Algorithm Perception When Using Threat Intelligence in Vulnerability Risk Assessment
Sarah van Gerwen, Aurora Papotti, Katja Tuma, Fabio Massacci

TL;DR
This study explores how people perceive bias in threat intelligence recommendations from humans versus AI, finding that participants often disagree with AI-generated advice.
Contribution
The study introduces a controlled experiment to measure bias perception in threat intelligence from human and AI sources.
Findings
Participants tended to disagree with AI-generated recommendations more than human ones.
Security expertise influenced agreement with recommendations, while ML expertise did not.
Perceived bias was statistically equivalent between human and AI sources when recommendations were accepted.
Abstract
Recent government and commercial initiatives have pushed for the use of the automated, artificial intelligence (AI)–based, analysis of cyber threat intelligence. The potential bias that might be present when evaluating threat intelligence coming from human and AI sources has to be better understood before deploying automated solutions to production. We present a controlled experiment with n=57 master students who had a mix of experience in security and machine learning to measure the bias introduced by the source of intelligence (human vs. AI). Each participant analyzed eight threat intelligence reports from the Dutch National Cyber Security Center where the source of the final recommendation was manipulated as for coming from a human expert or an AI algorithm. Our findings revealed that participants tended to disagree with the recommendation when it was coming from AI. While expertise…
Click any figure to enlarge with its caption.
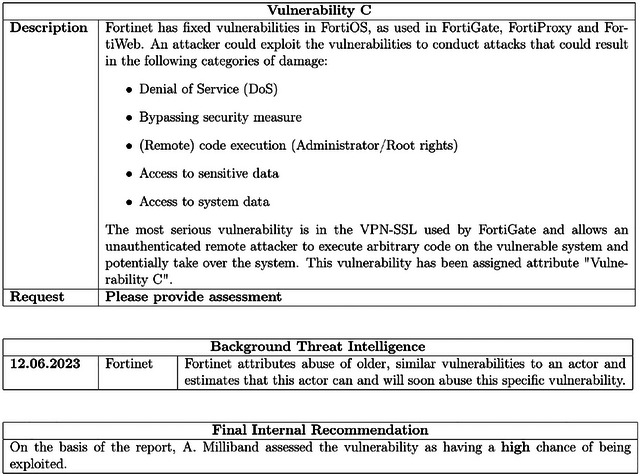 FIGURE 1
FIGURE 1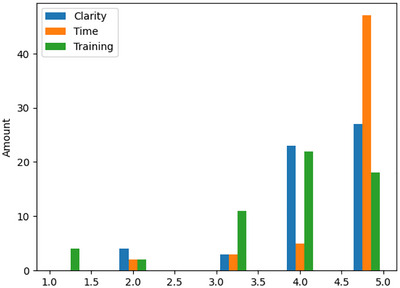 FIGURE 2
FIGURE 2| Question | Option 1 | Option 2 | Option 3 | |||
|---|---|---|---|---|---|---|
| Is the vulnerability present in the standard configuration/installation? | No | 1 | Unclear/Yes | 3 | ||
| Is there Exploit Code available? | None | 1 | Proof‐of‐Concept (PoC) | 4 | Exploit | 6 |
| Are there any technical details available? | None | 1 | Somewhat | 2 | Completely | 3 |
| Required Access? | Physical | 1 | LAN/Direct Environment | 4 | Internet | 6 |
| Required credentials? | Admin | 1 | User | 2 | None | 4 |
| How complex is it technically to exploit the vulnerability? | Complex | 1 | Average | 2 | Simple | 3 |
| Is there user interaction necessary? | Complex | 1 | Simple | 3 | None | 4 |
| Is the vulnerability exploited in the wild? | No | 1 | Limited scale | 2 | Large scale | 3 |
| Is the expectation that the vulnerability will be exploited in the short term? | No | 1 | Yes | 3 | ||
| Is there a solution available? | Older than 2 months | 1 | Up to 2 months old | 2 | None | 3 |
| ID | Report | Main CVE |
|---|---|---|
| 1 | NCSC‐2023‐0428 | CVE‐2023‐38035 |
| 2 | NCSC‐2023‐0277 | CVE‐2023‐20887 |
| 3 | NCSC‐2023‐0282 | CVE‐2023‐27997 |
| 4 | NCSC‐2022‐0368 | CVE‐2022‐22972 |
| 5 | NCSC‐2022‐0334 | CVE‐2022‐1388 |
| 6 | NCSC‐2022‐0056 | CVE‐2022‐23131 |
| 7 | NCSC‐2023‐0256 | CVE‐2023‐2868 |
| 8 | NCSC‐2023‐0346 | CVE‐2023‐29300 |
| First measurement/SecA | ||||||||
|---|---|---|---|---|---|---|---|---|
| Report | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|
| ||||||||
| A | H‐C‐M | H‐I‐H | A‐C‐H | A‐I‐M | A‐I‐M | A‐C‐H | H‐I‐H | H‐C‐M |
| B | H‐I‐H | A‐C‐H | A‐I‐M | H‐C‐M | H‐C‐M | A‐I‐M | A‐C‐H | H‐I‐H |
| C | A‐C‐H | A‐I‐M | H‐C‐M | H‐I‐H | H‐I‐H | H‐C‐M | A‐I‐M | A‐C‐H |
| D | A‐I‐M | H‐C‐M | H‐I‐H | A‐C‐H | A‐C‐H | H‐I‐H | H‐C‐M | A‐I‐M |
| E | H‐C‐M | A‐C‐H | A‐I‐M | H‐I‐H | H‐I‐H | A‐I‐M | A‐C‐H | H‐C‐M |
| F | H‐I‐H | A‐I‐M | H‐C‐M | A‐C‐H | A‐C‐H | H‐C‐M | A‐I‐M | H‐I‐H |
| G | A‐C‐H | H‐C‐M | H‐I‐H | A‐I‐M | A‐I‐M | H‐I‐H | H‐C‐M | A‐C‐H |
| H | A‐I‐M | H‐I‐H | A‐C‐H | H‐C‐M | H‐C‐M | A‐C‐H | H‐I‐H | A‐I‐M |
| I | H‐C‐M | A‐I‐M | A‐C‐H | H‐I‐H | H‐I‐H | A‐C‐H | A‐I‐M | H‐C‐M |
| J | H‐I‐H | H‐C‐M | A‐I‐M | A‐C‐H | A‐C‐H | A‐I‐M | H‐C‐M | H‐I‐H |
| K | A‐C‐H | H‐I‐H | H‐C‐M | A‐I‐M | A‐I‐M | H‐C‐M | H‐I‐H | A‐C‐H |
| L | A‐I‐M | A‐C‐H | H‐I‐H | H‐C‐M | H‐C‐M | H‐I‐H | A‐C‐H | A‐I‐M |
|
| |||||
|---|---|---|---|---|---|
| Coeff. | Std. Err |
| [0.025 | [0.095] | |
| Source | 0.6519 | 0.195 | 0.001 | 0.269 | 1.035 |
| Inconsistency | 0.3523 | 0.195 | 0.071 | −0.030 | 0.735 |
| ML Exp. | 0.1274 | 0.213 | 0.549 | −0.289 | 0.544 |
| Security Exp. | −0.7078 | 0.237 | 0.003 | −1.173 | −0.243 |
|
|
| ||||
| 0.03778 | −297.63 | ||||
|
| |||||
|---|---|---|---|---|---|
| Coeff. | Std. Err |
| [0.025 | [0.095] | |
| Source | 0.0051 | 0.068 | 0.941 | −0.129 | 0.140 |
| Inconsistency | 0.0346 | 0.068 | 0.611 | −0.099 | 0.168 |
| ML Exp. | −0.0425 | 0.074 | 0.565 | −0.187 | 0.102 |
| Security Exp. | −0.0007 | 0.080 | 0.993 | −0.157 | 0.156 |
| Disagreement | 0.5831 | 0.070 | 0.000 | 0.445 | 0.721 |
|
|
| ||||
| 0.133 | 14.86 | ||||
| Main findings | Risk researcher | Practicing risk analyst |
|---|---|---|
| When the source of the recommendation is algorithmic, participants disagreed with the recommendation more. | A possible implication is that, in absence of quality information about the algorithm, a novice technical understanding is enough to instill algorithm aversion. This should be taken into account when tailoring algorithmic advice to different populations. | Following the recommendation of Paté‐Cornell ( |
| Recommendations that are consistent with the information cues lead to equal perception of bias compared to the recommendations that are inconsistent. | The implication is that enough information should be presented in reports for a novice population to be able to retrace the steps. Researchers could test the border where additional information is just right (instead of too little or too much). | Analysts using AI to support their risk decisions should adopt such technologies with care, as they tend to provide inconsistent advice (Collier et al. |
| Participants with more security expertise agreed more with the recommendation. | Replications including senior experts could be an interesting avenue for future research to see whether the latter might be more sensitive to “wrong” recommendations presenting interaction effects. | Making judgments based on limited information might rely more on pattern recognition than on analysis (Gigerenzer and Gaissmaier |
| The higher the disagreement the more the participants perceived bias of the source and recommendation | This finding confirms the findings of Logg et al. ( | One recommendation would be to make the levels of individual analyst disagreement explicit and transparent before the final risk decision takes place. |
| Equivalence in perceived bias | Replications and new research in algorithm aversion under uncertain risk decision‐making with AI should be considered. | Training practitioners to focus on quality of information but also reflecting on the source, should be considered, as well as implementing checks and balances also on algorithmic decisions. |
- —Nederlandse Organisatie voor Wetenschappelijk Onderzoek10.13039/501100003246
- —European commission
- —Ministero dell'Universita e della Ricerca
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsDeception detection and forensic psychology · Information and Cyber Security · Stalking, Cyberstalking, and Harassment
Introduction
1
US Federal executive orders push federal agencies and private companies to “streamline access to cybersecurity data to drive analytics for identifying and managing cybersecurity risks” (Biden 2021). To do so, organization needs reliable and manageable information on impact and likelihood, which are the two basic pillars of risk analysis.
