Comparative effectiveness research with average hazard for censored time-to-event outcomes: simulation study and application to observational data
Hong Xiong, Jean Connors, Deb Schrag, Hajime Uno

TL;DR
This paper introduces a new way to compare treatment effects using average hazard in observational studies, showing it's reliable even with partial model errors.
Contribution
The study evaluates and validates average hazard as a robust alternative to hazard ratios for comparative effectiveness research with censored survival data.
Findings
All six confounding adjustment methods performed well in estimating average hazards.
Augmented inverse probability of treatment weighting (AIPTW) showed robustness under partial model misspecification.
Average hazard analysis is a feasible and reliable alternative to traditional hazard ratios for survival outcomes.
Abstract
The average hazard is a summary measure of event time distributions with a given time window, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}\end{document} and allows intuitive interpretation as an average person-time incidence rate over the time window. This metric is calculated as the ratio of the cumulative incidence probability at \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}\end{document} to the restricted mean survival time…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
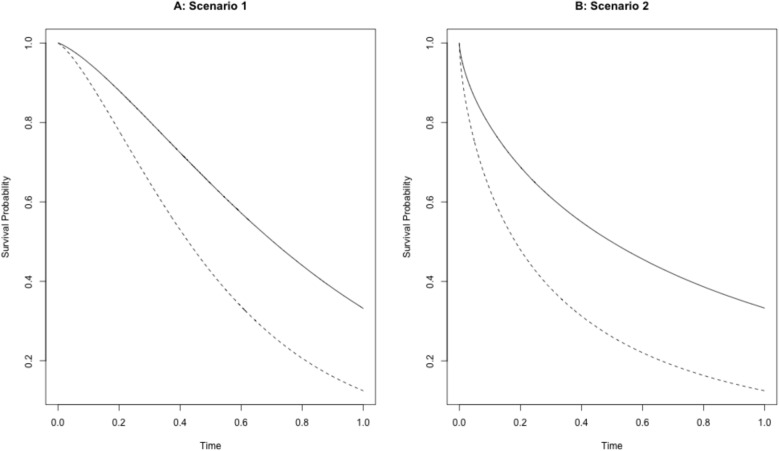 Figure 1
Figure 1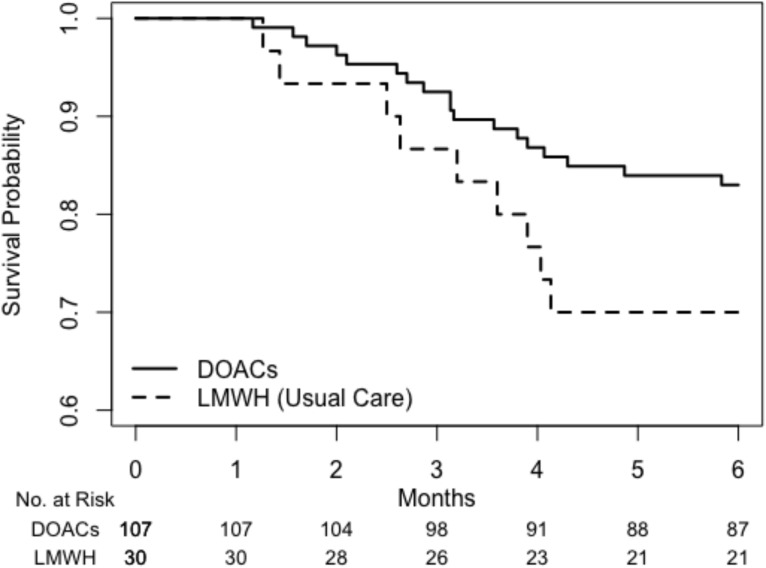 Figure 2
Figure 2- —https://doi.org/10.13039/100006093Patient-Centered Outcomes Research Institute
- —https://doi.org/10.13039/100000057National Institute of General Medical Sciences
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAdvanced Causal Inference Techniques · Health Systems, Economic Evaluations, Quality of Life · Statistical Methods and Inference
Introduction
For decades, the hazard ratio (HR), derived from Cox’s proportional hazards (PH) model [1], has been the predominant metric for quantifying treatment effects on time-to-event outcomes in clinical research. While Cox’s HR benefits from desirable statistical properties and an elegant theoretical foundation, its interpretation becomes problematic when the PH assumption is violated [2–6]. Under non-proportional hazards, the estimated HR is influenced by the study-specific censoring distribution, which compromises its generalizability to other settings or populations [7–10]. To address this limitation, the average hazard ratio (aHR) was proposed by Kalbfleisch and Prentice [7] and further developed and discussed by other authors [11–13]. The aHR is defined as a weighted average of the time-specific HRs. Unlike Cox’s HR, the aHR does not rely on the PH assumption and can be consistently estimated under general censoring mechanisms.
However, an important limitation remains from the perspective of clinical interpretation: neither Cox’s HR nor aHR is designed to estimate group-specific absolute hazards, as both focus solely on the relative contrast between groups. From a statistical standpoint, it is generally more efficient to estimate the HR or aHR directly rather than to first estimate the absolute hazards in each group and then compute their ratio. Nevertheless, the lack of group-specific absolute hazard estimates constrains the interpretability of these relative measures. For example, an HR or aHR of 0.97 numerically suggests a small treatment effect. Yet, its clinical interpretation depends on the absolute hazard in the control group: if the baseline hazard in the control group is low, a 3% reduction in hazard may be a negligible improvement by the treatment; if it is high, the same relative reduction could indicate a meaningful clinical benefit. Conversely, even a seemingly large relative effect (e.g., HR or aHR = 0.5) may lack clinical significance if the baseline hazard in the control group is very low.
Having access to group-specific absolute hazard estimates would enable simultaneous presentation of treatment effects in both absolute and relative terms, as recommended by the Annals of Internal Medicine’s statistical guidance for survival outcomes [14]. A similar recommendation exists for binary outcomes in the CONSORT 2025 guidelines [15]. Without such group-specific summary measures, yielding the between-group contrast measures such as ratios or absolute differences, it becomes difficult to assess treatment benefit from a clinical perspective, potentially limiting the interpretability of study findings.
Given these limitations, alternative approaches have been proposed to quantify between-group differences using summary measures of the event time distribution, such as median survival, cumulative incidence probability, and restricted mean survival time (RMST). Notably, these summary measures can be estimated non-parametrically without imposing strong modeling assumptions and are thus robust [5]. The summary measures of the event time distributions from the treatment group and control group easily allow for the expression of the treatment effect magnitude in both absolute difference and relative terms. This enhances the interpretation of the treatment effect magnitude, as suggested by the aforementioned guidelines [14, 15].
