MAFMamba: A Multi-Scale Adaptive Fusion Network for Semantic Segmentation of High-Resolution Remote Sensing Images
Boxu Li, Xiaobing Yang, Yingjie Fan

TL;DR
This paper introduces MAFMamba, a new network for segmenting high-resolution satellite images that better handles scale variations and balances local and global features.
Contribution
MAFMamba introduces a novel multi-scale adaptive fusion network with hybrid encoders and efficient modules for remote sensing image segmentation.
Findings
MAFMamba outperforms existing CNN, Transformer, and Mamba-based methods on standard remote sensing datasets.
The model achieves high accuracy with linear computational complexity and low memory usage.
The proposed modules effectively bridge the semantic gap and enhance multi-scale feature representation.
Abstract
With rapid advancements in sub-meter satellite and aerial imaging technologies, high-resolution remote sensing imagery has become a pivotal source for geospatial information acquisition. However, current semantic segmentation models encounter two primary challenges: (1) the inherent trade-off between capturing long-range global context and preserving precise local structural details—where excessive reliance on downsampled deep semantics often results in blurred boundaries and the loss of small objects and (2) the difficulty in modeling complex scenes with extreme scale variations, where objects of the same category exhibit drastically different morphological features. To address these issues, this paper introduces MAFMamba, a multi-scale adaptive fusion visual Mamba network tailored for high-resolution remote sensing images. To mitigate scale variation, we design a lightweight hybrid…
Click any figure to enlarge with its caption.
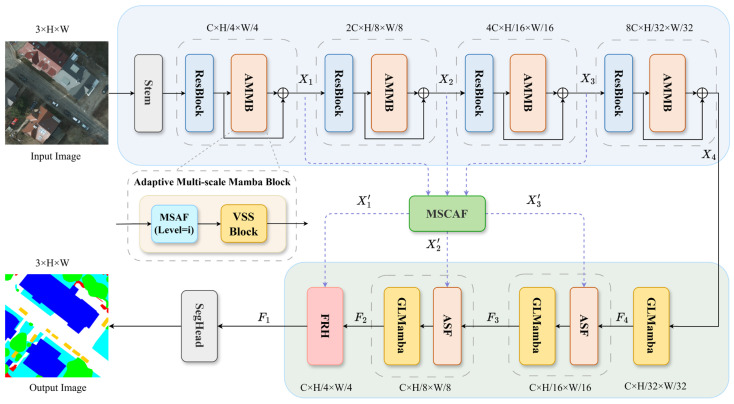 Figure 1
Figure 1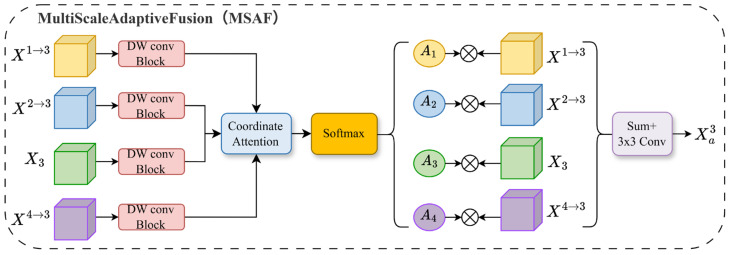 Figure 2
Figure 2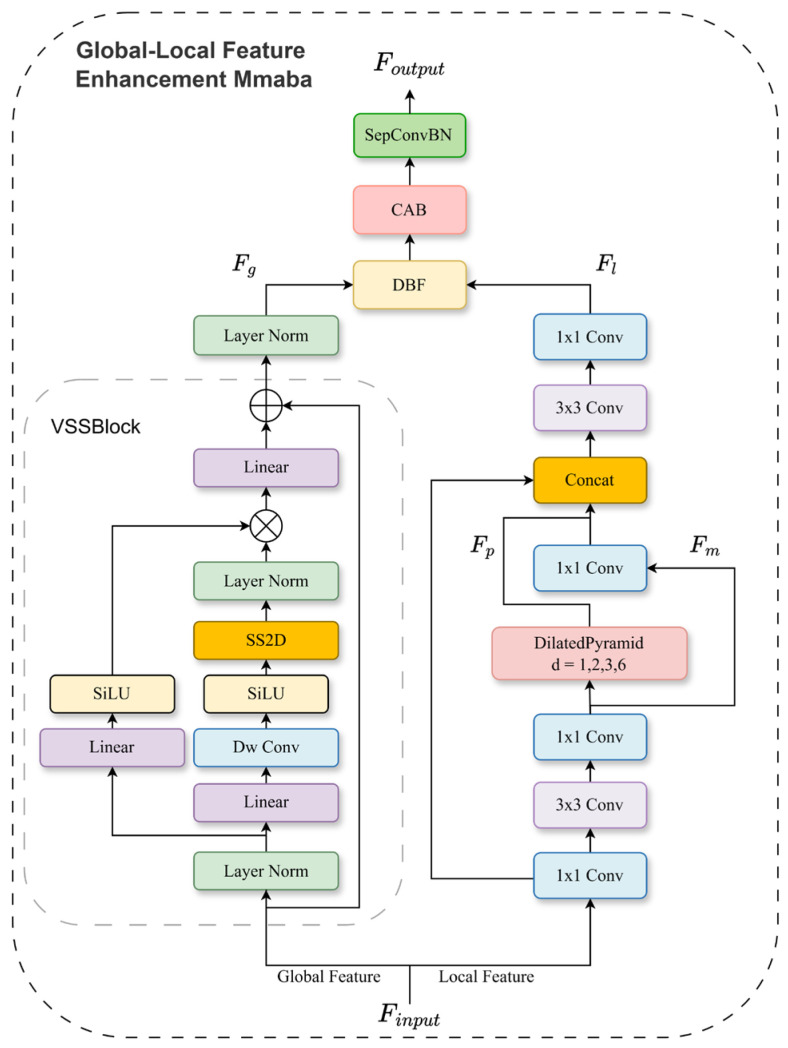 Figure 3
Figure 3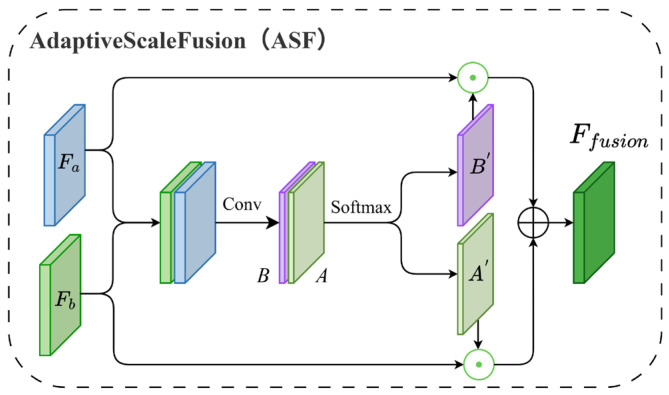 Figure 4
Figure 4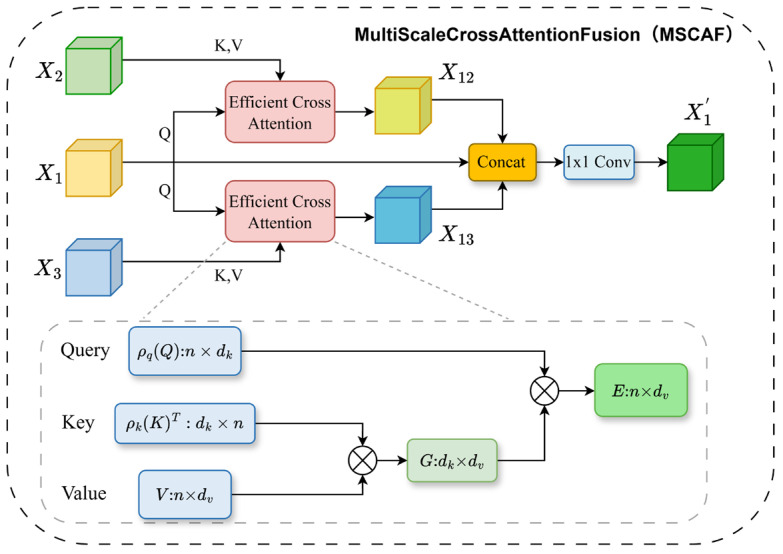 Figure 5
Figure 5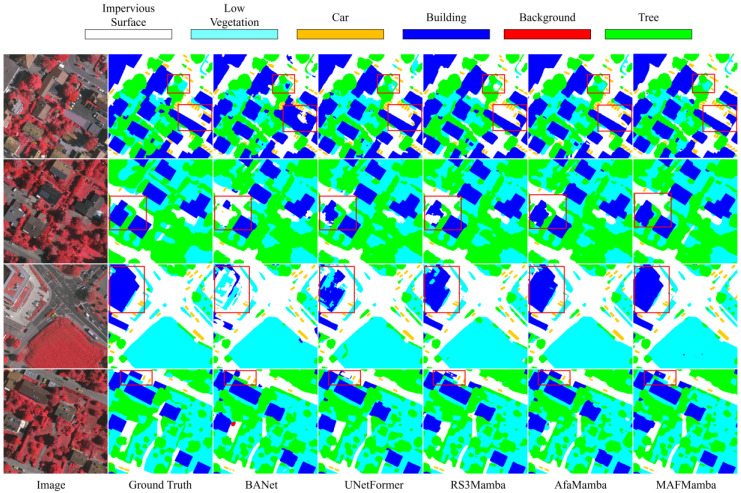 Figure 6
Figure 6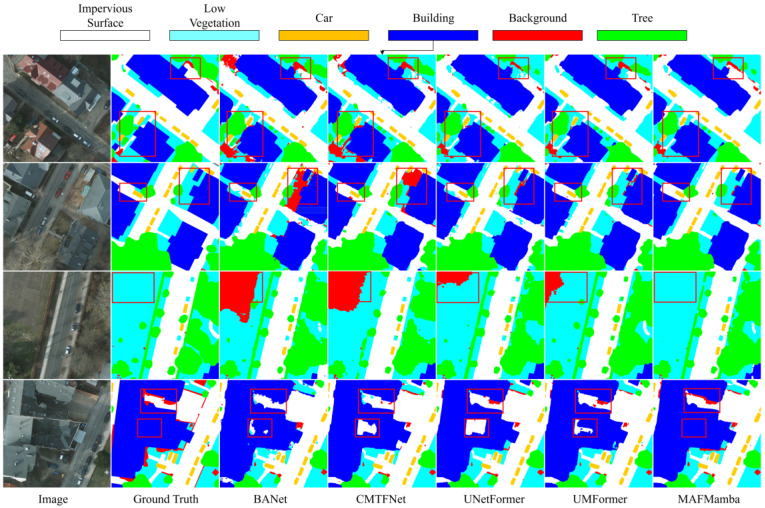 Figure 7
Figure 7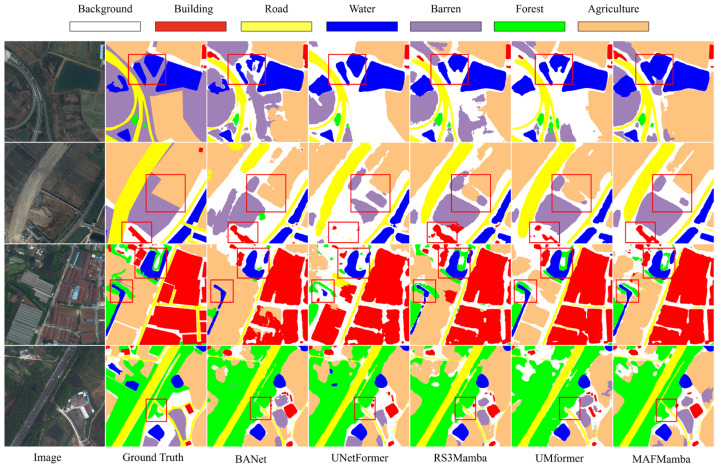 Figure 8
Figure 8Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAdvanced Neural Network Applications · Remote-Sensing Image Classification · Domain Adaptation and Few-Shot Learning
1. Introduction
Remote sensing imagery serves as a critical data source for geospatial information, finding widespread application in various fields including environmental monitoring [1], urban planning [2], agricultural management [3], and disaster assessment [4]. Advancements in satellite and aerial imaging technologies have significantly lowered the barriers to accessing high-resolution imagery, offering unprecedented visual detail for fine-scale object recognition [5]. These high-resolution images provide not only sub-meter spatial resolution but also shorter revisit times, enabling clear depictions of object structures, contours, and contextual information. Consequently, they provide robust data support for both scientific research and industrial decision-making [4].
Semantic segmentation of high-resolution remote sensing imagery acts as a vital link between raw image data and practical applications. The objective is to assign precise land cover labels to each pixel, facilitating industrial land use planning, intelligent urban management, and automated surface information extraction. Traditional segmentation techniques, which rely heavily on low-level features such as spectra and textures, struggle to address issues related to intra-class heterogeneity and inter-class similarity in high-resolution images, often resulting in inadequate performance in complex environments [6]. As spatial resolution increases, these traditional methods encounter growing difficulties in accurately delineating boundaries and identifying small targets.
