A Universal Method for Identifying and Correcting Induced Heave Error in Multi-Beam Bathymetric Surveys
Xiaohan Yu, Yang Cui, Jintao Feng, Shaohua Jin, Na Chen, Yuan Wei

TL;DR
This paper introduces a two-stage method to identify and correct induced heave errors in multibeam bathymetric surveys, significantly improving data accuracy and terrain mapping quality.
Contribution
A novel two-stage methodology combining regression diagnostics and PLSR for identifying and correcting induced heave errors in bathymetric data.
Findings
The method reduces the root mean square of bathymetric discrepancies by approximately 78.8% after correction.
Periodic stripe-shaped distortions along the track direction are nearly eliminated.
The quality of terrain mosaicking is significantly improved in complex topographic conditions.
Abstract
Addressing the difficulty of intuitively identifying and effectively correcting induced heave error in multibeam measurements, this paper proposes a two-stage methodology comprising error identification and correction. This scheme includes an error discrimination method based on regression diagnostics and an error correction method based on Partial Least Squares Regression (PLSR). By establishing a mathematical model between bathymetric discrepancies and attitude parameters, statistical diagnosis and effective identification of the error are achieved. To further mitigate the impact of induced heave error on bathymetric data, an elimination model based on PLSR is developed, enabling high-precision prediction and compensation of the induced heave error. Validation using field survey data demonstrates that this method can effectively estimate the installation offset parameters of the…
Click any figure to enlarge with its caption.
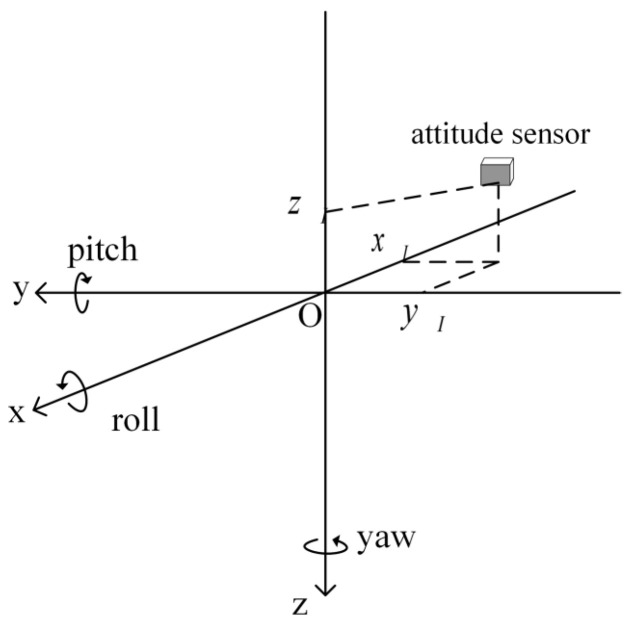 Figure 1
Figure 1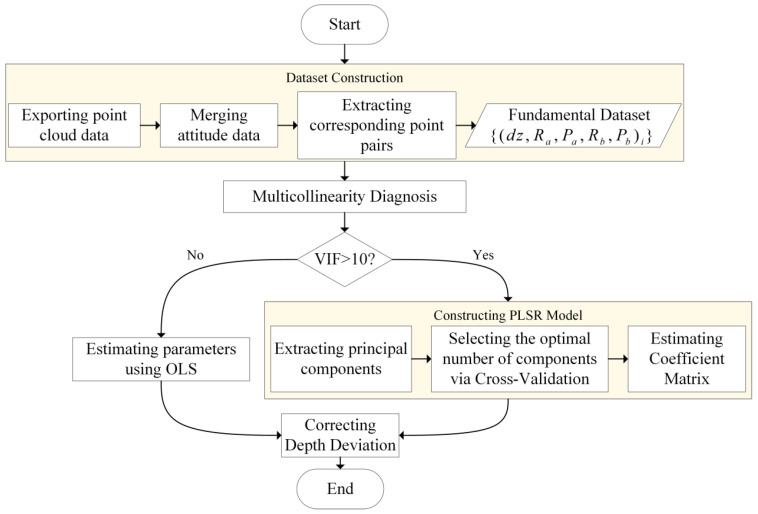 Figure 2
Figure 2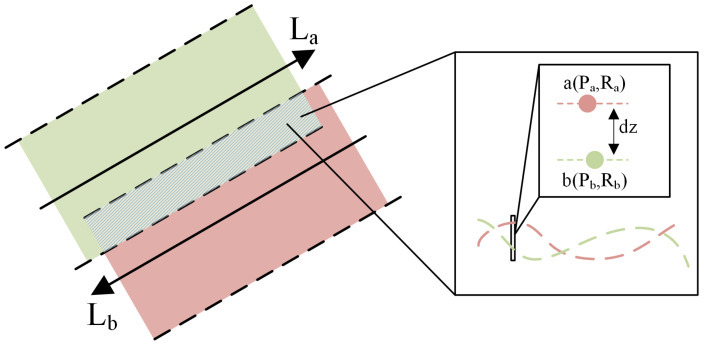 Figure 3
Figure 3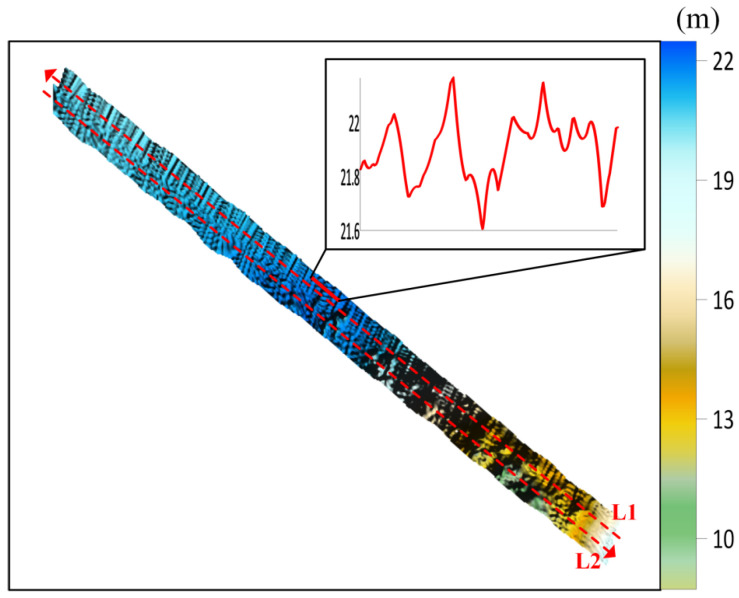 Figure 4
Figure 4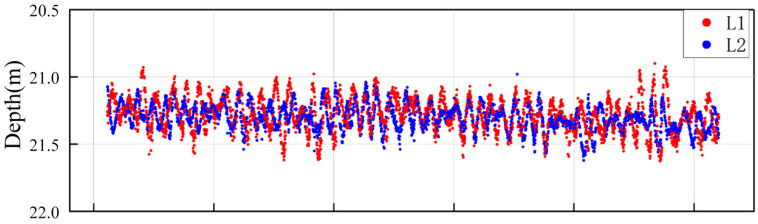 Figure 5
Figure 5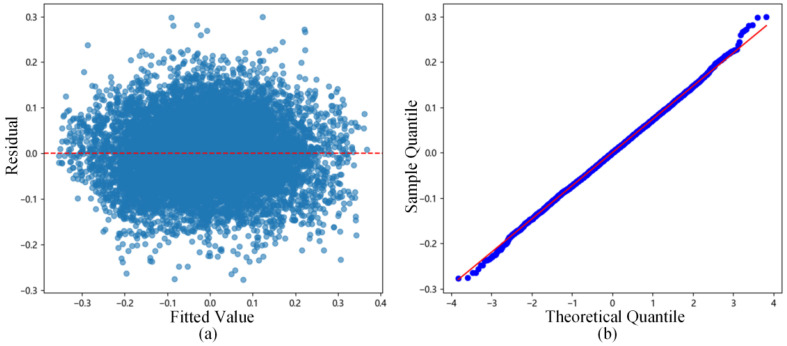 Figure 6
