SADQN-Based Residual Energy-Aware Beamforming for LoRa-Enabled RF Energy Harvesting for Disaster-Tolerant Underground Mining Networks
Hilary Kelechi Anabi, Samuel Frimpong, Sanjay Madria

TL;DR
This paper introduces a new deep reinforcement learning framework to improve energy efficiency in underground mining networks after disasters.
Contribution
The novel SADQN framework enhances energy beamforming by incorporating residual energy awareness and dual-variable updates for constraint handling.
Findings
SADQN increases cumulative harvested energy by 11% over DQN and 40% over PSO.
The framework achieves fairness indices above 0.90 and converges 27% faster than Safe-DQN.
SADQN shows 33% lower performance variance than Safe-DQN, ensuring stability in disaster scenarios.
Abstract
The end-to-end efficiency of radio-frequency (RF)-powered wireless communication networks (WPCNs) in post-disaster underground mine environments can be enhanced through adaptive beamforming. The primary challenges in such scenarios include (i) identifying the most energy-constrained nodes, i.e., nodes with the lowest residual energy to prevent the loss of tracking and localization functionality; (ii) avoiding reliance on the computationally intensive channel state information (CSI) acquisition process; and (iii) ensuring long-range RF wireless power transfer (LoRa-RFWPT). To address these issues, this paper introduces an adaptive and safety-aware deep reinforcement learning (DRL) framework for energy beamforming in LoRa-enabled underground disaster networks. Specifically, we develop a Safe Adaptive Deep Q-Network (SADQN) that incorporates residual energy awareness to enhance energy…
Click any figure to enlarge with its caption.
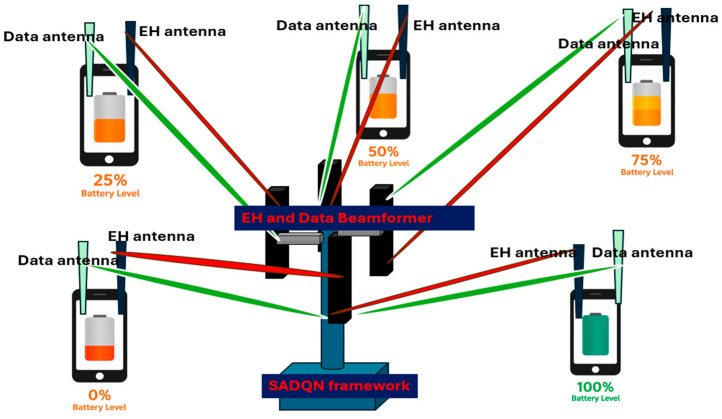 Figure 1
Figure 1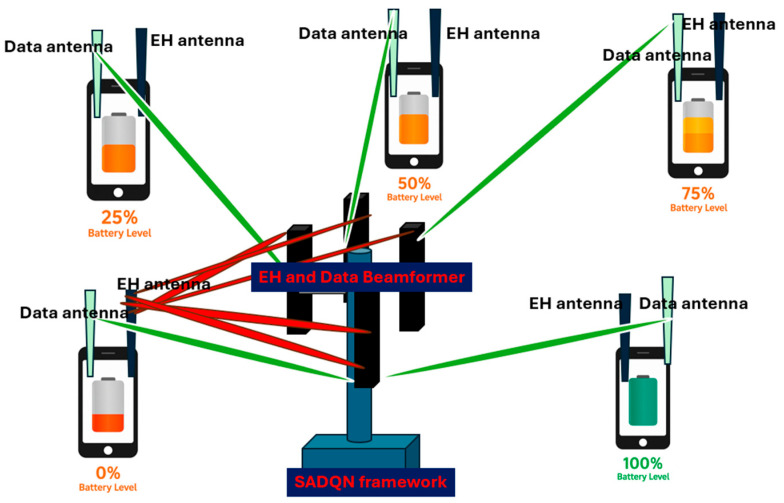 Figure 2
Figure 2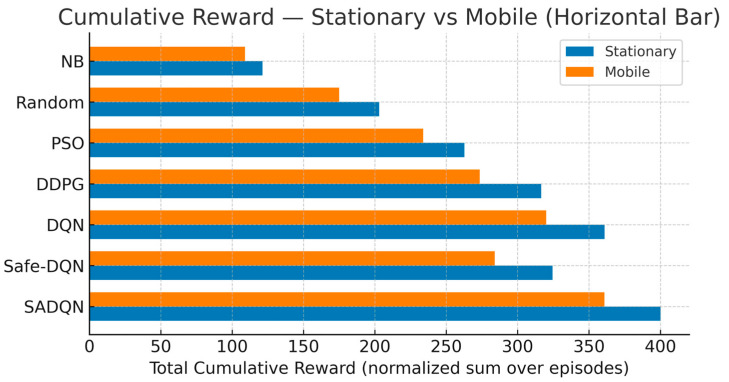 Figure 3
Figure 3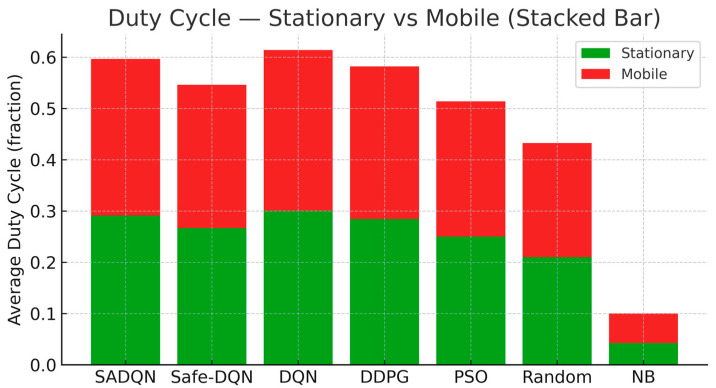 Figure 4
Figure 4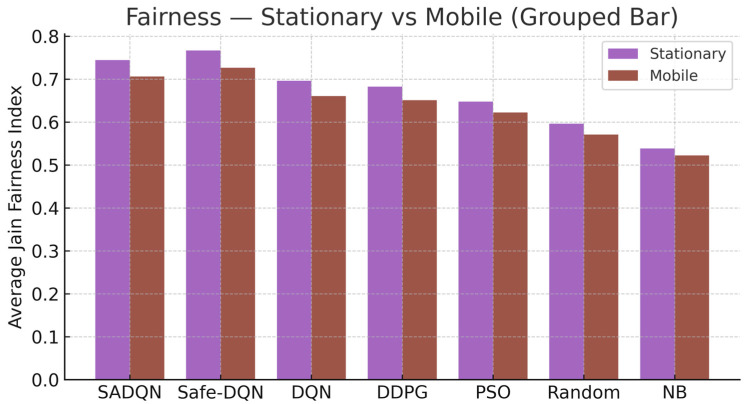 Figure 5
Figure 5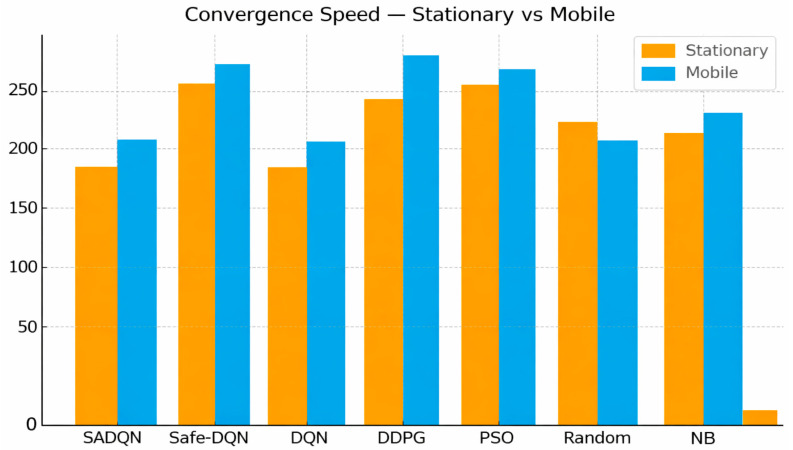 Figure 6
Figure 6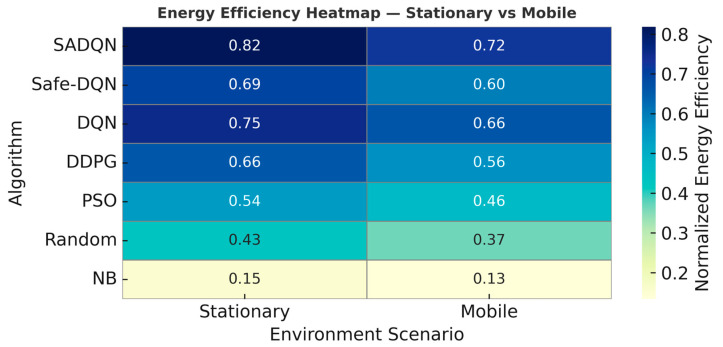 Figure 7
Figure 7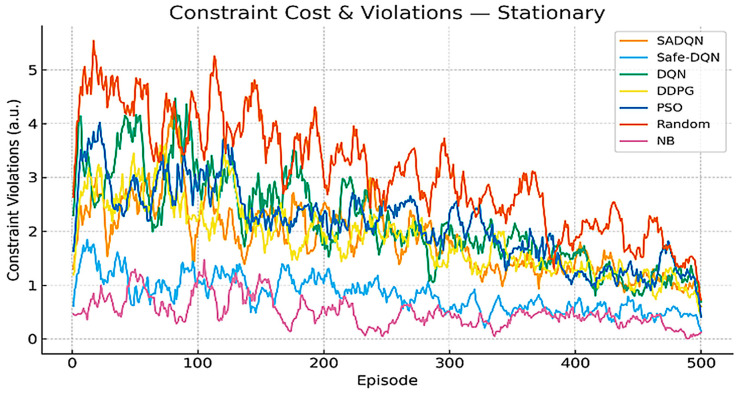 Figure 8
Figure 8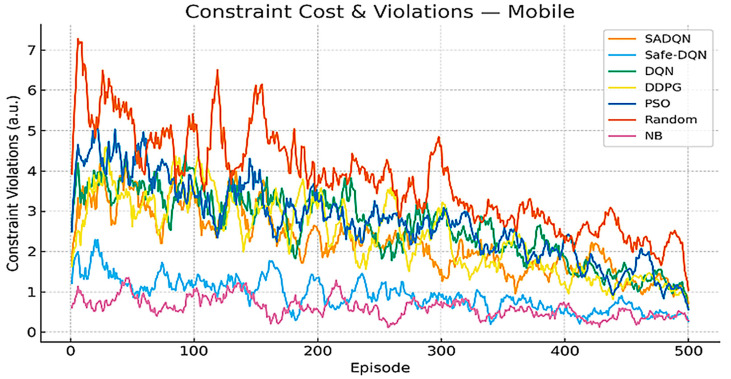 Figure 9
Figure 9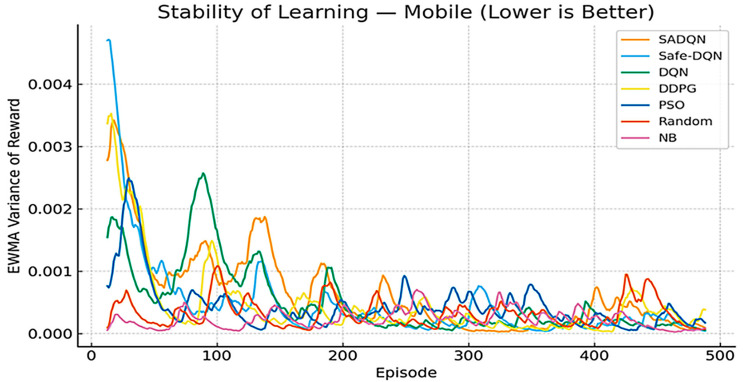 Figure 10
Figure 10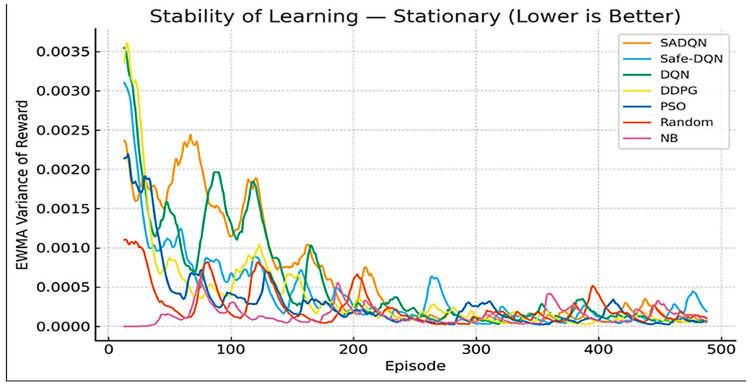 Figure 11
Figure 11| Parameter | Symbol | Value | Unit |
|---|---|---|---|
|
| |||
| Carrier frequency |
| 860 | - |
| Wavelength |
| 0.349 |
|
| Transmit power |
| 30 | dBm |
| Number of antenna elements |
| 16 | - |
| Antenna gain per element |
| 3 | dBi |
| Inter-element spacing |
|
|
|
| Angular span |
| 120° | degrees |
| Angular codebook size |
| 48 | beams |
|
| |||
| Number of nodes |
| 4 | - |
| LoRa uplink frequency |
| 915 | MHz |
| Energy storage capacitance |
| 1.0 | Farad |
| Minimum stored energy |
| 0.5 | J |
| Maximum stored energy |
| 5.0 | J |
| Load power consumption |
| 2 | mW |
| RF-to-DC conversion efficiency |
| 0.6 | |
