Consistency evaluation and performance optimization of deep learning-based auto-contouring for nasopharyngeal carcinoma
Linghui Yan, Yuhao Lin, Zirong Li, Liuling Wang, Xiaoting Lin, Jianming Ding, Zixuan Leng, Qichao Zhou, Chuanben Chen, Zhaodong Fei

TL;DR
This paper evaluates and improves deep learning models for contouring in nasopharyngeal carcinoma radiotherapy, highlighting current limitations and proposed solutions.
Contribution
The study introduces two novel model frameworks to enhance the accuracy and reliability of automatic contouring in radiotherapy.
Findings
DL models showed poor consistency in delineating GTV, pituitary gland, and temporomandibular joints.
Proposed frameworks improved contouring accuracy for GTV, brainstem, and eyes.
DL-generated contours still differ significantly from manual delineations by oncologists for critical structures.
Abstract
Contour delineation is crucial for ensuring the efficacy and side effects of radiotherapy (RT), but it inevitably involves inter-observer variability (IOV). Deep learning (DL) models have been used to assist in contour delineation, but further evaluation is needed to guide healthcare professionals in the judicious application of DL models. The contours of 22 anatomical structures and the gross tumor volume (GTV) for 30 patients with nasopharyngeal carcinoma were delineated using four DL models: AccuContour, RT-Viewer-contour, RT-Mind, and PVmed Contouring. The overall kappa values and generalized conformity indices of these contours were calculated to assess consistency. The Dice similarity coefficient (DSC), Relative Volume Difference (RVD), 95th percentile Hausdorff Distance (HD95), and Average Symmetric Surface Distance (ASSD) were calculated to evaluate the accuracy of the contours.…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
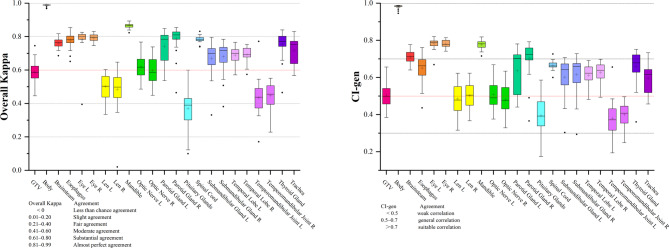 Figure 1
Figure 1Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAdvanced Radiotherapy Techniques · Head and Neck Cancer Studies · Radiomics and Machine Learning in Medical Imaging
Introduction
Radiotherapy (RT) stands as a pivotal treatment strategy for tumor, offering the promise of tumor control while simultaneously posing the risk of damaging adjacent healthy tissues. In the course of head and neck RT, there exists the risk of damaging over 20 critical organs at risk (OARs), which could inadvertently trigger a spectrum of adverse effects, including xerostomia, dysphagia, hypopituitarism, and other lower cranial neuropathies. Consequently, a paramount responsibility for radiation oncologists during the RT planning phase is the scrupulous assurance that the radiation doses delivered to these OARs remain confined to acceptable safety margins.
Contour delineation, which is paramount in influencing the therapeutic efficacy and side effect profile of RT, is recognized as an exceedingly time-intensive duty for radiation oncologists. It demands a high level of expertise and can extend up to 180 min for complex head and neck regions^1^. The process is susceptible to inter-observer variability (IOV), arising from discrepancies in professional knowledge, clinical experience, and selection of imaging modalities among practitioners. This IOV can persist insidiously, even when employing diverse imaging methods^2^ or adhering to guidelines^3^. Moreover, extant literature substantiates that IOV in the delineation of target volume could escalate the toxicity associated with RT and adversely impact patient survival^4^. Therefore, mitigating IOV and bolstering the uniformity in contour delineation present a formidable challenge for radiation oncologists.
Deep learning (DL) models have emerged as powerful tools with the potential to improve quality, standardization, and efficiency in RT workflows^5^. By leveraging automated software for contouring, the aim is to reduce the time spent on manual delineation, attenuate IOV, and improve the uniformity and accuracy of dose distributions^6,7^. A growing number of commercial DL-based auto-contouring systems have been introduced to assist radiation oncologists with head-and-neck target and OAR delineation in clinical practice or prospective evaluation studies, with early reports suggesting that they can reduce contouring time while maintaining clinically acceptable accuracy in selected settings^7–13^. However, most prior investigations have focused on the performance of a single auto-segmentation system—often in a research or pre-clinical setting—rather than on systematic comparison of multiple commercial tools within the same clinical scenario. Furthermore, even when a model performs well on average, its generalizability can be limited: small subsets of cases that fall outside the training data distribution may still yield suboptimal contours, underscoring the need for rigorous, ongoing validation before routine clinical use^7,8,14^. In addition to manual IOV among clinicians, differences in training data, network architectures, and post-processing strategies can introduce inter-model variability between distinct DL auto-contouring systems, complicating efforts to harmonize treatment protocols across centers^6^. While several studies have evaluated individual commercial or in-house DL models for head and neck auto-segmentation^7,8,10–13^, there is a relative paucity of work systematically assessing the consistency between multiple commercial systems and exploring methods to stabilize their combined output.
