Secure Hierarchical Asynchronous Federated Learning with Shuffle Model and Mask–DP
Yonghui Chen, Daxiang Ai, Linglong Yan

TL;DR
This paper introduces SHAFL, a secure framework for federated learning that improves privacy and robustness in hierarchical and asynchronous settings.
Contribution
SHAFL introduces a novel mask–DP exchange protocol and shuffle model to enhance privacy and robustness in hierarchical federated learning.
Findings
SHAFL reduces the impact of malicious and stale models on system performance during global aggregation.
Theoretical analysis and experiments show SHAFL outperforms existing methods in convergence and security.
SHAFL uses homomorphic encryption to prevent collusion attacks among training nodes.
Abstract
Hierarchical asynchronous federated learning (HAFL) accommodates more real networking and ensures practical communications and efficient aggregations. However, existing HAFL schemes still face challenges in balancing privacy-preserving and robustness. Malicious training nodes may infer the privacy of other training nodes or poison the global model, thereby damaging the system’s robustness. To address these issues, we propose a secure hierarchical asynchronous federated learning (SHAFL) framework. SHAFL organizes training nodes into multiple groups based on their respective gateways. Within each group, the training nodes prevent inference attacks from the gateways and committee nodes via a mask–DP exchange protocol and employ homomorphic encryption (HE) to prevent collusion attacks from other training nodes. Compared with conventional solutions, SHAFL uses noise that can be eliminated to…
Click any figure to enlarge with its caption.
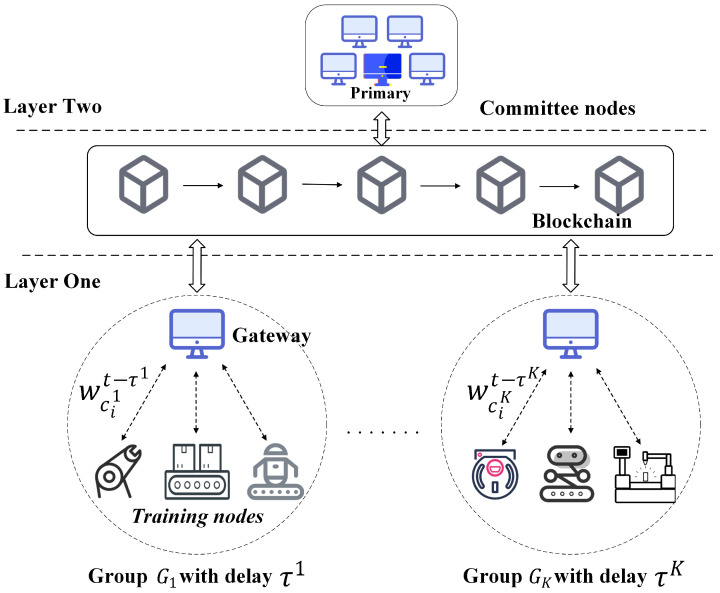 Figure 1
