Advancing Medical Decision-Making with AI: A Comprehensive Exploration of the Evolution from Convolutional Neural Networks to Capsule Networks
Ichrak Khoulqi, Zakariae El Ouazzani

TL;DR
This paper reviews CNNs and CapsNets for medical imaging, comparing their strengths and weaknesses to improve AI-based medical decision-making.
Contribution
A structured comparison of CNNs and CapsNets in medical imaging, highlighting their complementary roles and future hybrid system directions.
Findings
CNNs struggle with spatial variability in medical images, affecting diagnostic reliability.
CapsNets better capture spatial relationships, improving model generalization and stability.
Hybrid systems combining both architectures are proposed for more efficient and explainable clinical AI.
Abstract
In this paper, we propose a literature review regarding two deep learning architectures, namely Convolutional Neural Networks (CNNs) and Capsule Networks (CapsNets), applied to medical images, in order to analyze them to help in medical decision support. CNNs demonstrate their capacity in the medical diagnostic field; however, their reliability decreases when there is slight spatial variability, which can affect diagnosis, especially since the anatomical structure of the human body can differ from one patient to another. In contrast, CapsNets encode not only feature activation but also spatial relationships, hence improving the reliability and stability of model generalization. This paper proposes a structured comparison by reviewing studies published from 2018 to 2025 across major databases, including IEEE Xplore, ScienceDirect, SpringerLink, and MDPI. The applications in the reviewed…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
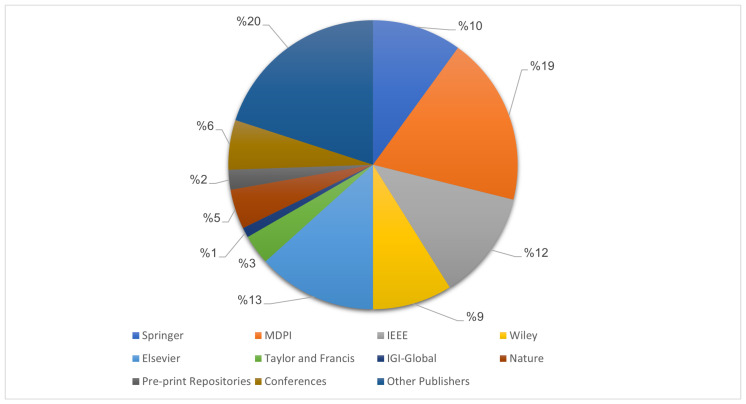 Figure 1
Figure 1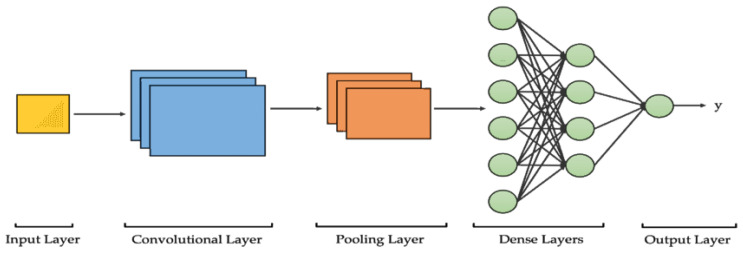 Figure 2
Figure 2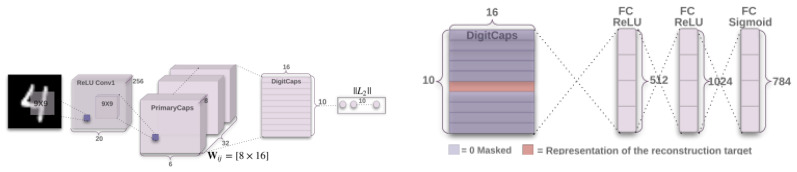 Figure 3
Figure 3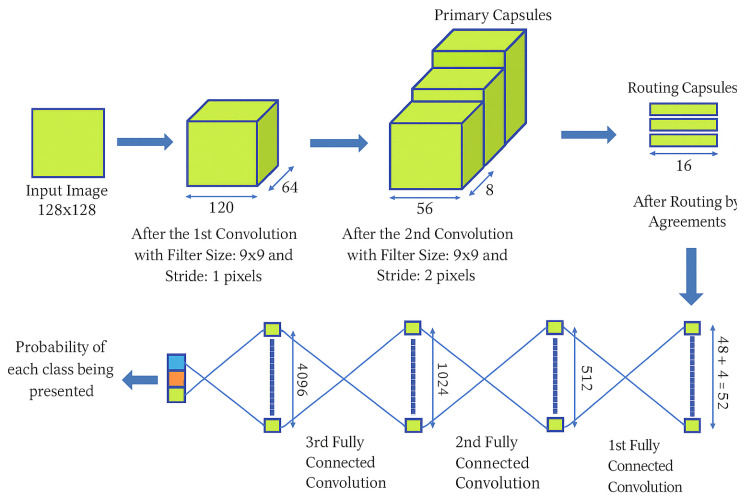 Figure 4
Figure 4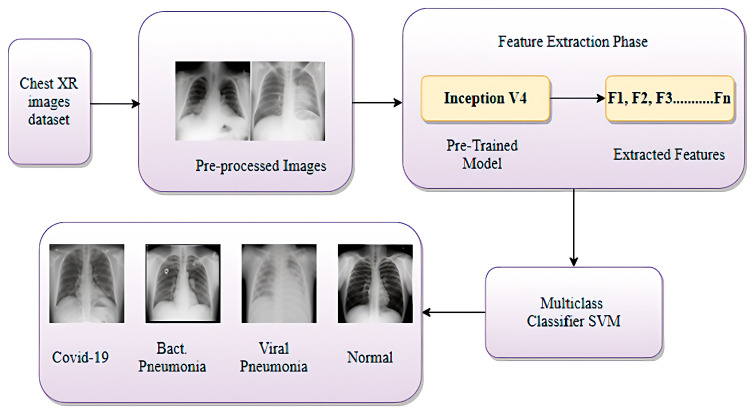 Figure 5
Figure 5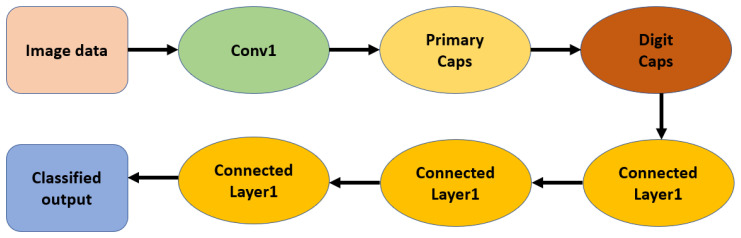 Figure 6
Figure 6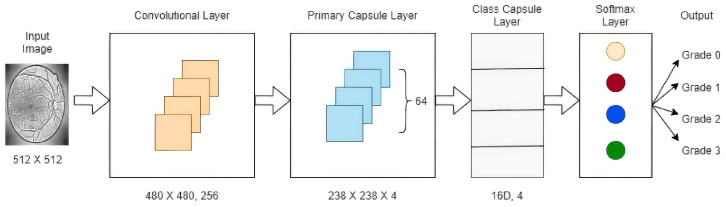 Figure 7
Figure 7Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsMachine Learning in Healthcare · COVID-19 diagnosis using AI · Explainable Artificial Intelligence (XAI)
1. Introduction
Biomedical image processing typically starts with the conversion of raw pixels into useful visual information. Fundamental operations, such as convolution filtering, edge or texture detection, and gradient computation, assist in revealing local contrast information and features necessary for later-stage diagnosis. The variables used during this early processing have been known to assist in detection, even with slight variation in terms of the system capacity to extract information necessary for diagnosis [1,2,3]. These developments have been further accelerated by machine learning (ML) and deep learning (DL), which enable algorithms to extract useful features directly from data without relying on human-designed descriptors. Nonetheless, even with these developments, models used for medical imaging are vulnerable to several issues: these models are heavily dependent on large and heterogeneous datasets, respond poorly to noise or imaging artifacts, and typically do not deal with patient or imaging device variability. Such issues are responsible for the challenges in constructing good models for healthcare [4]. CNNs have proven to be the backbone of various medical imaging analyses. These methods are useful for segmentation, classification, and detection. The hierarchical structure facilitates automatic representation learning in CNNs. CNNs enhance the accuracy of computer-aided diagnosis, disease models, and identification systems separately [1,2,3]. CNNs have limitations in situations where correct spatial information is required. It can be noted that because of the pooling layers, which greatly decrease dimensions by discarding position information, CNNs are sensitive to translation and rotation variability; hence, they do not work well in complex medical imaging problems [4]. CapsNets seem to manifest themselves as a necessary architectural answer to these deficits and limitations, and attempts have been made to understand not only whether these features exist but also how they are arranged in space and positioned [5]. Rather than relying on individual value activations, CapsNets use small capsule structures to encode part–whole relationships and transform them. Hence, CapsNets can retain geometric information even with high amounts of contamination or topological transformations, which is a crucial and necessary supplementary advantage for any clinical application involving topological precision, such as lesion identification, organ segmentation, and tissue classification [5,6]. Despite this, the CapsNet architecture has yet to gain widespread clinical implementation. Their relatively high computational cost and difficulty in understanding their representations are still limiting factors for their implementation in clinical applications. Although previous studies have demonstrated improved performance compared to CNN architectures in dealing with spatial transformations, more efficient models and enhanced understandability are necessary for both architectures to play a role in clinical decision-making. CNNs and CapsNets play significant roles in boosting research on disease detection, segmentation and computer-aided diagnosis. Therefore, a formal comparison between these architectures is necessary to highlight their strengths and weaknesses. Ultimately, this study aims to highlight how these architectures can be combined or modified to develop more comprehensible AI models.
