A tandem reinforcement learning framework for localized prostate cancer treatment planning and machine parameter optimization
Nathan Shaffer, Avinash Reddy Mudireddy, Joel St‐Aubin

TL;DR
This study introduces a reinforcement learning framework to automate prostate cancer radiation treatment planning, achieving results comparable to traditional methods without relying on commercial software.
Contribution
A deep reinforcement learning framework for VMAT machine parameter optimization that operates independently of commercial treatment planning systems.
Findings
The RL algorithm generated treatment plans in an average of 6.3 seconds per case.
RL-generated plans showed improved sparing of the bladder and rectum compared to reference plans.
Plans met all clinical objectives and achieved statistically significant improvements in dosimetric endpoints.
Abstract
Volumetric modulated arc therapy (VMAT) machine parameter optimization (MPO) is a complex, high‐dimensional problem typically solved with inverse planning solutions that are both temporally and computationally expensive. While machine learning techniques have been explored to automate this process, they often supplement rather than replace conventional optimizers and are fundamentally limited by the quality and diversity of training data. Reinforcement learning (RL) offers a promising alternative, finding optimal strategies through trial‐and‐error by maximizing a narrowly tailored reward function, which can potentially discover novel solutions beyond mimicking features present in existing plans. The purpose of this study was to develop and validate a deep reinforcement learning‐based VMAT MPO algorithm capable of automatically generating clinically comparable treatment plans for…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
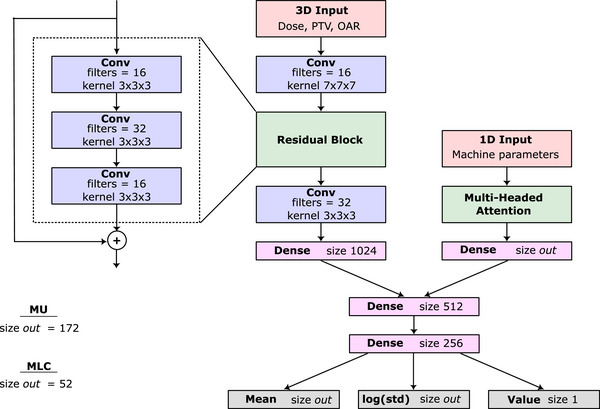 FIGURE 1
FIGURE 1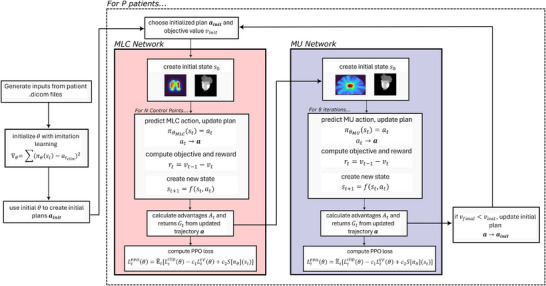 FIGURE 2
FIGURE 2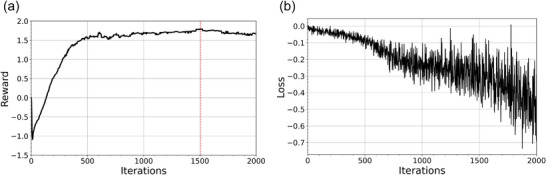 FIGURE 3
FIGURE 3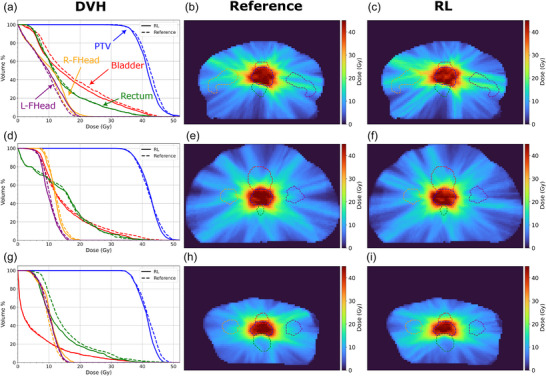 FIGURE 4
FIGURE 4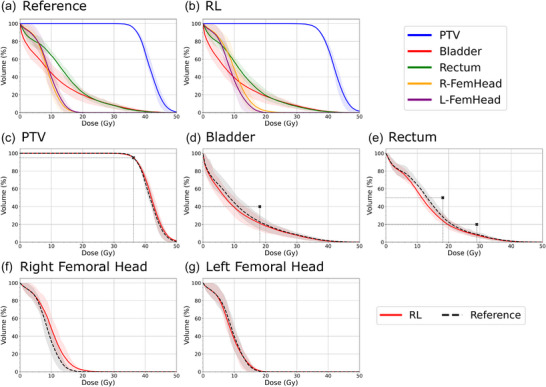 FIGURE 5
FIGURE 5| Structure | Weight | Constraint | Factor () |
|---|---|---|---|
|
| 50 | 0.75 | |
|
| 20 | 0.5 | |
|
| 20 | 0.7 | |
| Structure | Metric | Reference | RL |
|
|---|---|---|---|---|
|
| (Gy) | 0.304 | ||
| (Gy) |
| |||
| (Gy) | 0.224 | |||
|
| 0.251 | |||
|
| (Gy) | 0.417 | ||
| (Gy) | 0.607 | |||
|
| (Gy) |
| ||
| (Gy) | 0.130 | |||
| (Gy) | 0.417 | |||
|
| (Gy) | 0.626 | ||
| (Gy) | 0.892 | |||
|
| (Gy) |
| ||
| (Gy) |
|
- —Iowa Initiative for Artificial Intelligence
- —Department of Radiation Oncology at the University of Iowa
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAdvanced Radiotherapy Techniques · Prostate Cancer Diagnosis and Treatment · Mathematical Biology Tumor Growth
INTRODUCTION
1
