Perceiving Unpredictability for New Energy Power and Electricity Consumption Forecasting
Lin Zhao, Jian Dong, Ruojing Chen, Yifeng Wang, Yichen Jin, Yi Zhao

TL;DR
This paper introduces a new loss function that improves forecasting accuracy by accounting for unpredictable events in sensor data, helping stabilize power grids and urban traffic systems.
Contribution
The novel Unpredictability Perception loss dynamically adjusts supervision based on signal randomness and temporal distance.
Findings
The Unpredictability Perception loss improves forecasting accuracy on multiple benchmark datasets.
Combining spectral entropy and temporal decay weights enhances model performance for unpredictable sensor signals.
The approach provides a more reliable foundation for critical infrastructure stability.
Abstract
Accurate prediction of sensor network data in critical domains such as electric power systems and traffic planning is a core task for ensuring grid stability and enhancing urban operational efficiency. Although deep learning models have achieved significant architectural advancements, their training strategy implicitly assumes that all future events are equally predictable, ignoring that the future evolution of sensor signals intertwines deterministic patterns with stochastic events and that prediction difficulty increases with temporal distance. Forcing a model to fit inherently unpredictable events with a uniform supervision may impair its ability to learn generalizable patterns. To address this, we introduce an Unpredictability Perception loss that dynamically computes a supervision weight. The computation of this weight unifies two assessment dimensions of the intrinsic…
Click any figure to enlarge with its caption.
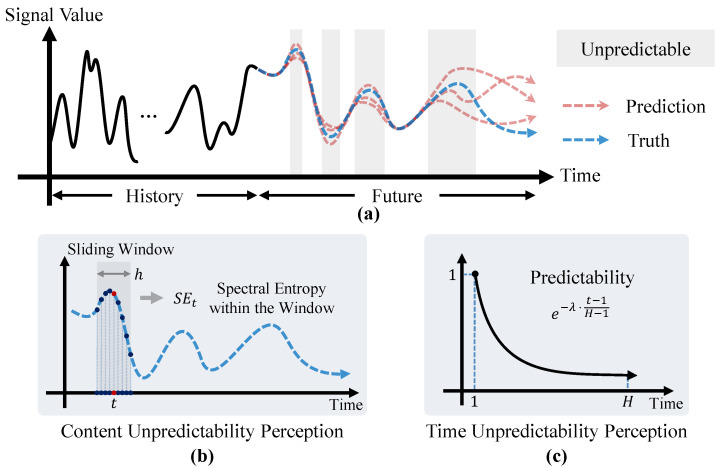 Figure 1
Figure 1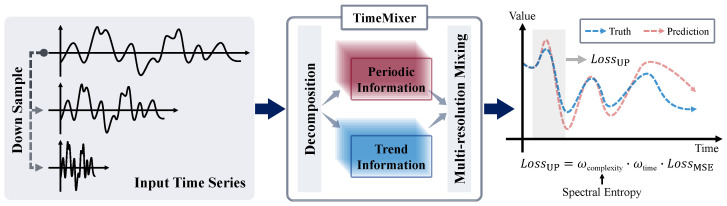 Figure 2
Figure 2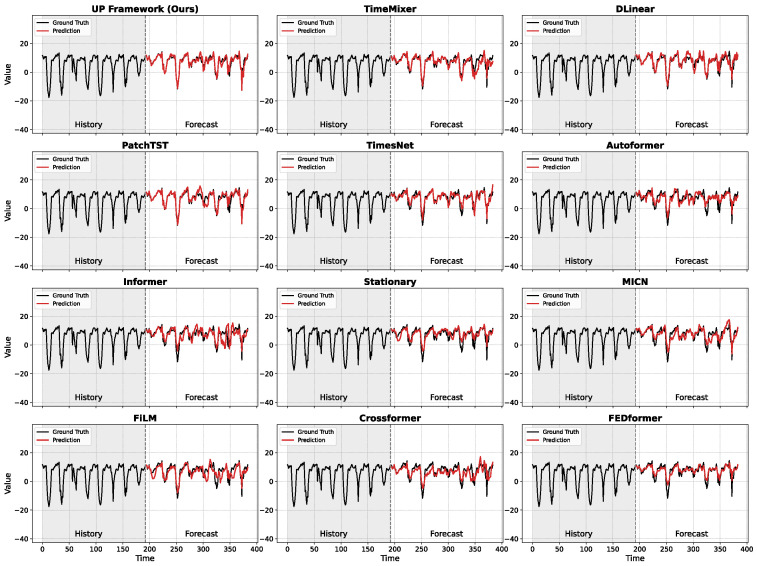 Figure 3
Figure 3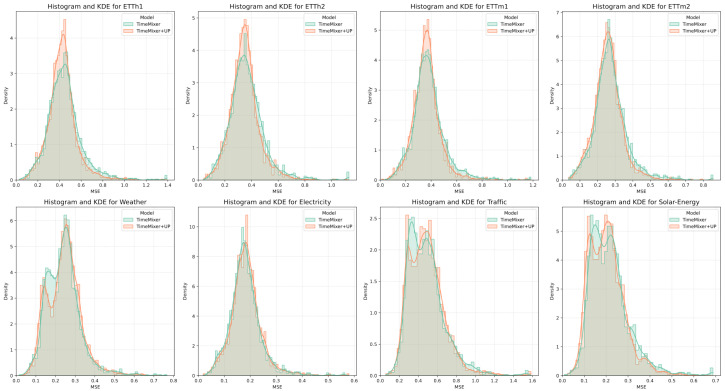 Figure 4
Figure 4Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsEnergy Load and Power Forecasting · Traffic Prediction and Management Techniques · Time Series Analysis and Forecasting
1. Introduction
Time series forecasting is an indispensable technology in modern scientific and industrial decision-making [1,2,3]. In the domain of energy management, the precise prediction of electricity load, informed by feedback from thousands of sensor nodes within smart grids, serves as the cornerstone for ensuring grid stability, optimizing energy dispatch, and integrating volatile renewable sources such as wind and solar power [4,5,6]. In urban traffic systems, the accurate forecasting of traffic flow, derived from data collected by road sensor networks, provides critical support for intelligent traffic guidance and public resource planning, thereby effectively mitigating daily commuter congestion and responding to traffic disruptions caused by unforeseen incidents [7,8,9]. Similarly, in meteorological science, the long-term prediction of key indicators such as temperature and humidity, monitored by distributed weather sensors, is directly related to agricultural production, extreme weather event warnings, and societal well-being [10,11]. A commonality among these high-stakes applications is the urgent need for models capable of understanding and predicting the high-dimensional time series data generated by massive sensor arrays [12,13]. However, these data themselves are often interwoven with complex dynamic characteristics [14,15], which encompass both learnable, deterministic patterns governed by physical laws or societal rhythms, and are inevitably accompanied by inherently unpredictable, random events triggered by internal system perturbations or abrupt environmental changes [16]. In recent years, the rapid development of deep learning has provided powerful tools to address this challenge. From Transformer-based architectures such as PatchTST [17] and iTransformer [18], to MLP-based models renowned for their simplicity and efficiency like TimeMixer [19], the academic community has made significant progress in enhancing predictive accuracy. These state-of-the-art methods, through their sophisticated structural designs, have far surpassed traditional statistical models in capturing long-term dependencies and complex patterns.