Figure 6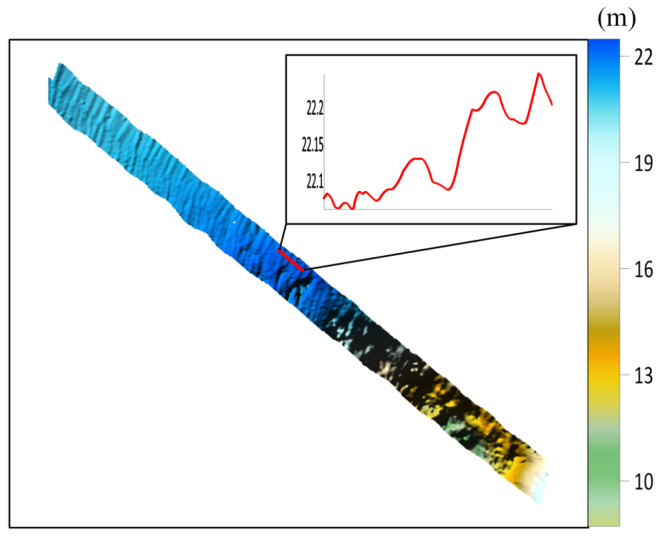 Figure 7
Figure 7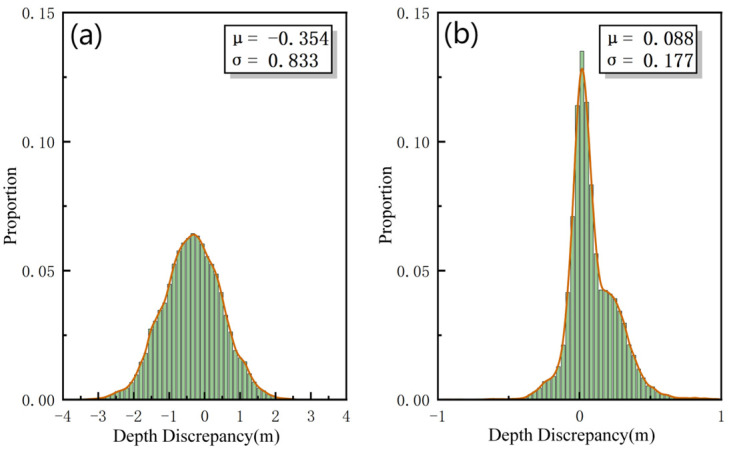 Figure 8
Figure 8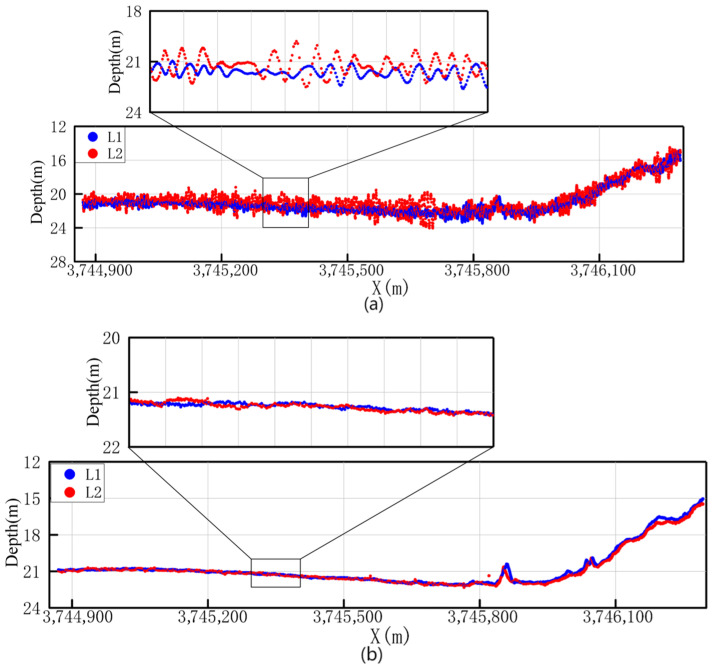 Figure 9
Figure 9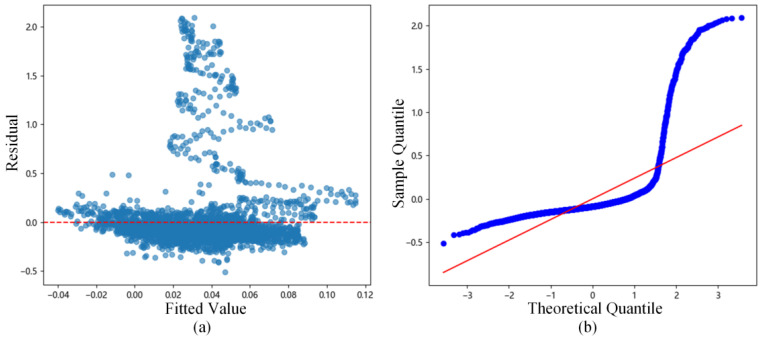 Figure 10
Figure 10- —National Natural Science Foundation of China
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsUnderwater Acoustics Research · Coastal and Marine Dynamics · Geophysics and Gravity Measurements
1. Introduction
The Multibeam Echo Sounder (MBES), renowned for its wide coverage, high efficiency, and high-resolution capabilities, has revolutionized the operational paradigm of traditional single-beam sounding and become a primary technique for acquiring high-resolution seabed topographic data [1,2]. Induced heave error, resulting from the installation deviation of attitude sensors, is one of the key factors affecting the quality of multibeam bathymetric data [3]. When the actual installation position of an attitude sensor deviates from its theoretically designed location, the pitch and yaw motions of the vessel will, through the lever arm effect, cause the transducer to generate additional vertical heave error, known as induced heave error. This error typically manifests as periodic stripe-like distortions along the track direction in bathymetric products, significantly degrading the accuracy and usability of seabed topographic data.
Currently, compensation for induced heave error often relies on precise calibration during the sensor installation phase. However, in practical operations, residual installation biases are difficult to completely avoid due to complex working conditions, imperfect calibration, or equipment displacement, leading to induced heave error systematically affecting sounding results [4]. Particularly in areas with complex topography, the morphological similarity between natural seabed variations (e.g., sand waves, valleys) and distortions caused by induced heave error makes effective distinction challenging through visual interpretation or empirical analysis alone, thereby increasing the difficulty of error identification and correction.
