Using GeoAI and Machine Leaning Tools for Consistent High-Resolution Land Cover Mapping Based on Time-Series NAIP Imagery
Jie Liu, Xusheng Tang, Chao Wang, Zhengxiao Yan, Yuchen Dai, Qi Zhang, Conghe Song

TL;DR
This paper presents a new method using GeoAI and machine learning to create consistent high-resolution land cover maps from NAIP imagery over multiple years.
Contribution
A dual-track adaptive workflow is introduced to handle sensor shifts in NAIP imagery without historical training samples.
Findings
The algorithm achieved overall accuracies of 0.874 in 2014, 0.848 in 2017, and 0.788 in 2004.
Structure, Water, Wetland, and Cropland showed consistently high F1-scores across years.
The method maintains spatial fidelity and temporal consistency despite sensor differences in imagery.
Abstract
High-resolution land-cover maps are essential for ecological monitoring and landscape-level analysis, yet long-term high-resolution time-series products remain scarce. The National Agricultural Imagery Program (NAIP) provides highly valuable aerial imagery, but strong temporal heterogeneity across years, primarily caused by shifts in sensor characteristics, limits the ability to generate consistent multi-year land cover maps. This study aims to (1) develop an algorithm capable of producing spatially detailed and temporally coherent 1-m land-cover maps using the state-of-the-art GeoAI/Machine Learning (ML) tools based on time-series NAIP imagery, and (2) address cross-year sensor characteristic shifts without relying on historical training samples. We designed a dual-track adaptive workflow that applies different strategies to NAIP imagery with different qualities. NAIP imagery…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
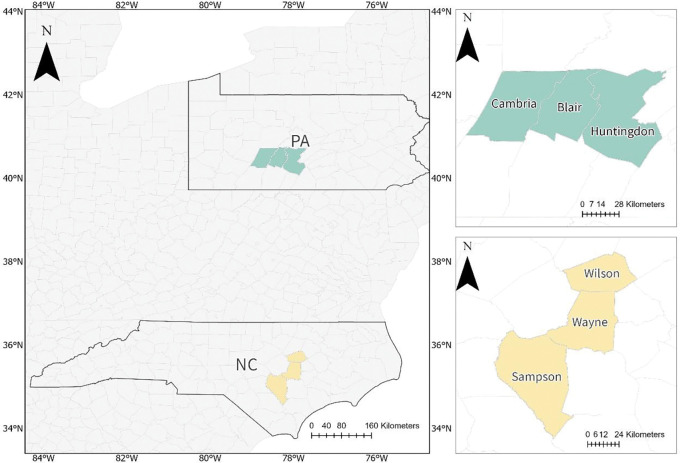 Figure 1
Figure 1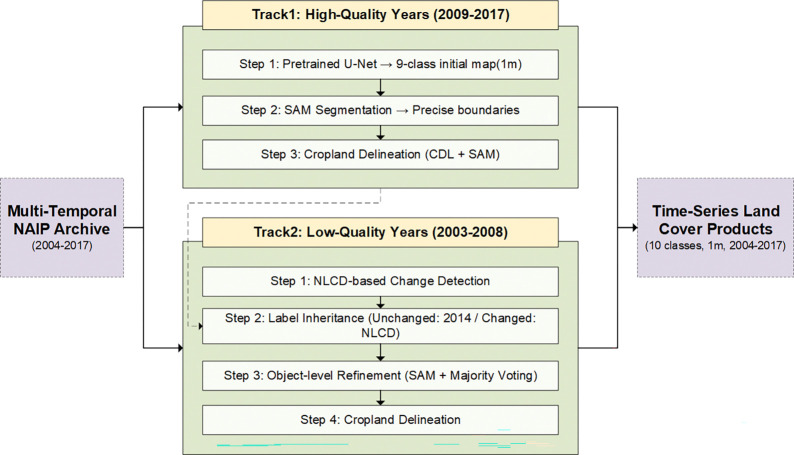 Figure 2
Figure 2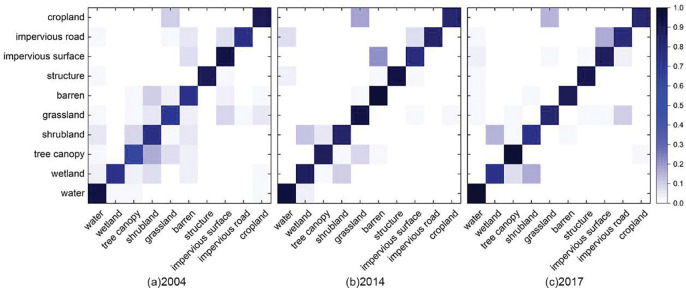 Figure 3
Figure 3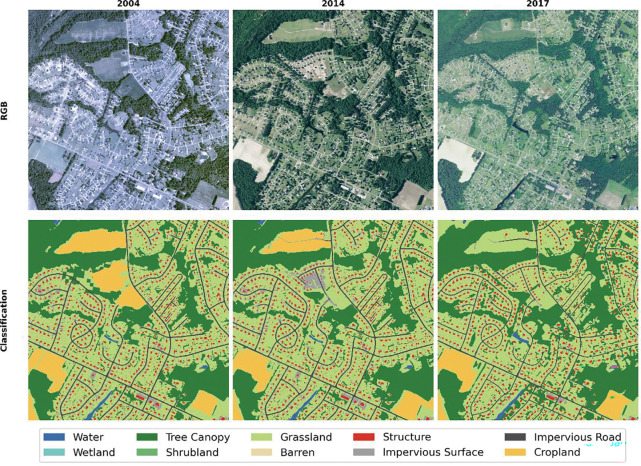 Figure 4
Figure 4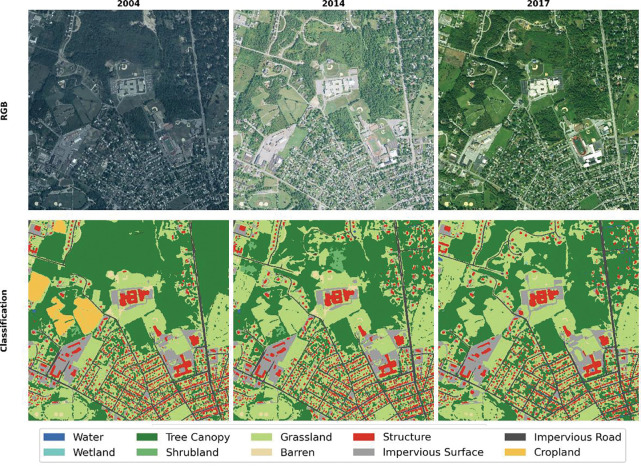 Figure 5
Figure 5- —National Institutes of Health
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsRemote Sensing in Agriculture · Soil Geostatistics and Mapping · Remote-Sensing Image Classification
Introduction
Land cover information is fundamental for monitoring environmental and ecological processes. Land cover classification based on remote sensing imagery can provide a foundational dataset for a wide range of applications, including climate modeling (Wulder et al. 2018), biodiversity assessment (Pettorelli et al. 2014) and landscape change analysis (Pielke et al. 2011). Over the past decades, numerous studies based on medium-resolution imagery, such as Landsat (Wulder et al. 2022), have produced long-term land cover products, such as the National Land Cover Database (NLCD), providing critical support for the continuous monitoring of terrestrial processes (Hansen and Loveland 