Machine learning-based COVID-19 prognostic models lag behind in reporting quality: findings from a TRIPOD/TRIPOD + AI systematic review
Ioannis Partheniadis, Persefoni Talimtzi, Adriani Nikolakopoulou, Anna-Bettina Haidich

TL;DR
This study finds that machine learning-based models for predicting outcomes in COVID-19 patients are poorly reported compared to traditional models, highlighting a need for better adherence to reporting standards.
Contribution
The study introduces a systematic comparison of reporting quality between conventional and machine learning-based prognostic models for COVID-19 using TRIPOD and TRIPOD+AI guidelines.
Findings
Machine learning-based studies showed significantly lower adherence to TRIPOD+AI guidelines compared to conventional models.
No study fully adhered to abstract reporting requirements, and appropriate titles were rare.
Both model types had major gaps in model description and performance reporting.
Abstract
Reporting of COVID-19 prognostic models frequently falls short of established standards. The TRIPOD checklist and its 2024 AI extension (TRIPOD + AI) provide a comprehensive framework for assessing reporting quality. We therefore evaluated and compared reporting completeness in conventional versus machine-learning models. Studies reporting the development, and internal and external validation of prognostic prediction models for COVID-19 using either conventional or machine learning-based algorithms were included. Literature searches were conducted in MEDLINE, Epistemonikos.org, and Scopus (up to July 31, 2024). Studies using conventional statistical methods were evaluated under TRIPOD, while machine learning-based studies were assessed using TRIPOD + AI. Data extraction followed TRIPOD and TRIPOD + AI checklists, measuring adherence per article and per checklist item. The protocol was…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
 Figure 1
Figure 1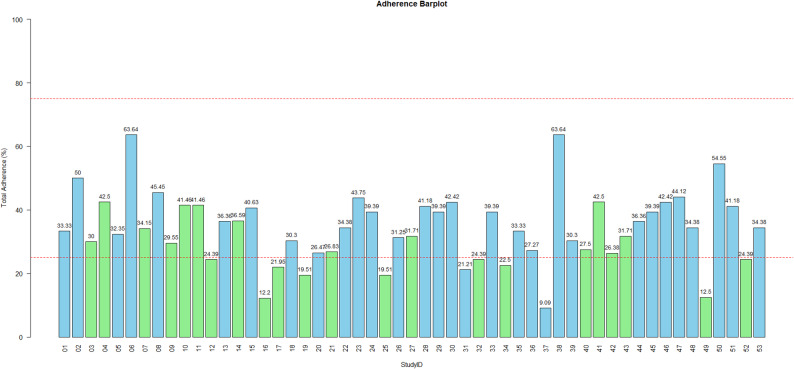 Figure 2
Figure 2- —Universitätsklinikum Freiburg (8975)
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsCOVID-19 diagnosis using AI · COVID-19 Clinical Research Studies · Artificial Intelligence in Healthcare and Education
Introduction
COVID-19, while no longer designated a public health emergency of international concern, continues to pose a major global health challenge [1]. As all countries have eased restrictions, concerns remain about the long-term behavior of SARS-CoV-2, which may become endemic with recurring seasonal surges that could burden healthcare systems [2]. The unpredictable nature of viral mutations, along with gaps in surveillance and response mechanisms, highlights the potential for future outbreaks [3]. In this context, accurate prognostic modeling plays a vital role in guiding clinical decisions, optimizing resource distribution, and shaping public health strategies. In response, the research community has produced a wide array of predictive models to estimate the risk of severe outcomes among individuals infected with COVID-19 [4]. These models are especially important in resource-constrained settings, where prioritizing care for the most at-risk patients is essential. Given the unprecedented volume of scientific data generated during the pandemic, critically evaluating and synthesizing this body of work remains a pressing need.
A major obstacle to the effective use and evaluation of clinical prediction models is the incomplete reporting of critical methodological and outcome-related information [5, 6]. Insufficient transparency not only hampers the ability to assess how a study was conducted or interpret its findings but also limits opportunities for independent validation by other researchers [7, 8]. Systematic reviews serve as a key bridge between model development and clinical use by aggregating and critically appraising available evidence, identifying promising models, and informing the local validation efforts necessary for safe and effective implementation. However, poor reporting undermines efforts to include such studies in systematic reviews and, in turn, restricts their translation into clinical practice. As a result, it contributes to research inefficiency and delays the integration of valuable tools into healthcare decision-making.