Figure 1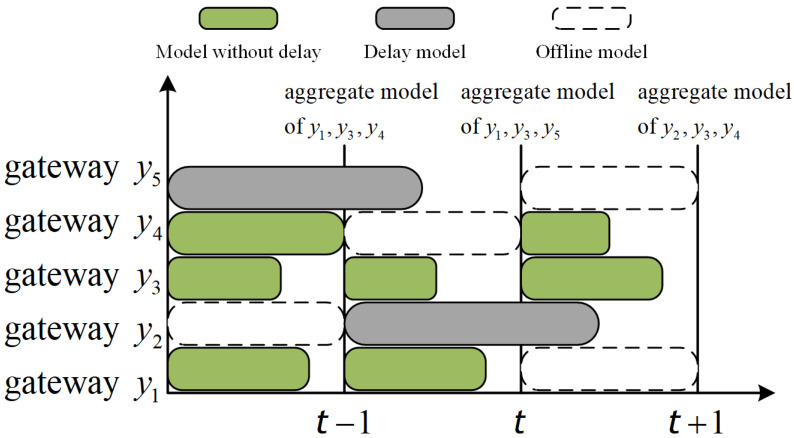 Figure 2
Figure 2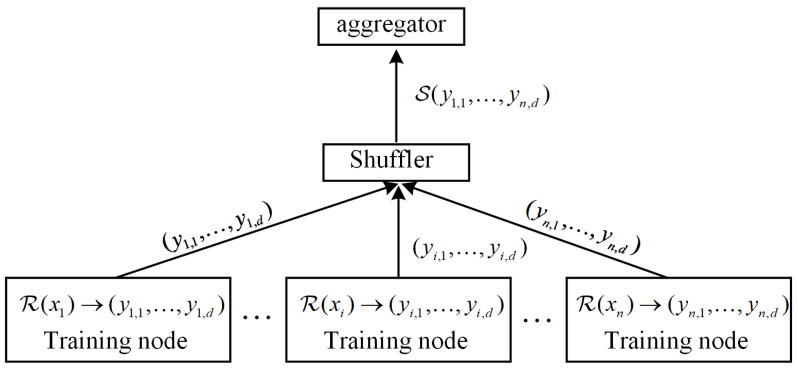 Figure 3
Figure 3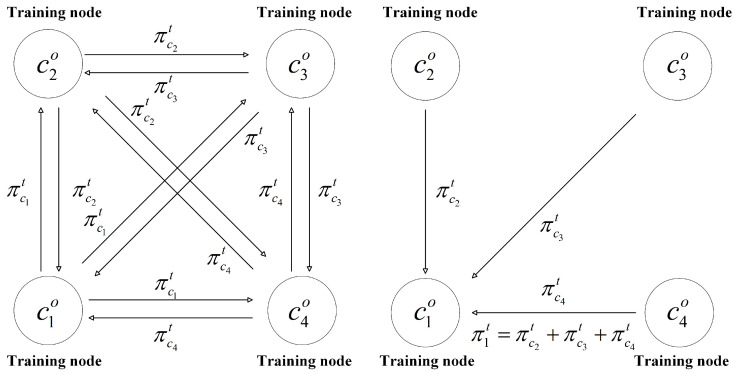 Figure 4
Figure 4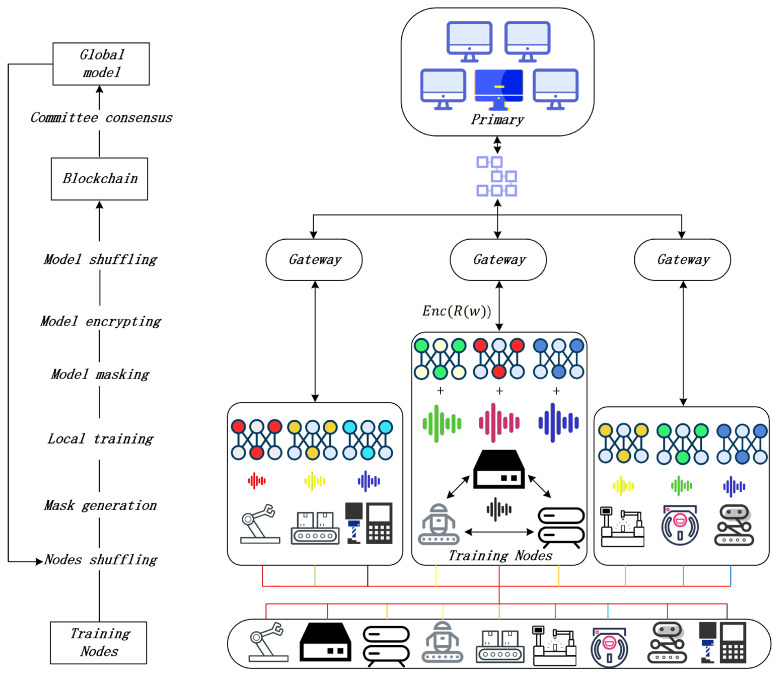 Figure 5
Figure 5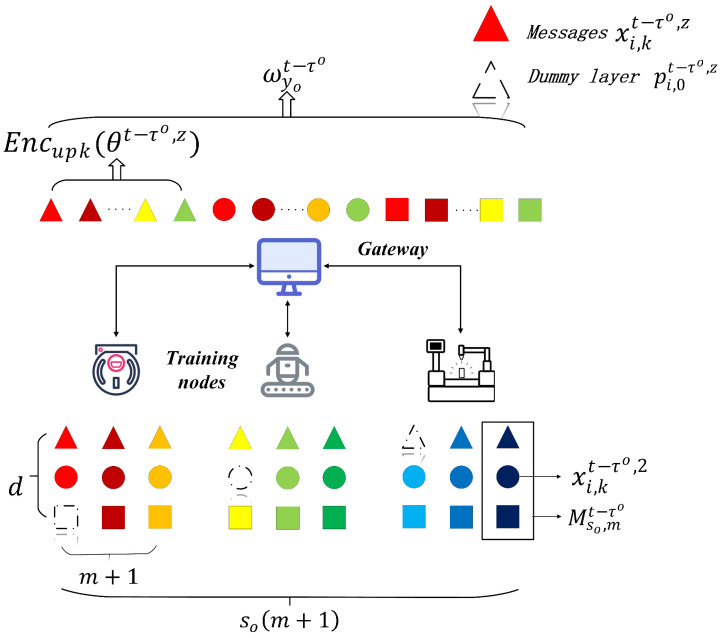 Figure 6
Figure 6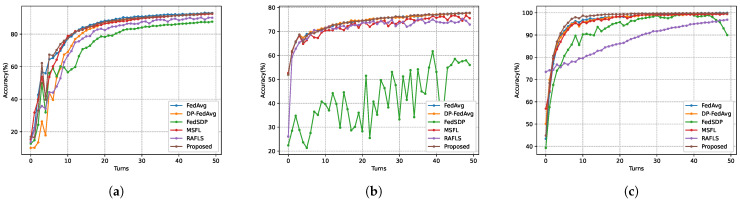 Figure 7
Figure 7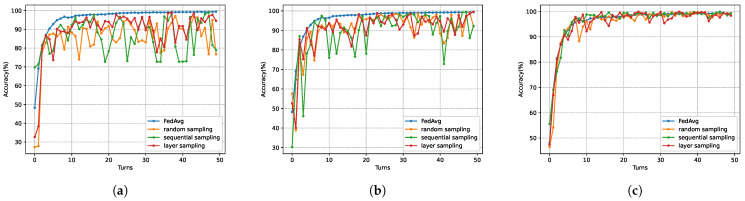 Figure 8
Figure 8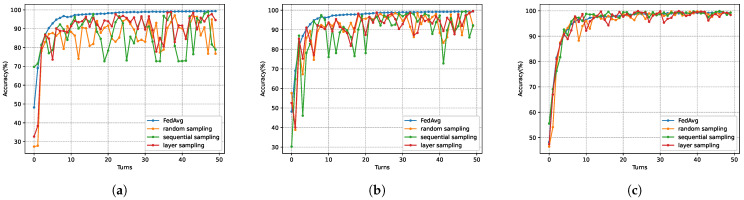 Figure 9
Figure 9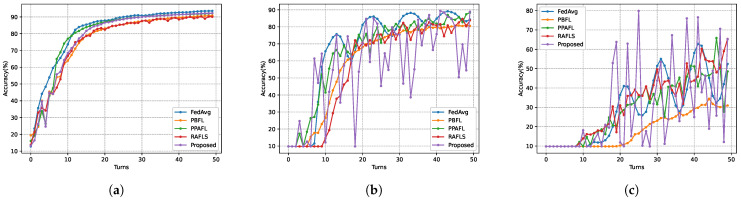 Figure 10
Figure 10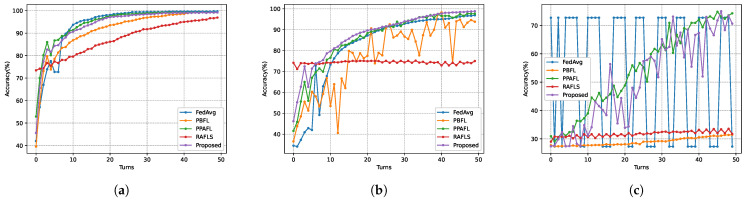 Figure 11
Figure 11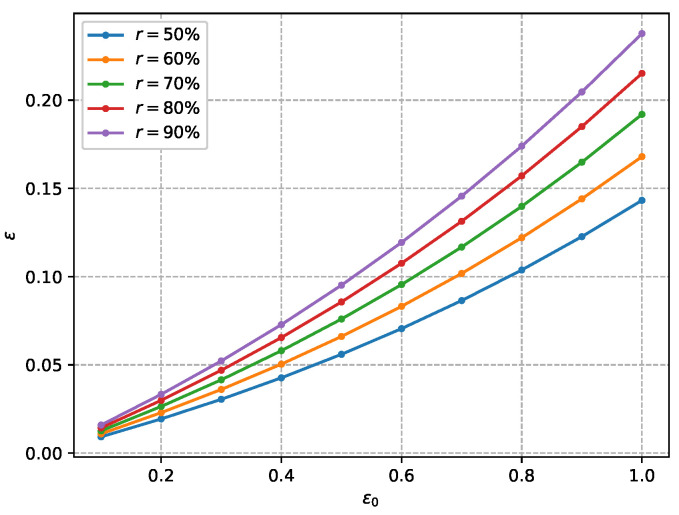 Figure 12
Figure 12- —National Natural Science Foundation of China
- —Hubei University of Technology Green Industry Technology Leading Program Project
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsPrivacy-Preserving Technologies in Data · Cryptography and Data Security · Stochastic Gradient Optimization Techniques
1. Introduction
Hierarchical asynchronous federated learning (HAFL) has been widely applied and studied across various academic and industrial scenarios [1,2,3,4,5]. HAFL can adapt to more realistic networking systems with hierarchical structures and be compatible with heterogeneous training nodes through an asynchronous update mechanism. Typical applications include the Internet of Vehicles (IoV) [6,7,8] and the Internet of Things (IoT) [9,10,11,12]. However, HAFL still faces FL-specific security issues, including single-point failure, data privacy, and Byzantine fault tolerance. Attackers may conduct inference attacks to reconstruct the training nodes’ datasets from their updated models [13,14]. Malicious nodes may launch Byzantine attacks to compromise system robustness by poisoning the model [15,16].