| Leakage time constant |
| 1000 | s |
|
| |||
| Rician K-factor |
| 5 | dB |
| Shadowing std. deviation |
| 6.0 | dB |
| Reference path loss |
| 40 | dB |
| Corridor propagation exponent |
| 2.2 | |
| Node maximum speed |
|
|
|
| AoA drift variance |
|
| rad |
| Waypoint tolerance |
|
|
|
|
| |||
| Maximum duty cycle | 0.40 | ||
| Fairness threshold |
| 0.85 | |
| Minimum energy threshold |
| 0.5 | J |
| Maximum uplink utilization |
| 0.30 | |
| Smooth switching threshold |
| 20° | degrees |
| Time slot duration |
| 0.5 | s |
|
| |||
| Discount factor |
| 0.95 | |
| Learning rate |
| 0.001 | |
| Replay buffer size |
| 10,000 | transitions |
| Batch size |
| 64 | samples |
| Initial exploration rate |
| 1.0 | - |
| Minimum exploration rate |
| 0.05 | - |
| Exploration decay factor |
| 0.995 | - |
| Target network update rate |
| 0.005 | - |
| Hidden layer dimensions | - | [128, 128] | neurons |
| Activation function | - | ReLU | - |
|
| |||
| Adaptive exploration scaling |
| 0.3 | - |
| Energy-aware weight |
| 0.5 | - |
| Switching penalty weight |
| 0.2 | - |
| Fairness bonus weight |
| 0.3 | - |
| Top-K minimum |
| 3 | actions |
| Top-K maximum |
| 10 | actions |
| EWMA factor |
| 0.05 | - |
| Dual ascent step size |
| 0.01 | - |
|
| |||
| Actor learning rate |
| 0.0001 | - |
| Critic learning rate |
| 0.001 | - |
| Soft update parameter |
| 0.001 | - |
| Ornstein–Uhlenbeck noise |
| 0.2 | - |
|
| |||
| Swarm size | - | 20 | particles |
| Inertia weight |
| 0.7 | - |
| Cognitive coefficient |
| 1.5 | - |
| Social coefficient |
| 1.5 | - |
|
| |||
| Number of episodes | - | 500 | - |
| Steps per episode | - | 100 | - |
| Random seeds | - | 10 | - |
| Evaluation frequency | - | 10 | episodes |
| Moving average window |
| 20 | steps |
- —CDC-NIOSH U60 Program
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsEnergy Harvesting in Wireless Networks · IoT Networks and Protocols · Advanced Wireless Communication Technologies
1. Introduction
Traditional battery-powered tracking and localization devices face fundamental energy limitations in post-disaster underground mine scenarios [1]. Wireless power transfer (WPT) offers a valuable path to sustain these nodes, but underground propagation is highly lossy and time-varying due to attenuation, irregular tunnel geometry, obstructions, and multipath, which can sharply reduce the end-to-end radio-frequency WPT (RF-WPT) efficiency [2]. The feasibility of deploying radio-frequency energy harvesting (RF-EH) in underground mining environments has been demonstrated empirically with appropriate technical adjustments [3]. However, the end-to-end RF-WPT efficiency in underground mines remains substantially low, necessitating adaptive techniques for optimizing WPT in such complex and rapidly changing environments [4]. Efficient techniques such as waveform optimization, energy beamforming (EB), and distributed antenna systems are therefore essential to achieve the optimal performance of underground RF-WPT [5,6].
