Robust Distribution‐Free Tests for the Linear Model
Torey Hilbert, Steven N. MacEachern, Yuan Zhang

TL;DR
This paper introduces a new statistical method for testing associations in biological data affected by skewed or heavy-tailed noise.
Contribution
The paper introduces RobustPALMRT, a permutation framework that improves type I error control and expands testing capabilities in linear models.
Findings
RobustPALMRT maintains type I error control even with heavy-tailed or skewed noise.
Using robust loss functions in model evaluation improves performance regardless of model fitting method.
The method reveals novel differences in Long-COVID patient data despite highly skewed noise.
Abstract
Recently, there has been growing concern about heavy‐tailed and skewed noise in biological data. We introduce RobustPALMRT, a flexible permutation framework for testing the association of a covariate of interest adjusted for control covariates. RobustPALMRT controls type I error rate for finite‐samples, even in the presence of heavy‐tailed or skewed noise. The new framework expands the scope of state‐of‐the‐art tests in three directions. First, our method applies to robust and quantile regressions, even with the necessary hyper‐parameter tuning. Second, by separating model‐fitting and model‐evaluation, we discover that performance improves when using a robust loss function in the model‐evaluation step, regardless of how the model is fit. Third, we allow fitting multiple models to detect specialized features of interest in a distribution. To demonstrate this, we introduce…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
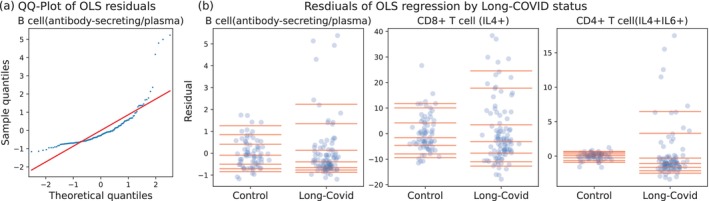 FIGURE 1
FIGURE 1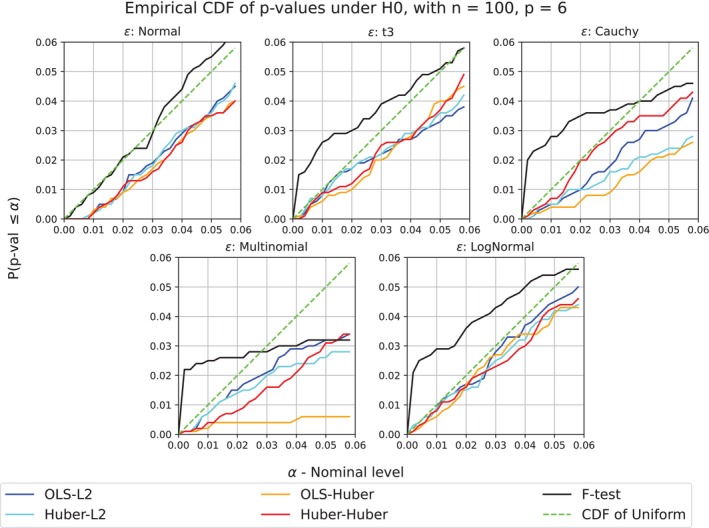 FIGURE 2
FIGURE 2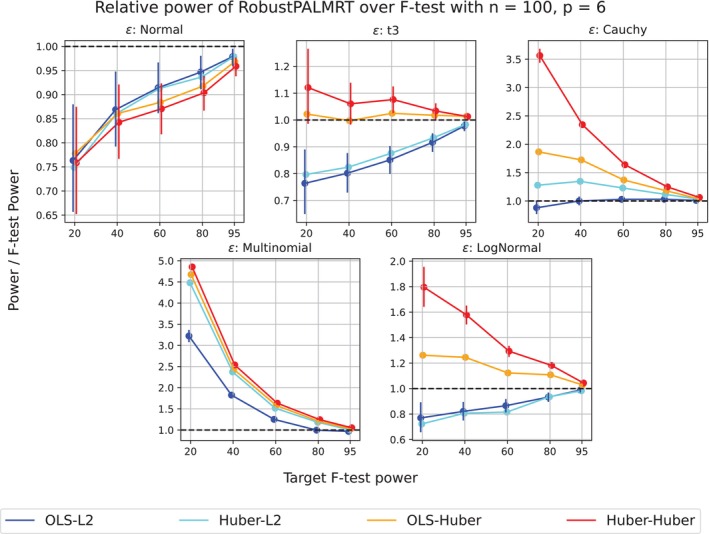 FIGURE 3
FIGURE 3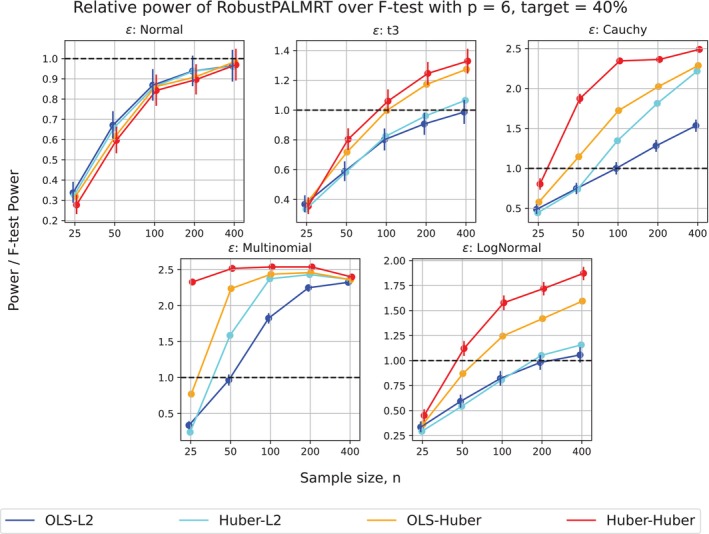 FIGURE 4
FIGURE 4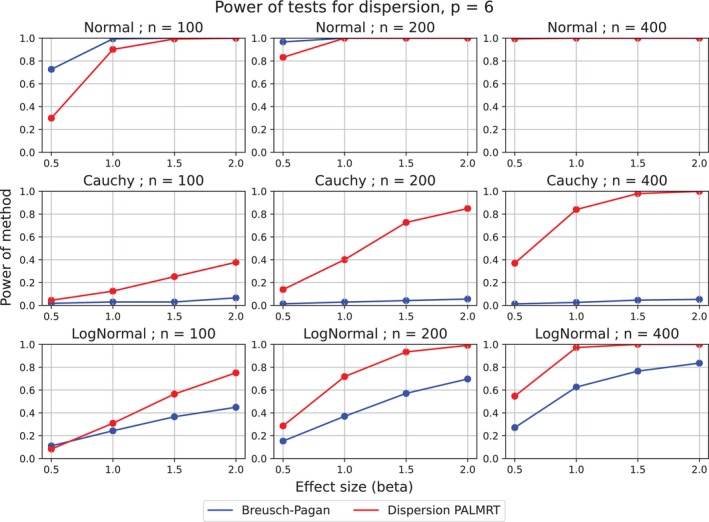 FIGURE 5
FIGURE 5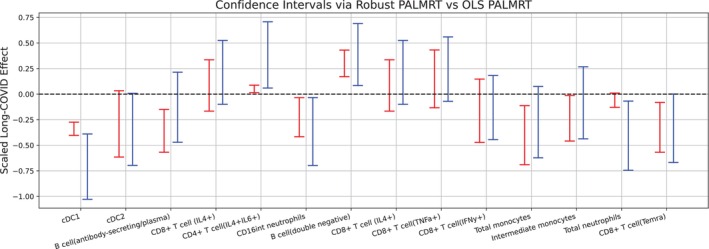 FIGURE 6
FIGURE 6- —National Science Foundation10.13039/100000001
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsStatistical Methods and Inference · SARS-CoV-2 detection and testing · SARS-CoV-2 and COVID-19 Research
Introduction: Long‐COVID Immunological Features
1
Biological experiments producing high‐throughput data yield massive data sets, but the data are often unclean: Heavy‐tailed, skewed, correlated, and generally irregularly distributed. These shortcomings challenge type I error control in standard statistical analyses [1, 2, 3]. Perhaps most dramatically, Hawinkel et al. [4] found that even commonly used nonparametric methods can suffer inflated false discovery rates in differential abundance testing. Guan [5] gives explicit examples of standard permutation tests failing to control type I error.
