Artificial Intelligence Chatbots in Peritoneal Dialysis Education: A Cross-Sectional Comparative Study of Quality, Readability, and Reliability
Engin Onan, İlter Bozaci, Yelda Deligoz Bildaci, Sevinc Puren Yucel Karakaya, Ruya Kozanoglu, Rumeyza Kazancioglu

TL;DR
This study compares AI chatbots for peritoneal dialysis education, finding significant differences in readability and reliability.
Contribution
First systematic evaluation of AI chatbots for peritoneal dialysis education using quality and readability metrics.
Findings
Gemini Pro 2.5 outperformed other chatbots in readability and reliability scores.
LLaMA Maverick 4 had the lowest scores across all evaluated metrics.
Chatbots showed variability in addressing PD-related questions, highlighting the need for clinical oversight.
Abstract
Background: Peritoneal dialysis (PD) remains underutilized worldwide, partly due to limited patient education, misconceptions, and barriers to accessing reliable health information. Artificial intelligence (AI)-based chatbots have emerged as promising tools for improving health literacy, supporting shared decision-making, and enhancing patient engagement. However, concerns regarding content quality, reliability, and readability persist, and no study to date has systematically evaluated AI-generated content in the context of PD. Therefore, this study aimed to systematically evaluate the quality, reliability, and readability of AI-generated educational content on peritoneal dialysis using multiple large language model-based chatbots. Methods: A total of 45 frequently asked questions about PD were developed by nephrology experts and categorized into three domains: general information (n =…
Genes, proteins, chemicals, diseases, species, mutations and cell lines named across the full text — each resolved to its canonical identifier and authoritative record.
Click any figure to enlarge with its caption.
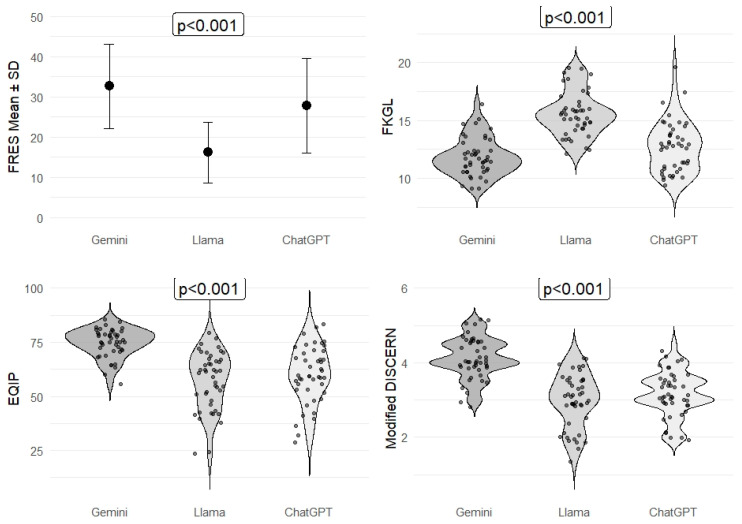 Figure 1
Figure 1Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsArtificial Intelligence in Healthcare and Education · AI in Service Interactions · Health Literacy and Information Accessibility
1. Introduction
PD remains an underutilized modality for the management of kidney failure despite its advantages in terms of cost-effectiveness, patient autonomy, and quality of life [1]. Multiple studies have highlighted that limited patient education, misunderstandings, and barriers to accessing reliable health information significantly contribute to the low adoption rates of PD worldwide [2,3]. Patients frequently encounter difficulties in understanding complex medical terminology, evaluating the reliability of online health information, and distinguishing evidence-based recommendations from misinformation. These factors may negatively influence decision-making, adherence to therapy, and ultimately, clinical outcomes.
