Application of a virtual imaging framework for investigating a deep learning-based reconstruction method for 3D quantitative photoacoustic computed tomography
Refik Mert Cam, Seonyeong Park, Umberto Villa, Mark A. Anastasio

TL;DR
This paper introduces a realistic virtual imaging framework to evaluate a deep learning method for 3D quantitative photoacoustic imaging of the breast.
Contribution
The first realistic virtual imaging testbed for assessing 3D learning-based qPACT reconstruction methods.
Findings
The method was tested across subject variability and physical factors like noise and acoustic aberrations.
The study provides insights into the strengths and limitations of the deep learning-based reconstruction approach.
Abstract
Quantitative photoacoustic computed tomography (qPACT) is a promising imaging modality for estimating physiological parameters such as blood oxygen saturation. However, developing robust qPACT reconstruction methods remains challenging due to computational demands, modeling difficulties, and experimental uncertainties. Learning-based methods have been proposed to address these issues but remain largely unvalidated. Virtual imaging (VI) studies are essential for validating such methods early in development, before proceeding to less-controlled phantom or in vivo studies. Effective VI studies must employ ensembles of stochastically generated numerical phantoms that accurately reflect relevant anatomy and physiology. Yet, most prior VI studies for qPACT relied on overly simplified phantoms. In this work, a realistic VI testbed is employed for the first time to assess a representative 3D…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
 Figure 1
Figure 1 Figure 2
Figure 2 Figure 3
Figure 3 Figure 4
Figure 4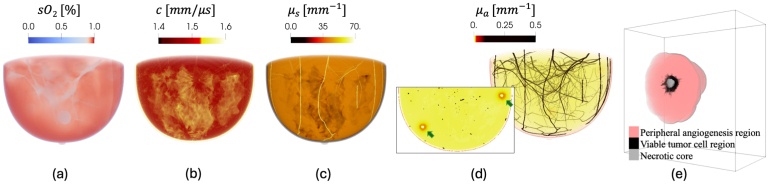 Figure 5
Figure 5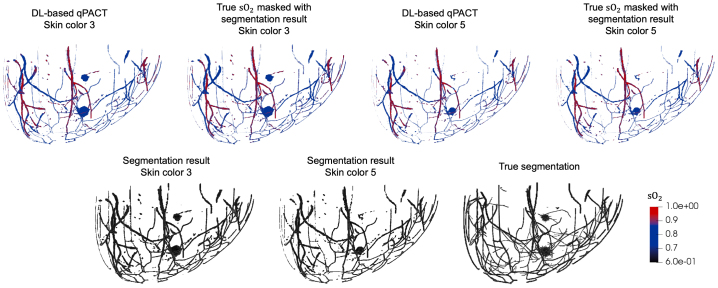 Figure 6
Figure 6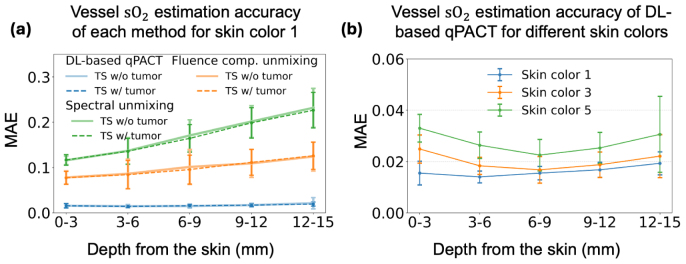 Figure 7
Figure 7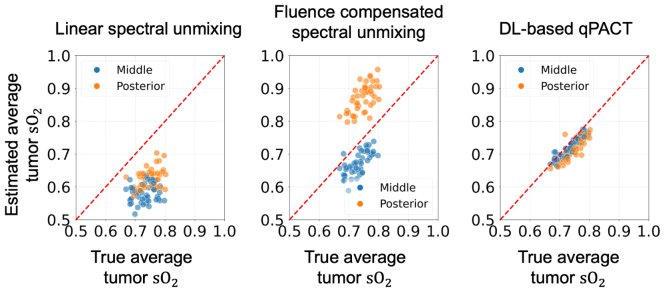 Figure 8
Figure 8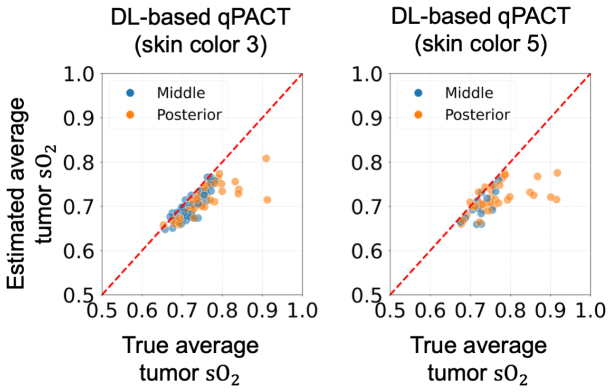 Figure 9
Figure 9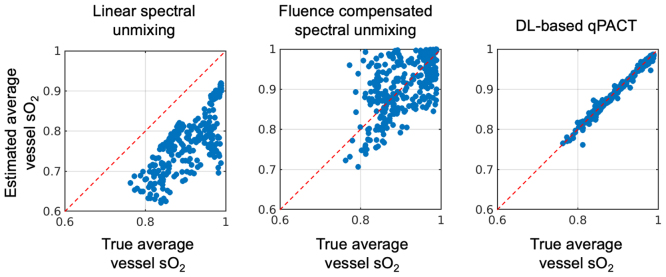 Figure 10