Energy beamforming (EB) has emerged as an innovative technique to enhance the efficiency and range of WPT systems by steering concentrated beams of energy toward one or more energy harvesting (EH) devices simultaneously. Through coordinated antenna control, EB focuses RF energy on target devices, limiting dispersion, lowering path loss, and improving spatial filtering. This targeted power delivery greatly improves transfer efficiency, making EB especially valuable in environments with dynamic channels, severe multipath fading, and limited coverage conditions that are endemic to underground mining. As a result, EB provides a promising pathway to achieve reliable and energy-efficient wireless power transfer in complex underground mine settings where conventional omnidirectional transmission techniques often fall short [7,8].
Conventional EB systems are designed under the assumption of perfect channel state information (CSI) to achieve the optimal beamforming performance. However, obtaining accurate CSI is often impractical, particularly in dynamic and infrastructure-limited environments where frequent channel variations, multipath effects, and limited feedback mechanisms make real-time estimation highly challenging. These challenges are exacerbated in post-disaster underground mining scenarios where communication infrastructure may be partially destroyed, feedback channels unreliable, and rapid environmental changes render CSI outdated almost immediately. To address these limitations, approaches based on convex optimization and deep reinforcement learning (DRL) have shown significant promise, enabling EB systems to adaptively optimize beam directions and power allocation while maintaining high energy transfer efficiency even in complex and rapidly changing wireless environments [9,10,11]. More recently, DRL has emerged as a powerful alternative, enabling autonomous decision-making and learning optimal beamforming strategies directly from environmental interactions, making it particularly effective for EB applications in scenarios with imperfect or time-varying CSI [12].
By interacting with the environment, DRL agents learn optimal policies from environmental dynamics to perform complex tasks without explicit programming and modeling. DRL methods address several limitations of conventional techniques by providing real-time, online learning solutions capable of operating in highly dynamic and uncertain environments [13,14]. Compared to conventional beamforming techniques, DRL-based frameworks are better suited for time-sensitive and resource-constrained applications due to their scalability, policy adaptability, and ability to learn directly from environmental interactions without requiring complete system models or perfect CSI. Despite significant progress in both adaptive beamforming and DRL-based wireless optimization, existing approaches suffer from three critical limitations when applied to underground disaster scenarios [15,16,17].
First, they lack explicit safety mechanisms. In post-disaster mining networks, violating operational constraints can have catastrophic consequences: allowing nodes to drop below minimum energy thresholds means losing tracking capability for trapped miners; and unfair energy distribution may leave some nodes powerless while others are over-provisioned. Second, existing methods do not prioritize nodes based on residual energy awareness. Most beamforming algorithms treat all energy-harvesting nodes equally or optimize for aggregate metrics like sum energy or minimum energy across all nodes. Third, they do not address the unique requirements of long-range, low-power communication. Post-disaster underground environments demand communication technologies that can maintain connectivity over extended distances through debris, collapsed structures, and hostile RF conditions. Long-range (LoRa) technology, with its sub-GHz operation, spread-spectrum modulation, and ability to achieve ranges exceeding 10 km in favorable conditions [18,19], is uniquely positioned for this application given its extremely low power consumption (−140 dBm receiver sensitivity).
The problem of jointly optimizing beamforming direction, energy allocation, and constraint satisfaction in underground disaster networks is fundamentally an NP-hard constrained optimization problem. This computational complexity is particularly problematic in disaster scenarios where decisions must be made in real-time on resource-constrained embedded hardware without external connectivity to cloud computing resources. To address these critical gaps, this work first proposes the Safe Deep Q-Network (Safe-DQN)-based energy beamforming framework tailored specifically for underground mining disaster scenarios. Unlike standard DQN-based beamforming strategies that optimize solely for energy delivery, the proposed method explicitly incorporates operational constraints such as minimum voltage thresholds, fairness among EH nodes, duty-cycle limits, and uplink utilization bounds directly into the learning objective using Lagrangian penalized reward functions, enabling the framework to maximize harvested energy while ensuring system safety, operational reliability, and stability in harsh underground wireless environments. Safe-DQN is not an adaptive algorithm, and hence, it is limited.
We then proposed Safe Adaptive DQN (SADQN), which extends the baseline Safe-DQN by incorporating residual energy-aware scoring that prioritizes the weakest nodes those at risk of failure, and adaptive exploration mechanisms that dynamically adjust exploration rates based on system conditions: increasing exploration when energy distribution is highly unbalanced and prioritizing exploitation when the system is stable and fair. The major contributions of this work include the following:
- Safe-RL formulation for energy beamforming: We model beamforming as a constrained Markov decision process (CMDP) with sequential charging of the weakest node and penalties for unsafe beam-switching, voltage drops, fairness violations, and excessive duty-cycle usage, employing Lagrangian relaxation with dual-variable updates to address the NP hardness of this problem.
- Residual energy-aware adaptive mechanisms: We introduce energy-aware scoring that prioritizes nodes with the lowest residual energy, combined with fairness-aware top-K action selection and adaptive exploration that responds to system stability.
- LoRa voltage feedback for beam optimization: To the best of our knowledge, this is the first work to use real-time LoRa voltage feedback as the observable state for reinforcement learning in RF-WPT systems, with a dual-band architecture (860 MHz for WPT, 915 MHz for LoRa uplink) enabling long-range, low-power feedback without requiring extensive CSI acquisition.
The rest of the paper is organized as follows: Section 2 presents the related studies. Next, in Section 3, we present our system model and the optimization problem. In Section 4, we discuss our proposed solution, while Section 5 provides numerical results. Finally, Section 6 concludes the work.
2. Related Studies
EB has recently gained renewed attention as a critical enabler of high-efficiency wireless power transfer for energy-constrained nodes, particularly in challenging environments such as underground mines and disaster-prone areas. Since 2022, there has been a notable shift toward integrating machine learning, hardware-efficient beamforming, and low-CSI paradigms to improve system robustness and adaptability. This section reviews recent advances across four key areas: energy beamforming techniques, reinforcement learning for wireless systems, safe and constrained optimization, and LoRa-based underground communications. Recent work has focused on improving beamforming efficiency through novel hardware architectures and CSI-reduction techniques. For instance, Azarbahram et al. (2024) designed an energy beamforming solution using Dynamic Metasurface Antenna (DMA) transmitters, which minimize transmit power while maintaining energy delivery constraints [20]. Unlike conventional fully digital or hybrid arrays, their approach enables frequency-domain beam shaping at a reduced RF chain cost, achieving a 40% improvement in energy efficiency for the same coverage. However, their work assumes static propagation environments and perfect knowledge of user locations, limiting applicability to dynamic disaster scenarios where infrastructure may be compromised. Similarly, Zhang et al. (2024) proposed a two-stage beamforming protocol leveraging radar-like sensing to extract path direction and gain without requiring explicit CSI feedback [16]. Their method closely matches the performance of full CSI-based beamforming, making it a promising solution for feedback-constrained and underground deployment scenarios. However, it does not address energy-aware node prioritization or operational safety constraints critical in life-threatening situations.
Yang, Zhang, and Wang (2022) introduced a joint optimization framework for simultaneous radar sensing and WPT [17], demonstrating the feasibility of dual-function antenna systems for 6G networks. While innovative, this work optimizes for sensing-WPT trade-offs rather than fairness, minimum energy guarantees, or node survival essential requirements in disaster response operations. RL has been increasingly integrated into beamforming research to address uncertainty in dynamic wireless environments. Joint optimization of trajectory, beamforming, and power allocation in UAV-enabled WPT networks has been explored using DRL combined with water-filling algorithms [21], enabling UAVs to dynamically adjust flight paths to maximize the minimum harvested energy across users. Narengerile et al. (2022) applied DRL for mmWave beam training, achieving improved spectral and energy efficiency under real-time dynamics [22]. Zhou et al. [23] proposed a DQN-based algorithm to improve spectral efficiency in mmWave systems under train mobility, while Ge et al. [24] utilized a deep deterministic policy gradient (DDPG) approach for optimizing the sum rate in multi-user MISO systems. Dantas et al. [25], introduced actor–critic models to address beam selection in fast-varying wireless environments.
Although these contributions demonstrate significant progress, they share critical limitations when applied to underground disaster scenarios. The majority focus on maximizing data throughput (spectral efficiency, sum rate) rather than optimizing wireless energy transfer and node survivability. They lack explicit safety mechanisms, failing to incorporate hard constraints on minimum energy thresholds, fairness guarantees, or duty-cycle compliance essential to prevent catastrophic node failures during rescue operations. Most assume availability of CSI or stable feedback channels, which may be unreliable or unavailable when communication infrastructure is compromised. Finally, none addresses the unique challenge of long-range, low-power communication required in post-disaster underground environments.
