Gaze patterns during visual mental imagery reflect part-based generation
Enea J. Weber, Fred W. Mast

TL;DR
Eye movements during mental imagery resemble part-by-part viewing, suggesting images are generated in parts.
Contribution
Shows gaze patterns during imagery reflect part-based generation, independent of prior perception.
Findings
Fixation scanpaths during imagery mirror part-based viewing (GCW condition).
Refixation patterns during imagery align with part-based perception.
Gaze patterns during imagery remain part-based regardless of initial encoding method.
Abstract
Eye movements during visual mental imagery resemble those made during prior perception. Across two experiments, we investigated whether eye movements during imagery reflect a part-by-part generation of mental images, by comparing gaze patterns during mental imagery to those during part-based viewing (using a gaze-contingent window, GCW) and to those during holistic viewing (using an artificial scotoma, AS). In Experiment 1, participants freely encoded and imagined pictures before reinspecting them either part-by-part (GCW condition), or holistically (AS condition). The results show that fixation scanpaths (MultiMatch) and refixation patterns (recurrence quantification analysis) during mental imagery largely mirror those during GCW viewing. In Experiment 2, we examined whether this effect depends on prior perceptual encoding. Pictures were initially encoded either freely, with the AS, or…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
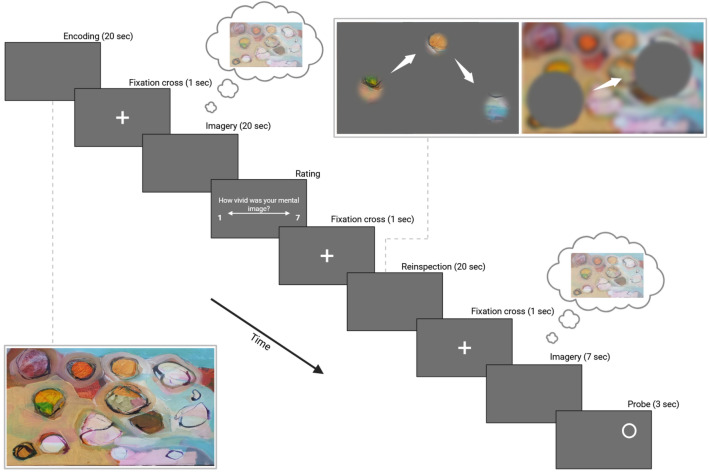 Figure 1
Figure 1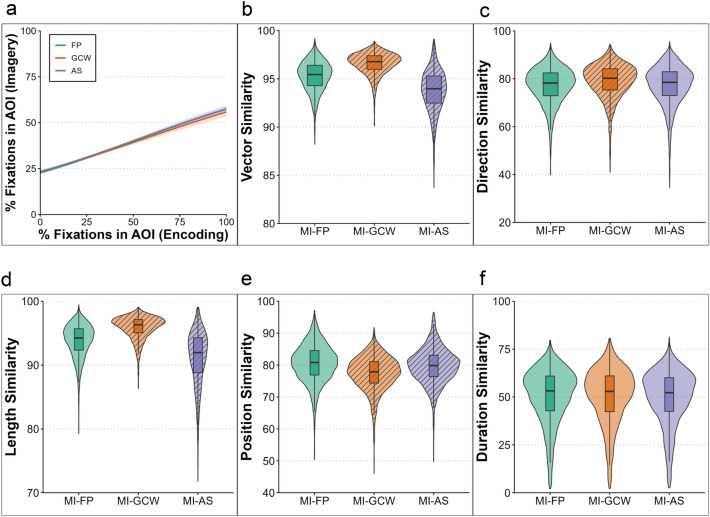 Figure 2
Figure 2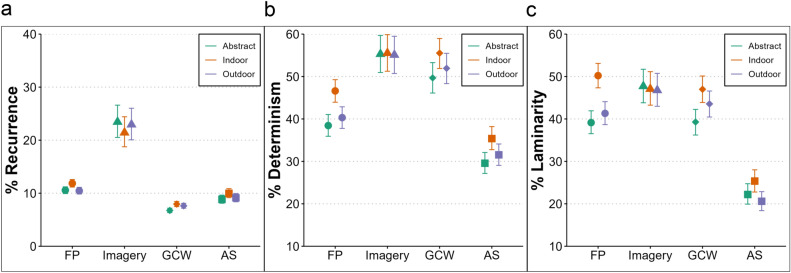 Figure 3
Figure 3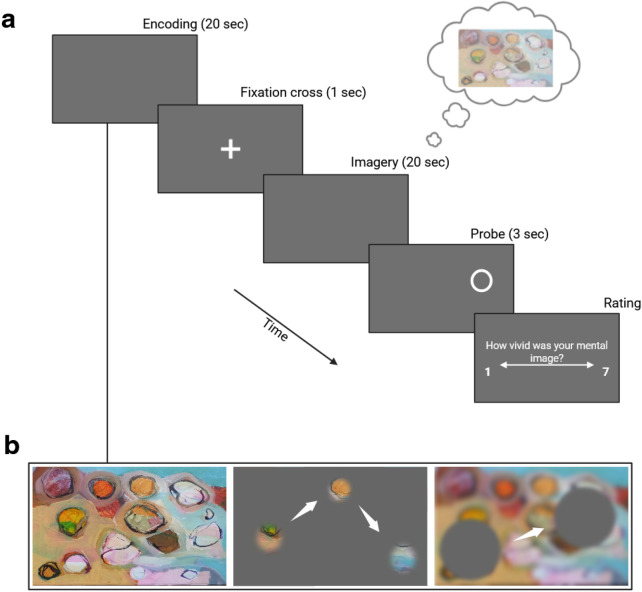 Figure 4
Figure 4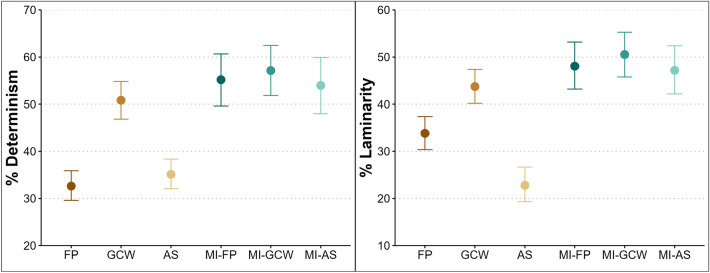 Figure 5
Figure 5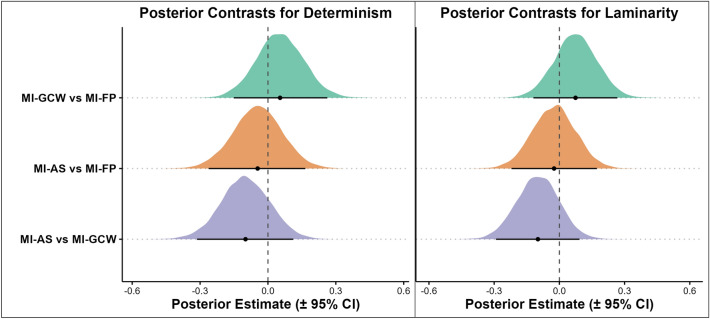 Figure 6
Figure 6- —https://doi.org/10.13039/501100001711Schweizerischer Nationalfonds zur Förderung der Wissenschaftlichen Forschung
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsFace Recognition and Perception · Visual perception and processing mechanisms · Visual Attention and Saliency Detection
Introduction
Seeing and imagining feel different, but our eyes tell a strikingly similar story. When we imagine a visual scene, eye fixations tend to return to the same locations visited during perceptual encoding. This phenomenon is known as the “Looking at Nothing” (LAN) effect^1–4^. Previous studies show that restricting eye movements when recalling a scene impairs memory performance^5–9^, suggesting that eye fixations help generate and maintain mental images^1,5,7,10^. It has been proposed that spatial indices tied to specific fixations are automatically stored in memory^3,11,12^. During subsequent mental imagery of the scene, the eyes return to these spatial indices and thereby help to reactivate visual information stored in memory and to arrange the different parts in their corresponding spatial location^5,6,13^.