Against this background, the present study has three main aims. First, we seek to quantify the inter-model variability of four commercial DL auto-contouring systems for the gross tumour volume (GTV) and a broad set of OARs in nasopharyngeal carcinoma (NPC). Second, we aim to identify specific structures that require heightened clinical attention because they are particularly vulnerable to disagreement between models. Third, we propose and evaluate two post-processing frameworks—one based on an image-confidence algorithm and the other on a deep-learning fusion strategy—designed to enhance the robustness of automatic contours without degrading the baseline performance of the best individual model. Together, these contributions extend prior work by moving beyond single-model evaluation to a systematic analysis of inter-model variability and by introducing practical fusion-based approaches to improve the stability of commercial auto-contouring in NPC.
Methods
Dataset preparation
30 patients with previously untreated nasopharyngeal carcinoma who received radical RT at our hospital were included in this study. Planning computed tomography (CT) images were acquired on a Brilliance CT Big Bore scanner (Philips Healthcare, Cleveland, OH, USA) with a slice thickness of 3.0 mm, covering from the vertex to 2 cm below the clavicle. Each patient’s dataset comprised CT images and contour files generated by four distinct DL models. Contours on the planning CT images, serving as reference standards, were meticulously delineated on AccuContour software (Version 3.0, http://www.manteiatech.com/). The GTV and OARs were delineated on CT imaging by a single observer (clinical radiation therapist, 10 years of experience) under the guidance of an experienced senior radiation oncologist (20 years of experience) according to consensus^15^. Pretreatment contrast-enhanced magnetic resonance imaging (MRI) and/or diagnostic positron emission tomography–computed tomography (PET-CT), when available, were used as auxiliary reference imaging to assist GTV delineation on the planning CT; PET-CT was not used as the primary CT dataset for RT planning. The study was conducted in compliance with the Declaration of Helsinki, and the Ethics Committee of Fujian Cancer Hospital approved this research (Ethics Approval Number: YKT2020-011-01).
Deep learning model preparation
Four comprehensively trained NPC delineation models were prepared, identified as follows: AccuContour (Manteia Medical Technologies Co., Ltd.), RT-Viewer-contour (Linkingmed Technology Co., Ltd.) (https://www.linkingmed.com/), RT-Mind (Medmind Co., Ltd.) (http://www.medicalmind.cn), and PVmed Contouring (Guangzhou Perception Vision Medical Technologies Co., Ltd.) (https://www.pvmedtech.com/). These models were applied to each patient case to generate contours for a specified list of Regions of Interest (ROI) pertinent to NPC. 22 organs that were common to all 4 models were identified: body, brainstem, esophagus, eyes, lens, mandible, optic nerves, pituitary glands, parotid glands, submandibular glands, spinal cord, temporal lobes, temporomandibular joints, thyroid gland, and trachea. It should be noted that GTV delineations were exclusively derived from the outputs of AccuContour and RT-Mind. According to information provided by the vendors, the commercial DL models evaluated in this study were developed independently by their respective companies using proprietary multicentre training datasets. The 30 nasopharyngeal carcinoma cases used for the comparative evaluation were retrospectively identified from our institutional database and, to the best of the authors’ knowledge, were not used for training, fine-tuning, or internal validation of these commercial models. Because the commercial training datasets are anonymized multicentre collections, a small inadvertent overlap cannot be completely excluded and is therefore acknowledged as a potential limitation.
Consistency analysis
First, the “Computational Environment for Radiotherapy Research (CERR)”^16^ was used to calculate the volumes of each OARs and GTVs for each patient, as well as the minimum, maximum, mean, standard deviation, intersection, and union volumes per case. The latest version of CERR includes a consensus tool for more probabilistic and quantitative analyses, such as apparent consistency, kappa-corrected consistency, and “Simultaneous Truth and Performance Level Estimation (STAPLE)” based on probability, sensitivity, specificity, and the overall Kappa coefficient with its associated p-value (testing the null hypothesis κ = 0).
In studies assessing consensus on target volumes, the overall kappa value is frequently employed as a single metric for evaluating consistency. Based on the kappa value, the overall agreement is categorized as follows: 0 represents no agreement, 0-0.2 indicates slight agreement, 0.21–0.4 suggests fair agreement, 0.41–0.6 implies moderate agreement, 0.61–0.8 denotes substantial agreement, and values above 0.81 signify almost perfect agreement^17^.
The conformity index (CI) serves as an alternative conventional approach for assessing agreement. The generalized CI (CI-gen) introduced by Kouwenhoven et al.^18^. was employed, as this method is not limited by the number of observers. The specific calculation methods for CI-gen are provided in Supplementary Material (Supplement 1).
Assessment of clinical feasibility
The clinically acceptable manual contours were selected as a substitute for the gold standard. The contours generated by four DL models were compared against the manual contours. And 4 commonly used contour metrics were selected to ensure the reliability of results. Specifically, these encompass the Dice similarity coefficient (DSC)^19^, Relative Volume Difference (RVD), the 95th percentile Hausdorff distance (HD95)^20^, and Average Symmetric Surface Distance (ASSD)^21–23^. The specific calculation methods for the four contour metrics were detailed in the supplementary material (Supplement1). All structures were transferred to the same CT image, and contour statistics were analyzed in AccuContour software.
