Impact Analysis of the Market Penetration Rate of Connected Vehicles and the Failure Rate of Roadside Equipment on Data Accuracy
Fengping Zhan

TL;DR
This paper studies how connected vehicle penetration and roadside equipment failure affect data accuracy, showing that data fusion improves accuracy more than fixing missing data.
Contribution
Proposes a SAGA-based RSE deployment method and compares data fusion with missing data imputation for traffic data accuracy.
Findings
SAGA outperforms SA and GA in optimizing RSE locations for data accuracy.
Multi-source data fusion is more effective than missing data imputation when MPR exceeds 15% or failure rate exceeds 40%.
Fused data is less affected by sensor failure rates compared to single-source data.
Abstract
What are the main findings? The optimal deployment method solved by the Simulated Annealing Genetic Algorithm (SAGA) outperforms the SA algorithm and GA, which are superior to the uniform method and the hotspot method in optimizing RSE locations for improving data accuracy.The accuracy of single-source data can be improved along with the increase in CV MPR but decreases with the increase in sensor failure rate. The fused data is less affected by the failure rates. Multi-source data fusion is much more effective in improving data accuracy than missing data imputation. When the MPR is higher than 15% or the failure rate exceeds 40%, it is recommended to adopt data fusion rather than repairing missing data. The optimal deployment method solved by the Simulated Annealing Genetic Algorithm (SAGA) outperforms the SA algorithm and GA, which are superior to the uniform method and the hotspot…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
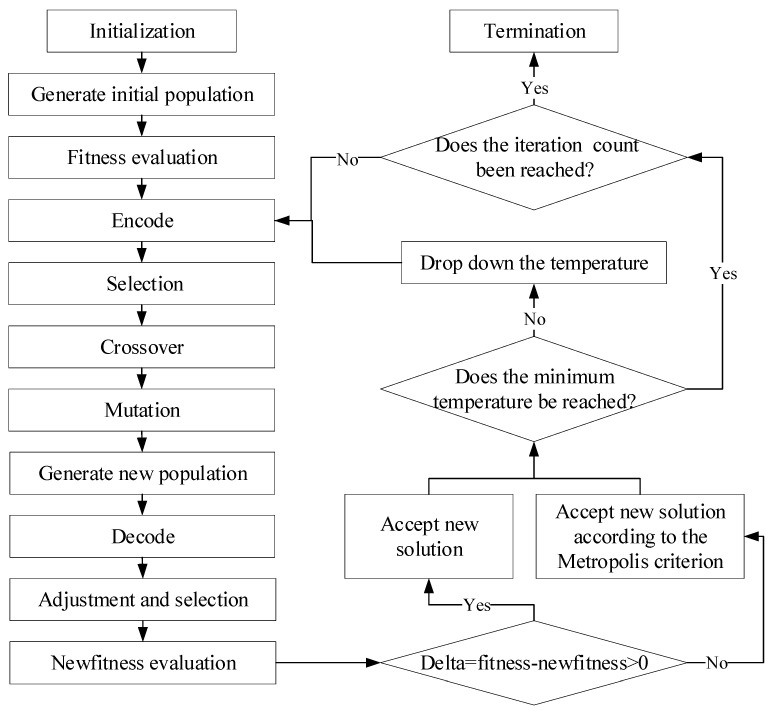 Figure 1
Figure 1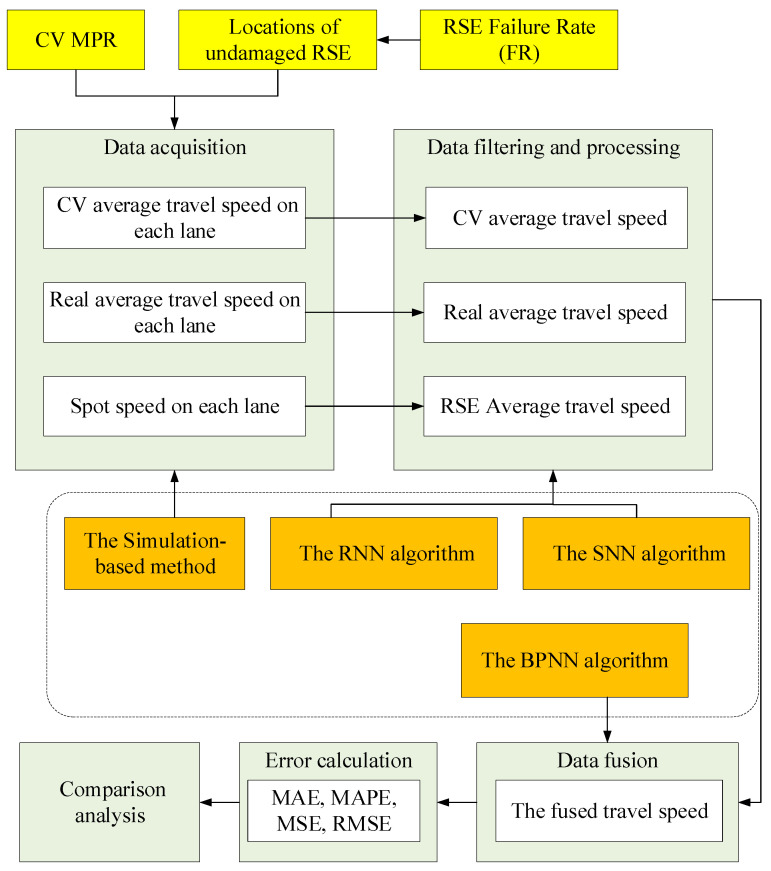 Figure 2
Figure 2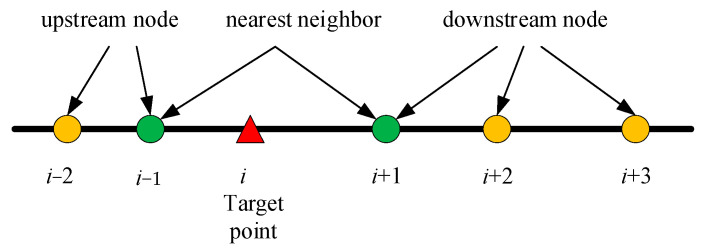 Figure 3
Figure 3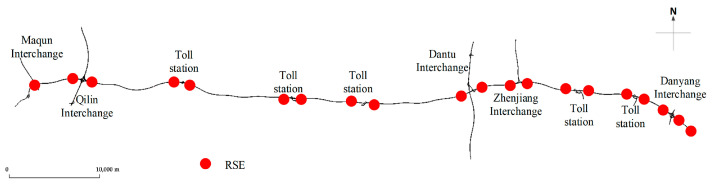 Figure 4
Figure 4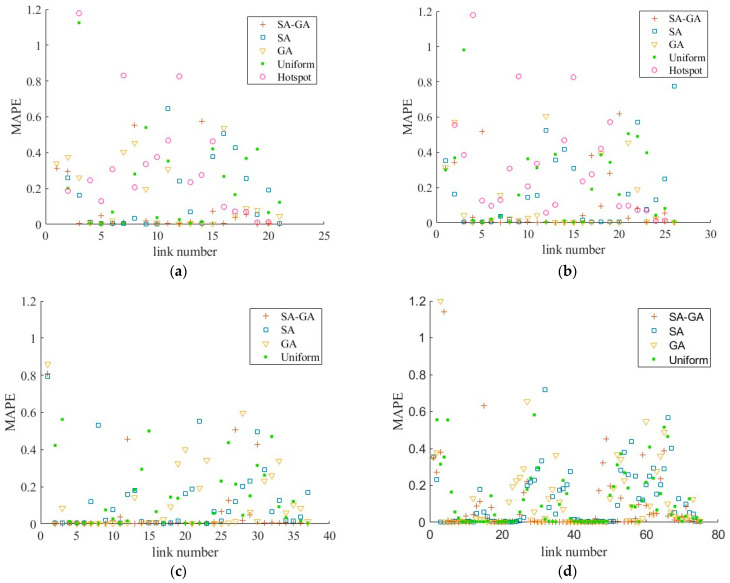 Figure 5
Figure 5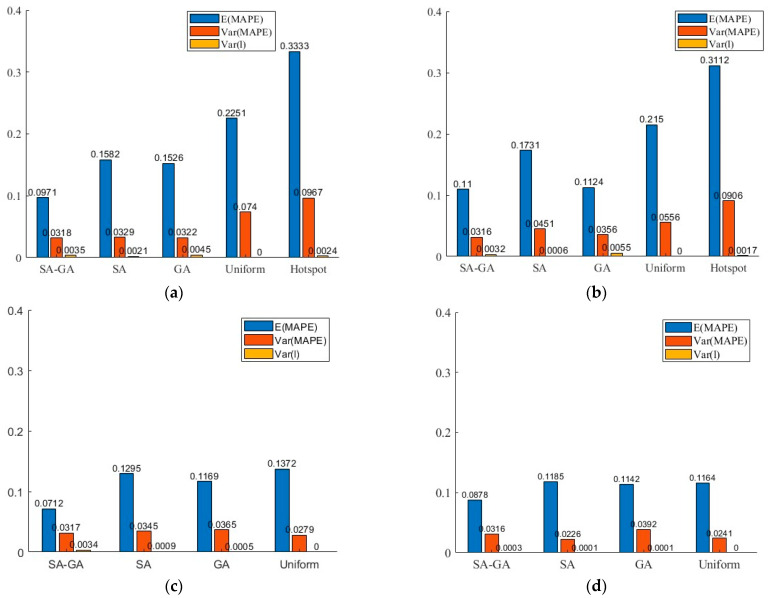 Figure 6
Figure 6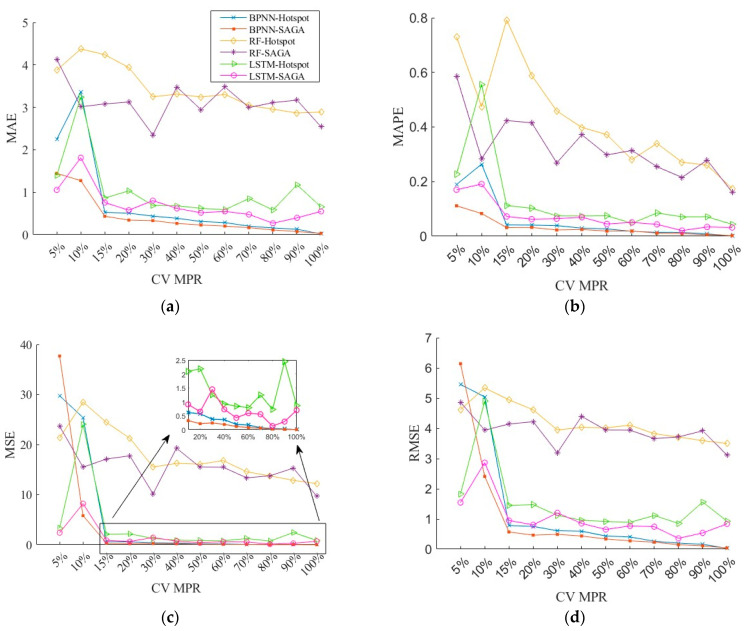 Figure 7
Figure 7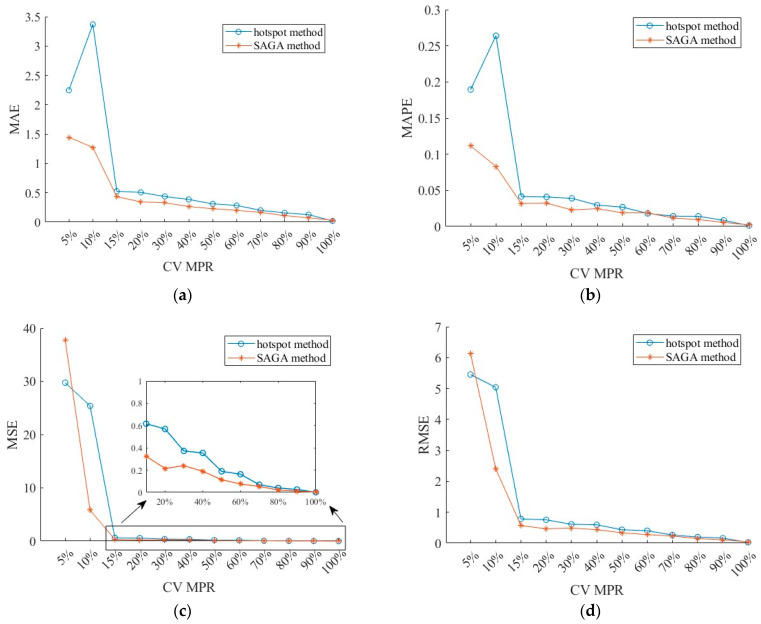 Figure 8
Figure 8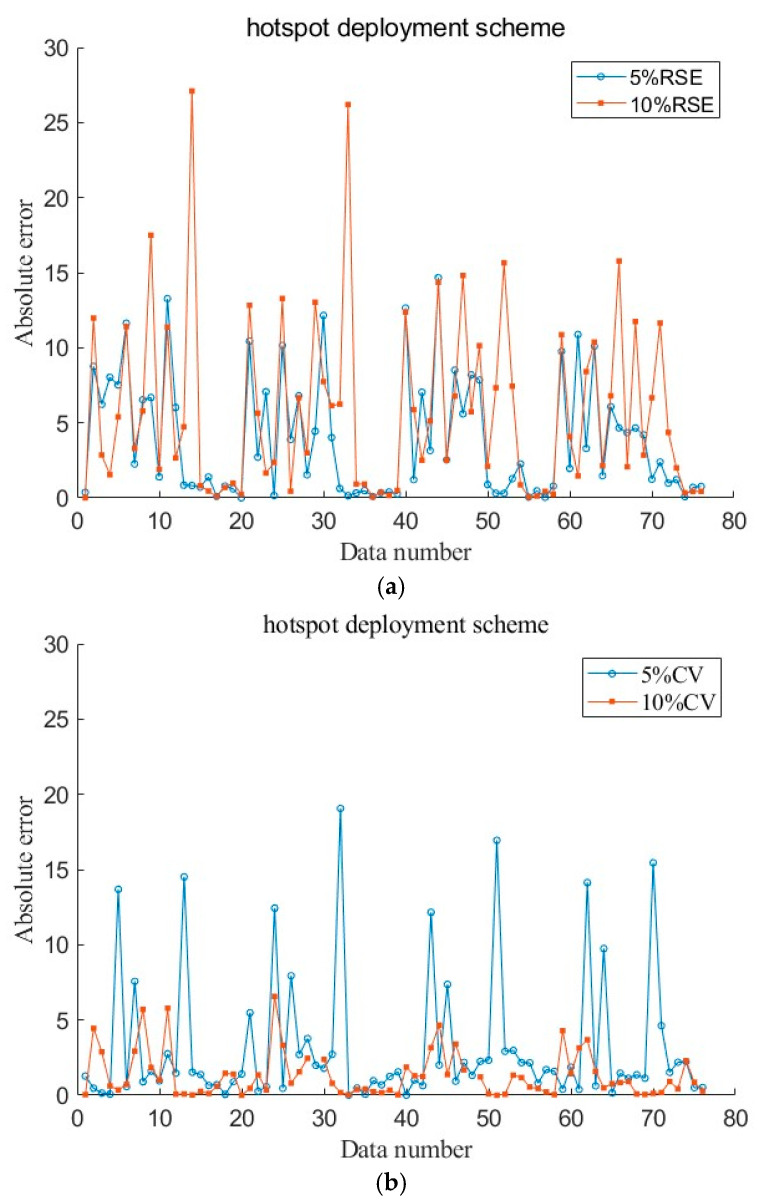 Figure 9
Figure 9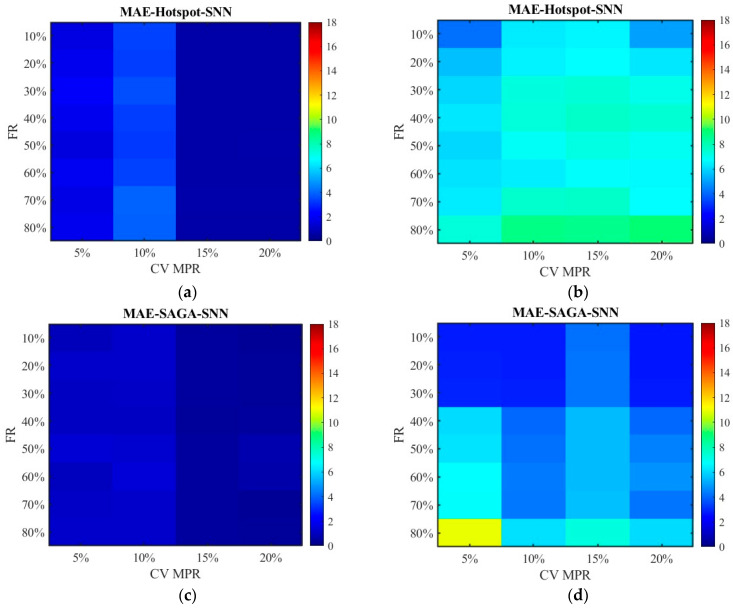 Figure 10
Figure 10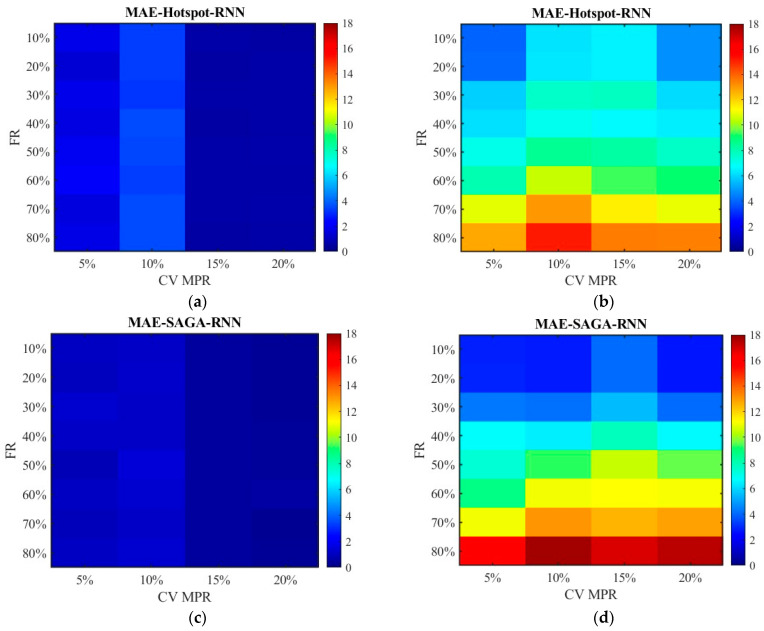 Figure 11
Figure 11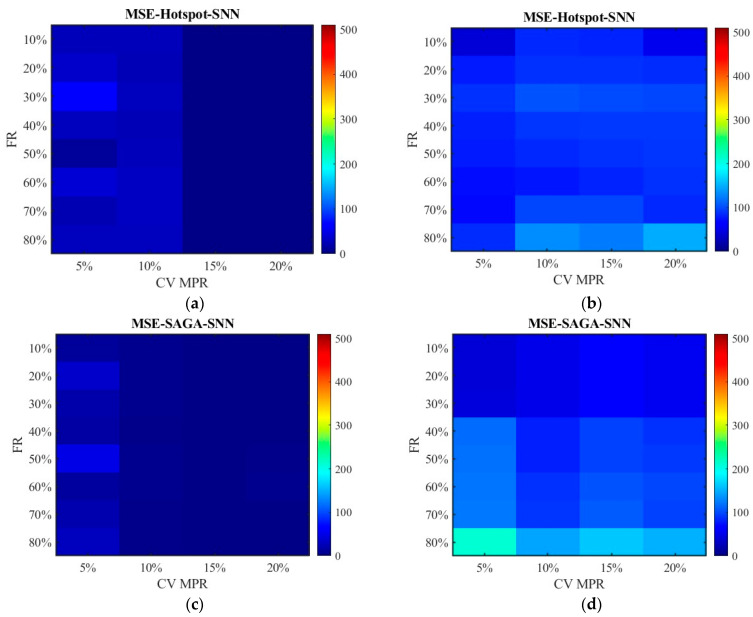 Figure 12
Figure 12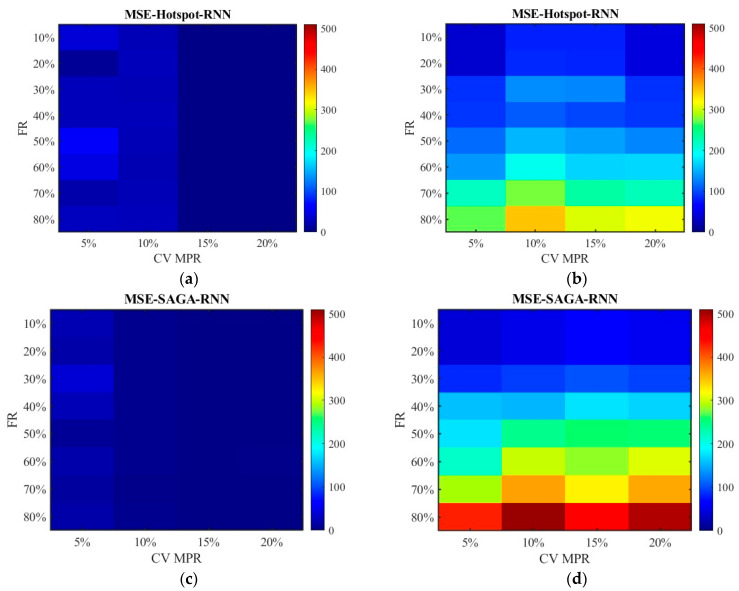 Figure 13
Figure 13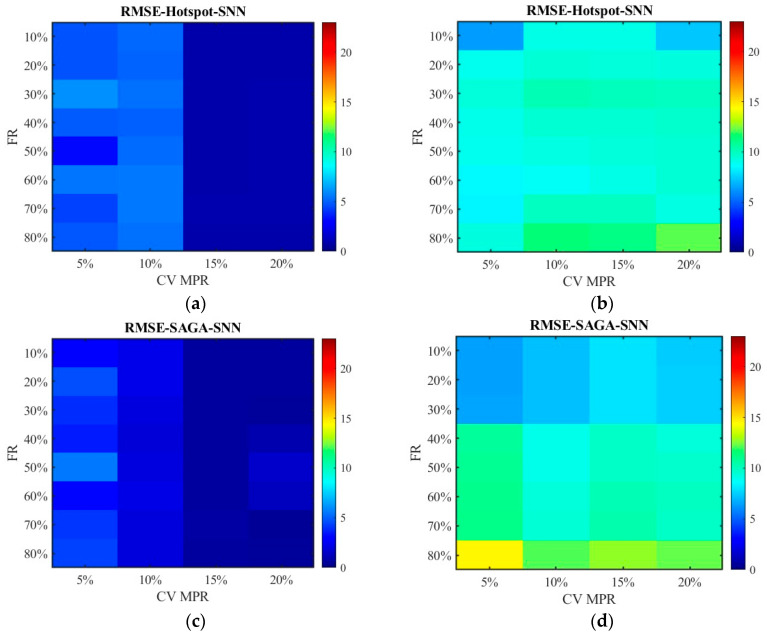 Figure 14
Figure 14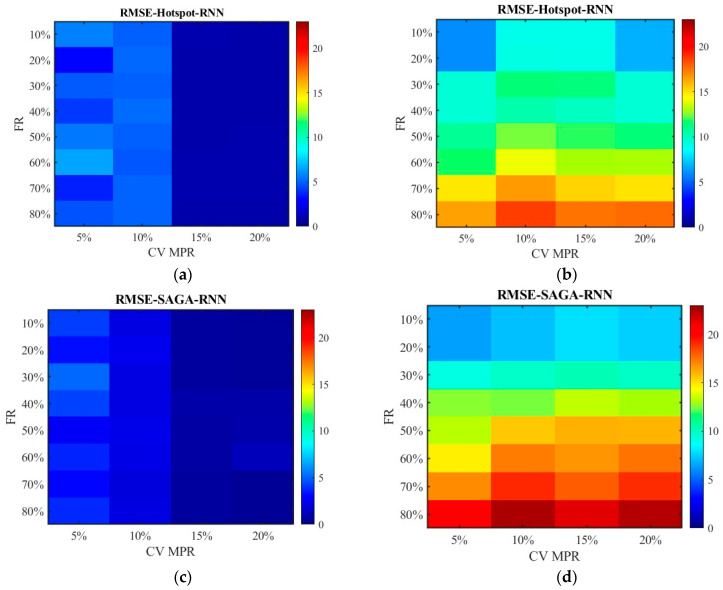 Figure 15
Figure 15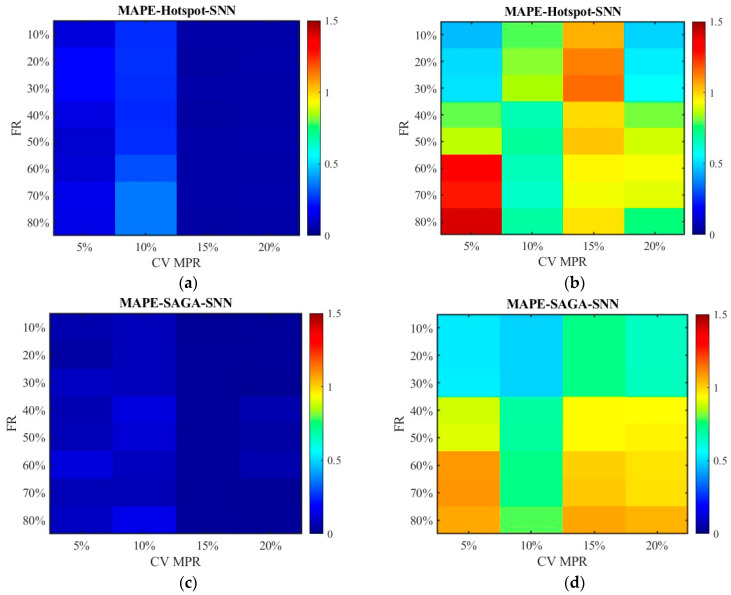 Figure 16
Figure 16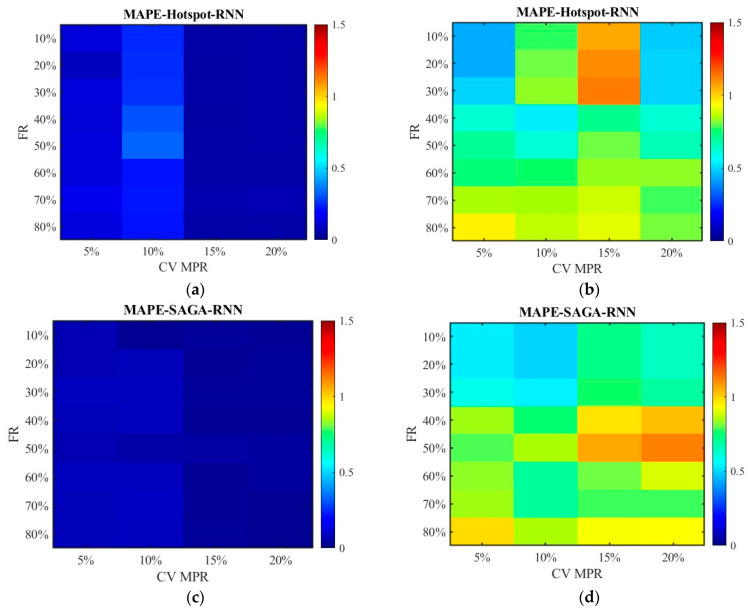 Figure 17
Figure 17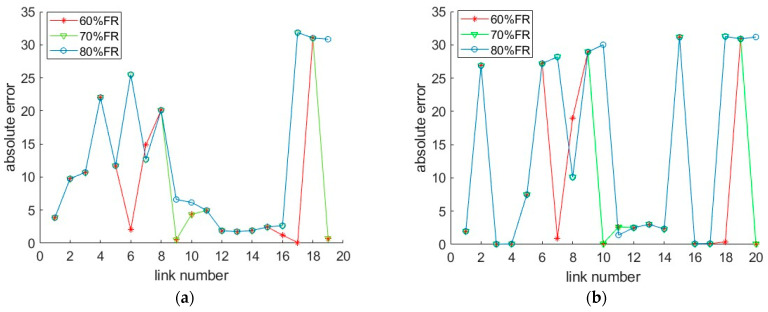 Figure 18
Figure 18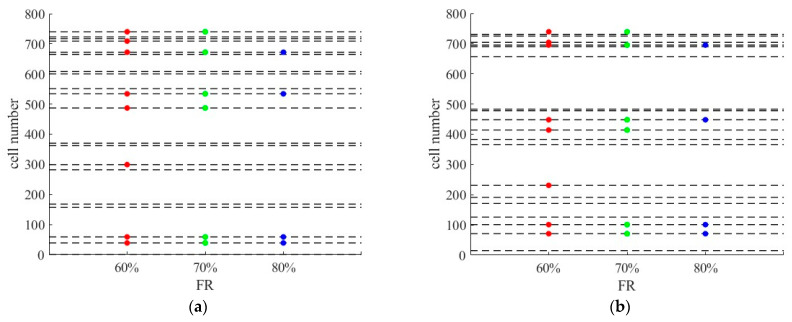 Figure 19
Figure 19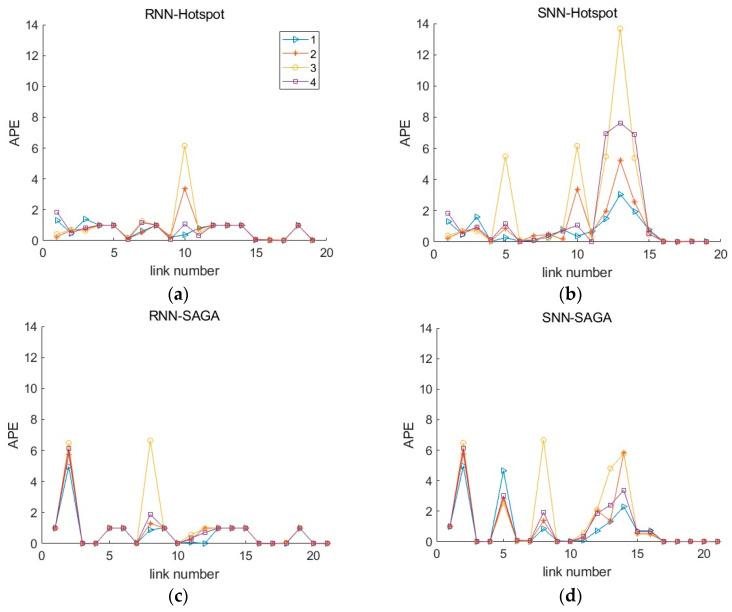 Figure 20
Figure 20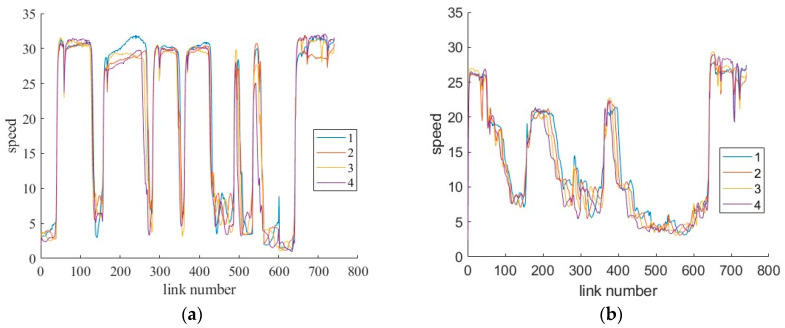 Figure 21
Figure 21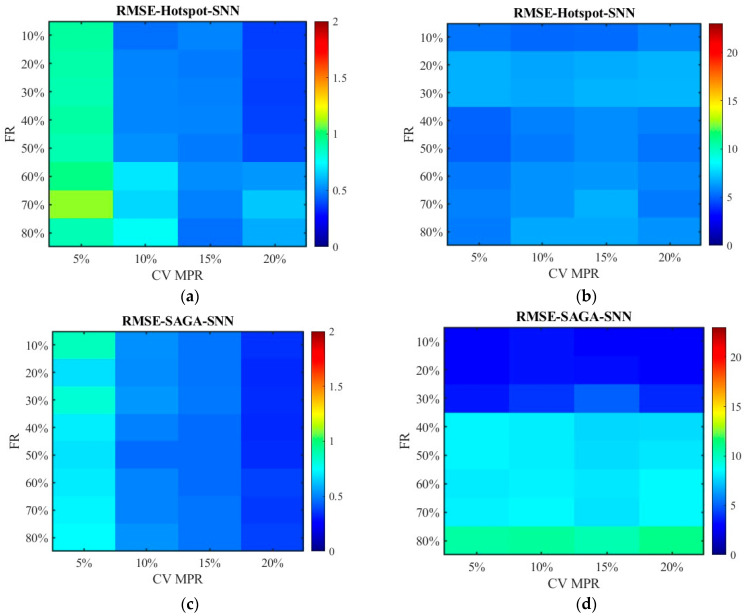 Figure 22
Figure 22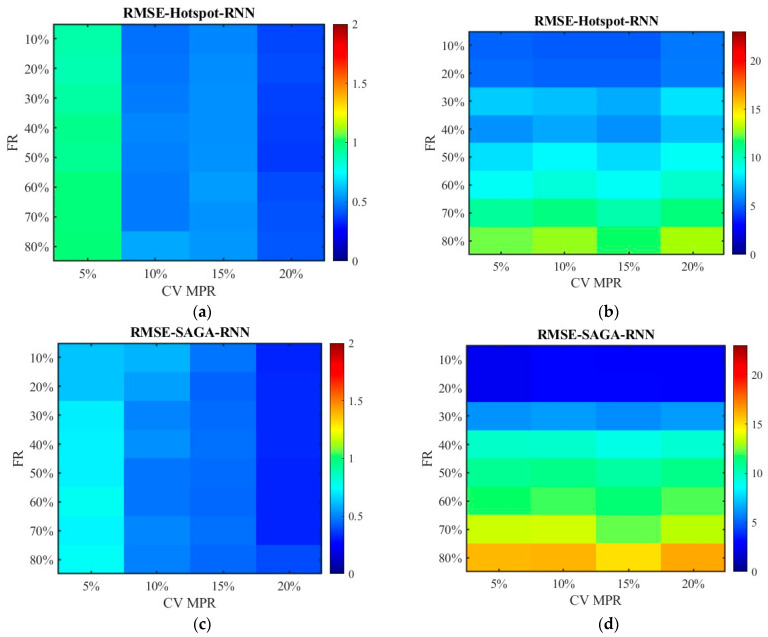 Figure 23
Figure 23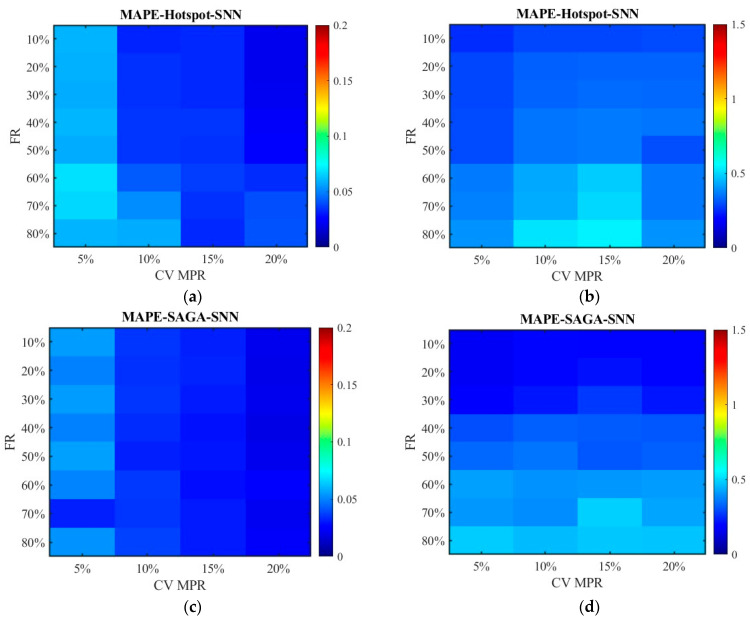 Figure 24
Figure 24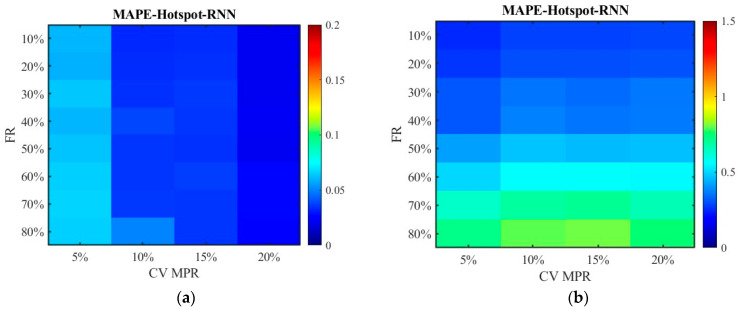 Figure 25
Figure 25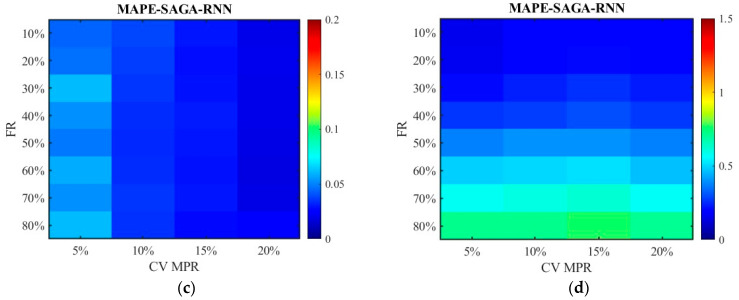 Figure 26
Figure 26- —National Natural Science Foundation of China (NSFC)