Despite the notable achievements in architectural design, nearly all existing models adhere to a common supervision principle during training, which involves optimizing model parameters by minimizing the Mean Squared Error (MSE) [20]. This supervision principle contains a fundamental assumption that all future events are accurately predictable based on historical information. However, the evolutionary processes of the real world are naturally intertwined with both deterministic patterns and stochastic events. For instance, the electricity load data involved in our experiments contains learnable daily and weekly periodic patterns determined by social production and life rhythms, but it also inevitably includes random disturbances that are inherently unpredictable from historical data, caused by factors such as the random behavior of a large number of individual users, sudden equipment failures, or extreme weather. Likewise, traffic flow data also mixes predictable peak-hour patterns with unpredictable sharp fluctuations caused by contingent events like traffic accidents. The traditional MSE loss function, by imposing a uniform penalty on prediction errors at all future time points, effectively forces the model to fit these intrinsically random and unpredictable future events. This form of supervision may not only lead to the model overfitting to artifacts in the training data but could also impair its ability to learn generalizable underlying patterns, as it compels the model to expend valuable modeling capacity in pursuit of a theoretically unattainable goal.
Therefore, a more effective training paradigm should shift from uniform supervision to adaptive supervision, aligning the learning objective with the intrinsic predictability of future events. This is the core motivation of our research. We posit that the model training process should be redefined as a selective knowledge extraction process rather than a uniform data-fitting task. Specifically, the supervision strength applied to the model should dynamically match the predictability of the task itself. The model should be incentivized to accurately capture predictable dynamics that are close in time and exhibit high signal regularity, while for dynamics that are distant in time or have high signal randomness and thus low predictability, the supervision strength should be appropriately attenuated. Such an adaptive supervision strategy holds the promise of fundamentally optimizing the model’s learning process without adding any architectural complexity, thereby significantly enhancing its robustness and final prediction accuracy.
To this end, we propose an Unpredictability Perception (UP) loss function. This method dynamically computes a supervision weight for each time point in the prediction horizon by fusing a posterior analysis of the signal’s local complexity with a priori knowledge of temporal distance. This weight accurately reflects the intrinsic credibility of each prediction sub-task, thereby guiding the model toward more effective and robust learning. By encoding this inductive bias directly into the optimization objective, we provide a simple yet powerful functional extension to state-of-the-art time series forecasting models, enabling them to make more reliable and precise judgments in complex predictive environments.
