Development and validation of an interpretable machine learning model for predicting the risk of 8-year all-cause mortality in Cardiovascular-Kidney-Metabolic Syndrome among older adults: A multicenter and cohort study
Zhiren Zhu, Jie Zhang, Peirao Wu, Huiping Xue, Dongmei Gu

TL;DR
This study developed a machine learning model to predict 8-year mortality risk in older adults with Cardiovascular-Kidney-Metabolic Syndrome, showing good accuracy and identifying key risk factors.
Contribution
The novel contribution is an interpretable machine learning model validated across Chinese and American populations for long-term mortality prediction in CKM syndrome.
Findings
The Cox model achieved an AUC of 76.7% in internal validation and 76.6% in external validation.
Each CKM stage increase was associated with a 40% higher mortality risk in HRS and 15% in CHARLS.
Age, smoking, and cystatin C were the top predictors of mortality risk.
Abstract
Cardiovascular-kidney-metabolic syndrome (CKM) among elder adults due to age-related physiology is a high burden, but long-term mortality risk prediction is understudied. This study aims to develop and validate an explainable machine learning model to predict 8-year all-cause mortality. This study used HRS (2012–2020) and CHARLS (2011–2020) database, performed data cleaning and multiple imputation, plotted Kaplan–Meier curves with log-rank tests, conducted competing risk analyses, and pooled estimates using Rubin’s rules. Cox regression was used to adjust for confounders. In CHARLS, variables were selected using LASSO (retained if selected ≥ 70%), after sensitivity and collinearity checks. We compared six survival models with 10-fold cross-validation and evaluated performance with AUC, DCA, calibration curves, and the Brier score, with external validation in HRS. SHAP was used to…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
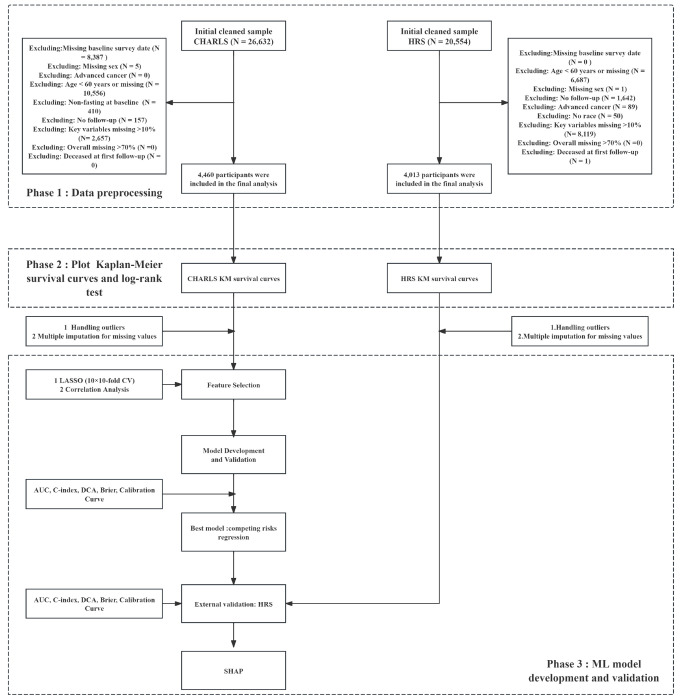 Figure 1
Figure 1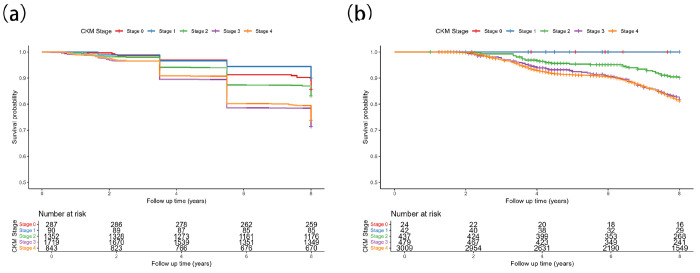 Figure 2