Centralized federated learning (FL) approaches always suffer from a single point of failure and untrusted aggregation [17,18]. Owing to features such as decentralization, immutability, traceability, and consensus mechanisms, Blockchain-based technologies offer effective solutions [6,18,19]. They use Blockchain to store the global model, computational metadata, and other relevant data generated during the training process, ensuring transparency, traceability, and tamper resistance. However, Blockchain-based FL still faces privacy-preserving problems, e.g., membership inference attacks [13,20], model inversion attacks [14], Byzantine attacks, e.g., poisoning the models [15,16], and label flipping [21,22].
Differential privacy (DP) has been widely used for privacy in FL [23,24,25]. Compared to homomorphic encryption (HE) [26,27,28] and secure multi-party computation (SMC) [29,30,31], DP has low computational overhead and is more suitable for multiple iterations of computation [32]. Central differential privacy (CDP) [33] inputs calibrated noise into the global model via a central server that aggregates the model. Local differential privacy (LDP) [34] eliminates the dependence on a trusted central server and allows each training node to add noise to the uploaded model. However, the accumulated noise may degrade the performance of the global model. Yuan et al. [35] proposed an adaptive perturbation scheme that adjusts the variance of the perturbation online to reduce the performance degradation. Sun et al. [24] combined LDP with a shuffle model to reduce noise variance and enlarge the privacy budget. However, they can only reduce, but not eliminate, the impact of noise.
To suppress Byzantine attacks, e.g., additive noise (AN) [36,37], A Little Is Enough (ALIE) [22], inner product manipulation (IPM) [38], sign flipping (SF) [39,40], and label flipping (LF) [21,41], numerous robust aggregation algorithms have been proposed, e.g., Euclidean distance-based methods [42,43,44,45], cosine similarity-based approaches [46,47], and median/mean-based statistical techniques [48]. These algorithms distinguished between honest and malicious nodes by leveraging geometric distances or statistical features in high-dimensional spaces.
However, in LDP-based HAFL, the geometric distances or statistical characteristics are disturbed by noise, making it hard to distinguish malicious and delay models. Designing an HAFL system that simultaneously ensures privacy-preserving and Byzantine robustness remains hard.
This study proposes a secure hierarchical asynchronous federated learning (SHAFL) framework that ensures both privacy preservation and Byzantine robustness. Our contributions are summarized as follows:
- SHAFL proposes a decentralized mask exchange protocol that uses eliminable noise to prevent the gateway from compromising the privacy of the training node and to reduce the impact of noise on global model performance. Based on HE, it prevents collusion attacks among training nodes.
- The SHAFL scheme introduces a novel mechanism for continuous layer subsampling and dummy-layer padding. Combining continuous-layer subsampling, dummy-layer padding, and a shuffle model, SHAFL enhances the privacy-preserving capability of local models during the server aggregation phase.
- SHAFL designs a secure aggregation scheme that leverages the upload model’s test accuracy to mitigate the impact of malicious nodes on system robustness.
- With an eliminable noise, SHAFL reduces the damage to system robustness caused by node offline before model shuffling in groups.
- Experiments on the MNIST, CIFAR-10, and Heart Disease datasets validate the privacy, convergence, and robustness of the proposed SHAFL.
The remainder of this study is organized as follows: Section 2 analyzes the related work; Section 3 discusses the system model; Section 4 presents the proposed SHAFL framework; Section 5 and Section 6 discuss the convergence and security of the proposed SHAFL; Section 7 presents an experimental analysis of the proposed SHAFL; and Section 8 is the conclusion.
2. Related Work
Xie et al. [49] proposed an asynchronous federated optimization algorithm (FedAsync) addressing the straggler issue. Miao et al. [50] proposed a time-weighted asynchronous PPFL that integrates stale models. Wu et al. [51] designed an aggregation method to control asynchronous aggregation errors. Chen et al. [52] proposed an adaptive semi-asynchronous federated learning (ASAFL) approach to balance learning latency and accuracy. However, the distributed architecture of FL makes it susceptible to privacy-preserving issues [13,14] and Byzantine attacks [22,36,37].
There are three typical privacy protection methods in FL: HE [26,27], DP [18,32,53,54], and SMC [29,30,31]. Compared with DP and SMC, HE-based methods exhibit higher computational complexity and overly conservative safety assumptions. For example, Yang et al. [26] proposed a secure FL scheme that prevents privacy attacks from external attackers and half-honest servers without requiring a shared homomorphic key. It can not defend against internal attacks from training nodes that share homomorphic keys. Miao et al. [27] proposed a privacy-preserving and Byzantine-robust FL framework with a fully homomorphic encryption (FHE) algorithm CKKS, assuming a trusted verifier. DP is widely used to preserve privacy in FL due to its quantifiable privacy loss and low computational overhead [18,32,53,54]. Wei et al. [53] proposed a Gaussian–DP-based privacy-preserving FL scheme. Jiang et al. [54] proposed a Laplace–DP-based algorithm to improve performance. Yan et al. [18] proposed a Laplace–DP-based asynchronous FL scheme for an IoT system, while analyzing the dropout tolerance of DP-based FL. However, the noise introduced by DP inherently degrades the model’s accuracy and utility and requires a larger privacy budget. In theory, Mask-based SMC schemes can eliminate the effects of noise. However, security concerns arise in the generation and aggregation of the mask/noise. For example, Feng et al. [29] proposed a Blockchain-enabled, horizontally decentralized FL with a mask that may be generated by a malicious node. Hiroki et al. [30] proposed a mask-based decentralized FL scheme; however, it cannot protect against collusion attacks. Shen et al. [31] proposed a LiPFed scheme in which each training node generates its own masks, thereby eliminating reliance on intermediate nodes for security. However, the divided model may result in insecure aggregation. Moreover, if the aggregation node cannot obtain all the noisy models, the mask/noise cannot be eliminated. In our proposed scheme, we introduce a mask-DP exchange protocol that, in theory, eliminates noise and improves performance when used with PBFT.
