MonoPrior-Fusion: Monocular-Prior-Guided Multi-Frame Depth Estimation with Multi-Scale Geometric Fusion
Zhiwei Lin, Bohan Sun, Zhan Zhang, Linrui Qian, Nianyu Yi

TL;DR
This paper introduces a new method for depth estimation in indoor environments using monocular priors and multi-scale fusion to improve 3D perception.
Contribution
The novel framework, MonoPrior-Fusion, integrates monocular priors into multi-view matching and introduces a geometric consistency loss for better 3D coherence.
Findings
MPF outperforms state-of-the-art methods in challenging indoor scenarios.
The method improves 3D reconstruction accuracy and completeness in volumetric fusion pipelines.
Abstract
Precise 3D perception is critical for indoor robotics, augmented reality, and autonomous navigation. However, existing multi-frame depth estimation methods often suffer from significant performance degradation in challenging indoor scenarios characterized by weak textures, non-Lambertian surfaces, and complex layouts. To address these limitations, we propose MonoPrior-Fusion (MPF), a novel framework that integrates pixel-wise monocular priors directly into the multi-view matching process. Specifically, MPF modulates cost-volume hypotheses to disambiguate matches and employs a hierarchical fusion architecture across multiple scales to propagate global and local geometric information. Additionally, a geometric consistency loss based on virtual planes is introduced to enhance global 3D coherence. Extensive experiments on ScanNetV2, 7Scenes, TUM RGB-D, and GMU Kitchens demonstrate that MPF…
Click any figure to enlarge with its caption.
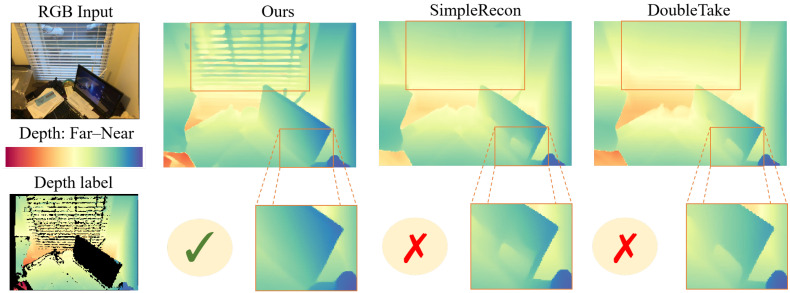 Figure 1
Figure 1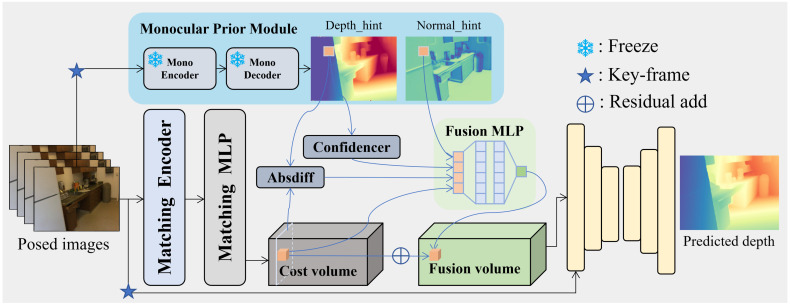 Figure 2
Figure 2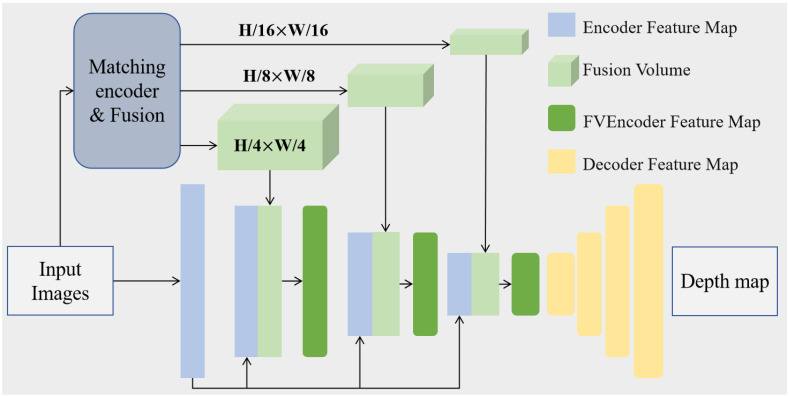 Figure 3
Figure 3 Figure 4
Figure 4 Figure 5
Figure 5 Figure 6
Figure 6 Figure 7
Figure 7- —Research Fund of Xiangtan University
- —National Natural Science Foundation of China (NSFC)
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAdvanced Vision and Imaging · Robotics and Sensor-Based Localization · Advanced Neural Network Applications
1. Introduction
Depth estimation plays a central role in visual perception systems, enabling downstream tasks such as autonomous navigation, robotic interaction, and augmented reality. Recent advances in monocular depth estimation have achieved remarkable progress by leveraging large-scale datasets and powerful neural architectures [1,2,3,4,5]. However, monocular predictions inherently suffer from scale ambiguity and often become unreliable in low-texture or low-parallax regions where appearance cues provide insufficient geometric constraints [6].