Volumetric Modulated Arc Therapy (VMAT) is an advanced form of radiation therapy that delivers highly conformal dose distributions by continuously modulating the beam as the gantry rotates around the patient.1 A critical aspect of VMAT delivery is machine parameter optimization (MPO), which involves defining a sequence of machine parameters, specifically the multi‐leaf collimator (MLC) positions and monitor units (MUs), at each control point (CP) over the range of an arc. MPO is a high‐dimensional, constrained problem and is usually handled with a variety of inverse planning solutions.2 These methods typically involve minimizing a cost function defined by chosen dose‐volume objectives and weights. Although GPU‐acceleration has greatly increased the efficiency of these methods,3, 4, 5 inverse planning remains highly sensitive to the choice of dose objectives and their relative weights necessitating iterative, expert‐driven weight tuning. This trial‐and‐error workflow contributes to prolonged planning times and inter‐planner variability. The limitations are especially acute in adaptive radiotherapy and real‐time planning, where plans must be generated or re‐optimized rapidly in response to daily anatomical changes. Consequently, there is a clear need for planning methods that are accurate, clinically robust, and fast enough for seamless integration into modern treatment workflows.6, 7
To overcome these challenges, there have been many attempts to automate the VMAT planning process such as automated rule implementation, knowledge‐based planning, and multicriteria optimization (MCO).8 Within these categories, Artificial Intelligence (AI)‐based supervised learning algorithms have been used to predict dose distributions9, 10, 11, 12 and objective function weights.13, 14 While improving the overall planning process, these methods typically only simplify the dose‐objective and weight defining steps, meaning that they still rely on the same VMAT MPO algorithms used in manual planning to generate a deliverable plan. Additionally, supervised learning methods are fundamentally constrained by the quantity, quality, and diversity of the training data. Because they are designed to reproduce features present in the training plans, these models are bound on achievable plan quality and may struggle to generalize to novel patient anatomies or changes in clinical goals.15
In contrast to supervised learning methods that aim to mimic existing examples, reinforcement learning (RL) learns by maximizing a reward indicative of desirable outcomes. An agent interacts with an environment by taking actions, receives feedback in the form of a reward, and learns over time which actions maximize rewards.16 Through this trial‐and‐error learning process, the agent incrementally improves the strategies it uses to best satisfy its specific goals in a wide range of domains.17, 18, 19 These strategies are generally referred to as the policy, or mapping from states to actions, designed to maximize the cumulative reward over time. Instead of acting as a one‐off optimizer, a generalized policy can utilize a reward that is tailored to represent the desired clinical dose goals, suggesting potential success in treatment planning workflows over a wider range of scenarios.