While measures to understand cybersecurity impact are well understood and standardized, estimating likelihood has always been a hard problem (Bozorgi et al. 2010, Allodi and Massacci 2014). Let alone capturing adversaries and game theoretic aspects (Hausken et al. 2024), likelihood estimation requires processing a significant amount of data (Allodi and Massacci 2017), and organizations are increasingly overwhelmed by the amount of threat intelligence data (Bouwman et al. 2020, de Smale et al. 2023).
The traditional solution to the problem has been relying on the national security agencies for prioritization. For example, the Dutch National Cyber Security Centre (NCSC) bases the risk assessment of the likelihood of vulnerability exploitation on a combination of technical knowledge of the vulnerability and threat intelligence. It is essentially an ad hoc scoring systems for likelihood calculation with all the known limitation of risk matrices (Cox 2008). The “algorithm” is provided but eventually the likelihood value is determined by two/three fields based on expert judgment (e.g., “Likely to be exploited in the near future”). Italy and China do not even report the individual metrics, just the global risk level. In a nutshell, the cyber risk analyst has to trust the national security expert. Experiments have shown that intelligence expert judgment may not be reliable (Irwin and Mandel 2023) and that participants may consider the suggestions by experts biased (Commons et al. 2004,2012).
Artificial intelligence (AI) and machine learning (ML) seem an algorithmic alternative to blindly trusting the national experts. In other domains, such as predicting the risk of extreme weather events, models are openly published and discussed (Bellprat et al. 2019).
A recent industry initiative is the Exploit Prediction Scoring System (EPSS) with over 200 members including among others the US Department of Homeland Security and the Cybersecurity and Infrastructure Security Agency. EPSS gathers threat intelligence on the web and tries to predict potential exploits using ML (Jacobs et al. 2023). One of the key aspects is that the prediction of the likelihood is completely back‐box. A paper describes the model at a very high level (Jacobs et al. 2023) and the company producing the EPSS scores, only makes available the final prediction. Essentially, the cyber risk analyst has to trust the AI algorithm. Also in this case, several experiments have shown the presence of algorithmic bias in which participants with different level of domain knowledge have shown both algorithm aversion (Dietvorst et al. 2015, Castelo et al. 2019) and algorithm appreciation (Logg et al. 2019, Rieger et al. 2023). Such change in sign of appreciation depends often on the actual knowledge: either in the algorithmic knowledge or the domain knowledge.
At this point, an interesting scenario present itself: in presence of such uncertain, essentially black‐box, threat intelligence recommendations by the AI or the human what would cyber risk analysts do? Would they exhibit algorithmic risk aversion or algorithm appreciation? Would such bias change depending on their expertise (e.g., security knowledge vs. ML knowledge) as the literature seems to suggest?
The contribution of this paper is to report the result of a controlled experiment to answer the questions above by using threat intelligence report as close as possible to the ones actually used on the field. We adopted a Taguchi Balanced design (Tsui 1992) as made available from Massacci et al. (2024) with a total of n=57 master students in computer science with a mix of background in security and ML. We tasked our participants with assessing English‐translated threat intelligence reports from the Dutch NCSC. Due to the narrow student sample and constrained laboratory setting of the current experiment, the current study should be interpreted as a preliminary effort, a plausibility probe, to explore whether this phenomenon merits further investigation in more realistic settings. In addition, choosing students as the population can lead to limitations such as replicating realistic challenges such as decision‐making pressures, contextual familiarity, or accountability constraints. We think that training the participants in advance may reduce the severity of this issue, but it cannot eliminate the gap in real‐world experience; therefore, the findings of this paper to be considered generalized, require further experiments including cybersecurity professionals.
Our findings revealed that participants tended to disagree with the recommendation when it was coming from AI. While expertise on ML did not have any impact, we found that participants with more security expertise tended to disagree less with the recommendation. However, the source had no impact on the perceived bias, and intuitively, only when the participants disagreed they found the recommendation to be biased. The results show that reporting data from AI might be trusted slightly less than human recommendation albeit not to the point of being seen as explicitly biased.
Most importantly, the perceived bias by AI and human sources was found to be statistically equivalent using two one‐sided tests. This result is particularly important because it counters simplistic narratives about widespread algorithm aversion. That AI and human sources were judged similarly in bias perception (even in an unfamiliar and uncertain domain) is a valuable finding.
Such findings are useful to assess the likely reactions by junior cyber risk analysts who are normally the rank‐and‐file officers of cyber‐security operations centers (SOCs) as Tier 1 analysts (Vielberth et al. 2020).
The generalization of our results to professional practice requires more experiments with security professionals (e.g., SOC Tier 3 analysts or threat intelligence specialists) as they might have different frames of mind both in general (Kahneman and Klein 2009) and specifically for security risk analysis (Labunets et al. 2023).
In the rest of the paper, we introduce some terminology (Section 2) and discuss the theoretical background and some key gaps in the literature (Section 3). Then we introduce our research questions (Section 4) and briefly summarize the analysis procedure (Section 5). Section 7 describes the experimental artifacts, whereas Section 8 summarizes the experimental design. Ethical aspects are summarized in Section 6. Eventually, the results of the experiment are presented (Section 10) and discussed with their potential implications (Section 12 and the threats to validity (Section 11). Section 13 concludes the paper.
Artifact Availability Statement
1.1
The data that support the findings of this study are openly available in Zenodo at https://doi.org/10.5281/zenodo.16418849 (van Gerwen et al. 2025).
Terminology
2
In this section, we present some basic terminology of the artifact and topic of analysis used in this paper.
Software vulnerabilities can be defined as flaws in the design, implementation, or configuration of software systems. The exploitation of these flaws violate the security and/or safety of the system. Vulnerability risk assessment is the process of identifying, prioritizing, and mitigating these weaknesses. Risk assessment of vulnerabilities dictates prioritization and ultimately, further mitigation steps (Initiative 2012).
Threat intelligence is evidence‐based knowledge representing threats that can inform decisions (Tounsi and Rais 2018). This evidence‐based knowledge can be seen as the result of a process that has been described as sensemaking (Klein et al. 2007). Sensemaking can be seen as a form of abductive reasoning where the most plausible conclusion about a situation is the end goal (Klein et al. 2023). Threat intelligence reports can be technical or narrative and vary between a multitude of standardized and non‐standardized formats (Yang and Lam 2020, Irshad and Basit Siddiqui 2023). Ontologies exist for the standardization of cyber threat intelligence (Tounsi and Rais 2018). Two well‐known vocabularies are STIX (Structured Threat Information eXpression) (Committee 2023) and MITRE ATT&CK (Corporation 2023). Domain objects and relationship objects are part of the structured language STIX. Adversary tactics and real‐world techniques are part of the vocabulary of MITRE ATT&CK. Uncertainty information is not covered by these ontologies. Perry et al. (2019) mention that free‐text reports do often include similar attack details such as the attacked party, related attacks, and a technical analysis.
