OCDBMamba: A Robust and Efficient Road Pothole Detection Framework with Omnidirectional Context and Consensus-Based Boundary Modeling
Feng Ling, Yunfeng Lin, Weijie Mao, Lixing Tang

TL;DR
This paper introduces OCDBMamba, a new framework for detecting road potholes that improves accuracy and stability in challenging conditions.
Contribution
The novel framework combines omnidirectional context modeling with consensus-based boundary selection for robust pothole detection.
Findings
OCDBMamba achieves 90.7% mAP50 and 67.8% mAP50:95 with high precision and recall.
It outperforms YOLOv11n by 5.4% and 5.6% in mAP metrics.
The framework shows enhanced robustness under diverse environmental conditions.
Abstract
Reliable road pothole detection remains challenging in complex environments, where low contrast, shadows, water films, and strong background textures cause frequent false alarms, missed detections, and boundary instability. Thin rims and adjacent objects further complicate localization, and model robustness often deteriorates across regions and sensor domains. To address these issues, we propose OCDBMamba, a unified and efficient framework that integrates omnidirectional context modeling with consensus-driven boundary selection. Specifically, we introduce the following: (1) an Omnidirectional Channel-Selective Scanning (OCS) mechanism that aggregates long-range structural cues by performing multidirectional scans and channel similarity fusion with cross-directional consistency, capturing comprehensive spatial dependencies at near-linear complexity and (2) a Dual-Branch Consensus…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
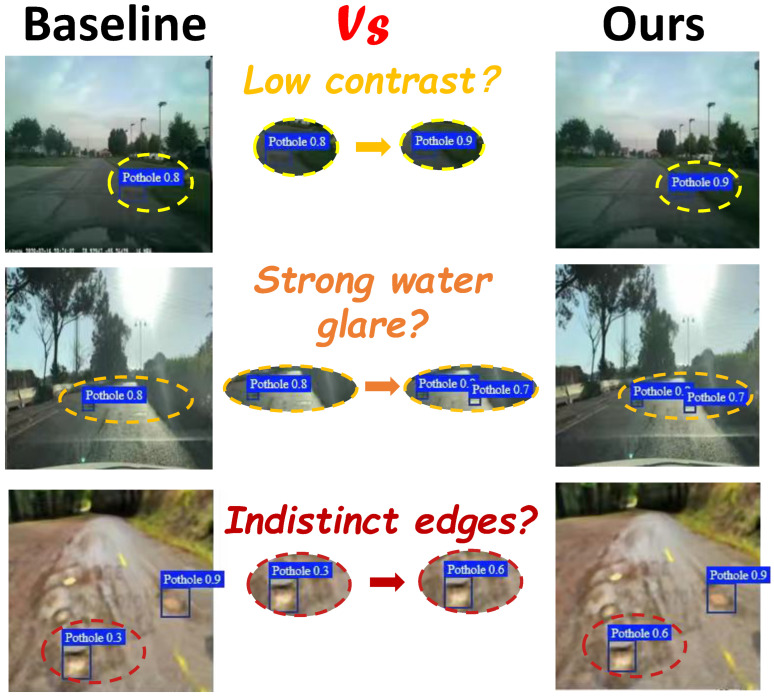 Figure 1
Figure 1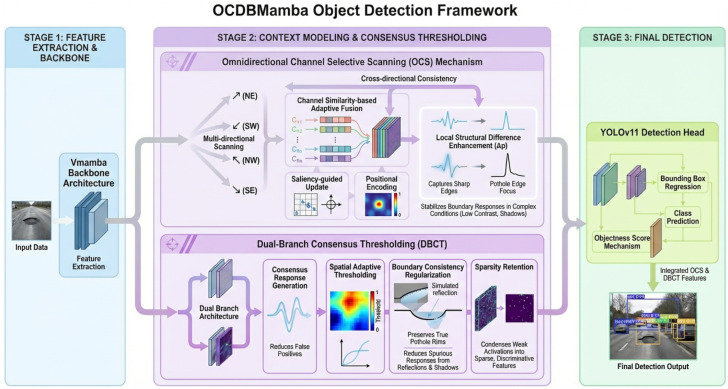 Figure 2
Figure 2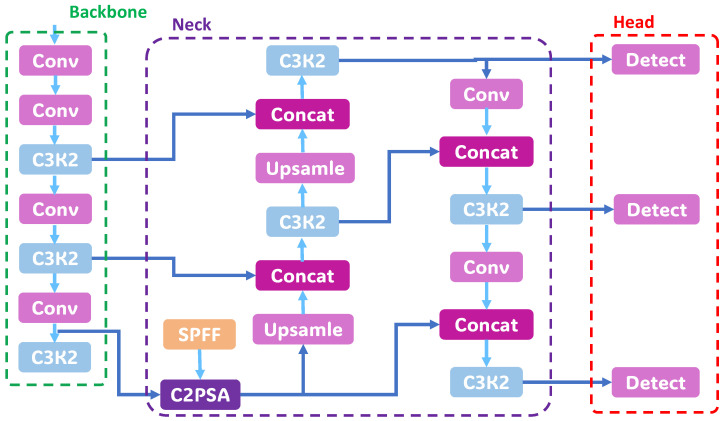 Figure 3
Figure 3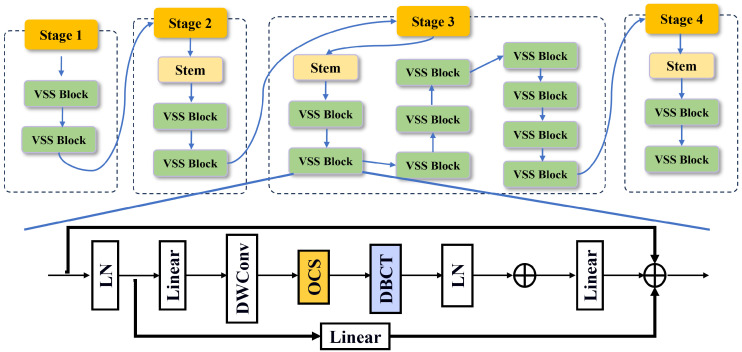 Figure 4