The immune profiles of Long‐COVID patients from the Mount Sinai‐Yale study [6] (MY‐LC hereafter) show many of these shortcomings. In MY‐LC, the proportions of immune cells of various types, Yi, are compared between patients experiencing Long‐COVID (LC) and healthy patients. The “types” of cells considered varies from very broad, such as the proportion of live cells that are natural killer cells, to very specific, such as the proportion of CD8+ T‐cells that express IL6. The proportions also vary with general demographic features such as patient age and BMI, and we aim to investigate differences between healthy and LC patients after adjusting for these demographics. Following Klein et al. [6] and Guan [5] we write the model
where ZiT=(1,agei,sexi,BMIi,agei×BMIi,sexi×BMIi) is the vector of covariates for which we wish to adjust, β and θ are parameters, and ϵi is a noise term. We wish to test the null hypothesis that Long‐COVID has no effect on the cell type proportion Y after adjusting for the covariates Z. More specifically, in model (1), we wish to test H0:β=0. We make no assumptions on θ, and search for a test that is valid for any value of θ.
Figure 1a shows a normal QQ plot from a fit of model (1), assuming ϵi's are i.i.d. normal, for the proportions Y for one type of cell. We see that there is strong right‐skewness, clearly violating the assumption that the ϵi's are normally distributed. In Figure 1b we plot the residuals for a fit from model (1) for three different types of cells. We see that the residuals for control patients are mildly skewed, while the residuals for the Long‐COVID patients are much more skewed and have greater dispersion. This suggests that Long‐COVID impacts the shape and dispersion of the error distribution and that explicit modeling of these effects will be scientifically informative.
Residual analysis showing nonnormality and differences between Long‐COVID and control patient cell proportions under model (1) when fit via OLS. (a) A QQ‐plot of the OLS residuals regressing one cell type proportion. (b) Scatterplot of the OLS residuals for three different cell type proportions. The red lines are {0.05,0.10,0.25,0.50,0.75,0.90,0.95} quantiles.
Klein et al. [6] noted the increase in variation in immune response in Long‐COVID patients, but did not formally test for this increase. We propose extending model (1) to
In this extended model, we test H0:fdepends onLCi. Our RobustPALMRT framework allows us to test for this difference in variation after adjusting for background demographic covariates while controlling the type I error rate, which we term DispersionPALMRT.
Prior Work
2
Classical Methods
2.1
We consider a generalization of (1) as the following linear regression problem
where Y∈ℝn×1 is the response, X∈ℝn×d and Z∈ℝn×p are fixed covariates, and ϵ∈ℝn×1 is an error term whose entries are exchangeable. Under model (3), we aim to test H0:β=0. Here we make no assumptions on θ, and aim for tests that are valid for every θ.