1.1. Background and Motivation
The interaction between artificial intelligence and medicine has evolved through several technological phases. The first phase was based on rule-based expert systems to obtain early computer-aided diagnosis systems, where the medical and clinical knowledge is encoded manually, and it necessitates an extensive number of experts in the field to have a large dataset that covers all cases concerning the area of study. Classical machine learning approaches, such as Support Vector Machines (SVMs) and Random Forests (RFs), rely on handcrafted imaging features to extract meaningful information that will help in diagnosis and medical support. The emergence of deep learning (DL) has produced a radical transformation in basic concepts, allowing neural networks (initially CNNs and, more recently, CapsNets) to learn hierarchical representations and features from medical images, which significantly improve the diagnostic performance and automated detection. Extensive research is ongoing in building technical capabilities to develop even more advanced applications in the medical domain, as it fundamentally addresses one of the most essential human needs: physical health. Artificial intelligence is a new and fast-growing field that comes with advanced capabilities to handle complex tasks at a level where computer-based performance surpasses that of even the most skilled humans. CNNs are a prevalent category of AI-based technology that are extremely efficient at processing visual input to perform many object recognition and image classification tasks, given their ability to stably learn underlying patterns in massive volumes of complex visual data. CapsNets are a more complex type of AI-based technology that improves some of CNNs’ shortcomings, most notably improving the ability to handle multi-scale features present in visual patterns. This makes CapsNets particularly suited for complex image recognition, including ambiguities [7,8], distortions [9], occlusions or low resolutions [10,11].
1.2. Structure of the Review
This paper aims to provide medical professionals and researchers with a comprehensive and systematic review of the development and current capabilities of AI-based technologies relying on CNNs and CapsNets. It focuses on their use in medical decision-making and how these models contribute to improving healthcare.
The remainder of this paper is structured as follows:
-
Section 2: Review MethodologyThis section outlines the main approach followed to collect, select, and analyze the related studies for this review.
-
Section 3: Theoretical BackgroundProvides an overview of CNN and CapsNets architectures and explains how CapsNets address some of the major limitations of CNNs.
-
Section 4: Applications of CNNs and CapsNets in Medical ImagingIn this section, an introduction to the general topic of medical imaging and applications involving CNN and CapsNet would be discussed.
-
Section 5: Comparative Analysis of CNNs and CapsNets in Medical Image AnalysisThis section will compare and examine the performance of CNNs and CapsNets regarding accuracy, precision, computational efficiency, and scalability. At the end we discuss the main advantages and shortcomings of both methods.
-
Section 6: Real-World Applications and Comparative ResultsThis aspect of the literature review will emphasize the implementations and case studies that show the comparative results and outputs of the systems that use CNN and CapsNets.
-
Section 7: Discussion and Future PerspectivesIn order to address future outlooks, one section will be allocated to recapitulate the findings, point out new research patterns, and discuss potential future enhancements regarding the use of AI for the support of medical decisions.
-
Section 8: ConclusionsIn order to conclude our review, major comparative insights and their potential impacts on future clinical and research developments are summarized in the following section. Main contributions of this review:
-
We provide a structured and pedagogical comparison between CNNs and CapsNets, describing their mathematical foundations, architectural principles, and operational differences.
-
We synthesize recent medical imaging applications of both architectures across major diagnostic tasks, including classification, detection, and segmentation.
-
We analyze the technical and clinical barriers that currently prevent CapsNets from achieving real-world deployment, highlighting computational constraints, lack of regulatory validation, and integration challenges in clinical workflows.
-
We discuss emerging hybrid paradigms that combine CNNs, CapsNets, and attention-based models, and outline future research directions toward explainable, efficient, and clinically reliable AI decision-support systems.
2. Review Methodology
This review uses a structured approach to make it more rigorous and consistent, while still retaining its analytical and interpretable parts. The main purpose of this review is to analyze the development, progression, and evolution of two different variants of neural networks CNNs and CapsNets, concerning their usage within medical image support applications.
2.1. Scope and Temporal Coverage
The comprehensive review of the literature encompasses an array of studies conducted between the years 2018 and 2025. This era can be characterized by the significant advancement of CapsNets architectures and the subsequent integration of deep Convolutional Neural Networks within the medical domain. It is a period of recognition of the inadequacies associated with CNNs and the need for advanced spatial representation mechanisms.
2.2. Sources and Search Strategy
We used several databases for the selection of publications for this review, including IEEE Xplore, MDPI, ScienceDirect (Elsevier), SpringerLink, Wiley, IGI-Global, Taylor and Francis and Nature as well as preprint repositories like ResearchSquare, medRxiv, and ArXiv, to cover sources related to medical decision-making. Conference papers were also considered, and the search engines Semantic Scholar, Google Scholar and Academia were used to broaden the search. Figure 1 presents the percentage of publications from various publishers and preprint repositories analyzed in this study.
The search methodology employed Boolean operators alongside domain-specific terminology, incorporating keywords such as CNN, Capsule Networks, Deep Learning, Medical Imaging, Segmentation, Classification, Decision making, and Clinical Diagnosis. Subsequent to the initial search phase, publications were scrutinized for pertinence based on criteria in their titles, abstracts, and full texts. The focus was exclusively on studies pertaining to CNN or CapsNets architectures within the realm of medical imaging.
2.3. Inclusion and Exclusion Criteria
The criteria for choosing studies were based on relevance and scientific quality. The following inclusion criteria were applied:
- Published in English between 2018 and 2025;
- Related to the application or comparison of CNNs and CapsNets in medical imaging tasks such as classification, segmentation, or disease diagnosis;
- Systematic reviews specifically addressing CNN or CapsNets approaches;
- Reported measurable performance metrics (e.g., accuracy, sensitivity, specificity, precision, or F1-score);
- Used benchmark or publicly available datasets (e.g., BraTS, INbreast, ISIC);
- Contributed to research on interpretability, robustness, or hybrid deep learning architectures. Studies were excluded if they:
- Were unrelated to biomedical imaging;
- Were purely theoretical without experimental validation;
- Were editorials, brief communications, or not peer-reviewed.
