Artificial intelligence as a surrogate brain: bridging neural dynamical models and data
Yinuo Zhang, Demao Liu, Zhichao Liang, Jiani Cheng, Kexin Lou, Jinqiao Duan, Ting Gao, Bin Hu, Quanying Liu

TL;DR
This paper explores how artificial intelligence can simulate brain dynamics, offering a new way to study and predict complex neural systems.
Contribution
The paper introduces a unified framework for AI-based surrogate brains that integrates modeling, prediction, and evaluation of brain dynamics.
Findings
AI-based surrogate brains can accurately predict future whole-brain dynamics using historical data.
The framework enables simulation, analysis, and control of brain dynamics with high adaptability and non-linearity.
Surrogate brains serve as a bridge between theoretical neuroscience and translational neuroengineering.
Abstract
Recent breakthroughs in artificial intelligence (AI) are reshaping the way we construct computational counterparts of the brain, giving rise to a new class of ‘surrogate brains’. In contrast to conventional hypothesis-driven biophysical models, the AI-based surrogate brain encompasses a broad spectrum of data-driven approaches to solve the inverse problem, with the primary objective of accurately predicting future whole-brain dynamics with historical data. Here, we introduce a unified framework of constructing an AI-based surrogate brain that integrates forward modeling, inverse problem solving and model evaluation. Leveraging the expressive power of AI models and large-scale brain data, surrogate brains open a new window for decoding neural systems and forecasting complex dynamics with high dimensionality, non-linearity and adaptability. We highlight that the learned surrogate brain…
Click any figure to enlarge with its caption.
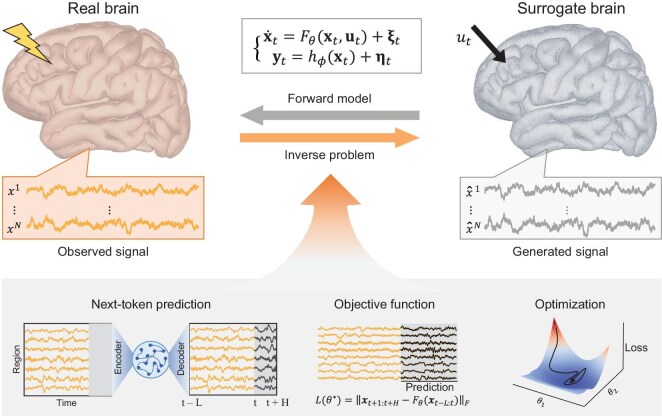 Figure 1
Figure 1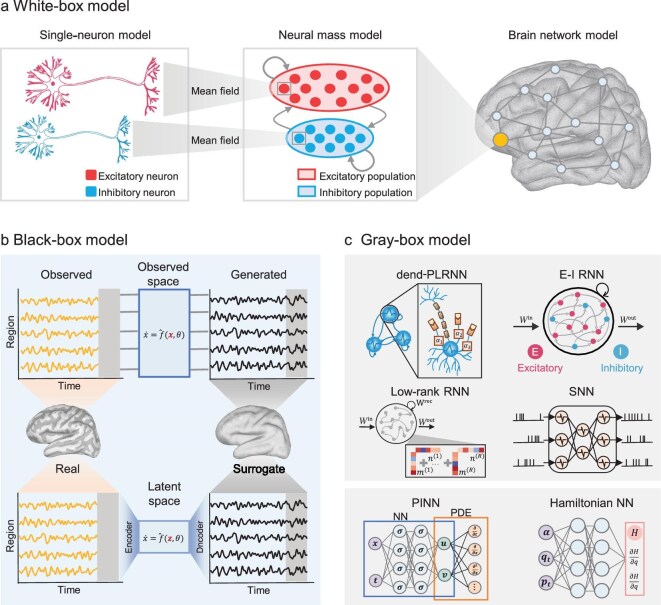 Figure 2
Figure 2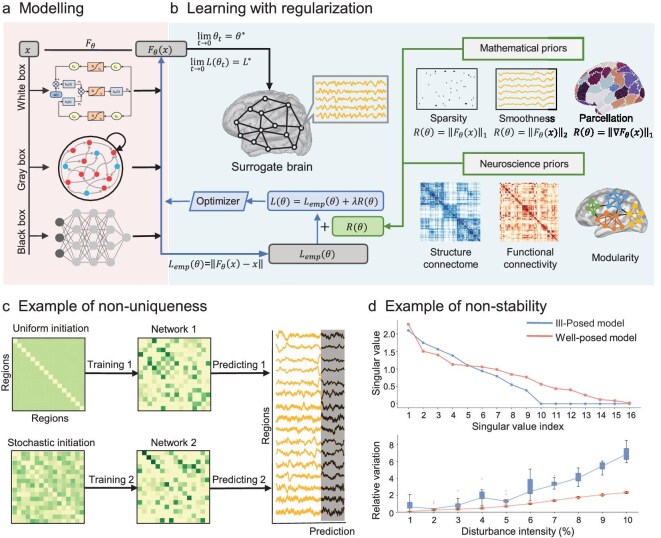 Figure 3
Figure 3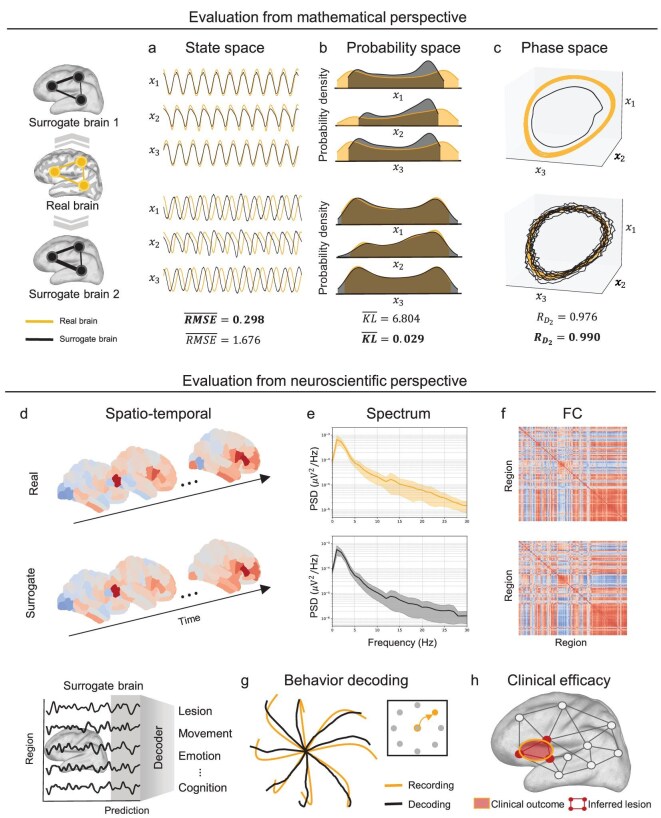 Figure 4
Figure 4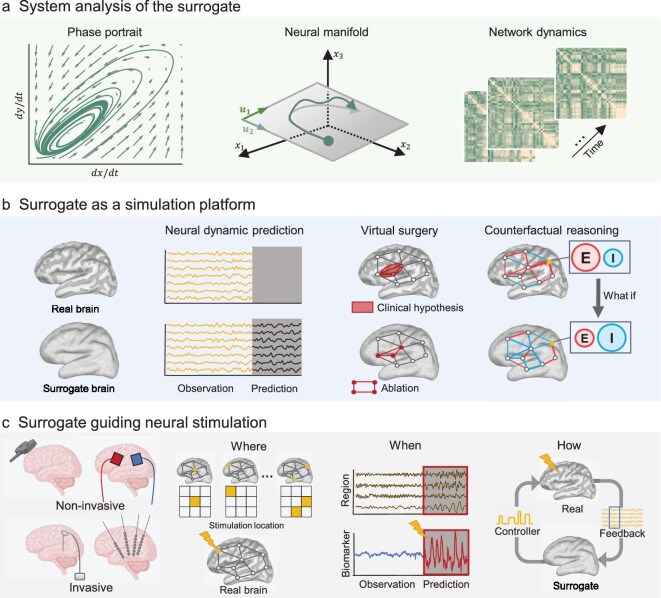 Figure 5
Figure 5| Application scenario | Core algorithm | Update formula/key mechanism |
|---|---|---|
| Unconstrained | Gradient descent (GD) |
|
| Newton’s method |
| |
| Levenberg–Marquardt algorithm |
| |
| Constrained | Penalty function method |
|
| Interior point method |
| |
| Sequential quadratic programming | Transformed into quadratic programming subproblems | |
| High dimensional | BFGS |
|
| L-BFGS | Based on the most recent | |
| Conjugate gradient method |
| |
| Large-scale data | Stochastic gradient descent (SGD) | Mini-batch samples replace full dataset |
| Adam optimizer | Momentum smoothing and adaptive step size | |
| Non-differentiable Difficult to compute | Nelder–Mead simplex method | Updated through reflection/expansion/contraction operations of the simplex |
| Surrogate gradient method | Smooth surrogate functions approximate non-differentiable functions | |
| Trust region framework |
|
- —National Natural Science Foundation of China10.13039/501100001809
- —National Key Research and Development Program of China10.13039/501100012166
- —International Collaboration Fund for Creative Research Teams of the National Natural Science Foundation of China
- —Guangdong Basic and Applied Basic Research Foundation10.13039/501100021171
- —Guangdong-Dongguan Joint Research Fund
- —Shenzhen Science and Technology Innovation Committee10.13039/501100010877
- —Science and Technology Commission of Shanghai Municipality10.13039/501100003399
- —Cross Disciplinary Research Team on Data Science and Intelligent Medicine
- —Guangdong Provincial Key Laboratory of Mathematical and Neural Dynamical Systems
- —Center for Computational Science and Engineering at Southern University of Science and Technology
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsNeural Networks and Applications
INTRODUCTION
The quest to understand and predict brain activity has long relied on mathematical and computational models of neural dynamics, which provide a rigorous mathematical foundation to describe how neural states evolve in time and space [1]. However, despite decades of progress with mechanistic models, ranging from single-neuron Hodgkin–Huxley equations [2] to large-scale neural mass models [3], traditional forward modeling remains fundamentally constrained by fixed-form equations and population-averaged parameters. These constraints limit its ability to capture the rich, non-linear and context-dependent dynamics of individual brains, particularly in high-dimensional, noisy and behaviorally relevant settings.
