Data profile: cancer sample cohorts (stomach, breast, colorectal, and liver) in Korea
Daewoo Pak, Suk Yong Jang, Jin-Ha Yoon, Dong Wook Kim, Jin-Won Noh, Dong-Woo Choi, Minyeong Guk, Hyeri Kim, Ju-Won Oh, Heejung Chae, Hyun-Joo Kong, Gi Hyun Kim, Ji Woong Nam, Ga Ram Lee, Dayun Park, Jehoo Jeon, Byungyoon Yun, Ki-Bong Yoo, Kui Son Choi

TL;DR
This paper introduces a new Korean cancer sample cohort dataset from four cancer types, combining multiple public health data sources for research.
Contribution
The paper presents a new nationally representative sample cohort dataset for four cancers in Korea, integrating diverse public health data sources.
Findings
The dataset includes approximately 21% of all cancer patients in Korea from 2012 to 2019.
It covers stomach, breast, colorectal, and liver cancers with 51,951 to 39,586 patients per cohort.
The data includes demographics, health utilization, cancer screening, and mortality information.
Abstract
Cancer Public Library Database (CPLD) links data from four major population-based public sources: the Korea National Cancer Incidence Database in the Korea Central Cancer Registry, cause-of-death data in Statistics Korea, the National Health Information Database in the National Health Insurance Service, and the National Health Insurance Research Database in the Health Insurance Review & Assessment Service. The National Cancer Data Center has developed a new nationally representative sample cohort dataset from Korean Clinical Data Utilization for Research Excellence project (K-CURE) CPLD: Stomach Cancer Sample Cohort, Breast Cancer Sample Cohort, Colorectal Cancer Sample Cohort, and Liver Cancer Sample Cohort. The sample populations consisted of approximately 21% of all cancer patients from 2012 to 2019. The populations of the Stomach Cancer Sample Cohort, Breast Cancer Sample Cohort,…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
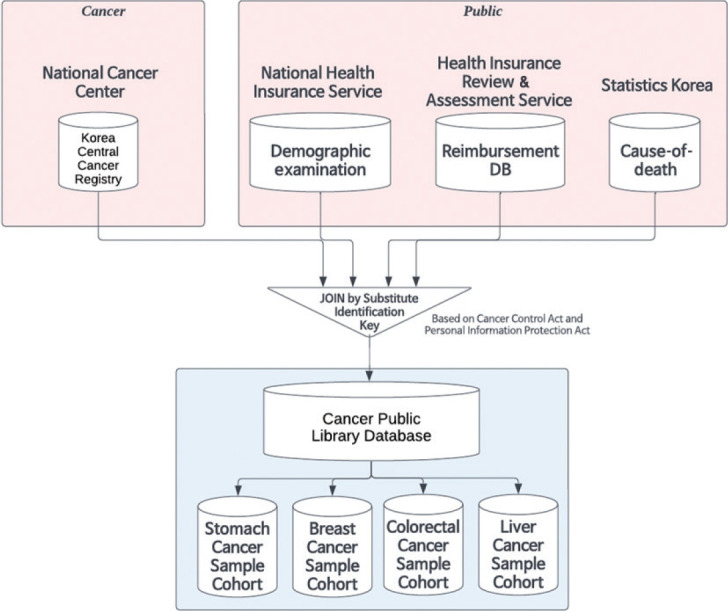 Figure 1
Figure 1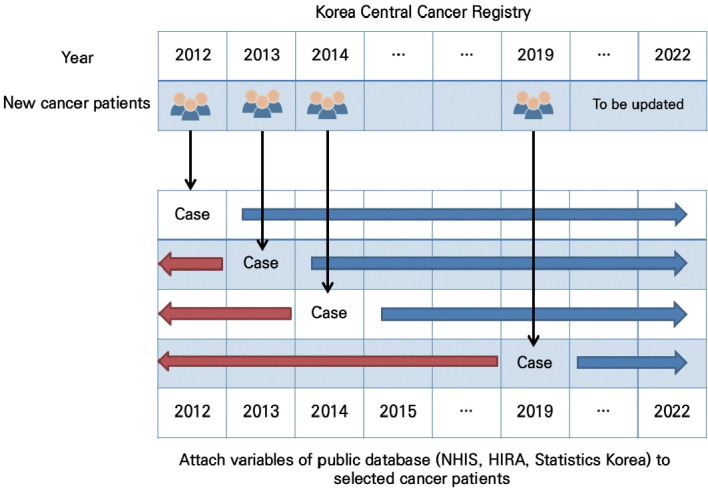 Figure 2
Figure 2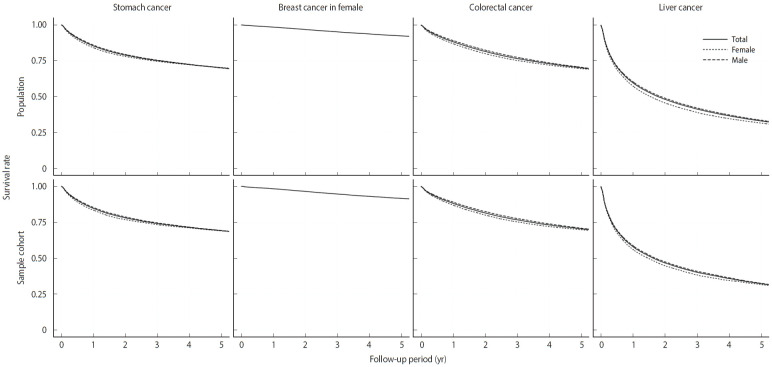 Figure 3
Figure 3Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsNutrition and Health in Aging · Nutrition, Health and Food Behavior
INTRODUCTION
The need for samples and customized databases is emerging in Korea with the increasing demand for public health big data [1-3]. The frequently used national health insurance big data includes the entire population, making it an excellent data source for representativeness and sample size [4]. In Korea, this data source comprises three institutions: the Health Insurance Review & Assessment Service (HIRA), the National Health Insurance Service (NHIS), and Statistics Korea. HIRA encompasses health utilization, including expenditures, length of stay, encounter types, procedure codes, diagnosis information, and medications. NHIS manages insurance eligibility and health examination data, while Statistics Korea comprises cause-of-death data.