2.4. Analytical Approach
The comparative analysis was conducted across three main dimensions:
- Architectural Analysis: Examining the model organization, feature retrieval procedures, and spatial encoding strategies.
- Performance Assessment: Evaluating performance metrics and computational efficiency as presented in the literature.
- Clinical Relevance: Discussing model interpretability, robustness to morphological variability, and potential applicability in real-world decision-support systems.
Unlike statistical aggregation, this review employs a conceptual synthesis, drawing comparisons across multiple studies to highlight major progress, persistent challenges, and future research directions in CNN and CapsNets development. Since this is a literature-based review, ethical approval was not required. No patient data or experimental procedures were involved. All references are properly cited and attributed to their original authors.
3. Theoretical Background
In this section, we will provide the foundational principles of two deep learning architectures that are the main focus of this review paper, namely CNNs and CapsNets. The following subsections give the theoretical background of each architecture in sequence.
3.1. Fundamentals of CNNs
CNNs are now considered the building block technology for contemporary vision systems. They grew out of biologically inspired models in the 1980s to mimic the hierarchical processing architecture of the human visual cortex. The notion that complex perceptions are generated through composition processes involving primitive patterns makes image understanding a natural task for a CNN. Following the pioneering efforts reported by LeCun et al., advances in data availability, computing resources, and training methodologies have collectively made CNNs the preeminent technology platform for image classification or pattern recognition. The capability to learn features automatically without human intervention has enabled impressive advances in a variety of applications including face or object recognition, natural scene understanding, or medical imaging [12,13,14,15]. A CNN can be thought of as a hierarchical model wherein each subsequent layer attempts to learn a new form of abstraction based on the input. Early layers usually focus on identifying local details in images like edges or corners. As we move to intermediate layers, these pieces of information are combined to convey textures or shapes. The final layers finally use these to represent larger concepts like organs or lesions [16,17]. These layers are generally followed by convolutional layers that are used to extract features, pooling layers to pool these features, and finally fully connected layers to map these features to output classes (Figure 2). Pooling operations play an essential role in CNNs by progressively reducing the spatial resolution of feature maps while preserving the most informative activations. Max pooling selects the highest activation within a local region, whereas average pooling computes the mean value. Both strategies reduce the number of parameters, improve computational efficiency, and introduce a degree of translational invariance, allowing the network to recognize relevant structures even when their precise spatial position changes. This mechanism helps retain the most salient information while discarding redundant details, which is particularly beneficial in medical image analysis where anatomical structures may appear at slightly varying locations across patients. From a functionality point of view, the difference between traditional feed-forward networks and CNNs lies in two architectural principles: local connectivity and weight sharing. Rather than processing entire images with filters or kernels, convolutional layers use small filters to analyze small parts of images. Finally, pooling layers improve translation invariance properties possessed by CNNs compared to traditional networks. The networks use optimization algorithms to learn filters to focus on specific features or areas within images based on which features are most informative. The effectiveness of CNNs can be demonstrated using larger benchmark datasets like ImageNet Large-Scale Visual Recognition Challenge (ILSVRC). Architectures like AlexNet, VGG, GoogLeNet, or ResNet illustrated the benefit of increasing model depth using residual or dense connections. In medical imaging, these concepts have found applications in domain-related tasks. Apart from lesion detection, tumor segmentation, or classification tasks in medical images like MRI, CT, or mammography images [18,19,20], there are numerous applications of these architectures. Also, one important component was transfer learning. Pre-trained models based on large datasets like natural images could easily learn smaller medical datasets. In terms of concepts, CNNs can actually be viewed as feature extractors that are arranged in layers to transform spatially extracted input features into more abstract features. Every subsequent layer implements a transformation that discovers more complex dependencies in images. In this way, a multi-level representation of semantics can actually be formed. In fact, this explains the effectiveness of generalization associated with CNNs. They are efficient and easy to modify because there are currently available frameworks that enable researchers to adapt quickly to new image problems. Further methodological studies have examined the optimization behavior and feature-learning dynamics of CNN layers across diverse image domains [21,22,23,24,25,26,27]. Although successful, there are structural weaknesses in CNNs which serve as driving forces for other architectural choices. Inherent to these networks are the characteristics of pooling layers or scalar activation functions which generally ignore specific details in the spatial arrangements of features identified. Although helpful in terms of translation invariance, these networks ignore orientation, scale factor, or geometric characteristics which are particularly relevant in biomedical contexts [28,29,30]. In these situations, features that are similar in appearance but differ in geometric arrangement are considered to be equal. Recently, there has been an effort to mitigate these inadequacies using architectural improvements like residual pathways, attention mechanisms, or multi-scale fusion. These are still improvements within the same convolutional framework. The need to not only encode what features are there but how these features are spatially arranged has led to emerging architectures. Among these architectures are those based on Capsule Networks (CapsNets), which are a natural progression or an extension of CNNs. The CNN architecture typically includes convolutional and pooling layers that extract and condense features, followed by fully connected layers that associate the learned representations with output categories. Despite their strong representation capacity, CNNs exhibit several limitations when applied to medical imaging. Their reliance on spatially invariant pooling makes them sensitive to large geometric deformations, and their internal feature representations remain difficult to interpret for clinicians. CNNs are also known to be vulnerable to adversarial perturbations, where imperceptible image modifications can produce incorrect diagnoses, and they generally require large-scale annotated datasets to achieve reliable performance in clinical settings. Moreover, high-performance CNN models typically require GPUs or TPU-based training infrastructures, and their deployment in real-time clinical workflows remains dependent on specialized hardware acceleration.
3.2. Fundamentals of Capsule Networks
CapsNets have brought about a paradigm shift in artificial neural networks (ANNs) and can be considered a remedy for several inherent flaws that prevail in conventional CNNs and fully connected networks (Figure 3). This novel piece of work was introduced by Geoffrey Hinton and his team for the first time in 2017. Thus, they have substantially improved CNNs. The basic architecture of CapsNets is designed to retain spatial hierarchical relationships. Although CNNs are known for their efficiency in feature extraction, their performance is largely dependent on pooling. This makes them vulnerable with respect to spatial information regarding object orientation. Thus, there is great relevance of CapsNets here, which can now solve these problems [31,32]. CapsNets can solve these problems by retaining information about the existence of features and spatial information. In addition to architectural differences, CNNs and Capsule Networks also rely on different loss functions during training. Conventional CNN classifiers are typically optimized using categorical cross-entropy, but this formulation assumes a balanced distribution of normal and pathological samples. Since medical datasets are frequently imbalanced, focal loss is commonly adopted to reduce the influence of easy negative examples and force the model to focus on clinically relevant minority cases. For segmentation problems such as tumor or lesion boundary detection, Dice loss is often preferred because it directly measures spatial overlap between prediction and ground truth, making it more appropriate for small or irregular anatomical structures. Capsule Networks, however, do not operate on scalar probabilities but on vector activations, and therefore cannot be trained with standard cross-entropy. Instead, they use the margin loss introduced by Sabour et al. [33] which enforces high vector lengths for the target class and suppresses all remaining capsules. This mechanism helps avoid overly confident predictions and improves robustness when detecting small abnormalities, a frequent difficulty in early cancer diagnosis. Some later studies have also explored spread loss as an alternative to margin loss in order to increase inter-class separation without relying on softmax. Beyond differences in the training objective, CapsNets also differ from CNNs in how they encode information: instead of scalar activations, they use vector-valued units called capsules. Each capsule is a small collection of neurons that represents a particular entity or object, with the magnitude of this vector representing the likelihood of its presence and the direction representing attributes such as orientation, angle, or size [33]. This allows CapsNets to identify objects irrespective of their orientation and capture the hierarchical relationships between a part and the whole. Hence, CapsNets can be considered to have improved representations compared with CNNs because they are more aligned with human visual processing. The key innovation in CapsNets is based on the dynamic routing by agreement algorithm developed by Sabour et al. (2017), which is used instead of the pooling operation in traditional CNNs. Here, lower-level capsule layers predict the vectors for higher-level capsule layers using transformation matrices, on which connections are strengthened if there is agreement with the prediction. Such communication between capsule layers makes it feasible for CapsNet models to have strong hierarchical representations without storing spatial information [34,35,36].
where denotes the routing coefficient between capsule i and capsule j. The softmax ensures that the probabilities of routing from each lower-level capsule sum to one, strengthening consistent predictions and weakening inconsistent ones. Another critical role is played by the squashing non-linearity, which normalizes the vectors coming out of capsules such that short vectors tend towards zero, whereas long vectors tend towards a unit vector.
where is the total input to capsule j, and the squashing function keeps the output length within , preserving orientation while ensuring numerical stability.
