Evaluating the capability of large language models in radiotherapy through professional certification examinations in Japan
Noriyuki Kadoya, Yoshiyuki Takahashi, Seiya Koga, Hikaru Tanno, Kazuhiro Arai, Shohei Tanaka, Yoshiyuki Katsuta, Hinako Harada, So Omata, Takaya Yamamoto, Rei Umezawa, Ken Takeda, Keiichi Jingu

TL;DR
This study tested how well large language models perform on Japanese radiotherapy certification exams, finding that some models, like ChatGPT-5 Pro, achieved over 90% accuracy.
Contribution
The study evaluates LLMs on professional radiotherapy certification exams in Japan, revealing their high accuracy and potential for clinical applications.
Findings
ChatGPT-5 Pro achieved the highest average accuracy of 94.7% across exams.
All tested LLMs scored above 75% accuracy on radiotherapy certification questions.
Advanced LLMs show strong potential for use in radiotherapy tasks like treatment planning.
Abstract
Large language models (LLMs), such as ChatGPT and Grok, have rapidly advanced in natural language understanding and are increasingly being applied to specialized fields, including medicine. In this study, we evaluated the domain-specific knowledge of LLMs in radiotherapy by assessing their performance on three certification examinations in Japan: the Japanese Medical Physicist Examination, the Japanese Board Examination for Radiologists and the Japanese Board Examination for Radiation Oncologists. We assessed five LLMs—ChatGPT-5, ChatGPT-5 Pro, Grok 4, Grok 4 heavy and Gemini 2.5 Pro—by inputting all multiple-choice questions from these exams into each model and recording their responses. The AI-generated answers were compared with reference answers determined by experienced medical physicists and radiation oncologists. The results demonstrated average accuracies of 84.7 ± 2.0%…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
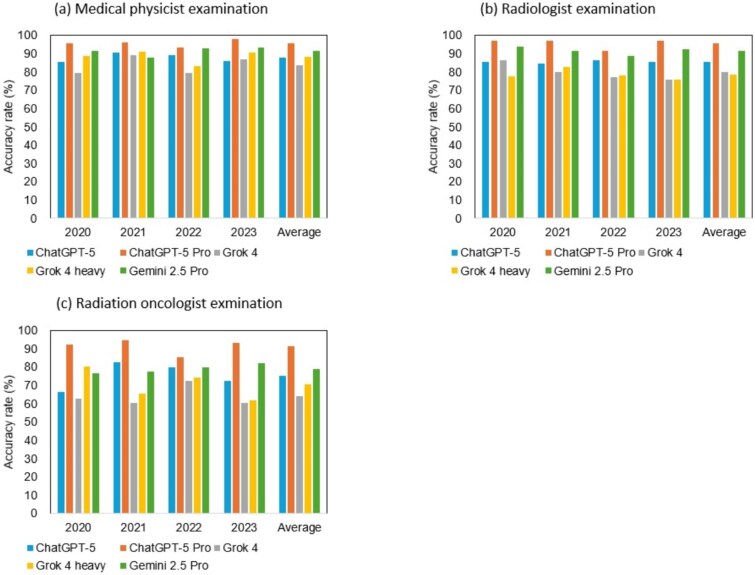 Figure 1
Figure 1 Figure 2
Figure 2 Figure 3
Figure 3 Figure 4
Figure 4 Figure 5
Figure 5Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsArtificial Intelligence in Healthcare and Education · Radiomics and Machine Learning in Medical Imaging · Explainable Artificial Intelligence (XAI)