Machine Learning-Assisted DNA Origami Shape Sorting Using Fingerprinting Nanosensors and Feature Engineering
Shubhajit Singha, M. Mikail Demir, Vinod Morya, Ken Halvorsen, M. Abdullah Canbaz, Arun Richard Chandrasekaran, Mehmet V. Yigit

TL;DR
This paper introduces a machine learning method combined with nanosensors to accurately identify different DNA origami shapes, offering a low-cost alternative to traditional imaging techniques.
Contribution
The novel integration of a nanosensor array with machine learning for DNA origami shape sorting is presented.
Findings
A nanosensor array with 11 fluorophore-labeled DNA probes was used to detect DNA origami shapes.
Machine learning achieved 94% accuracy in distinguishing DNA origami triangles, nanotubes, and scaffold strands.
The method enables high-throughput, label-free classification of DNA nanostructures.
Abstract
Reconfigurable DNA nanostructures have emerged as a promising research area with applications in drug delivery, molecular computing, biosensing, and stimuli-responsive soft nanomaterials. While significant progress has been made in creating novel DNA nanostructures and exploring their applications, comparatively little effort has focused on developing new methodologies to confirm their folding. Conventional imaging approaches typically rely on sophisticated microscopy techniques including atomic force and transmission electron microscopy. Alternative low-cost methods for verifying DNA nanostructure assembly and shape sorting are thus highly valuable. Here, we present a fingerprinting nanosensor array integrated with machine learning (ML) to distinguish between two DNA origami shapes (triangle and nanotube) and to differentiate them from an unfolded scaffold strand. The nanosensor array,…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