2. Related Work
2.1. Time Series Forecasting Architectures
The field of time series forecasting has undergone a profound evolution from classic statistical methods such as ARIMA and Exponential Smoothing to sophisticated deep learning architectures [21,22,23]. The powerful capabilities of deep learning in capturing complex non-linear dependencies have made it the mainstream approach in recent years. This progression has been primarily driven by innovations in model architecture. Initially, Recurrent Neural Networks (RNNs) and their variants like LSTMs became the foundational models for processing sequential data [24,25,26]. Subsequently, the introduction of Convolutional Neural Networks (CNNs) in models like Temporal Convolutional Network (TCN) demonstrated the effectiveness of causal convolutions in capturing temporal features [27,28].
In recent years, the Transformer architecture, with its self-attention mechanism, has brought about a paradigm shift in the field. The vanilla Transformer [29], however, suffers from quadratic complexity with respect to sequence length, making it inefficient for long-term forecasting. To address this, a series of innovative Transformer variants emerged. Informer introduced the ProbSparse self-attention mechanism and a generative decoder to reduce complexity [30]. Autoformer proposed a decomposition architecture and replaced self-attention with an auto-correlation mechanism [31]. FEDformer further advanced this by leveraging Fourier and Wavelet transforms to perform attention operations in the frequency domain [32]. More recently, PatchTST approached the problem from a new perspective by treating the time series as a sequence of patches [17], similar to Vision Transformers [33], which proved highly effective in capturing local semantic information. Crossformer designed a two-stage attention mechanism to explicitly model cross-time and cross-variable dependencies [34].
While Transformer-based models were rapidly advancing, another line of research began to re-examine the necessity of complex architectures. This led to the emergence of surprisingly simple yet powerful models. DLinear, a straightforward linear model, demonstrated that through proper decomposition, it could outperform many complex Transformer models on several benchmarks [35]. This spurred the development of MLP-based architectures. TimeMixer, a pure multi-layer perceptron model, processes time series across multiple scales and has achieved state-of-the-art performance with remarkable efficiency [19]. Other notable approaches include TimesNet [36], which transforms a 1D time series into a 2D tensor to capture multi-periodicity using a CNN-based method, and MICN [37], which employs multi-scale inception blocks with causal convolutions.
A common thread connects all these architectural explorations. The predominant research focus has been on learning predictable patterns from the past, while overlooking the inherent unpredictability of future events themselves. This standard loss function implicitly assumes that all future events are equally predictable, a premise that does not hold for real-world time series interwoven with deterministic patterns and stochastic events. This highlights a significant research gap, suggesting that optimizing the training objective itself, rather than solely refining the model architecture, offers a promising and underexplored avenue for enhancing forecasting performance.
2.2. Adaptive Supervision and Uncertainty Modeling
A parallel stream of research, distinct from architectural design, focuses on the optimization objective itself, particularly on adapting supervision based on data uncertainty. One prominent approach is heteroscedastic regression, which aims to model aleatoric (data) uncertainty [38,39]. These methods typically modify the model’s architecture, for example, by adding a second output head to predict a per-point variance ( ). The loss function, often a Gaussian Negative Log-Likelihood ( ), then uses this learned, model-dependent variance to down-weight uncertain time points. Another category, often termed confidence-based weighting, focuses on epistemic (model) uncertainty, employing techniques like Monte Carlo Dropout to approximate a Bayesian posterior [40]. The variance of multiple stochastic forward passes is used as an indicator of the model’s confidence.While powerful, these learning-based approaches introduce new challenges. Their efficacy is entirely contingent on the model’s capability to successfully learn the uncertainty itself, which can be an unstable optimization target. Furthermore, they often require modifications to the model architecture (e.g., variance heads) or training process (e.g., stochastic sampling). This suggests a need for an alternative paradigm: an adaptive supervision mechanism that does not depend on a learned uncertainty, but rather on analytically-derived, model-independent properties of the forecasting task.
2.3. Causality-Based Forecasting
A distinct and emerging research direction is causality-based forecasting, which moves beyond mere correlation by attempting to model the underlying causal structures that govern time series dynamics [41]. Models in this area aim to identify the true drivers of future events, thereby enhancing robustness against distribution shifts and enabling counterfactual analysis. Recent works have applied these principles to complex, policy-driven domains. For example, Han et al. [42] proposed a causal neural network to improve probabilistic forecasting for carbon prices, leveraging causal insights to handle influencing factors.It is essential to differentiate our UP framework from this causal paradigm. Causality-based models seek to answer why a phenomenon occurs by identifying its structural drivers. Our approach, in contrast, is focused on whether a future event is predictable, based on its own intrinsic signal properties (i.e., local randomness via spectral entropy) and its temporal distance. Therefore, our method is not a causal inference model but rather an associative forecasting model equipped with an analytical, predictability-aware optimization objective. It provides an orthogonal contribution by focusing on the quality of supervision rather than the structural identification of the data generating process.