Recent advances in machine learning, coupled with the explosive growth of large-scale neural datasets [4–6], hold promising potential to model the spatio-temporal dynamics of the brain in a data-driven fashion [7]. Artificial intelligence (AI) models such as recurrent neural networks (RNNs) [8] and transformer-based architectures [9] have achieved state-of-the-art performance in forward modeling across domains. This convergence has catalyzed the emergence of surrogate brains: a broad family of computational models spanning white-box formulations with explicit mechanistic equations [10,11], black-box deep networks trained directly from data [12,13] and gray-box hybrids that embed neurobiological priors into adaptive architectures [14,15]. Unlike traditional modeling approaches that primarily emphasize anatomical correspondence, surrogate brains place priority on dynamical fidelity and predictive utility, offering a flexible computational counterpart to living brains that integrates prior knowledge with scalable, data-driven learning.
A surrogate brain serves not only as a forward model, predicting future neural states and transitions between brain states, but also a solver of the inverse problem: inferring latent states and dynamical rules that best explain observed neural activity. This dual role is essential for bridging theory and experiment, enabling mechanistic interpretation of complex signals, and supporting applications such as hypothesis testing, virtual perturbation and model-guided neurostimulation. Traditionally, inverse problems in neuroscience have been approached by fitting predefined dynamical models to data through optimization [16] or Bayesian inference [17]. While these methods have yielded valuable insights, their reliance on certain equation structures limits their expressivity and adaptability. In contrast, surrogate brains can directly learn dynamical rules from data, supporting white-box, black-box and gray-box formulations that adaptively balance mechanistic interpretability with empirical fidelity.
In this review, we focus on data-driven approaches for solving inverse problems in neural dynamical systems. We propose a surrogate brain framework that bridges the neural dynamical model with observed neural data (Fig. 1). The framework covers (i) modeling neural dynamics using varying degrees of prior knowledge, (ii) solving the inverse problem and learning model parameters via fitting data and (iii) evaluating the learned surrogate brain on signal fidelity, functional consistency and task-level performance. Building on this foundation, we highlight their applications in system analysis, virtual experimentation and neural stimulation. Finally, we discuss the remaining challenges and future directions in realizing fully personalized, real-time surrogate brains.
Conceptual framework for AI-based surrogate brains in neural dynamical systems. A surrogate brain is constructed through two interconnected processes: forward modeling and inverse problem solving. Forward modeling describes how latent brain states \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \end{document} evolve according to a dynamical operator \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \end{document} and produce observable signals via an observation mapping \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \end{document}. Here, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \end{document} represents external inputs, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \end{document} captures intrinsic dynamical noise and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \end{document} models measurement uncertainty. Inverse problem solving entails learning \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \end{document} from data, which involves selecting training strategies (e.g. next-token prediction), defining objectives and optimizing parameters. The framework accommodates white-box, gray-box and black-box formulations of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \end{document}, enabling the surrogate brain to flexibly integrate mechanistic priors with data-driven adaptation. Together, these steps yield a personalized, predictive model of brain dynamics that supports mechanistic insight, virtual experimentation and model-guided neurostimulation.
MODELING OF NEURAL DYNAMICAL SYSTEMS
To address the inverse problem, the first step is to construct an appropriate forward model, which simulates the brain’s neural activity over time. The forward model is defined by the equations
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \begin{eqnarray*} \dot{\mathbf {x}}_t &=& F_{\theta }(\mathbf {x}_t, \mathbf {u}_t) + \bf{\xi }_t, \\ \mathbf {y}_t &=& h_{\phi }(\mathbf {x}_t) + \bf{\eta }_t. \end{eqnarray*}\end{document}Here, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \mathbf {x_t}\end{document} represents the latent brain state at time t, which encapsulates the internal neural dynamics, while \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \mathbf {u}t\end{document} denotes the external inputs to the system (e.g. sensory stimuli or experimental interventions). The term \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} F\theta (\cdot )\end{document} describes the system dynamics, parameterized by \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \theta\end{document} , which governs how the brain’s state evolves over time. Additionally, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \bf{\xi }_t\end{document} represents the process noise, which captures any unmodeled dynamics or inherent randomness in the system’s evolution. The second equation defines the observation model, where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \mathbf {y}t\end{document} is the observable signal at time t (e.g. EEG or fMRI). This observable signal is related to the latent brain state \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \mathbf {x}t\end{document} through the function \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} h\phi (\cdot )\end{document} , which maps the brain’s internal state to the observed data, with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \bf{\eta }t\end{document} representing measurement noise or uncertainty in the observations. This formulation, as shown in Equation (1), serves as the foundation for the surrogate brain framework in Fig. 1. The forward model generates neural dynamics over time, based on parameters \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \theta\end{document} , initial conditions \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \mathbf {x_0}\end{document} and external inputs \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {\mathbf {u}(0), \mathbf {u}(1), \dots , \mathbf {u}(T)}\end{document} . The framework uses data-driven learning to estimate \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} F\theta (\cdot )\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} h\phi (\cdot )\end{document} from real neural data, enabling personalized, predictive models of brain activity. In this review, we do not consider the physical mapping from the observation space to the state space. Instead, we simplify the objective function in Equation (1) to the identity mapping, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \mathbf {y}_t = \mathbf {x}_t\end{document} . As a result, the system can be described as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {\dot{\mathbf {x}}t} = F\theta (\mathbf {x}_t, \mathbf {u}_t) + \bf{\xi }_t\end{document} .
From a machine learning perspective, we categorized neural dynamical models into three classes (Fig. 2), namely, white-box models (model-driven), black-box models (data-driven) and gray-box models (hybrid approach), depending on the incorporation of prior knowledge into the model structure. Specifically, white-box models, such as the Hodgkin–Huxley model, heavily rely on detailed neurobiological principles and physical laws to simulate specific neural processes. In contrast, black-box models, such as artificial neural networks, are primarily data-driven, making minimal use of prior knowledge but excelling in their ability to fit complex real-world data. Gray-box models aim to bridge the gap between the two, integrating prior knowledge with data to enhance interpretability while maintaining strong predictive performance.
Three types of neural dynamical models: white-box, black-box and gray-box models. (a) White-box models at multiple scales: (left) biophysical single-neuron models; (center) a neural mass model obtained by mean-field reduction of many single neurons; (right) a whole-brain network in which each node is a neural mass model. The neural mass model in (a) is an original schematic adapted from the conceptual framework in [3]. (b) Black-box models: (top) modeling directly in the observation space, where a neural network predicts the future neural dynamics, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \end{document}; (bottom) modeling in a latent space, where the data are first encoded/decoded and dynamics are learned as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \end{document}. (c) Gray-box models incorporating priors: (top) neural dynamics models constrained by neuroscientific priors (including a dend-PLRNN (reproduced from [14] under a CC BY 4.0 license, by Manuel Brenner), an E-I RNN [18], a low-rank RNN [19] and a spiking neural network (SNN)); (bottom) dynamical models constrained by physical-law priors (including a physics-informed neural network (PINN) and Hamiltonian neural network (HNN)).
White-box models
White-box models are distinguished by their capacity to incorporate mechanistic principles derived from neurobiology and physics, providing a structured and interpretable approach for simulating neural dynamics across hierarchical levels of organization, from single neurons to large-scale brain networks.
A unified dynamical systems framework for a single neuron can be expressed as
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \begin{eqnarray*} C\frac{dv}{dt}=-\sum _{k}I_{k}(t)+I_{\rm ext}(t), \end{eqnarray*}\end{document}where C represents the membrane capacitance, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {dv}/{dt}\end{document} is the rate of change of the membrane potential, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \sum {k}I{k}(t)\end{document} represents the sum of ionic and synaptic currents, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} I_{\mathrm{ext}}(t)\end{document} is the externally applied current.
Classical models like the Hodgkin–Huxley (HH) equations are viewed as biophysically enriched specializations of this framework [2]. The HH model uses a set of non-linear differential equations to characterize ion fluxes across the neuronal membrane, thereby generating action potentials and enabling signal propagation [20]. While providing detailed and mechanistically interpretable insights into neuronal firing dynamics [21], its computational complexity poses challenges for large-scale simulations. To address this, simplified models such as the integrate-and-fire (IF) [22] and leaky integrate-and-fire (LIF) models [23] are commonly employed, especially for large-scale simulations of spiking neural networks. While these models are less detailed than the HH model, they provide a balance between simplicity and computational efficiency, making them well suited for large-scale simulations of neural networks [24].