3.3. Illustrative Example of Dynamic Routing
To provide an intuitive explanation of how dynamic routing operates, consider a simple case with two lower-level capsules and , and two higher-level capsules and . Each lower capsule predicts the output of each higher capsule through learned transformation matrices, producing four prediction vectors:
At the beginning of routing, all coupling coefficients are initialized uniformly:
The total input to each higher capsule is computed as:
After applying the squashing function (Equation (2)), the capsule activations become:
The agreement between each prediction and output vector is given by the scalar product:
These agreements update the routing logits , which after softmax yield new coupling coefficients:
After only one routing iteration, both capsules begin to send more information to , because it better agrees with their predicted votes. After two or three iterations, these coefficients converge, producing selective routing toward the capsule that best explains the input pattern. This simple numerical example illustrates how CapsNets achieve part-to-whole agreement without relying on max-pooling operations. Sabour et al. proposed the first applicable model of CapsNets in November 2017 with TensorFlow code, showing improved recognition performance on MNIST with affine transformations compared to traditional CNNs. They tested the robustness by introducing several variants with different squashing functions and by exploring alternative objective functions in subsequent capsule-based studies, including spread loss, which compares model-predicted class activations with the target activations and has been investigated as an alternative to the traditional softmax cross-entropy [37]. Their experiment verified the efficiency of CapsNet in parameter usage compared to CNNs for capturing geometric information.
where for the target class and 0 otherwise; and represent positive and negative margins, respectively. This margin-loss encourages correct capsules to have long output vectors and suppresses irrelevant activations. From an architectural perspective, a standard CapsNet model generally has three processing levels: The first processing level is a convolutional level. At this level, low-level features are extracted, similar to CNN models, but without any pooling operations. The second processing level is used to constitute the PrimaryCaps layer. It is mainly used to combine low-level features and obtain vector capsules that generally encode transformations and local patterns. The third processing level is called the DigitCaps or classification layer. At this processing level, high-level representations are attained via a process known as routing by agreement [33]. CapsNets can thus be regarded as a bridge combining CNNs and more understandable probabilistic models because they represent both the what (presence) and where (pose) information about features. Their inherent capacity to provide both rotational and translational invariance renders data augmentation and a feature pyramid unnecessary. Hence, CapsNets can represent small objects contained in larger entities, complex spatial transformations, and representations related to three-dimensional spaces compared to scalar architectures [34,35,36]. Although promising, CapsNets remain computationally expensive. Indeed, both the computations involved in routing and memory usage increase with the use of CapsNets, particularly when dealing with high-resolution images. Despite these limitations, several studies have proposed optimizations and efficient routing algorithms for CapsNets [32]. CapsNets are beneficial in medical imaging because they can preserve spatial information, allow perspective transformations, and model hierarchical part–whole relationships, which are critical for diagnostic imaging. CapsNets have demonstrated promising performance in locating small lesions, tumor identification across imaging modes, and enhancing the classification performance for geometric transformations in radiological images. They enable more robust and interpretable decision-support systems because CapsNets can maintain a more complex internal representation. With improvements in computational capabilities, CapsNets will inevitably play a significant role in model development for robust and interpretable clinical diagnosis systemss.
4. Applications of CNNs and CapsNets in Medical Imaging
This section reviews the most relevant applications of CNNs and Capsule Networks in medical imaging. Both architectures have contributed substantially to disease detection, image segmentation, and computer-aided diagnosis across diverse imaging modalities. The discussion highlights representative studies, datasets, and architectural adaptations that illustrate their respective strengths and limitations in real clinical contexts.
4.1. Disease Classification and Detection
Deep learning deployed in CNNs has shown potential in making more effective use of the large amounts of medical data that the healthcare sector can access. Different image modalities such as X-ray [38], CT [20,39], MRI [40], fundus [41], skin [42], endoscopy, dental [43,44], mammography [45], and pathology [46] images can be effectively processed and analyzed in deep learning-based CNN models, with further detailed classifications and detection of the diseases. Benchmark datasets such as BraTS for brain tumor MRI, ChestX-ray14 and COVIDx for thoracic disease detection, INbreast for mammographic cancer analysis, ISIC and HAM10000 for skin lesion classification, and CCE or HyperKvasir for endoscopic lesion detection have been widely used to validate CNN-based diagnostic models. According to the medical image types, models may perform slight adjustments to fit the need of experts, but the basic architecture of CNN models remains the same. One strength of CNNs is their ability to maintain high classification accuracy by using deep convolutional layers to extract image features directly from the raw pixels, which avoids time-consuming handcrafted feature extractions and filter design. In addition, deep learning models can leverage valuable transfer learning via fine-tuning and external datasets to resolve issues such as data insufficiency, hardware acceleration, and generalization when encountering relatively lower economic resources, small sample size, and finite computation power [47,48]. In view of the tremendous potential value and technical facility of CNNs, in this context, some early-stage trials, proofs of concept, and reviews proposed great possibilities and provided both intrinsic motivation and extrinsic knowledge of using deep learning models in medical decision-making as well as in disease prediction and classification. Nonetheless, despite the notable efforts by researchers and the real progress being made, reaching a mutual consensus on the potential value achieved by CNNs and other deep learning models for imaging diagnosis and improved patient treatment is still the subject of ongoing discussion. More importantly, the optimization, integration, and scalability of the CNNs, other types of deep learning models, and the practical decision-making process for healthcare professionals and their clients in the clinical setting may raise different requirements, standards, and needs compared with general IT applications, general level AI and ML implementations, and practice scenarios in other fields. CapsNets have emerged as a promising approach for disease detection and classification in medical imaging [49,50,51,52]. This new architecture proposes a novel means of feature representation and processing in medical images, which is highly beneficial and recommended for classifying and detecting various diseases. The key strength of this architecture is its ability to extract, capture, and maintain spatial information (the spatial arrangement of pixels), which is crucial for identifying and localizing abnormalities or disease in medical scans. This important spatial information is preserved through the unique capsule structure and the routing mechanism [53,54].
CapsNets architecture is well-suited for handling the challenges posed by medical imaging, such as variations in viewpoint, pose, and scale of anatomical structures. This is especially beneficial when dealing with diseases that manifest differently across various stages or in noisy image conditions. The capsules in CapsNets can encode the presence, pose, and spatial relationships of features, allowing for robust and accurate disease detection and classification. Moreover, CapsNets has demonstrated the ability to achieve high performance in disease detection tasks. Recent studies reported competitive results on datasets such as BraTS and Brain MRI (Kaggle) for tumor identification, 3D-IRCADb-01 for liver lesion classification, Messidor and ORIGA for retinal disease detection, and ISIC 2019 and HAM10000 for dermatological analysis. This efficiency is particularly valuable in medical applications where large, diverse datasets may be limited. CapsNet’s capacity to extract non-linear transformation features and capture discriminative characteristics makes it an attractive option for automated disease diagnosis systems.
Researchers are increasingly investigating CapsNets for diverse medical imaging applications, including the detection and classification of diseases across different modalities such as X-rays, MRI, and CT scans. The network’s natural capacity to capture complex spatial relationships and its resilience to image variations make it a promising tool for enhancing the accuracy and reliability of computer-aided diagnosis in healthcare.
