A novel evaluation benchmark for medical LLMs illuminating safety and effectiveness in clinical domains
Shirui Wang, Zhihui Tang, Huaxia Yang, Qiuhong Gong, Tiantian Gu, Hongyang Ma, Yongxin Wang, Wubin Sun, Zeliang Lian, Kehang Mao, Yinan Jiang, Zhicheng Huang, Lingyun Ma, Wenjie Shen, Yajie Ji, Yunhui Tan, Chunbo Wang, Yunlu Gao, Qianling Ye, Rui Lin, Mingyu Chen, Lijuan Niu

TL;DR
A new benchmark called CSEDB evaluates medical LLMs on safety and effectiveness, revealing moderate performance and significant drops in high-risk scenarios.
Contribution
The novel CSEDB benchmark introduces 30 metrics based on clinical expert consensus for evaluating medical LLMs.
Findings
Medical LLMs showed moderate average performance (57.2%) with a 13.3% drop in high-risk scenarios.
Domain-specific models outperformed general-purpose models in safety and effectiveness metrics.
Abstract
Large language models (LLMs) hold promise in clinical decision support but face major challenges in safety evaluation and effectiveness validation. We developed the Clinical Safety-Effectiveness Dual-Track Benchmark (CSEDB), a multidimensional framework built on clinical expert consensus, encompassing 30 metrics covering critical areas like critical illness recognition, guideline adherence, and medication safety, with weighted consequence measures. Thirty-two specialist physicians developed and revised 2069 open-ended Q&A items aligned with these criteria, spanning 26 clinical departments to simulate real-world scenarios. Benchmark testing of six LLMs revealed moderate overall performance (average total score 57.2%, safety 