In parallel, the rapid development of AI has introduced novel tools that can potentially address some of these challenges. AI-based chatbots, powered by large language models, are increasingly being integrated into various healthcare settings to enhance health literacy, improve patient engagement, and facilitate shared decision-making between patients and clinicians [4]. Previous research in fields such as oncology, hepatology, and cardiovascular medicine has shown that AI-driven chatbots can deliver educational content with reasonable accuracy and user satisfaction [5,6,7]. Moreover, large language models have demonstrated high accuracy and clinical acceptability when responding to physician-generated questions across multiple medical specialties, as highlighted in a recent study evaluating ChatGPT-5 responses to 284 clinical queries, which reported a median accuracy score of 5.5 out of 6 and a completeness score of 3.0 out of 3 [8,9]. Similarly, studies in chronic kidney disease (CKD) have shown that AI-driven chatbots can provide accurate and accessible information, with performance improving across successive versions of ChatGPT-5 Bard AI, and Bing AI [10]. However, these studies also identified limitations such as occasional misleading responses, lack of references, and the need for collaboration between clinicians and AI developers to ensure guideline-based, reliable patient education.
Peritoneal dialysis represents a unique clinical context in which accurate, comprehensible, and accessible patient education materials are essential for informed decision-making and long-term adherence. However, no study to date has systematically evaluated the quality, reliability, and readability of AI-generated content specific to PD. Moreover, variations in model performance, regional access limitations, and the lack of standardized assessment tools pose additional challenges to the safe integration of AI into clinical practice.
Against this background, we hypothesized that AI-based chatbots would differ in content quality, readability, and reliability, with potential implications for patient education in PD. Therefore, this study aimed to provide a comprehensive and multidimensional evaluation of three widely used AI-based chatbots for PD patient education.
2. Materials and Methods
Three large language model (LLM) chatbots, ChatGPT-5 (OpenAI), Gemini Pro 2.5 (Google), and Meta LLaMA Maverick 4 (Meta), were evaluated for their responses to frequently asked questions about PD. At the time of the study, these were the AI chatbots that were publicly accessible and available for evaluation.
The question set was developed by nephrology experts to address the most common patient concerns and misunderstandings about peritoneal dialysis (PD). This cross-sectional study was conducted between August 2025 and September 2025, using the most recent publicly available versions of each chatbot. A total of 45 questions were included, categorized into three main domains: General Information (n = 15), Technical and Clinical Concerns (n = 21), and Myths and misconceptions (n = 9). The full list of questions in each category is presented in Table 1. The questions were selected through a combination of online searches (Google) to identify the most frequently asked patient queries regarding PD and the authors’ clinical expertise in managing PD patients, ensuring coverage of both routine clinical inquiries and commonly misunderstood topics. The final list of questions is presented in Table 1 under the specified categories.
The question set was developed by nephrology experts based on their clinical experience in peritoneal dialysis care and informed by commonly encountered patient concerns in routine practice. To further ensure relevance, frequently asked questions were identified through structured online searches (Google) reflecting common patient inquiries regarding PD. Patients were not directly involved in the question development process. This approach was chosen to ensure clinical accuracy and comprehensive coverage of both routine and complex aspects of PD education, while patient involvement is planned as a key component of future studies. Although patients were not directly involved in the development of the question set, the selected questions were deliberately designed to reflect real-life decision-making scenarios commonly discussed during peritoneal dialysis counseling, including employment, caregiving responsibilities, travel, body image concerns, home environment requirements, and social participation. These domains represent key preference-sensitive factors known to influence modality choice and long-term adherence in PD patients.
All questions were submitted to each chatbot using identical wording to ensure standardization. Interactions were conducted in isolated chat windows equivalent to an ‘incognito’ session, with each question asked in a separate, new session without prior prompts or conversational history. No sequential questioning was performed, thereby preventing any carryover effects or contextual memory from influencing subsequent responses. This approach ensured that all responses were generated independently under identical, context-free conditions. Responses were obtained in unprocessed text format without additional prompts and recorded in a “Question–Model–Answer” format using Microsoft Word. In total, 135 responses (45 per model) were collected, and all transcripts were independently cross-verified by a second researcher for accuracy. All questions were presented to the chatbots in English to ensure linguistic consistency and facilitate standardized evaluation. Responses were generated using paid versions of each chatbot to ensure access to the most advanced model capabilities available at the time of evaluation.