Many procedures exist to test H0. Until recently, these tests split into two groups. The first group imposes strong parametric assumptions on ϵ, such as ϵ∼N(0,σ2I) (e.g., dating back to Fisher [7]). The second group appeals to asymptotic arguments and large sample sizes, typically through a central limit theorem for some estimator of β in (3). Later, the distributional assumptions on ϵ are relaxed, and one might, for example, use robust regression or quantile regression techniques (e.g., Ronchetti and Huber [8] and Koenker and Bassett [9]). Lei and Bickel [10] describe the “century‐long effort” to develop tests for the partial correlation β, and provide an extensive literature review. Guan [5] summarizes and critiques the finite‐sample performance of many proposed permutation‐based methods designed to yield an approximate type I error rate under weaker‐than‐normality conditions on the distribution of ϵ [11, 12, 13, 14, 15, 16, 17]. In general, thick‐tailed distributions and outlier points can pose a problem for these classical methods.
Finite‐Sample Distribution‐Free Tests
2.2
Lei and Bickel [10] developed the first test for H0 that controls the type I error rate in finite samples under (3). Their cyclic permutation test (CPT) relies on rank‐constraints on the design matrix to construct a set of vectors η0,…,ηm such that the linear statistics (y⊤η0,…,y⊤ηm) are distributionally invariant to cyclic permutations. However, the method requires n/p to be at least 19 to perform a test at level α=0.05. Furthermore, the method does not have much higher power than the F‐test in heavy tailed settings. However, notice that distribution‐free methods are most important with highly nonnormal noise, and so we should particularly aim to have strong performance in heavy tailed settings.
Since then, several other methods have been developed [5, 18, 19, 20, 21, 22, 23]. Many of these methods are tailored for specific variants of (3). For example, Spector et al. [22] aim to test the goodness of fit of a very specific model form and permits finite‐sample heteroskedasticity according to that structure. Meanwhile, Guo and Toulis [19], Young [20], and D'Haultfœuille and Tuvaandorj [21] all involve carefully constructed invariant substructures, similar to Lei and Bickel [10]. While these methods are useful in testing for partial correlation, our focus is on moving beyond simple partial correlation to pick up (and understand) patterns such as those appearing in the MY‐LC data.
Guan [5] introduced a strikingly novel method called the permutation augmented linear regression test (PALMRT). Previous permutation tests for the partial correlation assign a score to each permutation of the data and then compare the score for the observed data to this reference set. A typical score is the residual sum of squares from an OLS fit, perhaps accounting for the leverage of individual cases. In contrast, PALMRT considers scores from pairs of permutations, establishes exchangeability of the rows of a certain matrix, and uses a technique from multisplit conformal prediction methods [24, 25, 26, 27, 28] to ensure type I error control based on the comparison of an observed score to a set of permuted scores. Guan showed that PALMRT has up to 20 times higher empirical power than CPT in some settings, and nearly the same power as the F‐test in many settings.
To the best of our knowledge, most existing works aim to match the performance of the F‐test while adequately controlling for type I error in the difficult settings. However, if the analyst anticipates that the covariate and error distributions are thick‐tailed, it is important to ensure that the method has high power in precisely those settings. Our work closes this gap and designs tests that specifically have high power when the error distributions are thick‐tailed or skewed, potentially at the cost of slightly lower power if the errors are normal.
Our Contributions
2.3
We develop RobustPALMRT, a highly flexible framework that expands the scope of PALMRT well beyond least squares. The extensions are designed with the motivating data example in mind (viz. the MY‐LC study). They focus on settings where the error distribution may be far from normal—precisely those settings where traditional tests have severely inflated type I error rates. We make several specific contributions.
First is expansion of the fitting procedure to any shift invariant method, that is, any method that returns the same result for both Y and Y+Zθ for any θ∈ℝp. These methods include robust regression, quantile regression, and many additional techniques. Unlike least squares and quantile regression, most of these methods require specification (or estimation) of a tuning parameter, typically tied to the scale of the error distribution. Estimation of the scale parameter must be handled carefully, as standard methods destroy type I error control. Our framework allows for the estimation of the scale parameter in a fashion that maintains control of the error rate. To our knowledge, this is the first test for robust regression parameters with scale estimation that is valid in a distribution‐free setting without moment assumptions in finite‐samples. We illustrate the utility of this with a robust test for differences in center in the MY‐LC study.
Second, we separate model fit from model evaluation. This allows the analyst to tailor their measure of fit to the alternative. This allows one to fit the model efficiently under a solid set of assumptions while basing the test on a more robust summary of the residuals. We illustrate the value of this split in a simulation study, where we find that the choice of the evaluation measure has a strong effect on power.
Third, we enable the analyst to fit multiple models and combine the results for a single test. This gives the analyst access to specific features of the residual distribution. We illustrate this by developing DispersionPALMRT, where we fit multiple quantile regression models to test for a difference in dispersion in the MY‐LC study.
The General Framework
3
To test the null hypothesis that X has no effect on Y after adjusting for Z, it suffices to test the adequacy of the following model:
where Sn is the set of permutations of the integers 1,…,n, and where the notation Aπ denotes permuting the rows of matrix A by permutation π∈Sn. Since the null model does not include X, if X has an effect on Y then ϵ will depend on X. Thus we wish to create a test that is sensitive to dependence between X and ϵ.
We briefly recall the core idea of PALMRT [5]. One considers the pair of augmented linear models Y∼X+Z+Zπ and Y∼Xπ+Z+Zπ, where the Zπ augmentation allows for fair comparison of the effect of X and Xπ on Y.