Figure 4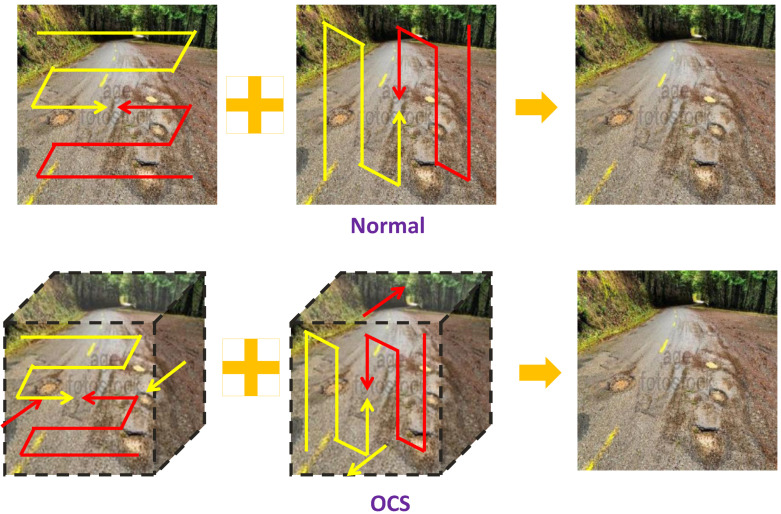 Figure 5
Figure 5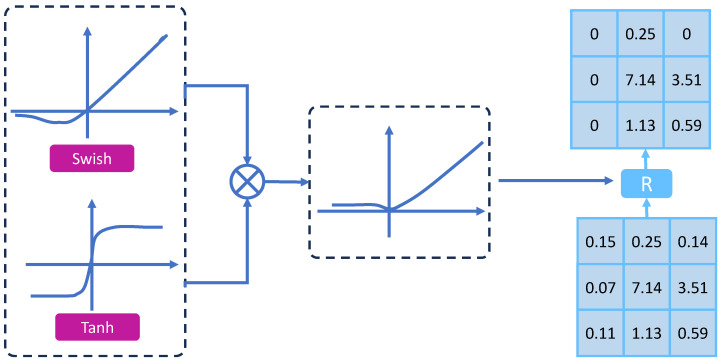 Figure 6
Figure 6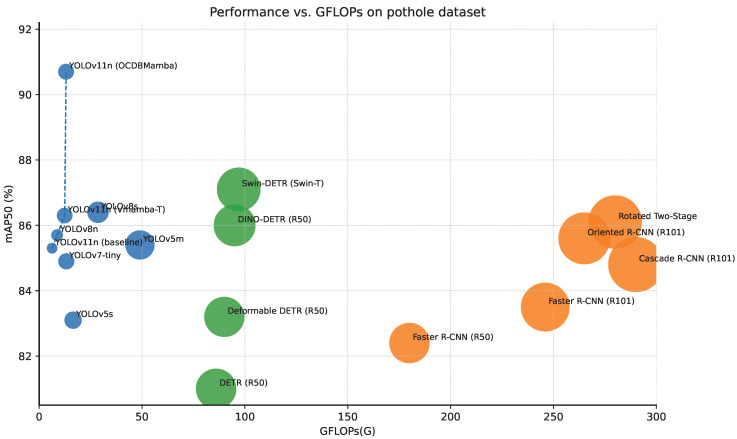 Figure 7
Figure 7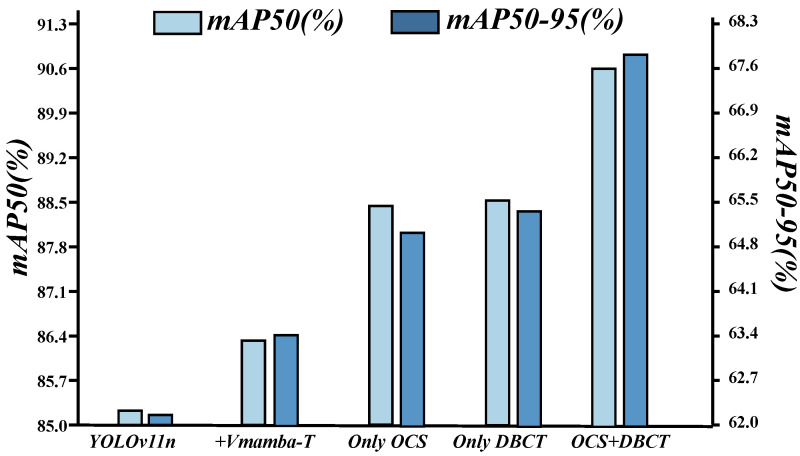 Figure 8
Figure 8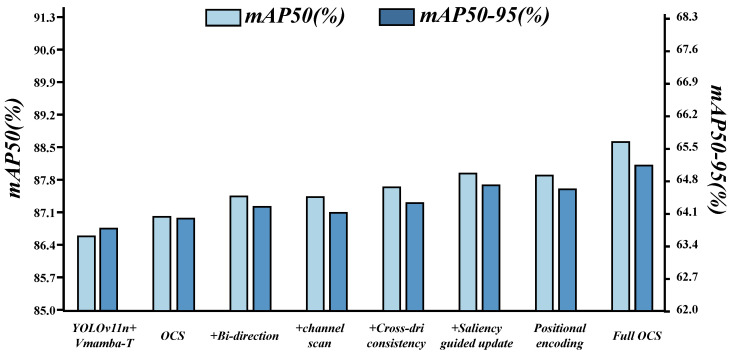 Figure 9
Figure 9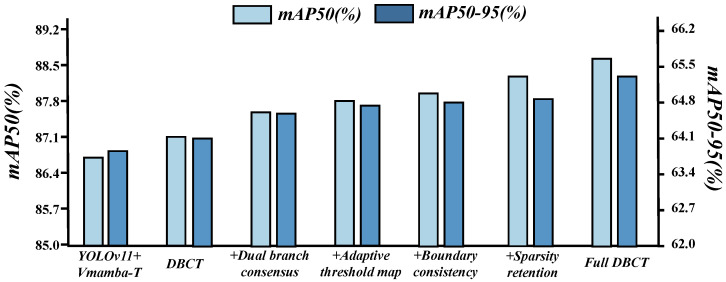 Figure 10
Figure 10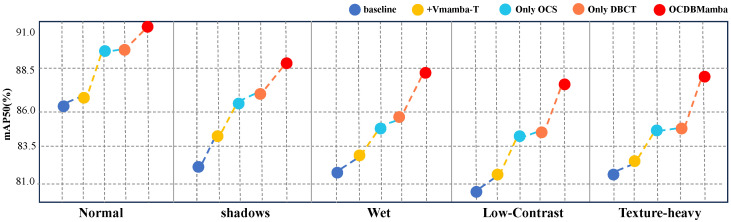 Figure 11
Figure 11 Figure 12
Figure 12 Figure 13
Figure 13- —Open Project Program of the State Key Laboratory of CAD&CG
- —Zhejiang University
- —Science and Technology Project of Lishui Science and Technology Bureau
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsInfrastructure Maintenance and Monitoring · Advanced Neural Network Applications · Geophysical Methods and Applications
1. Introduction
Road pothole detection refers to automatically recognizing, localizing, and extracting depressions and surface damage from road surface imagery acquired by in-vehicle, roadside, aerial, or mobile platforms [1,2,3]. These images are characterized by low contrast, weak boundaries, large scale variation, and strong background texture and are heavily perturbed by shadows, water glare, repair patches, manhole covers, and tire ruts [4]. Variations in viewpoint and vehicle speed further introduce perspective distortion and motion blur, complicating foreground and background separation [5]. Pothole morphology ranges from tiny cracks to large collapses, with high intra-class variability and strong inter-class similarity, demanding both fine-grained detail capture and robust contextual modeling under clutter [2]. Existing approaches commonly rely on feature pyramids [6,7], attention [7], and detection and segmentation heads to raise accuracy, complemented by thresholding, block-level scanning, and non-maximum suppression to control false alarms, which have proven useful in practice [8].