Figure 10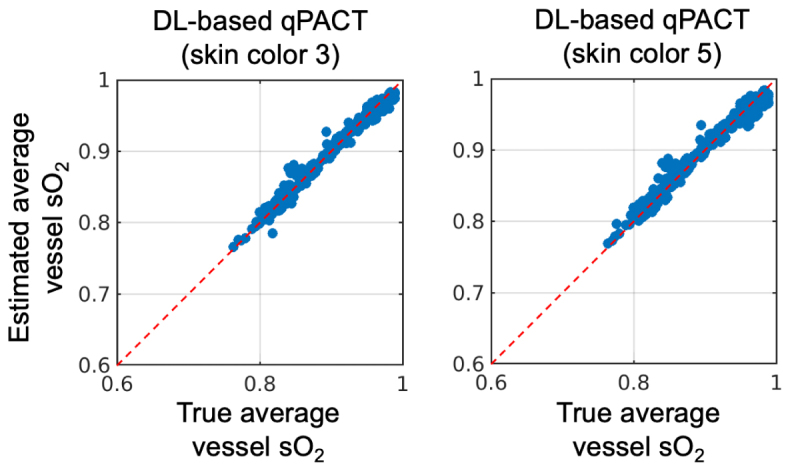 Figure 11
Figure 11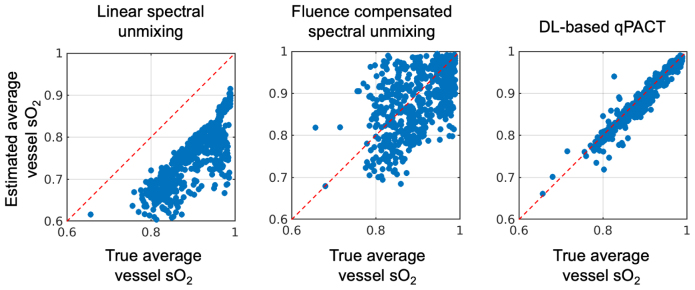 Figure 12
Figure 12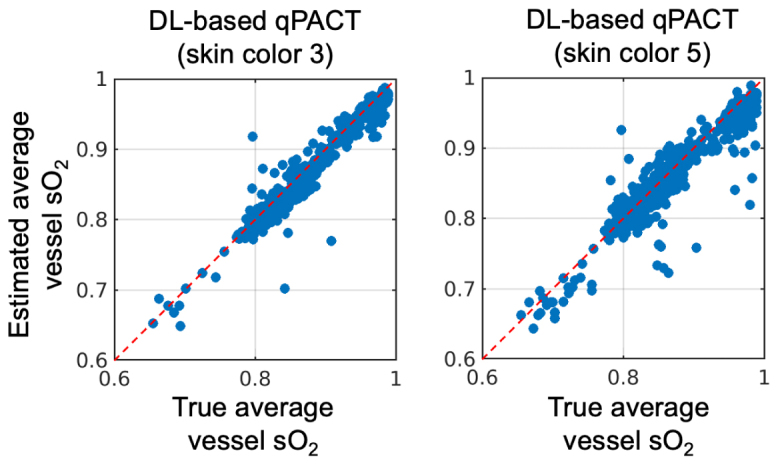 Figure 13
Figure 13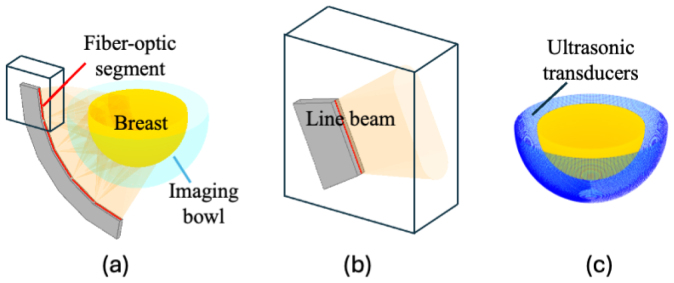 Figure 14
Figure 14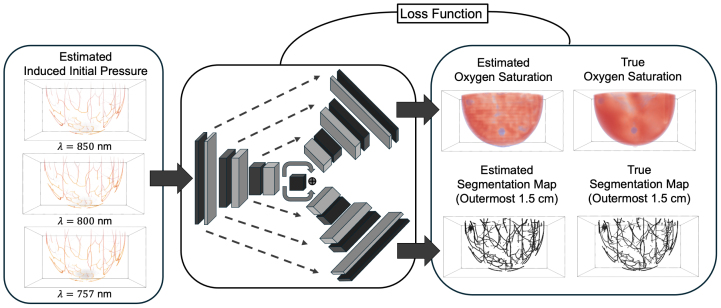 Figure 15
Figure 15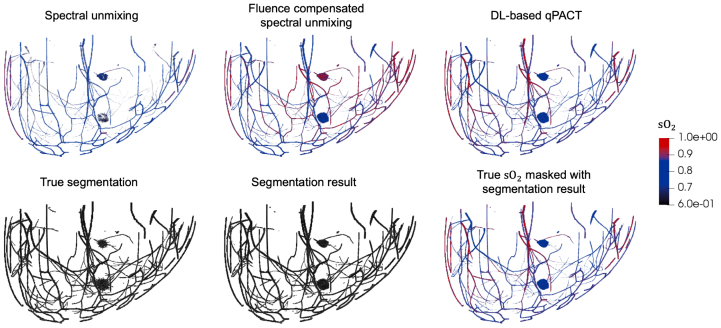 Figure 16
Figure 16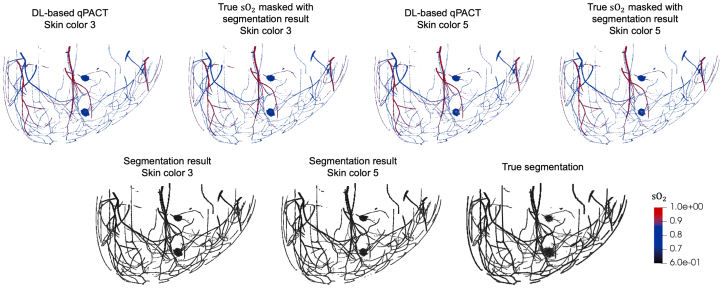 Figure 17
Figure 17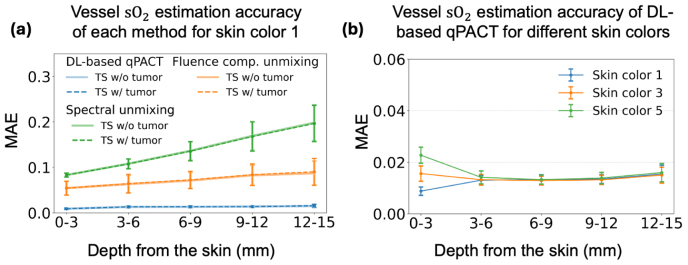 Figure 18
Figure 18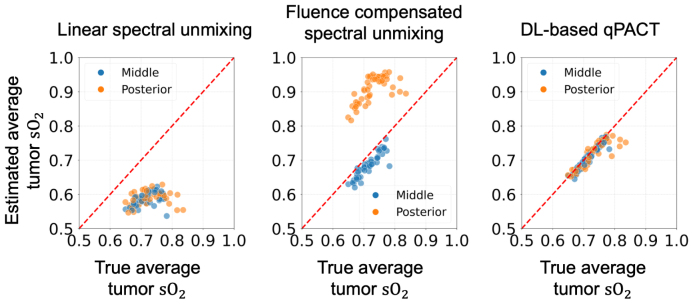 Figure 19
Figure 19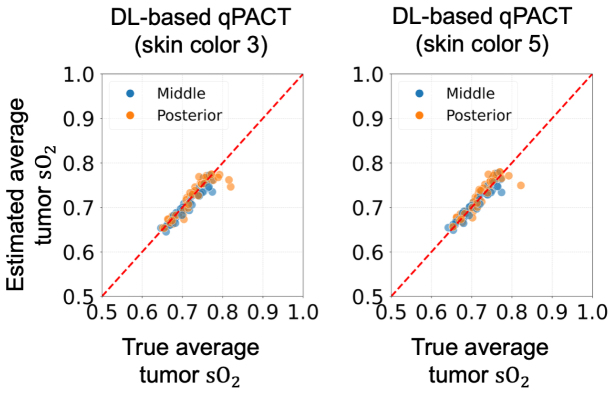 Figure 20
Figure 20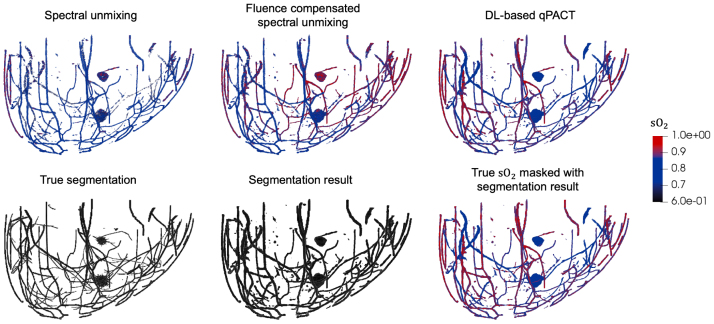 Figure 21
Figure 21Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsPhotoacoustic and Ultrasonic Imaging · Thermography and Photoacoustic Techniques · Infrared Thermography in Medicine
Introduction
1
Photoacoustic computed tomography (PACT) is an emerging non-invasive modality that offers high spatial resolution and optical contrast [2], [3], [4], [5]. PACT is employed for structural and functional imaging of biological tissues across preclinical and clinical contexts [2], [3], [4], [5], [6], [7]. It is a hybrid imaging technique that combines optical excitation and ultrasonic detection, leveraging the photoacoustic effect, where absorbed optical energy causes rapid thermoelastic expansion, resulting in the generation of acoustic waves [3], [4]. These acoustic waves then propagate through tissue and are detected by an array of ultrasonic transducers positioned around the imaging target. The recorded signals are subsequently employed for image reconstruction, enabling visualization of the spatial distribution of absorbed optical energy. By using PACT measurements acquired at multiple excitation wavelengths, it is, in principle, possible to estimate absolute or relative physiological quantities (e.g., blood oxygen saturation) and molecular quantities (e.g., concentrations of chromophores) within biological tissue [8], [9], [10], [11], [12]. This technique is referred to as quantitative PACT (qPACT) [8], [11], [12], [13].