At the neural population level, white-box models extend the principles of single-neuron dynamics to capture the interactions within and between neural populations. This transition is typically achieved via the mean-field approximation, which replaces detailed, neuron-specific dynamics with macroscopic variables (e.g. mean membrane potential), reflecting the collective activity of the population [25]. Neural mass models (NMMs), a prominent class of such models, build on the mean-field approximation to describe population-level dynamics using low-dimensional, biophysically interpretable equations [26]. By reducing the complexity of high-dimensional neuronal systems, NMMs provide a computationally efficient framework for simulating large-scale neural activity. They are typically formulated as systems of ordinary differential equations (ODEs) that represent the temporal evolution of population states, such as the membrane potential of excitatory neurons. Notable examples of NMMs include the Wilson–Cowan model [27] and the Jansen–Rit model [28], which represent the dynamics of excitatory and inhibitory populations using coupled ODEs. Other notable NMMs include the Epileptor [29], the Thalamus model [30], and the Larter–Breakspear model [31]. A merit of NMMs is incorporating neurobiological factors, such as synaptic connectivity, neurotransmitter dynamics and network topology, to simulate phenomena like neural oscillations (e.g. EEG [32]), synchronized activity (e.g. visual attention [33]) and transitions between different brain states (e.g. epileptic seizure onset [29]). Another merit of NMMs is their computational efficiency, achieved by simplifying and reducing the complexity of large-scale network simulations while maintaining the essential dynamics of individual neural interactions [3].
While NMMs primarily focus on temporal dynamics, they can be generalized to incorporate spatial effects through neural field models (NFMs) [34]. These models extend NMMs by describing the spatial propagation of neural activity alongside its temporal evolution. NFMs enable the study of phenomena like traveling waves [35], synchronization patterns [36] and multi-scale spatial interactions in the brain [37]. NFMs offer a finer-grained depiction of neural activity across space; for instance, Jirsa et al. demonstrated that NFMs can achieve up to 1000-fold improvements in spatial resolution over NMMs when localizing epileptogenic networks [10]. More recently, neural field theory has been used to investigate how brain geometry constrains activity patterns [38], with successful applications to source localization tasks [39]. By bridging detailed local interactions and global brain activity, NMMs and NFMs provide a critical framework for understanding population-level neural dynamics within a biologically grounded, mathematically tractable paradigm.
At the large-scale brain network level, white-box models aim to capture the macroscopic organization of brain activity by modeling interactions between distinct brain regions and functional networks. These models often employ coupled differential equations or neural field theories to simulate dynamic interactions across brain regions. A prominent approach is brain network models (BNMs), which integrate the NMM as the node dynamics to simulate the interactions and dynamics of entire brain networks [40,41]. The dynamical system for BNMs can be expressed as
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \begin{eqnarray*} \frac{d}{d t} x_i(t) &&= f(x_i(t)) \\ &&+ \sum _{j=1}^N g(G_{i j}, x_i(t), x_j(t\!-\!D_{i j})) + \xi _i(t). \\ \end{eqnarray*}\end{document}Here \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} x_i\end{document} represents the state of the ith brain region, and the local node dynamics f of node i are determined by the NMM. The second term describes the global coupling between interconnected regions, determined by the adjacency matrix G, which typically encodes structural connectivity derived from empirical data (e.g. diffusion tensor imaging (DTI)). This term also incorporates the delayed influence of the jth brain region on the ith brain region, which is defined by the delay matrix D. The third term, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \xi _i(t)\end{document} , accounts for noise input to each node. This allows BNMs to simulate how both structural and functional interactions contribute to large-scale brain activity [42]. By integrating whole-brain structural and functional information, BNMs open a window to understanding how distributed neural circuits coordinate to support complex cognitive functions, such as cognition, perception, and emotion [43].
In support of these white-box models, several public computational platforms have been developed to implement BNMs, including BrainPy [44], The Virtual Brain (TVB) [45] and neurolib [46]. Notably, when coupling local dynamical models into a whole-brain framework, the required number of parameters increases exponentially. Thus, it is necessary to develop more advanced inverse problem-solving approaches for parameter inference [47,48].
Black-box models
Black-box models provide a data-driven alternative to white-box approaches for representing complex brain dynamics, especially when the underlying biophysical mechanisms are poorly understood or cannot be expressed explicitly with differential equations. In contrast to mechanistic models, black-box approaches make no explicit assumptions and instead learn neural dynamics implicitly through ANNs. As universal approximators, ANNs can theoretically capture any data pattern [7], making them particularly suited for modeling the non-linear and high-dimensional processes characteristic of brain activity. Over the past decade, AI-based black-box models, such as RNNs, neural ODEs [49], MAMBA [50] and transformers [51], have demonstrated remarkable success in modeling dynamic systems and predicting complex data across various domains, from weather forecasting [52] to molecular dynamics [53], and from financial modeling [54] to large-scale language modeling [9,50]. These advances now enable their direct application to neural dynamical systems, where black-box models can capture the intricate features of brain activity (Fig. 2b).
The success of black-box models depends heavily on aligning the model architecture with the specific characteristics of the neural signals being analyzed. Different modalities, such as fMRI and EEG, often require distinct AI architectures due to their unique temporal and spatial properties. For fMRI, Luo et al. showed that a simple multilayer perceptron (MLP) can predict future dynamics from the preceding three time steps within a self-supervised framework. Despite its simplicity, the model accurately forecasts brain activity and revealed latent structural relationships across regions [12]. In contrast, EEG demands architectures that can handle rapid temporal fluctuations [55]. Pankka et al. applied WaveNet, a probabilistic deep learning model, to predict signals across multiple frequency bands. Their model captured amplitude, phase and oscillatory peaks in theta and alpha activity, demonstrating its ability to represent fine-grained temporal patterns [56]. These studies underscore the importance of tailoring AI model architectures to the properties of specific neural signals, ensuring both accuracy and interpretability in modeling neural dynamics.
Transitioning from direct modeling in the observation space to modeling in latent spaces provides a complementary perspective on understanding neural dynamics. The motivation for latent space modeling stems from the inherent complexity of neural data, which are often high-dimensional, while the cognitive states or functional dynamics of interest typically reside in lower-dimensional subspaces. Latent space modeling aims to uncover low-dimensional representations through neural embeddings, enabling the study of their temporal evolution. A prominent method in this domain is the variational autoencoder (VAE), which encodes high-dimensional data into a latent space, learns dynamic patterns within this reduced representation and subsequently decodes the information back into the original space [57]. Building upon this framework, LFADS encodes neural spike trains into latent trajectories via an RNN, revealing low-dimensional patterns underlying complex dynamics [13]. Similarly, Chen et al. combined neural ODEs with VAEs to capture continuous latent dynamics [49]. VAEs have proven effective in reconstructing low-dimensional trajectories. Beyond VAEs, RNNs have demonstrated their broad applicability in capturing latent neural dynamics. Leveraging their ability to model sequential data, RNNs have been employed in tasks such as simulating cerebellar computations [58], reverse-engineering cognitive functions [59,60] and uncovering hierarchical dependencies across temporal and spatial scales in neural data [61,62]. Manifold learning methods further complement these models by reducing dimensionality and improving interpretability [63,64]. While most latent models focus on emphasizing dimensionality reduction, an alternative strategy projects neural activity into higher-dimensional space. This facilitates the linearization of non-linear dynamics, making them more amenable to prediction and control [65]. For example, the deep Koopman model maps epileptic brain dynamics into a high-dimensional linear framework, enabling online updates and model-based predictive control [66].
Large pretrained models based on Transformer architectures, such as GPT, have transformed data-driven modeling by learning universal representations from massive datasets [67,68]. With the advancement of neural data collection technologies, large-scale, multimodal neural datasets such as HCP [4], UK Biobank [5], TUAB [6], THINGS-EEG [69], HUP [70] and SEED [71] have emerged, providing the foundation for neuroscience to adopt similar strategies. These datasets support the development of large-scale models that capture universal features of neural information [51,72–74]. Examples include Brant [75,76], a model with over 500 million parameters trained on intracranial EEG, and LaBraM [77], pretrained on more than 2500 hours of EEG recordings. A growing family of brain foundation models, such as NEURO-GPT [78], NeuroLM [79] and BrainWave [80], highlights this trend. In fMRI, contrastive alignment models, such as BrainCLIP [81] and CLIP-MUSED [82] map fMRI embeddings into CLIP space to enable visual decoding, while self-supervised methods including BrainLM (MAE-style pretraining) [83] and BrainMass [84] focus on spatio-temporal dynamics and functional connectivity, respectively. Despite these advances, a fundamental distinction remains. Pretrained foundation models capture population level, task agnostic features, whereas a surrogate brain is an individualized dynamical state space model calibrated to a single person. Turning the former into the latter requires subject-specific adaptation through fine-tuning and calibration on the individual’s recordings, ensuring that the model’s forward dynamics reproduce that brain’s trajectories.
Gray-box models
White-box models offer mechanistic interpretability but often struggle to accommodate the complexity and variability of real neural data. In contrast, black-box models excel at learning from large-scale datasets, yet typically lack transparency and biological plausibility. Positioned between these two extremes, gray-box models represent a hybrid modeling paradigm that integrates prior theoretical knowledge—derived from neuroscience or physics—with the flexibility of data-driven learning algorithms [85]. By embedding biologically or physically meaningful constraints into modern neural networks, these models preserve interpretability while retaining expressive power, offering a promising route toward constructing surrogate brains. Neuroscience priors serve as inductive biases that guide learning (Fig. 2c). They can shape model architectures directly or act as regularization terms during optimization, as discussed further in the section entitled ‘Solving inverse problems for predicting brain dynamics’ below.
One prominent example comes from the study of dendritic processing in neurons, which plays a pivotal role in the non-linear integration of synaptic inputs. Inspired by this, researchers have developed artificial neurons and network modules that emulate dendritic processing [86,87]. Liu et al. proposed Dit-CNN architectures augmented with quadratic neurons reflecting dendritic integration, which substantially boosted performance with minimal added complexity [88]. Similarly, Durstewitz et al. introduced dend-PLRNN, incorporating dendritic mechanisms into recurrent dynamics to enhance non-linear reconstruction while reducing model dimensionality [14].