Figure 2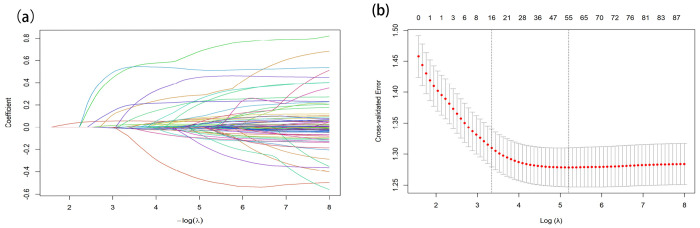 Figure 3
Figure 3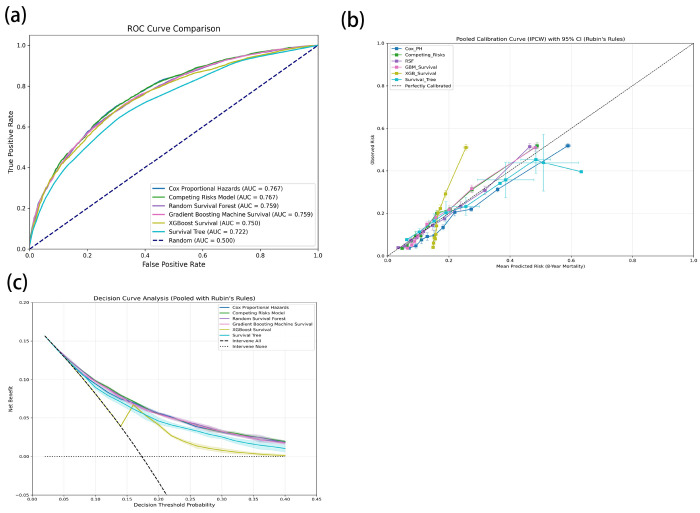 Figure 4
Figure 4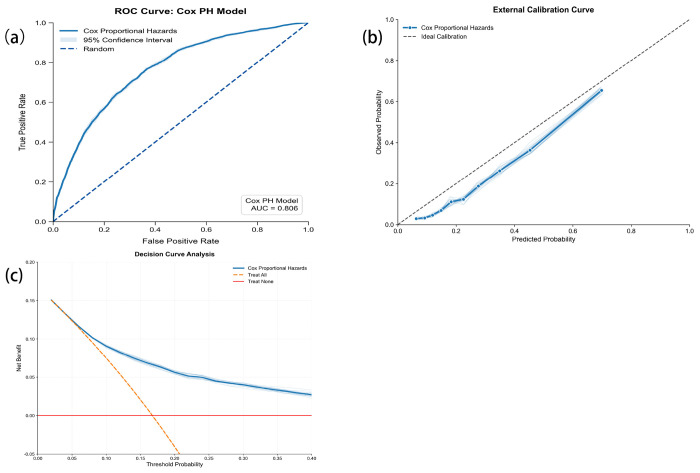 Figure 5
Figure 5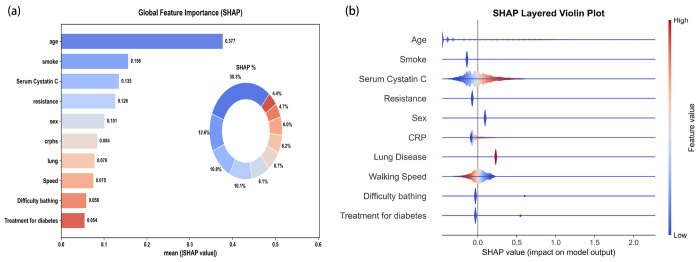 Figure 6
Figure 6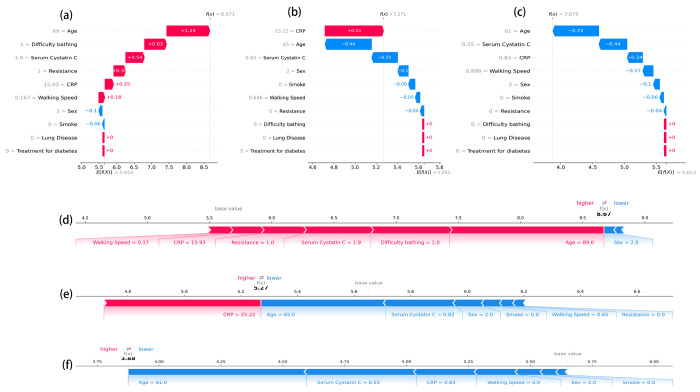 Figure 7
Figure 7- —Affiliated hospital of Nantong University
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsChronic Kidney Disease and Diabetes · Artificial Intelligence in Healthcare · Machine Learning in Healthcare
Introduction
Noncommunicable diseases (NCDs) pose a global public health challenge, causing approximately 41 million deaths annually, accounting for about 74% of all deaths worldwide [1]. Cardiovascular disease (CVD), kidney disease, and metabolic disorders (such as type 2 diabetes) frequently coexist, are pathophysiologically interconnected, and significantly increase mortality risk [2–4]. Recognizing these interactions, the American Heart Association (AHA) Presidential Advisory proposed the Cardiovascular-Kidney-Metabolic (CKM) Syndrome, which stratifies individuals into five progressive stages on the basis of metabolic risk, kidney function, and CVD risk to strengthen multidisciplinary approaches to prevention, risk stratification, and management [5].
Consistent with this framework, the 2021 Global Burden of Disease (GBD) study reports that, among adults aged ≥ 55 years, CVD remained the leading cause of death from noncommunicable diseases from 2017 to 2021, with a consistent upward trend. In 2021, there were 17,348,107 CVD deaths, led by ischemic heart disease and stroke as the top two CVD causes. Mortality from diabetes and chronic kidney disease likewise increased annually, totaling 2,724,913 deaths in 2021 and ranking fourth overall; diabetes and CKD were the fifth and sixth leading individual causes of death, respectively [6]. Poor CKM health is a major determinant of all-cause mortality, posing a significant burden on global public health systems and socio-economics [7].
