Fairness Correction in COVID-19 Predictive Models Using Demographic Optimization: Algorithm Development and Validation Study
Naman Awasthi, Saad Abrar, Daniel Smolyak, Vanessa Frias-Martinez

TL;DR
This paper introduces a fairness correction method called DemOpts to reduce bias in COVID-19 case predictions across racial and ethnic groups.
Contribution
The novel Demographic Optimization (DemOpts) method improves fairness in forecasting models by reducing error parity differences.
Findings
State-of-the-art models show significant error differences across racial and ethnic groups.
DemOpts achieves better error parity than existing debiasing approaches.
The method generates fairer forecasting models for aggregate geographic levels.
Abstract
COVID-19 forecasting models have been used to inform decision-making around resource allocation and intervention decisions, such as hospital beds or stay-at-home orders. State-of-the-art forecasting models often use multimodal data, including mobility or sociodemographic data, to enhance COVID-19 case prediction models. Nevertheless, related work has revealed under-reporting bias in COVID-19 cases as well as sampling bias in mobility data for certain minority racial and ethnic groups, which affects the fairness of COVID-19 predictions across racial and ethnic groups. This study aims to introduce a fairness correction method that works for forecasting COVID-19 cases at an aggregate geographic level. We use hard and soft error parity analyses on existing fairness frameworks and demonstrate that our proposed method, Demographic Optimization (DemOpts), performs better in both scenarios.…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
 Figure 1
Figure 1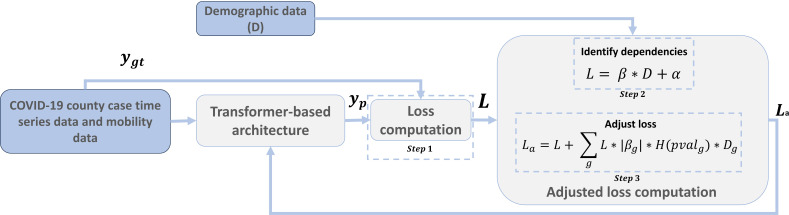 Figure 2
Figure 2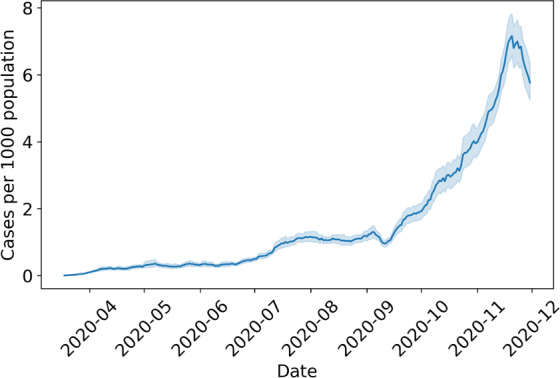 Figure 3
Figure 3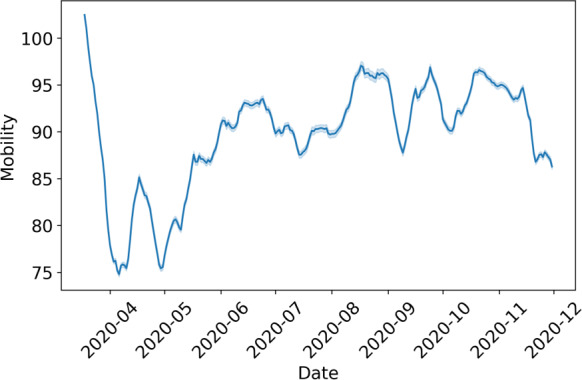 Figure 4
Figure 4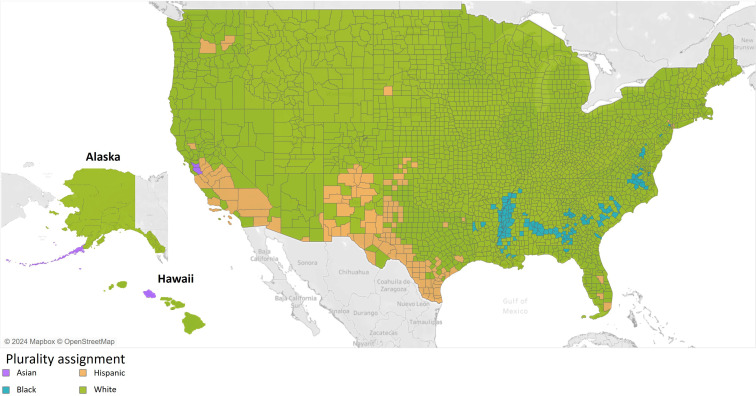 Figure 5
Figure 5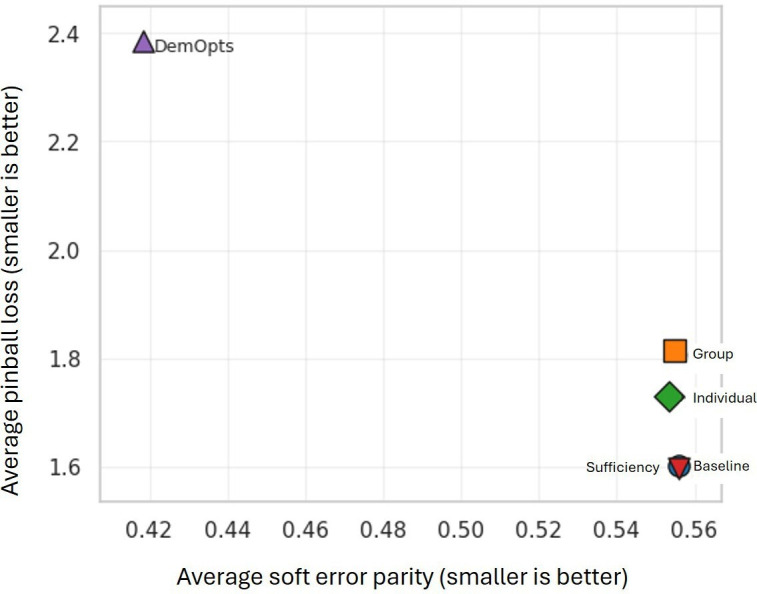 Figure 6
Figure 6| Majority label | Count, n (%) |
|---|---|
| Asian | 6 (0.194) |
| Black | 127 (4.118) |
| Hispanic | 126 (4.085) |
| White | 2825 (91.601) |
| Fairness method | F statistic ( |
|---|---|
| Baseline | 1195.398 |
| Group | 1455.528 |
| Individual | 1469.698 |
| Sufficiency | 1195.651 |
| DemOpts | 668.769 |
| Groups 1 and 2 | Baseline | Group | Individual | Sufficiency | DemOpts |
|---|---|---|---|---|---|
| Asian | |||||
| Black | −0.11 | −0.20 | −0.12 | −0.11 | 1.32 |
| Hispanic | −2.30 | −2.65 | −2.50 | −2.29 | −0.77 |
| White | −2.06 | −2.51 | −2.51 | −2.06 | −0.96 |
| Black | |||||
| Hispanic | −2.18 | −2.45 | −2.38 | −2.17 | −2.09 |
| White | −1.94 | −2.31 | −2.39 | −1.94 | −2.29 |
| Hispanic | |||||
| White | 0.23 | 0.14 | −0.01 | 0.23 | −0.19 |
| Group | Baseline | Group | Individual | Sufficiency | DemOpts |
|---|---|---|---|---|---|
| Asian | 0.811 | 0.842 | 0.850 | 0.811 | 0.454 |
| Black | 0.764 | 0.774 | 0.807 | 0.764 | 0.681 |
| Hispanic | 0.093 | 0.048 | 0.003 | 0.093 | 0.12 |
| Group | Baseline | Group | Individual | Sufficiency | DemOpts |
|---|---|---|---|---|---|
| Asian | 0.482 | 0.472 | 0.444 | 0.479 | 1.741 |
| Black | 0.600 | 0.674 | 0.570 | 0.598 | 1.015 |
| Hispanic | 2.784 | 3.131 | 2.951 | 2.776 | 3.597 |
| White | 2.546 | 2.987 | 2.961 | 2.540 | 3.192 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsCOVID-19 epidemiological studies · Ethics and Social Impacts of AI · Explainable Artificial Intelligence (XAI)
Introduction
Background
Forecasting the number of COVID-19 cases, hospitalizations, or deaths is crucial to inform decision-making. For example, COVID-19 forecasts can be used by hospitals to evaluate medical needs and required resources, such as supplies or beds, or by public health officials to inform closure policies at various geographical scales. In the United States, COVID-19 forecasts have been used at the state and county levels to inform social distancing or masking, such as the publicly available forecasts on the COVID-19 Forecast Hub that the Centers for Disease Control and Prevention (CDC) has routinely used in their communications [12].