3. Methodology
3.1. Framework Overview
Deep learning models have achieved significant success in time series forecasting, largely guided by the optimization of a loss function. The Mean Squared Error (MSE) is widely adopted for its simplicity and ease of optimization. However, a fundamental deficiency of the MSE loss is that it applies a uniform penalty weight to all points within the prediction horizon, failing to differentiate among the intrinsic difficulties of various forecasting tasks. In fact, prediction uncertainty stems from two distinct sources. The first is the inherent randomness of the signal itself, meaning that the sequence dynamics in some time segments are intrinsically harder to predict than in others. The second is the a priori difficulty of the forecasting task, where predictions for the distant future naturally contain more uncertainty than those for the near future. An advanced training paradigm should be able to recognize and adapt to both types of uncertainty, thereby intelligently allocating the model’s learning resources to patterns that are genuinely learnable in both a content and temporal sense. To this end, we propose the UP loss function, which guides the model toward more effective and robust learning by dynamically computing a supervision weight for each time point in the prediction horizon. The construction of this weight integrates a posterior analysis of the signal’s local complexity with a priori knowledge of temporal distance, as conceptually illustrated in Figure 1.
To elucidate the complete computational flow and the integration of our loss function with a backbone forecasting model, we present a systematic framework diagram in Figure 2. As depicted, the input time series is first processed by the core forecasting model (e.g., TimeMixer), which utilizes its internal architecture, such as decomposition and multi-resolution mixing, to generate the prediction sequence . The proposed UP Loss module then operates as the optimization objective. It takes both the model’s prediction and the ground-truth sequence Y as inputs. Critically, it computes the complexity weight ( ) by analyzing the spectral entropy of the ground-truth signal itself, while concurrently calculating the temporal decay weight ( ). These two weights are multiplicatively combined to modulate the standard Mean Squared Error, forming the final . This adaptively weighted loss is then used to compute the gradients and update the parameters of the forecasting model via backpropagation.
3.2. Local Complexity Quantification via Spectral Entropy
The first component of our method aims to quantify the predictability of the signal content itself. This addresses what is formally known as aleatoric uncertainty, the irreducible randomness inherent in the data generation process. In time series analysis, particularly in volatile energy systems, segments dominated by aleatoric uncertainty (e.g., sensor noise or chaotic wind power fluctuations) theoretically lack extractable patterns. Forcing a model to fit these segments leads to overfitting. Therefore, we require a metric to distinguish between deterministic patterns and stochastic noise.
Ideally, Kolmogorov complexity from algorithmic information theory offers the ultimate theoretical measure of randomness, defining the complexity of a sequence as the length of its shortest generative program [43,44]. However, since this complexity is theoretically uncomputable, it inspires the search for an effective and computable proxy. We employ Spectral Entropy (SE) [45] for this purpose. By calculating the Shannon entropy of a signal’s power spectral density, spectral entropy effectively measures the signal’s structural regularity rather than just its amplitude [46,47]. A signal segment with a simple, regular structure has its energy concentrated in a few frequencies, resulting in low spectral entropy and indicating high predictability. Conversely, a segment resembling white noise has its energy uniformly distributed across the frequency domain, yielding high spectral entropy and indicating weak predictability. This makes SE an ideal, theoretically grounded proxy for modulating supervision based on inherent signal learnability.
To capture these time-varying local dynamics, we adopt a sliding window strategy. For any time point within the ground-truth future sequence , we define a local window of length centered at that point. To compute its spectral entropy, we first estimate the Power Spectral Density (PSD). The signal within the window is processed by the Fast Fourier Transform (FFT) to obtain its frequency representation. The periodogram, a common estimator for the PSD, is then calculated as
where is the n-th sample in the window and f represents the discrete frequency bins. To treat the power distribution as a probability distribution, we normalize the PSD across all K frequency bins
The Shannon entropy of this distribution is then computed as
To ensure the entropy value is scaled between 0 and 1, facilitating its use as a weight, we normalize it by the maximum possible entropy for a K-bin distribution, which is . This yields the final Local Spectral Entropy :
From this, we define the first weight component, the complexity weight , which is inversely proportional to the signal’s randomness:
This weight assigns a value approaching 1 to time points in regular, predictable regions and a value approaching 0 to those in noisy, random regions. This mechanism compels the model during training to focus its attention more on signal segments that exhibit clear and learnable patterns.
3.3. Temporal Weighting via Exponential Decay
The second component addresses epistemic uncertainty, which arises from the model’s lack of knowledge about the future state. A fundamental axiom in forecasting is that this uncertainty accumulates as the prediction horizon extends, often referred to as the “butterfly effect” in dynamical systems. To model this horizon-dependent uncertainty, we introduce a temporal decay weight . We specifically select an exponential decay function, , rather than a linear one, to align with the information-theoretic principle that the mutual information between the current state and the future state decays exponentially in chaotic or mixing systems. This non-linear formulation effectively penalizes errors in the near-term (where high precision is feasible) while gracefully relaxing constraints in the long-term (where uncertainty is dominant), thereby aligning the optimization objective with the theoretical limits of predictability.
where t is the time step index in the prediction horizon, ranging from 1 to H. The term normalizes the time step to the interval from 0 to 1, ensuring that the decay process is independent of the specific forecast horizon and thus preserving the generalizability of the mechanism across different tasks. is a non-negative hyperparameter that controls the rate of decay. When is zero, temporal decay has no effect, and the model treats all time points equally regardless of their distance. When is greater than zero, more distant prediction points are assigned a stronger decay in their weights.