To date, an assessment of the risk behind the threat of exploitation of a software vulnerability is often a manual process (Khan and Parkinson 2018). The analysis of advanced persistent threats by Di Tizio et al. (2022) had to sieve through over 150 threat intelligence reports written by human experts. What is therefore distilled as actionable (“high or critical”) threat intelligence is a product of human decision‐making. In other words, in most if not all cases there remains a human in the loop. The recent research and practice has been pushing toward the automation of threat intelligence collection and analysis by means of AI models as a “black‐box” such as the mentioned EPSS industry initiative (Jacobs et al. 2023).
Theoretical Background and Related Work
3
Risk Communication, Source Credibility, and Trust
3.1
A considerable amount of literature has been published on risk and uncertainty communication in the past (Balog‐Way et al. 2020, Spiegelhalter 2017). This literature spans multiple fields, including threat intelligence (Mandel 2020), and focuses on different aspects of communication. In their overview, Balog‐Way et al. (2020) put forward three areas that underline risk communication research: messengers, message attributes, and audiences.
Research with respect to messengers often focuses on source credibility and trust (Balog‐Way et al. 2020). Research in source credibility illuminates how different aspects of a source influence the extent to which a receiver senses this source as reliable and in turn, accepts and uses the source's message (Hovland and Weiss 1951). Within the field of cyber threat intelligence, past research focused on user evaluations of sources to detect deception (Ormond et al. 2016) as well as CERT experts' credibility evaluation of messages on Twitter (Basyurt et al. 2022). Trustworthiness and expertise have been identified as key aspects of source credibility (Wiener and Mowen 1986, Flanagin and Metzger 2020). The trustworthiness of a source is explained as the perception that a source is objective and honest while expertise is explained as the perception that a source has obtained the required skills and knowledge for the task at hand (Hovland and Weiss 1951). Previous research indeed suggests that the perceived usefulness of a message and the adoption of the message is influenced by source credibility in general or specifically by source expertise and source trustworthiness in many fields such as electronic worth of mouth (Ismagilova et al. 2020) and online reviews (Aghakhani et al. 2022).
However, the aforementioned research mainly focuses on how the broader public is influenced by different sources that are assumed to be human. In the field of threat intelligence, it is often experts who are tasked with making credibility assessments. Moreover, the concept of trustworthiness of sources in threat intelligence is complicated, since the exact data often cannot be shared, and the receiver of the risk communication must therefore rely on a multitude of different institutions, individuals, and systems. Some of these sources might be known to the receiver, but many are unknown. Additionally, some of these sources are possibly not human or the messages attached to these sources are partly based on algorithmic decisions. Furthermore, besides possible misinformation, it is also possible that sources are intentionally spreading disinformation. There is therefore a need to understand whether there is a difference between human and algorithmic sources within the specific context of threat intelligence. Additionally, Wallace et al. (2020) showed that perceived bias influenced source credibility beyond effects of trustworthiness, expertise, and likeability. Therefore, trustworthiness and bias should be differentiated when it comes to source credibility.
Besides source credibility, trust is a major area of study when it comes to messengers (Balog‐Way et al. 2020). Following the conceptualization of Gill et al. (2024), trust is seen as organizational trust which is composed of trust attitudes (affect‐based and cognition‐based) and trust intentions (reliance and disclosure). Affect‐based trust attitudes are relational and grounded in an emotional bond, whereas cognition‐based trust is more rational and focused on the perception of reliability and competence (Gill et al. 2024). Reliance is about depending on the source in question, whereas disclosure is about the inclination to share sensitive information (Gill et al. 2024). The current research can be framed as focusing on the trust intention of reliance. It is out of the scope of the current study to measure the difference between affect‐based trust and cognition‐based trust.
Research with respect to message attributes often focuses on framing, affects and uncertainty communication (Balog‐Way et al. 2020). Communicating uncertainty successfully with respect to threat intelligence has been object of inquiry for a long time (Mandel 2020). This is the case because there is an effect of the way uncertainty is represented on decision‐making (Durbach and Stewart 2011). Although transparency about uncertainty is needed, it can also lead to less trust and less effective decision‐making (Balog‐Way et al. 2020). Moreover, when introducing AI as part of the equation, information about the accompanied uncertainty can be insufficient or altogether unavailable. At the same time, utility of threat intelligence is dependent on the quality of the intelligence which in turn, is contingent on a judgment of how uncertain or biased information is (Wagner et al. 2019).
Research on audiences focuses often on different aspects of the audiences risk perception and how communication affects these perceptions (Balog‐Way et al. 2020). Risk perceptions and risk based decision‐making are discussed in more detail in the Section 3.2.
Different theories have been posited and researched to incorporate and situate these different areas of risk communication. One such theory is the risk‐as‐feeling theory, which suggests that messages do not only have a cognitive component but that their persuasiveness is strongly influenced by affective components (Loewenstein et al. 2001). Closely related is research concerning the affect heuristic (Slovic et al. 2007, Finucane et al. 2000) that posits that mental representations of an object or event are constructed with varying affect degrees. These degrees of affect are used as a cue for judgment (Slovic et al. 2007). Although most research on the affect heuristic is performed outside of the current field, there is prior research in cybersecurity that tested the affect heuristic (van Schaik et al. 2020) found that parts of the conceptualization of affect (i.e., valence) indeed impacted the risk perception of participants in the field of cybersecurity. To avoid bias in one direction or another, it might be important to present the machine or the human decision as neutrally or minimally as possible.
Another theory is the social amplification of risk framework (Kasperson et al. 2022). The idea behind this theory is that the communication of the risk of hazards can amplify or attenuate the risk itself (Kasperson et al. 2022). This is the case because technical issues that will interact with the specific hazard can arise from public perceptions, responses, and behaviors (Kasperson et al. 2022). Audiences are therefore active participants in the amplification or attenuation of risks. Prior research with respect to threat intelligence shows, for example, that cybersecurity firms focus their threat reporting on major firms instead of smaller firms and civil society (Maschmeyer et al. 2021, Egloff 2020). This underrepresentation can steer academic and policy debates away from these underreported threats which can amplify the risk itself. Interestingly, recently Makridis et al. (2024) argued that media coverage of cyber conflicts is driven by different indicators than non‐cyber threats. Mainly, Makridis et al. (2024) found that coverage was heightened for cyber operations that included technical novelty such as zero‐day exploits.
Key Gap. Most existing studies on risk assume that the source is human, overlooking the increasing relevance of nonhuman, algorithmic sources‐especially in the context of cyber threat intelligence. Furthermore, while source credibility research has extensively explored trustworthiness and expertise, it often neglects to differentiate between trust and perceived bias. Additionally, most research focuses on general public audiences, whereas in cyber threat intelligence, expert users must assess credibility without direct access to source data, relying instead on a fragmented web of unknown sources. Therefore, there is need to investigate how human versus algorithmic sources are perceived and trusted in expert cybersecurity contexts.
Risk‐Based Decision‐Making
3.2
In this section, we discuss the theoretical background on risk‐based decision‐making under uncertainty and the role of algorithmic bias in such decisions and how it impacts the potential implications of using AI for threat intelligence.
Risk Decisions Under Uncertainty and Time Pressure. In presence of time pressure and incomplete information, risk decision makers need to make certain trade‐offs. Risk analysis research has been interested in understanding risk perception (Slovic 1987) and risk decisions under uncertainty and extreme time pressure. Early work by Kahneman and Tversky (1979) explores heuristics and biases which laid out the foundations for cognitive limitations in risk decisions. Subsequently, Fischhoff (1982) and Dubois (2010) place debiasing techniques in the foreground and investigate the roles of uncertainty theories. The aim of debiasing techniques, such as hindsight bias and overconfidence, is to improve decision‐making accuracy by understanding and addressing the psychological processes that lead to biased judgments. Particularly relevant in this space is also the imprecise probabilities theory in risk analysis, framing the space of risk decisions when decision makers are faced with incomplete information. Dubois (2010) argues integrating objective and subjective approaches to better capture expert judgments under such conditions. On this point, Gigerenzer and Gaissmaier (2011) review heuristic decision‐making and find that, in uncertain, real‐world problems, the literature shows that heuristics can often be more accurate than complex “rational” strategies.