Safe reinforcement learning extends conventional RL by incorporating operational constraints to guarantee an acceptable performance during both learning and deployment. While safe RL has been applied to robotics and autonomous systems, its application to wireless energy transfer remains limited. Zhang et al. [26] applied Q-learning to distribute RF energy fairly among IoT devices, and Mao et al. [27] developed an RL-based dynamic charging scheduler to optimize wireless power delivery under varying network conditions. However, these approaches optimize for fairness or charging efficiency without explicitly enforcing hard safety constraints such as minimum voltage thresholds, beam-switching stability, or regulatory duty-cycle limits. Zhang et al. [28] explored multi-agent reinforcement learning (MARL) for mobile charger path optimization in wireless sensor networks. While effective for temporal scheduling, these models assume ideal channels or centralized control, lacking spatial selectivity and adaptability to channel impairments such as obstruction, multipath fading, and dynamic interference characteristic of underground mines. Moreover, existing energy-aware RL methods do not implement residual energy-based prioritization, a triage principle essential for disaster scenarios where the most energy-starved nodes must be charged first to maintain tracking and localization of trapped miners.
In the domain of LoRa-based wireless energy harvesting, ref. [19] examined LoRa network performance under ambient energy harvesting and random transmission schemes, demonstrating feasibility but not addressing directional energy delivery or adaptive beamforming. Emmanuel [18] characterized LoRa signal behavior in underground tunnels, providing valuable propagation insights but without integrating wireless power transfer. Kumar et al. [29], presented robust gas-monitoring devices leveraging LoRa for Through-The-Earth (TTE) communication, validated under non-line-of-sight underground conditions, and designed a disaster-tolerant LoRa communication framework tailored for underground mine environments. While these studies emphasize connectivity, reliability, and environmental robustness, they do not address power sustainability, directional energy delivery, or learning-based adaptive control. None explore the dual-band architecture required to simultaneously support RF energy transfer and LoRa-based feedback, nor do they address the 125+ dB power asymmetry between energy-harvesting requirements (−15 dBm minimum) and LoRa communication sensitivity (−140 dBm). Table 1 summarizes the key differences between prior work and our proposed approach. In contrast, our work introduces a Safe Adaptive Deep Q-Network (SADQN) energy-beaming framework for RF energy delivery to LoRa-enabled energy-harvesting nodes in underground disaster environments.
3. System Model
Conventional beamformers, while simple and effective, perform poorly in environments with multiple signal directions, high noise levels, and dynamic channel conditions typical of post-disaster underground mines. To address these challenges, adaptive beamforming techniques dynamically adjust beam weights based on real-time environmental conditions, enabling robust operation in complex and rapidly changing scenarios. In this section, we present our adaptive energy beamforming system model for underground mine disaster environments. Some of the symbols and meanings are shown in Table 2.
3.1. System Architecture and Network Model
We consider a multi-antenna RF wireless power transfer (RF-WPT) system operating in an underground mine environment, where a transmitter is equipped with a uniform linear array (ULA) and antennas deliver RF energy to uniform linear array N LoRa EH double-antenna nodes, as depicted in Figure 1. Each LoRa EH node is equipped with a dual-antenna configuration: one antenna dedicated to RF energy harvesting and the other to LoRa-based wireless communication. This design allows nodes to sustain energy harvesting and data transmission concurrently, ensuring continuous operation in energy-constrained underground environments. To avoid cross-interference between the two functions, separate frequency bands are employed. Specifically, 860 MHz is selected for RF energy harvesting , following our prior experimental validation in underground mine environments [3], while the U.S. LoRa frequency of 915 MHz is adopted for uplink communication. This dual-band architecture enables real-time voltage feedback from energy-starved nodes without interfering with the downlink power transfer process. It is important to note that RF energy harvesting imposes stringent requirements on received signal power. For practical EH operation, the received RF power must be at least −15 dBm [3], whereas reliable LoRa information decoding can be sustained at power levels as low as −140 dBm. This 125 dB disparity highlights the fundamental challenge of RF-EH in underground mine environments, which are inherently lossy due to multipath fading, shadowing, and complex dielectric properties of geological materials.
3.2. Underground Mine Propagation Model
The underground mine wireless propagation channel is characteristically different from other legacy wireless environments. Node i received power in (dBm) from a WPT transmitter placed at a distance that can be estimated using Equation (1):
denotes the total radiated transmit power including the contribution of the external power amplifier (PA), is the environment calibrated path loss term, and represents log-normal shadowing in dB, typically, 3–10 dB in underground settings. Underground mines employ a specific path loss model accounting for tunnel geometry [30],
- : the reference path loss at .
- : the corridor propagation exponent deduced from free space due to waveguide effects.
- dB: additional loss per rock wall or rough surface penetration.
- dB: scattering loss per tunnel intersection or crosscut.
- = 2–5 dB: absorption due to water vapor in mine air.
- , : number of walls and junctions traversed along the propagation path.
This model captures the unique waveguide-like propagation in underground tunnels, where reflections from walls can either constructively or destructively interfere with the direct signal. Equation (2) is a combination of a basic pathloss formula and underground-specific pathloss component, as stated in [30].
3.3. Channel Fading Model
The wireless channel between the transmitter and each node experiences both deterministic and stochastic components. We model the channel as Rician fading, which captures both the line-of-sight ( ) component and scattered non-line-of-sight ( ) components. The baseband channel coefficient for node i is expressed as in Equation (3):
is the Rician -factor, defined as the power ratio between the and components. In underground mine environments, typically ranges from depending on tunnel geometry and the presence of obstructions. The term denotes the deterministic component, while represents Rayleigh distributed scattering with independent and identically distributed (i.i.d.) complex Gaussian entries. In the special case where the LoS path is completely blocked (e.g., by collapsed debris), the model reduces to pure Rayleigh fading with as given by Equation (4):
Underground mine openings are predominantly tunnel-like structures with maze-like interconnections. The confined geometry makes the Rician model particularly appropriate, as it captures both the strong guided component and the scattered multipath caused by reflections and diffractions from tunnel walls.
3.4. Received Power and Beamforming Gain
Combining the propagation and fading models, the instantaneous received power at node i at time t is expressed as Equation (5):
- is the total transmit power (including PA gain).
- is the beamforming gain in the direction of node i.
- is the instantaneous channel gain (from Equation (3) or (4)).
- is the free-space path loss term.
- converts the dB path loss from Equation (2) to a linear scale.
This formulation integrates the array gain, channel fading, distance-dependent path loss, and underground-specific attenuation into a unified received power expression.
3.5. Steering Vector and Beam Gain Model
To realize directional RF energy transfer, the transmitter employs an array steering vector to form a beam pattern corresponding to the desired azimuth angle in 2D. For a uniform linear array (ULA) with elements and inter-element spacing d, the array manifold vector is expressed as Equation (6):
is the wavenumber associated with the carrier wavelength and is the azimuth angle (in radians) measured from broadside. The beamforming objective is to steer the transmit beam toward a designated direction This is achieved using conjugate beamforming with unit-norm weight vectors:
When steering toward a conjugate phase shift is applied across the array elements such that radiated waves combine coherently in that direction. The corresponding array response is given by Equation (8):
The associated power gain is the squared magnitude of this response, given by Equation (9):
It is evident from (8) that the maximum beamforming gain occurs under perfect alignment, i.e., when In this case, the array achieves coherent combining, and the gain scales linearly with the number of antennas. The beamforming gain quantifies the power amplification achieved by the antenna array when steered toward direction and evaluating the response at angle . It represents the radiated power intensity in direction to the average radiated power intensity that would result from an isotropic radiator with the same total input power.
3.5.1. Perfect Alignment (θ=θ0)
Under perfect alignment, all array elements contribute constructively, yielding maximum gain in Equation (10):
This shows that the peak beamforming gain scales linearly with the number of antenna elements. For example, with elements, the maximum gain is or equivalently .
3.5.2. Off-Boresight Angles (θ≠θ0)
When the observation angle deviates from the steering angle , the gain decreases due to destructive interference among array elements. The gain pattern exhibits sidelobes and nulls characteristic of array antenna radiation patterns.
