Peer Reporting: Sampling Design and Unbiased Estimates
Kang Wen, Jianhong Mou, Xin Lu

TL;DR
This paper introduces a new method for estimating population proportions in social networks using peer reports, which improves accuracy and privacy.
Contribution
The paper introduces the Activity Ratio Corrected ECM estimator (ECMac), which provides unbiased estimates in heterogeneous networks.
Findings
ECMac reduces estimation error by up to 70% compared to conventional methods in simulations and real-world networks.
ECMac provides unbiased and stable estimates even when network degrees are heterogeneous and correlated with attributes.
Abstract
The Ego-Centric Sampling Method (ECM) leverages individual-level reports about peers to estimate population proportions within social networks, offering strong privacy protection without requiring full network data. However, the conventional ECM estimator is unbiased only under the restrictive assumption of a homogeneous network, where node degrees are uniform and uncorrelated with attributes. To overcome this limitation, we introduce the Activity Ratio Corrected ECM estimator (ECMac), which exploits network reciprocity to recast the population–proportion problem into an equivalent formulation in edge space. This reformulation relies solely on ego–peer data and explicitly corrects for degree–attribute dependencies, yielding unbiased and stable estimates even in highly heterogeneous networks. Simulations and analyses on real-world networks show that ECMac reduces estimation error by up…