Regarding the elimination of anomalous stripes caused by induced heave error, two main technical approaches have been developed: The first is filtering methods based on signal processing, such as trend surface filtering and frequency-domain filtering, which aim to separate the error signal from the true terrain by constructing background trend surfaces or designing filters. For instance, Huang et al. [5] proposed using a Least Squares Support Vector Machine model to construct a terrain trend surface for filtering, showing some suppression effect on stripes induced by heave error. Dong et al. [6] proposed a bathymetric data filtering method based on the rolling circle transform, processing multibeam data Ping by Ping; however, this method is primarily suitable for flat areas and has limited effectiveness in complex terrains. Zhang et al. [7] proposed an improved trend surface filtering algorithm for multibeam sounding data based on the local minimum range of scattered sounding points, which gradually filters outliers through local surface fitting and better preserves true seabed features, but its effectiveness in mitigating regular stripe errors is not significant. Zhang et al. [8] introduced median filtering before trend surface filtering to perform weighted correction on depth data, enhancing the algorithm’s robustness, yet like other filtering methods, it still does not achieve ideal results in eliminating systematic stripes along the track. These methods are straightforward to implement and computationally efficient, offering good smoothing effects for isolated outliers and slight stripe noise in flat or gently sloping terrain. However, they also have notable limitations. Firstly, the filtering effectiveness heavily depends on the selection of polynomial order and local window size; inappropriate parameters can lead to under-filtering or over-smoothing. Secondly, in areas with complex and rugged topography, low-order polynomials struggle to accurately fit the real terrain, potentially misidentifying normal steep features as outliers or failing to effectively detect stripe errors superimposed on complex topography.
