Broken adaptive ridge method for variable selection in generalized partly linear models with application to the coronary artery disease data
Christian Chan, Xiaotian Dai, Thierry Chekouo, Quan Long, Xuewen Lu

TL;DR
This paper introduces a new statistical method for analyzing high-dimensional data in generalized partly linear models, with an application to coronary artery disease.
Contribution
The broken adaptive ridge (BAR) estimator is proposed as a novel method for variable selection and parameter estimation in generalized partly linear models.
Findings
The BAR estimator outperforms other penalty-based variable selection methods in simulations.
The method was applied to coronary artery disease data, revealing new insights in both genetic and non-genetic covariates.
Abstract
Motivated by the CATHGEN data, we develop a new statistical method for simultaneous variable selection and parameter estimation in the context of generalized partly linear models for data with high-dimensional covariates. The method is referred to as the broken adaptive ridge (BAR) estimator, which is an approximation of the L0-penalized regression by iteratively performing reweighted squared L2-penalized regression. The generalized partly linear model extends the generalized linear model by incorporating a non-parametric component, allowing for the construction of a flexible model to capture various types of covariate effects. We employ the Bernstein polynomials as the sieve space to approximate the non-parametric functions so that our method can be implemented easily using the existing R packages. Extensive simulation studies suggest that the proposed method performs better than other…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
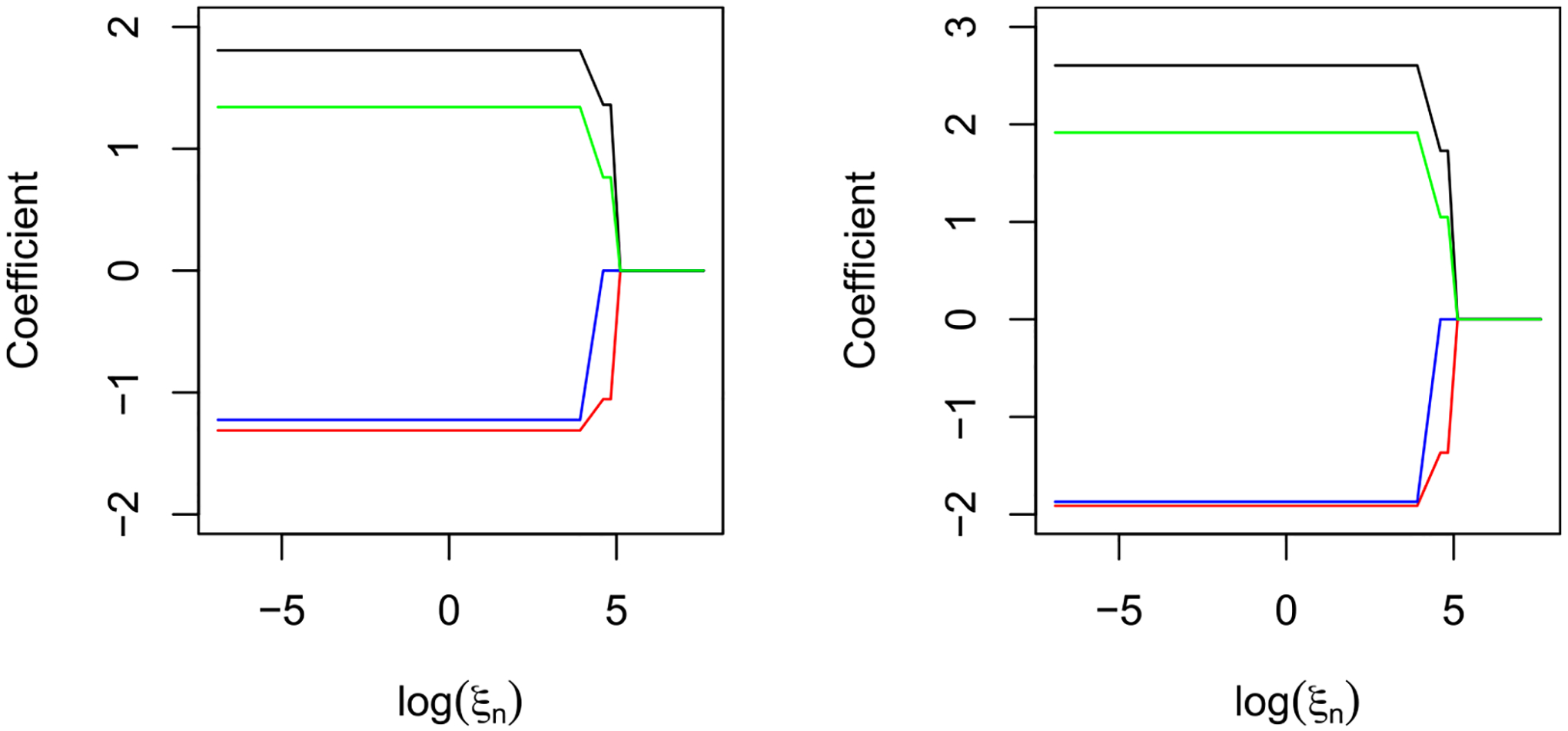 Figure 1
Figure 1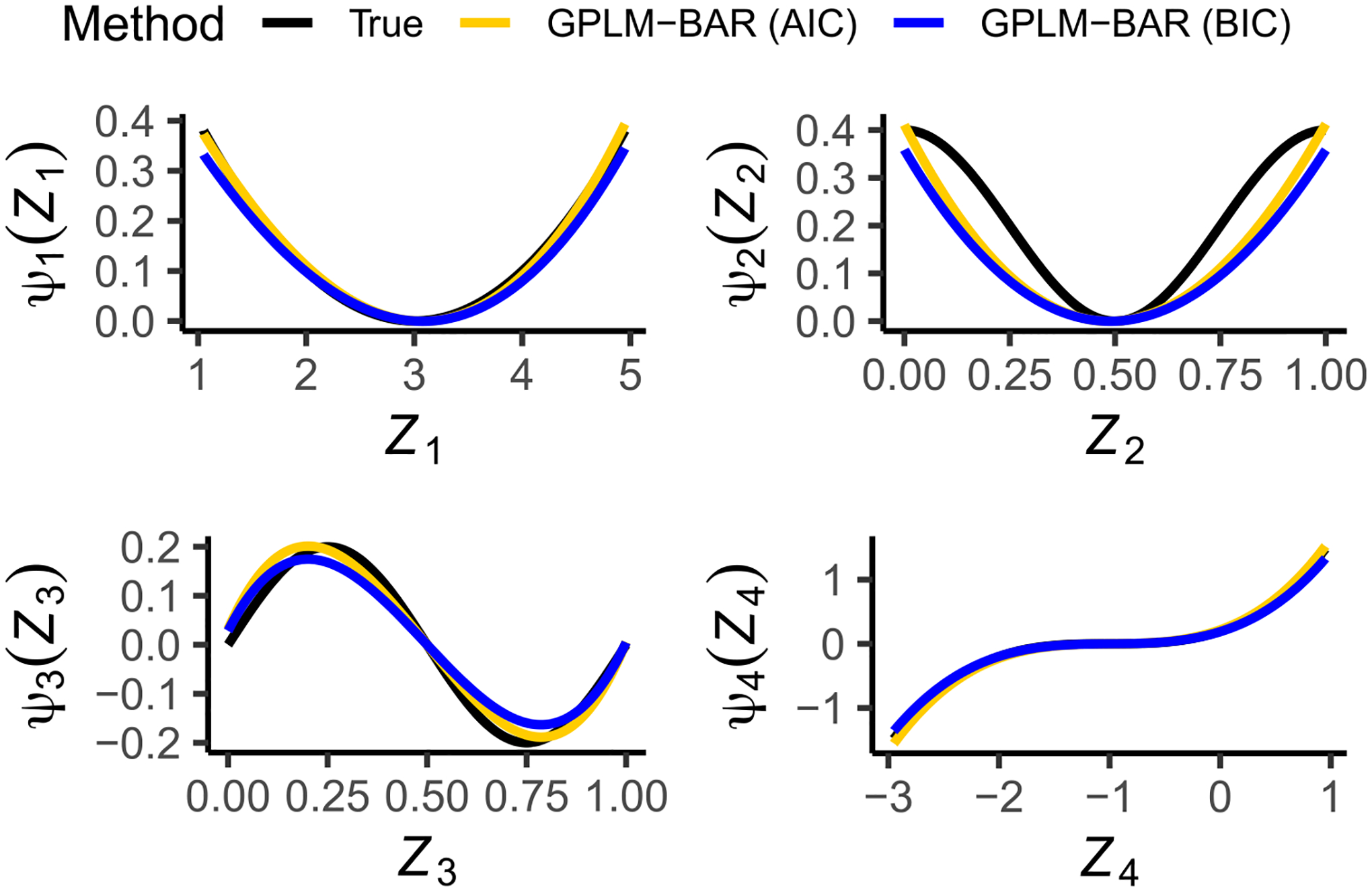 Figure 2
Figure 2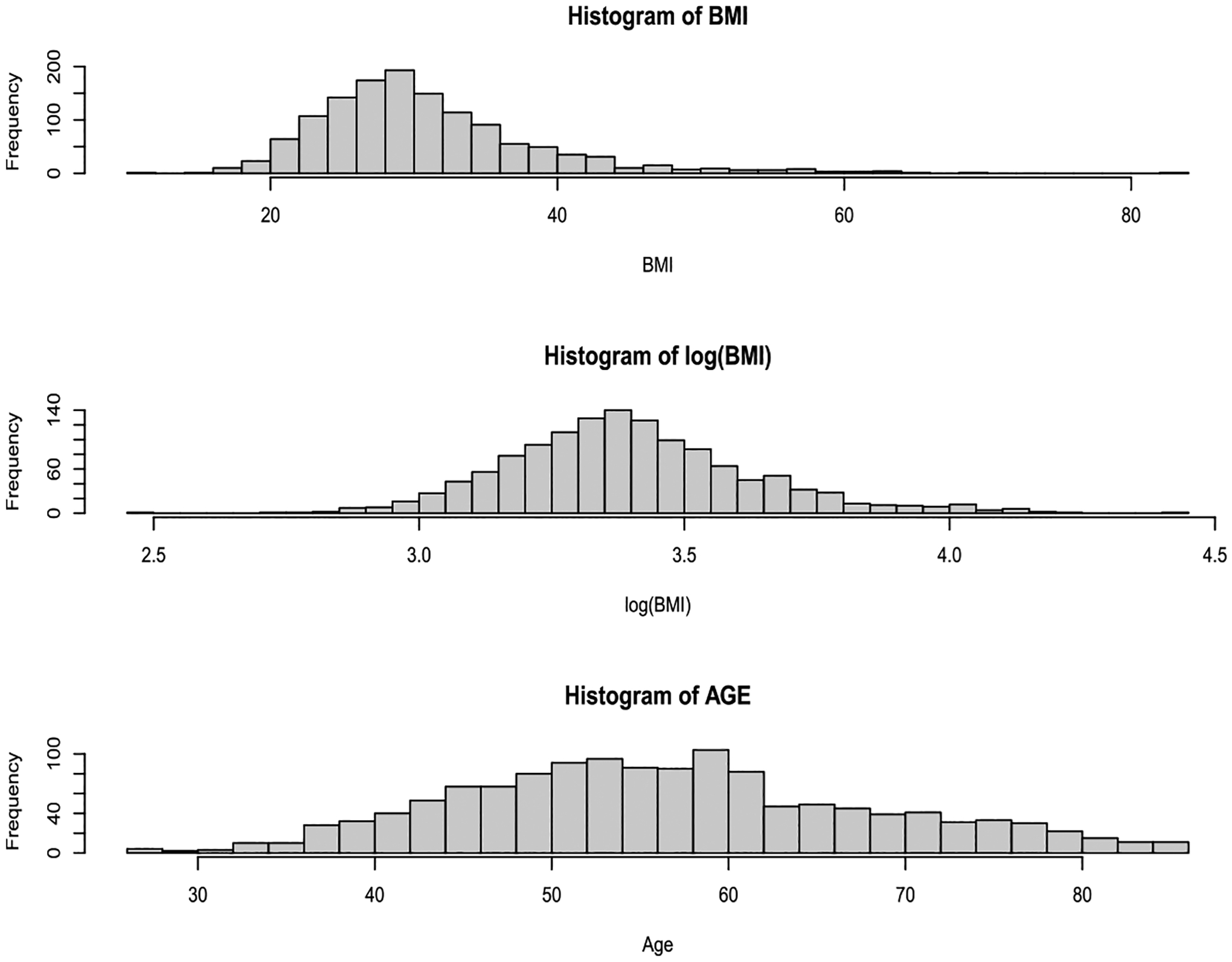 Figure 3
Figure 3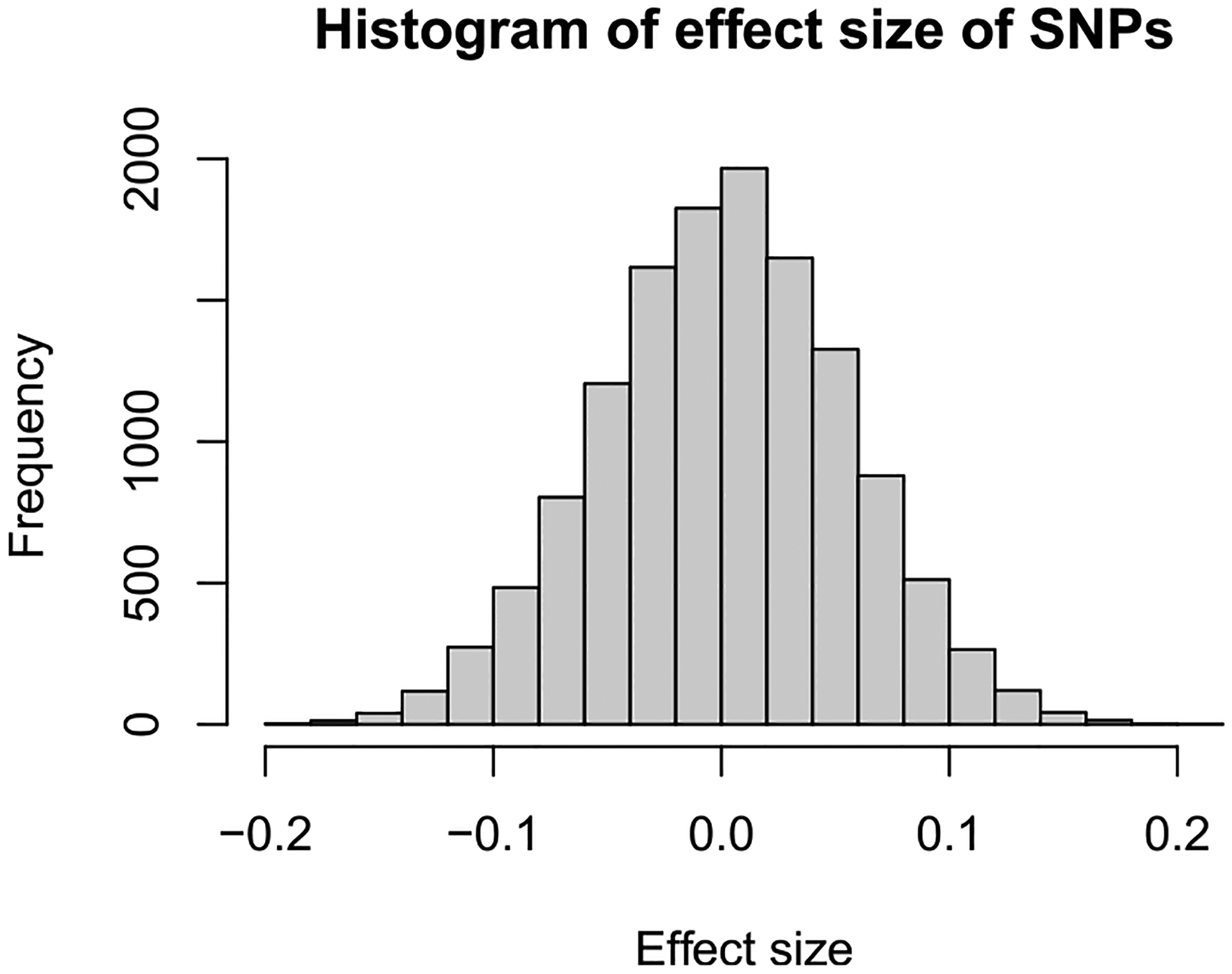 Figure 4
Figure 4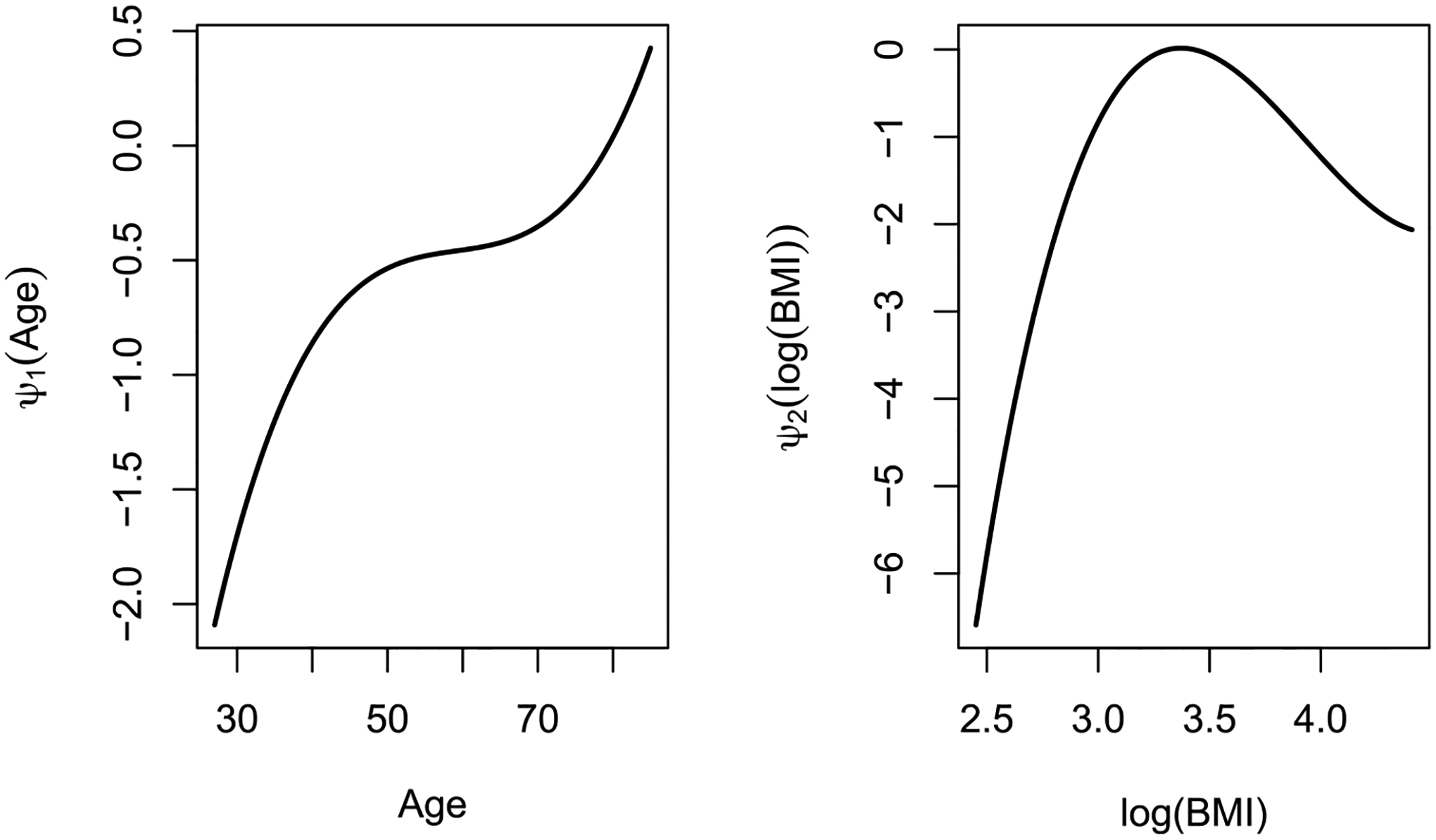 Figure 5
Figure 5Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAccounting Theory and Financial Reporting · Finance, Markets, and Regulation · Financial Reporting and Valuation Research
Introduction
In the era of high technology and supercomputing power, the combination of lower financial costs and greater accessibility to DNA sequencing technology has contributed to the rapid rise in omics research [1]. The high-throughput DNA sequencing equipment produces high-dimensional data, which motivates researchers to identify the genetic variations in the genome that are relevant to the phenotype. In our research, we develop a new statistical method to further decode acquired data and help scientists to