Reducing manual workload in CT and MRI annotation with the Segment Anything Model 2
Leo Misera, Sven Nebelung, Zunamys I. Carrero, Keno Bressem, Marta Ligero, Jens-Peter Kühn, Ralf-Thorsten Hoffmann, Daniel Truhn, Jakob Nikolas Kather

TL;DR
This paper shows that the Segment Anything Model 2 can reduce the manual effort needed to annotate CT and MRI scans while maintaining high-quality segmentation results.
Contribution
The study introduces a workflow using SAM 2 to reduce annotation workload in medical imaging with minimal loss in segmentation accuracy.
Findings
30% of SAM 2-generated masks for femoral bone segmentation in MRI were accepted without modification.
53% of SAM 2-generated masks for liver tumor segmentation in CT were accepted without modification.
Segmentation models trained on SAM 2-assisted masks achieved nearly identical performance to those trained on ground truth masks.
Abstract
Volumetric segmentation in CT and MRI is valuable for artificial intelligence workflows in radiology, yet creating the large, precisely annotated datasets required for training segmentation models remains laborious. Here, we tested in simulation whether the foundation model “Segment Anything Model 2” (SAM 2) can reduce expert annotation workload. In our workflow, annotators provide a single box at the object’s center, and SAM 2 automatically segments the object across slices; annotators then review and correct the masks as needed. Workload reduction was defined as the proportion of SAM 2’s predicted segmentation masks that were accepted without modification. Downstream segmentation models were then trained on the SAM 2-assisted masks and compared with reference models trained on ground truth masks. For femoral bone segmentation in MRI and liver tumor segmentation in CT, 36,614…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
