The Epidemiologic Comparison of Two Correlated Relative Risks: A Simple but Efficient Clinical Trial Design for Assessing Risk-Reduction and Treatment Significance
Jimmy T. Efird, Genevieve N. Dupuis, Yuk Ming Choi, Hongsheng Wu

TL;DR
This paper introduces a clinical trial design that compares two treatments using a shared control group, reducing study time and costs while accurately assessing risk reduction.
Contribution
A novel method for comparing two correlated relative risks using a shared control group in clinical trials.
Findings
Using shared controls reduces study time and costs in platform trials.
Multiplicity adjustment is unnecessary on the log-difference scale for three-group designs.
The method is illustrated with a practical example on LDL-C statin risk reduction.
Abstract
In the context of platform design, umbrella trials are a type of master protocol in which multiple treatments are randomized and evaluated with respect to a common, referent-control arm. In a simplified (1:1:1), non-adapted case, this is equivalent to the epidemiologic comparison of two correlated relative risks for assessing risk-reduction on the log-difference scale. The use of shared controls has the potential to reduce study time and costs but infers greater complexity to account for the covariance between relative effect estimates (i.e., dependence arising because treatment arms use the same referent group). Multiplicity adjustment is unnecessary on the log-difference scale (three-group design) as this is a single test statistic for interaction. An intuitive, risk-reduction (LDL-C statin) example is presented to illustrate the practical application of this method.
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
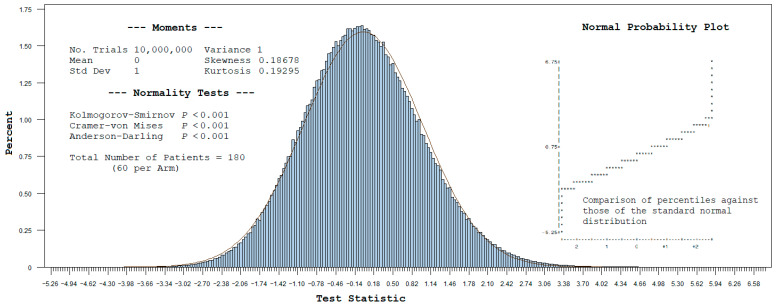 Figure 1
Figure 1 Figure 2
Figure 2- —National Institutes of Health
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsStatistical Methods in Clinical Trials · Advanced Causal Inference Techniques · Statistical Methods and Bayesian Inference
1. Introduction
An efficient and cost-effective clinical trial design involves comparing two or more treatment groups to a single, shared referent-control arm. This reduces the overall number of patients randomized to a comparison group by half, offering greater appeal to patients, drug companies, and investors [1]. In the basic instance of a new versus legacy therapy, relative to a common control group, this epidemiological approach is innovative, practical, and methodologically rigorous. A key advantage of the (1:1:1) design entails the simultaneous assessment of risk-reduction and treatment significance.
Parallel drug comparisons of this type are known as master protocol, platform studies, with the term “umbrella trial” denoting the assignment of patients to one of many therapies, typically based on their molecular characteristics [2]. When aptly applied, this strategy has clear and direct implications for real-world, clinical trial practice, culminating in reduced study time, costs, and bias.
The shared reference group usually consists of a mutually distinct, random collection of patients, but it can also be assembled from pooled controls of previously conducted clinical trials, historic collections, or registries. In the case of an observational, targeted trial emulation, controls need to meet the eligibility criteria at the time of case definition [3]. Regardless of study type, the sharing of controls is appropriate only if treatment arms are comparable with respect to the referent base population in terms of key attributes (e.g., time period, geographic location, and demographic makeup).
An important feature of this design is the correlated structure of the data, requiring the incorporation of a covariance term into the denominator of the test statistic. The need to account for multiplicity adjustment is offset in the simple, three-group (risk-reduction) design, as the analysis is based on a single log-difference test for interaction [4]. A generalized linear model (GLM) with a log-link function may be used to analyze the correlated data, which can accommodate both univariable and adjusted models for risk-reduction [5].
