Machine Learning Classifiers for Voice Health Assessment under Simulated Room Acoustics
Ahmed M. Yousef, Eric J. Hunter

TL;DR
This paper studies how well machine learning models can detect voice disorders in different room acoustics, showing that data augmentation is key for real-world reliability.
Contribution
The study introduces a method to evaluate ML classifiers for voice health under simulated room reverberation, emphasizing the need for data augmentation.
Findings
Support Vector Machine and k-Nearest Neighbors showed reliable accuracy in short reverberation conditions.
Random Forest had the highest accuracy on clean data but failed to generalize in simulated room conditions.
Training on augmented data is crucial for robust voice disorder detection in real-world settings.
Abstract
Machine learning (ML) robustness for voice disorder detection was evaluated using reverberation-augmented recordings, highlighting data quality’s impact. Common vocal health assessment voice features from steady vowel samples (135 pathological, 49 controls) were used to train and test six ML classifiers. Detection performance was evaluated using clean and 2 simulated room reverberation situations (short=0.48s, long=1.82s). Support Vector Machine and k-Nearest Neighbors demonstrated reliable accuracy under short/acceptable reverberation, while Random Forest achieved the highest accuracy on clean data but lacked generalizability in augmented room conditions. Training/testing ML models on augmented data is essential to enhance their reliability in real-world voice assessments.
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
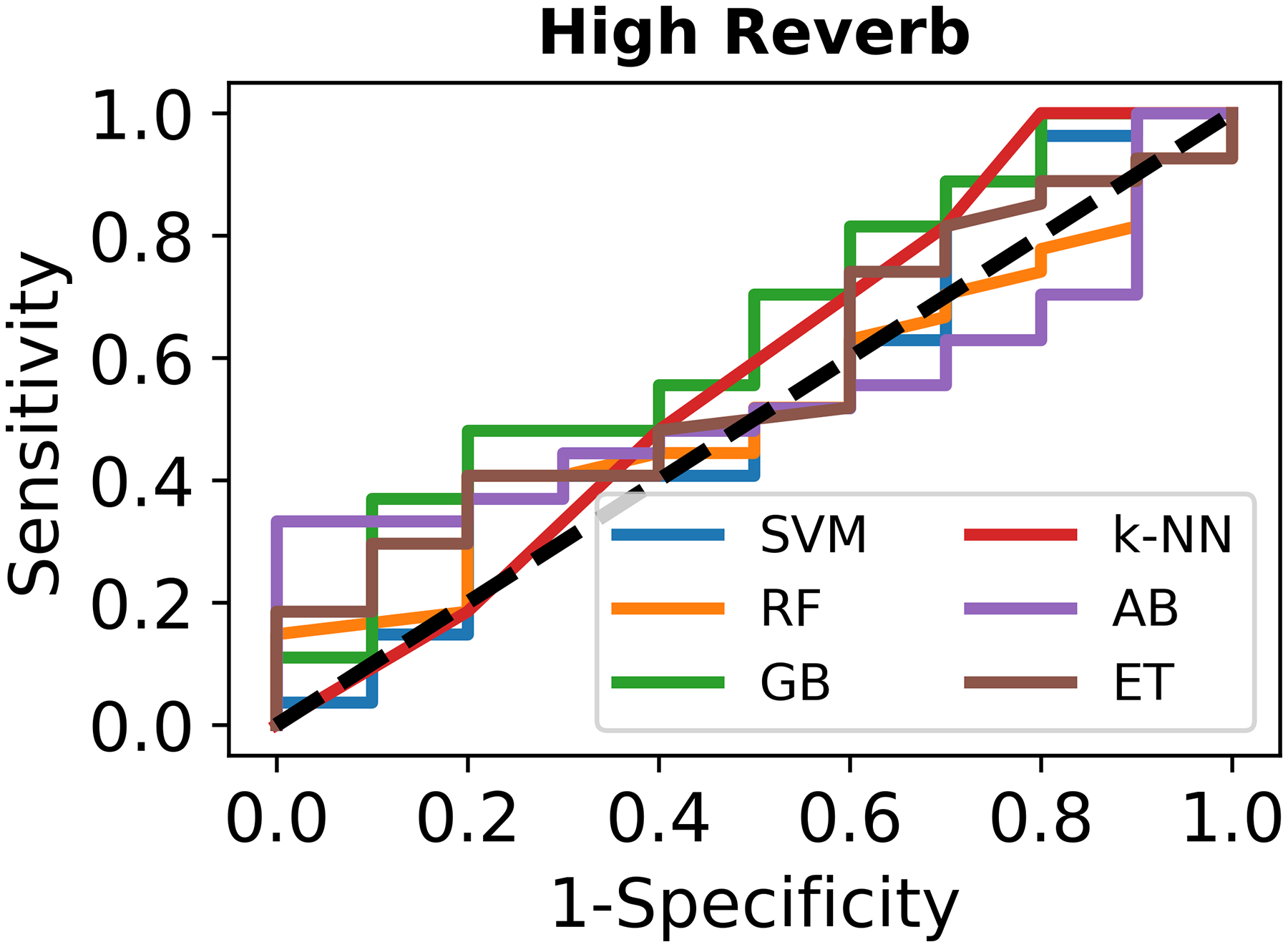 Figure 1
Figure 1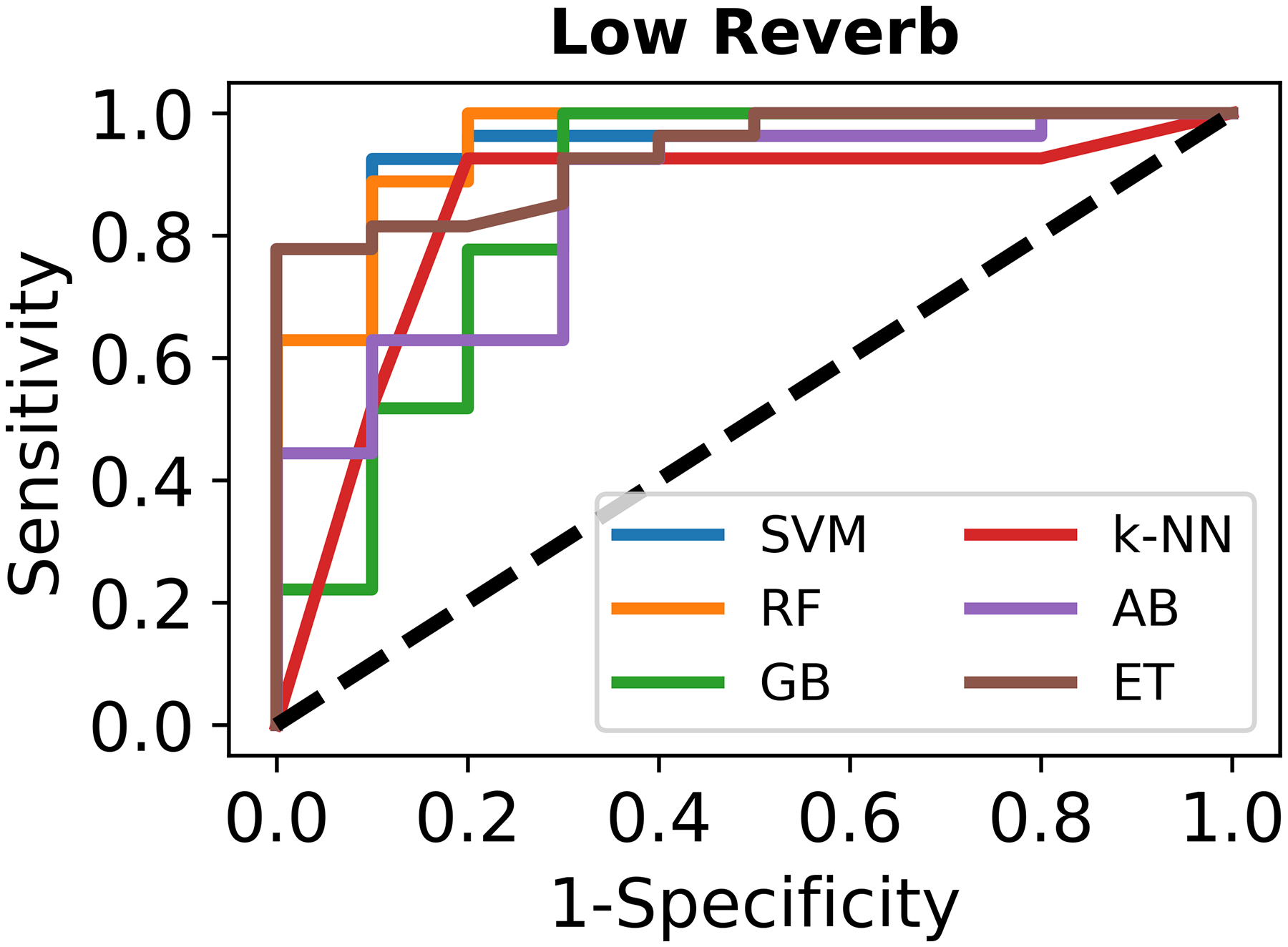 Figure 2
