A comparative analysis of video vision transformers on word-level sign language datasets
Jubayer Ahmed Bhuiyan Shawon, Md Kamrul Hasan, Hasan Mahmud

TL;DR
This paper compares video vision transformers for recognizing Bangla Sign Language signs, showing they outperform traditional methods with high accuracy on small and large datasets.
Contribution
The study introduces a comparative analysis of video transformers on Bangla Sign Language datasets, including novel benchmarking and evaluation techniques.
Findings
VideoMAE achieved 96.9% accuracy on the BdSLW60 dataset with corrected frame rates.
VideoMAE also reached 81.04% accuracy on front-facing signs in the larger BdSLW401 dataset.
Video transformers outperformed traditional machine learning and deep learning approaches.
Abstract
Sign Language Recognition (SLR) involves the automatic identification and classification of sign gestures from images or video, converting them into text or speech to improve accessibility for the hard-of-hearing community. In Bangladesh, Bangla Sign Language (BdSL) serves as the primary mode of communication for many individuals with hearing loss. This study fine-tunes state-of-the-art video transformer architectures VideoMAE, ViViT, and TimeSformer on BdSLW60, a small-scale BdSL dataset with 60 frequent signs. We standardized the videos to 30 FPS, resulting in 9,307 user trial clips. To evaluate scalability and robustness, the models were also fine-tuned on BdSLW401, a large-scale dataset with 401 sign classes. Additionally, we benchmark performance against public datasets, including LSA64 and WLASL. Data augmentation techniques such as random cropping, horizontal flipping, and…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