Multi-view or multi-frame depth estimation, in contrast, grounds reconstruction on calibrated geometric relationships across views [7,8]. While this paradigm naturally alleviates scale ambiguity, its performance is strongly tied to photometric consistency. When the baseline is small, textures are weak, or repetitive patterns dominate the scene, feature correspondence becomes unstable, degrading the reliability of traditional cost-volume or plane-sweep matching. As a result, existing multi-frame pipelines struggle to maintain accurate and consistent depth in challenging real-world environments.
Despite recent efforts, three fundamental limitations persist in current multi-frame approaches. First, feature matching remains sensitive to the quality of photometric cues; small baselines or weak textures often cause ambiguous cost distributions even with multi-view aggregation [9,10]. Second, geometric consistency is typically enforced through local warping or single-plane evaluations, providing only limited global regularization and making predictions susceptible to noise. Third, although monocular depth priors contain rich structural information, prior works [11,12] generally incorporate them only as pseudo-labels or coarse regularizers, preventing these priors from influencing the core multi-view correspondence generation process.
To overcome these limitations, we propose MonoPrior-Fusion (MPF), a new multi-frame depth estimation framework that integrates pixel-wise monocular priors directly into multi-view matching. Unlike previous strategies that rely on monocular predictions only as auxiliary supervision or low-resolution initialization, MPF injects dense prior cues—depth, surface normals, and confidence—into the hypothesis space of the cost volume itself. This design enriches the matching evidence at a fine-grained level, enabling the network to disambiguate weak photometric cues and preserve structural details in low-texture or small-baseline scenarios.
Beyond prior-guided correspondence, MPF introduces a geometric consistency loss based on virtual planes that regularizes depth by enforcing agreement across a set of randomly sampled planes in 3D. This plane-level supervision complements local photometric and normal-based cues, providing stronger global geometric coherence than traditional warping-based constraints. To further enhance robustness across large depth ranges and complex indoor layouts, MPF employs a hierarchical fusion architecture across multiple scales that propagates geometric information from coarse global structure to fine spatial detail. Throughout the pipeline, MPF operates under known camera intrinsics and poses, following established practice in calibrated multi-view estimation.
Figure 1 illustrates the advantage of our approach: MPF preserves sharper geometry and cleaner depth boundaries compared to purely photometric methods. To summarize, the main contributions of this work are as follows:
- We propose MonoPrior-Fusion (MPF), a novel framework that integrates pixel-wise monocular priors directly into the multi-view matching process to address ambiguities in low-texture scenarios.
- We design a hierarchical fusion architecture across multiple scales that propagates geometric cues from coarse to fine resolutions, improving structural coherence.
- We introduce a geometric consistency loss based on virtual planes that enforces plane-level alignment in 3D space, providing stronger global regularization.
- Extensive experiments on ScanNetV2, 7Scenes, TUM RGB-D, and GMU Kitchens demonstrate that MPF outperforms state-of-the-art methods and exhibits superior zero-shot generalization.
The remainder of this paper is organized as follows: Section 2 reviews related work. Section 3 details the MPF framework. Section 4 presents experimental results and ablation studies. Finally, Section 5 concludes this paper.