2012). However, sub-meter aerial imagery, such as that collected by the National Agriculture Imagery Program (NAIP), captures much finer boundaries and spatial structures of complex urban and rural surfaces, offering irreplaceable value for accurately detecting and quantifying long-term changes (Nagel and Yuan 2016; Hussain and Shan 2016; Coleman et al. 2020). Despite such an advantage, existing land cover datasets rarely possess such fine spatial details with long-term temporal consistency. Therefore, constructing a land cover dataset that combines high spatial resolution with long-term temporal consistency is essential for accurately tracing historical dynamics, evaluating policy outcomes (Hansen et al. 2013), and modeling future scenarios (Hoffmann et al. 2023).
Obtaining long-term and consistent high-resolution land cover products faces a core challenge—the temporal heterogeneity of archival imagery (Van Den Broeck et al. 2022). This heterogeneity arises because acquisition standards and imaging technologies in NAIP have continuously evolved over the past two decades, leading to notable inter-annual variations in spatial resolution, spectral composition (e.g., the transition from three-band RGB to four-band RGB–NIR), sensor characteristics, and radiometric consistency (Prior et al. 2022; Bhatt and Maclean 2023). These cross-temporal inconsistencies violate the assumption of data homogeneity (Du et al. 2002; Canty and Nielsen 2008; Prior et al. 2022), making it difficult for a single, unified modeling strategy to maintain stable performance across a multi-decadal time span (Tuia et al. 2016; Luo and Ji 2022a).
Early attempts to generate multi-temporal land-cover maps primarily followed two steps: (1) training a classifier based on training samples and (2) classification of images based on radiometric normalization of time-series images to the image where the training samples were collected, i.e., signature extension (Minter 1979; Gray and Song 2013). However, radiometric normalization cannot effectively address nonlinear signature drift that originates from multiple sources, which include the sensor characteristics, atmospheric condition, viewing and illuminating geometries, and phenology, leading to unstable temporal trajectories (Lu and Weng 2007). To address this limitation, the Automatic Adaptive Signature Generalization (AASG) framework was proposed which uses stable pixels as temporal anchors to ensure signature consistency between the training samples and the image to be classified. The AASG has been shown to be effective for classification of long time-series Landsat images (Gray and Song 2013; Dannenberg et al. 2018). However, the requirement of sub-pixel accuracy for geometric registration is far more challenging to achieve for sub-meter NAIP imagery than Landsat imagery, making AASG (a method that relies on radiometric consistency) unsuitable for direct application to NAIP imagery.
