StaticPigDetv2: Performance Improvement of Unseen Pig Monitoring Environment Using Depth-Based Background and Facility Information
Seungwook Son, Munki Park, Sejun Lee, Jongwoong Seo, Seunghyun Yu, Daihee Park, Yongwha Chung

TL;DR
This paper introduces a new method for pig detection in monitoring environments that improves accuracy and reduces processing time by using background and facility information.
Contribution
The novel approach uses static background and infrastructure data to enhance detection accuracy and efficiency without retraining models.
Findings
The proposed method improves AP50 accuracy from 75% to 86% on the unseen Korean Hadong pig dataset.
Jetson Orin Nano latency is reduced from 67 ms to 41 ms using the proposed method compared to the baseline YOLOV12m model.
Abstract
The three graphs present overall performance improvements in accuracy and latency across different YOLO models. The red lines indicate the baseline models, while the blue lines indicate the proposed models. The black lines represent the performance changes for each model, highlighting the improvement from the baseline to the proposed method. What are the main findings? What is the implication of the main finding? With YOLOv8, YOLOv10, and YOLOv12 nano models, the proposed method improves the baseline accuracy, while slightly increasing the execution time due to the fixed preprocessing operations, by exploiting the background and facility information.With YOLOv8, YOLOv10, and YOLOv12 small, medium, and large models, however, the proposed method improves both the baseline accuracy and execution time because the portion of the fixed preprocessing operations is relatively decreased with…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
