A Multi-Object Tracking Method with an Unscented Kalman Filter on a Lie Group Manifold
Xinyu Wang, Li Liu, Fanzhang Li

TL;DR
This paper introduces a new multi-object tracking method using an unscented Kalman filter on a Lie group to improve accuracy in challenging scenarios.
Contribution
The novel contribution is a lightweight MOT method, LUKF-Track, using a UKF on a Lie group for better tracking in complex conditions.
Findings
LUKF-Track achieves state-of-the-art results on MOT17, MOT20, and DanceTrack benchmarks.
The method improves tracking accuracy in scenarios with nonlinear motion and heavy occlusions.
It uses a motion model with a UKF on a Lie group for object state prediction and association.
Abstract
Multi-object tracking (MOT) has attracted increasing attention and achieved remarkable progress. However, accurately tracking objects with homogeneous appearance, heterogeneous motion, and heavy occlusion remains a challenge because of two problems: (1) missing association due to recognizing an object as background and (2) false prediction caused by the predominant utilization of linear motion models and the insufficient discriminability of object appearance representations. To address these challenges, this paper proposes a lightweight, generic, and appearance-independent MOT method with an unscented Kalman filter (UKF) on a Lie group called LUKF-Track. The method utilizes detection boxes across the entire range of scores in data association and matches objects across frames by employing a motion model, where the propagation and prediction of object states are formulated using a UKF on…
Click any figure to enlarge with its caption.
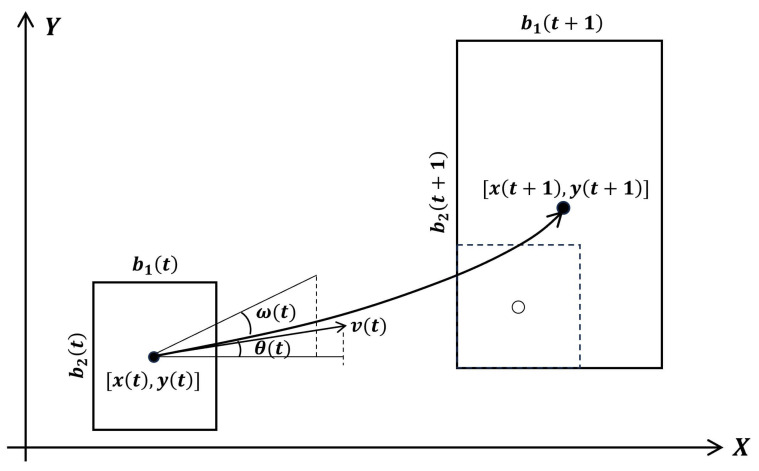 Figure 1
Figure 1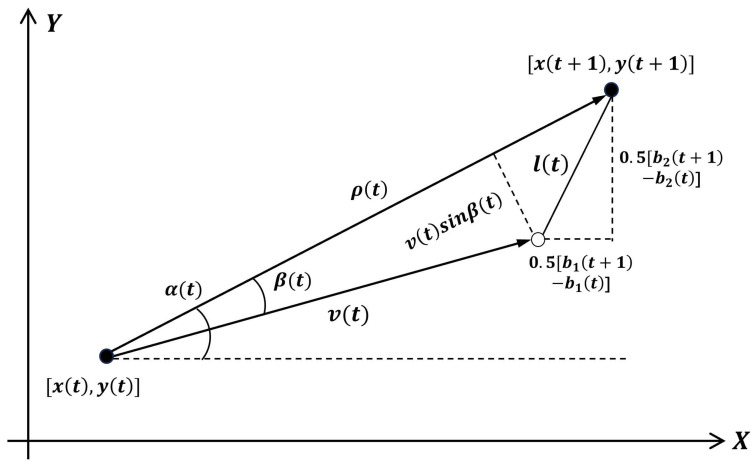 Figure 2
Figure 2 Figure 3
Figure 3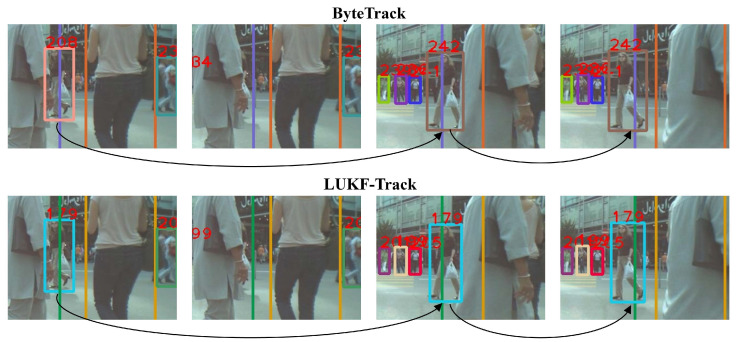 Figure 4
Figure 4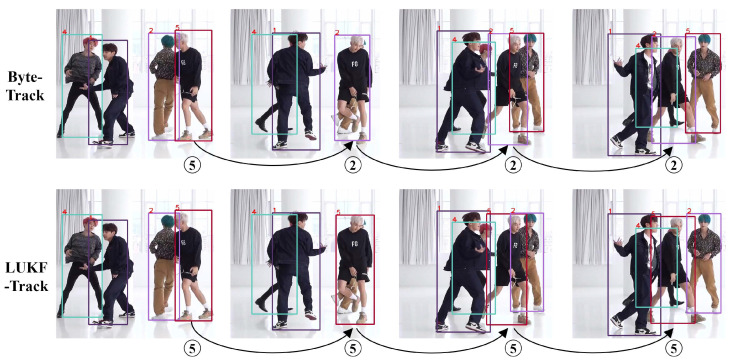 Figure 5
Figure 5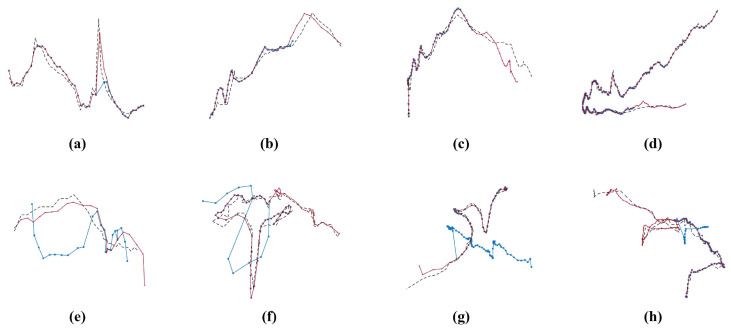 Figure 6