While the RMST-based approach in this class is gaining more attention [3–6] and is beginning to be used in practice [16–19], the average hazard with survival weight (AH) has emerged more recently as another promising approach in this class [20–22]. The AH (or generalized hazard [23, 24]) is defined as
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \eta (\tau ) = \frac{\int _{0}^{\tau } h(u)S(u)du}{\int _{0}^{\tau } S(u)du} = \frac{E\{I(T\le \tau )\}}{E\{ T \wedge \tau \}}, \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\tau$$\end{document} is a truncation time point, h(u) and S(u) are the hazard function and survival function for the event time T, respectively, I(A) is an indicator function for the event A, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$x \wedge y$$\end{document} denotes \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\min (x,y).$$\end{document} The AH is closely related to the person-time incidence rate (IR) commonly defined as ‘the number of observed events divided by the total observation time’ [25] that is,
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} IR = \frac{\sum \nolimits _{i=1}^{n}I(T_i \le C_i)}{\sum \nolimits _{i=1}^{n}( T_i \wedge C_i )}, \end{aligned}$$\end{document}where n is the sample size of the analysis population, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\{ T_i \}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\{ C_i \}$$\end{document} for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$i=1 \ldots , n$$\end{document} are the independent copies from the event time T and censoring time C, respectively. As \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n \rightarrow \infty ,$$\end{document} this converges to
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \frac{E\{ I(T \le C) \} }{E\{ T \wedge C \} }. \end{aligned}$$\end{document}Note that this quantity depends on the censoring time distribution, except in special cases where the event time T follows an exponential distribution. On the other hand, (1) does not involve C but a fixed time point \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\tau .$$\end{document} In contrast to the conventional person-time incidence rate, (2) or (3), the AH provides an average person-time incidence rate over a specified time window, removing the effect of the nuisance censoring time distribution. It should be noted that, as with the conventional IR, the unit of measurement for AH is “events per person-time,” which allows for unambiguous interpretation. For example, if the estimated AH with truncation time \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\tau =24$$\end{document} months is 0.4, this indicates that we would observe 0.4 events per person-month on average during the 24-month period in the absence of censored observations.
For a comparison between Group 0 and 1, difference in AH (DAH) and ratio of AH (RAH) can be defined as
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \eta _1(\tau )-\eta _0(\tau ) = \frac{1-S_1(\tau )}{\int _{0}^{\tau } S_1(u)du} - \frac{1-S_0(\tau )}{\int _{0}^{\tau } S_0(u)du}, \end{aligned}$$\end{document}and
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \eta _1(\tau )/\eta _0(\tau ) = \left\{ \frac{1-S_1(\tau )}{1-S_0(\tau )} \right\} \left\{ \frac{\int _{0}^{\tau } S_0(u)du}{\int _{0}^{\tau } S_1(u)du}\right\} , \end{aligned}$$\end{document}respectively, where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$S_k(t)$$\end{document} is the survival function for the group k. It is important to note that the RAH (i.e., ratio of average hazards) (5) is a fundamentally different quantity from the average hazard ratio (aHR) [7] introduced earlier, despite the similarity in naming. A non-parametric approach for the inference of DAH and RAH is to plug in the Kaplan-Meier (KM) estimates for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$S_1(t)$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$S_0(t)$$\end{document} in equations (4) and (5). This approach has already been investigated under randomized trial settings by Uno and Horiguchi [20]. An R package (survAH) [26] is also available for implementation of the KM-based inference.
It is important to note that there are several appealing features of using the AH, compared with the survival function or RMST. First, as shown in Equation (1), the AH is the ratio of cumulative incidence probability at \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\tau$$\end{document} to RMST with truncation time \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\tau .$$\end{document} Therefore, AH is generally less sensitive to the choice of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\tau$$\end{document} than cumulative incidence probability or RMST, offering a more robust summary across different time horizons. A result of numerical investigation with this regard is seen in Uno et al. [21]. Second, unlike cumulative incidence probability or RMST, AH provides a hazard-based summary that connects naturally to the widely used Cox’s hazard-based analysis, thereby offering continuity with the familiar concept of hazard ratio. In terms of power, power advantages depend on the underlying patterns of difference between two survival curves. Specifically, RMST tends to be more powerful when treatment differences occur early, whereas cumulative incidence probability is more powerful when differences occur late; AH, as a combination of the two, typically yields intermediate power across a range of scenarios [20].
Currently, the application of the AH-based approach to general comparative effectiveness research (CER), where interventions are not allocated through randomization, has yet to be well investigated. In general within CER, the KM-based approach previously outlined for calculating DAH and RAH falls short in adequately adjusting for variations in case-mix between groups and can result in biased estimates of differences between groups. However, it is evident from equations (4) and (5) that DAH and RAH are derived as functions of the survival functions of the respective groups. This suggests that the AH approach can be seamlessly integrated into CER by combining it with existing methods developed to derive adjusted survival functions [27–34]. Yet, the statistical performance of this combined approach remains underexplored for AH.
This paper seeks to address the existing gap by merging established techniques for deriving adjusted survival functions with the AH-based approach in CER. Through extensive numerical studies, we evaluated the statistical performance of these integrated methods. We explored the practical applicability of these approaches for real-world CER studies, supplemented by an illustrative example using real data from an effectiveness study evaluating direct oral anticoagulants (DOAC) compared with low-molecular-weight heparin (LMWH) for the prevention of recurrent venous thrombosis (VTE) events in cancer patients who experienced an initial VTE event [35].
Methods and materials
Overview
The objective of our numerical studies was to systematically evaluate the performance of various statistical methods for adjusting survival curves under different experimental settings when performing statistical inference regarding the treatment effects on survival time outcomes using AH as the summary measure of the survival time distribution.
For each experimental setting, survival data were generated and analyzed by various confounding adjustment methods with details described in the next subsection. We employed several specialized R packages, including the survival, survAH, riskRegression, pammtools, Matching, geepack, and adjustedCurves packages.
For each analytical method, the adjusted survival curves \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hat{S}_1(t)$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hat{S}_0(t)$$\end{document} were computed for the treatment (Group 1) and control (Group 0) groups, respectively. The adjusted AH’s were calculated as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hat{\eta }_1(\tau ) = \left\{ 1-\hat{S}_1(\tau )\right\} /{\int _{0}^{\tau } \hat{S}_1(u)du}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hat{\eta }_0(\tau ) = \left\{ 1-\hat{S}_0(\tau )\right\} /{\int _{0}^{\tau } \hat{S}_0(u)du},$$\end{document} respectively. The treatment effect parameters of interest, DAH and RAH, were then computed by \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hat{\eta }_1(\tau ) - \hat{\eta }_0(\tau )$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hat{\eta }_1(\tau ) / \hat{\eta }_0(\tau ),$$\end{document} respectively. Corresponding 95% confidence intervals were also computed using a standard error that was derived by bootstrapping with 300 resamples. We chose bootstrapping for our numerical studies because not all included confounding-adjustment methods had an available analytical variance formula. Adopting bootstrap confidence intervals for all methods, regardless of the availability of an analytic variance formula or software, allows for a consistent resampling-based approach to comparing the performance of the adjustment methods.
This process from data generation to analysis was repeated 2000 times. The final step of our simulation studies involved collating and summarizing the results across all iterations, evaluating each method through statistical performance metrics regarding inference of DAH, RAH, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\eta }_0(\tau ),$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\eta }_1(\tau ).$$\end{document}
Confounding adjustment methods outline
The following six confounding adjustment methods were selected based on Denz et al. [36] and included in our simulation study: 1) Direct Standardization, 2) Inverse Probability of Treatment Weighted Kaplan-Meier Estimates, 3) Inverse Probability of Treatment Weighted Survival via Cumulative Hazard, 4) Propensity Score Matching, 5) Empirical Likelihood Estimation, and 6) Augmented Inverse Probability of Treatment Weighting. It is also theoretically possible to combine these approaches with the pseudo-value approach used for adjustment of censored observations [37]. However, due to our focus on main approaches for confounding adjustment, we excluded methods that combine these with the pseudo-value approach. Additionally, the standard Kaplan-Meier approach was included as a reference to demonstrate the effect of the absence of confounding adjustment. A brief introduction to each method is given below, and more details with mathematical expressions along with assumptions on censoring are provided in Supplementary Appendix A.