The resemblance of eye movements during visual mental imagery and perceptual encoding is in line with concepts of mental imagery as a simulation of perception^14,15^ or as “vision in reverse”^16^. This view is supported by both neuroimaging^17,18^ and behavioral research^19,20^ showing substantial overlap between imagery and perception. However, clinical cases show that the two processes can dissociate, with selective impairments in visual imagery^21^ or in perception^22,23^.
Several studies suggested that oculomotor patterns are encoded alongside visual information and later reinstated during imagery^6,24,25^. However, there is growing evidence that eye fixations during imagery are not replayed from perceptual encoding. Previous studies showed that even when participants had to keep central fixation during encoding, they still made spread out fixations during subsequent imagery^5,11^. Yet another study showed that participants made spontaneous eye movements toward the respective side of an imagined map of France in response to verbal cues, despite not having seen the map during the experiment^26^. Moreover, fine-grained analyses in fixation scanpaths using the MultiMatch algorithm (which compares scanpaths along multiple dimensions) show less similarity between imagery and perception^27^, and the analysis of temporal gaze patterns reveal substantial differences between mental imagery and perception^28,29^. Recurrence quantification analysis (RQA) shows more frequent refixations during imagery, and these refixations follow a sequential order that is less pronounced during perceptual encoding^27–29^. The temporal patterns suggest a reactivation of place-bound pictorial content during imagery^29^, providing further evidence that eye movements during imagery are not simply replayed from perception.
During perceptual encoding, the visual system creates a coherent representation of the scene by integrating information part-by-part and at the same time forming a holistic representation of the scene^30^. Unlike percepts, mental images are generated entirely from memory and are likely constructed part-by-part^31^. Spatial indexes serve to guide the eyes, and assemble from memory different parts of the mental image^5,6,10,13^. In the same vein, consistent refixations to specific parts reactivate visual representations, preventing the mental image from fading^28,29^. Thus, eye movements during imagery can resemble those during perception not necessarily because they are replayed, but because they rely on part-based processes.
In the present study, we manipulate the way participants inspect scenes and compare the resulting eye movements to those during visual mental imagery. Specifically, we compared eye movements during imagery to those observed under viewing conditions that promote either part-based (gaze-contingent window, GCW) or holistic perceptual encoding (artificial scotoma, AS). By means of a GCW, participants see only a small circular region of the locations around their fixation (similar to tunnel vision), leading them to gather information in discrete chunks^32–34^. This encourages participants to create a coherent percept from isolated parts. When using an artificial scotoma (AS), participants lose central vision but retain peripheral visual input. As a result, they rely on peripheral vision to encode the general gist of the scene without focusing on individual details. This encourages a more holistic encoding strategy^33–35^. Prior work has demonstrated that holistic and part-based encoding give rise to distinct scanpaths^36,37^. If mental imagery involves assembling a scene from individual parts, spatial and temporal gaze patterns should resemble those observed under GCW viewing. If, however, eye movements during AS viewing turn out to be similar to those during mental imagery, this would imply a holistic representation. Finally, if gaze patterns during imagery resemble those from free viewing (as suggested by a replay of perception), this would suggest the involvement of holistic and part-based processes.
In Experiment 1, pictures were always encoded freely prior to the imagery phase. This is the usual procedure for research in mental imagery. In order to investigate the role of encoding, we designed Experiment 2, in which we varied how participants viewed the pictures for the first time (freely, holistically, or part-by-part). If mental imagery involves a part-based construction process, we expected spatiotemporal gaze patterns during imagery to resemble those observed during GCW viewing, independent of the type of encoding.
Results
Experiment 1
In Experiment 1, we investigate spatiotemporal similarities between eye movements during mental imagery compared to part-based and holistic perception. To ensure that eye movements during imagery were not influenced by encoding, participants first encoded the pictures freely, then imagined what they saw, and viewed the pictures again under GCW or AS conditions (see Figure 1). We used pictures from three categories (abstract art, landscapes and indoor scenes) to test how different contents affect eye movements.Fig. 1. Procedure for Experiment 1. First, participants freely encoded pictures from three categories (art, indoor, and outdoor scenes) for 20 s, before a 1 sec fixation cross. Afterwards, they were instructed to imagine the content of the picture as vividly as possible for 20 s, and they had to rate the vividness of their mental image on a scale from 1 to 7. Subsequently, another fixation cross (1 s) appeared and participants saw the initial picture again with either a gaze-contingent window (GCW) or an artificial scotoma (AS) for 20 s. After the reinspection, participants saw a fixation cross (1 s) and imagined the picture again for 10 sec. A probe appeared within the 3 last seconds, followed by a question about whether a specific object or color fell under it. The first encoding was without any constraints, and the reinspection occurred either by means of a GCW (left panel) or by means of an AS (right panel). In the AS illustration, the image is blurred to illustrate that participants had access only to peripheral vision.
