Self-supervised learning on graphs predicts non-coding RNA and disease associations
Qingwen Wu, Sujuan Tang

TL;DR
This paper introduces SSLGRDA, a self-supervised learning method that improves the prediction of non-coding RNA-disease associations using graph-based models.
Contribution
SSLGRDA combines self-supervised learning and machine learning to robustly predict ncRNA-disease associations with high generalization.
Findings
SSLGRDA outperforms state-of-the-art methods in predicting ncRNA-disease associations.
The model demonstrates strong generalization across nine ncRNA-disease datasets.
Case studies confirm SSLGRDA's ability to discover potential ncRNA-disease links.
Abstract
Non-coding RNAs (ncRNAs) play crucial roles in regulating the initiation and progression of various cancers. Accurate identification disease-related ncRNAs would provide a unique opportunity to design better therapeutic interventions. Graph convolutional network-based methods have been proposed to identify potential ncRNA-disease associations (RDAs). However, some methods only use the graph structure and ignore the similarity information of nodes, and some methods integrate multi-source relation data which will introduce noise and have poor generalization. Learning robust node embeddings using graph convolutional network to build RDA predictive frameworks with high generalization remains a key challenge. We proposed a new RDA prediction scheme, SSLGRDA, composed of graph self-supervised learning and machine learning. Since SSLGRDA works on both heterogeneous and homogeneous graphs, we…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
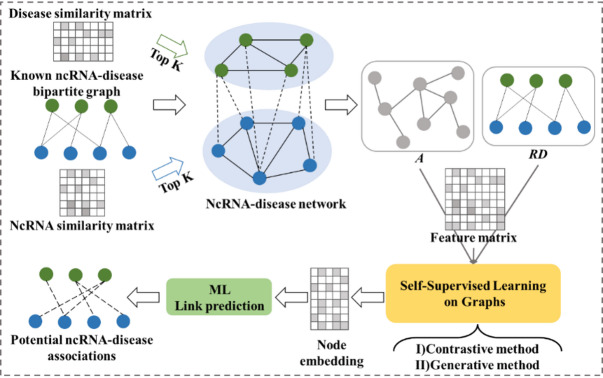 Figure 1
Figure 1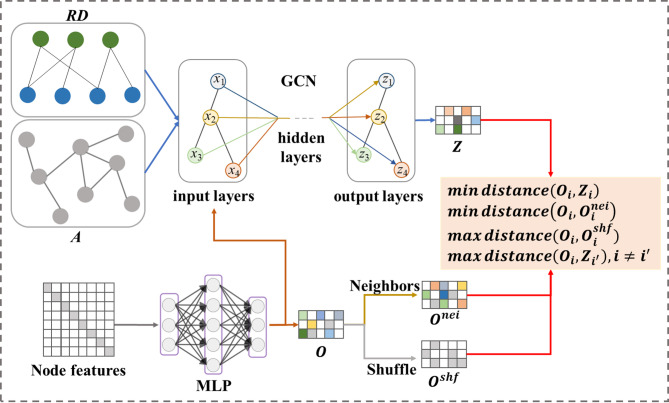 Figure 2
Figure 2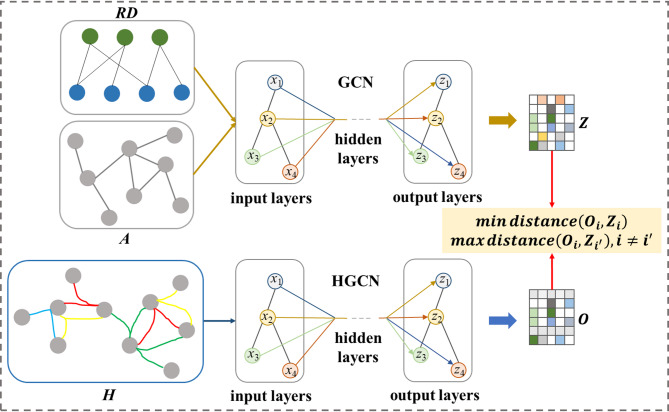 Figure 3
Figure 3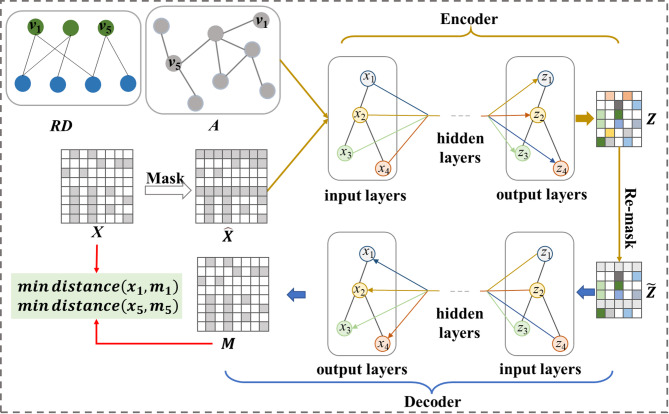 Figure 4
Figure 4 Figure 5
Figure 5- —Clinical Research Fund of Affiliated Hospital of Jining Medical University
- —PhD Research Foundation of Affiliated Hospital of Jining Medical University
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsCancer-related molecular mechanisms research · Machine Learning in Bioinformatics · MicroRNA in disease regulation
Introduction
As a template for protein synthesis, messenger RNAs (mRNAs) have become the major research focus for a long time, while non-coding RNAs (ncRNAs) were considered as by-products of massive transcription with less biological meaning^1^. Pervasive transcription produces a vast repertoire of ncRNAs of all sizes and shapes, including microRNAs (miRNAs), long non-coding RNAs (lncRNAs), and circular RNAs (circRNAs)^2^. Work from the past decade has altered our perception of ncRNAs from ‘junk’ transcriptional products to functional regulatory molecules that mediate cellular processes including chromatin remodeling, transcription, post-transcriptional modifications and signal transduction^3^. Most ncRNAs are now known as key regulators in various networks in which they could lead to specific cellular responses and fates. Especially in major malignant diseases, ncRNAs have been identified as oncogenic drivers and tumor suppressors^4^.
Clinicopathological findings and studies have elucidated the multi-faceted and frequently divergent effects ncRNAs impose both directly and indirectly on the formation and progression of complex disease. Potential new therapeutic targets and strategies have been identified from these findings, which may pave the way for further translational research and potentially advance clinical applications. Traditional experimental methods remain the most reliable approach for identify ncRNA-disease associations (RDAs), but the process is complex and time-consuming. Computational tools can augment existing knowledge, guide biological and biomedical applications and reduce costly experimental efforts. Widely used strategies for computationally predicting ncRNA-disease associations can be broadly categorized into three main classes: matrix transformation (MT), machine learning (ML), and graph neural network (GNN)-based methods.
MT strategy mainly uses matrix factorization algorithm. MFLDA^5^ decomposed lncRNA-disease heterogeneous matrix into low-rank matrices by matrix tri-factorization and optimized, and then the association matrix was reconstructed using the optimized low-rank matrices. MRLDC^6^ developed a matrix factorization with dual manifold regularization to infer potential circRNA-disease associations. However, those methods are shallow learning ones which cannot fully extract deep and complex associations between ncRNAs and diseases. DBN-MF^7^ applied deep belief network-based matrix factorization to predict miRNA-disease association. DBN-MF only rely on the confirmed real existing associations, but ignores ncRNA and disease attribute information. CKA-HGRTMF^8^ proposed a ncRNA-disease association prediction method of three-matrix factorization with hypergraph regularization terms (HGRTMF) based on central kernel alignment (CKA). Nevertheless, CKA-HGRTMF requires multiple ncRNA/disease similarity information to improve model performance. RNMFLP^9^ combined robust nonnegative matrix factorization and label propagation algorithm to predict circRNA-disease associations. These methods rely on the definition of similarity. At present, it is difficult to have an evaluation method to illustrate the accuracy of the definition of similarity. Therefore, the matrix-based method has the problem of how to verify the rationality of the definition of similarity, and the balance between avoiding noise and introducing more evidence should be carefully taken into consideration.