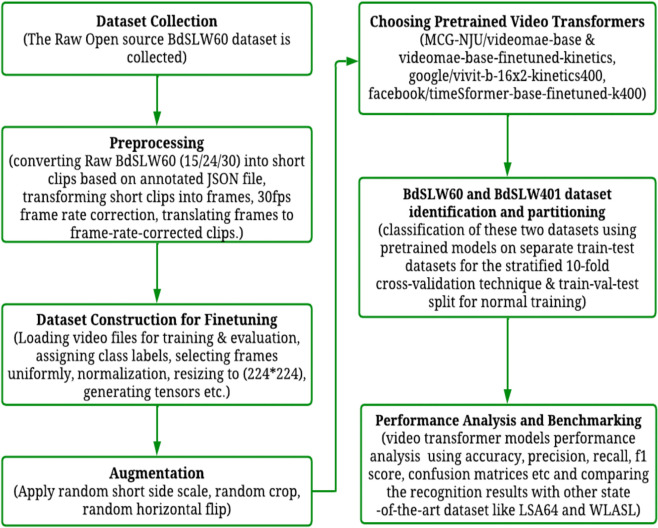 Fig 1
Fig 1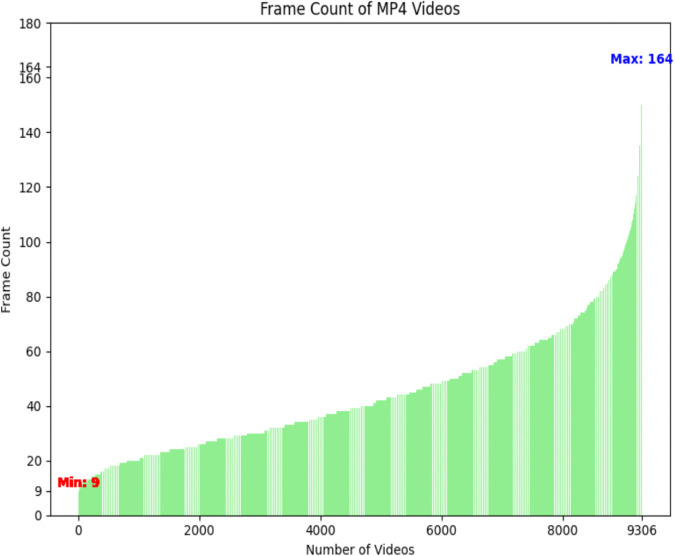 Fig 2
Fig 2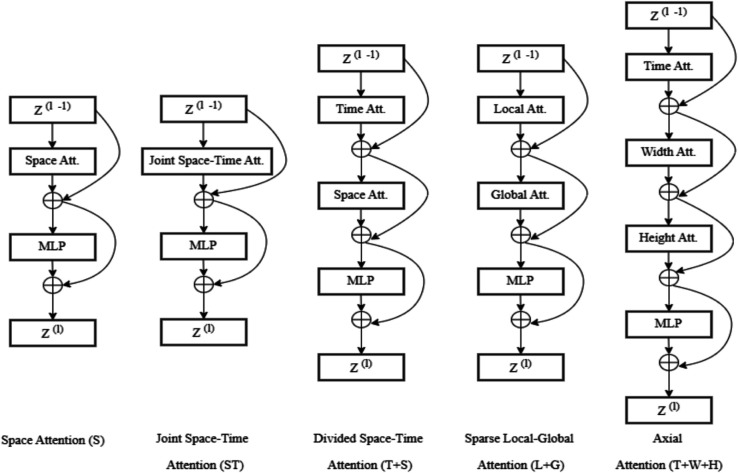 Fig 3
Fig 3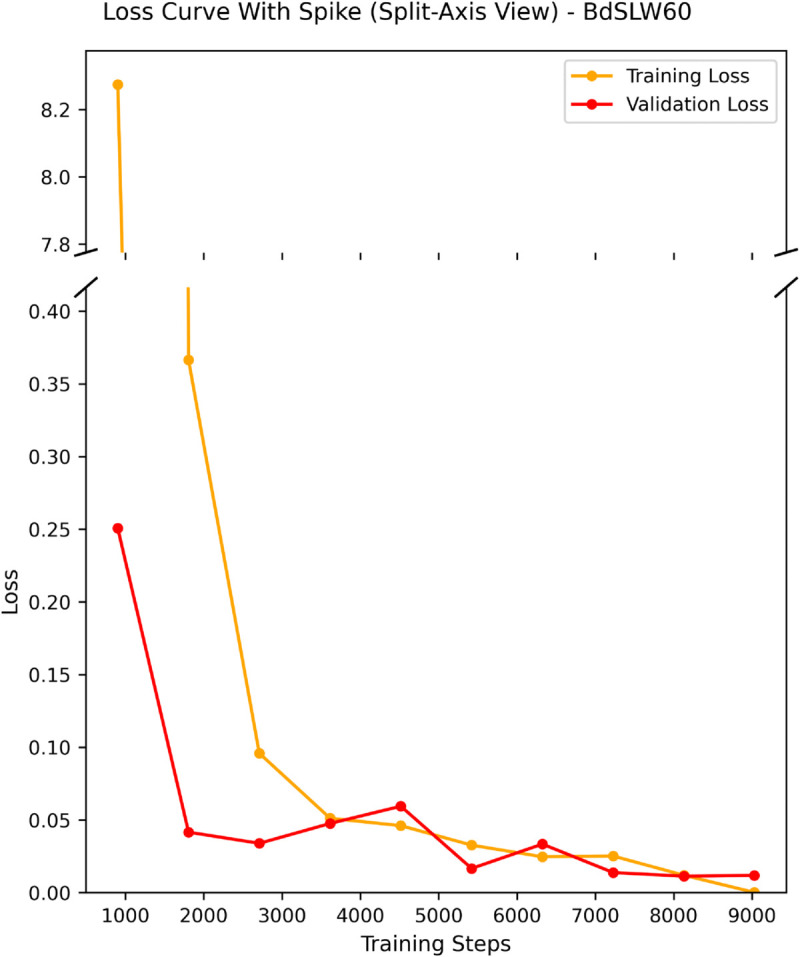 Fig 4
Fig 4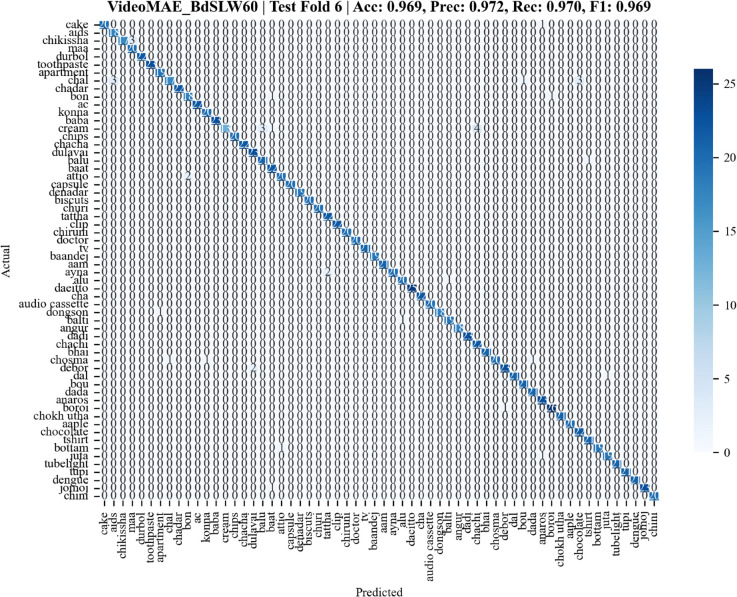 Fig 5
Fig 5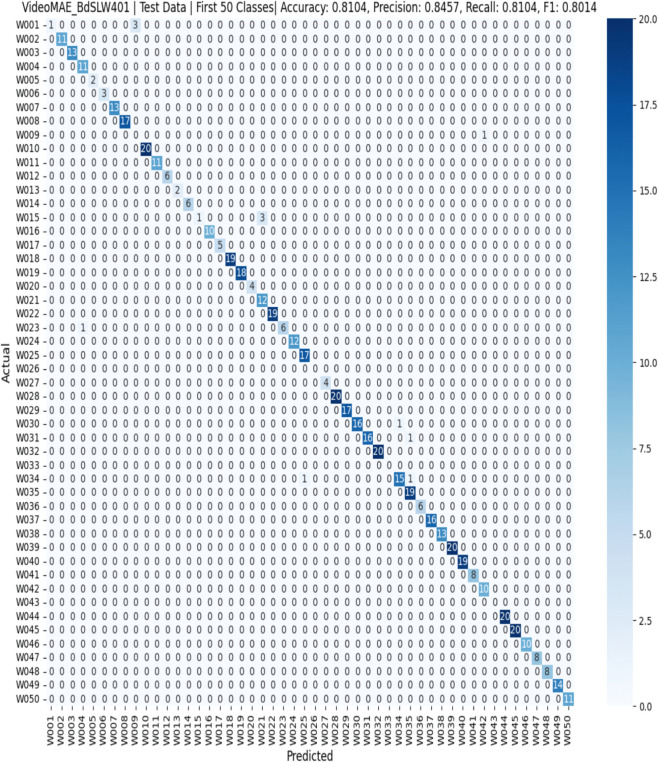 Fig 6
Fig 6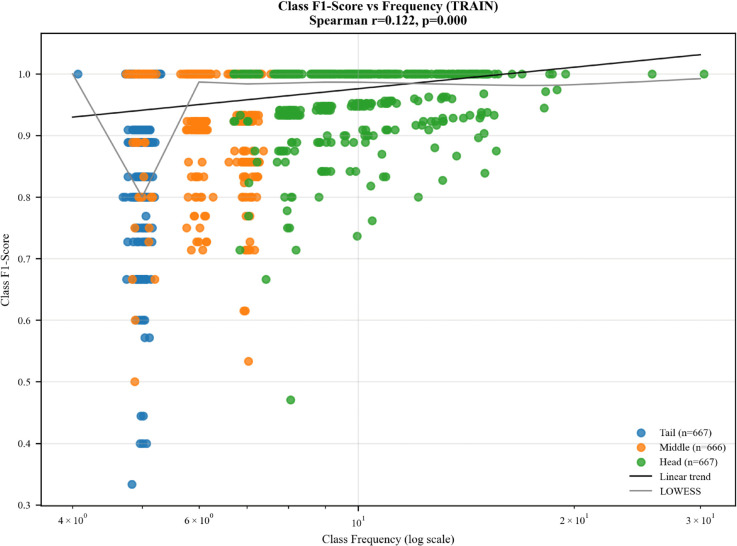 Fig 7
Fig 7Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsHand Gesture Recognition Systems · Hearing Impairment and Communication · Face recognition and analysis
1 Introduction
More than 430 million people worldwide, including approximately 34 million children, experience some form of hearing loss constituting about 5% of the global population. Alarmingly, this number is projected to double by 2050, underscoring the urgent need for scalable and effective communication solutions for the Deaf and hard-of-hearing community [1]. Sign languages, which rely on intricate combinations of hand gestures, movements, postures, and facial expressions, serve as the primary mode of communication for many of those affected by hearing loss [2]. However, communication remains a significant challenge, as most hearing individuals lack fluency in sign language. This communication barrier is further exacerbated by the scarcity, high cost, and limited accessibility of professional sign language interpreters, thereby impeding the social inclusion and daily interaction of Deaf individuals [3].