Readability was assessed using two validated metrics: the Flesch Reading Ease Score (FRES) and the Flesch-Kincaid Grade Level (FKGL). The FRES ranges from 0 to 100, with higher scores reflecting easier readability, while the FKGL indicates the U.S. school grade level required for comprehension. Both metrics were computed automatically using Python’s textstat library (v3.11; Python Software Foundation, Wilmington, DE, USA) or equivalent R-based packages. The formulas used were as follows:
where WC = word count, SS = sentence count, WCS = words per sentence, YC = syllable count, and SYC = syllables per word.
To evaluate the quality and reliability of the chatbot responses, two independent, blinded physician reviewers with clinical experience in nephrology used the Ensuring Quality Information for Patients (EQIP) tool and the Modified DISCERN instrument [11,12]. The EQIP score was calculated as a percentage using the following formula:
Here, Yes denotes the number of criteria fully met, Partly indicates partial fulfillment, and Not Applicable refers to items excluded from scoring. Scores between 0–25% indicated severe quality issues, 26–50% serious deficiencies, 51–75% good quality with minor issues, and 76–100% well-written content.
The Modified DISCERN score ranged from 1 (very poor quality) to 5 (excellent quality). Any discrepancies between reviewers were resolved by a third evaluator.
As this study did not involve human participants or patient responses, no data regarding patients’ educational level or dialysis status were collected. The question set was designed to reflect commonly encountered concerns during PD counseling rather than characteristics of a specific patient population. The full list of questions, standardized prompts, and anonymized scoring templates are provided in Supplementary File S1 to support transparency and reproducibility.
3. Statistical Analysis
All statistical analyses were performed using IBM SPSS Statistics for Windows, Version 20.0 (IBM Corp., Armonk, NY, USA) [IBM Corp. Released 2011]. Categorical variables were expressed as numbers and percentages, whereas continuous variables were summarized as mean and standard deviation and as median and IQR (interquartile range) where appropriate. The normality of distribution for continuous variables was confirmed with the Shapiro–Wilk test. For comparison of three chatbot groups, one-way ANOVA or Kruskal–Wallis test was used depending on whether the statistical hypotheses were fulfilled or not. For normally distributed data, regarding the homogeneity of variances, Bonferroni or Games&Howell tests were used for multiple comparisons of chatbot groups. For nonnormally distributed data, Bonferroni adjusted Mann–Whitney U test was used for multiple comparisons of chatbot groups. The statistical level of significance for all tests was considered to be 0.05.
4. Results
Regarding textual characteristics, Gemini Pro 2.5 produced the longest and most detailed responses with higher word, sentence, and syllable counts. For general information questions, the median word count (IQR) was highest for Gemini Pro 2.5 (873 [759–925]), followed by ChatGPT-5 (346 [283–436]) and LLaMA Maverick 4 (352 [212–376]) (p < 0.001). Similar trends were observed for sentence and syllable counts, with Gemini outperforming both models (p < 0.001). LLaMA Maverick 4 consistently generated the shortest and least elaborate answers, while ChatGPT-5 demonstrated an intermediate performance. Detailed comparisons of word counts, syllable counts, and sentence counts across the three chatbots are shown in Table 2. These findings highlight substantial variation among the models in terms of content richness and elaboration.
Readability analysis using the Flesch Reading Ease Score (FRES) showed a comparable pattern across chatbot models. Gemini achieved the highest FRES values across general information (35.9 ± 5.6), technical/clinical issues (33.8 ± 4.7), and myths/misconceptions (28.3 ± 3.9), all significantly higher than those of LLaMA Maverick 4 (18.0 ± 8.0, 17.6 ± 7.1, and 14.9 ± 6.5, respectively; p < 0.001). ChatGPT-5 demonstrated intermediate FRES scores across all categories. Although all responses were classified within the ‘difficult’ readability range (FRES <50), statistically significant differences in FRES values were observed among the models. Detailed readability (FRES, FKGL) and content quality/reliability (EQIP, Modified DISCERN) scores for all subgroups and overall comparisons are presented in Table 3, and summarized in Figure 1.