ML strategy mainly uses traditional machine learning and convolutional neural network (CNN) algorithms. MDA-CNN^10^ employed an autoencoder to learn the essential features of each miRNA-disease pair and utilized a convolutional neural network to predict the final label. RFLDA^11^ implemented a random forest and feature selection based lncRNA-disease prediction model. CDASOR^12^ proposed a method for predicting circRNA-disease associations based on convolutional and recurrent neural networks. Deepthi et al.^13^ introduced an ensemble method (AE-RF) by combining a deep autoencoder and a random forest to predict circRNA-disease association. Although CNN can extract latent features effectively, it can only learn local interactive features, but not global features. Additionally, most of the above methods ignore the topological information of ncRNA-disease network, and unable to learn the high order relations between them.
However, standard ML and CNN-based methods often treat associations as independent samples, largely ignoring the complex topological information of the ncRNA-disease network and the high-order relations between nodes. Recently, due to the strong modeling ability of graph convolutional network (GCN) on graph structure data, and the biochemical relation-ship between ncRNA and disease can be regarded as graph structure, GCN algorithm has gradually been used to predict unknown RDAs. GATMDA^14^ proposed a novel attention-based framework to integrate multi-source information effectively. Similarly, GGAECDA^15^ explored high-order graph correlations to enhance prediction accuracy, while NAGTLDA^16^ introduced a robust learning strategy to mitigate data noise and sparsity issues. These works highlight the growing importance of learning robust representations from complex graph structures. LR-GNN^17^ presented a graph neural network based on link representation to identify potential ncRNA-disease associations. LR-GNN applied a GCN-encoder to obtain node embedding and designed a propagation rule that captures the node embedding to construct the link representation. However, it ignored the semantic feature of the RDA network. GMNN2CD^18^ employed a graph Markov neural network algorithm to predict unknown circRNA-disease associations. MINIMDA^19^ fused mixed high-order neighborhood information of miRNAs and diseases in multimodal networks via GCN, and feed them into the multilayer perceptron to predict miRNA-disease underlying associations. Nevertheless, integrating different types of data effectively is a challenging task. Considering the heterogeneity of RDA networks, researchers introduced multiple association data to construct heterogeneous graphs, and used heterogeneous GCNs to identify unknown RDAs. However, reliable labeling data is expensive and difficult to obtain, and fusing multi-source data may bring the noise to the models. Overall, although GCN models have achieved remarkable success in the task of ncRNA-disease association prediction, they rely on a large amount of annotated association data on the one hand and rich feature transformation operations on the other. This leads to the disadvantages of severe label dependence, poor generalization and over-parameterized. Therefore, it is still a challenge to build GCN models with high generalization ability based on RDA network that can learn more effective representations from limited labeled data.
Inspired by the significance of graph self-supervised learning methods, we construct a Graph Self-Supervised Learning (SSL) Prediction scheme and named SSLGRDA. The flowchart of SSLGRDA is shown in Fig. 1. Simply put, given an ncRNA disease association graph and node attribute features, we obtain node embedding using SSL contrastive method or generative method, and then feed them into ML for link prediction. This framework provides a new simple and effective solution for solving homogeneous or heterogeneous graph-based RDA prediction problems.Fig. 1. The flowchart of SSLGRDA. Mining robust node representation using graph self-supervised learning. Based on different self-supervised learning modes and input structures, SSLGRDA is further divided into six sub-models. See Materials and methods for details.
Materials and methods
In order to comprehensively evaluate model generalization, we collected multiple ncRNA-disease datasets from different literatures, which are widely used for RDA prediction. Specifically, Human circRNA-disease association (CDA) dataset was downloaded from CircR2Disease^20^. CircRNA similarity and disease similarity was downloaded from CKA-HGRTMF and GMNN2CD, respectively. In addition, we constructed another circRNA-disease association dataset based on^21^. Human lncRNA-disease association (LDA) dataset was downloaded from LncRNADisease^22^ and MNDR^23^. LncRNA similarity and disease similarity were downloaded from MFLDA, IDSSIM^24^ and MCGLDA^25^, respectively. Human miRNA-disease association (MDA) datasets were downloaded from HMDD2.0^26^ and HMDD3.0^27^, respectively. MiRNA similarity and disease similarity were downloaded from CKA-HGRTMF and MINIMDA, respectively.
Table 1 shows the statistical information of each ncRNA-disease dataset. CDA1 contains 585 circRNAs and 88 diseases, and 650 CDAs. CDA2 contains 590 circRNAs and 88 diseases, and 650 CDAs. CDA3 contains 533 circRNAs and 89 diseases, and 595 CDAs. LDA1 contains 240 lncRNAs and 386 diseases, and 2093 LDAs. LDA2 contains 89 lncRNAs and 190 diseases, and 1529 LDAs. LDA3 contains 194 lncRNAs and 128 diseases, and 577 LDAs. MDA1 and MDA2 contain 495 miRNAs and 383 diseases, and 5430 MDAs. MDA3 contains 788 miRNAs and 374 diseases, and 8968 MDAs. It is worth noting that the above ncRNA-disease datasets differ by the ncRNA (and disease) similarities, as each work has their own approach to processing.Table 1. The statistical information of ncRNA-disease datasets.DatasetNcRNAsDiseasesLinksSparsenessSourceCDA1585886500.0126PMID:33,443,536CDA2590886510.0125PMID: 32,241,268CDA3533895950.0125PMID: 35,157,027LDA124038620930.0225PMID:29,228,285LDA28919015290.0904PMID:32,736,513LDA31941285770.0232PMID:32,153,646MDA149538354300.0286PMID:35,524,503MDA249538354300.0286PMID:33,443,536MDA378837489680.0304PMID:35,524,503
NcRNA-disease heterogeneous graph
Given r ncRNAs and d diseases, they are regarded as two types of vertices, and the associations between them are regarded as edges, which constitutes a heterogeneous graph of ncRNAs and diseases. The adjacency matrix is denoted by \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$RD \in {\mathbb{R}}^{r \times d}$$\end{document} . If there is a known association between ncRNA i and disease j, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$RD_{i,j} = 1$$\end{document} , otherwise \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$RD_{i,j} = 0$$\end{document} .
NcRNA-disease homogeneous graph
Furthermore, we ignore types of nodes and edges, and combine RD, ncRNA similarity and disease similarity to construct ncRNA-disease homogeneous graph. Specifically, the ncRNA similarity is represented by SR ∈ \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathbb{R}}$$\end{document} ^r×r^, and the disease similarity is denoted by SD ∈ \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathbb{R}}$$\end{document} ^d×d^. We only consider the top k (set to 5 based on our previous work GAERF) most similar lncRNAs (or diseases) for each row in the SR (or SD), and set them values to 1, the other values in the same row to 0. This threshold was selected to ensure that each node has sufficient neighbors for effective feature aggregation while avoiding the introduction of noise from weakly correlated nodes. After preprocessing, we obtain new similarity matrix SR (or SD). Then, we spliced SR, SD and RD together to form an ncRNA-disease homogeneous graph. The adjacency matrix A \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\in {\mathbb{R}}^{{\left( {r + d} \right) \times \left( {r + d} \right)}}$$\end{document} of the homogeneous graph can be represented as
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$A = \left[ {\begin{array}{*{20}c} {SR} & {RD} \\ {RD^{T} } & {SD} \\ \end{array} } \right]$$\end{document}In this way, on the one hand, the similarity information can be used to expand the graph structure, and on the other hand, it can prevent the generation of isolated nodes during cross-validation, that is, if a node has only one edge, dividing the edge into the test set during cross-validation will cause the node to an isolated node, which makes graph convolutional network unable to learn its neighbor nodes information.