3.6. Gauss–Markov Drift Mobility Model
In underground mine environments, node mobility and scattering-induced perturbations introduce fluctuations in the angle of arrival (AoA), which directly affect beam alignment and energy transfer efficiency. These variations are characterized by the instantaneous angular drift at time modeled here using the Gauss–Markov drift process in Equation (11):
is the temporal correlation coefficient. A value corresponds to uncorrelated white noise, while values approaching unity indicate highly correlated angular drift. The innovation term represents Gaussian perturbations, with the standard deviation set to radians, modeling small mobility-induced deviations. In a steady state, the drift variance is given as Equation (12):
and the temporal covariance at lag is given by Equation (13):
The beam angle is then updated as Equation (14):
and enforce the angular span constraint , corresponding to a total beam search space of . To also capture spatial displacement, node motion is represented by a two-dimensional Gaussian random walk, given by Equation (15):
where is the innovation noise introducing random perturbations into correlated motion. The displacement speed is bounded by and a waypoint tolerance of , which ensures that a node is considered to have reached a waypoint once within this proximity.
3.7. RF Energy-Harvesting Storage Dynamics
We next model the RF-EH capacity of the LoRa EH device. Assuming a linear harvesting process, the energy storage dynamics are expressed as
where the operator constrains the stored energy to the feasible interval . The terms in Equation (16) represent the following:
- : residual stored energy in the capacitor or battery .
- : harvested RF energy with conversion efficiency .
- : energy consumed by the sensor, microcontroller, and LoRa transceiver load .
- : leakage losses due to capacitor self-discharge or battery leakage current.
Here, is the energy transmission duration per time slot. The voltage at node i is related to stored energy, which is given by Equation (17):
is the capacitance of the energy storage element. This voltage feedback is transmitted via the LoRa uplink and serves as the primary observable for the SADQN beamforming agent.
3.8. Beyond Far-Field Beamforming Propagation Region
The primary motivation for adopting RF-WPT in underground mine post-disaster scenarios lies in its ability to support far-field energy delivery, which is essential for powering tracking and localization systems when conventional infrastructure is compromised. The far-field boundary for an antenna array of maximum physical aperture size D operating wavelength [20] is given by Equation (18):
For ULA with elements with inter-element spacing , the effective aperture size is . When substituting this into (15), the far-field distance becomes Equation (19):
As a practical example, consider a UHF-based RF-WPT transmitter operating at = 860 MHz, corresponding to a wavelength of . For ULA with elements, (18) yields a far-field distance of approximately 1.57 m. Consequently, a LoRa receiver must be positioned at least 1.57 m from the transmitting array for the far-field propagation assumption to remain valid. The overarching objective of this work is not merely to satisfy the minimum far-field condition but to enable efficient energy beamforming beyond the conventional far-field region, ensuring robust and reliable RF energy delivery throughout the complex underground mine environment. This far-field foundation underpins the design of our SADQN beamforming algorithm, which dynamically exploits angular steering to maximize harvested energy while satisfying safety constraints in underground disaster networks.
4. Safe Reinforcement Learning Problem Formulation
Safe RL is a branch of the general RL paradigm that, in addition to maximizing expected returns, explicitly incorporates safety constraints to guarantee an acceptable performance during both the learning and deployment phases. Unlike conventional RL frameworks that optimize solely for cumulative reward, Safe RL enforces operational limits to prevent unsafe or infeasible actions, making it particularly suited for safety-critical environments such as underground mine communications and RF energy transfer.
In this section, we present the details of our environment modeling, the baseline Deep Q-Network (DQN) formulation, and the associated constrained problem setup. Building upon this foundation, we develop the proposed Safe Adaptive DQN framework (SADQN), which extends the Safe-DQN architecture by introducing adaptive exploration and energy-aware constraint handling tailored to underground wireless power transfer scenarios.
4.1. Environment Modeling
The Markov decision process (MDP) provides a well-established mathematical framework for RL and DRL optimization problems [31]. A task consists of a set of related states, actions, and rewards [32]. In this work, we extend the MDP to a constrained Markov decision process (CMDP) to capture the safety-critical requirements of WPT in underground mine environments. The CMDP is defined by the tuple in Equation (20):
denotes the state space, is the action space, the reward function, the state transition probabilities, and the discount factor. In addition, represents the cost constraint functions, and the corresponding budget thresholds. Without safety constraints, the CMDP reduces to the standard MDP formulation ( ). The objective is to learn an optimal policy that maximizes the expected discounted return while satisfying the safety constraints given Equation (21):
is the reward at time step t.
4.1.1. State Space S
The state space encapsulates all information required to characterize the environment at time t. For the LoRa-EH beamforming problem, the state vector is defined as Equation (22):
is the exponentially smoothed harvested voltage, is the previous beam angle, and the smoothed Jain’s fairness index. The fairness metric is defined as Equation (23):
The smoothed harvested voltage is computed using an exponentially weighted moving average (EWMA), given by Equation (24):
with being the forgetting factor that controls how quickly the smoothed estimate adapts to new measurements.
4.1.2. Action Space A
The action space represents the set of beamforming decisions available to the agent . At each time step, the agent selects a beamforming direction from a predefined angular codebook or chooses an idle (no transmission) action, given by Equation (25):
Thus, corresponds to either steering the beam toward one of the quantized angular positions or remaining idle, balancing energy delivery against regulatory and safety considerations.
4.1.3. Reward Function R
The reward function quantifies the immediate benefit of an action. Unlike conventional formulations that average energy across nodes, our framework uses a sequential charging strategy, as depicted in Figure 2, where the beamformer targets the weakest node until it reaches a survival threshold before moving to the next.
The weakest node at time is defined as
where the residual energy is modeled as Equation (27):
with being the capacitance of the node’s energy storage element and its voltage at time . The reward combines incremental energy improvement, alignment bonuses, spillover penalties, and survival shaping, stated in Equation (28):
- The first term normalizes the weakest node’s energy increment by .
- The second adds an alignment bonus proportional to beamforming gain.
- The third applies a spillover penalty discouraging unnecessary energy delivery to non-target nodes.
- The final term provides a survival bonus when the weakest node surpasses the critical threshold .
4.1.4. State Transition Probability Function P
The transition probability function captures how the system evolves under a given action. It reflects environmental dynamics including RF channel fading, obstacle-induced shadowing, node mobility, capacitor storage leakage, and beam steering effects. Due to the non-stationarity and partial observability of underground tunnels, these dynamics are generally unknown and are best approximated by stochastic models.
4.1.5. Cost C and Budget Functions B
The CMDP incorporates multiple cost functions, each penalizing violations of safety or operational requirements, as in Equation (29):
Each cost is paired with a strict budget that sets the maximum allowable violation level. Table 3 summarizes the constraint definitions, and the mathematical formulations are as follows:
- Beam-Switching Constraint in Equation (30):
This constraint penalizes abrupt beam direction changes that exceed the threshold ensuring smooth beam transitions that prevent destabilization of the energy-harvesting process.
ii.Fairness Constraint in Equation (31):
denotes the positive part operator. This constraint ensures that the Jain fairness index remains above the target threshold , promoting equitable energy distribution across nodes.
iii.Minimum Energy Constraint in Equation (32):
This constraint penalizes scenarios where any node’s energy falls below the minimum survival threshold , ensuring that all nodes maintain sufficient energy for critical operations.
iv.Duty-Cycle Constraint in Equation (33):
with the averaged fraction of the active slots, defined mathematically as in Equation (34):
where is a binary transmission activity variable. is the sliding window size. This ensures compliance with regulatory duty-cycle limits .
v.Uplink Constraint in Equations (35) and (36):
where
This constraint prevents excessive uplink feedback traffic that could congest the LoRa communication channel.
4.1.6. Discount Factor γ
The discount factor controls the trade-off between immediate and long-term returns. In the EB problem, balances short-term voltage gains against long-term objectives such as fairness, survival, and stability of the LoRa-EH network. A typical value of prioritizes long-term network sustainability while remaining responsive to immediate energy needs.