The Transparent Reporting of a multivariable prediction model for Individual Prognosis Or Diagnosis (TRIPOD) statement was introduced to enhance the quality and transparency of clinical prediction model reporting, offering a 22-item checklist with 37 sub-items that specify the essential elements for publishing studies on the development and validation of diagnostic or prognostic models, primarily those based on regression techniques [9]. Since its release, the use of machine-learning approaches to build clinical prediction models has surged, particularly amid the COVID-19 pandemic, as larger datasets and more accessible software have lowered the barrier to model development even when rigorous validation is lacking [10]; nevertheless, there is limited research assessing how comprehensively such machine learning-based prediction models are reported in the literature [11].
While many key reporting elements (study dates, sample size) are relevant to both regression-based and machine learning–based prediction model studies, it cannot be assumed that the reporting quality and methodological practices are consistent across these approaches. There is limited understanding of the specific reporting challenges associated with machine learning models and how these differ from those seen in traditional regression models [12]. In response to these challenges, an updated guideline (TRIPOD + AI) has been introduced to specifically address the reporting standards for machine learning-based prediction models, offering a structured framework for evaluating their completeness [13].
The present work offers a critical assessment of the reporting completeness of prognostic models developed using either conventional statistical or machine learning methods, with a focus on models reporting development, internal and external validation. It evaluates the extent to which these models adhere to the TRIPOD and TRIPOD + AI reporting guidelines, providing a basis for reflecting on the transparency of reporting practices in prognostic model studies. While TRIPOD + AI supersedes TRIPOD, it introduces AI-specific reporting requirements that do not apply to traditional regression-based models. Given the retrospective nature of this work, and the fact that many included studies were published before the release of TRIPOD + AI, using both guidelines enables a more balanced and historically grounded assessment of model reporting, without penalizing either group for failing to report items irrelevant to their methodology. This dual-framework approach also offers a unique opportunity to explore how evolving reporting standards affect the evaluation of models developed under different methodological paradigms and timeframes. The findings may contribute valuable insights for enhancing the quality and transparency of prognostic model reporting in COVID-19 research.
Materials and methods
Protocol and registration
This study was prospectively registered with a predefined protocol at the Open Science Framework (OSF), accessible at https://osf.io/kg9yw. Despite being methodological in nature, the reporting of the study follows the principles of the Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) 2020 statement [14] (Appendix Table 1), when applicable.
Eligibility criteria
This study includes prognostic model studies for COVID-19 reporting model development, internal validation, and external validation, as identified through systematic reviews (SRs) that met predefined eligibility criteria. These SRs served as sources for identifying eligible primary studies and were selected based on the criteria defined by Talimitzi et al. [15]. Briefly, reviews were considered eligible if they explicitly identified themselves as SRs, outlined a predefined research question, and clearly specified both the scope of the review and the inclusion criteria for studies. Only SRs published in English were included. Exclusion criteria encompassed reviews centered on epidemic forecasting models, diagnostic test accuracy, randomized controlled trials comparing COVID-19 treatments, methodological and genetic association reviews, as well as letters to the editor and commentaries. Within each included review, we selected prognostic model studies if they reported all following elements: model development, internal validation, and external validation. Studies lacking any of these components were excluded. This criterion was chosen to ensure that reporting completeness could be assessed across the full modeling process, from development to external validation, which is critical for evaluating model readiness for clinical application.
Databases and search strategy
The literature search was conducted using the following bibliographic databases: MEDLINE (via Ovid), Scopus, the Cochrane Database of Systematic Reviews, and Epistemonikos (epistemonikos.org), covering publications up to July 31, 2024. In addition, a citation chasing approach, both backward and forward referencing, was applied using the ‘citationchaser’ package in R [16] to identify related studies cited by or citing the included articles. The search strategy (Appendix Table 2) followed the methodology proposed by Talimtzi et al. [15]., which was an adaptation of the approach used by Wynants et al. [10]., with the goal of capturing all SRs focused on COVID-19 prognostic models.
Screening and selection of studies
Data was extracted for each prognostic model identified within the included systematic reviews using structured forms in Microsoft Excel^®^. Duplicate records were removed, after which one reviewer (I.P.) screened the titles and abstracts of the remaining articles. Full-text reviews were conducted for all potentially relevant studies by one reviewer (I.P.), and those that met the inclusion criteria were incorporated into the present study.