Click any figure to enlarge with its caption.
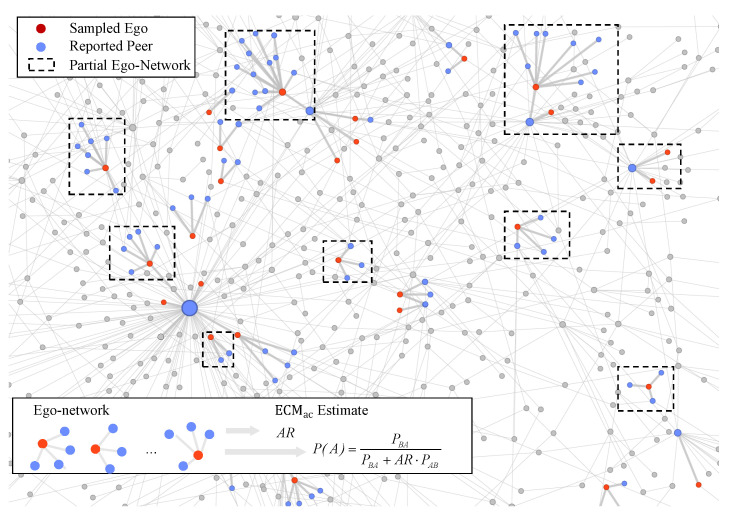 Figure 1
Figure 1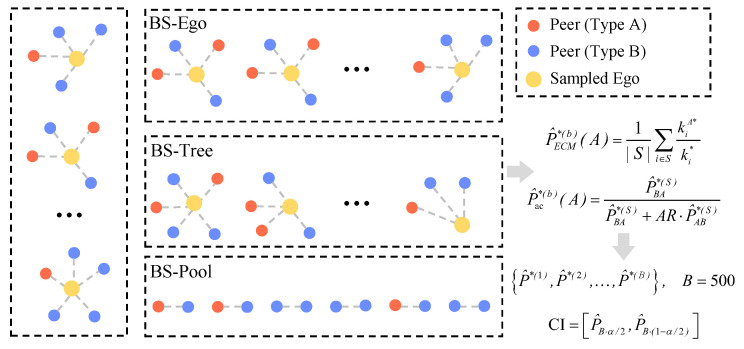 Figure 2
Figure 2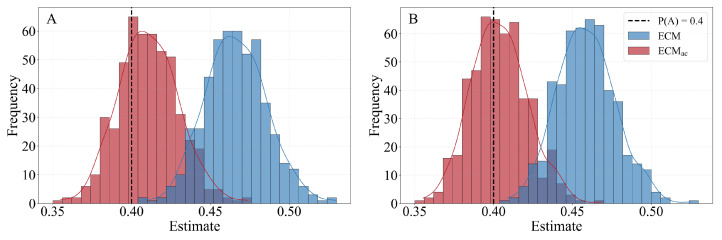 Figure 3
Figure 3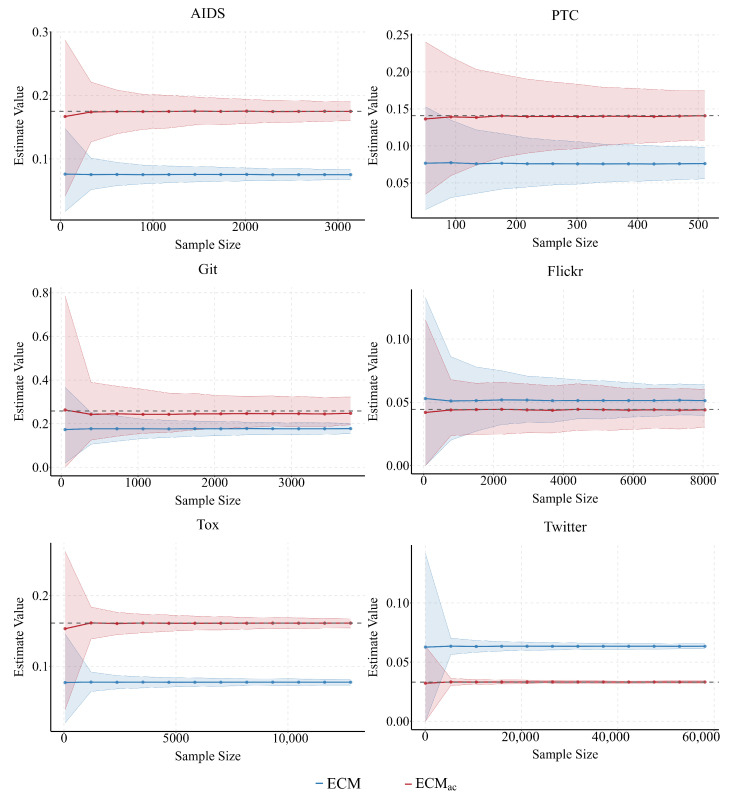 Figure 4
Figure 4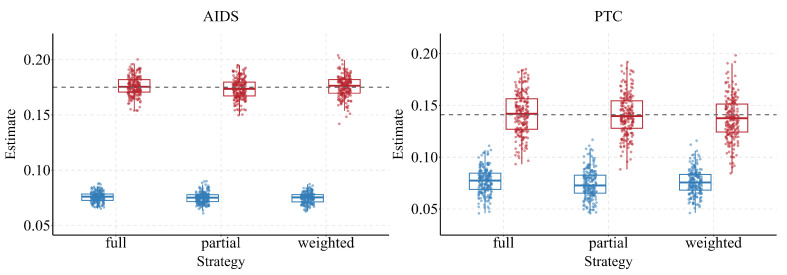 Figure 5
Figure 5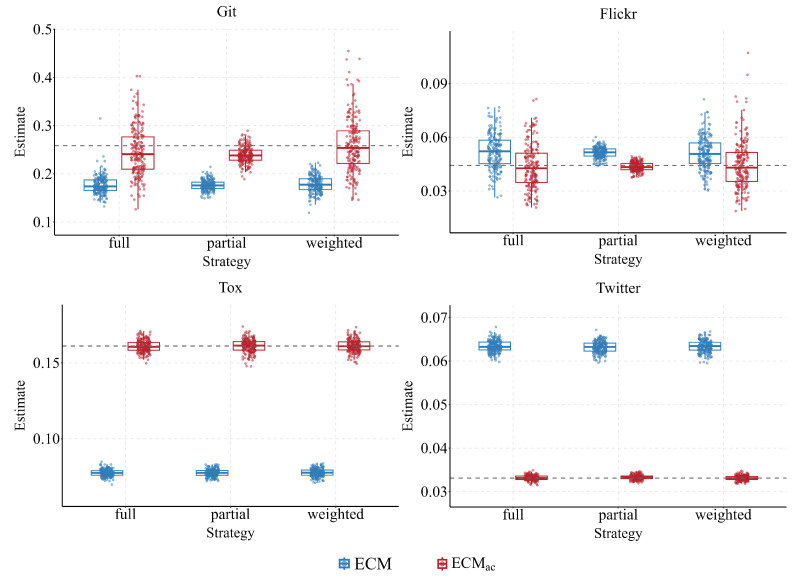 Figure 6
Figure 6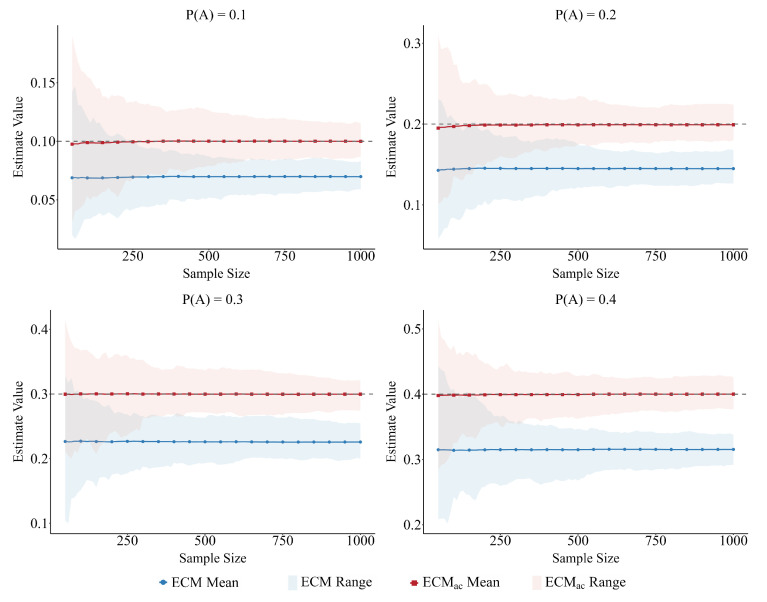 Figure 7
Figure 7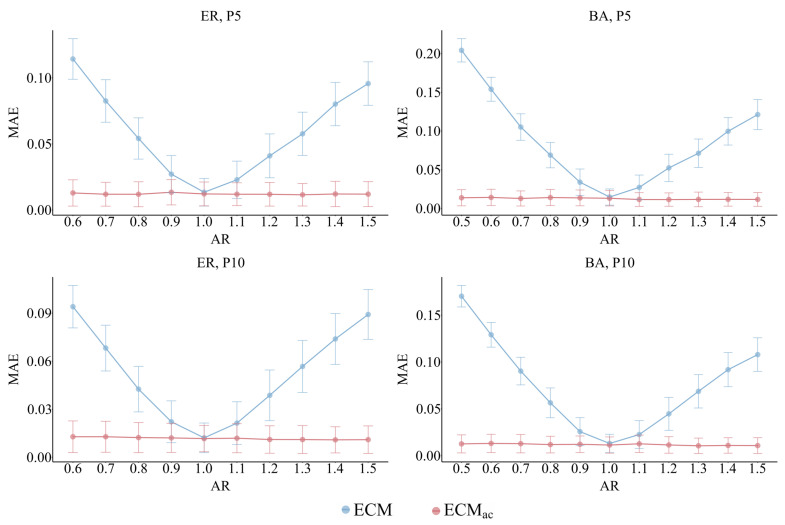 Figure 8
Figure 8 Figure 9
Figure 9 Figure 10
Figure 10 Figure 11
Figure 11 Figure 12
Figure 12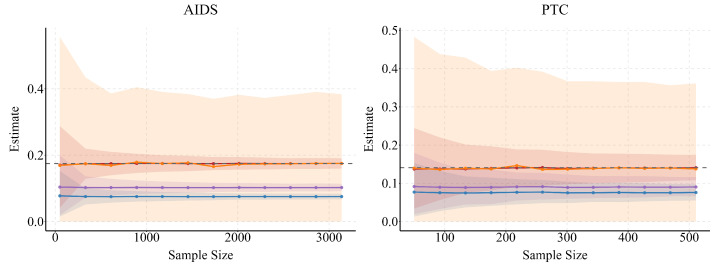 Figure 13
Figure 13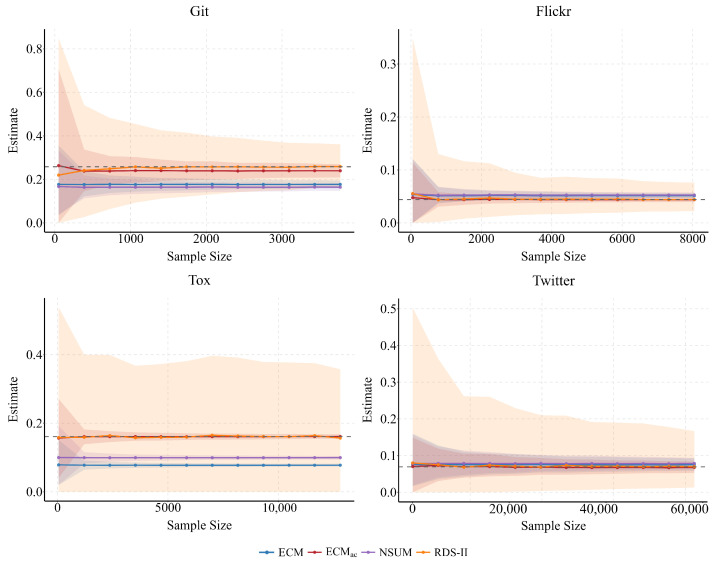 Figure 14
Figure 14- —National Natural Science Foundation of China
- —National Science and Technology Major Project for Brain Science and Brain-like Intelligence Technology
- —Hunan Science and Technology Plan Project
- —Major Program of Xiangjiang Laboratory
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsMobile Crowdsensing and Crowdsourcing · Privacy-Preserving Technologies in Data · Complex Network Analysis Techniques
1. Introduction
Sample surveys are fundamental to quantitative research in social, behavioral, and health sciences, forming the empirical basis for understanding population characteristics and health reasoning [1]. More broadly, recent work in informatics emphasizes that reliable inference often relies on extracting essential structure from incomplete and noisy observations rather than from fully observed data [2,3]. However, the validity of survey data is severely challenged when surveys involve sensitive topics, such as illicit drug use, sexual behaviors, or political dissent [4]. When faced with such questions, respondents may exhibit protective behaviors due to fears of disclosure and social judgment. These behaviors include direct refusal to participate (unit nonresponse), skipping specific questions (item nonresponse), or providing socially desirable answers. For example, populations at high risk for sexually transmitted infections, such as sex workers, injecting drug users, or men who have sex with men (MSM), often avoid responding to questions about highly sensitive or illegal behaviors, thereby concealing their health conditions [5,6,7]. In these settings, supplementing ego-level responses with information about social connections provides an opportunity to access broader population signals without relying solely on direct self-disclosure. Such measurement issues can cause systematic errors in estimates, which may misinform policy, distort scientific understanding, and ultimately undermine evidence-based decision-making [8,9].