1) Direct Standardization
The Direct Standardization (DS) method, or “G-Formula”, estimates adjusted survival curves via the Cox regression model [27, 28, 38]. This method fits the data to a Cox regression model, including the treatment group indicators and confounding factors. Based on the fitted model, the predicted survival curves are derived for all subjects in the dataset, assigning them to Group 1. The adjusted survival curve for Group 1 is then given by the average of these predicted survival probabilities. This is then repeated in the same manner to give the adjusted survival curve for Group 0. The validity of this approach relies on the adequacy of the specified model to predict the time-to-event outcome.
2) Inverse Probability of Treatment Weighted Kaplan-Meier Estimates
In the Inverse Probability of Treatment Weighted Kaplan-Meier Estimates (IPTW KM) approach, the Kaplan-Meier estimator is applied to samples that are weighted using the Inverse Probability of Treatment Weighting (IPTW) method to yield adjusted survival curves. The IPTW methodology is designed to address confounding by modeling the mechanism of treatment assignment [39]. Typically, logistic regression is employed to calculate propensity scores for each individual across different levels of treatment [40]. Subsequently, individuals are assigned weights based on these estimated propensity scores. The Kaplan-Meier estimator is then used on these weighted samples to generate adjusted survival curves [30]. Assuming accurate modeling and estimation of weights, this method effectively mitigates confounding, leading to consistent estimates.
3) Inverse Probability of Treatment Weighted Survival via Cumulative Hazard
The Inverse Probability of Treatment Weighted Survival via Cumulative Hazard (IPTW CH) approach was introduced by Cole and Hernán [29]. It utilizes a stratified Cox regression model in conjunction with IPTW. In the Cox model, confounding factors are not included; instead, the model includes only the treatment group indicator as a stratification factor and utilizes IPTW for individual weighting. Statistical software, such as the coxph function in R and PROC PHREG in SAS, is used to calculate the adjusted cumulative hazard function for each treatment group. The adjusted survival function is subsequently obtained by exponentiating the negative of this adjusted cumulative hazard function.
4) Propensity Score Matching
Propensity Score Matching (Matching) represents an alternative, well-established method to control for confounding by employing the application of propensity scores [40]. This approach differs by using propensity scores for individual weighting. Instead, it involves the creation of a new dataset, composed of individuals who exhibit similar estimated propensity scores. This methodology aims to achieve a balanced distribution of confounding factors across treatment groups. Specifically, it adopts a bidirectional matching approach in which each treated patient is matched to a control patient and, conversely, each control patient is matched to a treated patient. This construction preserves representation from both treatment groups, ensuring that the resulting matched sample corresponds to the overall study population. Accordingly, the estimand targeted by this method is the average treatment effect in the overall population, rather than an effect limited to one subgroup. Subsequently, the Kaplan-Meier estimator is applied to these matched samples, enabling the derivation of the adjusted survival curve for each group. Assuming correct specification of the propensity score model and the efficacy of the matching algorithm, the resultant survival curves are expected to be consistent [31].
5) Empirical Likelihood Estimation
Empirical Likelihood Estimation (EL) represents a non-parametric approach grounded in likelihood estimation [32]. By maximizing a constrained likelihood function, the EL methodology aims to align moments of covariates between treatment groups, thus achieving similarity in distributional characteristics and removing bias. Notably, given the absence of a specified outcome model and treatment assignment model, the EL approach exhibits enhanced robustness to potential model misspecifications compared to methods necessitating a model, such as IPTW.
6) Augmented Inverse Probability of Treatment Weighting
Augmented Inverse Probability Weighting (AIPTW) approach marks a notable advancement in statistical methodologies for causal inference. Initially proposed by Robins and Rotnitzky [33], it has been further refined by various researchers in different contexts [34, 41–43]. This method distinctively integrates both the outcome and treatment models, leveraging the strengths of each to enhance the estimation process. Specifically, AIPTW utilizes the outcome model to enhance the IPTW estimate based on the treatment model, with the goal of improving its efficiency. This approach ensures asymptotic unbiasedness, provided that at least one of the models — either the outcome model or the treatment model — is correctly specified. This grants AIPTW its notable doubly robust property. This feature is a significant strength of AIPTW, offering a robust layer of protection in the face of potential inaccuracies in model specification.
7) Standard Kaplan-Meier method
The Kaplan-Meier (KM) method offers a non-parametric approach to estimate the survival time distribution of time-to-event outcomes [44]. In this approach, we estimate the survival functions for Group 0 and Group 1, separately. This unadjusted approach was included in the numerical studies as a reference.
Data description
Data generation procedure for covariates and treatment group indicator
We followed the settings from Denz et al. [36] to generate the simulation datasets. First, we generated the covariate vector \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{X}=(X_1,\ldots ,X_6)^\prime .$$\end{document} Specifically, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$X_1 \sim \text {Bernoulli}(0.5),$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$X_2 \sim \text {Bernoulli}(0.3 + X_3 \cdot 0.1),$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$X_3 \sim \text {Bernoulli}(0.5),$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$X_4 \sim \mathcal {N}(0, 1),$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$X_5 \sim 0.3 + X_6 \cdot 0.1 + \mathcal {N}(0, 1),$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$X_6 \sim \mathcal {N}(0, 1),$$\end{document} where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\mathcal {N}(0,1)$$\end{document} denotes the standard normal distribution. We then generated the treatment group indicator Z from a Bernoulli distribution with probability \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$g(a) = \exp (a)/\left\{ 1+\exp (a)\right\} ,$$\end{document} where
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} a = -1.2 + \log (3) \cdot X_2 + \log (1.5) \cdot X_3 + \log (1.5) \cdot X_5 + \log (2) \cdot X_6. \end{aligned}$$\end{document}Data generation procedure for event time
Let U denote a random variable that follows a uniform distribution ranged from 0 to 1. For the event time T, the following two scenarios were considered:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} & \text {Scenario 1:}\ T\\ & = \left( \frac{-\log U}{\exp (\log (1.8) \cdot X_1 + \log (1.8) \cdot X_2 + \log (1.8) \cdot X_4 + \log (2.3) \cdot X_5^2 - 1 \cdot Z)} \right) ^{0.5} \\ & \text {Scenario 2:}\ T\\ & = \left( \frac{-\log U}{\exp (\log (1.8) \cdot X_1 + \log (1.8) \cdot X_2 + \log (1.8) \cdot X_4 + \log (2.3) \cdot X_5^2 - 1 \cdot Z)} \right) . \end{aligned}$$\end{document}Note that conditioned on the covariate vector \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{X}$$\end{document} , the event times for the two groups (i.e., \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Z=0$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Z=1$$\end{document} ) follow Weibull distributions under Scenario 1 and exponential distributions under Scenario 2, respectively. Figure 1 presents the marginal survival time distributions for two groups under Scenarios 1 and 2.Fig. 1. Marginal survival time distributions for Group 0 ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Z=0$$\end{document} , dashed line) and Group 1 ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Z=1$$\end{document} , solid line) in (A) Scenario 1 and (B) Scenario 2
Data generation procedure for censoring time
The censoring time, C, was generated independently of T. Three censoring patterns were considered as follows:
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} \text {Censoring Pattern A:}\ C & = \min (C^*, 1.0), C^* \sim \text {Exp}(0.1) \\ \text {Censoring Pattern B:}\ C & = \min (C^*, 1.0), C^* \sim \text {Exp}(0.2), \\ \text {Censoring Pattern C:}\ C & = \min (C^*, 1.0), C^* \sim \text {Exp}(0.01 + 0.4 X_2), \end{aligned}$$\end{document}where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\text {Exp}(\lambda )$$\end{document} denotes the exponential distribution with the rate parameter \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\lambda .$$\end{document} Censoring Patterns A and B were for scenarios with completely random censoring, that is, censoring independent of both treatment and covariates. Censoring Pattern C was for covariate-dependent censoring.