Although epidemiological studies on CKM syndrome remain limited, existing studies consistently indicate a high population burden with meaningful heterogeneity and prognostic implications. Specifically, analyses based on the U.S. National Health and Nutrition Examination Survey (NHANES) database indicate that CKM syndrome is prevalent among U.S. adults, with its prevalence increasing with age and varying across different genders, racial and ethnic groups [8, 9]. Analyses based on the China Health and Retirement Longitudinal Study (CHARLS) indicate that CKM syndrome is also prevalent among Chinese adults, with prevalence patterns similar to those observed in the United States [10]. In a large prospective cohort study from the UK, 80% of participants were classified as CKM stages 2–4, and CKM stage was positively associated with all-cause mortality, with risk increasing across stages; by stage 4, the all-cause mortality rate reached 30.09%. Using stage 0 as the reference and adjusting for variables, the hazard ratio (HR) for all-cause mortality at stage 4 was 2.13 (95% CI, 1.94–2.34) [11].
Adults ≥ 60 years are more likely to present with advanced CKM stages, and CKM prevalence rises with age [11]. Most studies evaluate mixed-age populations, with insufficient focus on older adults, who bear the highest absolute mortality risk and often have multimorbidity. CKM stages for long-term outcomes such as 8-year all-cause mortality are scarce, and few studies rigorously assess external validity across countries. Critically, current risk stratifications mainly rely on broad staging systems, potentially overlooking complex, non-linear interactions among risk factors in older adults, and few studies have rigorously assessed the external validity of predictive models across different countries.
Machine learning (ML) has recently demonstrated exceptional performance in clinical prognosis and diagnostic prediction due to its powerful ability to handle complex interactions and nonlinear relationships, and it is being increasingly applied in clinical research [12–15]. Addressing the black boxes issue, the introduction of model interpretability technology is crucial. By revealing the decision-making process of algorithms, it enhances model transparency, helping clinicians understand and trust model outputs, thereby accelerating the practical application of artificial intelligence in clinical diagnosis and treatment [16].
To address these gaps, this study aimed to develop and validate an interpretable machine learning (ML) model using longitudinal data from CHARLS and Health and Retirement Study (HRS) to predict the risk of 8-year all-cause mortality among older adults with CKM syndrome and to assess the feasibility of explainable ML models in clinical practice, with the goal of informing clinical decision-making and interventions.
Methods
Study design
This is a multicenter and cohort study. We generated Kaplan–Meier (KM) survival curves for all patients and conducted significance testing. To predict the 8-year mortality risk among patients with CKM syndrome from the diagnostic baseline, we developed and compared six modeling approaches: two regression methods (Cox proportional hazards and competing risks regression) and four machine-learning methods (Random Survival Forests, Survival Gradient Boosting, XGBoost survival, and Survival Decision Tree). To ensure transparent and complete reporting of AI-based prediction model development and evaluation, we adhered to TRIPOD (Transparent Reporting of a multivariate predictive model for Individual Prognosis or Diagnosis) [17].
Sample size calculations
The sample size for this study was determined using the events-per-variable (EPV) methods [18, 19]. According to the UK Biobank data, CKM stages (0-4) exhibited all-cause mortality rates ranging from 6.32% to 30.1% over 14.7 years of follow-up period [11]. The study population comprised CKM patients aged ≥60 years, predominantly in stages 3–4, so the study selected 30.1% as the projected 8-year all-cause mortality rate and planned including 10 candidate predictor variables and sets the EPV to 20. We calculated the required sample size using the following formula:
Considering a 15% non-response rate, we ultimately require 783 participants.
CKM syndrome stages and outcome definitions
CKM syndrome followed the 2023 American Heart Association (AHA) Presidential Advisory was defined from 0 to 4 [5]. Stage 0 (No risk factors): individuals with normal body mass index (BMI) and waist circumference, normal glycemia, blood pressure, and lipids, and no metabolic risk factors (diabetes, hypertension, hypertriglyceridemia), with no evidence of CKD or subclinical/clinical CVD; Stage 1 (Excess or dysfunctional adiposity): population with overweight/obesity, abdominal obesity, or adipose tissue dysfunction, without other metabolic risk factors or CKD; Stage 2 (Metabolic risk factors and CKD): metabolic risk factors or moderate-to high-risk CKD, or both; Stage 3 (Subclinical CVD in CKM): meeting Kidney Disease: Improving Global Outcomes (KDIGO) criteria for very high-risk CKD or with a predicted 10-year CVD risk ≥20%; Stage 4 (Clinical CVD in CKM): clinical CVD among individuals with excess/dysfunctional adiposity, other CKM risk factors, or CKD.