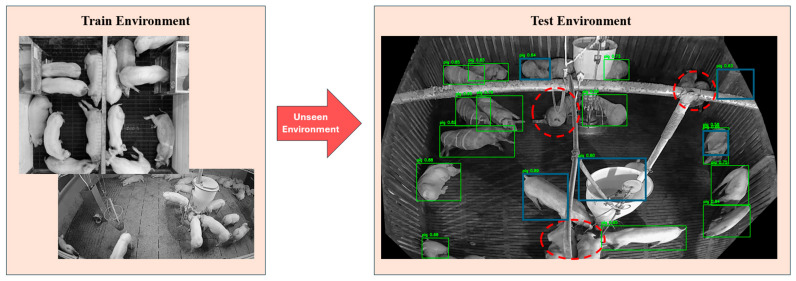 Figure 1
Figure 1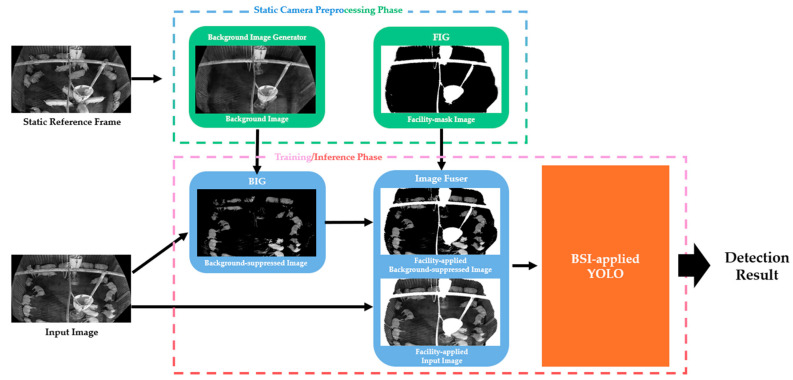 Figure 2
Figure 2 Figure 3
Figure 3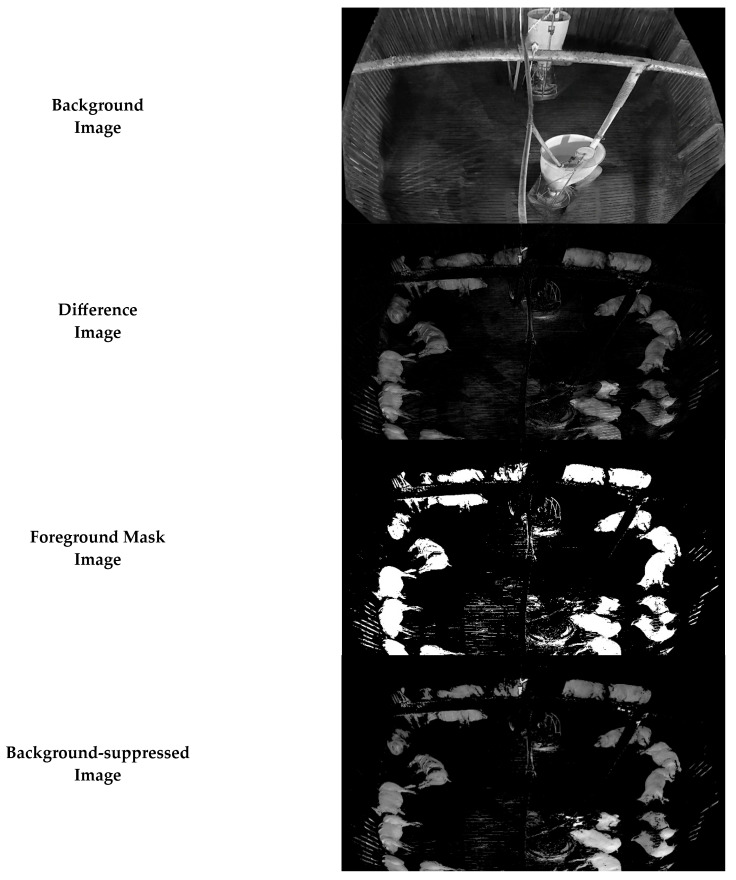 Figure 4
Figure 4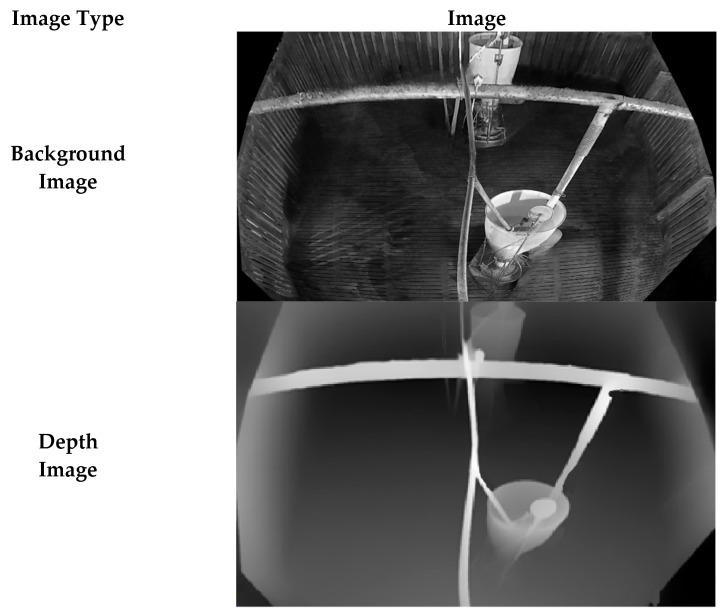 Figure 5
Figure 5 Figure 6
Figure 6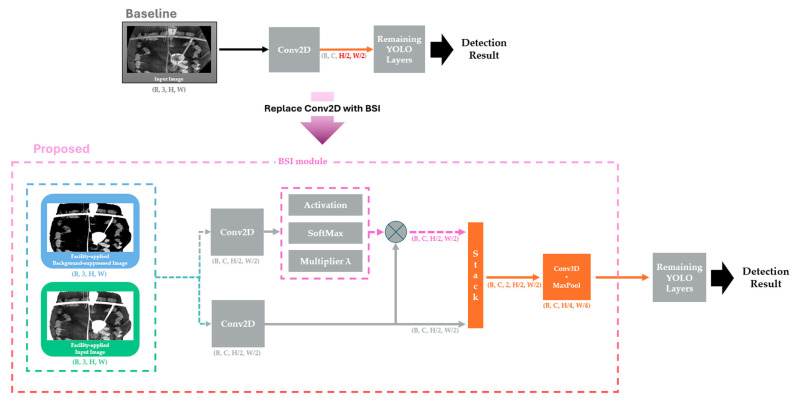 Figure 7
Figure 7 Figure 8
Figure 8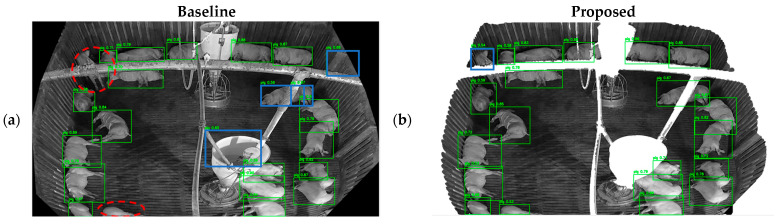 Figure 9
Figure 9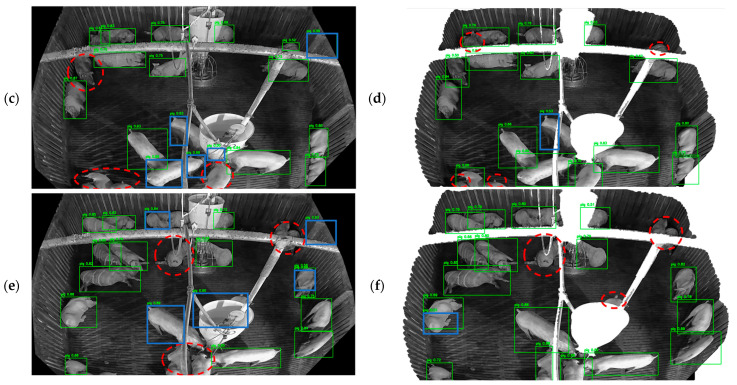 Figure 10
Figure 10 Figure 11
Figure 11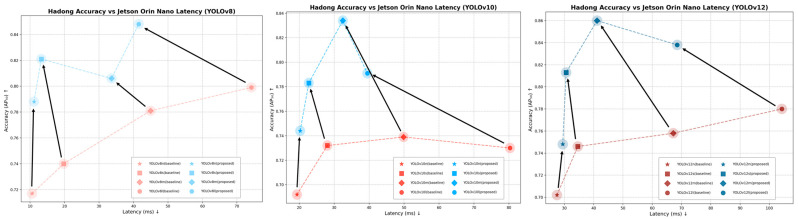 Figure 12
Figure 12- —Ministry of Agriculture, Food and Rural Affairs
- —Ministry of Agriculture, Food and Rural Affairs
- —Ministry of Science and ICT
- —Rural Development Administration
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAnimal Behavior and Welfare Studies · Advanced Neural Network Applications · Food Supply Chain Traceability
1. Introduction
Pork consumption is projected to grow at an average annual rate of approximately 1.2% over 2018–2027 [1]. As production scales, management that relies solely on human labor faces inherent limitations in cost, consistency, and coverage, which motivates automated pig monitoring systems [2,3,4]. Computer vision has therefore been widely adopted for monitoring tasks such as pig detection, counting, tracking, posture recognition, and behavior analysis in commercial barns [5,6,7,8,9]. By training object detectors to localize pigs in images, the positions of pigs can be estimated and subsequently used as inputs for downstream management functions within each pen (e.g., counting, tracking, and activity analysis) [10,11,12,13,14,15,16].