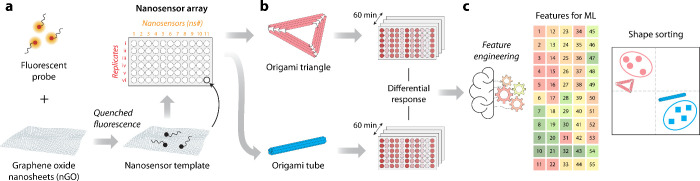 Figure 1
Figure 1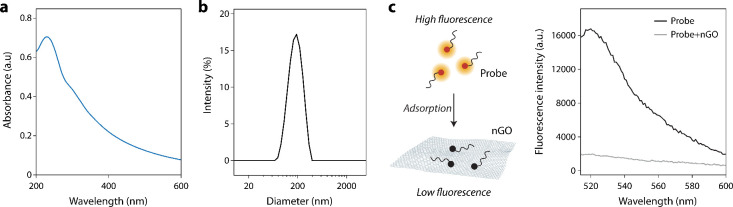 Figure 2
Figure 2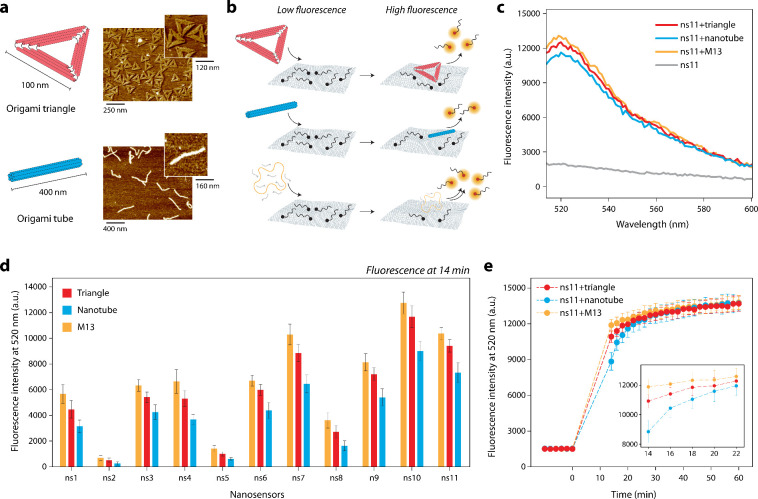 Figure 3
Figure 3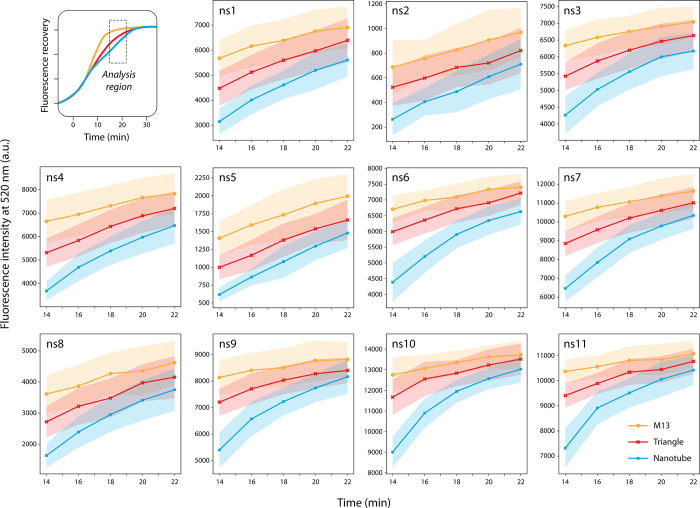 Figure 4
Figure 4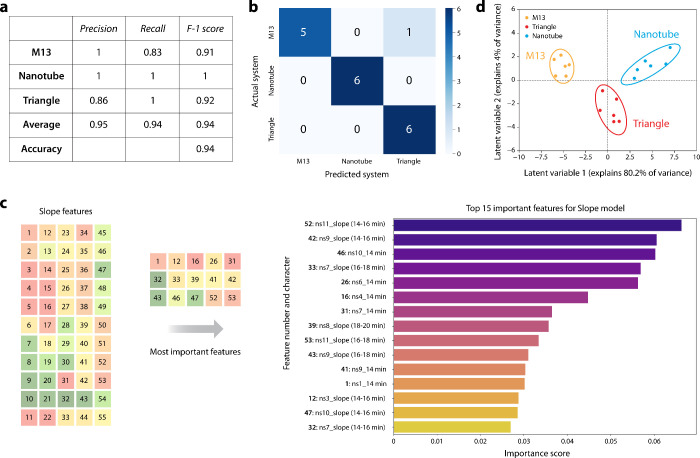 Figure 5
Figure 5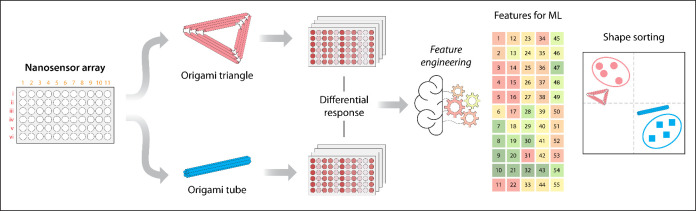 Figure 6
Figure 6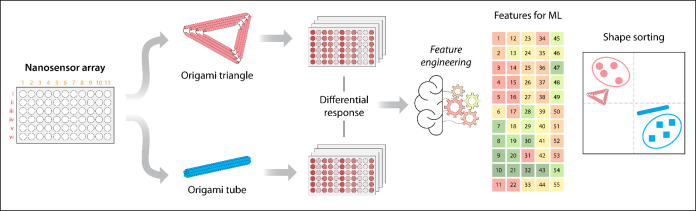 Figure 7
Figure 7- —National Institute of General Medical Sciences10.13039/100000057
- —National Institute of General Medical Sciences10.13039/100000057
- —National Institute of General Medical Sciences10.13039/100000057
- —National Institute of Food and Agriculture10.13039/100005825
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAdvanced biosensing and bioanalysis techniques · Nanopore and Nanochannel Transport Studies · DNA and Nucleic Acid Chemistry
DNA nanotechnology enables the assembly of nucleic acids with nanometer scale accuracy to create sequence-defined shapes. ?,? Advances in DNA origami and chemical modifications have enabled the creation of nanometer to micrometer scale structures with different functionalities. As the design strategies and construction capabilities are expanding, there is an increased need for newer techniques to analyze the variety of DNA nanostructures being assembled. ?,? Gel electrophoresis remains one of the most common methods,? while more specialized techniques such as atomic force microscopy (AFM) and transmission electron microscopy (TEM) provide high-resolution analysis to visualize and distinguish DNA nanostructures. New methods are being developed for automated, rapid characterization of DNA nanostructures including the use of artificial intelligence.?