In recent years, deep learning has demonstrated impressive feature learning and abstraction capabilities in remote sensing image segmentation, particularly improving accuracy in sub-meter imagery tasks. Nevertheless, the intricate features and geometric details of high-resolution images remain difficult for medium- and low-resolution models to capture effectively. Moreover, a focus on high-level semantics can compromise edge and shape retention, negatively impacting overall classification accuracy [7,8]. Remote sensing scenes exhibit distinct multi-scale characteristics [9]; the same object categories often display significant variations in morphology and context across different scales, necessitating models that incorporate cross-scale joint modeling capabilities [10]. Current deep learning-based approaches for remote sensing image semantic segmentation generally fall into three categories: Convolutional Neural Networks (CNNs), Vision Transformers (ViTs), and emerging Mamba architectures grounded in State Space Models (SSMs).
1.1. Convolutional Neural Network Segmentation Methods
CNNs excel at detailed feature extraction due to their local receptive fields and weight-sharing mechanisms. Fully Convolutional Networks (FCN) [11] was the first to propose an end-to-end fully convolutional segmentation approach compatible with images of any size; however, its simple upsampling often leads to a loss of spatial details and blurred boundaries. U-Net [12] introduced a symmetric encoder–decoder architecture with skip connections for multi-level feature fusion, effectively compensating for down-sampling losses and becoming a mainstream structure for semantic segmentation. Subsequent works such as [13,14,15,16] further optimized CNN architectures; for example, the DeepLab series introduced Atrous Spatial Pyramid Pooling (ASPP) [17]; ABCNet [18] designed bilateral context attention modules to enhance edges; and MANet [19] improved road extraction efficiency from aerial imagery using lightweight multi-scale aggregation units.
In addition to architectural optimizations, novel learning paradigms such as masked supervised learning [20] have been proposed to force the network to capture more robust global contextual representations. Beyond remote sensing, advanced multi-scale feature fusion strategies have also emerged in general object and text detection tasks. For instance, AFPN [21] proposes an asymptotic feature pyramid network to facilitate direct interaction across non-adjacent levels. Similarly, CM-Net [22] utilizes concentric masks to capture distinct shape characteristics, while Zoom Text Detector [23] employs a zoom-in strategy to handle extreme scale variations. Although these methods demonstrate effective feature fusion capabilities, they are primarily tailored for instance-level detection or specific shape priors. In contrast, our strategy focuses on dense pixel-level semantic modeling, employing adaptive Coordinate Attention (CA) to dynamically recalibrate weights for the complex, unstructured scale variations inherent in remote sensing scenes. However, the fixed receptive field of CNNs limits their global context modeling capability, making it difficult to effectively distinguish intra-class heterogeneity and inter-class similarity in complex remote sensing scenes, thereby limiting segmentation performance.
1.2. Vision Transformer Segmentation Methods
To overcome the limitations of local constraints in convolutional feature extraction, Transformers were introduced into remote sensing image semantic segmentation tasks. Vision Transformers (ViT) [24] convert 2D image data into 1D sequences, utilizing self-attention mechanisms to model global dependencies between pixels, thereby effectively capturing global contextual information within images. Architectures relying solely on Transformers—such as Segmenter [25] and SegFormer [26]—have demonstrated superior performance over conventional CNNs by explicitly modeling global relationships. Hybrid structures combine the local feature extraction of CNNs with the global modeling advantages of Transformers. For example, FTransUNet [16] uses CNNs for shallow detail extraction and employs a three-stage fusion Transformer (FVit) for cross-modal global semantics, achieving complementary local–global feature integration. DC-Swin [27] and UNetFormer [28] utilize Swin Transformer [29] parallel branches and cross-scale attention to achieve local–global complementarity. However, the quadratic complexity of self-attention results in high inference memory usage for high-resolution images. Reformer [30] and Longformer [31] use sparse attention matrices, significantly reducing computational load and memory usage by selectively focusing on local or globally important information. Nevertheless, these methods inevitably lose some critical global contextual information, especially in high-resolution image processing, which weakens global feature extraction capabilities.