Related work over the past 4 years has shown a diverse variety of COVID-19 forecasting approaches [3-10, 11] using datasets such as the New York Times (NYT), Johns Hopkins University, COVID-19 Community Vulnerability Index, Google, and Apple [12-16], among others. Most publications focused on COVID-19 case prediction have reported results around the accuracy of the models, that is, minimizing the difference between the predicted cases and the actual number of cases reported. Nevertheless, previous work has shown that the accuracy of COVID-19 predictions can depend on various social determinants, including race or ethnicity [17], income, or age [18], revealing worse performance for protected attributes and pointing to a lack of COVID-19 predictive fairness that can affect resource allocation and decision-making. This lack of predictive fairness might be related to bias in the datasets used to train the model, that is, bias in COVID-19 case reporting [19] or bias in mobility data [20].
Given the presence of bias in the training datasets frequently used by COVID-19 forecast models, and previous work demonstrating that COVID-19 prediction accuracy can vary across social determinants, it becomes critical to devise methods to prevent data biases from percolating into the COVID-19 forecasts to guarantee fair decision-making based on case predictions. In this paper, we focus on in-processing bias mitigation approaches given their scarcity in the COVID-19 literature and propose Demographic Optimization (DemOpts), a debiasing method designed to achieve COVID-19 case prediction error parity across racial and ethnic groups in the context of deep learning models, that is, guarantee that county prediction errors are not significantly different across racial and ethnic groups. Although there exists a diverse set of COVID-19 predictive approaches, we focus on deep learning models because these are the most frequently used models in the machine learning community [21], and narrow down our choice to transformer-based architectures because they are state-of-the-art in time series predictions [22].
The main objective of DemOpts is to improve the fairness of the COVID-19 case predictions at the county level by achieving error parity in a regression setting [17]. DemOpts proposes a novel debiasing approach that leverages county racial and ethnic data during training to modify conventional deep learning loss functions to penalize the model for statistically significant associations between the predictive error and the race or ethnicity distribution of a county. Our main contributions are:
We present DemOpts, a novel debiasing method for deep learning architectures that attempts to increase the fairness of the COVID-19 county case predictions by achieving error parity, that is, guaranteeing that prediction errors are similar across racial and ethnic groups. The DemOpts architecture is designed to optimize error parity across race and ethnicity using a novel multilabel approach that allows each county to be characterized by its own racial and ethnic group distribution during the debiasing process, instead of by a unique label.We propose a novel evaluation protocol for the COVID-19 context, and we show that (1) state-of-the-art COVID-19 county case prediction models based on transformer architectures with no debiasing approach lack error parity, that is, prediction errors are statistically significantly different across racial and ethnic groups, (2) DemOpts applied to transformer-based architectures improves the error parity of the prediction models, increasing the similarity between mean prediction errors across racial and ethnic groups, and (3) the DemOpts debiasing approach performs better than state-of-the-art debiasing methods for regression settings.