Self-supervised learning on graphs
In recent years, due to the problems of over-fitting, poor generalization, and weak robustness of graph supervised or semi-supervised learning, self-supervised learning on graph (SSLG) has become a promising and trending learning paradigm for graph data^28,29^. In SSLG, models are learned by solving a series of handcrafted pretext tasks, in which the supervision signals are acquired from data itself automatically without the need for manual annotation. With the help of well-designed pretext tasks, SSLG enables the model to learn more informative representations from unlabeled data to achieve better performance, generalization and robustness on various downstream tasks.
Existing SSLG methods can be roughly divided into two categories: contrastive method^30–32^ and generative method^33,34^. Contrastive methods use information on commonalities and differences between data-data pairs as self-supervision signals by comparing different views. Generative methods focus on the information inside the graph data, generally based on tasks such as feature/structure reconstruction, and use the attributes and structure of the graph itself as a supervision signal. In this study, combined with the ncRNA-disease networks, we explore effective node embedding learning frameworks through above two approaches, aiming to build high-performance, generalized and robust predict models.
Contrastive method
Contrastive method aims to learn the commonality information of different views of the same node and the difference information of different views of different nodes. Inspired by SUGRL^30^ and HCCF^31^, we implement the contrastive learning of different views through multiple strategies, and further classify them into homogeneous SSLG and heterogeneous SSLG according to the input graph structure.
The first strategy, we compare graph structure features and attribute features and call it SSLG_GM (see Fig. 2), which has strong scalability, computationally inexpensive, and can generate high-quality representations.Fig. 2. Framework of contrastive method SSLG_GM. With given graph data, GCN and MLP are applied to learn the structural features \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Z$$\end{document} and attribute features \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$O$$\end{document} respectively. Randomly shuffle attribute features as negative sample features \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$O^{shf}$$\end{document} and constructing local features \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$O^{nei}$$\end{document} using neighborhood node features. The graph self-supervised learning model learns robust node representations by minimizing the feature distance of positive sample pairs and maximizing the feature distance of negative sample pairs.
Specifically, given an ncRNA-disease homogeneous graph adjacency matrix A and node feature matrix X \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\in {\mathbb{R}}^{{\left( {r + d} \right) \times \left( {r + d} \right)}}$$\end{document} (composed of One-Hot Encoding), we use Multi-Layer Perceptron (MLP) and LightGCN^35^ to learn attribute feature \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$O$$\end{document} and node structure feature \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Z$$\end{document} , respectively,
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$O = \sigma \left( {XW_{o} } \right)$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Z = \sigma \left( {\hat{A}O} \right)$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$W_{o} \in {\mathbb{R}}^{{\left( {r + d} \right) \times n}}$$\end{document} is learnable weights matrix, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hat{A} = D^{{ - \frac{1}{2}}} \left( {A + I} \right)D^{{ - \frac{1}{2}}}$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$D$$\end{document} is the degree matrix and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$I$$\end{document} is the identity matrix, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\sigma \left( \cdot \right)$$\end{document} denotes the ReLU activation function. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Z$$\end{document} will be used for downstream tasks, and we call this sub-model SSLG_GM_homo.
For node \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$i$$\end{document} , we compute the feature representation \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$O_{i}^{nei}$$\end{document} of its neighbors according to the adjacency matrix A
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$O_{i}^{nei} = \frac{1}{n}\mathop \sum \limits_{j = 1}^{n} O_{j} , if A_{i,j} = 1$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n$$\end{document} is the number of sampled neighbors. To generate negative sample views, we randomly shuffle the attribute feature matrix \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$O$$\end{document} row-wise and denote as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$O^{shf}$$\end{document} .
For SSLG methods, either reducing the intra-class variation or enlarging the inter-class variation has been demonstrated to be an effective solution to reduce generalization error^30^. Therefore, the multiple loss for contrastive learning between different views is formulated as
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathcal{L}}_{1} = \frac{1}{m}\mathop \sum \limits_{i = 1}^{m} max\left\{ {0,d\left( {O,O^{nei} } \right) - d\left( {O,O_{i}^{shf} } \right) + \alpha } \right\}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathcal{L}}_{2} = \frac{1}{m}\mathop \sum \limits_{i = 1}^{m} \max \left\{ {0,d\left( {O,Z} \right) - d\left( {O,O_{i}^{shf} } \right) + \alpha } \right\}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathcal{L}}_{3} = \frac{1}{m}\mathop \sum \limits_{i = 1}^{m} \max \left\{ {0,d\left( {O,Z} \right) - d\left( {O,O_{i}^{shf} } \right) - \alpha - \beta } \right\}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathcal{L}}_{ctr} = \lambda_{1} {\mathcal{L}}_{1} + \lambda_{2} {\mathcal{L}}_{2} + \lambda_{3} {\mathcal{L}}_{3}$$\end{document}where m is the number of negative samples, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$d\left( \cdot \right)$$\end{document} is L2-norm distance measurement, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\alpha$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\beta$$\end{document} are non-negative tuning parameters, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda_{1}$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda_{2}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda_{3}$$\end{document} are the weights of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathcal{L}}_{1}$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathcal{L}}_{2}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathcal{L}}_{3}$$\end{document} , respectively. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathcal{L}}_{1}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathcal{L}}_{2}$$\end{document} are able to the enlarge inter-class variation, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathcal{L}}_{3}$$\end{document} can reduce intra-class variation.
Furthermore, given that node initial features are represented by one-hot encoding, adding supervision information helps to learn high-quality node embeddings. Therefore, pairwise marginal loss is introduced as the supervise signal, which is defined as
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathcal{L}}_{sup} = \mathop \sum \limits_{i = 1}^{k} \mathop \sum \limits_{j = 1}^{s} {\mathrm{max}}\left( {0, 1 - pos_{i,j} + neg_{i,j} } \right)$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$k$$\end{document} denotes the number of training samples, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$s$$\end{document} denotes the number of positive and negative samples corresponding to node i, pos and neg represent the prediction scores of positive and negative samples, respectively. Finally, we integrate the supervise loss \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathcal{L}}_{sup}$$\end{document} with the contrastive loss \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathcal{L}}_{ctr}$$\end{document} into a unified objective as
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathcal{L}} = \lambda_{4} {\mathcal{L}}_{sup} + \lambda_{5} {\mathcal{L}}_{ctr}$$\end{document}The sub-model applied to the heterogeneous graph is called SSLG_GM_hete. SSLG_GM_hete contains two GCN modules and two MLP modules for learning feature representations for different views of ncRNA and disease, respectively. Due to some nodes in the heterogeneous graph have only one neighbor or no neighbors, we use the InfoNCE loss to train the model. The InfoNCE loss is defined as follows:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathcal{L}}_{rna} = \mathop \sum \limits_{i = 1}^{r} - log\frac{{{\mathrm{exp}}\left( {sim\left( {O_{i} ,Z_{i} } \right)/\tau } \right)}}{{\mathop \sum \nolimits_{{i^{\prime} = 1}}^{r} {\mathrm{exp}}\left( {sim\left( {O_{i} ,Z_{{i^{\prime}}} } \right)/\tau } \right)}}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathcal{L}}_{dis} = \mathop \sum \limits_{j = 1}^{d} - log\frac{{{\mathrm{exp}}\left( {sim\left( {O_{j} ,Z_{j} } \right)/\tau } \right)}}{{\mathop \sum \nolimits_{{j^{\prime} = 1}}^{r} {\mathrm{exp}}\left( {sim\left( {O_{j} ,Z_{{j^{\prime}}} } \right)/\tau } \right)}}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathcal{L}}_{ctr} = {\mathcal{L}}_{rna} + {\mathcal{L}}_{dis}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$sim\left( \cdot \right)$$\end{document} denotes the cosine similarity function and τ denotes the tunable temperature hyperparameter. The subscript \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$rna$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$dis$$\end{document} denote ncRNA and disease, respectively.