The HIRA and NHIS have released various sample cohort data [4-8]. However, these datasets include health utilization information based on only claims data. They lack detailed clinical information and laboratory tests and have limitations regarding coding accuracy [9]. Additionally, these data sources cannot identify the cancer stage and detailed topography. In contrast, the Korea Central Cancer Registry (KCCR) managed by the National Cancer Center (NCC) consists of staging and detailed clinical information on cancer, offering reliable data accuracy [10]. However, it lacks data on the socioeconomic status and healthcare utilization in patients with cancer [11-13].
Consequently, combining these databases can complement their strengths and weaknesses. The National Cancer Data Center (NCDC) of the NCC developed a novel database called the Cancer Public Library Database (CPLD) under the Korean Clinical Data Utilization for Research Excellence project (K-CURE) [14]. The NCDC began providing CPLD data for research purposes on demand in 2023. The customized data based on demand can satisfy various research topics; however, its use is restricted due to de-identification issues and security concerns. Therefore, researchers are required to visit designated offline research centers to access the data. To address this inconvenience, the NCDC has developed and opened sample cohorts for stomach, breast, colorectal, and liver cancers to promote cancer research with a simple and fast administration process and a remotely accessible environment.
DATA RESOURCE AND POPULATION COVERAGE OF THE CANCER SAMPLE COHORTS
All cancer sample cohorts were derived from the CPLD, which links data from the KCCR, HIRA health insurance claim data, NHIS insurance eligibility and examination data, and cause-of-death data of Statistics Korea (Figure 1). As a cancer registry data, KCCR has included all patients diagnosed with cancer or treated in hospitals since 1999 [15]. To merge data from multiple institutes, linkage tables for the Substitute Identification Key were generated for internal integration and de-identification across the four institutions. The Substitute Identification Key is a series of values assigned by the data-providing institutions to uniquely identify individuals. Per the Personal Information Protection Act and the Cancer Control Act [16], the data-providing institutions share de-identified personal information after anonymization upon requesting data from the NCDC.