To address these challenges, several indirect questioning methods have been developed. Classical examples include the Randomized Response Technique (RRT) [10] and the Item Count Technique (ICT) [11,12]. In RRT, respondents follow a simple randomization rule so that their answers remain confidential, allowing them to deny revealing sensitive information while still contributing to accurate group estimates. Such designs can also be implemented anonymously to further protect privacy [13,14]. Building on these ideas, the Network Scale-Up Method (NSUM) [15,16] asks respondents to report how many of their peers (alters) belong to a target group, thereby enabling indirect estimation of hidden populations. Many studies have extended NSUM to account for degree heterogeneity, social visibility, and non-random mixing, giving rise to generalized scale-up estimators [17,18,19]. While effective for population size estimation, these methods typically rely on additional assumptions, external information, or auxiliary samples, and often involve complex survey designs with limited statistical efficiency [20,21]. These trade-offs motivate the development of simpler yet robust alternatives for network-based inference.
An alternative approach utilizes the structure of social networks, building on the observation that respondents are often more willing to report on their peers than to disclose their own sensitive attributes [22,23]. Unlike scale-up methods that target population size, this line of work focuses on estimating population proportions from ego-centric samples. This innovative idea was first developed and implemented in the context of Respondent-Driven Sampling (RDS) [24,25]. By exploiting ego-centric network information, the inclusion probability of each ego being reported can be analytically derived, and the asymptotically unbiased estimator [26] was proposed to estimate population proportions in hidden populations [27]. Simulation studies on real-world networks as well as field applications among hard-to-reach populations have shown that substantially outperforms other RDS estimators in terms of both bias and efficiency [28,29,30].
Building on this idea, the Ego-Centric Sampling Method (ECM) [31] collects information through respondents’ ego-centric networks to infer sensitive attributes indirectly. In this design, a representative sample of egos is drawn from the population. Each ego reports the size of their personal network (degree) and the number of peers who possess a specific sensitive attribute (for example, attribute A). Instead of asking egos to disclose their own attributes, ECM makes use of their knowledge about peers to estimate population-level proportions. This indirect approach protects respondents’ privacy while retaining the statistical rigor of standard sampling, making it a simple and effective framework for studying sensitive attributes in social and behavioral research.
However, the conventional ECM estimator is unbiased only under the assumption of a homogeneous network, where node degrees are uniform and uncorrelated with attributes. This assumption often fails in heterogeneous networks that exhibit strong degree–attribute correlation. Specifically, if members of one group (for example, attribute A) are more active, meaning they have a higher average degree, they are more likely to be reported and thus included in the ego-centric sample once any of their peers is selected. The conventional ECM estimator does not adequately correct for this overrepresentation caused by differences in node activity, which is measured by the activity ratio (AR). As a result, it produces a structural bias that does not diminish with increasing sample size. To date, no general correction for this bias has been established.
To address this limitation, we propose the Activity Ratio Corrected ECM estimator ( ). The key idea of is to use the reciprocity property of undirected networks to correct for the imbalance in node activity. Instead of directly estimating the overall population proportion of nodes with attribute A, the method focuses on the probabilities of connections between groups (for example, links between A and B nodes). These edge-based quantities can be measured directly from the ego-centric sample, allowing to obtain an unbiased estimate of even when node degree and attribute are correlated. This correction substantially improves estimation accuracy in heterogeneous networks where the conventional ECM tends to be biased.
The remainder of this paper is organized as follows. Section 2 details the theoretical framework of the method. We then describe our experimental design, present the simulation and empirical results, and conduct a systematic sensitivity analysis. The paper concludes with a summary of our findings and discusses future research directions.
2. Estimation Framework
This section develops the theoretical foundation for our work. We first analyze the statistical properties of the conventional ECM estimator to derive the source of its bias, and then introduce our adjusted estimator, , as a direct correction.
2.1. Notation and Model Specification
Let be an undirected simple graph, where is the set of nodes and is the set of edges. Undirectedness implies , where indicates that an edge exists between nodes i and j. Each node i carries a binary attribute , where denotes nodes belonging to attribute class A, and denotes nodes belonging to attribute class B. The degree of node i and its decomposition by neighbor attributes are defined as
The quantity of interest is the population proportion of nodes with attribute A, which is the main target of estimation:
Let and with sizes and . The group mean degrees and the activity ratio are defined as
2.2. Observables from Ego-Centric Sampling
Ego-centric sampling collects local network information in two stages. First, a set of S respondents (egos) is drawn from the population, typically by simple random sampling. Second, each sampled ego reports their degree and the number of peers in each attribute class, recorded as , as illustrated in Figure 1.