The second approach is correction methods based on error modeling, which involve establishing a mathematical model between attitude parameters and bathymetric discrepancies to directly estimate the sensor installation bias parameters, thereby eliminating the error influence from the raw data. For example, Long et al. [9] proposed a method for the quadratic detection of attitude sensor position bias based on depth discrepancies between corresponding soundings from reciprocal survey lines. By modeling the relationship between sensor position bias and depth discrepancies and using support vector regression to estimate the position bias, they effectively removed the influence of induced heave error from the bathymetric data. This type of method can fundamentally eliminate systematic errors, and its correction results have clear physical significance, maximizing the retention of true seabed topographic details and avoiding the potential terrain blurring associated with filtering methods. However, the challenge lies in the accurate diagnosis of the error source and the precise establishment of the error model, requiring considerable operator experience and data analysis skills.
Based on an analysis of the mechanism generating induced heave error, this paper systematically investigates its discrimination and correction methods. Firstly, an error discrimination method based on regression diagnostics is proposed. This involves establishing a multiple linear regression model between bathymetric discrepancies and attitude parameters, combined with significance testing and residual analysis, to achieve objective identification of the error source. Furthermore, addressing the instability of traditional least squares estimation under multicollinearity conditions, the Partial Least Squares Regression (PLSR) method is introduced to construct a high-precision correction model for induced heave error, providing effective technical support for enhancing the quality of multibeam bathymetric data.
2. Method for Identifying Induced Heave Error
In complex topographic areas, the natural undulating features of the seabed (such as sand waves, ripples, grooves, etc.) are highly similar in morphology to the distortions caused by induced heave error, leading to easy confusion between the two in the data [10]. Since sand wave topography itself exhibits periodic fluctuations, its spatial distribution characteristics may overlap in spectrum and spatial scale with the wavy depth offsets caused by induced heave error [11]. Relying solely on subjective interpretation or empirical analysis makes it difficult to effectively distinguish between them. Therefore, there is an urgent need to construct an objective discrimination method based on mathematical modeling and statistical diagnosis. By quantitatively analyzing the correlation between bathymetric discrepancies and attitude parameters, the characteristics of residual distribution, and the laws of error propagation, the coupling effect between natural topographic variation and error distortion can be decoupled, thereby enabling accurate identification and correction of induced heave error in complex scenarios. This paper proposes a heave error discrimination method based on regression diagnostics [12]. It establishes a mathematical relationship between bathymetric discrepancies and attitude parameters using a linear regression model and systematically identifies error sources by comprehensively applying parameter significance testing, goodness-of-fit analysis, and residual distribution verification.
2.1. Impact of Induced Heave Error on Sounding Point Position
During operations, the survey vessel is affected by swells, leading to periodic heave motion, which can be monitored by the attitude sensor. Due to roll and pitch motions, the vessel cannot maintain a perfectly horizontal state, resulting in differences in heave motion at different locations on the vessel. This phenomenon of inconsistent heave between the transducer and the attitude sensor caused by roll and pitch is termed induced heave. The positional relationship between the attitude sensor and the transducer is shown in Figure 1.
In Figure 1, the origin of the coordinate system is the center of the transducer, the x-axis points towards the bow, the y-axis points towards the starboard side, and the z-axis points towards the seabed. The roll angle is defined as positive when the starboard side pitches downward, and the pitch angle is positive when the bow pitches upward. The induced heave can be calculated from the offset of the attitude sensor relative to the transducer and the roll angles and pitch angles provided by the attitude sensor at different times using the following formula [13]:
The heave of the transducer is the algebraic sum of the measured heave and the induced heave:
The heave of the transducer affects the depth of the sounding point. From Equation (2), it can be seen that when errors exist in the measured heave and the induced heave, they will cause depth deviation in the sounding point, with a value of:
where is the measurement error of the heave measured by the attitude sensor, and is the induced heave error resulting from the positional offset of the attitude sensor relative to the transducer and the measurement errors in the roll and pitch angles provided by the attitude sensor. Its value is:
where represent the true value of the attitude sensor positional offset, and are the observed value containing measurement errors.
2.2. Induced Heave Error Discrimination Method Based on Regression Diagnostics
2.2.1. Establishment of the Induced Heave Error Regression Model
Assuming that only induced heave error is present in the survey lines, the depth values of a corresponding point pair at the same location in two adjacent lines, a and b, are, respectively:
where is the true water depth at that location, and are the induced heave errors contained in the depth values of the corresponding point pair, and are the residual error. Taking the difference of the depth values for this corresponding point pair and combining it with Equation (4) yields the bathymetric discrepancy :
where are the true value of the attitude sensor positional offset, are the observed value containing measurement errors, and is the difference in residual errors, which should follow a normal distribution. To simplify the expression, three explanatory variables are defined:
Analyzing Equation (6) shows that when induced heave error is present in the survey lines, the bathymetric discrepancy between corresponding point pairs in the two lines satisfies a linear relationship with ; conversely, if no induced heave error exists, the linear relationship between them is not significant.