The second strategy, we compare different graph structure features and call it SSLG_GH (see Fig. 3). SSLG_GH captures the intrinsic and implicit dependencies between ncRNA and disease through the mutual cooperative supervision between global structure and local relations. Similarly, SSLG_GH uses two types of inputs: heterogeneous graph and homogeneous graph, which we call SSLG_GH_hete and SSLG_GH_homo, respectively. Take homogeneous graph as an example, given an ncRNA-disease homogeneous graph adjacency matrix A, we use GCN to learn node representations and treat them as local features \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Z$$\end{document} . At the same time, we construct a parameterized ncRNA-disease hypergraph, using a HyperGraph Convolutional Network (HGCN) to learn global features \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$O$$\end{document} of nodes. By contrasting local features and global features, we can obtain more robust node embedding representations.Fig. 3. Framework of contrastive method SSLG_GH. With given graph data, GCN and HGCN are applied to learn the local structural features \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Z$$\end{document} and global structural features \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$O$$\end{document} respectively.
For local features, we also use LightGCN to learn node embeddings
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Z = \sigma \left( {\hat{A}E} \right)$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$E \in {\mathbb{R}}^{{\left( {r + d} \right) \times e}}$$\end{document} denotes the learnable parameterized feature matrix, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$e$$\end{document} represents node embedding dimension.
To adaptively learn hypergraph-based dependent structures across nodes, we use parameterized hypergraph structure learning to obtain global features. Parameterized hypergraph structure is defined as below:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$H = E \cdot W_{H}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$W_{H} \in {\mathbb{R}}^{e \times h}$$\end{document} represents the learnable embedding matrices for hyperedges, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$h$$\end{document} denotes the number of hyperedges. In order to further supercharge hypergraph neural architecture with a high-level of hyperedge-wise feature interaction, different layers of hyperedges are stacking as follow:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$F^{\left( 0 \right)} = H^{T} \cdot E$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$F^{\left( l \right)} = \sigma \left( {W^{{\left( {l - 1} \right)}} F^{{\left( {l - 1} \right)}} } \right) + F^{{\left( {l - 1} \right)}}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$W^{{\left( {l - 1} \right)}} \in {\mathbb{R}}^{h \times h}$$\end{document} is a trainable parametric matrix, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$l$$\end{document} denotes the number of hypergraph embedding layers. After the hierarchical hypergraph mapping, we refine the global features:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$O = \sigma \left( {HF^{\left( l \right)} } \right)$$\end{document}Same as SSLG_GM, SSLG_GH_homo is trained with triplet loss and SSLG_GH_hete is trained with InfoNCE loss. Finally, we integrate the task loss and the auxiliary constraints to form the overall loss, which is optimized by
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathcal{L}} = \lambda_{1} {\mathcal{L}}_{sup} + \lambda_{2} {\mathcal{L}}_{ctr} + \lambda_{3} {\Theta }_{F}^{2}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\Theta }$$\end{document} denotes the weight-decay regularization term.
Generative method
Contrastive learning has been the dominant approach in SSLG, while the progress of generative SSLG has thus far not reached its true potential. Generative method aims to learn robust node embeddings by reconstructing graph structure or node attributes. Inspired by GraphMAE^33^, we introduce a self-supervised learning method SSLG_MA for node attribute reconstruction, whose node embedding module consists of a GCN encoder and a GCN decoder (see Fig. 4). SSLG_MA uses a masking strategy to achieve feature reconstruction, which is beneficial to obtain robust node embeddings. We also divide SSLG_MA into SSLG_MA_homo and SSLG_MA_hete. To the best of our knowledge, this is the first attempt that semantic features have been reconstructed in a graph self-supervised manner in RNA-disease association prediction. Here, semantic features refer to the intrinsic biological attributes of nodes (represented by the similarity feature matrix derived from sequence or functional data), as opposed to the structural features represented by the graph adjacency matrix. By reconstructing these attributes, the model is encouraged to capture the underlying biological context of ncRNAs and diseases beyond their topological connections.Fig. 4. Framework of generative method SSLG_MA. Given the graph data and node features, the node features are masked randomly, and the masked features are reconstructed by using GCN encoder and decoder, and effective node representations are learned by comparing the differences between the original features and the reconstructed features.
Given an ncRNA-disease homogeneous graph adjacency matrix A and node feature matrix X (consist of node similarity), a set of nodes \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\tilde{v}$$\end{document} (such as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$v_{1} ,v_{5}$$\end{document} ) will be randomly selected with their initial features replaced by learnable vectors \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$x^{\prime}$$\end{document} (such as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$x_{1}{\prime} ,x_{5}{\prime}$$\end{document} ). Thus, the new feature representation of the node \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$v_{i}$$\end{document} is as follows,
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hat{x}_{{v_{i} }} = \left\{ {\begin{array}{*{20}c} {x_{{v_{i} }}{\prime} v_{i} \in \tilde{v}} \\ {x_{{v_{i} }} others} \\ \end{array} } \right.$$\end{document}The encoder maps the features \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hat{X}$$\end{document} to the latent space and denoted by \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Z$$\end{document} ,
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Z = En\left( {A,\hat{X}} \right)$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$En\left( \cdot \right)$$\end{document} denotes the GCN encoder.
To further encourage the encoder to learn compressed representations, the representations of node \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$v_{i} \in \tilde{v}$$\end{document} in \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Z$$\end{document} are again replaced by another learnable vectors \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$z_{i}^{\prime }$$\end{document} , the re-masked node representations is denoted as:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\tilde{z}_{{v_{i} }} = \left\{ {\begin{array}{*{20}c} {z_{{v_{i} }}{\prime} v_{i} \in \tilde{v}} \\ {z_{{v_{i} }} others} \\ \end{array} } \right.$$\end{document}Then, the decoder is to reconstruct the input as
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$M = De\left( {A,\tilde{Z}} \right)$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$De\left( \cdot \right)$$\end{document} denotes the GCN decoder.
To obtain node representations that are beneficial for association prediction, InfoNCE loss is used to train SSLG_MA model. On the one hand, it reduces the distance between the reconstructed feature and the original feature, and on the other hand, it increases the difference be-tween the features of different nodes. The loss function is defined as:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$L = \mathop \sum \limits_{i = 1}^{{\left| {\tilde{v}} \right|}} - \log \frac{{\exp \left( {sim\left( {Z_{i} ,M_{i} } \right)/\tau } \right)}}{{\mathop \sum \nolimits_{i\prime = 1}^{{\left| {\tilde{v}} \right|}} \exp \left( {sim\left( {Z_{i} ,M_{i\prime } } \right)/\tau } \right)}}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\left| {\tilde{v}} \right|$$\end{document} indicates the number of nodes to be masked. For downstream task, the encoder is applied to the input graph without any masking. The generated node embeddings \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Z$$\end{document} are used for association prediction.