Figure 2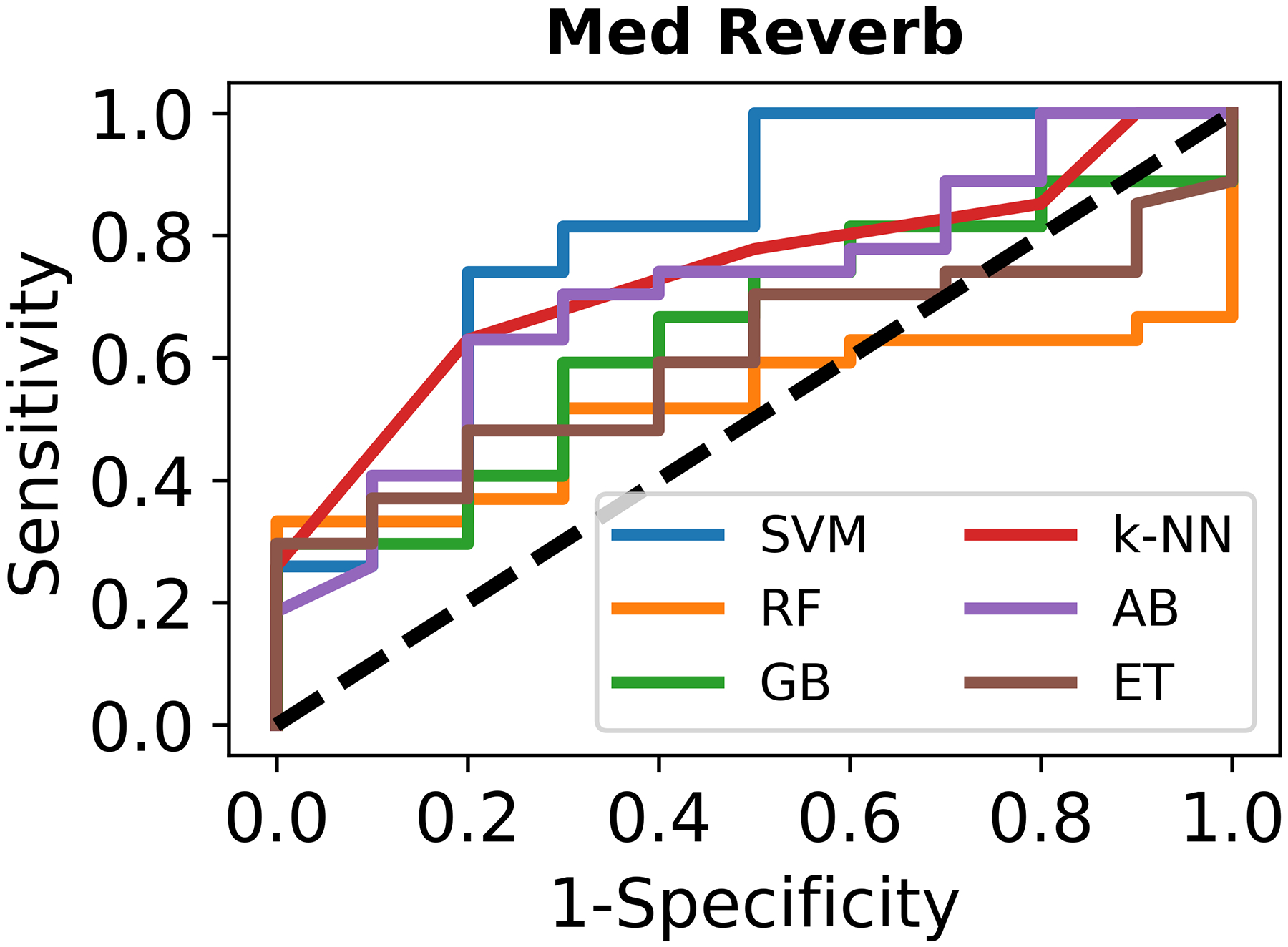 Figure 3
Figure 3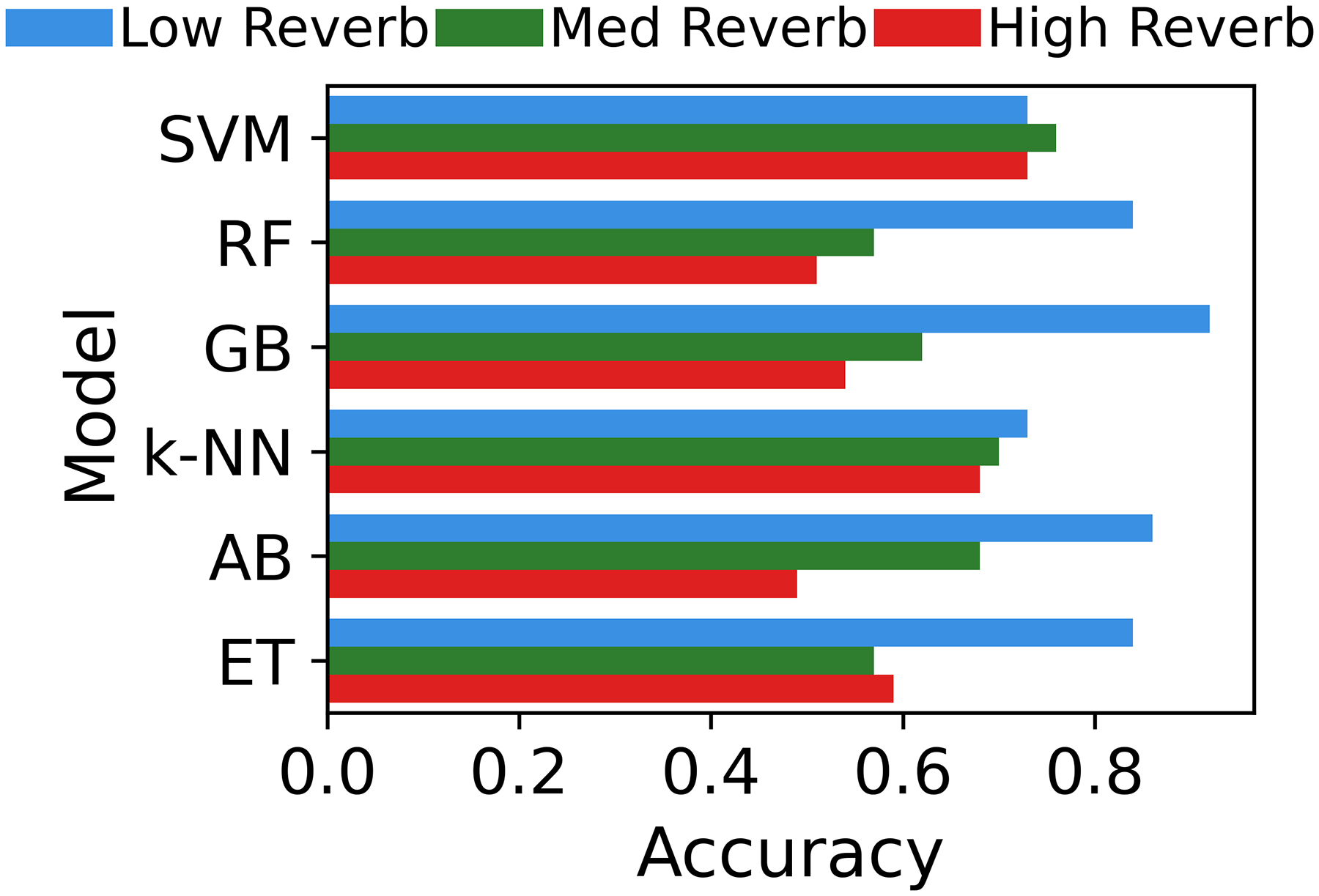 Figure 4
Figure 4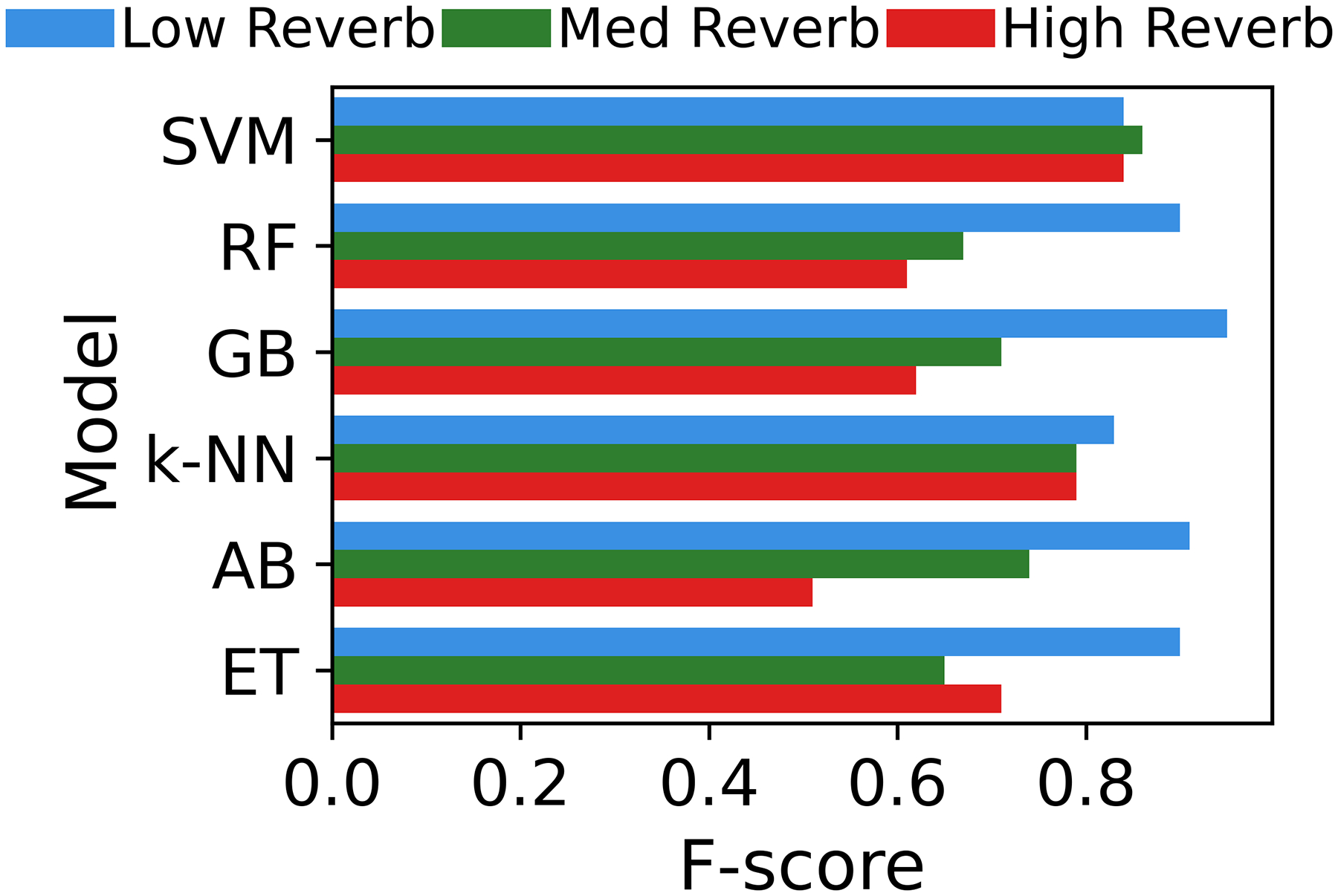 Figure 5
Figure 5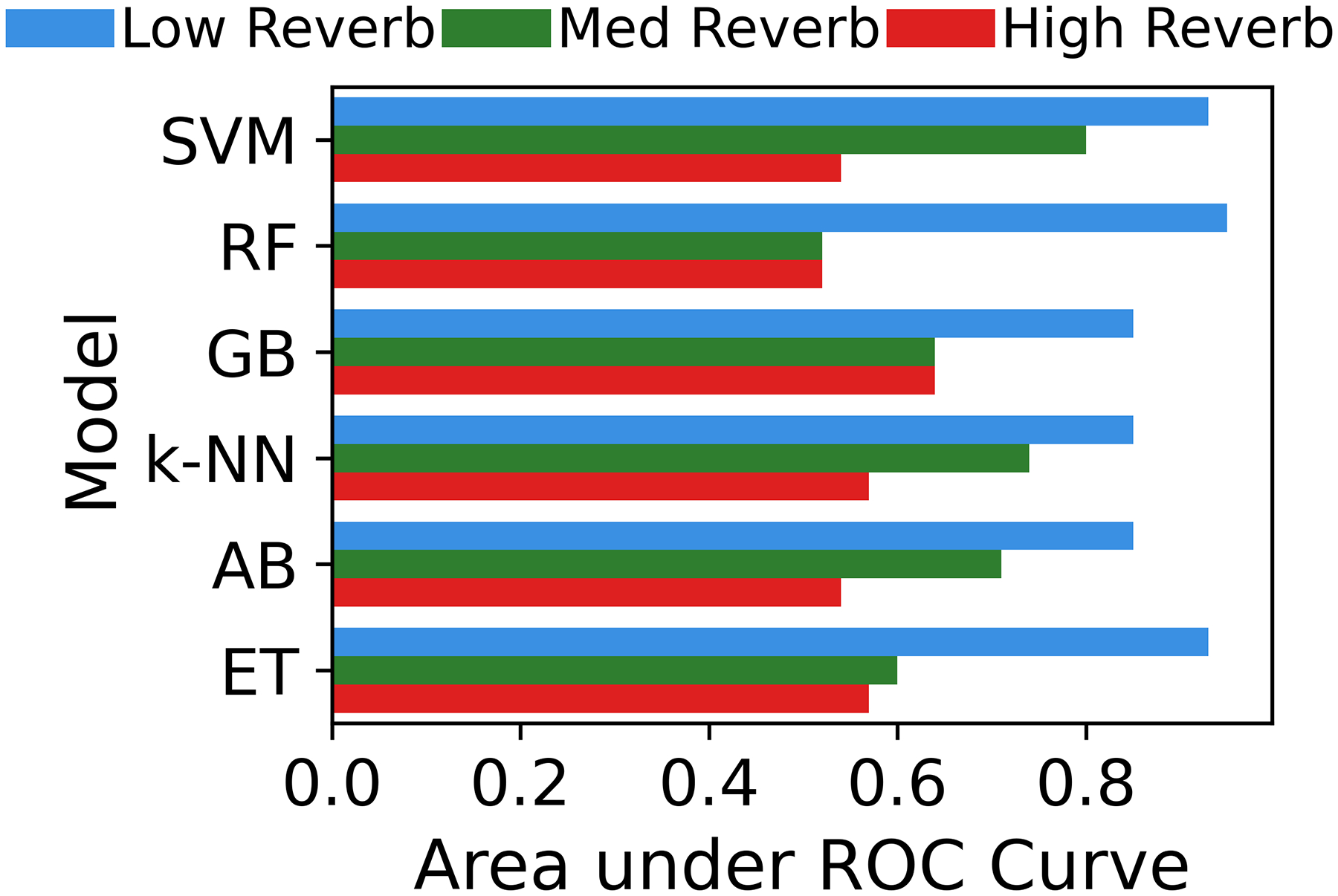 Figure 6
Figure 6Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsSpeech Recognition and Synthesis · Speech and Audio Processing · Voice and Speech Disorders
Introduction
Using voice and speech signals as a potential key marker of vocal health, machine learning (ML) has emerged as a powerful tool in automating voice assessment and screening for voice disorders [1–3]. These capabilities hold great potential for monitoring treatment progress, tracking patient follow-ups, and improving accessibility to voice care [4,5].
Previous studies have demonstrated the high efficacy of ML models in classifying and identifying those with vocal abnormalities, dysfunctions, and voice disorders, which conditions are often linked to broader health conditions [6–9]. However, most of this research has relied on voice samples collected under highly controlled recording conditions, such as in soundproof rooms with minimal noise and reverberation [10–12], which is not reflective of real-world clinical settings, which often include varied noise and reverberation conditions [13–15]. As a result, the generalizability of these models remains significant limitations due to a lack of understanding of the impact of various room conditions. With increased understanding of the impact, there is an opportunity to use a larger dataset [16,17], diverse voice samples [7,18], model optimization [19,20], and other techniques [21–24] which could significantly expand the widespread adoption of ML in clinical practice [1,2,4,25].