Figure 6 Figure 7
Figure 7- —General Program of National Natural Science Foundation of China
- —Youth Program of National Natural Science Foundation of China
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsVideo Surveillance and Tracking Methods · Target Tracking and Data Fusion in Sensor Networks · Gaze Tracking and Assistive Technology
1. Introduction
Multi-object tracking (MOT) involves detecting and tracking multiple objects within a video and is always a research hotspot in computer vision. MOT has a wide range of applications in scenarios including surveillance systems [1], self-driving vehicles [2], sports [3], behavior analysis [4], and augmented reality [5], to name but a few. However, MOT can be very challenging because maintaining the identities of multiple objects in complex environments requires handling various problems such as occlusions, motion blurs, interactions between objects, and changes in object appearances.
MOT methods fall into either tracking-by-detection (TBD) or tracking-free detection (TFD). For a long time, TBD has prevailed over TFD by virtue of its fewer interaction requirements, greater ability to identify randomly appearing objects in the middle of videos, and better performance in coping with various appearance distributions. Based on association metrics, MOT methods under the TBD framework can be broadly categorized as follows: motion-based (IoU matching, Kalman filter (KF)) [6,7,8], appearance-based (ReID embedding) [9,10,11], or a combination of both [12,13,14]. The motion model is used to predict the states and locations of objects based on their current observations, while the appearance model represents objects as fine-grained feature maps extracted from regions of detections and predictions. Using the calculated affinities between each pair of objects across frames, a matching strategy assigns identities to objects by the Hungarian algorithm [15] or greedy assignment [16,17].