While COVID-19 research was particularly prominent from 2020 to early 2024, challenges related to data biases and sampling issues in predictive modeling remain highly relevant. Our approach, leveraging the regression fairness model DemOpts, provides a robust framework to address these challenges. As future pandemics and public health crises arise, similar issues will persist, making our contribution valuable for ensuring fairness and reliability in predictive models.
Literature Review
Deep LearningBased Forecasting Models
Deep learning models have started to become popular in time series prediction tasks. The available methods include (1) autoregressive models, such as Long Short-Term Memory or Gated Recurrent Network [23]; (2) graph-based neural networks, such as graph attention networks [24], Spatio-temporal Graph Convolutional Network [25], neighbor convolution model [26], or graph convolutional network; and (3) transformers, including Logarithmic Sparse Transformer [27], Informer [28], Autoformer [29], Frequency Enhanced Decomposed Transformer [30], Pyramidal Attention–based Transformer [31], and Patch Time Series Transformer [32]. In this paper, we specifically focus on the temporal fusion transformer (TFT) architecture [22], since it allows us to easily incorporate exogenous variables (eg, mobility data) as well as static variables (eg, demographic data) on top of the COVID-19 time series.
Bias in Mobility and COVID-19 Data
The COVID-19 epidemic was closely monitored and had extensive data available about the counts of cases, hospitalizations, and deaths, as well as fine-grained information about mobility of people, policy implementations, vaccinations, and so on. Reducing the impact of mobility data or COVID-19 case bias in COVID-19 case predictions, as we do in this paper, is of critical importance to support decision-making processes focused on resource allocation during pandemics, to reduce harm and guarantee that decisions are fair and just across racial and ethnic groups. Human mobility data has been used to characterize human behaviors in the built environment [33-37], for public safety [3839], during epidemics and disasters [40-45], as well as to support decision-making for socioeconomic development [46-53]. During the COVID-19 pandemic, human mobility has played a central role in driving decision-making, acknowledging the impact of human movement on virus propagation [79101854]. Previous work has revealed sampling bias in mobility data collected via mobile apps, with Black and older individuals being underrepresented in the datasets [20], and has exposed biases in COVID-19 forecasting models [5556]. COVID-19 underreporting bias has been discussed in the literature [57-59] and points to multiple causes, including inadequate testing across certain minority groups or a lack of consistency in reporting race and ethnicity for COVID-19 cases [19].
Fairness Metrics and Fairness Corrections
Transformer-based COVID-19 case forecast models require the use of fairness metrics for regression settings, given that the loss optimization process in gradient-based deep learning architectures uses real-number predictions instead of classes.
Agarwal et al [60], Fitzsimons et al [61], and Gursoy and Kakadiaris [17] outline the different aspects of fairness in regression settings and propose a set of fairness metrics for regression-type models. For this paper, we use the error parity metric proposed in [17]. Error parity requires error distributions to be statistically independent of racial and ethnic groups. We expand this definition and relax the statistical significance requirement to be able to also evaluate whether the proposed DemOpts method can at least reduce the differences in error distributions across racial and ethnic groups, even when they are still statistically significantly different. To correct for bias and unfair performance in deep learning models, researchers have used preprocessing [6263] and in-processing correction approaches [64-67]. Preprocessing approaches focus on creating a better input for learning deep neural network models by removing bias from the datasets [6263], and there have been successful efforts focused on debiasing underreporting COVID-19 datasets to estimate actual cases or deaths before they are fed into predictive models [6869]. On the other hand, in-processing approaches to improve the fairness of deep learning models, like the one we use in this paper, focus on the model and its regularization, usually adding a bias correction term in the loss function [6567]. In this paper, we will compare our proposed debiasing approach against 3 state-of-the-art methods for debiasing in regression settings, which are individual fairness correction [70], group fairness correction [70] (both Lagrangian-based), and sufficiency [71]. Individual and group fairness calculate penalties by determining overestimations across different groups and weighting the loss by a factor proportional to the overestimations, while sufficiency-based regularizers propose to make the loss independent of sensitive data attributes by simultaneously training a joint model and subgroup-specific networks to achieve fair predictions [71].
Methods
Proposed DemOpts
Our modeling focus is on deep learning models, which are the most frequently used approach for COVID-19 county case forecasts in the machine learning community [21]. We specifically focus on the TFT model introduced in [22] for several reasons. First, this model is state-of-the-art in interpretable time series prediction [22]. Second, this model allows for the use of static reals as input to the model (ie, attributes that do not change over the duration of the training process, such as demographic percentages or population statistics). Third, the model works well with time-dependent features, including COVID-19 cases or mobility data, whereby past data influences future statistics.
DemOpts is an in-processing algorithm that modifies the standard training procedure for deep learning models at the loss computation stage. The algorithm modifies conventional loss functions to penalize the model for any statistically significant association (P<.005) between the county prediction loss (error) and the county’s racial and ethnic groups. In other words, DemOpts performs a race-based correction on the error to account for county demographic, racial, and ethnic distributions.