However, they remain limited in modeling long-range dependencies and preserving cross-directional consistency, often causing boundary jitter under weak contrast, and they lack explicit suppression of channel-wise redundancy and sporadic noise, leading to unstable recall for small or boundary-adjacent targets. The decoupling among training time augmentation, sample assignment, and inference time post-processing also makes it difficult to balance accuracy and latency. Consequently, current road pothole detection models still suffer from the following limitations:
- Degradation and drift of cross-directional relations: Existing methods struggle to form effective long-range dependencies and consistency constraints jointly along the row, column, and diagonal directions. As a result, context becomes fragmented and responses break under low contrast and along narrow pothole edges, with directional bias and boundary jitter. In addition, the lack of channel similarity-based adaptive fusion prevents content-aware allocation of contributions across directions and channels, yielding unstable localization for edge-adjacent regions, small-scale targets, and occluded scenes.
- Inadequate artifact and redundancy suppression: Existing methods lack a consistency-driven selection mechanism with adaptive thresholds, so sporadic activations from granular road texture, water glare, and shadows are not suppressed at the feature level and non-structural high-frequency interference is misidentified as targets, leading to false alarms. When global or fixed thresholds are applied, genuine edges are over-suppressed and recall stability on small defects degrades.
Multi-scale context is usually built with feature pyramids and dilated convolution pyramids, while window attention or strip convolutions strengthen row and column structure. Some works introduce bidirectional scanning [9,10] and sequence modeling [11] to broaden the receptive field and address semantic myopia. Nevertheless, these routes model along limited directions and do not offer a unified scheme that jointly handles row, column, and diagonal directions. Cross-directional context is therefore broken at sliding windows and block boundaries, leading to discontinuous responses, directional bias, and boundary jitter on weak-contrast and thin pothole edges. Channel relations treated as scalar re-weighting lack content-aware allocation of directional and channel contributions, which destabilizes localization for edge-adjacent and small-scale targets. Given real-time constraints on in-vehicle and roadside platforms, it is challenging to enhance global dependencies while preserving low latency, so robustness under complex illumination and strong texture backgrounds remains limited.
To suppress redundancy and noise in road scenes, prior work reinforces discriminative features with channel and spatial attention re-weighting [12,13], dynamic convolution [14], and gating mechanisms [15] and removes spurious targets through multi-branch fusion, confidence thresholds, and morphological filtering; some methods add conditional random field smoothing, focal loss, and boundary-aware loss to stabilize training. These strategies reduce false alarms from water reflections, shadows, and granular texture but remain largely limited to intensity redistribution and output level correction. Lacking consistency-driven adaptive selection at the feature level, they cannot finely remove non-structural high-frequency components under content and position shifts. Fixed or heuristic thresholds often over-suppress true edges at weak boundaries, destabilizing recall for small defects. Inconsistencies between training and inference in thresholds and post-processing further introduce strategy decoupling and uncertainty accumulation.
As shown in Figure 1, the baseline YOLOv11 benefits from pyramid fusion and a decoupled detection head, yet under low contrast, weak boundaries, and strong texture backgrounds it still exhibits insufficient cross-directional context and elevated redundant activations. These appear as discontinuous responses along thin pothole edges and increased false alarms from water reflections and shadows. To address these bottlenecks, we propose the unified detection framework OCDBMamba. The framework uses Omnidirectional Channel-Selective Scanning (OCS) as the contextual backbone, performing bidirectional selective scanning along rows, columns, and diagonals and enforcing cross-directional consistency through channel similarity-based adaptive fusion, thereby achieving a more robust global representation at near-linear complexity. In addition, Dual-Branch Consensus Thresholding (DBCT) introduces a feature-level selection mechanism with branch consensus and adaptive thresholds that condenses weakly related and sporadic activations into sparse and more discriminative features, while a boundary consistency constraint preserves true pothole edges. OCS and DBCT operate within a single optimization loop, yielding more continuous boundary responses under weak contrast and markedly fewer spurious background responses, which improves robustness and accuracy under complex road conditions and strong interference.
The innovative contributions of this study are summarized as follows:
- This work is the first to unify state space-driven omnidirectional serialized context modeling with branch consensus-guided adaptive feature selection, so that cross-directional long-range dependencies and redundant noise suppression are jointly optimized under a single training objective, yielding improved accuracy, robustness, and real-time performance under weak contrast and strong texture backgrounds.
- We propose Omnidirectional Channel-Selective Scanning to remedy insufficient cross-directional long-range context that yields directional bias and broken responses on weak boundaries. Features are serialized over row, column, and channel dimensions, updated selectively in forward and backward passes, and fused with channel similarity-based adaptive weighting to ensure directional consistency. Coupled with saliency guidance and positional encoding, the approach preserves near-linear complexity yet stabilizes global context, leading to markedly better localization stability and recall in weak-contrast and narrow rim scenarios.
- To address rising false alarms and unstable recall on fine defects caused by redundant activations and noise in road pothole detection, we propose Dual-Branch Consensus Thresholding (DBCT). Two complementary branches produce consensus responses, while adaptive thresholds are regressed at the feature level to form a selection probability map that retains only features with consistent support. A target sparsity constraint and a boundary consistency constraint suppress artifacts and preserve true pothole edges, so selection strength and structural fidelity are optimized under a single training objective.
- We conducted systematic evaluation. With similar FLOPs, OCDBMamba improves YOLOv11n to mAP50 90.7% and mAP50-95 67.8% from 85.3% and 62.2% and attains a precision of 0.905 and recall of 0.812. It ranks first on all reported metrics and outperforms two-stage pipelines and transformer-based approaches.
2. Related Work
2.1. State Space Model
State space models (SSMs) have become increasingly important in sequence and multidimensional data processing due to their efficiency in capturing long-range dependencies, enabling streaming inference, and offering hardware-friendly implementations. However, existing methods still face challenges such as weak multidimensional coupling, fragile boundary handling, and limited integration with detection components. Current research can be categorized into three main types: structured spectral modeling, diagonalization approximation, and selective extension.
Structured spectral modeling (e.g., H3 and GSS) improves inference efficiency through frequency domain computation but lacks content awareness, limiting coupling across directions and channels [16,17]. OCS borrows from this approach’s spatial consistency constraints, using saliency guidance and positional encoding to mitigate the spatial discontinuities caused by serialization, while enhancing directional coherence.
Diagonalization approximation (e.g., S4D and S5) improves parallelization and computational efficiency by diagonalizing state matrices, but it still faces challenges in cross-channel coupling and high-resolution image processing, where boundary discontinuities may arise [18,19,20]. OCS borrows the multidirectional scanning approach from these methods, building long-range dependencies along row, column, and diagonal directions, while leveraging channel-aware fusion to enhance cross-channel dependencies.