Despite recent progress, deep learning-based detectors often perform well only when the deployment environment is similar to the training environment, where the model has already learned the visual patterns of that specific scene which is “Seen Environment”. When the trained model is deployed in an environment with different backgrounds, facility structures, occlusions, illumination, or camera viewpoints not included in training dataset, performance can degrade substantially due to domain shift [17,18], which is “Unseen Environment”. Reducing the gap between seen and unseen environments is therefore crucial for achieving stable and reliable pig detection in practical monitoring systems.
Figure 1 illustrates typical failure cases in a commercial pig pen environment. The detector is trained using images collected from a different barn with different flooring, facility occlusions, and viewpoints, and the test environment is unseen during training. This domain discrepancy produces diverse detection errors, including missed detections under pipe occlusion and false positives in which facility components (e.g., walls) are misclassified as pigs. In pig production facilities, such domain shift is particularly critical because farm layouts, facility designs, and lighting conditions vary considerably, and pigs are frequently occluded by fences, feeders, and other equipment [19]. Conventional detectors may inadvertently learn spurious correlations between pig appearance and environment-specific background cues, which can lead to overfitting to a particular facility and poor generalization to new barns or camera viewpoints. Consequently, detectors that are accurate in the training environment can still miss pigs or produce unstable outputs in unseen facilities [17,18].
For continuous 24/7 monitoring in commercial barns, pig detection models must operate in real time on cost-effective embedded hardware, where computational resources and power budgets are limited [14,16]. Accordingly, we adopt YOLO-based detectors as a baseline due to their favorable accuracy–latency trade-off and practical deployment maturity for real-time applications [20]. However, because the structural layout and background of each pig pen differ substantially, conventional models often experience a sharp drop in accuracy in unseen environments [17,18]. While domain adaptation and self-training can mitigate this issue, they typically require additional environment-specific tuning or training procedures for each new target facility [18]. Unlike conventional domain adaptation or domain generalization methods that enforce domain-invariant representations through additional training objectives, this study adopts a deployment-driven generalization strategy by explicitly removing domain-specific nuisance factors at the input and feature fusion stages.
In this study, we propose StaticPigDetv2, a pig detection framework designed to reduce the gap between seen and unseen environments by explicitly modeling background and facility information [21]. StaticPigDetv2 introduces three modules: Background-suppressed Image Generator (BIG), Facility Image Generator (FIG), and Background Suppression Integration (BSI). BIG uses depth-based background estimation together with Depth Anything V2 [22] and Inpaint Anything [23] to generate background-suppressed images that emphasize foreground pig cues while suppressing environment-specific details. FIG models facility structures so that pigs occluded by equipment can still be inferred using contextual information from the surrounding scene. Finally, BSI fuses the complementary representations acquired from BIG and FIG to train the detector with explicit foreground and facility cues, thereby encouraging robust detection under facility occlusion and across diverse barn environments.
We use an inference-time input preprocessing strategy that improves both accuracy and latency by leveraging recent Transformer-based vision models—Depth Anything V2 [22] and Inpaint Anything [23]—to extract background and infrastructure information from the monitored pig pen. Although Transformer-based models are usually computationally demanding, we consider a deployment scenario in which they are executed only once during the initial static-view camera installation. The static information obtained from this one-time execution is then reused to enhance detection robustness during real-time inference, without imposing additional computational burdens on the embedded detection pipeline.
The remainder of this paper is organized as follows. Section 2 reviews related work; Section 3 describes StaticPigDetv2 and the BIG, FIG, and BSI modules; Section 4 presents experimental results; and Section 5 concludes the paper and suggests directions for future work.
The contributions are as follows:
- We propose a method that extracts background and facility information without additional training per unseen environment as additional training for each seen environment is not practical.
- We propose a feature fusion method that utilizes 3D convolution to effectively fuse the extracted information, improving both detection accuracy and latency. The overall performance gains observed across multiple YOLO models demonstrate the effectiveness of the proposed approach.
2. Related Works
The primary objective of this study is to address the performance degradation that occurs when deep learning-based detectors are deployed in unseen pig farm environments. Research has evolved from automated counting [10] and part detection [24] to sophisticated posture analysis [25,26,27,28,29,30,31,32]. While these advancements are significant, a persistent challenge remains achieving high detection accuracy while maintaining the low latency required for commercial viability [14,33]. Current state-of-the-art architectures, such as YOLOv10 [34] and YOLOv12 [35], offer impressive real-time performance but still struggle with the domain shift caused by varying farm layouts and facilities [17,36].
In large-scale smart farming, system latency is a critical constraint [14,33]. Monitoring is typically conducted via overhead surveillance streams [12,37], requiring lightweight models [38,39] or ensemble-based post-processing [40] to ensure reliable results on embedded boards [14,16]. To provide long-term data, tracking algorithms [12,13,15,16,41] follow individual pigs to detect health anomalies [42,43]. Recent trends emphasize the use of spatiotemporal information and graph convolutional networks to analyze complex social behaviors and feeding patterns [44,45,46].