AOI analysis
We found a main effect of fixations across all types of encoding (estimate = 0.018, lower CI = 0.017, upper CI = 0.019) on fixations during mental imagery (MI), showing a clear LAN effect. The credible intervals of the interaction between fixations during encoding and the GCW (estimate = -0.001, lower CI = -0.003, upper CI = 0.001), and the AS condition (estimate = -0.000, lower CI = -0.002, upper CI = 0.001) included 0. Thus, the similarity in the spatial distribution was comparable between MI and all viewing conditions (see Fig. 2a).Fig. 2. Spatial analyses. (a) shows the relationship between the percentage of fixations within a specific AOI (LAN effect) during perception (x-axis) and mental imagery (y-axis), for free perception (green), gaze-contingent window (orange), and the artificial scotoma (purple) encoding conditions. Solid lines represent predicted values (estimates of the Bayesian model), and shaded areas show the 95 percent credible intervals. Overall, the LAN effect is robust and similar across all conditions. All other panels show the MultiMatch similarity scores (y-axes) between mental imagery (MI) and the different encoding conditions (x-axes) for the different parameters. The violins display the distribution of the similarity scores for each participant and trial across the different comparisons. Striped violins indicate comparisons (MI-GCW or MI-AS) for which the Bayesian model estimated a credible difference from the MI-FP reference condition, with 95% credible intervals that did not include zero. The similarity between MI and GCW was higher compared to the other comparisons for the general vector shape (b), the length of saccades (c), and the direction of saccades (d). However, this was not the case for the similarity in the absolute position of the fixations (e) and for the fixation durations within the scanpaths (f).
Scanpaths
The vector (shape) similarity (Fig. 2b) was higher between MI and GCW (estimate = 0.349, lower CI = 0.323, upper CI = 0.375) and lower between MI and AS (estimate = -0.243, lower CI = -0.265, upper CI = -0.221) compared to the similarity between MI and FP. For the direction parameter (Fig. 2c), the similarity between MI and GCW was higher than with FP (estimate = 0.085, lower CI = 0.052, upper CI = 0.116). The similarity between MI and AS did not differ from the similarity with FP (estimate = -0.021, lower CI = -0.052, upper CI = 0.011). Thus, participants made saccades following similar directions between MI and part-based encoding. The similarity in length (Fig. 2d) was also higher for the MI-GCW comparison (estimate = 0.432, lower CI = 0.398, upper CI = 0.466) and lower for the AS-MI comparison (estimate = -0.312, lower CI = -0.340, upper CI = -0.284), compared to the MI-FP comparison, showing that the length of saccades during MI was most closely aligned with those during part-based encoding. The similarity score for position (Fig. 2e) was lower between MI-GCW (estimate = -0.258, lower CI = -0.285, upper CI = -0.230) and between MI-AS (estimate = -0.078, lower CI = -0.106, upper CI = -0.049) compared to MI-FP. Thus, the distance between the fixation locations within the scanpaths was smallest between MI and FP compared to the other encoding conditions. The credible intervals for the similarity in duration (Fig. 2f) of fixations between MI and GCW (estimate = -0.015, lower CI = -0.057, upper CI = 0.028) as well as MI and AS (estimate = -0.039, lower CI = -0.082, upper CI = 0.002) included 0, suggesting that both these comparisons did not differ from the comparison between MI and FP.
Temporal gaze dynamics
Recurrence was higher during MI compared to FP (estimate = 0.865, lower CI = 0.694, upper CI = 1.033), and lower during GCW (estimate = -0.490, lower CI = -0.535, upper CI = -0.443) and AS encoding (estimate = -0.231, lower CI = -0.308, upper CI = -0.157) compared to FP (Fig. 3a). Pictures of indoor scenes led to more recurrent fixations (estimate = 0.131, lower CI = 0.056, upper CI = 0.205) compared to abstract art pictures. Pictures from outdoor scenes did not differ from abstract pictures in terms of recurrent fixations (estimate = -0.011, lower CI = -0.086, upper CI = 0.065).
Determinism was higher during both MI (estimate = 0.730, lower CI = 0.552, upper CI = 0.912) and GCW encoding (estimate = 0.457, lower CI = 0.338, upper CI = 0.577) compared to FP, and lower in the AS compared to the FP condition (estimate = -0.376, lower CI = -0.478, upper CI = -0.273, Fig. 3b). Moreover, determinism was generally higher for indoor compared to abstract pictures (estimate = 0.335, lower CI = 0.259, upper CI = 0.410).Fig. 3RQA results for Experiment 1. Recurrence (a), determinism (b), and laminarity (c) within each condition (x axis), for abstract art (green), indoor (orange), and outdoor (purple) picture categories. The shapes represent predicted values (estimates of the Bayesian model) while controlling for the fixation spread, and the bars represent the 95% credible intervals. Recurrence was higher during imagery, with more refixations (a), while determinism was greater in imagery and GCW encoding (b) but lower in AS. Laminarity was lower in AS (c), and both determinism and laminarity were higher for indoor scenes.
Laminarity was higher during MI compared to FP (estimate = 0.368, lower CI = 0.216, upper CI = 0.527). This indicates that during imagery, participants tend to cluster refixations within specific regions more frequently. The GCW did not lead to a change in laminarity compared to free perception (estimate = 0.015, lower CI = -0.080, upper CI = 0.113). The AS substantially decreased laminarity (estimate = -0.781, lower CI = -0.887, upper CI = -0.676), meaning that participants were less likely to make clustered refixations (Fig. 3c). Compared to abstract art, indoor scenes led to higher laminarity (estimate = 0.458, lower CI = 0.367, upper CI = 0.551), while laminarity for outdoor scenes did almost not differ from abstract art (estimate = 0.093, lower CI = 0.002, upper CI = 0.182).
Probe and vividness
Participants answered the questions following the probes with an overall accuracy of 70%. Accuracy was 70% for GCW trials and 69% for AS trials. Accuracy per category was 67% for abstract art, 77% for indoor scenes, and 65% for outdoor scenes.
The overall average vividness rating was 4.07 (on a 7-point scale). The average vividness rating was 4.13 for GCW trials and 4.02 for AS trials. Separately for each category, vividness ratings were 3.02 for abstract art, 4.55 for indoor scenes, and 4.65 for outdoor scenes.
Discussion
Experiment 1 shows that gaze patterns during mental imagery (MI) align with those during part-based viewing (GCW) and not with those during holistic viewing (AS) or free perception (FP). Specifically, MultiMatch results show that the overall shape of the fixation scanpaths during MI closely aligns with the scanpaths during GCW viewing, and differs most from those during AS viewing. The length and direction of saccades also show the highest similarity between MI and GCW viewing. A replay of eye movements during MI is not supported by these findings^24,38^. Instead, the results are in line with findings showing that fixations during MI are focused on specific parts that are important for mental reconstruction^7^. This aligns with the view that mental images are constructed by combining elements rather than retrieving the entire image holistically^39^. The similarity to part-based viewing supports the concept that different parts need to be reassembled to form a coherent mental scene^5,6,10^.
During encoding, visual exploration helps to construct robust memories. Eye movements assist in later recognition by focusing on specific parts to verify whether the scene matches a stored memory^40^. Similarly, in pattern completion tasks, gaze is directed to regions previously fixated during encoding that are most informative for recognizing an encoded image over a similar lure^41^. Thus, in the present study, it is likely that participants have selectively reinstated fixations to regions most relevant for constructing the mental image; similar to GCW viewing, where scanpaths had to be adapted to efficiently encode and assemble isolated parts into a coherent representation.