find relevant genetic covariates. Variable selection is one of the statistical methods and is an important task when building a statistical model. Given a large number of explanatory variables in a particular study, we want to select the variables that are relevant to the response variable. One way to do this is by using the best subset selection, which is based on the -regularization. The best subset selection method directly penalizes the cardinality of a model subject to an information criterion, like the AIC [2] and BIC [3]. There are several disadvantages to the -regularization method, the most important of which is the computational complexity at scales of , where is the dimension of the covariates, thus making it computationally expensive for even a moderately large number of covariates. Additionally, Breiman [4] also showed that the -regularization is unstable in terms of variable selection. Penalty-based variable selection methods were introduced to solve the computational inefficiency of -regularization. The significance of penalty-based variable selection is the reformulation of the sparse estimation problem into a continuous and nonconvex or convex optimization problem with a smaller number of candidate models. Such methods include the Least Absolute Shrinkage and Selection Operator (LASSO) [5], Smoothly Clipped Absolute Deviation (SCAD) [6], the Elastic-Net penalty [7], the Adaptive LASSO [8], and the Minimax Concave Penalty (MCP) [9].
Recently, the Broken Adaptive Ridge (BAR) regression method has been introduced as an approximation to the -regularization for variable selection. The BAR regression can be summarized as an iteratively reweighted squared -penalized regression, where the estimators of the BAR method are taken at the limit of the algorithm. Liu and Liu [10] first considered the implementation of the BAR method under generalized linear models (GLM). Since then, many papers have investigated the BAR method for different models and data types, including the Cox PH model with large-scale right-censored survival data [11], the linear model with uncensored data [12], the additive hazards model with recurrent event data [13], the Cox PH model with interval-censored data [14], the partly linear Cox PH model with right-censored data [15], and the accelerated failure time model with right-censored data [16], among others. Most recently, Mahmoudi and Lu [17] incorporated the BAR method for semi-competing risks data under the illness-death model. Previous works [11–13] have also proved that the BAR method possesses two desired large-sample properties: consistency for variable selection and asymptotic normality, which are called the oracle properties in the literature.