Further, when risk decisions are made in a group context, such as during safety analysis with methods like Failure Mode and Effects Analysis (FMEA) (Zhang and Liu 2022, Collier et al. 2023), expert judgment plays a pivotal role in group decision‐making dynamics, as argued by Otway and von Winterfeldt (1992), Winter et al. (2022), and Sniezek (1992). Such advancements have over decades led to more robust risk analysis methods, improving decision quality in high‐stakes, time‐sensitive situations.
Machine Augmented Risk Decisions in the Intelligence Domain. Kelly et al. (2023) surveyed factors contributing to the acceptance of AI and found that not all papers define what AI is nor do they check participants understanding of AI, which makes result comparison difficult. While the AI Device Use Acceptance model emerged as promising theoretical model, more research is required to assess the actual uptake of AI.
Threat intelligence environments are complex situations where information is aggregated from various sources (Paté‐Cornell 2002, Menkveld 2020). Time pressure (Irwin and Mandel 2019, Florig et al. 2001, Morgan et al. 2001, Jaspersen and Montibeller 2015), secrecy of information (Pedersen and Jansen 2019), the possibility of deception (Whitesmith 2019), and the high stakes of decisions (Jensen 2012) are characteristics of these situations. In addition, the process of sharing obtained information and the data it is based upon might be limited for operational, strategic, or legal reasons (Wagner et al. 2019). Due to this highly restricted information sharing, accurate representations of risk‐based decision‐making in security communities are rare (Wagner et al. 2019, Landon‐Murray 2016). This leads to information being lost or only being available to a highly limited group of organizations and individuals within the organization. The net result is that “normal organizations” have to trust the intelligence that they receive.
Past research investigated how uncertainty is handled by human analysts in risk decisions when augmented with machine reasoning. Paté‐Cornell (2024) investigated the discrepancy between the risk attitudes embedded in AI decision algorithms and the preferences of actual decision makers and those affected by their decisions. According to Paté‐Cornell, this discrepancy can lead to significant issues in risk management, thus making AI factors transparent and adjustable to better align with the preferences of decision makers and stakeholders is advisable. Irwin and Mandel (2023) conduct experiments with 41 intelligence analysts to investigate their preferences in communicating uncertainty. Interestingly, while nonexperts generally prefer numeric formats, experts are divided, and both groups often conflate probability and confidence, leading to inconsistent and sometimes incoherent numeric translations of verbal probabilities. Karvetski et al. (2020) conduct an empirical evaluation of structured methods used to process intelligence data, and often promoted in intelligence organizations, and find that such methods were ineffective and even impeded some aspects of quality in probability judgments in intelligence analysis. Isaksen and McNaught (2019) conduct semi‐structured interviews with senior consumers of military intelligence and focus group interviews with groups of analysts, and found that respondents found it difficult to conceptualize uncertainty analytically. This further highlights the importance of understanding human bias toward machine‐augmented risk decisions in threat intelligence.
Previous work conducted validation of bias in threat intelligence. For example, Mandel and Barnes (2014) analyzed intelligence forecasts and found that under‐confidence (assigning more uncertainty to a given forecast than needed) was more pronounced in forecasts that were important for policy‐making. Menkveld (2020), analyzing a set of reports from the Dutch secret services (AIVD), observed that analysts had to fill in larger gaps and were less confident when complexity in intelligence problems increased.
Ranade et al. (2021) used human cybersecurity experts to validate that generated fake cyber threat intelligence was considered equally true as authentic threat intelligence. Whyte (2022) crafted scenarios and used military professionals as well as workshop participants to observe that, within a cyber conflict scenario, algorithm aversion was found unless there was the perception of humans in the loop. This was the case even though the information presented stayed the same. Whitesmith (2019) used a crafted scenario and a population consisting of students and staff from the university and different governmental departments. The study found that the possibility of deception is most likely to be considered in cases where information contradicts already held beliefs. Pedersen and Jansen (2019) used crafted scenarios to show that analysts gave more weight to secret information in comparison to open‐source information. Their sample consisted of a combination of intelligence studies students and intelligence professionals. However, this effect was no longer found when the problems decreased in complexity (Pedersen and Jansen 2019) or when only meta‐information was provided (Mandel et al. 2023). For the study on meta‐information, Mandel et al. (2023) used professional intelligence analysts and meta‐information pieces of information based on the NATO standard.
Isaksen and McNaught (2019) performed semi‐structured interviews with senior consumers of military intelligence and intelligence analysts. The study found that consumers and analysts perceived the analytic conceptualization of uncertainty to be difficult and suggested using a differentiated, in both level of uncertainty and situation, framework for uncertainty communication.
Key Gap: A large body of knowledge deals with the problem of combining expert judgments to raise the validity of the final decision (Stroop 1932, Scholz and Hansmann 2007), and algorithm aversion widely studied in machine‐augmented risk decision‐making (Burton et al. 2020, Mahmud et al. 2022, Hou and Jung 2021, Dietvorst et al. 2015, Feng and Gao 2020, Prahl and Van Swol 2017). But little focus was put on investigating whether judgments coming from experts and AI can be differently perceived as biased in the threat intelligence domain.
Algorithm Aversion and Appreciation
3.3
Research on Judgment. When looking at research on judgment, there is a difference in the influence of algorithmic judgment in comparison to human judgment on human decision‐making (Dietvorst et al. 2015, Castelo et al. 2019, Logg et al. 2019, Hou and Jung 2021). This influence is connected to the preference for using algorithmic or human conclusions (Dietvorst et al. 2015). A much debated question is the effect of the difference between algorithmic and human judgment. Studies have shown that human judgment is preferred over algorithmic judgment, even in cases where algorithms outperform humans (Dietvorst et al. 2015, Castelo et al. 2019). This phenomenon is called algorithm aversion. In contrast, multiple studies found an opposite effect coined as algorithm appreciation (Logg et al. 2019, Rieger et al. 2023). Here, findings illustrated that people prefer algorithmic judgment to human judgment.
To account for the differences, several inquiries have been conducted into the factors that constitute algorithm aversion and appreciation. Studies are numerous (Burton et al. 2020, Mahmud et al. 2022) and possible factors include corroboration with own decision (Logg et al. 2019) and quality of information provided (Gönül et al. 2006). Expertise seems to have a mitigating effect and can even induce the opposite effect (Hou and Jung 2021). In addition, within a cyber conflict scenario where algorithmic threat intelligence was used, the perception alone of humans in the loop reduces algorithm aversion, even when the judgments are the same (Whyte 2022). Without the perception of a human in the loop, experts showed algorithm aversion in this scenario (Whyte 2022). This experiment was validated in the domain of cyber conflicts.
In recent years, more investigations have been made to develop a conceptual framework or model to capture algorithm aversion. Burton et al. (2020) proposed a framework consisting of five factors: expectations and expertise, decision autonomy, incentivization, cognitive compatibility, and divergent rationalities. Mahmud et al. (2022) presented a framework consisting of four factors: high‐level factors, individual factors, task factors, and algorithm factors. These two conceptualizations can be seen as complementary and touch upon similar ideas. What can be construed from both conceptualizations is that algorithm aversion is highly dependent on the current context and population. Studies review some experiments in several domains such as the hiring process, diagnostic decision‐making, and financial forecasting but not in the field of threat intelligence.
Therefore, in the present study, the perception of algorithmic recommendations will be studied as it is pertaining to the usage of threat intelligence in likelihood risk assessment. The focus of the study is on individual decision‐making and not on the organizational and societal factors that also play a large role in algorithm perception.
Key Gap: Validation studies with human participants measuring algorithm aversion but remains largely unexplored in the context of risk analysis and threat intelligence.
Domain Knowledge Versus Technical Expertise
3.4
Expertise enables analysts to make decisions in real time in a different way than novices (Kahneman and Klein 2009). Logg et al. (2019) found that novice forecasters tend to display the phenomenon of algorithm appreciation (as opposed to algorithm aversion).
A difference within the algorithm aversion literature is made between different kinds of expertise (Burton et al. 2020, Mahmud et al. 2022). The distinction is made between the concept of experience with the decision domain and algorithmic literacy. The former is about experience with the task at hand and according to some increases algorithm aversion even though others found no impact of task experience (Burton et al. 2020, Kawaguchi 2021). The latter concept is about experience in the interaction with algorithmic tools and could decrease algorithm aversion.
Experience with the decision domain has been proposed as the reason for an increase in algorithm aversion, as seen in Logg et al. (2019). Here, experts rely on their professional or specialized knowledge (Logg et al. 2019) and/or reliance on their schema (Okoli et al. 2016) instead of following the algorithm. This finding has been confirmed also by the series of experiments and interviews by Labunets et al. (2023) which showed that experts uses security knowledge to check that “nothing is forgotten” as opposed to novices who actually rely on it to find the actual solution.