In recent years, deep learning–based pretrained foundation models have shown outstanding abilities in feature learning and knowledge transfer for remote sensing image interpretation, substantially reducing dependence on task-specific training samples under limited-annotation conditions (Wang et al. 2022; Yao et al. 2023; Huo et al. 2025). Existing studies have widely explored zero-shot and few-shot domain transfer paradigms to address data inconsistencies caused by differences in spatial regions or sensor types (Xu et al. 2022). However, most of these studies focused on horizontal model transfer between high-resolution images of consistent quality (Tong et al. 2020; Li et al. 2023), while temporal heterogeneity across multi-year archives remains largely unaddressed (Tuia et al. 2016; Luo and Ji 2022a). Therefore, effectively leveraging advanced models to generate land cover products that are both temporally consistent and spatially detailed remains a critical scientific problem yet to be solved (Tang et al. 2025).
Existing zero-shot and few-shot domain transfer methods have mainly targeted at high-resolution imagery with consistent quality (Xu et al. 2022). These approaches typically fine-tune pretrained models by combining pseudo-label and sample selection with patch-based classification and object- or hierarchy-based segmentation (Hossain and Chen 2019; Tong et al. 2020; Li et al. 2023). Their goal is to balance class identification with boundary precision across sensors or regions. However, for heterogeneous aerial archives such as NAIP, imagery acquired within the same year can still show pronounced domain discrepancies across regions. Consequently, few-shot fine-tuning and pseudo-labeling cannot ensure stable model transfer under such conditions. Moreover, current studies remain limited to model transfer itself and lack an operational workflow for producing long-term, high-quality land cover maps across diverse temporal and quality conditions (Luo and Ji 2022b; Tang et al. 2025).
To address this challenge, this study proposes and validates a dual-track adaptive workflow designed to generate temporally consistent and reliable 1-m resolution land-cover maps from the highly heterogeneous NAIP archive, using GeoAI/ML tools and existing land-cover products (Maxwell et al. 2019). The core idea of this framework is to apply differentiated processing strategies according to image quality. For the high-quality modern epoch (2009–2017), a pretrained deep learning model is used for robust initial classification (ArcGIS Online 2025), and subsequently, the visual foundation model, Segment Anything Model (SAM) (Kirillov et al. 2023), is incorporated to refine class boundaries—particularly for the delimitation (Ma et al. 2024; Janowski and Wr blewski 2024). For the low-quality early epoch (2004–2008), a data-fusion and back-casting pipeline is developed, using high-quality classifications and the NLCD as a spatiotemporal bridge. This approach enables the reliable reconstruction of historical land-cover information without additional labeling or model retraining for those years. Overall, this study developed an innovative GeoAI/ML approach that enables temporally heterogeneous high-resolution imagery to produce consistent long-term high-resolution land cover maps.
Materials and Methods
Study area
2.1.
This study centers on six counties in two Eastern U.S. states: Sampson, Wayne, and Wilson counties in North Carolina (NC), and Blair, Cambria, and Huntingdon counties in Pennsylvania (PA) (Figure. 1). These areas were selected to support an NIH project (R21-MH140292–01) that aims at evaluating longterm exposure of children to green space on their mental health. The historical NAIP imagery archives systematically capture the program’s technological evolution ranging from early lower-quality imagery (e.g., 2004) to recent high-quality acquisitions (e.g., 2017), and encompassing variations in spectral composition, sensor characteristics, and radiometric consistency (Homer et al. 2020; Schroeder et al. 2022). This makes them ideal case studies for examining the core challenge addressed in this research—the pronounced temporal heterogeneity across more than a decade of high-resolution imagery (Maxwell et al. 2019; Prior et al. 2022; Bhatt and Maclean 2023).
In addition, the two study regions differ markedly in both physical geography and human–landscape patterns (Omernik and Griffith 2014). The selected NC region, located in the Atlantic Coastal Plain, features predominantly flat terrain characterized by intensive agriculture and more dispersed patterns of recent urban expansion. In contrast, the selected PA region, situated within the Appalachian Ridge and Valley province, exhibits pronounced topographic relief, dominated by extensive deciduous forests and compact post-industrial urban forms. This strong geographical and socio-environmental contrast provides an ideal testbed for evaluating the spatial generalization, robustness, and transferability of the proposed algorithm across regions with diverse spectral signatures, topography, and land use configurations (Maxwell et al. 2019; Homer et al. 2020).
Data
2.2.
NAIP Imagery
2.2.1.
This study primarily utilizes the National Agriculture Imagery Program (NAIP) orthoimage archive, which contains high-resolution aerial imagery across the contiguous United States to support agricultural and environmental applications (Schroeder et al. 2022). NAIP imagery collected between 2004 and 2017 was employed in this study. Only RGB bands were used to ensure consistent spectral inputs across the full 2004–2017 archive. Incorporating NIR from later years would incur band inconsistency for the foundation model used in the study.