Motivated by the CATHGEN data detailed below, our goal in this research is to extend the BAR method to select important variables in generalized partly linear models (GPLMs) with a large number of genetic covariates, in the presence of some low-dimensional non-genetic covariates. Particularly, we apply the proposed method to select important single nucleotide polymorphisms (SNPs) in a logistic partly linear model in the presence of both categorical and continuous low-dimensional non-genetic covariates, which belongs to a family of generalized partly linear models. In the CATHeterization GENetics (CATHGEN) study, the primary objective was to assess the association of multiple genetic markers with cardiovascular disease phenotypes. The study, conducted by Duke University Medical Centre, collected peripheral blood samples from consenting patients between 2001 and 2012. The follow-up period of the recruited patients was between 2004 and 2014. Aside from the high-dimensional genetic data, low-dimensional baseline clinical and demographical variables were also measured when patients were first recruited to the study. The data can be downloaded from the U.S. National Institute of Health dbGaP data accession number phs000704.v1.p1. We will use the proposed method to analyze the data to identify important SNPs and the associated genes relevant to coronary artery disease (CAD).
The contributions of our work can be summarized into three main aspects. First, we develop a new statistical method for simultaneous variable selection and estimation under the context of generalized partly linear models using the BAR method. GPLMs extend GLMs by adding a non-parametric component to them to allow for flexible modeling of linear and non-linear covariate effects. Our method extends the work by Li et al. [18], which incorporates the BAR method under GLM with sparse high-dimensional and massive sample size data for variable selection. Since the low-dimensional covariates in our work contain both categorical and continuous variables, our method treats them separately; only the continuous variables are considered to possess potential non-linear effects. Second, we focus specifically on the logistic partly linear regression model, as motivated by the presence of the binary response variable (CAD vs. no CAD) and various types of covariates in the CATHGEN data. We apply our proposed method to the CATHGEN data to identify relevant genetic markers (i.e., SNPs) in high dimensions that contribute to developing CAD. We are also interested in the estimation of the low-dimensional relevant non-genetic covariate effects, which can handle both linear and non-linear covariate effects. Third, our method can be easily implemented using existing R packages developed for GLM, since we can use Bernstein polynomials to construct a linear sieve space for estimating the non-parametric functions of the low-dimensional covariates so that the resultant model form mimics a GLM and the existing GLM R packages can be used for estimation and variable selection. We make our code available at https://github.com/chrischan94/GPLM-BAR.
The rest of this article is organized as follows. In the next section, we give a comprehensive introduction to GPLMs, and a detailed explanation of our proposed method and its algorithm. In the section titled Simulation Studies, we present the results of our extensive simulation studies, where we compare our method to a few common variable selection methods. In the section titled Real Data Analysis, we present the results of the real data analysis of the CATHGEN study and the biological interpretation of the results. In the final section, we conclude our findings in this article and discuss possible future directions for research. The description of the involved algorithm and more simulation results are relegated to the supplementary material.
Models and methods
Generalized partly linear models
2.1.
Working under the framework of GLM, consider a random sample , where makes a response vector and matrix makes a design. The observations are mutually independent. The distribution of conditional on is from the exponential family with the following density,
where and are known specific functions, is assumed to be twice differentiable, is the canonical parameter and denotes the dispersion parameter. Model (1) indicates that and . Through a link function , the canonical parameter is connected to by a linear combination of the coefficient parameter vector , where is the intercept parameter. When , it is called the canonical link function. Commonly used canonical link functions in GLMs include the identity function for linear regression, the logit link function for logistic regression and the log function for Poisson regression. Given our observed data, the likelihood function of for GLMs is
and the log-likelihood is
GLM assumes a linear relationship between the independent variables and the canonical link function. If this assumption is violated for a subset of variables that may have a non-linear relationship with the response, an alternative model form is desirable. Motivated by the CATHGEN data that contains both genetic and non-genetic variables, the covariates can be broadly grouped into three distinct sets: a design matrix , a design matrix , and a design matrix . The design matrix contains the high-dimensional genetic covariates, contains the low-dimensional and non-genetic categorical covariates, and contains the low-dimensional and non-genetic continuous covariates. Then we define the generalized partly linear model as follows, which extends GLM by adding a non-parametric component in the linear predictor,
where ’s are unknown smooth functions, which model possible non-linear effects as shown in the analysis of the CATHGEN data. In this model, an intercept parameter is absorbed into one of the functions. For identifiability consideration, without loss of generality, we assume and , where is the middle point of the interval where takes value. For variable selection, the effect of each variable is measured on the same scale, we assume each variable is normalized such that and . A special case of GPLM is the logistic partly linear model. Let , then the logistic partly linear model has the model equation given by
For the observations , the likelihood function of the logistic partly linear model can be constructed as
where . From the likelihood function, the log-likelihood can be easily derived as follows
Direct estimation of in (2) will not be possible because of the presence of the unknown functions , which are infinitely dimensional. Hence, approximating the non-parametric part is needed. As the unknown functions are infinitely dimensional, we propose to construct a sieve space to linearize them. To apply the sieve method, we employ the Bernstein polynomials to approximate , then the Bernstein polynomials approximation reduces the infinitely dimensional space to a finitely dimensional space. Let denote the parameter space of where
where
is a positive constant, and denotes the collection of all bounded and continuous functions over the range of the observed for . Subsequently, the sieve space is defined as
where
for and . The Bernstein basis polynomial of degree, denoted by in (3), has the equation
Therefore, the sieve log-likelihood of the logistic partly linear model using the Bernstein polynomial to approximate is
where .
Simultaneous estimation and variable selection using the GPLM-BAR method
2.2.