2. Related Work
2.1. Monocular Depth Estimation and Prior-Based Guidance
Monocular depth estimation has advanced significantly with the emergence of deep CNN- and transformer-based architectures. Early supervised methods [15,16] introduced multi-scale prediction pipelines that progressively refined feature representations, leading to consistent improvements in metric depth accuracy. Self-supervised approaches, such as Monodepth2 [17] and view-synthesis-based frameworks [18,19], further demonstrated that enforcing photometric consistency across adjacent frames provides a powerful supervisory signal, enabling depth learning without reliance on ground-truth depth annotations. More recently, large-scale pretrained models—including MiDaS [20], Depth Anything V2 [21], ZoeDepth [22], UniDepth [23], and Metric3Dv2 [24]—have shown strong generalization across diverse imaging conditions and camera settings, alongside architectural refinements that improve multi-scale feature utilization [25].
Monocular priors have also been incorporated into multi-view or multi-frame systems. Existing methods typically use monocular predictions to initialize cost volumes [11], refine sparse depth [26], or serve as auxiliary supervision [12,27]. However, these priors are usually injected only at late stages—as pseudo-labels, global regularizers, or coarse initialization—and therefore do not participate in early correspondence formation [28]. Consequently, the matching process remains largely photometric and often fails in textureless or low-parallax regions. To address this limitation, MPF integrates pixel-level monocular cues directly into the depth-hypothesis space, enabling finer structural discrimination during matching.
2.2. Learning-Based Multi-View Stereo and Geometric Consistency
Classical learning-based multi-view stereo (MVS) methods reconstruct metric depth by enforcing geometric consistency across calibrated views. MVSNet [7] introduced differentiable plane sweeping and learned cost-volume regularization, inspiring subsequent works such as CasMVSNet [10], DPSNet [29], and hybrid PatchMatch-based pipelines. Video-based extensions, including DeepVideoMVS [9] and SimpleRecon [8], adapt MVS principles to sequential frames, improving efficiency through temporally aligned features and lightweight correlation modules. More recently, MVSAnywhere [30] has demonstrated the potential of zero-shot MVS by leveraging large-scale pretraining, though often at a higher computational cost.
Despite these advances, cost-volume aggregation still relies heavily on local photometric consistency, making MVS vulnerable to small baselines, motion blur, low-texture regions, and repetitive patterns. Moreover, most methods enforce geometric consistency through local warping or single-plane evaluation, limiting their ability to incorporate global geometric constraints. In contrast, MPF stabilizes correspondence by augmenting the hypothesis space with monocular structural cues and introduces a geometric consistency loss based on virtual planes to enhance global regularization beyond local photometric signals.
2.3. Feed-Forward Multi-View Reconstruction
Recent feed-forward 3D reconstruction models aim to recover geometry without explicit triangulation or depth sweeping. DUSt3R [31] and MASt3R [32] estimate dense point maps or 3D correspondences directly from image pairs, while transformer-based architectures such as VGGT [33] jointly infer depth, camera parameters, and feature tracks through large-scale pretraining. These methods demonstrate impressive generalization and robustness to unconstrained viewpoints.
However, feed-forward models typically recover geometry only up to an unknown global scale, depend strongly on learned priors rather than explicit geometric reasoning, and often require joint processing of multiple images, which can be computationally demanding. Such properties limit their applicability in robotics or SLAM pipelines where metric, calibrated, and lightweight inference is required. MPF operates in a complementary setting: by leveraging calibrated camera geometry while injecting pixel-level monocular priors, it achieves metric depth estimation with improved robustness in challenging visual conditions.
Table 1 provides a comprehensive taxonomy of current paradigms. While pure monocular methods offer dense priors, they lack metric grounding, and feed-forward models often recover geometry only up to an unknown scale. Conversely, traditional MVS relies heavily on photometric consistency, making it vulnerable to textureless regions. Unlike existing prior-based MVS frameworks such as MVSAnywhere [30] that incorporate monocular cues as late-stage initialization or postprocessing, MPF implements a pixel-wise early fusion. By directly modulating the cost-volume hypothesis space with monocular priors (Equations (2)–(4)), MPF disambiguates matches at the source, effectively unifying the complementary strengths of both geometric and monocular paradigms.
3. Method
This section presents MPF, a framework for geometric fusion from multiple sources that integrates multi-frame matching, pixel-level monocular priors, multi-scale geometric reasoning, and consistency checks based on virtual planes. Traditional learning-based MVS systems rely heavily on photometric consistency and therefore degrade on weak textures and repetitive patterns or in small-baseline scenarios. Conversely, monocular depth models provide sharp structural priors but lack geometric grounding and metric scale.