2. Preliminaries
2.1. Definition of Two Correlated Relative Risks in Terms of a 3 × 2 Cross-Tabulation Table
Let denote the cell sizes for a contingency table with rows and columns (see Table 1). Here, the rows represent the treatment exposures while the columns correspond to an unfavorable vs. favorable outcome in the context of risk-reduction. Define the two relative risk (RR) estimates being compared with respect to a common referent-control group as follows:
and
where are binomially distributed variables. Accordingly, represents the ratio of the event probability under to , while compares to .
2.2. Test Statistic and p-Value
Consider the following sample test statistic for comparing the ratio of two correlated RR estimates on the log-difference scale (i.e., ), with respect to a common referent-control group:
where the denominator estimates the square-root of the variance for denote the expectation, variance and covariance of the quantities indicated within parenthesis. The expectation of the log-difference, i.e., , equals zero under the null hypothesis (H_0_) that the two RRs are equivalent (i.e., ), versus the alternative (H_1_) that they differ (i.e., ).
When the sample sizes for each group are sufficiently large, will tend to be conditionally independent, and one can simply estimate the denominator of by , where is defined as the standard error. That is, as sample estimates become more reliable and stable, with the covariance term approaching zero and assuming a standard normal distribution. However, for smaller sample sizes, the relative effect estimates are less accurate and more prone to random fluctuation (variability). To warrant approximate normality of the test statistic for reasonably sized, non-asymptotic samples, it remains integral to account for the sample covariance term in the denominator.
The corresponding p-value for interaction is computed as follows:
where
2.3. Analytic Details
2.3.1. Delta Approximation
The “Delta (δ) method” provides a first-order Taylor series approximation for the variance of a function involving random variables with known, finite moments [6]. By defining as the function of two variables , each with a small coefficient of variation, it follows that
where the partial derivatives of with respect to are evaluated at their respective mean values. The method assumes a local linear approximation of the underlying response surface, with optimal results realized when the function assumes an asymptotically Gaussian distribution.
2.3.2. Sample Variance and Covariance Estimates
Applying the δ-method, it is easily seen that
Accordingly,
Likewise,
As the only common term for is , it readily follows from the δ-method that
This result reflects the variance component attributable to the shared, referent-control arm (i.e., the first two terms of
2.4. Comparison of Two Correlated Odds Ratios
Rather than RRs, the relative effect measure of interest may be odds ratios (ORs). An important aspect of ORs is that the estimate is “invariant to rotation”, meaning that the disease and exposure ORs are equivalent. Importantly, ORs are a versatile measure of association, whether analyzing incidence-density or cumulative-incidence studies. When the outcome is rare in both the exposed and unexposed groups, the RR and OR estimates are approximately equal. Independent of the rare disease assumption, ORs are also fairly accurate estimates for rate ratios when the proportion of the population exposed and disease incidence remain constant over time.
Analogous to the test statistic for correlated RR estimates, two ORs may be compared with respect to a common referent-control group on the log-difference scale. That is, with the covariance term implicit in the denominator,
where the subscript in denotes the log-ratio of and . Again, using the 3 × 2 cross-tabulation table notation, the two sample ORs being compared with respect to a common referent-control group are defined as follows:
and
Applying the δ-method and rearranging, we have the following [7]:
and
2.5. Multinomial Distribution and Simulated Exact Statistics
Parameter estimates and the underlying distribution for may be easily obtained by simulating observations from a multinomial distribution [8,9]. In effect, this provides exact statistics, which may be preferable when the sample sizes are very small and the normality of the test statistic is questionable. The simulated values are also useful for validating the large sample variance and covariance estimates obtained by the δ-method.
Conditioning on the total number of patients , the probability that a mutually exclusive set of non-negative random variates takes on a particular value ( ) is given as follows:
where
and
The estimated probability for the cell of a 3 × 2 multinomial table for comparing two correlated relative effect estimates is given as .