To conduct simultaneous estimation and variable selection in GPLMs, we propose the GPLM-BAR method, which is an iterative method. Following the BAR method by Li et al. [18] for GLM, starting from an initial value vector computed from the following the ridge regression,
For , the estimator is iteratively updated by a reweighted squared -penalized regression
where and are non-negative tuning parameters. The updated step in (6) is continued until a pre-specified convergence criterion is reached, where the estimators are taken at the limit as
The implementation of the proposed method indicates the variable selection is done only on high-dimensional covariates , since the penalty is imposed on only. In addition, the proposed variable selection method can be applied in a similar fashion to the Poisson partly linear regression and the partly linear model for counts and continuous responses, respectively, since they are in the family of GPLMs.
A note on choosing the tuning parameters
2.2.1.
Choosing the optimal values of tuning parameters is crucial for penalty-based variable selection methods, as it greatly affects the variable selection accuracy. In the absence of an external validation set, common methods to find the optimal values of the tuning parameters include the -fold cross-validation (CV) method. The optimal tuning parameter value is the one that minimizes a criterion. Typically, this is the mean squared error for continuous outcome, or deviance for a binary outcome. However, doing this only adds to the computational complexity, and it is not ideal for larger datasets. In the GPLM-BAR algorithm, we have two tuning parameters: and . Unless the value of chosen is large, it is empirically shown that the value chosen is inconsequential on the estimation of , as seen in Fig. 1. Hence, is set to a relatively small value. For in the Cox-BAR regression, it has been argued by Kawaguchi et al. [11] that it can be fixed. One example is fixing , which corresponds to the BIC penalty. Another example is to fix , which corresponds to the AIC penalty. In our method, both the AIC and BIC penalties are considered.
Computational aspects for GPLM-BAR
2.2.2.
Except under the linear model, numerical approximation methods such as the Newton–Raphson algorithm are integrated into the implementation of the BAR penalty for simultaneous variable selection and estimation. When both the number of covariates and sample size are small, calculating the partial gradient vector and Hessian matrix at each iteration of the BAR algorithm is computationally feasible. However, when both the number of covariates and sample size become moderately large, numerical approximation becomes non-scalable because of the high computational costs and the numerical instability. Alternative optimization techniques for parameter estimation under large-scale regularization and regression problems [19,20] have been developed. The algorithm by Zhang and Oles [19] called column relaxation of logistic loss (CLG) can be classified as a cyclic coordinate descent algorithm.
The R package BrokenAdaptiveRidge [11] was created to implement BAR regression for GLM and the Cox model, which are linear models. Since we have reparameterized our GPLM into a form of GLM in (4), we are able to directly use the package to conduct variable selection and estimation under the context of GPLM. This package uses the R package Cyclops [21] for efficient implementation of the iterative method as described in Kawaguchi et al. [11]. The computation in the package is done by the cyclic coordinate descent algorithm. We describe this algorithm for the GPLM-BAR regression in the supplementary material.
Simulation studies
In this section, we present the results of a comprehensive simulation study in five scenarios to demonstrate the effectiveness of our proposed method. The first and second scenarios assess the performance under strong signals and weak signals, respectively, under the setting of the logistic partly linear model. The third scenario performs a simulation study for the ultra-high-dimensional scenario, where . The fourth scenario uses the selected model in the real data analysis section for the CATHGEN data as a basis to simulate data, then assesses the performance of our method. The fifth scenario shows the performance under the setting of the Poisson partly linear model. The results for the fourth and fifth scenarios are relegated to the supplementary material.
Scenario 1: Strong signals in the logistic partly linear model
In this scenario, let and , and the number of non-zero elements in the true parameter -vector , for various values of . We generate the design matrix from a multivariate normal distribution with mean zero and variance–covariance matrix , where the th entry of it is . We fix . We first consider large effects, i.e., large values of , where the true value of is . We also generate a design matrix from independent Bernoulli distributions, with the same probability of success . And, the true value of is . Independently from and , we also generate a design matrix , where we draw from the uniform distribution over (1,5), and independently from the standard uniform distribution, and from the uniform distribution over (−3, 1). By setting the non-linear functions to be , and , respectively, we generate from the Bernoulli distribution with probability , where . The chosen non-linear functions have two common properties: (1) they are symmetric at the midpoint of the interval of their domains, (2) the values of the functions are zero at the midpoint for identifiability. We consider two different sample sizes and 800, and two different numbers of high-dimensional covariates and 450. Each combination is replicated 500 times. The number of basis functions for all non-linear functions is set at , since more than four basis functions only add to the computational complexity while only marginally improving the approximation of , conversely having fewer than four basis functions will not approximate well.
In the simulation studies, we compare our method with those of LASSO and Adaptive LASSO as well as the SCAD [6] and MCP methods [9]. We use the R package splines2 [22] to generate the Bernstein polynomials. The LASSO and Adaptive LASSO methods are implemented using the R package glmnet [23,24], and the SCAD and MCP methods using the R package ncvreg [25]. The hyperparameters of the SCAD and MCP methods were both set to 2. To evaluate the estimation accuracy, we compute the median mean squared error (MMSE), where the mean squared error is defined as . For the GPLM-BAR method, we fix to two values, and , which correspond to the AIC and BIC penalties, respectively. Since the value of was shown to have an inconsequential effect on estimation, we set . For the other methods, we use 10-fold CV method to select the optimal value. To evaluate the selection accuracy, we compute the average number of true positives (TP), the average number of false positives (FP), the total misclassification rate (MC) which is the sum of the average number of FP and the average number of false negative (FN), the frequency of true model (TM) selected, and the average estimated size of the model (MS), where MS = TP + FP.
From Table 1, it can be seen that the GPLM-BAR method outperforms the four competing methods. Although the average number of TP may be lower than that of the four competing methods when the BIC penalty is used, it does produce the smallest misclassification error. The SCAD and MCP methods perform better than the LASSO and ALSSO methods, but they produce larger MMSE values. It is interesting to observe a trade-off between the AIC and BIC penalties, where estimation accuracy is improved with the AIC penalty, contrasting with the better variable selection results obtained with the BIC penalty. This is explained by the larger tuning parameter in the BIC penalty, which shrinks the relatively smaller signals in to zero, thus causing a larger estimation bias. In addition, the estimation results of are reported in the Supplementary Material Table 3, where the estimates of our method are the best.