RQA results provide further support; recurrence was higher during imagery than during free perception, indicating that participants frequently returned to previously inspected locations. This is in line with previous studies indicating that refixations during imagery serve to refresh fragile internal representations^28,29^. Supporting this, fixations during imagery tend to favor low spatial frequencies^42^, suggesting that refixations help reactivate image regions that are represented with less detail. Importantly, determinism and laminarity were higher during both MI and GCW viewing, reflecting more clustered refixations occurring in the same sequential order. A prior study using GCW reported similar results^43^, and proposed that these gaze patterns reflect clustered refixations on specific regions for detailed inspection. Thus, high determinism and laminarity during imagery suggest a part-by-part construction of mental images rather than holistic retrieval. In line with this, both determinism and laminarity were higher for indoor scenes. Indoor scenes contain more objects, prompting systematic refixations to specific parts (higher determinism) and more clustered refixations for detailed inspection (higher laminarity)^43^. During imagery, stereotypical refixations can function as spatial anchors, linking visual details to specific locations. This allows retrieval by revisiting these areas in a consistent order, rather than relying on active maintenance in working memory^44^. Stereotypical refixations may also support the binding of spatial relations to a coherent representation. Refixations to previously occupied locations are known to facilitate such binding during sequential object encoding^45^. Furthermore, looking at empty screen regions during imagery has been proposed as a strategy to reduce cognitive load^13^. Therefore, repeated fixations in a consistent order might be the optimal strategy during imagery. In support of this, refixation sequences tend to follow systematic, sequential orders under high memory load^46^.
What determines which specific parts participants focus on during imagery? One possibility is that these parts were already prioritized during free encoding through covert attention shifts and were later revisited through overt fixations during imagery, ultimately resembling part-based viewing. Covert attention shifts have been shown to aid memory retrieval^47^. The GCW encourages overt attention to isolated parts, while the AS promotes a broader, global focus. Consequently, differences in initial exploration could lead to different gaze patterns during imagery. It is also possible that eye movements during mental imagery are independent of encoding. To investigate this, we conducted a second experiment that directly manipulates how pictures are initially encoded (freely, part-by-part, or holistically).
Experiment 2
In Experiment 2, we manipulate encoding before participants imagine the picture (see Figure 4). If gaze patterns during imagery mirror part-based viewing regardless of how the pictures are encoded, this would suggest that part-by-part construction is an intrinsic property of imagery. However, if gaze patterns during imagery vary depending on the encoding type, part-based eye movements in Experiment 1 could have been influenced by free encoding. Experiment 2 also addresses a potential confound in Experiment 1, where participants always viewed and imagined the scenes before reinspection with the GCW or AS, potentially biasing gaze patterns during reinspection. Hence, Experiment 2 investigates whether the part-based pattern stems from perceptual encoding or whether it reflects a characteristic intrinsic to mental image generation.Fig. 4. Procedure for Experiment 2. (a) First, participants encoded pictures from three categories (art, indoor, and outdoor scenes) either freely, with a gaze-contingent window (GCW), or with an artificial scotoma (AS) for 20 sec, before a 1 sec fixation cross. Afterwards, they were instructed to imagine the picture as vividly as possible for 20 sec, before a probe appeared during the 3 last seconds, and the participants were required to judge whether a specific object or color fell under the probe. At the conclusion of each trial, participants had to rate the vividness of their mental image from 1 to 7. (b) Illustration of the 3 encoding conditions: free perception (left), encoding with the GCW (center), and with the AS (right). In the AS illustration, the image is blurred to illustrate that participants saw the picture with peripheral vision.
Looking at nothing
We investigated whether the LAN effect differed after different encoding types. Similar to Experiment 1, the results reveal a significant main effect (estimate = 0.024, lower CI = 0.021, upper CI = 0.027), but no interaction between fixations during the initial encoding phase and the GCW condition (estimate = -0.002, lower CI = -0.006, upper CI = 0.003), nor between fixations during encoding and the AS condition (estimate = -0.001, lower CI = -0.005, upper CI = 0.003).
Scanpaths
The results show the same pattern of results as in Experiment 1: the vector similarity was higher between MI and GCW (estimate = 0.465, lower CI = 0.418, upper CI = 0.512) and lower between MI and AS (estimate = -0.193, lower CI = -0.233, upper CI = -0.152), compared to FP. The direction (estimate = 0.144, lower CI = 0.080, upper CI = 0.207) and length (estimate = 0.569, lower CI = 0.504, upper CI = 0.636) similarity were higher between MI-GCW compared to MI-FP. The position similarity was again lower between MI and GCW (estimate = -0.288, lower CI = -0.335, upper CI = -0.242), as well as between MI and AS (estimate = -0.105, lower CI = -0.152, upper CI = -0.057), compared to MI-FP. There was again no difference for the duration similarity, where the credible intervals for both MI-GCW (estimate = 0.073, lower CI = -0.005, upper CI = 0.150) and MI-AS (estimate = 0.050, lower CI = -0.027, upper CI = 0.129) included 0.
Temporal gaze dynamics
Results for determinism indicate higher values for MI after FP (estimate = 0.970, lower CI = 0.765, upper CI = 1.174), MI after GCW encoding (estimate = 1.023, lower CI = 0.778, upper CI = 1.269) and MI after AS encoding (estimate = 0.924, lower CI = 0.661, upper CI = 1.188), as well as for GCW encoding itself (estimate = 0.756, lower CI = 0.563, upper CI = 0.954) compared to FP (Fig. 5, left panel). Results for laminarity indicate higher values during MI following FP encoding (estimate = 0.623, lower CI = 0.438, upper CI = 0.811), GCW encoding (estimate = 0.698, lower CI = 0.463, upper CI = 0.931), and AS encoding (estimate = 0.599, lower CI = 0.358, upper CI = 0.841), compared to FP (Fig. 5, right panel). Similarly, GCW encoding showed increased laminarity (estimate = 0.418, lower CI = 0.220, upper CI = 0.615), while AS encoding showed reduced laminarity (estimate = -0.532, lower CI = -0.752, upper CI = -0.308).