Machine learning has been used in the optimization of nanoparticle preparation, analysis of nanobio interactions and for applications in nanotheranostics. ?,? In DNA nanotechnology, previous works have used convolutional neural network (CNN)? to detect multiple DNA origami structures and estimate their yield using annotated AFM images? and TEM images. ?,? Methods based on deep neural networks (DNNs) have also been developed to characterize large fluctuations in dynamic DNA devices.? However, these methods rely on prior characterization and use existing data to process and provide new structural information. A solution-phase approach that can discriminate different DNA nanostructures without requiring specialized and sophisticated techniques remains underexplored.
In this study, we report a nanographene oxide-based sensor array that acts as a chemical nose for the discrimination of DNA origami structures that differ in shape. Recent developments in optical nanosensor arrays have emerged as a powerful and flexible sensing platform, predominantly used for sensing biological markers. ?−? ? ? ? The nanosensor arrays reported here are made of two-dimensional graphene oxide nanoparticles (nGO) and fluorescently tagged short single stranded DNAs (fDNA). We have previously used nGO-fDNA assemblies for the detection of biomarkers such as microRNAs, proteins and small molecules. ?−? ? ? ? ?
In a conventional nGO-based sensor design, fDNAs are designed to be specific to the target ligand or biomarker. Upon target detection, the surface-adsorbed probe is displaced through target-probe binding, leading to the recovery of fluorescence initially quenched by nGO through graphene oxide-mediated fluorescence quenching. ?−? ? ? ? ? We have reimagined this sensing strategy and developed a new detection mode in which fluorescence is partially recovered when the target molecule displaces a fraction of the surface-adsorbed fDNA in the nGO-fDNA assembly via competitive displacement rather than target-probe binding. ?,? Since each target displaces a different fraction of fDNA through this displacement event, the resulting differential response can be utilized for sample discrimination. The fDNAs bind to nGO through a combination of noncovalent interactions, including van der Waals forces, hydrogen bonding, and π–π stacking, that stabilize the nGO-fDNA assembly in aqueous solutions. ?−? ? These fDNAs can detach from the surface when a stronger interaction competitively displaces them either through hybridization with complementary or partially complementary sequences, aptamer–target recognition, or stronger nGO–analyte interactions. ?−? ? ? ? ? Because no specific interaction is present between the fDNAs used in this study and the added DNA origami structures, the displacement observed here arises solely from the DNA origami structures disrupting the nGO-fDNA complex.
To enhance discrimination power, we engineered an array of multiple nanosensors rather than relying on a single nanosensor. Previously, we successfully used this approach for the detection and classification of proteins, bacterial species, and microRNAs, as well as for screening food samples for adulteration in food fraud cases. ?,?,?−? ? In these systems, the nanosensors in the array often generate complex, high-dimensional, and overlapping signals that are difficult to interpret with standard statistical tools.? We used machine learning (ML) to subsequently process this information, where one can spot meaningful trends and relationships even in large, complex, and noisy data sets. By uncovering hidden patterns, reducing noise, and capturing nonlinear behaviors, ML turns raw data into a clear and accurate classification data set for bias-free predictions. However, the predictive power of any ML model is fundamentally dependent on the quality and representation of the input data. To enhance prediction accuracy, feature engineering can be applied to the collected data sets to generate a more diverse set of data points. Feature engineering allows the refinement of raw data sets to introduce more distinct variability and increase the dimensionality that eventually strengthens the ML-model.?
Here, we assembled a nanosensor array for discriminating two DNA origami shapes (triangle and nanotube) through fluorescence signal responses that are processed with feature engineering and analyzed by ML for shape sorting (Figure). Briefly, nanosensors were assembled using nGO complexed with 11 fDNAs with different sequence information (Table S1). The adsorption of fDNAs on surface quenches the fluorescence signal through graphene oxide-mediated fluorescence quenching (Figurea). Our results demonstrate that the DNA origami nanostructure in solution interacts with the nanosensors and displaces a fraction of the surface-adsorbed fDNAs in a manner that correlates with the sequence and length of the fDNAs. This displacement produces a distinct fluorescence recovery profile for each nanosensor in the array (Figureb). Each DNA origami structure has a distinct overall dimension, shape and surface features; therefore, the nanosensor array produces a different response for each tested nanostructure. We recorded the fluorescence recovery patterns over a period of 60 min with 2 min time intervals for each origami structure to increase the data set that can be used for discriminating the tested origami structures (Figureb). To capture the dynamic evolution of the fluorescence signals, a feature engineering strategy termed the “Slope model” was implemented to discriminate between the different DNA origami shapes through Random Forest (RF) classifier and a Partial Least Squares Discriminant Analysis (PLS-DA) (Figurec).