The primary outcome of this study was all-cause mortality from baseline to 8 years. Participants with predetermined mortality risks, such as those with terminal cancer, were excluded at baseline. Deaths were recorded with exact dates; when only vital status was known without a date, the midpoint between adjacent survey waves was imputed. Then we conducted statistical modeling by outcome status, generated KM curves, and developed ML models to predict mortality risk.
Data sources and study population
The study is based on two nationwide longitudinal cohort studies: CHARLS and HRS. CHARLS covers 150 counties in 28 provinces and began in 2011 with over 17,000 enrollees, targeting policy and health issues among Chinese adults aged ≥45 years [20]. All participants completed standardized questionnaires to collect sociodemographic, lifestyle, and health-related data. HRS has followed a nationally representative sample of U.S. adults aged ≥50 years every two years since 1992, including more than 37,000 individuals from roughly 23,000 households; biomarker and genetic measures were added in 2006 [21]. Both cohorts feature rigorous quality control and long-term follow-up, providing a comparable data foundation for cross-national analyses. The CHARLS study has been approved by the Biomedical Ethics Committee of Peking University (approval number: IRB 00001052–11015), and the University of Michigan Institutional Review Board approved the HRS study. All participants provided written informed consent.
The study utilized the HRS (2012) and CHARLS (2011) as baseline. After data cleaning, participants were subsequently included or excluded as follows: Inclusion: (1) Age ≥ 60 years, (2) At least one follow-up record, (3) Key variable missing rate <10% (age, gender, CKM diagnosis: smoking, high-density lipoprotein cholesterol (HDL-C), stroke, waist circumference, heart disease, serum cystatin C, diabetes, hypertension, diabetes treatment, hypertension treatment); Exclusions: (1) Personal data missing rate >70%, (2) Death date prior to baseline survey, (3) Patients with terminal cancer, (4) Patients lacking key variables of gender or age, (5) Non-fasting baseline biochemical status in CHARLS, (6) Missing initial survey date.
Data extraction
We extracted the following variables for each participant: (1) Demographics (age, sex, race, marital status); (2) Chronic conditions (hypertension, diabetes, heart disease, chronic kidney disease, stroke, cancer, etc.); (3) Anthropometrics and physical function (height, weight, waist circumference, grip strength, gait speed); (4) Laboratory measures (HbA1c, creatinine, HDL cholesterol, etc.); (5) Vital signs (blood pressure, heart rate); (6) Scales/scores (Frailty Index, Activities of daily living (ADL)); and (7) Survey data (baseline interview date, date and cause of death).
Handling the missing values
Missing values were handled using multiple imputation implemented with the R package “MICE” creating 20 imputations [22, 23]. Predictive Mean Matching (PMM) was used for continuous variables, logistic regression for binary variables, and multinomial logistic regression for categorical variables with >2 levels [24]. We evaluated convergence with trace plots and assessed imputation quality by comparing densities of imputed and observed data. Estimates from the 20 datasets were combined using Rubin’s rules[25].
Feature selection
In CHARLS, we excluded leakage-prone and non-modeling variables via a prespecified blacklist, then ran LASSO with 10-fold CV, selecting λ by the 1-SE rule across multiple α values. Predictors chosen in ≥70% of imputations were deemed stable. Variable importance was then ranked based on the absolute values of the coefficients pooled via Rubin’s rules. We assessed collinearity via Spearman correlations and Variance Inflation Factor (VIF), removing variables with |r|>0.70 based on univariable information and clinical rationale.
Model development and validation
Using the CHARLS dataset for development, we trained six survival models: the Cox proportional hazards (COX), Competing-risks regression, Random Survival Forest (RSF), Gradient Boosting Machine (GBM Survival), Extreme Gradient Boosting (XGB Survival), and Survival Decision Tree (Survival Tree). Model were trained and tuned using 10-fold cross-validation using rigorous. Performance was assessed using the Area Under the Curve (AUC) and C-index for discrimination, and the Brier score for overall prediction error. The DeLong test was used to compare differences between models. Clinical utility was evaluated using Decision Curve Analysis (DCA). The final model was selected based on a composite criterion of high discrimination, net benefit, and low Brier score.
External validation
We validated the best-performing prediction model identified in CHARLS within each imputed dataset of HRS, obtaining the AUC and DCA metrics for every multiply imputed (MI) dataset. We then pooled these metrics across imputations using Rubin’s rules to generate an average ROC curve and evaluated performance using the DCA curves.
Model explanation
SHapley Additive exPlanations (SHAP) were used to interpret the ML models and quantify the impact of individual features on predictions. The SHAP feature-importance plot displays global importance, where larger mean absolute SHAP values indicate greater contribution of a feature to the model’s predictions. The SHAP summary plot visualizes each feature’s influence on the prediction across observations. By computing each feature’s contribution to the predicted outcome, SHAP provides both local and global explanations, thereby enhancing model transparency and interpretability[26].