Recent years have seen a transition toward more granular detection. Center clustering networks [36] and PDC-YOLO [47] have been developed to handle heavy occlusion in counting tasks. Furthermore, 3D point cloud segmentation [48] and dual-attention feature pyramid networks [49] have improved instance segmentation in crowded group-housed pens. Posture recognition now extends beyond basic lying or standing [8,25] to include engagement with enrichment objects [50], drinking behavior [29], and interaction recognition [51]. Systems like DigiPig [52] and hybrid YOLO-EfficientNet workflows [53] allow for 24/7 monitoring of physico-temporal activities [54].
Environmental challenges, such as dust-induced blur, often necessitate specialized denoising [19]. While traditionally used for motion detection via difference-imaging [15], background data also helps identify static pen facilities. Distinguishing subjects from infrastructure is essential for detecting specific targets like sows [55] or pig faces [56]. Our proposed Background-suppressed Image Generator (BIG) and Facility Image Generator (FIG) formalize this by utilizing one-time preprocessing to filter static noise.
Standard detectors frequently fail in unseen environments due to shifts in flooring, lighting, and internal facilities [17,36]. While systems may perform well in specific zones like hallways [16], environmental distribution shifts between training and deployment sites often lead to failure [39,43]. Recent research has explored self-training with augmented target dataset to mitigate this domain shift [18]. However, applying heavy foundation models like Depth Anything V2 [22] or Inpaint Anything [23] is often impractical for real-time monitoring due to computational limits. This necessitates efficient fusion methods, such as our Background Suppression Integration (BSI), which bridges the domain gap without requiring model retraining.
The works that are similar to the proposed works are StaticPigDet [21] and DOG [17]. In StaticPigDet [21], background and facility information were exploited to improve detection accuracy, particularly for pig objects occluded by facilities. However, StaticPigDet [21] still has several limitations related to unseen environments and reliance on surveillance video. Its experiments were conducted on datasets collected from a single environment, which may reduce detection accuracy under unseen conditions such as different flooring, lighting, or new facility structures. In addition, the background and facility images require long surveillance videos captured by static cameras, which may not be available for all farms.
In DOG [17], pig object detection was improved in unseen pig farm environments. By leveraging foundation models [22,23], foreground and background information were extracted to identify regions of interest (RoIs) [50], and this information was used as an additional input to improve object detection accuracy. However, this approach does not explicitly consider pigs occluded by facilities, which is a frequent scenario. Also, accuracy was only increased, but process speed decreased due to preprocessing.
While several studies consider unseen environments and some make use of background images; to the best of our knowledge, no prior work jointly addresses both factors. Recent studies that address unseen environments and utilize background images are summarized in Table 1.
3. Proposed Method
Differences in the object detection environment under unseen conditions lead to detection errors, because the new environment is not represented in the training dataset. To mitigate this issue, this study proposes a method that addresses accuracy degradation caused by environmental differences using image processing techniques. We propose BIG, FIG, and BSI modules to utilize foreground, background, and facility information, respectively. Background image and facility information is created once per static environment, thus naming it the Static Camera Preprocessing Phase. The spatial locations of each type of information are used to differentiate the various components of the image and to fuse them accordingly. The overview structure of the proposed method is as shown as Figure 2.
First, a background image and facility image are created from a static reference frame using Background Image Generator and FIG during the Static Camera Preprocessing Phase. Then, background-suppressed image is created by using the input image and generated background image. Then, facility mask information acquired from FIG is applied to both the input image and the background-suppressed image to create facility-applied background-suppressed image and facility-applied input image. Finally, BSI-applied YOLO is trained and inferenced using two inputs: facility-applied background-suppressed image and facility-applied input image.
3.1. Background-Suppressed Image Generator
In unseen environments, background regions that are absent during the training phase often cause detection errors because they are not represented in the training dataset. The proposed BIG module generates foreground-emphasized images in which the background is suppressed, allowing the network to focus on foreground features during training. Each step of this generation process is illustrated in Figure 3.
First, in the Background Image Generator during the Static Camera Preprocessing Phase, Inpaint Anything [23] is applied to a static reference frame to remove the detected pig foreground and to synthesize an appropriate background. The process is executed once per static environment rather than for every input image as this procedure is performed during the Static Camera Preprocessing Phase. Next, the generated background image is subtracted from the input image to produce a difference image, and the absolute value function is applied to ensure non-negative pixel values. In this difference image, pixels corresponding to background regions have values close to zero, whereas pixels at foreground locations have higher values. Otsu’s thresholding is then applied to the difference image to generate a foreground mask, in which pixels with higher values (foreground pixels) are labeled as foreground (e.g., value = 255) and near-zero pixels (background pixels) are labeled as background. Finally, background-suppressed images are created by applying the foreground mask to the input image: pixel values at foreground locations (mask value ≥ 128) are preserved to maintain the original texture of the pig objects, while pixel locations identified as background (mask value < 128) are set to 0. The overall process is summarized in Algorithm 1. Algorithm 1. Background-suppressed Image GeneratorInput: Output: Background-suppressed Image If > 128 then Else
3.2. Facility-Mask Image Generator
Many detection errors arise when pig objects are partially or fully occluded by facilities in the pig farm. A key issue is that the heterogeneous visual characteristics of these facilities, when blocking pigs, lead to missed detections. Therefore, if facility locations can be identified, this information can be leveraged to improve detection accuracy. Each step of the FIG process is illustrated in Figure 4.