Our RobustPALMRT framework has two components: A model‐fitting algorithm ℳ, and a model‐evaluation procedure ω. The algorithm ℳ(Y,X,[Z,Zπ]) produces a list of summary statistics describing how well the augmented model
fits the data. For example, if we choose to regress Y∼X+Z+Zπ, the algorithm might output the vector of residuals ℳ(Y,X,[Z,Zπ])=r=Y−Ŷ, the L2 norm of the residual vector, or some other quantity of interest. We then define the model evaluation function, ω:𝕄→ℝ, with the convention that models that fit the data better have a smaller value of ω(M). For an OLS model, ω(M) could be the sum of squared residuals. We compute:
Intuitively, if X has explanatory power for Y after adjustment for Z, then for “most” permutations π, MOrigπ should be a better fit than MPermπ, as in Guan [5]. To complete the test, select permutations, π1,…,πB∼iidUnif(Sn), and compute:
The Core Theorem
3.1
Here we present the core theorem that underlies RobustPALMRT.
Assumption 1 ϵ is an exchangeable random vector.
Assumption 2 Y is linear in Z, that is Yi=ZiTθ+f(Xi,ϵi), for some f.
In addition to these two assumptions, we require two conditions on the model fitting method. Note that these conditions are explicitly verifiable. The analyst can choose a procedure for which the conditions hold.
Condition 1 ℳ(Y+[Z,Zπ]γ,X,[Z,Zπ])=ℳ(Y,X,[Z,Zπ]) for every γ∈ℝ2p.
Condition 2 ℳ(Yσ,Xσ,[Z,Zπ]σ)=ℳ(Y,X,[Z,Zπ]) for every permutation σ∈Sn.
Condition 1 demands that the fitting algorithm depends only on the portion of Y that is perpendicular to the [Z,Zπ] subspace. For example, the residuals from any projection of Y onto a subspace containing the columns of [Z,Zπ] would satisfy this condition, along with many classical regression methods based on M‐estimators. Condition 2 simply requires that the algorithm treats all cases symmetrically.
Notice that in Assumption 1 we do not require ϵ to be symmetric, which is critical because the MY‐LC data exhibits high skewness. We use Assumption 2 in conjunction with Condition 1 to remove the effect of Z by demanding that our fitting procedure be invariant to a shift of Y by Zθ for any θ∈ℝp.
Theorem 1 Suppose that ℳ satisfies Conditions 1 and 2, and Y satisfies Assumptions 1 and 2. Then for any α∈[0,1] and θ∈ℝp, we have
This theorem allows the analyst to strictly control the type I error rate by using a p value cutoff of α/2 rather than α. However, the simulations in Section 5 suggest that for reasonable choices of ℳ the nominal type I error rate of α is attained without adjustment of the cutoff.
RobustPALMRT: Testing Flexible Hypotheses
4
Finite‐Sample Testing for M‐Estimators With Scale Estimation
4.1
Robust regression via M‐estimation is a standard method to ensure that an analysis is stable in the presence of skewed observations and outliers [3, 8]. To perform a robust regression, a criterion function, ρ, is chosen and the parameter estimates are found by empirical minimization of the criterion. To perform a robust regression on the model (3), compute (β^,θ^)=argminβ,θ∑i=1nρ(ri/ŝ), where the vector of residuals is r=Y−Xβ−Zθ and ŝ is an estimated scale. For a specific example, the criterion function may be Huber's linearization of quadratic loss,
where δ is traditionally set at 1.345, with scale estimation based on the median absolute deviation (MAD), computed by Median(|ri−Median(r)|).
To create a test that fits within the RobustPALMRT framework, we need an algorithm ℳ that satisfies conditions 1and 2. The scale ŝ is often concurrently estimated with (β^,θ^) using an Iteratively Reweighted Least Squares (IRLS) procedure [8, 29] Informally, this algorithm proceeds as follows:
- Initialize a value (β˜,θ˜) by OLS.
- Estimate the scale from the residuals in the model (β˜,θ˜).
- Update (β˜,θ˜) by weighted least squares with the fixed scale.
- Repeat Steps 2 and 3 until convergence.
In the Algorithm A1 of Data S1, we provide the explicit algorithm implemented in the statistical software package R in the MASS library [29] and prove that it satisfies Conditions 1 and 2. To give a sketch of the proof, notice that every step in the algorithm is symmetric, so that Condition 2 is automatically satisfied. Then notice that after passing to the OLS residuals, every step depends on Y only through the OLS residuals of Y on [X,Z,Zπ]; since OLS satisfies the shift invariance condition, Condition 1 is satisfied.
Our results show that one can choose ℳ to be the residuals of a Huber regression with MAD scale estimation and have type I error rate control for any comparison function ω. However, we are also concerned with power. If the two regressions, Y∼X+Z+Zπ and Y∼Xπ+Z+Zπ, are fitted with separate scales, the resulting residuals are not comparable since they optimize different loss functions. In our experience, it is more effective to estimate the scale from a preliminary regression, Y∼Z+Zπ, and then use the same scale for both regressions. The preliminary regression does not involve X and is valid under H0. It tends to overestimate the scale under Ha, pushing more of the residuals towards the center region of the loss function. This leads to a single scale estimate ŝ from the preliminary regression and the order statistics of the residuals from a Huber regression with scale fixed at ŝ. Denoting the ordered residuals as r, the output of the algorithm is
Model Evaluation
4.2
Model evaluation is distinct from model fitting. In its basic form, RobustPALMRT compares many pairs of fitted models, as in (6), identifying the member of each pair that fits the data better. When the summary of a model is a single vector of residuals, our focus has been on the norm of the residuals, and we might naturally consider ω(M)=‖r‖ for some norm ‖·‖. PALMRT uses the L2 norm for both model fitting (OLS) and model evaluation. In keeping with our desire for robustness, we use the Huber loss,1 ‖r‖Huber=∑i=1nρHuber(ri).