Beyond individual neurons, broader organizational principles of the brain have also guided model development. The Dale principle, which states that neurons are either purely excitatory or inhibitory, has been incorporated into E-I RNN. As shown by Song et al., enforcing this biological fidelity stabilizes dynamics and structures temporal representations of cortical circuits [18]. Some models, instead, emphasize the representation of higher-order assumptions about brain-wide activity. For example, the low-dimensional manifold hypothesis, suggesting that cortical activity resides on a constrained subspace, has inspired the design of low-rank RNNs. These models impose low-rank constraints on the recurrent weight matrices, yielding not only compact parameterizations, but also interpretable latent dynamics [19,89,90]. To demonstrate the effectiveness of these prior constraints, we constructed an AI-based surrogate brain benchmark using RNNs, highlighting how dend-PLRNN [14], E-I RNN [18] and low-rank RNN [90] exhibit distinct performance characteristics. The related code is available from GitHub (https://github.com/ncclab-sustech/Review_Surrogate_Brain.git), and further details can be found in the online supplementary material.
Incorporating neuroanatomical features is another powerful approach in gray-box model development. For example, Dapello et al. introduced a specific layer into a hierarchical CNN to simulate the primate V1 area, which in turn allowed the model to better handle adversarial perturbations in image classification tasks [91]. Jirsa et al. utilized DTI to create a data-driven whole-brain model, enabling the learning of the dynamics of the local nodes from both structural and functional data [92]. The integration of anatomical constraints allows these models to simulate more accurate whole-brain dynamics, offering region- and individual-specific parameterization for enhanced flexibility and precision.
Spiking neural networks (SNNs) provide another example of how neuroscientific priors can be embedded into model design. These networks exploit the pulse-based communication mechanism of biological neurons to process time-dependent information effectively [93]. Their architecture incorporates key neuronal mechanisms, including membrane potential accumulation, spike generation and refractory periods, thereby closely mirroring biological dynamics. Learning in SNNs often relies on spike-timing-dependent plasticity, a rule inspired by Hebbian plasticity that adjusts synaptic strengths according to the relative timing of pre- and postsynaptic spikes [94]. This intrinsic temporal dependence enables SNNs to encode and refine neural connections during learning, positioning them as a promising framework for neuromorphic computing. Several open-source platforms, such as BrainCog [15], SpikingJelly [95] and Nengo [96], now support SNN simulation and application development, making these tools widely accessible to the research community.
While neuroscientific priors have been widely applied, physical principles offer a promising approach for augmenting gray-box models. Despite being less frequently employed in biological modeling, these physical laws present great potential to enhance both the performance and interpretability of gray-box methodologies (see Fig. 2c). One example is PEMT-Net, which simulates the physical diffusion of neural signals using random walk processes, thereby capturing both local and long-range dependencies in fMRI signal decoding tasks. The results indicate that the physically enhanced model achieves a performance improvement exceeding 10 percentage points [97]. A particularly promising approach is the physics-informed neural networks (PINNs), which embed physical laws—such as differential equations—directly into the loss function. This allows the learning process to be constrained according to well-established physical dynamics [98]. Recent advances have extended PINNs to brain dynamics, demonstrating improved parameter inference and enhanced interpretability of neural processes [99]. Additionally, the physics-structure-preserving neural networks, such as the Hamiltonian neural network and Lagrangian neural network, have begun to show promise in improving long-term prediction capabilities [100,101]. While the direct application of these physics-based models to the creation of surrogate brains presents challenges, due to the complexity, adaptability and non-conservative nature of the brain, this framework provides a systematic approach for examining neural non-linearity, energy optimization and long-term stability [100–102].
In summary, gray-box models offer a compelling framework for integrating both mechanistic insights and data-driven learning, thereby facilitating more precise simulations of brain-like behavior. By integrating neuroscientific and physical priors, these models establish a robust foundation for modeling neural dynamics and constructing surrogate brains. Nevertheless, the integration of such priors is accompanied by challenges. The trade-off between model interpretability and expressiveness continues to be a persistent issue, as does the lack of strong theoretical underpinnings in certain instances. Despite these challenges, ongoing advancements in inverse problem solving, parameter estimation and prior engineering are expected to unlock the full potential of gray-box models, thereby enhancing our comprehension of neural dynamics and advancing the field of computational neuroscience.
SOLVING INVERSE PROBLEMS FOR PREDICTING BRAIN DYNAMICS
This section focuses on a systematic interpretation of the framework for solving inverse problems in brain systems. First, we investigate two mainstream paradigms for solving inverse problems: the probabilistic framework and the deterministic framework. Subsequently, from the perspective of neuroscience, we discuss the well-posedness of the solutions to inverse problems, with a particular emphasis on analyzing the existence, uniqueness and robustness of the solutions. Finally, combined with practical application scenarios, targeted strategies for alleviating ill-posed problems are proposed.
Solving data-driven inverse problems
To effectively solve inverse problems that infer unknown systems from observed data, researchers have established two main frameworks: the probabilistic framework based on the Bayesian theorem and the deterministic framework based on functional analysis.
The probabilistic framework treats the parameters to be solved as random variables [45], with Bayesian inference as its core principle. This framework quantifies the relationship between parameters and empirical data through the likelihood function. By integrating prior information and applying Bayes’ theorem, Bayesian inference derives the parameter posterior distribution, and then a point estimate is obtained via methods like maximum a posteriori estimation, thereby obtaining the model solution and quantifying its uncertainty. In practical implementations, since posterior distributions often lack an analytical form, their computation relies on sampling methods such as Markov chain Monte Carlo (MCMC) algorithms to approximate the posterior distribution [103]. However, when dealing with complex models (e.g. personalized brain models), MCMC incurs high computational costs. In this context, probabilistic machine learning methods such as neural density estimators [104] and variational inference [105] have emerged as more efficient alternatives. It is worth noting that the free-energy principle [106] posits that organisms optimize recognition density by minimizing free energy, thereby approximating the posterior distribution. This mechanism is highly consistent with the core logic of variational inference, providing a theoretically sound and biologically meaningful framework for applying variational inference to posterior inference tasks in complex biological systems such as personalized brain models.
The core advantages of Bayesian inference lie in the fact that the prior distribution can incorporate the knowledge of domain experts, the likelihood function can accurately characterize the data-generation mechanism and restore the real process, and the posterior distribution can quantify the uncertainty of the solution. These advantages naturally align with white-box models. However, in black-box models, the parameters lack interpretable mechanistic meanings, which forces the prior to default on uninformative assumptions. Because of the absence of an explicit generative structure, the likelihood relies on sampling-based approximations, and the posterior also fails to anchor meaningful biological or physical interpretations. Therefore, Bayesian inference is more widely applied in solving white-box models [45,106,107].
In the deterministic framework, the parameters to be solved are regarded as definite entities. The deviation between the output of the forward model and the observed data is quantified by defining the data fidelity term \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} d(F_{\theta }(\mathbf {x}),\dot{\mathbf {x}})\end{document} , where d is a distance function, its form depends on the nature of the noise term [108]. Under the assumption of Gaussian noise, the least-squares norm is usually employed as the distance metric. To incorporate prior knowledge, a regularization term \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} R(\theta )\end{document} needs to be introduced (which will be elaborated on in the following subsection). Subsequently, the data fidelity term and the regularization term are summed with weights to construct the objective function:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \begin{eqnarray*} \hat{\theta } \in {\rm arg}\,\mathop {\rm min}_{\theta } \lbrace d(F_\theta (\mathbf {x}), \dot{\mathbf {x}}) + \lambda R(\theta ) \rbrace . \end{eqnarray*}\end{document}Here, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \lambda\end{document} is a hyperparameter used to balance the trade-off between data fitting and the strength of prior constraints. Its value is often selected based on empirical knowledge and can also be obtained through cross-validation or the L-curve method [109]. Finally, the parameter solution is obtained by minimizing this objective function. In terms of computational implementation, the deterministic framework uses numerical optimization algorithms to solve the minimum of the objective function. The choice of optimization algorithm needs to be flexibly adjusted according to the nature of the loss function and the form of the problem. Table 1 summarizes common scenarios and the corresponding selection of optimization algorithms. For a more detailed analysis, see the online supplementary material.
The deterministic framework lacks the quantification of solution uncertainty, thus potentially posing certain risks in scientific inference and clinical applications. However, it does not require sampling from distributions and instead conducts calculations directly through optimization methods, offering high computational efficiency. Moreover, it adapts well to both black-box and gray-box models. These advantages lead to its widespread application in the field of neuroscience [12,18,89].
In recent years, the integration of the two frameworks has gradually emerged. For example, in the work of Sip et al. [92], variational inference is first used to construct approximate posteriors of system states, regional parameters, and other latent variables from observational and structural data. Then, the expectations and variances of these latent variables are used as inputs to a neural network for learning dynamical systems. Finally, by constructing a minimized evidence lower bound, the network parameters of the dynamical system function and the distribution parameters of the latent variables are jointly optimized. Through this combination, the probabilistic framework is utilized to capture the uncertainty of latent variables, while the efficient fitting ability of deterministic neural networks is utilized to characterize complex dynamic rules. Ultimately, this approach provides solutions for inverse problems that possess both probabilistic characteristics and mechanical interpretability. This is also one of the implementation methods of the gray-box model mentioned earlier.
Well-posedness of the learning problem
A core challenge in solving the brain’s inverse problem stems from its intrinsic nature: given the brain’s immense number of interacting components, it is fundamentally a high-dimensional and non-linear optimization problem (Fig. 3a and b). The objective function of such a problem is prone to having multiple local minima. Thus, during iterative optimization, different initial values may lead to distinct solutions that all fit the observed data well (Fig. 3c). This multiplicity of solutions directly results in ambiguity in the interpretation of neural mechanisms, making model-based physiological inferences unreliable. Additionally, neural data observed in the real world inevitably contain noise. If minor observational noise can cause drastic fluctuations in the solutions, it will limit the reliability of surrogate brain models in practical scenarios such as clinical diagnosis and neuromodulation. To ensure the credibility of the solutions, we introduce well-posedness as a prerequisite that modeling should satisfy. Well-posedness originates from Hadamard’s classical characterization of mathematical problems. Here, we provide an accessible introduction from a neuroscience perspective (detailed mathematical definitions can be found in the online supplementary material).