The qPACT inverse problem is nonlinear and inherently ill-posed because of the coupled physics of light transport and photoacoustically induced pressure generation. Even under ideal, noise-free conditions, different combinations of optical absorption, optical scattering, and the Grüneisen parameter can yield indistinguishable measurement data, leading to non-uniqueness and instability in the inversion [11], [12], [13]. Beyond this fundamental limitation, in practical cases, the difficulty of the qPACT inverse problem is further exacerbated due to multiple factors such as imperfect system characterization, model mismatch in the optical and acoustic forward models (e.g., uncertainty in heterogeneous optical and acoustic properties), and limited angular/aperture coverage [11], [12], [13]. Physics-based reconstruction methods with advanced regularization and learning-based methods have been proposed to address these challenges. However, the development of accurate and robust image reconstruction methods that are suitable for deployment in practice remains an active research topic [11], [12], [14], [15], [16], [17], [18], [19], [20], [21], [22], [23], [24], [25].
The development of rigorous evaluation frameworks is essential for advancing qPACT reconstruction methods. In vivo data generally lack ground truth of to-be-estimated quantities, which makes them unsuitable for quantitative evaluation. Physical phantoms offer controlled imaging conditions but are often overly simplistic and typically lack anatomical and physiological realism [8], [23], [26]. Moreover, fabricating large numbers of physical phantoms that realistically represent clinically relevant variability, such as acoustic heterogeneity, anatomical realism, and physiological complexity, can be prohibitively costly and impractical [27], [28].
Virtual imaging (VI) studies (i.e., computer-simulation studies that pair realistic numerical phantoms with high-fidelity forward models of data acquisition) offer an alternative principled route to such quantitative evaluations [25], [29], [30], [31]. Several prior works have introduced advanced numerical phantoms that enable VI studies of photoacoustic imaging, including human breast [29], [30], [32], [33], [34], head [35], [36], [37], and prostate phantoms [38], as well as a mouse whole-body phantom [39]. These phantoms provide the foundation for simulation-based investigations aimed at quantitatively evaluating and benchmarking photoacoustic imaging methods. In the context of qPACT, VI enables independent control of optical and acoustic parameters, acquisition geometry, noise, and reconstruction assumptions while preserving access to reference optical/functional maps. To be effective, VI studies require ensembles of numerical phantoms that capture clinically relevant anatomical and physiological variability and that support stochastic assignment of tissue-specific optical and acoustic properties. When designed in this way, VI studies can quantify performance across a cohort of virtual subjects, reveal failure modes, and guide algorithm design and translation [25], [29], [30], [31].
This work employs a realistic VI framework based on ensembles of anatomically and physiologically realistic three-dimensional (3D) numerical breast phantoms (NBPs) [29], [30] to enable the systematic and quantitative assessment of a qPACT reconstruction method. To our knowledge, this is the first time that a realistic VI testbed has been employed for this purpose. Specifically, a 3D learning-based qPACT method for breast imaging is systematically evaluated with consideration of an ensemble of to-be-imaged subjects and physical factors that include measurement noise and acoustic aberration in the measurement data. Two VI studies, each based on distinct modeling assumptions, are designed to assess robustness and generalization across a range of object-level variations. These include spatial heterogeneity in acoustic properties (sound speed, density, and attenuation), anatomical differences in breast size and tissue composition, as well as optical variations in skin tone. The resulting analyses reveal strengths and limitations of the considered learned qPACT method and, more importantly, demonstrate the value of realistic VI studies for accelerating the development and facilitating the validation of effective qPACT image reconstruction methods.
The remainder of this paper is organized as follows. Section 2 summarizes the imaging physics of qPACT and reviews reconstruction approaches. Section 3 presents the VI framework and describes the evaluation of a representative deep learning (DL)-based qPACT method using NBPs, realistic imaging conditions, and clinically motivated study designs. Section 4 reports the results of VI studies. Finally, Section 5 presents a combined discussion and conclusion, including limitations and directions for future work.
Background
2
Imaging physics of quantitative PACT
2.1
In PACT, a short laser pulse illuminates the object-to-be-imaged (typically biological tissue). Absorption of optical energy by various chromophores (light-absorbing molecules) within the object induces a localized increase in acoustic pressure through the photoacoustic effect [3], [4], [5]. Mathematically, the induced initial pressure distribution at position and excitation wavelength is expressed as [13], [40], [41]:
Here, , , and are the wavelength- dependent absorbed optical energy, optical absorption coefficient, and optical fluence, respectively, and is the Grüneisen parameter that describes the conversion efficiency from absorbed optical energy to acoustic pressure. The optical fluence is dependent on the tissue’s optical properties, specifically the absorption coefficient , the scattering coefficient , the scattering anisotropy factor , and the refractive index .
The optical absorption coefficient is determined by the concentrations of various chromophores present in the tissue [13], [29], [30], [42]:
where denotes the molar concentration of chromophore at position , and is the corresponding molar extinction coefficient at wavelength . The set denotes the chromophores in the object. Key chromophores in biological tissues within the optical wavelengths relevant to PACT include oxyhemoglobin ( ), deoxyhemoglobin (Hb), melanin, lipids and water [42].
Once the initial pressure is induced, it serves as the source of acoustic wave propagation. The resulting acoustic wavefield propagates through the medium and is recorded by ultrasonic transducers [3], [4], [5]. The recorded data can then be used to reconstruct the initial pressure distribution and, in the context of qPACT, to estimate spatial distributions of tissue optical properties and/or molecular constituents [16], [17], [18], [19], [20], [21], [22], [23], [24], [25]. This typically involves acquiring measurements under multiple different optical excitation conditions, most commonly by varying the illumination wavelength [11], [12], [13], [43]. The goal of qPACT may include recovering absolute or relative values of optical absorption coefficients, scattering properties, or concentrations of specific chromophores [11], [12], [13], [25], [41], [43].
Inversion methods for qPACT
2.2
Linear spectral unmixing, while not an accurate method, is nevertheless commonly employed for quantitative estimation from multispectral PACT measurements [43], [44], [45]. This method simplifies the nonlinear inverse problem to a linear one, neglecting wavelength-dependent optical fluence variations caused by differential absorption and scattering during light propagation in the object, known as spectral coloring effects [9], [10], [13], [16], [40]. These effects become increasingly significant at greater depths, where cumulative absorption and scattering degrade accuracy [9], [10], [13], [46]. To address this, physics-model-based inversion techniques have been developed [10], [11], [12], [14], [15], [46]. These methods incorporate detailed models of light propagation in biological tissues and employ carefully devised regularization schemes to address the ill-posed nature of the problem [11], [12], [14], [15], [46]. Despite their potential, physics-based qPACT methods face several challenges that limit their clinical applicability, including high computational demands, sensitivity to modeling errors, and the difficulties in designing robust regularization strategies to handle parameter uncertainty and incomplete or noisy data [43], [47], [48], [49].
DL-based approaches offer an alternative solution by leveraging data-driven models to approximate the mapping from photoacoustic measurements to tissue optical and/or functional properties [16], [17], [18], [19], [20], [21], [22], [23], [24], [25], [50]. Among these, convolutional neural networks (CNNs) represent one of the most widely used architectures and have been employed in qPACT methods to learn this mapping [16], [17], [18], [19], [21], [24], [25]. However, most existing studies have been conducted using only simplified numerical and/or physical phantoms, both of which lack anatomical and physiological realism [16], [17], [18], [19], [21], [24], [25]. Additionally, the majority of these works focus on two-dimensional (2D) imaging scenarios [17], [18], [19], [21], [24], [26]. Even the limited number of studies that explored 3D tomographic imaging using VI studies employed simplified numerical phantoms that do not accurately capture realistic heterogeneity in tissue properties [16], [25]. As a result, the performance of DL-based qPACT methods under clinically relevant scenarios remains insufficiently evaluated [25], [26]. In particular, robustness to epistemic uncertainty, which stems from limited knowledge of the to-be-imaged object, including generally inaccessible, spatially heterogeneous acoustic properties such as speed-of-sound (SOS), is a critical yet underexplored factor that can significantly impact estimation accuracy. This challenge is compounded by the fact that in vivo experimental imaging data generally lack reference values for optical and functional parameters, making rigorous validation difficult. Therefore, there is a critical need for VI studies that reflect realistic and clinically relevant variability, for systematic and quantitative evaluation of DL-based qPACT reconstruction methods.