Sign Language Recognition (SLR) aims to bridge this gap by leveraging computer vision and machine learning to automatically interpret sign language gestures [4]. SLR approaches are typically divided into two categories: isolated recognition, which focuses on identifying individual signs or fingerspelling frames, and continuous recognition, which interprets temporal sequences of signs to form phrases or sentences [5,6]. While continuous SLR must contend with ambiguous sign boundaries and temporal segmentation, isolated SLR operates at the gloss level, where each video contains exactly one sign.
A variety of isolated sign language datasets such as AUTSL, LSA64, WLASL, BosphorusSign22k, and LSM have propelled research forward in languages like Turkish, Argentinian and American Sign Language [7–11]. In contrast, studies on isolated Bangla Sign Language (BdSL) remain limited by data scarcity and resource constraints. The subtle intra-class variations and fine-grained hand movements in BdSL further complicate classification tasks, making high-accuracy recognition challenging.
Early efforts in SLR relied on traditional machine learning methods with hand-crafted features, which often struggled with scalability and robustness. The advent of deep learning (DL) particularly convolutional and recurrent neural networks has substantially improved visual recognition performance across many domains [12,13], including isolated SLR [14,15]. However, naive attempts to train attention-based DL architectures from scratch on BdSL data have yielded suboptimal performance, underscoring the need for more effective model adaptation strategies [16].
Recently, transformer-based architectures notably video transformers [17–19] and detection transformers [20] have demonstrated strong capabilities in modelling spatiotemporal dependencies for word-level sign recognition. In particular, a recent comparative study [21] evaluated the performance of VideoMAE and TimeSformer on the WLASL100 dataset, highlighting the effectiveness of transformer models in this domain. However, there remains a lack of comprehensive comparative analyses that account for key factors influencing performance across word-level sign language datasets varying in scale and complexity.
Transfer learning [22–27], wherein pre-trained models are fine-tuned on domain-specific data, has emerged as a powerful tool for boosting accuracy in data-scarce scenarios. Key considerations in transfer learning include the selection of which layers to transfer and whether to freeze or fine-tune them [28].
While prior studies have focused primarily on recognizing Bangla sign letters and numerals [29–31], limited work has addressed word-level BdSL recognition using modern deep learning techniques such as EfficientNet-B3, attention-based transformers, and BiLSTM [16,32,33]. To the best of our knowledge, no prior research has applied video transformers to word-level BdSL recognition.
In this work, we explore the potential of pre-trained video transformers such as VideoMAE, ViViT, and TimeSformer for isolated BdSL recognition. These models are fine-tuned separately on both the BdSLW60 and the larger BdSLW401 datasets. Their performance is evaluated to assess generalization and scalability across datasets of varying sizes. While earlier efforts in BdSL have predominantly focused on static fingerspelling or character-level recognition, our approach targets dynamic, word-level recognition using spatiotemporal modeling. Furthermore, we extend our evaluation across other sign language datasets to investigate the robustness of these models under varying frame rates, and class distributions, thereby addressing key challenges in low-resource sign language recognition.
In short, the key contributions of our work are as follows:
We examine accuracy fluctuations resulting from FPS correction and improve performance by introducing variations in uniformly chosen frames.We present the first large-scale benchmark of transformer-based video models (VideoMAE, ViViT, TimeSformer) fine-tuned on isolated BdSL datasets, and conduct a comprehensive comparative analysis across other public sign language datasets (LSA64, WLASL100, WLASL2000) to evaluate performance trends and dataset-specific challenges.We analyze the impact of frame imbalance, FPS (25, 30, 60) in small (BdSLW60, LSA64, WLASL100) to large-scale datasets (BdSLW401, WLASL2000), per-class sample size, model architecture, and signer appearance on the performance of video transformers.
We organise this work as follows: Sect 2 provides a survey of relevant literature and analyses contemporary methodologies and their deficiencies. Sect 3 outlines the proposed architecture, dataset preparation, an overview of the video transformers, configurations, and the fine-tuning process. Sect 4 outlines experimental results and performance evaluation. Sect 5 concludes the paper by delineating prospective research avenues.
2 Literature review
Sign language is a rich form of visual communication that encompasses both manual elements (hand movements, posture, position) and non-manual aspects (facial expressions, head gestures), assessed by traditional machine learning and deep learning methods [34]. Models such as support vector machines (SVM), hidden markov models (HMM), artificial neural networks (ANNs), and multilayer perceptrons (MLPs) have been applied with handcrafted feature extraction methods, including DCT, PCA, LDA, SURF, and SIFT, to improve classification accuracy [35,36].