Solving the inverse problem. (a) Modeling. (b) Learning with regularization. Priors on object attributes are added as regularization to the loss function, and the optimizer solves the learning problem. (c) Example of non-uniqueness. Different initializations in the optimization algorithm yield distinct solutions with comparable model performance. (d) Example of instability. Stability analysis via singular value spectra (top) and perturbation testing (bottom).
Mathematically speaking, three key criteria are usually considered in the inverse problem for the AI surrogate brain.
Existence: given observational data, there exists at least one set of latent variables such that the predicted data generated by the surrogate brain through these variables matches the observational data within acceptable error margins, and these latent variables must be biologically plausible. Uniqueness: for a given system and data, only one surrogate brain model is obtained. Stability: when observational data are subject to natural physiological perturbations, the model solution undergoes only minor changes within acceptable limits.
General well-posedness criteria stem from the properties of the objective function (Equation (4)) (denoted \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} J(\theta )\end{document} ). If \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} J(\theta )\end{document} is coercive, its minimizing sequence must be bounded. In compact spaces, bounded sequences contain convergent subsequences, and when the objective function is lower semi-continuous, the limit point of such subsequences is provably a global optimal solution. Additionally, if the loss function is strictly convex, the global optimal solution obtained above is unique. Regarding solution stability, the objective function can be extended to a bivariate function \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} J(\theta , \mathbf {y})\end{document} , where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \theta\end{document} is the solution and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \mathbf {y}\end{document} is the observational data. If J is Lipschitz continuous with respect to data \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \mathbf {y}\end{document} and strongly convex with respect to solution \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \theta\end{document} , then it can be proven that the solution \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \theta (\mathbf {y})\end{document} is Lipschitz continuous with respect to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \mathbf {y}\end{document} —meaning that solution fluctuations are controlled by perturbations in observational data. In probabilistic settings, the Lipschitz condition metric should be revised to the Hellinger distance[110,111].
In different modeling scenarios, the well-posedness theory takes on more specific forms. When inverse problems can be modeled by linear operators as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} K\mathbf {x} = \mathbf {y}\end{document} , the theory of their well-posedness can be found in any functional analysis textbook. Here, we introduce only the condition number as an index to measure a linear model’s resistance to perturbations. For an invertible linear operator K, the condition number is defined as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {\rm cond}(K) = \Vert K\Vert \Vert K^{-1}\Vert \end{document} in the operator-norm sense (equivalent to the ratio of maximum to minimum singular values under the 2-norm). If \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} {\rm cond}(K)\end{document} is small (e.g. close to 1), minor input perturbations induce only slight solution fluctuations, indicating stability. When inverse problems are modeled as the biophysical equation (3), relevant progress has also been made. Lang et al. [112] used a framework of joint graph-kernel optimization based on alternating least squares to solve such problems, and proved that solutions are identifiable when data satisfy rank-joint coercivity conditions. This condition further ensures that the matrices used in numerical computations are well-conditioned, with their minimum singular not excessively large).
However, in high-dimensional non-linear scenarios with noisy data, well-posedness theory may be difficult to satisfy, and AI models, even more so, lack such theories of well-posedness. In these circumstances, numerical verification methods, along with theoretical analysis, serve as an important approach. By experimentally observing the actual behavior of the model, the characteristics of well-posedness can be indirectly evaluated. Among them, multi-initial-value inversion sets multiple initial conditions to simulate the evolution paths of the system starting from various points, and judges whether the model has reliable solutions by comparing the convergence and consistency of the final results (Fig. 3c); noise perturbation testing artificially inputs random noise into the system to simulate the inevitable interference factors in reality, and observes the robustness of the model under perturbations (Fig. 3d). If the output results still fluctuate within an acceptable range, it indicates that the model has good stability. Sensitivity analysis systematically varies specific key elements, such as critical input features, core model parameters or data distribution attributes, to precisely gauge how outputs respond. It highlights cases in which minor perturbations to these targeted elements trigger significant output fluctuations, pinpointing vulnerabilities that may compromise stability.
It is important to note that the parameter solutions in white-box models and the inferred latent variables in gray-box models typically incorporate priors and often possess biological interpretability. Interpreting these parameters directly supports the model’s validity. Therefore, the requirements for the uniqueness and stability are natural. However, in black-box models, the weight parameters of neural networks often lack practical biological meaning; overparameterized networks may also lead to multiple sets of equivalent solutions (e.g. different parameters yielding consistent prediction performance). Therefore, the general requirements for uniqueness and stability of physical parameters, as outlined in inverse problem well-posedness theory, are not applicable to overparameterized AI models. For black-box models, the focus of evaluation should shift to aspects such as prediction performance, robustness to noise and generalization ability. Moreover, when black-box models are used as surrogate brains, we still expect the latent representations of their outputs to be stable, indicating that the model has found an appropriate embedding space for representing neural dynamics data.
Mitigation of ill-posed problems
For most systems, well-posedness theory provides sufficient, but not necessary conditions. Because of unique challenges in neuroscience research—strong non-linearity of neural dynamics, multi-scale coupled physical properties, and inherent noise and uncertainty in observational data—these well-posedness conditions may be difficult to meet. At the same time, the results of numerical verification are more likely to indicate that the model is ill-posed. Given the pervasiveness of this ill-posed phenomenon, we now introduce some strategies for addressing ill-posed problems.
Regularization theory is precisely the key approach to solving such problems. Its core idea is to introduce prior constraints by adding a regularization term, presetting the structural features of parameter solutions or model behavior to guide the optimization process. This ensures the stability of solutions when data are limited or disturbed by noise. In parallel, the constraints narrow the solution space, making the solutions conform to physiological characteristics. Even if the solutions are still not unique, they can be considered approximately unique in the equivalent sense of neuroscience. It primarily functions through two approaches: one directly constrains the model parameters; the other constrains the model output, indirectly constraining the parameters through the correlation between the output and the parameters. Here we first introduce two types of explicit regularization terms, which are derived from mathematical priors and neuroscience knowledge priors, and then briefly mention implicit iterative regularization and alternative strategies for mitigating ill-posed problems of AI surrogates.
Mathematical prior regularization uses mathematical structures to constrain the expected properties of the solution or the model’s behavior. The constraints on white-box model parameters and gray-box model latent variables are typically determined by their biological properties, which are discussed in the following paragraph with regard to neuroscience knowledge-based prior regularization. Here, we introduce the concept of constraining the model’s output and constraining the weights of the black-box model. Common forms can be divided into the following categories.
Sparsity constraints encode the regularization term as the L1 norm, enabling the model to retain only key components for computation [113,114]. In neural networks, sparsity constraints applied to parameters can eliminate redundant connections caused by noise [115], while applying constraints at the output level ensures that model prediction results align with the sparse characteristics of neural activities. Energy constraints involve using the L2 norm as the regularization term, which essentially restricts the sum of the squared magnitudes of parameters, keeping the fluctuations of parameter magnitudes within a reasonable range. This is one of the most commonly used regularization methods in neural networks. At the parameter level, energy constraints can prevent parameters from growing without restriction, avoiding overfitting to noise in the data; at the output level, they ensure that model outputs conform to the physiological thresholds of neural responses. Additionally, the introduction of the L2 norm can enhance the convexity of the objective function, facilitating the acquisition of a unique optimal solution [116]. Regularization terms for global smoothness constraints primarily act at the output level and are often defined as the L2 norm of the derivative of the model output with respect to the input [117]. Their core function is to penalize drastic changes in the output with respect to the input, forcing the model to learn a smooth mapping between inputs and outputs, thereby enhancing the model’s robustness to noisy neural data. The regularization term of total variation (TV) is typically defined as the L1 norm of the gradient operator, which suppresses local high-frequency fluctuations while preserving significant edge features. This property aligns well with the characteristic in neuroscience that neural data are locally continuous and have distinct regional boundaries [118]. At the parameter level, TV regularization can constrain the local changes in the weight matrix, preventing irregular jumps in neural connection patterns; at the output level, it can retain important edge information when decoding brain activities, ensuring consistency with the boundaries of known brain functional regions.
Neuroscience knowledge-based prior regularization systematically encodes prior knowledge from neuroscience—including anatomical structures, physiological mechanisms and neural dynamics—into regularization terms. This ensures that models not only yield numerical predictions, but also conform to biological principles. Here, we elaborate on constraint methods applied to the parameter solutions of white-box models, the latent variables of gray-box models (collectively referred to as ‘solutions’ hereafter) and the outputs of all models.
First, it should be noted that, when these solutions exhibit corresponding characteristics, the aforementioned mathematical prior regularization can be directly applied to impose constraints such as sparsity and energy constraints. Additionally, based on structural and functional knowledge, prior information about the solutions can be embedded in the loss function. At the anatomical level, integrating structural priors derived from techniques like DTI minimizes deviations between the model and structural connectivity, ensuring that latent representations align with the brain’s physical (anatomical) structure [119,120]. Meanwhile, region-specific constraints (e.g. penalizing violations of known functional hierarchies or functional connectivity patterns) can further guide the model to comply with cortical and subcortical structural organizations [121]. Functional priors (such as task-specific modularity) can enhance the model’s interpretability and performance [122]. Modularity-based penalty terms prompt the model to adjust its internal representations. These adjustments reflect distributed and specialized activity patterns in the brain. This aligns with the characteristics of functional segregation and integration observed in neural systems [123]. For model outputs, the primary approach is to adopt dynamic equations from first-principles physical models as constraints, incorporating the residuals of these physical models into the objective function. This forces the model to follow physical laws during training, effectively improving the model’s plausibility and predictive accuracy [99].
