LEARNet: A Learning Entropy-Aware Representation Network for Educational Video Understanding
Chitrakala S, Nivedha V V, Niranjana S R

TL;DR
LEARNet is a new framework that efficiently identifies key instructional content in educational videos by focusing on high-information frames.
Contribution
LEARNet introduces an entropy-aware architecture combining Temporal Information Bottleneck and Spatial–Semantic Decoder for educational video understanding.
Findings
LEARNet reduces visual redundancy by 70.2% while maintaining high annotation accuracy (F1 = 0.89, mAP@50 = 0.88).
The framework enables the creation of EVUD-2M, a large-scale benchmark with multi-level semantic labels for educational videos.
Abstract
Educational videos contain long periods of visual redundancy, where only a few frames convey meaningful instructional information. Conventional video models, which are designed for dynamic scenes, often fail to capture these subtle pedagogical transitions. We introduce LEARNet, an entropy-aware framework that models educational video understanding as the extraction of high-information instructional content from low-entropy visual streams. LEARNet combines a Temporal Information Bottleneck (TIB) for selecting pedagogically significant keyframes with a Spatial–Semantic Decoder (SSD) that produces fine-grained annotations refined through a proposed Relational Consistency Verification Network (RCVN). This architecture enables the construction of EVUD-2M, a large-scale benchmark with multi-level semantic labels for diverse instructional formats. LEARNet achieves substantial redundancy…
Click any figure to enlarge with its caption.
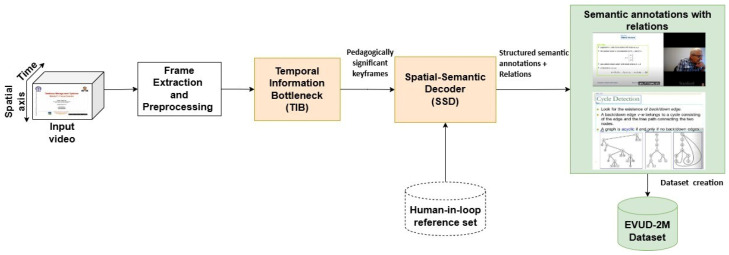 Figure 1
Figure 1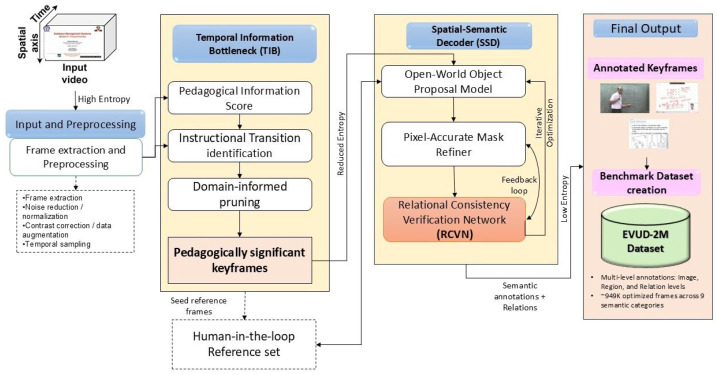 Figure 2
Figure 2 Figure 3
Figure 3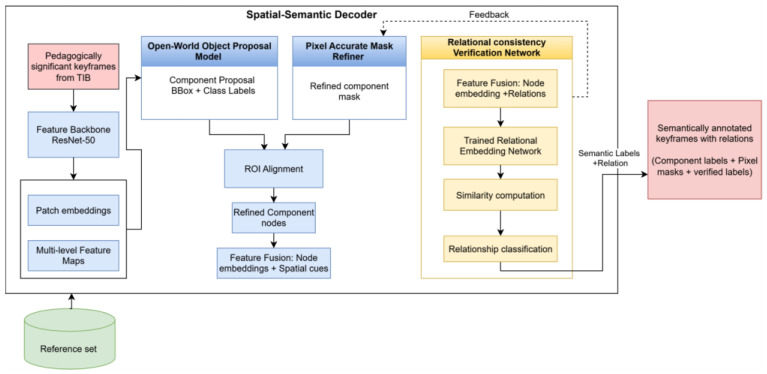 Figure 4
Figure 4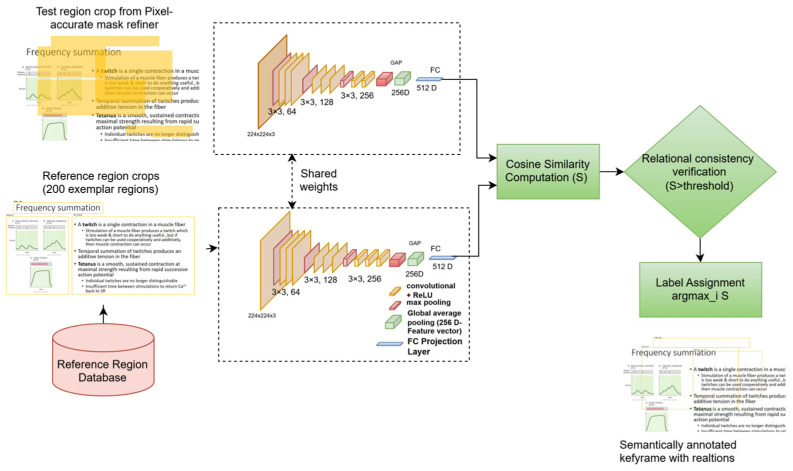 Figure 5
Figure 5 Figure 6
Figure 6 Figure 7
Figure 7 Figure 8
Figure 8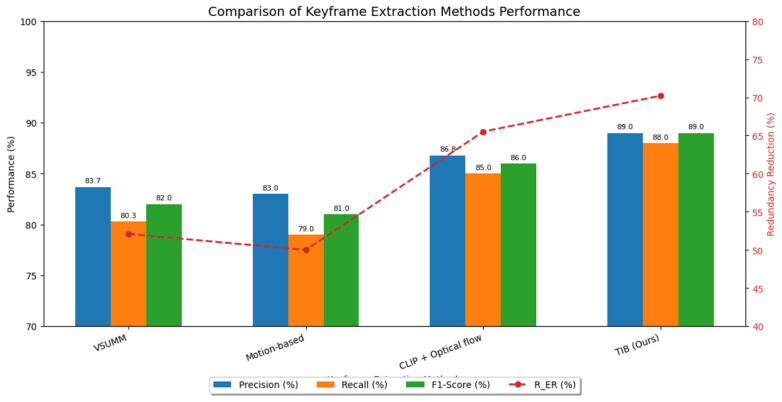 Figure 9
Figure 9 Figure 10
Figure 10 Figure 11
Figure 11 Figure 12
Figure 12 Figure 13
Figure 13 Figure 14
Figure 14 Figure 15
Figure 15 Figure 16
Figure 16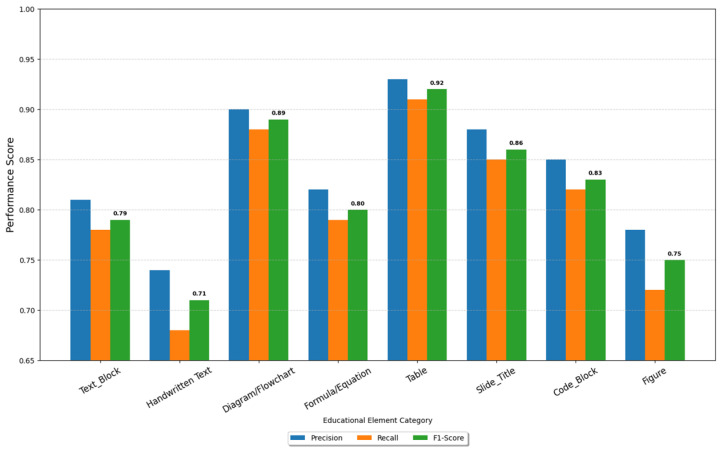 Figure 17
Figure 17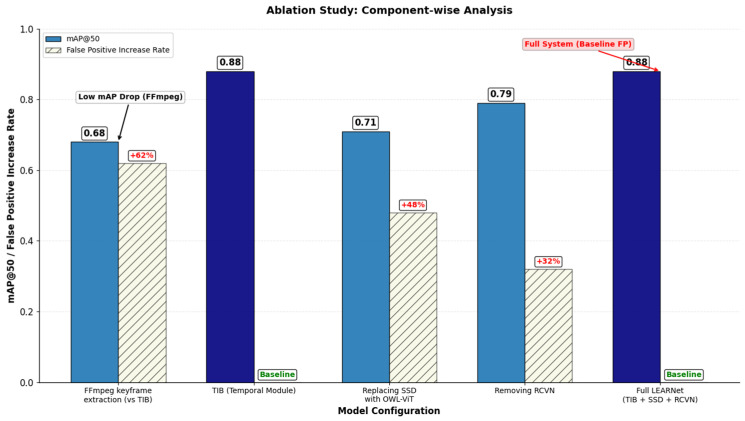 Figure 18
Figure 18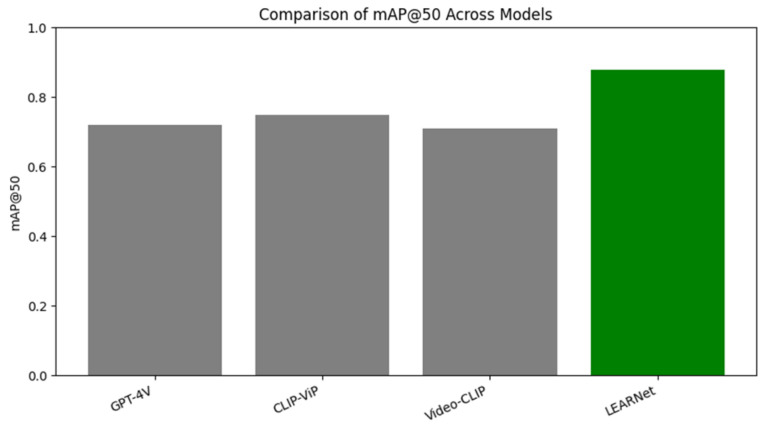 Figure 19
Figure 19 Figure 20
Figure 20Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsMultimodal Machine Learning Applications · Video Analysis and Summarization · Human Pose and Action Recognition