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsTraffic Prediction and Management Techniques · Traffic control and management · Distributed Sensor Networks and Detection Algorithms
1. Introduction
In the foreseeable future, connected vehicles (CVs) will coexist with human-driven vehicles resulting in a heterogeneity traffic flow. There would be a prolonged transition period towards full CV deployment, during which not all vehicles are connected and the complete information of the traffic is typically unavailable [1]. A connected vehicle is the vehicle that uses several different communication technologies to communicate with the drive, other vehicles on the road (V2V), roadside infrastructure (V2I), and the “Cloud” (V2C). V2I technology can enable vehicle probe data applications, providing detailed traffic information such as speed, volume, travel time, queue length, and stops [2]. The CV market penetration rate (MPR), which is generally defined as the ratio of the number of CVs to the number of all traffic traveling on the road over a period, is the fundamental component of tremendous applications (such as the traffic state estimation) [3]. To investigate operational or safety effects of CVs, it is essential to take MPR into consideration because the performance of CVs is significantly impacted by the MPR [4]. However, higher MPR is not guaranteed to yield greater benefits in a transportation system, especially in cases where the related technologies, facilities, and costs are not properly coordinated. Considering this, the optimal MPR becomes particularly important to achieve the best system benefits, according to which transportation agencies could adopt appropriate policies to promote or inhibit CV development.
To meet the increasing technological requirements for mixed traffic, infrastructure-aided solutions using roadside equipment (RSE) are critical for enhancing CV performance and traffic efficiency. The RSE, equipped with sensing and communications devices, can sense vehicles along its covered road section and communicate the beyond-line-of-sight motion information to CVs. It can collect vehicle-based information, which is not limited to kinematic parameters but includes also the measurements stored by vehicles’ sensors, to estimate and monitor the traffic conditions in their coverage areas. It provides the basis for providing wide-ranging and high-resolution lane-level information. It can help promote CV deployment by providing vehicles with scalable communication, sensors, and computational support. It is also a traffic information collection method that is highly likely to be widely deployed in the future. With the development of intelligent transportation and smart roads, most roads have already been equipped with point-based roadside devices over years. However, the service life of this equipment is usually no more than 15 years [5,6]. With the development of CVs, this equipment may undergo several rounds of maintenance, replacement, and upgrades. In addition, as the proportion of CVs increases, the data provided by CVs can meet the information requirement. At that time, data missing caused by partially damaged roadside equipment might no longer be a major issue affecting data quality. Hereupon, to explore this issue, it is necessary to analyze the relationship among the MPR of CVs, the failure rate (FR) of roadside equipment, and data quality.