The essence of mitigating the ill-posedness of inverse problems lies in constraining the solution space, which is not limited to being achieved through explicit regularization terms alone. Iterative regularization precisely stops the iteration before the model overfits the noise, simultaneously capturing the optimal solution and achieving regularization [124]. Since it avoids the need for constructing and storing high-dimensional regularization terms, it is suitable for large-scale problems. The direct sampling method explores the parameter space through random sampling or geometric partitioning, reducing the dependence on local noise and stabilizing the solution output. Moreover, it does not rely on gradients, making it especially suitable for ill-posed problems with strongly non-linear and non-smooth solutions [125]. Data prior guidance employs techniques such as parameter freezing and feature distillation to introduce the latent patterns in large-scale data as data priors into the model. This approach constrains the parameter distribution and output features, and reduces the sensitivity to noise and sparse data. Dynamic adjustment strategies [126] in neural network training use Dropout for random sparsification to reduce overfitting, batch normalization to stabilize the input distribution and data augmentation to increase data diversity. Together, these strategies guide the model to learn essential laws, ultimately contributing to the mitigation of ill-posedness.
Finally, we point out that the above strategies are only mitigations of ill-posed problems and cannot automatically guarantee the well-posedness of the inverse problem. However, taking regularization as a key example, extensive engineering practice has empirically validated that, when regularization strategies align closely with problem characteristics and hyperparameters are reasonably selected, regularization significantly reduces ill-posedness. In practical applications, regularized solutions not only meet accuracy requirements, but also demonstrate consistency with experimental observations and physical laws, providing reliable foundations for engineering decisions. Thus, despite theoretical limitations, regularization remains the core methodology for mitigating ill-posedness and obtaining practical solutions in inverse problems.
EVALUATION
Once the inverse problem of a neural dynamical system has been addressed, the next step is to evaluate the trained model. The goal is to determine whether the model captures the essential dynamics of neural systems and provides interpretable representations, functioning as surrogate brains. Neural dynamics are often only partially accessible. As a result, evaluation typically relies on comparing model-generated and empirical data. Evaluation can be approached from two complementary perspectives. From a mathematical standpoint, similarity analyses across different metric spaces highlight signal fidelity and reveal distinct system characteristics. From a neuroscientific perspective, the focus shifts to functional alignment, assessing whether models reproduce task-related activity and support consistent decoding. In what follows, we review evaluation metrics from both perspectives.
Mathematical perspective
The mathematical evaluation of the inverse problem in neural dynamical systems often begins with assessing data similarity across various metrics, as this reveals distinctive features of the investigated system [128]. A standard approach is to compute pointwise errors such as the mean squared error (MSE) [129], a simple and widely used measure of temporal similarity in machine learning (Fig. 4a).
Model evaluation from mathematical and neuroscientific perspectives. (a–c) Mathematical perspective. Synthetic data were generated with the stochastic Jansen–Rit model [127]. The upper and lower rows correspond to two surrogate brains derived from the same underlying system, evaluated across three representational spaces: (a) state-space trajectories (mean root-mean-square error, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \end{document}); (b) probability distributions (mean Kullback–Leibler divergence, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \end{document}); (c) phase-space dynamics (relative correlation dimension, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \end{document}). Surrogate 1 achieves lower \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \end{document}, while Surrogate 2 performs better in probabilistic and topological metrics. (d–h) Neuroscientific perspective. Metrics include (d) spatial-temporal similarity, (e) spectral similarity, (f) FC similarity, (g) behavioral decoding accuracy and (h) clinical efficacy in predicting lesion outcomes. Panels (d) and (e) focus on the surrogate brain’s ability to replicate biological signal characteristics, and panels (g) and (h) evaluate its capability to support downstream tasks. Yellow traces denote real brain data; black traces represent surrogate brain outputs.
However, their simplicity is a significant limitation: they fail to capture higher-order geometric and topological properties of complex systems. For instance, even if a generated system replicates the topological structure of the original trajectory, minor variations in initial conditions or phase shifts can lead to large norm errors that do not reflect meaningful dynamical differences (Fig. 4a–c). This issue is particularly relevant for the brain, a high-dimensional and highly sensitive dynamical system where small perturbations can drastically alter dynamics [3]. Therefore, while a low MSE may suggest good temporal alignment, it does not necessarily guarantee an accurate representation of the brain’s underlying structural or dynamical properties [8]. This limitation highlights the need for alternative evaluation strategies that better capture the complexity of brain dynamics. Beyond pointwise error metrics, goodness-of-fit measures are another important approach for model evaluation. Metrics such as explained variance and the coefficient of determination ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} R^2\end{document} ) quantify how much of the data variance the model accounts for, without relying on specific features [130,131]. These measures complement pointwise errors by offering a broader perspective on model accuracy and providing a more intuitive view of how well the generated dynamics reproduce empirical observations.
In addition to state space evaluations, probabilistic approaches provide complementary insights by analyzing the global properties of data distributions (Fig. 4b). These methods assess the overlap between real and surrogate brains by comparing probability distributions, providing insights into the structural characteristics of the system’s dynamics. Commonly used probabilistic metrics include the Kullback–Leibler divergence, Wasserstein distance and Hellinger distance [132–135]. For instance, the Wasserstein distance not only measures positional discrepancies between distributions, but also captures their geometric shapes, making it a powerful metric for evaluating high-dimensional data [136]. Such probabilistic measures are especially important in neuroscience, where stochastic variability and noise can profoundly influence neural trajectories, necessitating robust methods to evaluate model fidelity.
Topological and geometric properties are fundamental to characterizing the long-term behavior of dynamical systems. Key features, such as chaos, attractors and limit cycles, govern the system’s evolution and dynamic responses [8]. The brain is often hypothesized to operate at the edge of chaos, a critical state where order and adaptability are balanced. This state is thought to optimize signal propagation and enhance the system’s ability to respond flexibly to a dynamic environment [137]. A metric for quantifying sensitivity to initial conditions is the maximal Lyapunov exponent. This metric indicates whether a generated system accurately replicates the brain’s critical dynamical features, including its hypothesized operation near the edge of chaos [138]. Complementing this, the fractal dimension measures the geometric complexity and self-similarity of attractors, providing insights into the structure and dynamics of brain activity [3,139]. Comparable fractal dimensions between real and surrogate systems suggest that the surrogate not only preserves system complexity, but also reproduces its topological organization (Fig. 4c). In addition to these approaches, persistent homology, as a tool in topological data analysis, offers a powerful method for studying the multi-scale structure of state spaces by capturing the birth and death of topological features such as connected components, loops and voids across different scales [140]. This approach is particularly suited for analyzing complex, high-dimensional brain networks, as it extracts robust topological features across scales and is less sensitive to noise [141].
Neuroscientific perspective
From a neuroscientific perspective, a central question is whether surrogate brains preserve the physiological characteristics of real neural systems. Evaluation typically considers spectrotemporal properties, functional connectivity (FC) and task-related performance. These evaluations provide insights into fundamental features, dynamic properties and task-specific performance, all reflecting the functional and structural characteristics of neural systems (Fig. 4d–h) [142]. To address these concerns effectively, evaluation frameworks must extend beyond traditional mathematical error analyses by incorporating neuroscience-related metrics.
Unlike purely mathematical evaluations, neuroscientific assessments emphasize the consistency of spatial-temporal activation patterns, which capture the model’s ability to reproduce functional activity across both specific brain regions and the whole brain (Fig. 4d) [143,144]. High similarity in these patterns indicates that the surrogate brain retains the functional coordination characteristic of neural systems. Dynamic properties are further examined through spectral and FC analyses. Spectral analysis characterizes rhythmic activity across scales [145,146], ranging from micro-level neuronal firing to macro-level oscillatory states associated with EEG frequency bands (Fig. 4e). In parallel, FC analysis evaluates neural activity coordination across regions by quantifying spatio-temporal dependencies. Static FC, based on averaged correlations, provides a global assessment of whole-brain performance (Fig. 4f), whereas dynamic FC captures time-varying connectivity and the complex temporal organization of neural systems [147].
In practical applications, surrogate brains are typically validated through task-specific metrics that assess how well they replicate real brain functions [148]. For example, researchers compare whether the surrogate brain can decode lesions [149], behaviors [19], emotions [150] or cognitive states [151], aligning with actual neural data. For instance, in epilepsy localization, the overlap between clinically resected regions and the predicted epileptogenic zones derived from the surrogate brain serves as a key metric for assessing localization accuracy (Fig. 4i) [11,152]. This approach directly links model predictions to clinical outcomes, providing a robust measure of its practical utility. Similarly, task-related neural recordings allow researchers to evaluate model reliability through behavioral predictions. For example, decoding monkey movement trajectories from neural data and comparing them to observed behaviors offers a direct validation of the model’s task-level reliability (Fig. 4j) [19,153]. Such task-specific validations highlight the model’s ability to bridge theoretical dynamics with practical utility.