Despite the advancements in MOT, tracking objects with homogeneous appearance, heterogeneous motion, and heavy occlusion remains a challenge because of the problems of missing association and false prediction. Missing association, also known as false negatives, refers to recognizing an object as background, which is usually caused by occlusion and low resolution. False prediction is often caused by the predominant utilization of linear motion models and the insufficient discriminability of appearance representations. For one, current motion models often apply a Kalman filter for motion prediction. However, the classical Kalman filter is designed for linear estimation systems, and this inherent limitation becomes evident when a motion model is confronted with complex, nonlinear motions and occlusions prevalent in dynamic environments, such as sports and dance. Additionally, most appearance models are sensitive to large rotations and drastic illumination changes, not to mention the tremendous cost in task-specific training for supervised learning methods.
Targeting the challenges in MOT, this paper proposes an MOT method with an unscented Kalman filter (UKF) on the Lie group referred to as LUKF-Track. The method makes full use of detection boxes from high scores to low ones in a two-round association process and matches objects across frames by using a motion model where the propagation and prediction of object states are formulated by a UKF on the Lie group. The Lie group provides geometric representations of continuous transformation through manifold structures and offers algebraic solutions to the modeled problems on manifold spaces, which improves the accuracy of prediction and anti-interference performance for complex, nonlinear motions and occlusions prevalent in dynamic environments. LUKF-Track was validated against three benchmark datasets and compared with other trackers. The results demonstrate that LUKF-Track is particularly effective in scenarios characterized by highly nonlinear motion and severe occlusion. The primary contribution of this paper is twofold, as follows:
(1) We propose a generic and appearance-independent MOT method that pushes forward the state-of-the-art tracking performance in three MOT experiments.
(2) The locations and propagations of objects are represented as a motion model formulated by a UKF on the Lie group, which provides additional insight into the dynamics of objects and thus effectively solves the false prediction problem for tracking under occlusion and nonlinear motion.
2. Related Works
2.1. Multiple Object Tracking
In MOT, the current leading paradigm is TBD, which detects objects in each individual frame and subsequently associates the detections with the tracking process over time. The process of associating data for target tracking typically encompasses two fundamental components: the calculation of object similarity and the implementation of a matching strategy. The calculation of similarity is dependent upon the detection results (e.g., the boundary boxes and center coordinates of the objects) as the input and the calculation of the similarity between the detection target and the tracking target. This can be performed by defining an association metric of objects with either one or a combination of motion and appearance models.
Motion model. The motion model defines an association metric based on motion consistency and often involves corresponding measured states of detection to predicted states by using a variant of the Kalman filter. Typical trackers that use the motion model alone for data association include SORT [18], ByteTrack [6], and UCMCTrack [8]. SORT uses a standard Kalman filter to predict the location of the detected targets with high scores, then computes the IoU between detection boxes and predicted boxes as affinity. ByteTrack tracks by associating almost every detection box instead of only the high-score ones. For low-score detection boxes, the method utilizes their similarities with tracklets to recover true objects and filter out the background [6]. UCMCTrack replaces the IoU with the Mapped Mahalanobis Distance to calculate the affinity between objects by projecting the probability distribution onto the ground plane [8].
Appearance model. The appearance model defines an association metric based on the appearance similarity between object-level features. Different from the motion model, which mainly focuses on short-range matching, the appearance model is more helpful in long-range matching. Typical trackers that use an appearance model alone for data association include UniTrack [9], FineTrack [10], and the self-supervised learning appearance model [11]. UniTrack consists of a single and task-agnostic appearance model, which can be learned in a supervised or self-supervised fashion, and multiple “heads” that address individual tasks and do not require training [9]. FineTrack utilizes diverse local embeddings and background-filtered global embeddings to jointly describe appearance [10]. The self-supervised learning appearance model leverages Momentum Contrastive Learning (MoCo-v2) [19] to learn an appearance representation embedding model and extract features from detection without using tracking annotations [11].