1.3. Mamba Segmentation Methods
The Mamba architecture [32] based on State Space Models (SSM), has recently emerged as a potential alternative to Transformers due to its linear computational complexity and proficiency in long-range dependency modeling, demonstrating distinct advantages in remote sensing image semantic segmentation tasks. Visual State Space Models (VSS) optimize scanning strategies to better suit visual tasks, significantly improving segmentation accuracy and efficiency. Various SSM-based Mamba models have been successfully deployed across diverse applications, including Vision Mamba [33], VMamba [34], PlainMamba [35], and MambaVision [36] for general vision tasks. Samba [37] pioneered the application of SSMs in remote sensing image semantic segmentation, substituting the multi-head self-attention mechanism of Vision Transformers to markedly enhance segmentation accuracy and inference efficiency without relying on pre-trained weights. RS3Mamba [38] introduced a dual-branch structure, merging CNN and VSS features through a pre-trained VSS auxiliary branch, surpassing existing methods but at the expense of increased computational costs due to its complex structure. CM-UNet [39] integrates a ResNet-18 encoder with a Mamba decoder, incorporating channel-wise spatial attention mechanisms to boost feature representation, though gating mechanisms may impact inference efficiency. Additionally, Pan-Mamba [40] and ChangeMamba [41] further validate the potential of VSS in multi-scale feature extraction from remote sensing images. Recent advancements, such as DefMamba [42] and ACMamba [43], refine local feature extraction through deformable windows and asymmetric consensus mechanisms, striving to balance accuracy and efficiency. However, current VSS-based approaches typically flatten 2D images into 1D sequences for global scanning, inherently disrupting spatial structural integrity. Consequently, while these methods excel at global modeling, they often neglect local feature expression and lack effective mechanisms for cross-scale interaction. This limitation results in two critical issues in complex remote sensing scenarios: (1) the loss of high-frequency local details (e.g., edges and small targets) due to the dominance of global context and (2) the inability to effectively represent objects with large-scale variations, leading to semantic inconsistencies.
To overcome the limitations associated with insufficient local detail modeling and inadequate multi-scale fusion, we propose a Multi-scale Feature Adaptive Fusion Mamba network (MAFMamba) for the semantic segmentation of high-resolution remote sensing imagery. MAFMamba employs a hybrid encoder–decoder architecture designed to synergistically integrate local, global, and multi-scale information. Our primary contributions are summarized as follows. Our primary contributions are as follows:
- The MAFMamba Network: We propose MAFMamba, a novel multi-scale adaptive fusion network tailored for high-resolution remote sensing imagery. Extensive experiments on the ISPRS Potsdam and Vaihingen benchmarks demonstrate that MAFMamba achieves state-of-the-art results in terms of both mean Intersection over Union (mIoU) and mean F1-score (mF1).
- The Adaptive Multi-scale Mamba Block (AMMB): To specifically mitigate the challenge of scale variation, we design the AMMB for the encoder. It incorporates a novel Multi-scale Adaptive Fusion (MSAF) mechanism that utilizes coordinate attention to dynamically recalibrate features across different levels. This ensures a robust representation of objects at varying scales, which is subsequently processed by VSSLayers to incorporate long-range dependencies.
- The Global–Local Mamba Block (GLMamba): To address the loss of local details, we introduce the GLMamba block for feature enhancement within the decoder. Adopting a dual-branch structure, it complements local fine-grained features (extracted via convolution) with global long-range dependencies (modeled via VSS), thereby ensuring precise boundary delineation and improved small object detection.
- The Multi-Scale Cross-Attention Fusion Module (MSCAF): To transcend the limitations of standard skip connections, we propose the MSCAF module. It supersedes traditional connections by employing an efficient cross-attention mechanism with linear complexity. MSCAF explicitly aligns and merges multi-scale features sourced from different encoder stages, effectively bridging the semantic gap and enhancing cross-scale consistency.
2. Methods
This section elaborates on the proposed MAFMamba framework. We first present the Overall Architecture (Section 2.1), followed by the core components: the Adaptive Multi-scale Mamba Block (AMMB, Section 2.2) in the encoder, the Global–Local Mamba Block (GLMamba, Section 2.3) and Adaptive Scale Fusion (ASF, Section 2.4) in the decoder, and the Multi-Scale Cross-Attention Fusion (MSCAF, Section 2.5) module that bridges these stages. Finally, we define the loss function and evaluation metrics.
2.1. Overall Architecture
Our proposed MAFMamba network adopts an encoder–decoder architecture, as illustrated in Figure 1. The overall framework constitutes a standard encoder–decoder network comprising three principal components: (1) a lightweight CNN-based encoder integrated with Adaptive Multi-scale Mamba Blocks (AMMB) for multi-scale feature extraction and global dependency modeling; (2) a Multi-Scale Cross-Attention Fusion (MSCAF) module designed to bridge the semantic gap between low-level encoder features and high-level decoder features; and (3) a decoder network incorporating Global–Local Mamba blocks (GLMamba) and an Adaptive Scale Fusion (ASF) module. Specifically, given an input remote sensing image, the encoder is built upon a ResNet-18 backbone. Initial features are extracted via a convolutional layer, followed by batch normalization, an activation function, and a max-pooling operation, resulting in a feature stride of 4. Subsequently, four residual blocks (Layer1–Layer4) generate feature maps with progressively decreasing spatial resolutions, denoted as for , with dimensions defined as , , . To facilitate the adaptive fusion of multi-scale features and enhance global modeling capabilities, an AMMB is inserted after each residual block. Leveraging the interaction between the Multi-scale Adaptive Fusion (MSAF) mechanism and the VSSLayer, the AMMB performs progressive multi-scale interaction modeling across the four encoder stages. This process yields a sequence of four comprehensively enhanced multi-scale features. The encoder outputs—specifically and , which carry rich multi-scale information—are subsequently fed into the MSCAF module. Within this module, a computationally efficient cross-attention mechanism facilitates bidirectional feature interaction, producing refined auxiliary features and . The decoder receives high-level features from the encoder’s top layer and sequentially processes them through the ASF module and the GLMamba block to progressively restore spatial resolution and refine feature representations. Within each GLMamba, the global branch employs a VSSLayer to capture long-range contextual information, while the local branch enhances sensitivity to edges, textures, and shadows through a dilated pyramid convolution structure. Both branches feed into a lightweight dual-branch adaptive fusion mechanism to achieve the complementary integration of global and local information. Additionally, the ASF module is employed during successive upsampling stages. It utilizes Softmax-generated weights to adaptively fuse high-level semantic information with low-level details, thereby ensuring effective resolution recovery while maintaining semantic consistency. Finally, the output features undergo spatial and channel optimization via the Feature Refinement Head (FRH), followed by the generation of pixel-level classification results through the Segmentation Head.
2.2. Adaptive Multi-Scale Mamba Block
Effective fusion of multi-scale semantic information and global context modeling are critical for the semantic segmentation of remote sensing images, particularly where objects of vastly different scales frequent co-occur. Conventional Convolutional Neural Networks (CNNs) are constrained by limited local receptive fields, which hinders cross-hierarchical multi-scale semantic alignment. Conversely, while Transformer-based architectures excel at capturing global relationships, they incur substantial computational overhead. Pure State Space Model (e.g., Mamba) variants, although efficient in modeling long-range dependencies, typically lack explicit mechanisms for globally integrating multi-scale information. Existing Feature Pyramid Network (FPN) variants, such as ASFF [44] and MFAF [45], facilitate cross-layer feature fusion. However, they commonly rely on simplistic operations—such as channel concatenation and convolutions—to generate fixed fusion weights. This inability to adaptively recalibrate scale-wise contributions, based on local pixel context, often leads to semantic inconsistencies or blurred boundaries in regions exhibiting extreme scale variations, such as vehicles, narrow roads, and shadow edges.