First, during the Static Camera Preprocessing Phase, Depth Anything [22] is used to generate a depth image, , from the background image, , where pixel values represent distance from the camera, thereby making facility structures more distinguishable. Higher pixel values indicate regions closer to the camera, whereas lower values correspond to regions closer to the pen background. Next, Otsu’s thresholding is applied to to generate a facility mask image, , which separates regions at different depth levels and enables more precise identification of facility areas. In , pixels with values greater than 128 are treated as foreground and set to 255, whereas the remaining pixels are set to 0.
Finally, in the Image Fuser, the identified facility regions are assigned a pixel value of 255 in both the input image and the background-suppressed image so that they are visually masked and facility textures are equalized. Because this procedure is performed during the Static Camera Preprocessing Phase, it is executed once per static environment rather than for every input image. (Algorithm 2). Algorithm 2. Facility-mask Image GeneratorInput: Image: Background Image Output: Facility-mask Image If > 128 then
Else
3.3. Background Suppression Integration
Figure 5 presents an overview of BSI architecture. To fully exploit the background-suppressed image, we extend the baseline single-input detector to a dual-input architecture. The model takes two image tensors as input, each with shape , where , , and denote the batch size, height, and width, respectively. These two inputs capture different aspects of the scene, enabling the network to learn complementary representations from the facility-applied background-suppressed image and the facility-applied raw input image.
Each input is first processed by a 2D convolution layer with stride 2, reducing the spatial resolution by half and producing two feature maps of shape , where is the number of channels. For the background-suppressed branch, an activation function followed by a SoftMax operation is applied to obtain an attention-like feature map. This feature map is then scaled by a multiplier to increase its influence during fusion. The scaled map is used to guide feature selection by modulating the feature map from the input-image branch through element-wise multiplication, thereby emphasizing informative regions and attenuating irrelevant ones.
To further enhance feature interactions, we incorporate a 3D convolution layer to fuse the two feature maps more effectively. Specifically, the two 4D feature maps are stacked along a new depth dimension to form a 5D tensor , which is then passed to a 3D convolution layer whose channel size matches that of the preceding 2D convolution in BSI. This operation produces a fused representation with an additional depth dimension. The output is subsequently reduced back to a standard 4D feature map using max pooling, preserving the fused information for downstream 2D convolution layers. In BSI, stride 2 is applied in the spatial dimensions to mitigate the computational overhead introduced by the 3D convolution while retaining the combined information from both input streams.
4. Experimental Results
The study was conducted on an Intel Core i7-7700K @ 4.20 GHz processor (Intel Corporation, Santa Clara, CA, USA) and a GeForce RTX 3060 GPU (NVIDIA Corporation, Santa Clara, CA, USA). The operating system was Ubuntu 22.04 LTS (Canonical Ltd., London, UK), and the deep learning models were implemented in PyTorch 2.0.1 (Meta Platforms, Inc., Menlo Park, CA, USA) with CUDA 11.7 (NVIDIA Corporation, Santa Clara, CA, USA). For embedded-board evaluation, inference latency were additionally measured on an NVIDIA Jetson Orin Nano Developer Kit (NVIDIA Corporation, Santa Clara, CA, USA) running JetPack 6.2 (Linux for Tegra, Ubuntu-based). The same trained weights were deployed to the Jetson device, and all runtime measurements were collected with batch size 1 after an initial warmup.
Figure 6 shows the example of each pig dataset. The training dataset was taken from the German pig dataset [27], using 788 images for training, named “German”. The main experiments were conducted on a test dataset collected from a pig pen, located in Hadong-gun, Gyeongsangnam-do, Korea, which contained 200 images, named “Hadong”. The Hadong dataset was used as characteristics of large feeding facility and ceiling pipes occlusion as well as a camera deployed at 45 degrees tilted-view. Additional ablation studies to show robustness for unseen environment was conducted in a pig pen located in Jochiwon-eup, Sejong-si, Korea with total of 210 images, named “Jochiwon”. To collect this dataset, a camera was deployed on the ceiling of the Jochiwon pig pen, approximately 3 m above the floor showing top-view. The Jochiwon dataset has characteristics where many pigs tend to occlude one another in a group; thus, multiple pigs are detected as one pig. In terms of labels, only pigs that show more than a 20% visible region were labeled in both the training and test datasets. A perspective transformation image processing technique was applied to regularize the size of pig objects for the training and test dataset.
All models were trained with an input resolution of 640 × 640 for 100 epochs, and a fixed batch size of 8 and SiLU was used for activation function. For all YOLOv8/10/12 variants, BSI replaced the first convolution layer in the backbone, keeping the remainder of the architecture unchanged. The detector architectures used for training and testing were YOLOv8 [20], YOLOv10 [34], and YOLOv12 [35], and for each model, the n, s, m, and l variants were evaluated. We used the default training setting regarding optimizer, initial learning rate, learning rate schedule, weight decay, momentum, and warmup of the official YOLOv8/10/12 implementations.
We evaluated all models using Precision, Recall, AP_50_, and F1-Score, and report inference latency in ms measured on the RTX 3060 and Jetson Orin Nano with batch size 1. Specifically, AP_50_ denotes the average precision at an IoU threshold of 0.5, where IoU is defined as Equation (1).