A combination of both. A lot of trackers combine motion and appearance information into a more informed association metric. Examples include DeepSORT [20], BoT-SORT [12], and Rt-Track [14]. DeepSORT combines appearance information generated by a CNN-based deep appearance descriptor with motion information computed with a Kalman filter, which increases robustness against misses and occlusions while keeping the system easy to implement, efficient, and applicable to online scenarios [20]. BoT-SORT incorporates the re-identification (ReID) of objects by deep appearance cues and camera motion compensation to the framework of ByteTrack [12]. Rt-Track combines the direction consistency generated from a trajectory smoothing mechanism and the appearance features obtained by an ultra-granular feature extraction network to a similarity metric [14].
The proposed LUKF-Track associates objects predominantly based on their motion consistency and uses appearance similarity as an alternative option for some long-range association tasks.
2.2. The Application of Lie Group Machine Learning in Computer Vision
Lie group machine learning is an interdisciplinary research field combining Lie group theory with machine learning methods. Using the structural characteristics of Lie groups, Lie group machine learning has a unique advantage in processing data with transformation invariance. Since the early 2000s, a series of Lie group machine learning algorithms have been designed, including Lie group meta learning [21,22], Lie group semi-supervised learning [23,24], Lie group kernel learning [25], Lie group transfer learning [26], etc., and they have been used to solve problems in pattern recognition, robotics, computer vision, and natural language processing. Specifically in computer vision, Lie group machine learning finds its success in a variety of applications, such as object tracking [27], pose estimation [28], action representation and recognition [29,30], simultaneous localization and mapping (SLAM) [31], motion identification [32], and so on. In [27], an object tracking algorithm is presented based on an unscented particle filter for systems where the states of objects evolve on a Lie group space. In [28], a filter on the Lie group is proposed for pose estimation, where the time propagation of the state is formulated on the Lie algebra. To address the complexity and nonlinearity of human action recognition in videos, Lie group features are combined with deep learning to provide a natural representation of complex and diverse action data [29]. Wang et al. [30] develop a hand-worn prototype device for gesture recognition by using Lie group theory to capture the inherent structural changes in hand movements and the spatiotemporal dependencies between multiple bones. Labsir et al. [31] address the problem of monocular SLAM by estimating both the state and the map on Lie group space through a Lie group-based extended Kalman filter. Kachhoria et al. [32] acquire highly suitable Lie grouping characteristics, which enable 3D motion identification by integrating the Lie group topology into a deep networking design.
3. Proposed Method
3.1. System Modeling
The motion of a detection box across frames can be modeled as a target performing a trajectory with constant speed and angular rate in a plane. Figure 1 illustrates the motion of a detection box in two consecutive frames along with the parameters used for system modeling. As shown in the figure, x, y, , , , , and denote the state parameters of a detection box, corresponding to the x-position, y-position, width, height, heading angle, translational speed, and angular rate. Using triangle similarity and basic trigonometry, the relationships among these parameters can be approximately expressed as follows:
Considering the system noises in the motion, the final position of a detection box will not be deterministic, and the two expressions above can be further expanded to an equation set modeling the dynamics of the system:
where the vector is a white Gaussian noise in . According to [33], the pose of a moving object presents a banana-shaped distribution, and the matrix Lie Special Euclidean group provides a better means of handling the uncertainty distributions than in Euclidean space. Assuming that a detection box with dynamics modeled as Equation (3) presents a banana-shaped distribution, its pose can be represented by an Lie group. The translational speed and angular rate are expressed in . The resulting group is a 5-dimensional matrix Lie group G obtained by the Cartesian product of and , i.e., . The state can be estimated by a group element g on and is written as a matrix form:
Accordingly, the system dynamics described by (3) can be estimated by g written as follows:
where is a nonlinear function. Note that although is a matrix, G is a 5-dimensional Lie group. This happens because we employ matrices to represent , a two-dimensional space on the matrix Lie group. is assumed to be a concentrated Gaussian distribution on G: . The function captures the dynamics of the system, and it can be obtained from a formula manipulation to Equation (5):
where the logarithm map of is a Lie algebra associated with the matrix Lie group G:
with
3.2. Measurement Modeling
We consider three measurements from a detection: azimuth , range , and radial speed . As shown in Figure 2, the measurements at timestep t can be calculated from the state parameters once the detection box reaches timestep . Using triangle similarity and simple trigonometry, the relations between these parameters can be expressed as follows:
Considering the noise in measuring the motion as a white Gaussian noise , the measurements of a detection box at timestep t can be represented as the following function set:
The measurements arrive in polar coordinates and can be written in the structure of the Lie group . As stated in [33], the distributions of measurements also resemble banana-shaped contours. Because of this, the chosen Lie group for the measurements will be constructed as . Thus, the measurement map is given as follows:
Combining Equations (12) and (13), the dynamics of measurement can be modeled on the Lie group.