Data extraction
One reviewer (I.P.) carried out data extraction for all included studies after reaching > 90% agreement with a second reviewer (P.T.) who independently extracted data from a randomly selected 10% subset of the included studies. Any discrepancies between the two reviewers were resolved through discussion with a third reviewer (A.B.H.). For each eligible study, information such as the first author, journal, publication year, and additional methodological characteristics, as guided by the CHARMS checklist [17] and listed in Appendix Table 3, was recorded. When a study reported multiple models but identified one as the primary or “best” model, only data for that specific model were extracted. Conversely, if a study aimed to develop or present multiple models without prioritizing one, data were extracted for each model individually. Briefly, data extraction focused on model-specific details aligned with TRIPOD/TRIPOD + AI guidelines, including: target population and setting, participant characteristics, sample size, handling of missing data, study design and model development process, model performance, internal and external validation, and final model presentation. Transparency indicators were evaluated at both the study and journal levels. At the journal level, we extracted whether the journal in which each study was published had explicit policies on data sharing, code availability, and adherence to TRIPOD (Table 1).
Table 1. Characteristics of the included studiesCharacteristics on Study Level (n = 53)Publication YearN (%)202027 (50.9)202123 (43.4)20222 (3.8)20231 (1.9)Preprint onlyN (%)Yes3 (5.7)No50 (94.3)Number of ModelsN (%)144 (83.0)26 (11.3)31 (1.9)41 (1.9)81 (1.9)Study Design (Development & Internal Validation)N (%)Retrospective44 (83.0)Unclear5 (9.4)Prospective3 (5.7)Temporal Validation1 (1.9)Published in Journals with Code/Data Availability PolicyN (%)Yes (does not specify for code)23 (43.4)Yes (both data and code)21 (39.6)No9 (17.0)Reporting Adherence to TRIPOD StatementN (%)Yes16 (30.2)No37 (69.8)TRIPOD Checklist ProvidedN (%)Yes7 (13.2)No46 (86.8)Published in Journals Suggesting TRIPOD GuidelinesN (%)Yes4 (7.5)No49 (92.5)
TRIPOD and TRIPOD + AI adherence assessment
The adherence assessment approach followed the methodology outlined on the official TRIPOD statement website [18], as well as the guidance provided in the TRIPOD + AI statement [13] for models developed using supervised machine learning, and was consistent with the approach used in a previously published study [11, 19]. Applying both guidelines selectively avoided penalizing studies for omitting information not relevant to their modeling approach. For the purpose of this study, we categorized each prognostic model as either conventional (statistical) or machine learning–based, based on the methodology used. Models using traditional regression techniques (e.g., logistic regression, Cox regression) were assessed using the TRIPOD checklist, while models employing machine learning methods (e.g., random forests, neural networks, gradient boosting) were assessed using the TRIPOD + AI checklist. In cases where a single study reported both model types, each model was evaluated individually according to the appropriate guideline. Adherence was evaluated for each individual TRIPOD/TRIPOD + AI item. If all relevant adherence elements for a specific item were marked as “yes” or “Not Applicable,” the item was considered reported and assigned a score of “1”; otherwise, it was scored as “0.” An overall adherence score for each report was then calculated by dividing the number of reported items by the total number of applicable items. Each TRIPOD or TRIPOD + AI item was treated as a distinct reporting element with individual interpretive value; therefore, we conducted unadjusted item-level comparisons without applying corrections for multiple testing, consistent with the checklist-based structure of the guidelines. In addition, overall adherence for each individual item was determined by dividing the number of studies that adhered to that item by the number of studies for which that item was applicable.
Summary measures and synthesis of results
The results are presented using descriptive statistics, visualizations, and narrative summaries. For continuous variables, data is reported as mean and standard deviation (SD) when normally distributed, or as median and interquartile range (IQR) when distributions are non-normal. Categorical variables are summarized as frequencies and percentages. For each study, we calculated the events-per-predictor ratio by dividing the total number of observed outcome events by the number of candidate predictors initially considered, regardless of whether they were retained in the final model. While not a definitive measure of sample size adequacy, this ratio offers a heuristic indication of potential overfitting risk, with lower values generally associated with reduced model stability and reliability.
To explore differences in methodological practices between conventional and machine learning–based prediction models, adherence to the TRIPOD and TRIPOD + AI guidelines was evaluated. Comparisons are conducted on two levels: (a) adherence to each (sub-)item within the TRIPOD/TRIPOD + AI checklists, and (b) the overall adherence score for each study, representing the reporting quality of each developed model. Chi-square tests or Fisher’s exact tests (when expected cell counts were fewer than five) were used to compare adherence frequencies between statistical and machine learning models. Odds ratios (ORs) with 95% confidence intervals (CIs) were calculated to quantify the strength of association between model type and adherence to each individual reporting item. Mean differences in overall adherence between the two model types, along with their 95% confidence intervals (CIs), were assessed using independent-samples t-tests, as appropriate based on data distribution.