4.2. DQN Function Formulation
The DQN is a reinforcement learning algorithm that integrates the classical Q-learning framework with deep neural networks as function approximators. Its objective is to learn an optimal policy that maximizes the long-term cumulative reward within the CMDP formulation of our problem. In this work, DQN provides the computational foundation for adaptive decision-making in energy beamforming under underground RF-WPT constraints. Formally, the optimal state–action value function is defined recursively by the Bellman optimality equation [22] in Equation (37):
which expresses the expected utility of taking action in state , accounting for both immediate reward and discounted future returns. In DQN, the state action value function is approximated using a deep neural network parameterized by in Equation (38):
where represents the set of trainable weights and biases. The parameters are optimized by minimizing the Bellman loss in Equation (39):
with the target value defined as in Equation (40):
where are the parameters of a target network updated periodically to stabilize learning. The Double DQN (DDQN) extends this formulation by decoupling the action selection and action evaluation steps, thereby reducing overestimation bias. More broadly, DRL follows a trial-and-error learning paradigm, where the agent interacts with the environment, accumulates experience, and iteratively refines its policy. In the context of underground WPT, the agent must learn an adaptive beamforming policy conditioned on state information , which encodes harvested node voltages, fairness indicators, and the prior beam direction . The DQN evaluates the expected long-term utility of steering the beam toward candidate directions . A fundamental challenge lies in balancing exploration, i.e., testing new beam directions to improve environmental knowledge, with exploitation, choosing actions known to maximize energy transfer efficiency. This balance is particularly critical in dynamic, safety-critical underground networks, where channel fading, obstructions, and node mobility demand robust and adaptive beam-steering strategies.
4.3. Problem Formulation
The Safe DQN extends the conventional DQN framework by optimizing the expected return while explicitly enforcing one or more operational constraints, . The objective is to derive a policy that maximizes the discounted harvested energy reward while adhering to safety requirements such as beam-switching stability, fairness, minimum energy guarantees, and uplink usage limits. Formally, the primal problem is defined as Equation (41):
subject to
where denotes the constraint costs at time , and are the corresponding budget thresholds, as defined previously in (30)–(36). These constraints ensure that the learned policy maintains operational safety, fairness across nodes, and compliance with system-level limitations, which are critical in underground RF-WPT environments. In the literature, the standard approach to solving CMDPs is to transform the constrained optimization problem into an unconstrained one using the Lagrangian relaxation method. Specifically, ( ) is referred to as the primal problem, and by introducing non-negative Lagrange multipliers associated with each constraint, one can formulate the dual problem. This transformation enables the use of gradient-based learning to simultaneously update both the policy and the multipliers, ensuring that energy efficiency is maximized while constraint violations are adaptively penalized. The detailed solution approach is presented in Section 5.
5. Proposed EB Optimization Solution
Given the harsh RF propagation conditions in underground mines, our objective is to maximize real-time WPT efficiency while ensuring quality-of-service (QoS) constraints are satisfied. The optimization problem ( ) formulated in Section 4 is inherently nonlinear due to the structure of the constraint functions and is computationally intractable (NP-hard) to solve directly. This section presents our solution approach based on Lagrangian relaxation and dual optimization.
5.1. Safe-DQN Lagrangian-Based Solution
To address the NP-hard constrained optimization problem, we decompose the solution into three key steps: (i) Lagrangian relaxation to transform the constrained problem into an unconstrained one, (ii) dual optimization to solve the relaxed problem, and (iii) Lagrangian-based Q-function formulation for practical implementation with Deep Q-Networks.
5.1.1. Lagrangian Relaxation
The Lagrangian relaxation technique transforms the CMDP into an unconstrained optimization problem by introducing non-negative Lagrange multipliers for each constraint function The discounted-trajectory Lagrangian is expressed as Equation (42):
Equation (42) reformulates the Safe-DQN CMDP into a single-objective optimization problem where violations of safety constraints are penalized by the multipliers . The key insight is that when a constraint is violated, i.e., , the term reduces the reward, discouraging the agent from selecting actions that lead to constraint violations. Conversely, when constraints are satisfied, i.e., , the penalty is minimal or zero, allowing the agent to focus on maximizing energy harvesting. For computational efficiency, we define a shaped per-step reward that embeds these penalties directly as Equation (43):
With this formulation, the agent can treat the CMDP as a standard MDP with adjusted rewards that automatically incorporate safety considerations. This eliminates the need to explicitly check constraints at each step, simplifying the learning process while maintaining safety guarantees.
5.1.2. Dual Optimization
The Lagrangian relaxation leads to a saddle-point problem, defined as Equation (44):
A saddle point represents an equilibrium where
- The primal update (inner maximization) adjusts the policy π to maximize the penalized reward.
- The dual update (outer minimization) adjusts the multipliers’ λ penalize constraint violations.
Formally, a pair is a saddle point if Equation (45) holds:
Convergence Guarantee
The optimality of is characterized using the Karush–Kuhn–Tucker (KKT) conditions, which must hold simultaneously at equilibrium:
- Primal Feasibility (constraints satisfied) as Equation (46):
This ensures that the learned policy respects all safety constraints on average.
ii.Dual Feasibility (multipliers nonnegative) as Equation (47):
Non-negative multipliers ensure that constraint violations are always penalized, never rewarded.
iii.Stationarity (optimal policy maximizes the Lagrangian for fixed multipliers) as Equation (48):
At equilibrium, no policy can achieve higher penalized reward than given the multipliers .
iv.Complementary Slackness (constraints only “bind” if they are tight) as Equation (49):
If a constraint is not violated, i.e., then, and no penalty is needed. If a constraint is tight, i.e., , then and a penalty is active. This adaptive penalty mechanism ensures efficient constraint enforcement. At equilibrium, these KKT conditions guarantee that the algorithm maximizes long-term WPT efficiency while strictly satisfying all operational and safety constraints in underground RF-WPT environments.
5.1.3. Lagrangian-Based Q-Function
Finally, the principle of Bellman optimality can be extended to incorporate Lagrangian penalties. The Lagrangian-based Q-function is defined as Equation (50):
denotes the next action under the principle of optimality, and is the shaped reward from Equation (43). Equation (50) implies that the agent learns to always select the action that yields
- Energy-harvesting gains (positive contribution from ).
- Constraint violation penalties (negative contribution from ).
Thus, the proposed Safe Adaptive DQN algorithm alternates between
- Primal policy updates: Maximizing shaped rewards (maximizing energy while respecting penalties).
- Dual updates: Adjusting multipliers (increasing penalties when constraints are violated).
This iterative process ensures convergence to a policy that balances energy efficiency with strict adherence to QoS and safety constraints in underground RF-WPT environments.
5.2. Adaptive Mechanisms in Safe-DQN Beamforming
Thus far, the Safe-DQN framework has been described in terms of its fundamental reinforcement learning and constraint-handling principles. We now introduce the adaptive mechanisms that extend the baseline Safe-DQN agent beyond conventional reward maximization, enabling robust and resilient energy beamforming in underground RF-WPT networks. The proposed Safe Adaptive DQN (SADQN) integrates five key components:
- Energy-Aware (EA) score that prioritizes the most energy-starved node.
- Fairness Bonus (FB) that incentivizes a balanced energy distribution across all nodes.
- Adaptive Exploration that dynamically tunes the exploration probability based on system conditions.
- Composite Score to rank beamforming actions.
- Fairness-Aware Top-K action selection that prevents overly greedy or myopic behavior.
These mechanisms are fused into a composite score function, which ranks candidate beamforming actions by combining Q-values with adaptive penalties and incentives. The following subsections define and discuss each mechanism in detail.
5.2.1. Energy-Aware (EA)
The energy-aware score biases the agent toward nodes with critically low energy reserves, implementing a triage principle essential for disaster scenarios. The harvested energy increment for the weakest node under the beamforming direction is normalized to obtain Equation (51):
where denotes the predicted residual energy of the weakest node (identified via Equation (26)) after taking action and is the maximum storable energy. By emphasizing this score, the agent allocates beams that extend the operational lifetime of the most vulnerable nodes, an essential feature for disaster-resilient underground networks.
5.2.2. Fairness Bonus (FB)
To complement the hard fairness constraint , we introduce a fairness bonus as a soft incentive. This term evaluates how an action improves the energy balance across all nodes, leveraging Jain’s fairness index (Equation (23)), as Equation (52):
measures the fairness of the post-decision energy distribution, with indicating perfect fairness (all nodes have equal energy) and indicating extreme inequality. This encourages the agent to pursue actions that enhance equity across nodes, even when fairness constraints are not immediately binding.
5.2.3. Adaptive Exploration
Unlike conventional DQN, which employs a fixed or monotonic -decay schedule, our approach adjusts exploration dynamically in response to system variability. The key insight is
When harvested voltages across nodes exhibit high dispersion (unbalanced system), increase exploration to discover better beam directions.When the system is stable and balanced, prioritize exploitation of known good actions.
The adaptive exploration rate is defined as Equation (53):
- is the standard deviation of harvested voltages across nodes.
- is a scaling factor.
- are exploration bounds.
This mechanism enables the agent to adapt exploration rates to network conditions, improving responsiveness in highly dynamic underground environments.
5.2.4. Composite Score
The adaptive mechanisms are integrated into a composite score used to rank beamforming actions, defined as Equation (54):
- : Q-value predicted by the neural network (expected long-term return).