3.3. State Prediction
It is assumed that the posterior state distribution after the arrival of the measurement is a concentrated Gaussian distribution on Lie groups, i.e., . At each timestep , three sigma points , , and along with their weights are created for , , and according to Equations (1) and (2). The computed is propagated through the system model in Equation (5) and can be calculated as follows:
Based on the propagation of the sigma points in Equation (15), the predicted state along with its covariance can be calculated. It is noted that is a concentrated Gaussian distribution on G and can be written as or more directly with . To make sure the state prediction is also a concentrated Gaussian distribution, we replaced the numerical mean with a Lie group intrinsic mean:
The covariance calculation is modified accordingly:
3.4. State Update
In the update step, we apply the UT to the measurement model in Equation (14) to approximate the measurement statistics and further update the system state at timestep . Instead of creating a new set of sigma points for , the propagated sigma points and the sigma points of obtained in the previous section are used in calculating the propagation of the sigma points for :
It is noted that is a concentrated Gaussian distribution on H and can be written as with . To make sure the propagation of the measurement is also a concentrated Gaussian distribution, we compute the mean of the sigma point to update the state at the moment :
Accordingly, the covariance of the measurement and the cross-covariance between prediction and measurement can be modified as follows:
We cannot apply the filter update directly on based on the measurement because they are on different Lie group spaces; instead we update the random variable based on , which is obtained from the arrived measurement :
Finally, the prediction on state and the covariance of the prediction can be updated to and :
where and are the updated target state and variance at .
3.5. Data Association
LUKF-Track applies a two-round association process to match pairs of objects across frames. After separating low-scored and high-scored detected objects, motion models based on LUKF are constructed for all tracks to predict new locations in the current frame.
The first association is performed between high-scored detections and all tracks, including the lost tracks from previous frames. The association metric can be computed by either the IoU or the Re-ID feature distances between detection and prediction. Considering that appearance information is helpful in the long-range association for preserving the identity of tracks, we use appearance similarity as an alternative association metric to re-identify a pair of objects separated by a period of time. Following the method in [25], an appearance feature of an object is constructed by calculating a matrix Lie group from a series of extracted image features: color, gradient, texture, and local context. The appearance similarity between two objects is measured by a geodesic distance between the corresponding matrix Lie groups and :
where is the Frobenius norm. Then, the Hungarian algorithm is used to finish the matching.
The second association is performed between low-scored detections and the remaining tracks after the first association. Here, the IoU is chosen because low-scored detections often contain severe occlusion or motion blur, and appearance features are not reliable. For an unmatched track after the second association, only when it exists for more than a certain number of frames, such as 30, do we delete it from the tracking array.
The pseudo-code of LUKF-Track is shown in Algorithm 1.
4. Experiments and Analysis
4.1. Experiment Setting
Datasets. The experimental data presented in this paper comprises three benchmark datasets for multi-target tracking: MOT17 [34], MOT20 [35], and DanceTrack [36]. MOT17 and MOT20 are about pedestrian tracking, where targets mostly move linearly, and scenes in MOT20 are more crowded. DanceTrack [54] features dancers (i.e., objects) with similar appearances, fast motion, and heavy occlusion.