All statistical analyses were carried out using R (version 4.4.0; R Foundation for Statistical Computing, Vienna, Austria) and RStudio (version 2024.9.0.375).
Results
Study selection
A total of 1,529 records were retrieved from 17 SRs and initially screened by title and abstract. Following the removal of 530 duplicates, 999 studies proceeded to full-text review. Of these, 53 studies met the predefined eligibility criteria, collectively reporting 71 prognostic models that included details on model development, as well as internal and external validation. A complete list of the 17 SRs initially considered as sources, along with the studies ultimately included, can be found in the Appendix (Appendix Tables 4 and 5). The PRISMA flow diagram outlining the study selection process is presented in Fig. 1.
Fig. 1PRISMA flowchart of the study selection process
Characteristics of the included studies
Table 1 summarizes the characteristics of the included studies, including publication year, study design, number of models, and journal-level transparency policies. Most were published in 2020 (50.9%) and 2021 (43.4%), with the vast majority (94.3%) appearing in peer-reviewed journals. A single final model was reported in 83.0% of studies. Regarding study design for development and internal validation, most studies (83.0%) were retrospective in nature, while only a small proportion were prospective (5.7%) or used temporally split data (1.9%). In 9.4% of cases, the design was not clearly described. Journal-level transparency policies were relatively common: 83.0% of the journals had data or code availability requirements, although not all specified both elements. Specifically, 39.6% required both data and code availability, while 43.4% mentioned only data. However, only 30.2% of the studies themselves explicitly reported adherence to the TRIPOD Statement, and just 13.2% included a completed checklist as supplementary material. A small minority of journals (7.5%) explicitly recommended using TRIPOD in their author instructions.
Characteristics of the included models
Table 2 summarizes the characteristics of the 71 included models, which were nearly evenly split, with 58.5% being traditional statistical models and 41.5% being machine learning-based models. Common predictors included age (67.6%), C-reactive protein and lactic dehydrogenase (both 32.4%), lymphocyte count (29.6%), and oxygen saturation (29.6%). The most frequently predicted outcomes were in-hospital mortality (43.7%) and severe or critical illness (38.0%). Most models (71.8%) were based on single-country data, with China (50.7%) and the U.S. (26.8%) being the most common sources The models predominantly focused on hospitalized patients (87.3%) with confirmed COVID-19 (94.4%). Recruitment methods were often unclear (52.1%), though 47.9% used consecutive sampling. Most studies used multicenter data (87.3%), with few relying on single-center (8.5%) or nationwide cohorts (4.2%). Based on 64 models, the median participant age was 61 years (IQR: 58–63), and the average proportion of male participants was 54.8% (SD: 6.6%). Seven models did not report participant age and were therefore excluded from this summary.Table 2. Characteristics of the included modelsCharacteristics on Model Level (n= 71)Type of ModelsN (%)Conventional36 (50.7)Machine learning35 (49.3)Most Common PredictorsN (%)Age48 (67.6)C-reactive protein23 (32.4)Lactic dehydrogenase23 (32.4)Lymphocytes21 (29.6)Oxygen saturation21 (29.6)D-dimer12 (16.9)Neutrophils12 (16.9)Platelets11 (15.5)Sex11 (15.5)Blood urea nitrogen10 (14.1)Most Common OutcomesN (%)Mortality31 (43.7)Critical/severe illness27 (38.0)Single CountryN (%)Yes51 (71.8)No16 (22.6)Unknown4 (5.6)Countries of Setting/Center Location (most common)N (%)China36 (50.7)USA19 (26.8)Italy6 (8.5)UK6 (8.5)France4 (5.6)Spain4 (5.6)Iran2 (2.8)Kuwait2 (2.8)Target PopulationN (%)Hospitalized patients62 (87.3)Other