We are also interested in the estimation of non-linear covariate effects using the GPLM-BAR method. The estimated curves are shown in Fig. 2, which compares the averaged estimates of each of the four non-linear functions to the true function. Two observations are made. First, the Bernstein polynomial using three basis functions to approximate each is satisfactory, where the general shape of each function is captured well. Second, different tuning methods give slightly different estimates of , as the BAR method with the BIC penalty (blue curve) produces more biases than the AIC penalty (yellow curve). The GPLM-BAR also performs well for the other three combinations of and (see Supplementary Material Figures 1–3).
Scenario 2: Strong and weak signals in the logistic partly linear model
We perform another scenario where some signals of the non-zero entries in are weaker than those in Scenario 1. Here, we fix , and the true value of is . The true values of and the non-linear functions are the same as in Scenario 1. From Table 2, the GPLM-BAR method with the AIC penalty outperforms the other competing methods. However, in comparison to the results in Scenario 1, the selection and estimation accuracies become worse, because the weaker signals in have a greater tendency to be shrunk to zero. Using the GPLM-BAR method, the estimation results of the non-linear covariate effects (Supplementary Material Figures 4–7) and are satisfactory (Supplementary Material Table 4).
It is interesting to compare the computational time of the considered methods. In general, the proposed GPLM-BAR method uses the least time. Using Scenario 1 as an example, we report the computational time for each method in the Supplementary Material Table 5, which shows our method is computationally faster than the competing methods that we considered. It is roughly two times faster than the ALASSO method, eight times faster than the SCAD method, and more than ten times faster than the MCP.
Scenario 3: High-dimensional scenario
We perform a simulation study for the high-dimensional scenario, where . As in the first two scenarios, we let , and the number of non-zero elements in . We generate the design matrices , and in the same way as in Scenarios 1 and 2. The true values for are . To select the tuning parameter in this case, Fan and Tang [26] proposed a generalized information criterion (GIC), and Wang et al. [27] proposed a high-dimensional BIC (HBIC), both used . Based on the setting in Scenario 1, we generate data for the combinations of , where and and , respectively. We also include AIC and BIC for comparison with HBIC.
From Table 3, the GPLM-BAR method with the BIC penalty outperforms the same method with the HBIC penalty, both from the perspective of variable selection and estimation. We repeated this scenario when the non-zero signals become weaker and are the same as the in Scenario 2, where the results summarized in the Supplementary Material Table 6 show a similar pattern. We conclude that the BIC penalty is robust to the strength of the signals in when the GPLM-BAR method is used for variable selection in high dimensions.
Real data analysis
Coronary artery disease (CAD) is a major disease that inflicts death, and is one of the biggest causes of death globally [28]. Environmental factors that contribute to CAD are typically age, smoking status, obesity and lifestyle choices. However, genetic factors play a role in death due to CAD, especially in younger patients [29].
We apply our proposed method to the CATHGEN data, which was downloaded from dbGaP, with accession number phs000704.v1.p1. The study collected peripheral blood samples from consenting patients who were undergoing cardiac catheterization at Duke University Medical Center from 2001 to 2011. A total of 1327 patients were recruited and followed up between 2004 and 2014. The binary response variable is the affection status, where the stratification criteria are defined in Shah et al. [30]. The high-dimensional design matrix contains 13 991 columns of SNPs belonging to 331 genes that have been associated with CAD using Ingenuity Pathway Analysis [31]. In addition to the SNPs, there are ten clinical and demographic variables in the data. These variables include age (Mean = 57.0, SD = 11.6), BMI (Mean = 30.8, SD = 7.8), smoking status (671 cases out of 1327), race (897 Caucasian-Americans, 274 African-Americans and 156 Asian-Americans), hypertension status (900 cases out of 1327), diabetes status (379 cases out of 1327), hypercholesterolemia status (745 cases out of 1327), sex (684 males and 643 females), number of diseased vessels and history of myocardial infarction (HXMI) (277 cases out of 1327). All clinical and demographic variables of each subject were measured when they were included in the study. We exclude the number of diseased vessels from further analysis because of conversion issues when fitting the univariate logistic regression model.
In Fig. 3, the distribution of age is symmetrical on the original scale. However, the distribution of the BMI on the original scale is right-skewed. The natural logarithm transformation of it fixes the skewness. Thus, we decided to use the BMI on the log scale for further analysis. From Table 4, when fitting age and its second-order polynomial term in the logistic regression model, both terms are found to be statistically significant. Likewise, when fitting the log-transformed BMI and its second-order polynomial term in the logistic regression model, both terms are also significant. The results in Table 4 indicate that age and log-transformed BMI have a non-linear effect on the odds ratio of developing CAD. However, the functional form of the effect is unknown, and this motivates us to consider a logistic partly linear regression model.
Noticing that there are 13991 SNPs in the original data set, which is greater than the sample size . When we apply our GPLM-BAR method with BIC and HBIC to tune , none of the SNPs are selected, which indicates that the potential effects of the SNPs may be too weak to be detected. We then pre-screen the candidate SNPs to reduce the dimension of the SNPs. First, we remove SNPs with a minor allele frequency (MAF) of less than 0.1. Second, we further reduce the number of SNPs by performing univariate logistic regression, only selecting SNPs with a -value less than 0.1. At the end, a total number of 1242 SNPs with a -value less than 0.1 are retained for analysis.