Methods and Metrics. Seven MOT methods published in recent years were chosen for comparison: SORT [18], DeepSORT [20], StrongSORT [13], OC-SORT [7], QDTrack [37], FineTrack [10], and ByteTrack [6]. These methods can be further categorized into three groups by association metrics. The proposed LUKF-Track is implemented in two ways: one uses both motion and appearance information (i.e., LUKF-Track (M+A)); the other uses motion information only (i.e., LUKF-Track (M)). All methods are evaluated with three MOT metrics: HOTA [38] for higher-order tracking accuracy, MOTA [39] for multi-target tracking accuracy, and IDF1 for target recognition [40].
Implementation. For a fair comparison, we directly use the publicly available YOLOX [41] detector weights by ByteTrack. The detection score threshold is set to 0.6 for categorizing a detection as high- or low-confidence. The IoU threshold for matching is set to 0.2, which means that if the overlap between the detection box and prediction box is below 0.2, the matching calculation will not be triggered. A duration of 30 frames is set to prevent the missing of reappearing objects and filter out unreasonable association pairs.
4.2. Results and Discussion
The benchmark results of LUKF-Track and the chosen MOT trackers for comparison on three benchmark datasets are reported and compared. We then compare LUKF-Track (M) with ByteTrack in dealing with several typical challenging scenarios with visualization results. The reason why we chose ByteTrack instead of other trackers for further analysis is that LUFK-Track adopts the same weights of detection and a similar way of handling low-scored detections.
4.2.1. Benchmark Results
Table 1 summarizes the test results of all eight MOT methods on the three datasets. For each performance metric, the highest score is highlighted in bold and underlined, and the second highest score is highlighted by an underline.
MOT17. The two implementations of LUKF-Track rank second and third and are only outperformed by FineTrack, which achieves the best score in HOTA and the second best scores in both MOTA and IDF1. Specifically, LUKF-Track (M+A) achieves the best IDF1 (79.6) and the second best HOTA (63.7) and ranks third in MOTA (78.5). Moreover, it outperforms the two trackers that use both motion and appearance information (i.e., DeepSort and StrongSort). LUKF-Track (M) presents the third best overall performance and prevails in HOTA (63.7 vs. 63.1) and IDF1 (79.5 vs. 77.3) compared with ByteTrack. The relatively low scores of LUKF-Track in MOTA (i.e., 78.2 and 78.5 for the two implementations) may be attributed to the high ID switches caused by a suboptimal IoU setting.
MOT20. LUKF-Track (M+A) outperforms all other trackers in MOT20, which is under severe pedestrian occlusion, setting the highest MOTA of 78.1 and IDF1 of 79.2, and an average score of HOTA (61.9). As the runner-up, FineTrack achieves the highest HOTA (63.6), the second highest MOTA (77.9), and the third highest IDF1 (79.0). LUKF-Track (M), which ranks third among all trackers, prevails in HOTA (62.2 vs. 61.3) and IDF1 (79.1 vs. 75.2) compared with ByteTrack.
DanceTrack. Overall, LUKF-Track (M) achieves the second best performance after FineTrack by presenting the second best scores in both MOTA (91.3) and IDF1 (56.1), which is better than LUKF-Track (M+A) and outperforms ByteTrack by a large margin: +1.8 MOTA, +2.5 HOTA, and +3.6 IDF1. However, both implementations of LUKF-Track present relatively low scores in HOTA (i.e., 49.4 and 49.8), which can be explained by the unbalances among accurate detection, association, and localization.
In general, both implementations of LUKF-Track achieve competitive tracking performances, especially in the experiments on MOT17 and MOT20. The results demonstrate that the proposed motion model is effective, as it accumulates fewer tracking errors and assigns IDs to objects more accurately. As LUKF-Track is designed to be simple for better generalization, we use the default detection confidence threshold and apply a shared parameter stack across the three datasets, which is different from other trackers such as FineTrack and StrongSort. We believe that carefully tuning the parameters for each dataset can further boost their performance.