The final supervision weight is determined by the element-wise product of the complexity and temporal decay weights. This multiplicative fusion integrates two distinct dimensions of unpredictability assessment, one derived from a posteriori analysis of the signal and the other from a priori temporal knowledge, ensuring that a high supervision strength is assigned only to time points that are concurrently characterized by high signal regularity and temporal proximity.
Based on this dynamic weight, we construct the final UP loss function. Given the model’s predicted sequence , the UP loss is calculated as
This loss function, while operationally simple, profoundly alters the model’s learning paradigm. It guides the model to preferentially allocate its finite modeling capacity to recent and regular portions of the signal, while permitting greater error on distant or inherently noisy segments. This dual-dimension adaptive regularization aims to produce a model that is not only more accurate but also more aligned with the fundamental principles of inductive inference in its very design.
3.4. Algorithmic Implementation and Computational Flow
To ensure methodological clarity and reproducibility, we formalize the complete training procedure, which integrates the Unpredictability Perception loss with a backbone forecasting model M. To clarify the integration of our method, let denote the dataset, where X is the lookback window and Y is the forecast horizon. Let represent the backbone forecasting model (e.g., TimeMixer) parameterized by . Our UP loss replaces the standard loss function during the backward pass. The complete training procedure, detailing the interaction between the backbone model’s forward pass and the UP loss’s weight calculation, is formalized in Algorithm 1. Algorithm1: Training Procedure with Unpredictability Perception (UP) LossRequire: Training dataset , Forecasting Model with parameters Require: Hyperparameters: Learning rate , Local window size , Temporal decay factor , Max epochs EEnsure: Optimized model parameters
- 1: Initialize randomly
- 2: for epoch to E do
- 3: for each batch sampled from do
- 4: Forward pass
- 5:
- 6: Initialize weight vector
- 7: for to H do
- 8:
- 9:
- 10:
- 11:
- 12:
- 13: end for
- 14:
- 15: Update model parameters (Backpropagation)
- 16: end for
- 17:end for
- 18:**return **
The framework is designed to be model-agnostic, allowing M to be any forecasting architecture.The algorithm commences by obtaining a prediction from the model’s forward pass. It then iterates through the prediction horizon H to compute the two core weight components for each time step t. The complexity weight is derived by analyzing the local spectral entropy of the ground-truth signal Y, as detailed in Section 2.2. Concurrently, the temporal weight is calculated based on the exponential decay function described in Section 2.3. These two weights are multiplicatively fused to create the final weight . This final weight dynamically scales the point-wise squared error. The mean of these weighted errors constitutes the final , which is then used for backpropagation to optimize the model’s parameters. Key hyperparameters in this process include the local window size for spectral entropy calculation and the decay rate for temporal weighting. We set and as a robust default.
3.5. Computational Complexity Analysis
A critical consideration for any novel loss function is the potential introduction of computational overhead. The standard MSE loss has a time complexity of per sample, where H is the prediction horizon. Our proposed UP loss introduces two additional weight calculation steps. The temporal decay weight involves a constant-time operation per time step. The complexity weight requires computing the Spectral Entropy, which relies on the Fast Fourier Transform (FFT) applied to a local window of size . The complexity of the FFT operation is . Consequently, the total complexity of the UP loss calculation for one time step is .
It is important to note that since the calculation of weights depends solely on the ground truth Y, which remains static during training, these weights can theoretically be pre-computed offline, reducing the online training overhead to zero. However, to evaluate the worst-case scenario, we assessed the runtime cost when computing weights on-the-fly during training. We conducted a comparative experiment between the original TimeMixer and our proposed UP-TimeMixer under identical hardware and software configurations (NVIDIA RTX 4090 GPU, Batch Size 32, Input/Output Horizon 96). As detailed in Table 1, the theoretical time complexity of the UP loss calculation for one time step is . In practice, this introduces a marginal overhead during the training phase. The average training time per epoch increased from s (TimeMixer) to s (UP-TimeMixer), representing a relative increase of approximately 4.0%. This slight increase is attributable to the on-the-fly FFT computation for spectral entropy. Crucially, however, the proposed UP loss functions exclusively as an optimization objective and is detached from the model architecture after training. Consequently, the inference time remains strictly identical ( ms per batch), and the model parameter count is unchanged. This confirms that our method improves predictive accuracy without imposing any additional computational burden during the deployment phase, making it highly suitable for latency-sensitive applications.
