the study aims to clarify whether ML approaches truly offer superior predictive value or complementary advantages in clinical decision-making [25, 26]. The findings are expected to provide a methodologically rigorous and evidence-based overview that bridges the gap between computational innovation and bedside applicability.
Innovation and significance
The proposed review has several innovative aspects:
Comprehensive methodological scope
It integrates both English- and Chinese-language databases, thereby minimizing publication and language bias and ensuring global representativeness of the included evidence.
Tri-dimensional evaluation framework
It concurrently examines performance, calibration, and explainability, reflecting a holistic view of model quality rather than focusing solely on discrimination metrics.
Standardized quality appraisal
Risk of bias will be assessed using PROBAST + AI, and confidence in the body of evidence will be summarized using an adapted, GRADE-informed descriptive approach (without formal GRADE ratings).
Translational potential
By identifying methodological strengths and weaknesses, the findings will inform the development of future ML models that are both accurate and clinically interpretable, facilitating responsible implementation in neurocritical care [27].
Together, these features will make this review one of the first comprehensive efforts to systematically appraise ML versus traditional models for ICH outcome prediction.
Limitations and anticipated challenges
Several challenges are anticipated.
First, heterogeneity across studies in terms of patient populations, imaging protocols, model development procedures, and outcome definitions may limit the feasibility of quantitative pooling [28].
Second, reporting quality and incomplete data (e.g., missing calibration metrics or external validation) may hinder direct comparison between models.
Third, the rapid evolution of ML methods may lead to time-related publication bias, as newer algorithms may not yet be extensively validated or published.
To mitigate these challenges, the review will apply robust inclusion criteria, standardized data extraction templates, and sensitivity analyses to ensure methodological consistency and interpretative clarity.
Where quantitative synthesis is not feasible, a structured narrative synthesis will be presented to summarize patterns and highlight key research gaps.
Future directions and clinical relevance
The findings of this review are expected to guide both researchers and clinicians toward more reliable and interpretable predictive modeling practices [29].
Future research should focus on:
Conducting prospective, multicenter validations of ML-based prognostic tools [30];
Integrating multimodal data (e.g., clinical, imaging, and biomarker information) to enhance model robustness [31]; and.
Establishing standardized reporting frameworks (e.g., TRIPOD-AI, PROBAST-AI) to improve transparency and reproducibility in prognostic modeling [32, 33].
Ultimately, this review will contribute to advancing precision medicine in neurocritical care, promoting the responsible use of ML in the management of ICH, and supporting the translation of data-driven models into clinical practice.
Supplementary Information
Supplementary Material 1. Search Strategy. Detailed database search strategies including MeSH/Emtree terms and Boolean operators.Supplementary Material 2. PRISMA-P 2015 Checklist. Completed checklist indicating adherence to each PRISMA-P item.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1GBD 2019 Stroke Collaborators. Global, regional, and national burden of stroke and its risk factors, 1990–2019: a systematic analysis for the Global Burden of Disease Study 2019. Lancet Neurol. 2021;20(10):795–820.10.1016/S 1474-4422(21)00252-0PMC 844344934487721 · doi ↗ · pubmed ↗
- 2Miranda C, Tianjing L, Matthew J P, Jacqueline C, Vivian A W, Julian Pt H, et al. Updated guidance for trusted systematic reviews: a new edition of the Cochrane Handbook for Systematic Reviews of Interventions. Cochrane Database Syst Rev. 2019;10:ED 000142.10.1002/14651858.ED 000142 PMC 1028425131643080 · doi ↗ · pubmed ↗
- 3Obaid Ur Rehman K, Hanzala Ahmed F, Rayyan N, Hamna H. Advancements in prognostic markers and predictive models for intracerebral hemorrhage: from serum biomarkers to artificial intelligence models. Neurosurg Rev. 2024;47:382.10.1007/s 10143-024-02635-239083096 · doi ↗ · pubmed ↗
- 4Karel G M M, Johanna A A D, Tabea K, Lotty H, Constanza AN, Paula D, et al. PROBAST+AI: an updated quality, risk of bias, and applicability assessment tool for prediction models using regression or artificial intelligence methods. BMJ. 2025;388:e 082505.10.1136/bmj-2024-082505 PMC 1193140940127903 · doi ↗ · pubmed ↗
- 5Caspar J VL, Sara v E, Eli-Boaz C. Selecting relevant moderators with Bayesian regularized meta-regression. Res Synth Methods. 2023;14(2):301–322.10.1002/jrsm.162836797984 · doi ↗ · pubmed ↗
- 6Cheng-Chang Y, Oluwaseun Adebayo B, Lung C, Jia-Hung C, Chien-Tai H, Yi-Ting H, et al. Risk factor identification and prediction models for prolonged length of stay in hospital after acute ischemic stroke using artificial neural networks. Front Neurol. 2023;14:1085178.10.3389/fneur.2023.1085178 PMC 994779036846116 · doi ↗ · pubmed ↗
- 7Khalid S, Ahmed YA, Mostafa Hossam El Din M, Ibrahim S, Abdallah A, Ahmed ES. Automated Emergent Large Vessel Occlusion Detection Using Viz.ai Software and Its Impact on Stroke Workflow Metrics and Patient Outcomes in Stroke Centers: A Systematic Review and Meta-analysis. Transl Stroke Res. 2025(16):2258–227.10.1007/s 12975-025-01354-0PMC 1259629940335883 · doi ↗ · pubmed ↗
- 8Adrian M, Dhaval K, Vaibhav A, Kristin S, Eduardo C, Christian l F, et al. Optimizing stroke lesion segmentation: A dual-approach using Gaussian mixture models and nn U-Net. Comput Biol Med. 2025;192:110221.10.1016/j.compbiomed.2025.11022140318493 · doi ↗ · pubmed ↗