In this study, the nGO serves as the template for the nanosensors. Therefore, we first characterized the nGO using UV–visible absorption spectroscopy, which revealed the characteristic absorption peak at ∼230 nm (Figurea). Dynamic light scattering measurements indicated an average hydrodynamic diameter of ∼200 nm, consistent with our previous reports (Figureb). ?,?−? ? The amount of nGO required for optimal quenching (∼94%) was evaluated across a range of nGO concentrations using 20 nM of a representative fDNA (Figure S1). A concentration of 1.38 μg/mL nGO was found to be sufficient for efficient nanosensor formation. We then validated nGO-based fluorescence quenching for all 11 fDNAs used in this study (representative data in Figurec and all sensors in Figure S2). These fDNAs were chosen based on their adsorption and release properties on nGO based on our prior study where we evaluated the interaction of various fDNAs on two-dimensional nanoparticles. ?−? ? After confirming the properties of nGO and successfully demonstrating its quenching properties we then assembled an array of 11 nanosensors by adsorbing the 5′-fluorescein (FAM)-tagged fDNAs on the nGO. We specifically used fDNA strands (polyA, polyC, and polyT) with lengths of 23, 18, 12, and 7 nucleotides. PolyG was intentionally excluded because its strong tendency for tertiary structure formation inhibits effective adsorption onto the nGO surface. Longer DNA sequences exhibit stronger binding to graphene oxide due to a greater number of noncovalent interaction sites, which leads to reduced fluorescence recovery upon target binding. In contrast, shorter sequences bind weakly and therefore display higher fluorescence recovery. Furthermore, the binding affinity of nucleobases to graphene oxide generally follows the order G > A > C ≥ T.? Consequently, the use of different polynucleotides introduces additional variation in binding strength and sensor response. By combining DNA strands with different lengths and base compositions, we generated a nanosensor array capable of producing differential fluorescence responses upon interaction with target biomolecules, thereby enhancing discrimination performance. We optimized the array by ensuring the minimum number of nanosensors required for effective classification and found that an array consisting of 11 nanosensors composed of nGO and different polynucleotides was sufficient to achieve robust discrimination.
We then assembled and characterized the DNA origami structures to be discriminated using the nanosensor array. For this study, we selected two model DNA origami nanostructures assembled from the same M13 scaffold: a DNA origami tube (∼400 nm in length) and a DNA origami triangle (∼100 nm per edge). ?,? We assembled the DNA origami nanostructures using the M13 scaffold and complementary DNA staple strands (Tables S2–S3), and their proper folding was confirmed by atomic force microscopy (AFM) (Figurea). Our lab has extensively studied DNA nanostructures in both fundamental and applied research, allowing us to thoroughly characterize them and interpret the data collected. ?,? We chose these structures because they share the same sequence composition, being constructed from an identical scaffold. The DNA origami structures constitute the vast majority of the sample content. Any unincorporated oligonucleotides are present at comparable levels between the two origami constructs. Therefore, we tested our nanosensor array with these minimally perturbed samples without prior purification.
Our nanostructure discrimination strategy is based on the ability of the DNA nanostructure to differentially displace the fDNA probes previously adsorbed on the nGO surface (Figureb). To first evaluate our strategy, we tested the response of a single nanosensor (ns11) in the presence of the DNA origami structures, showing that addition of the target DNA nanostructure resulted in fluorescence recovery (Figurec). This analysis was then extended to all 11 nanosensors, where fluorescence recovery over time was monitored through changes in the fluorescence spectra (Figure S3). As a control, we used a mixture of M13 scaffold and staples but with no annealing. The fluorescence intensities after the addition of the DNA origami nanostructure and M13 scaffold were plotted for each nanosensor in the array. While the random M13 nanosensor consistently showed the highest fluorescence intensity and the nanotube the lowest, their overall fingerprint patterns were similar (Figured).