To address these limitations, we introduce an Adaptive Multi-scale Mamba Block (AMMB), serving as a core enhancement unit appended after each encoder stage. The AMMB design centers on a synergistic, two-phase workflow involving a novel Multi-scale Adaptive Fusion (MSAF) module and a Vision State Space Layer (VSSLayer). This “fuse-then-model” paradigm follows a strategy of “local enrichment followed by global diffusion”: it first dynamically integrates features across scales via the MSAF to provide a spatially rich representation, and subsequently injects long-range dependencies through the VSSLayer. Although this sequential structure prioritizes bottom-up refinement, we incorporate residual connections to prevent information bottlenecks and preserve original feature cues. Consequently, at each encoder stage, the AMMB achieves a cohesive integration of local fine-grained detail preservation, adaptive multi-scale fusion, and global dependency modeling. This approach effectively mitigates the issues of semantic inconsistency and boundary ambiguity prevalent in complex remote sensing scenarios.
2.2.1. Multi-Scale Adaptive Fusion Module
The MSAF serves as the initial stage within the AMMB. Its principal innovation is the adoption of a Coordinate Attention mechanism to facilitate pixel-wise dynamic weight generation. This approach supersedes conventional fusion strategies that rely on fixed or channel-wise weighting, enabling genuinely adaptive fusion across both spatial and scale dimensions. While inspired by prior works such as ASFF [44] and the MFAF module in AfaMamba [45], our key optimization lies in the weight generation mechanism. Specifically, we transcend simple convolutional operations or channel attention methods by incorporating a lightweight coordinate attention block. This design enables the concurrent capture of inter-channel dependencies and spatial positional cues, yielding precise, spatially aware fusion weights.
Specifically, at each encoding stage, the MSAF module receives features from all hierarchical levels, denoted as . Leveraging a coordinate attention mechanism for cross-scale adaptive fusion, it produces a semantically enhanced feature map that maintains the same spatial resolution as the current level . To facilitate understanding, we detail the process using Stage 3 as a representative example, as shown in Figure 2. The procedure is as follows:
Feature Scale Unification: To facilitate effective cross-scale information fusion, the first step involves resizing all input feature maps uniform spatial resolution, matching the target scale of the current stage (i.e., the dimensions of where . We employ an adaptive resizing strategy tailored to the resolution of each input feature map. For feature maps with higher resolution than the target (e.g., , ), channel numbers are first adjusted via a convolution, followed by spatial downsampling using bilinear interpolation with a scale factor . Conversely, for feature maps of lower resolution (e.g., ), a strided convolutional layer is applied for initial feature transformation, followed by bilinear interpolation for upsampling. The feature map , already at the target resolution, undergoes channel adjustment via a convolution. This procedure ensures the precise alignment of all feature maps in both spatial and channel dimensions, establishing a consistent foundation for subsequent adaptive weighted fusion. The overall operation can be formulated as follows:
Following this step, we obtain four feature maps of consistent dimensions: , , , .
Enhanced Weight Feature Extraction: To produce spatially aware fusion weights, the MSAF module incorporates a lightweight enhancement branch for each of the four spatially aligned feature maps . This branch sequentially applies a depthwise separable convolution, batch normalization, and a ReLU activation function to capture localized spatial context. Subsequently, a convolutional layer projects the extracted features into a lower-dimensional space (e.g., 16 channels), yielding a compact representation termed the weight feature map (where ):
This design effectively enhances the spatial representational capacity of weight prediction with negligible additional computational overhead.
Adaptive Weight Generation: In contrast to conventional channel attention mechanisms, the MSAF module employs coordinate attention to produce spatially adaptive fusion weights. Specifically, the set of four weight feature maps is first concatenated. The resulting tensor is then fed into a coordinate attention block, which independently captures long-range spatial dependencies along the horizontal and vertical axes. This process yields four pixel-wise fusion weight maps, formulated as follows:
Weighted Fusion and Feature Enhancement: The generated spatial weights are applied to the aligned multi-scale features to compute their pixel-wise weighted sum. This aggregated representation is then refined by a convolutional layer, ultimately producing the stage-specific, adaptively fused feature .
where denotes the element-wise multiplication, enabling the spatial weights to dynamically recalibrate the feature maps at the pixel level before aggregation.
Although the output of the MSAF module fuses multi-scale information, its receptive field is essentially limited by the convolutional operation. To capture global long-range dependencies, we feed into the corresponding Vision State Space Layer.
2.2.2. Visual State Space Layer
While the MSAF-generated feature incorporates multi-scale cues, its effective receptive field remains constrained by the locality of convolutional operations. To compensate for this limitation and enable comprehensive global dependency modeling, is processed by a subsequent Vision State Space Layer (VSSLayer). As established in prior work [30], the VSSLayer—specifically its core 2D Selective Scan module (SS2D)—constitutes a pivotal mechanism for establishing long-range contextual interactions. Within this layer, the input feature map is first unfolded into a sequential representation. At the core of the VSSLayer lies the Linear State Space Model (SSM), which can be represented by a linear ordinary differential equation (ODE) to model continuous system dynamics:
where represents the evolution parameter, and are projection parameters, and is the parameter for the skip connection. denotes the input sequence, represents the hidden state, and indicates the derivative of the hidden state. However, as the VSSM processes discrete 1-D image sequences, the continuous parameters and must be discretized using the Zero-Order Hold (ZOH) method. Specifically, a timescale parameter is introduced to transform the continuous parameters into their discrete counterparts and :
After discretization, Equation (9) can be rewritten in the recursive RNN form suited for efficient inference:
The core component of the VSSLayer is the 2D Selective Scan (SS2D) module. The SS2D module processes the input 2D feature map by performing selective scanning along four principal directions (upward, downward, leftward, and rightward), thereby modeling long-range spatial dependencies across varying propagation paths. The detailed workflow of the SS2D module is described below:
First, the input feature undergoes Patch Expansion to widen its receptive field, followed by layer normalization and channel projection through a linear embedding layer:
A depthwise separable convolution is then applied to enhance local feature responses, followed by SiLU activation to obtain an enriched representation:
Next, directional state sequences are extracted by scanning along the four predefined directions:
Each directional sequence is processed by the S6 (Selective Scan State Space) model to capture long-range dependencies, after which the resulting representations are merged:
In parallel, a bypass branch processes through another linear embedding and SiLU activation to produce an auxiliary feature map. The main output is normalized and then fused with the bypass output via element-wise multiplication, after which a residual connection from the original input is added:
where denotes the element-wise Hadamard product. The adaptively fused feature is subsequently passed into the corresponding VSSLayer. This layer effectively integrates global contextual information into multi-scale features, thereby strengthening representation of large objects and complex structural patterns:
To retain the high-frequency spatial details from the original encoder features and promote training stability, a residual connection is employed to combine the VSSLayer output with the encoder feature from the same stage:
The denotes the final output of the AMMB module at stage . It integrates multi-scale semantic information aggregated across different levels by the MSAF, is equipped with global context awareness via the VSSLayer, and retains the original fine-grained features.
Within the MAFMamba encoder, the VSSLayer and the MSAF module constitute the AMMB feature enhancement unit. This unit provides the subsequent decoder with a multi-scale feature sequence that is semantically coherent, rich in detail, and globally aware. In the decoder, the global branch leverages the VSSLayer to model long-range dependencies, thereby capturing broad-context information within the remote sensing imagery. The VSSLayer is built upon the visual state space mechanism of the Mamba model. Its primary objective is to capture global context and model long-range dependencies, addressing the constraint of the limited receptive field inherent in traditional convolutional operations. This capability contributes to enhanced segmentation accuracy of the MAFMamba network.
2.3. Global–Local Feature Enhancement Mamba
To fully exploit both local structural details and global contextual information in high-resolution remote sensing imagery, we design a Global–Local Feature Enhancement Mamba (GLMamba) module. It is tailored for the decoder stage to synergistically bolster local texture preservation and long-range dependency modeling. Unlike traditional approaches that simply concatenate local and global pathways, our GLMamba employs a dual-branch parallel architecture. Specifically, one branch extracts features via a local multi-scale convolutional path, while the other captures dependencies through a global state space modeling path. These complementary features are then dynamically integrated via an adaptive fusion mechanism. This design empowers the model to better perceive complex land-cover structures, fine edge details, and long-range semantic relationships. The overall structure of the GLMamba module is illustrated in Figure 3.