To address Byzantine attacks, it is necessary to distinguish between honest and malicious nodes using updated models [55,56]. With a consortium Blockchain, Yan et al. [18] adopt a Practical Byzantine Fault Tolerance (PBFT) protocol to ensure the credibility of aggregated results. Furthermore, Xu et al. [57] proposed a semi-asynchronous aggregation scheme resisting poisoning attacks, backdoor attacks, and Distributed Denial of Service (DDoS) attacks. Zhang et al. [56] proposed a robust and secure framework for FL with verifiable DP noise. However, their work is discussed in the context of synchronous FL but ignores the impact of asynchronous FL, particularly the effect of noise on the model accuracy of PBFT.
In addition, privacy amplification mechanisms, e.g., shuffler [58,59], subsampling [60], and dummy points [24], are introduced into FL to increase the privacy budget while reducing noise. The shuffling mechanism disrupts the correlation between the uploaded local models and the training nodes to enhance the LDP with anonymity [58,59,61]. Using the subsampling and dummy point algorithms, Sun et al. [24] proposed a privacy-enhancing DP-based FL, which amplified the privacy-preserving level of LDP at the aggregation stage. These methods can reduce the impact of DP noise. In our proposed scheme, we introduce a shuffling mechanism for asynchronous environments, reducing the impact of mask noise leakage on PBFT.
3. System Model
This section introduces the Blockchain-based hierarchical asynchronous federated learning, threat model, and privacy-preserving mechanism adopted by the SHAFL framework.
3.1. Blockchain-Based Hierarchical Asynchronous Federated Learning
Shown in Figure 1, our proposed SHAFL framework considers a Blockchain-based scenario that consists of two layers; In the first layer of the SHAFL framework, the training nodes have K groups , each group has a header node called gateway , and the size of group is . In group , each training node has a dataset . The basic FL [62] is
where is the task objective function, is the objective function of , and are weights of model aggregation, and is the loss function at .
In the first layer of the SHAFL framework, in turn , each training node first receives a global model from Blockchain; then, locally and iteratively trains with , and outputs : , after H iterations. In iteration , the local update is
where is the local update, is the delay of group and gateway , and is the start time of local training replacing synchronous tempo t; is the learning rate.
It assumes that all local training within a group is synchronous, meaning that all in a group are the same and are marked with . After collecting all local updates, the gateway obtains :
In the second layer of the SHAFL framework, all gateways can upload their updates to the Blockchain asynchronously, which means the primary committee node allows the gateways to have different delays . After a period, the primary committee node downloads the updates from the Blockchain and aggregates the global model as [1]
where is the hyperparameter weight of global update, is the weight of local update , and is the number of local updates uploaded in turn t. Figure 2 shows the asynchronous time workflow of the SHAFL framework.
3.2. Threat Model
In this study, we assume that a gateway can be honest but curious, and a training/committee node might be potentially malicious. The potential threats caused by training nodes, gateways, and committee nodes are shown as follows.
Training nodes: They try to extract other training nodes’ local data as much as possible from local updates, via launching inference attacks [13,14] and data reconstruction attacks [63,64,65]. Malicious training clients may engage in data poisoning or upload maliciously crafted local updates [66], which can lead to a degradation of the global model’s accuracy.Gateways: They follow predefined protocols and submit correct intermediate results. However, they are curious about the sensitive information contained in training nodes and may attempt to infer the training nodes’ private data, resulting in data leakage.Committee nodes: Malicious committee nodes may discard local updates from gateways or release a malicious global model, thus compromising the robustness of the system.collusion attacks: Malicious training nodes may collude to obtain the private model of the target node, such as attempting to remove the noise added to the target model. Furthermore, malicious training nodes could collude with gateways, or gateways could collude with malicious committee nodes to attack the training nodes’ privacy.
3.3. Privacy Preserving Mechanism
To tackle the privacy-preserving issues, the SHAFL framework introduces an LDP-based shuffle model, a mask–DP exchange protocol, and Paillier homomorphic encryption.
3.3.1. LDP Mechanism
Unlike CDP, an LDP-based FL allows the training node to add noise to the model locally to achieve decentralized privacy-preserving [32], which has no reliance on a trusted server.
Definition 1 ( -LDP [32]). A randomized algorithm satisfies -LDP if for any two adjacent datasets and for any subset of outputs , it holds that
Gaussian mechanism extracts random noise from the Gaussian distribution and adds noise to the query function to satisfy -DP.
Definition 2 (Gaussian Mechanism [32]). For a given query function f with sensitivity . The randomized algorithm satisfies -DP if
where is a Gaussian distribution with mean 0 and covariance , and is sensitivity of query function f.
3.3.2. LDP-Based Shuffle Model
The shuffle model disrupts the correlation between the local model and the training nodes through a confusion mechanism to provide anonymity to the local model [59,61]. A LDP-based shuffle model further enhances the privacy-preserving and anonymity [58,67]. The LDP shuffle model is shown in Figure 3 and defined as follows.
Definition 3 (LDP-based shuffle model [24]). A randomized mechanism is an LDP shuffle model if it includes three components: encoder , shuffler , and analyzer [24]. Considering that the shuffler (gateway) takes n training nodes’ upload in group :
- Encoder is a randomized algorithm that runs on the training nodes’ side and converts local data into d messages.
- Shuffler collects the messages uploaded by n training nodes and processes the messages into a random permutation.
- Aggregator aggregates the random permutation uploaded by training nodes to generate a model.
In summary, the shuffle DP can be denoted as
where is the privacy-preserving mechanism, d is the number of messages, are random numbers, and is the uploaded model of the shuffler (gateway). Encoder satisfies -LDP.
3.3.3. Mask–DP Exchange Protocol
An eliminable noise [68], mask , is generated through the Gaussian mechanism. In turn t, the mask exchange protocol is defined as detailed in [30]. The process is
Input the number of training nodes n, the number of exchange noises , and a set of privacy budgets .Each generates mask based on and receives mask from .After the exchange step, each aggregate received masks .Each training node generates m multi-masks as follows:
Each sends m multi-masks to gateways.
The local update satisfies -LDP. In a group , . The server can aggregate the global model without adding perturbation. Shown in Figure 4, in a group , the number of training nodes is n, e.g., , and the number of noises to be exchanged is . Each training node generates noise based on its privacy budget . Following the mask exchange protocol, m multi-mask messages are generated and transmitted to the gateway. The gateway then performs pre-aggregation as follows:
where denotes the local update of training node . After pre-aggregation, the noise is eliminated. Therefore, the server can aggregate a global model without perturbation.