As summarized in the taxonomy of Table 1, MPF unifies the complementary strengths of these two paradigms by implementing a pixel-wise early-fusion strategy. This is achieved through the following: (i) A multi-frame backbone that preserves camera geometry; (ii) A prior-guided modulation of depth hypotheses at the earliest stage of matching; (iii) Fusion volumes across multiple scales that propagate geometric cues across resolutions; (iv) Global 3D regularization via virtual planes.
Together, these components enhance depth accuracy, robustness, and cross-domain generalization. Finally, the high-quality depth predictions produced by MPF serve as input to a volumetric fusion pipeline to enable dense 3D reconstruction. An overview of the entire MPF architecture is shown in Figure 2.
3.1. Multi-Frame Backbone
We adopt SimpleRecon (SR) [8] as the multi-frame matching backbone. SR aligns reference-frame features into the keyframe coordinate frame using known camera intrinsics and poses. For each depth hypothesis , the warped reference features are correlated with keyframe features to form a 4D cost volume:
where C denotes the feature channels, D the number of depth hypotheses, and the spatial resolution.
A shared lightweight per-pixel MLP aggregates depth-dependent matching evidence for each pixel and each hypothesis , producing a scalar matching score . MPF preserves the cost-volume construction of SR, including the geometric warping and the D discretized depth planes, while following a causal-view protocol to maintain geometric consistency.
3.2. Pixel-Wise Monocular Prior Fusion
Multi-view photometric matching becomes unreliable when texture or parallax is weak. To address this, MPF distinguishes itself from traditional late-fusion methods by incorporating pixel-wise monocular priors directly into the matching hypothesis space.
A pretrained Metric3Dv2 model [24] is applied to generate a monocular depth hint and a surface-normal map . Additionally, a lightweight “Confidencer” module produces a reliability score to downweight ambiguous monocular predictions. To achieve direct integration at the source of matching, we construct a 4-D hypothesis cue for each depth hypothesis by concatenating the matching score with monocular geometric features:
where measures the discrepancy between the prior and the hypothesis. A four-layer Fusion MLP then maps this 4-D cue to a scalar:
The final hypothesis response is obtained by a residual combination:
Mechanistically, this formulation enables the network to leverage monocular structure to disambiguate matching. The prior discrepancy term acts as a soft geometric gate, suppressing hypothesis peaks that contradict the monocular hint. By modulating the hypothesis space directly, MPF ensures a geometry-aware representation that filters out photometric noise in challenging environments.
3.3. Multi-Scale Fusion Volume
Indoor scenes often exhibit large depth variations, yet SR constructs its cost volume only at spatial resolution, limiting the available global context. MPF introduces a hierarchical architecture for fusion volumes (FVs) that aggregates geometric cues across three resolutions, as illustrated in Figure 3.
The high-resolution FV is initialized by combining the backbone matching features (Section 3.1) with the prior-fused hypothesis responses from Section 3.2. This FV is then downsampled to generate mid- and low-resolution FVs, while maintaining a consistent depth discretization ( hypotheses) across all scales. The three spatial resolutions,
capture fine-grained details, mid-level structural layout, and coarse global geometry.
At each scale, the FV is refined by a residual BasicBlock [34]. Let denote the FV at scale i and let be the corresponding encoder feature map at the same spatial resolution. Following the coarse-to-fine structure shown in Figure 3, the FV from the previous coarser scale is first upsampled and fused with the current FV and its encoder features:
where denotes a single BasicBlock, applies two consecutive BasicBlocks, ⊕ denotes channel-wise concatenation, and error denotes bilinear upsampling. At the finest scale, the coarse feature does not exist and the refinement reduces to
This hierarchical fusion allows coarse-scale structure to guide finer refinements while preserving sharp depth boundaries. By propagating geometric cues across resolutions, MPF improves both global consistency and fine-grained structural accuracy.
3.4. Geometric Regularization
MPF enhances geometric fidelity through two complementary constraints, which operate at different spatial scales to improve depth consistency.