RL has shown promise for automating radiotherapy planning by adjusting tunable treatment planning system (TPS) parameters in the optimization process such as penalty weights for target coverage and organ‐at‐risk (OAR) sparing as well as dose thresholds.20 In this “virtual planner” setting, the agent interacts with a TPS, observes dose‐volume histograms (DVHs) or other plan‐quality metrics, and updates parameters to improve a reward tied to clinical objectives. This strategy has yielded strong results in intensity modulated radiation therapy (IMRT) for localized prostate cancer,21, 22 stereotactic body radiotherapy (SBRT),23 and high‐dose‐rate (HDR) brachytherapy,24 but to our knowledge only non‐RL approaches have been used for VMAT.25
RL has also been used in HDR brachytherapy where RL agents directly predict source dwell times and positions to shape dose distributions.26 In a similar fashion, RL has seen some success for direct VMAT MPO where the agent iteratively configures MLC leaf positions and beam intensities (MUs) across CPs to maximize a dosimetry‐based reward. In this work presented by Hrinivich et al. for VMAT MPO, the agent was trained to output deliverable parameter sets but needed to invoke a TPS in the final stage to achieve clinically comparable plans.27 In this work, we develop and validate an RL‐based VMAT MPO algorithm that automatically generates clinically comparable treatment plans that meet machine constraints without a commercial TPS optimizer.
METHODS
2
VMAT for MR‐Linac
2.1
We developed and evaluated our RL‐based VMAT MPO network to predict machine parameters to be delivered using the Elekta Unity MR Linac using a VMAT delivery model in a research build of the Monaco TPS (Elekta AB, Stockholm, Sweden). While VMAT is not yet clinically available on the Unity, it is shown to be technically feasible.28 The dataset comprised 100 prostate cancer patients, with a training‐validation‐testing split of 70‐10‐20. Retrospective patient data used in this study was reviewed and approved by the University of Iowa IRB (IRB00000099) under application 201805779. The set of reference VMAT plans were generated in Monaco based on the SBRT arm of the PACE‐B clinical trial29 prescribing 36.25 Gy in 5 fractions to the prostate and proximal 1 cm seminal vesicles with a 5 mm PTV margin. The RL‐generated plans used evenly spaced CPs every 2° in a single arc, with a gap between 4–23° to avoid the Unity MR‐Linac cryostat. Since this cohort involves prostate treatments where the target remains mostly centralized in the beam's field of view, only the central 26 leaf pairs were required for field modulation. Given the MLC leaf pair positions and an MU value, dose can be computed with an in‐house algorithm30 developed for MR‐Linac use and readily adaptable to non MR‐Linac machines. While initially developed for IMRT dose calculations, this algorithm was adapted for VMAT delivery and used to calculate the dose at each training iteration which is needed to assign rewards to the network and produce the next input state. The dose algorithm was written as a Python package for easy integration with open‐source machine learning packages required for RL network development. The RL algorithm was implemented in Tensorflow 2.12 and trained on a research server with 8 Tesla V100 SXM2 GPUs with 32 GB of memory each, and an Intel Xeon Platinum 8268 Processor 24‐core CPU with 384 GB of RAM.
Reinforcement learning
2.2
Environment and network definition
2.2.1
The goal of RL can be described as finding a policy that maximizes a cumulative reward in a Markov Decision Process (MDP) that models sequential decision‐making within an environment.16 Typically, MDPs are characterized by states (st), actions (at), and resulting rewards (rt). Here we denote the policy πθ, and approximate it using a neural network with weights denoted by θ. We can then treat VMAT MPO as a finite MDP over an arc discretized into N CPs, where the goal is to predict N sequential actions that achieve the best quality plan. The network takes the current state st as an input and provides a predicted action at which is the new set of machine parameters for the next CP. From this predicted action, the new state st+1 can be calculated and a DVH‐based reward rt can be awarded that represents the desired dosimetric objectives. After all CPs are predicted, the final VMAT plan is the set of all N actions predicted by the network. Predicting all N actions for a given batch of patients is one episode.
In our case, the policy πθ is represented by two networks working in tandem with the general structure shown in Figure 1. We will denote these as the MLC network (πθMLC) and MU network (πθMU). Both are convolutional neural networks which extract features from the 3D components of st and combine them with the 1D component where a decoder structure is used to predict (1) the action means, (2) the log of the standard deviation of the action, and (3) a value estimate for the input state. Key elements of the network include a residual block of convolutions to extract 3D features and a multiheaded attention block to capture relationships between the machine parameters represented in the 1D input. Each convolutional layer is separated by batch normalization and a ReLu activation function and each dense layer is separated by layer normalization. The MLC and MU networks differ in a few ways. First, input dimensions of both networks are different, detailed more in section 2.3.2. Second, the output shape, denoted size out in Figure 1, of the MLC network is of size 52, corresponding to the number of MLC positions predicted per CP (26 top and 26 bottom) positions. The MU network output is of size 172 as it predicts the MU values of all CPs at once. Finally, the MLC network final output layer uses a tanh activation function for the mean output layer since the MLC positions are bounded. The MU network uses a softplus activation to ensure they remain positive. The value and log standard deviation outputs both use a linear activation function.