We partition the sample according to the respondent’s attribute:
and define the total degrees within each group as
The cross-group neighbor counts, aggregated from the respondents’ side, are defined as
Based on these observations, we define as the probability that a neighbor of an A-node belongs to B, and as its reverse counterpart. The sample activity ratio is denoted by :
2.3. ECM Estimator
The traditional ECM estimator [31] begins with a decomposition by degree strata. Let be the number of nodes with degree k, and be the conditional probability that a node of degree k belongs to class A. The total number of edges emanating from A-nodes of degree k is given by
The expected number of nodes with attribute A in the population can therefore be written as
which implies that the population proportion is . Combining this with (8), an idealized (theoretical) form of the estimator can be expressed as
In studies involving hidden or hard-to-reach populations, the full network is typically unobservable. Therefore, the sample mean is used as a practical substitute for the corresponding population quantity, yielding the ECM estimator:
ECM assumes that node degree is independent of attribute type. Under this condition, the unweighted average across sampled egos’ proportions of A-type neighbors equals the population proportion . When groups differ in their mean degree, the more active group becomes overrepresented and the ECM estimator is biased, which motivates the adjusted estimator .
2.4. ECMac Based on Reciprocity
We derive from two basic equalities that hold in the undirected graph G. Because the graph is undirected, the number of cross-group edges counted from A to B must equal the number counted from B to A. This structural equality is referred to as reciprocity:
Let and denote the probabilities that an edge attached to an A-node or a B-node, respectively, connects to the other group. These are defined as
By definition, the number of cross-group edges can be expressed in two equivalent forms:
Starting from this relation, , we divide both sides by and use , , and to obtain:
From Equation (15), we derive a population-level relationship that forms the theoretical basis for the estimator: Expanding the right side of Equation (15), we get . Rearranging the terms to group yields .
From this, we derive the population-level relationship that forms the theoretical basis for the estimator:
The corresponding sample-based estimator is obtained by the plug-in principle, substituting the population quantities in Equation (16) with their empirical counterparts:
Using Equation (7), the estimator can be written directly in terms of the observed sample counts:
2.5. Variance Estimation
The analytical variance of network-based estimators is typically intractable. It depends on complex networks features such as topology, degree heterogeneity, and inter-node dependence. To obtain empirical variance estimates and construct confidence intervals for , we adopt a nonparametric bootstrap approach.
The bootstrap procedure proceeds as follows:
- (1)Draw a bootstrap replicate by resampling ego-centric networks (each ego together with its reported peers) with replacement, and denote the resulting bootstrap sample as ;
- (2)Based on , compute the corresponding estimator using ;
- (3)Repeat steps (1)–(2) for , obtaining a set of bootstrap estimates:
- (4)Sort these estimates in ascending order, and construct the percentile confidence interval as
Since different resampling schemes correspond to different assumptions about dependence in the data, we consider three bootstrap designs to reflect multiple sources of uncertainty:
BS-Ego assumes that ego-centric networks are independent sampling units. It captures between-ego variation and reflects uncertainty due to the limited number of egos.
BS-Tree adds within-ego resampling, treating each ego’s reported peers as nested observations. This design accounts for additional variability introduced by the hierarchical (ego–peer) structure of ego-centric data [32].
BS-Pool treats all ego–peer pairs as exchangeable edges and resamples them directly. It reflects uncertainty arising from the random formation of connections rather than from the selection of egos.
These three schemes differ only in how resampled ego-centric datasets are constructed. Together, they provide complementary perspectives on estimator variability under distinct dependence assumptions. BS-Ego assumes independent egos, BS-Tree allows dependent peers within the same ego, and BS-Pool assumes independence only at the edge level. A workflow overview is shown in Figure 2, and detailed algorithmic descriptions for each scheme are provided in Appendix A.
3. Experimental Design
3.1. Synthetic and Real-World Networks
We rigorously evaluate the performance of against the conventional ECM using a comprehensive framework spanning both synthetic and real-world networks.
Synthetic Networks. We generated Erdős–Rényi (ER) and Barabási–Albert (BA) networks of 10,000 nodes to represent homogeneous and heterogeneous degree distributions, respectively. Nodes were assigned a binary attribute (A or B) to achieve target proportions . Within these networks, we systematically control four key structural properties:
- (1)Density ( ): quantifies the overall connectivity of a network [33] and is calculated as
where E is the number of edges, and N is the number of nodes in the network.
- (2)Average Clustering Coefficient ( ): is a measure of how nodes tend to cluster together [34]. For each node i, the local clustering coefficient is defined as
where is the degree of node i, and is the number of triangles that node i forms with its peers. The overall average clustering coefficient is then the mean of all individual :
- (3)Homophily (H): quantifies the extent to which nodes prefer connections within their own group rather than across groups. Let denote the proportion of links among all links originating from A-nodes [35,36]. The definition of H is as follows:
when , all A-nodes only connect to other A-nodes (perfect assortative mixing); when , A-nodes connect to others proportionally to group sizes (random mixing); intermediate values indicate partial within-group preference. Negative values ( ) correspond to disassortative mixing, i.e., a tendency to connect across groups [37].