Statistical analyses
Continuous variables were first assessed for distribution using the Shapiro-Francia test; normally distributed variables are reported as mean ± SD, and non-normally as median (interquartile range, IQR). Categorical variables are presented as counts and percentages. All analyses were conducted in Stata/MP 18, R (Version 4.5.1), and Python (Jupyter Notebook). Statistical significance was set at P < 0.05 (two-sided).
Results
Baseline characteristics
The study included 8,473 individuals, including 4,460 from the CHARLS cohort and 4,013 from the HRS cohort (Figure 1). The mean age of the entire cohort was 69.9 ± 7.6 years (median: 69, IQR: 63-75), and 46.02% (3,899) were male.
In CHARLS (Table 1), the mean age of the cohort was 68.1 ± 6.7 years (median: 67, IQR: 63-72), and 49.26% were male. The median follow-up was 8.00 (IQR: 8.00-8.00) years, follow-up time was not normally distributed (p < 0.001), and among decedents the median survival was 5.5 (IQR: 3.5-7.3) years. There were striking differences in gender composition by CKM stage: stage 2 was predominantly female (84.6%), whereas stage 3 was predominantly male (81.5%) and had the highest prevalence of smoking (69.4%) and alcohol consumption (43.2%). With advancing CKM stage, blood pressure (systolic and diastolic), glucose, triglycerides, and waist circumference increased progressively, whereas high-density lipoprotein cholesterol (HDL-C) and glomerular filtration rate (eGFR) declined.
In HRS (Table 2), the mean age was 71.9 ± 8.0 years (median: 72, IQR: 65-77), and 57.59% were women, and Asians comprised 6.08%. Participants had a median follow-up of 8.00 (IQR: 5.83–8.00) years. CKM stages were predominantly in stages 3-4. Educational attainment was high (about 88% at high school or above). Smoking and alcohol use prevalences were 11.34% and 36.26%, respectively, though these variables had approximately 40%-46% missingness. The BMI was 28.82 kg/m^2^; waist circumference in both genders was within the range of central obesity. Median SBP/DBP was 134/80 mmHg. Comorbidities were common: hypertension (67.33%), diabetes (25.79%), heart disease (29.70%), stroke (7.63%), and chronic lung disease (11.56%). Median laboratory values were HbA1c 5.76%, HDL-C 52.3 mg/dL, Cystatin C 1.10 mg/L, and CRP 1.64 mg/L. Increasing CKM stage correlated with older age, higher adiposity and BP, greater inflammatory burden, reduced kidney function, accumulation of cardiovascular risk and clinical CVD, and poorer cognitive and functional status.
Kaplan-Meier curves
CHALRS
Figure 2 (a) presents the Kaplan–Meier curves for the first imputation 1. The log-rank test showed statistically significant separation of survival curves across CKM stages (X^2^= 83.6; df = 4; P < 0.001). In the first imputation, crude mortality by CKM stage was 14.3% (stage 0), 10.0% (stage 1), 16.8% (stage 2), 28.6% (stage 3), and 26.2% (stage 4). Pooling results from 20 imputations with Rubin’s rules yielded stage-specific 8-year mortality of 15.69% (SE = 0.0235), 9.92% (SE = 0.0341), 16.76% (SE = 0.0108), 28.51% (SE = 0.0111), and 26.19% (SE = 0.0151) for stages 0-4, consistent with the pattern observed in imputation set 1.
HRS
In imputation 1 (Figure 2 (b)), overall crude mortality was 14.46%. Stage-wise mortality was 0% for stages 0 and 1, 8.5% for stage 2, 14.8% for stage 3, and 15.6% for stage 4, with significant separation of survival curves by the log-rank test (X^2^ = 27.91, df = 4, P < 0.001). After pooling 20 imputations using Rubin’s rules, the 8-year mortality increased with higher CKM stage: 9.20% (SE = 0.0921) for stage 0, 4.94% (SE = 0.0406) for stage 1, 9.14% (SE = 0.0183) for stage 2, 16.57% (SE = 0.0228) for stage 3, and 18.97% (SE = 0.0083) for stage 4.
Screening for predictive factors
LASSO–Cox was fitted separately in each of the 20 multiply imputed CHARLS datasets. 17 features were selected: different bathing, age, BMI, Serum Cystatin C, C-reactive protein (CRP), Mini-Mental State Examination (MMSE), resistance, sex, smoking, date, glucose, lung disease, pulse, diabetes treatment, SBP, self-rated health, and speed. The LASSO results for imputation 1 are shown in Figure 3. Extracting coefficients at the “best λ” for each imputation and pooling them using Rubin’s rules, 14 variables were significantly associated with all-cause mortality (two-sided P < 0.05): difficulty bathing, age, BMI, Cystatin C, CRP, MMSE, resistance, sex, smoking, glucose, lung disease, pulse, diabetes treatment, and SBP. Multicollinearity assessment revealed no substantive collinearity, and no variables were removed (Supplementary Figure 3). Integrating statistical significance, cross-imputation stability, and clinical interpretability, we retained 10 predictors for downstream machine-learning modeling: Cystatin C, different bathing, resistance, smoke, diabetes treatment, Speed, sex, lung disease, age, and CRP.