We identified the target population to construct nationally representative cohorts as follows. Among patients with stomach cancer, breast cancer, colorectal cancer, and liver cancer in KCCR data, we excluded secondary cancers and missing data for the age, sex, region, year of diagnosis, cancer type, and cancer stage. To protect privacy, if there were fewer than five individuals within a strata defined by cancer diagnosis year, sex, age at diagnosis, region (metropolitan, city, or rural), cancer type, or cancer stage, such strata were excluded from the population. The target population of patients with breast cancer exclusively comprised females. So the target population of all cancer patients registered between 2012 and 2019 included 248,103 patients with stomach cancer, 192,907 with breast cancer, 261,291 with colorectal cancer, and 124,324 with liver cancer.
Stratified random sampling with proportional allocation was used to construct a representative sample cohort for each cancer type from the target population using. Sampling is conducted to extract newly registered patients with cancer every year. The population units were partitioned into strata defined by the year of diagnosis, sex, age at diagnosis, region, and Surveillance, Epidemiology, and End Results (SEER) summary stage (in situ, localized, regional, distant, and unknown). Additionally, a probability sample of units was selected from each stratum, while ensuring the representativeness of the total annual medical costs within the stratum. Owing to the small strata for patients aged <39 years or >80 years diagnosed with cancer, the age at diagnosis for stratification was recategorized into six groups as follows: <39 years, 10-year intervals between 40 years and 79 years, and ≥80 years. The region was categorized into 17 groups, namely, Seoul, Busan, Daegu, Incheon, Gwangju, Daejeon, Ulsan, Sejong, Gyeonggi, Gangwon, Chungbuk, Chungnam, Jeonbuk, Jeonnam, Gyeongbuk, Gyeongnam, and Jeju, for sampling stratification. However, it was recategorized into three groups: metropolitan, city, and rural, for public sample data because of de-identification. We constructed 3,117 strata for breast cancer, 6,021 for stomach cancer, 5,218 for liver cancer, and 6,296 for colorectal cancer.
In each stratum, samples were drawn at a sampling rate of 20%, much larger than the theoretically derived sizes required to achieve a 1% margin of error for the mean of total annual medical expenses. Due to de-identification, the sampling rates were limited to approximately 20%. Their representativeness was assessed by determining whether the population averages of the stratum fell within a 95% confidence interval (CI) for sampling without replacement, which is defined as
where, for the h-th stratum, is the sample mean, N_h_ and n_h_ are the population and sample sizes, respectively, and σ_h_ is the known population standard deviation. If the representativeness was not achieved for a stratum, independent random sampling was conducted up to 50 times to generate candidate sets of samples for the stratum. Among those ensuring representativeness, the samples with the mean closest to the population mean of the stratum were selected as the final samples. If the initial sample size was insufficient to achieve representativeness, we incrementally increased the sample size for the stratum and repeated the process until the representativeness was attained.
Finally, the samples of the stomach, breast, colorectal, and liver cancer sample cohorts comprised 51,951 (20.9%), 39,586 (20.5%), 53,485 (20.5%), and 27,375 (22.0%) patients, respectively (Table 1). The age-specific distribution of cancer incidence varied across cancer types. Among patients aged 60 years or older, the proportions were 65.2% for stomach cancer, 25.0% for breast cancer, 66.2% for colorectal cancer, and 61.8% for liver cancer, and these age-related incidence patterns were well represented in the sample cohorts. Note that the incidence of stomach, colorectal, and liver cancers increases with age due to the cumulative effects of carcinogenic exposures and biological aging [17], while breast cancer accounts for a lower proportion in older age groups because it more commonly occurs in their 40s and 50s in Asian populations, including Korea [18]. All cancers, except breast cancer, for which the population consisted only of female, showed a higher incidence in male than in female, with male-to-female rate ratios of 2.1 for stomach cancer, 1.5 for colorectal cancer, and 3.0 for liver cancer with corresponding values of 2.0, 1.5, and 2.6 in the sample cohorts, respectively. There were no substantial differences in the distribution of cancer incidence by year of diagnosis across all cancer types during the study period. The variables from the public database were attached to selected patients from 2012 to 2021 (Figure 2). The NCC plans to update the cancer clinical library sample database annually.