- : Constraint penalties from Lagrangian formulation.
- : Bonus for helping the weakest node (triage principle).
- : Penalizes abrupt beam switches through the switching indicator .
- : Bonus for improving fairness.
This composite score balances multiple objectives:
- High score good action (high energy, low violations, helps weak nodes, fair, smooth).
- Low score poor action (low energy, many violations, ignores weak nodes, unfair, erratic).
The weighting parameters , , allow for tuning the relative importance of each objective.
5.2.5. Fairness-Aware Top-K Selection
To avoid myopic selection of a single argmax action, we adopt a Fairness-Aware Top-K mechanism. At each decision step, a subset of high-ranking candidate actions is retained: selects a subset of strong candidate actions defined as Equation (55):
where adaptive is defined as
The final action is then selected from this candidate set according to Equation (57):
The idle action is always included to ensure compliance with duty-cycle constraints. Intuitively, when fairness is low, is small and exploration is restricted to a few high-priority beams, while high fairness allows larger , enabling broader exploitation of good beamforming directions.
5.3. SADQN Energy Beamforming Algorithm
We propose the Safe Adaptive Deep Q-Network (SADQN) algorithm to address the dynamic and safety-critical nature of underground mining disaster environments. Unlike plain DQN or self-DQN, the SADQN framework introduces adaptive mechanisms that adjust exploration in response to channel variability while strictly enforcing operational constraints. This ensures that the algorithm not only maximizes harvested energy but also maintains fairness, safety, and reliability under extreme RF conditions.
In practice, SADQN balances two competing goals: (i) maximizing received RF power through adaptive beam steering, and (ii) satisfying operational constraints, such as transmit duty cycle, fairness across nodes, and beam-switching stability. This makes SADQN particularly suitable for safety-critical underground networks, where reliable energy provisioning to LoRa-enabled nodes is essential for localization, sensing, and emergency communications. Algorithm 1 presents the proposed SADQN EB optimization algorithm.
Algorithm 1 Adaptive Safe-DQN-Based Energy Beamforming AlgorithmInputs:
- Angle codebook: plus idle action
- Discount: Replay capacity: ; Batch size: .
- Target update (soft): , EWMA factor: .
- Constraint targets: , , .
- Exploration: or adaptive .
- Switching threshold dual step: .
- Top-K bounds: ( ).
- Priority/fairness/switch weights: (bias toward low-energy node), (penalty for large abrupt beam switches), (fairness bonus). Initialization
- 1:Initialize Q-network with random weights; set target network
- 2:Create replay buffer of capacity
- 3:Initialize duals
- 4:Initialize parameters
- 5:Initialize sliding duty trackers: , ,
- 6:Loop
- 7:for each episode: do
- 8: Reset environment if episodic
- 9: for each time step t: do
- 10: State construction
- 11: Set : Equation (22) Optionally append and pooled statistic
- 12: Energy-Aware Scoring
- 13: Select target by residual energy: Equation (26)
- 14: for each do
- 15: predict one-step next energies Equation (16) predict voltages Equation (17)
- 16: Set switch flag
- 17: Compute: : Equation (51), : Equation (52) and Composite scoring function (Equation (54)) including , ,
- 18: End for
- 19: Fairness-Aware Top-K
- 20: Compute adaptive Equation (56) and form candidate set Equation (55)
- 21: Action Selection
- 22: With probability (adaptive) or (fixed) sample funiformly from
- 23: Otherwise ; Equation (57)
- 24: Environment Update
- 25: Execute set if else
- 26: Observe voltages update node energies; Equation (16)
- 27: Compute reward ; Equation (28)
- 28: Update trackers via EWMA factor ; Equation (24)
- 29: Constraints Costs
- 30: Compute ; Equations (30)–(36)
- 31: Shaped Rewards and Storage
- 32: Set ; Equation (40)
- 33: Push into
- 34: Learning (Double-DQN)
- 35: if Then
- 36: Sample a mini-batch from
- 37: for each sample, compute target; Equation (41)
- 38:
- 39:
- 40: Update by minimizing loss
- 41: End if
- 42: Soft update (every step)
- 43:
- 44: Dual Updates
- 45: for each constraint j: do
- 46:
- 47: End for
- 48:Bookkeeping
- 49:Update if using fixed decay
- 50:if then, update
- 51: End for (time steps)
- 52: End for (Episodes)
Output The algorithm yields a trained Q-network and optimized multipliers The final deployment policy augmented with Energy-Aware Top-K gating mechanism.
6. Simulations and Analysis
In this section, we present a comprehensive performance evaluation of the proposed Safe Adaptive Deep Q-Network (SADQN)-based energy beamforming framework through extensive simulations. To rigorously assess the effectiveness of our approach, we compare SADQN against a diverse set of baseline algorithms spanning reinforcement learning methods, classical optimization techniques, and analytical benchmarks. This comparative analysis aims to demonstrate the advantages of incorporating safety-aware learning mechanisms with adaptive exploration in underground wireless power transfer scenarios while quantifying the inherent trade-offs between energy maximization, constraint satisfaction, and system fairness.
6.1. Baseline Algorithms
The performance of SADQN is evaluated against the following eight baseline algorithms, each representing a distinct approach to the energy beamforming problem. Our algorithms were compared with the following baseline algorithms: (i) Deep Q-Network (DQN): The standard value-based deep reinforcement learning algorithm that optimizes beamforming decisions without explicit safety considerations, (ii) Safe-DQN: Our constrained reinforcement learning framework that integrates Lagrangian-based constraint handling into the DQN architecture through a dual variable, (iii) Deep Deterministic Policy Gradient (DDPG): An actor–critic reinforcement learning algorithm capable of handling continuous action spaces, (iv) Particle Swarm Optimization (PSO): A population-based metaheuristic optimization algorithm inspired by social behavior of bird flocking, (v) Random Beamforming: A naive policy that randomly selects beam directions from the angular codebook with uniform probability at each time step, without learning or optimization, and (vi) Non-Beamforming (NB): An omnidirectional transmission strategy where the transmitter radiates equally in all directions without spatial selectivity.
6.2. Performance Metrics
The algorithm performance is evaluated across five key categories critical for disaster-tolerant underground mining networks: (i) Energy-harvesting Metrics, (ii) Safety and Constraint Metrics, (iii) Fairness Metrics, (iv) Operational Metrics, and (v) Robustness Metrics.
6.3. Simulation Environment and Parameters
6.3.1. Underground Mine Channel Model
Simulations employ a realistic underground mine propagation model incorporating waveguide effects, multipath fading, shadowing, and moisture absorption as detailed in Section 3.2. The channel model combines
- Path loss with corridor propagation exponent .
- Rician fading with K-factor = 5 dB modeling LoS and scattered components.
- Log-normal shadowing with standard deviation σ = 6 dB.
- Wall penetration loss dB.
- Junction scattering loss dB.
- Moisture absorption dB.
Node mobility follows a Gauss–Markov random walk model with temporal correlation coefficient and angular drift variance radians, emulating realistic miner and equipment movement patterns in underground tunnels.
6.3.2. System Configuration
6.3.3. System Network Topology
The underground mine testbed consists of four LoRa-enabled energy-harvesting nodes deployed along a 50 m tunnel segment. Initial node positions are uniformly distributed within the tunnel, with subsequent positions evolving according to the Gauss–Markov mobility model. The transmitter is positioned at one end of the tunnel with a 16-element ULA capable of steering beams across Table 4: Simulation Parameters ±60° azimuth range, discretized into 48 beam directions (2.5° resolution).
6.3.4. Experimental Scenarios
Two primary scenarios are evaluated to capture the dual challenges of underground wireless power transfer:
- Stationary Scenario: Nodes remain at fixed positions throughout each episode, isolating the algorithms’ ability to learn optimal beam steering under static channel conditions with only fading variability. This scenario tests steady-state convergence and exploitation efficiency.
- Mobile Scenario: Nodes move according to the Gauss–Markov mobility model at speeds up to 0.5 m/s, emulating realistic miner and equipment movement. Dynamic positions introduce time-varying channel conditions requiring continuous adaptation. This scenario tests the algorithms’ ability to track moving targets and maintain energy delivery under non-stationary environments.
6.3.5. Evaluation Protocol
Each algorithm is trained and evaluated using the following protocol:
- Initialization: All learnable parameters are randomly initialized; replay buffers are empty; dual variables set to zero.
- Training Phase: Algorithms interact with the environment for 500 episodes (50,000 total time steps).
- Multiple Seeds: Each experiment is repeated across 10 random seeds to ensure statistical robustness.