Evaluation of a DL-based qPACT method using a virtual imaging framework
3
A representative DL–based qPACT reconstruction method is evaluated using a realistic VI framework for controlled, quantitative assessment across cohorts of virtual subjects. The VI setup, comprising the multispectral photoacoustic data simulation pipeline, together with an ensemble of 3D NBPs, is described in Section 3.1. The DL method, including network architecture, loss functions, and the training protocol with data augmentation, is specified in Section 3.2. Two study designs are introduced to probe robustness and generalization under clinically relevant variability in Section 3.3.
Virtual imaging framework
3.1
The VI framework comprises two essential components: (i) an ensemble of anatomically and physiologically realistic 3D NBPs that provide known optical, acoustic, and functional maps with population variability for quantitative evaluation, and (ii) a simulation pipeline configured with a VI system emulating a hemispherical breast PACT imager with multispectral illumination.
Stochastic numerical breast phantoms
3.1.1
3D NBPs were generated using a stochastic framework [29], [30], [51] that produces anatomically and physiologically realistic cohorts spanning breast size and shape, tissue composition across BI-RADS density categories (A–D) [52], realistic vasculature, and skin tone (Fitzpatrick 1-6). Unlike simplified models, these NBPs assign tissue-specific, literature-informed heterogeneous optical (i.e. optical absorption, scattering, anisotropy coefficients and refractive index), acoustic (i.e., speed of sound, density, attenuation coefficient and power law exponent), and functional (i.e., blood oxygen saturation and volume fractions of blood, water, fat, and melanosome) property maps. The framework also permits insertion of anatomically realistic tumors at physiologically plausible locations; malignant tumors are represented with a distinct viable tumor cell region exhibiting spiculated morphology, along with a necrotic core and a peripheral angiogenesis region [30]. In this study, tumors were positioned either in the posterior region adjacent to the chest wall, where optical fluence is reduced, and/or in the middle region of the breast. Representative property distributions of an NBP and the tumor model are shown in Fig. 1. These phantoms provide the controlled heterogeneity and reference values required for cohort-level, reproducible assessments within the VI studies. More detailed information regarding the numerical phantom generation framework and the assigned material properties can be found in prior works [29], [30], [51].
Fig. 1. Distributions of functional, acoustic, and optical properties of a representative type-B NBP with an embedded malignant tumor: (a) blood oxygen saturation , (b) speed of sound , (c) optical scattering coefficient at a wavelength of 757 nm, (d) optical absorption coefficient at a wavelength of 757 nm, and (e) a 3D malignant tumor model. For visualization purposes, the tumor is shown as a split volume in (e). The inset in (d) displays a cross-section with arrows indicating two tumor locations, one in the posterior region near the chest wall and another in the middle region of the breast. Volumetric renderings were generated using ParaView [53], and color maps were manually adjusted to enhance visual clarity. **These anatomically realistic numerical phantoms provide a versatile and clinically meaningful platform for developing and evaluating qPACT techniques under realistic physiological and anatomical variability.**Fig. 1
Virtual imaging system and data simulation
3.1.2
A VI system was configured to closely emulate an existing breast PACT imaging system, as illustrated in Fig. 2 [30], [54]. The optical delivery subsystem comprised 20 arc-shaped illuminators (each spanning 80°) uniformly arranged on a 145 mm-radius hemispherical shell around the -axis. Each illuminator contained five linear fiber-optic segments, producing a total of 100 custom line beams with a conical angular distribution characterized by a half-angle of 12.5°; further details can be found in [30], [31]. The acoustic detection subsystem was equipped with 108 idealized point-like transducers uniformly distributed on a rotating 85 mm-radius, 80° arc-array. In this configuration, each transducer recorded 3720 temporal samples at a 20 MHz sampling frequency across 480 evenly distributed tomographic views; see [30] for further details.
Synthetic measurement data were generated in two stages. First, the induced initial pressure distribution in Eq. (1) was simulated using the GPU-accelerated Monte Carlo eXtreme (MCX, v1.9.0) [55], [56] software to model photon transport at three wavelengths (757, 800, and 850 nm). The Grüneisen parameter was set to 1, as often assumed for soft tissue [30]. Second, the subsequent propagation and detection of pressure waves were simulated using the k-Wave GPU toolbox [57]. Transducer positions were approximated by assigning them to the nearest voxel centers on the acoustic simulation grid, discretized with voxel size of 0.25 mm.
Fig. 2. Virtual imaging system configuration: (a) Arc-shaped light delivery subsystem composed of linear fiber-optic segments, (b) schematic of a custom line beam with conical angular emission from a single fiber-optic segment, (c) all effective ultrasonic transducer positions from the rotating arc-shaped array around the breast across 480 tomographic view steps [30], [54].Fig. 2
DL-based qPACT method
3.2
A representative DL-based qPACT method was implemented to simultaneously estimate blood oxygen saturation ( ) and segment clinically relevant target anatomical structures, specifically vessels and tumor regions (viable tumor cells), from full-scale 3D breast PACT images. The framework takes as input reconstructed initial pressure estimates at three illumination wavelengths (757, 800, and 850 nm). It estimates both an map and a binary segmentation mask in which arteries, veins, and viable tumor cells (if present) are labeled as 1, and all other voxels as 0. Segmentation is limited to a 1.5 cm-thick shell defined by depth from the breast surface, because optical attenuation causes exponential decay of photoacoustic signal intensity with depth, limiting recoverable signal information in deeper regions [45]. In contrast, estimation is performed across the entire imaging volume to preserve the smoothness of the map; however, all analyses are ultimately conducted within the segmented regions, so the effective estimation is confined to those areas. While estimation and segmentation beyond this depth may be feasible, the 1.5 cm threshold represents an empirical design choice that may be revisited in future studies. The method leverages multi-task learning to improve accuracy by exploiting correlations between the map and the underlying anatomical structures. An overview of the dual-task network is illustrated in Fig. 3.
Fig. 3. Overview of the dual-task DL network for simultaneous estimation and anatomical segmentation in 3D photoacoustic tomographic images. Three reconstructed initial pressure distributions at illumination wavelengths of 757, 800, and 850 nm serve as inputs to a shared encoder. Two separate decoders then generate (i) a whole-breast map and (ii) a binary segmentation map restricted to the outermost 1.5 cm shell from the breast surface, where veins, arteries, and tumors (if present) regions are labeled as 1 and all other voxels as 0. A combined loss function compares the predicted outputs with the corresponding ground truth maps ( maps and segmentation masks).Fig. 3
Network architecture and loss functions
3.2.1
The architecture adopts a residual encoder–decoder design with a single residual encoder and two task-specific decoders. The encoder extracts features from input 3D PACT images. It consists of five levels, each comprising a single residual block that includes two sequential 3 × 3 × 3 convolutional layers with leaky ReLU ( ) activations. At each level, feature map dimension is reduced via 3D max pooling (2 × 2 × 2 kernel, stride 2), enabling hierarchical multi-scale feature extraction. Within each residual block, shortcut connections are realized through 1 × 1 × 1 convolutional layers that facilitate residual learning and stabilize gradient propagation.