When using an estimated scale ŝ from ℳ chosen as above, we should ensure that the models we are comparing are on the same scale before computing a Huber loss. With the choice of ℳ as above, we use ω(M)=‖r/ŝ‖Huber. We describe our method precisely in the upcoming Algorithm 1.
When considering a model evaluation procedure, it is useful to keep in mind that the evaluation of any particular fitted model in isolation is not meaningful, especially since both MOrigπ and MPermπ include the permuted covariate Zπ. Rather, to choose a good model evaluation procedure the analyst must consider what kind of evaluation will be sensitive to the differences between a pair of fitted models MOrigπ and MPermπ. To understand how this might matter, if the analyst is concerned about the undue influence of a few points on the conclusions of the analysis, using an evaluation procedure that emphasizes the performance of the model on the bulk of the residuals (such as a Huber loss) rather than on the extremes (such as an L2 loss) can stabilize the evaluation ω and make it substantially more sensitive to the important differences between the permuted and original models. This same reasoning again justifies our previous choice to use a shared estimated scale from the regression Y∼Z+Zπ. Stabilization of the estimated scale cascades into a more sensitive comparison of the two fitted models.
ALGORITHM 1Huber‐Huber RobustPALMRT with MAD scaling.
Our method provides a test for a specified value of β under H0. By inverting the family of such α‐level tests, we obtain a confidence interval for β with a guaranteed coverage probability of at least 100(1−2α)%. As a technical note, the minimizer of the empirical loss may not be unique, as with the median when the sample size is even. This issue is handled by specifying a convention that preserves Condition 1. Standard software packages do this.
Finite‐Sample Testing for Multiple Quantile Regression Fits
4.3
Using quantile regression [30], RobustPALMRT can target complex features of the response distribution. For example, with a pair of quantile regressions, one can estimate the conditional inter‐quantile range (IQR) to assess the dispersion of the response rather than the location.
In the MY‐LC study, we are interested in identifying whether Long‐COVID patients have increased variability in their cell type proportions controlled for demographic features. Let X be a vector of indicators for Long‐COVID status, let Z be the matrix of demographic features, and let Y be the proportions of interest. If we fit two quantile regressions, one for the 90th percentile and another for 10th percentile, we can estimate the 80% conditional IQR. This is a robust measure of the dispersion, and may also be more scientifically interpretable. For example, it is easier to interpret the implications of the statement “For 80% of the patients, the percent of CD8+ T‐cells expressing IL6 is between 0.3% and 11.4%” than it is to interpret the implications of a standard deviation of 7.8% when the population is highly skewed.
We state the DispersionPALMRT method more formally for any case/control dataset. Let n0 be the number of controls, and let n1 be the number of cases. Define qLow=0.10,qHigh=0.90. We fit four quantile regressions: Y∼X+Z+Zπ and Y∼Xπ+Z+Zπ at quantiles qLow and qHigh. Define rq,k as the ordered residuals from quantile q for cases in group k∈{Control,Case}. Then let
ALGORITHM 2DispersionPALMRT testing for differences in IQR.
Simulation Studies
5
Location Simulations
5.1
In our first set of simulations, we evaluate Algorithm 1 in model (3). In this setting, the F‐test is the standard choice when the noise is normally distributed. However, when the noise is substantially skewed, the F‐test can have inflated type I error rates as we will see. We compare RobustPALMRT, using several choices of model fitting and model evaluation procedures, to the both PALMRT and the F‐test.
We simulate data from model (3) for various choices of X, Z, ϵ, and β. We generate ϵ using (i) normal, (ii) t3, (iii) Cauchy, (iv) multinomial+normal, and (v) log‐normal distributions, respectively. The multinomial+normal model (iv) was proposed by Guan [5] as a challenging case for traditional permutation methods. There, n−1 entries of ϵ are i.i.d. N(0,1), while one randomly selected entry has distribution N(±104,1), representing a severe outlier. There are p=6 covariates in Z, while X is univariate. The entries of [X,Z] are i.i.d. Cauchy(0,1), except for one intercept column in Z. We use α=0.05 and B=999 permutations for both PALMRT and RobustPALMRT. Lastly, we both test settings where β=0, evaluating type I error rates, and where β is selected such that the F‐test has a specified power, thus evaluating power.
We consider two model fitting strategies: OLS and Huber robust regression, and three evaluation metrics: L1, L2 and Huber loss with an estimated scale parameter. We label the methods by fitting method and evaluation metric: PALMRT from Guan [5] is OLS‐L2 while Algorithm 1 is Huber–Huber.
First we assess type I error with β=0 with n=100 cases. The F‐test does well with the normal errors of setting (i). It controls the type I error rate and is more powerful than the other methods, as expected. For the thick‐tailed and skewed settings, the F‐test has a greatly inflated type I error rate for small values of α and is far less powerful than the best of the other methods. See Figure 2 for the empirical CDFs, and notice in particular that for very small nominal levels, say α<0.01, the F‐test particularly struggles. Inflation of type I error at these low levels can negatively affect the false discovery rate control procedures commonly used with these types of datasets.
Empirical CDF of PALMRT and RobustPALMRT for p values under H0. If the p values for a method are calibrated correctly, the simulated curve will lie near or below the dashed line, which is the cumulative distribution function (CDF) of the uniform distribution. Notice that for all nonnormal settings, the F‐test spikes far above the uniform CDF for small nominal levels, while all RobustPALMRT methods stay below the uniform CDF.
On the other hand, the type I error rate for both OLS‐L2 (PALMRT) and Huber–Huber (RobustPALMRT) was found to be less than α in all tested settings. Notably, Theorem 1 guarantees that both methods have type I error rate less than 2α. The fact that these methods control type I error at the nominal level α in the simulations justifies our choice to refer to α as the nominal level despite the theory only guaranteeing control at level 2α. We are aware of extreme cases where the factor of two is necessary, but the cases we know of require the use of model evaluation procedures that border on the absurd.