Machine learning models development and performance comparison
In development ML (Table 4), the AUC analysis indicated that the Cox and competing risks regression models demonstrated the best discriminative ability, with AUC values of 76.65% (95%CI: 76.55%-76.76%) and 76.68% (95%CI: 76.57%-76.78%), respectively (Figure 4 (a)). The performance of the remaining models, in descending order of AUC, was as follows: RSF (75.86%, 95% CI: 75.73%-75.99%), GbM (75.95%, 95% CI: 75.78%-76.12%), XGBoost (74.98%, 95% CI: 74.85%-75.11%), and ST (72.22%, 95% CI: 71.29%-73.15%). In terms of predictive accuracy, the Cox model achieved the lowest Brier score (0.146), indicating the most robust performance. The DeLong test indicates that the differences between the models are not significant. The Brier scores for the competing risks model, RSF, and GbM were comparable (0.152-0.153), while XGBoost and ST exhibited greater prediction error. Calibration curve assessments revealed that the Cox and competing risks models had similar and superior calibration performance compared to the other machine learning methods (Figure 4 (b)). The DCA showed that the CRR model yielded the highest net benefit across a range of threshold probabilities (Figure 4 (c)). Consequently, the Cox model was selected for the final 8-year prediction model in this study.
External validation
In external validation using the HRS cohort (Table 5), the pooled Cox model achieved a C-index of 77.2% (95% CI: 76.8-77.6), an AUC of 76.6% (95% CI: 76.5-77.0), a Brier score of 0.125 (95% CI: 0.123-0.128), AUC (Inverse Probability of Censoring Weighting, IPCW) of 80.6% (95% CI: 80.2-81.1) , Brier score (IPCW) of 0.114 (95%CI: 0.112-0.117), which was similar to that in the internal validation (Figure 5(a)). The calibration curve closely followed the ideal line (Figure 5 (b)). DCA indicated a net clinical benefit for threshold probabilities between 1% and 40%, supporting the model’s potential clinical value (Figure 5 (c)). This successful external validation confirms the model’s generalizability and suggests it is a reliable tool for clinical application.
Model explanation
Figure 6 illustrates the global feature importance analysis based on SHAP values. As shown in Figure 6(a), age was the most critical predictor of 8-year all-cause mortality, possessing the highest mean absolute SHAP value (0.377) and independently contributing approximately 30.3% to the model’s explanatory power. It was followed by Smoking and Cystatin C; together, these three features accounted for over 50% of the model’s total contribution. The SHAP beeswarm plot in Figure 6(b) further reveals the directional impact of these features on risk. Age and Serum Cystatin C showed a clear positive correlation, where higher values correspond to higher SHAP values and increased mortality risk. Conversely, Walking Speed demonstrated a negative correlation, with slower speeds predicting higher mortality risk. Additionally, the presence of CRP and difficulty bathing significantly increased the risk of death.
Figure 7 details individual prediction logic across three representative profiles: Low-Risk Case (Figure 7(c,f)): The waterfall plot shows that a younger age (61 years), normal Serum Cystatin C levels (0.55 mg/L), and low CRP (0.83 mg/L) acted as protective factors (blue bars), substantially reducing the risk score. Medium-Risk Case (Figure 7(b,e)): This patient had a risk score close to the average. Although highly elevated inflammation (CRP = 25.22 mg/L) significantly pushed the risk upward (red bar, +0.55), this was buffered by relatively younger age (65 years) and normal renal function (Cystatin C = 0.82 mg/L), preventing the total risk from becoming excessive. High-Risk Case (Figure 7(a,d)): This patient was classified by the model as extremely high-risk. The waterfall plot clearly visualizes the accumulation of risk factors: advanced age (89 years, +1.24), functional impairment (difficulty bathing, +0.63), impaired renal function (Cystatin C= 1.9 mg/L, +0.54), and slow walking speed (0.167 m/s). These factors combined to drive the predicted score significantly above the baseline.
The risk calculator
We employ Jupyter Notebook for parameter invocation, with the final predictive model integrated into an Excel spreadsheet for clinical risk assessment of patients. By inputting ten current patient values, the spreadsheet automatically predicts the 8-year all-cause mortality risk for CKM patients. The Excel spreadsheet is included in the supplementary materials.