a5 (7.1)Unclear2 (2.8)Outpatients1 (1.4)Patients at triage center1 (1.4)Population’s COVID-19 StatusN (%)Confirmed cases67 (94.4)Unclear3 (4.2)Confirmed or suspected cases1 (1.4)Characteristics on Model Level (n= 71) Recruitment Method (Development & Internal Validation)N (%) Unclear37 (52.1) Consecutive34 (47.9) Recruitment CenterN (%) Multicenter62 (87.3) Monocenter6 (8.5) Nationwide3 (4.2) Average Age Reported, *years, median (IQR)*61.00 (58.00–63.00) Not reported, N (%)7 (9.8) Sex, *% male, mean **(SD)*54.79 (6.58) Not reported, N (%)5 (7.1) C-statistic (Concordance Index) (Internal Validation), mean (SD)0.86 (15.63) Not reported, N (%)8 (11.3) Sensitivity (Internal Validation), %, median (IQR)73.50 (53.50–89.00) Not reported, N (%)41 (57.7) Specificity (Internal Validation), %, median (IQR)85.00 (77.00–89.00) Not reported, N (%)42 (59.2) C-statistic (Concordance Index) (External Validation), mean (SD)0.84 (0.09) Not reported, N (%)4 (5.6) Sensitivity (External Validation), %, median (IQR)76.00 (67.00–86.25) Not reported, N (%)39 (54.9) Specificity (External Validation), %, median (IQR)82.00 (73.00–92.25) Not reported, N (%)39 (54.9)^a^Other: all individuals undergoing a SARS-CoV-2 test, outpatients with diabetes, Elderly COVID-19 patients, In- and out-patients
Per item adherence to TRIPOD and TRIPOD + AI statements
Table 3 presents item-level adherence to the TRIPOD and TRIPOD + AI guidelines, along with ORs and corresponding 95% CIs comparing adherence between the two frameworks. Conventional model studies were assessed using TRIPOD, and machine learning model studies using TRIPOD + AI. Items are aligned by section/topic to facilitate meaningful comparisons, while preserving methodological appropriateness. A comprehensive list of the methodological characteristics of the included studies that were used for adherence evaluation can be found in Appendix Table 6.
However, the study has limitations. Reporting quality was assessed by a single reviewer, which may introduce bias although there was a good agreement in the subsample that was assessed independently by a second reviewer. Also, only the best-performing model from each study was evaluated, potentially underestimating broader reporting deficiencies. In addition, different reporting frameworks were applied to conventional and machine-learning models (TRIPOD and TRIPOD + AI, respectively). Because TRIPOD + AI contains several items that extend beyond AI-specific considerations and have no direct counterparts in TRIPOD, this discrepancy in checklist scope may influence overall adherence estimates. We therefore presented item-level adherence for both guidelines to clarify how individual items contributed to observed differences (Table 3), but comparisons of overall adherence should be interpreted cautiously in light of the structural differences between the two checklists. Lastly, while reporting guidelines aim to standardize transparency, they are not formal tools for evaluating study quality, which may affect interpretation.Table 3. Calculated % adherence per item to the TRIPOD and TRIPOD+AI (studies adhered to item/studies in which item was applicable) and odds ratio for the comparison TRIPOD vs. TRIPOD+AI together with 95% confidence intervals (n.a. stands for not applicable; n.e. stands for not estimated). Items are grouped by reporting section/topic to ensure interpretability across guidelines with differing scopesSection/TopicItemTRIPOD Item Adherence (%)95% CITRIPOD+AI Item Adherence (%)95% CITRIPOD vs. TRIPOD+AI OR (95% CI)p-valueTRIPODTRIPOD+AITitle1129.0 (9/31)16.1–46.613.6 (3/22)4.8–33.32.55 (0.53–16.74)0.3182Abstract220.0 (0/31)0.0–11.00.0 (0/22)0.0–14.9n.a.n.a.Introduction: Background3a3a48.4 (15/31)32.0–65.240.9 (9/22)23.3–61.31.35 (0.45–4.08)0.7957n.a.3bn.a.n.a.9.1 (2/22)2.5–27.8n.a.n.a.n.a.3cn.a.n.a.n.a.n.a.n.a.n.a.Introduction: Objectives3b467.7 (21/31)50.1–81.445.5 (10/22)26.9–65.32.52 (0.82–7.78)0.1804Methods: Source of Data4a5a90.3 (28/31)75.1–96.722.7 (5/22)22.7–43.431.73 (6.72–149.97)< 0.00014b5b32.3 (10/31)18.6–49.913.6 (3/22)5.5–37.63.02 (0.72–12.62)0.2192Methods: Participants5a6a90.3 (28/31)75.1–96.772.7 (16/22)51.8–86.93.41 (0.62–24.02)0.13965b6b41.9 (13/31)26.4–59.263.6 (14/22)43.0–80.30.41 (0.13–1.27)0.20115c6cn.a.n.a.n.a.n.a.n.a.n.a.Methods: Data Preparationn.a.7n.a.n.a.13.6 (3/22)4.8–33.3n.a.n.a.Methods: Outcome6a8a29.0 (9/31)16.1–46.636.4 (8/22)19.7–57.10.72 (0.22–2.29)0.7912n.a.8bn.a.n.a.0.0 (0/1)0.00–79.4n.a.n.a.6b8c45.2 (14/31)29.2–62.240.9 (9/22)23.3–61.31.19 (0.39–3.59)0.9788Methods: Predictors10b9a6.5 (2/31)1.8–20.750.0 (11/22)30.7–69.30.07 (0.01–0.41)< 0.00017a9b6.5 (2/31)1.8–20.79.1 (2/22)2.5–27.80.69 (0.05–10.32)0.99997b9b0.0 (0/31)0.0–11.09.1 (2/22)2.5–27.80.00 (0.00–3.73)0.1676n.a.9cn.a.n.a.0.0 (0/2)0.0–65.8n.a.n.a.Methods: Sample Size8100.0 (0/31)0.0–11.00.0 (0/22)0.0–14.9n.a.n.a.Methods: Missing Data91135.5 (11/31)21.1–53.19.1 (2/22)2.5–27.85.50 (1.08–28.05)0.0606Methods: Analysisn.a.12an.a.n.a.4.6 (1/22)0.8–21.8n.a.n.a.10a12b19.4 (6/31)9.2–36.340.0 (6/15)19.8–64.30.36 (0.09–1.41)0.164910b12c6.5 (2/31)1.8–20.74.6 (1/22)0.8–21.81.44 (0.07–89.41)0.9999n.a.12dn.a.n.a.n.a.n.a.n.a.n.a.10c12g16.1 (5/31)7.1–32.636.4 (8/22)19.7–57.10.34 (0.09–1.23)0.172910d12e48.4 (15/31)32.0–65.20.0 (0/22)0.0–14.9n.e.n.e.10e12fn.a.n.a.n.a.n.a.n.a.n.a.Methods: Risk groups11n.a.64.3 (9/14)^a^38.8–83.7n.a.n.a.n.a.n.a.Methods: Model Outputn.a.15n.a.n.a.68.2 (15/22)47.3–83.6n.a.n.a.Methods: Class imbalancen.a.13n.a.n.a.100.0 (1/1)^b^20.7–100.0n.a.n.a.Methods: Fairnessn.a.14n.a.n.a.n.a.n.a.n.a.n.a.Methods: Development vs. Validation12163.2 (1/31)0.6–16.29.1 (2/22)2.5–27.80.34 (0.01–6.95)0.5633Methods: Ethical Approvaln.a.17n.a.n.a.95.5 (21/22)78.2–99.2n.a.n.a.Open Science: Funding2218a41.9 (13/31)26.4–59.227.3 (6/22)13.2–48.21.93 (0.59–6.26)0.4202Open Science: Conflicts of interest2118b74.2 (23/31)56.8–86.368.2 (15/22)47.3–83.61.34 (0.40–4.48)0.8656Open Science: Protocol2118c74.2 (23/31)56.8–86.30.0 (0/22)0.0–14.9n.e.n.e.Open Science: Registration2118d74.2 (23/31)56.8–86.313.6 (3/22)4.8–33.318.21 (4.23–78.36)< 0.0001Open Science: Data Sharing2118e74.2 (23/31)56.8–86.331.8 (7/22)16.4–52.76.16 (1.85–20.56)0.0053Open Science: Code Sharing2118f74.2 (23/31)56.8–86.331.8 (7/22)16.4–52.76.16 (1.85–20.56)0.0053Patient and Public Involvementn.a.19n.a.n.a.13.6 (3/22)4.8–33.3n.a.n.a.Results: Participants13a20a6.5 (2/31)1.8–20.74.6 (1/22)0.8–21.81.44 (0.07–89.41)0.999913b20b19.4 (6/31)9.2–36.363.6 (14/22)43.0–80.30.14 (0.04–0.48)0.002813c20c54.8 (17/31)37.8–70.8n.a.n.a.n.a.n.a.Results: Model Development14a2132.3 (10/31)18.6–49.940.9 (9/22)23.3–61.30.69 (0.22–2.14)0.721514bn.a.70.6 (12/17)46.9–86.7n.a.n.a.n.a.n.a.Results: Model Specification15a2212.9 (4/31)5.1–28.94.6 (1/22)0.8–21.83.05 (0.28–160.25)0.388615bn.a.54.8 (17/31)37.8–70.8n.a.n.a.n.a.n.a.Results: Model Performance1623a16.1 (5/31)7.1–32.60.0 (0/22)0.0–14.9n.e.n.e.n.a.23bn.a.n.a.n.a.n.a.n.a.n.a.Results: Model Updating1724n.a.n.a.n.a.n.a.n.a.n.a.Discussion: Interpretation19an.a.41.9 (13/31)26.4–59.2n.a.n.a.n.a.n.a.19b2596.8 (30/31)83.8–99.40.0 (0/22)0.0–14.9n.e.n.e.Discussion: Limitations182693.6 (29/31)79.3–98.286.4 (19/22)66.7–95.32.25 (0.24–29.35)0.6382Discussion: Implications2027a35.5 (11/31)21.1–53.10.0 (0/22)0.0–14.9n.e.n.e.2027b35.5 (11/31)21.1–53.127.3 (6/22)13.2–48.21.47 (0.45–4.83)0.73962027c35.5 (11/31)21.1–53.154.6 (12/22)34.7–73.10.46 (0.15–1.40)0.2720^a^Risk groups item was applicable only to 14 out of the 31 conventional studies; ^b^Class imbalance item was applicable only to 1 out of 22 machine learning-based studies**P*-values are presented for exploratory comparison of individual TRIPOD/TRIPOD+AI items. Each item represents a distinct reporting construct; therefore, no correction for multiple testing was applied