Based on the effective matching distance , corresponding point pairs between two adjacent survey lines are extracted. The value of is determined by the average point cloud density within the overlapping area of the main survey line and the check line, specifically defined as:
where is the number of multibeam sounding points in the overlapping area, and is the area of the overlapping region between the main survey line and the check line. Since factors such as sound velocity errors, vessel attitude, and installation biases can affect the horizontal position of sounding points, these errors must be preprocessed to ensure that the extracted corresponding point pairs indeed represent the same location on the seabed. After extracting the corresponding point pairs, calculate for each pair to fit the regression model. It is particularly important to note that the selected adjacent survey lines should be as parallel as possible and maintain a stable heading; otherwise, systematic errors related to the incidence angle might be introduced into the bathymetric discrepancies, affecting the normality of the regression model residuals.
Subsequently, based on Equation (6), a multiple linear regression model is established:
where is the intercept term, reflecting the combined influence of other residual systematic errors, and respectively represent the contribution coefficients of the independent variables to the bathymetric discrepancy. The model parameters are estimated using the least squares method, yielding the regression model.
2.2.2. Model Testing and Evaluation
After obtaining the regression model, its fitting performance is evaluated through significance testing and goodness-of-fit analysis [14].
1.Significance Testing
The statistical significance of the regression coefficients is assessed using the t-test. For each coefficient , assuming , the t-statistic is constructed:
where is the estimated value of the coefficient , and is the standard deviation of the regression coefficient. Under the null hypothesis , the t-statistic follows a t-distribution with degrees of freedom (where is the sample size, and is the number of independent variables). If the calculated -value is less than the significance level ( ), the null hypothesis is rejected, indicating that the influence of the corresponding independent variable on the bathymetric discrepancy is statistically significant, thereby excluding random noise interference. When the -value for all coefficient t-tests are less than 0.05, it can be considered that there is a possibility of a linear relationship between and , otherwise, the linear relationship between the variables should be negated.
2.Goodness-of-Fit Analysis
The explanatory power of the model is evaluated using the coefficient of determination and the adjusted coefficient of determination . is defined as the proportion of the variance explained by the model to the total variance:
where is the residual sum of squares, and is the total sum of squares. The closer is to 1, the more of the variation in bathymetric discrepancies can be explained by the attitude parameters. However, increases monotonically with the addition of independent variables, potentially masking the risk of overfitting. To address this, the adjusted coefficient of determination is introduced:
It penalizes the number of independent variables, providing a more robust reflection of the model’s true explanatory power. This study considers that when , the model can effectively capture the linear relationship between the variables.
2.2.3. Residual Analysis and Assumption Verification
The reliability of the regression model depends on the statistical assumptions about the error term (homoscedasticity, normality), which must be strictly verified through residual analysis.
1.Residuals vs. Fitted Values Plot
A scatter plot is drawn with the model predicted values on the horizontal axis and the residuals on the vertical axis. If the residuals are randomly distributed around the zero line without any discernible trend, the homoscedasticity assumption is satisfied, indicating that the model correctly captures the linear relationship between the variables. If the residuals exhibit a curved trend (such as U-shaped or parabolic), it suggests a violation of the homoscedasticity assumption. This can lead to misestimation of the standard errors of the regression coefficients, rendering confidence intervals invalid and significance tests ineffective.
2.Residual Quantile–Quantile (Q-Q) Plot
The normality of residuals is a core assumption for the validity of the linear regression model. The residual Q-Q (Quantile–Quantile) plot is used to check whether the residuals follow a normal distribution [15]. It compares the quantiles of the sample data against the quantiles of a theoretical normal distribution. If the points on the Q-Q plot approximately lie along a straight line, it indicates that the residuals approximately follow a normal distribution; if the points deviate from the line, it suggests skewness or other distributional characteristics.
3.Anderson–Darling Normality Test
The Anderson–Darling (A-D) normality test is a statistical method used to determine whether a dataset follows a normal distribution. The A-D test is employed for further quantitative analysis of the normality of the residuals [16], providing the corresponding statistic :
where is the cumulative distribution function of the standard normal distribution, and are the sorted residuals. If corresponding to the A-D statistic is less than the significance level, the normality hypothesis should be rejected, deeming the specified linear model unreasonable; conversely, it indicates that the residuals strictly conform to a normal distribution, and the model assumption is reasonable.
Finally, if the model passes the significance tests and the residuals satisfy the homoscedasticity and normality assumptions, it can be concluded that the heave error indeed exists.
3. Method for Correcting Induced Heave Error
When it is confirmed that the anomalous topographic stripes are caused by induced heave error, a secondary calibration of the installation position offset of the attitude sensor is necessary to mitigate the impact of this error on the topographic data. To this end, this paper proposes an induced heave error elimination method based on PLSR, which mainly includes four steps: dataset construction, multicollinearity diagnosis, parameter estimation, and depth deviation correction. The workflow is shown in Figure 2. The method is elaborated in detail below.