Link prediction
With the SSLG algorithm, we obtained robust node embeddings. Given a known ncRNA-disease pair, its features are denoted as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Fea = [Z_{rna} ||Z_{dis} ]$$\end{document} . The notation \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$||$$\end{document} means concatenation. Based on \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Fea$$\end{document} , we train Extra-Trees (ET) as predictors. For unknown ncRNA-disease pairs, we inferred their association scores by ET. Higher scores for ncRNA-disease pairs indicate that ncRNAs are more likely to be disease-related.
Overall, our SSLGRDA framework mainly explores graph self-supervised learning algorithms that can learn inherent, transferable, and robust knowledge in graph data from unlabeled data. This architecture has a wide range of application scenarios: RDA graphs can be either heterogeneous graphs or homogeneous graphs, and node attribute features can be composed of similarities between nodes or one-hot encoding. More importantly, the architecture has good prediction accuracy.
Results
Evaluation protocols and metrics
We adopt five-fold cross-validation (5-CV) to evaluate the performance of prediction models. The known associations are equally divided into 5 parts, 4 parts are used to build the graph, and the remaining one part is used for testing. Specifically, first, the graph of training data is utilized to learn node embeddings and the corresponding links are used to train a binary logistic classifier. The training set consists of 4/5 of the known associations and the same number of unknown associations. Then, test relations with a set of random negative (non-connected) links are used to evaluate the trained classifier. The test set consists of 1/5 of the known associations and 1/5 of the unknown association.
All models were implemented using the PyTorch framework and trained on an NVIDIA GeForce RTX 3090 GPU. The models were trained for 100 epochs using the Adam optimizer. Through grid search, we determined the optimal hyperparameters for each sub-model.
For SSLG_GM, the learning rate is set to 0.005 with a weight decay of 1e-4. The MLP hidden layer size is 128. The contrastive loss weights are set to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\uplambda }_{{1}} { = 5}$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\uplambda }_{{2}} { = 5}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\uplambda }_{{3}} { = 1}$$\end{document} , with tuning parameters \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\alpha = 0.8$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\beta = 0.4$$\end{document} . The Task weight \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\uplambda }_{{4}}$$\end{document} of supervise loss is 1e-5, the task weight \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\uplambda }_{{5}}$$\end{document} of contrastive loss is 1.
For SSLG_GH, the learning rate is 1e-3. The node embedding dimension is 128. The hypergraph structure is defined by 50 hyperedges (h = 50) and 2 embedding layers (l = 2).
For SSLG_MA, the learning rate is 0.005. The GCN encoder consists of 2 layers with 128 hidden units. The masking rate is set to 0.4, and the temperature parameter \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\uptau }$$\end{document} for InfoNCE is 0.9.
Treating ncRNA-disease association prediction as a binary classification task, we adopt three classification evaluation metrics to evaluate the performances of our model, i.e., the area under receiver-operating characteristic curve (AUC), the area under the precision-recall curve (AUPR) and F1 score, the higher the value, the better the model performance.
Drawing on the evaluation metrics of link prediction in knowledge graph, we introduced ranking metrics, namely Mean Rank (MR), Mean Reciprocal Ranking (MRR), and Hits@N. MR means that each positive and all negative samples in the test set are sorted in descending order according to the prediction score, and the average ranking of all positive samples is calculated according to the following formula
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathrm{MR}} = \frac{1}{\left| S \right|}\left( {rank_{1} + rank_{2} + \ldots + rank_{\left| S \right|} } \right)$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$rank_{i}$$\end{document} is the rank of the i-th positive sample, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\left| S \right|$$\end{document} is the number of positive samples. MRR represents the average value of the reciprocal of the ranking of positive samples, and can be calculated by
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathrm{MRR}} = \frac{1}{\left| S \right|}\left( {\frac{1}{{rank_{1} }} + \frac{1}{{rank_{2} }} + \ldots + \frac{1}{{rank_{\left| S \right|} }}} \right)$$\end{document}Hits@N represents the ratio of the number of top N positive samples to the number of all positive samples, the formula is expressed as
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\mathrm{Hits}}@{\mathrm{N}} = \frac{1}{\left| S \right|}\mathop \sum \limits_{i = 1}^{\left| S \right|} \left| {\left( {rank_{i} \le N} \right)} \right.$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\left| {\left( \cdot \right)} \right.$$\end{document} is the indicator function (if the condition is true, the function value is 1, otherwise it is 0). It should be noted that the smaller the MR is, the better the model performance is, and the larger the MRR and Hits@N are, the better the model performance is.
Moreover, we also locally ranked each RNA-related diseases and each disease-related ncRNAs in the test set to simulate specific retrieval tasks. Specifically, for MR_L_R (and MRR_L_R), we grouped the test samples by disease; for each disease, we ranked the true associated ncRNA against the negative ncRNAs paired with that specific disease. Similarly, for MR_L_D (and MRR_L_D), we grouped samples by ncRNA and ranked the true associated disease against the negative diseases paired with that specific ncRNA. These metrics were calculated as the Mean Rank and Mean Reciprocal Ranking within these local groups, where L represents local, R and D represent ncRNA and disease, respectively.
Baseline methods
Based on SSL contrastive methods, we proposed SSLG_GH and SSLG_GM sub-models, and based on SSL generative method, we proposed SSLG_MA sub-model. In addition, based on the input graph structure, the above models are further divided into homogeneous graph models: SSLG_GH_homo, SSLG_GM_ homo, SSLG_MA_ homo and heterogeneous graph models: SSLG_GH_hete, SSLG_GM_hete, SSLG_MA_hete.
To comprehensively evaluate the performance of SSLGRDA, we selected representative baseline methods based on their relevance to our methodological contributions, code availability, and wide recognition in the field. These methods cover three distinct categories to benchmark different aspects of our framework. Two SSL algorithms: AFGRL^32^ and GAE^34^, four ncRNA-Disease Association Prediction algorithms (RDAP): LR-GNN^17^, MINIMDA^19^, GMNN2CD^18^ and MLGCN^36^, three heterogenous Graph Neural Networks algorithms (HeteGNN): RGCN^37^, GATNE^38^ and HGB^39^. In particular, AFGRL is a contrastive method (SSLG_Con), which generates a second view by discovering nodes that share local structural information and global semantics with the original graph, and then performs contrastive learning to obtain node embedding. GAE is a generative method (SSLG_Gen) that reconstructs the structure of the graph through the encoder-decoder to obtain node embeddings.