Local Branch: As illustrated in the right branch of Figure 3, the local branch is designed to capture multi-scale contextual features. To achieve this efficiently, it first employs a bottleneck structure. This bottleneck expands the input features into a higher-dimensional space with minimal computational overhead, followed by feature encoding. This step yields a richer joint representation of local semantics without increasing channel complexity for subsequent operations. Subsequently, a Dilated Pyramid Module (DPM) is introduced. This module utilizes parallel dilated convolutions with different dilation rates (1, 2, 3, 6) to capture contextual information at multiple scales. All branches maintain the original spatial resolution. Features from each branch undergo batch normalization and ReLU activation for calibration. The resulting multi-scale features are then concatenated along the channel dimension and fused into a unified representation via a convolution. This design significantly enhances the model’s sensitivity to structures of varying scales, while preserving spatial information that is often lost in pooling operations. Given an input feature , the overall modeling process of the local branch can be formulated as follows:
where denotes the intermediate feature projected into a high-dimensional space for refined encoding, denotes a composite operation consisting of a convolution, followed by Batch Normalization and a ReLU activation function. denotes the Dilated Convolution Pyramid Module, where indicates a dilated convolution with a dilation rate . is a convolution that integrates the multi-branch outputs. The resultant local branch output , thus integrates rich fine-grained details with effective multi-scale contextual awareness.
Global Branch: This branch is designed to capture long-range dependencies and global contextual information from the input feature maps, as illustrated on the left side of Figure 3. Its core component is the VSSLayer (detailed in Section 2.2.2), which effectively processes global information while maintaining computational efficiency. The input features are first reshaped to suit the VSSLayer’s operation. After global modeling, they are projected back to the original spatial dimensions, thereby enhancing the feature representation without loss of spatial resolution. The output of the global branch is denoted as follows:
Feature Fusion Mechanism: To effectively integrate the local branch output and the global branch output , we propose an adaptive dual-branch fusion mechanism augmented by a channel-spatial attention module for refinement. The fusion process begins by concatenating and along the channel dimension. A global average pooling layer then compresses this concatenated feature into a descriptor . This descriptor passes through two consecutive convolutional layers (with a ReLU activation in between) to reduce its dimensionality to 2, followed by a Softmax function to generate a pair of spatially shared adaptive weights . These weights are applied to perform an adaptive fusion:
where denotes the preliminary fused feature map obtained by the adaptive weighted summation of local and global branches. This adaptive, sample-wise and channel-wise weighting allows the network to dynamically balance the contributions of fine-grained details and global semantics. It effectively mitigates the discrepancies caused by distributional or scale mismatches between the two feature types—a common issue with simple concatenation or fixed-weight fusion—thereby achieving more stable integration and improved semantic coherence.
To further suppress noise and accentuate informative regions, is refined by a Channel-Spatial Attention Block (CAB), yielding the final output:
where sequentially applies channel attention and spatial attention to adaptively recalibrate feature importance across their respective dimensions. The subsequent depthwise separable convolution (with batch normalization) efficiently aggregates multi-scale contextual information while maintaining a low parameter count.
2.4. Adaptive Scale Fusion
To effectively integrate multi-level features during the decoding phase—where high-resolution features possess rich spatial details but weak semantics, while low-resolution features contain strong semantics but lack spatial definition—we propose an Adaptive Scale Fusion (ASF) module. As illustrated in Figure 4, the ASF balances detailed and semantic information by fusing multi-scale features via adaptive weighting.
The ASF module accepts two primary inputs: (1) the three-stage feature maps (denoted as , , ) generated by the Multi-Scale Cross-Attention Fusion (MSCAF) module, and (2) the feature map from the preceding decoder stage, with . These features are first aligned in terms of channel dimensions and spatial resolution. Subsequently, they are concatenated and processed by the ASF module. Internally, the ASF employs convolutional layers followed by a Softmax activation to generate two spatial attention maps, and . These maps are utilized to adaptively weight the features for fusion. Specifically, a weighted summation is performed based on the learned attention weights:
where denotes the element-wise Hadamard product. and represent the learned spatial attention weights, while and denote the low-resolution and high-resolution features, respectively, which have undergone dimensionality reduction and upsampling. Finally, the fused features undergo refinement via convolution, Batch Normalization, and ReLU activation. This step eliminates redundancy introduced during fusion and enhances nonlinear expressive power, yielding the final fused feature map .
2.5. Multi-Scale Cross-Attention Fusion Module
In semantic segmentation tasks, the encoder–decoder architecture has established itself as the dominant paradigm. This architecture progressively downsamples input data via the encoder to extract high-level semantic features, and subsequently upsamples via the decoder to restore spatial resolution. While traditional skip connections preserve the spatial details of high-resolution features, they frequently overlook the significant semantic gap existing between shallow encoder features (e.g., ) and deep features (e.g., ). Shallow features are characterized by rich spatial detail but weak semantics, whereas deep features possess abundant semantic information yet suffer from low spatial resolution. Direct fusion often precipitates semantic inconsistencies and information redundancy, thereby introducing noise and irrelevant context. Consequently, this results in issues such as blurred object boundaries and the failure to detect small objects, ultimately limiting segmentation accuracy.
To mitigate these issues, we propose the Multi-Scale Cross-Attention Fusion (MSCAF) module. The core objective of this module is to supersede traditional skip connections with an efficient cross-attention mechanism, thereby facilitating explicit interaction and information alignment between features at different scales. This design not only bridges the semantic gap between hierarchical features but also enables features at each scale to pre-incorporate contextual information from other scales prior to decoding, thus enhancing semantic consistency and feature complementarity.
The MSCAF module takes as input features from three encoder stages: , where . It facilitates bidirectional information aggregation between these features through pairwise efficient cross-attention. The detailed workflow is formulated as follows:
Query, Key, and Value Projection: The query feature (target scale) and context feature (source scale, where ) are independently projected onto the query, key, and value subspaces via separate convolutions:
In this equation, are the learnable weight matrices of the convolutions. represents the query feature map containing the target spatial structure, while and represent t the key and value feature maps providing contextual information from the source scale. To reduce computational complexity, we apply a dimension reduction rate of (i.e., ).
Efficient Cross-Attention Computation: Traditional dot-product attention necessitates the construction of a correlation matrix with dimensions , where computational overhead increases significantly with resolution, rendering it unsuitable for remote sensing scenarios. Adopting the efficient attention mechanism utilized in [46], MSCAF reduces the quadratic complexity of standard cross-attention to linear complexity. Specifically, we first apply a column-wise Softmax along the channel dimension to the key matrix to derive a global context descriptor, followed by a row-wise Softmax along the spatial dimension of the query matrix for information retrieval:
where and represent the application of the Softmax function independently to each row and column of the matrix, respectively, forming the spatial query weights and context-scale semantic summaries. This formulation reduces the computational complexity from to , thereby ensuring the feasibility of high-resolution remote sensing feature fusion.
Bidirectional Aggregation and Enhancement: To achieve comprehensive cross-scale information exchange, MSCAF performs bidirectional efficient cross-attention computations for all feature pairs. Upon completion, each original feature is fused with its aggregated contextual information from other scales. Specifically, for each scale’s feature , we concatenate it with all attention results obtained using it as the query source. This concatenated feature then passes through a convolutional layer for channel fusion and dimensionality reduction, generating the final enhanced feature :
The module ultimately outputs three enhanced feature maps , For instance, as illustrated in Figure 5 (taking ), the enhanced feature is generated by aggregating complementary semantic contexts from and . These features preserve their intrinsic strengths while absorbing complementary information from other scales, providing the decoder with more robust and informative inputs. This significantly boosts segmentation accuracy in complex remote sensing scenes.
2.6. Loss Function
To enhance semantic segmentation performance on remote sensing imagery, we employ a composite loss function that integrates Soft Cross-Entropy (SCE) loss with Dice loss. This design jointly optimizes both pixel-wise classification accuracy and region-wise overlap consistency, thereby addressing segmentation challenges at varying granularities. The combined loss is formulated as
where and are weighting coefficients that balance the two loss terms. Based on sensitivity analysis, we empirically set = = 1.0, as this configuration yields optimal performance by effectively weighing pixel-level classification against region-level consistency. the SCE loss ( ) is defined as
The Dice loss ( ) is expressed as
where and denote the number of pixels and categories, respectively, represents the binary ground truth label, while indicates the predicted confidence that pixel belongs to category . By jointly optimizing the cross-entropy and Dice components, the model learns category discrimination from a probability distribution perspective while simultaneously enhancing boundary segmentation accuracy through regional overlap optimization.