Algorithmic literacy was proposed to diminish algorithm aversion because the person who has more experience interacting with algorithmic tools will have a better understanding on how to utilize and interpret algorithmic judgement (Burton et al. 2020). These findings are under the caveat that there is enough information about the quality of the algorithm output (Von Walter et al. 2022). In context of threat intelligence, however, the quality of information is uncertain, so we are interested to test whether experience has an impact on the perception of the intelligence source. For a more systematic account of the existing literature on explainability approaches for threat intelligence, we refer the interested reader to the review by Z. Zhang et al. (2022).
Key Gap: Previous research found that experience with the decision domain and algorithmic literacy have an effect on algorithm aversion. However, no previous study has looked at both forms of expertise/experience in a domain where quality of information is uncertain.
Research Questions
4
Based on the discussion above, our first research question is whether AI algorithms are considered to be better advisers for threat intelligence recommendations, even in presence of recommendations that are inconsistent with the cues present in the text.
- RQ1.Is there an association between the underlying source of the recommendation (algorithmic versus human) or consistency of the recommendation (consistent versus inconsistent) and agreeing with a recommendation?
The first hypothesis is in line with the theory of perfect automation schema by Dzindolet et al. (2002) which claims that people predict “near perfect performance” from algorithms. In uncertain environments, near perfect performance was attributed to the human source (Dietvorst and Bharti 2020). Given the risk‐decisions are made in a group context, such as during safety analysis (Zhang and Liu 2022, Collier et al. 2023), expert judgment plays a pivotal role in risk decision‐making dynamics (Otway and von Winterfeldt 1992, Winter et al. 2022, Sniezek 1992) Indeed, a recent study shows that experts had different preferences when interpreting AI decision algorithm results (Paté‐Cornell 2024).
Given our population of MSc students, we postulated that the lack of expertise will leads to displaying the perfect automation schema (Rieger et al. 2023).
- Hypothesis H1,1
The participants will disagree more with recommendations attributed to an AI algorithm compared to recommendations attributed to a human expert. □
The second hypothesis aligns with the findings on cue inconsistency (Slovic 1966, Mandel et al. 2023), where more information cues were used when pieces of information (in our case, the threat analysis text and the advice by either the human or the machine) were consistent with one another. This effect was found in classical intelligence scenarios both for direct information (Mandel 2020) and for meta‐information (Mandel et al. 2023). The latter is precisely our case as the advice is a summary information.
- Hypothesis H1,2
Participants will disagree more with the proposed recommendation when such recommendation is inconsistent with the cues in the text than when the recommendation is consistent with cues. □
- RQ2.What is the association between recommendations in terms of agreement, consistency, or underlying source and the overall perception of bias of the information?
The first hypothesis aligns with Birnbaum's finding in 1979 that agreeing with a source leads to perceiving that source as less biased (Birnbaum and Stegner 1979). This was especially the case when a source corroborated an already held judgment (Scharrer et al. 2019).
- Hypothesis H2,1
Participants will attribute more bias when they disagree with the recommendation.
The second hypothesis is symmetrical to the second hypothesis of RQ1 along with the utilization of information (Mandel et al. 2023).
- Hypothesis H2,2
Participants will attribute more bias when they are given an inconsistent recommendation.
In particular, Wallace et al. (2020) found that the perception of bias of a certain source decreased persuasion and source credibility beyond effects of untrustworthiness and lack of expertise. How this information combines with the literature on algorithm aversion and which direction a possible effect would take is not known to the best of our knowledge, so we only speculate that the participants will attribute more bias to an algorithmic source, testing the same direction as in H1,1.
- Hypothesis H2,3
Participants will attribute more bias to an algorithmic source than to a human source.
The final RQ tries to address the key aspects of threat intelligence, namely: the highly uncertain environment where lack of familiarity with either the algorithm or the domain will attribute different characteristics to each sources (Rieger et al. 2023).
RQ3. What is the relationship between knowledge of the domain or knowledge of AI and the overall perception of the underlying source of the recommendation?
A recent academic study of commercial cyber threat intelligence vendors showed that they do not provide comprehensive and consistent reports (Bouwman et al. 2020). This is also part of the folklore as reported by the head of threat intelligence at Microsoft: “I read several threat intelligence reports daily. It is painfully obvious how the lack of analytic skill is harming the discipline” (Caltagirone 2014).
Hence, in line with the theory of perfect automation schema by Dzindolet et al. (2002), people with expertise in ML and their faults should not predict perfect performance from algorithms, whereas domain expert should not attribute perfect performance to the human source which they know to be occasionally mistaken (Dietvorst and Bharti 2020).
- Hypothesis H3,1
The algorithmic source would be perceived as more biased by someone has more knowledge of AI algorithms than security knowledge than by someone who has more knowledge about security than AI algorithms. □
Analysis Procedure
5
RQ1. To answer the first research question, we perform a logistic regression, where the binary variable y1 is represented by the disagreement of the participant with the recommendation: the value y1=0 means the participant agrees with the recommendation, instead y2=1 means the participants disagrees with the recommendation. In this way, we model the condition of silent assent with the suggested recommendation (Rieger et al. 2023).
We then have four different independent variables. The first variable x1 is the source of the recommendation, when x1=0, the source is human, x1=1 represents the AI recommendation. The variable x2 is the inconsistency of the recommendation and when x2=0, the recommendation is consistent, instead when x2=1, the recommendation is inconsistent. Once again we try to model as the 0 condition the absence of perturbing factors in the decision.
We use two additional control variables, x3 and x4 which describe the participants' experience. When x3=0, the participant does not have any experience in ML, instead x3=1 describes the case which the participant has some experience in ML. When x4=0, the participant does not have any security experience, instead we used x3=1 to represents a participant with some security experience. They are obtained by discretizing a number of scale items.
RQ2. To answer this research question, we perform a linear regression, where the scale variable y2 is represented by the overall perception of bias of the information. This value is obtained by taking the average of a number of items ranging from 1 to 5 and then recentered on 0 (subtracting 3 from the scale).
We then have five different independent variables. The variables {x1,x2,x3,x4} are the same as used in the logistic regression to answer RQ1. The new variable x5 would be the variable y1 of the logistic regression. Therefore, x5=0 means that the participant agrees with the recommendation, and x5=1 means that the participant disagrees with the recommendation.
RQ3. To test for this variable, we expect the coefficient of x3 (knowledge of AI) is positive and significant (larger bias) and the coefficient of x4 is negative (smaller bias).
Equivalence as Alternative Validation for RQs. Given the possibility of no effect, we apply the Two One‐Sided Test (TOST) procedure, originally proposed by Schuirmann (1981), which is widely used in pharmacology and food sciences to determine whether two treatments are equivalent within a specified range, defined either as an additive constant or a ratio (Food and Drug Administration 2001, Meyners 2012). For each of the RQ, in case we obtain a failure to prove the presence of an effect, we also test whether the two conditions are actually equivalent from the perspective of bias.
According to the guidelines set by the US Food and Drug Administration (FDA) and the European Medicines Agency (EMA), two drugs are considered equivalent if their respective distributions, x and y, satisfy the conditions x·ρ<y (one‐sided test) and y<x·1ρ (the second one‐sided test), where ρ=0.8. To ensure a conservative approach, the final result is determined by taking the maximum of the two p‐values. The choice of the underlying directional test depends on the specific conditions, with either the Mann–Whitney U (MWU) test or the t‐test being used. In our study, we employed the MWU test. We set the significance level at p=0.05 and, to maintain a conservative evaluation, adopted the ρ value recommended by the FDA and EMA.
For example, to answer the third research question, we used TOST to test whether there is equivalence in the perceived bias among two sample groups: (1) participants with some AI experience but no security experience, (2) and participants with some security experience, but no experience in AI.
Ethical Approval
6
The experiment was part of two courses (in two consecutive years) taught by the experimenters at two different universities. Among other objectives, the courses had the intent to teach students about methods and measures of security experiments. The current experiment gave the students the opportunity to review and analyze the experiment and the obtained results. The students received grade points for the course for participating in the experiment.