3.3.4. Paillier Homomorphic Encryption
Our scheme is based on Paillier homomorphic encryption (PHE) [69], which is an additive homomorphic encryption scheme. It consists of three algorithms.
Key Generation: Select two large prime numbers, p and q. Calculate and ; denotes the least common multiple. Randomly select satisfying ; denotes the greatest common divisor, . Calculate . Output the public key and keep the private key .Encryption: Input a plain text and select a random number . Output the cipher text .Decryption: Input a cipher text . Output the plain text .
4. Proposed Framework
This section introduces our proposed secure hierarchical asynchronous federated learning (SHAFL) scheme, including design goals, the SHAFL framework, the shuffle model, and the committee consensus mechanism. Table 1 outlines the notation definitions in this study.
4.1. Design Goals
The design objectives of SHAFL are as follows:
- Prevent malicious training nodes, gateways, and committee nodes from compromising the local data privacy of training nodes.
- Solve the problem of collusion attacks among training nodes.
- Eliminate the impact of noise on global model performance.
- Prevent malicious training and committee nodes from compromising system robustness and global model performance.
4.2. Framework
The workflow of the SHAFL framework is shown in Figure 5. The SHAFL framework comprises four types of entities: task publishers, committee nodes U, training nodes C, and gateways Y. The task publisher initializes the global model (and rewards) in . The committee nodes share the same Paillier homomorphic key pair and act as aggregators. They receive messages from gateways, analyze and aggregate them, and then publish the global model and the hyperparameters. Gateways act as shufflers that receive m multi-masks from training nodes and upload the output of the shuffle model to the Blockchain. Each training node has the same Paillier homomorphic key pair . The training nodes under the same gateway are called a group , and the size of the group is . The SHAFL framework is presented in Algorithm 1 with six steps: Algorithm 1 Algorithm of SHAFLInput: Output:
- 1:Task publisher initializes the global model (and rewards) in
- 2:for do
- 3: for each do
- 4:
- 5: end for
- 6: sends the signed messages to Blockchain
- 7: for each do
- 8: According to and Gaussian Mechanism, calculates noise scale
- 9: = Mask generating
- 10: receives from other trainers
- 11: downloads and decrypts signed messages from Blockchain
- 12: = Local training( )
- 13: = Model masking( , , )
- 14: divides and encrypts to
- 15: end for
- 16: for each do
- 17:
- 18: signs and saves in Blockchain.
- 19: end for
- 20: for each do
- 21: Select by
- 22: = Committee consensus( , )
- 23: end for
- 24: signs and saves in
- 25:end for
- 26:
- 27:return Outputs
Node shuffling: In turn t, each training node randomly selects a gateway as its shuffler. Training nodes under the same gateway form a group .Mask generating: Training nodes process mask–DP exchange protocol. According to the differential privacy parameter and the Gaussian mechanism, calculates noise scale based on Equation (8) and generates masks based on Gaussian distribution . Then, exchanges masks with other training nodes within a group .Local training: All training nodes receive the signed and encrypted message from the gateway, decrypt with private key , obtain the global model , set their learning rate , and train the global model with locally using Equations (3) and (4).Model masking: Training node subsamples its local update and performs dummy layer filling on the sampled model to restore the original model shape. Using the filled model , masks and , and the training node generates m multi-masks messages according to Equation (10). m multi-masks are further divided into d-layer vectors , according to the shape of the global model. Then, training node encrypts these messages with the primary committee node’s public key and sends the encrypted messages to the gateway . The subsample, dummy-layer filling, and model masking are proposed in Algorithm 2. It is worth noting that the masks are additive Gaussian noises; the encrypted model has the same shape and location information as the global model.Model shuffling: After the gateway receives all messages from the training nodes, the gateway shuffles encrypted messages using Equation (9), and retains the location information of the layer. Then, the gateway generates a new model and sends it to the Blockchain with a delay asynchronously. If , stale models are discarded.Committee consensus: Committee nodes U select a primary node . Primary committee node downloads local updates from the Blockchain and decrypts them to obtain . Then, scores the model and signs and broadcasts the scores to other committee nodes. Other committee nodes then re-score the models and reach a consensus on scores . Once a consensus is reached, primary aggregates the local updates as
where denotes the hyperparameter of secure aggregation, and is the number of local updates uploaded by gateways in turn t. Primary committee node encrypts and uploads the new global model to the Blockchain for the next turn .
Algorithm 2 Model maskingInput: Output:
- 1:for each do
- 2: for each do
- 3: Calculated mask
- 4: for do
- 5: if then
- 6: and evaluated σ by Equation (8)
- 7:
- 8:
- 9:
- 10:
- 11:
- 12: by Equation (10)
- 13:
- 14:
- 15:
- 16:
- 17: using primary committee’s public key upk
- 18:
- 19: to gateway y_o_ synchronous
- 20:
- 21:return Outputs
Once t reaches the set parameter T or the global model converges, the FL ends.
4.3. Multi-Shuffle with Subsample and Dummy Layers
To enhance the LDP, the SHAFL framework introduces the shuffle model, which fills the subsample and dummy layers. These privacy-enhancing mechanisms reduce the required noise level in local updates while ensuring the performance preservation of models uploaded by training nodes [67]. However, the subsample will cause missing model layers, which makes it difficult for the committee node to combine and aggregate the local updates into an available model [24]. The SHAFL framework introduces dummy layers to ensure a valid model.
The subsample, dummy-layer filling, and model masking are shown in Figure 6 and Algorithm 2. After local training, the training node first performs continuous layer subsampling on its local updates . All training nodes perform subsampling and drop some model layers. They then evaluate the variance of the Gaussian noise using Equation (8), and fill the dropped layers with dummy layers generated from Gaussian noise , where
The filled model is denoted as . According to the mask–DP exchange protocol, the training node generates m multi-masks using masks and { }. It is worth noting that , and each training node generates multi-masks { }.
Before uploading the masks to the gateway, the training node divides them layer by layer:
where denotes the layer vector of , , and , . The value of is a float number, which can not be encrypted directly with PHE. Therefore, the value of layer vector should be expanded to an integer through quantization , where denotes the scale of quantization. Then, using primary committee node ’s homomorphic public key , the training node encrypts the layer vector to layer by layer and uploads messages to gateway .