To investigate whether encoding influences subsequent MI, we compared determinism and laminarity between the three MI conditions (MI-FP, MI-GCW, MI-AS). Results for determinism indicate no differences between mental imagery conditions (Fig. 6, left panel). Credible intervals for the comparison between MI-GCW and MI-FP (estimate = 0.054, lower CI = -0.151, upper CI = 0.262), MI-AS and MI-FP (estimate = -0.046, lower CI = -0.262, upper CI = 0.165), and the comparison between MI-AS and MI-GCW (estimate = -0.099, lower CI = -0.314, upper CI = 0.112) all included zero, indicating that the type of encoding did not result in distinct gaze patterns during mental imagery. Similarly, results for laminarity indicate no differences between MI conditions (Fig. 6, right panel). Credible intervals for the comparison between MI-GCW and MI-FP (estimate = 0.074, lower CI = -0.119, upper CI = 0.267), MI-AS and MI-FP (estimate = -0.024, lower CI = -0.220, upper CI = 0.172), and the comparison between MI-AS and MI-GCW (estimate = -0.099, lower CI = -0.292, upper CI = 0.093) all included zero, indicating that the type of encoding did not result in distinct laminarity during imagery.Fig. 5RQA results for Experiment 2. Determinism was higher during GCW encoding and the three imagery conditions (left). Laminarity was lower during AS encoding compared to the other encoding and imagery conditions (right). The plots demonstrate that determinism is similar between all three imagery conditions and GCW encoding. Laminarity differed substantially for AS encoding compared to the other encoding and imagery conditions. The shapes represent predicted values (estimates of the Bayesian model) while controlling for the fixation spread, and the bars represent the 95% credible intervals.Fig. 6. Posterior contrasts between mental imagery conditions for determinism (left) and laminarity (right) in Experiment 2. The plots display Bayesian model estimates of fixed-effect contrasts comparing mental imagery following different encoding types: free perception (MI-FP), gaze-contingent window (MI-GCW), and artificial scotoma (MI-AS). None of the 95% credible intervals excluded zero, indicating that determinism and laminarity during mental imagery did not substantially differ as a function of the prior encoding condition. Density shapes represent the posterior distributions of each contrast, and horizontal bars indicate the 95% credible intervals.
Probe and vividness
Participants answered the questions following the probes with an overall accuracy of 62%. Accuracy was 67% for FP trials, 66% for GCW trials, and 54% for AS trials. Accuracy by image type was 67% for abstract art, 64% for indoor scenes, and 55% for outdoor scenes.
The overall average vividness rating was 3.99 (on a 7-point scale). The average vividness rating was 4.16 for FP trials, 3.66 for GCW trials, and 4.16 for AS trials. By image type, vividness ratings were 2.78 for abstract art, 4.63 for indoor scenes, and 4.57 for outdoor scenes.
General discussion
In this study, we investigated the role of eye movements during visual mental imagery by comparing gaze patterns during imagery to those observed in part-based, holistic, and free perception. The results of Experiment 1 show that gaze patterns during imagery closely resemble those observed when pictures are encoded part-by-part (gaze-contingent window). Experiment 2 shows that this similarity persists regardless of whether the pictures were originally encoded freely, part-by-part, or holistically. This suggests that part-based patterns during imagery are independent of prior encoding. The results provide evidence that mental images are generated by assembling distinct elements^31^, and that eye movements reflect this construction process.
Several studies on gaze patterns during mental imagery suggest a reactivation of spatial indices tied to different parts of a picture to enable perceptual recall^5,6,13^. It has been concluded that eye movements organize the reassembly of mental images from individual parts^6,7^, but this hypothesis has not been tested directly. Moreover, these studies did not investigate the specific reasons why gaze patterns during imagery often differ from those during perception. It also remained unclear to what extent imagery-related eye movements depend on encoding. In the present study, we tested whether imagery-related gaze patterns reflect a part-by-part construction process, and whether this process depends on the initial encoding.
The results showed highest similarity in both experiments when comparing MI to part-based encoding (GCW). This finding challenges the assumption that free perception and imagery involve similar scanpaths, despite the LAN effect being consistently reported in the literature. Previous studies have mostly shown the LAN effect using area of interest (AOI) analyses^1,4,6,7,11^, and we replicate this in both experiments: participants re-fixated the same locations during imagery as during perception. However, the LAN effect did not differ across conditions, suggesting that AOI analyses are not sensitive enough to detect subtle differences in fixation scanpaths, such as those distinguishing between holistic and part-based viewing. Previous studies have shown that although the spatial distribution of fixations is similar in free viewing and mental imagery, this similarity becomes less systematic when investigating scanpaths and the temporal gaze patterns^27–29^. Indeed, our RQA and MultiMatch results show that the temporal gaze dynamics and fixation scanpaths during imagery resemble those observed during part-based viewing. Although eye fixations during imagery land in similar screen locations as during free perception, the underlying scanpaths and refixation patterns differ. Thus, gaze patterns during imagery are not merely a replay of fixations from perception.
Why do gaze patterns during imagery resemble part-based encoding? Visual imagery, like perception, involves two components: object imagery, which emphasizes visual details such as shape and color, and spatial imagery, which represents the spatial arrangement and configuration of objects^48,49^. Importantly, eye movements during imagery are tied to the spatial aspects of mental images. For instance, restricting eye movements during imagery impairs memory for spatial relations between objects rather than object features^8^. Indeed, keeping central fixation during imagery leads to a more holistic imagery strategy resulting in less detailed recall^5,6^. Individuals with less spatial imagery abilities show increased eye movements during imagery^50^, suggesting that eye fixations help to construct the spatial layout of mental images. These findings indicate that eye movements supporting part-based processing are essential for constructing spatially detailed mental images. Thus, because eye movements are tied to the spatial aspects of imagery^8,50^, and spatial imagery relies on part-by-part construction^48^, this may explain why gaze patterns during mental imagery resemble those observed during part-based encoding.
The results of Experiment 2 provide further insight into the origin of part-based gaze patterns during imagery. Despite clear differences in perceptual encoding between the AS and GCW conditions, participants showed similar gaze patterns during subsequent imagery. These findings are consistent with studies showing that imagery-related eye movements do not necessarily reflect those made during encoding^5,11,50^. In a previous study^5^, participants maintained central fixation during encoding, yet they still showed spread out fixations during imagery. However, it is possible that covert attention shifts during encoding accounted for later eye movements. Covert attention shifts are known to support memory retrieval^47^ similar to overt eye movements. This could explain why there were eye movements during imagery without overt gaze shifts during perceptual encoding. Here, in the AS condition, covert attention shifts were encouraged because fixating an area made it disappear immediately. In contrast, the GCW condition required overt attention (e.g.^51^), because participants could only see the part of the image they directly fixated. Since gaze patterns during imagery did not change across encoding conditions, covert attention shifts during perception cannot account for eye fixations during imagery. Instead, eye movements during imagery reflect an internal process that operates independently of prior encoding. This suggests that imagery-related gaze patterns are not reinstated from perception, but instead reflect the part-by-part generation and maintenance of mental images.