Because the individual estimated effect sizes of the SNPs using univariate logistic regression are small, as shown in Fig. 4, we decide to use AIC to choose the tuning parameters in GPLM-BAR. The value of and the number of basis functions are kept the same as in the simulation study. The tuning parameter values for the LASSO and Adaptive LASSO methods are chosen by 5-fold cross-validation. In Table 5, the estimated effects of the categorical clinical variables obtained from the GPLM-BAR method have a larger magnitude. The results in Table 5 indicate a positive risk association for hypertension, diabetes, hypercholesterolemia, smoking and HXMI, where HXMI is the strongest clinical indicator on the risk of developing CAD. We use the bootstrap method with 100 random bootstrap samples to obtain the estimated standard error in parentheses in Table 5. The GPLM-BAR method identified the fewest number of SNPs that contribute to CAD. Specifically, the GPLM-BAR identified 19 different SNPs that are associated with 17 unique genes, the LASSO and Adaptive LASSO methods identified 199 SNPs and 228 SNPs, respectively.
From the genes identified using GPLM-BAR, RBFOX1 is found to be associated with blood pressure and heart failure through transcriptome profiling [32]. CDH13 has been shown to be associated with blood cholesterol and CAD through a genome-wide association study undertaken in the British population [33]. F10 is associated with the lowering levels of coagulation factor X, which is protective against ischemic heart disease [34]. GABRG3 has been shown to be associated with the density of dodecanedioic acid, which plays a role in regulating blood sugar level [35]. ABCA1 has been shown to be associated with altered lipoprotein levels, which results in an increased risk for CAD [36]. IL1B belongs to the wider family of IL1 genes which is associated with coronary heart disease [37–39]. Certain subtypes of the APOE gene are identified associated with lipid levels and coronary risk [40]. We report the complete set of selected SNPs and genes in the supplementary material Table 10.
In addition to the results in Table 5, one can observe our method using Bernstein polynomials approximation has showed that the effects of age and BMI are non-linear, as seen in Fig. 5. The plot on the left in Fig. 5 shows that the risk of developing CAD increases non-linearly with age, and the plot on the right shows that the risk of developing CAD increases with BMI on the natural logarithm scale until 3.5. After this cutoff point, it then decreases. The unusual trend seen for BMI can be partially explained by the lack of data when BMI > 35 or log(BMI) > 3.5, as the BMI of the majority of patients recruited to this study falls between 15 and 35 on the raw scale. Both plots in Fig. 5 were centered at their respective midpoints of the intervals, and the plot that shows the estimated non-linear effect of age absorbed the intercept term.
Discussion and conclusion
In this article, we have proposed a new approach for simultaneous variable selection and estimation under the context of GPLM, with a focus on the logistic partly linear regression model. Our proposed approach was motivated by the CATHGEN study, where the data contain both high-dimensional genetic covariates and low-dimensional clinical and demographical covariates. We considered GPLM as it grants us the flexibility to model possible non-linear covariate effects. We employed the Bernstein polynomials to approximate the non-parametric component of the model, where it has several advantages over other approximation methods like splines and piecewise functions. First, unlike the piecewise functions, the Bernstein polynomials are differentiable and continuous everywhere. This is desirable as the first and second derivatives are calculated in each iteration of our algorithm. Second, the Bernstein polynomials possess computational scalability and optimal shape-preserving property for all approximating polynomials [41]. Third, the Bernstein polynomials do not require specification of the number of interior knots and their locations, unlike B-splines. From the results of our comprehensive simulation studies, we observe that our proposed method outperforms common variable selection methods under a few practical scenarios. Our method incorporating the BAR penalty produced the lowest total misclassification rate and the highest frequency of the true model selected, which is consistent with other empirical studies conducted by authors who also employed the BAR penalty [12,14,16]. Our method was also able to accurately estimate the true non-linear functions. As an application, we applied our proposed method to the CATHGEN data, where certain SNPs and genes were found to have a relevant contribution to CAD, which is consistent with other variable selection methods applied to this data [42,43].
There are several directions one can take from our research. Since our focus is variable selection in high-dimensional variables that appear in the linear part, and the dimension of the nonlinear covariates is small, we only considered variable selection in the linear part of the model. As a referee suggested, it would be interesting to see how to incorporate penalization on the gamma coefficients from the Bernstein polynomials, so that one can select significant variables simultaneously in both the linear and additive nonparametric parts. To do that, Huang et al. [44] proposed to use splines to approximate nonlinear functions and applied the adaptive group Lasso to select nonzero components in nonparametric additive models. Li et al. [45] extended their method to additive partially linear models. Using a similar approach, one could also select significant variables simultaneously in both the linear and additive nonparametric parts in our generalized partly linear models. The CATHGEN data also contains right-censored survival information. Under the context of survival models, it would be of interest to investigate which relevant genetic markers affect the survival probability, and the possible homogeneity or heterogeneity of the two sets of genetic markers selected based on the two different response outcomes and their biological interpretations. Additionally, choosing the optimal tuning parameter poses a significant challenge to researchers. The mixture of weak signals with strong signals poses a noteworthy problem to researchers and requires more thorough investigation.
Supplementary Material
Supplement
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Mardis ER. A decade’s perspective on DNA sequencing technology. Nature 2011;470:198–203.21307932 10.1038/nature 09796 · doi ↗ · pubmed ↗
- 2Akaike H A new look at the statistical model identification. IEEE Trans Autom Control 1974;19:716–23.
- 3Schwarz G Estimating the dimension of a model. Ann Statist 1978;461–4.
- 4Breiman L Heuristics of instability and stabilization in model selection. Ann Statist 1996;24:2350–83.
- 5Tibshirani R Regression shrinkage and selection via the lasso. J R Stat Soc Ser B Stat Methodol 1996;58:267–88.
- 6Fan J, Li R. Variable selection via nonconcave penalized likelihood and its oracle properties. J Amer Statist Assoc 2001;96:1348–60.
- 7Zou H, Hastie T. Regularization and variable selection via the elastic net. J R Stat Soc Ser B Stat Methodol 2005;67:301–20.
- 8Zou H The adaptive lasso and its oracle properties. J Amer Statist Assoc 2006;101:1418–29.