The ethical procedure was followed and it determined that a full ethical review was not necessary. In particular, this was determined because (1) upfront, opt‐in consent was asked, (2) no personal or sensitive information was involved, (3) it did not pose potential risks to either participants or researchers, (4) the confidentiality of the participants was guaranteed by collecting data by GDPR compliant tool and removing their details before processing the data for the analysis, (5) the participants were thoroughly debriefed afterward (they actually had full access to the anonymized data to use for their own report). Finally, (6) the incentives to participate were minimal: there was no monetary compensation, and the participants received a compensation in terms of coursework's bonus. Such value was minimal (less than 2% of the final grade), and the participants could deny the consent to use data for research, and still obtain the participation bonus. Besides name and student number which were necessary to grand the coursework's bonus, we did not collect any other personal information. Those personal identifiable information have been deleted from the dataset before moving to data analysis.
Reports Chosen as Experimental Artifacts
7
Data Source
7.1
The Dutch National Cyber Security Centre (NCSC) is the governmental single point of contact when it comes to cyber threats and incidents and has the legal obligation to analyze and research cyber threats and incidents (Kamara et al. 2020). The NCSC is comprised of experts and works together with other expert organizations. NCSC advisories are governmental reports with the purpose of describing what a specific vulnerability entails and what could potentially happen if this vulnerability is exploited (NCSC 2023c). The advisories themselves provide a “direct action perspective” for organizations (NCSC 2023a). The advisories include a risk assessment of the likelihood/chance of exploitation (“Kans”) and the impact/damages that possible exploitation could entail (“Schade”) (NCSC 2023c). These assessments result in a categorical value of low, medium, or high. The likelihood judgments are established by using a classification matrix (NCSC 2023b). See Table 1 for an overview of the likelihood classification matrix.
Selection Criteria of Original Reports
7.2
The chosen reports and the described vulnerabilities are presented in Table 2. Full reports were selected based on whether there was a transition from medium risk of chance of exploitation to a high risk. This transition was based on new updates that were viewed as pieces of threat intelligence. Only reports were chosen that either in their description or in the attached pieces of threat intelligence mention one specific vulnerability (some reports mention multiple vulnerabilities). Furthermore, reports were only chosen if they had a high impact/damages risk classification. This choice was made to operationalize the step from medium/high priority to the highest and most critical priority. The first eight reports that met these conditions are reported in Table 2.
Processing of Original Reports
7.2.1
To maximize ecological validity while keeping construct validity and providing a report that is easy to process in the allotted time, we have limited the simplification of the text to a minimum.
The full reports were abbreviated by removing details on version numbers (which could span for several sentences), and other irrelevant information. The specific sentences summarily revealed the NCSC classification were also removed as they would provide participants the “ground truth” (e.g., “The advisory has been changed to HIGH/HIGH”). Similarly, information on CVSS scores was removed from the text as it would provide this additional ground truth information.
All descriptions and pieces of threat intelligence that were attached to the risk classification were kept. The source of the threat intelligence, when available, were always presented (e.g., “The FBI reports that…”).
Since reports are updated in time, the additional sentences added after the initial risk classification of the first published report were removed from the main text and presented as background threat intelligence with a date. The rationale is that the sentences reflected pieces of obtained threat intelligence that were actually unknown at the time of initial risk classification and should be explicitly presented as such. If the experiment were executed across days with new information being posted into the system, the participants would have directly perceived this additional threat intelligence as “what's new.” We simply presented them as change log in Background Threat Intelligence.
The final result is presented in Figure 1.
Example of report with original recommendation according to the NCSC is high risk, and the source is human.
A limitation of the real data is that reports are never downgraded. So once something is high, it stays high. Hence, for report with medium risk, we could only use reports that show all pieces of threat intelligence that were available for medium risk to accompany medium reports. For high reports, we could use both threat intelligence in which the report was high from the very beginning and pieces of threat intelligence were taken that updated the risk classification from medium to high. We do not have pieces of threat intelligence evidence in which an initial high risk according to the NCSC is downgraded to medium.
Experimental Manipulations
7.3
In addition to the description and threat intelligence, a recommendation is added to the reports. The recommendations are the operationalization of the first two different conditions of the experiment: source and consistency. This is further described in the experimental design in Section 8. Figure 1 shows the third abbreviated high report with a human recommendation that is inconsistent with the NCSC recommendation. The information is hidden to the participant, they do not know what the original recommendation of NSCS was, as it was removed from the report. The presentation of the source as an AI or human sources does not essentially changes the ecological validity of the recommendation. To obtain some reports in which the recommendation is “wrong,” we have changed the recommendation (switching from high to medium or from medium to high). This is necessary to provide variety of scenarios and to make sure that participants are confronted with cases in which choice is wrong and therefore they might to disagree with it. Reporting only “right” recommendation would violate the construct validity of the experiment. See Appendix for the other conditions with respect to Report 3.
Experiment Design
8
Target Populations
8.1
The intended novice population was computer science master students. The participants, recruited from two different universities provide a mix of two different expertise. The first group consisted of students that had previous experience with risk assessment in their curriculum. The second group consisted of students that had previous experience with ML. In both cases, the students had English proficiency (both masters were taught in English) and a background in computer science as a BSc in CS was a prerequisite for enrollment.
Procedure
8.2
The participants received a specific training activity of before the experiment, which included an introduction to threat intelligence (1.5 h) and a lecture on vulnerability risk assessment (1.5 h). In addition, the participants were trained on using the classification matrix for likelihood and impact/damages of the NCSC (translated in English) and received a short walkthrough video was given with one example task (not part of the actual experiment) and two short exercises. The goal of these training activities was to ensure that the students had the ability to perform the task. Previous work in experimentation with students showed that under the correct conditions, students were able to perform tasks at a level comparable to experts (Allodi et al. 2020, Salman et al. 2015).
The experiment took place 1 day after the training activity and consisted of a maximum of 2 h. During the experiment, participants had access to all the training material and they could take breaks, finish, or stop at any time. The experiment was held in a room where at least one supervisor was present. The role of the supervisor was to help with technical difficulties but not answer any questions relating to the content of the assessments.
At the beginning of the experiment, the students were asked to give informed consent. Thereafter, the participants were able to read the task description and answer questions about previous experience. Then, the students were randomly assigned to 1 of 12 groups. These groups reflected the different order of manipulations to ensure a balanced design (i.e., the measurements obtained in each condition are roughly equal). An overview of the design of the groups can be observed at the top of Table 3.
The randomization was followed by the likelihood assessment of the eight abbreviated reports. The participants were asked to explain their answers. These questions were followed by manipulation and attention checks.
See Appendix for an overview of the attention checks per abbreviated report. Thereafter, questions about the report in question and the current assessment were answered. When all reports were assessed, questions were displayed about the quality and usability of the different sources.
Experimental Manipulation Variables and Dependent Variables
8.3
See Table A.1 for an overview of the variables in the experiment. For RQ1, the variable Source reflects the main condition where a recommendation is either “given” by a human or an AI source:
- A. Milliband, a senior risk assessment human analyst with over 15 years of experience in the field
- HackHunter, an established ML algorithm with high accuracy scores
Additionally, the variable Consistency represents the main condition where the likelihood recommendation is manipulated while keeping the text identical to the ground truth. The recommendation is represented with the categories “medium” and “high,” respectively.
Additional variables are taken as independent variables in the analysis. For RQ2, the discussed experimental manipulated variables are present but the previously dependent variable of Agreement with recommendation is added to the independent variables. For RQ3, the difference in groups is taken as the independent variable.
Dependent variables are collected in line with the three research questions. For RQ1, the binary variable Agreement with recommendation is measured as a behavioral proxy to trust (Prahl and Van Swol 2017). For RQ2, the Perception of bias of information is measured as the self‐reported perception of bias of the report and recommendation. This variable is operationalized as an aggregated Likert scale consisting of four items. For RQ3, the dependent variable is the Difference score between the overall perception of the human source and the overall perception of the algorithmic source. If the score is above 0, the difference is in favor of the human source. If the score is below 0, the difference is in favor of the algorithmic source. The difference score is calculated based on the perceived overall usability and quality for each source.
Control Variables
8.4
A number of other variables are collected to control the internal and construct validity of the results of the experiment. Assessment validation variables are collected to verify whether the vulnerability assessment will be completed on the basis of the information in the report. The purpose of the Manipulation check question is to measure whether the participant is aware of the recommendation source. Two questions about the reported information have the purpose to check whether the participant read the information (Variables for Attention checks, see Appendix).
Experiment validation variables are collected to verify whether the experimental process has been performed correctly. The purpose of the task understanding item is to verify whether the participant had a clear understanding of the task at hand. The participant is asked about the task time to see whether the participant had enough time to finish the task. In addition, the purpose of the task training item is to validate that the provided training materials were sufficient for completing the task.