The representativeness of the follow-up years cannot be guaranteed; nonetheless, a sufficient sample size for the initial cohort could help ensure representativeness. We assessed and confirmed the representativeness of all strata by examining whether the 95% CI for sampling without replacement consisted of the average total annual medical expenses and statistical power. Table 2 summarizes the frequencies and medical costs by cancer type and age group. Other stratification variables were omitted in Table 2. The medical costs in sample cohorts by cancer type and age group accounted for the medical costs of the population. Furthermore, it shows a clear trend of increasing medical costs with advancing age across most cancer types, particularly for stomach and colorectal cancers. Liver cancer exhibited the highest average medical costs across all age groups, while stomach cancer showed relatively lower medical costs compared to other cancer types. Breast cancer had the highest costs on average in the 50-69 age groups. The similarity in average medical costs between the sample cohorts and the population dataset further demonstrates the representativeness of the sample cohorts. These patterns highlight the age-related economic burden of cancer care and underscore the potential utility of this dataset for studies on healthcare resource allocation.
In Figure 3, Kaplan–Meier survival curves for patients in both the population and sample cohorts are depicted by sex for each cancer type. Both the population and sample cohorts showed similar survival curves. In each stratum, we further evaluated whether the samples adequately represented the survival distribution of the population using a one-sample log-rank test. This test is commonly used to compare the survival curve of a sample with that of a defined reference population [19]. The proportion of strata where the test did not reject the null hypothesis—that the survival of the sample population is the same as that of the corresponding population—at a significance level of 0.05 was 91.1% for stomach cancer, 97.9% for breast cancer in females, 92.7% for colorectal cancer, and 93.8% for liver cancer.
The follow-up times for each cancer type were consistent between the population and the sample cohorts. The median follow-up times for the population (the sample cohort) were 3.5 (3.6) years for breast cancer, 4.0 (4.0) years for colorectal cancer, 4.3 (4.3) years for liver cancer, and 4.1 (4.1) years for stomach cancer. Furthermore, the maximum follow-up times for the population (the sample cohort) were 8.9 (8.8) years for breast cancer, 9.0 (8.9) years for colorectal cancer, 9.0 (8.8) years for liver cancer, and 8.9 (8.7) years for stomach cancer, while the minimum follow-up time was 0 years across all cancer types. We further examined the median follow-up times by age at diagnosis. For cases diagnosed in 2012, the median follow-up time was approximately 7.5 years across all cancer types in both the population and the sample cohorts. In contrast, for cases diagnosed in 2019, the median follow-up times were approximately 0.5 years for breast and stomach cancers, 0.6 years for colorectal cancer, and 0.7 years for liver cancer, with consistent patterns observed in both the population and the sample cohorts.
MEASURES
Almost the same database was used for all cohorts (Table 3). The information was as follows: KCCR data and cancer screening records (stomach, breast, colorectal, and liver cancers) from the KCCR from 2012 to 2019; health insurance claim data, such as health utilization data, diagnosis records, and prescription details from HIRA from 2012 to 2022; insurance eligibility data and general health checkups from NHIS from 2012 to 2022; and cause-of-death data from Statistics Korea from 2012 to 2021.