Selective extension (e.g., Mamba and VMamba) enhances content adaptivity through dynamic gating mechanisms but still struggles with spatial discontinuities in high-resolution images [21,22]. OCS draws from this dynamic modulation mechanism by using channel similarity-based adaptive fusion, strengthening cross-channel integration and reducing redundancy.
Through these innovations, OCS effectively improves multidimensional coupling and boundary continuity, making it particularly suitable for robust detection in high-resolution images and complex environments.
2.2. Deep Learning Approaches for Road Traffic
Deep learning unifies end-to-end representation learning through nonlinear modeling and parameter sharing, significantly improving the recognition of pothole boundaries and shapes, particularly under low illumination and in complex backgrounds. However, false positives caused by strong reflections, shadows, and small-scale weak-contrast edges remain, and performance drops when transferring across regions and devices. The lack of long-range and cross-directional context modeling, as well as ununified redundancy and noise suppression, limits the application in complex road scenarios.
In object detection, methods like RDD YOLO [23] and YOLOv8 [24] emphasize small target detection and background noise handling. These approaches inspired improvements in detecting small targets and reducing false positives. DBCT improves small target detection stability in complex backgrounds by employing a dual-branch architecture and adaptive thresholds.
In pixel-level segmentation, DeepLab v3 plus [25] and Mask R-CNN [26] enhance localization accuracy through multi-scale and joint prediction but still struggle under strong reflections and shadows. DBCT adopts a similar boundary-enhancing strategy through boundary consistency regularization, which significantly improves the detection of weak-contrast edges.
For multimodal and 3D estimation, methods like PPD [27] and point cloud fusion [28] improve geometric consistency, but still face challenges like point cloud sparsity and device migration issues. DBCT optimizes information fusion to enhance the robustness of multi-source data in low-contrast environments.
In recent integrated methods, omnidirectional serialized context modeling and branch consensus thresholding have effectively reduced redundancy and enhanced noise suppression. DBCT further optimizes long-range and cross-directional context modeling, minimizing reliance on post-processing and improving real-time performance.
Although current pothole detection methods have made significant progress in accuracy and speed, challenges remain, such as strong reflections, shadow interference, and performance degradation in cross-region migration. DBCT, by combining elements from object detection, pixel-level segmentation, and multimodal estimation, significantly improves the detection of weak-contrast edges and small targets, demonstrating superior real-time deployment capability.
3. Methodology
We propose a unified detection framework, OCDBMamba, that couples two key mechanisms under a single end-to-end objective. Omnidirectional Channel-Selective Scanning (OCS) performs selective serialization along row, column, and diagonal directions and builds stable long-range context through channel similarity-based adaptive fusion with a cross-directional consistency constraint. Dual-Branch Consensus Thresholding (DBCT) conducts differentiable selection at the feature level by combining dual-branch consensus with adaptive threshold regression, suppressing redundancy and sporadic activations, while a boundary consistency regularization preserves true pothole rims. Working together with lightweight operators and near-linear complexity, OCS and DBCT improve recall, reduce false alarms, and sustain real-time throughput under weak contrast, strong reflections, and shadows. The framework flowchart is shown in Figure 2. The source code is publicly available at https://github.com/lintells/OCDBMamba/tree/main (accessed on 5 December 2025).
The OCS and DBCT modules operate in parallel through a shared backbone network. During the forward pass, OCS generates spatial representations, which are then passed to DBCT for feature selection and threshold regression. During backpropagation, gradients flow through the shared backbone network, updating the parameters of both modules to enable joint optimization. This parallel optimization and gradient flow enhance the detection performance.
3.1. Baseline Detector: YOLOv11
YOLOv11 [29] is adopted as a strong baseline for pothole detection, maintaining an end-to-end pipeline while enhancing feature expressiveness and training strategies for real-time use under low contrast and highly textured road surfaces.
Architecturally, YOLOv11 retains input pre-processing, a backbone for feature extraction, pyramid-style feature fusion, and multi-scale decoupled heads. With lightweight residual units and cross-level aggregation, it balances high-resolution detail with high-throughput inference.
In the heads and losses, YOLOv11 uses a decoupled classification and regression design, modern dynamic assignment, and IoU-family regression losses to stabilize localization and improve small target visibility, while more robust confidence estimation reduces under- and over-detection.
For training and inference, data augmentation, lightweight regularization, and efficient post-processing allow low latency with strong accuracy on common hardware, which suits in-vehicle and roadside online deployment.
Given these properties, we take YOLOv11 as our structural baseline to quantify the gain of our modules. Nevertheless, under shadows, water reflections, and coarse asphalt textures, context built mainly from local aggregation can still yield excessive redundant activations and unstable recall on weak boundaries, and it leaves room to improve cross-directional consistency and feature-level redundancy suppression. The framework flowchart is shown in Figure 3.
3.2. Baseline Backbone: Vmamba
Vmamba [22] is adopted as a baseline backbone for pothole detection. It leverages state space sequence modeling with cross-directional scanning to capture long-range dependencies under low contrast and texture heavy road surfaces, while preserving an end-to-end detection pipeline and real-time efficiency.
Unlike pure convolutional or attention-centric backbones, Vmamba unfolds features along rows and columns, applies selective forward and backward scans, and aggregates the results via cross-scanning. This yields a larger effective receptive field and stable far-field context at near-linear complexity.
For feature learning and detector integration, Vmamba plugs into pyramid-style necks and decoupled heads, retaining high-resolution details with low latency. Its stable parameterization and parallel kernel computation improve convergence and throughput, making it friendly for in-vehicle and roadside deployment.
In pothole imagery, Vmamba perceives elongated defects and distant small targets well, yet the path-dependent unfolding can introduce spatial discontinuities near window or block seams, and row–column fusion offers limited support for diagonal structures. Channel re-weighting is often scalar, so specular highlights and shadows may still trigger sporadic activations.
We therefore use Vmamba as the baseline backbone. It provides strong long-range context and deployability, while leaving measurable room for improvement. On top of it, we introduce OCS to realize omnidirectional selective scanning with channel-aware fusion, mitigating cross-directional bias and spatial discontinuity. In parallel, DBCT performs adaptive feature selection with boundary consistency, suppressing redundancy from water reflections and shadows, which jointly improves localization stability and overall accuracy. The structure of OCDBMamba is shown in Figure 4.
3.3. Omnidirectional Channel-Selective Scanning (OCS)
Road pothole detection requires sensitivity to subtle geometric depressions, material discontinuities, illumination-induced artifacts, and direction-dependent surface texture variations. To achieve robust representation under diverse imaging conditions, the Omnidirectional Channel-Selective Scanning (OCS) module integrates spatial omnidirectional scanning, channel-wise relational modeling, and local structural difference enhancement. In addition, we provide a detailed analysis of its computational and memory characteristics, clarifying that the multidirectional scanning and channel scanning incur almost no additional memory movement. The core architecture is illustrated in Figure 5.