Although scholars such as Alemazkoor et al. [7], Salari et al. [8], Ding et al. [9], and Zou et al. [10] have put forward relevant sensor failure viewpoints, in general, they did not take the MPR of CVs into account. Some scholars discussed the impact of CV MPR on traffic delay [11,12,13], traffic safety [1,14], and the capacity improvement [15,16], but overlooked the influence of roadside sensors or sensor failure. However, delving deeper into the mutual influence among the MPR of CVs, the failure rate of roadside equipment and data quality is of great significance for the development of CVs and the deployment of RSE. Few studies have suggested a causal relationship among these indicators or measured their contribution. Moreover, there are numerous studies addressing the issue of sensor location with failure consideration in road networks. Nevertheless, there has not been much research in this regard on road sections, especially on highway corridors. To fill this gap, this study proposed a simulation-based approach combined with several data processing algorithms to measure the impact of CV MPR and sensor failure on data accuracy. To optimize the locations of sensors on a freeway corridor, an optimal deployment method with spatial constraint is proposed and is solved by an improved Simulated Annealing Genetic Algorithm (SAGA). The main contributions of this work are as follows:
- (1)This is the first study to weigh the impact of CV MPR and the failure rate of RSE on data accuracy for the mixed traffic flow with CVs and human-driven vehicles on a freeway corridor.
- (2)A general optimization model, which refers to the spatial uniformity and error minimization as objective and subject to spacing constraints, is formulated to find the optimal sensor deployment scheme. It can better balance the spatial selection fairness of sensor locations by subdividing road segments into cells with relatively small spacing. By solving the model, an improved SAGA is given to find the global optimal solution. This method is more suitable to address the equipment optimization issue at the road segment level.
- (3)According to whether missing values are allowed or not, a rigid nearest neighbor algorithm and a soft nearest neighbor algorithm are proposed to handle the missing data caused by sensor failure. Based on these methods, the issue of missing single-source data at the road segment level can be addressed. Compared with missing RSE data imputation, the fusion with CV data can better enhance data quality.
- (4)The key parameters—CV MPR and sensor failure rate—affecting data accuracy are discussed in detail. The findings shed light on the trade-offs and benefits associated with improving RSE deployment and promoting CV development.
The remainder of this paper is organized as follows. Section 2 provides an overview of the related works. Section 3 elaborates the methodology framework and relevant data-processing approaches. Section 4 conducts the experiments and investigates the impact of CV MPR and RSE failure rate on data accuracy. Finally, Section 5 concludes the paper.
2. Literature References
2.1. RSE Allocation Methods