4. Experiments and Results
4.1. Datasets
To comprehensively evaluate the effectiveness and generalization capability of our proposed framework, we selected eight public benchmark datasets covering critical domains such as energy, meteorology, and traffic. These datasets exhibit significant diversity in their temporal characteristics, providing an ideal testbed for validating the core ideas of our method.
The ETT series (ETTh1, ETTh2, ETTm1, and ETTm2) [48] records key metrics of power transformers. This data is known for its clear seasonal periodicity but is also interspersed with substantial random noise introduced by grid load fluctuations and environmental factors. This coexistence of periodicity and randomness constitutes a perfect scenario for testing a model’s ability to distinguish between predictable patterns and unpredictable disturbances.
The Weather dataset contains 21 meteorological indicators. A meteorological system is inherently a complex chaotic system, with its long-term dynamics being theoretically unpredictable. In the short term, however, it exhibits discernible patterns governed by geophysical laws. This dataset offers an opportunity to test our model’s performance in a complex dynamical system with intrinsic prediction limits.
The Electricity dataset records the hourly electricity consumption of 321 clients. Its dynamics are dominated by strong periodic patterns determined by social production and life, such as daily and weekly rhythms. However, the aggregation of random behaviors from a massive number of individual users injects continuous random disturbances into this macroscopic regularity, which are difficult to model from historical data alone.
The Traffic dataset describes the occupancy rates of road sensors in the San Francisco Bay Area. Traffic flow data is a typical dual-characteristic signal; it contains predictable peak and off-peak patterns driven by commuting regularities, yet it is frequently impacted by sudden, contingent events like traffic accidents, which produce unforeseen sharp fluctuations.
The Solar-Energy dataset [49] records the power generation of 137 solar power plants. Photovoltaic power generation is directly subject to highly variable meteorological factors such as cloud cover and light intensity, causing the signal to exhibit extreme volatility and intermittency. The signal contains a large number of inherently unpredictable segments driven by the randomness of weather systems.
These datasets, sourced from various sensor networks, all exhibit an interweaving of deterministic patterns and stochastic fluctuations, providing a rigorous empirical foundation for evaluating the effectiveness of the proposed framework.
4.2. Experimental Setup
To verify the practical value of our proposed framework, we chose to integrate and validate it on TimeMixer, one of the current state-of-the-art models. As a pure MLP-based architecture, TimeMixer has achieved SOTA performance on numerous time series forecasting benchmarks, surpassing many structurally complex Transformer models. The pure MLP architecture of TimeMixer lacks sequence-specific inductive biases, making it particularly sensitive to the quality of the supervision signal. Our proposed optimization framework provides the precise guidance it needs to distinguish between deterministic patterns and random noise.
In all experiments, we evaluated all models on four progressively longer prediction tasks of 96, 192, 336, and 720 steps. To ensure a fair comparison and reproducibility, our experimental setup strictly aligns with the configurations of the baseline TimeMixer model. Specifically, all models were implemented using PyTorch 2.4.1 and trained on a server equipped with two NVIDIA RTX 4090 GPUs. Following the official implementation of TimeMixer, we utilized the Adam optimizer with a learning rate adjusted between and depending on the dataset characteristics, and a batch size ranging from 32 to 128. An early stopping mechanism with a patience of 10 epochs was employed to prevent overfitting. The local window size was set to 24 for hourly datasets. The calculation of Spectral Entropy relies on the frequency domain representation derived via the Discrete Fourier Transform (DFT). A window size of 24 provides the minimal sufficient spectral resolution (approximately 12 effective frequency bins up to the Nyquist limit) to generate a statistically stable entropy estimate. Smaller windows (e.g., 12 points) result in a sparse spectrum, leading to mathematically unstable entropy values that fail to distinguish noise from signal. Conversely, significantly larger windows risk smoothing out the local volatility that our method aims to capture. Furthermore, this setting maintains consistency with the moving average kernel size used in the backbone TimeMixer model, ensuring structural alignment. For the temporal decay factor, we set as a fixed default across all experiments. This parameter alignment strategy ensures that the performance improvements originate from the proposed method’s mechanism rather than extensive hyperparameter tuning. The source code will be made publicly available upon acceptance to promote uncertainty awareness in deep learning models.
4.3. Quantitative Comparison
Detailed experimental results are presented in Table 2 and Table 3. To thoroughly assess the performance of our method, we divided the comparison models into two groups based on their publication dates: the first group includes recent state-of-the-art models that are contemporary competitors, while the second group consists of influential and representative models from the past several years. The experimental data shows that our method achieves stable and significant performance improvements over the original TimeMixer model and sets new state-of-the-art performance records in the vast majority of test scenarios.
The performance gains achieved by our method are particularly prominent on the ETT series and Solar-Energy datasets, which are characterized by the coexistence of periodicity and noise. The signals in these datasets contain a large amount of endogenous randomness. The traditional MSE loss forces the model to fit this unlearnable noise, thereby impairing its ability to capture core periodic patterns. Our UP loss function, through its complexity-aware mechanism, effectively reduces the supervision weight on these highly random signal segments. This allows the model to focus more of its modeling capacity on learning the underlying patterns that have genuine generalization value, leading to a substantial improvement in prediction accuracy.