3.1. Dataset Construction
To build the induced heave error correction model, it is first necessary to acquire the fundamental dataset used for modeling. The core concept of the method proposed in this paper is to invert the installation offset parameters of the attitude sensor using the bathymetric discrepancies in the overlapping areas of adjacent survey lines [17]. The required data include the bathymetric discrepancies , as well as the roll angles and pitch angles from the attitude sensor corresponding to each sounding point, as shown in Figure 3. The data acquisition and processing workflow is as follows:
First, software such as CARIS HIPS 12.1 is used to perform preprocessing on the raw multibeam bathymetric data, including sound velocity correction, tidal correction, and outlier filtering [18]. The measurement data from two adjacent survey lines are exported, including the latitude and longitude coordinates, depth values, and corresponding timestamps of each sounding point. To effectively separate the induced heave error from bathymetric data affected by multiple error sources, interference from other error factors must be suppressed as much as possible. Considering that angle-dependent errors like sound velocity errors and installation biases significantly affect the positional accuracy of sounding points, only central beam sounding points with beam incidence angles between −30° and 30° are used for modeling [19].
Subsequently, the roll and pitch observations from the attitude sensor records at the corresponding time series are extracted. The bathymetric data and attitude data are matched based on the measurement timestamps, assigning the roll and pitch angles at the corresponding time to each sounding point. Then, the latitude and longitude coordinates of the sounding points are uniformly converted to UTM projected coordinates to facilitate planar distance calculations [20].
On this basis, corresponding point pairs meeting the criteria within the overlapping area of the two survey lines are extracted according to the effective matching distance, . Finally, sets of valid corresponding point pairs are obtained, forming the fundamental dataset for PLSR modeling. This dataset will provide the basis for subsequent multicollinearity diagnosis and parameter estimation.
3.2. Multicollinearity Diagnosis
Substituting the fundamental dataset into the regression model Equation (9) yields:
The matrix form of Equation (14) is
where is the dependent variable matrix of the model,
is the independent variable matrix of the model, is the coefficient matrix, and is the residual vector.
For Equation (15), the least squares estimate of the coefficient matrix should be [21]:
However, since the independent variables are all composed of trigonometric functions of the attitude angles, there may be strong multicollinearity among them. Multicollinearity causes the design matrix to tend towards singularity, thereby significantly increasing the diagonal elements of its inverse matrix (corresponding to the variance of the parameter estimates ) and ultimately severely undermining the accuracy of parameter estimation.
The Variance Inflation Factor (VIF) is an indicator measuring the degree of multicollinearity in a regression model. Its calculation formula is:
where is the coefficient of determination obtained by regressing one independent variable against the others. Calculate the for each independent variable sequentially and use the maximum value among them as the basis for multicollinearity diagnosis. indicates complete independence among variables, suggests mild multicollinearity, indicates moderate multicollinearity, and signifies severe multicollinearity [22]. In such cases, the estimates obtained by traditional least squares regression are unreliable. The following section will employ the PLSR model to estimate the coefficient matrix [23].
3.3. PLSR Model Construction
PLSR is a multivariate data analysis method in statistics and machine learning, particularly suitable for situations where multicollinearity exists between dependent and independent variables [24]. Its basic idea is to extract latent components from both the independent variable matrix X and the dependent variable matrix Y, such that these components not only summarize the information of the original variables well but also maximize the explanation of the dependent variable. The method is detailed below.
For Equation (15), extract the first component as:
where is the eigenvector corresponding to the largest eigenvalue of the matrix . Establish the regression of onto .
where are the residual matrix of , and are the model effect load. The value of the model effect load c1 is obtained based on the least squares principle as:
Using instead of , extract the second component , and repeat the steps in Equations (18)–(20) until after extracting the r-th component, the residual matrix of is close to zero. At this point, we have:
Substituting the score vectors of each component into Equation (21) gives:
where , . Comparing Equation (22) with Equation (15), the Partial Least Squares estimate of the coefficient matrix can be obtained as:
The selection of the number of components in PLSR has a significant impact on model performance. Too few components lead to underfitting, while too many may cause overfitting. This paper uses the k-fold cross-validation method to select the optimal number of components [25]. This method involves dividing the dataset into k subsets, repeatedly using k-1 subsets as the training set and the remaining one subset as the validation set, thereby evaluating the model’s generalization ability under different numbers of components.
The choice of the number of folds k in cross-validation requires a balance between bias and variance. When k is small, the training set size is relatively small, potentially leading to high estimation bias; when k is too large, the folds are highly correlated, leading to high estimation variance. Considering both computational efficiency and sample size, this paper adopts 5-fold cross-validation [26]. For each candidate number of components, the mean squared error of the 5-fold cross-validation is calculated, and the number of components that minimizes the cross-validation mean squared error is selected as the optimal number.
After obtaining the estimated value of the coefficient matrix , combined with the attitude parameters and , the depth of multibeam sounding points can be corrected according to the following formula:
where and represent the water depth before and after correction, respectively. The performance of the above method will be verified and analyzed using field survey data in the following sections.
4. Experimental and Analysis
4.1. Trial Description
To verify the applicability and effectiveness of the proposed method under complex topographic conditions—where heave errors are more challenging to identify and correct compared to flat, deep-water areas—a test area with significant topographic relief was selected in the Yellow Sea, China. The region has an average water depth of about 20 m and features varied seabed morphology, providing a demanding environment for method validation. Two adjacent parallel survey lines, each approximately 2200 m in length, were surveyed using an EM2040C multibeam echo sounder system. The system was configured with a ping update rate of 27 Hz, operating in equidistant measurement mode with a sector opening angle of 110° and 256 beams per ping. To retain the original error characteristics for analysis, although the offset parameters of the attitude sensor were measured during the survey, real-time compensation was not applied during data acquisition.