Model architecture
To provide potential improvements in treatment planning and outcomes for affected patients, this study aimed to enhance the robustness and precision of contour delineation by building upon established deep learning architectures. Two principal model frameworks were proposed, each tailored to harness the unique strengths of their respective computational paradigms.
Method A (confidence-based fusion) is based on the image confidence algorithm originally proposed by Yang et al.^24^, which assigns a confidence score to each voxel within a ROI using local image information. In this framework, the four commercial DL models first generate binary segmentation masks for each structure. The voxel-wise intersection and union of these masks are then used to construct a trimap: voxels inside the intersection are treated as definite foreground, voxels outside the union as definite background, and the remaining voxels as an uncertain region. This trimap is processed by a three-dimensional image confidence algorithm that computes a spatial correlation matrix in the feature space of the planning CT and assigns each uncertain voxel a confidence value between 0 and 1 based on its similarity to foreground and background voxels. For each ROI, a confidence threshold is selected on the training set to maximise the DSC, and this threshold is then applied to obtain the final segmentation. In this way, the inter-model variability is concentrated in the uncertain region and refined using the underlying image characteristics, while regions of strong agreement are preserved. This approach requires no additional network training.
Method B (deep learning fusion) extends the output of the image confidence algorithm by incorporating deep learning. While Method A effectively integrates multiple segmentation results to produce a confidence map, its reliance on empirically defined thresholds may introduce variability across patients. To address this, Method B takes the planning CT, a fused contour map summarizing the agreement pattern across the four DL models (obtained by summing and normalizing their binary masks), and the confidence map generated by Method A, and concatenates them as multi-channel inputs to a nnU-Net–based architecture. The network is trained with a combined Dice and cross-entropy loss, allowing it to learn systematic bias patterns in individual model outputs and to correct them using both multi-model contour information and local image features, while preserving the strengths of the best-performing models.
The two techniques (Method A and Method B) were described in detail in the supplementary material (Supplement1). The accuracy of proposed methods were evaluated with DSC. This metric provided insights into the spatial accuracy of model’s predictions by assessing the overlap between predicted segmentations and the ground truth. To fulfill the data quantity requirements of the model, the dataset was expanded by incorporating an additional 31 patients with previously untreated nasopharyngeal carcinoma. The resulting 61 cases were randomly split into a training set (n = 48) and an independent test set (n = 13).
Statistical analysis
Continuous geometric evaluation metrics, including the DSC, RVD, HD95, and ASSD, were summarized as mean ± standard deviation for each ROI and model. Because the main aim of the study was to describe patterns of variability and robustness across multiple DL models rather than to establish pairwise statistical superiority for every individual structure, and because performing formal hypothesis tests for each combination of structure and metric would result in extensive multiple comparisons with substantially reduced power after correction and a large number of potentially misleading p-values, these measures were analyzed descriptively, focusing on the magnitude and clinical relevance of the observed differences. For the inter-model agreement analysis, the overall Kappa coefficient and its associated p-value were calculated using the Kappa statistics module of CERR under the null hypothesis that the agreement among contours is no better than chance (κ = 0), so that p < 0.001 indicates agreement significantly higher than random.
Results
Consistency analysis
This study first analyzed the GTV and OARs generated by four DL models in 30 cases of NPC patients. The four DL models used in this study are commercially available systems that were independently developed by different vendors. Inter-model agreement for each structure was quantified using the overall Kappa coefficient and its associated p-value. All p-values were < 0.001 (Supplement 2: Tables S1–S23), indicating that the observed agreement among models was clearly higher than random, although the magnitude of agreement varied across structures. Nonetheless, regions with well-defined anatomical boundaries—such as the body, eyes, and mandible—exhibited almost perfect agreement among the models (Fig. 1). In contrast, lower consistency was observed for complex or low-contrast structures such as the GTV, lenses, pituitary glands, and temporomandibular joints. The remaining ROIs generally showed substantial agreement (0.61 < overall kappa values < 0.80, 0.5 < CI-gen < 0.7).
Fig. 1. Box plots of overall kappa and CI-gen for GTV and OAR contours generated by 4 deep learning models in 30 nasopharyngeal carcinoma patients. ROI (Regions of Interest), GTV (Gross Tumor Volume).
Assessment of clinical feasibility
For this section of the analysis, data from the same 30 NPC patients used in the first part were utilized. Through the analysis of two contour metrics, the DSC and RVD, it can be observed that in most OARs, the four DL models have an average DSC delineation value greater than 0.7 and an average RVD value less than 30%, demonstrating excellent contouring performance. However, compared to the manual contours, the four DL models still exhibit marked differences in contours such as the GTV, the lens, optic nerves, pituitary glands, and temporomandibular joints. The worst DSC mean is the GTV, with the mean DSC values less than 0.6 in both DL models. When it comes to pituitary gland, the discrepancy between manual and automated delineations can reach a magnitude of up to four times the reference volume. At the same time, some automatic contouring software may have marked differences in contours such as spinal cord, submandibular glands, temporal lobes and trachea compared to manual contours (Tables 1 and 2).