This study addresses this gap by evaluating the accuracy of different ML models in distinguishing voice disorder samples from healthy voice samples where the samples were augmented to represent extreme, common, and low reverberation conditions. By testing these models on samples from such diverse conditions, the study provides valuable insights into identifying robust models and strategies to enhance their generalizability—better reflecting their performance in real-world settings and improving their clinical utility.
Materials and Methods
Voice Samples under Simulated Room Acoustics
2.1.
Audio samples from 49 vocally normal individuals and 135 patients with clinically diagnosed voice disorders, including both organic and nonorganic pathologies, were used. Each sample consisted of a sustained vowel /a:/ produced at habitual pitch and loudness and later trimmed to 3 seconds of vowel, a common voice production assessment task [26,27]. These recordings were captured in acoustically treated room using a head mounted microphone with low noise and reverberation, serving as the baseline for the study. All original recordings from the low-reverberation condition (“low reverb”) were also augmented to simulate a common reverberation level of a standard clinic room (0.48 seconds, “med reverb”) and a high reverberation level like in a large church or gymnasium (1.82 seconds, “high reverb”). The overall dataset for training and testing thus consisted of all 184 “low reverb” audio samples and two more versions (“med reverb”, “high reverb”) for a total of 552 samples. The reverberation effects were simulated using the Reverb tool in Audacity (version 2.4.1), an audio editing software [28].
A training subset (80%) was created by randomly selecting “low reverb” samples (named “training recordings”) from both healthy speakers and patients using a stratified technique to ensure equal representation of both groups. The remaining 20% of the “low reverb” recordings were retained as a testing subset for evaluating the ML models. The “low reverb” testing subset recordings were matched with their corresponding “medium reverb” and “high reverb” versions, forming two additional testing subsets. Thus, the three testing subsets contain the identical audio content but differ in audio quality, simulating different room acoustic conditions.
Machine Learning for Voice Disorder Screening
2.2.
Twenty acoustic voice parameters commonly used in voice quality assessment were extracted from all audio recordings, representing various temporal, spectral, and cepstral features of the acoustic voice signal. These measures were computed using PRAAT, a freely available software for voice and speech analysis [29]. The acoustic metrics generated from the “training recordings” formed a training set used to develop a variety of supervised ML models. These models, implemented using the default Scikit-learn library in Python [30], were designed as binary classifiers to detect voice disorders in the audio samples and classify them as either healthy or pathological. The models included Random Forest (RF), Gradient Boosting (GB), Support Vector Machine (SVM), Extra Trees (ET), AdaBoost (AB), and k-Nearest Neighbors (k-NN).
Three different sets of features were extracted, corresponding to the three testing recording subsets: “low reverb”, “med reverb”, and “high reverb”. These testing features were used to evaluate the classification performance of the models. Each model was evaluated three times on each testing subset to assess its robustness against different levels of challenging audio quality, ranging from clean/regular (low reverberation) to highly reverberant recordings. The classifiers were evaluated using receiver operating characteristic (ROC) curves, Area Under the Curve (AUC), overall classification accuracy, and F-score to compare the impact on ML performance before and after adding reverberation effects.
Results
The results compare the ML models across different accuracy metrics under low, medium, and high reverberation, testing their sensitivity to simulated recording conditions. Figure 1 illustrates ROC curves for ML classifiers evaluated on three testing datasets with different challenging conditions (low, medium, and high reverberation levels added on the testing recording). Sensitivity is plotted against 1-specificity. In the low-reverberation dataset (a), most models demonstrate high sensitivity and specificity, with steeper ROC curves approaching the upper left corner. In the med-reverberation dataset (b), the performance of all the classifiers declines moderately, reflected in flatter ROC curves compared to the low-reverberation condition. SVM and k-NN showed relatively better sensitivity and specificity among the other models, while RF exhibited a noticeable drop in performance. Under high reverberation (c), performance of all models further diminishes, with ROC curves approaching the diagonal line (indicating random performance with no discriminatory ability).