Schematic of the MLC and MU network design. The network accepts a state and returns the action mean, log standard deviation, and value estimate for the input state.
A tandem network was chosen in this case due to the behavior exhibited by RL training, particularly the exploration steps needed to find an optimal policy. Initially, we used a single network with branching output heads to predict the MLC positions and MU values at each CP. In training, variance is added to each of these outputs to explore the solution space and find more optimal actions, however balancing exploration between the MU and MLC values proved to be incredibly difficult and led to unstable training. The MU network needs to have sufficient exploration to adequately vary the beam intensity between CPs, however large changes in the MU values make the effect of MLC position changes on the reward negligible. For this reason, the learning signal the network received in this framework from the reward was incredibly noisy and resulted in little to no improvement in reward over time. Based on these initial results, we split this problem into two parts to decouple the effects of the MU and MLC on the reward signal and this decoupling led to a significant improvement in training stability.
Rewards and advantages
2.2.2
The reward function was built to summarize the clinical evaluation of a given plan, similar to a typical objective function used in plan optimization. To calculate the reward, the predicted MLC and MU values are used to first calculate the patient dose normalized to 95% target coverage with the prescription dose scaled to 1.0. From this dose, the objective value is calculated using a mean squared error between the calculated dose and the ideal dose value for that structure. The ideal dose was set to 0.0 for OARs and set to 1.0 for the PTV, meaning lower OAR and more uniform PTV dose are always encouraged. This value is then scaled by a factor of f<1 each time the dose for a given structure satisfied an additional constraint detailed in Table 1. The total dose objective value v can then be expressed as
For structure iεS, weights wi, dose values di, ideal dose oi, and number of constraints satisfied n. The final reward is the difference in objective value between the old and new state, causing larger improvements in dose objective to return higher rewards. When a constraint is met, n increases by 1 causing the dose objective for the respective structure to be reduced by an additional factor of f, resulting in substantial decrease in objective value and increase in reward. These jumps encourage the network to prioritize meeting the chosen constraints since the biggest total reward over an episode comes when the most constraints are met. These constraints were chosen as they directly mimic the highest weighted constraints used to create the reference plans.
While a reward is assigned for each step in the RL process, it is rarely the case that a single step is solely responsible for achieving that reward. Particularly when applied to VMAT arcs, the reward given to the network at a given CP for meeting a dose constraint is dependent on the totality of all previous CPs. Properly assigning reward to individual steps over the entirety of an episode is known as the credit assignment problem, and is commonly addressed using advantages.16, 31, 32 We calculate the advantage using a generalized advantage estimation (GAE)33 that uses backward recursion after episode completion to adequately distribute later rewards to earlier steps. At a given step t, the advantage is defined
With reward rt, done flag dtε{0,1}, value estimate from the critic network Vt (section 2.2.3), and tunable discount and GAE parameters γ=0.99 and λ=0.95. Using the temporal‐difference residuals δt, advantages incorporate future rewards and value estimates from the network at each step giving the network a better evaluation of the future consequences of making a chosen action at the current state.
Proximal policy optimization
2.2.3
We trained our networks using a combined actor‐critic proximal policy optimization (PPO) approach.34 The policy (actor) network takes in the current state st of the environment and outputs a probability distribution over all possible actions. This distribution is described by two output layers, representing the means and log standard deviations of possible actions. During training, actions at are sampled from the resulting probability distribution, allowing the network to explore the action space. At inference, the mean action is used directly. The value (critic) network also takes in the current state st and estimates the expected cumulative reward, or value Vt, of being in that state. We combine these networks to share features and differentiate them using unique output layers. As the episode progresses, trajectories are collected that are defined by experiences consisting of corresponding state, action, reward tuples {st,at,rn} until termination. Once the episode terminates, the advantages At for all steps are computed which are then normalized by batch and used in the PPO loss shown in equation 4.
The constant values were chosen to be c1=0.45 and c2=0.005. The PPO loss function is designed to be maximized, but in practice, the negative of the loss is minimized.34 The PPO loss uses 3 terms to drive network training. The first term, Ltclip(θ), is a product of the advantage At and the importance ratio Rt(θ), which is the ratio of the probability of taking action at while in state st using the current and old policy weights.
This value is clipped to avoid large policy updates which can destabilize training. The clipping parameter ε was set to 0.15. The second term in Equation 4, LtVF(θ), is the value critic term that measures how accurately the network can predict the value of a state and is simply the mean squared error between the current network predicted value Vθ(st) and the actual return Gt which is a function of At and the old network predicted value Vθold(st).