4.2.2. Visualization Results
Figure 3 and Figure 4 present two chosen video sequences with tracking boxes to compare LUKF-Track (M) with ByteTrack when dealing with difficult cases in videos from MOT17, including partial occlusion, complete occlusion, changes in object appearance, and the appearance of new objects.
In Figure 3, a distant pedestrian (i.e., small object) in the orange box (the eighth in both ByteTrack and LUFK-Track) first approaches, then interacts with two pedestrians nearby. ByteTrack loses the tracking for the distant pedestrian in the fourth frame when the three people gather and assigns an ID of 8 to a person who blocks the first pedestrian, while LUFK-Track keeps the tracking on the distant pedestrian and assigns a new ID to the person nearby in the fourth frame.
In Figure 4, a pedestrian (208th in ByteTrack, 179th in LUKF-Track) is first partially occluded, then completely occluded, and finally reappears. After a temporary disappearance due to a complete occlusion in the second frame, ByteTrack reassigns an ID of 242 instead of the original 208 to the pedestrian in the third frame. In contrast, LUKF-Track is able to recognize the pedestrian and assigns the same ID to the person after her reappearance in the fourth frame.
Figure 5 presents a video sequence to compare LUKF-Track with ByteTrack in handling difficult cases in the videos of DanceTrack, including partial occlusion, complete occlusion, motion blur, interactions between objects, and changes in object appearance. The two dancers (second and fifth) in the first frame exchange positions from the second to the third frame, and due to the complete occlusion of the second frame, ByteTrack confuses the two dancers in the third frame, recognizing the dancer with the original ID of 2 as the dancer with the original ID of 5 and recognizing the dancer with the original ID of 5 as the dancer with the original ID of 2. While Lie-ByteTrac is able to recognize the dancer in the first frame and maintains the same ID after the two dancers interact with each other, the correct ID assignment is performed.
We further compare LUKF-Track with ByteTrack by their trajectory visualizations for the MOT17 dataset. In Figure 6, the black dashed line, blue dot, and red line are used to represent the ground truth (GT) trajectory and tracking trajectories output by the two methods. Overall, the tracking trajectory of LUKF-Track is closer to the GT and presents fewer ID switches, fragment tracks, and object losses from which ByteTrack suffers. In Figure 6a, LUKF-Track accurately tracks the occurrence of an abrupt jump in motion, and its trajectory is close to that of the GT, while ByteTrack fails to track this drastic motion by responding with a relatively weak one. In Figure 6b–d, the tracking trajectory of ByteTrack becomes abnormal after a certain point. This happens when the ID of an object is wrongly assigned to some other object (i.e., ID switch). In contrast, LUKF-Track avoids the occurrence of this problem in these scenarios. In Figure 6e, although the trajectories of both trackers are steeper than that of the GT, the difference in LUKF-Track compared with the GT is smaller. In Figure 6f–h, the trajectory of ByteTrack vanishes after a certain point when the tracker loses track of the object, while LUKF-Track persistently tracks the same object.
4.3. Component Ablation
To evaluate the effectiveness of the method’s design, we ablate the contributions of the proposed motion model and association method in LUKF-Track on the validation sets of MOT17 and DanceTrack in Table 2. As the data association makes the appearance information of objects an option in the first-round association, we form six trackers using different combinations of a motion model, appearance model, and data association. The two baseline trackers adopt a KF and UKF as motion models and a regular IoU calculation as the matching strategy. The fifth and sixth trackers are the two implementations of LUKF-Track. For a fair comparison, all trackers apply the same object detection, which is followed by that of ByteTrack. In the table, “✓” indicates that a proposed module is adopted in a tracker; “Fixed” indicates that the matching strategy associates the motion and appearance information with two fixed weights of 0.8 and 0.2.
Motion Model. Comparing the first and secnd trackers, we find that the UKF is a better motion model than the standard KF. The comparison between the second and third trackers shows that the performance gains from the proposed motion model are significant on both datasets for all metrics, which validates the effectiveness of modeling the dynamics and states of an object on the Lie group manifold. We also observe that the improvements to metrics are more significant on the DanceTrack dataset, where the motions of dancers are more complicated, and the interaction is heavier.