Derivation of analysis datasets
For a given sample size n, we generated \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\{(T_i,C_i,\textbf{X}_i,Z_i); i=1,\ldots ,n\}$$\end{document} and calculated the observable data \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\{(Y_i,\Delta _i,\textbf{X}_i,Z_i); i=1,\ldots ,n\},$$\end{document} where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Y_i = \min (T_i,C_i),$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\Delta _i$$\end{document} was 1 if \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$T_i \le C_i$$\end{document} and 0 otherwise. For each simulation configuration, we generated 2000 sets of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\{(Y_i,\Delta _i,\textbf{X}_i,Z_i); i=1,\ldots ,n\}$$\end{document} to evaluate the statistical performance of the methods described in Confounding adjustment methods outline section.
Analyses
Cases
Most of the methods introduced in Confounding adjustment methods outline section require users to specify either the outcome model, the treatment model, or both. Although it is preferred that the correct model is specified, this is not always the case in practice. Therefore, we considered the following five different cases regarding model specification by users.
Case 1: Both models correct
In Case 1, we assumed that both the outcome model and treatment model were correctly specified. Let \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$h(t | Z, \textbf{X})$$\end{document} be the hazard function for the event time T, given Z and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{X},$$\end{document} and let \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$E[I(Z = 1) | \textbf{X}]$$\end{document} denote the expected probability of getting the treatment for the subject with the covariate vector \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{X}.$$\end{document} The outcome model and treatment model in Case 1 are then given by
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} h(t | Z, \textbf{X}) & = h_0(t) \exp (\beta _0 Z + \beta _1 X_1 + \beta _2 X_2 + \beta _4 X_4 + \beta _5 X_5^2), \\ E[I(Z = 1) | \textbf{X}] & = g(\alpha _0 + \alpha _2 X_2 + \alpha _3 X_3 + \alpha _5 X_5 + \alpha _6 X_6), \end{aligned}$$\end{document}respectively, where \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$h_0(t)$$\end{document} is the baseline hazard function.
Case 2: Both models wrong by adding extra variables
In Case 2, we assumed that users included extra variables in both outcome and treatment models, and thus neither the outcome model nor the treatment model was correctly specified. Specifically, the outcome model included \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$X_3$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$X_6$$\end{document} , although these were not associated with the outcome. The treatment model included \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$X_1$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$X_4$$\end{document} that were not associated with Z.
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} h(t | Z, \textbf{X}) & = h_0(t) \exp (\beta _0 {Z}+\beta _1 X_1 + \beta _2 X_2 \\&+ \beta _3 X_3 + \beta _4 X_4 + \beta _5 X_5^2 + \beta _6 X_6), \\ E[I(Z = 1) | \textbf{X}] & = g(\alpha _0 + \alpha _1 X_1 + \alpha _2 X_2 + \alpha _3 X_3 \\&+ \alpha _4 X_4 + \alpha _5 X_5 + \alpha _6 X_6). \end{aligned}$$\end{document}Case 3: Wrong outcome model and correct treatment model
In Case 3, we assumed that users misspecified the outcome model with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$X_2$$\end{document} omitted but were able to specify the treatment model correctly.
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} h(t | Z, \textbf{X}) & = h_0(t) \exp (\beta _0 {Z} + \beta _1 X_1 + \beta _4 X_4 + \beta _5 X_5^2) \\ E[I(Z = 1) | \textbf{X}] & = g(\alpha _0 + \alpha _2 X_2 + \alpha _3 X_3 + \alpha _5 X_5 + \alpha _6 X_6). \end{aligned}$$\end{document}Case 4: Correct outcome model and wrong treatment model
In Case 4, we assumed that users correctly specified the outcome model but misspecified the treatment model with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$X_2$$\end{document} omitted.
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} h(t | Z, \textbf{X}) & = h_0(t) \exp (\beta _0 {Z} + \beta _1 X_1 + \beta _2 X_2 + \beta _4 X_4 + \beta _5 X_5^2) \\ E[I(Z = 1) | \textbf{X}] & = g(\alpha _0 + \alpha _3 X_3 + \alpha _5 X_5 + \alpha _6 X_6). \end{aligned}$$\end{document}Case 5: Both models wrong by variable omission
In Case 5, we assumed that users omitted \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$X_2$$\end{document} from the outcome model and the treatment model.
\documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\begin{aligned} h(t | Z, \textbf{X}) & = h_0(t) \exp (\beta _0 {Z} + \beta _1 X_1 + \beta _4 X_4 + \beta _5 X_5^2 )\\ E[I(Z = 1) | \textbf{X}] & = g(\alpha _0 + \alpha _3 X_3 + \alpha _5 X_5 + \alpha _6 X_6). \end{aligned}$$\end{document}Note that, regarding model properties, neither a treatment model nor an outcome model is used for KM. For DS, only outcome model is used. For IPTW KM, IPTW CH, and Matching, only treatment model is used. For EL, neither a treatment model nor an outcome model is used, but the covariates specified in treatment model will be used to estimate the likelihood in our numerical studies. For AIPTW, both outcome and treatment models are used.
Population parameters of interest and statistical inference
Our analyses focused on four key parameters to evaluate the AH with a truncation time \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\tau =0.7$$\end{document} : \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\eta }_1(\tau )$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\eta }_0(\tau )$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\eta }_1(\tau )-{\eta }_0(\tau )$$\end{document} , and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\eta }_1(\tau )/{\eta }_0(\tau )$$\end{document} , representing the AH in Group 1 and Group 0, DAH, and RAH, respectively. We estimated these parameters based on the adjusted survival curves, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hat{S}_1(t)$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\hat{S}_0(t),$$\end{document} derived through the methods described in Confounding adjustment methods outline section. We also calculated 95% confidence intervals using a bootstrap procedure. Specifically, for each dataset, we generated a bootstrap sample and reran the entire confounding-adjustment pipeline, including model fitting, score calculation, construction of weights or matched pairs, estimation of the adjusted survival curves, and calculation of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\eta }_1(\tau )$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\eta }_0(\tau )$$\end{document} , DAH, and RAH. This process was repeated 300 times, allowing us to compute standard errors of the point estimators and corresponding 95% confidence intervals that account for the uncertainty introduced by weighting or matching through model fitting. Note that the standard error and confidence intervals for RAH were calculated on the log-scale.
Performance evaluation
Derivation of true parameter values
The true values of the four parameters (i.e., \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\eta }_1(\tau )$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\eta }_0(\tau )$$\end{document} , DAH, and RAH) under each scenario were derived numerically. Specifically, we randomly generated 10,000 data points of the covariate vectors \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{X}.$$\end{document} We then generated the event time T when \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Z=1,$$\end{document} using the formula in Data description section. Using the exact same \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textbf{X},$$\end{document} we generated T when \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$Z=0$$\end{document} in the same manner. Combining these two datasets for the treatment \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$(Z=1)$$\end{document} and control \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$(Z=0)$$\end{document} groups together, we derived an estimate for each of the four parameters using the standard KM approach. To assure that the Monte Carlo error was negligible, we repeated the process 100 times and averaged the estimates for each parameter. The true values for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\eta }_1(\tau )$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\eta }_0(\tau )$$\end{document} , DAH, and RAH were 0.934, 1.728, −0.795 and 0.541 in Scenario 1, and 1.365, 2.892, −1.527 and 0.472 in Scenario 2.