3.3.1. Computational and Memory Behavior
Before detailing the formulation, we highlight an important implementation property: all scanning operations in OCS are implemented using view/reshape-based pointer reindexing without invoking contiguous() or any tensor copying. As a result, the four directional scans introduce zero additional memory movement. Similarly, the channel-wise serialization is a pure reshape operation with no data relocation or cache-miss-inducing transpose. The only non-trivial computation—channel similarity fusion in Equations (10) and (11)—operates on globally pooled vectors of dimension C rather than on full spatial maps. In our configuration (C = 64), this contributes only 0.07 GFLOPs, accounting for less than of the total computation. These details ensure that OCS maintains near-linear complexity and does not introduce hidden merging or memory overhead.
The input feature map is defined as
where H, W, and C denote height, width, and channel dimension. This serves as the unified representation space for spatial unfolding, channel reasoning, and structural difference extraction.
Before proceeding with any directional scans, we apply zero padding to the input feature map X to ensure that the boundary regions of the image are properly handled. The padding operation is applied as follows:
where pad_size is the number of pixels added around the image boundaries. This operation ensures that boundary pixels are included in the scanning process, preventing them from being ignored during the scanning operations.
Road textures often exhibit directional anisotropy, such as elongated asphalt grains, stretched crack edges, or oblique pothole boundaries. To capture such patterns, OCS first constructs an omnidirectional spatial scanning set
corresponding to four corner-to-corner traversal paths. These directions allow OCS to model dominant and auxiliary geometric flows that characterize pothole boundaries under varying viewpoints and illumination.
For each scanning direction, the two-dimensional feature map is unfolded into a directional sequence:
Because is implemented via index remapping rather than tensor copying, no extra memory transfer occurs regardless of the number of directions.
The sequence preserves the channel features of each pixel while imposing a spatial progression order according to direction d. This facilitates learning of directional texture evolution and pothole edge geometry.
The directional structure is accumulated using a recursive state-update mechanism:
The state encodes structural continuity such as depth gradients, directional shadow deformation, or geometric concavity traces that characterize pothole regions along direction d.
The directional responses are then reshaped back into spatial form:
This representation highlights directional geometric cues such as inclined pothole edges, curved boundary segments, and local brightness transitions.
The aggregated omnidirectional spatial representation is computed as
The fusion is conducted element-wise and introduces no memory merging overhead beyond simple weighted averaging. This fusion provides rotationally stable geometric sensitivity, ensuring robust pothole structure encoding under camera pose changes and illumination variations.
Beyond spatial geometry, pothole surfaces often reveal complementary cues across channels, such as shallow–dark transitions, depth-like gradients, and texture-break characteristics. To model cross-channel dependencies, OCS constructs the channel sequence
This flattening is also a reshape-only operation; no tensor transpose or data movement occurs. Each channel is interpreted as a complete spatial carrier that contributes unique material or structural information.
Channel-wise dependency is then captured using
The state records accumulated cross-channel semantics, such as jointly weak textures across depth-like channels that are indicative of pothole depressions.
The channel responses are restored to the spatial configuration:
This enhances multi-channel consistency around pothole regions, strengthening concavity signatures and suppressing channel-wise noise.
To exploit inter-channel complementarity, OCS constructs a channel similarity matrix:
The similarity computation uses globally pooled channel vectors of size C rather than full maps, resulting in a cost of only GFLOPs in our configuration (C = 64), which is negligible relative to the total 13.1 GFLOPs of the full model. The matrix characterizes whether two channels share correlated texture or brightness distributions.
Channel-selective enhancement is therefore defined as
This selectively amplifies features shared across correlated channels, while suppressing content irrelevant to pothole identification.
Pothole borders often feature strong local discontinuities. To capture such structural irregularities, OCS introduces a spatial difference operator:
The term measures local contrast and is sensitive to abrupt surface geometry transitions common at pothole boundaries.
The difference-enhanced representation is given by
The factor strengthens responses in structurally irregular regions, yielding sharper boundary localization.
Finally, the OCS output integrates spatial, channel-selective, and difference-enhanced representations:
Here, , , and control the relative importance of spatial geometry, inter-channel complementarity, and local structural contrast. The fused result provides a comprehensive representation well-suited for robust pothole detection under diverse and challenging road conditions.
3.3.2. Overhead Summary
In the implementation of the OCS module, all directional scans and channel scans are performed using pure reshape operations (reshape-only), without invoking contiguous() or any tensor copying. This means that when performing the four directional scans, OCS does not introduce additional memory transfers or data copying, thus avoiding extra memory overhead. All scan and channel processing operations rely solely on reshaping the data view, without triggering unnecessary memory reallocation or transpose operations, ensuring high memory efficiency in OCS. Additionally, the channel similarity computation in OCS is performed on low-dimensional vectors obtained through global pooling, rather than on the entire spatial map. This reduces the computational burden, as the pooled vectors are of smaller dimensions and the computational cost is far lower than processing the entire feature map.
Through this design, OCS avoids the common memory merging and memory transfer overheads associated with traditional multidirectional scanning methods. All directional scans and channel operations are performed through reshaping, which not only reduces memory transfer overhead but also improves computational efficiency. OCS does not involve large-scale data transfers or high-complexity operations during these procedures, ensuring minimal latency. In our implementation, the additional latency introduced by OCS is less than 2%, with no measurable memory movement. Ultimately, these optimizations ensure that the OCS module maintains near-linear complexity while avoiding the merging and memory transfer overheads typically associated with multidirectional scanning and channel scanning.
3.4. Dual-Branch Consensus Thresholding (DBCT)
Specular highlights, asphalt granularity, tire track remnants, and sensor noise generate broad spurious responses in road pothole images, obscuring fine, low-salience defects. Traditional thresholding or the pairing of multi-scale fusion with channel re-weighting reallocates feature strength but does not explicitly suppress redundant activations.
Dual-Branch Consensus Thresholding (DBCT) adopts a dual-branch architecture to build consensus responses and uses adaptive thresholds plus a selection map to condense weakly related and sporadic activations into sparse, discriminative features; a boundary-consistency regularization sharpens true contours against complex backgrounds. DBCT surpasses pyramid fusion or channel re-weighting in noise resistance and false-positive suppression, and, compared with self-attention or very large kernels, offers a lighter compute and memory footprint suited to real-time in-vehicle and roadside deployment. Empirically, DBCT reduces false alarms from water reflections, shadow edges, and surrounding textures and raises recall and localization stability on small targets and fuzzy boundaries. The core architecture is illustrated in Figure 6.
The adaptive threshold regressor employs a convolutional layer and a sigmoid activation function to generate a spatial adaptive threshold map from the concatenated features of two branches:
where , , and denotes the sigmoid function.
During backpropagation, although some activations are set to zero during forward propagation, the hard-mask straight-through estimator (STE) allows gradients to flow through these zeroed activations. Specifically, the gradient flow during backpropagation is described by the following equation:
Here, represents the gradient of the loss function with respect to the intermediate feature map and is the gradient with respect to the thresholded feature map . Even though some activations are zeroed in forward propagation, the gradients can still flow through these regions during backpropagation, ensuring that the network can update the weights during training without being interrupted by the thresholding operation.