At the network’s bottleneck, the encoded feature representations are refined via an integrated attention module that combine both spatial and channel attention mechanisms [58]. Following attention-guided feature enhancement, the network bifurcates into two decoder streams: one dedicated to the segmentation task and the other to the regression ( estimation) task. Both decoders utilize deconvolutional layers (2 × 2 × 2 kernel, stride of 2) for upsampling, interspersed with residual decoding blocks that mirror the encoder’s use of two 3 × 3 × 3 convolutional layers and leaky ReLU ( ) activations. At each scale, encoder–decoder skip connections are formed by concatenating the corresponding encoder feature maps with the decoder inputs to preserve high-resolution details. The final layer of each decoder applies a 1 × 1 × 1 convolution followed by a sigmoid activation.
The network is trained using a composite loss function that integrates a regression term for estimation and a segmentation term:
where denotes the weighted mean squared error for estimation, and is a combination of voxel-weighted binary cross-entropy and Dice loss for segmentation. The scalar is a tunable hyperparameter that balances the regression and segmentation terms. Further details of the loss functions are provided in A.1, A.2.
Training and data augmentation
3.2.2
The training and validation datasets consisted of NBP pairs generated exclusively with Fitzpatrick skin tone 1. Each pair contained one NBP representing a healthy breast and the corresponding NBP with an inserted tumor, differing in tumor presence while sharing identical breast anatomy. This design isolates the effect of the tumor without introducing other anatomical variability. The training set included 320 such pairs and was structured to reflect a clinically representative distribution of BI-RADS breast density categories: 10% each for types A and D, and 40% each for types B and C [52]. The validation set comprised 40 pairs and maintained the same distribution to ensure consistency.
Training was performed using the ADAM optimizer [59] with a step size of 10^−5^ and was conducted on two NVIDIA A100 GPUs, each with 80 GB of memory. To reduce training time, data parallelization was implemented, and the batch size was set to 2 due to memory constraints and model complexity. A curriculum-based [60], [61] weighting schedule for the composite loss was employed (Appendix A.3), and training proceeded for a total of 600 epochs.
During training, data augmentation was applied at each epoch. Specifically, NBPs were rotated by a randomly chosen integer multiple of 18°, matching the angular spacing of the 20-view illumination geometry. This approach exploited the inherent symmetry of the illumination setup [54] and ensured that the network was exposed to a diverse set of training samples generated from different orientations, thereby reducing overfitting and enhancing robustness to variations in spatial arrangement of the imaging target.
Virtual imaging study designs and evaluation
3.3
This section describes the design of two VI studies and the evaluation framework used to assess the DL-based qPACT method. The studies were formulated to examine robustness under varying levels of complexity by introducing modeling discrepancies during the reconstruction of induced initial pressure estimates. Baseline comparison methods and quantitative evaluation metrics are also presented.
Study definitions
3.3.1
Two VI studies were conducted to evaluate the representative DL-based qPACT method described in Section 3.2.
Study 1 represents an idealized scenario where reconstruction artifacts are absent and noise is the only source of image degradation. Instead of performing acoustic reconstruction to generate the input to the DL-based qPACT method, the ground truth induced initial pressure distributions were directly corrupted with colored noise. Specifically, independently and identically distributed (iid), zero-mean Gaussian measurement noise was mapped into the image domain using the time-reversal method [62], [63], [64], assuming a constant SOS of water. This process resulted in spatially correlated (colored) noise. The standard deviation of the noise distribution was set to 1% of the ensemble mean of the maximum acoustic signal strength across all three wavelengths (757, 800, and 850 nm), as determined from the simulated acoustic pressure measurements generated for Study 2.
Study 2 represents a more realistic and challenging scenario. The acoustic measurement data were simulated using NBPs (seeSection 3.1.1) that incorporate heterogeneous SOS, acoustic density, and attenuation. The acoustic forward simulation employed grid discretization with 0.25 mm voxels. The resulting simulated pressure data were corrupted with additive iid Gaussian noise, with zero mean and a standard deviation equal to 1% of the ensemble mean of the maximum acoustic signal strength across all three wavelengths (757, 800, and 850 nm). Following the simulation, time-reversal reconstructions were performed to generate the input to the DL-based qPACT method, which assumed a constant SOS, uniform acoustic density, and the absence of acoustic attenuation. The SOS of the water, the acoustic coupling medium, was assumed. A computational grid discretized with a voxel size of 0.3 mm was employed for time-reversal reconstruction, introducing grid mismatch. During reconstruction, transducer positions defined on the 0.25 mm forward simulation grid were approximated by the closest voxels on the coarser 0.3 mm grid. When multiple positions mapped to the same location, only one was retained. This scenario reflects the complexities encountered in practical imaging environments.
The progression from Study 1 to Study 2 represents a systematic exploration of the DL-based qPACT method’s performance under increasingly realistic and adverse conditions, thereby establishing a framework for evaluating the robustness of the reconstruction method.
Baseline comparison methods
3.3.2
Two baseline methods were employed to benchmark the DL-based qPACT method: linear spectral unmixing and fluence-compensated linear spectral unmixing [43], [44], [45]. These methods serve as reference standards for evaluating accuracy and robustness in estimating blood oxygen saturation.
The first baseline, linear spectral unmixing, assumes wavelength-invariant optical fluence. The second baseline, fluence-compensated linear spectral unmixing, seeks to reduce errors from this assumption by incorporating estimated optical fluence maps for each wavelength. This approach assumes prior knowledge of the breast volume segmentation and uniform optical properties (absorption, scattering, anisotropy coefficients and refractive index) within the breast region. The property values were computed as ensemble averages from the training dataset, while the water region was assigned the corresponding optical properties of water. Fluence maps were generated with MCX simulations and applied to rescale the initial pressure estimates, thus compensating for wavelength-dependent fluence variations before spectral unmixing. Although this method does not fully eliminate errors, it improves accuracy by partially accounting for spatial and spectral variations in light propagation, making it a stronger baseline than standard linear spectral unmixing.
Evaluation strategy
3.3.3
A comprehensive evaluation was performed using both qualitative and quantitative analyses on ensembles of NBPs. Two categories of test data were considered: an in-distribution (ID) test set, whose characteristics match the training data and which was used to assess accuracy of the learned model, and out-of-distribution (OOD) test sets, whose characteristics differ from the training data and which were used to evaluate generalizability. The ID test set consisted of 64 NBP pairs, each comprising a breast without a tumor and the corresponding breast with tumors. In these test sets, BI-RADS breast density types A-D were evenly distributed, in contrast to the 1:4:4:1 ratio used in training. The term “in-distribution” denotes that the test set was generated using the same anatomical parameterization and within the same ranges of optical and acoustic tissue properties as the training set. A balanced distribution of breast density types in the ID test set was intentionally adopted to prevent performance metrics from being skewed by overrepresented categories. The OOD test sets each consisted of 64 NBPs with Fitzpatrick skin tones 3 (OOD-I) and 5 (OOD-II). They shared identical breast anatomy with the ID set but included only tumor-bearing cases, differing solely in skin pigmentation. These sets were designed to evaluate the robustness of the DL-based qPACT method against real-world variability in skin pigmentation.
Separate evaluation within tumor and vessel regions is critical, as the photoacoustic signal originating from tumors is significantly weaker than that from vascular structures. This disparity necessitates tailored assessment strategies to accurately characterize model performance across these regions. To mitigate class imbalance during training and simplify the segmentation task, the model was designed to produce a unified binary mask encompassing both tumors and vessels. Because these structures differ in morphology, effective post hoc separation was feasible. A dedicated post-processing pipeline was implemented to achieve this differentiation. A multiscale Frangi vesselness filter was applied to the segmentation output to enhance vascular features [65], and the resulting vesselness map was thresholded to generate a binary vessel mask. Connected component analysis was then used to identify contiguous vascular regions, with components classified as vessels if more than 50% of their voxels were labeled as vessel in the thresholded map. To disjoin adjacent tumors and vessels, morphological operations consisting of erosion followed by dilation were applied. Minor manual refinements were subsequently performed to correct vessel components that were erroneously labeled as tumors upon visual inspection.