Ancillary Datasets
2.2.2.
Two auxiliary datasets at 30 m spatial resolution were incorporated to support and enhance the classification workflow. The first is the National Land Cover Database (NLCD), released by the U.S. Geological Survey (USGS), which provides multi-temporal nationwide land cover information (Yang et al. 2018). In our study, the NLCD served as a key spatiotemporal bridge within the back-casting module, helping to identify potentially changed and stable areas and to supply cross-year reference cues. The second is the Cropland Data Layer (CDL), produced by the U.S. Department of Agriculture (USDA), offering annual crop-type and spatial distribution data (USDA NASS, 2024). The CDL was incorporated as a raster-based auxiliary layer to supply crop-type priors and seed masks, which guided the refinement of cropland delineation and complemented the missing cropland class in the initial foundation model classification results.
The Dual-Track Adaptive Workflow
2.3.
To address the pronounced temporal heterogeneity of the NAIP imagery archive, we developed a dual-track adaptive workflow that applies different processing strategies according to image quality. For high-quality years (2009–2017), land-cover mapping is performed using a pretrained foundation model followed by object-level boundary refinement with Segment Anything Model (SAM) to achieve high accuracy (Track 1); For low-quality years (2004–2008), a composite approach integrating NLCD-based spatiotemporal bridging, label back-casting, and object-level optimization is employed to reliably reconstruct historical classifications without additional training samples (Track 2). This step is similar to the concept developed in the AASG (Gray and Song 2013). The overall framework is illustrated in Figure 2.
Track 1: Classification of High-Quality Imagery (2009–2017)
2.3.1.
For high-quality NAIP imagery (2009–2017), we first applied ESRI’s pretrained high-resolution land-cover classification foundation model, implemented within the ArcGIS Living Atlas of the World (ArcGIS Online 2025). This model, based on a U-Net architecture with a ResNet-34 backbone, produces a robust baseline 9-class pixel-level prediction (Water, Wetland, Tree Canopy, Shrubland, Low Vegetation, Barren, Structure, Impervious Surface, and Impervious Road) with a reported overall accuracy of approximately 86.5% (ArcGIS Online 2025). We then employed the Segment Anything Model (SAM) for cropland boundary delineation. Pretrained on large-scale visual datasets, SAM provides effective zero-shot generalization for object and boundary delineation in remotely sensed images (Kirillov et al. 2023). Following the implementation settings of SAM for high-resolution remote sensing imagery proposed by Ma et al. (Ma et al. 2024), we applied SAM to the NAIP imagery to produce well-defined feature objects, thereby improving geometric fidelity while preserving the semantic integrity of the pixel-level classification. After generating the land boundaries, we derived the cropland class through a region-growing method using 30 m CDL pixels as seed points, which were expanded only within the 1 m object boundaries generated by SAM. This hybrid approach mitigated the scale mismatch between the CDL and NAIP data, and the resulting 1 m cropland layer was merged with the nine-class base map to produce the complete ten-class land cover product.
Track 2: Back-casting for Low-Quality Imagery (2004–2008)
2.3.2.
The core challenge in this study is to generate the reliable classification of low-quality images in early years (2004–2008). To mitigate these issues, we developed a change-detection strategy that leverages the NLCD as a stable inter-annual bridge. We selected 2014 as the high-quality reference year because its NAIP imagery was used for training the ESRI foundation model and it represents a reasonable temporal midpoint within the archive. For each low-quality target year (e.g., 2004), the corresponding NLCD map (NLCD 2004) was compared with the reference map (NLCD 2014). Areas retaining identical NLCD classes were labeled as unchanged, whereas those with different classes were flagged as changed, producing a 30 m resolution land-cover change mask.
Based on the 30 m change mask generated in the previous step, label propagation was conducted according to two rules: pixels within unchanged areas directly inherited land-cover labels from the high-quality 2014 classification results, whereas pixels within changed areas directly inherited preliminary labels from the target year’s NLCD map (e.g., NLCD 2004), meaning no supervised classifier was involved at this stage. Because the preliminary labels assigned to the changed areas were derived from the 30 m NLCD map, their boundaries may be coarse and spatially ambiguous. To smooth these boundaries, we applied SAM to the original NAIP imagery to generate fine-scale objects. We retained only the SAM-derived objects that intersected the NLCD change mask, and for each retained SAM object, a single land-cover label was assigned according to the dominant NLCD-derived pixel class within that object. In other words, object-level label assignment was determined by the most representative class present within the SAM-defined region. This procedure transformed the coarse, pixel-based classification into a clean, object-based land-cover map with geometrically accurate boundaries at 1×1 meter spatial resolution. To complete the historical land-cover maps, agricultural land was delineated using the same procedure as in Track 1 (a region-growing algorithm seeded by CDL pixels and constrained by SAM-derived object boundaries), ensuring methodological consistency and yielding the high-resolution final ten-class land-cover product for each low-quality target year.
Accuracy Assessment
2.4.