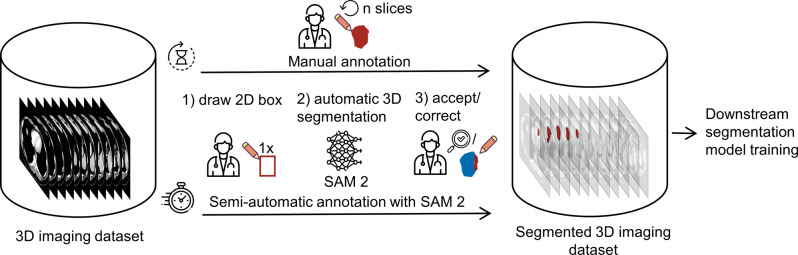 Figure 1
Figure 1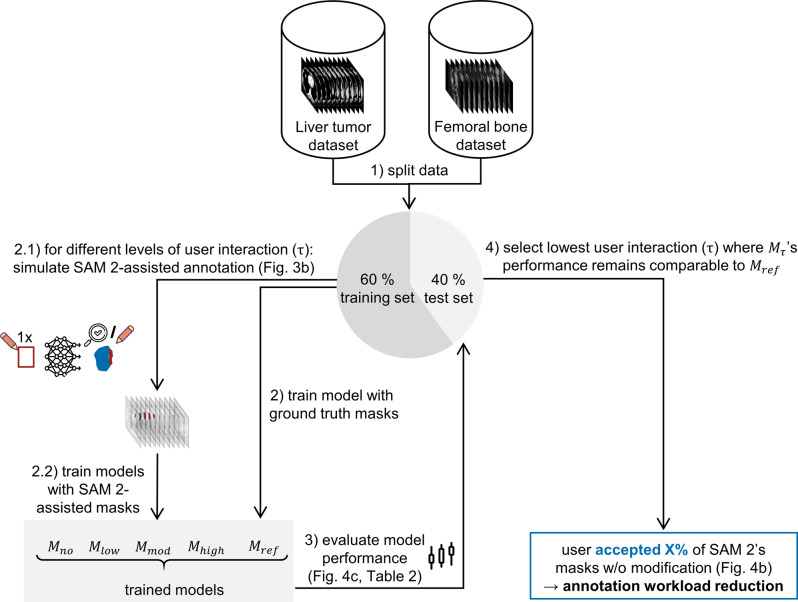 Figure 2
Figure 2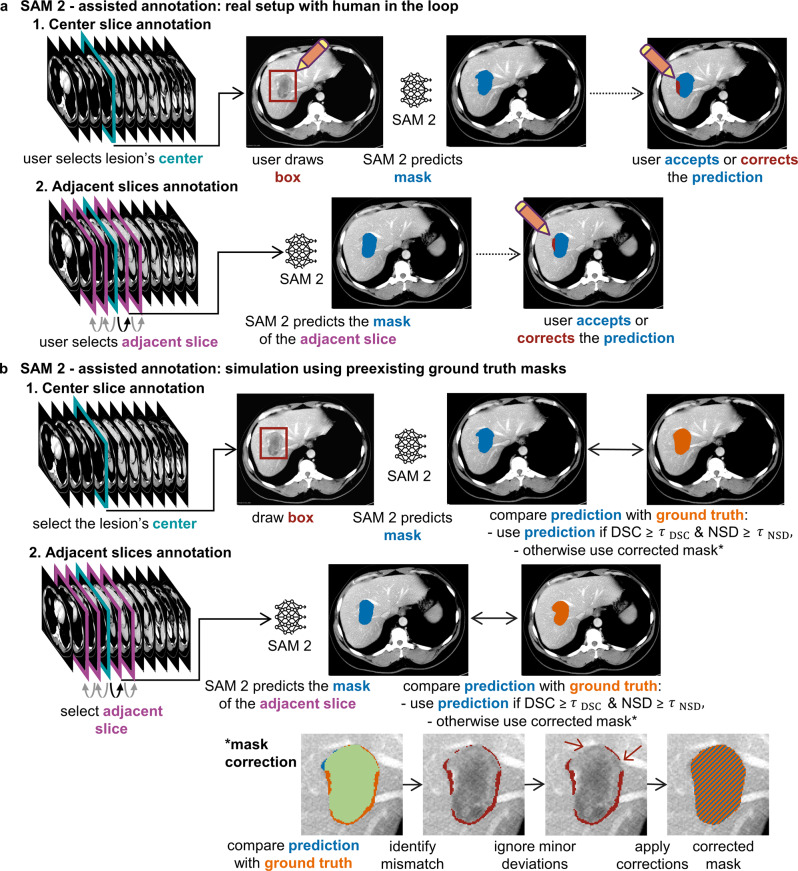 Figure 3
Figure 3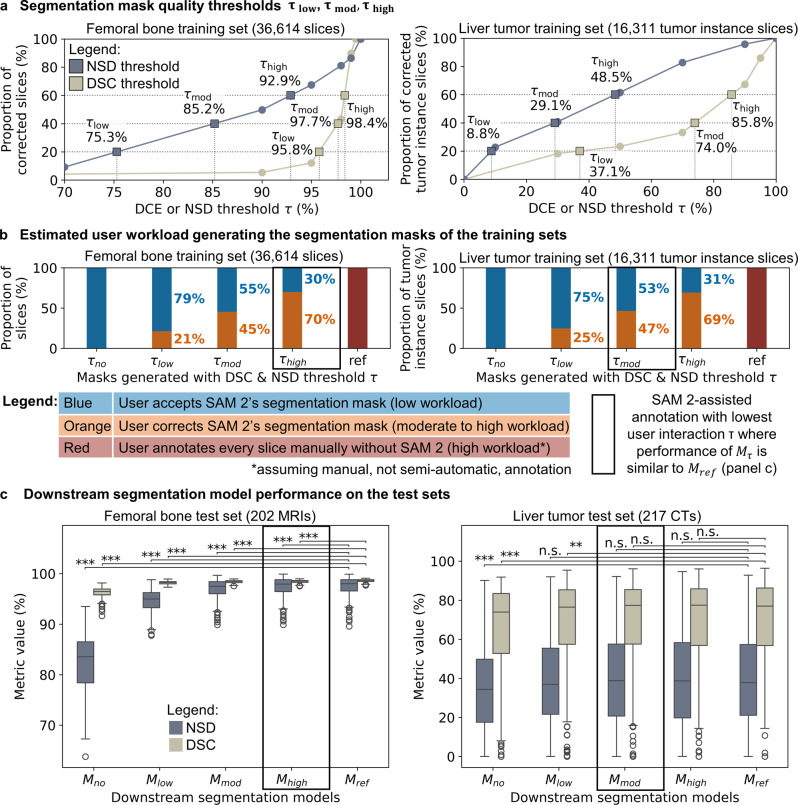 Figure 4
Figure 4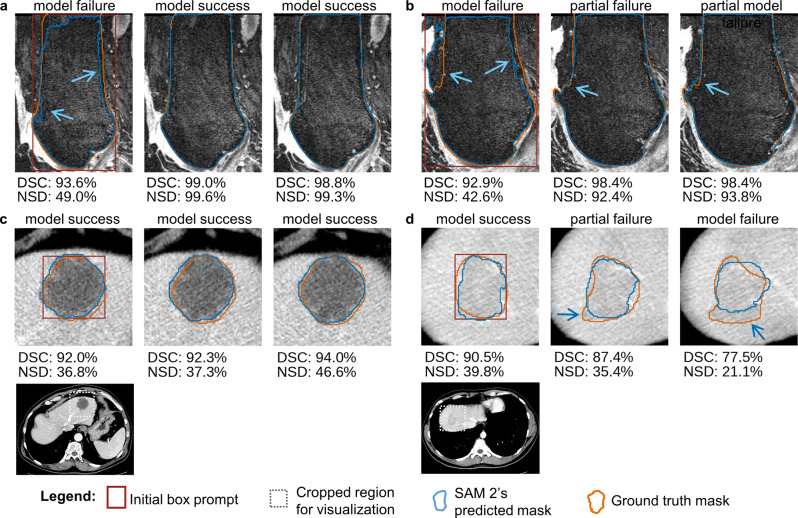 Figure 5
Figure 5- —Technische Universität Dresden (1019)
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsArtificial Intelligence in Healthcare and Education · Radiomics and Machine Learning in Medical Imaging · Medical Imaging and Analysis
Introduction
Volumetric segmentation of anatomical structures or lesions from 3D imaging data, such as computed tomography (CT) and magnetic resonance imaging (MRI), is widely used in clinical practice and research, including volumetric assessment [1, 2], texture analysis [3, 4], and radiation planning [5, 6]. However, creating these segmentation masks relies on expert annotators, such as radiologists or radiation oncologists, who must manually delineate each object, a process that is both time-consuming and resource-intensive [7]. For instance, delineating organs at risk around a tumor for radiation planning can take several hours per patient [8, 9], potentially leading to treatment delays and worse clinical outcomes [10]. Deep learning-based automatic segmentation offers a promising solution to support physicians and researchers in these tasks [11]. However, training such models requires large datasets [12], with precise object delineations, which are often created through manual annotation. Thus, reducing annotation workload is crucial.