The algorithm can be divided into 3 steps (refer to Figure 1, Figure 2, and “S.1 DemOpts Method” in Multimedia Appendix 1 for mathematical details).
Algorithm: Demographic Optimization (DemOpts). TFT: Temporal Fusion Transformer.
Flow diagram for the Demographic Optimization (DemOpts) method.
Step 1: Calculate Loss
We use quantile predictions, as standard in COVID-19 forecasting literature [272], instead of point-value predictions. Quantile predictions are measured for 7 quantiles (0.02, 0.1, 0.25, 0.5, 0.75, 0.9, and 0.98) to gain insights into the uncertainty ranges and CIs of the COVID-19 county case predictive models. When using quantile predictions, the error is computed using quantile loss, also known as pinball loss (PBL), and defined as follows:
For quantile q, the PBL for the prediction of a given input X_i_ is PBL_q_(y_ip_, y_i_), where y_i_ is the ground truth, and y_ip_ is the predicted value. The average over all quantiles can be represented as .
Step 2: Identify Dependencies Between Prediction Errors, Race, and Ethnicity
To achieve error parity, that is, mean errors being independent of racial and ethnic population distributions, we determine the relationship between errors and race and ethnic distributions. For that purpose, DemOpts fits a regression model between the prediction losses PBL (y_ip_,y_i_) across data points i and their corresponding county race and ethnicity distribution for each race D_i_:
where d_i_ are the corresponding county demographic features extracted from the US census data (represented as the percentage of each racial and ethnic group of the county for datapoint i), and lookahead refers to the number of days into the future the COVID-19 case prediction was generated for. In matrix representation:
Once the regression model is fit, both regression coefficients (β) and their statistical significance (P value) are passed on to Step 3 to modify the adjusted loss and attempt to decouple race from the errors (loss).
Step 3: Adjust the Loss
DemOpts modifies the conventional loss of deep learning models by adjusting for racial or ethnic bias in the error, that is, the loss is increased whenever a statistically significant regression coefficient for a race or ethnicity is found in Step 2 (with P value threshold=.005). By increasing the loss, DemOpts attempts to reduce the association between errors and race. Specifically, the loss is adjusted by the product of the original loss PBL (y_ip_,y_i_), the percentage race or ethnicity D_j_ that holds a significant relationship with the error, and its coefficient β_j_ in absolute value:
Evaluation Protocol
In this section, we present a novel evaluation protocol to assess changes in fairness for TFT forecasting models when debiasing approaches, including DemOpts, are applied. We first describe the TFT COVID-19 county case prediction model we use, and the different debiasing approaches we evaluate on that prediction model. Next, we describe the error parity metrics we use to evaluate the fairness of each prediction model, and finally, we present the approach to analyze whether DemOpts improves the error parity metrics when compared to other state-of-the-art debiasing approaches for regression settings.
Predictive Model and Debiasing Approaches
We use the TFT with the conventional PBL function (PBL is the standard metric for reporting model performance in CDC Forecast Hub [2]) as our baseline model (TFT_Baseline_) to predict the number of COVID-19 county cases for a given day.
Input data to the TFT model includes past COVID-19 cases per county, mobility data from SafeGraph, and race and ethnicity data for the county. We also train and test another TFT enhanced with the DemOpts debiasing method, TFT_DemOpts_, that adjusts the loss computation to attempt to eliminate or reduce the dependencies between error and race to achieve error parity. In addition, we train and test 3 more TFTs enhanced with state-of-the-art debiasing methods for regression settings, namely, individual fairness TFT_Individual_ [70], group fairness TFT_Group_ [70], and the sufficiency-based regularizer TFT_Sufficiency_ [71]. Individual and group fairness methods calculate penalties by determining overestimations across different groups and weighting the loss by a factor proportional to the overestimations, while the sufficiency-based regularizer trains a joint model and group-specific networks to achieve fair predictions. We replicate their methodology and adapt it to the forecasting setting by keeping TFT as the common network.
Measuring Model Fairness
We choose error parity as our fairness metric [17], with a focus on evaluating whether the distribution of predictive errors at the county level is independent of county majority race and ethnicity, that is, prediction errors are not statistically significantly different across racial and ethnic groups. To measure the fairness of each of the models TFT_Baseline_, TFT_DemOpts_, TFT_Individual_, TFT_Group_and TFT_Sufficiency_, we propose a 2-step process.
Step 1: Associate Errors With County Race or Ethnicity
To carry out the fairness analysis, we need to associate the PBL error of each county with race and ethnicity labels. However, that would require access to race-stratified COVID-19 case data at the county level, which is unfortunately not available due to systemic data collection failures during the pandemic [73]. Hence, we propose to associate each county and its error with the majority race, that is, we label each county with the race or ethnicity that has the highest population percentage in that county. During the fairness analysis, we refer to majority White counties as the unprotected group and majority minority counties, such as Black or Hispanic, as the protected groups (details about the racial and ethnic groups considered in the evaluation are provided in the “Datasets” section).
In addition, we normalize each county’s PBL error by county population size. The normalization by county population allows us to scale the errors appropriately, since higher-population counties will have higher case counts and thus, higher-magnitude errors. Normalizing by population fairly compares the error per unit population of one county with another:
where y_ti_ is the ground truth, y_pi_ is the predicted value, and pop_i_ is the county population.
We then calculate the average normalized PBL for each racial or ethnic group:
where g represents the racial or ethnic group and c_g_ is the set of all counties with as the majority group. This gives us the average normalized PBL for each demographic group.