In Equation (1), is the predicted bounding box, is the ground-truth bounding box, is the intersection area between and , and is the union area between and . A detection is considered a true positive when with the correct class (one-to-one matching). Precision and Recall are computed as and , where is the number of true positives, is the number of false positives, and is the number of false negatives.
AP_50_ is computed as the area under the precision–recall curve at IoU = 0.5, which is given in Equation (2).
In Equation (2), denotes precision as a function of recall , is the recall level, is the recall value at the -th operating point (threshold), and is the interpolated precision at recall (commonly defined as the maximum precision obtained for any recall ). The summation form is a discrete approximation of the integral using sampled points on the precision–recall curve.
Computational complexity is reported as GFLOPs, defined as the total number of floating-point operations for a single forward pass divided by (counting one multiply–accumulate as two operations). For a standard convolution layer, FLOPs are computed as Equation (3).
In Equation (3), and are the output feature map height and width, is the number of output channels, is the number of input channels, is the number of groups in grouped convolution (with for standard convolution), and and are the kernel height and width, respectively. The factor 2 accounts for one multiplication and one addition per multiply–accumulate operation. The network GFLOPs is obtained by summing FLOPs across all layers and normalizing by , as shown in Equation (4) where denotes the FLOPs of the -th layer in the model.
Table 2 compares the baseline and StaticPigDetv2 across YOLOv8/10/12 (n/s/m/l) in the unseen Hadong pig pen test set. StaticPigDetv2 improves AP_50_ and F1-Score for all variants, with gains typically driven by higher recall (fewer missed pigs). For example, YOLOv12m increases Precision/Recall/AP_50_/F1-Score from 0.767/0.696/0.758/0.730 (baseline) to 0.883/0.792/0.860/0.835 (proposed), corresponding to +0.116 Precision, +0.096 Recall, +0.102 AP_50_, and +0.105 F1-Score. Similarly, YOLOv8s improves AP_50_ from 0.740 to 0.821 and F1-Score from 0.715 to 0.808, while YOLOv10m improves AP_50_ from 0.739 to 0.834 and F1-Score from 0.710 to 0.803. Although a few cases show small precision drops (e.g., YOLOv12n: 0.824 to 0.796; YOLOv10l: 0.839 to 0.812), recall increases substantially in these models (YOLOv12n: 0.620 to 0.704; YOLOv10l: 0.630 to 0.742), which still yields higher AP_50_ and F1-Score. Overall, the results suggest that combining background-suppressed cues (BIG), facility masking (FIG), and dual-stream fusion (BSI/BIM) is especially effective at recovering pigs under occlusion and in visually novel pen layouts.
Table 3 reports detection accuracy (AP50, consistent with Table 2) together with computational cost (GFLOPs) and runtime performance (latency) measured on an RTX 3060 GPU and the embedded Jetson Orin Nano board. Although the proposed method requires additional time to generate the background-suppressed image, this step is lightweight, adding less than 0.01 ms of latency. In addition, the background image and facility mask are generated once per static test environment and are therefore excluded from the per-image latency measurement.
For the medium and large variants, StaticPigDetv2 improves both accuracy and latency. For example, YOLOv12m increases AP_50_ from 0.758 to 0.860 while reducing GFLOPs from 33.90 to 9.20 and latency from 18.48 ms to 9.18 ms on the RTX 3060; on the Jetson Orin Nano, latency decreases from 67.18 ms to 41.14 ms. Similarly, YOLOv8l increases AP_50_ from 0.799 to 0.848 while reducing latency from 24.34 ms to 10.31 ms on the RTX 3060 and from 74.20 ms to 41.51 ms on the Jetson Orin Nano.
The computational reduction mainly stems from the modified first-stage design in BSI, which applies stride-2 downsampling earlier. As illustrated in Figure 5, this reduces the spatial resolution entering later stages and yields substantial GFLOPs reductions across all model sizes (e.g., YOLOv8m: 39.50 to 10.40 GFLOPs; YOLOv10l: 63.60 to 16.60 GFLOPs; YOLOv12l: 44.70 to 11.90 GFLOPs). Because most backbone and neck layers subsequently operate on smaller feature maps, the proposed models typically achieve lower latency despite the additional dual-input fusion layers.
In contrast, the nano variants exhibit a small runtime regression because their baseline backbones are already highly lightweight, making the fixed overhead of the added fusion layers relatively more pronounced. This leads to reduced GFLOPs but slightly increased latency. For instance, YOLOv8n reduces GFLOPs from 4.1 to 1.2 while latency increases from 4.03 ms to 4.59 ms on the RTX 3060 and from 10.56 ms to 11.13 ms on the Jetson Orin Nano. Similarly, YOLOv10n reduces GFLOPs from 4.2 to 1.3 while latency increases from 4.87 ms to 5.35 ms on the RTX 3060 and from 19.36 ms to 20.27 ms on the Jetson Orin Nano. YOLOv12n reduces GFLOPs from 3.2 to 1.0 while latency increases from 7.90 ms to 8.42 ms on the RTX 3060 and from 27.45 ms to 29.42 ms on the Jetson Orin Nano. Nevertheless, these nano models still achieve AP_50_ gains (e.g., YOLOv8n: 0.717 to 0.788), suggesting that StaticPigDetv2 remains beneficial when deployment constraints favor smaller detectors.