Background variables are collected to test whether the planned differences among groups is actually realized in the sample. Two background variables are measured for security. First, Knowledge of vulnerability risk assessment is measured to gauge the participant's amount of previous experience with vulnerability risk assessment. Second, Knowledge of reading threat intelligence is measured to gain insight into the participant's amount of previous experience with reading threat intelligence reports. To capture experience with algorithms, Knowledge of using ML algorithms is measured to gauge the participant's amount of previous experience with using ML algorithms. In addition, Knowledge of developing ML algorithms is measured to gain insight into the participant's amount of previous experience with developing ML algorithms.
Study Execution
9
Participants
9.1
Our population is composed by a total of 57 computer science MSc students. We can identify two main groups: (1) one composed of participants with no experience in the security field (60% of the population) (2) and the other one with no experience in AI (47% of the population). A total of 29 participants (51%) said that they have some security experience, and 53% of the population has some experience in AI.
Experimental Controls
9.2
One participant failed one manipulation check from a total of eight manipulation checks. Five participants failed 1 attention check from a total of 16 attention checks. The authors analyzed the explanations given by the participants for the assessment reflected by these data points. These explanations were deemed plausible by the researchers and no participant was removed.
To test the validity of the experiment, in terms of the ability of participants to understand and complete it, the self‐reported responses of control questions were tested. These experimental validation variables are presented in Figure 2.
Graphical representation of the scores of the three experiment validation variables (clarity, time, and training) in relation to the amount of participants.
A validation variable was considered sufficient if it scored 4 or higher. Task time was considered sufficient by 95% of the participants. Task understanding was considered sufficient by 89% of participants. Task training was considered sufficient by 70%, while only 10% of the participants thought that the training was insufficient (i.e., gave a score less than 3). Therefore, it is assumed that all three controls are sufficiently met.
The analysis confirms that the construction of the experimental groups is appropriate for the purpose of the study.
Results
10
In this section, we report the results of our investigation. In Section 10.1, we describe the findings we obtained to answer RQ1, instead in Sections 10.2 and 10.3, we answer respectively to RQ2 and RQ3. The statistical analysis was performed according to the choice of the analysis procedure described in Section 5.
RQ1
10.1
Table 4 reports the results we obtained from the linear regression that we performed using the variable y1 to describe the disagreement (when y1=1, the participant disagree with the recommendation). Each row of the table is a different dependent variable of the regression.
To verify if H1.1 is satisfied, x1 (which is 1 when the source is AI) has to be positive and statistically significant, which is what we observed from the results we obtained; therefore, the data support H1.1, and we can conclude that the participants tend to disagree with the recommendation when the source is AI.
Finally, we observe that the variable x2 is positive and not statistically significant; therefore, the data do not support H1.2; therefore, it seems the inconsistency with the original NCSC recommendation (hidden from the participant) do not have an impact.
We also observed that the more experience the participants have in the security field, the less they disagree with the recommendation. We also tested for interaction effects between people with security experience and the disagreement with the recommendation was actually “wrong” (inconsistency = 1) as it was not what the NCSC would have recommended it. However, we did not find any significant interaction effect.
RQ2
10.2
Table 5 reports the results we obtained from the regression that we performed using the variable y2 representing the overall perception bias of the recommendation. We adjusted this variable computing y2=y2−3 and the resulting value was then used in the regression. As for Table 4, each row is a different dependent variable of the regression.
To verify if H2.1 is satisfied, the variable x5 (that when it is equal 1 means that the participant disagrees with the recommendation) has to be positive and statistically significant. As we observe from the results reported in Table 5, the data support H2.1.
In contrast, the data do not support H2.2 and H2.3 as both x1 and x2 are not statistically significant. Therefore, we performed a TOST to verify if there is an equivalence between the two sample groups. For the case of H2.2, we considered the inconsistency variable x2 and we obtained Ulower_bound=13607,p=2.04·10−18,Uupper_bound=16505,p=2.19·10−11; therefore, the group of participants that have an inconsistent recommendation is equivalent to the one with a consistent recommendation. For the case of H2.3, we considered the source variable x1 and we obtained Ulower_bound=13757,p=5.27·10−18,Uupper_bound=16324,p=9.04·10−13; therefore, the group with human source is equivalent to the algorithmic source.
RQ3
10.3
To answer RQ3, we performed TOST to verify if there is an equivalence between the two sample groups: (1) participants with some experience in the security field, but no experience in AI and (2) participants with some experience in ML, but no experience in the security field. The result is Ulower_bound=1869,p=3.31·10−05,Uupper_bound=1901,p=4.59·10−05; therefore, the two groups are statistically equivalent, and the data do not support H3.1. It actually supports the opposite of the hypothesis: some experience does not make a difference.
Robustness Checks
10.4
Possible noise factors have been analyzed to increase the robustness of the results in Appendix.
Threats to Validity
11
Order Effects of Algorithmic Errors. The overall perception of a source is dependent on the position of the observed errors of algorithmic performance. Observing an algorithm make an error at the beginning could lead to greater algorithm aversion (Dietvorst et al. 2015). The current study may be impacted by order effects of algorithmic errors. However, the present research follows a balanced design seen in Table 3 which controls for these effects, since there is an equal amount of randomly assigned groups encountering their first algorithmic judgment as inconsistent (group ID D, F, H, I, J, and L) as well as consistent (group ID A, B, C, E, G, and K). The general theory shows that if scenarios (threat descriptions in our case) are sufficiently different, the impact is minimal (Massacci et al. 2024).
Self‐Report Scales. The current study uses self‐report scales to measure two outcome variables: overall perception of bias and perception of source. The idea that sources and information can be biased is prevalent in the threat intelligence community (Belton and Dhami 2020). The items concerning bias were therefore constructed to be taken at face value (i.e., “The overall final recommendation looks biased”). No external validity tests have been performed. One possibility is that the items only are not an accurate measurement and thus, skew the results. Evaluating cyber threat intelligence sources can be done based on the complex concept of information quality of the source (Schaberreiter et al. 2019). In the current study, that information would be the recommendation. Currently, the concept is measured using one item to capture the concept at face value, and one item to capture the continued usability. More sophisticated items might be necessary to capture the entire concept.
Risk of Differentiated Measures. The experiments have been executed with two different groups at two different times and places. In addition, there were three nonstructural changes made between the two measurements. These changes were based on lessons learned from conducting the first experiment with the SecA group and consisted of: an additional extra item measuring impact assessment, the location of the manipulation checks, and an extra set of questions measuring expert level. Changes occurring with differentiated measures can introduce confounding factors. However, the first experiment was replicated with the intention to keep the differences to a minimum by using the same training and lecturers, the same experimental design (including number of rooms), and the same experimental objects. Controlled by the fact that not much was changed, the same scripts were able to run in the same way as the first experiment.
Choice of Population. We acknowledge that the background and prior experience of participants may affect the validity of experimental results. However, several studies with students have reported encouraging results (Chong et al. 2021, Naiakshina et al. 2017, 2018, Rong et al. 2012). In particular, Salman et al. (2015) compared the performance of students and professionals to determine to what extent students can serve as valid proxies for professionals in SE research. Their findings indicate that, when confronted with a task for the first time, the performance of both groups tends to be comparable. Furthermore, Tahaei and Vaniea (2022) conducted an experiment investigating programming skills, privacy and security attitudes, and self‐efficacy in secure development among participants recruited from a student mailing list for CS and four crowd‐sourcing platforms (Appen, Clickworker, MTurk, and Prolific). Their results show that 89% of the CS students correctly answered all programming skill questions, compared to only 27% of the participants on crowd‐sourcing platforms. However, we acknowledge that the findings shown in this study are considered preliminary results due to the choice of population; therefore, more experiments should be conducted, including with cybersecurity experts, to further investigate the results obtained and fill the gap with real‐world scenarios.
Measuring Experience in Students. Measuring domain experience in a student population can cause difficulties since the spread of expertise might not exist (i.e., the group is too homogeneous and represents only the novice perspective). Additionally, experience might only translate to knowledge of the decision domain without the actual practice (Labunets et al. 2023). This is also the case in the present experiment where most participants have either no experience or university experience with the decision domain. Although this experiment does include an actual item measuring the self‐reported previous experience with vulnerability risk assessment, an additional proxy measure was introduced to mitigate this issue. The proxy used is the experience in reading threat intelligence reports. The proxy shifts the focus of experience with “real” decisions in the domain to experience with just one facet, the reading of the reports. To generalize our results to a broader range of security professionals, it can only be drawn with more experiments.