The deployment of RSE has been studied for years with a view to traffic flow observability [17,18], travel time estimation [19,20,21], network coverage [18,22,23], and origin–destination estimation [24] and so on. The commonly used deployment methods in the early stages are the fixed-spacing method and the hotspot method. With the change in demand and the development of technology, optimizing sensor deployment is essential to use as few devices as possible while meeting the requirements under budget constraints. Various models and algorithms, the dynamic programming model [25], the stochastic model [24], the integer programming model [19,26,27], the heuristic algorithm, the genetic algorithm [28] and the simulated annealing algorithm [29], and the clustering algorithm [30], were proposed to solve the sensor allocation problem. Recently, the cooperative vehicle-infrastructure system has put forward new requirements for the deployment of roadside equipment. RSE plays a crucial role in enabling vehicle-to-infrastructure communication, as it can gather and broadcast traffic information in the road network. Methods for the deployment of roadside equipment are proposed in terms of road coverage [31,32,33], vehicle connectivity [29,34,35], and V2I communication performance [36]. The mathematical programming models [37,38] and heuristic algorithms [39,40] are still the popular methods.
2.2. The Influence of CV MPR on Traffic Application
In terms of CV MPR, one commonly discussed benefit is to improve traffic operations (that is, improved efficiency, decreased congestion, and delay) with the varying MPR of CVs in the mixed-flow traffic conditions. Stern et al. [41] studied the effect of AV (Automated Vehicle) MPR on traffic control and found that 5% or less of the AVs could control the traffic flow. Zheng et al. [42] analyzed the impact of AV MPR on uncertainty and instability of mixed traffic. They concluded that higher MPR can reduce the uncertainty inherent in human-driven vehicle behavior and improve the stability of mixed traffic flow. Argote-Cabanero et al. [11] proposed a method to determine the minimum penetration rate of CVs to estimate traffic speed and traffic delay accurately, and found that 15% would meet the target. Stanek et al. [12] found that 30–50% of AVs yield a decrease in network delay and an increase in network speed, which is almost the same as the 100% AV case. Abdeen et al. [13] concluded that vehicle delays were reduced by 26%, 34.4%, 63.7%, and 74.2%, when the MPRs of AVs are 25%, 50%, 75%, and 100%. Gao et al. [43] studied the real-time queue length at signalized intersections by taking connected vehicles as the mobile sensor, and found that the sensing accuracy is proportional to the penetration rate. Similarly, Željko Majstorović et al. [44] concluded that the accuracy of the speed transition matrices could be increased by the CVs penetration rate, but not linearly. Di et al. [45] used the average total travel time on the mainline and the average queue length of on-ramps as the indicator to optimize CV MPR, and found that the optimal MPR tends to be high when the weight of total travel time is high. Yao et al. [46] analyzed the stability of the mixed traffic flow with different automation levels, and found that the mixed traffic flow is more unstable than traditional human driving traffic flow when the CAV MPR is 80%. However, with the increase in MPR and the automation level of CAVs, mixed traffic flow tends rapidly to a stable state.