Experiments evaluating the effect of applying facility masks generated by FIG to the input images are summarized in Table 4. In both configurations, the detector uses the background-suppressed images produced by BIG and the 3D convolution-based feature fusion of BSI; the only difference is whether the facility mask is applied to the inputs.
Applying the facility mask yields higher AP_50_ and F1-Score for most models. The AP_50_ improvement ranges from approximately 1% to 10%, with the largest gain observed for the YOLOv12m model, and the F1-Score improvement ranges from approximately 3% to 10%, again with the largest improvement for YOLOv12m. Although a few model variants exhibit small decreases in AP_50_ or F1-Score, the highest recorded accuracy is obtained with the facility-masked YOLOv12m model, and most models show clear accuracy gains. These results indicate that masking facility regions during training helps the detector better detect objects in unseen environments.
Table 5 studies the SoftMax multiplier used to scale the background-suppressed feature branch inside BSI. A 2× multiplier provides the most consistent performance across models: for YOLOv12m, AP_50_ increases from 0.828 (1×) to 0.860 (2×), with F1-Score improving from 0.786 to 0.835. While some models prefer stronger scaling (e.g., YOLOv12n AP_50_: 0.745/0.748/0.768 for 1×/2×/3×), the 2× setting offers a stable trade-off that avoids the occasional degradation observed at 3× (e.g., YOLOv8n AP_50_ drops to 0.740 at 3×).
Table 6 compares three fusion strategies for combining features from the original and background-suppressed streams: element-wise addition, concatenation followed by a 2D convolution, and the proposed 3D convolution. The 3D convolution consistently yields the highest AP_50_ and F1-Score across all backbones. For example, on YOLOv10m, AP_50_ improves from 0.806 (addition) and 0.816 (concat + 2DConv) to 0.834 (3DConv), and F1-Score improves from 0.762 and 0.772 to 0.803. On YOLOv8n, AP_50_ increases from 0.766/0.764 to 0.788 with 3DConv. Although recall can be slightly higher with alternative fusions in isolated cases (e.g., YOLOv8s recall 0.771 with concat + 2DConv vs. 0.754 with 3DConv), 3DConv better preserves the overall precision–recall balance, leading to higher AP_50_/F1-Score.
Table 7 compares a standard difference-image input with the proposed background-suppressed image produced by BIG. The background-suppressed representation is generally more effective because it preserves the original foreground texture while zeroing out background pixels. This yields notable gains for mid-to-large models (e.g., YOLOv8m AP_50_: 0.771 to 0.806; F1-Score: 0.741 to 0.777, and YOLOv12l AP_50_: 0.797 to 0.838; F1-Score: 0.791 to 0.816). For some small models, the difference image can be competitive (YOLOv8n F1-Score: 0.790 vs. 0.781), likely because the residual-only representation simplifies the input. Overall, BIG’s background-suppressed image provides a richer and more transferable signal for unseen environments than raw pixel residuals.
Table 8 compares the proposed method to DOG [17], which also targets unseen-environment robustness using depth-oriented preprocessing. Across all model variants, StaticPigDetv2 achieves higher accuracy, especially by improving recall. For example, on YOLOv12m, DOG obtains Precision/Recall/AP_50_/F1-Score of 0.790/0.649/0.706/0.713, whereas StaticPigDetv2 reaches 0.883/0.792/0.860/0.835 with increase of 0.154 on AP_50_ and 0.122 on F1-Score. On YOLOv10l, AP_50_ increases from 0.699 (DOG) to 0.791 (proposed) and F1-Score from 0.669 to 0.775. These results indicate that explicitly modeling both background suppression (BIG) and facility occlusions (FIG), together with dual-stream fusion (BSI), provides additional generalization benefits beyond depth-oriented grayscale preprocessing alone.
To assess robustness across unseen environment, Table 9 reports results on the secondary Jochiwon dataset. StaticPigDetv2 improves F1-Score for all evaluated models, with especially large gains for YOLOv10s (F1-Score: 0.652 to 0.807; AP_50_: 0.681 to 0.808). Several variants also show clear precision improvements (e.g., YOLOv8n Precision: 0.787 to 0.897), while recall changes are generally modest. In a few cases, AP_50_ decreases despite an F1-Score increase (e.g., YOLOv12m AP_50_: 0.772 to 0.749; F1-Score: 0.735 to 0.756), suggesting that the proposed preprocessing and fusion mainly stabilizes correct detections at the operating point used for F1-Score, while the IoU distribution across matched boxes can vary by scene. Overall, the consistent F1-Score improvements across two distinct unseen farms support the claim that StaticPigDetv2 mitigates domain gaps without environment-specific retraining.
Figure 7 illustrates the differences in Hadong detection results between the baseline and the proposed method. Each image pair corresponds to the same scene, with detections obtained from models trained under the two different settings. The YOLOv12m model, which achieved the highest accuracy among all evaluated models, was used for this comparison. False positives are marked with blue rectangles while false negatives are marked with dotted red circles. In Figure 7a, detection boxes that are fragmented by facility pipes are reconnected in Figure 7b, and missed detections due to occlusion by the feeding facility and partially visible pigs lying near the bottom of the image are recovered. However, pigs that are occluded by the pipe located around upper-left corner in Figure 7a are partially detected in Figure 7b. Similarly, in Figure 7c, pigs occluded by facility pipes and those located at the bottom of the image are not detected, whereas in Figure 7d these pigs are mostly correctly identified. The false positives associated with the large feeding facility disappear. Although a few pigs remain undetected, many false negative and false positive detection boxes by the facility pipe in Figure 7e are resolved in Figure 7f. Additionally, false positive detection boxes by the upper right corner in all three examples disappear with the proposed StaticPigDetv2 method. Overall, Figure 7 demonstrates that while some errors occur in proposed method, many detection errors arising in unseen environments are mitigated by the proposed method.