Several early efforts reported promising results. Al-Rousan et al. [37], for instance, used HMM and DCT to classify 30 Arabic signs, achieving 94.2% accuracy in signer-independent settings. Similarly, Fagiani et al. [38] applied HMM to 147 Italian signs, although the accuracy reached only 50%, suggesting the need for more expressive models. Deep learning (DL) approaches emerged as a more powerful alternative, automating feature extraction and enabling end-to-end learning. A BiLSTM-based model with DeepLabv3+ hand segmentation achieved 89.5% accuracy for 23 Arabic signs [7], while Fatmi et al. [39] found that ANN and SVM outperformed HMM in American Sign Language (ASL) recognition.
More recently, hybrid DL models have improved word-level recognition. Masood et al. [40] integrated inception-based CNNs with RNNs for real-time Argentine sign language detection. Similarly, ResNet50 combined with LSTM was used in [41] for Persian sign videos, achieving accurate recognition across 100 signs. In another approach, spatial-temporal features from pretrained networks were fused, achieving 98.97% accuracy on the Montalbano dataset [42]. Additionally, [43] a multimodal fusion technique using quantized depth images with skeleton-based LSTM and depth-based CRNN models achieved 90.82% and 89.21% accuracy for 14 and 28 gestures, respectively, on the DHG-14/28 dataset, and 93.81% and 90.24% on the SHREC-2017 track dataset. CNN-transformer combinations have also shown promise: Shin et al. [44] used such a hybrid to attain 88.8% accuracy on a 77-class Korean Sign Language (KSL) dataset.
Research on Bangla Sign Language (BdSL) has also progressed. Raihan et al. [45] introduced channel-wise attention using squeeze-and-excitation blocks in a CNN model, reaching 99.86% accuracy on the KU-BdSL alphabet dataset with a lightweight model optimized for mobile deployment. In another study, Begum et al. [31] utilized quantization on YOLOv4-Tiny with LSTM to achieve 99.12% accuracy on the BdSL49 dataset. Other works have employed pose-based recognition using tools like OpenPose and Mediapipe. For example, [46] used OpenPose for Flemish sign recognition, while [16,32,47,48] explored Mediapipe-based keypoints for dynamic body part tracking in Arabic and Bangla sign language recognition.
Attention mechanisms and transformer architectures have also made significant contributions. Rubayeat et al. [16] applied attention-based BiLSTMs with SVM to BdSLW60, achieving 75.1% accuracy, and Hasan et al. [32] used an attention-based transformer for BdSL word-level recognition. These advances illustrate the growing utility of attention-based models, especially when combined with pose or spatiotemporal features. Knowledge transfer and transfer learning have further improved performance, as shown by [49], who used MobileNetV2 with transfer learning to achieve 95.12% accuracy on CSL-500 and a 2.2% word error rate on CSL-continuous. Follow-up studies on BdSL also leveraged pretrained models like DenseNet201 and MobileNetV2 to boost recognition accuracy [50,51].
In parallel, video transformers have emerged as powerful tools for sign language recognition due to their ability to model complex temporal and spatial dependencies. For example, a study in [19] evaluated several video transformer models, including VideoMAE and SVT, on the large scale WLASL2000 dataset—demonstrating the effectiveness of pretraining and fine-tuning in large-scale sign language recognition. Similarly, Detection Transformers (DETR) have been adapted to identify signs from RGB video inputs [21]. Beyond sign language, BERT has been combined with TimeSformer to improve the classification of short video clips [52], and the ViViT model has been applied to detect mild cognitive impairment from video sequences, showing competitive performance [53].
Recognizing the limitations in existing BdSL research particularly the underutilization of transformer-based video models this work explores isolated BdSL word recognition using state-of-the-art video transformers. We fine-tune models pretrained on the Kinetics-400 action recognition dataset, which includes gestures and movements similar to isolated sign language actions. Our focus is on improving recognition performance from raw RGB videos using models such as VideoMAE, ViViT, and TimeSformer. Additionally, we analyze critical design factors such as frame distribution, frame rate (FPS), and model architecture that influence recognition outcomes.
3 Methodology
This study addresses the classification of isolated BdSL signs, with particular attention to the challenges posed by limited resources and the inherent complexity of sign language datasets. To tackle these issues, we fine-tune transformer-based video classification models to effectively capture temporal patterns in sequential data. In this work, three models are trained on BdSLW60, and to assess scalability, BdSLW401 is used marking its first use as a benchmark. Their performance is rigorously evaluated and compared with results from other benchmark datasets, including WLASL and LSA64, highlighting the models’ generalization and robustness.
3.1 Framework overview and dataset preparation
Fig 1 presents the overall architecture of the proposed approach, illustrating the complete pipeline from dataset acquisition through preprocessing, model training, and ultimately, evaluation.
Architecture of frame rate-corrected dataset construction, recognition, and benchmarking.This figure illustrates the end-to-end workflow adopted for isolated sign language recognition across diverse datasets. The process begins with data collection and preprocessing, including clip segmentation, frame extraction, and frame rate correction. After preparing the dataset through frame selection, resizing, and tensor generation, data augmentation techniques such as horizontal flipping are applied to improve model generalization. Pretrained video transformer models (VideoMAE, ViViT, and TimeSformer) are then fine-tuned and evaluated using standard metrics, including accuracy, precision, recall, and F1-score. The results are compared with existing state-of-the-art approaches to assess model performance.
The BdSLW60 dataset [16] is employed in this study, with dedicated preprocessing applied to ensure robust training and evaluation. The dataset, sourced from Kaggle, comprises Bangla sign language videos recorded by 18 individuals. Each sample includes raw video footage and corresponding gloss annotations provided in JSON format. The videos were originally recorded at varying frame rates—15, 24, and 30 FPS—but were standardized to 30 FPS for consistency. The JSON annotations facilitated the extraction of individual frames, resulting in clip lengths ranging from 9 to 164 frames per gloss. As shown in Fig 2, most samples contain fewer than 130 frames. In addition to BdSLW60, we employed the BdSLW401, WLASL100, WLASL2000, and LSA64 datasets to comprehensively evaluate the performance and generalizability of our approach.