By integrating mathematical and neuroscientific techniques, the surrogate brain can be evaluated in terms of accuracy, functionality and practical applicability. Mathematical approaches, including error-based, probabilistic and topological measures, characterize the structural and geometric fidelity of the models. Neuroscientific assessments, such as spatial-temporal activation patterns, spectral analysis, functional connectivity and task-related decoding, ensure alignment with physiological functions. Together, these complementary perspectives provide a robust framework for refining surrogate brain models. They improve predictive stability during training [154,155], and enhance decoding accuracy in applied settings [156,157]. Nevertheless, evaluating these complex systems remains challenging. Different metrics often capture distinct aspects of neural data, sometimes leading to divergent conclusions. Moreover, neural signals vary across spatial and temporal scales, requiring evaluation strategies that are sensitive to these dynamics. Careful selection of metrics, tailored to the objectives of each task, is therefore essential for producing meaningful and reliable insights. To better address these challenges, we introduce a preliminary surrogate brain benchmark that incorporates 10 complementary evaluation metrics to systematically assess model performance. Consistent with prior observations, we find that different metrics can yield markedly different evaluations of the same model (see Fig. S1).
Beyond fidelity in signal reconstruction, functional correspondence and task-level decoding, surrogate brain models must also demonstrate robustness and generalizability. This requirement is especially important in real-world applications such as brain-computer interfaces, where data are often noisy or incomplete. Robustness can be tested by perturbing inputs, such as adding noise or masking temporal and spatial segments, to assess resilience against signal corruption and missing information [157]. Generalizability, in turn, relies on rigorous cross-validation procedures. K-fold cross-validation supports reliable performance estimation, while leave-one-subject-out approaches are particularly suitable for small-sample neuroscience datasets [158]. For models requiring hyperparameter tuning, nested cross-validation provides unbiased performance estimates [159,160]. These multi-level assessments of fidelity, robustness and generalizability establish a comprehensive framework for benchmarking surrogate brain models.
APPLICATIONS
The surrogate brain, a neural dynamical system that generates brainlike spatio-temporal dynamics and physiological behaviors, offers broad opportunities for advancing both basic neuroscience and translational applications (Fig. 5).
Applications of the surrogate brain. (a) System analysis of the surrogate brain. The surrogate allows direct inspection of fundamental system properties, including phase portrait exploration, neural manifold geometry and network dynamics profiling. (b) Surrogate as a simulation platform. As an in-silico testbed it enables neural dynamics prediction, virtual surgery (e.g. locating epileptogenic foci to aid clinical planning) and counterfactual experiments such as perturbing connection weights or the excitation-inhibition ratio to probe their functional roles. (c) Surrogate guiding neural stimulation. For both non-invasive (e.g. TMS, tES) and invasive (e.g. DBS, SEEG) stimulations, the surrogate brain helps determine where to stimulate, when to target and how to optimize stimulation parameters.
System analysis of the surrogate
A surrogate brain can be considered a parameterized representation of neural dynamics. To examine its system properties, two complementary approaches are typically employed: direct parameter analysis and perturbation-based analysis.
In the direct approach, changes in system parameters are analyzed within phase space. A typical example is the NMM. By analyzing fitted parameters that correspond to physiological indicators, such as the average membrane potential, we can uncover associated brain states [161]. Constructed using differential equations, NMMs allow for in-depth exploration through dynamical and bifurcation theories [14,162]. Complementary insight can be obtained by examining the model’s attractor landscape. Analysis of its landscape—often represented as an energy or quasi-potential surface [163,164]—makes it possible to describe both limit cycles (oscillations) and multiple fixed points (multistability)—two motifs thought to jointly underpin rich brain activity. Such analyses have clarified mechanisms of resting-state maintenance [165], distributed working memory [166] and motor pattern generation [167]. Notably, Ye et al. used an energy-landscape plus minimum-action-path framework to show that, even in the absence of external cues, a working memory network can reside in three co-existing attractors and demonstrated how targeted landscape control can steer transitions between them [168]. Fitting non-linear dynamical systems to whole-brain scales is computationally demanding, so linear approximation models are often used. In state-space form \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \mathbf {x}(t+1) = A \mathbf {x}(t) + B \mathbf {u}(t)\end{document} , the transition matrix A and input matrix B capture state evolution and input-output mapping. Analyzing A uncovers intrinsic dynamics such as oscillation frequencies and stability, while adjusting B helps explain behavioral differences [169,170]. Linear models have also been applied to localize epileptogenic zones by quantifying changes in network connectivity [159].
For models lacking explicit functional forms, such as neural networks, direct parameter analysis moves towards exploring their weight matrices. However, the opaque relationship between system parameters and model outputs complicates the direct monitoring of changes in network parameters [171]. Moreover, the high-dimensional and interdependent latent dynamics within neural networks increase the complexity of analysis and interpretation. Disentangled representation learning offers a promising solution to these issues. It separates latent structures based on statistical or physical principles, enabling the learning of independent factors through distinct latent variables [172]. For example, Miller et al. introduced information bottlenecks in the RNN to encourage sparsity and independence among state variables, thereby enhancing the transparency of cognitive models [173].
Another method for analyzing system properties is through perturbation-based approaches. This indirect method, grounded in statistical physics, involves modifying specific structures or parameters and observing the resultant changes in the dynamical system. For example, altering the excitatory-inhibitory (E-I) activity ratio [174] is a common perturbation method. The E-I balance is crucial for efficient neural encoding and information processing [175,176]. Adjusting this ratio can change the firing rates of neural populations, thereby inducing shifts in brain states [177]. Additionally, structural parameters play key roles in brain dynamics. For instance, in the Kuramoto oscillator model, modifying coupling strengths can induce synchronization among neurons. This framework helps explain parameter variations driven by brain heterogeneity, including differences in neural density and signal transmission speeds across regions [92,178]. Furthermore, tracking parameter updates in network models during learning and memory processes helps one to understand the mechanisms of neural plasticity, revealing how the nervous system adapts over time [179].
In summary, direct parameter analysis provides detailed insights into specific parameters and their roles within the system. On the other hand, perturbation-based indirect methods reveal the system’s responses to changes. Combining these two approaches offers a comprehensive understanding of the system properties of surrogate brains, thereby supporting neuroscience research and clinical applications.
Surrogate as a simulation platform
Traditional wet-lab experiments in neuroscience are limited by long preparation times, high costs and ethical risks, especially in clinical contexts [11]. Moreover, counterfactual testing of ‘what if’ scenarios is often technically or ethically infeasible. These issues have driven the development of simulation platforms based on surrogate brains, which allow for simulating neural dynamics at a lower cost and reduced risk, offering flexibility for research that would be difficult or even impossible to conduct directly in clinical environments.
A notable example is the virtual epileptic patient (VEP), a personalized whole-brain simulation platform for epilepsy surgery planning. By reconstructing patient-specific dynamics, VEP predicts intervention outcomes and optimizes strategies, showing potential to outperform traditional experience-based planning [10,11]. This modeling framework has been expanded into a larger platform, The Virtual Brain, and is used for research on modeling multiple neurological diseases [43,180].
Beyond clinical use, surrogate brains also enable counterfactual reasoning in theoretical research. For instance, simulations comparing ‘thalamic drive and interoceptive drive’ showed that the latter significantly improved the similarity between simulated and empirical resting-state activity [181]. Such controlled perturbations are nearly impossible in vivo, yet become feasible through surrogate platforms.
Using the surrogate brain as a simulation platform significantly facilitates the analysis and validation of experimental research. However, most current models rely on resting-state or task-specific neural activity data for training and fail to adequately account for the dynamic responses following interventions. This limitation poses a challenge for the broader application of surrogate brains. In particular, data-driven models, as opposed to those based on first principles, have not encountered neural data from post-intervention or ‘out-of-specific-input’ scenarios during their training. This limitation makes it difficult to determine whether the surrogate brain’s responses after intervention align with real brain responses, raising concerns about the reliability of simulation platforms. A promising solution lies in combining out-of-distribution (OOD) detection with uncertainty quantification techniques. OOD detection can identify ‘unfamiliar’ inputs [182], while uncertainty quantification assesses the confidence in the predictions [183–185]. By combining these methods, the adaptability and reliability of the surrogate brain as a simulation platform are significantly enhanced.
Surrogate guiding neural stimulation
Traditional neuromodulation techniques, such as deep brain stimulation (DBS), can alleviate symptoms of disorders like Parkinson’s disease [186]. However, its reliance on fixed empirical parameters limits adaptability, leading to inconsistent outcomes [187,188]. Closed-loop neurostimulation incorporating neural feedback addresses this limitation, and surrogate model-guided stimulation has recently emerged as a promising direction. It centers on three key questions: where, when and how to stimulate (see Fig. 5c).
Where to stimulate is a critical aspect of neural stimulation, as different brain regions or neural pathways may respond differently to stimulation. Computational surrogates may help identify brain regions that are likely to be more responsive to stimulation, based on an individual’s functional brain networks [159]. For example, in patients with Parkinson’s disease, a surrogate model can predict the optimal deep brain stimulation site based on the individual’s symptoms and fMRI maximizing the improvement of motor function [189,190]. Similarly, for patients with depression, data-driven surrogates identify brain areas involved in emotional regulation, precisely locating stimulation sites to enhance therapeutic effects [191]. Lu et al. used data-driven models to identify the seizure onset zone in the epileptic brain network [192], laying the foundation for targeted neuromodulation.
When to stimulate plays a decisive role in its effectiveness. For example, the effectiveness of orbitofrontal cortex stimulation is influenced by the brain’s state at the time of stimulation, with outcomes varying according to neural activity associated with specific mood states [188]. The surrogate model requires identifying the sustained biomarker that triggers the neural stimulator in real time [193]. These biomarkers serve as indicators of optimal stimulation conditions, ensuring that the intervention is effective and timely. For example, in conditions like epilepsy, the surrogate model could monitor specific frequency patterns or low-dimensional representations that are associated with an imminent seizure. Meng et al. utilized data-driven models to predict seizure onset in a low-dimensional spatio-temporal recurrent dynamics [194]. Scangos et al. used \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \gamma\end{document} oscillations as biomarkers in closed-loop treatment of severe depression [195]. In DBS for Parkinson’s disease, the controllers adapt the stimulation parameters according to the power or duration of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{upgreek} \usepackage{mathrsfs} \setlength{\oddsidemargin}{-69pt} \begin{document} \beta\end{document} oscillations to track ongoing state changes [196,197].