On the Weather, Electricity, and Traffic datasets, the results exhibit different characteristics. The signal dynamics in these datasets are dominated by energy-concentrated, low-frequency periodic components. This causes the local spectral entropy of the signal to remain at a low level for most of the time, thereby weakening the differential adjustment capability of the complexity weight in UP-TimeMixer and making the supervision signal it provides somewhat approximate that of standard MSE. However, the prior knowledge that prediction difficulty increases with the time step still holds true in these tasks. Therefore, the temporal decay weight in UP-TimeMixer plays a key regularization role. Especially in long-term forecasting tasks, by reducing the supervision strength on distant future points, it effectively prevents the model from overfitting in regions of higher uncertainty. This explains why, although the advantage of our method is less pronounced on these datasets, it still consistently outperforms others in most long-term forecasting scenarios. It also demonstrates the complementarity and robustness of the two weight components designed within the UP-TimeMixer.
Ultimately, the experimental results indicate that guiding a model’s learning process through a more refined optimization objective is an equally effective, and perhaps even more efficient, path to improving prediction performance than continually designing more complex model architectures. A simple MLP model, when equipped with our unpredictability perception framework, can systematically outperform numerous structurally complex Transformer models. This offers an inspiring new perspective for the future development of the time series forecasting field.
4.4. Visualization Comparison
A qualitative analysis of the forecast results, as visually presented in Figure 3, reveals that the uniform training objectives of conventional models result in characteristic failure modes. For instance, earlier Transformer models like Informer and Autoformer tend to produce erratic, high-amplitude oscillations decorrelated from the ground truth. This suggests that forcing a model to equally fit all future points, including inherently unpredictable ones, can impair the learning of stable long-term patterns. Models with strong smoothing biases, such as DLinear and TimesNet, exhibit another reaction to this uniform objective by systematically dampening the amplitude of sharp peaks, effectively prioritizing more predictable low-frequency trends over volatile, high-frequency details. Even robust architectures like PatchTST may occasionally produce spurious, high-amplitude patterns, a behavior suggesting that a uniform training objective may cause overfitting to locally complex yet globally insignificant features. The baseline TimeMixer successfully captures the signal’s primary dynamics and periodicities, but its prediction curve contains excessive high-frequency oscillations, indicating its uniform training objective may have misinterpreted random noise as an intrinsic signal pattern to be fitted. Our proposed UP-TimeMixer, however, visibly overcomes this specific limitation, yielding a prediction that is both structurally accurate and significantly less noisy. By encoding signal predictability and temporal distance into its loss function, our method mitigates the inherent limitations of uniform supervision. The model’s capacity to precisely approximate both low-frequency trends and high-frequency transients demonstrates the efficacy of this adaptive training paradigm. By concentrating modeling resources on learnable signal components, it effectively prevents overfitting to stochastic, unpredictable dynamics.
4.5. Ablation Study
To evaluate the contribution of each component of the proposed UP Loss, we conduct an ablation study across all eight datasets used in our experiments. We compare the baseline model (using only the standard MSE loss) with three variants: one using only the temporal weight , one using only the complexity weight , and the full UP Loss that combines both components. The results, summarized in Table 4, show that the full UP-TimeMixer consistently outperforms the baseline MSE in most cases, confirming the effectiveness of re-weighting the loss function. The most significant improvements are observed in datasets such as ETTh1, ETTm2, and Solar-Energy, where the full UP Loss reduces the average MSE and MAE by a small but consistent margin.
However, the impact of the individual components of the UP Loss varies across datasets. On datasets like ETTh2 and ETTm1, where horizon-dependent uncertainty is more pronounced, the temporal weight contributes more to the reduction in error than the complexity weight . For instance, on ETTh2 at the 720-step horizon, using only yields a better MSE than using only . On the other hand, for datasets with more regular periodicity, such as Solar-Energy and ETTh1, the complexity weight proves to be more beneficial. For example, on ETTh1 at the 96-step horizon, the complexity-based model performs slightly better than the temporal-only variant. Interestingly, the full UP Loss does not always outperform the baseline on datasets with some predictable signals, such as Weather and Electricity. In these cases, the addition of re-weighting does not result in substantial gains, and the baseline MSE performs comparably or even slightly better.
To visualize the contribution of our proposed Unpredictability Perception loss, we compare the empirical distributions of mean squared errors between the baseline TimeMixer and TimeMixer+UP on the test sets. Figure 4 presents histograms overlaid with kernel density estimates (KDE) for the baseline TimeMixer and TimeMixer+UP, derived from per-instance MSE values aggregated over the prediction horizons (96, 192, 336, 720 steps). In datasets such as ETTh1, ETTh2, ETTm1, ETTm2, and Solar-Energy, where TimeMixer+UP yields lower average MSE, the distributions exhibit modes centered at reduced error levels, often accompanied by narrower spreads and diminished high-error tails, reflecting improved generalization and robustness to stochastic signal components. Overall, these visualizations affirm the efficacy of the UP loss in modulating supervision to match the intrinsic predictability of sensor signals, thereby fostering more stable and accurate forecasts in critical applications like power grid management and urban traffic optimization.