Results for circRNA-disease datasets
Table 2, Supplementary Table 1 and Supplementary Table 2 summarize classification accuracy and ranking results of all methods on three circRNA-disease datasets, where the best results are highlighted in bold. In general, SSLG_GM_homo performs best on CDA1 and CDA2, SSLG_GH_homo performs best on CDA3, and second-best on CDA1 and CDA2. For other models, there may be one or more best metrics, such as GATNE has the best MRR on CDA1 and the best F1 on CDA2.Table 2. Classification accuracy and ranking results of all methods on CDA1.DatasetCategoryModelAUCAUPRF1Hits@10Hits@50Hits@100CDA1ContrastiveSSLG_GH_hete0.722920.017100.019470.006450.022580.04839ContrastiveSSLG_GH_homo0.946760.726110.429440.538460.72615**0.80462ContrastiveSSLG_GM_hete0.697280.017150.000440.005160.020000.04032ContrastiveSSLG_GM_homo0.958950.832010.579520.689690.84600****0.85708GenerativeSSLG_MA_hete0.715610.018460.026980.016130.025810.04516GenerativeSSLG_MA_homo0.939660.308960.175830.098460.310770.41231SSLG_ConAFGRL0.864790.370180.172640.176920.300000.41538SSLG_GenGAE0.937170.723730.345480.527690.684620.76923RDAPLR-GCN_hete0.798530.052630.065690.013390.078390.12365RDAPLR-GCN_homo0.704200.039220.049830.006150.038460.06308RDAPGMNN2CD0.914050.310320.035860.221540.233850.28308RDAPMINIMDA0.667610.025120.050080.000770.003080.01462RDAPMLGCN0.888630.162280.121190.053850.132310.21077HeteGNNGATNE0.895220.711460.361700.576920.661540.74615HeteGNNHGB0.802910.160130.058390.061540.176920.23846HeteGNNRGCN0.788270.084690.144980.026150.066150.11231DatasetCategoryModelMR↓MRRMR_L_R↓MR_L_D↓MRR_L_RMRR_L_DCDA1ContrastiveSSLG_GH_hete2845.770.002849.2563540.028180.257030.16390ContrastiveSSLG_GH_homo505.540.212711.753659.495390.891030.66816ContrastiveSSLG_GM_hete3135.590.004109.0098840.035640.254630.14122ContrastiveSSLG_GM_homo447.120.386142.048627.202350.893650.72038GenerativeSSLG_MA_hete2869.970.005058.4449540.222650.260710.16896GenerativeSSLG_MA_homo614.740.044222.1944310.482460.786970.43954SSLG_ConAFGRL1361.110.094582.9404821.239050.752610.56210SSLG_GenGAE633.290.385492.2616811.093630.868420.61310RDAPLR-GCN_hete1013.190.008383.5497019.806540.495110.19655RDAPLR-GCN_homo2978.080.004805.4035148.799990.371750.07248RDAPGMNN2CD874.760.157214.5986614.840500.647090.29004RDAPMINIMDA3345.460.001215.2798973.324540.437070.02757RDAPMLGCN1125.890.031463.0989218.015030.653330.27742HeteGNNGATNE1066.200.50440**2.1048419.685200.839910.58592HeteGNNHGB2004.590.037373.6309530.502310.542510.10612HeteGNNRGCN2153.420.018464.2531829.659930.515580.14081↓ means the smaller the better. Best results in the experiment are highlighted in bold, and the second-best result is italic.
Results for lncRNA-disease datasets
The averaged results of all methods on three lncRNA-disease datasets are reported in Table 3 Supplementary Table 3 and Supplementary Table 4. In summary, SSLG_GH_homo significantly outperforms the other models on LDA1 and LDA3, SSLG_GM_homo performs second-best on LDA1 and LDA3. On LDA2, SSLG_MA_hete has the best classification accuracy and Hits@N score, followed by SSLG_GH_hete.Table 3. Classification accuracy and ranking results of all methods on LDA1.DatasetCategoryModelAUCAUPRF1Hits@10Hits@50Hits@100LDA1ContrastiveSSLG_GH_hete0.965660.615040.390350.173210.368420.49234ContrastiveSSLG_GH_homo0.986530.733450.413540.242420.50080****0.64833ContrastiveSSLG_GM_hete0.955290.495560.292380.130140.267460.36172ContrastiveSSLG_GM_homo0.986120.716030.402660.202680.45823**0.59067GenerativeSSLG_MA_hete0.938850.315730.220260.021960.108660.20349GenerativeSSLG_MA_homo0.955920.432620.261160.192340.229670.32679SSLG_ConAFGRL0.976170.623380.342230.186600.363640.48325SSLG_GenGAE0.976840.588370.356960.162200.316750.43923RDAPLR-GCN_hete0.926380.341570.129050.081330.164780.23286RDAPLR-GCN_homo0.876910.295300.185830.056460.137320.21435RDAPGMNN2CD0.710030.282050.059230.214830.261720.27033RDAPMINIMDA0.915480.341520.229090.088520.190190.24282RDAPMLGCN0.985240.710190.401720.200630.452500.58150HeteGNNGATNE0.842560.113780.166900.004780.031100.05502HeteGNNHGB0.878480.207650.166100.052630.093300.12440HeteGNNRGCN0.877490.190660.241810.008610.048800.08612DatasetCategoryModelMR↓MRRMR_L_R↓MR_L_D↓MRR_L_RMRR_L_DLDA1ContrastiveSSLG_GH_hete595.300.110686.265414.031840.560280.63097ContrastiveSSLG_GH_homo201.230.119492.857291.995210.720390.77153ContrastiveSSLG_GM_hete810.860.085887.456724.113680.515690.56362ContrastiveSSLG_GM_homo260.470.093293.066692.153340.721890.75809GenerativeSSLG_MA_hete1109.070.013139.881745.335580.445660.49817GenerativeSSLG_MA_homo792.750.19660**8.886064.401370.471600.52967SSLG_ConAFGRL424.780.086364.144732.726290.671310.68541SSLG_GenGAE412.880.090014.570672.510830.625890.68842RDAPLR-GCN_hete1309.430.0463211.334876.688530.396360.44263RDAPLR-GCN_homo2189.630.0338615.143839.339040.355910.41329RDAPGMNN2CD5252.060.105258.4454818.316460.542070.15131RDAPMINIMDA1503.190.0437614.278126.204060.361080.48175RDAPMLGCN268.500.117483.726572.223220.684980.72732HeteGNNGATNE2852.100.0029211.855689.285140.342120.32491HeteGNNHGB2201.590.022048.950577.749270.462470.34281HeteGNNRGCN2219.450.0086016.939098.266600.288750.35444↓ means the smaller the better. Best results in the experiment are highlighted in bold, and the second-best result is italic.
Results for miRNA-disease datasets
The performances of all models on three miRNA-disease datasets are reported in Table 4, Supplementary Table 5 and Supplementary Table 6, respectively. In a word, SSLG_GM_homo has the best Hits@50, 100 score and local ranking on MDA1, and has the best classification accuracy on MDA2 and MDA3. SSLG_GH_homo has the second-best classification accuracy on MDA3.Table 4. Classification accuracy and ranking results of all methods on MDA1.DatasetCategoryModelAUCAUPRF1Hits@10Hits@50Hits@100MDA1ContrastiveSSLG_GH_hete0.938830.468420.305490.04309**0.134440.20773ContrastiveSSLG_GH_homo0.926930.445920.286150.048800.144870.22376ContrastiveSSLG_GM_hete0.933990.463670.308040.050090.155430.21584ContrastiveSSLG_GM_homo0.931220.470290.291920.055140.16041****0.23396GenerativeSSLG_MA_hete0.931080.443750.300710.047700.130200.19797GenerativeSSLG_MA_homo0.916780.391780.242470.106450.119520.18195SSLG_ConAFGRL0.922340.461170.283100.057090.157460.22468SSLG_GenGAE0.915130.396180.264810.048620.103310.16943RDAPLR-GCN_hete0.920040.386720.207670.035970.104340.16088RDAPLR-GCN_homo0.881100.326910.210980.021920.085270.14291RDAPGMNN2CD0.813970.283310.036660.070530.159850.20534RDAPMINIMDA0.896600.377100.295340.035730.105340.15580RDAPMLGCN0.923520.437500.286590.078450.142360.20589HeteGNNGATNE0.724380.063130.058080.000920.002760.00737HeteGNNHGB0.872140.187750.185460.004600.020260.04972HeteGNNRGCN0.805660.146030.057330.002580.015100.03057DatasetCategoryModelMR↓MRRMR_L_R↓MR_L_D↓MRR_L_RMRR_L_DMDA1ContrastiveSSLG_GH_hete2199.960.025378.3647515.947550.409220.31673ContrastiveSSLG_GH_homo2749.870.031469.9459816.177520.426860.30483ContrastiveSSLG_GM_hete2437.270.026169.0762115.800730.398830.31493ContrastiveSSLG_GM_homo2478.450.028268.9731415.293720.428600.33502GenerativeSSLG_MA_hete2545.190.026919.2853416.609460.405590.31130GenerativeSSLG_MA_homo3066.780.1089210.8061617.622100.388890.28082SSLG_ConAFGRL2794.090.025419.2204616.885360.421610.30959SSLG_GenGAE3053.890.0488610.2918716.804590.382130.29028RDAPLR-GCN_hete2876.550.016689.6872317.983850.361980.21618RDAPLR-GCN_homo4279.570.0133112.0578524.415510.369250.18333RDAPGMNN2CD6852.570.0332912.3987438.401440.391200.09914RDAPMINIMDA3719.300.0160410.0038916.862310.384590.23586RDAPMLGCN2817.910.082689.7603416.380380.399020.29795HeteGNNGATNE10,152.230.0007130.4826028.814250.077390.11567HeteGNNHGB4710.200.0027710.5398024.009200.365270.18400HeteGNNRGCN7158.690.0033918.8298428.921830.224600.13941↓ means the smaller the better. Best results in the experiment are highlighted in bold, and the second-best result is italic.