Mental images are fragile and begin to fade once a part is activated, and they need to be maintained by repeatedly re-focusing attention on the same parts^52^. Since eye movements overtly reflect the spatial focus of attention^53^, they may serve as external markers of how each part of the mental image is assembled and maintained. Increased determinism and laminarity support this interpretation: clustered refixations following the same sequential order likely reflect the systematic reactivation of image parts. Crucially, eye movements were independent of how the image was originally encoded (freely, part-by-part, or holistically). While the initial content retrieved from memory may vary depending on the conditions of encoding, the way the image is mentally constructed relies on a part-based process. Hence, eye movements during imagery reflect shifts in spatial attention to arrange and maintain parts of a mental image, and this process is independent of how the information was encoded.
When recalling spoken facts, participants tend to fixate the screen location where a speaker had previously appeared, indicating that spatial indices can guide eye movements even when the remembered information is purely auditory and semantic^11^. In fact, Ferreira et al. (2008)^3^ proposed that eye movements are guided by internally constructed spatial indices, regardless of whether they were originally derived from visual, linguistic, or conceptual input. Likewise, the current results show that imagery-related eye movements reflect internally constructed mental representations, independent of how the information was visually encoded. Thus, the current findings suggest that mental images are not stored as holistic representations in memory, but are assembled part-by-part during recall. Gaze patterns during imagery consistently resemble those observed during part-based viewing, even when the image was originally perceived holistically.
Several limitations must be acknowledged. While there are no established standards for selecting the threshold radius in RQA, we followed the approach used in previous studies^28,29,54,55^ to ensure comparability of results. Another potential limitation concerns the probe task, which appeared after the imagery phase and asked participants to recall specific visual details (e.g., an object or a color). This may have encouraged attention toward specific image regions and, in principle, biased gaze patterns during imagery toward part-based viewing. However, in Experiment 1, the probe was only shown after the second imagery phase, whereas our analyses were based exclusively on the first imagery phase, which did not include a probe. Moreover, despite imagery always being followed by a probe in Experiment 2, the pattern of results closely matched those of Experiment 1. This makes it unlikely that the observed effects were driven by a task-induced focus on specific image regions. Finally, the similarity between imagery and part-based viewing may arise from the fact that we used complex scenes as visual stimuli. Previous studies showed that eye movements follow more systematic and repeated scanpaths under high memory workload^46^. Future studies could investigate whether these part-based patterns persist with less complex visual stimuli.
To conclude, the present study provides direct evidence that eye movements during mental imagery are not simply replayed from perception. Instead, they resemble the spatiotemporal dynamics of part-based viewing, suggesting that they support the construction of mental images piece by piece. Crucially, this pattern emerged regardless of whether the scenes were initially encoded freely, holistically, or part-by-part. Mental images are not retrieved as holistic visual representations from memory. Instead, they are reconstructed part-by-part during recall, and eye movements reflect this generative process.
Methods
Participants
For Experiment 1, 52 participants (mean = 22.77, sd = 2.53, range = 19-35, female = 42) were recruited for the study. Three participants were excluded. One because a lot of tracking time was missing, and two because of unusual gaze behavior (see supplementary materials S7.1 for details). The final sample consisting of 49 participants (mean = 22.80, sd = 2.59, range = 19-35, female = 39) was kept for subsequent analyses. For Experiment 2, 55 new participants that did not participate in the first experiment were recruited. Two participants were excluded because of calibration issues during the eye-tracking experiment, and 3 participants had to be excluded because their gaze behavior was highly unusual (see supplementary materials S7.2 for details). This resulted in a final sample of 50 participants (mean = 22.72, sd = 3.16, range = 18 - 34, female = 39). Exclusion criteria for both experiments were the use of medication that can impair consciousness or vision or wearing glasses. Furthermore, participants were asked if they were able to generate mental images, and those with self-reported aphantasia were excluded. All participants gave their informed consent prior to the study. The study was approved by the Ethics Committee of the Faculty of Human Sciences at the University of Bern. All methods were performed in accordance with the ethical standards of the institutional research committee and with the 1964 Declaration of Helsinki and its later amendments or comparable ethical standards.
Apparatus
Fixation data was acquired with an EyeLink 1000 Plus eye-tracker (SR Research, Canada). For each participants the dominant eye was determined using the Miles Test^56^ and tracked with a sampling rate of 1000 Hz. Fixations were defined as the absence of saccade and blink^57^. Thus, each sample was considered as part of a fixation when both the velocity and acceleration were below a threshold of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$30^{\circ }\hbox {/sec}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$8000^{\circ }\hbox {/sec}$$\end{document} , respectively. When the pupil was missing, very small, or distorted, samples were not labeled as part of a fixation. The fixation data was exported with the SR research Data Viewer software (SR Research Ltd., version 4.3.210) for preprocessing and further analyses.
Gaze-contingent windows
Two types of gaze-following objects were used for the experiment. The first was a gaze-contingent window (GCW) which is comparable to “tunnel vision” where only the center of the current fixation position is visible, the peripheral part being covered with gray pixels. The second was an artificial scotoma (AS), where the center of the current fixation location was covered in gray pixels, and thus only peripheral information remained visible. We conducted a small pretest (n=5) to determine which eye-tracking parameters led to the smoothest gaze-following with the least possible latency. We concluded that there were no subjective differences between using both eyes or only the dominant eye to move the window. Furthermore, monocular tracking with the EyeLink 1000 Plus allows for a sampling rate of 1000 Hz, whereas binocular was limited to 500 Hz. Thus, we decided to track the dominant eye and use its position to move the GCW and the AS. The size of the GCW corresponded to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$5^{\circ }$$\end{document} of the visual angle, which in our case was 270 pixels diameter. The size of the AS was 377 pixels diameter, corresponding to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$7^{\circ }$$\end{document} of visual angle. The AS was bigger than the GCW, as prior research suggests that smaller central scotomas do not sufficiently interfere with scene processing or fixation behavior^58^. Both masks were created in Photoshop^59^, and a Gaussian filter was applied to make the edges less sharp, and reduce afterimages.
Stimuli and materials
45 pictures (15 abstract art, 15 indoor, and 15 outdoor pictures) were displayed at a distance of 855 mm from the participants on a 1920 \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\times$$\end{document} 1080 computer screen with a refresh rate of 144Hz. Pictures of indoor and outdoor scenes were selected from the FIGRIM^60^ and LaMem^61^ databases. Details about the selection of stimuli can be found in the supplementary material S1.
For Experiment 2, the same set of 45 stimuli (15 from each category) was used as in Experiment 1. However, each picture was shown only once per condition (GCW, AS, FP), resulting in 15 pictures per condition, with 5 from each category.
The VVIQ 2 was used to assess vividness in mental imagery^62^, and participant’s cognitive styles with the OSIVQ^63^. We used Vanderberg’s task^64^ to assess mental rotation, and a visual n-back task for visual working memory programmed in MATLAB^65^ with PsychToolbox-3^66^. These were used for exploratory purposes and more information can be found in the supplementary material S6.