3.4.1. Regularization Based on Surface Normals
Given a predicted depth map , we estimate local geometric slopes using Sobel filters ( ). The resulting depth gradients are mapped to a 3D vector under the pinhole model:
where setting follows the small-angle approximation [35]. This vector is then normalized to obtain the predicted unit surface normal:
Ground-truth normals are either provided by the dataset or computed from ground-truth depth using the same procedure. The surface-normal loss penalizes angular deviation via
where denotes the set of valid pixels.
3.4.2. Consistency Based on Virtual Planes
While enforces local smoothness, it remains sensitive to noise. To introduce a more global geometric constraint, we adapt virtual-normal supervision [35] to the multi-view depth setting by enforcing consistency over randomly sampled 3D planes.
For a pixel with depth , back-projection into 3D yields
where denotes the principal point. We sample non-degenerate triplets within the keyframe only to avoid pose-induced noise. Each triplet satisfies
Using ground-truth depth, each triplet defines a plane normal:
Applying the same construction to the predicted depth yields the estimated normal . The geometric consistency loss based on virtual planes is defined as follows:
Compared with purely local normal supervision, enforces geometric alignment over larger spatial regions by constraining entire planar surfaces in 3D. Crucially, this global constraint helps rectify scale ambiguities often present in monocular priors, ensuring that the fused depth map respects the structural layout of the scene while preserving sharp discontinuities.
3.5. Training Objective
MPF is trained using a combination of depth, gradient, multi-frame consistency, and geometric regularization losses. The overall objective follows the training protocol of SimpleRecon (SR) [8], while incorporating our proposed constraints derived from surface normals and virtual planes.
3.5.1. Baseline Losses
Following SR, we supervise the predicted depth map using three standard losses:
- Depth regression loss , implemented as an loss on inverse depth, identical to SR.
- Gradient loss , computed using first-order finite differences on depth to encourage edge alignment.
- Multi-view consistency loss , following SR’s formulation based on reprojection depth consistency between the reference views and the predicted keyframe depth.
These baseline terms encourage photometric and geometric agreement across the multi-frame backbone.
3.5.2. Proposed Geometric Losses
The surface-normal loss (Section 3.4) provides local geometric refinement and improves high-frequency details. The consistency loss based on virtual planes enforces global geometric alignment by encouraging predicted 3D points to agree with ground-truth planar structures.
Together, and provide complementary local and global geometric constraints.
3.5.3. Total Loss
The full training objective is
where we follow SR and set and . The weight for the loss based on virtual planes is . All losses are computed only at the final output resolution and normalized by the number of valid pixels.
This combination jointly supervises fine-scale local geometry, cross-view photometric reasoning, and global structural consistency, consistent with the design for geometric fusion from multiple sources of MPF.
3.6. Implementation Details
We follow the causal-view training protocol of SR [8], where each keyframe aggregates seven preceding reference frames sampled with stride 1. MPF is trained for 20 epochs using AdamW with an initial learning rate of . All remaining optimization and hardware configurations—including batch sizes, learning rate scheduling, and memory management strategies—are provided in Appendix A. A detailed analysis of computational efficiency (runtime and memory) is presented in Section 4.5.
4. Experiments
This section evaluates MPF on large-scale indoor RGB-D datasets, examining depth accuracy, cross-domain generalization, ablation behaviors, 3D reconstruction quality, and computational efficiency. To maintain clarity, complete metric definitions, extended qualitative comparisons, and additional tables are provided in the Appendix B.
4.1. Datasets and Evaluation Protocol
MPF is trained exclusively on ScanNetV2 [13] and evaluated in a strictly zero-shot manner on 7Scenes [36], TUM RGB-D [37], and GMU Kitchens [38]. These datasets exhibit diverse challenges, including low texture, repetitive indoor patterns, motion blur, strong lighting variation, and high-resolution imagery. Dataset statistics are summarized in Table 2.
We report the standard depth metrics AbsRel, AbsDiff, SqRel, and -accuracy thresholds. Full definitions are available in Appendix B. Invalid or missing ground-truth depth pixels are masked out following common RGB-D evaluation protocols.
We compare MPF against representative multi-view and multi-frame methods: DPN [29], DELTAS [39], GPMVS [40], DVMS [9], SimpleRecon (SR) [8], DoubleTake (DT) [14], and MVSA [30]. This selection covers both established baselines and the most recent state-of-the-art approaches.