- (4)Activity Ratio (AR): is set to values in the range by swapping attributes between high- and low-degree nodes to induce specific levels of degree–attribute correlation, while preserving both the network topology and marginal attribute counts [38].
Each network property was systematically tuned by modifying one factor at a time from its baseline BA configuration, ensuring that all other metrics remained stable within 1%. Specifically, was increased by randomly adding edges, was adjusted through targeted triad closure rewiring, and H was tuned by randomly reconnecting cross-group or within-group links. The controlled parameter ranges were (step t = 0.002), (t = 0.001), (t = 0.05), and (t = 0.1).
3.2. Real-World Networks
To evaluate performance in practical settings, we selected six diverse real-world networks spanning both molecular and social domains, with broad variation in size, semantics, and degree heterogeneity. Each dataset provides node-level categorical labels and undirected connectivity from publicly available repositories.
AIDS: Derived from the Network Repository [39], representing molecular graphs where nodes are atoms and edges are chemical bonds (single, double, or aromatic).
PTC: From the Predictive Toxicology Challenge dataset [39], containing chemical compounds for carcinogenicity prediction, generated using the Chemistry Development Kit (v1.4).
Git: A GitHub developer network collected from the public API [40], where users are connected via mutual following relationships. Node metadata include location, employer, and starred repositories.
Flickr: An online community network [39], with users linked by shared interests or mutual following. Labels identify user groups or communities.
Tox: From the Tox21 toxicity database [39], comprising molecular graphs with atoms as nodes and bonds as edges. Labels correspond to atom types.
Twitter: A social interaction network from the Network Repository [39], where users are connected through interaction edges. Labels are derived from dominant textual themes (e.g., “love” and “sleep”).
For all datasets, the A-class is defined as the less frequent label to mimic imbalance in real populations. Summary statistics are reported in Table 1.
3.3. Sampling and Estimation Procedure
To implement our simulation protocol, we first draw a simple random sample of egos (10% of total nodes) without replacement from each network. For each sampled ego, we then collect neighborhood information using one of four distinct sampling strategies: full reporting (F); partial random sampling of 5 (P5) or 10 (P10) peers; and weighted sampling (W), where 10 peers are drawn with probabilities inversely proportional to their degrees.
3.4. Evaluation Metrics
Estimator performance is evaluated using Bias, Standard Deviation (SD), and Root Mean Squared Error (RMSE) for point accuracy, and empirical coverage rates for interval reliability. We also report the percentage of trials where an estimator achieves the lowest error ( ).
3.5. Bootstrap Confidence Intervals
We evaluate interval estimation through a simulation-based bootstrap experiment. For each network configuration with a given , 10% of nodes are randomly sampled to form ego-centric samples. Using the bootstrap procedure in the Variance Estimation, 90% and 95% confidence intervals are constructed from resamples, and the process is repeated times to estimate empirical coverage. All simulations follow the same sampling settings described above.
4. Results
4.1. Performance on Synthetic Networks
We begin by examining the fundamental performance of the estimators in scale-free BA networks. Figure 3 illustrates a representative setting with homophily fixed at , AR , and a true population proportion . The results clearly show that the conventional ECM estimator is severely biased, with its estimate distribution peaking near 0.475, a substantial overestimation of the benchmark. In contrast, the distribution is centered on the true value, demonstrating its ability to correct for degree–attribute bias.
This finding is quantitatively substantiated in Table 2 and Table 3. Table 2 summarizes results across both BA and ER network models, showing that consistently achieves lower bias and RMSE than ECM whenever AR . For instance, in BA networks with AR and , reduces the RMSE by more than 70% relative to ECM. As predicted by theory, when AR the two estimators perform identically. Table 3 further demonstrates that ’s advantage is robust across different sampling protocols (F, P5, P10, and W). Across all cases, not only yields the lowest RMSE but also attains the highest winning percentage ( ), underscoring its practical utility.
4.2. Performance on Real-World Networks
Our empirical analysis across six diverse real-world networks further validates the effectiveness of , showing robustness in both molecular and social settings. We assess two complementary aspects: (i) how estimates converge as the sample fraction grows, and (ii) how bias distributions behave under different sampling strategies (F, P, W). Across all networks, remains centered on the true proportion and exhibits stable performance, whereas ECM shows systematic deviations whenever AR departs from one.
The results show that consistently aligns more closely with the true across all networks, whereas the conventional ECM exhibits systematic deviations whenever AR departs from one (see Figure 4).
For example, in networks with such as AIDS (AR ), Git (AR ), and Tox (AR ), the conventional ECM persistently underestimates . In Git, this downward bias is particularly severe, with ECM converging to an estimate nearly 30% below the true value, effectively eliminates this discrepancy. Conversely, in networks with , such as Twitter (AR ), ECM systematically overestimates the population proportion. Across all cases, produces estimates centered on the true value, underscoring that correcting for degree–attribute correlation is essential for accurate inference in empirical networks.