With ongoing research, CapsNets show strong promise for improving automated disease detection and classification, enabling greater precision and effective diagnostic tools in clinical practice.
4.2. Medical Image Segmentation
Image segmentation is a critical task in medical image analysis, involving the partitioning of an image into multiple segments or regions of interest. While traditional methods such as thresholding, region growing, and edge detection have been used historically, the advent of deep learning, particularly CNNs, has revolutionized this field.
CNNs have emerged as powerful tools for image segmentation due to their ability to automatically learn hierarchical features from raw image data. Unlike traditional techniques that are based on handcrafted features, CNNs can capture complex spatial relationships and contextual information, making them particularly well-suited for the intricate nature of medical images.
Several CNN architectures have been developed specifically for medical image segmentation:
- U-Net: Introduced by Ronneberger et al. in 2015 [55,56], U-Net has become a cornerstone in medical image segmentation. Its symmetric encoder-decoder structure with skip connections allows for precise localization and effective use of context.
- V-Net: An extension of U-Net for 3D image segmentation [57], V-Net incorporates residual learning and is particularly useful for volumetric medical imaging data.
- SegNet: This architecture uses an encoder-decoder approach with indices-based unpooling [58], allowing for more efficient upsampling in the decoder.
- DeepLab: Employs atrous convolutions and atrous spatial pyramid pooling to capture multi-scale contextual information [59,60], beneficial for segmenting structures of varying sizes.
These CNN-based methods work by learning to classify each pixel (or voxel in 3D) into predefined classes, effectively creating a pixel-wise mask of the image. They have achieved excellent segmentation accuracy on benchmark datasets such as BraTS 2020 for brain tumors, DRIVE and ORIGA for retinal vessel and glaucoma segmentation, and ISIC for dermoscopic lesion boundaries. CNNs provide several advantages in the context of medical image segmentation:
- Feature Extraction: CNNs can learn and extract relevant features directly from the data in order to reduce the need for manual feature engineering.
- Contextual awareness: The hierarchical nature of CNNs allows them to capture both local and global context, crucial for accurate segmentation.
- Adaptability: CNNs can be fine-tuned for specific medical imaging modalities and anatomical structures.
- End-to-end learning: CNNs can be trained in an end-to-end manner, optimizing the entire segmentation pipeline simultaneously.
Nonetheless, challenges remain in applying CNNs to medical image segmentation:
- Limited training data: Medical imaging datasets are often small due to privacy concerns and the cost of annotation.
- Class imbalance: In many medical segmentation tasks, the region of interest may be much smaller than the background.
- Three-dimensional data handling: While 2D CNNs have shown success, efficiently processing 3D volumetric data remains challenging.
Despite the above-mentioned challenges, CNNs achieved remarkable success regarding various biomedical image segmentation tasks. For instance, CNNs were applied successfully for the segmentation of brain tumors from MRI images [61], lung nodules from CT images [62], and retinal artery–vein vessel segmentation from fundus images, supported by a high-quality public dataset (Fundus-AVSeg) [63].
As the research and development community progresses, there are expectations for improvement and development regarding the architecture and learning process of the CNNs, which could overcome the aforementioned challenges and allow the widespread use of such efficient tools for the analysis of biomedical images. The use of CapsNets for biomedical image segmentation leverages the accomplishments achieved by the latter for disease identification and diagnosis, and it also offers exclusive and innovative advantages for the segmentation of complex anatomical objects. Specific architectures for the segmentation tasks were developed for CapsNets, such as SegCaps [64], which adapted the original architecture of CapsNets for the use case concerning the problems of dense prediction. This model adapted the U-Net architecture, added skip connections, and replaced the classical convolutional layers with capsule layers for the conservation of the spatial information inside the network. In other works, the architecture named the Capsule-UNet [65] combines capsule layers with the U-Net architecture, and utilizes the advantages offered by this combination for the enhancement of segmentation accuracy. Experimental work has validated that the SegCaps achieved high Dice scores for the segmentation of brain tumors on the BraTS 2020 dataset, and the Capsule-UNet correctly segmented the retina and lung on the ORIGA and LUNA16 datasets, respectively. Multi-scale architectures for the segmentation using CapsNets have been designed, allowing the network to extract characteristics of the images for multiple resolutions, which is particularly effective for biomedical images concerning the objects of various sizes. This would allow for the generation of highly detailed segmentation maps, which are important for medical imaging concerning the boundary definition of tumors and for the definition of organ volumes. The ability to maintain spatial relations along with the hierarchy of the objects increased both the accuracy and detail of the segmentation maps, especially for the case of biomedical images. As research and development continue to progress, there are many prospects for improving and advancing the performance of CapsNets during image segmentation, especially in relation to increasing the efficiency for the processing of 3D biomedical images and strengthening simultaneous segmentation of multiple objects. Also, there are many prospects for the development of new and insightful capsule networks that would provide information concerning the decision-making processes by the network, which are important for the development and acceptance of the model by the biomedical community.
4.3. Multimodal Analysis and Computer-Aided Diagnosis
Medical Image Processing is at the core of early diagnosis of diseases and progress monitoring of pathologies. Recently, CNNs have significantly helped to develop this field over the last decade.
Segmentation is still one of the core tasks in a medical image analysis process. For example, architectures such as U-Net and a handful of variants all achieve excellent performance by accurately delineating areas of interest (tumors, organs, lesions, etc.) as they appear in the images. Their encoder–decoder structures enable the network not only to learn local patterns but also to capture more general contextual cues, leading to high accuracy and scalability in a variety of imaging paradigms [66,67,68,69,70].
Classification is also an important feature, where images are categorized in such a way as to reflect what is defined, for example, labeling the images as disease-present or -absent. CNNs are highly effective for this because they learn hierarchical features automatically from raw pixels. Some tried and tested algorithms, including AlexNet, VGGNet, and ResNet have demonstrated strong diagnosis performance on pneumonia, brain tumors, and diabetic retinopathy. They have been tested successfully on commonly performed datasets like ChestX-ray14, BraTS, and Messidor. Additionally, transfer learning improves performance even further; a transfer learning problem is performed where a network pre-trained on large natural-image corpora is fine-tuned to perform medical tasks in a single model. In addition to segmentation and sorting, object detection now relies on modern CNN-based techniques. Conventional methods (mostly based on handcrafted features and model-centric suggestions) also failed on accuracy and robustness. With the advent of detectors such as YOLO, Faster R-CNN, and SSD, among others, this terrain has been reshaped. And these models can automatically localize and classify the abnormalities at the same time by bounding the box (sometimes a rotated one), using region proposal networks or using anchor-based priors [71,72,73,74]. Their performance has been proven on standard datasets (e.g., ISIC for skin lesion localization, INbreast for mammography and BraTS for brain lesion detection). Nevertheless, the remaining challenges are the adaptation of natural image-training detectors to the special features of medical images as well as improvements in robustness to multi-scale and geometric variations. However, CNNs have undoubtedly advanced medical image analysis beyond previous research limitations [75] and could continue to be used further to overcome known limitations as well as improve diagnostic application. CapsNets have been proposed as a promising alternative for various medical imaging tasks in addition to CNNs. Its ability to model hierarchical–feature relationships is what makes them especially powerful (as well as relevant especially in the case of complex anatomical structures or fine pathological changes), where it is a key advantage. In real-life applications, CapsNet-based methods appear to have strong capabilities for different tasks. The methodologies have effectively been applied for use in disease recognition in endoscopic imaging (Kvasir-v2, CCE) analysis, ophthalmic imaging methods (Messidor, ORIGA) and brain lesion analysis with BraTS. Meanwhile, CapsNets have been studied for detecting anomalies within radiographs, allowing us to point out abnormal results that are not expected to meet a specific diagnostic standard. Recently, CapsNet architectures have been applied to multi-modal imaging such as MRI and PET scans for more complex diagnostic evaluations [50,76]. CapsNets have also been studied on how they can assist in image reconstruction in case of noise or lack of ability to obtain images, and that robust representation has brought advantages to this field [52,64]. An additional emerging trend is longitudinal work, and due to neural network sensitivity to spatial aspects, it provides a means to represent subtle structural changes over a period of time and therefore is quite useful for monitoring disease progression or response to treatments [77]. As the field further matures, CapsNets are also being applied to more complex analytical pipelines and are co-developed even with reinforcement learning or other AI-driven decision-making systems. The flexibility and development of CapsNets are underscored by these changes as the applications of these emerging technologies continue to broaden the field of automated medical image analysis.