Discussion
This study successfully developed and validated a ML prediction model for estimating 8-year all-cause mortality risk in older adults with CKM syndrome, utilizing two large, distinct cohorts from CHARLS and HRS. While we evaluated multiple advanced algorithms, the Cox proportional hazards model was selected as the final predictive tool due to its superior balance of performance, parsimony, and interpretability. The model demonstrated excellent internal and external validation performance. SHAP interpretation identified age, smoking status, cystatin C, and gait speed as key risk drivers, underscoring the model’s clinical utility and robustness across diverse populations.
The cohorts exhibited notable demographic and clinical differences: HRS population was older, had a higher level of education, and exhibited a greater burden of chronic conditions, the CHARLS was somewhat younger but had a higher proportion of smokers and lower educational attainment. The distribution of CKM stages further illuminated population-specific patterns. The concentration in stages 2–4 within HRS, and the gender difference, mirrors findings from US-based studies [8, 9]. The predominance of stage 3 in the elderly CHARLS cohort, while differing from some broader summaries [10, 27], is corroborated by data focused on older adults and aligns with Chen et al.’s report of advanced staging in this age group [11].
Despite these disparities, both cohorts demonstrated a consistent graded trend: higher CKM stages were associated with greater mortality risk, supporting the generalizability of the AHA-proposed CKM staging system across diverse populations [5]. It is noteworthy that although the median age in the CHARLS was lower than in HRS, the overall mortality rate was higher. This discrepancy may be partly explained by the lower education levels and higher smoking rates within the CHARLS cohort [28, 29]. Consequently, these findings underscore a potential need for healthcare providers in China to prioritize the earlier identification and intervention of high-risk CKM populations compared to practices in the United States.
Feature selection plays a critical role in the development of machine learning model [30]. Our comparative analysis, leveraging 20 imputations and 10-fold cross-validation, revealed that the Cox and competing risks regression models offered marginally better discrimination than several machine learning alternatives. The Cox model was prioritized as the final tool, because it achieved the best performance, such as C-index, AUC and Brier Score and demonstrated the highest net benefit across a broad range of threshold probabilities (1%–40%) in DCA. External validation in the HRS cohort further affirmed the model’s robustness and transferability. These findings suggest that in real-world clinical scenarios—often characterized by limited variables and competing risks—a structurally simpler, interpretable model like the Cox regression is often superior to “black-box” algorithms for long-term survival prediction.
SHAP analysis provided a quantitative assessment of both feature importance and the direction of their effects. In this study, age emerged as the strongest and most consistent non-modifiable risk factor, aligning with its role in the majority of chronic conditions [31]. In this study, smoking refers to having a history of smoking and being a current smoker. Smoking, a major modifiable risk factor, demonstrated a significant impact, which is consistent with its well-established, profound effects on cardiovascular, renal, and metabolic diseases, and its role in exacerbating conditions like hypertension and diabetes that further impair renal function [32, 33].
Cystatin C ranked as a top predictor of intervention in our model. Current study con^rms that elevated Cystatin C is significantly associated with an increased risk of cardiovascular diseases, even after adjusting for traditional risk factors [34, 35]. It is implicated in vascular wall remodeling, inflammation, and atherosclerosis by inhibiting cysteine proteases, leading to extracellular matrix degradation, plaque instability, and thrombosis [35–37]. Furthermore, Cystatin C is recognized as an independent risk factor for CKD progression and a predictor of renal function decline and mortality [38], and it has significant associations with metabolic diseases [39], solidifying its role as a central biomarker in the CKM spectrum. SHAP importance scores directly demonstrate the importance of Cystatin C in the prediction. The force plots visually demonstrate how protective factors (e.g., younger age, good functional status) can offset high-risk features (e.g., smoke, elevated Cystatin C) in individual patients. This makes SHAP a valuable tool for visualizing risk and facilitating shared decision-making in clinical practice.
Gait speed represents a modifiable functional indicator. Walking has been demonstrated to reduce the risk or severity of a range of health outcomes, including all-cause mortality, cardiovascular and cerebrovascular diseases and type 2 diabetes [40–44]. The relationship with mortality is non-linear, even a modest increase (e.g., from 0.6 to 0.7 m/s) can reduce risk by 10% [45]. Consequently, our results strongly support the implementation of targeted physical function exercises for patients. We posit that interventions designed to improve gait speed can initiate a positive feedback loop, whereby enhanced mobility leads to broader functional gains, thereby creating a virtuous cycle that mitigates the 8-year all-cause mortality risk [46].
The stable net benefit of our model, as demonstrated by DCA across a wide threshold range (1%-40%), validates its application for risk stratification in clinical practice. This supports a stratified intervention approach: younger seniors with risk driven by Cystatin C and smoking require aggressive management of these modifiable factors, whereas those with functional decline, indicated by slow gait speed, should be referred for prompt physical therapy and rehabilitation. Crucially, successful implementation demands that these strategies be tailored to local demographics and risk factor profiles—such as educational attainment and smoking rates—to ensure they are contextually relevant and thus more likely to succeed.