Sample Size. Given our small sample size, it is possible that the failure to produce significant results might have been due to lack of power. To mitigate this risk, we have also tested for statistical equivalence among conditions doing a number of two one‐sided tests. In some cases, this allowed to prove that there was really no difference between the conditions. In other cases also, the TOST was not significant and more experiments would be needed.
Selection of Original Reports. At first, the entire advice was fully derived from the NCSC which preserved all key elements of ecological soundness. The main experimental manipulation (the AI vs. human source) was textually minor as it just changed the name of the source and therefore could not impact the soundness of the advice. The consistency manipulation may indeed affect the ecological validity but cannot be eliminated while keeping the construct validity of the experiment: To assess potential bias and disagreement, we need some scenarios in which the recommendation is wrong. If the recommendation was always right, participants would eventually tend to agree with it irrespective of the source. Assuming that the NCSC knows what they are doing when giving advice on the Internet, their final recommendation is likely right (at least to the best of expert knowledge). Therefore, the only way to have a wrong recommendation is to actually change it.
Experimental Manipulation. The current manipulation oversimplifies how professionals build trust in recommendations by focusing on the label of the source. For example, factors such as accumulated performance (Dietvorst et al. 2015) and peer discussion within specific team dynamics (Chun and Park 1998) are not taken into account. Therefore, it is not clear whether participants responded to the label itself or assumptions about quality, transparency, or accountability. Although this choice was made for experimental clarity, future research is necessary to explore these nuances.
Implications for Research and Practice
12
An overview of the main findings and the implications for research and our recommendations for practice are found in Table 6.
Policywise, our research pinpoint at two major gaps in the US industrial policy recommendations for cyber threat intelligence sharing (NIST‐800‐150; Johnson et al. 2012):
- while it is recommended to investigate the technical skills and proficiencies of the target communities (“What are the technical skills and proficiencies of the community members?” (Johnson et al. 2012)), there is no concrete guidance on how to present CTI to different populations.
- the existing guidelines encourage the organizations to find multiple sources of intelligence to confirm its credibility (like, internal sources and open sources). But, to date, there is no guidance regarding the triangulation process when sources used in practice are of fundamentally different types (expert vs. AI‐based).
- assuming that participants would be skeptical of AI suggestions is not necessarily supported, so check and balances by independent algorithms should be foresee also for algorithmic decisions
Conclusion and Future Work
13
More automated analysis in vulnerability assessment and cyber threat intelligence is the new trend pushed by industry and governments alike. To test how the difference (human vs. AI) of cyber threat intelligence recommendations might be perceived by users, we designed a controlled experiment. We have asked n=57 MSc students in computer science with a varied experience in ML and security to assess a number of cyber threat intelligence recommendations extracted from original reports from the Dutch National Cyber Security Center, for a total of 456 data points.
Our findings revealed that participants tended to disagree with the recommendation when it was coming from AI showing a general tendency of algorithm aversion. While expertise on ML did not have any impact, we found that participants with more security expertise tended to agree with the recommendation. In contrast to simplistic narratives of algorithm aversion, we found that the perceived bias was statistically equivalent whether the recommendation was coming from a human or from an AI (TOST). In a nutshell, our participants are algorithm neutral when it comes to judging bias, they exhibit neither aversion nor appreciation in terms of bias. This is in line with the ideas of Wallace et al. (2020). We only measured perceived bias when participants disagreed with the recommendation (irrespective whether it was human or AI). This is to be expected and it is re‐assuring in terms of the validity of the experiment that what is obvious is also statistically confirmed.
These results provide insight on the possible impact of introduction on AI on rank‐and‐file Tier 1 SOC analysts. Although the current findings provide a useful addition to ongoing discussions about algorithm aversion, it is important that the results are interpreted with modesty. Students and professionals do not face the same decision‐making pressures, contextual familiarity, or accountability constraints. Research shows that workload, complexity of the decision, complexity of the decision domain, and cognitive strain influence the extent to which decision makers rely on automated advice (Chugunova and Sele 2022, Kaufmann et al. 2023). In addition, organizational influences like team dynamics, the placement of automation within the organizational structure, and the degree to which a decision maker is held accountable for the task at hand influence decision‐making and reliance on automated advice (Chun and Park 1998, Selten and Klievink 2024, Mahmud et al. 2022). Some research showed that the perception of more accountability leads to a reduction in automation bias (Goddard et al. 2012) while others challenged this finding (Skitka et al. 2000). On top of this, factors such as different political and bureaucratic systems influence how similar automated tools can yield different results within an organizational context (Giest and Samuels 2023). Another big difference when performing the current study with experts lies in measuring the conceptual difference between social trust and confidence. Social trust is based on perceived similarities in values and intentions, while confidence is based on experience and/or evidence (Siegrist 2021). As discussed in Siegrist (2021), it is possible that a similar question could measure social trust in novices while measuring confidence in experts. To validate and generalize our finding, replication experiments must be performed with a larger and more diverse population (e.g., including professional security experts and data scientists) and consider to expand the current method with follow‐up questions to uncover the differentiation between trust and confidence. However, some of the aforementioned factors are difficult and sometimes impossible to recreate within a laboratory setting but are vital in understanding the phenomenon. Future research could therefore focus on follow‐up studies in a field setting. Furthermore, as discussed in Section 11, the experimental manipulation was kept simple for experimental clarity. Future work might explore more realistic instantiations of AI systems (e.g., varying explainability) to explore the different nuances. An interesting theoretical study would be to analyze what happens when likelihood of exploitation is downgraded. Such study cannot be derived from the real data as no such a thing as a risk downgrade can be found in government‐managed data sources of cybersecurity vulnerabilities (for the obvious reasons). Finally, new balanced designs should be tested to capture whether the order in which inconsistent judgments are received influences the overall perception of the source.
Author Contributions
Sarah van Gerwen: conceptualization, methodology, software, investigation, writing – original draft, writing – review and editing. Aurora Papotti: methodology, software, validation, investigation, data curation, writing – review and editing, visualization. Katja Tuma: conceptualization, validation, writing – review and editing, supervision, project administration, funding acquisition. Fabio Massacci: conceptualization, methodology, validation, writing – review and editing, supervision, project administration, funding acquisition.
Funding
This study was supported by HEWSTI.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Aghakhani, N. , O. Oh , D. Gregg , and H. Jain . 2022. “How Review Quality and Source Credibility Interacts to Affect Review Usefulness: An Expansion of the Elaboration Likelihood Model.” Information Systems Frontiers 25: 1–19.
- 2Allodi, L. , M. Cremoninih , F. Massacci , and W. Shim . 2020. “Measuring the Accuracy of Software Vulnerability Assessments: Experiments With Students and Professionals.” 25, no. 2: 1063–1094.
- 3Allodi, L. , and F. Massacci . 2014. “Comparing Vulnerability Severity and Exploits Using Case‐Control Studies.” ACM Transactions on Information and System Security (TISSEC) 17, no. 1: 1–20.
- 4Allodi, L. , and F. Massacci . 2017. “Security Events and Vulnerability Data for Cybersecurity Risk Estimation.” Risk Analysis 37, no. 8: 1606–1627.28800378 10.1111/risa.12864 · doi ↗ · pubmed ↗
- 5Balog‐Way, D. , K. Mc Comas , and J. Besley . 2020. “The Evolving Field of Risk Communication.” Risk Analysis 40, no. S 1: 2240–2262.33084114 10.1111/risa.13615 PMC 7756860 · doi ↗ · pubmed ↗
- 6Basyurt, A. S. , J. Fromm , S. Stieglitz , and M. Mirbabaie . 2022. “Credibility of Cyber Threat Communication on Twitter–Expert Evaluation of Indicators for Automated Credibility Assessment.”Wirtschaftsinformatik 2022 Proceedings. 2.
- 7Bellprat, O. , V. Guemas , F. Doblas‐Reyes , and M. G. Donat . 2019. “Towards Reliable Extreme Weather and Climate Event Attribution.” Nature Communications 10, no. 1: 1732.10.1038/s 41467-019-09729-2PMC 646525930988387 · doi ↗ · pubmed ↗
- 8Belton, B. K. , and M. K. Dhami . 2020. Cognitive Biases and Debiasing in Intelligence Analysis Routledge.