Furthermore, to validate the statistical significance of these results, we performed paired t-tests on the fivefold cross-validation outputs. Supplementary Table 7 indicate that the improvements of SSLGRDA over the second-best methods are statistically significant with p < 0.05 in terms of AUC and AUPR.
All in all, based on the experimental results and data characteristics, we have the following observations and analyses: (a)The contrastive strategy generally outperforms the generative strategy. This is likely because contrastive learning optimizes for discriminative representations by maximizing mutual information between views, which directly benefits the downstream binary classification task. In contrast, generative methods focus on feature reconstruction, which may force the model to encode noise present in the raw similarity data. (b)The homogeneous graph variants (SSLG_homo) often perform slightly better than heterogeneous ones. This can be attributed to our graph construction strategy (Section "NcRNA-disease homogeneous graph"), where similarity matrices are integrated as edges in the homogeneous graph. This densifies the sparse ncRNA-disease network, allowing GCNs to aggregate information more effectively than in the heterogeneous setting where relation types are strictly separated. (c)Among the sub-models, SSLG_GM (Graph-MLP contrast) demonstrates high robustness. By contrasting the topological view (GCN) with the attribute view (MLP), SSLG_GM effectively captures both the local structural context and the intrinsic semantic similarity of the nodes. Finally, our proposed approach significantly outperforms the existing RDAP and HeteGNN algorithms, demonstrating that self-supervised pre-training provides a more generalizable initialization for link prediction than purely supervised end-to-end training.
Performance on other datasets
To illustrate the potential generalization of our model, we applied SSLG_GM_homo and SSLG_GH_homo to other real-world networks: microbe-disease associations (MeDiA)^40^ and microbe-drug associations (MeDrA)^41^. MeDiA contains 2 subnets of HMDAD and Disbiome, and MeDrA contains 3 subnets of MDAD, aBiofilm and DrugVirus. The fivefold CV was implemented according to GATMDA and GCNMDA. Table 5 records the results on MeDiA datasets. Table 6 reports the results on MeDrA datasets. The results show that both SSLG_GM_homo and SSLG_GH_homo outperform all baseline models.Table 5. The summary of model performance on MeDiA datasets.MethodsHMDADDisbiomeAUCAUPRAUCAUPR^BiRWHMDA0.8890 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.01940.8969 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.01460.8344 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.00890.8104 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.0103^NGRHMDA0.8921 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.03270.9062 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.02680.8313 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.00520.8202 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.0043^BRWMDA0.8916 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.00290.9064 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.01520.8266 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.00310.8031 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.0041^GRNMFMDA0.8806 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.01560.8914 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.01620.8609 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.00470.8669 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.0060^GATMDA0.9554 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.01840.9334 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.04170.9307 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.00790.9211 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.0088SSLG_GM_homo0.9676 * \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} * 0.01150.9737 * \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} * 0.00880.9330 * \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} * 0.0046**0.9375 * \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} * 0.0050SSLG_GH_homo0.9692 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.0056****0.9739 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.0046****0.9508 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.0034****0.9488 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.0078′^′ indicates that the results for these models are from GATMDA. Best results in the experiment are highlighted in bold, and the second-best result is italic.Table 6. The summary of model performance on MeDrA datasets.MethodsMDADaBiofilmDrugVirusAUCAUPRAUCAUPRAUCAUPR ~ WMGHMDA0.866 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.0120.838 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.0080.845 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.0060.890 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.0060.723 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.0210.769 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.022 ~ GCMDR0.849 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.0060.851 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.0040.877 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.0080.885 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.0060.824 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.0170.821 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.014 ~ BLM-NII0.923 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.0170.926 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.0150.926 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.0840.934 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.0630.891 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.0190.892 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.022 ~ WNN-GIP0.872 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.0160.892 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.0140.902 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.0190.941 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.0130.800 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.0190.844 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.018 ~ GCNMDA0.942 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.0110.938 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.0110.952 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.0030.949 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.0030.899 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.0310.904 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.037SSLG_GM_homo0.976 * \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} * 0.0050.981 * \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} * 0.0040.986 * \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} * 0.0030.988 * \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} * 0.0020.910 * \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} * 0.018**0.911 * \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} * 0.020SSLG_GH_homo0.983 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.004****0.987 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.005****0.990 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.003****0.991 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.002****0.917 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.019****0.916 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pm$$\end{document} 0.021′ ~ ′ indicates that the results for these models are from GCNMDA. Best results in the experiment are highlighted in bold, and the second-best result is italic.