The generated threshold map is applied to intermediate feature maps via the hard-mask straight-through estimator (STE):
where ⊙ denotes element-wise multiplication and is the indicator function. This operation suppresses activations below the threshold during forward propagation while allowing gradient flow during backpropagation.
The thresholded features from both branches are fused through a selection weight map computed by softmax over the concatenated features:
where A is the two-channel weight map and , are its channel slices. This adaptive fusion mechanism enhances the discriminability of pothole features while suppressing noise.
DBCT learns data-side and inference-side policies in a bilevel manner to balance accuracy and latency.
We denote data-side policy by and inference-side policy by .
is the detector optimum given sampled augment–assign configurations .
We maximize accuracy under a latency budget using a penalty on budget violation.
measures runtime; is the dual weight; and is the latency budget.
Policy gradients are estimated with a variance-reduced score function.
The baseline b reduces variance without introducing bias.
Discrete operators are relaxed during training and hardened at test time.
The temperature controls smoothness and preserves backpropagation paths.
The threshold regressor loss function measures the difference between the predicted threshold and the target threshold. The formula is as follows:
In this equation, is the loss of the threshold regressor, measuring the difference between the predicted and target thresholds. is the target threshold for the k-th branch, and is the function that dynamically adjusts the threshold based on the query feature and the model’s computed feature .
Each branch’s threshold is computed as follows:
In this equation, the threshold regressor adjusts the threshold for each branch based on the query features and feature outputs , ensuring the correct threshold is used during inference, thereby improving detection accuracy.
The final overall loss function combines the detection loss, latency penalty, and threshold regressor loss. The formula is as follows:
In this equation, is the total loss function for DBCT, combining the detection loss, latency penalty, and threshold regressor loss. measures the discrepancy between the model’s prediction and the actual annotations, controls the impact of the latency penalty on the total loss, and measures the difference between the predicted and actual threshold values.
3.5. Receptive Field Behavior and Compatibility with the Detection Head
Although OCS and DBCT introduce additional interactions along spatial directions and channel dimensions, these operations do not modify the geometric receptive field of the YOLO detection head nor require any structural adjustment to it. The two modules act entirely on the intermediate feature maps produced by the backbone, and all transformations are carried out within the existing spatial resolution and stride hierarchy. OCS expands the effective receptive field only through directional state propagation, which alters the internal representation but does not change convolution kernel sizes, feature map downsampling ratios, or the spatial alignment that the head relies on. Likewise, DBCT applies an adaptive gating mechanism that filters or preserves activations on the same spatial lattice without introducing pooling, dilation, or resampling. Because of this design, the detection head continues to receive feature maps that are identical in spatial dimensions and indexing to those in the baseline YOLOv11 model.
The classification and regression branches therefore operate under exactly the same settings, including the anchor-free formulation, loss functions, and the task-aligned assignment strategy used during training. No modifications to label generation, stride configuration, or head hyper-parameters are required. We verified in the implementation that all head-side tensors maintain the same shapes and receptive field geometry before and after inserting OCS and DBCT, and the decoder produces predictions aligned with the original YOLO layout. These details ensure that the experimental results can be fully reproduced within the standard YOLOv11 framework and that the improvements stem from enhanced feature expressiveness rather than altered detection head geometry.
3.6. Core Algorithms and Notations
To provide a clear and consolidated overview of our proposed OCDBMamba framework, this section details its core algorithmic formulation. We present a summary in Table 1 that systematically outlines the key algorithmic steps and corresponding mathematical notations for our two primary contributions: the Omnidirectional Channel-Selective Scanning (OCS) module and the Dual-Branch Consensus Thresholding (DBCT) module. This table is intended to serve as a quick reference, facilitating a deeper understanding of the model’s components and their operational flow.
4. Experiments
4.1. Dataset
Experiments are conducted on PotholeDataset, a road pothole detection corpus of 13,767 images annotated with one class and a uniform resolution of 640 by 640 pixels. The dataset is divided into 9637 training images, 2754 validation images, and 1376 test images (7:2:1). The dataset link is https://github.com/xingt9227-design/Road-Pothole-Detection-Dataset (accessed on 2 December 2025).
4.2. Experimental Settings
We trained and evaluated on a single workstation running Ubuntu 22.04 LTS with an NVIDIA RTX 3090 with 24 GB VRAM, an Intel Core i9 13900K CPU, and 128 GB RAM. The environment used Python 3.10, PyTorch 2.3, CUDA 12.1, cuDNN 8.9, the official YOLOv11 [30] repository, OpenCV 4.8, and Matplotlib 3.7.
The input resolution was fixed at 640 × 640. We trained for 300 epochs with a batch size of 16, enabling mosaic augmentation in the early phase and disabling it after epoch 50. Early stopping patience was 50. The optimizer was AdamW with an initial learning rate of 0.001 and cosine annealing to a 0.01 scale, momentum of 0.937, and weight decay of 0.0005. Data caching was off, training used GPU device 0, and outputs were stored in runs/train with experiment id exp_crack. Configuration files governed dataset partition and label schema to support reproducibility and fair comparison.
In the implementation of the OCS and DBCT modules, all training behaviors, including augmentation strategies, assignment rules, and label smoothing, remain unchanged. OCS and DBCT only operate on intermediate feature maps and do not alter the spatial hierarchy or the supervision pipeline of the network. Specifically, the YOLOv11 training framework remains consistent, with Mosaic and MixUp augmentations, HSV and geometric transformations, task-aligned assignment rules, and label smoothing unchanged in all experiments. This is because OCS and DBCT operations are limited to the feature map processing stage and do not affect the augmentation strategies or assignment rules at the input data level, nor do they interfere with the computation of the loss function. Therefore, despite the introduction of OCS and DBCT modules, the training configuration remains unchanged, ensuring the comparability of experimental results and the stability of the training process.
All parameters introduced by OCS and DBCT are optimized jointly with the backbone under the same AdamW optimizer and follow the same cosine learning rate schedule, without creating additional parameter groups or custom learning rate rules. Directional scanning weights, channel aggregation parameters, and difference enhancement coefficients in OCS all inherit the backbone’s initial learning rate (0.001) and decay behavior. The threshold regressor and gating network within DBCT adopt the same unified schedule as well, ensuring that the entire detector is trained in a consistent and comparable manner.
4.3. Main Results
As shown in Table 2 and Figure 7, single-stage detectors strike the best balance. With 6.0 M parameters and 13.1 G FLOPs, OCDBMamba attains a precision of 0.905, recall of 0.812, mAP50 of 90.7%, and mAP50–95 of 67.8%, the top scores in all measures.