Performance metrics
For each of these parameters, we employed a comprehensive set of metrics to assess the performance of various confounding adjustment methods when used with the AH-based approach in CER. Firstly, we calculated the mean relative bias of point estimates, providing a scaled perspective of the bias relative to the true parameter value. Secondly, we computed the square-root of the Mean Squared Error (rMSE) for the point estimates. This metric, by incorporating both bias and variance, provides a comprehensive overview of the overall estimation error. Thirdly, we assessed the coverage probability of 95% confidence interval, which reflected the proportion of times the true parameter value falls within the calculated 95% confidence interval. Fourthly, the median length of 95% confidence interval, while being robust to the outliers, was calculated to offer insight into the efficiency of the estimating procedures.
Results
Independent censoring patterns
We present results from DAH (Tables 1, 2, 3 and 4), one of our four AH-based parameters, with the four performance metrics mentioned above when the total sample size is \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n=300$$\end{document} under Censoring Patterns A and B. Results for the remaining parameters are provided in the Supplementary Appendix B (see Tables B1 to B12).Table 1. Mean relative bias for DAHScenarioCensoringMethodCase123451AKM−0.2887−0.2887−0.2887−0.2887−0.2887DS−0.0068−0.0065−0.1320−0.0068−0.1320IPTW KM−0.0071−0.0088−0.0071−0.1436−0.1436IPTW CH−0.0103−0.0119−0.0103−0.1453−0.1453Matching−0.0002−0.0098−0.0002−0.1386−0.1386EL0.00410.00440.0041−0.1515−0.1515AIPTW−0.0082−0.0074−0.0090−0.0064−0.14591BKM−0.2891−0.2891−0.2891−0.2891−0.2891DS−0.0069−0.0068−0.1321−0.0069−0.1321IPTW KM−0.0072−0.0089−0.0072−0.1434−0.1434IPTW CH−0.0106−0.0122−0.0106−0.1452−0.1452Matching−0.0005−0.0103−0.0005−0.1389−0.1389EL0.00290.00450.0029−0.1508−0.1508AIPTW−0.0089−0.0082−0.0096−0.0067−0.14592AKM−0.2612−0.2612−0.2612−0.2612−0.2612DS−0.0056−0.0054−0.1298−0.0056−0.1298IPTW KM0.0005−0.00170.0005−0.1364−0.1364IPTW CH−0.0067−0.0089−0.0067−0.1414−0.1414Matching0.0032−0.00190.0032−0.1315−0.1315EL0.00890.01060.0089−0.1451−0.1451AIPTW−0.0013−0.0010−0.00220.0001−0.13972BKM−0.2623−0.2623−0.2623−0.2623−0.2623DS−0.0061−0.0062−0.1305−0.0061−0.1305IPTW KM−0.0010−0.0032−0.0010−0.1376−0.1376IPTW CH−0.0084−0.0105−0.0084−0.1427−0.1427Matching0.0017−0.00370.0017−0.1327−0.1327EL0.00700.00840.0070−0.1463−0.1463AIPTW−0.0024−0.0020−0.0032−0.0007−0.1405Methods for deriving survival curves: KM, Standard Kaplan-Meier based approach (unadjusted); DS, Direct Standardization via a Cox model (G-formula); IPTW KM, Xie and Liu’s approach; IPTW CH, Cole and Hernan’s approach; Matching, Propensity score matching; EL, Empirical Likelihood approach; AIPTW, Augmented Inverse Probability of Treatment Weighting approachTable 2Square-root of Mean Squared Error (rMSE) for DAHScenarioCensoringMethodCase123451AKM0.29280.29280.29280.29280.2928DS0.11440.12030.15620.11440.1562IPTW KM0.20640.19990.20640.23020.2302IPTW CH0.20340.19680.20340.22890.2289Matching0.23520.23130.23520.25310.2531EL0.25800.23550.25800.24890.2489AIPTW0.16970.17040.17070.16320.20031BKM0.29530.29530.29530.29530.2953DS0.11560.12200.15720.11560.1572IPTW KM0.21000.20410.21000.23310.2331IPTW CH0.20700.20080.20700.23180.2318Matching0.23970.23600.23970.25610.2561EL0.26170.23790.26170.25040.2504AIPTW0.17920.18000.18020.17280.20802AKM0.52070.52070.52070.52070.5207DS0.23520.24540.30640.23520.3064IPTW KM0.37800.36310.37800.42160.4216IPTW CH0.37130.35640.37130.42070.4207Matching0.43670.42340.43670.46720.4672EL0.46100.43450.46100.45270.4527AIPTW0.31420.31550.31640.30570.37072BKM0.52430.52430.52430.52430.5243DS0.23730.24820.30860.23730.3086IPTW KM0.38270.36860.38270.42600.4260IPTW CH0.37590.36170.37590.42500.4250Matching0.44040.43030.44040.47150.4715EL0.46530.43880.46530.45610.4561AIPTW0.32360.32480.32560.31430.3777Methods for deriving survival curves: KM, Standard Kaplan-Meier based approach (unadjusted); DS, Direct Standardization via a Cox model (G-formula); IPTW KM, Xie and Liu’s approach; IPTW CH, Cole and Hernan’s approach; Matching, Propensity score matching; EL, Empirical Likelihood approach; AIPTW, Augmented Inverse Probability of Treatment Weighting approachTable 3Coverage probability of 95% confidence interval for DAHScenarioCensoringMethodCase123451AKM0.7640.7640.7640.7640.764DS0.9540.9550.8470.9540.847IPTW KM0.9540.9500.9540.9120.912IPTW CH0.9550.9490.9550.9090.909Matching0.9470.9530.9470.9240.924EL0.9560.9710.9560.9160.916AIPTW0.9530.9540.9550.9520.8991BKM0.7690.7690.7690.7690.769DS0.9550.9540.8580.9550.858IPTW KM0.9570.9480.9570.9150.915IPTW CH0.9560.9480.9560.9150.915Matching0.9450.9520.9450.9260.926EL0.9600.9680.9600.9250.925AIPTW0.9510.9490.9540.9510.9032AKM0.7740.7740.7740.7740.774DS0.9530.9540.8470.9530.847IPTW KM0.9530.9560.9530.9070.907IPTW CH0.9530.9540.9530.9010.901Matching0.9510.9550.9510.9240.924EL0.9650.9690.9650.9140.914AIPTW0.9560.9550.9540.9540.8942BKM0.7780.7780.7780.7780.778DS0.9550.9570.8510.9550.851IPTW KM0.9540.9540.9540.9090.909IPTW CH0.9540.9510.9540.9010.901Matching0.9490.9530.9490.9220.922EL0.9630.9700.9630.9110.911AIPTW0.9600.9640.9610.9590.895Methods for deriving survival curves: KM, Standard Kaplan-Meier based approach (unadjusted); DS, Direct Standardization via a Cox model (G-formula); IPTW KM, Xie and Liu’s approach; IPTW CH, Cole and Hernan’s approach; Matching, Propensity score matching; EL, Empirical Likelihood approach; AIPTW, Augmented Inverse Probability of Treatment Weighting approachTable 4Median Length of 95% Confidence Interval for DAHScenarioCensoringMethodCase123451AKM0.71780.71780.71780.71780.7178DS0.44840.47130.45430.44840.4543IPTW KM0.78730.75290.78730.76850.7685IPTW CH0.77740.74140.77740.75990.7599Matching0.90870.90310.90870.88350.8835EL0.93680.98840.93680.82930.8293AIPTW0.65300.65740.65410.63750.64031BKM0.73100.73100.73100.73100.7310DS0.45800.48100.46450.45800.4645IPTW KM0.80190.76790.80190.78220.7822IPTW CH0.79100.75570.79100.77340.7734Matching0.92340.91890.92340.89740.8974EL0.94871.00080.94870.84090.8409AIPTW0.68870.69370.69100.67230.67622AKM1.34021.34021.34021.34021.3402DS0.92880.97370.92560.92880.9256IPTW KM1.48031.41021.48031.43511.4351IPTW CH1.45361.38261.45361.41351.4135Matching1.70051.68491.70051.65331.6533EL1.72431.80301.72431.52721.5272AIPTW1.23911.24471.24581.21391.20542BKM1.35521.35521.35521.35521.3552DS0.93870.98540.93610.93870.9361IPTW KM1.49791.42741.49791.45091.4509IPTW CH1.46881.39921.46881.42831.4283Matching1.71941.70071.71941.66951.6695EL1.73411.81351.73411.54341.5434AIPTW1.28221.28811.28611.25471.2475Methods for deriving survival curves: KM, Standard Kaplan-Meier based approach (unadjusted); DS, Direct Standardization via a Cox model (G-formula); IPTW KM, Xie and Liu’s approach; IPTW CH, Cole and Hernan’s approach; Matching, Propensity score matching; EL, Empirical Likelihood approach; AIPTW, Augmented Inverse Probability of Treatment Weighting approach