One approach to reducing annotation effort is using promptable foundation models, such as Segment Anything Model (SAM 1) [13], which accepts sparse inputs [14, 15], such as dots or bounding boxes. These sparse annotations prompt the model to generate precise segmentation masks. Its successor, Segment Anything Model 2 (SAM 2) [16], extends this capability by propagating generated segmentation masks across frames in a video or slices in a cross-sectional image volume, thus potentially reducing manual workload in annotating 3D medical imaging data (Fig. 1).Fig. 1. Annotation workflows, illustrated for liver tumor segmentation in CT. In the manual workflow, the user annotates each tumor slice-by-slice (upper arrow), which is inherently laborious. The SAM-2 assisted annotation workflow (lower arrow) requires only little user input during annotation. The segmentation outlines enable training downstream segmentation models, for example for research or clinical use. CT adapted from [17, 18]
Recent technical studies [19, 20] have shown that prompting SAM 2 with a single bounding box at the object’s center is an efficient method for generating segmentation masks across slices for various anatomical structures and lesion types in 3D CT and MRI. In a real-world SAM 2-assisted annotation workflow, an annotator would first select the center slice of an object (e.g., a lesion) and draw a single bounding box, from which SAM 2 automatically generates segmentation masks across slices in the 3D volume. Instead of manually segmenting each slice, the annotator would then only need to review and correct segmentation masks where SAM 2’s predictions were inaccurate (Fig. 1). However, it remains unclear to what extent the manual workload associated with annotating large training datasets for downstream segmentation model training can be reduced by using the SAM 2-assisted annotation workflow.
To address this, we investigated what proportion of SAM 2’s predicted segmentation masks can be accepted without modification while maintaining the performance of downstream segmentation models trained on these masks. To this end, we performed a SAM 2-assisted annotation workflow with varying levels of user interaction and trained segmentation models using the resulting masks. This evaluation was conducted across two representative use cases: femoral bone segmentation in MRI and liver tumor segmentation in CT. By analyzing the relationship between the proportion of accepted masks and downstream model performance, we evaluated SAM 2’s potential to reduce manual annotation workload. This study, in turn, serves as a proof of concept for integrating SAM 2 into 3D medical imaging annotation workflows. Our findings indicate that SAM 2 can substantially reduce manual workload in CT and MRI dataset annotation for segmentation model training, with promising implications for both clinical and research applications.
Materials and methods
We evaluated whether SAM 2 can reduce annotation workload while maintaining downstream segmentation model performance. The study comprised four main steps: data preprocessing, simulating SAM 2-assisted annotation under varying degrees of user interaction, training downstream segmentation models on the SAM 2-assisted segmentation masks, and evaluating workload reduction and model performance compared to models trained on ground truth segmentation masks (Fig. 2).Fig. 2. Study design measuring manual annotation workload reduction via the proportion of SAM 2-generated masks accepted as is without compromising downstream segmentation model performance. CT and MRI adapted from [17, 18, 21–24]
Datasets
For femoral bone segmentation, the OAI-ZIB dataset [21–24] was used. This dataset comprised MRI scans from 507 patients with ground truth segmentation masks. Note that only 505 patients were included while two MRI scans, (IDs 9539084 and 9445105), were excluded due to missing or implausible ground truth segmentation masks. To remove small, disconnected regions erroneously marked as femoral bone beyond the actual bone in a small number of ground-truth masks, only the largest connected volume corresponding to the femoral bone was retained; smaller connected regions were reclassified as background.
For liver tumor segmentation, we combined the liver tumor segmentation dataset [25] (LiTS), the colorectal liver metastases dataset [17] (CLM) and the WAW-TACE dataset [26] (WAW) to increase the sample size. From LiTS, we excluded any CT scans without a segmented tumor, reducing the original 131 scans to 118. From CLM, which initially had 197 CT scans, we excluded two scans (IDs 1187 and 1034) because of misaligned segmentation masks. The WAW dataset contained 233 CT scans acquired in multiple phases per patient, but segmentation was available for only one phase. We included only the phase with a corresponding segmentation mask, while native (non-contrast-enhanced) scans were excluded (IDs 13, 458, 501).
Simulation of SAM 2-assisted annotation
Prior to using SAM 2, we preprocessed the scans. For the CT scans, we extracted axial slices, clipped intensities to −55 and 155 Hounsfield Units, following [27], and scaled the resulting intensities between 0 and 255. For the MRI scans, we extracted the sagittal slices, clipped intensities at the 1st and 99th percentiles to remove extreme values, and scaled the resulting intensities to values between 0 and 255.