Frame Count vs Number of short clips of BdSLW60 dataset.This figure displays the distribution of frame counts across 9,307 short video clips in the BdSLW60 dataset. Each bar represents the frame count of an individual MP4 clip, sorted in ascending order. The minimum and maximum frame counts are highlighted in red and blue, respectively—ranging from 9 to 164 frames per clip.
3.2 Video processing
Determining the appropriate sample rate—defining the duration of each video clip used in training—requires a thorough understanding of the frame distribution across the dataset. This step is particularly critical for transformer-based models, which rely on fixed-length input sequences due to the patch embedding mechanism. The clip duration is calculated using the following equation: , where is the clip duration, is the number of frames to sample, is the sample rate, and is the frame rate (fps).
To mitigate the impact of class imbalance and ensure robust performance evaluation, we adopted a 10-fold stratified cross-validation procedure. Frame rate-corrected (FRC) samples were employed to partition the dataset into training, validation, and testing subsets for video processing tasks, or into training and testing sets for stratified folding. The number of frames per clip was determined based on model-specific requirements and a predefined sampling rate. Clips with fewer frames than required were temporally padded to match the duration of the longest clip, ensuring input consistency. Additionally, all video frames were resized to 224×224 pixels and standardized to maintain uniformity and compatibility across model architectures.
3.3 Augmentation for training
During the data augmentation phase, we applied several techniques to improve dataset diversity and model generalization. These included random cropping, horizontal flipping, and short-side scaling. The isolated sign videos were subsequently trained in batches using three fine-tuned transformer-based models: VideoMAE [54], ViViT [55], and TimeSformer [56]. To optimize frame-level feature extraction, we utilized image processors specifically designed for each pretrained model architecture. Model performance was continuously monitored on both validation and test sets throughout the training process. Upon completion, the best-performing model checkpoints were uploaded to the Hugging Face (HF) repository for public access and reproducibility.
3.4 Model configurations
We employed three transformer architectures for training and evaluation, with one model implemented in two distinct configurations, as summarized in Table 1. All models were pretrained on the Kinetics-400 human action recognition dataset [57], which enables the transfer of temporal and spatial pattern recognition capabilities applicable to isolated sign classification. Fine-tuning on the BdSLW60 and auxiliary datasets led to high accuracy on both test and validation splits, demonstrating the models’ ability to effectively generalize to the target task.
Table 1: Comparison of different video transformer models and their architecture details.
3.4.1 Video Mask Auto Encoder—VideoMAE architecture.
The idea of VideoMAE is found in Image-MAE [58], where the image masking strategy is described for better accuracy gain in recognition tasks. VideoMAE [59] is a simple masked video autoencoder with an asymmetric encoder-decoder design. To efficiently handle sampled frames, it introduces cube embedding and high-ratio tube masking, where only a small subset of visible tokens is encoded, and the decoder reconstructs the masked tokens for self-supervised learning [54].
Tube masking is implemented to address video redundancy, employing a high masking ratio (90-95%) to avert information loss and improve reconstruction, especially in low-motion segments. The model incorporates an encoder that exclusively handles unmasked cubes and a streamlined decoder. Video segments are subjected to cube embedding, with merely 5-10% of tokens inputted into the encoder. The model subsequently forecasts the masked tokens by reducing the discrepancy between target and projected clips. Tube masking surpasses alternative techniques by employing a uniform mask across the frames. The disordered tokens are reconstituted, and absent tokens are acquired through backpropagation. A compact decoder reconstructs video segments to assess performance. By encoding fewer tokens and using joint space-time attention [55] with a ViT backbone [60], this method shortens the time needed for training.
3.4.2 Video Vision Transformer—ViViT architecture.
Researchers have extended ViT [60], originally developed for image classification, to create transformer-based models for video classification [55]. These models use self-attention in the encoder to capture long-range contextual relationships within video sequences. Earlier approaches tackled this challenge using deep 3D CNNs [61,62] and by incorporating self-attention in later layers [63–65].
ViViT improves the Vision Transformer by integrating attention variations specifically designed for video data. It employs solely the encoder of the transformer [66], analysing video clips transformed into token sequences . Two techniques—uniform frame sampling and tubelet embedding—convert videos into non-overlapping tokens, with tubelet embedding more efficiently integrating the temporal dimension. A tubelet possesses dimensions t × , with the quantity of tubelets along each axis defined as , , and . Following the incorporation of positional embeddings, tokens are input into the encoder, where self-attention scores are calculated. The ViViT model comprises 12 encoder layers and 12 attention heads. Four attention mechanisms are examined:
Spatio-temporal Attention: Employs Multi-Head Self-Attention (MSA) [66] across all tokens, leading to quadratic complexity.Factorised Encoder: Distinguishes between spatial and temporal tubelet processing, reducing floating-point operations while preserving global context.Factorised Self-Attention: Executes attention initially in the spatial domain, followed by the temporal domain, preserving Model 2’s complexity while enhancing parameter efficiency.Factorised Dot-Product Attention: Distributes attention heads evenly over spatial and temporal domains, optimising complexity and parameter quantity.
Ultimately, a multilayer perceptron (MLP) forecasts class labels during the training process. This method improves efficiency while preserving robust performance in video representation learning.
3.4.3 TimeSformer architecture.
TimeSformer is a video categorization model that operates without convolution, utilizing a Vision Transformer. It separates video frames into N separate patches, uses learnable positional encoding, and a 12-layer transformer encoder to process them. The initial token, , functions as a classification token, with patch embeddings articulated as:
Self-attention improves computational efficiency by employing various attention techniques on patches, as demonstrated in Fig 3.
Five self-attention blocks of TimeSformer [56].Each variant illustrates a different way of modeling spatial and temporal relationships in video data using transformer blocks. (1) Space Attention (S): attends only across spatial dimensions in each frame. (2) Joint Space-Time Attention (ST): computes attention jointly across space and time. (3) Divided Space-Time Attention (T+S): separates temporal and spatial attention sequentially. (4) Sparse Local-Global Attention (L+G): combines local and global spatial attention for broader context. (5) Axial Attention (T+W+H): factors attention across time, width, and height axes independently. Each block outputs updated video representations used for downstream tasks.