The gateway (shuffler) receives messages from training nodes and shuffles them by layer. Specifically, the gateway will collectively shuffle the order of the layer vectors from all clients at the same layer. After shuffling, according to the hierarchical relationship, the encrypted layer vectors are stored in order to form a new local update . Then, the gateway uploads it to the Blockchain. The local update before aggregating is denoted as
where m is the number of multi-masks, and is the layer vector of mask in turn t before encryption. The number of training node messages is . The layer of the new local update is
Due to homomorphism,
The SHAFL framework uses the gateways as shufflers. The shuffling and pre-aggregation of model are shown in Figure 6 and Algorithm 3. Algorithm 3 Model shufflingInput: Output:
- 1:for each do
- 2: Receives the encrypted messages
- 3: for do
- 4: Shuffles by Equation (9)
- 5:
- 6:
- 7: end for
- 8: uploads local update to Blockchain asynchronous
- 9:end for
- 10:return Outputs
4.4. Committee Consensus
The committee consensus is shown in Algorithm 4. In the round of the SHAFL framework, the primary committee node first downloads an encrypted local update from the Blockchain and decrypts it using a homomorphic private key layer by layer. Since the layer vectors are quantized during encryption, mapping floating-point numbers to integers, it is necessary to dequantize the decrypted layer vectors to restore them to their original floating-point format. According to the hierarchical relationship, the layer vectors are reconstructed into a decrypted local update . Then, the primary committee node tests each local update and global model using the committee nodes’ local dataset to obtain the accuracy and . By using , , and the delay , calculates the score for each local update as
After scoring, the primary committee node sends the scores of local updates to other committee nodes . downloads and re-scores them, and uses a consensus mechanism, PBFT, to reach a consensus on scores . Once a consensus is reached, aggregates the local updates to obtain a new global model through secure aggregation using (12). Then, encrypts and uploads to . Algorithm 4 Committee consensusInput: Output:
- 1:Primary committee node downloads local updates from Blockchain and decrypts it
- 2:for do
- 3: for do
- 4:
- 5: Dequantization:
- 6:
- 7:
- 8:
- 9: end for
- 10: Obtain the decrypted local update of gateway
- 11:
- 12:end for
- 13: Tests the accuracy of global model by to obtain
- 14: for do
- 15: test the accuracy of by to obtain
- 16: Calculates score of model by Equation (17)
- 17:
- 18: end for
- 19: Sent scores to all committee node
- 20: for do
- 21: Re-score each local update by
- 22: Sent scores to other committee node
- 23: end for
- 24: All reach a consensus on scores
- 25: Pirmary node process secure aggregation by Equation (12)
- 26: encrypts the global model to by training nodes’ public key
- 27: Uploads to
- 28:return Outputs
5. Convergence Analysis
In this section, we present the theorem and proof for the convergence analysis of the SHAFL framework.
Definition 4 (L-smooth [1]). Function f is L-smooth if exists:
Definition 5 ( -strongly convex [1]). Function f is μ-strongly convex if exists:
Theorem 1. Assume the global loss function F is L-smooth and μ-strongly convex. For the group , let the learning rate be and the local iterations be . For , the expected square norm of the gradients is bounded:
*For the initial global model and optimization model *
After T turns, the convergence bond of the global loss function is
Proof of Theorem 1. Since prior studies [1,70] have established convergence analysis for hierarchical asynchronous federated learning frameworks, we specifically focus on presenting several distinct components in this study. For a training node in an arbitrary group , after performing H a local update, the convergence bound is
where is derived from by H iterations. Then, the committee nodes will aggregate local updates from the gateway to obtain a new global model . Thus, the convergence bound of the SHAFL framework after t turns is
Using Equations (23) and (24), after performing T global turns, the convergence bound of the SHAFL framework is
Thus, Theorem 1 derives the convergence bound after T turns. □
6. Security Analysis
This section describes the security analysis of the SHAFL framework as follows: privacy-preserving analysis, system robustness analysis, and model security analysis.
6.1. Privacy-Preserving Analysis
Lemma 1 (Amplification by shuffling [58]). Let be an -LDP mechanism. Then, the shuffle model satisfies -DP, where
- If
for any , it has
Lemma 2 (Amplification by subsampling [60]). If satisfies -DP with the relationship on the set n, then satisfies -DP.
Theorem 2. In the SHAFL framework, the training node employs the Gaussian mechanism-based -LDP to preserve data privacy. Through the integration of the shuffle model and subsample, the privacy parameters of the local model satisfy
Equations (28) and (29) demonstrate the conversion relationship between local privacy parameters and central differential privacy parameters .
Proof of Theorem 2. In Algorithm 2, layers of the model are dropped and replaced with dummy layers . Therefore, the SHAFL framework samples layers from the model parameter space. According to Lemma 2, the local model satisfies
where is the subsampling rate. After subsampling, the local model satisfies -DP. Since the training nodes send the subsampled model to the gateway, the gateway performs a random permutation on the subsampled model. According to Lemma 1, the local model processed with subsampling and shuffling satisfies
as shown in Theorem 2. □
6.2. System Robustness Analysis
The SHAFL framework introduces a novel secure aggregation algorithm. Before the committee nodes aggregate a new global model , the primary committee node evaluates the test accuracy of each local update using a globally shared test dataset . The algorithm then calculates a score for each model based on its accuracy and delay , which serves as the aggregation weight of . A suboptimal model uploaded by a malicious training node will achieve low test accuracy and therefore receive a low aggregation weight. The SHAFL framework mitigates the impact of malicious training nodes on the global model’s performance using the secure aggregation algorithm described above. In the latter rounds of training, the accuracy of both the global model and the local models becomes high and similar. The aggregation weight of the model uploaded by with a high delay is significantly lower than that of normal models, thereby mitigating the detrimental impact of stale models on the performance of the global model.
In the event of node disconnections after the mask–DP exchange protocol, the mask–DP introduced by the SHAFL framework is equivalent to a Gaussian noise-based DP. When training node is offline, each training node generates noise with a variance of
where is the variance of noises , and m is the number of exchange masks.
6.3. Model Security Analysis
The proposed SHAFL framework employs a combination of consortium Blockchain technology, HE, and DP-based masks to ensure the privacy and security of local data for training nodes. The consortium Blockchain, as a private chain, restricts data access to authorized nodes only, thereby mitigating privacy threats from external nodes. Within the SHAFL framework, all committee nodes and training nodes each possess homomorphic key pairs . When committee nodes distribute the global model to training nodes via an intermediate gateway node, they encrypt the global model with the training node’s homomorphic public key . Except for the training node, no one else can access the global model. Before sending local updates to the gateway, all training nodes encrypt their messages using the committee nodes’ homomorphic public key , preventing the gateway and the training nodes from extracting any original model information. The gateway shuffles received messages from training nodes and disrupts the mapping between messages and training nodes. The committee nodes can only receive the shuffled model from the gateway, not the original model from the training node. If the gateway and committee nodes collude, they can use the committee node’s private key to decrypt the local updates uploaded by the training nodes. However, since the local updates uploaded by the training nodes are masked, they cannot obtain the original local updates of the training nodes.