To systematically evaluate the performance of our dual-track workflow across the full spectrum of NAIP data quality, we conducted a detailed accuracy assessment for three representative years: 2004, 2014, and 2017. These years were carefully selected to capture distinct conditions and challenges within the time series: 2004 represents the earliest and lowest-quality imagery, providing a rigorous test of the Track 2 back-casting method; 2014 serves as a critical benchmark year, functioning as the high-quality reference for workflow; and 2017 represents the most recent and highest-quality imagery, enabling the evaluation of Track 1 performance under near-ideal conditions.
For each of these three years, an independent validation dataset was generated through a multi-stage stratified sampling design (Olofsson et al. 2013, 2014). First, fifty geocoded household addresses were randomly selected from a list of approximately 1,000 residential addresses in our cohort across the six counties and used as sampling centers. A 1 km radius buffer was created around each selected address. Within these buffers, ground-truth land-cover classes were determined through detailed visual interpretation of the corresponding NAIP imagery. For each land-cover class present in a buffer, two candidate validation points were randomly generated. All candidate points from the 50 buffers were then pooled, and a final validation set was constructed by stratified random selection of 50 validation points per land-cover class. Using this validation dataset, we generated confusion matrices for each of the three classification maps (2004, 2014, and 2017) and computed Overall Accuracy (OA), Producer’s Accuracy (PA), User’s Accuracy (UA), and F1-score. The Kappa coefficient was also reported for completeness, although it is known to have limitations in land-cover accuracy assessment (Pontius and Millones 2011).
Implementation Details
2.5.
All geospatial processing and deep learning inferences were conducted within the ArcGIS Pro (Version 3.4) software environment. The 9-class baseline classification for Track 1 was generated using ESRI’s pretrained high-resolution land-cover classification foundation model (U-Net/ResNet-34 backbone). Key inference parameters were set as follows: padding = 128, batch_size = 8, tile_size = 512, predict_background = True, detailed_classes = True, and test_time_augmentation = True. These parameter values follow the recommended configuration for ESRI’s high-resolution land-cover classification foundation model(ArcGIS Online 2025).
Object segmentation with Meta AI’s Segment Anything Model (SAM) was employed locally using Python (3.9) in a Jupyter Notebook. We utilized the ViT-H model checkpoint (sam_vit_h_4b8939.pth) with the SamAutomaticMaskGenerator and the following parameters: pred_iou_thresh = 0.96, points_per_side = 16, points_per_batch = 32, crop_nms_thresh = 0.5, and box_nms_thresh = 0.5. The imagery was processed in patches using a patch_size of 512 and a stride of 256. These settings are consistent with commonly used configurations in SAM applications on high-resolution aerial imagery and were found to produce stable and geometrically precise boundaries (Ma et al. 2024).
All computations were performed on a workstation equipped with a 13th-generation Intel i9 CPU, (32GB) of RAM, and an NVIDIA GeForce RTX 4080 GPU. With this configuration, processing a 4 km^2^ area with the SAM mask generator took approximately 5 minutes and 1.5 min with ESRI’s pretrained high-resolution land-cover classification foundation model.
Results
Overall Classification Accuracy
3.1.
The overall accuracy metrics for the three representative years are summarized in Table 1. The workflow achieved Overall Accuracy (OA) values of 0.788, 0.874, and 0.848 for 2004, 2014, and 2017, respectively, with corresponding Kappa coefficients of 0.764, 0.860, and 0.831. The Macro F1-scores exhibited a consistent pattern (0.784, 0.871, and 0.849). The highest accuracy was recorded for 2014. In contrast, performance in 2004 was lower as expected, given the absence of high-quality training data and the dependence on NLCD-based back-casting strategy. Nevertheless, even in the most challenging case (2004), the OA remained close to 0.80, indicating that the workflow can produce reliable and temporally coherent land cover maps across the full-time span.
Per-Class Performance
3.2.
The per-class performance metrics, including User’s Accuracy (UA), Producer’s Accuracy (PA), and F1-scores, are summarized in Table 2. An inter-annual comparison of these results reveals several consistent and significant patterns. The Structure and Water classes demonstrated exceptionally stable and high performance, consistently maintaining F1-scores above 0.89 across all evaluated years, which indicates the workflow’s consistent reliability in identifying built-up features and water bodies. Similarly, the ‘Cropland’ class, generated using our hybrid approach of CDL-seeding constrained by SAM-delineated boundaries, achieved high F1-scores ranging from 0.842 to 0.891, validating the effectiveness of the strategy. The Tree Canopy and Wetlands classes also showed robust performance, with F1-scores generally exceeding 0.77 across all years. In contrast, the Grassland class exhibited greater spectral ambiguity, resulting in comparatively lower F1-scores that ranged from 0.687 to 0.796. Notably, classes that are often challenging to distinguish, such as Shrubland, Barren, Impervious Surfaces, and Roads, achieved strong results within our framework, with F1-scores for most categories surpassing 0.80 in the higher-quality years of 2014 and 2017.