Spatial attention functions independently on a frame-by-frame basis, executing N + 1 query-key comparisons. Joint space-time attention encompasses both spatial and temporal dimensions; nonetheless, it is computationally demanding, necessitating NF + 1 comparisons, F denoting the total number of frames. Conversely, divided space-time attention successively analyzes temporal and spatial dimensions, attaining maximal accuracy with N + F + 2 comparisons.
To improve efficiency, sparse local-global and axial attention equilibrate local and global emphasis while allocating attention across temporal, spatial width, and height dimensions. A multilayer perceptron with residual connections ultimately enhances the attention outputs.
3.5 Fine-tuning of video transformers
Fine-tuning is a process that adapts a pretrained classification model to a new task by retraining it on task-specific data [67]. The full configuration of training parameters is summarized in Table 2.
Table 2: Training hyperparameters.
In this study, we fine-tuned video transformer models on the BdSLW60 dataset to classify isolated Bangladeshi Sign Language (BdSL) words. Leveraging the Hugging Face Transformers library, we initialized models with pretrained weights, modified the classification head to match the number of target classes, and utilized previously learned features to enhance generalization.
To further improve performance, we integrated a task-specific classification head into the final layer and systematically tuned key hyperparameters, including batch size, learning rate, and weight decay. A dynamic learning rate scheduler was employed to adjust learning rates throughout training, while model weights were optimized via backpropagation. To mitigate overfitting, an early stopping mechanism was implemented, enabling the training process to terminate when performance plateaued on the validation set.
3.6 Model evaluation
Evaluating the performance of ML and DL models is crucial for both model development and deployment in real-world applications. Key evaluation metrics include accuracy, precision, recall, and the F1 score, each providing unique insights into model behaviour. Precision quantifies the proportion of correctly identified positive predictions, while accuracy measures the overall correctness across all classes. Recall evaluates the model’s ability to detect true positive instances, and the F1 score provides a harmonic mean of precision and recall, offering a balanced measure of classification performance [68].
To comprehensively assess the fine-tuned transformer models, we computed accuracy, precision, recall, and F1 scores on the test datasets. In addition, confusion matrices were generated to visualize class-wise performance and identify potential misclassifications. The loss curve was also analyzed throughout training to monitor convergence behavior and detect signs of overfitting.
4 Result analysis
The primary objective of this study was to identify the most effective pretrained video transformer model for classifying isolated BdSL signs using the BdSLW60 dataset, along with additional benchmark datasets.
Notably, this work also presents the first benchmarking results for the BdSLW401 dataset, contributing a valuable reference point for future research in BdSL recognition. To evaluate the impact of data augmentation on model performance, we examined two video preprocessing strategies: one incorporating augmentation techniques such as random horizontal flipping and cropping, and another that excluded such modifications.
The training hyperparameters were kept consistent across all experiments to ensure fair comparison. Table 3 summarizes the dataset partitioning strategies employed for training, validation, and testing. To support subject-independent evaluation, we implemented user-specific splits for BdSLW60, designating users U4 and U8 for testing and U5 for validation. For the LSA64 dataset, signer IDs 001 and 002 were assigned to the test set, while 10% of the remaining samples were used for validation.
Table 3: Dataset splitting configurations.
In the case of BdSLW401, we utilized the front-view subset and adhered to its original train/validation/test split, where users S04 and S08 were reserved for testing. For WLASL100 and WLASL2000, we adopted the official JSON-based partitions. Additionally, to assess model robustness, we conducted experiments using a 10-fold stratified version of the BdSLW60 dataset.
4.1 Training approaches
Training was conducted using computational resources comprising a 32GB GPU and 164GB of CPU memory, enabling efficient processing across both large- and small-scale datasets. Models trained with data augmentation consistently outperformed those trained without it. Validation results using VideoMAE, ViViT and TimeSformer (Table 4) confirmed that augmentation led to improved test accuracy, surpassing prior benchmarks such as those in [16], which employed SVM and attention-based Bi-LSTM architectures. Despite BdSLW60 offering more samples per gloss, its inherent class imbalance negatively affected model accuracy. This issue was partially addressed through stratified K-fold cross-validation, which preserved the original class distribution across all folds, thereby enhancing evaluation robustness. Additionally, the use of 16-level relative quantization (RQ) in VideoMAE resulted in reduced accuracy, indicating a potential limitation of quantization-based compression in this context.
Table 4: Performance of VideoMAE, ViViT and TimeSformer with and without augmentation.
4.2 Comparing results among existing datasets
To enhance the validation of model performance, we extended our evaluation to include two public benchmark datasets: LSA64 [11] and WLASL [70]. Our primary focus, however, remained on isolated Bangla Sign Language recognition, using two datasets: BdSLW60 and BdSLW401. On the smaller-scale BdSLW60 dataset, Our transformer-based approach achieved an accuracy of 96.9% and a top-5 accuracy of 99.05%, surpassing existing baselines and demonstrating the model’s strong capability in recognizing isolated signs.
On the more extensive BdSLW401 dataset, which comprises 401 Bangla sign words, the model attained an accuracy of 81.04% after just 20 training epochs using the “MCG-NJU/videomae-base-finetuned-kinetics” architecture. This result is particularly promising given the dataset’s complexity and the prolonged training time of over five days. To further benchmark the generalization capacity of our approach, we evaluated performance on LSA64, WLASL100, and WLASL2000. Our model demonstrated improvements over previous deep learning methods on both LSA64 and WLASL100. However, performance on WLASL2000 was comparatively limited, which may be due to the highly imbalanced and sparse distribution of samples across its 2000 classes.
Table 5 summarizes the performance across the BdSLW and LSA64 datasets and presents Part 1 of our experimental evaluation, with boldface used to highlight the highest accuracies for each dataset.
Table 5: Experimental results on different models and datasets - Part 1.