3. Computational Methods
Analyses were performed and validated in SAS 9.4 (Cary, NC, USA). The GENMOD procedure for implementing GLMs was used to compute RRs (log-link function), ORs (logit-link function), and respective p-values for interaction. The interactive matrix language procedure (PROC IML) was used to simulate values from a multinomial distribution.
4. Relative Risk-Reduction Example
Consistently high blood levels of low-density lipoprotein (LDL-C) underlie a condition known as atherosclerotic cardiovascular disease (ASCVD), which manifests as the accumulation of plaque in the arteries (Table 1). Cardiologists recommend achieving LDL-C levels of less than 70 mg/dL following therapeutic intervention. A randomized clinical trial was undertaken to assess the benefit of a new (molecularly targeted) statin drug over a previously approved (standard) agent , by way of a common referent-control arm of diet and exercise . A 33% relative risk-reduction on the log-difference scale was observed following 18 months on the new statin therapy combined with diet and exercise (PInt = 0.01994), versus standard treatment. In comparison, the estimated OR reduction on a log-difference scale was 167%, with a p-value for interaction of 0.01857, illustrating an exaggerated result for the ratio of ORs, owing to the frequent outcome event.
The manually obtained results provided in Table 1 are easily validated within rounding error against the PROC GENMOD output shown in Appendix A. For example,
and,
5. Simulated Exact Results
A multinomial distribution was used to obtain 10 million 3 × 2 tables based on the cell values in Table 1, with the frequency (histogram) plot for the test statistic shown in Figure 1. Given the relatively small sample size of 60 patients per arm, this is seen to follow a slightly skewed standard normal distribution (compared with solid Gaussian line), with non-zero skewness (0.18678) and kurtosis (0.19295). In this specific case, the distribution is right (positive)-skewed, wherein the tail is longer on the right side. Also note the higher peak of the simulated distribution, representing the value with the greatest probability.
The simulated exact results are given in Table 2. The area to the right of the test statistic under this distribution gives the simulated exact p-value for the interaction. Comparatively, the variance and covariance estimates obtained by the δ-method are reasonably close to the simulated exact statistics. Given the mild, right skewness of the simulated distribution, the p-value for interaction obtained by the exact method (i.e., 0.01566) is slightly more significant than that obtained by the normal theory method (i.e., 0.01994). However, this may not always be the situation for other examples, and one cannot assume that the normal theory result will universally yield the more conservative p-value.
6. Discussion
6.1. Overview
Master protocol platform studies embody an optimal approach for conducting parallel, clinical trials. Efficiencies are gained by using a shared control arm, which conveys a correlated, economical structure to the data. The manuscript at hand focuses on a non-adaptive (1:1:1) design. This simplified approach is equivalent to the assessment of two relative-risk estimates, with each epidemiologic measure being dependent on a collective denominator (single comparison group). When the disease outcome is rare among the two drugs being compared, a clinical trial may be emulated as a population-based, retrospective design, with a common referent group.
For moderately sized studies, as demonstrated with an example of patients (60 per arm), the (1:1:1) design is reasonably robust to departures from normality and can be easily analyzed as a GLM with a log-link function for RRs, which transforms the mean (µ) to the natural logarithm of (µ). This is in contrast with the logit-link function for ORs, which transforms the probability (µ) to the log-odds. The single, p-value for interaction offsets the need for multiplicity adjustment. Furthermore, the procedure is readily implemented using standard statistical software, with the option of including covariates to account for confounding.
In addition to clinical trials, the analysis of correlated data occurs in many epidemiologic settings (e.g., matched-pairs designs, pre- and post-studies, twin research, and cross-over investigations) [8]. A 2 × 2 × 2 three-way contingency design entailing the analysis of two paired binomial responses (measured on two treatments) has been used to compare side-effects of general anesthesia [10]. An overlapping collection of ~3000 controls has been implemented in a large genome-wide association study of ~2000 cases collected from seven diseases [11]. While methods to correct for a common referent-control group in association studies have been amply described in the literature, the emphasis has mainly been on correlated proportions and ORs [12,13]. In contrast, the current effort focuses on measuring the risk-reduction encountered when comparing two correlated RR estimates with a shared, dependent control arm. As a marginal method (versus ORs), the technique is appropriate to use for common diseases and prospective clinical analyses.