Table 1 presents relative bias for DAH given different confounding adjustment methods under various scenarios, censoring patterns, and cases. KM showed large bias (ranging from −0.29 to −0.26) in all situations, due to the lack of confounding adjustment. The relative bias by DS was low (around −0.006) when the outcome model was correctly specified (Case 1 and 4), but it was remarkable (around −0.13) when the outcome model failed to include a predictor (Case 3 and 5). For Case 2, where the outcome model included extra variables, the relative bias was almost identical to the ones in Case 1 and 4. This suggests that the relative bias by the DS method is more significantly affected by omitting covariates compared to adding extra covariates. Since the model used for DS is nonlinear, covariate omission generally leads to attenuation of treatment effects. While such shrinkage may be beneficial in certain statistical settings, its implications depend on the research context. In cases 3 and 5, we observed that the attenuation was substantial enough to warrant consideration, particularly when interpreting treatment effects in the presence of unmeasured confounders. The relative bias produced by IPTW KM, IPTW CH, and Matching depended on the adequacy of the treatment model, as a treatment model is used for adjustment in these approaches. When the treatment is correct (Case 1 and 3), the resulting relative bias was small (ranged from −0.01 to 0.003). For IPTW KM and IPTW CH, the relative bias in Case 2—where two extra variables were included in the treatment model—was comparable to that in Cases 1 and 3, whereas Matching showed a modest increase in the magnitude of bias under Case 2. In contrast, when a prognostic factor \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$X_2$$\end{document} was omitted from the treatment model (Case 4 and 5), large relative biases (ranged from −0.15 to −0.13) were observed. In EL, the covariates included in the treatment model were used for adjustment. Thus, Case 1 and 3 were the situations where all variables associated with the treatment assignment were included in the analysis, and the relative biases were negligible as expected. In the case where two extra variables were included (Case 2), the absolute value of the relative bias produced by EL was less than 0.02. Where EL failed to include a variable that was associated with the treatment assignment (Case 4 and 5), large relative biases of approximately −0.15 were observed. As AIPTW has the doubly robust property, theoretically, it would produce a consistent estimate when either the outcome model or the treatment model is correctly specified (Case 1, 3, and 4). As expected, the absolute values of the relative bias in these cases were at most 0.01 in our simulation scenarios. Similar to the other methods, Case 2 produced similar results. However, when neither model was correct (Case 5), AIPTW produced large relative biases (around −0.14).
Table 2 presents the results of the rMSE for DAH. Analogous to the findings related to relative bias, the rMSE was significantly influenced by the appropriateness of the specified model(s) for each method. For instance, the DS method relies on the outcome model. The rMSE values were lower in cases where the outcome model was correctly specified (Case 1 or 4) or included all necessary predictors (Case 2), compared to cases where the outcome model omitted a crucial predictor. In Case 1, where both the outcome and treatment models were correct, the DS method provided the lowest rMSE compared to other methods. Specifically, under Scenario 1 with Censoring Pattern A and Case 1, the rMSE of DS was 0.114, while the rMSE of the other adjusted methods ranged from 0.170 to 0.258. The rMSE of Matching (0.235) was larger than the other propensity score adjustment methods (0.206 with IPTW KM and 0.203 with IPTW CH). The EL method provided the largest rMSE (0.258) among these adjusted approaches.
Table 3 presents coverage probability of 95% confidence interval for DAH given different confounding adjustment methods under various scenarios, censoring patterns, and cases. KM provided lower coverage probabilities (around 0.77) than the nominal level in all situations, due to the lack of confounding adjustment. DS had low coverage probabilities under Case 3 and 5, where the outcome model failed to include a predictor. Otherwise, the coverage probabilities of DS were closer to the nominal level. The coverage probabilities of IPTW CH, IPTW KM, and Matching were also off from the nominal level when the treatment model did not include a crucial variable (Case 4 and 5). The coverage probabilities of EL ranged from 0.956 to 0.965, which were close to the nominal level, when a correct set of variables were specified for the adjustment (Case 1 and 3). When extra variables were included for adjustment (Case 2), the coverage probabilities were higher (around 0.97) than the nominal level. When a crucial variable was not included for adjustment (Case 4 and 5), EL had low coverage probabilities (0.91 to 0.93). AIPTW performs well under Cases 1, 3, and 4 due to its doubly robust property. When either the outcome model or the treatment model is correctly specified, the coverage probabilities of AIPTW are close to the nominal level. Case 2 yields similar results. However, when neither model is correctly specified (Case 5), the coverage probability of AIPTW deviates from the nominal level (around 0.90).
Table 4 presents median length of the confidence interval for DAH. Overall, the median length of DS was shorter than those of the other methods. For example, in Case 1 under Scenario 2 with Censoring Pattern A, the median length of DS was 0.93, while the lengths of the other adjusting methods ranged from 1.24 to 1.72. The Matching and EL methods produced relatively wider confidence intervals compared to the other adjusting methods. For example, in Case 1 under Scenario 2 with Censoring Pattern B, the median lengths of Matching and EL were 1.72 and 1.73, respectively, while the lengths of the other adjusting methods ranged from 0.94 to 1.50.
Similar results were observed for the other parameters, including AH in Group 0 and Group 1 and RAH (see Supplementary Appendix Table B1 to B12).