Step 2: Compute Fairness Metric
Once PBLs have been calculated for each racial and ethnic group in the United States, we can compute the error parity, that is, the fairness metric focused on evaluating whether the prediction errors are different across race and ethnicity. We propose 2 metrics to measure the error parity of COVID-19 county case predictions: hard error parity and soft error parity.
Hard Error Parity Metric
Model predictions exhibit hard error parity when no statistically significant differences exist between normalized mean case prediction errors (AvgNormPBL) across racial or ethnic groups. In other words, normalized mean PBL errors across counties of different racial and ethnic groups are similar and hence, not biased by race or ethnicity. To test for the hard error parity of a prediction model, we propose to run one-way ANOVA followed by post hoc Tukey honestly significant difference (HSD) tests between the normalized mean error distributions of all racial and ethnic groups. ANOVA tests are an adequate choice even in violation of normality for large sample sizes, and in the presence of unequal sample sizes with homogeneous variance; thus, we choose this parametric test due to its superior strength [7475].
Rejecting the null hypothesis for ANOVA would point to significantly different mean error values across some racial or ethnic groups and to a lack of perfect hard error parity. The subsequent analysis of the post hoc Tukey HSD test would reveal the pairs of racial and ethnic groups whose mean error values are significantly different and the numerical difference. The Tukey test also highlights the pairs of racial and ethnic groups for which the mean error is not statistically significantly different, pointing to instances where hard error parity exists for that model.
Soft Error Parity Metric
Instead of measuring the statistical significance of the relationship between county race labels and county errors, we propose to use the Accuracy Equity Ratio (AER) metric [76]. AER computes the ratio between the errors of the protected and unprotected groups as follows:
where subscript pg indicates counties labeled as the protected group (majority minority counties). unpg indicates counties labeled as the unprotected group (White), and AvgNormPBL is the average of the normalized PBL across counties for a given racial group g (pg or unpg).
As defined, the AER metric goes from 0 to ∞. AER values in the range [0, 1] indicate comparatively lower normalized PBL for protected groups, which means the model predictions could be biased—have higher errors—for White majority counties; while AER values larger than one indicate that the model could be biased against the protected group, that is, the prediction errors are larger for counties with majority-minority groups. Values close to 1 indicate parity in error distribution between the protected group counties and the majority White counties. We claim that a predictive model achieves soft error parity for a given protected group when the AER value is close to 1, that is, the mean predictive error between that protected group and the White race is similar.
An alternative approach to assigning majority race or ethnicity would be to explore the associations between PBL errors and the distribution of racial and ethnic groups in a county (independent of COVID-19 cases, since that data are not available). Using a quantile regression, we can explore whether DemOpts eliminates significant associations between racial or ethnic percentages and the PBL errors, or at least reduces their magnitude. This approach removes the majority race requirement, but does not allow us to perform analyses with well-established fairness metrics in the literature, such as AER. Results are provided in the Multimedia Appendix 1.
DemOpts Over State-of-the-Art
To assess whether DemOpts is a better debiasing approach than state-of-the-art methods, we need to compare the error parity metrics of the COVID-19 county case prediction model enhanced with the DemOpts method, TFT_DemOpts,_ against the error parity metrics of the same prediction model enhanced with the other debiasing approaches (individual TFT_Individual_, group TFT_Group_, or sufficiency TFT_Isufficiency_), as well as with the baseline COVID-19 county case prediction model without any debiasing approach, TFT_Baseline_. Next, we describe how we carry out this analysis for the hard and soft error parity metrics.
Hard Error Parity
We computed the hard error parity metric for each of the COVID-19 county case prediction models, using one-way ANOVA and the post hoc Tukey HSD test. An exploration of the statistical significance of the mean error difference for each pair of racial and ethnic groups will reveal whether applying DemOpts to the COVID-19 case prediction model produces fewer instances of significant mean error differences than any of the other debiasing methods or the baseline. In other words, a decrease in the number of significantly different mean PBL errors between races would point to an achievement of hard error parity for more racial and ethnic groups than other state-of-the-art debiasing approaches or the baseline.
Soft Error Parity
To assess whether DemOpts applied to a COVID-19 case prediction model has higher soft error parity than any of the other state-of-the-art debiasing approaches, we propose to compare the AER values for each protected race and ethnic group across the 5 models: TFT_DemOpts_, TFT_Individual_, TFT_Group_, TFT_Sufficiency_, and TFT_Baseline_. Since AER values represent the quotient between the normalized mean prediction errors of a protected race or ethnicity vs White counties, the model with AER values closer to 1 will be the approach with the highest soft error parity. To measure AER’s distance to 1, we compute the distance=|1-AER_race_| for each race and ethnic group, which represents the distance to a perfect soft parity error of 1. Distances closer to zero reveal better soft error parities.
Datasets
In this section, we discuss the datasets we use in the DemOpts evaluation in the “Results” section. We train COVID-19 county case prediction models for the United States using COVID-19 case data, as well as mobility and demographic data. Mobility data has been used by previous work to inform case predictions via human mobility behaviors, under the assumption that the way people move might have an impact on the spreading of the epidemic. On the other hand, demographic data, either raw from the census or combined in different types of vulnerability indices, has also been shown to help predict COVID-19 prevalence, given the fact that COVID-19 has heavily affected vulnerable populations [59].
COVID-19 Case Data
We use the COVID-19 case data compiled by the NYT at the county level [12]. We account for delayed reporting by using the 7-day daily rolling average of COVID-19 cases (computed as the average of its current value and 6 previous days) instead of raw counts. Figure 3 charts the daily COVID-19 reported cases throughout the data collection period.