Stomach cancer screening included results of an esophagogastroduodenoscopy. Breast cancer screening included results of mammography and tissue biopsy. Liver cancer screening included abdominal ultrasonography and serum alpha-fetoprotein test; colorectal cancer screening included fecal occult blood test for the first test, and colonoscopy (biopsy) or double contrast barium enema for the second test. The K-CURE portal (https://k-cure.mohw.go.kr/) contains all information on the variables [14,20].
In summary, the sample cohort included detailed information on cancer incidence. Additionally, it included demographic and socioeconomic variables, health utilization data (including procedures, diagnoses, and medications), general health checkup data before and after cancer incidence, and death and cancer screening data. More variables in CPLD were present, but those related to administrative purposes were excluded from the sample cohorts.
Ethics statement
This sampling process was exempt from the Institutional Review Board of Yonsei University Mirae.
DATA RESOURCE USE
Several studies on machine learning research take a long time to analyze because the sample data is accessible remotely 24 hours a day. In Kang et al. [21]’s paper, a machine learning model was proposed to predict survival of young breast cancer patients. Cancer type was breast cancer defined as International Classification of Diseases, 10th revision (ICD-10) C500-C506, C508, and C509 and primary endpoint was all-cause mortality within 5 years of diagnosis. They concluded random survival forest, gradient boosting survival analysis, extra survival trees, and penalized Cox probability hazard lasso using Tensorflow version 1.15.5 and Python version 3.7.5. The highest area under the curve (AUC) were 0.87 in young patients and 0.83 in elderly patients by the extra survival trees model.
Kang et al. [22] published a study on mortality and gastric cancer. This research used various machine learning including extensions of gradient boosting machine models and random forests. Gastric cancer was defined as C16 in ICD-10 and the outcomes were the all-cause mortality and disease-specific (gastric cancer) mortality. The highest AUCs were 0.795 for all-cause mortality using the gradient boosting machine and 0.867 for disease-specific mortality using the light gradient boosting machine. This study used R version 3.8.1 (R Foundation for Statistical Computing, Vienna, Austria), Python version 3.8.10, Optuna version 3.3.0.
These two recent studies [21,22] demonstrate that researchers can conduct diverse prognostic analyses on cancer incidence cases by leveraging detailed cancer-related data and advanced analytical environments. While the NHIS National Sample Cohort [6] poses challenges for implementing machine learning methods due to computational limitations, NCDC facilitates such analyses by providing a Python-compatible environment through a remote virtual machine. It is expected to run not only prediction models, but also various causal inference models to find out the relationship between treatment, demographic or lab test variables and subsequent diseases or mortality.
STRENGTHS AND WEAKNESSES
Compared to Korean health insurance claims [9,23], the sample cohorts are specialized for cancer research. These datasets have detailed information on cancer and its screening [24,25]. Additionally, a sample representing approximately 21% of the data was selected to ensure representativeness. As the data are longitudinal, researchers can track all medical utilization and prognosis before and after cancer onset, as well as analyze the time-to-event for mortality, treatment outcomes, comorbidity conditions after cancer diagnosis, and risk factors of cancer incidence. In Korea, all medical services can be tracked through health insurance claim data because of a single national health insurance system. Moreover, as the sample cohorts are pre-established, the data usage application process is simplified, allowing researchers to access and analyze the data remotely.
This study has few limitations. The database does not include the general population without cancer as a control group; however, it will be updated in the future. Although approximately 20% of the sample satisfied the statistical representativeness, the absolute sample sizes were small. As the sample cohorts allow remote access, the higher the sampling percentage, the greater the possibility of personal identification. Hence, the number of samples cannot be increased to maintain security. However, compared to that in the existing cancer-related cohort data [26], the number of participants in our cancer sample cohorts is not small [27-29]. Therefore, our cancer sample cohorts are suitable for conducting general cancer research. The sample size might limit data analysis when considering secondary cancers, detailed comorbidities, or rare populations. In such cases, researchers can use customized data from CPLD. Data on uninsured treatments and medications, cosmetic procedures, laboratory tests, clinical information, and the use of over-the-counter medications were excluded.