Some studies pay more attention on the influence of the MPR of CVs on traffic safety. Ye et al. [14] evaluated the impact of the connected and automated vehicle (CAV) penetration rate on traffic safety and found velocity difference between vehicles is decreased and traffic flow is greatly smoothed with the increase in the CAV MPR. Mousavi et al. [1] found that the number of rear-end conflicts and lane-changing conflicts were significantly decreased with the increase in the AV MPR. Chin et al. [47] found that less than 40% of CV MPR provided a safer traffic network in special conditions to maintain the standard mobility. Xiao et al. [48] proposed a meta-analysis approach to estimate the safety effects of intelligent CVs by MPR, and found the number of conflicts is exponentially reduced with the increase in the MPR. They expect the proportion of CVs in 2025 and 2035 will be 17–20% and 40–48%. Zhang et al. [49] found that adopting AVs at a low MPR of 2% can reduce 90% of the parking demand for clients. Yang et al. [50] observed that the likelihood of secondary crashes can decrease by up to 33% under high-volume conditions, when the MPR hits 25%. Papadoulis et al. [51] evaluated the safety impact of CAVs by developing a decision-making CAV control algorithm in the simulation software VISSIM, and found that estimated traffic conflicts were reduced by 12–47%, 50–80%, 82–92%, and 90–94% for 25%, 50%, 75%, and 100% CAV penetration rates, respectively.
There are also some other works researching the capacity improvements under different penetration rates of CVs. Jiang et al. [15] proposed a cellular automata model to study the influence of CAVs on mixed traffic flow. They found that the road capacity under the pure CAV environment has increased by 3.24 times compared with the pure HDVs, and the velocity fluctuation decreases significantly when the MPR reaches 80%. Liu et al. [16] concluded that the road capacity did not improve much when the penetration rate is less than 60%, but it increases by 90% with 100% CV. Shladover et al. [52] pointed out that the capacity improvements can result from different CAV MPRs due to potential vehicle platooning and reduction in the space required for CAVs on the road network. They found that the capacity can be improved by 22%, 50%, and 80% with the MPR of 50%, 80%, and 100%, respectively.
2.3. Sensor Failure on Traffic Data Acquisition
Sensor failure, as the main factor affecting traffic data perception, has been considered for several years. Most of the studies addressing intermittent equipment failures preferred to give the methods for missing traffic data imputation [23,53,54,55] and sensor allocation on a network [18]. Li et al. [56] considered the sensor failure probabilities in selecting sensor locations on a network for OD flow surveillance. They found that the path coverage was sensitive to sensor failure and installation budget, and high sensor failure probabilities showed a tendency to cluster sensors. Zhu et al. [57] proposed a stochastic conditional value at risk model to optimize the sensor locations on a freeway corridor. They found that considering sensor failure improves the placement pattern. Alemazkoor et al. [7] proposed an online recursive regression approach to predict the traffic flow for locations with faulty sensors by using neighboring sensor data solely, and found the prediction accuracy can generally reach 95%. An et al. [23] introduced a mixed integer linear programming approach to improve data accuracy by considering the risk of sensor failure. By minimizing the effect of sensor failure on the link flow inference of unobserved links, Salari et al. [18] proposed a method to identify the minimum set of links in a traffic network to reach full link flow observability. They suggested that minimizing the number of sensors for unobserved link and installing advanced sensors on links involved in the link flow inference is a solution for full link flow observability. On this basis, Salari et al. [8] applied a non-homogeneous Poisson distribution to deal with the time-varying failure rates of count sensors, and established a model to identify the optimal sensor locations for OD demand estimation. They found that the budget and the locations of damaged sensors play a key role in repairing failed sensors or installing new sensors. Sun et al. [58] proposed new robust models for deploying multi-type sensors by considering the factors such as sensor failure rate, sensor type, OD demands, and budget constraints. The Weibull distribution was used to characterize the time-varying sensor failure rate, and a nonlinear least squares method was utilized to estimate the parameters of the failure rate function. However, their research mainly focuses on the occasional sensor failure instead of physical damage. Ding et al. [9] gave a deep-learning approach to identify and eliminate redundant sensors in a traffic network, leading to a potential reduction in sensor nodes by 43% and connectivity edges by 82%. This implies that redundant sensor failure might not necessarily lower the benefits of the traffic networks. Zou et al. [10] proposed a framework based on long short-term memory and the multilayer perceptron to predict network-level traffic volumes with sensor failure. The results showed that the increase in mean absolute error (MAE) is less than 1 veh/5 min when the failure rate of the detector increases to 20%. Liang et al. [59] considered the possibility of roadside unit failures when deploying the roadside unit in a road network for traffic event information transmission. They found that decentralized deployment is suitable for low failure probabilities, while centralized deployment is preferred for high failure rates.
3. Methodology
3.1. The Optimal Deployment Method
Data accuracy and completeness, as exclusive factors for deploying sensors, directly affect the decision control system’s assessment of traffic conditions. The most commonly used parameter in evaluating data accuracy is travel time in consideration of its significance in determining traffic parameters and traffic state estimation. In terms of RSE deployment, a wealth of literature has provided various methods and measures. The uniform method, also called the fixed length method, is straightforward. A uniformly fixed spacing, for example 1000 m, was chosen as the unit length. However, this method may result in biased traffic condition estimations [60]. The hotspot deployment method, in which RSE is positioned at the accident-prone areas, the on-/off-ramps, or the crowded areas, is largely used due to budget constraint. The biggest benefit of this method is that it is inexpensive to deploy and maintain. Nevertheless, it is challenging to provide precise data for vehicle and road control. Another commonly used approach is the optimal method. It is used to find an optimal solution to an objective function subject to given constraints. Different optimization methods have their own advantages and are suitable for different scenarios and problem types. Based on this method, the locations of a finite set of sensors are optimized by minimizing the estimation errors of traffic parameters. Assuming the road is divided into cells with equal length, and each cell is considered as a candidate location for sensor deployment. The cells are numbered from 1 along the direction of traffic flow, facilitating the confirmation of the specific locations of roadside equipment. The selected deployment locations of RSE serve as the dividing points for sub-segments. The objective function in this study is to minimize both the expectation and the variance of the mean absolute percentage error (MAPE) of travel time. Not only does this function reduce the overall error, but it also lowers the error for each individual section. It should be noted that during the optimization process, adjacent cells may be selected as deployment locations. If the cell length is too small (such as 50 m or 100 m), the deployment plan with adjacent cells is meaningless. However, if the length is too large, some location points have no chance to enter the optimization process. This being thought of, a constraint (8) is adopted to ensure the minimum spacing of sensors no less than the communication range, r, to fully utilize the limited roadside equipment. In this case, even if the cell length is relatively small, there will be no excessively small positional spacing. In addition, to achieve spatial uniformity, spacing variance, , has been added to the objective function. The optimization model is as follows:
In the above formulas, n refers to the link number related to the number of sensors; m is the time series number, which is equal to the total sampling time divided by the sampling interval; a, b, and c are real numbers that keep the expectation and the variance of MAPE, the variance of adjacent sensor spacing, l, at the same order of magnitude; N is the number of RSE subject to budget constraints; is the spacing between sensor i and sensor i + 1; L is the length of the road. Equation (2) is the mean absolute percentage error on link i; Equation (3) is the variance of MAPE for all sections of the entire road; Equation (4) is the variance of sensor spacing. It is used to prevent the equipment locations from being too concentrated or too far apart.
Heuristic optimization methods (such as the genetic algorithm (GA) and the simulated annealing (SA) algorithm) perform well in solving complex nonlinear and multi-objective optimization problems. They can find near-optimal solutions in a relatively short time through empirical rules and random search. GAs simulate the natural selection and genetic mechanisms in biological evolution, iteratively generating better solutions through selection, crossover, and mutation operations. They have strong parallel search capability, making them suitable for handling complex problems. However, they are prone to premature convergence in immature regions, leading to local optima. SA is a probabilistic technique used to avoid becoming stuck in local optima during the search process. At high temperatures, SA allows for a greater probability of accepting inferior solutions, avoiding becoming stuck in local minima. As the temperature decreases, the probability of accepting inferior solutions also decreases. It becomes more focused on fine-tuning the current solutions. SA has low dependence on initial solutions and can escape from local optima during the search process. However, it is less efficient in high-dimensional search spaces. Combining the global search capability of SA with the parallel search and diversity maintenance capabilities of GA, the simulated annealing genetic algorithm (SAGA) might be an appropriate method for solving the optimization model.
The flowchart of SAGA is shown in Figure 1. The left half represents the process of GA, while the right half represents the process of SA algorithm. First, the initial parameters, including the population size, the number of sensors, crossover rate, mutation rate, temperature and its attenuation coefficient, and the number of iterations, and so forth, are all given. The next step is to randomly generate a set of solutions in the solution space as the initial population. One thing to note here is that individuals in the population should meet constraint (8). If not, adjustments need to be made. For example, if the spacing between sensor i and sensor (i + 1) is less than 2r, the position of sensor (i + 1) is adjusted so that the spacing is equal to 2r. In this case, if the distance between the location of sensor (i + 1) and the end of the road is less than 2r, the position of sensor i is adjusted instead of sensor (i + 1). The fitness of the algorithm is the objective function, F(N). The following steps—encoding, selection, crossover, mutation, and decoding—are the normal process of GA. Before calculating the fitness value of the new population, selection and adjustment should also be adopted to make sure the individuals with aberrant values be excluded from the population. After each iteration of the genetic algorithm, the acceptance criteria of SA are applied to the individuals in the current population to escape from local optima. Based on current temperature and fitness value, the new solutions are accepted if the new fitness values are smaller. Otherwise, the inferior solutions are accepted with a certain probability according to the Metropolis criteria. The algorithm terminates when the number of iterations is met.
3.2. The Simulation-Based Approach Combined with Data Processing Algorithms
Sensor failure involves two cases: the sensor is damaged and the sensor occasionally fails [61,62]. In the former case, the sensor cannot function properly, and no traffic data will be collected. In contrast, a small number of traffic data will occasionally be missing in the latter case. The lifespan of a sensor is usually represented by the Bathtub curve and can be conceptually divided into three stages: the initial damage stage, the effective lifespan stage, and the decay stage [63]. During the initial stage, also called the running-in period, the failure rate experiences a rapid decrease after continuous trial operation. Then, the failures occur randomly without predictable timing but tend to converge towards a constant value after being observed over a period. Finally, the failure rate increases rapidly to a very high value since the sensor has reached the stage of aging and wear. This study primarily focuses on the damage failure of sensors in the second to third stage.
Assume the failure rate of roadside equipment is , which is a random number that increases over time. For the road with previously existing sensors, the total number of RSE on the road is N(0), and the number will be after a period of time (where || indicates rounding down). The data accuracy is influenced by the parameters, such as the number of RSE, the location of RSE, sensor type, and the MPR of CVs. Hereupon, the relationship among these indicators can be expressed as follows:
In the formula, A(t) is the overall data accuracy of a transportation network at time t. is the location matrix of RSE at time t. It is obtained by eliminating the positions of damaged equipment, , from the initial positions, . is the MPR of CVs at time t. is a stochastic disturbance.