7. Experiments
7.1. Experimental Setting
7.1.1. Benchmarks
The baseline algorithms used in the experiments are introduced as follows.
FedAvg [62], as the canonical synchronous federated learning framework, was adopted as the baseline comparative scheme in our experiments. This implementation deliberately excludes privacy-preserving mechanisms and Byzantine fault tolerance capabilities.DP–FedAvg [71] is a privacy-preserving federated learning framework based on LDP. By injecting noise into their local models, training nodes ensure that the uploaded local models satisfy LDP requirements, thereby defending against inference attacks from the server.FedSDP [24] is a synchronous privacy-preserving federated learning framework designed for the Internet of Vehicles (IoV), which enhances privacy and improves data utility through a tripartite mechanism that combines Top-k gradient subsampling, virtual point padding, and shuffle-based anonymization.MSFL [61] is a privacy-preserving federated learning framework that synergistically integrates multi-stage shuffling mechanisms and Byzantine-resilient consensus algorithms. It enhances privacy by shuffling training nodes and local updates.PBFL [27] is a synchronous, centralized privacy-preserving federated learning framework that achieves privacy-preserving through HE and ensures Byzantine fault tolerance via cosine similarity-based gradient validation.PPAFL [18] is an asynchronous privacy-preserving federated learning framework that implements LDP via the Laplace mechanism.RAFLS [34] is an RDP-based adaptive FL scheme. It uses the sensitivity of different layers’ weights to determine the amount of noise injected into the model, adopts a model-parameter shuffling mechanism to achieve local model anonymity, and proposes a fine-grained model-weight aggregation scheme.
Table 2 compares the computational complexity of the evaluated schemes from three aspects: local training, aggregation, and privacy preserving. The FedSGP scheme’s marginally higher local training loss is a consequence of the additional Tok sparsification operation performed locally. Regarding aggregation and privacy preservation, due to the use of homomorphic encryption, PBFL and SHAFL exhibit significantly higher computational complexity than other schemes.
7.1.2. Datasets and Models
Three benchmark datasets were rigorously employed in our experiments: MNIST [72], CIFAR-10 [73], and a Heart Disease dataset [74]. The MNIST dataset is a classic handwritten digital image dataset, comprising a training set of 60,000 grayscale images and a test set of 10,000 grayscale images, each standardized to a resolution of 28 × 28 pixels. The test set of 10,000 grayscale images is used to form . The committee nodes utilize to evaluate the accuracy of local updates uploaded by the gateways and assign aggregation weights to each gateway’s local updates based on their accuracy. The training set comprising 50,000 images is evenly distributed across the training nodes. The training nodes then conduct training using their allocated subsets of the training data. The model used on the MNIST dataset is a two-layer CNN. The CIFAR-10 dataset includes 60,000 labeled RGB images (32 × 32 pixels) across 10 object classes, which are divided into 50,000 training images and 10,000 test images. For the CIFAR-10 dataset, the partitioning method for and the training dataset is the same as that for the MNIST dataset. The model architecture employed on the CIFAR-10 dataset is ResNet-18. The Heart Disease dataset is a real-world IoMT dataset. The dataset contains approximately 37,000 heart activity samples, each with a 50-dimensional feature vector including heart rate, body mass index, glucose levels, and a label indicating coronary heart disease. There are 1,500 heart health samples across these sample nodes. For the Heart Disease dataset, the model and dataset partitioning scheme are adopted from Reference [74].
7.1.3. Experimental Parameters
The experiment was implemented with Python 3.9 and PyTorch 2.1.0 on a computer equipped with an Intel CPU i5-12400F (Santa Clara, CA, USA) and a NVIDIA GPU 3060Ti (Santa Clara, CA, USA). The random seed was 42, and the key size was 2048-bit, as referenced in [75]. Different experimental parameters were adopted for the three datasets, as shown in Table 3, Table 4, Table 5, where denotes the number of training nodes, denotes the number of committee nodes, denotes number of local iterations, denotes the proportion of malicious nodes within the training node set, denotes the aggregation hyperparameter of FedAvg [62], denotes number of global iterations, denotes learning rate, denotes the aggregation hyperparameter of SHAFL, denotes differential privacy parameters, and denotes the maximum aggregation delay.
7.2. Experimental Result
7.2.1. Performance Analysis
In the absence of malicious nodes, Table 6 presents the model accuracy of each scheme across three datasets. Except for the non-privacy-preserving baseline scheme FedAvg, all other schemes employ a privacy budget of and , coupled with a subsampling rate of . As evidenced by Table 6, under identical privacy budget conditions, the proposed scheme achieved superior model accuracy across all three datasets compared to other schemes, with the exception of the non-privacy-preserving baseline FedAvg.
Figure 7 illustrates the global model performance of five schemes across three datasets. As observed in Figure 7a on the MNIST dataset, the proposed SHAFL framework achieved comparable accuracy to the non-privacy-preserving baseline FedAvg, with a marginal difference of merely 0.26%. Furthermore, after the 40th training iteration, SHAFL, MSFL, and FedAvg all showed convergence in model accuracy. This demonstrates that the SHAFL framework maintains strong model utility and convergence properties under identical privacy budget constraints. Similarly, as depicted in Figure 7b,c, the SHAFL framework demonstrates robust performance on both the CIFAR-10 dataset and the Heart Disease dataset. Notably, on CIFAR-10, the model accuracy of the SHAFL framework surpasses FedAvg by a narrow margin of 0.06%, which can be attributed to the enhanced generalization capability enabled by the minimal noise injection. Additionally, SHAFL, FedAvg, and DP-FedAvg all converged around the 40th training iteration, collectively demonstrating stable optimization trajectories. After the 10th round, both MSFL and RAFLS exhibited persistent oscillations. This occurs because, as the model approaches convergence, excessive noise injection causes the model parameters to fluctuate around the optimum. In contrast, the SHAFL scheme employs eliminable noise, thereby effectively mitigating the occurrence of oscillations. On the Heart Disease dataset, the SHAFL framework exhibited 0.18% lower model accuracy than the non-privacy-preserving baseline FedAvg, yet outperformed all other comparative schemes. Additionally, the SHAFL framework demonstrated a marginally faster convergence rate than the remaining approaches. In conclusion, compared with the baseline approach, FedAvg and the SHAFL framework achieved comparable model accuracy while providing enhanced privacy protection for local data on training nodes. Compared with other privacy-preserving schemes under the same privacy budget, the SHAFL framework achieved higher model accuracy and superior convergence properties.