Next we assess the power under various alternatives. We calibrate β such that the F‐test has an approximate power of {0.20,0.40,0.60,0.80,0.95}. In particular, we use a simulation‐based root finding approach to select the β in each of the 25 settings such that the F‐test will have the desired power. Calibrating β in this way ensures that our tests cover a large range of power in each setting, and give a fair baseline for comparison with RobustPALMRT.
The OLS‐L2 and Huber‐Huber methods show similar performance when the errors are normal. OLS‐L2 has slightly greater power than Huber‐Huber here. In Figure 4, we see that both methods converge toward the F‐test's power as the sample size grows when the errors are normal.
For the thick‐tailed and skewed error distributions of settings (ii) through (v), Huber‐Huber has much more power than OLS‐L2. In Figure 3 we see that the Huber‐Huber method uniformly outperformed all other methods, sometimes by a large margin. Interestingly, moving from OLS‐L2 to OLS–Huber increases power substantially while preserving control of the type I error rate, suggesting that the model evaluation procedure plays a very important role. This supports an emerging pattern in the literature on model choice where robust model evaluation leads to substantial improvement in power when the data is produced by a thick‐tailed distribution [31].
Relative power of RobustPALMRT to the F‐test. More specifically, (Power of RobustPALMRT)/(F‐test power) versus F‐test power. Error bars are provided for the OLS‐L2 and Huber–Huber methods, but are very small. The curves in these panels have been “jittered” horizontally to preserve their shapes while enhancing the visualization. The nominal level of the F‐test is 0.05. Notice that for all nonnormal settings, the Huber–Huber method uniformly performed the best, followed by the OLS–Huber method.
Figure 4 presents results on sample sizes ranging from n=25 to n=400. The patterns described above hold across this range of sample sizes. We note that, for small sample size and nonnormal errors, the level of the F‐test may be greatly inflated.
Relative power of RobustPALMRT to the F‐test. More specifically, (Power of RobustPALMRT)/(F‐test power) vs sample size n, fixing F‐test power at 40%. Error bars are provided for the OLS‐L2 and Huber–Huber methods, but are very small. The curves in these panels have been “jittered” horizontally to preserve their shapes while enhancing the visualization. The nominal level of the F‐test is 0.05. Notice that for all nonnormal settings, the Huber–Huber method uniformly performed the best, followed by the OLS–Huber method.
In addition to the simulations presented in this section (p=6), we performed the same studies when p=2 and p=16 under various distributions of the covariates. As observed by Guan [5] in her study of OLS‐L2 PALMRT, for a given sample size, the relative power of PALMRT compared to the F‐test decreases as p increases. In the heavy‐tailed Cauchy and multinomial settings for ϵ we observe a strong benefit to the use of RobustPALMRT even when p=16.
The distribution of the covariates has a mild effect on the relative power of RobustPALMRT to the F‐test. The patterns observed here are essentially the same for covariates that are normal, t3, Cauchy, or that follow the balanced ANOVA design proposed by Guan [5]. Our simulations suggest that the relative power of RobustPALMRT over the F‐test mildly increases when the tails of the design are lighter. The simulation conditions are fully described in the Section B in Data S1. We present detailed results from these additional simulations in Section D in Data S1.
PALMRT has been designed to provide a test with a (provable) bound on the finite‐sample type I error rate when ϵ is not normally distributed. It is in precisely these settings of nonnormal, but exchangeable, errors that RobustPALMRT outperforms PALMRT. Our recommendation is to use Huber‐Huber RobustPALMRT instead of PALMRT in these cases. As a fallback position for those who wish to use OLS to fit the model, we recommend the use of a robust evaluation criterion (Huber loss) to increase the power of PALMRT while retaining the guaranteed type I error rate.
Dispersion Simulations
5.2
In our next set of simulations, we assess the performance of the quantile focused approach of Section 4.3, which we hereafter refer to as DispersionPALMRT. We generate data from the following model:
where β∈ℝ and X∈{0,1}n. We generate ϵ according to (i) normal, (ii) Cauchy, (iii) log‐normal distributions, respectively. We use p−1=5 covariates in Z, with one intercept column and the rest drawn as Zij∼iidCauchy. To examine both type I error rate and power, we select β∈{0,0.5,1.0,1.5,2.0}, and perform the hypothesis tests at level α=0.05. Lastly, we select the sample size as n∈{100,200,400}.
We compare DispersionPALMRT to the Breusch–Pagan test [32, 33], a classic test for heteroskedasticity such as that in model (8). For robustness in heavy tailed settings, we use the correction to the Breusch–Pagan test described by Koenker [34], using the implementation in the statsmodels Python package [35]. This test rests on either normality assumptions or asymptotic theory, and so we expect that the test will perform well in the normal noise of setting (i) but suffer in the nonnormal noise of settings (ii) and (iii).
All methods controlled the type I error rate in all tested settings, so we omit plots of performance under the null. We note, however, that in all tested settings DispersionPALMRT was highly conservative. For example, it has a type I error rate of 0.004 in the normal errors setting with n=100. This suggests that there is room to recalibrate the test to the nominal level. The Breusch–Pagan test was similarly conservative in the Cauchy errors setting, likely owing to the studentization correction from Koenker [34] dominating the signal.
The power curves for the two method are shown in Figure 5. In the normal setting (i), we see that the Breusch–Pagan test outperforms the dispersion focused PALMRT method. This is expected, since purely quantile‐based methods are generally less efficient than least squares based approaches in normal settings.