Assessment of content quality and reliability revealed significant differences among the chatbots. Overall EQIP scores were highest for Gemini Pro 2.5 (median [IQR]: 75.4 [71.3–81.9]), followed by LLaMA Maverick 4 (61.5 [47.2–67.3]) and ChatGPT-5 (59.4 [53.1–70.4]) (p < 0.001). Similarly, Modified DISCERN scores were highest for Gemini Pro 2.5 (4.0 [4.0–4.5]), compared with ChatGPT-5 (3.5 [3.0–4.0]) and LLaMA Maverick 4 (3.0 [2.5–3.5]) (p < 0.001).
Taken together, the findings demonstrate consistent differences among the evaluated chatbots across textual characteristics, readability, and quality metrics.
5. Discussion
This study is one of the first to systematically evaluate the responses of three different AI-based chatbots to frequently asked questions about PD in terms of readability, content quality, and reliability. It is well established that limited patient education, misconceptions, and barriers to accessing accurate information play a significant role in the underutilization of PD worldwide [13,14]. In recent years, AI-based chatbots have gained increasing attention for their potential to improve health literacy and support patient–physician communication [14,15,16]. However, uncertainties regarding the quality, reliability, and clinical applicability of the information they provide remain unresolved.
This study was not designed to validate AI-generated responses against established clinical standards or physician-provided information. Rather, the primary aim was to conduct a comparative evaluation of different large language models under identical, context-free conditions to highlight relative differences in readability, content structure, and quality metrics. Accordingly, comparisons were made among AI chatbots rather than against a clinical gold standard. While such an approach does not establish clinical validity, it provides insight into the variability of AI-generated information and underscores the need for cautious interpretation and further validation studies involving clinician benchmarks.
In this study, Gemini Pro 2.5 showed higher values across textual features (word, sentence, and syllable counts), as well as readability and content quality metrics (FRES, EQIP, and Modified DISCERN), compared with the other evaluated models. Higher word and sentence counts indicate that the responses generated by Gemini were more detailed in structure under the evaluated conditions. In contrast, LLaMA Maverick 4 generated lower values across these metrics, while ChatGPT-5 demonstrated intermediate performance. These findings are consistent with previous reports suggesting that Google-based language models tend to generate longer and more elaborated responses [13].
Several questions included in the evaluation were inherently context-dependent and do not have a single universally correct answer. Accordingly, AI-generated responses should be interpreted as general informational outputs rather than individualized recommendations.
The finding that FRES scores were significantly higher for Gemini across all domains is noteworthy. However, it is important to emphasize that readability scores for all three chatbots remained within the ‘difficult’ range (FRES < 50). Therefore, these differences should be interpreted as relative rather than absolute improvements in readability. Although longer texts are often assumed to be less readable, Gemini-generated responses demonstrated comparatively higher FRES scores despite greater length, suggesting better linguistic organization under identical prompting conditions. In contrast, LLaMA produced both shorter responses and lower readability scores. These differences may reflect variation in language processing capabilities and training data characteristics among models [17].
An important finding of this study is that all evaluated AI chatbots generated responses within the ‘difficult’ readability range (FRES < 50), representing a major barrier to real-world peritoneal dialysis (PD) decision-making. This limitation is particularly relevant for patients newly diagnosed with kidney failure, who often experience high cognitive load and decisional anxiety. Current recommendations for patient education materials generally target a readability level corresponding to approximately the 6th–8th grade. Achieving this threshold may require deliberate linguistic simplification strategies, such as shorter sentences, avoidance of medical jargon or the inclusion of plain-language definitions, structured bullet-point formats, and teach-back prompts to reinforce understanding. While response length was not treated as an independent marker of quality in this study, longer responses are not inherently superior in the context of patient education. Rather, textual length should be interpreted in conjunction with readability indices and content quality metrics, as greater length may reflect more comprehensive coverage only when accompanied by improved clarity and patient-centered presentation.
Beyond technical performance, patient trust is a critical determinant of the real-world utility of AI-based educational tools. Previous patient-centered research has shown that although many patients believe AI may improve healthcare, substantial concerns persist regarding diagnostic errors, data privacy, and increased healthcare costs. In a recent cross-sectional survey of patients, Erul et al. reported that one-third of participants were very uncomfortable with AI-led diagnoses and that concerns about incorrect decisions and data confidentiality were particularly pronounced among individuals with lower educational levels. These findings suggest that the quality, reliability, and readability of AI-generated information are central to patient acceptance and underscore the importance of careful evaluation and clinician oversight when integrating chatbot-based tools into patient education [18].