To observe their relationship more intuitively, this study proposed a simulation-based approach combined with several data-processing algorithms to address the data performance under different CV MPRs and different sensor failure rates. The framework of the approach is shown in Figure 2, and the specific steps are as follows:
Step 1. Data acquisition. Based on the road geometry, traffic parameters of the target road, including traffic volume, driving speed, and vehicle types, as well as existing sensor information, are used to establish a simulated environment. The spot speed data and the road segment data at different CV MPRs can be obtained with the help of the simulation tool.
Step 2. Data filtering and data processing. Given that this research mainly focuses on the effect of travel time and travel speed, the spot speed collected by RSE and the average travel speed provided by CV and all types of vehicles are screened from the simulation data. Since the data is collected in separate lanes, the spot speed can be obtained by using Equation (12), which is a weighted arithmetic average value of the instantaneous speed of vehicles passing a point of the road over some specified time. Similarly, the average speed of all vehicles occupying a given section of the road, also called the travel speed, can be calculated by Equation (13).
In the formulas, n is the lane number. is the number of vehicles passing a point of lane j. is the instantaneous speed of vehicles passing a point of lane j. is the travel speed of vehicles on lane j. is the number of vehicles passing through a section of lane j. To conduct a comparative analysis, it is necessary to convert the point speed into the travel speed. Equation (14) is a solution to estimate the travel speed by using the spot speed. However, it is only applicable for calculating non-zero values. Given that there will be a significant amount of data missing in this study, Equation (15) is adopted to estimate the travel speed.
When it comes to dealing with the data-missing issue caused by sensor failure, the nearest neighbor (NN) algorithm is addressed. The nearest neighbor concept, particularly the KNN algorithm, is a fundamental technique in machine learning and data mining. Since the target road of this study is a freeway corridor, the distribution of data collection points exhibits a strong upstream-downstream relationship. In addition, this study assumes that no data will be collected from the sensor once it is damaged. Moreover, the data volume is not particularly large. Taking these factors into consideration, the nearest neighbors algorithm is more suitable for solving the problem of data missing in this situation. In this study, two points, namely the upstream node and the downstream node of the target point, were involved. As shown in Figure 3, the red triangle is the target point, and the two green circles are the nearest neighbor nodes of the target. According to the rule whether missing value on node is allowed or not, two methods are given to deal with the data. One is the rigid nearest neighbor (RNN) algorithm, in which only the nearest adjacent node (the green circle) in the upstream or downstream of the target position can be selected as the nearest neighbor. In this case, the missing data of the target node can be substituted for the one collected from the upstream or the downstream node. If the data collected by the adjacent nodes are all missing, no available data can be provided. According to this rule, the data collected from the target point, i, over time, t, can be obtained by Equation (16). In the equation, is the speed matrix of node i, and O is the 0-matrix of the same rank. For a more detailed description of the algorithm, see Algorithm 1.
Algorithm 1 The rigid nearest neighbor algorithmInput: spot speed matrix , damaged RSE location matrix Output: travel speed matrix 1: Initialize the spot speed matrix based on ; 2: The elements in every two rows of the matrix are added and multiplied, marked as and ; 3: Find 0 in and , marked the locations as ; 4: Find 0 in but not in , marked the locations as ; 5: Set the values in that are zero to 1; 6: Compute the according to Equation (16); 7: Set the values = 0; 8: Replace the row elements of with that of if . otherwise, 9: Replace the row elements of with that of the next row of ; 10: Return ;
The other method is the soft nearest neighbor (SNN) algorithm. In the SNN algorithm, all the nodes around the target area will be traversed in sequence to find the nearest upstream node and the nearest downstream node with non-missing values. The travel speed for all sections between these two nodes has the same value. Briefly, if the RSE on node i − 1, node i and node i + 1 is all damaged, while on node i − 2 and node i + 2 it is not, then the travel speed of link (i − 2, i − 1), (i − 1, i), (i, i + 1) and (i + 1, i + 2) is equivalent to that of link (i − 2, i + 2). For a more detailed description of the algorithm, see Algorithm 2. Different from RNN algorithm, the SNN algorithm results in no occurrence of null values, even if there are multiple consecutive sections with equipment failures. Algorithm 2 The soft nearest neighbor algorithmInput: spot speed matrix , damaged RSE location matrix Output: travel speed matrix 1: Initialize the spot speed matrix = { } based on ; 2: For , Compute the travel speed according to Equation (15); 3: do 4: Check if then 5: Repeat check until ; 6: Check if then 7: Repeat check until ; 8: Compute the travel speed of link (i − j, i + k) according to Equation (15); 9: Assign the speed to all the sections between point (i − j) and point (i + k); 10: end for 11: repeat 12: Update the travel speed matrix ; 13: until all elements in be considered 14: Return ;
Step 3. Data fusion. Data fusion is a prevalent way to deal with imperfect raw data for capturing reliable and accurate information. Typical data fusion strategies, including the Bayesian estimation, Kalman filtering, Dempster–Shafer theory and some other machine-learning methods (such as neural networks), are often used to improve data quality. The neural network, which has excellent performance of powerful nonlinear fitting capabilities, self-organize, self-study, and strong generalization ability, is the most popular fusion method. Since images or complexly structured data are not involved, this study employs the Back Propagation Neural Network (BPNN) algorithm as the fusion algorithm. The steps are listed in Algorithm 3. Algorithm 3 The BPNN algorithmInput: travel speed from RSE, the CV travel speed, the true travel speed and the CV MPROutput: the fused travel speed 1: Splitting training data and testing data according to the train-test split ratio. 2: Normalization of training data. 3: Build a BP neural network with input layer, hidden layer and output layer. The transfer functions of the hidden layer and the output layer are tansig and purelin, respectively. The training is conducted by using the trainlm method. 4: Setting network parameters, such as the number of training iterations, learning rate, minimum error of training target, etc. 5: BP neural network training. 6: Normalization of testing data. 7: BP neural network prediction. 8: Prediction result normalization.
Step 4. Error calculation. To assess and measure the data quality, the indicators used in this study are MAE, MSE (Mean Squared Error), RMSE (Root Mean Square Error), and MAPE. The MAE measures the average absolute difference between predicted and actual values without considering their direction. it can accurately reflect the magnitude of the error. Compared with MAE, MSE squares each error before averaging which makes it more sensitive to large errors. RMSE is the square root of MSE. It puts the error back into the original units, which makes it easier to interpret than MSE. Like MSE, RMSE gives more weight to large errors. The MAPE is a variation of the MAE. MAPE not only considers the error between the predicted value and the actual value but also considers the ratio of the error to the actual value. This value is presented in the form of a percentage and is not affected by outliers. Since the dividing points of the road section are the locations of RSE, the amount of data for the predicted values is . The calculation formulas are Equations (17)–(20).
Step 5. Randomly select the location(s) of the damaged equipment based on the failure rate and the number of RSE. To make the results robust and the data comparable between different experiments and research groups, the selection of the damaged position for the next round should retain the results of the previous round. In other words, the number of damaged sensors will increase by a fixed percentage during each round. Repeat steps 2–5 until all the pre-determined failure rates be considered.
Step 6. An error matrix, the rows of which correspond to the different sensor failure rates and the columns correspond to the different CV MPRs, will be addressed. The effect of CV MPR and the failure rate of roadside equipment on traffic perception accuracy can be obtained by analyzing the matrix data.
4. Case Analysis
4.1. Simulation Set-Up
The software-based micro-simulation has been used to evaluate the feasibility and effectiveness of various approaches. The Simulation of Urban Mobility (SUMO), which is an open-source, highly portable, microscopic, and continuous traffic simulation package, is applied to construct relevant scenarios for obtaining required data. The simulation is conducted on a basic freeway segment from Nanjing to Danyang, which is a unidirectional four lane freeway with 74 km, in the mixed traffic environment including regular human-driven vehicles and CVs. For easy numbering, the road is divided into cells with equal length of 100 m, resulting in 740 road section numbers. The communication range of RSE is set as 250 m, which means the spacing between RSE is no less than 500 m. Figure 4 shows the sketch map of the simulated road. E1 detectors (induction loop detectors) are deployed on these cells to collect the information of vehicles passing the cross-section, and E2 detectors (lane area detectors) are used to collect the segmental level information. Additionally, different car-following models—CACC and IDM—are used for CVs and human-driven vehicles. The CVs, featured in the simulation, possess dimensions of 5 m in length and are configured with a maximum speed of 70 m/s, alongside maximum acceleration and deceleration rates set at 2.0 m/s^2^ and 2.0 m/s^2^, respectively. They adhere to a minimum distance of 2 m from the preceding vehicle. The human-driven vehicles, featured in the simulation, possess dimensions of 5 m in length and are configured with a maximum speed of 50 m/s, alongside maximum acceleration and deceleration rates set at 1.5 m/s^2^ and 1.5 m/s^2^, respectively. The lane-change model is LC2013. The MPR of CVs is from 10% to 100% with an interval of 10%. In addition, the values of 5% and 15% were also included to enrich low CV MPR scenarios. The detailed simulation parameters are shown in Table 1.
4.2. Failure Rate Setting and Data Processing
The failures of RSE occur randomly without predictable timing. However, after a period of observation, they tend to converge to a constant value. Instead of capturing the time-varying behavior of sensor failure, this work focuses on proving the impact of sensor failure on data accuracy under fixed failure rates. The failure rate of RSE ranges from 10% to 80% with an interval of 10%. To adhere to the principle of fairness, the damaged cell deploying with RSE is randomly generated based on the given failure rate. Assuming the damaged equipment will not be replaced or maintained during the period when CV MPR remains unchanged, the damaged cells selected from the previous round will be included in the next round. The randomly generated numeric sequence representing the failure sensors is {12, 9, 15, 19, 18, 5, 14, 1, 6, 4, 13, 8, 17, 7, 10, 20}.
As a highly functional and widely used tool, MATLAB R2022a is renowned for its powerful computing capabilities and features a distinctive matrix-oriented programming language. The library packages it comes with are much more extensive than those provided by other simple programming tools, and it also has a robust graphical user interface. These characteristics make it a better option for data processing and algorithm development. Therefore, data processing and data fusion in this study is achieved through programming in MATLAB R2022a. The data will be analyzed in detail in the next section.
4.3. Results Analysis
4.3.1. Comparison and Analysis of RSE Deployment Methods
The locations of RSE obtained by using the uniform method, the hotspot method and the optimal method are listed in Table 2. In addition to the starting and ending positions, RSE is deployed near the ramps in the hotspot method (see Figure 4). The number of RSE locations is 20 and its location cells are listed in the third column of the Table. At this value, the spacing between two adjacent RSE placements is 3700 m which is selected as the parameter of the uniform method. The location of the cells can be seen in the second column. In the optimal method, the initial deployment scheme is randomly generated and is optimized by using the ASGA, the AS algorithm, and the GA. The initialization parameters of these optimal algorithms are listed in Table 3, and the results are listed in the last three columns of Table 2.