To comprehensively evaluate model performance, targeted assessments were conducted for tumor detection, vascular segmentation, and regional estimation. Considering the potential diagnostic application of PACT [66], [67], the evaluation emphasized tumor detection rather than segmentation accuracy over tumor regions. Tumor detection was determined by comparing the predicted segmentation to the ground truth binary tumor mask; a tumor was considered detected if the overlap exceeded 500 voxels, and undetected otherwise. The ground truth tumor region comprised 3808 voxels, with a fixed shape and size across all datasets containing tumors. Vascular segmentation accuracy was quantified using the Dice similarity coefficient, computed between the post-processed vessel map and the corresponding ground truth binary vessel mask. The mean and standard deviation of the Dice scores were reported across the dataset to characterize segmentation consistency. This dual evaluation framework enabled a nuanced understanding of the model’s ability to detect tumors and delineate vasculature.
Quantitative assessment of the estimated maps was performed separately for tumor and vascular regions, based on the network’s predicted segmentations. This approach reflects a clinically realistic scenario in which labeled segmentation maps are unavailable, and functional interpretation must rely directly on the model’s output. Similar evaluation strategies have been adopted in prior DL-based qPACT studies [16], [17], [26]. Tumor estimation was assessed by comparing the estimated average values within the model-identified tumor regions with the corresponding true average values. Vascular estimation was evaluated as a function of depth to account for the exponential decay of optical fluence, which reduces the signal-to-noise ratio with increasing depth. Mean absolute error (MAE) was calculated at varying vessel depths to assess performance across the imaging volume.Fig. 4. Visual comparison of estimated distributions and segmentation maps of vessels and tumors for the ID test set (skin color 1) in Study 1. Top row: estimated maps obtained using spectral unmixing, fluence-compensated unmixing, and DL-based qPACT (left to right), each masked using the corresponding estimated segmentation map. Bottom row: true segmentation map (left), estimated segmentation map (center), and true masked with the estimated segmentation map (right). DL-based qPACT provided more consistent maps and more accurate segmentation.Fig. 4. Fig. 5Visual comparison of DL-based qPACT results for the OOD test sets (skin colors 3 and 5) in Study 1. Top row: estimated (first and third) and true (second and fourth) maps, each masked with the corresponding estimated segmentation map, for skin color 3 (first and second) and skin color 5 (third and fourth). Bottom row: estimated segmentation masks for skin colors 3 (left) and 5 (center), and the corresponding true segmentation mask (right). DL-based qPACT maintained high visual fidelity in both segmentation and blood oxygenation estimates across diverse skin tones, demonstrating robust generalization.Fig. 5
For generalization assessment using the OOD test sets, the region within 0.6 mm depth from the skin surface was excluded from the outputs as post-processing. This region encompassed the epidermis, where melanin is concentrated. Because variations in melanin concentration determine skin tone, results in this superficial region can be comparatively inaccurate when the model encounters the test data with skin tones not represented in the training set. However, from a clinical perspective, the performance within the underlying breast tissue is of greater relevance than inaccuracies in the skin layer. Moreover, assuming skin thickness as prior knowledge is feasible. For these reasons, the superficial region was excluded when evaluating generalization with the OOD test sets.
Results
4
In the presented results, all values are reported on a normalized scale from 0 to 1, corresponding to fractional values ranging from 0 to 100%. The MAE is computed as an absolute deviation on this scale; for instance, an MAE of 0.05 corresponds to an average deviation of 5 percentage points in .
Study 1 results
4.1
Fig. 4 shows sample results for vessel and tumor segmentation, along with estimated distributions in blood vessels and tumors, under ID test conditions. Notably, the DL-based qPACT method produced estimates that more closely approximate the ground truth maps compared to the conventional approaches. The bottom row of Fig. 4 shows the true and estimated segmentation masks, confirming that the DL-based qPACT method was able to localize vascular and tumor regions with high spatial fidelity. Fig. 5 presents the corresponding results for OOD skin colors. The close alignment between the estimated and ground truth maps demonstrates the robust generalization of the DL-based qPACT method to the variations in skin tone.
Fig. 6 shows the depth-wise accuracy of the estimated within vessels in Study 1. Panel (a) presents MAE values for ID skin color 1, evaluated on both tumor-absent and tumor-present test sets. The close agreement between these cases demonstrates that the presence of tumors does not substantially impact vascular estimation. Among the evaluated methods, the conventional spectral unmixing method exhibited considerable errors (close to 10%) even at shallow depths (0 to 3 mm), with errors increasing at greater depths due to increased spectral coloring effects with optical attenuation. Fluence-compensated spectral unmixing showed improved performance, although it still showed noticeable accuracy degradation with depth. In contrast, the DL-based qPACT method consistently achieved lower errors (below 3%) across all depths, demonstrating improved robustness against depth-dependent optical variations. Panel (b) further demonstrates that DL-based qPACT maintained comparably low errors across different skin tones, including OOD skin colors 3 and 5, suggesting robust generalization to OOD skin tone scenarios with minimal performance degradation. Note that for panel (b), only tumor-present test sets were used, and for skin colors 3 and 5, tumor-absent versions were not generated. The per-vessel average estimated and true scatter plots provided in Appendix B further confirm the trends observed in the MAE results.Fig. 6. Depth-wise MAE of estimated in segmented vessels for Study 1. (a) Comparison of spectral unmixing (green), fluence-compensated unmixing (orange), and DL-based qPACT (blue) on the ID test set (skin color 1). Results are shown separately for the test set with tumors (dashed, denoted TS w/ tumor) and the test set without tumors (solid, denoted TS w/o tumor). (b) Performance of DL-based qPACT across different skin tones for the test set with tumors (TS w/ tumor): skin color 1 (blue, ID), and skin colors 3 (orange) and 5 (green), representing OOD conditions. Error bars indicate standard deviation. DL-based qPACT maintained MAE below 3% across all depths and skin tones, highlighting its robustness to depth-dependent fluence variations and distribution shifts.Fig. 6
Table 1 presents tumor detection performance for Study 1. The DL-based qPACT method achieved high tumor detection accuracy for the ID test set (skin color 1), detecting 89 true positives with 6 false positives and 1 false negative. Additionally, the method maintained consistent performance on the OOD test sets, detecting 88 true positives in each case, with similarly low false positive and negative rates. These results suggest a reliable generalizability of the DL-based qPACT method.Table 1. Tumor detection results in Study 1.Table 1. Test setTrue positiveFalse positiveFalse negativeID (skin color 1)8961OOD-I (skin color 3)8852OOD-II (skin color 5)8832The total number of tumors present across all NBPs in each test set (number of true positives plus number of false negatives) is 90.