This ablation study demonstrates that the full UP Loss generally improves forecasting performance by effectively re-weighting the loss to prioritize more predictable segments. The individual components (temporal and complexity weights) have different impacts depending on the dataset, with the temporal weight being more effective on datasets with higher uncertainty and the complexity weight being more useful on datasets with regular patterns. These findings validate the proposed loss function and highlight its adaptability across different types of time series data.
To rigorously validate the selection of the hyperparameter , we conducted a comprehensive parameter sensitivity analysis on the representative ETTh1 dataset. We evaluated the model’s performance by varying across the set while keeping all other parameters fixed. The results, summarized in Table 5, reveal a distinct pattern. When is small, the temporal weight function approximates a uniform distribution, resulting in a supervision signal similar to the standard MSE; consequently, the performance improvement over the baseline is marginal. As increases to 0.5, the loss function effectively down-weights the supervision for distant, high-uncertainty time steps, allowing the model to prioritize learnable short-term dynamics, which leads to the lowest average MSE of 0.436. However, as continues to increase beyond 0.7, the excessive decay overly relaxes the constraints on long-term predictions. This causes the model to essentially neglect the supervision for the distant future, resulting in a degradation of overall forecasting accuracy. This empirical evidence confirms that provides the optimal equilibrium between enforcing prediction accuracy and accommodating temporal uncertainty.
5. Conclusions
This study introduced an Unpredictability Perception Framework to address the inherent limitations of the mean squared error loss function in time series forecasting. Our approach redefines the model’s optimization objective through an innovative loss function that dynamically computes supervision weights based on a dual assessment of the forecasting task’s intrinsic unpredictability. This assessment unifies a posterior analysis of signal content randomness via local spectral entropy with an a priori consideration of temporal distance via exponential decay. This mechanism guides the model to prioritize learning high-certainty deterministic patterns while reducing the fitting intensity on inherently random or distant uncertain events. By applying this framework to the advanced TimeMixer model, experimental results across multiple public benchmarks demonstrate that this optimization at the loss function level systematically enhances prediction accuracy without any architectural modifications. The findings of this research reveal that matching the supervision strength to the intrinsic predictability of the forecasting task provides a simple yet effective path toward enhancing the robustness and accuracy of deep learning forecasting models, offering a new optimization perspective for sensor network data analysis.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Li M. Yang M. Chen S. Li H. Xing G. Li S. FCP-Former: Enhancing Long-Term Multivariate Time Series Forecasting with Frequency Compensation Sensors 202525564610.3390/s 2518564641012884 PMC 12473902 · doi ↗ · pubmed ↗
- 2Xia M. Shao H. Ma X. de Silva C.W. A Stacked GRU-RNN-Based Approach for Predicting Renewable Energy and Electricity Load for Smart Grid Operation IEEE Trans. Ind. Inform.2021177050705910.1109/TII.2021.3056867 · doi ↗
- 3Qiao W. Li Z. Liu W. Liu E. Fastest-growing source prediction of US electricity production based on a novel hybrid model using wavelet transform Int. J. Energy Res.2022461766178810.1002/er.7293 · doi ↗
- 4Imani M.H. Bompard E. Colella P. Huang T. Forecasting Electricity Price in Different Time Horizons: An Application to the Italian Electricity Market IEEE Trans. Ind. Appl.2021575726573610.1109/TIA.2021.3114129 · doi ↗
- 5Liu H. Wang H. Yu M. Wang Y. Luo Y. Long Short-Term Memory–Model Predictive Control Speed Prediction-Based Double Deep Q-Network Energy Management for Hybrid Electric Vehicle to Enhanced Fuel Economy Sensors 202525278410.3390/s 2509278440363222 PMC 12074296 · doi ↗ · pubmed ↗
- 6Park M.J. Yang H.S. Comparative Study of Time Series Analysis Algorithms Suitable for Short-Term Forecasting in Implementing Demand Response Based on AMI Sensors 202424720510.3390/s 2422720539598981 PMC 11598777 · doi ↗ · pubmed ↗
- 7Lu X. Qiu J. Lei G. Zhu J. An Interval Prediction Method for Day-Ahead Electricity Price in Wholesale Market Considering Weather Factors IEEE Trans. Power Syst.2024392558256910.1109/TPWRS.2023.3301442 · doi ↗
- 8Li F. Wang X. Bao X. Wang Z. Li R. Energy Management Strategy for Fuel Cell Vehicles Based on Online Driving Condition Recognition Using Dual-Model Predictive Control Sensors 202424764710.3390/s 2423764739686181 PMC 11644990 · doi ↗ · pubmed ↗