Before simulating the annotation workflow, we first compared two prompt modes, a center dot and a bounding box, to determine which provided more accurate segmentations as the basis for subsequent experiments. The center dot or bounding box was placed on the object’s center slice, which was identified by computing the center of mass of the object’s 3D ground truth segmentation mask. To mimic realistic user imprecision, the dot and box prompts were slightly varied. For the dot prompt, the centroid of the 2D ground truth segmentation mask was computed and then shifted by up to ± 2 mm, but not more than 10% of the object’s maximum width or height, ensuring the dot remained within the object. For the box prompt, a bounding box was derived from the 2D ground truth segmentation mask and then slightly varied in size and position. The box width and height were independently scaled by up to ± 2 mm, but by no more than 5% of their width or height, and additionally shifted by up to ± 1 mm, but not more than 5% of their width or height. SAM 2 then generated a segmentation mask for the object’s center slice based on either prompt. Segmentation mask quality was measured using the dice similarity coefficient (DSC), and statistical differences between the two prompt types were tested with two-tailed Wilcoxon signed-rank tests. In practice, this setup reflects how a user might roughly mark an object’s center with a dot or draw a bounding box, with small placement errors.
For subsequent experiments, only the box prompt was used. The real annotation workflow was simulated as follows (Fig. 3a, b). First, the center slice of each target object (e.g., the femoral bone in an MRI or an individual liver tumor in a CT) was selected. SAM 2 was then prompted with a bounding box, based on which SAM 2 then segmented the object slice-by-slice from the object’s center to its boundaries. In practice, a human annotator would review each of SAM 2’s predicted 2D segmentation masks and decide whether to accept or correct them. In our simulation, this decision was approximated using two quantitative criteria: the DSC to measure overlap and the normalized surface dice with 1 mm tolerance (NSD) to measure boundary agreement against the respective 2D ground truth mask. SAM 2’s predicted segmentation mask was accepted only if both the DSC and NSD exceeded their respective threshold; otherwise, it was corrected. To avoid the unrealistic assumption of perfect corrections, a human-like strategy was implemented: areas where the predicted and ground truth segmentation masks differed were identified with an element-wise XOR operation and grouped into connected regions. A region was corrected only if at least one voxel lay more than 1 mm away from the ground truth boundary, thereby mimicking a user who corrects major errors while tolerating minor inaccuracies (Fig. 3b, bottom). The resulting corrected segmentation mask was used both as the final segmentation mask for training the respective downstream model and to re-prompt SAM 2 for correction. For volumes containing multiple objects, such as several liver tumors, the workflow was applied separately to each object. Notably, SAM 2’s state was reset before each new bounding box prompt or correction prompt.Fig. 3(a) real world SAM 2-assisted annotation workflow illustrated for liver tumor segmentation. (b) simulated workflow using ground truth masks, with dice similarity coefficient (DSC) and normalized surface dice at 1 mm tolerance (NSD) measuring segmentation mask quality and threshold τ controlling user interaction and workload. CT adapted from [17, 18]
To explore different degrees of user involvement, four simulation scenarios were defined. In all scenarios, the user provided a bounding box in the object’s center and indicated the object’s longitudinal extent. The first scenario considered no further manual segmentation mask edits, i.e. the user accepted all of SAM 2’s predicted segmentation masks within the object’s longitudinal extent. In the other three scenarios, the annotator corrected SAM 2’s predicted segmentation masks if necessary, reflecting low, moderate, and high degrees of user interaction.
To define thresholds for the four simulation scenarios, we measured how often corrections were required under different acceptance thresholds of DSC or NSD. For the femoral bone dataset, DSC thresholds ranging from 0.90 to 0.995 were evaluated while NSD was fixed at zero, and NSD thresholds ranging from 0.70 to 0.99 were evaluated while DSC was fixed at zero. For the liver tumor dataset, DSC thresholds ranged from 0.30 to 0.95, and NSD thresholds from 0.10 to 0.90, each again evaluated with the other threshold fixed at zero. For each threshold setting, the proportion of instance slices that required correction was recorded. Scenario-specific thresholds \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\tau _{no}}$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\tau _{low}}$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\tau _{mod}}$$\end{document} , and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\tau _{high}}$$\end{document} were then derived by linear interpolation so that approximately 0%, 20%, 40%, and 60% of instance slices required correction, corresponding to no edits, low, moderate, and high degree of user interaction. Suitable threshold values were obtained for DSC and NSD separately, but both were applied jointly in the downstream simulations to determine segmentation mask quality.
All simulations were performed on a local computer with a NVIDIA RTX 6000 GPU using python 3.11.12. We used SAM 2 version 1.0 with the sam2_hiera_tiny model throughout the simulation of SAM 2-assisted annotation.
Downstream segmentation model training and performance evaluation
The nn-UNet framework [28] (version 2.2.1) was used for downstream segmentation model training due to its proven effectiveness on numerous medical segmentation tasks [11]. We split each dataset into a training set (60%) and a test set (40%). Each downstream model employed the 3D_fullres architecture and was trained for 150 epochs using five-fold cross-validation with a batch size of 8.
For liver tumor segmentation, we first cropped each CT volume to a rectangular cuboid enclosing the liver based on liver masks automatically obtained via TotalSegmentator [29] (version 2.4.0) to remove irrelevant areas of each CT scan before training the nn-UNet, and clipped intensities to −55 to 155 Hounsfield units [27]. For femoral bone segmentation, we applied z‑score normalization to the MRI scans and did not crop the volumes.