The resemblances in the fluorescence recovery spectra obtained with each DNA structure and similar fingerprint response trend observed across all nanosensors made us consider what additional fluorescence features could be used to improve our ability to discriminate them. All three DNA nanostructures share the same M13 genetic sequence, so relying solely on fluorescence intensity differences at a single time point carries a risk of inaccurate prediction. The collective physicochemical properties of the DNA origami including dimensions, shape, charge distribution, and diffusion behavior as well as their interactions with nGO and the fDNAs, influence the displacement kinetics of the fDNAs adsorbed on the nGO surface. ?−? ? ? ? ? To capture any differences in fluorescence recovery kinetics, we then recorded fluorescence response over a course of 60 min with 2 min intervals instead of collecting data points at single time point (Figuree for ns11 and Figure S4 for rest of the array). The data demonstrated that each sample exhibits a distinct recovery profile, which can be used to extract parameters for machine learning analysis. Analysis of the complete kinetic profiles revealed that the largest separation in fluorescence recovery rates among different DNA origami structures consistently occurred within the 14–22 min interval (Figure). This time window corresponds to the transition phase between the initial rapid interaction and the slower adsorption–desorption equilibrium. During this regime, displacement kinetics are most sensitive to target-dependent interactions, resulting in enhanced contrast and improved discriminatory power. Therefore, we incorporated the rate of fluorescence recovery observed between 14 and 22 min into the ML analysis, performing feature engineering within this time window to generate additional parameters for ML–assisted classification of the DNA nanostructures.
To move beyond static fluorescence intensity values (Supporting Data Set 1), we found that the kinetic behavior of the sensor array response provides more informative and discriminative features for classification. To quantify these temporal dynamics, we engineered a set of 55 features based on a “Slope Model” (Supporting Data Set 2). This approach included the initial fluorescence reading from the 14 min time point for each sensor, plus the calculated slope (i.e., the change in fluorescence) between each consecutive pair of time points within the 14–22 min window (e.g., 14–16 min, 16–18 min, etc.). To distinguish among the DNA nanostructures, we employed two complementary supervised learning techniques: Random Forest (RF) classification and Partial Least Squares Discriminant Analysis (PLS-DA) using the engineered features. We first directly compared the performance of a Random Forest classifier trained on these slope-based features against an identical model trained on the raw static fluorescence data (Table).
The model using the engineered slope features achieved a significantly higher cross-validated accuracy of 94.4%, a dramatic improvement over the 72.2% accuracy achieved by the model using raw data (GitHub repository). The RF model demonstrated excellent predictive power, achieving a weighted average F1-score of 0.94, which indicates a strong balance between precision and recall and average accuracy of 0.94 (Figurea). A subsequent confusion matrix, generated from cross-validated predictions, confirmed this high performance, showing only a single misclassification across all test samples (Figureb). This result confirms that capturing the kinetic fingerprint of the nanostructure-sensor interaction is critical for successful discrimination. Therefore, all subsequent analysis was performed using this superior, slope-based feature set. Feature engineering enables the extraction of more discriminative information than what is available from the raw fluorescence intensity values alone. Single intensity values at fixed time points differ only marginally between the two origami structures, which limits their power to separate the classes. In our case, incorporating slope-based features captures the kinetic behavior of the fluorescence recovery, specifically, how the signal changes over defined intervals (14–22 min). By taking these rates of change into account, the engineered slope features result in stronger accuracy compared to using raw fluorescence data alone. Among the 55 total features, the 15 most influential ones, ranked by their importance scores, are presented in Figurec.
In parallel, PLS-DA was used to reduce the dimensionality of the features and visualize the separation between the classes. The resulting score plot revealed distinct, well-separated clusters for each nanostructure, each enclosed within a 95% confidence ellipse (Figured). The first two latent variables effectively captured the system’s variance, with LV1 explaining 80.2% and LV2 explaining 4% of the variance, respectively. Collectively, these engineered features form a unique “machine learning fingerprint”, enabling the accurate and reliable classification of different DNA nanostructure geometries.