COVID-19 reported case counts per 1000 population across the United States.
Mobility Data
SafeGraph open-sourced the mobility patterns of smartphone app users at the onset of the pandemic. These data points are curated by tracking the movements of millions of pseudonymized users via mobile app Software Development Kits (SafeGraph). Based on the data available, we use the daily origin-destination (OD) county-to-county flows [77]. OD flows represent the volume of trips between pairs of counties across the United States for each day. For OD flows, we only use SafeGraph inflow (ie, mobility into the county). The inflow mobility is measured as changes in volumes of flows with respect to a baseline of normal behavior computed by SafeGraph using mobility data from February 17, 2020, to March 7, 2020.
Previous work has shown sampling bias in mobility datasets, revealing that not all races and ethnicities are equally represented due to variations in smartphone penetration rates [2078]. It has also been shown that sampling bias in mobility data can negatively impact downstream tasks such as COVID-19 forecasting [56]. While the addition of mobility data could potentially help improve prediction accuracy and support better decision-making, it also introduces bias. Our empirical analysis of DemOpts aims to understand whether the debiasing method proposed in this paper can improve the fairness of COVID-19 county case predictive models when mobility data is used as input to the predictive model. Figure 4 shows the aggregate mobility data across the country. We see an initial drop in mobility in April (2020‐04), which corresponds to the first lockdown period. We then observed an increase in mobility a month later, which partially stabilizes after April.
Mobility for all ethnic and racial groups.
Race and Ethnicity Data
We retrieve the race and ethnicity data from each county in the United States from the 2019 5-year American Community Survey. This survey collects data annually from all 50 states, Puerto Rico, and Washington, DC. As described in Step 1 of the evaluation protocol, we associate each county and its errors with the majority race (ie, we label each county with the race or ethnicity that has the highest population percentage in that county). Following this procedure identifies 4 racial and ethnic groups for the majority of counties: Asian, Black, Hispanic, and White. Table 1 shows the distribution of US counties into these 4 racial and ethnic groups, and Figure 5 show color-coded maps with the majority racial or ethnic group for each county.
Counties and majority-based label. (Mapbox and OpenStreetMap were used to create this map [7980,81].)
Model Training
For evaluation purposes, we use COVID-19 case and SafeGraph mobility data from March 18, 2020, to November 30, 2020, for the training (207 days) and testing (49 days) of the TFT COVID-19 county case prediction models. The forecast task is the prediction of the number of COVID-19 cases for a given county from day X+1 to X+50, that is, the following 2 months (long-term forecasting with lookahead values from 1 to 50). Specifically, we train and test (1) the TFT_Baseline_, a TFT prediction model without a debiasing method; (2) the TFT_Individual_, TFT_Group_, and TFT_Sufficiency_, TFT prediction models with state-of-the-art debiasing methods; and (3) TFT_DemOpts_, a TFT prediction model enhanced with our proposed debiasing method. All 5 models are trained and tested for the same temporal range, and all are implemented using the PyTorch Forecasting library [82]. We limit the period of analysis to a time before COVID-19 vaccines were available, given that after that event, research has revealed a less clear relationship between mobility data and postvaccines COVID-19 case volumes [83]. We use the prediction errors (PBL) per racial and ethnic group to analyze and compare the hard and soft error parity of all trained models.
Ethical Considerations
We used openly available datasets for mobility data (SafeGraph), COVID-19 case count (NYT), and demographic data (American Communities Survey). There was no human participant recruitment in this study, and thus we did not require institutional review board approval. All the datasets were aggregated at the county level and do not pose the risk of deanonymization.
Results
Hard Error Parity Results
ANOVA tests of the normalized mean PBL error distributions across racial and ethnic groups for each debiasing approach were all significant, pointing to a dependency between race and the normalized prediction errors.
Table 2 shows the F statistic and test significance for each of the prediction models with and without debiasing approaches. The significant ANOVA tests reveal that perfect hard error parity is not achieved by any of the debiasing methods. In other words, for some racial and ethnic groups, there exist statistically significant differences between their mean PBL prediction errors of different racial and ethnic groups; this effect occurs for the TFT_Baseline_ model as well as across all the other predictive models enhanced with a debiasing approach.
Nevertheless, post hoc Tukey HSD tests revealed interesting, nuanced results, showing significant differences in errors only between specific pairs of racial and ethnic groups. Table 3 shows the post hoc Tukey HSD test results for each COVID-19 case predictive model: the baseline, the baseline enhanced with 1 of the 3 state-of-the-art debiasing approaches, and the baseline enhanced with our proposed method (DemOpts). Each row represents the output of the post hoc test, that is, the difference between the normalized mean PBL error of Group 1 and Group 2 (NormPBL_Group1_ - NormPBL_Group2_). If the difference is positive, it means that the normalized mean predictive error is higher for Group 1; if the difference is negative, the normalized PBL error is higher for Group 2 (superscript b indicates statistically significant differences).
The first relevant observation when examining the table is that the baseline model, focused on predicting COVID-19 county cases with no debiasing approach is highly biased, with statistically significant differences between the mean normalized errors across all pairs of races, except for the comparison between Asian and Black counties as well as Hispanic and White counties, for which there is no statistically significant difference. These results reveal that there is no racial or ethnic group that achieves hard error parity and motivate our exploration of whether state-of-the-art debiasing methods or our proposed DemOpts can improve the hard error parity results of the baseline model.