Procedure
Experiment 1
First, participants read a cover story, telling them that we were measuring pupil dilatation with respect to image complexity. This was to avoid that participants focus on their eye movements during mental imagery. Subsequently, participants read the instructions and a 9-point-calibration was performed after determining the infrared light intensity threshold. The experiment began with a habituation phase with 10 GCW trials and 10 AS trials. Each trial lasted 10 sec, and consisted of images different from those used in the experimental phase. Additionally, there were 2 practice trials (one with GCW and one with AS). Each trial started with a drift correction dot. First, a picture was displayed during 20 sec, followed by a fixation cross for 1 sec. Then, a blank gray screen appeared during 20 sec, on which participants had to visually imagine the picture they just saw as vividly and precisely as possible. Longer duration during imagery ensures that eye movements do not merely stem from visual after effects, and are required to gather enough data for RQA. Subsequently, participants were asked how precisely and vividly their mental image was, and had to press a key from 1 (no imagery) to 7 (like a real picture). After, participants saw a fixation cross (1 sec) and the same image again for 20 sec with either a GCW (block 1) or an AS (block 2). Finally, participants had to imagine the picture again on a blank gray screen displayed for 10 sec, and a probe appeared during the last 3 seconds, followed by a question whether it appeared on a specific object of the previously perceived image. Participants had to answer “yes” or “no” by pressing a key on the keyboard and the amount of correct responses being “yes” and “no” were equal. A second imagery phase was necessary for the probe, to avoid that participants focus their fixations on verifying their response accuracy regarding the probe during the reinspection. The experiment consisted of 2 blocks, one in which the image was reinspected with a GCW, and with an AS in the other block. Both the order of blocks and images was randomized, and the same images were used in both the GCW and AS blocks. This allowed us to compare eye movements during imagery with those during GCW and AS for the same pictures. Each block lasted approximately 1 hour, with a 10 minutes break in-between. After the eye-tracking experiment, participants completed the OSIVQ, the mental rotation task, the VVIQ, and the visual n-back task. More information about the n-back task can be found in the supplementary material S6.1.4. To conclude the experiment, participants were asked what they believed the aim of the eye-tracking experiment was, before a debriefing. None of the participants guessed the real purpose of the experiment.
Experiment 2
The procedure was essentially the same as in Experiment 1, except that there was no reinspection phase, and the encoding type was manipulated during the first encoding. Like in Experiment 1, participants read a cover story, telling them that we were measuring pupil dilatation with respect to image complexity. The experiment also began with a habituation phase with 10 GCW trials and 10 AS trials, and there were 3 practice trials (one for each condition, FP, GCW and AS). First, a picture was displayed during 20 sec and encoded either freely (block 1), with a GCW (block 2), or with an AS (block 3), followed by a fixation cross for 1 sec. Then, a blank gray screen appeared during 20 sec, on which participants had to visually imagine the picture they just saw, and a probe appeared for 3 seconds, followed by a question whether it appeared on a specific object of the previously perceived image. At the end of each trial, participants had to press a key from 1 (no imagery) to 7 (like a real picture). The block order as well as the stimulus presentation within each block were randomized.
After the eye-tracking experiment, participants completed exactly the same tasks as described in Experiment 1 (i.e. VVIQ, OSIVQ, mental rotation, and n-back). To conclude the experiment, participants were asked what they believed the aim of the eye-tracking experiment was, before a debriefing. None of the participants guessed the real purpose of the experiment.
Eye movement analyses
Raw fixation reports from the Data Viewer software were preprocessed to remove fixations outside of the screen, and fixations longer than 5000 ms or shorter than 100 ms. The time spent on fixating the screen as well as the number and duration of fixations for each participant were compared in relation to the other participants to detect outliers in gaze behavior and potential technical problems. A detailed report can be found in the supplementary materials S7.
Area of interest analysis
To investigate the LAN effect, we separated the screen into four equally sized quadrants (AOIs), following the procedure of previous studies^7,28^. For each trial and participant, we calculated the amount of fixations falling in each AOI within the different experimental phases. Then, we tested whether fixations during mental imagery are predicted by fixations during encoding. Thus, the fixation locations during visual imagery were used as an outcome variable, and fixation locations during the other phases as predictors.
MultiMatch
MultiMatch^67,68^ computes the similarity between two scanpaths represented as geometrical vectors across different dimensions. Vector (shape) refers to the similarity of the geometrical shape between two aligned vectors (saccade pairs) regardless of their relative position in space. Length compares the similarity between the amplitude of two saccades, in terms of length between endpoints. Direction indicates whether the angular distance between two vectors is similar. Position compares the Euclidean distance between the fixation points of two aligned vectors. Finally, Duration represents the similarity of the temporal duration between aligned fixations. In the current study, these similarity metrics were computed for the comparisons between mental imagery and the different encoding conditions (FP, GCW, and AS) for each participant and trial.
Recurrence quantification analysis
While MultiMatch quantifies and compares gaze scanpaths in the spatial domain, recurrence quantification analysis (RQA) is a method providing various measures to characterize the temporal dynamics of fixation data. RQA provides a non-linear analysis of complex dynamic systems. More recently, RQA has been successfully implemented for the analysis of temporal dynamics of gaze patterns^43,69^. Importantly, RQA parameters have been used to reveal unique temporal properties of eye movements during mental imagery, and allowed to distinguish gaze properties that are unique to imagery^27,28^.
Recurrence
Recurrence is the fundamental unit in RQA which is then used to compute several other parameters. Two fixations are considered recurrent if the Euclidean distance between them is equal or below a given distance threshold. Recurrent fixations are usually represented in a two dimensional recurrence plot, where each axis represents the sequence of fixations, denoted as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$S$$\end{document} , from the first ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$S_1$$\end{document} ) to the last ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$S_n$$\end{document} ). The Euclidean distance is calculated for each pair ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$S_i$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$S_j$$\end{document} ) of fixations within this sequence. If this distance is less than or equal to a predetermined threshold, indicating that the fixations are spatially close, a dot is plotted at the coordinates \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$(i, j)$$\end{document} on the recurrence plot. Each dot on a recurrence plot shows that the fixations at positions \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$i$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$j$$\end{document} within the sequence \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$S$$\end{document} are considered recurrent. Thus, a square recurrence matrix can be derived with:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} R_{i,j} = \Theta (\epsilon - \Vert x_i - x_j \Vert ) \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$R_{i,j}$$\end{document} represents an element of the recurrence matrix, indicating whether the fixations \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$x_i$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$x_j$$\end{document} are recurrent within the threshold \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\epsilon$$\end{document} . \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\Theta$$\end{document} denotes the Heaviside step function, which is 1 if its argument is non-negative (i.e., \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$x_i$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$x_j$$\end{document} are within the threshold distance \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\epsilon$$\end{document} ) and 0 otherwise. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\Vert x_i - x_j\Vert$$\end{document} is the chosen distance (in our case Euclidean) between the fixations \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$x_i$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$x_j$$\end{document} ^70^. The recurrence threshold was set to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$2.5^{\circ }$$\end{document} of visual angle (135px in our setup). Similar threshold values have been used in eye-tracking RQA studies^55,69,71^, including prior work on eye movements during mental imagery^27,28^, allowing direct comparison of parameter values. Thresholds in this range correspond to a spatial scale that encompasses the fovea and extends into the parafoveal region, which provides a sensible spatial radius for identifying recurrent fixations^69^.
