The First Cadenza Challenge: Perceptual Evaluation of Machine Learning Systems to Improve Audio Quality of Popular Music for Those with Hearing Loss
Scott Bannister, Jennifer Firth, Gerardo Roa-Dabike, Rebecca Vos, William Whitmer, Alinka E. Greasley, Simone Graetzer, Bruno Fazenda, Trevor Cox, Jon Barker, Michael A. Akeroyd

TL;DR
This study tested machine learning systems to improve music quality for people with hearing loss, finding that none outperformed a baseline method.
Contribution
The first perceptual evaluation of machine learning systems for music enhancement in hearing aid users across varying hearing loss severities.
Findings
No submitted system outperformed the baseline HDemucs-based audio enhancement method.
Clarity and distortion ratings were most predictive of overall audio quality for hearing aid users.
Systems with higher objective loudness and clipping received lower quality ratings for moderately severe hearing loss.
Abstract
Music is central to many people's lives, and hearing loss (HL) is often a barrier to musical engagement. Hearing aids (HAs) help, but their efficacy in improving speech does not consistently translate to music. This research evaluated systems submitted to the 1st Cadenza Machine Learning Challenge, where entrants aimed to improve music audio quality for HA users through source separation and remixing. The HA users (N = 53, ranging from “mild” to “moderately severe” HL) assessed eight challenge systems (including one baseline using the HDemucs source separation algorithm, remixing to original mixes of music samples, and applying National Acoustic Laboratories Revised amplification) and rated 200 music samples processed for their HL. Participants rated samples on basic audio quality, clarity, harshness, distortion, frequency balance, and liking. Results suggest no entrant system surpassed…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
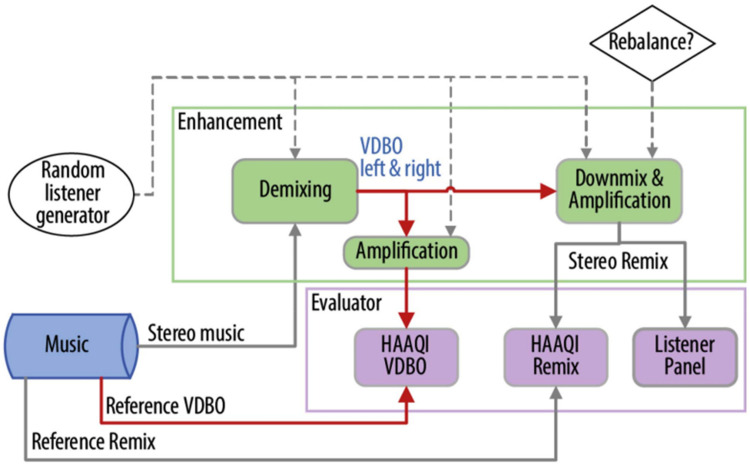 Figure 1
Figure 1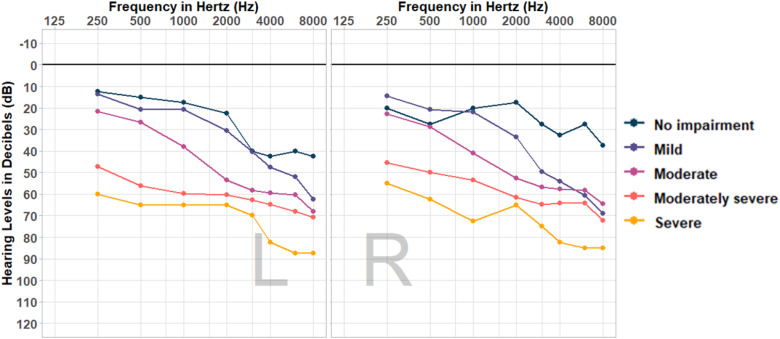 Figure 2
Figure 2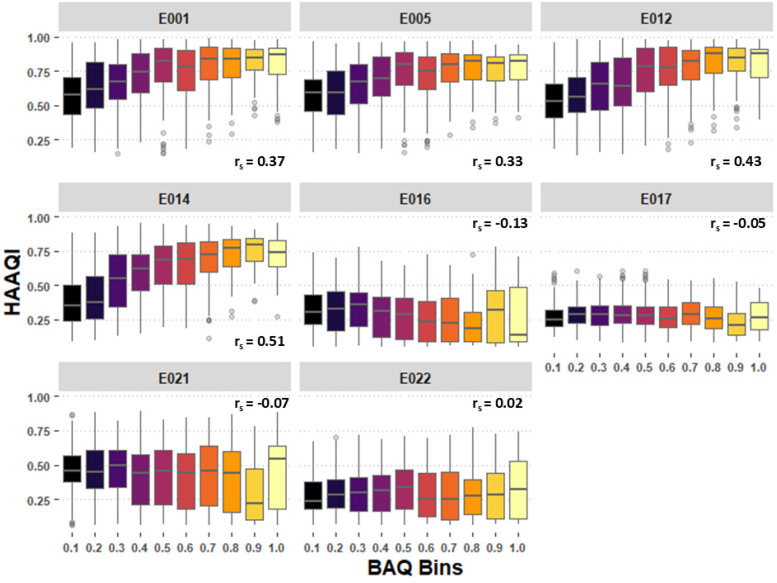 Figure 3