The third term in Equation 4, Sπθ, is an entropy bonus term35, 36 calculated from the probability distributions predicted by the network defined from the output means and log standard deviations. This term exists to encourage exploration and avoid collapsing into a definite policy prematurely.
In traditional supervised learning, loss functions are designed in a way to satisfy the primary goal of minimizing the distance between the network output and selected target. This is not the case in a PPO loss where instead, we aim to maximize an expected return. For this reason, the PPO loss function was designed to be maximized,34 or in practice, the negative of the PPO loss is designed to be minimized to better suit standard optimizers used in network training. Supervised learning also typically compares network outputs to a stationary target, meaning that there is a theoretical lower limit to the loss, usually 0. In contrast, the PPO loss is instead compared to a moving target (Equation 7 and Equation 8) and assumes no limit to the expected return. As a result, there is no theoretical lower limit to the loss. For these reasons, typically the loss is only monitored to assess gradient stability, and the reward is monitored instead to assess the health of network training.
Network training
2.3
Initialization
2.3.1
The trial‐and‐error process used in RL training offers unique benefits over other types of machine learning algorithms, however these benefits come at the cost of sample inefficiency and instability inherent to a training system that requires a wide variety of experiences. This problem is exacerbated when dealing with complex, high‐dimensional environments.16, 37 Imitation learning (IL) has emerged as a way to address these limitations, where supervised learning is used to initialize network weights before the RL training begins.38 We used a version of IL called behavioral cloning. Here, the network first learns from the actions of an expert demonstrator to discourage exploring states that are obviously detrimental, leading to faster convergence when RL is subsequently used.39, 40 A subset of 10 of the MLC positions of the reference VMAT plans were used in the initialization of the MLC network. A mean square‐error loss between these reference MLC positions and the network outputs was minimized over 500 epochs using an Adam optimizer to complete the supervised learning phase of the IL process. The resultant network weights were then used as a starting point for the RL phase, and the MLC positions predicted by the network using these initialized weights were used as the initial states for RL training loop.
RL workflow
2.3.2
The two networks interact with the environment using distinct state and action space definitions tailored to their respective tasks:
- The MLC Network operates sequentially per CP. A state of this network consists of a (1) three‐channel, three‐dimensional (3D) tensor input (48 × 48 × 128) containing the beam's‐eye‐view (BEV) aligned dose, PTV, and OAR masks, and (2) a 1D vector of length 53 (52 MLC positions + 1 MU). Its action is to predict the 52 MLC positions for the subsequent CP.
- The MU Network operates globally, for all CPs. A state of this network consists of a (1) three‐channel, 3D tensor input (48 × 128 × 128) of cumulative dose and full anatomical masks, and (2) a single comprehensive 1D vector of length 9116 ([52 MLC positions + 1 MU] × 172 CPs). Its action is to predict all 172 MU values simultaneously.
Three dimensional inputs were used in both the MLC and MU networks to capture the full dosimetric impacts of the different states predicted by the RL network, and to enable to network to understand the geometric shapes, locations, and proximity of the target and OARs. A flowchart of the major steps of the training algorithm can be seen in Figure 2. MLC training begins first using the IL initialized weights and MLC positions from which an initial state s0 is created. The MLC network takes this state and outputs the mean MLC positions together with a value estimate and a learned log standard deviation. At each step, the action at is sampled from the distribution defined by the output MLC position means and log standard deviations. The updated dose distribution is calculated using the predicted MLC positions for the CP together with the other unchanged CP doses to get a cumulative dose distribution. The difference in dose objective value between the previous and current state is the resulting reward rt of that step. After the network has completed a full episode (predicted all N CPs), the collected trajectories are used to calculate advantages. MLC network weights are updated using an Adam optimizer to minimize the negative of the PPO loss function in Equation 4.
Flowchart demonstrating the entire training process including weight initialization and reinforcement learning updates for both the MLC and MU networks.