We evaluated model performance on the test sets using the preexisting ground truth segmentation masks. For each dataset, a reference model ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${M_{ref}}$$\end{document} ) was trained using the ground truth segmentation masks from the training set. Additional models ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${M_{no}}$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${M_{low}}$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${M_{mod}}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${M_{high}}$$\end{document} ) were trained using segmentation masks derived from the SAM 2-assisted annotation simulation at different thresholds τ. Model performance was quantified by the DSC and NSD with a 1 mm tolerance [11, 30]. Here, both metrics were computed based on the 3D segmentation masks. To determine significant performance differences between segmentation models trained with SAM 2‑generated segmentation masks \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${M_\tau } $$\end{document} and the ground truth model \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${M_{ref}}$$\end{document} , we conducted two-tailed Wilcoxon signed‑rank tests with Holm correction applied separately for each dataset.
Results
Datasets
To evaluate the extent to which SAM 2 reduces manual annotation workload while maintaining performance of downstream segmentation models, we conducted experiments on two datasets: the femoral bone dataset (OAI-ZIB [21–24]) and the liver tumor dataset (LiTS [25]; CLM [17, 18], WAW [26]) (Table 1). The femoral bone dataset comprised 505 3D MRI scans, one per patient, with preexisting annotations delineating the femoral bone. Of these, 303 scans (60%) were selected as the training set to simulate the annotation workflow and train downstream segmentation models, containing 36,614 sagittal slices with femoral bone. The remaining 202 scans (40%) were used to test downstream segmentation model performance. The liver tumor dataset contained 543 3D CT scans, one per patient. Of these, 326 scans (60%), including 997 tumors, were designated for training. This subset contained 12,085 axial slices that showed at least one tumor. Because multiple tumors can appear on the same slice, the total number of individual tumor instance slices requiring annotation was 16,311. The remaining 217 scans (40%), comprising 795 tumors, were selected to test downstream model performance.Table 1. Main dataset characteristics. The statistics refer to the data used in the experiments without the excluded samplesDatasetOsteoarthritis Initiative (OAI-ZIB) [21–24]Liver Tumor Segmentation train set (LiTS) [25]Colorectal-Liver-Metastases (CLM) [17, 18]WAW-TACE (WAW) [26]Number of patients505118195230Imaging modalityMRI (DESS sequence)Contrast-enhanced CTContrast-enhanced CTContrast-enhanced CTSegmentation masksFemoral boneLiver tumorLiver tumorLiver tumorImage resolution in-plane (px)384 ×384512 ×512512 ×512512 ×512 or 768 × 768OrientationSagittalAxialAxialAxialSlice thickness: mean [min, max] (mm)0.7 [0.7, 0.7]1.57 [0.7, 5]2.18 [0.8, 7.5]1.76 [0.63, 5]Notably, the LiTS, CLM and WAW dataset were combined, comprising the liver tumor dataset
Simulation of SAM 2-assisted annotation
In a preliminary comparison of prompt modes applied to the center slice of each object, bounding boxes substantially outperformed central dots. For these center slices, the median and interquartile range (IQR) of the DSC was 94.5% (IQR: 93.2% − 95.5%) compared with 42.3% (IQR: 24.6% − 70.9%) for the center slices of the femoral bone dataset (n = 303), and 85.7% (IQR: 79.2% − 90.2%) compared with 3.9% (IQR: 0.7% − 70.4%) for the center slices of the liver tumor dataset (n = 997), with both differences significant (both p < 0.001). All subsequent experiments therefore used bounding boxes for prompting the center slice of each object.
For each dataset, thresholds for the four scenarios (no edits, low, moderate, and high degree of user interaction) were calibrated by simulating the annotation workflow across a range of DSC and NSD thresholds, separately, measuring the proportion of corrected masks. In the femoral bone dataset, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\tau _{low}}$$\end{document} was defined as 95.8% for DSC and 75.3% for NSD, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\tau _{mod}}$$\end{document} as 97.7% and 85.2%, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\tau _{high}}$$\end{document} as 98.4% and 92.9%, respectively (Fig. 4a, left). In the liver tumor dataset, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\tau _{low}}$$\end{document} was defined as 37.1% for DSC and 8.8% for NSD, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\tau _{mod}}$$\end{document} as 74.0% and 29.1%, and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\tau _{high}}$$\end{document} as 85.8% and 48.5%, respectively (Fig. 4a, right). For the no edits scenario, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\tau _{no}}$$\end{document} , both DSC and NSD thresholds were set to zero for each dataset. In the downstream simulations, the respective DSC and NSD thresholds were applied jointly, such that a segmentation mask predicted by SAM 2 was accepted only if it exceeded both thresholds when compared to the ground truth.Fig. 4(a) segmentation mask quality dice similarity coefficient (DSC) and normalized surface dice at tolerance 1 mm (NSD) thresholds \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\tau _{low}}$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\tau _{mod}}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\tau _{high}}$$\end{document} , obtained through interpolation, corresponding to low, moderate, high degree of user interaction. (b) estimated manual user workload for annotating all slices in the training set. (c) test set performance of the downstream segmentation models trained with SAM 2-assisted segmentation masks ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${M_{no}}$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${M_{low}}$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${M_{mod}}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${M_{high}}$$\end{document} ) and ground truth segmentation masks ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${M_{ref}}$$\end{document} ). The box plots’ whiskers extend to 1.5× of the interquartile range. P-values, adjusted using Holm method for each dataset, compare model performance using Wilcoxon signed-rank test: p ≥ 0.5 (n.S.), p < 0.05 (), p < 0.01 (), p < 0.001 ()
The annotation simulation was then performed for the four scenarios defined by the above calculated thresholds \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\tau _{no}}$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\tau _{low}}$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\tau _{mod}}$$\end{document} , and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\tau _{high}}$$\end{document} , corresponding to no edits, low, moderate, and high degree of user interaction, respectively (Fig. 2).