Case studies
To further evaluate the performance of SSLGRDA, we demonstrate its ability to predict new ncRNA-disease associations. We conduct case studies on MDA1, CDA1 and LDA1 dataset. All known ncRNA-disease associations are used to train the SSLGRDA model, and all unknown ncRNA-disease pairs are used as the candidate ncRNA-disease associations for prediction. After prediction by SSLGRDA model, given a specific disease, we rank those candidate ncRNAs based on their prediction scores. For MDA and LDA, we select Breast Cancer and Colon Cancer to predict new disease-associated ncRNA. The top 15 prediction results have been validated by public databases: dbDEMC^42^, miR2disease^43^, Lnc2Cancer^44^, LncRNADisease^45^, and published literature (see Tables 7 and 8). For CDA, we selected 10 ncRNA-disease pairs out of the top 15, and validated the predictions of each pair by searching the published literature (see Table 9).Table 7. The top 15 breast cancer-related candidate ncRNAs.RanklncRNAEvidencemiRNAEvidence1CDKN2B-AS1LncRNADiseasehsa-mir-106adbDEMC2MEG3Lnc2Cancer&LncRNADiseasehsa-mir-130adbDEMC3MIR17HGUnknownhsa-mir-150dbDEMC4H19Lnc2Cancer&LncRNADiseasehsa-mir-142PMID: 33,785,3325MALAT1Lnc2Cancer&LncRNADiseasehsa-mir-99adbDEMC6KCNQ1OT1Lnc2Cancer&LncRNADiseasehsa-mir-98dbDEMC&miR2disease7HOTAIRLnc2Cancer&LncRNADiseasehsa-mir-138dbDEMC8TP53COR1LncRNADiseasehsa-mir-99bdbDEMC9PVT1Lnc2Cancer&LncRNADiseasehsa-mir-192dbDEMC10GAS5Lnc2Cancer&LncRNADiseasehsa-mir-196bdbDEMC11MIATLnc2Cancer&LncRNADiseasehsa-mir-15bdbDEMC12ESRGUnknownhsa-mir-449aPMID: 30,488,44313NEAT1Lnc2Cancer&LncRNADiseasehsa-mir-212dbDEMC14XISTLnc2Cancer&LncRNADiseasehsa-mir-185dbDEMC15UCA1Lnc2Cancer&LncRNADiseasehsa-mir-130bdbDEMCTable 8The top 15 colon cancer-related candidate ncRNAs.RanklncRNAEvidencemiRNAEvidence1H19Lnc2Cancer&LncRNADiseasehsa-mir-21dbDEMC&miR2disease2MEG3Lnc2Cancer&LncRNADiseasehsa-mir-20adbDEMC&miR2disease3TP53COR1Unknownhsa-mir-155dbDEMC&miR2disease4MALAT1Lnc2Cancer&LncRNADiseasehsa-mir-18adbDEMC&miR2disease5MIR17HGPMID: 35,116,852hsa-mir-19bdbDEMC&miR2disease6HOTAIRLnc2Cancer&LncRNADiseasehsa-mir-34adbDEMC&miR2disease7PVT1Lnc2Cancer&LncRNADiseasehsa-mir-16dbDEMC8GAS5Lnc2Cancerhsa-mir-143dbDEMC&miR2disease9KCNQ1OT1Lnc2Cancerhsa-mir-146adbDEMC10UCA1Lnc2Cancer&LncRNADiseasehsa-mir-92aUnconfirmed11TUG1Lnc2Cancer&LncRNADiseasehsa-mir-15adbDEMC12XISTLnc2Cancer&LncRNADiseasehsa-mir-19adbDEMC&miR2disease13AFAP1-AS1Lnc2Cancerhsa-mir-106bdbDEMC&miR2disease14HULCLnc2Cancerhsa-mir-125bdbDEMC15BANCRUnknownhsa-mir-29adbDEMC&miR2diseaseTable 9Case study of 10 diseases predicted associations.DiseaseCircRNAEvidencePapillary thyroid carcinomacircPVT1/hsa_circ_0001821PMID: 35,520,785Esophageal squamous cell carcinomahsa_circRNA_100782/circHIPK3/hsa_circ_0000284PMID: 35,443,871Rheumatoid arthritishsa_circRNA_100782/circHIPK3/hsa_circ_0000284PMID: 35,291,619Colorectal cancercircSMARCA5/hsa_circ_0001445PMID: 34,948,079Breast cancercircGFRA1/hsa_circ_005239PMID: 34,668,628Prostate cancerhsa_circRNA_100782/circHIPK3/hsa_circ_0000284PMID: 34,142,340Gastric cancerCir-ITCH/hsa_circ_0001141/hsa_circ_001763PMID: 33,060,778Clear cell renal cell carcinomahsa_circRNA_100782/circHIPK3/hsa_circ_0000284PMID: 32,409,849Oral squamous cell carcinomacircRNA_100290/hsa_circ_0013339/hsa_circ_100290PMID: 31,187,488Pancreatic ductal adenocarcinomahsa_circ_0001649PMID: 29,969,694
Visualization of feature representations
To intuitively evaluate the quality of the representations learned by SSLGRDA, we utilized t-SNE to visualize the feature distributions of ncRNA-disease pairs before and after model training. We selected three representative datasets (CDA1, LDA1, and MDA1) and randomly sampled balanced positive and negative pairs from the training sets. Figure 5 displays the visualization results.Fig. 5. The t-SNE visualization of feature representations on CDA1, LDA1, and MDA1 datasets. The left column displays the distribution of original input features, while the right column shows the distribution of high-level node embeddings learned by the SSLGRDA model. Blue circles (Class 0) represent negative samples (non-associations), and orange triangles (Class 1) represent positive samples (known associations).
As observed in the ‘Original Features’ plots, the positive and negative samples are heavily entangled with ambiguous boundaries, making them difficult to distinguish based on raw features alone. In contrast, in the ‘Learned Features’ space generated by SSLGRDA, the distribution of samples becomes more structured. The positive and negative classes form relatively concentrated regions, and the inter-class overlap is significantly reduced. This clearer separation demonstrates that SSLGRDA successfully captures discriminative topological and semantic patterns, projecting the data into a space that is much more favorable for the binary classification task.
Discussion
We have successfully established a self-supervised learning model for the prediction of ncRNA-disease association. SSLGRDA offers a concise and generalizable model that boosts node embedding with self-supervised learning on graph. In our study, different contrastive strategies of graph self-supervised learning were considered, and contrasts topological structures and semantic features of the ncRNA-disease graph. Therefore, we can use a GNN module to capture more generalized network-level embedding and rely on a supervised label to perform predictions. We conduct comprehensive experiments and demonstrate significant improvements over competitive baselines on nine public datasets. Moreover, case studies on three RDA datasets demonstrate that our method achieves reliable prediction performance. In general, our model is highly flexible, applicable to both homogeneous and heterogeneous graphs, and can be easily extended to other applications such as microbe-disease association, microbe-drug association.
Although SSLGRDA performs well on RDA prediction, it still has a few limitations. First, failure to fully utilize ncRNA/disease similarity data, using only top-k similarities per ncRNA/disease, although reducing noisy information, may lose useful data. Second, lack of effective strategies to fuse node embeddings from different views together to form more robust features. In the future, we plan to address these limitations through two specific directions. First, to better utilize similarity data without introducing noise, we will explore graph attention mechanisms to assign learnable weights to similarity neighbors, replacing the rigid top-k thresholding. Second, to enhance feature integration, we intend to develop adaptive fusion modules or cross-view attention mechanisms that can dynamically weigh the importance of structural versus semantic views for each node, avoiding the limitations of simple concatenation.
Supplementary Information
Below is the link to the electronic supplementary material.
Supplementary Material 1
Supplementary Material 2
Supplementary Material 3
Supplementary Material 4
Supplementary Material 5
Supplementary Material 6
Supplementary Material 7
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Wu, L. R., Lin, H. T., Gao, Z. Y., Tan, C. & Li, S. Z. Self-supervised on Graphs: Contrastive, Generative,or Predictive. ar Xiv preprintar Xiv:2105.07342 (2021).
- 2Liu, Y. X. et al. Graph Self-Supervised Learning: A Survey. ar Xiv preprintar Xiv:2103.00111 (2021).
- 3Mo, Y., Peng, L., Xu, J., Shi, X. & Zhu, X. In Proc. of the 36th AAAI Conference on Artificial Intelligence 7797–7805 (2022).
- 4Xia, L. et al. In Proc. of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval (Madrid, Spain, 2022).
- 5Lee, N., Lee, J. & Park, C. In Proc. of the 36th AAAI Conference on Artificial Intelligence 7372–7380 (2022).
- 6Hou, Z. et al. In Proc. of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (Washington, DC, USA, 2022).
- 7Kipf, T. N. & Welling, M. in NIPS Workshop on Bayesian Deep Learning (2016).
- 8He, X. et al. In Proc. of the 43th International ACM SIGIR Conference on Research and Development in Information Retrieval (Xi’an, China, 2020).