The performance metrics—accuracy (a), F-score (b), and AUC (c)—of the classifiers are plotted in Figure 2 across the three testing datasets. SVM and k-NN maintained relatively high scores across all metrics, with almost no changes in accuracy and F-score across the three conditions. The figure, in contrast, shows that RF achieved the highest scores across all metrics in the low-reverberation condition, though these scores dropped noticeably, ranking among the lowest under the med- and high-reverberations. The rest of the models also exhibit a clear decline in their accuracies, but at varying levels of impact.
Discussion
This paper presents a comparative evaluation of various ML models for classifying voice samples as nonpathological or pathological. While previous studies have explored the potential of ML in detecting voice pathology from audio recordings with promising results [1,2,4], this work takes an additional step by testing the generalizability and robustness of common ML models. By augmenting the testing dataset with med- and high-reverberation conditions, creating more challenging versions of the recordings, this study identifies the most robust models that are less sensitive to variations in recording quality during data collection.
Overall, the results highlight the varying robustness of ML models under simulated recording conditions (reverberation levels), emphasizing the impact of environmental factors on the performance of audio-based ML models. SVM demonstrated consistent robustness, making it a strong candidate for real-world voice assessment applications with variable recording conditions. Similarly, k-NN, while not a top performer on clean recordings, was less affected by reverberation and ranked among the best under adverse conditions. In contrast, RF revealed the highest classification accuracy on the clean recordings, aligning with its strong performance reported in the literature [1,31], but its accuracy dropped significantly with augmented recordings, revealing high sensitivity to environmental variability and limited generalizability. These findings underscore the importance of evaluating models under challenging and diverse testing conditions, as high accuracy on clean datasets alone can be misleading. Real-world robustness requires testing with varied techniques and data collection environments to ensure reliable performance.
Conclusions
This study underscores the importance of testing machine learning models for voice disorder classification under diverse recording conditions (data quality), an important step towards more widespread usability of ML models. Various ML models were evaluated on augmented recordings with simulated reverberation to mimic adverse acoustic environments and audio data quality. SVM and k-NN demonstrated consistent reliability under these conditions, whereas RF, despite strong performance on low reverberation conditions, showed reduced generalizability with heavily augmented recordings with higher reverberation. These findings highlight the necessity of training and evaluating models on datasets that reflect real-world acoustic environments to ensure reliable and practical applications in voice assessment.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Hegde S; Shetty S; Rai S; Dodderi T A Survey on Machine Learning Approaches for Automatic Detection of Voice Disorders. J. Voice 2019, 33, 947–e 11.
- 2Idrisoglu A; Dallora AL; Anderberg P; Berglund JS Applied Machine Learning Techniques to Diagnose Voice-Affecting Conditions and Disorders: Systematic Literature Review. J. Med. Internet Res 2023, 25, e 46105.37467031 10.2196/46105 PMC 10398366 · doi ↗ · pubmed ↗
- 3Yousef AM Laryngeal Mechanisms and Vocal Folds Function in Adductor Laryngeal Dystonia During Connected Speech. Ph.D. Dissertation, Michigan State University, 2023.
- 4Al-Hussain G; Shuweihdi F; Alali H; Househ M; Abd-Alrazaq A The Effectiveness of Supervised Machine Learning in Screening and Diagnosing Voice Disorders: Systematic Review and Meta-Analysis. J. Med. Internet Res 2022, 24, e 38472.36239999 10.2196/38472 PMC 9617188 · doi ↗ · pubmed ↗
- 5Yousef AM; Deliyski DD; Zacharias SR; Naghibolhosseini M Detection of Vocal Fold Image Obstructions in High-Speed Videoendoscopy during Connected Speech in Adductor Spasmodic Dysphonia: A Convolutional Neural Networks Approach. J. Voice 2022.
- 6Saidi P; Almasganj F Voice Disorder Signal Classification Using M-Band Wavelets and Support Vector Machine. Circuits Syst. Signal Process 2015, 34, 2727–2738, doi:10.1007/s 00034-014-9927-x. · doi ↗
- 7Sharma RK; Gupta AK Processing and Analysis of Human Voice for Assessment of Parkinson Disease. J. Med. Imaging Health Inform 2016, 6, 63–70.
- 8Yousef AM; Deliyski DD; Zacharias SR; Naghibolhosseini M Deep-Learning-Based Representation of Vocal Fold Dynamics in Adductor Spasmodic Dysphonia during Connected Speech in High-Speed Videoendoscopy. J. Voice 2022.