The collected raw bathymetric data underwent quality control and position calculation. After removing abnormal sounding points and outer beam data, the multibeam point cloud data were obtained. After gross error removal and grid interpolation processing, the measured topographic map shown in Figure 4 was generated. Obvious stripe-shaped topographic distortions along the track direction can be observed in the figure, with significant fluctuations in local topographic profiles. Due to the inherently complex topographic variations in this area, the natural topographic features are morphologically similar to the distortions caused by induced heave error, making them difficult to distinguish effectively. Therefore, it is necessary to conduct the identification and correction of the induced heave error.
4.2. Validation of the Effectiveness of the Error Discrimination Method
The induced heave error was discriminated according to the method described in Section 2. Bathymetric data from the same along-track profile of the two survey lines were extracted for linear regression model fitting. Based on the distance, corresponding point pairs were extracted, resulting in a total of 10,390 pairs. A partial point cloud profile is shown in Figure 5. The depth values of each corresponding point pair were integrated with the roll and pitch data of the survey vessel at the corresponding time, and the regression model was established according to Equation (9). The regression results and significance analysis results are detailed in Table 1. The results show that the -value of the t-test for each independent variable are all less than the significance level of 0.05, indicating that the variables have a statistically significant linear driving effect on the bathymetric discrepancy. Meanwhile, the calculated adjusted coefficient of determination for the model is 0.742, verifying the strong correlation between the heave error and the attitude parameters.
The residuals of the fitting results were analyzed, and the residuals vs. fitted values plot (Figure 6a) and the residual Q-Q plot (Figure 6b) were drawn. Observing Figure 6a, the residuals are evenly distributed between −0.3 and 0.3, indicating homoscedasticity of the residuals. Observing Figure 6b, the points are basically distributed along the diagonal, supporting the assumption of residual normality. Simultaneously, the Anderson–Darling normality test was performed on the residuals, yielding a statistic value of 0.4270 and a -value of 0.3131. This -value is higher than the significance level of 0.05, statistically strictly proving the normality of the residuals.
This series of quantitative analyses confirms the objective existence of the induced heave error from a statistical perspective, demonstrating that the method proposed in this paper can effectively identify induced heave error and provide a quantifiable decision basis for error discrimination in complex topographic scenarios.
4.3. Validation of the Effectiveness of the Error Correction Method
The induced heave error was corrected according to the method described in Section 3. Based on the effective matching distance, corresponding point pairs with beam incidence angles between −30° and 30° were extracted from the overlapping area of the two survey lines, resulting in 55,299 sets of valid matching data. For each corresponding point pair, the bathymetric discrepancy was calculated, and combined with the roll and pitch observations recorded by the attitude sensor at the corresponding time, the fundamental dataset for regression modeling was constructed. The three explanatory variables were calculated based on Equation (7), and the for each variable was calculated, with the results listed in Table 2. From Table 2, , indicating a severe multicollinearity problem among the variables. Therefore, the PLSR method was adopted to robustly estimate the coefficient matrix.
During the construction of the PLSR model, the 5-fold cross-validation method was used to determine the optimal number of components. The validation results showed that when the number of components was 3, the cross-validation Root Mean Square Error (RMSE) reached the minimum value of 0.233, indicating that the model has the best predictive performance and generalization ability under this configuration. Finally, the PLSR model was established based on 3 principal components, and the estimated values of the obtained regression coefficients are listed in Table 3.
After obtaining the estimated regression coefficients, the depth values of all beam points in survey lines L1 and L2 were corrected according to Equation (24). Figure 7 shows the topographic map generated based on the corrected point cloud data. Compared with Figure 4, the original anomalous stripes along the track direction in the two survey lines have been basically eliminated after correction. The topographic profile morphology is smoother and more continuous, reflecting the undulations of the real seabed topography more reasonably. This result verifies the correctness of the earlier conclusion regarding the discrimination of induced heave error and also demonstrates the good effectiveness of the proposed error correction method in handling stripe-shaped topographic distortions caused by induced heave error.
To objectively evaluate the correction effect of the induced heave error, quantitative and qualitative analyses were conducted from two aspects: the statistics of discrepancies in the survey line overlap area and the consistency of along-track topographic profile mosaicking.
1.Status of Discrepancies in the Survey Line Overlap Area.
The distribution characteristics of depth discrepancies directly reflect the consistency and accuracy level of the data. Figure 8a,b show the distribution of depth discrepancies in the overlap area of survey lines L1 and L2 before and after the induced heave error correction, respectively. Comparing Figure 8a,b, it can be seen that the histogram of the corrected discrepancies is significantly more concentrated and has a taller, narrower shape. Statistical results show that the standard deviation of the discrepancies decreased from 0.833 m before correction to 0.177 m after correction, and the mean absolute value decreased from 0.354 m to 0.088 m. This change indicates a significant reduction in systematic bias and a clear decrease in dispersion in the corrected data, verifying the effectiveness of the proposed method in improving data quality.
2.Analysis of Along-Track Profile Mosaicking for Adjacent Survey Lines.
To further intuitively evaluate the correction effect, profiles along the track direction were extracted and analyzed from the point cloud data before and after correction. Figure 9a,b show the topographic mosaicking situation of the two survey lines on the same along-track profile before and after correction, respectively. By comparison, it is evident that the corrected point clouds show better consistency in the profile morphology, with significantly improved mosaicking effect and enhanced topographic continuity.