For femoral bone segmentation, to create the training dataset comprising 303 MRI scans, 36,614 sagittal MRI slices required annotation. The user accepted 100%, 79%, 55%, and 30% of SAM 2’s masks without modification at \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\tau _{no}}$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\tau _{low}}$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\tau _{mod}}$$\end{document} , and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\tau _{high}}$$\end{document} , respectively, while corrections were required for the remaining 0%, 21%, 45%, and 70% (Fig. 4b, left).
For liver tumor segmentation, to create the training dataset comprising 326 CT scans, 16,311 tumor instance slices required annotation. The user accepted 100%, 75%, 53%, and 31% of SAM 2’s masks without modification at \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\tau _{no}}$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\tau _{low}}$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\tau _{mod}}$$\end{document} , and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\tau _{high}}$$\end{document} , respectively, while corrections were required for the remaining 0%, 25%, 47%, and 69% (Fig. 4b, right).
Downstream model training & assessment of workload reduction
Next, we determined the extent to which manual annotation workload (i.e., user interaction) can be reduced while maintaining downstream segmentation model performance. To this end, using segmentation masks generated at each degree of user interaction ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\tau _{no}}$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\tau _{low}}$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\tau _{mod}}$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\tau _{high}}$$\end{document} ), we trained downstream segmentation models ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${M_{no}}$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${M_{low}}$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${M_{mod}}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${M_{high}}$$\end{document} ) and compared their performance to that of the model trained on preexisting ground truth segmentation masks ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${M_{ref}}$$\end{document} ). Manual annotation workload reduction was quantified by identifying the lowest τ value at which the performance remained comparable to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${M_{ref}}$$\end{document} on the test set (Fig. 2).
For femoral bone segmentation, only the downstream model trained with SAM 2-assisted segmentation masks at high annotator interaction ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${M_{high}}$$\end{document} ) achieved performance comparable to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${M_{ref}} $$\end{document} on the test set. \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${M_{high}}$$\end{document} achieved a median DSC of 98.5% and median NSD of 97.9%, closely matching \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${M_{ref}}$$\end{document} ’s DSC of 98.7% and NSD of 98.0% (Fig. 4c, left; Table 2, left).Table 2. Downstream segmentation model performance on each test set, reported as the median and interquartile range (IQR) for dice similarity coefficient (DSC) and normalized surface dice at tolerance 1 mm (NSD)Femoral bone dataset (n = 202)Liver tumor dataset (n = 217)Model \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${M_{no}}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${M_{low}}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${M_{mod}}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${M_{high}}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${M_{ref}}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${M_{no}}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${M_{low}}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${M_{mod}}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${M_{high}}$$\end{document} \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${M_{ref}}$$\end{document} DSC96.5% IQR: 95.8% − 97.0%98.3% IQR: 98.0% − 98.4%98.5% IQR: 98.2% − 98.6%98.5% IQR: 98.3% − 98.6%98.7% IQR: 98.4% − 98.8%73.9% IQR: 52.8% − 83.5%76.5% IQR: 57.5% − 85.3%77.3% IQR: 57.6% − 85.5%77.5% IQR: 56.9% − 85.9%77.0% IQR: 56.8% − 86.3%p < 0.001 < 0.001 < 0.001 < 0.001n/a < 0.001 < 0.0010.170.62n/aadj. p < 0.001 < 0.001 < 0.001 < 0.001n/a < 0.0010.0010.691n/aNSD83.5% IQR: 78.4% − 86.5%95.0% IQR: 93.3% − 96.3%97.5% IQR: 96.0% − 98.4%97.9% IQR: 96.5% − 98.8%98.0% IQR: 96.6% − 98.8%34.4% IQR: 17.5% − 49.8%36.9% IQR: 21.6% − 55.4%38.9% IQR: 20.7% − 57.6%38.7% IQR: 19.8% − 58.3%37.8% IQR: 21.1% − 57.3%p < 0.001 < 0.001 < 0.001 < 0.001n/a < 0.0010.040.970.43n/aadj. p < 0.001 < 0.001 < 0.001 < 0.001n/a < 0.0010.211n/aP-values were derived from pairwise comparison of DSC and NSD of model \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${M_{no}}$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${M_{low}}$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${M_{mod}}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${M_{high}}$$\end{document} with \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${M_{ref}}$$\end{document} using Wilcoxon signed-rank test. Adjusted p-values were calculated through Holm correction for each dataset, separately
For liver tumor segmentation, the downstream models trained with SAM 2-assisted segmentation masks \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${M_{mod}}$$\end{document} and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${M_{high}}$$\end{document} performed comparably to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${M_{ref}} $$\end{document} on the test set. Of note, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${M_{mod}} $$\end{document} , which required the least user interaction, achieved a median DSC of 77.3% and a median NSD of 38.9%, closely matching \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${M_{ref}}$$\end{document} ’s 77.0% DSC and 37.8% NSD (Fig. 4c, right; Table 2, right).