Table 1. Comparison of DSC for GTV and OAR automatic delineation of 30 nasopharyngeal carcinoma patients by four deep learning models.ROIDL-1DL-2DL-3DL-4GTV 0.588 ± 0.167
0.569 ± 0.171 Body0.989 ± 0.0120.991 ± 0.0110.994 ± 0.0120.992 ± 0.012Brainsteam0.886 ± 0.0340.862 ± 0.0480.866 ± 0.0340.848 ± 0.034Esophagus0.822 ± 0.0960.782 ± 0.1140.850 ± 0.0960.823 ± 0.096Eye L0.895 ± 0.0550.884 ± 0.0610.860 ± 0.0570.887 ± 0.063Eye R0.896 ± 0.0360.898 ± 0.0270.882 ± 0.0340.881 ± 0.045Len L0.721 ± 0.123 0.535 ± 0.144
0.681 ± 0.154
0.682 ± 0.114 Len R0.735 ± 0.114 0.611 ± 0.134
0.690 ± 0.128
0.693 ± 0.099 Mandible0.911 ± 0.0370.878 ± 0.0450.906 ± 0.0370.911 ± 0.037Optic Nerve L 0.650 ± 0.107
0.619 ± 0.123
0.690 ± 0.123
0.656 ± 0.109 Optic Nerve R 0.626 ± 0.106
0.695 ± 0.085
0.697 ± 0.105
0.728 ± 0.085 Parotid Gland L0.791 ± 0.1180.733 ± 0.1320.813 ± 0.1120.802 ± 0.118Parotid Gland R0.835 ± 0.1270.794 ± 0.0800.851 ± 0.1180.857 ± 0.117Pituitary Glands 0.667 ± 0.174
0.587 ± 0.215
0.603 ± 0.174
0.511 ± 0.174 Spinal Cord0.726 ± 0.1150.813 ± 0.0750.808 ± 0.1150.815 ± 0.115Submandibular Glands L0.752 ± 0.1150.741 ± 0.1280.765 ± 0.1650.742 ± 0.154Submandibular Glands R0.784 ± 0.1250.752 ± 0.1480.807 ± 0.1400.777 ± 0.108Temporal Lobes L0.857 ± 0.055 0.671 ± 0.094 0.799 ± 0.0720.871 ± 0.075Temporal Lobes R0.847 ± 0.060 0.690 ± 0.088 0.818 ± 0.0770.855 ± 0.083Temporomandibular Joints L 0.646 ± 0.181
0.540 ± 0.129
0.579 ± 0.186
0.594 ± 0.181 Temporomandibular Joints R 0.667 ± 0.143
0.605 ± 0.158
0.581 ± 0.189
0.640 ± 0.173 Thyroid Gland0.835 ± 0.0890.842 ± 0.0950.799 ± 0.0890.848 ± 0.089Trachea0.856 ± 0.0780.861 ± 0.0710.880 ± 0.078 0.640 ± 0.078 Average DSC (Dice Similarity Coefficient) with standard deviations for autocontours from DL-1 (AccuContour), DL-2 (RT-Viewer-contour), DL-3 (RT-Mind), and DL-4 (PVmed Contouring). Values with a mean DSC less than 0.7 are shown in bold. ROI (Regions of Interest), GTV (Gross Tumor Volume).
Table 2. Comparison of RVD (%) for GTV and OAR automatic delineation of 30 nasopharyngeal carcinoma patients by four deep learning models.ROIDL-1DL-2DL-3DL-4GTV 41.894 ± 27.278
61.530 ± 59.372 Body1.345 ± 1.9051.042 ± 1.8370.981 ± 2.2221.022 ± 2.182Brainsteam12.823 ± 10.77620.077 ± 13.30111.873 ± 9.86810.006 ± 5.822Esophagus10.088 ± 12.42911.796 ± 18.0339.248 ± 13.25913.675 ± 20.468Eye L12.907 ± 13.47618.044 ± 17.76225.009 ± 21.16818.044 ± 17.762Eye R12.749 ± 7.93413.033 ± 7.91318.042 ± 12.79418.209 ± 10.150Len L 43.570 ± 39.985
134.982 ± 101.209
57.227 ± 68.725
39.058 ± 33.444 Len R 47.706 ± 47.876
111.263 ± 86.731
49.444 ± 56.641
27.362 ± 20.868 Mandible9.406 ± 6.04019.249 ± 12.34114.705 ± 11.66610.786 ± 8.282Optic Nerve L23.592 ± 15.840 54.437 ± 54.586 24.924 ± 25.89625.013 ± 20.970Optic Nerve R 31.167 ± 14.494
42.996 ± 35.130 28.051 ± 25.29620.570 ± 15.868Parotid Gland L25.676 ± 25.56627.219 ± 23.90925.180 ± 32.223 38.867 ± 42.865 Parotid Gland R15.456 ± 16.57616.336 ± 18.20312.684 ± 14.45017.824 ± 15.925Pituitary Glands 59.030 ± 78.293
411.000 ± 1688.964
125.858 ± 159.979
180.919 ± 196.285 Spinal Cord 66.928 ± 53.319 26.422 ± 21.245 35.345 ± 35.503 26.771 ± 28.933Submandibular Glands L 30.087 ± 31.462
31.841 ± 28.700
44.013 ± 74.227
74.741 ± 79.049 Submandibular Glands R20.392 ± 18.02922.050 ± 16.83618.684 ± 18.080 50.053 ± 34.642 Temporal Lobes L11.134 ± 9.745 60.285 ± 39.880 18.810 ± 13.43913.763 ± 16.318Temporal Lobes R12.144 ± 9.201 65.883 ± 37.451 11.708 ± 10.32914.331 ± 13.907Temporomandibular Joints L 38.528 ± 52.675
88.366 ± 63.431
24.173 ± 15.991
50.629 ± 67.870 Temporomandibular Joints R 30.867 ± 29.036
53.930 ± 44.571 26.074 ± 20.841 34.944 ± 25.428 Thyroid Gland19.049 ± 21.06615.534 ± 14.025 42.925 ± 31.185 14.536 ± 16.589Trachea18.133 ± 15.82114.160 ± 14.10113.555 ± 15.744 96.264 ± 99.486 Average RVD (Relative Volume Difference) with standard deviations for autocontours from DL-1 (AccuContour), DL-2 (RT-Viewer-contour), DL-3 (RT-Mind), and DL-4 (PVmed Contouring). Values with a mean RVD more than 30% are shown in bold. ROI (Regions of Interest), GTV (Gross Tumor Volume).