Furthermore, demonstrates strong robustness across different sampling strategies (F, P, W), as shown in Figure 5. This consistency is evident across all six networks. For instance, in Twitter (AR ), the distribution of estimates remains centered near the true value ( ) under all strategies, whereas ECM consistently overestimates the proportion by approximately to . A symmetric pattern is observed in networks with , such as AIDS (AR ) and Git (AR ), where ECM exhibits a downward bias of about to , while stays closely aligned with the true benchmark.
In summary, empirical evidence from these diverse real-world networks confirms that substantially reduces estimation bias relative to ECM, particularly when AR deviates substantially from one. These improvements establish as a reliable and practical estimator for network-based attribute inference in real-world applications.
For completeness, we provide an additional supplementary comparison with two representative baseline approaches (RDS-II and NSUM) on real-world networks in Appendix B. Because these methods rely on different sampling mechanisms and target estimands, the results are presented for reference only.
4.3. Bootstrap Coverage Rate
To evaluate interval reliability under controlled structural conditions, we conduct bootstrap experiments on synthetic networks generated by the BA model. We vary from 0.8 to 1.8 and from 0.10 to 0.40, and construct 90% and 95% percentile confidence intervals using three resampling schemes.
Table 4 and Table 5 report the empirical coverage. At the 95% level, BS-Ego is consistently closest to the nominal target across the grid, whereas BS-Tree is conservative and BS-Pool exhibits systematic under-coverage.
BS-Ego provides the best-calibrated inference for 95% confidence intervals, while BS-Tree only yields acceptable 90% coverage at the cost of wider intervals. This difference follows from the data-generating mechanism of ego-centric sampling: egos are the primary sampling units, with peer reports clustered within each ego-network. By resampling intact ego-networks, BS-Ego preserves this dependence structure and accurately reflects sampling variability, whereas BS-Tree inflates variability by resampling peers and BS-Pool ignores ego-level clustering.
5. Sensitivity Analysis
We now turn to a systematic analysis of how estimator performance varies with key network and attribute parameters. All supporting tables for the figures in this section are included in Supporting Information Tables S1–S5.
5.1. Population Proportion P(A)
We evaluate the effect of the population proportion on estimator accuracy using BA networks under fixed sampling settings, varying from 0.1 to 0.4 while keeping all other parameters constant. As shown in Figure 6, increasing leads both estimators to become more precise, as indicated by narrower 95% confidence intervals. Across all tested conditions, however, remains centered on the true population proportion, whereas ECM exhibits a persistent downward bias that becomes more pronounced when is small. For example, when , the mean estimate of ECM is approximately 0.07, underestimating the true value by nearly 30%, while yields a mean of 0.10, closely matching the benchmark. When increases to 0.4, the mean estimate of ECM remains around 0.32, which is still about 20% below the true value, whereas stays nearly unbiased.
This demonstrates that even when sampling uncertainty decreases with larger , the degree–attribute bias inherent in ECM persists, while effectively eliminates it.
5.2. Activity Ratio (AR)
We examine the impact of degree–attribute imbalance by varying AR in both ER and BA networks while keeping other parameters fixed. Figure 7 presents results under the P5 and P10 sampling strategies, which represent realistic partial-reporting scenarios where egos disclose only a limited number of peers. The omitted full-reporting (F) and weighted (W) schemes exhibit nearly identical bias patterns, differing only in the overall width of confidence intervals rather than in systematic trends, with all showing the same direction of bias relative to AR.
Across both network types, ECM displays a distinct U-shaped error curve as AR deviates from one. In BA networks, the MAE of ECM rises sharply from approximately 0.03 at to over 0.20 at and . By contrast, remains almost flat across all tested AR values, with MAE typically below 0.02 even under strong imbalance. This corresponds to an 85–90% reduction in MAE relative to ECM when or .
These results demonstrate that accounting for degree–attribute correlation is essential for reducing activity-induced bias, particularly under realistic partial-reporting conditions.
5.3. Network Density and Clustering
We further investigate how structural connectivity influences estimator performance by varying network density ( ) and average clustering coefficient ( ) while keeping and fixed. As shown in Figure 8, increasing either density or clustering slightly reduces estimation accuracy for both estimators. However, the deterioration of is much less pronounced. When network density increases from 0.002 to 0.10, the median bias of ECM rises gradually from approximately 0.03 to 0.08, whereas remains close to zero, with deviations below 0.01. A similar pattern is observed when reaches 0.03, where ECM’s bias stabilizes around 0.18 to 0.20, roughly six times higher than that of , whose bias remains below 0.03.
These results indicate that denser or more clustered networks amplify the bias arising from degree–attribute correlation, but the correction introduced by effectively stabilizes estimation performance across a wide range of structural conditions.
5.4. Combined Effects of AR and H
Building upon the previous single-factor analyses, we further examine how the interaction between degree–attribute imbalance and assortative mixing jointly shapes estimator bias. Specifically, we vary both AR and the homophily (H) to capture their combined influence on estimator performance.