Association Method. Comparing the fourth with the fifth tracker, which both use motion and appearance information as the association metric, we find that the proposed two-round data association generally enhances the metrics of HOTA (i.e., from 68.6 to 71.5), which largely reflects the association performance.
The Usage of Appearance Information. The comparison between the fifth and sixth trackers shows that the effectiveness of appearance information is trivial and only presents notable improvements on the MOT17 dataset, in which the motion of objects is slower and the appearances of objects are more heterogeneous. It is worth noting that the three metrics are even reduced after adding the appearance model for DanceTrack; this could be explained by the negative effect caused by the homogeneous appearances of dancers.
5. Conclusions
We analyze popular MOT trackers and identify two major challenges in MOT tasks: missing association due to recognizing an object as background and false prediction caused by the predominant utilization of linear motion models and the insufficient discriminability of object appearance representations. Targeting these challenges, we propose a simple yet generic MOT method with a UKF on the Lie group named LUKF-Track. The method makes full use of detection boxes from high scores to low ones in a two-round data association and matches objects across frames by using a motion model where the propagation and prediction of object states are formulated by a UKF on the Lie group. In the experiments on three public MOT datasets, LUKF-Track outperforms other MOT trackers for comparison. The gain is especially significant for scenarios of severe occlusion and nonlinear object motion. We hope the high accuracy and simplicity of LUKF-Track can make it attractive in real applications.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Amosa T.I. Sebastian P. Izhar L.I. Ibrahim O. Ayinla S.L. Bahashwan A.A. Bala A. Samaila Y.A. Multi-camera multi-object tracking: A review of current trends and future advances Neurocomputing 202355212655810.1016/j.neucom.2023.126558 · doi ↗
- 2Chiu H.k. Wang C.Y. Chen M.H. Smith S.F. Probabilistic 3D Multi-Object Cooperative Tracking for Autonomous Driving via Differentiable Multi-Sensor Kalman Filter Proceedings of the IEEE International Conference on Robotics and Automation (ICRA)Yokohama, Japan 13–17 May 2024
- 3Cao W. Wang X. Liu X. Xu Y. A deep learning framework for multi-object tracking in team sports videos IET Computer Vision 20241857459010.1049/cvi 2.12266 · doi ↗
- 4Zhou X. Chan S. Qiu C. Jiang X. Tang T. Multi-Target Tracking Based on a Combined Attention Mechanism and Occlusion Sensing in a Behavior-Analysis System Sensors 202323295610.3390/s 2306295636991667 PMC 10056893 · doi ↗ · pubmed ↗
- 5Li S. Schieber H. Corell N. Egger B. Kreimeier J. Roth D. GBOT: Graph-Based 3D Object Tracking for Augmented Reality-Assisted Assembly Guidancear Xiv 202410.48550/ARXIV.2402.07677 · doi ↗
- 6Zhang Y. Sun P. Jiang Y. Yu D. Weng F. Yuan Z. Luo P. Liu W. Wang X. Byte Track: Multi-object Tracking by Associating Every Detection Box Proceedings of the Computer Vision–ECCV 2022 Tel Aviv, Israel 23–27 October 2022 Avidan S. Brostow G. CisséM. Farinella G.M. Hassner T. Springer Cham, Switzerland 2022121
- 7Cao J. Pang J. Weng X. Khirodkar R. Kitani K. Observation-Centric SORT: Rethinking SORT for Robust Multi-Object Tracking Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)Los Alamitos, CA, USA 17–24 June 20239686969610.1109/CVPR 52729.2023.00934 · doi ↗
- 8Yi K. Luo K. Luo X. Huang J. Wu H. Hu R. Hao W. UCMC Track: Multi-Object Tracking with Uniform Camera Motion Compensation Proc. AAAI Conf. Artif. Intell.2024386702671010.1609/aaai.v 38i 7.28493 · doi ↗