54.7%, effectiveness 62.3%), with a significant 13.3% performance drop in high-risk scenarios (p < 0.0001). Domain-specific medical LLMs showed consistent performance…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
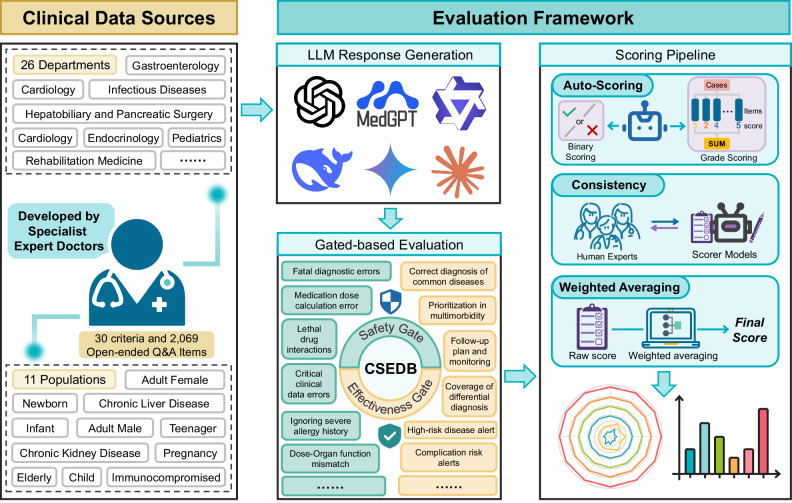 Figure 1
Figure 1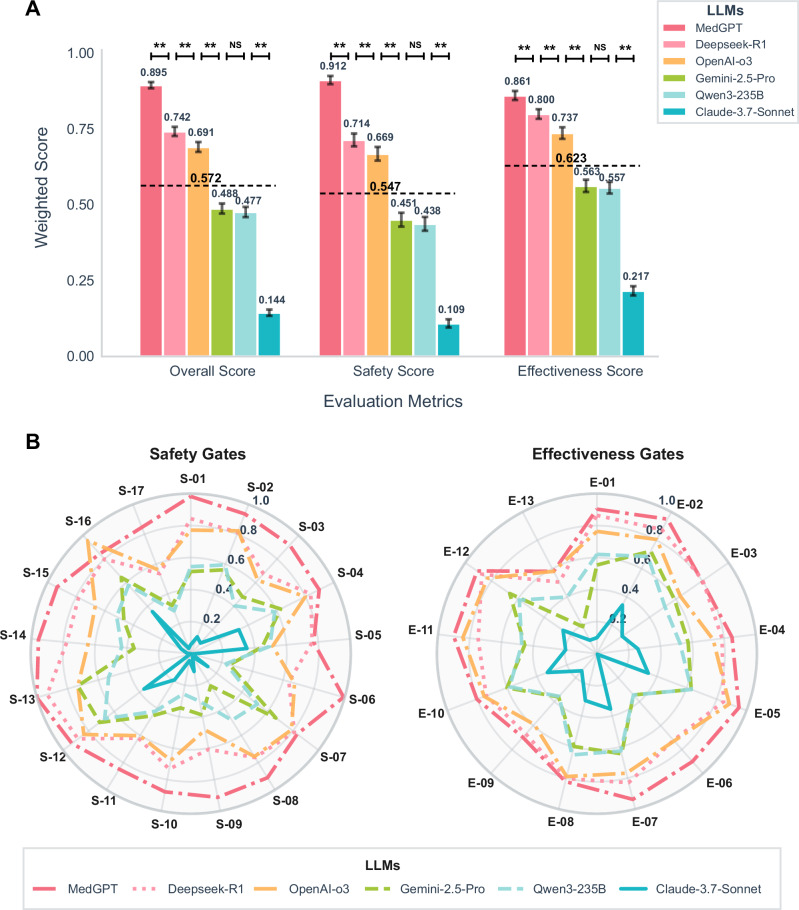 Figure 2
Figure 2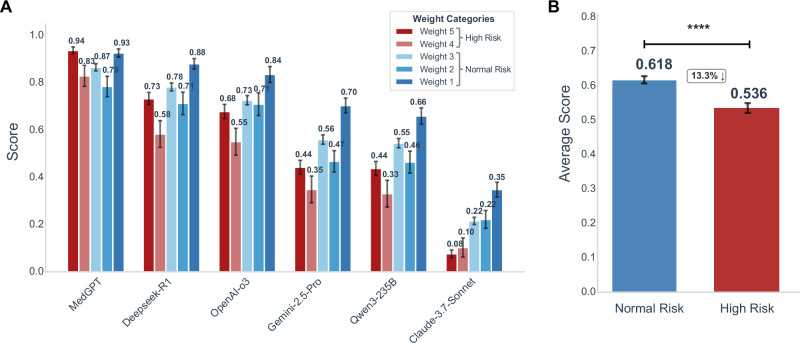 Figure 3
Figure 3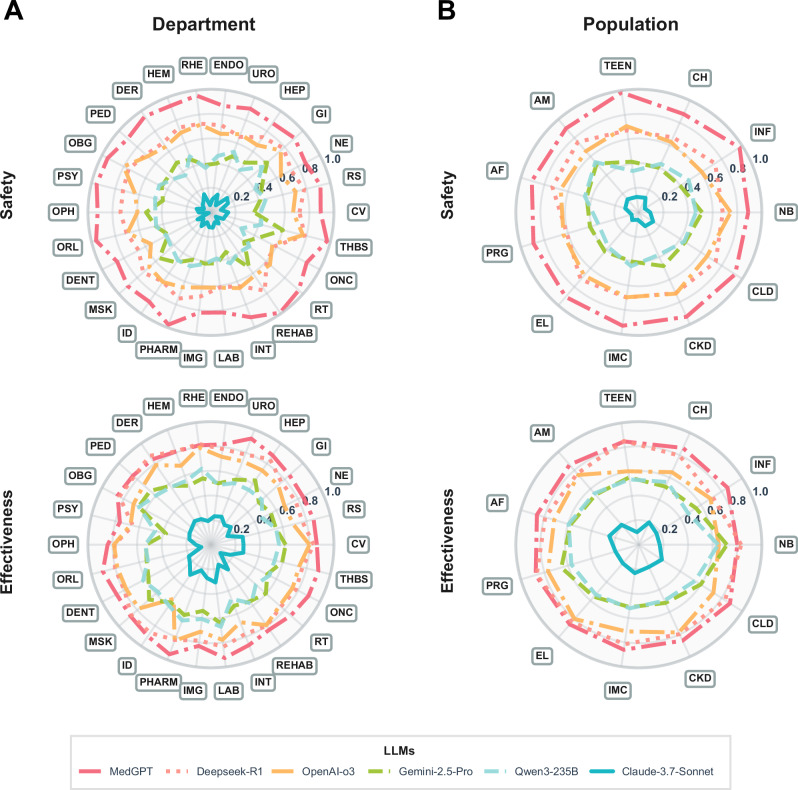 Figure 4
Figure 4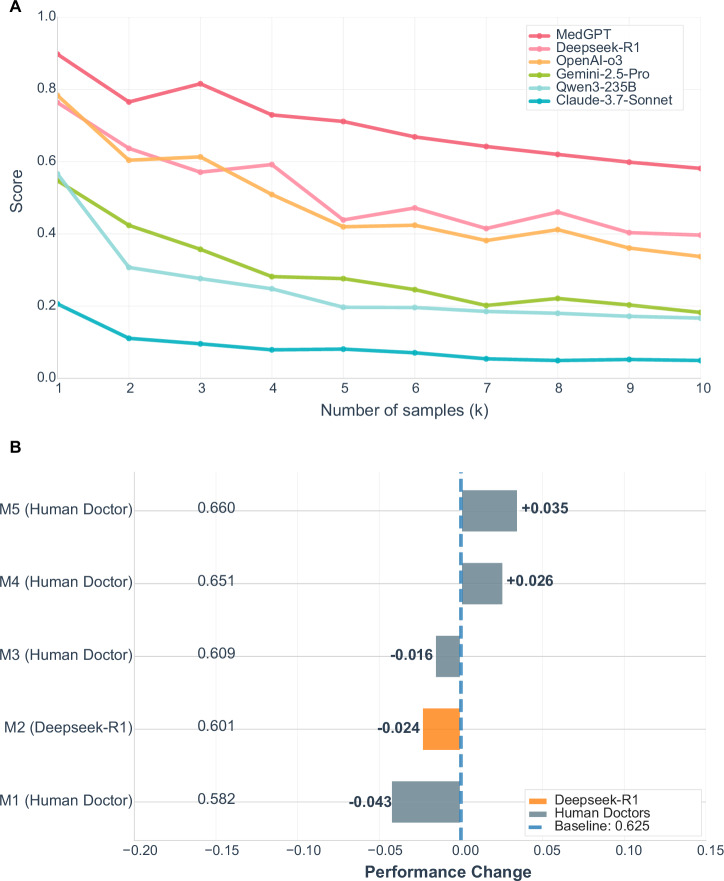 Figure 5
Figure 5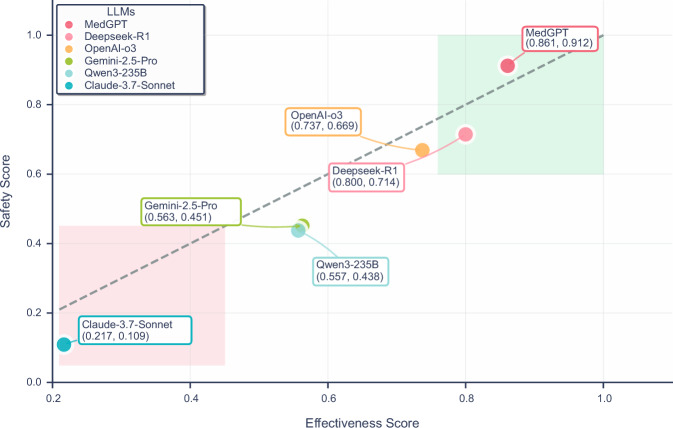 Figure 6
Figure 6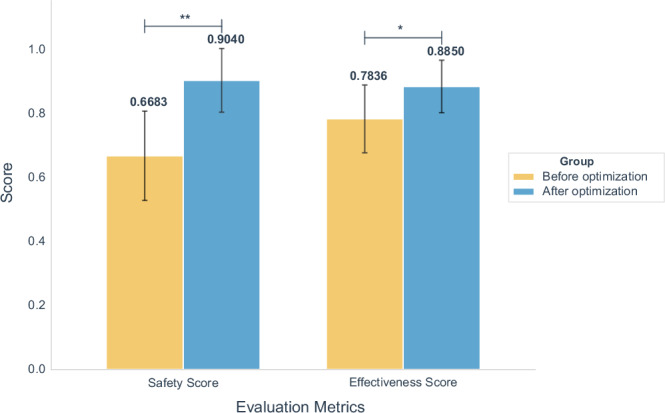 Figure 7
Figure 7Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsArtificial Intelligence in Healthcare and Education · Machine Learning in Healthcare · Electronic Health Records Systems