2.7. Evaluation Metrics
To comprehensively evaluate the segmentation performance of the proposed model, we employ three standard metrics: mean Intersection over Union (mIoU), Overall Accuracy (OA), and mean F1-Score (mF1). Specifically, mIoU quantifies the average spatial overlap between predicted and ground truth regions across all categories. OA measures global pixel-wise classification accuracy. mF1, representing the harmonic mean of per-class precision and recall, offers a robust assessment, particularly in the presence of class imbalance. The mathematical formulations for these metrics are defined as follows:
where denotes the number of classes in the dataset, , , , and represent the number of true positive, false positive, true negative, and false negative pixels for class k, respectively.
3. Experiment
In this section, we first detail the Experimental Setup (Section 3.1) and Datasets (Section 3.2). Subsequently, we present comprehensive Performance Comparisons (Section 3.3) against state-of-the-art methods on the ISPRS Potsdam, Vaihingen, and LoveDA datasets. To validate the effectiveness of our core components, we conduct Ablation Studies (Section 3.4). Finally, we provide a Complexity Analysis (Section 3.5) to assess the model’s computational efficiency.
3.1. Experimental Setup
All experiments were conducted on NVIDIA Tesla V100 GPUs (32 GB VRAM, Nvidia, Santa Clara, CA, USA) using the PyTorch 2.1.0 framework with Python 3.10 and CUDA 12.1. We adopted a consistent training protocol across all models. The network was optimized using the AdamW optimizer with an initial learning rate of and a weight decay of 0.01. The parameters of the pre-trained backbone were fine-tuned at a reduced learning rate of . The learning rate was scheduled via a cosine annealing restart strategy. Training was performed for 80 epochs with a batch size of 4. To enhance model robustness, we applied extensive data augmentation during training. This included random horizontal/vertical flips, random rotations by multiples of , and random resizing with scaling factors sampled from {0.5, 0.75, 1.0, 1.25, 1.5}. Furthermore, Smart Crop and mosaic augmentation were incorporated with a probability of 0.25. All training images were resized to a fixed resolution of 1024 × 1024. During inference, we employed random flipping and multi-scale evaluation to ensure fair performance assessment.
To guarantee a rigorous comparison, all baseline methods—encompassing CNN-based, Transformer-based, and Mamba-based models—were retrained using their official open-source implementations. We strictly unified the experimental protocols: all methods were trained on the same hardware with identical input resolutions ( ), data augmentation strategies, and optimizer settings.
3.2. Dataset
To evaluate the performance of the proposed MAFMamba, experiments were conducted using three publicly available remote sensing semantic segmentation datasets: ISPRS Vaihingen, ISPRS Potsdam, and LoveDA.
ISPRS Potsdam Dataset: The Potsdam dataset comprises 38 True Orthophotos (TOP), each measuring pixels with a Ground Sampling Distance (GSD) of 5 cm. The dataset encompasses six object categories: Impervious Surfaces, Building, Low Vegetation, Tree, Vehicle, and Clutter (background). It provides four spectral bands (Red, Green, Blue, and Near-Infrared) alongside a Digital Surface Model (DSM). In our experiments, only the RGB bands were utilized. We strictly followed the official benchmark partition: 24 images were used for training, while the remaining 14 images (IDs: 2_13, 2_14, 3_13, 3_14, 4_13, 4_14, 4_15, 5_13, 5_14, 5_15, 6_13, 6_14, 6_15, 7_13) were reserved exclusively for testing. All images were cropped into pixel patches.
ISPRS Vaihingen Dataset: The Vaihingen dataset consists of 33 high-resolution image tiles, averaging pixels with a GSD of 9 cm. It includes five foreground categories (Impervious Surfaces, Building, Low Vegetation, Tree, Vehicle) and one background category (Clutter). The dataset provides three multispectral bands (Near-Infrared, Red, Green) as well as DSM and normalized DSM (nDSM) data. In our study, only the Near-Infrared (IR), Red, and Green bands were utilized. To adhere to the official protocol and prevent data leakage, we divided the dataset into mutually exclusive subsets: 17 tiles (IDs: 2, 4, 6, 8, 10, 12, 14, 16, 20, 22, 24, 27, 29, 31, 33, 35, and 38) were reserved for the Test Set. The remaining 16 tiles formed the Training Set. For hyperparameter optimization, we randomly partitioned 20% of the training patches to constitute a Validation Set, ensuring no spatial overlap between the training/validation samples and the Test Set. All tiles were cropped into pixel patches.
LoveDA Dataset: The LoveDA dataset contains 5987 high-resolution optical remote sensing images, each measuring pixels with a GSD of 0.3 m. Unlike the urban-centric ISPRS datasets, LoveDA encompasses both urban and rural landscapes collected from three different cities (Nanjing, Changzhou, and Wuhan). This diversity introduces significant challenges related to multi-scale objects, complex background clutter, and inconsistent class distributions. The dataset defines seven land-cover categories: Background, Building, Road, Water, Barren, Forest, and Agriculture. Only the RGB images were utilized in our experiments. We strictly adhered to the official data partition, using 2522 images for training, 1669 for validation, and 1796 for testing. All images were used as model inputs at their original resolution of pixels.
3.3. Performance Comparison
The quantitative comparisons of MAFMamba against state-of-the-art models on the ISPRS Vaihingen, Potsdam, and LoveDA datasets are summarized in Table 1, Table 2, and Table 3, respectively. The comparative analysis encompasses three distinct paradigms: (1) CNN-based models, including ESDINet [47], BANet [48], and MANet [19]; (2) CNN–Transformer hybrids, such as CMTFNet [49], UNetFormer [28], and DC-Swin [27]; and (3) CNN–Mamba hybrids, including PyramidMamba [50], RS3Mamba [38], AfaMamba [45], and UMFormer [51]. To ensure a rigorous evaluation, all models were trained and tested under identical experimental protocols. We employ four standard metrics: per-class F1 score, mean F1 (mF1), Overall Accuracy (OA), and mean Intersection over Union (mIoU). These metrics collectively assess pixel-wise classification precision, global correctness, and region-level segmentation overlap.
Performance Comparison on the Vaihingen Dataset: Table 1 presents the quantitative results for the Vaihingen test set. Notably, the proposed MAFMamba sets a new benchmark, achieving state-of-the-art performance across all three comprehensive metrics: mF1 (91.79%), OA (93.66%), and mIoU (85.09%). Compared to the second-best method, AfaMamba [45], our model demonstrates improvements of 0.46%, 0.32%, and 0.73%, respectively. At the category level, MAFMamba secures the highest F1 scores in three classes: Impervious Surface (97.09%), Building (96.30%), and Car (90.40%). Most significantly, it surpasses AfaMamba [45] by 0.96% in the “Car” category, a small target class typically susceptible to scale variations and shadow occlusions. When compared to classical CNN methods—such as ESDINet [47], which achieves an mF1 of only 89.99%—MAFMamba significantly enhances long-range dependency modeling through the integration of the Adaptive Multi-scale Mamba Block (AMMB) in the encoder and global–local interaction in the decoder. Furthermore, relative to CNN–Transformer hybrids like DC-Swin [28], our model achieves superior accuracy with reduced memory consumption. Compared to other Mamba-based baselines, the strategic incorporation of the MSCAF and ASF modules effectively bridges the semantic gap between multi-scale features. This robustness is particularly evident in the model’s ability to distinguish low vegetation from trees and to precisely delineate building boundaries.
Qualitative comparisons are illustrated in Figure 6. To ensure visual clarity, we selected representative state-of-the-art methods from different paradigms. As highlighted by the red rectangles, in scenarios characterized by complex shadow occlusions and dense building structures, BANet [48] and UNetFormer [28] exhibit noticeable boundary artifacts and fail to detect small vehicles. While RS3Mamba [38] improves overall coherence, it still misclassifies isolated vehicles and specific low vegetation regions. Similarly, AfaMamba [45] shows confusion between low vegetation and trees in certain areas. In contrast, the segmentation maps produced by MAFMamba display the smoothest boundaries, the most comprehensive detail preservation, the highest detection accuracy for small vehicles, and the clearest distinction between low vegetation and trees. This vividly demonstrates the model’s superior capability in balancing global–local features and aligning multi-scale information.