Determinism
Different RQA measures are extracted from scale structures of the recurrence matrix defined above, such as vertical and diagonal lines. Determinism shows refixations that occur in the same sequential order as previous fixations. It is computed as the percentage of recurrence points which lie on diagonal lines in the recurrence matrix:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \text {DET} = 100 \cdot \frac{\sum _{L=L_{\text {min}}}^{n} D_L}{\sum _{i,j=1}^{n} (1 - \delta _{ij}) R_{i,j}} \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$D_L$$\end{document} represents the number of recurrence points in the recurrence matrix \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$R_{i,j}$$\end{document} forming diagonal lines of a minimum length \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$L$$\end{document} . The Kronecker delta \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\delta _{ij}$$\end{document} is used in the equation to exclude the diagonal of self recurrence, where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$i$$\end{document} = \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$j$$\end{document} . A recurrence matrix is by definition symmetrical, thus only one triangle can be taken into account when computing determinism. The DET value increases when areas of an image are reinspected in the same sequential order for at least \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$L$$\end{document} (generally \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$L = 2$$\end{document} ) fixations. Therefore, a high DET value indicates that the order in which parts of an image are inspected is dependent on previous fixations on those same areas.
Laminarity
Laminarity represents the percentage of vertical and/or horizontal lines in the recurrence matrix, and can be defined as
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \text {LAM} = 100 \cdot \frac{\sum _{L=L_{\text {min}}}^{n} H_L + V_L}{\sum _{i,j=1}^{n} (1 - \delta _{ij}) R_{i,j}} \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$H_L$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$V_L$$\end{document} represent the number of recurrence points belonging to horizontal or vertical lines of minimum length \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$L$$\end{document} , respectively. A high LAM value either indicates that areas were first inspected with a single fixation, and later reinspected with at least \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$L$$\end{document} refixations (vertical lines); or that areas were initially inspected in detail before being briefly reinspected with a single fixation (horizontal lines).
Data analysis
Implementation details
To compute the different RQA parameters, we used the MATLAB functions from^43^. The MultiMatch parameters were computed in Python with the re-implementation of MATLAB functions^68^ into Python^72^.
Statistical analyses
All statistical analyses were performed with R^73^, in RStudio^74^, with Bayesian hierarchical generalized regression models implemented in the brms package^75^. In all our models to estimate RQA parameters, we used zero-one-inflated beta (zoib) regressions, as they are suitable for proportion data while accounting for zero and one’s present in the data (unlike simple beta regressions). Moreover, zoib regressions have the potential to model the zero-one inflation (i.e. the probability of a score being exactly zero or one, denoted as zoi) as well as the conditional one inflation (i.e. if a score is exactly zero or one, its probability of being one, denoted as coi). For the MultiMatch analyses, we used Beta regressions because all similarity scores were bounded between 0 and 1. Thus, the model does not predict values outside the range of possible values. Bayesian models provide posterior distributions for each estimated parameter. This distribution represents the probability of different parameter values given the observed data and prior information. From these, we derive credible intervals, which indicate the range within which the true parameter likely falls. A 95% credible interval means there is a 95% probability that the true parameter value lies within this interval. If this interval does not include zero, it suggests the presence of an effect. The brms package uses Hamiltonian Monte Carlo (HMC), as MCMC sampling method. We used 4 Markov-Chains with 6000 iterations each to ensure convergence in all our models. Both the pareto-k and visual inspection of the posterior predictive distribution were used as a criteria to assess the goodness of fit of all our models. Posterior predictive checks consist in comparing the distribution of the observed data to the distribution of data generated based on the parameters specified in a given model. If these two distributions look similar, it suggests good fit. To assess model convergence and sampling efficiency, we examined the potential scale reduction factor (Rhat), bulk effective sample size, and tail effective sample size. All model information and specifications can be found in the supplementary material S2 (Experiment 1) and S3 (Experiment 2).
Supplementary Information
Supplementary Information.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Kumcu, A. & Thompson, R. L. Spatial interference and individual differences in looking at nothing for verbal memory. In Proceedings of the Annual Meeting of the Cognitive Science Society. Vol. 38 (2016).
- 2Dijkstra, N., Zeidman, P., Ondobaka, S., van Gerven, M.A. J. & Friston, K. Distinct top-down and bottom-up brain connectivity during visual perception and imagery. Sci. Rep.7, 5677. 10.1038/s 41598-017-05888-8 (2017).10.1038/s 41598-017-05888-8PMC 551601628720781 · doi ↗ · pubmed ↗
- 3Dijkstra, N., Bosch, S. E. & Gerven, M. A.J.V. Vividness of visual imagery depends on the neural overlap with perception in visual areas. J. Neurosci.37, 1367–1373. 10.1523/JNEUROSCI.3022-16.2016 (2017).10.1523/JNEUROSCI.3022-16.2016 PMC 659685828073940 · doi ↗ · pubmed ↗
- 4Neisser, U. Cognitive psychology. In Century Psychology Series (Appleton-Century-Crofts, 1967) (OCLC: 192730).
- 5Gurtner, L. M., Bischof, W. F. & Mast, F. W. Gaze restriction and reactivation of place-bound content drive eye movements during mental imagery. J. Cognit.6. 10.5334/joc.316 (2023).10.5334/joc.316PMC 1047316737663138 · doi ↗ · pubmed ↗
- 6van Diepen, P. M. J., Wampers, M. & d’Ydewalle, G. Functional division of the visual field: Moving masks and moving windows. In Eye Guidance in Reading and Scene Perception. 337–355. 10.1016/B 978-008043361-5/50016-X (Elsevier Science Ltd, 1998).
- 7Van Belle, G., De Graef, P., Verfaillie, K., Rossion, B. & Lefèvre, P. Face inversion impairs holistic perception: Evidence from gaze-contingent stimulation. J. Vis.10. 10.1167/10.5.10 (2010).10.1167/10.5.1020616142 · doi ↗ · pubmed ↗
- 8Johansson, R., Holsanova, J. & Homqvist, K. The dispersion of eye movements during visual imagery is related to individual differences in spatial imagery ability. Proc. Annu. Meet. Cognit. Sci. Soc.33 (2011).