Covariate-dependent censoring pattern
The assumptions regarding the censoring time distribution differ across the seven methods included in our numerical study (summarized in Supplementary Appendix A). Direct standardization employs a Cox regression model as the outcome model. While this approach requires correct specification of the outcome model for asymptotic unbiasedness, it does not require the independent censoring assumption of Censoring Patterns A and B. Instead, censoring may depend on variables included in the outcome model, provided that event time and censoring time are independent conditional on those variables, as in Censoring Pattern C.
In contrast, Censoring Pattern C does not satisfy the censoring assumptions of several other methods considered. The AIPTW approach we employed in this study incorporates both an outcome model and a treatment model and is doubly robust in the sense that it achieves asymptotic unbiasedness if either the outcome model or the treatment model is correctly specified provided that the censoring mechanism is also correctly modeled. Because censoring is handled via inverse probability of censoring weights (IPCW), consistency of AIPTW further relies on a correct model for the censoring time distribution used to construct these weights, while this requirement can be a little relaxed with alternative AIPTW implementations [41, 42].
In this study, our AIPTW implementation accommodates covariate-dependent censoring by estimating the censoring distribution with a Cox model when appropriate. Specifically, in simulations with independent censoring (Censoring Patterns A and B) we used the pooled Kaplan–Meier (KM) estimator to construct IPCW; in simulations with covariate-dependent censoring (Censoring Pattern C) we used a Cox proportional hazards model for censoring that included the true covariate driving censoring. Thus, the censoring model was correctly specified in all simulation scenarios for AIPTW.
We conducted numerical studies under covariate-dependent censoring (Censoring Pattern C) to assess the impact of censoring assumptions on performance across methods. Results for total sample size \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$n=300$$\end{document} are presented in Supplementary Appendix C (Tables C1–C16). Overall, the simulation results under Censoring Pattern C were very similar to those obtained under Censoring Patterns A and B, and our main findings were robust to this form of covariate-dependent censoring; as expected, coverage for methods relying on independent censoring (IPTW-KM/CH, Matching, EL) declines primarily when their own working model is misspecified, mirroring Patterns A and B, while AIPTW remains near nominal when its censoring model is correctly specified.
Summary
The results of this simulation study suggest two primary insights. First, when there is confidence in the correct specification of the outcome model, DS emerges as the optimal method for confounding adjustment due to its consistently stable performance across our experiments. If the outcome model’s specification is uncertain, then AIPTW is generally recommended. AIPTW is preferred over approaches that only use either a treatment model or an outcome model due to its doubly robust property, which is particularly advantageous given the similar efficiency reflected by the median length of confidence intervals. Second, despite the theoretical expectations of EL due to its robust property, it did not perform well within the framework of our numerical studies. We found that across all assessed performance measures, AIPTW was generally superior to EL under our simulation settings.
Example: the CANVAS trial
To illustrate the methods explored in this study, we utilized data from the pragmatic effectiveness CANVAS trial (NCT02744092; AFT-28) comparing DOACs and LMWH in preventing recurrent VTE among cancer patients with an initial VTE event. This study was conducted across 67 oncology practices in the US, and had a hybrid design with a randomization cohort and a preference cohort. A total of 671 patients consented to randomization and were randomized to receive either DOACs or LMWH. Another 140 patients declined randomization and were placed in the preference cohort where they chose either DOACs or LMWH. Of the 140, three patients did not receive the selected treatment. The primary outcome was recurrent VTE. Major bleeding and death were secondary outcomes. The detailed results with the randomization cohort data have been reported in Schrag et al. [35].
In this paper, we used the overall survival data from the 137 patients who received the selected treatment in the preference cohort. Figure 2 shows the unadjusted survival curves for the DOAC and LMWH groups based on the KM method. The estimated survival probabilities for the DOAC group were uniformly higher than those of the LMWH group throughout the observation period. The unadjusted AH values for the DOAC and LMWH groups, derived from the Kaplan–Meier plug-in method, were 0.031 (95% CI: 0.016–0.046) and 0.059 (95% CI: 0.019–0.099.019.099) per person-month, respectively. This indicates that the average number of events per 100 person-months would be 3.1 and 5.9 in the DOAC and LMWH groups, respectively, over the six-month study period, assuming no censored observations occur prior to six months.Fig. 2. Estimated survival curves for DOAC (solid line) and LMWH (dashed line) using the Kaplan-Meier method
In the unadjusted analysis, while the DOAC group seemed to perform better than the LMWH group, this difference was not statistically significant. Specifically, the estimated difference in AH was −0.028, with a corresponding 95% CI ranging from −0.071 to 0.015, which included zero.
Due to the lack of randomization in the treatment allocation for patients within the preference cohort, the unadjusted analysis was potentially influenced by selection bias. Thus, we performed the adjustment methods outlined in previous sections. For the execution of these adjusted analyses, we derived an outcome model and a treatment model. The details of these models are presented in Table 5 for the outcome model and Table 6 for the treatment model, respectively.Table 5. Outcome model: Cox regressionFactorHazard Ratio0.95 CIp-valueTreatment (DOACs vs LMWH)0.70(0.31, 1.60)0.397Sex (Female vs Male)2.95(1.21, 7.19)0.017Albumin (high vs low)0.23(0.09, 0.56)0.001Metastases (Yes vs No)2.97(0.85, 10.38)0.088Pulmonary Embolism (Yes vs No)0.58(0.26, 1.31)0.190Table 6Treatment model (propensity score model): logistic regressionFactorOdds Ratio0.95 CIp-value(Intercept)6.10(2.48, 14.98)< 0.001Sex (Female vs Male)0.50(0.20, 1.24)0.134Indwelling central venous (Yes vs No)3.32(1.22, 9.03)0.019Metastases (Yes vs No)0.39(0.14, 1.12)0.080Bevacizumab (Yes vs No)0.27(0.08, 0.94)0.039
Table 7 presents both unadjusted and adjusted AH, based on pre-selected sets of adjustment variables, with a truncation time of 6 months. For example, the AH values adjusted by the AIPTW method were 0.032 per person-month for the DOAC group and 0.046 per person-month for the LMWH group. Difference in the adjusted AH was −0.014 per person-month (95% CI: −0.048 to 0.020). All methods for adjusting confounders yielded numerically similar results. These approaches uniformly indicated that, in the preference cohort, after adjustment for confounding factors, DOAC does not offer a significant survival benefit over LMWH. This outcome aligns with the observations from the randomized cohort study.Table 7. Unadjusted and adjusted AH ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\tau = 6$$\end{document} months) with the CANVAS mortality data from the preference cohortMethodDOAC (0.95 CI)LMWH (0.95 CI)Difference (0.95 CI)Ratio (0.95 CI)DS0.034 (0.018 to 0.050)0.046 (0.019 to 0.073)−0.012 (−0.042 to 0.018)0.741 (0.346 to 1.586)IPTW KM0.030 (0.016 to 0.045)0.049 (0.015 to 0.083)−0.019 (−0.056 to 0.019)0.621 (0.241 to 1.602)IPTW CH0.030 (0.016 to 0.045)0.048 (0.015 to 0.081)−0.018 (−0.054 to 0.018)0.632 (0.247 to 1.619)Matching0.031 (0.016 to 0.045)0.057 (0.013 to 0.101)−0.027 (−0.073 to 0.020)0.536 (0.185 to 1.555)EL0.030 (0.013 to 0.048)0.056 (0.019 to 0.092)−0.025 (−0.065 to 0.015)0.549 (0.129 to 2.341)AIPTW0.032 (0.017 to 0.047)0.046 (0.015 to 0.077)−0.014 (−0.048 to 0.020)0.690 (0.278 to 1.716)KM (Unadjusted)0.031 (0.016 to 0.046)0.059 (0.019 to 0.099)−0.028 (−0.071 to 0.015)0.523 (0.208 to 1.316)
Discussion
We confirmed that existing methods for deriving adjusted survival curves reasonably worked with the AH method in CER. If the outcome model is correct, the DS method will give consistent results. If the treatment model is correct, methods based on propensity score will give consistent results. If either outcome or treatment model is correct, AIPTW has decent performance. This conclusion is consistent with those obtained by Denz et al. [36] for other summary measures defined as a function of the survival function, such as RMST or t-year event rate.