When examining Table 3, we can observe that predictive models enhanced with the individual, group, or sufficiency debiasing methods do not improve the hard error parity over the baseline. On the one hand, similarly to the baseline model, the state-of-the-art debiasing methods (TFT_Individual_, TFT_Group_, and TFT_Sufficiency_) achieve hard error parity between Asian and Black counties and between Hispanic and White counties, that is, the mean error difference between these counties is not significant, pointing to a fair distribution of errors. On the other hand, for each pair of racial and ethnic groups whose prediction error distributions are significantly different for the baseline (rows with asterisks in the Baseline column), they remain significantly different for the individual, group, and sufficiency debiasing methods (rows with superscript b in the individual, group, and sufficiency columns).
When examining the significant mean PBL differences between racial and ethnic groups for the baseline and the state of the art debiasing models, we observe that all coefficients have similar values, signaling similar significant mean PBL differences between racial and ethnic groups (with values between 1.942 and 2.659 error cases per 1000 population). The sign of the coefficients reveals higher mean PBL errors for Hispanic and White counties when compared to Asian or Black counties, and higher mean PBL errors for White counties when compared to Hispanic counties across all models. For example, Hispanic and White counties have mean prediction errors 2.302 and 2.064 cases higher, respectively, when compared to Asian counties and while using the baseline model; and Hispanic and White counties have errors 2.457 and 2.313 cases higher, respectively, when compared to Black counties using the baseline model enhanced with the Group debiasing approach.
Moving on to DemOpts, the table shows that our proposed approach is the only debiasing method that achieves hard error parity in more cases than the baseline, effectively removing some of the associations between race and ethnicity and the normalized mean error distribution (PBL). Specifically, DemOpts removes the significant difference between the prediction errors of Asian and White counties and of Asian and Hispanic counties (refer to values with supercript c in Table 3), effectively achieving hard error parity for Asian counties, that is, the mean PBL in Asian counties is always similar to the mean error in counties of all the other racial and ethnic groups. These improvements occur additionally to hard error parity already seen in TFT_Baseline_ (hard error parity between Asian and Black counties and between Hispanic and White counties), which are also present in the other 3 debiasing methods. In other words, DemOpts improves the hard error parity of case predictions for 2 additional racial and ethnic pairs compared with any of the other debiasing methods.
Finally, when looking specifically at the hard error parity between protected (Asian, Black, and Hispanic) and unprotected groups (White), DemOpts achieves hard error parity for Asian and Hispanic groups; that is, their mean prediction errors are not significantly different from those of White counties, while the baseline and the other 3 debiasing methods only achieve hard error parity for the Hispanic group when compared to White counties. These findings with respect to White counties motivate the evaluation of the soft error parity of the different models to determine, for example, whether DemOpts achieves the best soft error parity for the Black group (since hard error parity was not achieved), or to see if DemOpts has better soft error parity than other debiasing methods for Asian or Hispanic groups. Next, we explore the soft error parity metric for the TFT baseline and for all TFT models enhanced with debiasing approaches.
Soft Error Parity Results
Table 4 shows the distance to the perfect soft error parity for each of the debiasing approaches across all protected racial and ethnic groups. As we can observe, DemOpts has the smallest values—closest distances to perfect soft error parity—for Asian and Black counties, while the individual debiasing method almost achieves perfect soft error parity for the Hispanic counties. In other words, DemOpts is the debiasing approach that produces the most similar errors between Asian and White counties and between Black and White counties, thereby achieving the largest reduction in predictive bias. On the other hand, the Individual debiasing method achieves errors for Hispanic counties that are closest to the White group. In addition, it is important to highlight that the Group and Sufficiency debiasing methods achieve soft error parities that are close to the TFT_Baseline_, which is not enhanced with any debiasing method.
Overall, these results reveal that DemOpts is the debiasing approach that improves the soft error parity of case prediction models, with errors for Asian and Black counties being the closest to errors in White counties. When accounting for additional factors, DemOpts outperforms the other methods by reducing the racial associations of model error.
In Table S1 in Multimedia Appendix 1, we provide and discuss the results for the quantile regression analysis in detail. Overall, the results confirm our findings with majority race labels, with DemOpts consistently outperforming other methods, showing the smallest coefficient magnitude for associations between the percentage of Asian, Black, and Hispanic populations and model error.
Discussion
Principal Findings
Through our comparison of model performance for COVID-19 case prediction across counties of differing racial demographics, we showed that DemOpts outperforms other baselines for debiasing predictions. In our analysis of hard error parity, we found that DemOpts was the only debiasing method to eliminate statistically significant relationships between prediction error and racial demographics when compared with the baseline. While some significant associations remained, DemOpts achieved hard error parity for Asian vs White counties and Asian vs Hispanic counties. In the soft error parity analysis, DemOps substantially outperformed the baselines for Asian and Black counties, with a 69.4% reduction and 23% reduction, respectively, compared with the next closest method.
Why is DemOpts Better?
The results showed that DemOpts is the only debiasing approach to achieve both hard and soft error parity for all 3 racial minority groups when compared with White counties.
In an attempt to understand why DemOpts succeeds in increasing both hard and soft error parity in the context of COVID-19 county case predictions, and compared with other debiasing methods, we computed the average PBL for each racial and ethnic group and for each predictive model enhanced, or not, with a debiasing method (refer to Table 5). We observed that DemOpts achieves better hard and soft error parity metrics because it considerably increases the errors for Asian and Black counties with respect to the baseline, until the differences with Hispanic and White are made not statistically significant (hard error parity) or closer to the White mean errors (soft error parity). Comparing Tables 4 and 5, we observed that DemOpts achieves considerably higher fairness for the Hispanic group (when compared to White) than for the Asian and Black groups (0.12 vs 0.454 and 0.681 in Table 4). As a result, the average PBL error for the Hispanic group (3.59 in Table 5) is considerably higher than the Asian and Black racial groups (1.7 and 1, respectively). We hypothesize that the differences in average errors and performance across racial and ethnic groups could be due to differences in the bias present in the training data, that is, mobility data or COVID-19 case counts could be more biased for Asian or Black groups, thus making it harder to achieve fair predictions when compared to White, and, in turn, due to the fairness-accuracy trade-off, making them more accurate (lower errors).