This work provides a novel, dually-validated, and interpretable prediction model for 8-year mortality in CKM, derived from major international cohorts. The research strengths include a focus on readily obtainable variables, methodological rigor through multiple imputation, the appropriate application of a competing risks model that showed strong transportability, and the integration of SHAP values for individual-level interpretation.
While this study has limitations, the absence of data on Peripheral Artery Disease (PAD) and key cardiac biomarkers represents an important omission. Direct comparison between cohorts is complicated by the use of different assays for estimating renal function (creatinine in CHARLS vs. cystatin C in HRS). Estimates for CKM stages 0–1 were unstable due to their low prevalence and few events in HRS. The historical nature of the data (2011–2012) may limit contemporary relevance, and the observational design cannot preclude residual confounding. Prospective studies are needed to confirm the model’s applicability across diverse age ranges, healthcare settings, and ethnicities. Future studies should also investigate interventions tailored to the specific characteristics of different populations.
Future research should include multi-center, prospective studies to validate the model’s clinical utility. Integrating a broader panel of cardiorenal biomarkers and vascular phenotypes (e.g., PAD), alongside multi-modal data from imaging and wearable devices, could improve early-stage detection and risk stratification. Finally, in-depth investigations into interventions tailored to specific population groups are critically needed.
Conclusion
This study developed and validated the Cox model that robustly identifies the graded mortality risk associated with CKM staging across international cohorts, confirmed by its discrimination, calibration, and clinical utility. The model identifies age, smoking, and cystatin C as pivotal risk drivers, and gait speed and functional status as critical indicators. Ultimately, this study provides a practical, easy-to-use tool for personalized risk assessment, facilitating more precise clinical decision-making for CKM management in aging populations globally.
Supplementary Material
This is a list of supplementary files associated with this preprint. Click to download.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Organization WH. Noncommunicable diseases. 23 December 2024. https://www.who.int/news-room/fact-sheets/detail/noncommunicable-diseases.
- 2Ostrominski JW, Arnold SV, Butler J, Fonarow GC, Hirsch JS, Palli SR, Donato B, Parrinello CM, O’Connell T, Collins EB, Prevalence and Overlap of Cardiac, Renal, and Metabolic Conditions in US Adults, 1999-2020. JAMA Cardiol. 2023;8(11):1050–60.37755728 10.1001/jamacardio.2023.3241 PMC 10535010 · doi ↗ · pubmed ↗
- 3Fitzmaurice C, Abate D, Abbasi N, Abbastabar H, Abd-Allah F, Abdel-Rahman O, Abdelalim A, Abdoli A, Abdollahpour I, Abdulle A, Global, Regional, and National Cancer Incidence, Mortality, Years of Life Lost, Years Lived With Disability, and Disability-Adjusted Life-Years for 29 Cancer Groups, 1990 to 2017: A Systematic Analysis for the Global Burden of Disease Study. JAMA ONCOL. 2019;5(12):1749–68.31560378 10.1001/jamaoncol.2019.2996 PMC 6777271 · doi ↗ · pubmed ↗
- 4Sebastian SA, Padda I, Johal G. Cardiovascular-Kidney-Metabolic (CKM) syndrome: A state-of-the-art review. Curr Probl Cardiol. 2024;49(2):102344.38103820 10.1016/j.cpcardiol.2023.102344 · doi ↗ · pubmed ↗
- 5Ndumele CE, Rangaswami J, Chow SL, Neeland IJ, Tuttle KR, Khan SS, Coresh J, Mathew RO, Baker-Smith CM, Carnethon MR, Cardiovascular-Kidney-Metabolic Health: A Presidential Advisory From the American Heart Association. Circulation. 2023;148(20):1606–35.37807924 10.1161/CIR.0000000000001184 · doi ↗ · pubmed ↗
- 6GBD Results. Institute for Health Metrics and Evaluation. https://vizhub.healthdata.org/gbd-results.
- 7Ndumele CE, Neeland IJ, Tuttle KR, Chow SL, Mathew RO, Khan SS, Coresh J, Baker-Smith CM, Carnethon MR, Després J, A Synopsis of the Evidence for the Science and Clinical Management of Cardiovascular-Kidney-Metabolic (CKM) Syndrome: A Scientific Statement From the American Heart Association. Circulation. 2023;148(20):1636–64.37807920 10.1161/CIR.0000000000001186 · doi ↗ · pubmed ↗
- 8Minhas A, Mathew RO, Sperling LS, Nambi V, Virani SS, Navaneethan SD, Shapiro MD, Abramov D. Prevalence of the Cardiovascular-Kidney-Metabolic Syndrome in the United States. J Am Coll Cardiol. 2024;83(18):1824–6.38583160 10.1016/j.jacc.2024.03.368 · doi ↗ · pubmed ↗