5. Comparative Analysis of CNNs and CapsNets in Medical Image Analysis
Affine transformations such as rotation, scaling, and translation pose notable challenges in medical image analysis. Achieving robustness to these transformations is crucial for accurate diagnosis and treatment planning. In this section, we explore various modifications applied to CapsNets and CNNs to enhance their performance under affine transformations, and we also provide a conceptual comparison between these two deep learning architectures. Table 1 provides a structured conceptual overview of CNNs and CapsNets, summarizing their core architectural paradigms, computational characteristics, and generalization behavior. Table 2 then presents a more detailed comparative analysis of CNNs and CapsNets, highlighting key differences in the context of medical decision-making. Finally, Table 3 provides a comprehensive summary of the main modifications designed to improve robustness to affine transformations, detailing their intended impact and specific enhancements. Together, these tables offer a clear and structured roadmap for the quantitative and qualitative analyses that follow.
Representative benchmark datasets illustrating these behaviors, including BraTS, ISIC, INbreast, DRIVE, LUNA16, COVID-CT, and others, are detailed in the application-focused tables and subsections, ensuring traceability between architectures, data characteristics, and reported performance. However, reported improvements are not always consistent across datasets, imaging modalities, or evaluation metrics, indicating that performance differences between CNNs and CapsNets remain context-dependent rather than universally conclusive.
5.1. Performance Metrics
There are two common approaches to compare and contrast the performance of different machine learning models. One way is comparing them without considering the thresholds and aiming to obtain a figure that may be interpreted as a comprehensive performance measure. The other way is computing several performance scores by adopting different thresholds and imbalance considerations before evaluating the models. The latter approach is beneficial to healthcare practitioners as they can select and compare the model in question using the suitable trade-off point for the specific patient population, which will be explained later in this section. We present both methods and demonstrate how to compare models by visualizing The precision-recall curve (PRC) and its area under the curve (AUC), along with the receiver operating characteristic (ROC) curve and its corresponding AUC, Youden’s J statistic, and the scatter plot of the standardized (unrestricted) means of specificity, accuracy, sensitivity, positive predictive value (PPV), and negative predictive value (NPV).
AUC obtained from ROC (AUCROC) is the most established and well-known performance metric where it describes the probability of a model accurately classifying the samples (e.g., benign and malignant). In clinical practices, a model with an AUCROC larger than 0.7 is considered to have clinical utility or usefulness. Despite this, it is understandable that samplings are from an imbalanced class and that different patients are sensitive to the severity of a misclassification. For example, a disease prediction model should have much more robust performance for individuals with a high severe stage (i.e., needing high penalty for the advanced severity of the disease) compared to those at the early stage (i.e., lower penalty for the advanced stage). Hence, obtaining models that balance sample misclassification and developing models that achieve balanced performance across different severity levels should be taken into account.
5.2. Accuracy, Precision, Computational Efficiency, and Scalability
When comparing CNNs and CapsNets for medical image analysis, it is essential to examine their performance across several critical metrics: accuracy, precision, computational efficiency, and scalability.
Accuracy and Precision: CNNs have demonstrated high accuracy and precision in a range of medical imaging tasks, benefiting from extensive research and optimization. These networks excel in detecting and classifying features from medical images, particularly when large datasets are available. In contrast, CapsNets offer improved accuracy and precision in scenarios where spatial relationships and geometric transformations are critical. By maintaining hierarchical feature representations, CapsNets can achieve more nuanced interpretations, enhancing performance in complex image analysis tasks.
Computational Efficiency: CNNs are generally optimized and adjusted for performance and benefit from well-established hardware and software support. They are efficient in terms of training and inference due to mature optimization techniques. CapsNets, however, are computationally more intensive because of their dynamic routing algorithms and complex feature representations. This increased computational cost can impact training time and resource usage but may offer benefits in terms of robustness and feature extraction capabilities.
Scalability: CNNs are highly scalable, allowing them to effectively handle large datasets and a wide range of medical imaging applications. They can effectively handle increasing volumes of data with established architectures and methods. CapsNets show potential for scalability, but their computational complexity poses challenges. As dataset sizes and model complexity increase, managing the computational demands of CapsNets becomes more challenging, though ongoing advancements may mitigate these issues. In summary, while CNNs offer robust performance and efficiency, CapsNets provide advantages in feature preservation and spatial awareness. Both architectures have their strengths and weaknesses, and the choice between them should be guided by specific application requirements and resource constraints.
5.3. Strengths and Weaknesses of CNNs and CapsNets
CNNs utilize weight sharing and have a limited receptive field, which reduces the number of parameters and enhances efficiency. Yet, their sensitivity to translation and lack of spatial awareness can hinder their performance in tasks requiring an understanding of positional and spatial relationships. CapsNets address these limitations by enabling hierarchical feature learning, which improves position translation and deformation invariance. The dynamic routing mechanism in CapsNets strengthens feature learning, measures node activation levels, and provides more robust features. CNNs benefit from multi-resolution fusion methods, enhancing accuracy and reducing gradient loss by incorporating super-pixel-based segmentation methods into the shallow layers. CapsNets, alongside transfer learning models, help overcome the limitations of small datasets and improve robustness and accuracy through techniques like data enhancement and shuffled pooling. Fusion frameworks based on multiple deep model networks further enhance performance and applicability in various medical contexts. CapsNets address these limitations by enabling hierarchical feature learning, which improves position translation and deformation invariance. The dynamic routing mechanism in CapsNets strengthens feature learning, measures node activation levels, and provides more robust features.
6. Real-World Applications and Comparative Results
In this section, we provide a comprehensive comparative analysis of CNNs and CapsNets using real-world case studies in medical image analysis. We review a range of studies, detailing their application domain, architectures, datasets, and performance metrics. This comparative analysis aims to elucidate the strengths and limitations of each approach across various medical imaging tasks, providing insights into their effectiveness and applicability in real-world scenarios.
The proposed CapsNet architecture by Goceri [8] addresses the challenge of classifying brain tumors, such as pituitary, glioma, and meningioma, from magnetic resonance images. This architecture incorporates three fully connected layers and employs an expectation-maximization-based dynamic routing algorithm, optimized with the Sobolev gradient-based SASGradD method. Using a dataset of 120 T1-weighted contrast-enhanced brain MR images, the study achieved an accuracy of 92.65%. However, manual segmentation of tumor regions was identified as a limitation due to its time-consuming and subjective nature. Further refinement of the CapsNet architecture and testing with larger datasets are suggested for improved outcomes (see Figure 4).
In another study, Aziz et al. [16] focused on accurately segmenting glioma tumors in MR images using a novel CapsNet architecture called SegCaps, which requires fewer training images compared to traditional CNNs like U-Net. Utilizing the BraTS2020 dataset, consisting of MRI scans from 369 patients, SegCaps achieved a Dice Similarity Coefficient (DSC) of 87.96% with only 1.5 million parameters, outperforming U-Net’s 85.56% DSC with 31 million parameters. Despite its slower routing algorithms and higher computational complexity, further optimization of SegCaps is recommended for complex medical imaging tasks.
Akinyelu and Bah [17] proposed CapsNetCovid, a deep learning model for diagnosing COVID-19 using X-ray and CT images. The architecture, comprising Conv layers, primary capsule layers, and a capsule layer digit, achieved high scores of 99.929% accuracy for CT images and 94.721% for X-ray images. Despite the model’s high performance, its decreased accuracy on augmented datasets highlights the need for further research to enhance generalization and robustness, particularly for multi-class classification.