Table 6 presents Part 2 of our experiments, detailing the performance of our finetuned models on the WLASL dataset. We conducted experiments on WLASL for both 20 and 200 training epochs. Additionally, we evaluated “MCG-NJU/videomae-base” for 40 and 50 epochs and “MCG-NJU/videomae-base-finetuned-kinetics” for 30 epochs on WLASL100, reporting all results.
Our findings indicate that the pretrained and finetuned models, except for the VideoMAE base variant, tend to converge rapidly in the early epochs but experience a performance drop at higher epoch counts due to overfitting. Furthermore, we surpass the results reported in [21] while using a batch size of 2, whereas their experiments utilized batch sizes of 4 and 6.
Table 6: Experimental results on different models and datasets - Part 2.
The loss curve and confusion matrices offer additional insights into training behavior and classification performance. On BdSLW60, the loss curve (Fig 4) demonstrates rapid convergence followed by stability after approximately 2000 training steps, suggesting effective learning and strong generalization. The validation loss exhibits a slight spike early in the training process but quickly stabilizes, indicating minimal overfitting and a well-generalized model.
Loss curve for fold 6 of the BdSLW60 dataset.This figure shows the training and validation loss curves on BdSLW60 using a split-axis visualization to highlight the initial loss spike and subsequent convergence. After a brief early spike, both losses decrease rapidly and remain closely aligned, indicating stable learning, minimal overfitting, and good generalization throughout training.
The confusion matrix for BdSLW60 (Fig 5) confirms accurate class-wise predictions, while Fig 6 illustrates the confusion matrix for BdSLW401, demonstrating the model’s ability to scale effectively to a larger vocabulary.
Confusion matrix for fold 6 of the BdSLW60 test set.This confusion matrix shows how well the model classified each of the 60 sign language gestures. The diagonal cells represent correct predictions, with darker shades indicating better performance. Most predictions fall along this diagonal, showing that the model accurately recognized the majority of signs. The few lighter cells outside the diagonal indicate occasional misclassifications, but overall, the results suggest strong and consistent performance across all classes.
Confusion matrix for BdSLW401 test set (visualizing first 50 classes).This confusion matrix presents the model’s classification results for the first 50 classes out of a total of 401 in the BdSLW401 test set. Each row represents the actual class label, while each column shows the predicted label. The darker diagonal cells indicate correct predictions, suggesting the model has learned to recognize many of the signs accurately within this subset. The few lighter off-diagonal entries represent misclassifications, pointing to some confusion between certain signs. This visualization provides insight into the model’s performance on a portion of the full class set.
Together, these comparisons underscore the robustness and adaptability of transformer-based video models across both low- and high-resource sign language datasets.
4.3 Ablation studies
To optimize computational efficiency on our system, a batch size of two was employed. Larger batch sizes were avoided due to the associated increase in memory and storage requirements. During training, the entire pretrained model was initialized, and all layers were fine-tuned on our task-specific datasets. A learning rate scheduler dynamically adjusted the learning rate post-initialization, while the AdamW optimizer with decoupled weight decay—was used to mitigate overfitting, making it particularly effective for large-scale model fine-tuning despite substantial memory demands.
We applied Frame Rate Correction (FRC) to BdSLW60 clips originally recorded at 15 and 24 FPS, converting them to 30 FPS for consistency. However, this led to frame duplication, which negatively affected generalization by distorting attention patterns and gradient updates. As a result, VideoMAE showed reduced accuracy on FRC clips compared to uncorrected samples. To address this, we introduced variability into the duplicated frames through random flipping, cropping, and scaling during preprocessing. This enhancement consistently improved performance, as shown in Table 4.
Frame sampling rate played a crucial role in ensuring reliable and consistent input across clips, as detailed in Table 7. For instance, WLASL2000 was trained for 200 epochs, with most outputs stabilizing after 40–50% of the training cycle.
Table 7: Dataset details with FPS, models, SR and clip durations.
We construct a correlation table to analyze the relationship between classification accuracy and several class-wise factors, including average temporal length (number of frames), number of samples, and signer identity. The analysis reveals that classification accuracy varies across signers for all evaluated models and datasets, while the remaining factors show no, weak, or moderate levels of association with performance. The resulting correlation statistics are summarized in Table 8.
Table 8: Correlation summary across datasets and models.
Among the evaluated models, TimeSformer achieved a high accuracy of 99.06% on the LSA64 dataset. Its superior performance is attributed to LSA64’s balanced class distribution, 60 FPS recording rate, and clip lengths ranging between 90 and 180 frames.
We standardized each clip to 3.2 seconds (192 frames), applying a sampling rate of 24 to extract 8 frames per video. Extending shorter clips to match this duration helped retain critical temporal information. In contrast, BdSLW60, frame rate corrected to 30 FPS with imbalanced class distribution, posed additional challenges. Given that 99% of BdSLW60 clips contain fewer than 128 frames, we extracted 4.27-second clips for uniformity.
Although BdSLW60 exhibits variable clip lengths (9–164 frames), the average frame count does not correlate with classification accuracy. This is likely due to the sufficient number of samples per class, with averages of 21 test samples and 10 validation samples, a trend further supported by the weak correlation observed when evaluating the TimeSformer model on BdSLW60 without data augmentation or a folding approach.
In contrast, WLASL100 contains only about three samples per class, where uniform temporal subsampling with limited data leads to a moderate correlation between average frame count and per-class accuracy. However, this correlation is very weak in WLASL2000, as larger class sizes and more uniform temporal lengths across classes reduce the impact of frame count on performance.
Due to the sufficient number of samples across all classes and the limited variation of unique signers (12-15) among classes in the training set, no relationship is observed between class frequency or the number of unique signers and classification accuracy. A similar trend is observed in the LSA64 dataset.
On BdSLW60, VideoMAE achieved superior performance by sampling 16 frames at an 8-frame rate and employing a high-ratio masking strategy that retains only 10% of tokens for encoding while reconstructing the remaining 90% using mean squared error. This approach enables effective preservation of essential spatiotemporal features, whereas ViViT and TimeSformer exhibit comparatively lower accuracy.