Adherence to Title and Abstract reporting was poor across both TRIPOD and TRIPOD + AI studies. Notably, no study fully adhered to the abstract reporting requirements, and many failed to report essential details such as the number of participants and outcome events. Title adherence was higher in TRIPOD studies (29.0%) than TRIPOD + AI (13.6%), though this difference was not statistically significant (OR: 2.55; 95CI%: 0.53–16.74).
Significant differences in adherence were observed in several key methodological domains. For example, reporting on the source of data (TRIPOD Item 4a vs. TRIPOD + AI Item 5a) was substantially better in TRIPOD studies (90.3%) compared to TRIPOD + AI studies (22.7%), (OR = 28.64, 95% CI: 5.65–212.03).
However, predictor selection and pre-processing (TRIPOD 10b vs. TRIPOD + AI 9a) was less thoroughly reported in TRIPOD studies (6.5%) than in TRIPOD + AI studies (50.0%), (OR = 0.07, 95% CI: 0.01–0.41). Furthermore, adherence to items detailing predictor definitions, measurements, and blinding was extremely poor across both frameworks, with no meaningful difference between the two.
Several areas demonstrated complete non-adherence. Not a single study provided a justification or calculation for sample size (TRIPOD Item 8; TRIPOD + AI Item 10). Likewise, model performance stability reporting, as outlined in TRIPOD + AI Item 23a, had 0.0% adherence, with machine learning studies failing to report on performance variability or bootstrap-based model evaluations. Protocol registration and access (TRIPOD + AI Item 18c) also showed 0.0% adherence.
In the interpretation of findings, there was a striking discrepancy: while 96.8% of TRIPOD studies adhered to Item 19b, none of the TRIPOD + AI studies met the requirements of the corresponding Item 25. Similarly, performance metric reporting (TRIPOD 10 d vs. TRIPOD + AI 12e) revealed a substantial gap. Most machine learning studies failed to report performance metrics at all evaluated time points.
Encouragingly, some areas showed stronger performance. Reporting of study limitations was generally high in both groups. Ethical approval reporting (TRIPOD + AI Item 17) was also well adhered to (96%). TRIPOD + AI studies also demonstrated full adherence (100%) to class imbalance reporting (Item 13).
Total adherence to TRIPOD and TRIPOD + AI statements
Figure 2 shows the overall adherence of the included studies to the TRIPOD and TRIPOD + AI reporting guidelines illustrated in a bar chart. The overall mean adherence across all studies was 34.07% (SD: 11.15). Studies using conventional statistical models had a higher mean adherence to TRIPOD (38.11%, SD:10.39) compared to studies employing machine learning approaches, which showed lower adherence to TRIPOD + AI (28.37%, SD: 8.91; p = 0.0012).
Fig. 2. Barplot of total adherence to the TRIPOD (blue bars) and TRIPOD + AI (green bars) statements (red horizontal dashed lines represent 25% and 75% adherence, respectively)
Discussion
This review provides a comprehensive assessment of reporting practices in 53 studies that developed and validated 71 COVID-19 prognostic models, offering insights into how these models were reported during a period of intense global research activity. Of these, 36 models (from 31 studies) used traditional statistical approaches, while 35 models (from 22 studies) relied on machine learning algorithms. Adherence to reporting guidelines for COVID-19 prognostic models was generally suboptimal, with several areas demonstrating significant deficiencies, particularly among machine learning-based studies. Although most models demonstrated moderate to excellent predictive performance, overall compliance with reporting standards was poor with average adherence being below 35%. Conventional models achieved a mean adherence of 38.1%, whereas machine learning–based studies lagged behind at 28.4%. This discrepancy is unsurprising given that TRIPOD + AI was only released in April 2024, two years after our latest included study.