After an MLC training loop is completed, the MU network training begins. The MU network operates similarly to a segment weight optimizer, taking in all the predicted MLC positions and iterating the MU values of all CPs to find the optimal dose distribution. Like the MLC network, the MU network takes a state and predicts the MU means together with a learned log standard deviation and a value estimate. At each step, an action is sampled from the distribution defined by the output MU means and log standard deviations. The new predicted MUs are used to calculate a new cumulative dose distribution. Our IMRT dose calculator was adapted to VMAT deliveries by using a weighted sum of open field dose calculations at angles where the open field doses overlap based on the distance to each field edge. To validate this adaptation, a gamma analysis with a 3%/2 mm gamma criterion, and 10% threshold was used to compare the VMAT radiation plan dose calculated using this algorithm against the GPUMCD calculated reference plans of the 20 patient testing cohort. The resulting reward is therefore the difference in dose objective value between the previous and current state. This process is repeated 8 times per episode. The trajectories collected from this loop are used to calculate advantages and returns which are used to update the MU network weights using an Adam optimizer to minimize the negative of the PPO loss function in Equation 4. After both training loops have been completed, the predicted set of MU and MLC parameters are chosen as the new initial state if the resulting plan achieved a better reward than the previous initial state.
The overall training process involves a nested loop structure. A full training run consists of 2000 iterations and within each iteration, the algorithm processes every patient in the training cohort. For a single patient, the plan generation process is defined as an episode. An episode begins with the MLC network sequentially predicting MLC positions for all CPs to complete a full arc. Following this, the MU network takes the full set of predicted MLC positions and performs 8 inference steps to adjust the MUs for all CPs collectively. The final plan from this episode is compared to the plan used at the start of the episode; if the new plan yields a better total reward value, it becomes the new initial state for that patient in the subsequent training iteration. This ensures a progressively improving baseline for each patient throughout training.
Plan evaluation
2.4
Timing statistics were reported for all parts of the workflow. After training, the RL policy networks were used to create VMAT plans for a set of 20 test patients. During evaluation, the network loop was repeated as many times as needed until the plan was no longer improved, or the final plan reward no longer increased. The RL VMAT plans of the 20 test patients were compared to the reference VMAT plans created in the Monaco TPS using traditional inverse optimization methods. The evaluation compared the Dmean, Dmax, and other clinically relevant dose objectives for each structure as shown in Table 2. Conformity was calculated as the ratio between the 95% prescription volume and target volume. The mean dosimetric values were compared across the reference and RL cohorts with the statistical significance of their differences, computed using Wilcoxon ranked sum tests.
TABLE 2: Mean ± SD dose metrics for RL generated and reference plans for the test patients. Statistically significant differences (p < 0.05) are denoted in bold with an asterisk.
RESULTS
3
Workflow timing
3.1
Before training began, network inputs and patient‐specific open‐fields30 needed to be calculated from dicom files exported from the TPS. In Monaco, these open fields took 24.2±6.0 s to calculate at 5 mm isotropic grids. After exporting the open‐field doses in addition to patient structure files, input generation took an additional 22.4±8.3 s per patient on average. After these inputs were generated, the RL plans were generated by the MLC and MU networks in 6.3±4.7 s on a single Telsa V100 GPU. The large variance in plan generation time was due to the varying amount iterations run during inference. Each patient began another iteration through each network as long as their cumulative reward continued to increase. Some patients required only two passes through the network, while others saw continual improvement for up to 8 iterations.
Training
3.2
The IL process used to initialize network weights took 32 min for the 500 epochs of supervised learning‐based training. Training of the RL network for 2000 iterations took 71 h to complete on our 8 GPU cluster. The relevant training metrics are shown in Figure 3. On average, the total plan reward increased steadily, reaching a maximum at iteration 1506, shown in Figure 3a. Network weights from this iteration were used during inference on the patient test set.
(a) Plot of mean total plan reward versus RL iteration number for patients in the validation cohort during training. The dotted red line shows the iteration where the mean total plan reward was the highest. (b) Plot of the negative total policy loss versus RL training iteration for the MLC network.
Figure 3b shows negative loss versus RL training iteration. As stated in section 2.2.3, this behavior is expected in PPO training where we are aiming to minimize this quantity over the course of training.
Plan evaluation
3.3
The evaluation of our VMAT dose calculator showed an accuracy of 95.13 ± 2.82% gamma pass rate against the Monaco GPUMCD Monte Carlo dose calculation for the testing cohort. The RL generated plans were capable of appropriately sparing the rectum and bladder while achieving the needed PTV coverage. This validates the ability of the networks to respond to the dosimetric reward and set clinically priorities. This is demonstrated in the sample cases shown in Figure 4 that include both reference and RL plan dose distributions with their corresponding DVHs. In these cases, the RL generated plans achieved similar or improved OAR sparing with similar or slightly hotter PTVs.
DVH of three sample patients (a, d, g) with corresponding axial slices of the reference (b, e, h) and RL generated (c, f, i) dose distributions. The target, bladder, rectum, right femoral head, and left femoral head contours are shown in blue, red, green, orange, and purple dashed lines respectively in the 2D dose views.