Power of the Breusch–Pagan test and DispersionPALMRT in model (8). The power was computed by 1000 Monte‐Carlo replicates at level α=0.05. Error bars are plotted, but are nearly invisible due to their negligible width. The title of each plot indicates the noise distribution and sample size. Notice that in the nonnormal settings, DispersionPALMRT (Algorithm 2) requires around n=200 observations to detect a two‐fold increase in standard deviation of the noise (i.e., β=1.0).
In the nonnormal settings (ii) and (iii), the quantile based approach of DispersionPALMRT is much more effective than the Breusch–Pagan test. We attribute this to the fact that the quantile regressions are unaffected by the extreme observations that the heavy tailed errors create.
Case Study: Long‐COVID Immunological Features
6
RobustPALMRT for Location Effects in the MY‐LC Dataset
6.1
We use the RobustPALMRT framework to analyze the MY‐LC study Long‐COVID dataset presented in Section 1. This dataset was also analyzed by Guan [5] using PALMRT, and so we compare the conclusions of the analyses between OLS‐L2 PALMRT and Huber‐Huber RobustPALMRT with scale estimation.
Seven patients were excluded from the study for biological reasons [6], leaving 99 Long‐COVID patients and 77 control patients. We analyze the proportions of 65 different cell types, with each type modeled separately. The proportion of each cell type will serve as a response variable, say Y(k), k=1,…,65. For each response, we use Model 1.
Figure 6 shows confidence intervals for the Long‐COVID effect using OLS‐L2 PALMRT and Huber‐Huber RobustPALMRT for 14 selected cell types. These confidence intervals are constructed by inverting a family of RobustPALMRT hypothesis tests. That is, the interval consists of values β⋆ for which we fail to reject H0:β=0 when replacing Y with Y⋆=Y−Xβ⋆. Notice that for several cell types, one interval covers zero while the other does not, implying that the two tests result in different conclusions. For many cell types the intervals are similar, with the RobustPALMRT interval tending to be a little shorter than the corresponding PALMRT interval. However for some cell types there is a dramatic difference in interval width. In these cases, we also find that the centers of the intervals are quite different. We attribute these differences to the lack of robustness of OLS‐L2 PALMRT. The focus on the mean and variance that is implicit in the procedure produces a test (and interval) that is sensitive to extreme observations. Huber–Huber RobustPALMRT reduces this sensitivity.
95% CI's for the effect of Long‐COVID using Huber‐Huber (red, left) and OLS‐L2 (blue, right). The intervals are scaled by the standard deviation of the cell type proportion (Y(k)).
DispersionPALMRT for Scale Effects in the MY‐LC Dataset
6.2
Klein et al. [6] were particularly interested in understanding variation in the immune response of patients. Their study included both flow cytometry data about immune cell concentrations (studied here) and a more fine‐grained experiment known as Rapid Extracellular Antigen Profiling (REAP). The REAP data show that Long‐COVID patients have a wide variety of unique reactions to introduced antigens, known as private reactivities. The REAP data suggest that Long‐COVID patients have highly variable immune responses in general, and this encouraged us to develop a formal test to assess whether there is also an increase in variation among Long‐COVID patients in the immune cell concentration flow cytometry data.
We designed DispersionPALMRT to test for differences in dispersion. Recall that Figure 1 suggests that, for some cell types, the most evident impact of Long‐COVID is on the dispersion and skewness of cell type proportion. We use the quantile regression approach described in Section 4.3 to test for differences in the 80% IQR between the Long‐COVID and healthy control patients adjusted for control covariates. Our dispersion‐focused analysis found a significant effect of Long‐COVID at the α=0.05 level for 15 of the 65 cell types. The significant effects include several cell types for which there was no apparent impact of Long‐COVID on mean cell concentration; in particular for three cell types, the F‐test did not find a significant difference in mean cell concentration while our dispersion‐focused method found strong evidence (p<0.01) of a difference in dispersion of cell concentration between the groups. Specifically, we found strong differences in the dispersion of the cell concentrations between Long‐COVID and control patients in the following subpopulations: TNFα‐expressing T‐cells among all CD8+ T‐cells, IL4‐expressing T‐cells among all CD8+ T‐cells, and IFNγ‐expressing T‐cells among all CD4+ T‐cells.
Proof Sketch of Theorem 1
7
To prove the validity of Theorem 1, we build off of the work of Guan [5]. We first give a sketch of that work, and then we show how our framework fits into that work. In the Section C in Data S1 we give a full proof of an extended “population version” of the result that includes weights.
Guan [5] introduced the idea of forming an array of direct comparisons of permuted and unpermuted versions of the model rather than forming a “one‐dimensional” list of summary statistics T(π1)≤⋯≤T(πB). Let π1,π2∈Sn be an arbitrarily selected pair of permutations. We construct an array T(π1,π2;ϵ) with a very specific symmetry property, namely that T(σ∘π1,σ∘π2;ϵσ)=T(π1,π2;ϵ).
From here, we construct the B×B comparison matrix Aπ1,π2=I(T(π1,π2;ϵ)≥T(π2,π1;ϵ)). This matrix is stochastic, but appealing to a classic result from tournament theory [25, 27, 28, 36] one can deterministically show that there are at most 2αB columns j∈{1,…,B} of Ai,j such that 1B∑b=1BAπb,πj≤α. By the exchangeability of ϵ and the aforementioned symmetry property, the “identity column” pvalue=1B∑b=1BAπb,Id is exchangeable with the other B−1 columns, and so ℙ(pvalue≤α)≤2α.
Two things remain to be done:
- Construct an array of comparisons T(π1,π2;ϵ) with the necessary symmetry property.