Confusion Matrices
3.3.
To further examine category-level classification errors, Figure 3 presents the confusion matrices for 2004, 2014, and 2017. Overall, a strong diagonal dominance is evident, indicating high agreement between predicted and reference classes across most land-cover categories. In the high-quality years (2014 and 2017), misclassifications were largely confined to spectrally or structurally similar classes, such as Grassland vs. Cropland and Shrubland vs. Low Vegetation, consistent with the per-class F1 patterns summarized in Table 2. In contrast, the 2004 results display more widespread off-diagonal errors, primarily among vegetation-related categories, reflecting the limitations of the NLCD-based back-casting approach in distinguishing fine-scale vegetation structures within lower-quality imagery. Nevertheless, key land-cover types such as Water, Structure, and Impervious Roads remained accurately identified across all years, underscoring the workflow’s robustness and temporal consistency even under heterogeneous image qualities.
Visualizing Spatial-temporal Consistency
3.4.
Figures 4 and 5 illustrate examples of the land-cover classification results and corresponding NAIP imagery from two representative areas: a dispersed residential landscape in North Carolina (NC) and a compact urban area in Pennsylvania (PA). The visual comparisons highlight substantial variations in radiometric tone, sharpness, and feature clarity across different years and regions—differences primarily attributed to sensor upgrades, acquisition timing, and atmospheric conditions. Despite these pronounced discrepancies, the proposed dual-track workflow consistently maintained high spatial accuracy and temporal coherence. In both regions, cropland boundaries closely align with their true extents, demonstrating the effectiveness of integrating 30 m CDL-derived seed information with 1 m SAM-delineated object boundaries. Furthermore, the workflow successfully captured realistic land-cover transitions over time. In the NC example (Figure 4), cropland in the upper section of the 2004 image was converted into residential land by 2014 and 2017; in the PA example (Figure 5), a forested area visible in 2004 had transitioned into residential and built-up zones by 2014, with additional structures appearing by 2017.
Discussion
Interpretation of Overall Performance
4.1.
The 2014 results (OA = 0.874) are on par with the publicly reported accuracy of the ESRI High-Resolution Land Cover (HRLC) model (OA = 0.87), indicating that the workflow—while introducing an additional Cropland category—maintained overall performance comparable to the foundation model nine-class baseline (ArcGIS Online 2025). The slightly lower accuracy observed in 2017 (OA = 0.848) reflects seasonal and phenological differences among acquisition dates, which can affect land cover class separability even within high-quality imagery. For our six study counties, the 2014 NAIP scenes were acquired mainly in May and August, while the 2017 scenes span May, June, September, and October. This wider temporal spread increases variability in vegetation greenness and illumination, reducing land-cover class separability even within high-quality imagery.
The more pronounced decline in accuracy for 2004 (OA = 0.788) reflects a combination of limitations in early NAIP imagery and uncertainties introduced by the NLCD-based spatiotemporal bridging and label inheritance approach. The primary source of uncertainty lies in propagating 30 m NLCD-derived change information onto the 1 m object-based classification, which can introduce coarse boundaries and miss fine-scale transitions such as small new constructions or localized vegetation changes. On the other hand, the lower radiometric and spatial quality of early NAIP imagery may also degrade SAM performance, leading to less accurate object boundaries in these years. Given these constraints, an OA of 0.79 for 2004 represents an acceptable outcome and reflects the expected performance range for a back-casting workflow that relies solely on coarse ancillary products. This result indicates that the workflow remains effective even under minimal reference-data conditions.
Comparison with ESRI HRLC and Interpretation
4.2.
In the recent years (2014 and 2017), the overall accuracies achieved by our workflow are comparable to those reported for the ESRI High-Resolution Land Cover (HRLC) foundation model (ArcGIS Online 2025), while delivering equivalent or higher F1-scores for several key classes, including Shrubland, Barren, Impervious Surfaces, Impervious Roads, Wetlands, and Structure. Two main factors may contribute to these differences. The first factor is the evaluation domain differences. The ESRI-reported metrics represent nationwide aggregates, whereas our study focuses on six counties in North Carolina and Pennsylvania, which are not only more homogenous but also geographically proximate to the Chesapeake Bay watershed, an area where the HRLC model itself performs comparatively well (ArcGIS Online 2025), thereby benefiting from the proximity to the high performance area. The second factor is the divergent sampling strategies. Our validation employed stratified random sampling within residential address buffers, ensuring representation of both feature interiors and edges. This approach introduces a more realistic proportion of boundary-affected samples than systematic grid sampling, which tends to underestimate errors near class transitions and may inflate PA and UA values. Therefore, our evaluation is conservative rather than optimistic, especially for classes with complex edges.
The Differentiated Role of SAM: Class Completion and Boundary Refinement
4.3.