This trend is further observed in the DVH curves generated from the 20 patient test cohort shown in Figure 5 with the aggregate dose metrics shown in Table 2. Most of the metrics measured showed no statistically significant difference between the reference and RL plans. Of the metrics used in building the reward, only the difference in D2% for the PTV and the rectum Dmean showed statistical significance, with the RL plans resulting in a slightly higher D2% and slightly lower rectum Dmean. Of the two femoral heads, only the right showed a statistical difference in Dmean and V40%, where the RL plans were hotter.
Mean DVH plots of the reference (a) and RL generated (b) plans. OAR‐specific mean DVH curves for the PTV (c), bladder (d), rectum (e), right femoral head (f), and left femoral head (g) with small black markers denoting the constraints used in the dose objective reward function. Shaded regions represent the banded interquartile range.
All RL generated and reference plans evaluated met or exceeded every constraint in Table 1. This further demonstrates the ability of the network to respond to the chosen dosimetric reward.
DISCUSSION
4
In this study, we developed a deep RL framework capable of end‐to‐end VMAT machine parameter optimization, generating clinically acceptable SBRT treatment plans for prostate cancer without a commercial TPS optimizer. Once trained the two RL networks work in tandem to generate plans in an average of approximately 6 s. The conventional VMAT planning process can often take hours and involve iterative, manual adjustments by a planner so this rapid generation time highlights the potential of our approach for online adaptive radiotherapy workflows where treatment plans must be created or modified quickly in response to daily anatomical changes. The current network uses a single arc which is sufficient for localized prostate cancer but generalizing the network to intermediate and high‐risk groups will require multiple arcs which is the subject of future work. Additionally, avoidance angles and partial arcs can easily be incorporated into our framework through the addition of a geometric constraint in the reward function. The geometric reward would penalize angles that deliver entrance dose though a prosthesis or organ to be avoided. Our tandem RL framework provides the ability to incorporate geometric rewards in addition to the dosimetric rewards presented here and is the subject of future work to generalize our framework.
The RL algorithm was able to meet all predefined clinical constraints for the PTV, bladder, and rectum. This success can likely be attributed to the design of the reward function, which was structured to heavily prioritize achieving the specific dosimetric objectives. By rewarding the agent for meeting these goals, the training process effectively taught the network to generate plans that adhere to clinical standards. This further suggests that manipulating these constraints in the reward function can encourage the network to prioritize other such constraints without needing completed treatment plans optimized to those objectives. The RL generated plans also demonstrated improved OAR sparing for both the bladder and rectum when compared to the reference plans, though this often came with slightly higher maximum doses within the PTV and right femoral head. This trade‐off suggests that the weights assigned to the OAR constraints within the reward function may have been overprioritized compared to PTV homogeneity and may benefit from additional tuning. The test plans met the mechanical constraints of the machine as well. The Unity MR‐Linac has a dose rate of 425 MU/min with a conservative MLC leaf speed of 6 cm/s and all predicted RL plans predicted MLC leaf positions and MU values that meet these constraints. While the current framework predicts MUs delivered per CP at set gantry angles, future iterations could predict dose rate at variable angles subject to the minimum and maximum constraints of the treatment machine. The MLC and MU information can be formatted into a DICOM RT plan file for importing into a TPS, but currently the clinical Monaco TPS does not allow for external DICOM RT plan files to be imported and recalculated for the Unity MR‐Linac beam model. However, once this function is available, and VMAT becomes clinically available on the Unity MR‐Linac system, we plan on performing these tests as further validations as the subject of future work.
The use of a tandem‐network architecture was a deliberate design choice to effectively manage the complexity of the VMAT optimization task. The MLC network utilized beam's‐eye‐view inputs, which provided the necessary spatial context to find the optimal aperture shape for each individual CP. In contrast, the MU network was designed to take a global perspective, assessing the cumulative dose distribution and MLC positions from all CPs to modulate the intensity of segment. This separation of duties allowed the MLC network to focus on spatial modulation and the MU network to determine the optimal doses for the given MLC positions. This comes with the downside of requiring significantly more computational resources to train two separate networks simultaneously.