No long-tail effect is observed in the WLASL100 and BdSLW60 datasets. In WLASL100, the VideoMAE-Kinetics model shows a weak negative correlation between class accuracy and class frequency; however, this correlation is negligible and does not indicate a meaningful long-tail behavior.
In contrast, the WLASL2000 dataset exhibits a clear long-tail effect, as shown in Fig 7. This behavior is consistently observed across all evaluated models, although we present results only for the VideoMAE kinetics model for clarity. The model performs strongly on frequent classes but struggles with rare ones, and increasing class frequency particularly for tail classes generally leads to improved F1-scores.
Long-tail nature of WLASL-2000 on VideoMAE kinetics model.This figure illustrates the long-tail effect in WLASL-2000, showing class-wise F1-score versus training-set class frequency (log scale), grouped into head, middle, and tail classes. A weak but statistically significant positive correlation is observed (Spearman r = 0.122, p < 0.001), with higher variability among tail classes.
Additionally, WLASL2000 contains between 2 and 18 unique signers per class in the training set, and we observe a slight accuracy gain for classes with a higher number of unique signers, suggesting that signer diversity contributes modestly to improved generalization. The WLASL2000 dataset presented additional challenges, including severe class imbalance, and small per-class sample sizes, all of which contributed to degraded performance. These findings suggest that transformer-based video models perform optimally when trained on datasets without long-tail effects and with sufficient class representation.
5 Conclusion and future work
Sign language recognition plays a vital role in reducing communication barriers between deaf and hearing communities by translating visual gestures, including hand and facial expressions, into meaningful language.
To evaluate the robustness and scalability of our approach, we carried out extensive experiments using three different video transformer architectures across multiple sign language datasets, with fine-tuning initiated on BdSLW60 as our primary data source before extending to larger and more diverse benchmarks. The raw videos were first standardized to a uniform frame rate and segmented into shorter clips for effective training, followed by data augmentation strategies including random cropping, flipping, and scaling to enhance model generalization.
Using BdSLW60, the MCG-NJU/videomae-base-finetuned-kinetics model achieved a test accuracy of 96.9%, demonstrating strong performance in isolated BdSL recognition. To further evaluate model scalability, we introduce the first benchmark results on the BdSLW401 dataset, a larger and more diverse collection of 401 Bangla signs. On this dataset, the model achieved 81.04% accuracy, with an F1 score of 80.14%, recall of 84.57%, and precision of 81.14%.
Additional experiments on LSA64 and WLASL showed that factors such as frame distribution, sample size, and architecture significantly affect recognition accuracy. Overall, our approach outperforms prior methods in Bangla word-level sign language recognition. Future work will extend to sentence-level BdSL recognition and real-time translation applications.
Supporting information
S1 FileList of trained checkpoints links.This pdf file contains the URLs of all best-validation checkpoints hosted on Hugging Face that were obtained in this research.(PDF)
S1 FigCorrelation between accuracy and average frames on WLASL-2000 (ViViT Model).(TIFF)
S2 FigCorrelation between accuracy and class sample size on WLASL-2000 (ViViT Model).(TIFF)
S3 FigCorrelation between accuracy and number of unique signers on WLASL-2000 (ViViT Model).(TIFF)
S4 FigAccuracy per signer ID on WLASL-2000 (ViViT Model).(TIFF)
S5 FigCorrelation between accuracy and average frames on WLASL-100 (VideoMAE Model).(TIFF)
S6 FigCorrelation between accuracy and class sample size on WLASL-100 (VideoMAE Model).(TIFF)
S7 FigCorrelation between accuracy and number of unique signers on WLASL-100 (TimeSformer Model).(TIFF)
S8 FigCorrelation between accuracy and average frames on BdSLW60 (TimeSformer Model) with augmentation.(TIFF)
S9 FigCorrelation between accuracy and average frames on BdSLW60 (TimeSformer Model) without augmentation.(TIFF)
S10 FigCorrelation between accuracy and average frames on LSA64 (ViViT Model).(TIFF)
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1World Health Organization. Deafness and hearing loss. 2021. https://www.who.int/news-room/fact-sheets/detail/deafness-and-hearing-loss
- 2Sharma S, Gupta R, Kumar A. Continuous sign language recognition using isolated signs data and deep transfer learning. J Ambient Intell Human Comput. 2021;14(3):1531–42. doi: 10.1007/s 12652-021-03418-z · doi ↗
- 3Fang B, Co J, Zhang M. Deep ASL. In: Proceedings of the 15th ACM Conference on Embedded Network Sensor Systems, 2017. p. 1–13. 10.1145/3131672.3131693 · doi ↗
- 4Zhang Y, Jiang X. Recent advances on deep learning for sign language recognition. CMES. 2024;139(3):2399–450. doi: 10.32604/cmes.2023.045731 · doi ↗
- 5Aly S, Aly W. Deep Ar SLR: a novel signer-independent deep learning framework for isolated arabic sign language gestures recognition. IEEE Access. 2020;8:83199–212. doi: 10.1109/access.2020.2990699 · doi ↗
- 6Kumar EK, Kishore PVV, Kiran Kumar MT, Kumar DA. 3D sign language recognition with joint distance and angular coded color topographical descriptor on a 2 – stream CNN. Neurocomputing. 2020;372:40–54. doi: 10.1016/j.neucom.2019.09.059 · doi ↗
- 7Mercanoglu Sincan O, Keles HY. Using motion history images with 3D convolutional networks in isolated sign language recognition. IEEE Access. 2022;10:18608–18. doi: 10.1109/access.2022.3151362 · doi ↗
- 8Vázquez-Enríquez M, Alba-Castro JL, Docío-Fernández L, Rodríguez-Banga E. Isolated sign language recognition with multi-scale spatial-temporal graph convolutional networks. In: 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW); 2021. p. 3457–66. 10.1109/cvprw 53098.2021.00385 · doi ↗