Figure 5 compares five sets of MAPEs for the data collected under different deployment schemes. In Figure 5a, the number of sensors is 20 and the locations of sensors are listed in Table 4. It can be seen from the figure that MAPEs of the SAGA are mostly distributed near the 0-axis. Compared with SAGA, the SA and the GA have higher MAPEs, almost half of which are distributed within the range of 0.2 to 0.4. Even though the MAPEs of the uniform method fall within the range of 0.2 to 0.4 as well, they have relatively higher values. The MAPEs of the hotspot method are nearly the highest on the first fourteen links, whereas on the last five links are the lowest except for the ones obtained by the SAGA. Therefore, we can draw a conclusion that the optimal method outperforms the uniform method and the hotspot method. To elaborate further, SAGA is superior to SA and GA. To verify the validity of the conclusion, the number of sensors has increased to 25 and the results are shown in Figure 5b. Five hotspots, whose cell numbers are {11, 86, 474, 640, 657} which correspond to the service area and the upstream and downstream areas of the Danyang bridge, are added to the initial hotspot scheme. Through comparison, it can be found that Figure 5b presents the same results as Figure 5a. Subsequently, the number of sensors is increased to 36, in which the average spacing between sensors is almost 2000 m, to observe the effect of the proposed optimization algorithms. For comparison, the uniform method is chosen since the locations are relatively dense, and the results are shown in Figure 5c. Similarly, the result is consistent with the previous conclusion. Figure 5d compares the MAPEs when the number of sensors is 74. Since the spacing between devices is already very small (e.g., 1000 m), the disparity in results between different methods was narrowed. However, it can still be observed that the errors of SAGA are smaller than those of other methods. As can also be seen from the figure, the error decreases as the number of sensors increases, which is consistent with previous research findings.
To further observe the performance of these schemes, Figure 6 gives the expectation and the variance of MAPE, and the variance of sensor spacing for each method. As shown in the figure, the SAGA undoubtedly performs the best, followed by the GA, the SA, the uniform method, and the hotspot method. On the whole, the optimal method outperforms the uniform method and the hotspot method, and the GA has an edge over the SA. Relatively speaking, the performance of SAGA is stable under different sensor numbers. The variances of MAPE and the sensor spacing of this method are basically unchanged. The expectation of MAPE fluctuates slightly, but it does not decrease continuously with increasing number of sensors. This is due to the need to strike a balance between spatial uniformity and data accuracy. Even so, it still performs the best among various methods. In addition, there is no doubt that the error will decrease as the number of sensors increases for the uniform and the hotspot method. By comparing Figure 6c,d, it is found that the differences in results between various methods have narrowed as the number of sensors increases. This is because a sufficient number will reduce the diversity of the samples, which in turn reduces the performance differences among different methods. In addition, although the number of sensors has doubled, the improvement in data accuracy is tiny. This indicates that simply increasing the number of sensors cannot continuously improve data accuracy. It is consistent with the findings of [21,60].
4.3.2. The Impact of CV MPR on Data Accuracy
To observe the impact of CV MPR and equipment failure on data quality, this study chooses the deployment schemes obtained by the optimal method solved by the SAGA (called the SAGA deployment scheme in subsequent content) and the hotspot method as examples. The locations of RSE placements are listed in the third and the fourth column of Table 2. The RSE data and CV data at different MPRs are fused by using the proposed BPNN algorithm. The initialization parameters of this algorithm are listed in Table 4. The number of the input layer is three, corresponding to the three parameters of RSE data, CV data, and CV MPR. The output layer is the fused data. The number of the hidden layer is five, which is determined by using the trial-and-error method based on the numbers of the input layer and the output layer. For comparison, this study also adopted other machine-learning methods, such as the Long Short-Term Memory (LSTM) model and the Random Forest (RF) model, to fuse the data. In LSTM, the initial learning rate, the layer numbers, and the train-test split ratio are all the same as BPNN. In addition, the learning rate optimization algorithm is the adaptive moment estimation (Adam) algorithm, and the maximum epochs is 84 which is equal to the test population. In RF, the number of trees is set as 100 and the depth is 5.
Figure 7 plots four types of errors—MAE, MSE, RMSE, and MAPE—when the MPR of CVs varies from 5% to 100% for different methods. To enhance the robustness of the results, the mean value of the results obtained by running the program 10 times repeatedly for BPNN and LSTM is taken as the final value. For the RF, a random seed is added to the algorithm. It can be seen from the figure that the fused data obtained by using the BPNN algorithm substantially has the smallest errors, followed by the LSTM and the RF algorithm. When the MPR is lower than 10%, the LSTM performs better than the BPNN. Once the MPR exceeds 10%, the advantage of the BPNN algorithm becomes evident. It can also be clearly seen in the figure that the errors generally follow a downward trend with the increase in CV MPR. However, the fluctuations are large at different MPRs for RF in the SAGA deployment scheme, although the overall trend is downward. Therefore, this study chooses BPNN as the data fusion algorithm. To further observe the relationship between CV MPR and data accuracy, the results of BPNN are extracted separately from the figure.
Figure 8 displays the MAE, MSE, RMSE, and MAPE of the fused data obtained by using the BPNN algorithm. It can be seen from the figure that the performance of the SAGA method is still superior to that of the hotspot method, and the errors generally follow a downward trend with the increase in CV MPR. However, when it exceeds 15%, the rate of decline is gradually slowing down. The MAPEs under the two deployment schemes are lower than 0.05 when the MPR is 15%, and they are lower than 0.02 when the MPR exceeds 60%. To put it another way, data accuracy can reach over 95% as the MPR is higher than 15%. Even though the number of CVs has increased from 15% to 60%, the accuracy has only improved by less than 2.5%. This implies that adding more CVs might not be able to significantly improve the data quality since the data accuracy is already quite high. Referring to RMSE, the value is lower than 1.0 as the MPR is higher than 15%, in which it is below 0.5 for the SAGA deployment scheme. When the MPR exceeds 60%, the RMSE is less than 0.5. After exceeding 60%, moreover, its rate of decline becomes even slower. At this point, we can safely draw this conclusion that 15% MPR is a turning point in improving data accuracy, which is in line with the research findings of [11], while 60% is another one.
As an unintended consequence, in addition, MAE and MAPE at 10% MPR are a little higher than that at 5% MPR under the hotspot deployment scheme. This discrepancy could be attributed to the interference of extreme errors on certain segments, which can be seen in Figure 9. Figure 9 shows the absolute error of the pre-fusion data collected by RSE and by CVs separately at 5% CV MPR and 10% CV MPR. The abscissa represents 76 data points from 19 road segments across four time periods. In the legend, 5%RSE refers to the RSE data and 5%CV refers to the CV data collected under a 5% CV MPR scenario. For convenience, we use the names in the legend to refer to each curve. In Figure 9a, 10%RSE data exhibit significant fluctuations and have a larger error than 5%RSE. However, the 5%CV data in Figure 9b exhibit obvious fluctuations and have a larger error than 10%CV. The high error of the source data pushes up the error of the fused data. Another point of anomaly is that the MSE and RMSE under the SAGA deployment scheme are a little higher than the hotspot scheme at 5% MPR. This is due to the MSE and the RMSE are sensitive to extreme values, only a few of which could elevate these errors.
4.3.3. The Impact of RSE Failure Rate on Data Accuracy
Based on the failure rates, the damaged locations of RSE given in Section 4.2 and the cells representing the deployment locations in Table 2, the spot speed data is filtered and fused with the CV data. The errors between the pre-fusion data, fusion data, and the true data at different RSE failure rates are calculated. From the above analysis, we already knew that data accuracy is relatively high when the CV MPR is above 15%. Thus, this section mainly focuses on the cases where the proportions are below 20%. Figure 10, Figure 11, Figure 12, Figure 13, Figure 14, Figure 15, Figure 16 and Figure 17 display the error distribution of MAE, MSE, RMSE and MAPE, among which Figure 10, Figure 12, Figure 14 and Figure 16 show the error distribution for the data processed by the SNN algorithm, while Figure 11, Figure 13, Figure 15 and Figure 17 show the data processed by the RNN algorithm. Each sub-graph in the figure represents the error of the data obtained under the hotspot deployment scheme and the SAGA deployment scheme. These data include both pre-fusion data and post-fusion data, where the left side shows the post-fusion data error and the right side shows the pre-fusion data error.
It can be seen from Figure 10 that the MAEs under the SAGA deployment scheme are lower than that under the hotspot deployment scheme regardless of whether the data is fused or not. Upon further comparison between fused data and non-fused data, it can be observed that the fused data exhibits smaller errors. For unfused data under the hotspot deployment scheme, the MAE increases as the failure rate increases. Although the fluctuation range of error values is small under the SAGA deployment scheme, it is also on a slow increasing trend. For the fused data, the MAE does not increase linearly with the increase in failure rate but rather experiences a slight fluctuating growth. When the proportion of CVs is 15% or higher, the MAEs remain relatively small and show little variation under different sensor failure rates. There are several possible explanations for this result. Data fusion is the most significant influencing factor, as it directly enhances the completeness, accuracy, and usability of the data by combining diverse data. Through data fusion, the missing data were supplemented by highly accurate connected vehicle data, which makes the accuracy of the data not greatly affected by the loss of data. Another possible explanation is that some missing data might be supplemented by their neighbors according to the SNN algorithm. Through this process, the data was not actually missing in a strict sense as long as the equipment around it is not damaged. There is also a possibility that the RSE data that have been excluded might correspond to the part with relatively large errors, or the damaged equipment is redundant.
It can be observed from Figure 10a,c and Figure 11a,c that the quality of data has been significantly improved with the increase in CV MPR. Only fusing 5% of the CV data has reduced the MAE of the RSE data from 2.85 to 15.65 in Figure 11d to 0.96–1.31 in Figure 11c, and from 3.98 to 12.74 in Figure 11b to 1.37–2.09 in Figure 11a. Although the error in 10% MPR is relatively large, due to the reasons mentioned in Section 4.3.2, it is still much lower than that of the unfused data. The MAE of the RSE data in 10% MPR is reduced from 10 to 3 on average. When the MPR reaches 15%, The MAE of the RSE data is reduced from 10 to below 0.5 on average. Based on the results, it can be inferred that multi-source data fusion, especially with the high-precision data, is much more effective in improving data accuracy than missing data imputation.
By comparing Figure 10b,d and Figure 11b,d, the data processed by the SNN algorithm is less sensitive to failure rate than the RNN algorithm. When the failure rate exceeds 40%, the error of the data processed by RNN algorithm has significantly increased. This is due to the inherent characteristics of the algorithm. When the failure rate is relatively high, equipment damage at consecutive positions may occur, resulting in zero-values in the data processed by RNN, but not in the data processed by SNN. This indicates that inserting data from a point at a greater distance is better than having no data at all. The SNN algorithm performs better than the RNN algorithm in restoring the extensively damaged data. Another point to note is that the MAEs of the SAGA deployment scheme are larger than that of the hotspot scheme when the failure rate exceeds 40%, as shown in Figure 11b,d. However, when the failure rate is below this value, the result is just the opposite. This is primarily due to sensors near the off-ramps being damaged at a predetermined failure rate, which results in the missing of data with relatively low speed values caused by ramp queuing. Using adjacent data, especially the data from locations with large spatial distances, may lead to significant errors. Figure 18 displays the absolute error between the RSE data with 60–80% sensor failure rate and the true data at 5% CV MPR. It can be seen from the figure that the values with higher errors in the SAGA scheme are more than those in the hotspot scheme. Based on the spatial distribution of sensors in Figure 19, the error value directly increases in the segment where the damaged equipment is located. Figure 20a shows the speed distribution at 5% CV MPR across the entire road. Vehicles are queued at some off-ramps due to lane-changing interference, which results in the speed on these segments is relatively low. Upon comparing Figure 18, Figure 19 and Figure 20, it can be inferred that the equipment located near the ramp in the SAGA deployment scheme is damaged when the failure rate exceeds 60%, which results in a significant discrepancy between the data processed using the RNN algorithm and the original data. Since sensors are all located on the ramps in the hotspot scheme, even if the above situation occurs, the differences between the data are not so significant. This explains why the MAEs of the SAGA deployment scheme are larger than those of the hotspot scheme when the failure rate exceeds 40%, especially 60%.