Figure 8 illustrates the differences in Jochiwon detection results between the baseline and the proposed method. Each image pair corresponds to the same scene, with detections obtained from models trained under two different settings. Unlike the Hadong dataset, the Jochiwon dataset does not have any occluding facility, hence, there is no facility mask. The YOLOv12m model was used for this comparison. False positives are marked with blue rectangles, while false negatives are marked with dotted red circles. In the three examples shown in Figure 8a,c,e, false positives caused by the feeding facility are effectively mitigated in the corresponding proposed method’s results (Figure 8b,d,f). In Figure 8a, detection boxes that are merged into a single box for multiple clustered pigs are mostly separated into individual detections in Figure 8b. However, a pig located on a white surface in Figure 8a is missed in Figure 8b. Similarly, in Figure 8c, detection boxes that are grouped into one box for multiple pigs on the right side are largely separated in Figure 8d, although a few false negatives remain. In addition, missed detections in the upper-left and bottom-left corners in Figure 8c are correctly detected in Figure 8d. Lastly, while multiple pigs that are undetected in Figure 8e are mostly detected in Figure 8f, two pigs near the white surface are missed. Overall, Figure 8 demonstrates that although some errors still occur with the proposed method, many detection failures observed in different unseen environments are alleviated.
5. Conclusions
Unseen pig monitoring environments pose a substantial challenge for accurate pig detection. When there are discrepancies between the training and test datasets in terms of background or facility appearance, numerous detection errors occur despite recent advances in object detectors.
In this study, we proposed a method to improve both detection accuracy and latency by using BIG, FIG, and BSI, which explicitly leverage background and facility information. BIG (Background-suppressed Image Generator) produces background-suppressed images that reduce the impact of background information during training. FIG (Facility-mask Image Generator) generates facility masks that localize facility regions and enhance the features of pig objects occluded by these facilities. BSI (Background-Suppressed Integration) integrates background-suppressed information into the original feature maps to create a leverage-like feature map.
The proposed method improved detection performance in unseen pig monitoring environments across various YOLO models, including YOLOv8, YOLOv10, and YOLOv12. The proposed method improved the baseline model’s performance with YOLOv8 (accuracy from 79.9% to 84.8% and latency from 74.20 ms to 41.51 ms), YOLOv10 (accuracy from 73.9% to 83.4% and latency from 49.85 ms to 32.47 ms), and YOLOv12 (accuracy from 75.8% to 86.0% and latency from 67.18 ms to 41.14 ms). Future work will explore additional feature fusion strategies to further improve feature representation using background information. Also, criteria for defining nano/small/medium/large models for StaticPigDetv2 will be studied in order to consistently provide better accuracy with bigger models. Additionally, future work will also consider quantitative evaluation of the depth estimation and/or inpainting components on pig farm datasets (e.g., assessing depth prediction fidelity and inpainting quality under farm-specific occlusions), to better characterize how the quality of these intermediate outputs relates to downstream detection performance.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1OECD-FAO Agricultural Outlook. OECD-FAO Agricultural Outlook 2018–2027 Available online: https://www.oecd.org/en/publications/oecd-fao-agricultural-outlook-2018-2027_agr_outlook-2018-en.html(accessed on 23 November 2025)
- 2Tu G. Karstoft H. Pedersen L. Jørgensen E. Foreground detection using loopy belief propagation Biosyst. Eng.20131168810.1016/j.biosystemseng.2013.06.011 · doi ↗
- 3Ott S. Moons C. Kashiha M. Bahr C. Tuyttens F. Berckmans D. Niewold T. Automated video analysis at pen level highly correlates with human observations of pig behavioural activities Livest. Sci.201416013210.1016/j.livsci.2013.12.011 · doi ↗
- 4Kashiha M. Bahr C. Ott S. Moons C. Niewold T. Berckmans D. Automatic monitoring of pig activity using image analysis Proceedings of the International Conference on Advanced Concepts for Intelligent Vision Systems (ACIVS 2013)Poznań, Poland 28–31 October 2013555563
- 5Gronskyte R. Clemmensen L.K.H. Hviid M.S. Kulahci M. Monitoring pig movement at the slaughterhouse using optical flow and modified angular histogram Biosyst. Eng.20161411910.1016/j.biosystemseng.2015.10.002 · doi ↗
- 6Buayai K. Luangpirom T. Sornsrivichai V. Boundary detection of pigs in pens based on adaptive thresholding using an integral image and adaptive partitioning CMU J. Nat. Sci.20171614510.12982/cmujns.2017.0012 · doi ↗
- 7Matthews S.G. Miller A.L. Clapp J. Plötz T. Kyriazakis I. Automated tracking to measure behavioural changes in pigs for health and welfare monitoring Sci. Rep.201771758210.1038/s 41598-017-17451-629242594 PMC 5730557 · doi ↗ · pubmed ↗
- 8Nasirahmadi A. Hensel O. Edwards S. Sturm B. Depth-based detection of standing-pigs in moving noise environments Sensors 20171727572918606010.3390/s 17122757 PMC 5751748 · doi ↗ · pubmed ↗