Reis and Turk [78] introduced COVID-DSNet, a novel DCNN for rapid COVID-19 diagnosis using medical imaging techniques. Employing depthwise separable convolution and residual networks, the architecture achieved high accuracy (97.60%) in multi-class classification using CT, chest X-ray, and hybrid CT + CXR images. The study suggests future work involving data augmentation and transfer learning to improve model performance due to limitations such as small datasets and potential image noise.
Kaur et al. [79] introduced C19D-Net, a deep learning model designed for diagnosing COVID-19 from chest X-ray images, as illustrated in Figure 5. Utilizing InceptionV4 for feature extraction and a multiclass SVM classifier, the model attained an accuracy of 96.24% across four classes: COVID-19, bacterial pneumonia, viral pneumonia, and normal. The study highlights the need for larger datasets to improve model performance and addresses potential observer variability in manual diagnoses.
Rahman et al. [18] addressed efficient breast cancer diagnosis from complex mammographic images using a CNN architecture, specifically ResNet-50. Utilizing the INbreast dataset, The study reported performance metrics including 93% accuracy, 93.86% specificity, and 93.83% sensitivity. Recommendations include exploring alternative networks like VGG and AlexNet for future improvements, while limitations involve potential performance variability across different datasets.
Swaraj et al. [80] focused on liver cancer classification from CT images using a CapsNet. The architecture, consisting of 41 layers, achieved over 86% classification accuracy using the 3D-IRCADb-01 dataset. The study suggests using false positive filters or training on larger datasets to mitigate the presence of false positives.
Wang et al. [81] presented a liver cancer recognition method based on CapsNet as shown in Figure 6, achieving 92.9% accuracy for liver CT images compared to 87.6% for CNN. Despite potential overfitting, further validation on larger datasets is recommended to enhance generalization.
Iyyanar et al. [82] introduced a hybrid approach for effective glaucoma segmentation and classification using UNet++ and CapsNet. Utilizing the ORIGA dataset, the study achieved an overall accuracy of 97.6%. Future work should integrate Generative Adversarial Networks to enhance dataset availability and applicability to other datasets, addressing challenges posed by variations in image quality.
Kalyani et al. [83] focused on diabetic retinopathy detection and classification using a reformed capsule network architecture. The proposed architecture, avoiding pooling layers, achieved 97.98% accuracy for healthy retina using the Messidor dataset. Further training on additional datasets is recommended to improve classification across more stages of diabetic retinopathy (see Figure 7).
Mascarenhas et al. [84] introduced a CNN model for detecting colonic mucosal lesions and the presence of blood in colon capsule endoscopy (CCE) images. The study employed the Xception model, achieving a sensitivity of 96.3% and a specificity of 98.2% for mucosal lesion detection. Larger multicenter studies are recommended to validate findings and enhance CNN applications in clinical practice for CCE.
Afriyie et al. [85] proposed a denoising capsule network (Dn-CapsNets) for gastrointestinal tract disease recognition, achieving 94.16% accuracy using the Kvasir-v2 dataset. Further improvements on larger and more complex datasets like HyperKvasir are recommended, acknowledging the limitation of potential class imbalance.
Saraiva et al. [19] introduced a CNN model for the automatic identification and differentiation of small bowel lesions with distinct hemorrhagic potential using capsule endoscopy (CE) images. Utilizing the Xception model, the study achieved 99% accuracy. Larger studies are recommended to assess clinical impact and enhance generalizability across different CE systems. Mascarenhas et al. [84] presented another CNN model for the automatic detection of colonic mucosal lesions and blood in CCE images, achieving similar performance metrics. Prospective studies are recommended to confirm clinical applicability and enhance model robustness. Another method proposed by Hasnain et al. [86] in which a deep learning-based method for dental disease classification using X-ray images, achieving 97.87% accuracy. Further research to enhance model performance and generalizability is recommended due to the small dataset size.
Haghanifar [14] Introduced in this study is PaXNet, a groundbreaking and technologically advanced automated decision support system specifically designed for the purpose of dental caries detection in panoramic radiography. With an impressive accuracy rate of 86.05%, the findings of this study strongly advocate for the expansion of the dataset utilized to further enhance the capabilities and accuracy of PaXNet. Furthermore, it is recommended that segmentation methods be improved, resulting in even higher levels of precision and reliability. By following these proposed enhancements, the potential impact of PaXNet in the field of dental caries detection can be further amplified, ultimately leading to more effective diagnoses and improved patient outcomes.
AlSayyed et al. [87] employed an ensemble of CNN models to classify dental caries using oral photographs, achieving 97% accuracy. Larger, higher-quality datasets are recommended for improved model robustness and extending the framework to other medical domains.
Lan et al. [12] proposed FixCaps, an improved capsNet for skin cancer diagnosis, achieving 96.49% accuracy using the HAM10000 dataset. Further exploration of FixCaps’ generalization performance is recommended due to the limitation in its current evaluation scope.
Albraikan et al. [13] presented an Automated Deep Learning-Based Melanoma Detection and Classification (ADL-MDC) model, achieving 98.27% accuracy using the ISIC dataset. Further improvements in classification performance through advanced deep learning-based image segmentation techniques are suggested, addressing challenges in handling diverse image qualities.
Adla et al. [88] introduced a deep learning-based Computer-Aided Diagnosis (CAD) model for skin cancer detection, achieving 98.50% accuracy. Testing the model on larger datasets and in IoT environments is recommended, acknowledging challenges in segmenting lesions due to variations in texture, size, and color.
Alwakid et al. [15] proposed a deep learning-based method for detecting melanoma from dermoscopic images, achieving 0.86 accuracy for CNN using the dataset HAM10000. Further experiments on larger datasets are suggested, incorporating additional types of skin lesions to enhance model robustness.
Table 4 summarizes the real-world applications published in the literature.
CapsNets have shown considerable promise in medical imaging, attaining outstanding accuracy and efficiency across multiple applications. For instance, CapsNet models have reached up to 99.929% accuracy in diagnosing COVID-19 and 98.27% in melanoma detection. This high accuracy underscores the value of CapsNet in medical diagnostics. CapsNets are particularly advantageous due to their ability to capture spatial hierarchies and relationships between features. This capability is crucial in medical imaging tasks where understanding spatial context significantly impacts diagnostic precision.
Despite their strengths, CapsNets typically require longer training times and more computational resources compared to CNNs. Although this increased computational cost can be a drawback, the performance gains achieved by CapsNets often justify the additional resources. The improvements in accuracy and feature handling can be substantial, particularly in complex applications, making the investment in computational resources worthwhile. CNNs, while generally more efficient in terms of training time and computational resources, excel in tasks such as breast cancer detection and skin lesion classification. They deliver high accuracy with shorter training periods, which is advantageous in settings with limited computational power. However, CNNs can struggle with spatial variability and occlusions due to their less effective handling of hierarchical feature representations compared to CapsNets. In conclusion, while CNNs remain a powerful tool for many medical image analysis tasks due to their efficiency, CapsNets offer compelling advantages in applications requiring intricate spatial modeling and superior accuracy. Their ability to handle complex feature interactions and spatial hierarchies positions them as a promising alternative to traditional CNN methods. Future research should focus on optimizing CapsNet architectures to reduce training times and computational costs, while exploring integrations with advanced techniques like Generative Adversarial Networks (GANs) to enhance performance and applicability in medical imaging diagnostics.