Performance Comparison on the Potsdam Dataset: Table 2 details the quantitative results for the Potsdam test set. Consistently, MAFMamba achieves state-of-the-art performance, recording an mF1 of 92.83%, OA of 91.35%, and mIoU of 86.89%. It outperforms the runner-up, UMFormer [51], by margins of 0.11%, 0.22%, and 0.59% in mF1, OA, and mIoU, respectively, and surpasses AfaMamba [45] by 0.34%, 0.40%, and 0.63%. Regarding per-class performance, MAFMamba obtains the highest F1 scores in three categories: Low Vegetation (88.29%), Tree (90.23%), and Car (96.71%). The substantial lead of 1.20% over UMFormer [51] on the challenging “Tree” class can be attributed to the adaptive cross-scale texture recalibration within the AMMB encoder and the effective global–local feature interplay in the GLMamba decoder.
Compared to traditional CNN methods, MAFMamba markedly reduces intra-class confusion. Against CNN–Transformer hybrids like CMTFNet [49], its linear-complexity state-space modeling ensures higher inference efficiency. Furthermore, relative to other Mamba-based approaches, the MSCAF module enables more precise multi-scale semantic alignment via efficient cross-attention. This results in superior segmentation fidelity in fine-grained regions, such as road-impervious surface boundaries and intricate tree canopy structures.
Qualitative results are presented in Figure 7. We again selected representative baselines to verify model robustness. In typical urban scenes featuring interleaved road networks and vegetation, BANet [48] and CMTFNet [49] exhibit frequent misclassifications at road edges and within background clutter. Although UNetFormer [28] successfully outlines large-scale buildings, its reconstruction of internal tree structures remains relatively coarse. UMFormer [51] also retains noise in background areas. Conversely, the prediction map generated by MAFMamba most closely resembles the Ground Truth, featuring sharp road boundaries, complete internal canopy textures, and minimal background noise. This is particularly notable in complex intersections and densely vegetated areas (highlighted by red boxes), demonstrating remarkable detail recovery and discriminative capability. These advantages stem primarily from the multi-scale adaptive fusion module and the hierarchical feature reconstruction strategy in the decoder, which enable a more refined integration of spatial structures and semantic relationships.
Performance Comparison on the LoveDA Dataset: To assess the model’s generalizability across varying spatial resolutions and diverse landscape types, we further evaluated MAFMamba on the LoveDA test set. The quantitative results are presented in Table 3. In contrast to the urban-centric ISPRS benchmarks, LoveDA features a lower spatial resolution (0.3 m) and poses unique challenges due to its inclusion of complex rural and agricultural scenes, characterized by large-scale unstructured textures (e.g., farmlands, forests, and water bodies) and sparse building distributions.
As shown in Table 3, MAFMamba achieves top-tier performance with an mIoU of 53.46%, surpassing the runner-up UMFormer [51] and AfaMamba [45] by 0.97% and 1.14%, respectively. Notably, our model demonstrates exceptional robustness in non-urban categories, obtaining the highest scores in Agriculture (64.51%), Water (81.47%), and Forest (46.81%). Specifically, compared to RS3Mamba [38], our method improves accuracy for the Agriculture class by 3.14%. This suggests that the proposed Multi-Scale Adaptive Fusion (MSAF) mechanism effectively aggregates multi-level semantics to resolve the scale variations inherent in vast farmland and natural terrains. Furthermore, in the Building category, which involves sparse and multi-scale rural structures, MAFMamba achieves a leading score of 59.26%, outperforming the CNN-based MANet [19] by 3.06%. These results confirm that MAFMamba possesses strong generalizability, maintaining high segmentation fidelity not only in dense urban areas but also in complex rural environments with varying image resolutions.
Qualitative comparisons for LoveDA are provided in Figure 8. As observed, BANet [48] and UNetFormer [28] exhibit noticeable misclassifications in complex transition zones; for instance, they fail to accurately delineate the irregular boundaries of water bodies (Row 1) and often confuse barren land with agriculture (Row 2). While Mamba-based methods like RS3Mamba [38] and UMFormer [51] improve global coherence, they still retain “salt-and-pepper” noise in regions with scattered objects, such as the sparse building areas in Row 3. In contrast, MAFMamba produces segmentation maps closest to the Ground Truth, yielding sharp, continuous boundaries for rural water bodies and effectively reconstructing the complete shapes of sparse buildings with minimal background noise. This demonstrates the model’s superior capability in handling the unstructured details of rural imagery, largely attributed to the AMMB module’s ability to strictly balance local fine-grained features with global context.
3.4. Ablation Experiments
To systematically validate the efficacy and necessity of each core component within the proposed MAFMamba model, we conducted a comprehensive series of ablation studies on the ISPRS Vaihingen dataset. To ensure a rigorous comparison, all ablation variants were trained and evaluated under identical protocols and parameter settings (e.g., input resolution, optimizer, and data augmentation strategies) as detailed in Section 3.1. As evidenced in Table 4, the complete MAFMamba model—comprising the AMMB, GLMamba, ASF, and MSCAF modules—achieved optimal performance across three key metrics: mF1, Overall Accuracy (OA), and mean Intersection over Union (mIoU). This performance significantly surpasses that of all ablated variants, fully demonstrating the superiority of the holistic architectural design.
The specific contribution of each module is analyzed as follows:
- Impact of AMMB: The exclusion of the Adaptive Multi-scale Mamba Block (w/o AMMB) precipitated decreases of 0.44%, 0.81%, and 0.54% in mF1, OA, and mIoU, respectively. This decline underscores the critical role of the AMMB in modeling multi-scale semantics and long-range dependencies. By degrading the encoder to a standard ResNet-18 architecture stripped of AMMB, the model loses the capability for dynamic multi-scale feature adjustment, significantly weakening the representation of cross-scale objects such as “Tree” and “Low Vegetation”.
- Impact of GLMamba: The omission of the GLMamba module resulted in a 0.38% decrease in mF1 and a 0.47% decrease in mIoU. GLMamba is designed to explicitly model the interaction between global and local contexts at the decoder end. Without this module, the decoder relies solely on conventional upsampling and feature concatenation, struggling to effectively balance high-resolution spatial details with low-resolution deep semantics. Consequently, this led to increased misdetection rates for small objects like cars and heightened edge blurring in building segmentation.
- Impact of VSS (w/o AMMB & GLMamba): The concurrent removal of both AMMB and GLMamba—effectively eliminating all Mamba components to retain only a lightweight ResNet-18 encoder and standard decoder path—resulted in the most severe performance degradation: mF1 dropped by 0.87% and mIoU by 1.20%. This outcome unequivocally demonstrates the pivotal role of the Visual State Space (VSS) model within MAFMamba. Its ability to model long-range dependencies with linear complexity constitutes the foundational basis for the model’s superiority over traditional CNN–Transformer hybrid architectures. Absent the VSSLayer, the network fails to effectively capture the pervasive global context and cross-scale semantic correlations inherent in remote sensing imagery.
- Impact of MSCAF: The absence of the MSCAF module caused mF1 to decrease by 0.27% and mIoU by 0.41%. MSCAF supersedes conventional skip connections, enabling bidirectional information aggregation and semantic alignment of multi-scale features via efficient cross-attention. Its removal reduces the model to simple feature concatenation, creating a significant semantic gap between high-resolution features in shallow encoder layers and deep decoder features. This results in markedly reduced boundary accuracy for the “Impervious Surface” and “Building” categories.
- Impact of ASF: Finally, removing the ASF module yielded a 0.19% decrease in mF1 and a 0.27% decrease in mIoU. ASF assigns adaptive spatial weights to features of differing resolutions during decoding, thereby enhancing fusion stability. Although MSCAF facilitates cross-scale interaction, the lack of pixel-level dynamic weighting in the absence of ASF reduces the consistency of merging high-resolution details with low-resolution semantics, particularly affecting the distinction between “Low Vegetation” and “Tree”.
Our proposed MAFMamba model achieves an optimal balance between global semantics, local details, and computational efficiency through the organic integration of multi-scale adaptive fusion, global–local interactions, and an efficient cross-scale attention mechanism. Consequently, it delivers the best segmentation performance on the Vaihingen dataset.