In summary, the analysis above demonstrates that the method proposed in this paper can effectively suppress the impact of induced heave error on topographic data and significantly improve the accuracy and reliability of multibeam bathymetric data.
4.4. Reverse Verification of the Correctness of the Error Discrimination Method
The corrected data were used again for error discrimination. The new regression results and significance analysis results are shown in Table 4. The results show that the p-values of the t-test for variables and are greater than 0.05, indicating that the linear driving relationship between the attitude parameters and the bathymetric discrepancy has been significantly weakened. The adjusted coefficient of determination ( ) further corroborates that the attitude parameters can only explain 0.4% of the variation in bathymetric discrepancies, forming a significant contrast with the pre-correction result ( ).
New residuals vs. fitted values plot (Figure 10a) and residual Q-Q plot (Figure 10b) were drawn. It can be seen in Figure 10a that the residual distribution is uneven, and in Figure 10b the points deviate severely from the diagonal. Meanwhile, the Anderson–Darling normality test statistic is 663.9711 with a -value of 0.0000, which is below the significance level of 0.05, indicating that the residuals do not possess homoscedasticity and normality.
Based on the above analysis, it can be concluded that in the absence of induced heave error, there is no statistically significant correlation between the bathymetric discrepancies and the attitude parameters. This reversely verifies the specificity and correctness of the discrimination method proposed in this paper in capturing the error characteristics.
5. Conclusions
This paper systematically investigated and proposed a complete technical workflow, from discrimination to correction, targeting the induced heave error caused by attitude sensor installation biases in multibeam bathymetry. Firstly, regarding error discrimination, an objective identification method based on regression diagnostics was proposed. By establishing a multiple linear regression model between bathymetric discrepancies and attitude parameters, and comprehensively applying parameter significance testing, goodness-of-fit analysis, and tests for homoscedasticity and normality of residuals, effective detection and statistical confirmation of induced heave error were achieved. This method overcomes the difficulty of empirically distinguishing error-induced distortions from natural topographic components in complex seabed environments. Secondly, concerning error correction, the Partial Least Squares Regression (PLSR) method was introduced to address the multicollinearity problem among independent variables in the regression model. By extracting latent variables that best explain the dependent variable, PLSR constructs a stable model for estimating installation offset parameters, effectively avoiding the estimation instability of traditional least squares methods under ill-conditioned scenarios and laying a theoretical foundation for high-precision error correction. Finally, the proposed methods were tested using field survey data. The results indicate:
- (1)The discrimination method based on regression diagnostics can effectively identify the presence of induced heave error with strong specificity and no misjudgment occurred, verifying the reliability of this method under complex topographic conditions.
- (2)The PLSR correction method can accurately estimate the installation offset parameters of the attitude sensor. After correction, the Root Mean Square Error (RMSE) of depth discrepancies between adjacent survey lines significantly decreased from 0.833 m to 0.177 m, a reduction of 78.8%, demonstrating the notable effectiveness of this method in error suppression.
- (3)Visualization of the topographic point cloud results shows that the periodic stripe-shaped distortions along the track direction were basically eliminated after correction, and the continuity of topographic profiles and the consistency of mosaicking were markedly improved. Reverse regression diagnostics performed on the corrected data further indicated that the systematic correlation between attitude parameters and depth discrepancies has been effectively removed, confirming the validity of the error correction.
In summary, the methodological framework proposed in this paper provides an effective solution for the objective identification and high-precision correction of induced heave error, offering robust technical support for enhancing the quality and reliability of multibeam bathymetric data under complex topographic conditions.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Sun H. Li Q. Bao L. Wu Z. Wu L. Progress and Development Trend of Global Refined Seafloor Topography Modeling Geomat. Inf. Sci. Wuhan Univ.20224715551567
- 2Loureiro G. Dias A. Almeida J. Martins A. Hong S. Silva E. A Survey of Seafloor Characterization and Mapping Techniques Remote Sens.202416116310.3390/rs 16071163 · doi ↗
- 3Zhao J. Liu J. Multi-Beam Sounding and Image Data Processing Wuhan University Press Wuhan, China 2008
- 4Jin S. Liu G. Sun W. The Research on Depth Reduction Model of Multibeam Echosounding Considering Ship Attitude and Sound Ray Bending Hydrogr. Surv. Chart.2019391
- 5Huang X. Zhai G. Sui L. Huang M. Application of Least Square Support Vector Machine to Detecting Outliers of Multi-beam Data Geomat. Inf. Sci. Wuhan Univ.201035118811961188–1191+1196
- 6Dong J. Peng R. Zhang L. Wang Z. An Algorithm of Filtering Noises in Multi-beam Data Based on Rolling Circle Transform Geomat. Inf. Sci. Wuhan Univ.2016418692
- 7Zhang Z. Peng R. Huang W. Dong J. Liu G. An Improved Algorithm of Tendency Surface Filtering in Multi-beam Bathymetric Data Considering the Natural Neighboring Points Influence Field Acta Geod. Cartogr. Sin.2018473547
- 8Zhang X. Pan G. Zhang J. Trend Surface Filtering Method for Multibeam Sonar Echo-sounding Data Based on Median Filter Weighed Correction Mar. Sci.2018423239