Fig. 7 provides a comparison of the methods in estimating average levels within tumors under the ID testing conditions. The scatter plots indicate that spectral unmixing consistently underestimated the true average values, consistent with previous reports [68], [69]. Fluence-compensated spectral unmixing partially mitigated spectral coloring effects, although its effectiveness varied with tumor location. For tumors located in the middle region of the breast, fluence-compensated spectral unmixing produced estimates that closely followed the identity line, whereas for tumors in the posterior region near the chest wall, where optical fluence was reduced, the estimated values appeared slightly higher. In contrast, DL-based qPACT estimates aligned closely with the true values, displaying minimal deviation and clustering tightly around the identity line. These results demonstrate the effectiveness of the DL-based qPACT method in quantitatively estimating tumor oxygenation under simplified acoustic conditions assumed in Study 1.Fig. 7. Estimated vs. true average tumor values in Study 1 for the ID test set (skin color 1). Scatter plots compare spectral unmixing (left), fluence-compensated unmixing (center), and DL-based qPACT (right). The red dashed line denotes the identity line, corresponding to perfect estimation. Tumor positions corresponding to the posterior and middle breast regions are indicated by different colors. DL-based qPACT achieved the highest estimation accuracy, with estimates tightly clustering along the identity line, outperforming conventional methods.Fig. 7
Fig. 8 presents the generalization performance of the DL-based qPACT method in estimating average within tumors for OOD skin tones in Study 1. Despite not being trained on skin colors 3 and 5, the method maintained a strong agreement between the estimated and true values, with points aligning closely along the identity line in both cases. This demonstrates high estimation accuracy with minimal bias introduced by variations in skin tone.Fig. 8. Estimated vs. true average tumor values in Study 1 for the OOD test sets (skin colors 3 and 5). Scatter plots show DL-based qPACT results for skin color 3 (left) and skin color 5 (right). DL-based qPACT demonstrated robust generalization, maintaining accurate tumor oxygenation estimates even under OOD conditions.Fig. 8
The accuracy of vessel segmentations by the DL-based qPACT method, measured using the Dice coefficient, was highest for the ID test set (skin color 1), achieving 0.8721 ± 0.0094, which indicates strong overlap with the ground truth. Under OOD conditions, performance declined, with Dice scores of 0.7004 ± 0.0266 for skin color 3 and 0.6985 ± 0.0260 for skin color 5. Despite this reduction, the model maintained a reasonable level of performance, suggesting a certain degree of generalization to unseen skin tones.Fig. 9. Visual comparison of estimated and segmentation maps of vessels and tumors for the ID test set (skin color 1) in Study 2. Top row: estimated maps obtained using spectral unmixing, fluence-compensated unmixing, and DL-based qPACT (left to right). Bottom row: true segmentation map (left), estimated segmentation map (center), and true masked with the estimated segmentation map (right). Despite reduced segmentation accuracy, DL-based qPACT preserved physiologically plausible estimates, demonstrating robustness to errors in reconstructed initial pressure images caused by uncompensated acoustic heterogeneity.Fig. 9. Fig. 10Visual comparison of DL-based qPACT results for the OOD test sets (skin colors 3 and 5) in Study 2. Top row: estimated (first and third) and true (second and fourth) maps, each masked with the corresponding estimated segmentation map, for skin color 3 (first and second) and skin color 5 (third and fourth). Bottom row: estimated segmentation masks for skin colors 3 (left) and 5 (center), and the corresponding true segmentation mask (right). DL-based qPACT maintained estimation fidelity in detected regions, but showed declines in segmentation accuracy and sensitivity for OOD skin tones, underscoring potential challenges.Fig. 10
Study 2 results
4.2
Fig. 9 shows an estimated segmentation mask and the corresponding estimated maps obtained with different methods, under ID conditions for Study 2. Despite the uncompensated acoustic heterogeneities in reconstructing the induced initial pressure, the DL-based qPACT method maintained its ability to produce accurate estimates. The estimated segmentation maps exhibited greater structural fragmentation than in Study 1, most likely due to artifacts present in the reconstructed acoustic images used as input to the DL-based qPACT method. In particular, acoustic modeling mismatch between the forward simulation and reconstruction introduced out-of-focus blurring and geometric distortions, while additional artifacts such as reduced contrast and streak patterns arose from the hemispherical measurement geometry and measurement noise. These degradations in the input images, in turn, contributed to fragmented vessels in the estimated segmentation maps. Nonetheless, the estimated within the segmented regions remained consistent with the ground truth. These results indicate that the DL-based qPACT method retained its strength in estimation, even though segmentation quality degrades under more realistic and challenging simulation conditions.
The visualizations in Fig. 10 illustrate the challenges of generalization under the more realistic modeling conditions of Study 2. For skin color 3, the DL-based qPACT method continued to generate accurate maps within detected tumor and vessel regions, although segmentation quality was visibly degraded. In the more challenging skin color 5 case, a tumor near the chest wall was entirely missed, likely due to reduced optical fluence and the resulting lower signal strength in this deeper region. For tumors that were successfully segmented, the estimated values remained accurate, indicating the model’s capacity to provide reliable oxygenation estimates.
Fig. 11 shows the depth-wise MAE for the estimated within vessels in Study 2. Panel (a) presents MAE values under ID testing conditions, evaluated on both tumor-present and tumor-absent test sets. The close agreement between the results with these different test sets confirmed that tumor presence does not significantly influence estimation within the vessels for the considered methods. Across all depths, the DL-based qPACT method outperformed both spectral unmixing and fluence-compensated unmixing. Panel (b) displays the DL-based qPACT results for ID and OOD skin tones. Slightly higher estimation error observed in the shallow region (0–3 mm) relative to deeper regions (e.g., 3–6 mm) could possibly be attributed to acoustic heterogeneities at the interface between the acoustic coupling medium (water) and the breast tissue, which degrade signal quality near the surface. Nevertheless, panel (b) demonstrates that DL-based qPACT generalized well across skin tones in estimating vascular , even under the more realistic simulation conditions of Study 2. The per-vessel average estimated and true scatter plots for Study 2, included in Appendix B, also confirm the MAE-based observations.Fig. 11. Depth-wise MAE of estimated in segmented vessels for Study 2. (a) Comparison of spectral unmixing (green), fluence-compensated unmixing (orange), and DL-based qPACT (blue) on the ID test set (skin color 1). Results are shown separately for the test set with tumors (dashed, denoted TS w/ tumor) and the test set without tumors (solid, denoted TS w/o tumor). (b) Performance of DL-based qPACT across different skin tones for the test set with tumors (TS w/ tumor): skin color 1 (blue, ID), and skin colors 3 (orange) and 5 (green), representing OOD conditions. Error bars represent standard deviation. DL-based qPACT retained robust accuracy of vessel estimates despite challenges posed by acoustic heterogeneity and distribution shifts.Fig. 11
Table 2 presents tumor detection performance for Study 2 across both ID and OOD skin tones. For the ID test set, the method achieved near-perfect results, with 89 true positives, only 2 false positives, and 1 false negative. However, detection performance declined under OOD testing conditions. For skin color 3, the number of true positives dropped to 77, accompanied by 13 false negatives. For skin color 5, the detection performance showed a more substantial decrease, with only 42 tumors detected and 48 missed. Although the false-positive rate remained relatively low across all skin tones, the decrease in true positive detection for the OOD skin tones indicates a reduction in sensitivity under increased distributional shift. This decline in sensitivity may stem from a combination of factors, including reduced optical fluence due to darker skin color and the absence of darker skin tones in the training data.Table 2. Tumor detection results in Study 2.Table 2. Test setTrue positiveFalse positiveFalse negativeID (skin color 1)8921OOD-I (skin color 3)77513OOD-II (skin color 5)42648
Fig. 12 presents scatter plots comparing estimated and true average values in tumors under Study 2 for the ID test dataset. As observed in Study 1, the conventional spectral unmixing method (left) significantly underestimated tumor , exhibiting a clear downward bias and wide variability. Fluence-compensated spectral unmixing (center) partially mitigated spectral coloring but showed overestimation for tumors in the posterior region of the breast, resulting in noticeable deviations relative to the identity line. In contrast, the DL-based qPACT method (right) demonstrates the closest agreement with the true values. This indicates that the DL-based qPACT method effectively mitigated modeling errors in the acoustic reconstruction, leading to more accurate tumor estimation.Fig. 12. Estimated vs. true average tumor values in Study 2 for the ID test set (skin color 1). Scatter plots compare spectral unmixing (left), fluence-compensated unmixing (center), and DL-based qPACT (right). DL-based qPACT provided the most accurate estimates of average tumor , indicating effective compensation for modeling errors in acoustic image reconstruction.Fig. 12
Fig. 13 illustrates the performance of the DL-based qPACT method in estimating the average tumor for OOD cases in Study 2. The method maintained reasonable accuracy for skin color 3, with the results moderately aligned around the identity line, whereas performance noticeably deteriorated for skin color 5. The scatter plot for skin color 5 revealed increased deviation from the identity line and greater variance, indicating a clear drop in tumor estimation accuracy.Fig. 13. Estimated vs. true average tumor values in Study 2 for the OOD test sets (skin colors 3 and 5). Scatter plots show DL-based qPACT results for skin color 3 (left) and skin color 5 (right). Introducing more physiologically accurate acoustic properties in this study led to a notable decline in accuracy, particularly for skin color 5.Fig. 13
The accuracy of vessel segmentation markedly declined under the more realistic simulation conditions of Study 2. For the ID test set with skin color 1, the Dice coefficient dropped to 0.5268 ± 0.0260, representing a substantial reduction compared to Study 1. Performance further deteriorated in OOD cases, with Dice scores of 0.4123 ± 0.0257 for skin color 3 and 0.3864 ± 0.0304 for skin color 5. These results suggest that the segmentation accuracy of the DL-based qPACT method diminished as the acoustic complexity increased, particularly for darker skin colors that were not represented in the training data.