The HD95 results showed that the deviations generated by automatic contouring are more severe in the delineation of structures such as the GTV, optic nerves, parotid glands, pituitary glands, temporal lobes, temporomandibular joints and trachea. The GTV contours generated by the two DL models showed marked differences, as the mean HD95 values were greater than 15 mm (Table 3). On the other hand, the ASSD results showed that except for structures such as the GTV, parotid glands, temporal lobes, temporomandibular joints, and trachea, the errors in automatic contours were relatively small, with the mean ASSD value less than 3 mm (Table 4).
Table 3. Comparison of HD95 (mm) for GTV and OAR automatic delineation of 30 nasopharyngeal carcinoma patients by four deep learning models.ROIDL-1DL-2DL-3DL-4GTV 22.330 ± 45.798
16.346 ± 9.098 Body2.408 ± 6.2052.573 ± 7.217 5.386 ± 21.883
5.743 ± 20.225 Brainsteam3.778 ± 2.6824.026 ± 2.6123.726 ± 1.987 6.290 ± 3.724 Esophagus3.164 ± 2.220 6.586 ± 11.834 3.901 ± 6.8763.075 ± 2.562Eye L4.315 ± 10.7844.753 ± 10.7464.753 ± 10.746 5.248 ± 10.670 Eye R2.447 ± 0.9114.066 ± 9.7983.243 ± 0.9972.789 ± 0.761Len L4.679 ± 11.767 7.250 ± 15.031
5.064 ± 11.434
5.270 ± 11.216 Len R2.422 ± 1.1232.872 ± 1.1143.096 ± 1.5312.890 ± 1.075Mandible2.114 ± 1.0813.097 ± 1.4062.762 ± 1.3052.581 ± 1.999Optic Nerve L 6.204 ± 8.476
7.036 ± 10.897
6.783 ± 11.906
5.436 ± 8.302 Optic Nerve R 7.074 ± 9.241 4.508 ± 7.7532.997 ± 0.6592.777 ± 0.547Parotid Gland L 6.585 ± 3.792
22.410 ± 32.224
10.443 ± 21.234
9.107 ± 5.810 Parotid Gland R 5.041 ± 3.852
14.209 ± 20.235 4.784 ± 2.861 5.720 ± 3.436 Pituitary Glands 5.121 ± 12.454
5.387 ± 12.889
5.292 ± 12.861
5.719 ± 12.532 Spinal Cord 5.454 ± 10.473
6.264 ± 10.413 4.476 ± 9.8915.741 ± 10.501Submandibular Glands L4.982 ± 2.645 8.044 ± 13.377 4.780 ± 3.1655.714 ± 3.617Submandibular Glands R4.643 ± 4.3914.823 ± 2.6274.030 ± 3.2134.500 ± 2.298Temporal Lobes L 9.894 ± 13.052
28.119 ± 26.703
14.877 ± 13.589
10.336 ± 13.411 Temporal Lobes R 9.075 ± 4.025
14.788 ± 5.563
12.341 ± 5.481
8.906 ± 2.832 Temporomandibular Joints L 5.800 ± 3.191
13.592 ± 25.069
6.426 ± 3.823
6.844 ± 4.013 Temporomandibular Joints R4.880 ± 2.406 9.039 ± 18.141
5.874 ± 3.322
5.418 ± 2.515 Thyroid Gland2.989 ± 1.9623.099 ± 1.6503.261 ± 1.8492.603 ± 2.060Trachea 11.044 ± 12.430
11.964 ± 14.893
15.163 ± 18.111
29.831 ± 26.663 Average HD95 (the 95th percentile Hausdorff Distance) with standard deviations for autocontours from DL-1 (AccuContour), DL-2 (RT-Viewer-contour), DL-3 (RT-Mind), and DL-4 (PVmed Contouring). Values with a mean HD95 more than 5 mm are shown in bold. ROI (Regions of Interest), GTV (Gross Tumor Volume).