Figure 12 and Figure 13 show the distribution of MSE. Consistent with the results in Figure 10 and Figure 11, the SAGA deployment scheme outperforms the hotspot deployment scheme, and the fused data exhibits smaller errors than the non-fused data. It can also be clearly seen that the MSE of the unfused data increases with the increase in the failure rate in Figure 13b,d; however, the fluctuation range of error values is small in Figure 12b,d though they are also on a slow increasing trend. This also approves the conclusion that the data processed by the SNN algorithm is superior to the RNN algorithm. Compared with Figure 12 and Figure 13, there have been basically no other trend changes in Figure 14 and Figure 15 apart from the changes in numerical values. Relatively speaking, RMSE puts the error back into the original units, making it easier to observe and compare.
Figure 16 and Figure 17 show the distribution of MAPEs. Different from the above results, the data processed by the SNN algorithm has higher MAPEs than those processed by the RNN algorithm. This is primarily because, under conditions of a relatively high failure rate, SNN substitutes missing data with data from locations farther away from the target, leading to an overestimation or underestimation of the travel time for the segment and subsequently generating a higher MAPE value. Nevertheless, the RNN algorithm only utilizes data from the sensors closest to the target location, and the value is zero if the adjacent sensor also damaged, which makes the value of MAPE not exceed 1. The MAPEs higher than 1 pushed the overall MAPE up, which resulted in a discrepancy between the results of this indicator and that of MAE, MSE, and RMSE for unfused data.
To further observe this impact, Figure 20 plots the Absolute Percentage Errors (APEs) of the unfused data across four sampling time periods at 60% sensor failure rate when the CV MPR is 5%. As shown in the figure, peaks appear at the road segments where sensors are damaged, especially for the data processed by SNN. Take link 12–14 as an example for the explanation. The sensors numbered with 12, 13, 14, 15 (as listed in Section 4.2), which correspond to location cells of 551, 600, 608, and 665 under the hotspot scheme, and cells of 478, 483, 657, and 690 under the SAGA deployment scheme (see Table 1 and Figure 19), are all damaged at 60% sensor failure rate. The SNN uses the data collected on cells 534 and 672 for the hotspot scheme, while using the data on cells 448 and 695 for the SAGA scheme, to estimate the travel time between them. This kind of estimation data across a large span, i.e., 13.8 km and 24.7 km, leads to a significant deviation between the estimated value and the actual value. Spontaneously, it will result in large MAPEs. This explains why the MAPE in Figure 16b at 60% failure rate is so large. In this case, if possible, employing data fusion would be a better approach in improving data quality. Otherwise, it is necessary to either conduct equipment maintenance or install additional equipment.
From a comprehensive view of Figure 10, Figure 11, Figure 12, Figure 13, Figure 14, Figure 15, Figure 16 and Figure 17, the impact of sensor failure rate and the CV MPR on the MAE, MSE, and RMSE exhibits consistency, but there is a slight deviation for the MAPE. This implies that, to avoid misleading or implicit biases in the results, it is better to use indicators from different categories, such as RMSE and MAPE in this study. Another noteworthy trend is that, though the data is not fused with CV data, there are also deviations in data accuracy under different proportions of connected vehicles. Even if traffic volume remains unchanged, changes in vehicle composition can also lead to variations in traffic parameters such as travel speed and travel time. Although both the test data and the validation data come from the same driving environment, the accuracy of the data may deviate since sensor locations are predefined for every driving environment. This can also be confirmed from Figure 9.
To further investigate the performance of these indicators under different traffic environments, the traffic volume on the mainline has increased to 4000 veh/h and the ramp volume has also increased by 300–500 veh/h. The lane-changing parameter is adjusted (for example, the lcCooperative is changed from 0.5 to 1 for human-driving vehicles) to enhance the willingness of human-driving vehicles to collaborate during lane changes to reduce the resulting queues near ramps. The speed distribution under the two traffic scenarios is shown in Figure 21. It used the spot speed of the last four sampling periods, which are used for contrastive analysis. Compared to the speed distribution across the entire sampling interval, the data within this sample period can generally represent the overall trend, except for the data fluctuations occurring during the formation of congestion at the bottom of the curve. Vehicles are queued at some off-ramps due to lane-changing interference in the initial traffic environment, while vehicles are moving slowly without queuing on the segments with heavy traffic in the new scenario. The data error of the latter will be smaller since there is no vehicle queue. Due to / MAE, MSE, and RMSE exhibiting the same trend of change, the two error indicators, RMSE and MAPE, are selected for the following analysis.
Figure 22 plots the RMSE distribution for the data processed by the SNN algorithm, while Figure 23 shows the data processed by the RNN algorithm. Subgraph (a) and (b) represent the error of the data obtained under the hotspot deployment scheme, whereas subgraph (c) and (d) are under the SAGA deployment scheme. Subgraph (a) and (c) displays the RMSE of fusion data, whose values are smaller than 2. Thus, to clearly observe the trend of change, the color gamut range in heat map is set as 2. Different from them, the color gamut ranges of subfigure (c) and (d) are consistent with Figure 14 and Figure 15. The results in Figure 22 and Figure 23 are in agreement with those in Figure 14 and Figure 15, except that the overall RMSE values in Figure 22 and Figure 23 are lower. This is due to the change in road environment, which has reduced vehicle queues caused by low lane-changing cooperation and improved data quality.
Figure 24 and Figure 25 display the distribution of MAPEs. The color gamut range of the fused data is set as 0.2, while it is still 1.5 for the unfused data to be consistent with Figure 16 and Figure 17. The results in Figure 24 and Figure 25 are in line with those in Figure 16 and Figure 17, and these values are also lower. This indicates that even though the scenario has changed, the conclusion remains unchanged. Therefore, it is safe to conclude that the accuracy of the fused data is less affected by sensor failure rate but increases with the increase in CV MPR. The SNN algorithm is superior to the RNN algorithm in dealing with missing data. Under the SAGA deployment scheme, better data accuracy can be achieved. When the failure rate exceeds 40%, especially when it surpasses 60%, it is better to adopt multi-source data fusion, equipment restoration, or additional equipment deployment to improve data quality.
5. Conclusions
In this work, a simulation-based framework combined with data processing algorithms was proposed to explore the influence of CV MPR, sensor failure rate, and their combined effect on data accuracy. An optimal deployment method with spatial constraint, which incorporates the spatial uniformity of sensor locations into the optimization objective, was proposed to optimize the locations of RSE. Combining the global search capability of SA with the parallel search and diversity maintenance capabilities of GA, an improved SAGA incorporating spacing constraints was given to solve the optimal model. A rigid nearest neighbor algorithm and a soft nearest neighbor algorithm were addressed to handle the missing RSE data caused by sensor failure. Additionally, the BPNN algorithm was adopted to fuse the RSE data and the connected vehicle data. For comparison, other machine-learning methods, such as the LSTM model and the RF model, were also adopted to fuse the data. Subsequently, the error indicators, including MAE, MAPE, MSE, and RMSE, were calculated and compared to evaluate the data quality in different scenarios. A case study was conducted on a unidirectional four-lane freeway with sensors deployed under the hotspot deployment scheme and the optimal deployment scheme. Two distinct traffic scenarios are presented: one involves queuing at off-ramps, while the other depicts slow-moving traffic under high-volume conditions. The spot speed data and the travel speed data were acquired in SUMO by creating mixed traffic flow with CVs and human-driven vehicles. Finally, our simulation results yield several key findings as listed in Table 5: (1) The optimal deployment method is superior to the uniform method and the hotspot method in optimizing sensor deployment. Furthermore, the improved SAGA outperforms the SA algorithm and the GA in solving the proposed optimal model. (2) Data accuracy can be improved along with the increase in CV MPR. However, this improvement slows down when the MPR exceeds 15% and 60%, respectively. The MAPEs are lower than 0.05 when the MPR is 15%, and they are just lower than 0.02 when the MPR is 60%. The fused data obtained by using the BPNN algorithm substantially yielded smaller errors than the LSTM and the RF algorithm. (3) For single-source data, data accuracy decreases with the increase in sensor failure rate. However, this trend of change does not apply to fused data. The performance of the SNN method is better than the RNN method in fixing single-source missing data. However, multi-source data fusion, especially with the high-precision data, is much more effective in improving data accuracy than missing data imputation. When sensor failure rate exceeds 40%, careful selection of data-fixing methods is necessary. For sensors that are damaged at a long distance or in three or more consecutive locations, it is recommended to adopt methods such as multi-source data fusion or equipment maintenance and redeployment, rather than repairing missing data from a single source, to improve data accuracy.
In a mixed-vehicle driving environment, the functions of RSE might not only include data perception but also data communication to meet the requirements for data acquisition and data sharing between road users and infrastructure. This study only considers the impact of sensor failure on perception function, without considering the impact on the communication function. However, damage to the communication function or communication equipment will affect data acquisition for CVs. Due to the differences in functional requirements and evaluation metrics between data perception and data communication, the deployment schemes are also distinct. Under this deployment scheme, it is more appropriate to explore the impact of failures in two types of functional equipment on the mixed traffic environment. Research will be conducted on it in the next step.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Mousavi S.M. Osman O.A. Lord D. Dixon K.K. Dadashova B. Investigating the safety and operational benefits of mixed traffic environments with different automated vehicle market penetration rates in the proximity of a driveway on an urban arterial Accid. Anal. Prev.202115210598210.1016/j.aap.2021.10598233497855 · doi ↗ · pubmed ↗
- 2Shladover S.E. Connected and Automated Vehicle Systems: Introduction and Overview J. Intell. Transp. Syst.20182219020010.1080/15472450.2017.1336053 · doi ↗
- 3Wong W. Shen S. Zhao Y. Liu H.X. On the estimation of connected vehicle penetration rate based on single-source connected vehicle data Transp. Res. Part B Methodol.201912616919110.1016/j.trb.2019.06.003 · doi ↗
- 4Talebpour A. Mahmassani H.S. Influence of connected and autonomous vehicles on traffic flow stability and throughput Transp. Res. C Emerg. Technol.20167114316310.1016/j.trc.2016.07.007 · doi ↗
- 5Martin P.T. Feng Y. Wang X. Detector Technology Evaluation University of Utah Traffic Lab Salt Lake City, UT, USA 2003
- 6Jung Y. Oh J. Lifespan Evaluation of Traffic Detector for Automated Traffic Recorders Based on Weibull Distribution J. Trans. Eng. A Syst.20171430501700610.1061/JTEPBS.0000003 · doi ↗
- 7Alemazkoor N. Wang S. Meidani H. A Recursive Data-driven Model for Traffic Flow Predictions for Locations with Faulty Sensors Proceedings of the 2018 21st International Conference on Intelligent Transportation Systems (ITSC)Maui, HI, USA 4–7 November 20181646165110.1109/ITSC.2018.8569748 · doi ↗
- 8Salari M. Kattan L. Lam W.H.K. Ansari Esfeh M. Fu H. Modeling the effect of sensor failure on the location of counting sensors for origin-destination (OD) estimation Transp. Res. C Emerg. Technol.202113210336710.1016/j.trc.2021.103367 · doi ↗