The role of the Segment Anything Model (SAM) differed significantly between the two tracks of our workflow. For recent years (2014, 2017), SAM’s primary function was class completion. In conjunction with CDL seeds, it constrained a region-growing algorithm to add the ‘Cropland’ class, which was absent from the HRLC foundation model, thereby producing a clear, well-defined agricultural layer at 1-meter resolution. In contrast, for the back-casting year (2004), SAM played a more critical role in boundary refinement. To counteract the blocky artifacts introduced by the 30 m NLCD change mask, we selectively retained only the SAM objects that intersected with the change mask. By assigning each SAM object the dominant NLCD-derived class within its boundary, we transformed the coarse, pixelated results into a map with smoother, more realistic object boundaries, partially mitigating the 30 m to 1 m scale mismatch. In essence, SAM’s role transitioned from “class completion” in more recent years to “boundary refinement” in earlier years, with both functions serving the overarching goal of inter-annual consistency. Similar object-constrained refinement has been demonstrated in SAM-assisted segmentation of VHR remote sensing imagery, but its differentiated role across temporal tracks has not been discussed in prior studies (Ma et al. 2024).
Class-Level Mechanisms: Cropland Expansion and Statistical Bias in Grassland
4.4
The class-level mechanisms highlight the methodological trade-offs of our workflow. The new Cropland class, introduced via a conservative “CDL seed + SAM boundary” approach, achieved high F1-scores (0.842–0.891) and produced morphologically coherent polygons with crisp boundaries. This strategy, however, induced an explainable fidelity-omission trade-off in the Grassland class. Excluding small (<1 ha) cropland patches to ensure seed purity meant that genuine small cropland parcels were often omitted and subsequently absorbed by the Grassland class. This created a stable pattern, corroborated by the confusion matrices and per-class metrics, where Grassland’s User’s Accuracy was consistently and significantly lower than its Producer’s Accuracy—a tunable statistical bias resulting from a methodological choice, rather than a failure of the classification model itself. This limitation is not inherent to the framework but arises from a conservative threshold selection. In future applications, adaptive seed sizes or object-level probability filtering could be incorporated to retain small cropland patches while minimizing false positives. Thus, the observed bias reflects a controllable design decision rather than an irreversible weakness of the workflow.
Justification for Track 2 and Comparison with AI Domain Adaptation Paradigms
4.5
The algorithm developed in this study, particularly the Track 2 back-casting method, is fundamentally distinct from end-to-end AI domain adaptation (DA) methods. The development of this algorithm was motivated by an initial assessment in which conventional DA paradigms failed to address the extreme temporal and sensor heterogeneity present in the NAIP archive. We evaluated the two primary AI-based DA paradigms, model transfer and image-to-image translation.
For model transfer, this approach was found to be not viable for two reasons. First, it requires manually labeled data from the target domain (e.g., 2004). However, early NAIP imagery exhibits strong inter-county radiometric variability and acquisition inconsistencies, making it impossible to construct a representative training dataset across a large geographic area, such as that in this study. To avoid manual labeling, we attempted to bypass this by fine-tuning with synthetic data (i.e., down sampling 2014 imagery and applying histogram matching to mimic 2004). However, fine-tuned models produced unstable predictions and severe class biases (e.g., F1-score for Water = 0.14), characterized by a massive over-prediction of spectrally ambiguous classes.
Image-to-Image Translation involves translating the target domain (2004) into the source domain (2014) using a model of Cycle GAN which also did not work well. The generated images suffered from significant visual artifacts, failed to reconstruct valid textures, and were unusable for classification. This qualitative failure was confirmed by quantitatively poor results, with high Fréchet Inception Distance (FID) scores (A: 99.86, B: 111.60).
In contrast to these direct AI adaptation approaches, our Track 2 strategically integrates multiple complementary data sources: the temporally consistent NLCD product, high-quality reference year classifications for stable areas, and SAM-derived boundaries. This integration strategy effectively counters the temporal heterogeneity problem by decomposing it into manageable components, achieving balanced historical reconstruction that direct AI methods failed to deliver.
Comparison with Existing Domain-Adaptation Approaches
4.6
Recent cross-domain approaches in high-resolution remote sensing mainly include model transfer or fine-tuning, image-to-image translation, and weakly supervised refinement methods that project low-resolution labels onto high-resolution imagery. However, these paradigms have clear limitations when applied to NAIP’s multi-decade, quality-heterogeneous archive. For example, Previous work (Tong et al. 2020) reported that zero-shot cross-sensor transfer in a 15-class setting yielded overall accuracies as low as 50.12% (JL-1(1)) and up to 80.97% (ZY-3(1)), with pseudo-label fine-tuning only partially recovering performance to 52.86% and 82.50%. This fluctuations reflect the unstable performance when applied on different domains。End-to-end feature-alignment frameworks such as Domain Adaptation for Cross-Spatio-Temporal classification (Luo and Ji 2022b) achieve state-of-the-art performance on multi-scene and multi-platform benchmarks, substantially improving mean Intersection over Union (mIoU) relative to conventional domain adaptation. Nevertheless, their training cost and architectural complexity pose scalability challenges for multi-decade NAIP time series, where heterogeneous imaging conditions—even across counties within early years 。Weakly supervised low resolution to high resolution label-refinement approaches (Tang et al. 2025) improves segmentation quality by 5–15 percentage points by using low-resolution supervision to guide high-resolution learning. Yet, the inherent spatial coarseness of low-resolution labels prevents them from capturing the fine object boundaries and small structures characteristic of 1m NAIP imagery, such as building footprints or small agricultural parcels.