Table 4. Comparison of ASSD (mm) for GTV and OAR automatic delineation of 30 nasopharyngeal carcinoma patients by four deep learning models.ROIDL-1DL-2DL-3DL-4GTV 6.052 ± 7.533
5.628 ± 3.427 Body0.662 ± 1.6250.855 ± 2.2481.118 ± 2.8991.047 ± 2.703Brainsteam0.926 ± 0.5391.158 ± 0.6201.115 ± 0.6851.455 ± 0.813Esophagus0.767 ± 0.5231.785 ± 3.1020.632 ± 0.6280.753 ± 0.802Eye L0.569 ± 0.4230.750 ± 0.4470.664 ± 0.4110.920 ± 0.400Eye R0.568 ± 0.2771.001 ± 2.6470.752 ± 0.2710.657 ± 0.250Len L0.995 ± 1.8311.312 ± 0.8861.321 ± 1.8381.155 ± 1.771Len R0.564 ± 0.3570.926 ± 0.4780.759 ± 0.4370.702 ± 0.299Mandible0.455 ± 0.1910.686 ± 0.2860.611 ± 0.3790.526 ± 0.329Optic Nerve L1.135 ± 1.2571.939 ± 4.0881.656 ± 3.8351.081 ± 1.246Optic Nerve R1.450 ± 0.9091.341 ± 3.7420.637 ± 0.2510.520 ± 0.185Parotid Gland L1.948 ± 1.455 9.117 ± 15.902 2.896 ± 5.9802.717 ± 2.076Parotid Gland R1.328 ± 1.211 3.915 ± 9.985 1.209 ± 0.9191.312 ± 0.857Pituitary Glands2.070 ± 6.7182.416 ± 6.9682.385 ± 6.9482.620 ± 6.755Spinal Cord1.644 ± 1.6451.322 ± 1.4751.202 ± 1.4921.385 ± 1.816Submandibular Glands L1.755 ± 2.1332.707 ± 4.7441.734 ± 2.2852.176 ± 2.417Submandibular Glands R1.250 ± 1.3291.391 ± 0.9411.064 ± 1.1531.264 ± 0.703Temporal Lobes L2.466 ± 3.162 9.568 ± 10.491
3.772 ± 3.597 2.531 ± 3.236Temporal Lobes R2.152 ± 0.929 4.630 ± 2.068 2.896 ± 1.4632.082 ± 1.021Temporomandibular Joints L1.919 ± 1.4392.830 ± 1.6502.429 ± 1.5662.484 ± 1.590Temporomandibular Joints R1.629 ± 0.926 3.463 ± 7.512 2.196 ± 1.4231.828 ± 1.000Thyroid Gland0.834 ± 0.6430.829 ± 0.6151.060 ± 0.7080.725 ± 0.674Trachea2.217 ± 2.7822.599 ± 3.435 3.302 ± 4.199
8.460 ± 11.141 Average ASSD (Average Symmetric Surface Distance) with standard deviations for autocontours from DL-1 (AccuContour), DL-2 (RT-Viewer-contour), DL-3 (RT-Mind), and DL-4 (PVmed Contouring). Values with a mean ASSD more than 3 mm are shown in bold. ROI (Regions of Interest), GTV (Gross Tumor Volume).
Model architecture
After random division, data from 13 nasopharyngeal carcinoma patients were selected for testing (Table 5). The same ROIs were selected to compute the DSC as the evaluation metric. Results demonstrated that both (Method A) and (Method B) achieved stable and reliable optimization effects for GTV, exhibiting higher means and lower standard deviations.
Table 5. Comparison of DSC for GTV and OAR automatic delineation of 12 nasopharyngeal carcinoma patients by four deep learning models and method A and method B.ROIDL-1DL-2DL-3DL-4Method AMethod BGTV0.625 ± 0.1350.581 ± 0.133 0.664 ± 0.121 0.659 ± 0.100Body0.992 ± 0.0010.993 ± 0.0010.999 ± 0.0020.995 ± 0.0020.996 ± 0.0010.991 ± 0.002Brainsteam0.886 ± 0.0280.856 ± 0.0330.891 ± 0.0370.810 ± 0.0750.886 ± 0.024 0.905 ± 0.019 Esophagus0.825 ± 0.0180.730 ± 0.1400.920 ± 0.0450.862 ± 0.0500.801 ± 0.1600.885 ± 0.014Eye L0.907 ± 0.0180.876 ± 0.0300.907 ± 0.0410.848 ± 0.030 0.913 ± 0.019
0.915 ± 0.012 Eye R0.902 ± 0.0110.883 ± 0.0220.894 ± 0.0260.872 ± 0.041 0.911 ± 0.013
0.920 ± 0.014 Len L0.693 ± 0.1470.484 ± 0.1220.744 ± 0.0990.721 ± 0.1470.703 ± 0.093 0.815 ± 0.110 Len R0.689 ± 0.1000.603 ± 0.0980.754 ± 0.1080.729 ± 0.1120.766 ± 0.053 0.815 ± 0.087 Mandible0.849 ± 0.0630.803 ± 0.0890.943 ± 0.0380.768 ± 0.1480.902 ± 0.0180.925 ± 0.023Optic Nerve L0.542 ± 0.0640.533 ± 0.0920.542 ± 0.1260.598 ± 0.0820.559 ± 0.0600.588 ± 0.169Optic Nerve R0.495 ± 0.2280.701 ± 0.0720.826 ± 0.0800.730 ± 0.0660.610 ± 0.1300.710 ± 0.073Parotid Gland L0.713 ± 0.1710.690 ± 0.1840.899 ± 0.0790.798 ± 0.0790.783 ± 0.1080.871 ± 0.048Parotid Gland R0.828 ± 0.0750.809 ± 0.0330.845 ± 0.2930.859 ± 0.0550.811 ± 0.109 0.892 ± 0.035 Pituitary Glands0.623 ± 0.0940.545 ± 0.1300.687 ± 0.1390.720 ± 0.1870.613 ± 0.0710.669 ± 0.078Spinal Cord0.778 ± 0.0980.828 ± 0.0460.892 ± 0.1000.826 ± 0.0700.851 ± 0.0510.872 ± 0.087Submandibular Glands L0.756 ± 0.1330.771 ± 0.1740.866 ± 0.1910.810 ± 0.1680.861 ± 0.1280.851 ± 0.029Submandibular Glands R0.762 ± 0.1470.728 ± 0.1940.841 ± 0.1840.775 ± 0.154 0.858 ± 0.136