In summary, we developed a fingerprinting nanosensor array combined with machine learning to effectively distinguish between two DNA origami shapes (triangle and nanotube) and to differentiate them from the random-coiled M13 genome template. The nanosensor array generated comprehensive fluorescence data sets, which were preprocessed through feature engineering to enable robust ML-based classification. The results indicate that our ML-model can classify DNA origami triangle, DNA origami nanotube and their common template (random-coiled M13 genome template) with 95% confidence ellipses in PLS-DA plot with clear separation among the systems. This model can efficiently discriminate and sort the DNA origami triangle and DNA origami nanotube based on shape with 94.4% accuracy. To maximize the information extracted from each experiment while maintaining a manageable experimental throughput, we employed only 11 nanosensors to analyze two DNA origami structures using six replicates. While this design provides sufficient data for robust analysis, further increasing the number of replicates and number of nanosensors would enable even more refined ML performance. The nanosensor array reported here inherently integrates the different properties of the DNA origami including dimensions, shape, charge distribution and processes them to generate a fluorescence recovery profile. Although it is not feasible to quantify each contributing force individually, the fluorescence recovery data provide a comprehensive aggregate signal that can be effectively analyzed using machine learning.
While our current analysis focuses on discriminating between DNA nanostructures of different geometries, the same nanosensor array and slope-based feature extraction strategy could be applied to classify other structural or nanoscale features provided that comprehensive optical data sets with discriminative features are obtained. With further optimization, our strategy could offer a broader potential for applications in monitoring reconfiguration, detecting misfolded species, or classifying unknown nanoscale assemblies in complex environments by establishing methods that are sensitive to the underlying DNA structure. Incorporating additional DNA origami structures to further increase separation between classes would likely require a broader nanosensor array and the engineered features would need to be redesigned to expand data diversity. Similarly, a generalizable ML-based shape sorting strategy would also require the ML algorithms to be re-evaluated using newly generated training and validation data sets. Therefore, any analysis involving a different set of DNA origami structures would necessitate the development of a new workflow. Our method relies on kinetic fluorescence monitoring (up to 60 min), which may be shortened or lengthened depending on the fluorescence response. The approach for this DNA origami sorting provides a practical and accessible solution using only a benchtop fluorescence reader, avoiding the need for complex instrumentation. It is also important to note that the nanosensor array does not require structural labeling, chemical modification, or individualized probe design for each origami type. Nevertheless, our work here highlights the powerful synergy between fluorescence profiling, nanosensor arrays and machine learning. It provides a platform for nanoscale feature recognition, offering new avenues for shape-sorting in DNA nanotechnology.
Supplementary Material
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Seeman N. C.DNA in a Material World Nature 2003421692142743110.1038/nature 0140612540916 · doi ↗ · pubmed ↗
- 2Xavier P. L.Chandrasekaran A. R.DNA-Based Construction at the Nanoscale: Emerging Trends and Applications Nanotechnology 201829606200110.1088/1361-6528/aaa 12029232197 · doi ↗ · pubmed ↗
- 3Mathur D.Medintz I. L.Analyzing DNA Nanotechnology: A Call to Arms For The Analytical Chemistry Community Anal. Chem.20178952646266310.1021/acs.analchem.6b 0403328207239 · doi ↗ · pubmed ↗
- 4Neyra K.Everson H. R.Mathur D.Dominant Analytical Techniques in DNA Nanotechnology for Various Applications Anal. Chem.20249693687369710.1021/acs.analchem.3c 0417638353660 PMC 11261746 · doi ↗ · pubmed ↗
- 5Kachwala M. J.Smith C. W.Nandu N.Yigit M. V.Reprogrammable Gel Electrophoresis Detection Assay Using CRISPR-Cas 12a and Hybridization Chain Reaction Anal. Chem.20219341934193810.1021/acs.analchem.0c 0494933404234 PMC 8177748 · doi ↗ · pubmed ↗
- 6Huzar J.Coreas R.Landry M. P.Tikhomirov G.AI-Based Prediction of Protein Corona Composition on DNA Nanostructures ACS Nano 20251944333434510.1021/acsnano.4c 1225939772513 PMC 11803750 · doi ↗ · pubmed ↗
- 7Rao L.Yuan Y.Shen X.Yu G.Chen X.Designing Nanotheranostics with Machine Learning Nat. Nanotechnol.202419121769178110.1038/s 41565-024-01753-839362960 · doi ↗ · pubmed ↗
- 8Kuznetsova V.CooganÁ.Botov D.Gromova Y.Ushakova E. V.Gun’ko Y. K.Expanding the Horizons of Machine Learning in Nanomaterials to Chiral Nanostructures Adv. Mater.20243618230891210.1002/adma.202308912 · doi ↗