- Show that the constructed array of comparisons actually describes the p value in (1).
We construct the following array of comparisons between permutations π1,π2∈Sn:
Then we have, for any σ∈Sn,
Then by theorem 4.1 in [5] from Guan, under the null model we have
Notice that, for any θ∈ℝp and π∈Sn, we have
Hence (9) implies ℙ(pvalue≤α)≤2α, as desired.
Discussion and Extensions
8
We have established that RobustPALMRT controls the type I error rate for a test of model (4) under only exchangeability of ϵ and linearity of Z. The introduction of the shift invariance condition to replace least squares projection expands the capabilities of PALMRT in directions that align with sound data analysis. In particular, we show that it is possible to perform scale estimation while maintaining shift invariance, and so our method can be applied to settings that are not scale invariant, something that commonly arises when conducting a data analysis.
The extension covers a broad swath of robust regression methods. Our simulations show that the common pattern in robust regression holds in this setting—little is lost when stringent parametric assumptions hold and much is gained when they do not hold. In particular, we found that RobustPALMRT dramatically outperforms competing methods when there is strong skewness or heavy tails, while the method is nearly as efficient as the F‐test when the errors are normal.
We have also demonstrated the flexibility of the framework by designing a quantile‐based test for heteroskedasticity in immune responses of Long‐COVID patients. Our simulations suggest that our test is more efficient than existing tests when the response has varying dispersion, a property the MY‐LC dataset has. We envision that an observant analyst can follow our pattern here to develop other novel tests for complex features of a response within the RobustPALMRT framework.
While we have only demonstrated two possible uses for this framework, there are a vast number of potential extensions. For example, we dealt exclusively with univariate responses, but theory also holds for multivariate responses. In immunology, it is common to look at sets of markers, and this can easily fit within RobustPALMRT. Future work in this direction might look into ways to take advantage of classical multiple comparison methods to search through these sets of markers.
Furthermore, the model fitting procedure could return an entire family of solutions, such as the entire model fitting path when varying the regularization parameter λ in a LASSO fit. In particular, this means that one can use a high dimensional set of features for X. Unfortunately, Z is currently limited to being of modest dimension; we do know how to include high dimensional Z given known bounds on the norm of θ, but the method has low power, and so we did not include it in this work.
While powerful, the RobustPALMRT framework is not a panacea. The theoretical results rest on the assumption that all nonlinearity is captured in the covariates of interest and the error, namely model (4). Exchangeability is an essential part of our current proofs, and our own preliminary investigation (not shown here) suggests that the type I error rate may not be controlled when this assumption is violated, for example, when there is moderately strong unmodeled heteroskedasticity.
Finally, given the scope of the framework, RobustPALMRT is not narrowly proscriptive. Analysts have the flexibility to select from many possible robust regression methods and many possible evaluation criteria. Our simulations suggest that the (often neglected) latter choice can be influential. We suggest that researchers seeking a formal test that guarantees type I error rate control while having scope for creative applications consider using RobustPALMRT.
Author Contributions
Torey Hilbert wrote all code, data analysis, and proofs. Torey Hilbert conceptualized the project and wrote the draft. Steven N. MacEachern and Yuan Zhang contributed to refining the ideas and revising the manuscript.
Funding
This work was supported by the National Science Foundation (Grant numbers SES‐1921523, DMS‐2413823, DMS‐2311109).
Disclosure
The authors have nothing to report.
Conflicts of Interest
The authors declare no conflicts of interest.
Supporting information
Data S1. sim70404‐sup‐0001‐Supinfo.pdf.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1L. Wang , B. Peng , and R. Li , “A High‐Dimensional Nonparametric Multivariate Test for Mean Vector,” Journal of the American Statistical Association 110, no. 512 (2015): 1658–1669.26848205 10.1080/01621459.2014.988215 PMC 4734767 · doi ↗ · pubmed ↗
- 2A. Eklund , T. E. Nichols , and H. Knutsson , “Cluster Failure: Why f MRI Inferences for Spatial Extent Have Inflated False‐Positive Rates,” Proceedings of the National Academy of Sciences USA 113, no. 28 (2016): 7900–7905.10.1073/pnas.1602413113 PMC 494831227357684 · doi ↗ · pubmed ↗
- 3Q. Sun , W. X. Zhou , and J. Fan , “Adaptive Huber Regression,” Journal of the American Statistical Association 115, no. 529 (2020): 254–265.33139964 10.1080/01621459.2018.1543124 PMC 7603940 · doi ↗ · pubmed ↗
- 4S. Hawinkel , F. Mattiello , L. Bijnens , and O. Thas , “A Broken Promise: Microbiome Differential Abundance Methods Do Not Control the False Discovery Rate,” Briefings in Bioinformatics 20, no. 1 (2017): 210–221, 10.1093/bib/bbx 104.28968702 · doi ↗ · pubmed ↗
- 5L. Guan , “A Conformal Test of Linear Models via Permutation‐Augmented Regressions,” Annals of Statistics 52, no. 5 (2024): 2059–2080, 10.1214/24-AOS 2421. · doi ↗
- 6J. Klein , J. Wood , J. R. Jaycox , et al., “Distinguishing Features of Long COVID Identified Through Immune Profiling,” Nature 623, no. 7985 (2023): 139–148.37748514 10.1038/s 41586-023-06651-y PMC 10620090 · doi ↗ · pubmed ↗
- 7R. A. Fisher , “The Goodness of Fit of Regression Formulae, and the Distribution of Regression Coefficients,” Journal of the Royal Statistical Society 85, no. 4 (1922): 597–612.
- 8E. M. Ronchetti and P. J. Huber , Robust Statistics (John Wiley & Sons, 2009).