Median survival time is also a robust summary metric of event time distribution, and difference and ratio of median could be used for summarizing the magnitude of the treatment effect. Although assessing the median survival time using confounding adjustment approaches was beyond our scope, we expect the confounding adjustment approach through the adjusted survival curves would also work well for median survival time. It would be worth conducting similar numerical studies to confirm the statistical performance of the inference procedures for the median under various settings. However, it is important to note that the median is not always estimable nonparametrically, as demonstrated in the use case example. In contrast, similar to the RMST-based approach, the AH-based approach remains applicable even when the median is inestimable.
In our simulation studies, we employed Cox regression models for the outcome model. However, other models that can provide adjusted survival curves for each group, such as accelerated failure time models or proportional odds models, can also be used. While this paper focused on methods using adjusted survival curves, if the interest lies solely in a specific metric, a regression analysis for that metric can be employed. For instance, if the estimand is an RMST-based metric, a regression analysis specific to RMST [45] can be used, although this does not provide the adjusted survival curve. Similarly, if the estimand is an AH-based metric, the regression analysis for AH recently proposed by Uno et al. [21] can also be a viable option. However, their performance relies on model assumptions, and misspecifications can lead to biased estimates. Further research is needed to systematically assess the strengths and limitations of AH regression compared to the confounding adjustment approaches examined in this paper.
When the study population can be divided into strata defined by confounding factors, stratified analyses of AH, as recently proposed by Qian et al. [22], also provide an analytic option to obtain adjusted DAH and RAH. Because \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$AH(\tau )$$\end{document} is defined as the ratio of the cumulative incidence by \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\tau$$\end{document} to the RMST truncated at \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\tau$$\end{document} (Equation (1)), a simple weighted average of stratum-specific AHs does not generally equal the marginal \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$AH(\tau ).$$\end{document} Likewise, the AH-based association measures DAH and RAH are generally not collapsible; that is, the marginal (crude) association does not, in general, equal a weighted average of the stratum-specific associations [46]. Qian et al. [22] developed a standardized construction of AH and studied its nonparametric inference. Specifically, let Z denote the treatment indicator, X the stratum index with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\pi _x=\Pr (X=x)$$\end{document} , and define \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$F_{jx}(\tau )={E}[I(T \le \tau )\mid Z=j, X=x]$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$R_{jx}(\tau )={E}[\min (T,\tau )\mid Z=j, X=x]$$\end{document} for \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$j=0,1.$$\end{document} The standardized AH for group j is then given by \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textrm{AH}_j^{*}(\tau )=\{ \sum \nolimits _x \pi _x F_{jx}(\tau ) \} / \{ \sum \nolimits _x \pi _x R_{jx}(\tau ) \},$$\end{document} which coincides with the marginal \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textrm{AH}_j(\tau ).$$\end{document} The adjusted DAH and RAH are subsequently defined as \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textrm{AH}_1^{*}(\tau )-\textrm{AH}_0^{*}(\tau )$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\textrm{AH}_1^{*}(\tau )/\textrm{AH}_0^{*}(\tau ),$$\end{document} respectively.
In this numerical study, we exclusively used bootstrapping to derive standard errors for constructing confidence intervals across all methods, even though an analytic variance formula was available for some. We did so to ensure a consistent resampling-based approach when comparing the performance of the adjustment methods. Derivation of analytic variance associated with AH for each confounding adjustment method is a promising direction for future research. Such an analytic framework could significantly reduce computational time, facilitating the execution of experiments across a broader range of scenarios.
For the matching procedure, bidirectional matching was used so that the estimand corresponds to the treatment effect in the overall study population. Standard errors were then obtained using the bootstrap procedure described in Population parameters of interest and statistical inference section, which accounts for both the sampling variability in the estimated propensity scores and the dependence induced by the matched sample. If the matched data were instead treated as independent replicates and analyzed using the standard Kaplan–Meier estimator with Greenwood’s variance formula, the resulting standard errors would be biased.
The choice of truncation time \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\tau$$\end{document} is central to defining the average hazard, as it specifies the time horizon over which survival is summarized. Similar to analyses based on RMST or cumulative incidence probability, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\tau$$\end{document} should be selected to align with the clinical context and scientific objectives of the study, and ideally prespecified in the study protocol, especially for confirmatory analyses. When there is a prespecified follow-up duration that reflects the primary clinical question (e.g., 3-year disease-free survival or 5-year overall survival), setting \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\tau$$\end{document} to that time point yields an average hazard directly interpretable within that clinically meaningful window. For example, in the CANVAS trial, outcomes over a 6-month window were of primary interest, and thus \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\tau =6$$\end{document} months was chosen. From an analytical perspective, it is also important that sufficient numbers of patients remain at risk at \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\tau$$\end{document} to ensure stable estimation. For ad hoc analyses, the choice of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\tau$$\end{document} should respect this constraint, whereas for prospective studies, the design should ensure that adequate follow-up is achieved at the prespecified \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\tau .$$\end{document}
The ratio of AH is closely related to Cox’s hazard ratio, and in some special cases they coincide in estimand but differ in inference procedures. We conducted a simulation study to examine the impact of censoring rates on inference for the RAH in comparison to Cox’s HR (Supplementary Appendix D). As expected, both approaches showed negligible bias across censoring levels. When the expected size of the risk set at \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$$\tau$$\end{document} became small due to a combination of sample size and censoring rate, the AH-based approach showed somewhat reduced performance relative to Cox’s HR. This result highlights an important design consideration: ensuring an adequate risk set at the chosen truncation time is essential for stable RAH inference. Full details are provided in Supplementary Appendix D.
Conclusions
Our study has successfully demonstrated the feasibility of applying commonly used confounding adjustment methods for survival function to AH, with all methods delivering satisfactory performance as expected. Importantly, our findings underscore the robustness of the AIPTW method, attributed to its doubly-robust property, making it a recommended approach for future research. We also identified limitations within the EL method. Despite its theoretical benefits, EL was characterized by wider confidence intervals and relatively unstable point estimates, suggesting the need for further research before its practical application can be endorsed for AH.
In summary, this study demonstrated that AH-based analysis represents a valuable addition to the survival analysis toolkit for CER. To facilitate its application, we have developed an R package that implements confounding-adjusted analyses using AH, available on GitHub (https://github.com/kkevin821/survAHadjust).
Supplementary Information
Additional file 1: Supplementary Appendix for “Comparative Effectiveness Research with Average Hazard for Censored Time-to-Event Outcomes: Simulation Study and Application to Observational Data”.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Annals of Internal Medicine. Information for Authors: General Statistical Guidance (Section 4: Measures of Effect and Risk). n.d. https://www.acpjournals.org/journal/aim/authors/statistical-guidance. Accessed 25 Jun 2025.