6.2. Advantages
A commonly employed clinical trial design involves directly comparing a new treatment against a standard agent and assessing the absolute effect risk-reduction (i.e., event rate difference between groups). However, the results may be biased because this design does not compare therapies with respect to a common, referent-control arm. For example, it may be challenging to prove the clinical usefulness of the new treatment if the standard drug was approved many years ago and is no longer as effective, owing to manufacturing changes, practice deviations, interactions with newer concomitant medications, and variations in the disease process. Assessing relative effect risk-reduction on a log-difference scale, using a shared referent group, effectively minimizes this threat to internal validity.
Another advantage of this design is accelerated drug development (i.e., shorter study time) and reduced resource allocation. Minimizing redundant control groups decreases the sample size of a study while increasing study power.
6.3. Limitations
A limitation of the normal theory approach is that the sample test statistic is reliant on the δ-method for obtaining variance and covariance estimates. This technique assumes that the first three partial derivatives of the underlying function are continuous, differentiable, and assume an asymptotic Gaussian form [14]. In most computer applications, only a first-order Taylor series approximation is used to derive variance estimates. Consequently, the asymptotic normality assumption may be questionable in small sample cases, with the conditional central limit theorem failing to hold true [15]. Increasing the sample size or using a second-order or higher Taylor series approximation may help to reduce bias. The exact method may need to be used if the data is particularly sparse or the rate of approaching normality is ostensibly slower than Barring extreme degenerate examples, the test statistic in practice typically assumes a moderately well-behaved, bell-shape distribution (for treatment groups of ~60 or more participants), and one may posit that the underlying data is sufficiently close in form to safely proceed with normal theory methods.
Under certain circumstances, convergence issues with the Bernoulli likelihood may occur when implementing the GLM approach with a log-link function. That is, the estimated probability of success vis-à-vis the Newton–Raphson algorithm may fall on or near the boundary of the parameter space (i.e., unity) [10]. One solution is to assume a Poisson likelihood and use the robust “generalized estimation equations method” to estimate the variance [16]. However, since Poisson regression allows predicted probabilities to exceed one, resulting confidence intervals will be slightly biased. An alternative workaround is to obtain estimates by applying the expectation–maximization (EM) algorithm [17]. The exact method based on re-parametrization of covariates is another promising approach. However, a rate-limiting aspect of the latter method is that the covariate vector of fitted probabilities equals unity and needs to be confirmed in advance [18].
The potential for misclassification bias may be a concern if a shared control is using either of the drugs under consideration at baseline, or begin their use after randomization (immortal time effect) [19]. Protocol deviations of this type must be carefully monitored during the course of the study and appropriately accounted for in the statistical analysis and reporting of results. Investigators should be vigilant of concomitant medications that may either intensify or diminish the referent effect. The selection of controls in a non-random fashion, or from a hospital source related to the outcome measure, poses another limitation that can be exacerbated with the use of a single-arm control group.
While reducing the time and cost of a study, combining external controls with randomized trial data can introduce complications, such as unmeasured confounding and collider bias. Chronological bias represents another concern, wherein aspects of the control group may change over time because of dependent temporal effects (e.g., practice changes, staff learning, unobserved time trends) [20]. Furthermore, the randomization of participants to the two treatment groups versus a common control arm “does not preclude confounding except for extremely large studies” [21].
Early termination or the censoring of participants poses a source of bias if differential in effect. Appropriate imputation methods suitable for correlated data may need to be implemented in such cases. State transition models or a counting process approach present other options for mitigating bias. When the effect is believed to be non-differential, the sample size may be increased in an adaptive fashion to offset bias toward the null. Deleting the affected participants from the analysis, if small in number, may be reasonable if appositely acknowledged.