Figure 9 illustrates these joint effects, showing that the bias field of remains stable across the full range of structural conditions. For ECM, bias patterns form a pronounced gradient across the plane, where negative homophily and extreme AR values ( or ) yield the largest deviations, with estimation errors reaching about +0.25 or −0.18. When homophily becomes positive, ECM tends to overestimate the true proportion, whereas negative homophily induces underestimation. In contrast, exhibits an almost uniform error surface, with absolute bias remaining below 0.03 under both P5 and P10 sampling.
It is worth noting that in highly assortative networks ( ), cross-group connection probabilities approach zero ( ), theoretically risking numerical instability. In practice, this is rare in connected networks and can be addressed by applying a small smoothing factor, as implemented in our bootstrap procedure.
These findings demonstrate that effectively mitigates the compounded bias arising from the coexistence of degree–attribute correlation and homophily.
5.5. Combined Effects of AR and P(A)
To further investigate how degree heterogeneity and group proportion jointly influence estimator performance, we analyze bias across the parameter space under partial reporting. Figure 10 presents the resulting bias surfaces for both P5 and P10 sampling strategies.
For ECM, bias increases sharply when either or becomes large, forming a pronounced ridge around , where the bias reaches approximately 0.24. Under P10 sampling, the mean bias for ECM is 0.104 (SD = 0.061). In contrast, produces a much flatter bias surface, with values remaining below 0.04 and a mean of 0.026 (SD = 0.016). The lower panels show that local bias reduction can reach 0.25 at , confirming the consistent advantage of the activity-corrected estimator.
Smaller sampling strategies (P5) lead to slightly higher overall biases than P10, indicating that including more peers per ego improves estimator stability even when the number of egos is fixed. Overall, these results highlight that remains robust under the combined effects of group imbalance and degree heterogeneity, maintaining low bias across a wide range of network conditions.
6. Conclusions
While the conventional ECM estimator relies on degree-based weighting to infer group proportions from ego-centric samples, it often exhibits systematic bias in heterogeneous networks—particularly when node degree is correlated with node attributes. To overcome this limitation, this study introduces the Activity Ratio Corrected ECM estimator ( ), which explicitly incorporates degree–attribute correlation through an activity ratio adjustment, thereby enhancing both the adaptability and accuracy of proportion estimation in complex networks.
By leveraging the principle of reciprocity, we reformulated the group proportion estimation problem into an edge-based framework that estimates cross-group connection probabilities ( and ) without requiring global network information. This formulation effectively mitigates the structural bias inherent in the traditional ECM approach and enables unbiased proportion estimation using only locally observed ego-network data.
Simulation experiments demonstrate that consistently reduces estimation bias and lowers RMSE across a broad range of network structures, including variations in density, clustering, and homophily. Sensitivity analyses further show that maintains robustness across different attribute ratios and sampling designs, producing nearly flat bias surfaces and stable performance even under extreme network heterogeneity. Empirical validations on six real-world networks confirm that accurately corrects the overestimation and underestimation observed in traditional ECM.
Overall, the proposed estimator provides a theoretically sound and practically effective framework for attribute estimation in complex social networks. By addressing the key limitations of traditional ECM in heterogeneous environments, this method offers a reliable foundation for privacy-preserving surveys, social network inference, and other applications requiring indirect estimation from local sampling data.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Beyrer C. Baral S.D. van Griensven F. Goodreau S.M. Chariyalertsak S. Wirtz A.L. Brookmeyer R. Global Epidemiology of HIV Infection in Men Who Have Sex with Men Lancet 201238036737710.1016/S 0140-6736(12)60821-622819660 PMC 3805037 · doi ↗ · pubmed ↗
- 2Lu X. Qin W. Informatics in the Era of AI Innov. Inform.2025110000210.59717/j.xinn-inform.2025.100002 · doi ↗
- 3Wan M. Wang J. Wang Y. Cao R. Wang Z. Wang Z. Shi P. Zhao Z. Understanding as Compression: A New Evaluation Framework for Large Language Models Innov. Inform.2025110000310.59717/j.xinn-inform.2025.100003 · doi ↗
- 4Tourangeau R. Rips L.J. Rasinski K. The Psychology of Survey Response Cambridge University Press Cambridge, UK 200010.1017/CBO 9780511819322 · doi ↗
- 5Krumpal I. Determinants of Social Desirability Bias in Sensitive Surveys: A Literature Review Qual. Quant.2013472025204710.1007/s 11135-011-9640-9 · doi ↗
- 6Cai M. Huang G. Kretzschmar M.E. Chen X. Lu X. Extremely Low Reciprocity and Strong Homophily in the World Largest MSM Social Network IEEE Trans. Netw. Sci. Eng.202182279228710.1109/TNSE.2021.3085984 · doi ↗
- 7Ward M.K. Meade A.W. Dealing with Careless Responding in Survey Data: Prevention, Identification, and Recommended Best Practices Annu. Rev. Psychol.20237457759610.1146/annurev-psych-040422-04500735973734 · doi ↗ · pubmed ↗
- 8Yan T. Consequences of Asking Sensitive Questions in Surveys Annu. Rev. Stat. Its Appl.2021810912710.1146/annurev-statistics-040720-033353 · doi ↗