Figure 3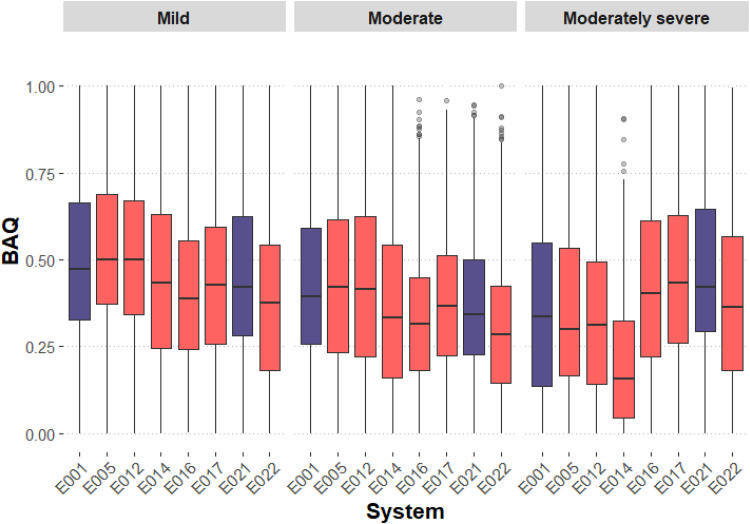 Figure 4
Figure 4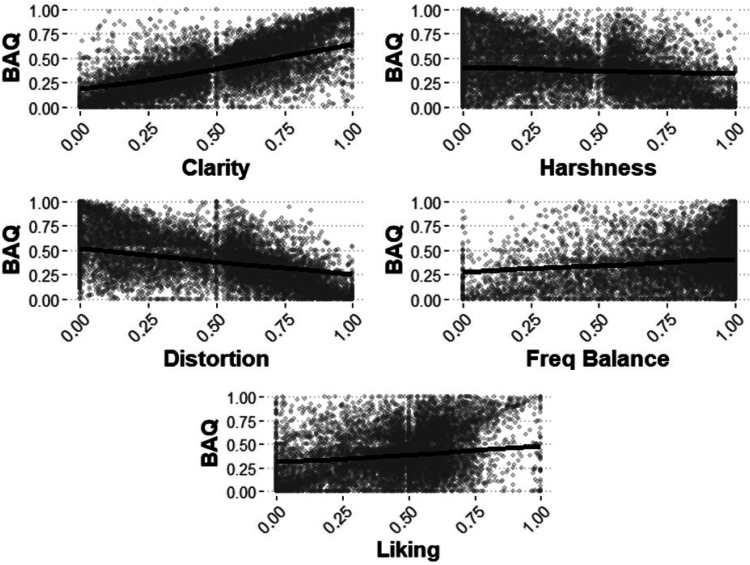 Figure 5
Figure 5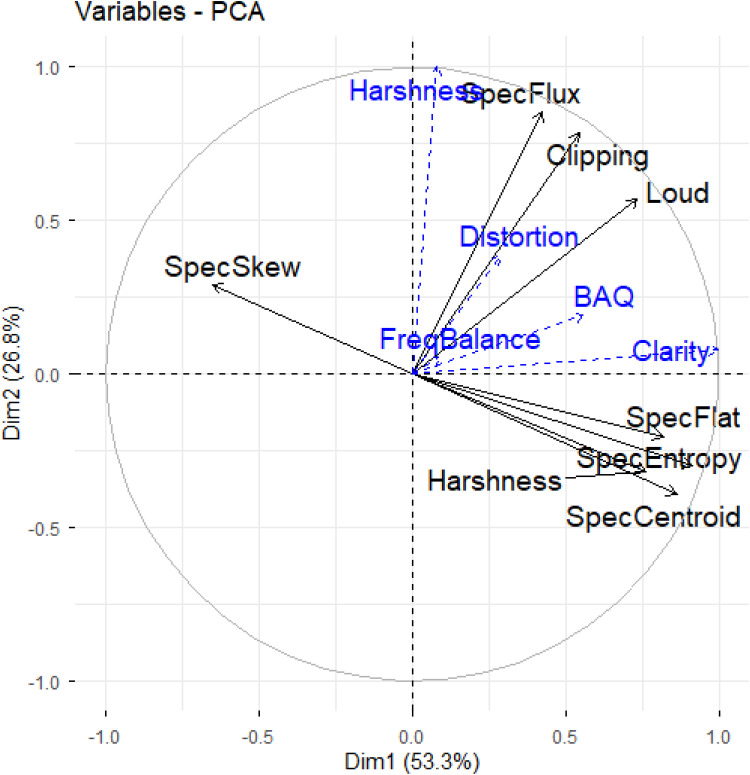 Figure 6
Figure 6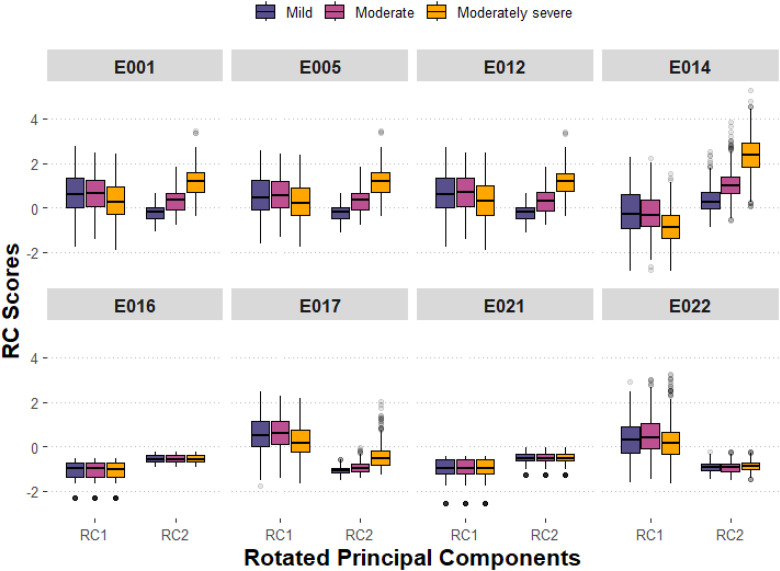 Figure 7
Figure 7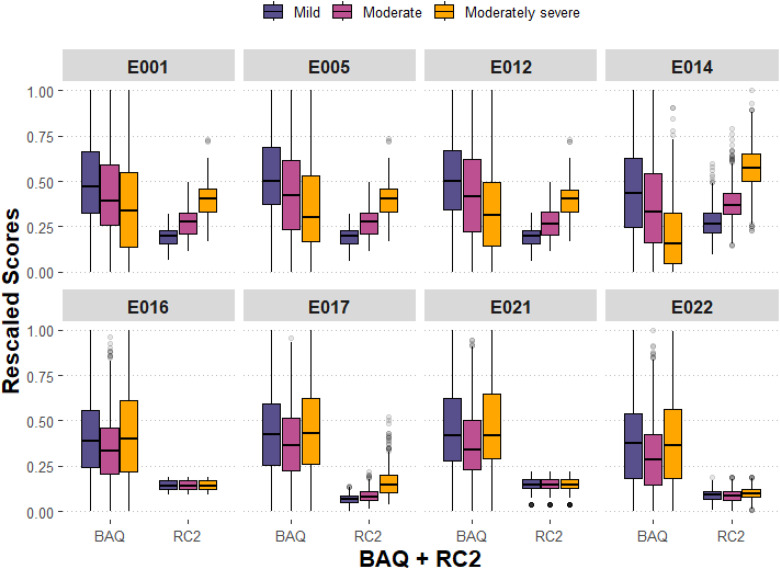 Figure 8
Figure 8 Figure 9
Figure 9 Figure 10
Figure 10 Figure 11
Figure 11 Figure 12
Figure 12 Figure 13
Figure 13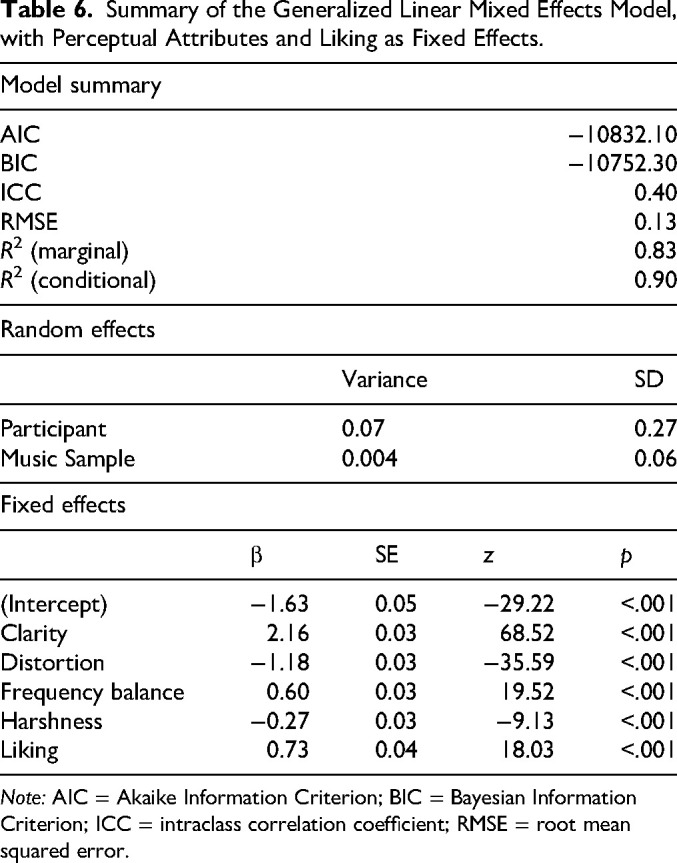 Figure 14
Figure 14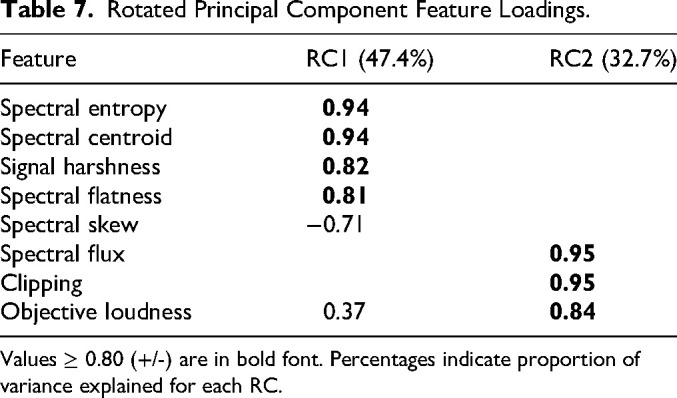 Figure 15
Figure 15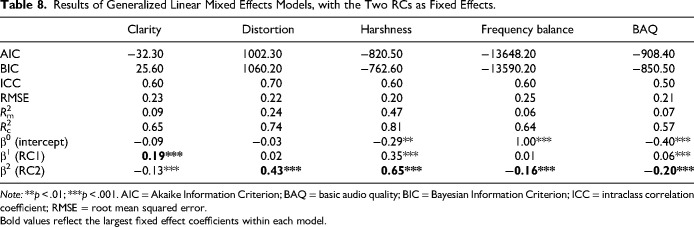 Figure 16
Figure 16Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsHearing Loss and Rehabilitation · Voice and Speech Disorders · Speech and Audio Processing