4.2. Results on ScanNetV2 (Seen Domain)
Table 3 summarizes the quantitative evaluation on the ScanNetV2 test set. MPF achieves state-of-the-art performance, outperforming both the strong baseline SimpleRecon (ECCV 2022) and the recent DoubleTake (ECCV 2024). Specifically, compared to SimpleRecon, MPF reduces AbsRel by 11% and SqRel by approximately 35%. This significant improvement validates that our proposed prior-guided modulation effectively disambiguates cost volumes in regions where photometric consistency alone fails (e.g., white walls and reflective floors), preventing the “oversmoothing” artifacts common in traditional multi-frame methods. Qualitative comparisons in Figure 4 further confirm that MPF recovers sharper object contours and thinner structures.
4.3. Zero-Shot Generalization to 7Scenes, TUM, and GMU
To evaluate robustness, we test models trained on ScanNetV2 directly on unseen datasets without fine-tuning.
7Scenes. As shown in Table 4 (left), MPF achieves the best performance across all metrics on 7Scenes. Since 7Scenes contains extremely low texture and repetitive patterns (e.g., stairs and cabinets), purely photometric methods like SR and DT struggle to find reliable correspondence. By leveraging monocular structural priors, MPF effectively rectifies these ambiguities, preserving planar structures and depth discontinuities even in textureless regions.
TUM RGB-D. Results on the large-scale TUM dataset are shown in Table 4 (right). It is worth noting that MVSA [30] achieves high -accuracy ( ) due to its large-scale pretraining, which learns robust relative depth. However, MVSA suffers from scale ambiguity in zero-shot transfer, resulting in higher absolute errors (AbsDiff). In contrast, MPF delivers superior metric accuracy (lowest AbsDiff and AbsRel), demonstrating that our framework successfully grounds monocular cues with multi-view geometry to maintain precise metric scale.
GMU Kitchens. GMU presents extreme challenges with dramatic lighting variation and reflective surfaces. As shown in Table 5, classical baselines exhibit catastrophic failure modes (high AbsDiff > 0.27) due to unreliable photometric cues. In contrast, MPF maintains stable performance (AbsDiff ≈ 0.09), substantially outperforming all baselines. Note that we report only stable multi-frame results; MVSA produced unstable predictions on this dataset due to the severe domain shift and sensor noise and is thus excluded from this specific comparison (raw outputs provided in Appendix B). Qualitative visualizations in Figure 5 show that MPF produces clean depth on strongly lit surfaces where other methods exhibit noisy or fragmented geometry.
4.4. Ablation and Component Analysis
Ablation experiments are performed on the 7Scenes dataset using a 40% randomly sampled subset of the ScanNetV2 training data. This reduced subset accelerates experimentation while maintaining a representative distribution of indoor scenes.
4.4.1. Component Effectiveness
Table 6 summarizes the effect of progressively adding each MPF component. The baseline configuration (MPF-base w/o F,M,V) preserves only the multi-frame matching backbone. Given that the baseline is architecturally equivalent to SR, the qualitative comparisons in Figure 4 and Figure 5 serve as a direct visual ablation, demonstrating the cumulative geometric gains achieved by our proposed prior-guided fusion and consistency constraints over the pure photometric baseline.
As shown in Table 6, the baseline exhibits the lowest accuracy (AbsRel 0.0630), reflecting the inherent limitations of purely photometric correspondence. Incorporating the fusion module (w/F) integrates monocular priors directly into the cost volume, which noticeably improves depth hypothesis discrimination. Adding the hierarchical fusion volume (w/F,M) further strengthens geometric reasoning by enabling coarse-to-fine feature aggregation. Finally, the full model (w/F,M,V) achieves the highest accuracy, demonstrating that the geometric consistency loss based on virtual planes provides complementary global geometric constraints. Visually, this corresponds to the recovery of sharp planar structures and fine edges in MPF compared to the oversmoothed baseline results (SR) in Figure 4.
4.4.2. Cost-Volume Discriminability
To verify that our method improves the quality of the matching distribution itself (and not just the final regression), Table 7 evaluates Rank Percentile (RP), Depth Margin (DM), and Quadfit MAE (Q-MAE) before and after applying the Fusion Network. Remarkably, the fusion module reduces the Rank Percentile error by over at the resolution (0.354 → 0.051). This provides direct quantitative evidence of how our pixel-wise early fusion manifests in practice: by modulating the hypothesis space at the source (as described in Section 3.2), MPF effectively “sharpens” the probability distribution around the true depth. This structural improvement enables the network to recover correct geometry even when photometric signals are ambiguous, which is a direct consequence of our proposed direct integration strategy.