Reporting weaknesses were most apparent in areas such as data preprocessing, clear definitions of predictors and outcomes, strategies for handling missing data, and justification of sample size. Such omissions obscure the risk of overfitting. Moreover, the limited sample sizes and low event counts in many studies heighten that risk. Inadequate detail on missing-data methods, lack of optimism correction in performance estimates, and insufficient calibration and validation approaches further undermine confidence in the reported C-index values, which often appear unrealistically high. Moreover, less than half (42.3%) of the studies made their final model fully available, with only 12.9% meeting TRIPOD minimums and a mere 4.6% satisfying TRIPOD + AI requirements. This lack of transparency poses serious barriers to replication and external validation.
These findings align with previous reviews showing poor adherence to TRIPOD guidelines in COVID-19 and other biomedical fields. They mirror earlier meta-research showing substandard TRIPOD adherence in COVID-19 prognostic modeling. Wynants et al.. highlighted widespread reporting deficiencies and high bias risk across COVID-19 prediction studies [10]. Yang et al.. reported TRIPOD completeness between 31% and 83% in COVID-19 models [20], while Dhiman et al.. found a median adherence of 41% in oncology machine learning models [12], and Liu et al.. observed 46.4% adherence in obstetric prognostic models [21]. Similarly, Navarro et al. [11]. found that reporting quality and risk of bias were suboptimal across machine learning–based clinical prediction models, reinforcing concerns about the transparency of such studies even beyond the COVID-19 context. The lower adherence observed in our study compared to previous reviews may be partly explained by our stricter inclusion criteria, which focused only on studies that reported development, internal validation, and external validation, thus excluding many earlier-stage or partial modeling studies included in previous reviews. Moreover, the application of the TRIPOD + AI update, which introduces more specific reporting expectations for AI-based models, could also contributed to lower adherence values than previously reported. Noncompliance with TRIPOD and TRIPOD + AI may also stem from misusing these tools as methodological guidelines instead of reporting standards. Furthermore, the urgency and volume of COVID-19 research contributed to rushed publications with inadequate reporting.
To improve the reliability and usability of prediction models, whether for COVID-19 or other conditions, researchers must rigorously apply TRIPOD or TRIPOD + AI in their reporting. Journal editors and peer reviewers should insist on these guidelines: in our sample, only 7.5% of studies appeared in journals that explicitly recommended TRIPOD, and just 20% of top-tier medical journals mention it in their author instructions [22].
This study employed a comprehensive search strategy and adhered to a pre-registered protocol (OSF: https://osf.io/kg9yw). A key strength was the integration of TRIPOD + AI, which addresses the unique reporting needs of machine learning-based models.
Conclusions
Adherence to the TRIPOD and TRIPOD + AI reporting guidelines among COVID-19 prognostic prediction models was found to be notably low, particularly in the Methods and Results sections, which are critical for reproducibility, and was significantly worse among machine learning-based models (TRIPOD + AI) compared to conventional statistical models (TRIPOD) (p < 0.001). This poor reporting compromises the ability to assess model validity, limits clinical applicability, and often prevents external validation, at times making it unclear which predictors were included in the final model.
Raising awareness among researchers about the importance of complete and transparent reporting is essential, continued meta-research, and stronger editorial policies are needed to enforce compliance. Additionally, reporting guidelines themselves should be refined by moving beyond expert opinion to incorporate structured methodological frameworks. To address these issues, future studies should consistently follow TRIPOD + AI guidelines, and journals and peer reviewers should take a more active role in enforcing their use.
Supplementary Information
Supplementary Material 1.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1WHO. Statement on the fifteenth meeting of the IHR. Emergency Committee on the COVID-19 pandemic 2023, 2005. [Available from: https://www.who.int/news/item/05-05-2023-statement-on-the-fifteenth-meeting-of-the-international-health-regulations-(2005)-emergency-committee-regarding-the-coronavirus-disease-(covid-19)-pandemic.
- 2Heus P, Damen JAAG, Pajouheshnia R, Scholten RJPM, Reitsma JB, Collins GS et al. Assessing adherence of prediction model reports to the TRIPOD guideline 2019. [Available from: https://www.tripod-statement.org/wp-content/uploads/2020/03/Heus-2019-BMJ-Open-Supplementary-material-1-1.pdf.