The concept of the CPLD is similar to that of the National Cancer Institute’s SEER-Medicare–linked database [30]. Compared to the SEER-Medicare cohort, our cohorts lacked hospital information and a patient assessment variable; however, they included not only patients aged >65 years, but also younger patients because of the single-payer system. Korea has only one national health insurance system, which enables comprehensive tracking of each patient’s diagnosis, procedures, and examination history. Consequently, our cohort covered all age groups and health utilization before and after cancer diagnosis [31]. Therefore, our data are representative of the entire population.
In conclusion, the Stomach Cancer Sample Cohort, Breast Cancer Sample Cohort, Colorectal Cancer Sample Cohort, and Liver Cancer Sample Cohort are powerful data sources, providing information on health utilization, demographics, socioeconomic status, detailed cancer information, health checkups, and cancer screening results before and after cancer incidence. These cohorts will facilitate evidence for cancer prevention, diagnosis, treatment, and management. The K-CURE project plans to continuously open sample cohorts for different types of cancer. In 2025, it plans to open sample cohorts for lung and pancreatic cancer, followed by sample cohorts for kidney, cervical, and blood cancers in 2026.
DATA ACCESSIBILITY
The data can be accessed through the K-CURE portal (https://k-cure.mohw.go.kr/). A person must register on the portal and apply for access to the Cancer Sample Cohorts through the “Application for the Data” menu. Researchers must complete the application forms, research proposals, and institutional review board approval documents. Applications are reviewed by the Review Committee of the NCDC. Subsequently, the data and receipts are provided to the applicant at a fee. Sample cohorts can be accessed remotely through a virtual computer environment. Downloading data offline is impossible.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Kim JA Yoon S Kim LY Kim DS Towards actualizing the value potential of Korea Health Insurance Review and Assessment (HIRA) data as a resource for health research: strengths, limitations, applications, and strategies for optimal use of HIRA data J Korean Med Sci 20173271872810.3346/jkms.2017.32.5.71828378543 PMC 5383602 · doi ↗ · pubmed ↗
- 2National Health Insurance Service. Introduction [cited 2024 Feb 4]. Available from: https://nhiss.nhis.or.kr/en/a/a/001/lpaa 001m 01en.do
- 3Health Insurance Review & Assessment. (HIRA). HIRA bigdata open portal [cited 2024 Feb 4]. Available from: https://opendata.hira.or.kr/op/opb/select Helh Med Data View.do (Korean)
- 4Park JS Lee CH Clinical study using healthcare claims database J Rheum Dis 20212811912510.4078/jrd.2021.28.3.11937475998 PMC 10324900 · doi ↗ · pubmed ↗
- 5Kim JH Lee JE Shim SM Ha EK Yon DK Kim OH Cohort profile: national investigation of birth cohort in Korea study 2008 (NIC Ks-2008)Clin Exp Pediatr 20216448048810.3345/cep.2020.0128433445832 PMC 8426098 · doi ↗ · pubmed ↗
- 6Lee J Lee JS Park SH Shin SA Kim K Cohort profile: the National Health Insurance Service-National Sample Cohort (NHIS-NSC), South Korea Int J Epidemiol 201746 e 1510.1093/ije/dyv 31926822938 · doi ↗ · pubmed ↗
- 7Seong SC Kim YY Park SK Khang YH Kim HC Park JH Cohort profile: the National Health Insurance Service-National Health Screening Cohort (NHIS-HEALS) in Korea BMJ Open 20177 e 01664010.1136/bmjopen-2017-016640 PMC 562353828947447 · doi ↗ · pubmed ↗
- 8Kim YI Kim YY Yoon JL Won CW Ha S Cho KD Cohort profile: National Health Insurance Service-senior (NHIS-senior) cohort in Korea BMJ Open 20199 e 02434410.1136/bmjopen-2018-024344 PMC 661581031289051 · doi ↗ · pubmed ↗