- Performance Logging: Metrics are recorded at every time step and aggregated at episode boundaries.
- Statistical Analysis: Results are reported as mean ± standard deviation across seeds, with box plots showing the distribution.
All simulations are implemented in Python 3.9 using PyTorch 1.12 for neural network components. The complete codebase, including environment models and trained weights, will be made publicly available upon publication to ensure reproducibility.
6.4. Results and Discussion
The following subsections present a detailed comparative analysis organized by performance dimensions. Each subsection includes quantitative results, visual comparisons, and qualitative insights into algorithm behavior.
6.4.1. Cumulative Reward
Figure 3 compares the total cumulative rewards achieved by the proposed SADQN, Safe-DQN, and benchmark algorithms under both stationary and mobile scenarios.
The cumulative reward integrates the agent’s long-term optimization of harvested energy, fairness, and duty-cycle constraints within the constrained MDP formulation. SADQN exhibits the highest cumulative reward, validating its adaptive exploration and energy-aware scoring strategy for sustainable WPT operation. The marginal reduction in the mobile case reflects the performance trade-off introduced by temporal channel fading and node mobility dynamics. PSO can become trapped in local optima, degrade as dimensionality increases (the curse of dimensionality), and adapt poorly in changing environments. In contrast, DQN leverages deep neural networks to handle large, complex state spaces and learn near-optimal policies, which makes it more suitable for dynamic, sequential decision problems—although it typically requires more data and computational resources. PSO is comparatively simpler and can converge faster on continuous, static optimization tasks, but it generally falls short on problems with complex time-coupled decisions where deep reinforcement learning performs best.
6.4.2. Duty Cycle
The stacked bars in Figure 4 depict average duty-cycle utilization, showing the proportion of active transmission time for stationary and mobile environments. Duty-cycle regulation ensures compliance with underground wireless standards and prevents excessive channel occupancy in disaster-recovery conditions. SADQN maintains near-optimal transmission duty levels, balancing channel access with harvested-energy fairness to maximize network longevity. The increased duty usage in mobile conditions highlights the adaptive scheduling overhead required for dynamic topology updates and link re-synchronization.
6.4.3. Fairness
Figure 5 presents the mean Jain fairness index across episodes, capturing energy distribution equity among LoRa EH nodes. Fairness optimization is embedded in the SADQN reward design via the energy-aware Top-K constraint and Lagrange-penalized dual update. SADQN and Safe-DQN achieve superior fairness stability, minimizing variance in harvested energy across heterogeneous nodes. Minor fairness degradation in the mobile setting stems from spatial energy fluctuation and intermittent relay selection during motion-induced fading.
6.4.4. Convergence Speed
Figure 6 compares the learning convergence rate of each algorithm, expressed as the number of episodes required to reach 90% of steady-state reward. SADQN converges significantly faster than Safe-DQN, DDPG, and PSO, confirming the efficiency of its adaptive exploration and energy-aware policy updates. Its rapid convergence indicates enhanced learning stability and reduced sample complexity in dynamic wireless power transfer environments. The slower convergence in mobile conditions reflects additional exploration required under time-varying channel and topology uncertainty in underground scenarios.
6.4.5. Energy Efficiency
The heatmap in Figure 7 visualizes the normalized energy efficiency of all algorithms under stationary and mobile network conditions. Energy efficiency quantifies the ratio of harvested-to-transmitted power achieved by each policy during long-term RF wireless power transfer. SADQN demonstrates the highest efficiency across both environments, validating its energy-aware reward design and adaptive beam selection capability. Efficiency degradation in mobile conditions highlights the impact of dynamic channel fading and positional drift, reinforcing the need for adaptive safe reinforcement learning in underground mining scenarios.
6.4.6. Constraint Cost Analysis
Figure 8 and Figure 9 analyze the constraint cost violation. These plots track the cumulative constraint violations across training episodes for all algorithms under stationary and mobile network conditions. Constraint costs arise from the exceeding predefined energy, duty cycle, fairness, and uplink utilization limits in the CMDP. SADQN and Safe-DQN maintain the lowest violation levels, confirming their ability to satisfy multi-constraint safety requirements during adaptive beamforming. Mobile scenarios exhibit slightly higher violations due to mobility-induced channel fluctuations and topology reconfiguration overhead, emphasizing the importance of safe policy regularization in dynamic underground environments.
6.4.7. Stability Learning Analysis
Figure 10 and Figure 11 present the exponential moving variance of the learning reward, serving as an indicator of training stability. SADQN and Safe-DQN maintain the lowest variance throughout training, demonstrating robust policy updates and stable reward prediction. Low-variance performance ensures a reliable convergence under fluctuating SINR and harvested-power feedback typical of underground mine channels. Higher fluctuations in DQN and PSO signify sensitivity to exploration noise and lack of embedded constraint awareness in their reward models.
7. Conclusions
This paper presented a Safe Adaptive Deep Q-Network (SADQN) framework for energy beamforming in LoRa-enabled RF wireless power transfer systems designed for disaster-tolerant underground mining networks. The proposed approach addresses three critical limitations of existing beamforming techniques: the absence of explicit safety mechanisms, lack of residual energy-aware node prioritization, and inadequate support for long-range, low-power communication in post-disaster underground environments. The SADQN framework formulates the beamforming problem as a constrained Markov decision process (CMDP) and employs Lagrangian relaxation with dual-variable updates to transform the NP-hard constrained optimization into a tractable problem.
Comprehensive simulation results validated the effectiveness of the proposed approach. SADQN achieved significant improvements in cumulative harvested energy: approximately 11% versus DQN, 15% versus Safe-DQN, and 40% versus PSO in mobile scenarios. The framework maintained fairness indices above 0.90, converged 27% faster than Safe-DQN and 43% faster than DQN, and exhibited 33% lower performance variance than Safe-DQN. Safe-DQN reduced constraint violations by 66% versus SADQN and 59% versus DQN, demonstrating the critical trade-off between energy maximization and safety compliance.
The framework incorporates five key adaptive mechanisms: energy-aware scoring, fairness bonus incentives, adaptive exploration, composite scoring, and fairness-aware top-K action selection. These mechanisms enable safe, efficient beamforming policies without requiring perfect channel state information. The dual-band architecture (860 MHz for WPT and 915 MHz for LoRa uplink) successfully addressed the 125+ dB power asymmetry between energy-harvesting requirements and LoRa communication sensitivity, enabling real-time voltage feedback without extensive CSI acquisition. The sequential charging strategy, which prioritizes the weakest nodes, proved particularly effective for disaster scenarios where maintaining tracking and localization capabilities is paramount.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Stafford A. Requist K.W.B. Lopez S.L. Gordon J. Momayez M. Lutz E. Underground mining self-escape and mine rescue practices: An overview of current and historical trends Min. Metall. Explor.20234022432253
- 2Anabi H.K. Frimpong S. Madria S. Energy-Harvesting Concurrent Lo Ra Mesh with Timing Offsets for Underground Mine Emergency Communications Information 20251698410.3390/info 16110984 · doi ↗
- 3Kelechi A.H. Samuel F. Empirical Study of Far-Field Radio Frequency Wireless Power Transfer Testbed for Underground Mines Based on 1.8 G Hz IEEE Access 2025137923793810.1109/ACCESS.2024.3525068 · doi ↗
- 4Nerguizian C. Despins C.L. Affes S. Djadel M. Radio-channel characterization of an underground mine at 2.4 G Hz IEEE Trans. Wirel. Commun.200542441245310.1109/twc.2005.853899 · doi ↗
- 5López O.L. Alves H. Souza R.D. Montejo-Sánchez S. Fernández E.M.G. Latva-Aho M. Massive wireless energy transfer: Enabling sustainable Io T toward 6G era IEEE Internet Things J.202188816883510.1109/JIOT.2021.3050612 · doi ↗
- 6Clerckx B. Zhang R. Schober R. Ng D.W.K. Kim D.I. Poor H.V. Fundamentals of wireless information and power transfer: From RF energy harvester models to signal and system designs IEEE J. Sel. Areas Commun.20183743310.1109/JSAC.2018.2872615 · doi ↗
- 7Zeng Y. Clerckx B. Zhang R. Communications and signals design for wireless power transmission IEEE Trans. Commun.2017652264229010.1109/TCOMM.2017.2676103 · doi ↗
- 8Shen S. Clerckx B. Joint waveform and beamforming optimization for MIMO wireless power transfer IEEE Trans. Commun.2021695441545510.1109/TCOMM.2021.3075236 · doi ↗