Higher EQIP and Modified DISCERN scores observed for Gemini suggest comparatively stronger performance in content quality and reliability metrics under the evaluated conditions. LLaMA’s lower scores reflect its weaker performance in medical contexts, consistent with previous literature [13]. These results complement prior studies demonstrating the expanding role of AI and machine learning (ML) algorithms in peritoneal dialysis, including the prediction of peritonitis, technique failure, and cardiovascular complications, highlighting that AI applications extend beyond patient education to encompass risk stratification and individualized patient care [19].
These findings are consistent with recent studies in CKD patient education, which reported overall high accuracy for ChatGPT-5 and other AI models but also noted occasional misleading responses and lack of consistent referencing. Importantly, those studies observed performance improvements with newer AI versions, suggesting that iterative model refinement and alignment with clinical guidelines may further enhance reliability [10].
Our findings are similar to reports from other fields, such as oncology and hepatology, where model-dependent variations in performance have also been documented. For example, prior studies have shown that while ChatGPT-5 often provides accurate information, limitations in contextual appropriateness necessitate caution in clinical applications [16]. Our findings also align with recent evidence showing that AI-generated medical responses can achieve high levels of accuracy and completeness across diverse clinical topics [9]. However, by incorporating readability and patient education metrics, our study expands upon this prior work, highlighting dimensions beyond correctness alone.
ML algorithms have demonstrated strong predictive performance in forecasting PD complications and improving patient outcomes [13,17]. Our study highlights the additional value of AI in the realm of patient education. Integration of AI with remote patient management (RPM) and telemedicine applications has the potential to enhance both patient satisfaction and outcomes, particularly in aging populations [14]. The observed performance differences among chatbots underscore the importance of model selection in such integration efforts.
Furthermore, the incorporation of multi-omics data with AI in diabetic PD patients offers promising opportunities for the development of personalized nutritional and therapeutic strategies [20]. Our findings suggest that selecting the appropriate model will be crucial to ensuring the reliability of such data-intensive applications.
One notable finding of this study was the complete absence of references across all responses generated by the three AI chatbots. In the EQIP assessment, the item ‘Are sources or references provided?’ consistently received negative ratings from all reviewers. Although prompting the models explicitly to provide references can yield citation-like outputs, prior evidence and our own observations indicate that the accuracy of such references including journal name, year, and content validity cannot be guaranteed without manual verification. This limitation underscores a critical barrier to the safe and responsible use of AI chatbots in healthcare education at the current stage of technological development.
One of the strengths of our study is the use of validated tools such as EQIP and Modified DISCERN, with independent, blinded reviewers assessing all responses, thereby minimizing subjective bias. It should also be noted that LLMs are trained on globally diverse datasets and do not learn from real-time user interactions; therefore, geographical variations in usage intensity are unlikely to affect model performance. However, access to certain chatbots, such as ChatGPT-5, remains restricted in some regions due to infrastructural and legal limitations rather than training-related factors, and whether this introduces bias warrants further methodological investigation.
While accuracy, readability, and content quality are essential components of patient education, this study did not assess whether AI-generated information directly altered clinical or patient decision-making. Decision-making outcomes, such as modality choice or treatment adherence, were beyond the scope of the present analysis. Nevertheless, access to clear, reliable, and comprehensible information represents a fundamental prerequisite for informed decision-making.
Patient education in peritoneal dialysis is inherently preference- and lifestyle-sensitive. Factors such as work obligations, caregiving roles, physical appearance, travel flexibility, and home conditions strongly influence both modality choice and treatment adherence. Although patients were not directly involved in generating the FAQ set, the included questions intentionally targeted these real-world concerns. Nevertheless, the consistently low readability scores observed across all evaluated chatbots highlight an important equity issue. Patients with limited health literacy, restricted digital access, disabilities, or language barriers may face additional challenges when relying on AI-generated educational content. These findings underscore the need for clinician-mediated use of AI tools, readability optimization, and future co-design approaches involving patients and caregivers to ensure equitable and accessible PD education.