0.843 ± 0.061 Temporal Lobe L0.893 ± 0.0320.637 ± 0.1570.943 ± 0.0320.816 ± 0.0380.878 ± 0.0320.883 ± 0.025Temporal Lobe R0.888 ± 0.0240.688 ± 0.0290.962 ± 0.0370.859 ± 0.0340.888 ± 0.0200.917 ± 0.025Temporomandibular Joint L0.653 ± 0.0770.576 ± 0.1130.770 ± 0.0870.545 ± 0.1560.758 ± 0.057 0.791 ± 0.078 Temporomandibular Joint R0.653 ± 0.0770.627 ± 0.0980.758 ± 0.1350.512 ± 0.178 0.765 ± 0.030
0.806 ± 0.070 Thyroid Gland0.792 ± 0.0900.748 ± 0.1030.871 ± 0.1330.805 ± 0.0970.753 ± 0.1470.830 ± 0.047Trachea0.819 ± 0.0610.808 ± 0.0720.904 ± 0.0800.711 ± 0.1160.829 ± 0.0550.879 ± 0.073Average DSC (Dice Similarity Coefficient) with standard deviations for autocontours from DL-1 (AccuContour), DL-2 (RT-Viewer-contour), DL-3 (RT-Mind), DL-4 (PVmed Contouring), Method A, and Method B. Values for which Method A or Method B outperform the four deep learning models are shown in bold. ROI (Regions of Interest), GTV (Gross Tumor Volume).
As for the OARs, consistent optimization effects were visibly noted in the brainstem, eyes, lens, and temporomandibular joints. The mean DSC of the brainstem was greater than 0.9. In other OARs, while the outcomes from the proposed models did not demonstrate significant superiority over those derived from the existing DL models, they effectively precluded any significant negative optimization. The least favorable results were commensurate with those achieved by the DL models, thereby rendering them directly applicable in actual segmentation tasks.
Comparatively, the results from Method A and Method B were similar, but with the exception of the GTV and body, the segmentation performance of Method A for the other OARs was slightly inferior to that of Method B. Deep learning proved more effective in learning edge information, offering enhanced improvements particularly for segmentation results of OARs.
Discussion
The advent of artificial intelligence (AI) in the realm of RT has ushered in a new era of automatic delineation for target volumes and OARs, enhancing both the efficiency and reproducibility of contouring^9^. Despite these advancements, uncertainties persist, particularly in the realm of automatic contouring. Our study provides a comprehensive evaluation of the performance of commercial DL models for OAR contouring in NPC. The use of such models is motivated by the well-known challenges of manual contour delineation, including IOV among clinicians^7,8^. In the present work, however, we did not directly measure manual IOV; instead, our primary focus is on the variability between different DL-based auto-contouring tools and on strategies to mitigate this inter-model variability.
The evaluation of four distinct DL models in our study revealed a relatively poor consistency in the automatic contouring of certain structures, such as the GTV, lens, pituitary glands, and temporomandibular joints. The inconsistency may stem from the inherent low contrast of these structures on CT scans, ill-defined borders, or their small size. In contrast, structures with clear anatomical boundaries, such as the body, eyes, and mandible, showed almost perfect agreement across models. Taken together, these findings suggest that, particularly for small or low-contrast structures, physicians should pay closer attention to the review and, when available, consider integrating multimodal imaging to refine the automatic contours. Moreover, because different commercial DL models are trained on heterogeneous datasets with distinct architectures, appreciable inter-model variability can arise even when they are applied to the same institution and contouring guideline. When multiple auto-contouring tools are used within a clinic, it is therefore important to routinely assess their consistency and to verify that the resulting contours are clinically acceptable before integrating them into routine practice.