Compared with the approaches above, our back-casting workflow requires no model-side adaptation. Instead, it uses the high-resolution classification map of the reference year as a geometric and semantic anchor, leverages the temporal consistency of NLCD to identify changed areas, and employs SAM-derived object boundaries to eliminate errors caused by scale discrepancies. This procedure preserves 1-m geometric detail while ensuring semantic transferability. The mechanism avoids the information loss inherent in low-resolution supervision and bypasses the dependence of model transfer and image translation methods on target-domain data, enabling stable and production-ready outputs across NAIP’s long-term and quality-heterogeneous archive.
Future Directions
4.7
Future research will focus on extending this dual-track approach to other high-resolution multi-temporal datasets. While NAIP provides comprehensive coverage for the United States, similar approaches could be adapted for European aerial photography programs such as Copernicus VHR, EIM, DOP (Germany), or APGB (UK), which also exhibit temporal inconsistencies and sensor upgrades. Applying our workflow to these diverse datasets would further test its robustness across different acquisition standards and landscape patterns.
Conclusion
This study developed an algorithm that contains a dual-track adaptive workflow to classify the long-term NAIP image collection. The algorithm achieved temporally consistent and spatially detailed 1 m land-cover mapping without retraining or fine-tuning the foundational model. For recent years, the algorithm expands upon the nine-classes HRLC foundation model by incorporating an additional Cropland category; for early years, it completes historical reconstruction through NLCD-based temporal bridging and SAM-guided object-level refinement, generating unified ten-class high-resolution land-cover maps.
Assessment across three representative years across the time series showed that the overall accuracies for 2014 and 2017 were 0.874 and 0.848 (Kappa 0.860 and 0.831), respectively, which is on par with the public baseline. The back-cast result for 2004 achieved a reasonable overall accuracy of 0.788 (Kappa 0.764). Notably, this achievement required no additional training samples for early low-quality imagery, significantly lowering the cost and technical barriers to long-term land cover monitoring. At the class level, key categories such as Structure, Impervious surfaces (including Roads), Wetlands, Barren, and Shrubland performed comparably or better than the baseline, while the newly added Cropland class achieved consistently high accuracy. These results demonstrate that consistent, boundary-preserving, and temporally comparable high-resolution land cover maps can be generated from NAIP image collection even under severe cross-year image quality heterogeneity. The algorithm developed here can be used widely for producing high-resolution land cover maps in other countries with similar data archives.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Bhatt P, Maclean AL (2023) Comparison of high-resolution NAIP and unmanned aerial vehicle (UAV) imagery for natural vegetation communities classification using machine learning approaches. GI Science & Remote Sensing 60:2177448. 10.1080/15481603.2023.2177448 · doi ↗
- 2Canty MJ, Nielsen AA (2008) Automatic radiometric normalization of multitemporal satellite imagery with the iteratively re-weighted MAD transformation. Remote Sensing of Environment 112:1025–1036. 10.1016/j.rse.2007.07.013 · doi ↗
- 3Coleman RW, Stavros N, Yadav V, Parazoo N (2020) A Simplified Framework for High-Resolution Urban Vegetation Classification with Optical Imagery in the Los Angeles Megacity. Remote Sensing 12:2399. 10.3390/rs 12152399 · doi ↗
- 4Dannenberg MP, Song C, Hakkenberg CR (2018) A Long-Term, Consistent Land Cover History of the Southeastern United States. photogramm eng remote sensing 84:559–568. 10.14358/PERS.84.9.559 · doi ↗
- 5Du Y, Teillet PM, Cihlar J (2002) Radiometric normalization of multitemporal high-resolution satellite images with quality control for land cover change detection. Remote Sensing of Environment 82:123–134. 10.1016/S 0034-4257(02)00029-9 · doi ↗
- 6Gray J, Song C (2013) Consistent classification of image time series with automatic adaptive signature generalization. Remote Sensing of Environment 134:333–341. 10.1016/j.rse.2013.03.022 · doi ↗
- 7Hansen MC, Loveland TR (2012) A review of large area monitoring of land cover change using Landsat data. Remote Sensing of Environment 122:66–74. 10.1016/j.rse.2011.08.024 · doi ↗
- 8Hansen MC, Potapov PV, Moore R, (2013) High-Resolution Global Maps of 21st-Century Forest Cover Change. Science 342:850–853. 10.1126/science.124469324233722 · doi ↗ · pubmed ↗