Analysis of SAM 2’s segmentation mask quality
To further examine the quality of SAM 2-generated segmentations and identify cases requiring manual corrections, we visualized representative examples from τ settings that achieved the largest workload reduction maintaining downstream model performance, specifically \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\tau _{high}}$$\end{document} for femoral bone segmentation and \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\tau _{mod}}$$\end{document} for liver tumor segmentation (Fig. 5).Fig. 5. Visualization of adjacent slices and their segmentations, with segmentation mask quality measured by dice similarity coefficient (DSC) and normalized surface dice at tolerance 1 mm (NSD). The left image within each panel shows the center slice that was prompted with a bounding box. The middle and right image of each panel show the two subsequent slices and the respective predicted and ground truth mask. CTs and MRIs adapted from [17, 18, 21–24]
In cases where the foreground and background had a distinct boundary, SAM 2 consistently produced highly accurate segmentation masks requiring minimal or no correction at all (Fig. 5a, center and right; Fig. 5c). However, in low-contrast regions, predicted segmentation masks were often partially inaccurate, leading to increased manual correction efforts (Fig. 5a, left; Fig. 5b; Fig. 5d, center, right). These findings align with previous studies [19, 20, 31], which reported similar challenges in images with poor contrast. Nevertheless, even when the SAM 2-generated segmentation masks were partially inaccurate, a substantial portion of these segmentation masks were sufficiently accurate, likely reducing the effort needed for manual corrections compared to fully manual segmentation.
In summary, the annotator accepted 30% of SAM 2’s predicted segmentation masks without modification for femoral bone segmentation and 53% for liver tumor segmentation while preserving downstream segmentation model performance (Fig. 4b and c). These findings suggest that SAM 2-assisted annotation can substantially reduce manual annotation workload for both MRI and CT.
Discussion
In this study, we investigated the potential of SAM 2, a general-purpose promptable segmentation model, to reduce manual annotation workload in 3D medical imaging data for two representative tasks, while maintaining the performance of downstream segmentation models. Our experiments on femoral bone segmentation in MRI and liver tumor segmentation in CT demonstrated that SAM 2 indeed substantially reduced manual annotation workload while maintaining downstream segmentation model performance. Notably, only inaccurate regions of the predicted segmentation masks required manual correction, suggesting that substantial reductions in manual workload are feasible.
One possible explanation for the comparable performance of downstream segmentation models trained with SAM 2-assisted segmentation masks is that differences between SAM 2-generated segmentation masks and ground truth segmentation masks may often fall within the range of typical inter-rater variability (Fig. 5a, center, right; Fig. 5c; Fig. 5d, left). Consistent with this, on the liver tumor dataset, \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${M_{mod}}$$\end{document} , trained with SAM 2-assisted labels accepted above \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\tau _{mod}}$$\end{document} (DSC threshold 74.0%, NSD threshold 29.1%), achieved performance comparable to \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${M_{ref}}$$\end{document} . Prior work has reported a median inter-rater DSC of about 0.70 for liver tumor segmentation [25], closely matching threshold \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\tau _{mod}}$$\end{document} . In contrast, when labels with lower quality were included ( \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\tau _{no}}$$\end{document} , \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${\tau _{low}}$$\end{document} ), model performance declined. For the femoral bone dataset, no inter-rater variability has been reported. However, previous MRI studies on bone segmentation have reported a mean inter-rater DSC of 97.0% for manual femoral bone segmentation [32] and 98.8% for semi-automatic patella bone segmentation [33]. Consistent with this lower inter-rater variability, only \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${M_{high}}$$\end{document} , trained with SAM 2-assisted labels of near ground truth quality (DSC threshold 98.4%, NSD threshold 92.9%), closely matched the performance of \documentclass[12pt]{minimal} \usepackage{amsmath} \usepackage{wasysym} \usepackage{amsfonts} \usepackage{amssymb} \usepackage{amsbsy} \usepackage{mathrsfs} \usepackage{upgreek} \setlength{\oddsidemargin}{-69pt} \begin{document}$${M_{ref}}$$\end{document} . Together, these findings suggest that SAM 2-assisted segmentation masks are suitable for downstream model training, provided that their quality remains within typical inter-rater variability.
Although the annotation process in our experiments was simulated, realistic user behavior was approximated. Bounding box prompts were deliberately varied in position and size to mimic user imprecision. In addition, when SAM 2’s predicted segmentation masks required correction, only major inaccuracies were edited while minor errors in SAM 2’s segmentation masks were left untouched, mimicking how users refine masks rather than redrawing them entirely (Fig. 3b, bottom). Although simulated, the workflow captures key aspects of practical annotation.