7.2.2. Impact of Sampling Strategies on Model Accuracy
We evaluated the impact of three subsampling strategies on model accuracy. In the experiments, the model fixed the local noise variance and adjusted the scheme’s privacy budget to control the sampling rate. Three privacy budget values, , and 1, were selected, corresponding to sampling rates of , and , respectively. Figure 8 and Figure 9 illustrate the impact of different sampling strategies on model performance across datasets. As shown in Figure 8 and Figure 9, under privacy budgets of and , the layer sampling proposed by the SHAFL framework achieved a significant improvement in model accuracy compared to other schemes, while exhibiting smaller oscillation amplitudes. At , the accuracy of layer sampling outperforms sequential sampling and matches the baseline FedAvg scheme without sampling.
7.2.3. Analysis of Byzantine Attack Resistance
To evaluate the Byzantine attack resistance of the models, it compared model accuracy across several schemes at varying proportions of malicious nodes. FedAvg served as the baseline to reflect the Byzantine robustness of other schemes in asynchronous environments. In the experiments, it set the maximum number of delay rounds and the privacy budget . As shown in Figure 10 and Figure 11, all schemes experienced a significant drop in model accuracy at Turn 4. For instance, FedAvg in Figure 10 achieved an accuracy of 72.73% at Turn 6, but this plummeted to 49.18% at Turn 7, marking a 48.18% decline. These results indicate that the participation of stale models in aggregation during early training stages degrades accuracy more severely than the impact of a limited number of malicious nodes. From Figure 10 on the MNIST dataset, when , the accuracy of the SHAFL framework is 1.37% lower than FedAvg but 1.42% higher than PBFL. At , the SHAFL framework outperforms FedAvg, PBFL, and PPAFL by 4.59%, 8.35%, and 0.52%, respectively. When , the accuracy of the SHAFL framework surpasses FedAvg, PBFL, PPAFL and RAFLS by 12.75%, 34.26%, 16.62%, and 5.07%, respectively. Similarly, as shown in Figure 11, when , the accuracy of the SHAFL framework surpasses FedAvg, PBFL, PPAFL and RAFLS by 71.81%, 67.36%, 24.54%, and 67.09%, respectively. Figure 11 demonstrates that the SHAFL framework achieves higher accuracy than other schemes in environments with malicious nodes. Notably, when , the accuracy of the SHAFL framework exceeds FedAvg and PBFL by 43.37% and 39.19%, respectively. This superiority stems from the SHAFL framework’s mechanism: it evaluates each gateway-uploaded model’s accuracy on a test dataset before computing aggregation weights. This approach assigns lower aggregation weights to models from gateways that contain malicious nodes, thereby minimizing their influence on the global model.
7.2.4. Privacy Enhancement Analysis
As demonstrated in Figure 12, the correlation between local and central privacy across varying sampling rates shows that the local privacy budget of training nodes is significantly reduced by the subsampling mechanism and the shuffling model. This substantiates SHAFL’s inherent privacy-enhancing capability. Furthermore, the experimental results show that SHAFL’s privacy amplification effect strengthens as the subsampling rate decreases. This phenomenon occurs because lower sampling rates inherently retain fewer model parameters during aggregation, thereby containing a correspondingly lower amount of sensitive information susceptible to privacy leakage.
8. Conclusions
This study proposes a secure asynchronous hierarchical federated learning (SHAFL) framework. In the first layer, it introduces a decentralized mask–DP exchange protocol. Under a gateway, training nodes generate masks using the Gaussian mechanism and exchange them according to the protocol. Each training node then constructs a set of messages using its locally generated mask and those received from other nodes, such that their aggregation recovers the original local model without noise perturbation. To prevent gateways and training nodes from inferring private information from uploaded messages, it employs homomorphic encryption. At the gateway, a shuffling mechanism is applied to disrupt the order of uploaded messages, further enhancing the privacy-preserving level for the local models. In the second layer, it implements an accuracy-based, committee-consensus scoring mechanism, where the primary committee node uses a global test dataset to evaluate and score models uploaded by gateways, thereby determining their aggregation weights. This reduces the impact of malicious nodes on the global model. Theoretical analysis and experimental results demonstrate that our proposed SHAFL achieves superior performance in privacy-preserving and Byzantine-robustness. However, as our scheme employs the Paillier homomorphic encryption algorithm to resist collusion attacks, it incurs relatively high computational overhead. Additionally, our experimental results are obtained using an IID dataset, without considering the impact of Non-IID datasets on the convergence of model aggregation. In future work, we plan to explore ways to reduce computational cost under the existing security assumptions, while also accounting for the effects of non-IID datasets when designing the aggregation scheme.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Wang Z. Xu H. Liu J. Huang H. Qiao C. Zhao Y. Resource-efficient federated learning with hierarchical aggregation in edge computing Proceedings of the IEEE INFOCOM 2021-IEEE Conference on Computer Communications Vancouver, BC, Canada 10–13 May 2021 IEEE Piscataway, NJ, USA 2021110
- 2Xu C. Qu Y. Xiang Y. Gao L. Asynchronous federated learning on heterogeneous devices: A survey Comput. Sci. Rev.20235010059510.1016/j.cosrev.2023.100595 · doi ↗
- 3Jiang X. Sun A. Sun Y. Luo H. Guizani M. A Trust-Based Hierarchical Consensus Mechanism for Consortium Blockchain in Smart Grid Tsinghua Sci. Technol.202328698110.26599/TST.2021.9010074 · doi ↗
- 4Zhou H. Zheng Y. Huang H. Shu J. Jia X. Toward Robust Hierarchical Federated Learning in Internet of Vehicles IEEE Trans. Intell. Transp. Syst.2023245600561410.1109/TITS.2023.3243003 · doi ↗
- 5Huang X. Wu Y. Liang C. Chen Q. Zhang J. Distance-aware hierarchical federated learning in blockchain-enabled edge computing network IEEE Internet Things J.202310191631917610.1109/JIOT.2023.3279983 · doi ↗
- 6Tan H. Wang M. Shen J. Vijayakumar P. Moh S. Wu Q. Blockchain-Assisted Conditional Anonymous Authentication and Adaptive Tree-Based Group Key Agreement for VANE Ts IEEE Trans. Dependable Secur. Comput 202511610.1109/TDSC.2025.3628884 · doi ↗
- 7Wang B. Tian Z. Tang F. Pan H. She W. Liu W. Blockchain-empowered asynchronous federated reinforcement learning for Io T-based traffic trajectory prediction IEEE Internet Things J.202512170951710910.1109/JIOT.2025.3538887 · doi ↗
- 8Pan Y. Su Z. Wang Y. Zhou J. Mahmoud M. Privacy-Preserving Byzantine-Robust Federated Learning via Deep Reinforcement Learning in Vehicular Networks IEEE Trans. Veh. Technol.2025749461947510.1109/TVT.2024.3524834 · doi ↗