This study also has a few limitations. First, the reward function was limited to constraints for the PTV, bladder, and rectum to simplify the initial training process, as sequentially training two networks is inherently complex. This framework could be expanded to include additional OARs or more nuanced PTV objectives, though this would necessitate careful retuning of the reward function to ensure stable and effective training. There are also notable limitations that relate to the dose calculator30 used to determine the dosimetric rewards and input states. Both the input states and rewards are critically important parts of the training process, meaning that the performance of the RL network is directly linked to the performance of the dose calculation engine. Currently, the doses are predicted on 5 mm grids due to GPU memory limitations for training, but smaller 2–3 mm grids could be achieved with GPU processors with more memory (e.g., Tesla NVIDIA RTX Pro 6000 Blackwell Max‐Q GPUs with up to 96 GB memory). A finer resolution dose calculation would likely result in higher quality features from each of the networks as well as a more accurate reward signal for training. Additionally, current algorithm relies on Monte Carlo open field dose calculations which adds significant overhead time to the treatment plan prediction. There may be ways to improve this time, but this is the subject of future work. Pre‐processing the data for inputs into our networks can also be significantly improved by shifting the pre‐processing work from the CPU to the GPU. The current work also does not include dynamic jaw tracking which would act to further trim the edges of the MLC field, which is also the subject of future work.
CONCLUSION
5
We developed and validated a novel deep RL framework for the end‐to‐end optimization of VMAT treatment plans. Our approach demonstrates that an RL agent can rapidly generate clinically acceptable plans for prostate cancer that are dosimetrically comparable to those produced by conventional methods without the need for a commercial optimizer. The RL approach allows for significant generalizability and doesn't rely on the quality of previously generated treatment plans. Our proposed auto planning process generates a treatment plan in an average of less than 30 s (22.4±8.3 s for input pre‐processing and 6.3±4.7 treatment plan prediction) that meets the physical constraints of the machine. The speed and adaptability offered by this method make it a promising tool for auto‐planning, which is of growing importance in adaptive radiotherapy workflows where both speed and consistency are crucial. In the future we aim to incorporate patient‐specific clinical goals, further advancing the potential of RL to create more personalized treatment planning solutions.
CONFLICT OF INTEREST STATEMENT
Joel St‐Aubin acknowledges a research agreement with Elekta AB, Stockholm not directly pertaining to this work. All other authors have no pertinent conflicts of interest to report.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Palma D , Vollans E , James K , et al. Volumetric modulated arc therapy for delivery of prostate radiotherapy: comparison with intensity‐modulated radiotherapy and three‐dimensional conformal radiotherapy. Int J Radiat Oncol Biol Phys. 2008;72(4):996‐1001. doi:10.1016/j.ijrobp.2008.02.047 18455326 · doi ↗ · pubmed ↗
- 2Unkelbach J , Bortfeld T , Craft D , et al. Optimization approaches to volumetric modulated arc therapy planning. Med Phys. 2015;42(3):1367‐1377. doi:10.1118/1.4908224 25735291 PMC 5148175 · doi ↗ · pubmed ↗
- 3Men C , Romeijn HE , Jia X , Jiang SB . Ultrafast treatment plan optimization for volumetric modulated arc therapy (VMAT). Med Phys. 2010;37(11):5787‐5791. doi:10.1118/1.3491675 21158290 · doi ↗ · pubmed ↗
- 4Tian Z , Peng F , Folkerts M , Tan J , Jia X , Jiang SB . Multi‐GPU implementation of a VMAT treatment plan optimization algorithm. Med Phys. 2015;42(6):2841‐2852. doi:10.1118/1.4919742 26127037 · doi ↗ · pubmed ↗
- 5Peng F , Jia X , Gu X , Epelman MA , Romeijn HE , Jiang SB . A new column‐generation‐based algorithm for VMAT treatment plan optimization. Phys Med Biol. 2012;57(14):4569. doi:10.1088/0031-9155/57/14/4569 22722760 · doi ↗ · pubmed ↗
- 6Güngör G , Serbez İ , Temur B , et al. Time analysis of online adaptive magnetic resonance‐guided radiation therapy workflow according to anatomical sites. Pract Radiat Oncol. 2021;11(1):e 11‐e 21. doi:10.1016/j.prro.2020.07.003 32739438 · doi ↗ · pubmed ↗
- 7Tengler B , Künzel LA , Hagmüller M , et al. Full daily re‐optimization improves plan quality during online adaptive radiotherapy. Phys Imaging Radiat Oncol. 2024;29:100534. doi:10.1016/j.phro.2024.100534 38298884 PMC 10827578 · doi ↗ · pubmed ↗
- 8Wang C , Zhu X , Hong JC , Zheng D . Artificial intelligence in radiotherapy treatment planning: present and future. Technol Cancer Res Treat. 2019;18:1533033819873922. doi:10.1177/1533033819873922 31495281 PMC 6732844 · doi ↗ · pubmed ↗