4.5. Depth Reconstruction and Runtime Analysis
We integrate predicted depths into a volumetric fusion pipeline following TransformerFusion [41]. As shown in Table 8, MPF achieves the lowest geometric error and highest precision. Figure 6 illustrates that MPF reconstructs smoother planar surfaces, cleaner object boundaries, and finer geometric structures than SR, confirming the benefit of more accurate depth inputs for downstream 3D reconstruction.
Computational Efficiency
MPF processes each keyframe in 0.172 s on NVIDIA GeForce RTX 4090 GPU (NVIDIA Corporation, Santa Clara, CA, USA), of which 0.047 s is spent on the frozen monocular prior and 0.114 s on cost-volume construction and fusion. Peak memory consumption is 6.4 GB. With a 10:1 keyframe compression ratio, MPF achieves throughput compatible with real-time multi-frame pipelines.
4.6. Limitations and Discussion
While monocular priors significantly improve geometric detail, they introduce additional inference cost (approx. 47 ms) and may be sensitive to strong domain shifts where the pretrained prior fails. MPF also assumes known intrinsics and poses. Recent pose-free frameworks [32,33] suggest promising directions for removing this requirement. Future work will explore more efficient prior integration and pose-free multi-view depth estimation.
5. Conclusions
We presented MonoPrior-Fusion (MPF), a multi-frame depth estimation framework that combines monocular priors with multi-view geometric reasoning. A fusion module across multiple scales and a geometric consistency loss based on virtual planes were introduced to address textureless regions, small baselines, and challenging indoor conditions. Extensive experiments demonstrate that MPF achieves strong accuracy, robustness, and practical runtime efficiency across multiple benchmarks. These results highlight MPF’s potential for deployment in real-world 3D perception, reconstruction, and embodied AI systems. Future work will extend MPF to outdoor and dynamic environments and investigate integration with large-scale pretrained vision models.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Laina I. Rupprecht C. Belagiannis V. Tombari F. Navab N. Deeper Depth Prediction with Fully Convolutional Residual Networks Proceedings of the International Conference on 3D Vision (3DV)Stanford, CA, USA 25–28 October 2016
- 2Fu H. Gong M. Wang C. Batmanghelich K. Tao D. Deep Ordinal Regression Network for Monocular Depth Estimation Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)Salt Lake City, UT, USA 18–23 June 201810.1109/CVPR.2018.00214 PMC 660790031274971 · doi ↗ · pubmed ↗
- 3Yang L. Kang B. Huang Z. Xu X. Feng J. Zhao H. Depth Anything: Unleashing the Power of Large-Scale Unlabeled Data Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)Seattle, WA, USA 17–21 June 2024
- 4Bochkovskii A. Delaunoy A. Germain H. Santos M. Zhou Y. Richter S.R. Koltun V. Depth Pro: Sharp Monocular Metric Depth in Less Than a Second Proceedings of the International Conference on Learning Representations (ICLR)Singapore 24–28 April 2025
- 5Hemmati E. Jarahizadeh S. Aghabalaei A. Asadollah S.B.H.S. Enhanced Monocular Depth Estimation Using Novel Scale-Invariant Error Structure Similarity Index Measure Optimization in Convolutional Neural Network Architecture J. Vis. Commun. Image Represent.20259810405210.1016/j.jvcir.2025.104531 · doi ↗
- 6Chen S. Guo H. Zhu S. Zhang F. Huang Z. Feng J. Kang B. Video Depth Anything: Consistent Depth Estimation for Super-Long Videos Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)Nashville, TN, USA 11–15 June 2025
- 7Yao Y. Luo Z. Li S. Fang T. Quan L. MVS Net: Depth Inference for Unstructured Multi-View Stereo Proceedings of the European Conference on Computer Vision (ECCV)Munich, Germany 8–14 September 2018
- 8Sayed M. Gibson J. Watson J. Prisacariu V. Firman M. Godard C. Simple Recon: 3D Reconstruction without 3D Convolutions Proceedings of the European Conference on Computer Vision (ECCV)Tel Aviv, Israel 23–27 October 2022