Our study also scrutinized the clinical acceptability of automatic contours through established contouring metrics. Small-volume structures tended to exhibit more pronounced variability in DSC and RVD, highlighting the sensitivity of these metrics to even minor geometric perturbations^23^. For instance, the pituitary glands, which may span only 2 or 3 layers of CT images, are particularly susceptible to even minor vertical discrepancies. In most cases, however, the required edits for these structures were relatively limited and did not impose a substantial additional workload on physicians. Methodological work has indicated that HD95 may not be fully adequate for capturing contouring inaccuracies, because discrepancies are often distributed along the contour rather than concentrated in a single outlier segment^22,23^. In our data, elevated HD95 values for certain structures are better interpreted as indicators of boundary uncertainty and as a benchmark for assessing the precision of automatic contouring, rather than as a comprehensive measure of overall contour quality. For the majority of structures, the ASSD between automatic and manual contours typically remained below approximately 3 mm. This is consistent with reports advocating the use of margins on the order of 3 mm when defining planning organs-at-risk volumes (PRVs) in head and neck IMRT, and with the magnitude of observed setup and motion uncertainties in this region^25^. The discrepancies between automatic and manual contours in our cohort are thus likely to be dosimetrically acceptable for many OARs in routine practice. Nevertheless, PRVs are primarily designed to account for setup errors and organ motion and do not explicitly incorporate contouring errors or IOV^26^. Integrating the potential errors from automatic contouring into PRV design emerges as a promising strategy to ensure accurate organ dosimetry, thereby enhancing the reliability and clinical utility of automatic contouring techniques.
Consequently, for critical structures such as the GTV, lens, optic nerves, parotid glands, pituitary glands, temporal lobes, temporomandibular joints, and trachea, it is imperative to rigorously enhance the modification processes. This intensification is vital to address and mitigate the uncertainties inherent in automated contouring techniques. In contrast, for other structures, a straightforward review process proves to be adequate for attaining contours that meet clinical acceptability standards. These considerations can help guide the clinical workflow for applying and reviewing automatic contouring, thereby reducing the effective impact of contouring variability and expediting the overall planning process.
Finally, the two model frameworks proposed in this paper, rooted in image confidence algorithm and deep learning respectively, have demonstrated more stable and favorable performance for several key structures, including the GTV, brainstem, eyes, and lenses, while maintaining performance comparable to the best individual DL models for most other OARs. In Method A, the intersection and union of contours from multiple DL models are used to define a trimap, and an image-based confidence algorithm is applied only within the uncertain region. Regions where the models strongly agree are therefore preserved, whereas isolated discrepancies from any single model are down-weighted unless they are supported by the underlying image features, which reduces the influence of outlier segmentations and makes the final contour less sensitive to occasional model failures. In Method B, the planning CT, a fused contour map that summarizes agreement patterns across the models, and the confidence map from Method A are provided as multi-channel inputs to a nnU-Net–based network. By jointly encoding these complementary channels, the network can learn and correct systematic bias patterns of individual models, while retaining their strengths where they perform well. These mechanisms are consistent with the observed increases in mean DSC and reductions in standard deviation for the GTV and several OARs, as well as with the finding that the fused outputs rarely fall below the performance of the better individual models. Compared with recent approaches^10–13^, our fusion framework achieves DSC that are broadly comparable to, or better than, those reported in similar settings, and does so without requiring additional imaging sequences. Admittedly, rigorous cross-study comparisons remain limited by the absence of universally accepted ground-truth contours and standardized evaluation protocols. Nevertheless, by leveraging both in-house and publicly available datasets for localized training, our framework provides a practical solution to enhance the robustness of automatic contouring.
It should be noted that this study has several limitations. First, all evaluations were performed on a single-institution cohort, and our conclusions have not yet been validated on an external test set. Although the commercial DL models themselves were trained on large multicentre datasets, the robustness and inter-model variability observed here may differ in other settings. Theoretically, the proposed frameworks and findings might be applicable to other clinical centres that follow similar guidelines for target volume delineation, but this requires confirmation in future external and cross-institutional studies. Secondly, although manual contours were used as the reference, they may not represent an absolute ground truth. The constraints in contrast and resolution inherent to medical imaging techniques render the creation of perfect true contours an arduous task at present^27,28^. Therefore, our conclusion should be interpreted as the clinical acceptability of these automatic contours in our institution. The impact of contour variations on dosimetry and treatment outcomes is a more clinically relevant endpoint. However, the relationship between them is not clear^29^. The absence of additional dosimetric assessments should be recognized as a shortcoming of our research.
Conclusion
The contours generated by DL models still have deficiencies in the application of NPC radiotherapy. In structures such as the GTV, lens, optic nerves, parotid glands, pituitary glands, temporal lobes, temporomandibular joints, and trachea, physicians need to strengthen the review and modification to reduce the impact of contouring variability and delineation uncertainty. Two model frameworks, based on an image confidence algorithm and deep learning respectively, were developed to effectively optimize the contours of the GTV, brainstem, eyes, and lens, while ensuring that performance is not degraded, thereby improving the robustness and reliability of the automatic contouring process.
Supplementary Information
Below is the link to the electronic supplementary material.
Supplementary Material 1
Supplementary Material 2
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Dai, X. et al. Multi-organ auto-delineation in head-and-neck MRI for radiation therapy using regional convolutional neural network. Phys. Med. Biol.67, (2022).10.1088/1361-6560/ac 3b 34PMC 881168334794138 · doi ↗ · pubmed ↗
- 2Taha, A. A. & Hanbury, A. Metrics for evaluating 3D medical image segmentation: analysis, selection, and tool. BMC Med. Imaging 15 (1), 15. (2015).10.1186/s 12880-015-0068-x PMC 453382526263899 · doi ↗ · pubmed ↗