7. Discussion and Future Perspectives
Overall, this review highlights the limitations of conventional CNNs in computer-aided diagnosis (CAD), particularly their dependence on large annotated datasets and their sensitivity to geometric transformations. In contrast, Capsule Networks preserve hierarchical part whole relationships and spatial orientation, improving robustness to viewpoint changes and occlusions. These properties make CapsNets theoretically attractive for medical imaging tasks that require precise characterization of shape, size, and spatial localization of abnormalities. Nevertheless, both architectures still face major research and deployment challenges, and no single approach can currently be considered universally optimal. Building on the findings summarized throughout this work, several emerging trends can be identified. Recent studies increasingly explore hybrid paradigms, such as CNN Transformer pipelines that combine convolutional filters with self-attention, or CapsNet Attention models that enhance routing mechanisms through adaptive relevance weighting. These developments indicate a convergence of deep learning paradigms rather than a strict paradigm shift. However, practical limitations persist: CapsNets remain computationally expensive, difficult to scale to large 3D volumes, and have not yet demonstrated consistent benefits across large multi-centre datasets. In clinical practice, deep learning deployment is still dominated by CNN-based solutions. Several systems including Transpara™ [89] for mammography analysis and Aidoc™ [90] for CT triage have been cleared by the U.S. Food and Drug Administration (FDA), the federal regulatory agency responsible for authorizing the clinical use of medical AI systems, and are already integrated into Picture Archiving and Communication Systems (PACS) in hospitals worldwide. No CapsNet-based diagnostic tool has yet achieved regulatory approval, mainly due to the lack of large-scale prospective validation, the computational cost of dynamic routing, and the absence of mature industrial software support. As a result, CapsNets remain confined to experimental research environments. Despite their theoretical promise, current CapsNet architectures face multiple barriers to real-world clinical deployment. Their iterative routing mechanisms significantly increase memory usage and inference latency, preventing real-time deployment on standard hospital hardware. In addition, no industrial-grade toolchains, pretrained model repositories, or regulatory submissions currently exist for Capsule Networks, and no prospective multi-centre clinical trials have validated their safety or generalizability. For these reasons, CapsNet-based systems cannot yet be integrated into clinical decision-support workflows or PACS infrastructures. Finally, in addition to performance considerations, future medical AI systems must address key ethical requirements, including transparency, robustness, accountability, and protection of patient privacy. Future research should therefore prioritize explainable and computationally efficient architectures that can be reliably deployed in heterogeneous clinical settings, supported by standardized evaluation protocols and regulatory frameworks.
Emerging Hybrid Architectures and Future Directions
In more recent advances, deep learning has seen more focus on hybrid models, which attempt to harness the best of various paradigms. Taking the example of hybrid models involving the Transformer and CNN, models such as the CNN Transformer aim to harness the best of the feature-extraction capabilities of convolutions and the long-range dependencies modeled by the Transformer, which is particularly effective for applications such as tumor segmentation and histopathological image classification. Similarly, CapsNet Attention models aim to optimize the routing procedure and improve understandability by dynamically routing towards important areas. In doing so, models are able to correctly address noted limitations, including the limited receptive field of CNNs and the computational complexity of standard CapsNets, by promoting the utilization of feature selection and transforming.
Current studies indicate that such models may result not only in improvements to accuracy and efficiency but could potentially also support explainability and trustworthiness in clinical applications. As improvements and challenges simultaneously evolve, several future areas and priorities could potentially emerge. These areas and priorities include improving explainability and transparency as well as reliability and reproducibility under various conditions. Addressing bias and fairness of training data is also an important consideration. Other areas also include improving adaptability to distribution changes, assessing robustness and performing validation under various clinical conditions, and finally, improving patient safety and data confidentiality. In addition, integrations incorporating clinical prior knowledge, experience, and reasoning into models should also count towards future priorities. Additional multimodal patient inputs and hybrid models involving symbolic and data-driven models should also count towards future priorities. Lastly, guidelines and caution protocols should also count towards future priorities and could also act to support replicable, safe, and ethically sound clinical applications.
In summary, CapsNets show particular promise for tasks in which spatial dependencies directly influence diagnostic confidence, especially in problems involving subtle structural variations or shape-dependent abnormalities. Their potential is most evident in early-stage lesion characterization, microstructure detection, and cases where orientation or pose variability affects conventional CNN performance. Nonetheless, their integration into clinical workflows remains constrained by a limited body of large-scale validations and by the absence of standardized, deployment-ready implementations. These factors currently represent the main obstacles to their routine clinical adoption.
8. Conclusions
Recent advancements in CNNs and CapsNets have resulted in substantial progress in the domain of medical image analysis, especially within intricate decision-making contexts. CNNs continue to be the prevailing framework due to their robust empirical efficacy and well-established deployment infrastructure; however, their reliance on large annotated datasets and limited robustness to geometric variations represent important constraints. CapsNets were introduced to address these issues by preserving hierarchical spatial relationships and incorporating dynamic routing mechanisms, although their robustness and scalability require extensive validation on real medical datasets. Rather than being competing paradigms, CNNs and CapsNets can be considered as complementary. CNNs offer highly efficient feature extraction and have already demonstrated clinical utility, whereas CapsNets provide richer representational capabilities that can improve interpretability and fine-grained lesion characterization. However, both model families face practical barriers. CNNs remain vulnerable to adversarial perturbations and lack transparency owing to their black-box nature, whereas CapsNets suffer from high computational costs, limited scalability, and prolonged training times. Consequently, their successful translation into clinical workflows depends on rigorous validation, interoperability with decision support systems, and compliance with regulatory requirements. Future studies should focus on hybrid architectures that combine convolutional feature extractors, capsule-based geometric reasoning, and attention mechanisms derived from transformer m odels. Such unified systems may offer improved generalization, interpretability, and reliability in precision medicine. Large-scale prospective studies and interdisciplinary collaborations are essential for transitioning from theoretical advances to real clinical deployment. In addition to technical and clinical considerations, the adoption of deep learning in healthcare must comply with ethical and legal requirements. Issues related to privacy protection, algorithmic bias, and explainability of automated decisions are now considered essential components of medical AI validation. Therefore, future research should ensure that model development, evaluation, and deployment follow transparent and accountable procedures that preserve patient rights, while maintaining clinical safety and regulatory compliance.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Kumar Y. Koul A. Singla R. Ijaz M.F. Artificial intelligence in disease diagnosis: A systematic literature review, synthesizing framework and future research agenda J. Ambient. Intell. Humaniz. Comput.2023148459848610.1007/s 12652-021-03612-z 35039756 PMC 8754556 · doi ↗ · pubmed ↗
- 2Chan H.P. Hadjiiski L.M. Samala R.K. Computer-aided diagnosis in the era of deep learning Med. Phys.202047 e 218e 22710.1002/mp.1376432418340 PMC 7293164 · doi ↗ · pubmed ↗
- 3Battineni G. Sagaro G.G. Chinatalapudi N. Amenta F. Applications of machine learning predictive models in the chronic disease diagnosis J. Pers. Med.2020102110.3390/jpm 1002002132244292 PMC 7354442 · doi ↗ · pubmed ↗
- 4Zhou S.K. Greenspan H. Davatzikos C. Duncan J.S. Van Ginneken B. Madabhushi A. Summers R.M. A review of deep learning in medical imaging: Imaging traits, technology trends, case studies with progress highlights, and future promises Proc. IEEE 202110982083810.1109/JPROC.2021.3054390 PMC 1054477237786449 · doi ↗ · pubmed ↗
- 5Patrick M.K. Adekoya A.F. Mighty A.A. Edward B.Y. Capsule networks—A survey J. King Saud-Univ.-Comput. Inf. Sci.2022341295131010.1016/j.jksuci.2019.09.014 · doi ↗
- 6Sun Z. Zhao G. Scherer R. Wei W. Woźniak M. Overview of capsule neural networks J. Internet Technol.2022233344
- 7Mazzia V. Salvetti F. Chiaberge M. Efficient-capsnet: Capsule network with self-attention routing Sci. Rep.2021111463410.1038/s 41598-021-93977-034282164 PMC 8290018 · doi ↗ · pubmed ↗
- 8Goceri E. Caps Net topology to classify tumours from brain images and comparative evaluation IET I Mage Process.20201488288910.1049/iet-ipr.2019.0312 · doi ↗