To further substantiate the rationale behind our architectural choices, we conducted additional comparative experiments focusing on two key aspects: the selection of the attention mechanism within the MSAF module and the choice of the encoder backbone.
We investigated the influence of different attention mechanisms within the MSAF module by comparing the adopted CA with the Squeeze-and-Excitation (SE) Block and Convolutional Block Attention Module (CBAM). Quantitative results presented in Table 5 indicate that the SE-Block, despite being the most lightweight (29.28 M parameters), yields the lowest mIoU of 85.04% due to its inability to capture spatial structural information. Although CBAM improves mIoU to 85.07% by incorporating a spatial attention branch with large convolutions, it increases parameter complexity to 29.58 M and computational overhead to 56.45 GFLOPs. In contrast, our method utilizing Coordinate Attention achieves the superior segmentation performance of 85.09%. Unlike CBAM, CA captures long-range spatial dependencies along precise positional directions without relying on heavy convolution operations, maintaining a parameter count (29.39 M) and computational cost (56.19 GFLOPs) comparable to the lightweight SE-Block. This confirms that Coordinate Attention offers the optimal trade-off between spatial sensitivity and model complexity for remote sensing tasks.
Furthermore, we evaluated the impact of the encoder backbone by comparing our ResNet-18-based architecture against a deeper ResNet-50 and a Transformer-based Swin-T, as detailed in Table 6. The results underscore a distinct trade-off between accuracy and efficiency. While the Transformer-based Swin-T achieves the highest accuracy (85.19% mIoU) and ResNet-50 follows closely (85.16% mIoU), the performance gains over our method are marginal, at only +0.10% and +0.07%, respectively. However, these marginal improvements come at a substantial computational cost. Swin-T requires the largest number of parameters (71.82 M), and ResNet-50 nearly doubles the FLOPs to 108.55 G compared to our method. Consequently, our MAFMamba with ResNet-18 achieves a highly competitive mIoU of 85.09% while requiring only 29.39 M parameters and significantly lower computational resources. This justifies our selection of ResNet-18 to ensure the linear complexity of the proposed Mamba architecture, demonstrating that simply scaling up the backbone yields diminishing returns in accuracy while severely compromising efficiency.
3.5. Complexity Analysis
To validate the efficiency of the proposed framework, we compared MAFMamba against state-of-the-art methods on the Vaihingen dataset in terms of Parameters, GFLOPs, and mIoU. The comparative methods are categorized into three paradigms: CNN-based (C), CNN–Transformer (C–T), and CNN–Mamba (C–M).
As illustrated in Table 7, distinct trade-offs are observed across the different architectures. Among CNN-based methods, traditional models such as BANet [48] serve as the most lightweight baselines (13.06 GFLOPs). However, due to their limited global modeling capabilities, they yield the lowest accuracy (81.35%). Conversely, while MANet [19] increases model size, it achieves only disproportionate performance gains. Regarding hybrid architectures, UNetFormer [28] offers a reasonable balance between speed and accuracy. However, heavy-weight Transformers like DC-Swin [27] achieve higher accuracy (83.22%) only at the cost of significant computational overhead (112.16 GFLOPs) and increased model size. Existing Mamba-based approaches also struggle to achieve an optimal balance between efficiency and performance. For instance, RS3Mamba [38] and PyramidMamba [50] deliver competitive segmentation results but are computationally expensive, requiring over 300 GFLOPs. Notably, although AfaMamba [45] features a low parameter count (13.01 M), its computational complexity remains high (112.16 GFLOPs), while UMFormer [51] falls behind in segmentation accuracy despite its efficiency.
In contrast, MAFMamba secures the highest segmentation performance (85.09% mIoU) while maintaining a highly efficient computational footprint (56.19 GFLOPs). This result confirms that the proposed multi-scale adaptive fusion architecture successfully maximizes performance without incurring high computational costs.
4. Conclusions
This paper presents MAFMamba, a Multi-scale Adaptive Fusion visual Mamba network designed for the semantic segmentation of high-resolution remote sensing imagery. It effectively resolves the inherent trade-off between preserving local details and modeling global context found in existing approaches, while simultaneously mitigating the challenges posed by extreme scale variations. MAFMamba employs a hybrid encoder built upon ResNet-18 and VMamba. Central to this architecture is the proposed Adaptive Multi-scale Mamba Block (AMMB), which dynamically aggregates and recalibrates cross-level features via a Multi-Scale Adaptive Fusion (MSAF) mechanism. This operates in conjunction with the VSSLayer to achieve efficient multi-scale semantic extraction and long-range dependency modeling. For the decoder, we designed a Global–Local Feature Enhancement Mamba (GLMamba) and an Adaptive Scale Fusion (ASF) module. Crucially, we introduced the Multi-Scale Cross-Attention Fusion (MSCAF) module to explicitly align fine-grained encoder features with high-level decoder semantics, thereby effectively bridging the semantic gap across scales.
Extensive experiments on the ISPRS Potsdam, Vaihingen, and LoveDA datasets demonstrate that MAFMamba establishes new state-of-the-art performance. It achieves an mIoU of 85.09% on Vaihingen and 86.89% on Potsdam, surpassing leading CNN, Transformer, and other Mamba-based methods. Notably, performance on the LoveDA dataset (53.46% mIoU) confirms the model’s strong generalizability and robustness when processing complex rural agricultural scenes and imagery with varying spatial resolutions. Furthermore, complexity analysis confirms that MAFMamba achieves an optimal trade-off between accuracy and efficiency, delivering superior segmentation performance while maintaining a significantly lower computational footprint (in terms of Parameters and GFLOPs) compared to heavy Transformer-based architectures.
Notwithstanding these advancements, MAFMamba exhibits limitations in handling densely packed small objects and areas under heavy shadow occlusion, where boundary ambiguity and insufficient contextual reasoning from occluded regions remain challenging. Future research directions include refining boundary-aware learning mechanisms, enhancing feature representation for occlusion scenarios, and employing more rigorous validation protocols to further improve generalization. Overall, this work presents a novel and effective paradigm, offering a promising technical pathway for advancing efficient Mamba-based architectures in remote sensing semantic segmentation.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Yang Y. Sun X. Dong J. Lam K.-M. Zhu X.X. Attention-Conv Net Network for Ocean-Front Prediction via Remote Sensing SST Images IEEE Trans. Geosci. Remote Sens.202462421251610.1109/TGRS.2024.3496660 · doi ↗
- 2Xiang S. Xie Q. Wang M. Semantic Segmentation for Remote Sensing Images Based on Adaptive Feature Selection Network IEEE Geosci. Remote Sens. Lett.202219800670510.1109/LGRS.2021.3049125 · doi ↗
- 3Xu C. Du X. Fan X. Yan Z. Kang X. Zhu J. Hu Z. A Modular Remote Sensing Big Data Framework IEEE Trans. Geosci. Remote Sens.202260300031110.1109/TGRS.2021.3100601 · doi ↗
- 4Sun X. Zhang M. Dong J. Lguensat R. Yang Y. Lu X. A Deep Framework for Eddy Detection and Tracking from Satellite Sea Surface Height Data IEEE Trans. Geosci. Remote Sens.2021597224723410.1109/TGRS.2020.3032523 · doi ↗
- 5He X. Zhou Y. Zhao J. Zhang D. Yao R. Xue Y. Swin Transformer Embedding U Net for Remote Sensing Image Semantic Segmentation IEEE Trans. Geosci. Remote Sens.202260440871510.1109/TGRS.2022.3144165 · doi ↗
- 6Xin Y. Fan Z. Qi X. Zhang Y. Li X. Confidence-Weighted Dual-Teacher Networks with Biased Contrastive Learning for Semi-Supervised Semantic Segmentation in Remote Sensing Images IEEE Trans. Geosci. Remote Sens.202462561441610.1109/TGRS.2024.3376352 · doi ↗
- 7Peláez-Vegas A. Mesejo P. Luengo J. A Survey on Semi-Supervised Semantic Segmentationar Xiv 202310.48550/ar Xiv.2302.098992302.09899 · doi ↗
- 8Zheng Y. He L. Wu X. Pan C. Self-Training and Multi-Level Adversarial Network for Domain Adaptive Remote Sensing Image Segmentation Neural Process. Lett.202355106131063810.1007/s 11063-023-11341-x · doi ↗