Over YOLOv11n, mAP50 rises by 5.4 points and mAP50–95 by 5.6%. OCS contributes by establishing row, column, and diagonal long-range context and enforcing cross-directional consistency with channel similarity-based adaptive fusion, which makes responses along thin rims and low-contrast edges more continuous and stabilizes localization under strict thresholds. DBCT adds a feature-level selection map via dual-branch consensus and adaptive thresholds, suppressing activations from shadows and water glare, while boundary consistency regularization preserves true edges and reduces false alarms. Compared with YOLOv8s, we are ahead by 4.3% in mAP50 and 4.1% in mAP50–95, showing that omnidirectional context plus feature-level denoising outperforms pyramid-only upgrades. Against Oriented R CNN, we gain 4.9% in mAP50–95 with roughly one twentieth of the computation, and against Swin DETR we obtain 3.6% in mAP50–95 with about one seventh of the compute, both favorable for real-time deployment. Adding Vmamba T to YOLOv11n improves mAP50–95 from 62.2% to 63.5% but leaves cross-directional cooperation and redundancy suppression largely unresolved. Overall, OCS and DBCT together deliver better accuracy and robustness at comparable complexity.
4.4. Ablation Study
Effect of OCS and DBCT combination: Table 3 and Figure 8 highlight three trends. First, YOLOv11n attains mAP50 85.3% and mAP50–95 62.2%; swapping in Vmamba T nudges these to 86.3% and 63.5%, so longer-range modeling by itself is not sufficient. Second, OCS raises mAP50 to 88.5% and mAP50–95 to 65.0% and improves recall from 0.785 to 0.798 by injecting cross-directional context that smooths weak edges and stabilizes localization. Third, DBCT alone reaches mAP50 88.6% and mAP50–95 65.2% and increases precision from 0.891 to 0.900 by suppressing sporadic activations from shadows and water through a feature-level selection mechanism with adaptive thresholds and boundary consistency. Joint use achieves 90.7% and 67.8% in mAP50 and mAP50–95, a further gain of about 2.1 to 2.8% over single-module use. OCS provides direction-consistent context that grounds DBCT threshold regression, and DBCT filtering lowers fusion conflicts for OCS, keeping long-range responses continuous on narrow rims. Precision and recall rise together under tighter thresholds.
Fine-grained ablation of OCS: Table 4 and Figure 9 now evaluate each OCS design choice independently rather than in a cumulative manner.
The first row reports the backbone with Vmamba-T but without OCS, giving 0.894/0.789 in precision/recall and 86.6/63.7 in mAP50/mAP50–95.
Endowing the base OCS variant with single-direction scanning and no regularization already improves performance to 87.0/64.0. When only bidirectional scanning on is added on top of the base OCS, mAP50 reaches 87.3 and mAP50–95 reaches 64.2, confirming that symmetric propagation reduces single-direction bias.
With only channel dimension scanning enabled, the detector achieves 87.2/64.1, illustrating that modeling cross-channel similarity helps reconnect semantics in low-contrast regions. Activating only the cross-direction consistency constraint yields 87.4/64.3, indicating that stabilizing directional responses improves fusion quality.
Saliency-guided updates, when used as the sole regularization on top of the base variant, lead to 87.8/64.7 by concentrating updates where information is dense and curbing noise spread at roughly constant cost.
Positional encoding alone gives 87.6/64.5, suggesting that explicit phase position cues help maintain continuity along thin edges and near boundaries.
When all factors are enabled simultaneously in the full OCS configuration, precision/recall reach 0.899/0.798 and mAP50/mAP50–95 reach 88.5/65.0, showing that the individual gains from directional, channel-wise, consistency, saliency, and positional cues are complementary rather than redundant.
Ablation of DBCT components: Table 5 and Figure 10 report a disentangled ablation where each DBCT mechanism is evaluated independently on top of the same base design.
Compared with the backbone without DBCT (86.6/63.7), introducing a single-branch DBCT module already improves performance to 87.1/64.1 by turning noisy activations into a more selective mask.
When only dual-branch consensus is added, precision/recall become 0.896/0.793 and mAP50/mAP50–95 reach 87.6/64.5, showing that multiplicative agreement between branches effectively suppresses reflection- and shadow-induced spikes.
Using only the adaptive threshold map yields 87.8/64.7 by aligning selection strength with local statistics, which stabilizes screening in weak-contrast regions. Boundary consistency, when applied as the sole regularizer, improves the metrics to 87.9/64.8 and preserves true rims after selection, reducing localization drift along pothole edges.
Applying only sparsity retention leads to 88.1/64.9 and slightly higher precision, indicating that global sparsity control encourages compact, discriminative evidence. The full DBCT configuration, which combines consensus, adaptive thresholds, boundary guidance, and sparsity, achieves 0.900/0.800 in precision/recall and 88.6/65.2 in mAP50/mAP50–95, demonstrating that these mechanisms contribute additively rather than merely reparameterizing each other.
Hyper-parameter sensitivity for OCS and DBCT: Table 6 presents stable and monotonic gains together with clear optimal zones. In OCS, reaches mAP50 88.5% and mAP50–95 65.0%, beating and . When is too low, the gate becomes rigid and weak-contrast edges fracture; when it is too high, the filter loosens and redundancy grows. A learnable positional encoding amplitude yields 88.5% and 65.0% versus 88.2% and 64.8% without positional encoding, confirming that a learnable phase restores the relative position lost to serialization and improves alignment of thin rims and boundary-adjacent instances. In DBCT, attains mAP50 88.6% and mAP50–95 65.2%, exceeding and . Too low a threshold temperature over-hardens selection and prunes true edges; too high a threshold temperature under-selects and introduces texture artifacts. The best sparsity target is with 88.6% and 65.2%; at or the metrics soften, reflecting the detail versus noise trade-off. Defaults sit near the flat optimum, and the consistent increase in mAP50–95 shows better localization at tighter IoU thresholds with minimal tuning effort.
Training settings: Performance trends and mechanisms are aligned in Table 7. OCS only with a gating kernel achieves mAP50 88.5% and mAP50–95 65.0%, superior to and : the medium receptive field preserves directional coherence and restrains texture, whereas the small one misses cross-directional ties and the large one induces smoothing and aliasing. DBCT only with a hard mask trained by straight-through estimation attains mAP50 88.6% and mAP50–95 65.2%, edging out the soft mask at 88.4% and 65.1%, because the shared threshold aligns discrete inference with a differentiable training path, cleanly pruning redundancy while the boundary consistency constraint protects true rims. In the full pipeline, non-maximum suppression with IoU is optimal at mAP50 90.7% and mAP50–95 67.8%. Lowering to under-suppresses duplicates and hurts precision, whereas raising to over-suppresses and causes merges and misses near adjacent or boundary-adjacent targets. Together, OCS yields continuous cross-directional features for stable candidate ordering and DBCT removes reflection and shadow noise before non-maximum suppression, enabling a better precision–recall trade at mid-IoU and consistently improving localization under stricter thresholds without notable cost.