Overall, these findings indicate that SAM 2 could reduce manual annotation workload for other types of objects in 3D medical imaging data as well. As a result, more 3D images could be annotated in the same timeframe, thereby reducing the costs associated with training downstream segmentation models for research and medical device development. For example, accurate segmentations from these models could be applied to volumetric assessment [1, 2], texture analysis [3, 4], or radiation planning [5, 6]. SAM 2 also has a readily available plug-in for the widely used annotation tool 3D Slicer [34, 35], which facilitates easy integration into existing workflows.
This study has several limitations. First, we specifically focused on the default version of SAM 2 and did not include other available promptable segmentation models (e.g. [36–41]). This approach was chosen to maintain a consistent experimental design, as some alternatives to SAM 2 require other prompt modes or annotation workflows for optimum performance. Furthermore, foundation models trained on large datasets like SAM 2 can be applied zero-shot to other domains such as medical images [15, 19, 42, 43]. Importantly, to our knowledge, at the time of writing this manuscript, SAM 2 is openly available for both research and commercial use [44]. This stands in contrast to other models (e.g. [36–41]), which to our knowledge may remain restricted to research use only due to licenses of the training data. This made SAM 2 especially suitable for both academic and translational applications. Second, the annotation process in our experiments was simulated rather than performed by human annotators. While our design approximated realistic behavior, real annotators may place prompts differently, choose off-center slices for prompting, or rely on subjective rather than quantitative criteria for segmentation mask correction. Future user studies may therefore validate our findings under practical conditions, including quantifying the time savings using SAM 2 for both experienced and novice annotators and identifying cases where it is most effective. For instance, while large, well-defined structures may benefit from using SAM 2, very small or subtle targets could be faster to annotate from scratch. Third, we evaluated only two exemplary use cases, leaving open questions regarding SAM 2’s performance on other targets or imaging modalities. For example, certain anatomical structures with hollow or non-convex geometry like the myocardium may not be well suited for bounding box prompting and may require prompting strategies. Finally, we did not investigate whether SAM 2 introduces unintended biases, e.g. oversegmenting or undersegmenting certain structures, or whether performance differs between normal and pathological cases or across image quality. Any such biases could propagate into downstream models. To mitigate this risk, human annotators should always review SAM 2’s predicted segmentation masks, ensuring that systematic errors are identified and corrected. With appropriate human oversight, SAM 2 may therefore serve as a practical tool to reduce workload in real-world 3D medical imaging annotation workflows.
Conclusion
In conclusion, our results suggest that SAM 2-assisted annotation can substantially reduce manual workload associated with annotating large 3D imaging datasets for downstream segmentation model training, while maintaining downstream model performance. Thus, integrating SAM 2 into existing annotation tools (e.g., via the openly available plug-in for 3DSlicer [34, 35]) holds promising potential for reducing manual workload in human segmentation workflows, ultimately saving costs and fostering further research and medical device development for clinical routine.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Simpson AL, Peoples J, Creasy JM, Fichtinger G, Gangai N, Keshavamurthy KN, et al. Preoperative ct and survival data for patients undergoing resection of colorectal liver metastases. Sci Data. 2024;11:172.10.1038/s 41597-024-02981-2PMC 1084749538321027 · doi ↗ · pubmed ↗
- 2Simpson AL, Peoples J, Creasy JM, Fichtinger G, Gangai N, Lasso A, et al. Preoperative ct and survival data for patients undergoing resection of colorectal liver metastases (colorectal-liver-metastases). 2023.10.1038/s 41597-024-02981-2PMC 1084749538321027 · doi ↗ · pubmed ↗
- 3Dong H, Gu H, Chen Y, Yang J, Chen Y, Mazurowski MA. Segment anything model 2: an application to 2D and 3D medical images. ar Xiv [cs.CV]. 2024.10.1109/TBME.2026.365326741525616 · doi ↗ · pubmed ↗
- 4NDA. https://nda.nih.gov/oai. Accessed 17 Oct 2024.
- 5Yao Y, Zhong J, Zhang L, Khan S, Chen W. Carti Morph: A framework for automated knee articular cartilage morphometrics. Med Image Anal. 2024;91:103035.10.1016/j.media.2023.10303537992496 · doi ↗ · pubmed ↗
- 6Wasserthal J, Breit H-C, Meyer MT, Pradella M, Hinck D, Sauter AW, et al. Total Segmentator: robust segmentation of 104 anatomic structures in CT images. Radiol Artif Intell. 2023;5:e 230024.10.1148/ryai.230024 PMC 1054635337795137 · doi ↗ · pubmed ↗
- 7Maier-Hein L, Reinke A, Godau P, Tizabi MD, Buettner F, Christodoulou E, et al. Metrics reloaded: recommendations for image analysis validation. Nat Methods. 2024;21:195–212.10.1038/s 41592-023-02151-z PMC 1118266538347141 · doi ↗ · pubmed ↗
- 8Xia Y, Fripp J, Chandra SS, Schwarz R, Engstrom C, Crozier S. Automated bone segmentation from large field of view 3D MR images of the hip joint. Phys Med Biol. 2013;58:7375–90.10.1088/0031-9155/58/20/737524077264 · doi ↗ · pubmed ↗