Effective neural stimulation requires not only precise timing and location, but also consideration of stimulation strategies (e.g. intensity, frequency and pattern). For instance, high-frequency stimulation may be more effective for modulating excitability in certain brain regions, while low-frequency stimulation could be better suited for reducing overactivity in others. Recently, model-guided closed-loop optimal control has emerged as a promising approach for strategy design. Since explicit dynamical equations are often unavailable, data-driven surrogate models provide a practical alternative by capturing input-output relationships and predicting future dynamics [66,198]. Coupled with control theory, these surrogates can derive strategies that balance therapeutic goals with safety constraints, enabling adaptive and precise neuromodulation.
In real-time neuromodulation, a key challenge is balancing predictive accuracy and computational efficiency. Non-linear models often provide higher fidelity but are difficult to implement under strict time constraints. To address this, linearization techniques such as the deep Koopman framework project non-linear neural data into finite-dimensional linear spaces, enabling efficient quadratic solvers without losing predictive performance [66,170,199]. Additionally, dimensionality reduction methods inspired by oscillator theory (e.g. Ott–Antonsen ansatz) have been extended to neural populations, providing reduced-order models that retain stability properties and remain practical for clinical deployment [200].
OUTLOOK AND CHALLENGES
Surrogate brain models provide a powerful framework for linking neural dynamics with brain function, offering transformative opportunities in diagnosis, therapy and brain-machine interfaces. Their advancement, however, is constrained by fundamental challenges in data integration, model architecture and inferring latent dynamics. In the following, we discuss potential solutions across data, model structure and learning algorithms, with an emphasis on advancing surrogate brain models toward accuracy, interpretability and clinical utility.
Multi-scale neural data
Neural data span multiple levels, from cellular recordings to large-scale brain imaging, covering diverse spatial and temporal scales. For instance, microscale spike trains and macroscale fMRI signals differ in resolution, noise statistics and underlying biophysical mechanisms. Directly integrating such heterogeneous data poses risks of information loss or conflicts between modalities [201,202]. Thus, designing systematic strategies for aligning and integrating multi-scale data remains a central challenge. In white-box models, Lu et al. enabled cross-scale integration by combining neural priors with data assimilation to infer neuron-level parameters from macro-level measurements (EEG and fMRI) [48]. While biologically grounded, these models are computationally intensive and often severely ill-posed. Data-driven surrogate brain models face related but distinct challenges. Methods such as multi-layer networks [203], shared latent spaces [204] and domain adaptation [205,206] have been proposed to capture cross-scale relationships. However, preserving interpretability and biological plausibility across levels remains unresolved. Future progress may require embedding biologically informed constraints and adopting causal representation learning to align scales without sacrificing mechanistic fidelity.
Another major challenge arises from the intrinsic variability of neural data, stemming from individual differences, experimental conditions and dynamic task contexts, which complicates robust cross-scale integration. A promising direction is the development of personalized surrogate brain models trained from sparse individual data, initialized using population priors and adapted via sample-efficient fine-tuning (e.g. transfer learning or meta-learning) and generative modeling for data augmentation. Such personalized approaches should be paired with explicit uncertainty quantification and out-of-distribution detection to ensure reliable deployment.
AI model structure
Designing an appropriate model structure is a critical challenge in constructing surrogate brains. As the bridge between raw data and functional derivatives, the model needs to capture neural dynamics and provide a framework for solving inverse problems. This influences both the accuracy of data reconstruction and the ability to infer brain dynamics from observation.
Given the brain’s complexity, the surrogate model should possess sufficient representation capacity to handle high-dimensional, large-scale data. Recent foundation models trained on large datasets have shown promise in simulating complex neural patterns and approaching human cognitive performance [83]. However, the challenge remains to learn representative features from limited, noisy data. Interpretability is another critical aspect. While deep learning models offer high accuracy, their black-box nature complicates understanding how predictions emerge. Enhancing interpretability by incorporating biologically plausible mechanisms, such as synaptic connections and feedback loops, can improve alignment with actual brain function [207]. A key open problem is how to balance representational capacity and interpretability: overly expressive models risk becoming biologically opaque, whereas overly constrained models may fail to capture the brain’s complexity. Hybrid architectures combining biologically grounded priors with data-driven flexibility, or modular architectures informed by causal representation learning, may offer a promising path forward.
Beyond mechanistic interpretability, explainability addresses whether model predictions and decisions are understandable and actionable to human users. For instance, when a surrogate brain recommends a treatment plan, clinicians need to clearly understand which clinical indicators or neural features contributed to the output. Explainable AI tools such as guided backpropagation [208] and Shapley value-based attribution [209] have improved explainability, but they remain fundamentally correlation-based and often yield inconsistent results across methods. Moving toward causal autoencoders [210] may represent an exploratory direction for establishing clearer and more robust causal relationships between brain activity and behavior or clinical decision-making processes.
Generalization and personalization
From theoretical development to practical application, surrogate brain models must address two fundamental challenges: achieving robust generalizability under limited data conditions and advancing toward personalization.
In brain dynamics modeling, neural activity generates high-dimensional state variables, but the scale of available data, particularly individual-specific data, remains limited, often leading to overfitting [211]. Future progress may proceed in two complementary directions. On the one hand, enhancing data availability through international research collaborations and collecting dynamic data across diverse contexts, populations and pathological states [212] can provide richer and more comprehensive training resources. On the other hand, in data-constrained settings, incorporating neuroscientific priors and structured regularization into model design [213] may effectively enhance generalization performance and mitigate overfitting.
Nevertheless, robust generalization alone cannot fully address individual variability. The uniqueness of individual connectomes and the heterogeneity of regional brain dynamics call for models with strong adaptive capacity. Promising directions include adaptive transfer learning and few-shot fine-tuning [214], which enable population priors to be efficiently adapted and calibrated with limited individual data. One promising example is the alignment of latent dynamics that ensures stabilization throughout the day in the brain-computer interface closed-loop center-out cursor control task [133]. These strategies will help drive surrogate brain models from population-level generalizations toward individual-level customization, laying the foundation for personalized neuromodulation and precision interventions in neurological disorders.
Ethical considerations
Beyond technical advances, the development of surrogate brain models must also confront critical ethical challenges. These include protecting privacy and ensuring data security, addressing risks of algorithmic bias, and maintaining fairness and transparency when models are applied across diverse populations [215,216]. Because surrogate brain models inherently rely on sensitive neural and clinical data, robust anonymization, secure data sharing frameworks and rigorous governance structures are essential safeguards against misuse and unauthorized access. Furthermore, surrogate brain models may inadvertently inherit and amplify biases present in the training data [216]. Applying biased models to different patient populations could lead to discriminatory or erroneous outcomes in clinical practice. Proactively addressing these ethical concerns is therefore essential for ensuring that surrogate brain models are developed and deployed responsibly, ethically and equitably.
Although the challenges discussed above remain substantial, including limited generalizability under scarce data conditions, the need to balancing representational capacity with interpretability and the importance of addressing ethical considerations, several promising directions for overcoming these obstacles have been outlined. These advances pave the way toward individualized surrogate brain models with enhanced accuracy, increased robustness and broader applicability. Through continued interdisciplinary collaboration, surrogate brain models may not only deepen our understanding of brain dynamics, but also transform neurological care, ultimately enabling precision medicine and promoting equitable brain health.
Supplementary Material
nwaf457_Supplemental_File
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Siettos C, Starke J. Multiscale modeling of brain dynamics: from single neurons and networks to mathematical tools. Wiley Interdiscip Rev Syst Biol Med 2016; 8: 438–58.10.1002/wsbm.134827340949 · doi ↗ · pubmed ↗
- 2Hodgkin A L, Huxley AF. Currents carried by sodium and potassium ions through the membrane of the giant axon of loligo. J Physiol 1952; 116: 449.10.1113/jphysiol.1952.sp 00471714946713 PMC 1392213 · doi ↗ · pubmed ↗
- 3Breakspear M. Dynamic models of large-scale brain activity. Nat Neurosci 2017; 20: 340–52.10.1038/nn.449728230845 · doi ↗ · pubmed ↗
- 4Elam J S, Glasser M F, Harms M P, et al. The human connectome project: a retrospective. Neuroimage 2021; 244: 118543.10.1016/j.neuroimage.2021.11854334508893 PMC 9387634 · doi ↗ · pubmed ↗
- 5Miller K L, Alfaro-Almagro F, Bangerter N K, et al. Multimodal population brain imaging in the UK biobank prospective epidemiological study. Nat Neurosci 2016; 19: 1523–36.10.1038/nn.439327643430 PMC 5086094 · doi ↗ · pubmed ↗
- 6Kiessner A K, Schirrmeister R T, Gemein L A, et al. An extended clinical eeg dataset with 15,300 automatically labelled recordings for pathology decoding. Neuro Image: Clin 2023; 39: 103482.10.1016/j.nicl.2023.10348237544168 PMC 10432245 · doi ↗ · pubmed ↗
- 7Di Bello F. Unraveling the enigma: how can Chat GPT perform so well with language understanding, reasoning, and knowledge processing without having real knowledge or logic? About Open 2023; 10: 88–96.10.33393/ao.2023.2618 · doi ↗
- 8Durstewitz D, Koppe G, Thurm MI. Reconstructing computational system dynamics from neural data with recurrent neural networks. Nat Rev Neurosci 2023; 24: 693–710.10.1038/s 41583-023-00740-737794121 · doi ↗ · pubmed ↗