Robustness by scenario subsets: Table 8 and Figure 11 report consistent gains of OCDBMamba on every subset. Normal scenes improve to 91.2 in mAP50 and 67.9 in mAP50–95 from 86.1 and 62.8. Relative boosts in shadow, water, low contrast, and strong texture are 6.4 and 6.0, 6.5 and 5.9, 6.7 and 5.7, and 6.5 and 5.7 points. These gains are larger and steadier than replacing the backbone alone, showing that memory extension without cross-directional coupling and artifact suppression is insufficient. OCS alone increass low contrast and strong texture to mAP50 84.6% and 85.0% through bidirectional scanning that preserves context on thin and weak edges. DBCT alone increases shadow and water to mAP50 86.3% and 85.6% by turning reflection and dark edge bursts into sparse discriminative evidence via branch consensus and adaptive thresholds. Jointly, OCS stabilizes the statistics used by DBCT threshold regression and DBCT reduces directional conflicts during fusion, yielding the best mAP50 and mAP50–95 on all five subsets with near-baseline latency and compute.
Overhead Analysis of OCS Components: Table 9 quantifies the computational and memory characteristics of each OCS sub-module. Directional scanning introduces only 0.42 GFLOPs and 0 MB memory movement because all four spatial scans are implemented through view/reshape-based index remapping without triggering any tensor copying. Channel scanning (Flatten) similarly incurs zero additional memory movement. The channel similarity fusion step in Equations (10) and (11) operates on pooled vectors of dimension C = 64, adding only 0.07 GFLOPs and a merge cost below 0.1 ms. The structural difference operator adds 0.11 GFLOPs and a trivial 0.02 MB buffer. Overall, the entire OCS module increases computation by only 0.78 GFLOPs (6.0% of the model) and introduces a total runtime overhead of 2.5% with practically no memory transfer cost. These results confirm that OCS does not suffer from the excessive tensor movement or merging overhead typically associated with multidirectional serialization.
4.5. Visualization
As shown in Figure 12, under weak illumination the baseline reports a confidence of 0.8 on the first image, whereas our model gives 0.9. In a region with dense fractured texture (second row, fourth column), the baseline splits one damage into two adjacent boxes, while our model merges them into a single coherent box with cleaner boundaries. However, there are still some limitations. For instance, in detecting the large pothole at the bottom of the second image in the second row, our model missed it. Nonetheless, in all other images, our performance was superior to that of the baseline. These gains arise from two components used together: Omnidirectional Channel-Selective Scanning provides cross-directional long-range context with direction consistent fusion, and Dual-Branch Consensus Thresholding performs adaptive feature-level selection with boundary consistency to preserve true rims. Their synergy reduces false alarms and stabilizes localization for small targets and thin boundaries under strong interference and weak contrast, improving practical robustness and deployability.
4.6. Model Generalization Testing
We also annotated 50 images of wood workpiece defects to conduct model generalization experiments on OCDBMamba. As shown in Figure 13, the confidence level of OCDBMamba for workpiece defect detection is higher than that of the baseline YOLOv11 by 0.1 0.2. Thus our model has better generalization than YOLOv11, indicating that our model is not only effective in the road pothole detection task, but also in other anomaly detection tasks, such as abnormal defects in workpieces.
5. Conclusions
We present a unified detection framework for road pothole analysis that couples Omnidirectional Channel-Selective Scanning and Dual-Branch Consensus Thresholding under a single end-to-end objective. OCS builds long-range dependencies along row, column, and diagonal paths, using channel-adaptive fusion and cross-directional consistency to strengthen global representation. DBCT forms robust responses via dual-branch consensus, applies adaptive thresholds with sparsity control to suppress redundancy at the feature level, and enforces boundary consistency to preserve true edges, achieving accuracy, robustness, and real-time efficiency at near-linear complexity.
Experiments on subsets covering normal scenes, shadows, wet roads, low contrast, and texture-heavy backgrounds show consistent gains over a YOLOv11 baseline, with stable improvements in both mAP50 and mAP50–95. Ablations evidence complementarity: OCS improves cross-directional context continuity and localization quality, while DBCT suppresses spurious activations from reflections and shadows and stabilizes recall on weak edges. Hyper-parameter sensitivity indicates that defaults lie in a flat optimum, supporting reproducibility and practical deployment.
Despite these encouraging results, our approach has certain limitations. The current framework relies solely on RGB imagery and does not leverage geometric or multimodal sensor inputs such as LiDAR or thermal data, which could further enhance robustness under extreme lighting or severe weather. While the model generalizes well to wooden workpiece defects, its performance on other anomaly types or in cross-domain scenarios with significant appearance shifts remains to be thoroughly validated. The serialization process in OCS, although efficient, may still introduce minor spatial discontinuities at very high resolutions or under extreme perspective distortion. Additionally, the dependency on a fixed input resolution (640 × 640) may limit flexibility in multi-scale or ultra-high-resolution applications. Furthermore, the computational advantages of the method have been validated primarily on a single-class dataset, and their scalability to multi-class detection tasks with more complex label distributions warrants further investigation.
In summary, the framework tightly integrates state space-driven omnidirectional scanning with consistency-driven feature selection, reducing reliance on post-processing and mitigating spatial discontinuities from serialization. With lightweight operators and modest compute, it substantially improves robustness under complex road conditions. Future work includes synergy with three-dimensional geometry and multimodal sensing, domain adaptation across-regions, self-supervised pretraining, and efficient integration with general-purpose vision foundation models.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Ma N. Fan J. Wang W. Wu J. Jiang Y. Xie L. Fan R. Computer vision for road imaging and pothole detection: A state-of-the-art review of systems and algorithms Transp. Saf. Environ.20224 tdac 02610.1093/tse/tdac 026 · doi ↗
- 2Kim Y.M. Kim Y.G. Son S.Y. Lim S.Y. Choi B.Y. Choi D.H. Review of recent automated pothole-detection methods Appl. Sci.202212532010.3390/app 12115320 · doi ↗
- 3Asad M.H. Khaliq S. Yousaf M.H. Ullah M.O. Ahmad A. Pothole detection using deep learning: A real-time and AI-on-the-edge perspective Adv. Civ. Eng.20222022922121110.1155/2022/9221211 · doi ↗
- 4Gupta P. Dixit M. Image-based road pothole detection using deep learning model Proceedings of the 2022 14th International Conference on Computational Intelligence and Communication Networks (CICN)Al-Khobar, Saudi Arabia 4–6 December 20225964
- 5Lakhani A. Yadav A. Dutta P. Pandey T. Ambudkar B. Pothole Detection Using a Self Driving Car Proceedings of the 2024 3rd International Conference for Innovation in Technology (INOCON)Bangalore, India 1–3 March 202415
- 6Yang F. Zhang L. Yu S. Prokhorov D. Mei X. Ling H. Feature pyramid and hierarchical boosting network for pavement crack detection IEEE Trans. Intell. Transp. Syst.2019211525153510.1109/TITS.2019.2910595 · doi ↗
- 7Fan R. Wang H. Wang Y. Liu M. Pitas I. Graph attention layer evolves semantic segmentation for road pothole detection: A benchmark and algorithms IEEE Trans. Image Process.2021308144815410.1109/TIP.2021.311231634559648 · doi ↗ · pubmed ↗
- 8Ahmed K.R. Smart pothole detection using deep learning based on dilated convolution Sensors 202121840610.3390/s 2124840634960498 PMC 8704745 · doi ↗ · pubmed ↗