The simplified (1:1:1) design for assessing risk difference on a log-difference scale does not require multiplicity adjustment when using shared controls. However, this may not be true for more complicated, multiple-arm, platform or umbrella trials that similarly utilize a common, referent arm. In general, it is best to consult a PhD-trained Epidemiologist or Statistician when designing a master protocol to ensure that the selected approach is valid for the application at hand and appropriately powered. This is especially important if one plans to use a flexible design that allows for adding or deleting treatment arms after trial commencement.
6.4. Future Directions
Future investigations are directed at innovative extensions of the log-difference, risk-reduction approach for conducting and analyzing clinical trials. This includes Bayesian hierarchical, mixed-model alternatives, and nonparametric adaptive methods, as well as efficient algorithms to compute conditional power. Additional consideration of designs using a shared attention-control arm would be informative. The latter would be explicitly designed to account for the bias of interacting with study staff, which is distinct from the compounds under study.
While the FDA recognizes the use of external controls in situations where conventional controls are not medically feasible or ethical (e.g., “rare conditions or indications lacking clinical equipoise for a concurrent control”), it remains imperative that the selection of nonconcurrent referents are representative of and generalizable to the targeted treatment population currently under study, as is true for all controls [22,23]. This includes “diseases with high and predictable mortality or signs and symptoms of predictable duration or severity”. The future development of novel techniques for adjusting nonconcurrent referents to the base population will be beneficial as such control groups become more commonly used in the log-difference, risk-reduction method at hand.
The selection of controls from an observational source can pose methodologic concerns as patients may “enter and exit the database at various times, ages, disease states, etc.” [23]. Additional research addressing this concern is needed.
7. Conclusions
The epidemiologic assessment of risk-reduction on the log-difference scale, using a shared referent-control arm, presents an efficient clinical trial design for comparing two correlated relative risk estimates of treatment effects. This method represents a simplified version of a multi-arm, parallel designed umbrella-platform trial without the need for multiplicity adjustment. The resulting p-value for the interaction is readily obtained using a GLM algorithm available in standard statistical software packages.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Ren Y. Li X. Chen C. Statistical consideration of phase 3 umbrella trials allowing adding one treatment arm mid-trial Contemp. Clin. Trials 2021910653810.1016/j.cct.2021.10653834384890 · doi ↗ · pubmed ↗
- 2Renfro L. Sargent D. Statistical controversies in clinical research: Basket trials, umbrella trials, and other master protocols: A review and examples Ann. Oncol.201728344310.1093/annonc/mdw 41328177494 PMC 5834138 · doi ↗ · pubmed ↗
- 3Bunin G. Baumgarten M. Norman S. Strom B. Berlin J. Practical aspects of sharing controls between case-control studies Pharmacoepidemiol. Drug Saf.20051452353010.1002/pds.113015959880 · doi ↗ · pubmed ↗
- 4Altman D. Bland J. Interaction revisited: The difference between two estimates Br. Med. J.200332621910.1136/bmj.326.7382.21912543843 PMC 1125071 · doi ↗ · pubmed ↗
- 5Nelder B. Wedderburtn R. Generalized Linear Models J. R. Statist. Soc. A 197213537038410.2307/2344614 · doi ↗
- 6Armitage P. Statistical Methods in Medical Research John Wiley and Sons New York, NY, USA 1971
- 7Bagos P. On the covariance of two correlated log-odds ratios Stat. Med.2012311418143110.1002/sim.447422302419 · doi ↗ · pubmed ↗
- 8Del Rocco N. Wang Y. Wu D. Yang Y. New confidence intervals for relative risk of two correlated proportions Stat. Biosci.20231513010.1007/s 12561-022-09345-735615750 PMC 9122488 · doi ↗ · pubmed ↗