Although several AI-based chatbots offer free access with basic functionality, more advanced model versions—such as those used in the present study—may require paid subscriptions, and large-scale clinical implementation may involve additional costs related to infrastructure, data governance, and clinician oversight.
Limitations of our study include the evaluation of only three models, restriction to English-language content, and the lack of assessment of clinical outcomes. Although the Modified DISCERN instrument was applied using an overall score, individual sections of the DISCERN framework address different dimensions of information quality and clinical decision-making. Section-specific weighting was not performed in this study and may represent an important consideration for future research focusing on decision support. Although independent, context-free sessions were used to minimize memory effects, large language models may still generate variable responses due to inherent stochasticity. Moreover, because AI models are frequently updated, our findings reflect model performance during a specific timeframe.
6. Conclusions
This study provides the first comprehensive and multidimensional evaluation of AI-based chatbots in peritoneal dialysis patient education. It does not aim to recommend any specific AI chatbot for independent patient use. Rather, it highlights measurable differences among large language models when responding to identical PD-related questions, emphasizing the need for cautious interpretation and clinician oversight. Importantly, AI-generated information should not replace professional medical advice and must always be interpreted within appropriate clinical context and safeguards.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Elzorkany K. Alhamad M.A. Albaqshi B.M. Alhassan M.Y. Alahmed M.H. Almusalmi A. Khamis H.H. Ali E. Alhussaini H. Alabdulqader A. Knowledge about peritoneal dialysis among patients with end-stage kidney disease on hemodialysis: A cross-sectional study Ann. Med.202456241101910.1080/07853890.2024.241101939376132 PMC 11463005 · doi ↗ · pubmed ↗
- 2Tsai C.H. Eghdam A. Davoody N. Wright G. Flowerday S. Koch S. Effects of Electronic Health Record Implementation and Barriers to Adoption and Use: A Scoping Review and Qualitative Analysis of the Content Life 20201032710.3390/life 1012032733291615 PMC 7761950 · doi ↗ · pubmed ↗
- 3Shankar R. Bundele A. Low J. Hong W.Z. Mukhopadhyay A. Barriers and facilitators for the adoption of peritoneal dialysis: Protocol for a systematic review of qualitative studies BMJ Open 202414 e 09192810.1136/bmjopen-2024-09192839424385 PMC 11492933 · doi ↗ · pubmed ↗
- 4Clark M. Bailey S. Chatbots in Health Care: Connecting Patients to Information: Emerging Health Technologies [Internet]Canadian Agency for Drugs and Technologies in Health Ottawa, ON, Canada 202438564540 · pubmed ↗
- 5Lawson Mc Lean A. Hristidis V. Evidence-Based Analysis of AI Chatbots in Oncology Patient Education: Implications for Trust, Perceived Realness, and Misinformation Management J. Cancer Educ.20254048248910.1007/s 13187-025-02592-439964607 PMC 12310775 · doi ↗ · pubmed ↗
- 6Schattenberg J.M. Chalasani N. Alkhouri N. Artificial Intelligence Applications in Hepatology Clin. Gastroenterol. Hepatol.2023212015202510.1016/j.cgh.2023.04.00737088460 · doi ↗ · pubmed ↗
- 7Zargarzadeh A. Javanshir E. Ghaffari A. Mosharkesh E. Anari B. Artificial intelligence in cardiovascular medicine: An updated review of the literature J. Cardiovasc. Thorac. Res.20231520420910.34172/jcvtr.2023.3303138357567 PMC 10862032 · doi ↗ · pubmed ↗
- 8Kurniawan M.H. Handiyani H. Nuraini T. Hariyati R.T.S. Sutrisno S. A systematic review of artificial intelligence-powered (AI-powered) chatbot intervention for managing chronic illness Ann. Med.202456230298010.1080/07853890.2024.230298038466897 PMC 10930147 · doi ↗ · pubmed ↗