Discussion and conclusion
5
This work demonstrates how realistic VI studies can be employed to systematically evaluate qPACT methods, revealing both their strengths and limitations under clinically relevant conditions. The employed framework leveraged 3D NBPs that incorporated anatomical, optical, and acoustic heterogeneity, enabling controlled yet physiologically realistic assessments. The VI framework was utilized to assess a representative DL-based qPACT method trained to jointly estimate and segment vascular and tumor regions from multispectral photoacoustic data. The evaluation spanned multiple sources of variability, including acoustic heterogeneity and distinct skin tones and demonstrated the impact of each on performance and generalization.
Results from the VI studies revealed that the considered DL-based qPACT method effectively estimated within tumors and vessels across different acoustic modeling assumptions in reconstructing the induced initial pressure. In ID test scenarios, the model maintained high accuracy in estimation, even as errors in initial induced pressure reconstructions increased from Study 1 to Study 2. Notably, Study 2 demonstrated that, despite reduced segmentation accuracy, the DL-based qPACT method was still able to estimate accurately under complex, clinically relevant acoustic and optical variability. This observation highlights the potential of DL-based qPACT frameworks to deliver accurate functional imaging in scenarios with complex clinically relevant variability.
However, the accuracy of the estimated and segmentation maps by the DL-based qPACT method for the OOD test sets with darker skin tones declined from Study 1 to Study 2. While the method generalized well under the relatively simplified conditions of Study 1, its performance deteriorated under the more challenging conditions of Study 2. This was reflected in reduced tumor detection sensitivity, greater variability in estimates, and lower segmentation accuracy for darker skin tones not represented in the training data. These findings suggest that both physical factors, such as increased optical absorption and reduced signal-to-noise ratio in darker skin tones, and the lack of representative training data can limit model performance under clinically relevant distribution shifts. To ensure robust performance and applicability across a broad range of populations, it is essential to enhance training data diversity, particularly with respect to skin tone, and to account for the fundamental limitations imposed by the imaging physics.
The observed discrepancy between robust ID performance and declining accuracy in OOD cases highlights a critical challenge in the development of DL-based qPACT methods. Evaluations conducted under oversimplified conditions can overestimate model performance, as they fail to incorporate the complexities of real-world anatomical and optical variations as well as inaccuracies in the estimated initial pressure distribution. The progressive decline in performance from Study 1 to Study 2 emphasizes the need for comprehensive validation pipelines that reflect clinical variability, including variations in skin color.
A persistent challenge in the field of qPACT is the lack of reliable in vivo reference maps, which makes direct validation of reconstruction methods difficult. This limitation underscores the need for alternative evaluation strategies capable of yielding meaningful insights into method performance. The VI framework employed in this study provides such an alternative, enabling controlled and physiologically realistic assessments using realistic numerical phantoms. While not a substitute for in vivo validation, such VI studies are valuable tools for identifying method limitations, guiding algorithm development, and informing experimental design.
This study captures key aspects of the qPACT imaging process; however, several simplifying assumptions remain. The Grüneisen parameter was assumed to be spatially constant, which is a common approximation for soft tissues [29], [30]. The VI system employed idealized point-like acoustic detectors, without modeling frequency-dependent bandwidth or directional sensitivity, and the illumination geometry was treated as perfectly characterized, neglecting uncertainties in optical fluence. These assumptions improve computational tractability but contribute to a simulation-to-experiment gap that may affect translation to physical phantom or in vivo studies [70], [71]. Tumor angiogenesis was modeled implicitly by introducing spatial heterogeneity in the blood volume fraction, featuring elevated total hemoglobin concentration within the viable tumor subregion and in the surrounding peritumoral area, while large peritumoral vessels were not explicitly represented. Incorporating detector sensitivity characteristics, illumination uncertainty, and explicit modeling of peritumoral vasculature remain important avenues for future development. Nevertheless, the controlled and interpretable nature of VI studies enables systematic assessment of algorithmic performance and provides a valuable bridge between theoretical development, benchmarking, and experimental translation. Importantly, all simplifying assumptions described above can, in principle, be relaxed in future studies as computational and modeling capabilities advance, allowing for increasingly realistic and comprehensive representations of the qPACT imaging pipeline.
Overall, this study demonstrates the potential of the VI frameworks to evaluate the performance and robustness of qPACT methods in clinically relevant scenarios. By revealing both strengths and limitations of qPACT methods, VI studies can help ensure that future qPACT approaches are developed and validated with consideration for realistic anatomical and physiological variability.
CRediT authorship contribution statement
Refik Mert Cam: Writing – original draft, Visualization, Software, Methodology, Investigation, Formal analysis, Data curation. Seonyeong Park: Writing – review & editing, Supervision, Methodology, Data curation, Conceptualization. Umberto Villa: Writing – review & editing, Supervision, Project administration, Methodology, Funding acquisition, Conceptualization. Mark A. Anastasio: Writing – review & editing, Supervision, Project administration, Methodology, Funding acquisition, Conceptualization.
Declaration of competing interest
The authors declare the following financial interests/personal relationships which may be considered as potential competing interests: Mark A. Anastasio reports financial support was provided by National Institutes of Health. Umberto Villa reports financial support was provided by National Institutes of Health. If there are other authors, they declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Park S.Jeong G.Villa U.Anastasio M.A.Anatomy-matched multi-variant stochastic optoacoustic numerical breast phantoms and simulated OAT measurement data 202610.13012/B 2IDB-8164905˙V 1 · doi ↗
- 2Wang X.Pang Y.Ku G.Xie X.Stoica G.Wang L.V.Noninvasive laser-induced photoacoustic tomography for structural and functional in vivo imaging of the brain Nature Biotechnol.21720038038061280846310.1038/nbt 839 · doi ↗ · pubmed ↗
- 3Wang L.V.Hu S.Photoacoustic tomography: in vivo imaging from organelles to organs Science 33560752012145814622244247510.1126/science.1216210 PMC 3322413 · doi ↗ · pubmed ↗
- 4Wang K.Anastasio M.A.Photoacoustic and thermoacoustic tomography: image formation principles Second ed.Handbook of Mathematical Methods in Imaging Vol. 12015 Springer 10811116
- 5Wang L.Photoacoustic Imaging and Spectroscopy 2017 CRC Press
- 6Lozenski L.Cam R.M.Pagel M.D.Anastasio M.A.Villa U.Proxnf: neural field proximal training for high-resolution 4D dynamic image reconstruction IEEE Trans. Comput. Imaging 202410.1109/tci.2024.3458397 PMC 1230306440726753 · doi ↗ · pubmed ↗
- 7Cam R.M.Wang C.Thompson W.Ermilov S.A.Anastasio M.A.Villa U.Spatiotemporal image reconstruction to enable high-frame-rate dynamic photoacoustic tomography with rotating-gantry volumetric imagers J. Biomed. Opt.29S 12024 S 11516–S 1151610.1117/1.JBO.29.S 1.S 11516 PMC 1079826938249994 · doi ↗ · pubmed ↗
- 8Rosenthal A.Razansky D.Ntziachristos V.Quantitative optoacoustic signal extraction using sparse signal representation IEEE Trans. Med. Imaging 28122009199720061962845410.1109/TMI.2009.2027116 · doi ↗ · pubmed ↗