These results show that DemOpts’ optimization could not decrease prediction errors while trying to improve fairness, showing a fairness-accuracy trade-off that has been reported previously in the literature [84]. To further clarify this finding, Figure 6 shows both the average PBL and soft parity across all the models considered in this paper. As shown, DemOpts has the lowest soft error parity, but the highest PBL (top-left corner in the plot), while the other models decrease the PBL by sacrificing fairness (higher error parity in the bottom-right corner).
Fairness-accuracy tradeoff. Model error (average pinball loss) vs average soft error parity (|1-AER|) for each model.
Limitations
While DemOpts outperforms other state-of-the-art approaches in debiasing COVID-19 predictions, there are some limitations to DemOpts and our evaluation. First, DemOpts is unable to remove all statistical associations for the hard parity analysis, potentially because doing so would impose further reductions in model performance. For the soft parity analysis, the individual fairness approach is best for Hispanic counties, but the difference in parity levels is small. Regarding evaluation, our focus is exclusively on COVID-19 county case prediction—while evaluation on other datasets and prediction tasks would be helpful for future work, our current evaluation provides sufficient evidence to show its applicability to other contexts. In addition, we compare DemOpts to baselines only on error parity metrics. Other fairness metrics may apply to the COVID-19 context and should be evaluated in future work, but we focus on error parity because DemOpts is specifically designed to mitigate it. Finally, we only compare DemOpts and baseline debiasing approaches within TFT models—future work should compare with other commonly used models for COVID-19 case prediction.
Regardless, our novel debiasing approach shows that hard and soft error parity across protected and unprotected racial and ethnic groups can improve relative to other state-of-the-art approaches.
Finally, it is important to clarify that although in this paper, DemOpts focuses on bias mitigation in COVID-19 forecasting, it could also be applied to other health forecasting tasks where sampling bias in data collection can lead to bias in downstream tasks, for example, forecasting flu cases. These forecasts, when done at the county level and when using mobility data to model human spread, could benefit from the DemOpts method by reducing the effect of mobility bias or case count bias on other infectious diseases.
Conclusion
Researchers have worked tirelessly on the creation of accurate COVID-19 case prediction models to support resource allocation and decision-making. However, sampling and underreporting biases in the data used to train these models have resulted in worse prediction performance for certain protected attributes, pointing to a lack of COVID-19 predictive fairness that could affect decision-making. In this paper, we show that state-of-the-art architectures in COVID-19 case predictions (TFT models) incur unfair prediction error distributions, and we design a novel debiasing approach and evaluation method to increase the fairness of predictions in the context of COVID-19 county case forecasts. DemOpts modifies the loss function in deep learning models to reduce the dependencies between error distributions and racial and ethnic labels. Our results show that DemOpts improves both the hard and soft error parity of COVID-19 county case predictions when compared with state-of-the-art debiasing methods.
Supplementary material
10.2196/78235Multimedia Appendix 1Details on the differentiability and regression analysis of fairness method errors.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1COVID-19 forecasting and mathematical modeling Centers for Disease Control and Prevention (CDC)2023 UR Lhttps://www.cdc.gov/coronavirus/2019-ncov/science/forecasting/forecasting-math-modeling.html Accessed 27-12-2025
- 2COVID-19 Forecast Hub 2020 UR Lhttps://covid 19forecasthub.org/Accessed 27-12-2025
- 3Zou D Wang L Xu P Chen J Zhang W Gu Q Epidemic model guided machine learning for COVID-19 forecasts in the United Statesmed Rxiv Preprint posted online on 05242020 doi 10.1101/2020.05.24.20111989 · doi ↗
- 4Pei S Shaman J Initial simulation of SARS-Co V 2 spread and intervention effects in the continental U Smed Rxiv Preprint posted online on Mar 212020 doi 10.1101/2020.03.21.20040303 · doi ↗
- 5Chiang WH Liu X Mohler G Hawkes process modeling of COVID-19 with mobility leading indicators and spatial covariatesmed Rxiv Preprint posted online on Jun 62020 doi 10.1101/2020.06.06.20124149 PMC 827551734276115 · doi ↗ · pubmed ↗
- 6Galasso J Cao DM Hochberg R A random forest model for forecasting regional COVID-19 cases utilizing reproduction number estimates and demographic data Chaos Solitons Fractals Mar 2022156111779 doi 10.1016/j.chaos.2021.111779 Medline 35013654 PMC 8731233 · doi ↗ · pubmed ↗
- 7Arik S Li CL Yoon J Sinha R Epshteyn A Le L et al Interpretable sequence learning for COVID-19 forecastingar Xiv Preprint posted online on Aug 32020 doi 10.48550/ar Xiv.2008.00646 · doi ↗
- 8Zhang-James Y Hess J Salkin A et al A seq 2seq model to forecast the COVID-19 cases, deaths and reproductive R numbers in US counties Res Sq Apr 262021 rs.3.rs-456641 doi 10.21203/rs.3.rs-456641/v 1Medline 34013251 PMC 8132245 · doi ↗ · pubmed ↗